
Abstract
In this study, a neural network model is developed for the prediction of oil flow rates in wells lifted by electrical submersible pumps (ESPs). Three attributes of the model in this work make this study unique. First, the knowledge on the computational cost of models has been presented, a rarity in most neural network models on this subject; second, the models have been explicitly presented, a feature uncommon in published ANN predictive modelling studies; and third, it includes a sensitivity analysis of input variables. The dataset utilized for the model development comprises 275 data points collected from ESP-lifted wells in the Middle East. Statistical evaluation of the model’s performance using the metrics such as mean square error, root mean square error and coefficient of determination demonstrates high predictive accuracy with respective values of 0.0000201861, 0.00449 and 0.999. In order to ascertain the parametric importance of the inputs, Garson’s algorithm was utilized. In this regard, choke size and upstream pressure had the highest influence (19% and 16%, respectively), while casing head pressure had the least effect (4.8%) on oil flow rate. In terms of memory requirements and processing speed for software applications, the model had a memory footprint of 888 bytes and required 191 multiply and accumulate operations to give an output. By utilizing the proposed models, the time-consuming separator tests measurements of flow rate would no longer be necessary and real-time results could be provided in the field. This work would be useful to production engineers who seek a quick and accurate means of estimating oil flow rate from ESP wells in real time.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
The use of electrical submersible pumps (ESPs) as an oil and gas primary recovery method has gained wide acceptance with approximately 15 – 20% of one million wells globally using the technology (Breit and Ferrier 2011). Of the oilfield lift systems existing today, the ESP is regarded as one of the most versatile, handling a wide range of flow rates and suitable for both vertical and deviated wells. They are commonly called the champions of high volume and depth, delivering flowrates of over 45,000 bbl/day and working up to 12,000ft depth (Guo et al. 2007). They also present a small footprint making them useful even in offshore installations. However, a few drawbacks include: low efficiencies in dealing with high gas volumes (especially if the volume is > 10% at the pump intake); their low tolerance for solid laden fluids, etc. The anatomy of a typical ESP unit is shown in Fig. 1a. It essentially consists of surface equipment, namely electric power supply, a transformer, a control board, and a control valve, and the underground equipment comprise a centrifugal pump, an electric motor, seal electric cable, and sensors (Bafghi and Vahedi 2018).

a Components of a typical ESP unit, b Free body diagram of flow process in an ESP unit Source: Fontes et al. (2020)
The working principle of the ESP as described by Kimrays Inc (2023) is as follows: To power the motor, heavy duty cables connected to surface controls are used. The motor then rotates the shaft that is connected to the pump. The rotating impellers draw in reservoir fluids via the pump intake, pressurizing it and transporting it to the surface. Since the ESP comprises multiple stages of centrifugal pumps connected to a submersible electric motor, this process is repeated by the fluid in every stage of the pump (Takacs 2009). In a bid to optimize performance, a downhole sensor that communicates real-time system data such as pump intake and discharge pressures, temperatures, and vibration can be installed. The function of the seal-chamber is to isolate and protect the motor from corrosive wellbore fluids and pressure equalization in the wellbore with the oil pressure inside the motor. Figure 1(b) essentially illustrates the free body diagram of the process behind an ESP-assisted oil production system. To aid fluid lifting from an oil well, the ESP alters the following: the frequency (f) with which the pump rotates, and the choke opening (zc). This is done to exert further pressure to the reservoir fluid and to drive it to the surface through the production tubing (Fontes et al. 2020). The hydrocarbon flow rate (qp), flow type in the production column, and the electrical submersible pump head dynamics (H) stipulate the operational envelope constraints, namely upthrust and downthrust constraints. This envelope is essentially the region within which electrical submersible pumps are operated. This region is depicted in Fig. 1b and is the gap that exists between the minimum and maximum rate lines. The pump head is the quotient of the pressure and the fluid density. As the volumetric rate through the pump rises, its pump head drops (Hoffmann and Stanko 2017). The wellhead, bottom hole and manifold pressure are represented by Pwh, Pbh, Pm, respectively.
Numerous studies have been carried out by diverse researchers on various aspects of electrical submersible pumps using artificial intelligence techniques (AI). For instance, for ESP optimization studies, Mohammadzaheri et al. (2016) used genetic algorithm, while Dachanuwattana et al. (2022) utilized random forest algorithm and neural network. For failure predictions of ESP systems, Okoro et al. (2021), Chen et al. (2022), Brasil et al. (2023) utilized neural networks, while Ambade et al. (2021) utilized random forest algorithm. For flowrate predictions for ESP-lifted wells, Mohammadzaheri et al., (2016, 2019); Azim (2020), Popa et al.(2022), Sabaa et al. (2023) utilized neural networks, Hallo et al. (2017) used genetic programming, Ganat and Hrairi (2018) used nonlinear regression, Ricardo et al. (2018) used support vector machines, Franklin et al. (2022) used physics informed neural networks, while Abdalla et al. (2023) used support vector regression, extreme gradient boosting trees and convolutional neural networks for their model development. Other studies on ESP include: power consumption of ESP units (Khakimyanov et al. 2016); mathematical modelling of ESP electric motors (Cortes et al. 2019); comparison of ESP electric motors (Bafghi and Vahedi 2018); validation of empirical models for head and surging characteristics of ESPs (Ali et al. 2022); and the development of an automatic control mechanism for ESP units (Krishnamoorthy et al. 2016). Beyond the use of the conventional artificial neural networks, recent studies involving forecasting of production rate and production enhancement process have made extensive use of deep neural networks/deep learning approaches. For instance, development of data-driven proxy model for accurate production evaluation of shale gas wells with complex fracture network (Chu et al. 2023); ultimate recovery estimation of fractured horizontal wells in tight oil reservoirs (Luo et al. 2022); prediction of production data such as (production rate, cumulative oil production, and temperature field) of steam-assisted gravity drainage in heavy oil reservoirs (Wang et al. 2021a); image recognition models (Wang et al. 2021b); optimization of thermochemical production in heavy oil reservoirs (Zhou and Wang 2022); gas emissions (Zhou et al. 2022) and slope stability estimation (Huang et al. 2023).
This study is focused on developing a robust model for predicting fluid flow rate in ESP-lifted wells. The existing models for electrical submersible pump operated wells were developed without the model being made explicit, no computational cost evaluations and no sensitivity analysis of the input variables to the model. All these factors limit their usage in real-time prediction of oil flow rate. To fill this gap, this work would use artificial neural network to develop an explicit, computationally efficient and technically reproducible model for predicting oil production rate in an electrical submersible pump operated well with inputs that are easily obtainable at the surface.
Of the many machine learning algorithms, the neural network algorithm was chosen due to the significant advantage it possesses over traditional nonlinear modelling tools namely, that of being able to capture the complex nonlinear relationships that exists between a set of input variables and an output parameter without having the need for the models to be stated in advance (Livingstone et al. 1997). Other desirable features of neural networks include their fault tolerance property (Torres-Huitzil and Girau 2017) and the existence of several training algorithms. Despite these advantages, the vast number of tuning parameters coupled with the trial-and-error approach involved in finding the network’s optimal architecture all of which led to longer training times, are some of the drawbacks of this algorithm (Ng et al. 2020).
The attributes of the proposed model for which novelty is claimed include: First, knowledge on the computational cost of the models has been presented, a feature missing in most ANN models on this subject. Second, the explicit presentation of the proposed models has been done (something rarely found in published ANN predictive modelling studies), a feature which allows the models to be easily deployed in software applications, and third, a sensitivity analysis of the input variables has been advanced. A combination of all these features makes this study unique and counts to its contribution to knowledge.
This work is divided into five sections. To begin, the second section contains a critical review of extant literature on the use artificial intelligence in developing models for oil flow rate in artificially lifted wells. The third section describes the dataset used, data analytics approaches applied on the dataset, the method used for the modelling and the various metrics used to evaluate the developed model. The fourth section contains a discussion of the results obtained and a comparison of the results obtained with existing models, while the fifth section concludes the study by highlighting the significant findings and recommends some noteworthy subsequent works that might potentially be embarked upon by future researchers.
Review of related studies
Table 1 provides a summary of the models that were developed for use to estimate flow rate in artificially lifted wells. The researches are arranged in order of their evolution from the earliest to the latest. The key elements of each study such as the modelling strategy, fluid type, data size utilized to construct the models, inputs to the models and the research gaps in the studies are highlighted in the summary. Since the literature on the subject of artificial lift systems is vast, in order to keep the review in line with the aim of the study, papers focusing on modelling of oil flow rate in artificial lift wells were emphasized and given higher priority for inclusion in the summary. Furthermore, to make the review more concrete, critiques in the form of research gaps are highlighted for each reviewed work. The following are the key findings from this summary:
-
i.
Input variable selection: The inputs used by various researchers for their model development were wide and varied with each researcher choosing different input variables even when they were developing models for the same kind of artificial lift system. This is evidenced by the fact that while some researchers made use of a large number of input variables (as much as 28 input variables), there is a case where just one input was utilized to develop a model. This indicates no unanimity amongst researchers as to the parameters affecting the fluid flow in an artificially lifted well and by extension may be one of the reasons it is difficult to have a universal model for oil flow rate in artificially lifted wells. Some of these input variables are parameters that are not easily obtainable at the surface. Furthermore, some researchers have GOR or GLR as an input parameter which other researchers like Khan et al. (2020) have argued that it (GOR/GLR) reveals the output to the model and ultimately defeats the purpose of developing a model for oil flow rate.
-
ii.
Type of artificial lift system: The preponderant artificial lift system considered by most researchers is the gas lift system. The most probable reason for this focus on gas lift systems is because of its attractive characteristics enumerated by Garrouch et al. (2020) that includes: it uses essentially no moving parts; it has proven to be adaptable across a wide range of well parameters and reservoir characteristics; it has a relatively low operational cost owing to the fact that they take up very little space at the wellhead. This is particularly advantageous for offshore platforms where space is at a premium and every square inch is expensive (Ranjan et al. 2015). Finally, gas lift is advantageous in producing high gas–liquid ratio wells which tend to be problematic when pump-assisted methods such as electrical submersible pumps are used.
-
iii.
Parametric importance of input variables: It was observed that whereas Khan et al. (2020) had reported that oil API gravity had significant impact on oil rate predictions in artificially lifted wells, Elgibaly et al. (2021) posited that the oil API gravity had little contribution to the prediction of oil flow rate in artificially lifted wells. According to Ghareeb and Shedid (2007), factors that have significant effect on production rate include: producing depth variation, well head temperature and size of tubing while bottom-hole temperature, gas oil ratio and water cut have negligible effect on production rate.
-
iv.
Modelling technique adopted: The presented literature review indicates that numerous correlations have been developed to predict the flow rate in artificially lifted wells using machine learning techniques. About 95% of the models were developed using the ANN technique. The ANN models were mainly multiple input single output models. Other techniques such as SVR, Fuzzy logic and some hybrid intelligent models such as ANFIS were utilized, but their usage was few and far between. For the ANN technique, some of the models were complex, while a few were relatively simple in nature.
-
v.
Data set size: According to Syed et al. (2022) any machine learning process for developing predictive models requires a huge amount of data. Here is how machine learning-based models’ performance is impacted by the volume of training data: First, the expressive capability of neural networks – the ability to approximate functions (Lu et al. 2017) is significantly influenced by the amount of training data. In essence, more training data generally result in improved generalization of the learnt patterns and an increase in expressive ability. Second, it leads to better generalization: more different instances are provided by a larger dataset, which aids the neural network in learning a wider variety of patterns and changes in the data. Since the network can now perform better on previously unknown or fresh data, this frequently leads to enhanced generalization. Third, it leads to less overfitting. A larger dataset makes it less probable for the network to memorize noise or outliers that are present in a smaller dataset. This lessens the likelihood of overfitting, which occurs when a network becomes overly focused on training data and performs badly on fresh input. As Ajiboye et al. (2015) put it, employing a substantial amount of data can improve the accuracy and generalizability of a predictive model. However, the ambiguity surrounding what exactly is a big dataset remains undefined. However, with small datasets, techniques such as Bayesian regularization and general regression neural network (GRNN), a probabilistic network could be applied.
-
vi.
Generalizability of models: In predictive modelling using machine learning techniques, generalizability is the ability of a model to carry out its intended function on data from a fresh, independent, or unseen dataset (i.e. data that were never utilized during the development process), similar to the external validation of a model. If a model does not fit this criterion, it may have learnt biases from the methods used for data production and processing rather than the underlying link between the attributes and the desired output. This makes it more difficult to produce reliable results generally as well as to replicate results when used in practice. Most of the research failed to conduct an evaluation on the generalizability of the models they developed; rather they solely relied on training and testing the models on the same dataset. This approach can result in overestimating models performance and lead to suboptimal performance when subjected to a new dataset (Abdalla et al. 2023).
Materials and methods
This section's main purpose is to highlight the data sources and development methods required to create the model stated in the study's objectives. Also included in this part are specifics about the modelling process and its parameters.
Data description
The data used for this study were sourced from a field located in the western side of the Gulf of Suez area, Egypt. The reservoir structure is an elongated horst block trending NW–SE with general tilting to the NE direction. The data were collected from seven ESP-operated wells from an oil-bearing Miocene reefal vuggy carbonates and fractured Eocene with a permeability range of 10 to 100 md and a porosity range of 11 to 24%. The used ESP pumps are a Schlumberger G-series models (GN4000, 50 Hz, 2917 RPM, 86 stages, nominal housing diameter of 5.13 inches and minimum casing size of 6.625 inches) with an optimum operating range of 2667–4000 bpd, a shaft break horsepower limit of 500Hp, and a housing burst pressure limit of 6000 psi. The dataset consists of 275 data points, the main parameters in the dataset include: upstream pressure (UP P), downstream pressure (Down P), ESP pump intake pressure (Pi), pump discharge pressures (Pd), intake temperature (Ti), discharge temperature (Tm), casing head pressure (CHP), gas oil ratio (GOR), choke size (1/64 inch), and the output parameter oil flow rate (Q). Table 2 gives a statistical description of the input and output variables using statistical measures such as mean, standard deviation, and range.
Exploratory data analysis
According to Abdalla et al. (2023), exploratory data analysis (EDA) utilizes a variety of tools, including visualizations (scatter and box plots, histograms, etc.), dimensionality reduction techniques, etc., to assist in finding relationships, concealed patterns and anomalies. In this study, the box plot would be used to establish the distribution of the data for each variable. Figure 2 shows the box and whisker plot for both the normalized input and output variables.

Box plot of showing data distribution among normalized inputs and output variables
From Fig. 2, it is observed that almost all the variables except the pump intake temperature have dispersed data. This is evident by the length of the boxes. The principle is that the longer the box, the more dispersed the data is whereas the shorter the box, the less dispersed the data. Furthermore, since the median is not in the middle of the box, but closer to the bottom of the box, and the whisker is shorter at the lower end of the box, then the oil flow rate and discharge pressure data distribution are positively skewed while the pump intake pressure is negatively skewed.
Data normalization
The dataset utilized for the study needed to be normalized in order for the neural network to seamlessly understand the relationship between the input variables and the output variable, thereby improving the network’s performance. Put differently, the network concurrence is made easier by the normalization of these variables. To further reinforce the importance of data normalization, Khare and Shiva (2007) reported that if one input has large a number and another a small one, but both show comparable variance, then the possibility of the network ignoring the small input in favour of the larger one would be sufficiently high. These variables in this study originally have ranges that differ by several orders of magnitude. The mapmin-max method was used to normalize each input and output variable so that they all ranged from − 1 to + 1. The formula shown in Eq. 1 was used to normalize each variable in the dataset, reducing the range of potential values from 0 to 6172.1 to between − 1 and + 1.
where \({X}_{{\text{min}}}\) and \({X}_{{\text{max}}}\) are the minimum and maximum values of X, and X is the set of observed values of X whereas Y is the normalized value of X.
However, as soon as the training of the neural network is completed, since the value of the network output is normalized, there is need to de-normalize it in order to transform it into the actual value. Equation 2 is the formula used for the denormalization.
where \({X}_{{\text{min}}}\) and \({X}_{{\text{max}}}\) are the minimum and maximum values of X, and X is the set of observed values of X whereas Y is the normalized value of X.
Overview of artificial neural networks
Neural networks are essentially computational algorithms inspired by biological systems particularly the brain, created to learn and use that information to predict the outcomes of complicated systems. The neuron is a neural network's fundamental building block. These neurons are connected to form a network that can handle complex problems (Behnoud far and Hosseini, 2017). The three layers a neural network is made up of are: the input, hidden and output layers. The number of input parameters to the network is represented by the neurons in the input layer. The set of values or features in a dataset that are needed to forecast the outcome are known as the inputs. Feature extraction is the responsibility of the neurons in the hidden layer. The following describes how a neural network processes information: first, each of the inputs (I1, I2, I3, I4) is assigned connection weights (W1, W2, W3, W4). These weights are basically real numbers that are assigned to each input which defines the importance of the input in predicting the output. These inputs are then multiplied by their individual connection weights. The weighted sum of the inputs and connection weights are then combined and a bias term (b) is added to the summation. The essence of the bias is to either increase or decrease the input that goes into the activation function. The summation is passed through a transfer or activation function, and the output is then computed and transferred to another neuron. The responsibility of the activation function is to introduce nonlinearity into the neural network model. Sigmoid transfer function and linear activation function (purelin) are recommended for the hidden and output layers, respectively (Maier and Dandy 2000). All these are illustrated in Fig. 3.

Illustration of a neural network process
Procedure for developing a predictive model using neural networks
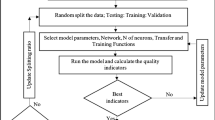
The series of steps outlined in Fig. 4 shows the pathway for developing a predictive model using neural networks based on supervised learning. The dataset before being divided into training, validation, and testing datasets, it is first normalized before being fed into the network. Whereas the training dataset represents that slice of the dataset which the network learns from or is used to train the model, the validation dataset provides an objective assessment of the network while adjusting the model’s hyperparameters. The test dataset on the other hand is utilized after the model is completely trained to evaluate how well the model fits the data. To establish the performance of the model, the mean square error (MSE) and the goodness of fit are the metrics employed. The network with the minimum MSE close to zero and goodness of fit close to one is chosen as the best performing model.

Flowchart for developing a predictive model using neural networks
Hyperparameter settings for model training, testing and validation
The settings used for the neural network model are presented in Table 3. By default, the MATLAB software partitions the data into three sets: the training data set (70%), validation data set (15%) and test data set (15%). Training data are used to adjust the weight of the neurons. Validation data are used to guarantee that the network generalizes at the training stage, the testing data are used to evaluate the network after being developed. Figure 5 is a schematic diagram showing the splitting of the data sets into training, validation and testing datasets.

Data splitting in the neural network
The stopping criteria are usually established by the preset error indices, e.g. mean square error (MSE) or when the number of epochs reaches 1000. For the neural network model, the lowest MSE was used. Furthermore, in order to prevent the problem of overfitting, the ‘early stopping’ strategy was adopted.
Protocol for finding the optimal neural network architecture
The learning and performance of a neural network are significantly impacted by the number of neurons present in the hidden layer of the network. The universal approximation theorem asserts that there exists a multilayer perceptron with a specified number of hidden layer neurons that is roughly right for any input–output mapping function in supervised learning. Sadly, the theory provides no guidance on how to locate this number. In order to discover this number, the trial-and-error method was used.
Model performance assessment methods
The task of evaluating the performance of a model is fundamental to predictive modelling. There are many error metrics existing in literature, however, since there is not yet any consensus on the most appropriate metric for evaluating model errors, this work has chosen to use three of the existing metrics. The error analysis metrics include: coefficient of determination (R2), mean square error (MSE) and root mean square error (RMSE). The choice of these three metrics is based on the following. First, in a recent study by Chicco et al. (2021), they suggested from their analysis that the coefficient of determination (R squared) should serve as a standard metric for regression models since it is more informative and does not have interpretability issues as other metrics. It has to be stated that the R2 value shows the discrepancy between the actual and predicted data and indicates how close the points are to the bisector in the scatter plot of two variables. Second, RMSE is a statistical measure of the variance of predicted data values around actual data values. The RMSE is said to be a good statistical criterion for model evaluation because the unit of the error is the same as the unit of the measured value thus making it more interpretable than MSE (Jierula et al. 2021). Furthermore, RMSE is optimal for normal (Gaussian) errors (Hodson 2022). The distinction between R-squared and RMSE is that while the former is a relative measure of fit, the latter is an absolute measure of fit. RMSE is a good indicator of how effectively the model predicts the output parameter. If the primary goal of the model is prediction, then this fit criterion is crucial. The MSE is the average squared difference between actual values and predicted values (Adamowski et al. 2012). A perfect model is described by an R2 of 1 and an RSME and MSE of 0. The mathematical descriptions of the three statistical metrics are shown in Eq. 3, Eq. 4 and Eq. 5.
For Eq. 3, Eq. 4 and Eq. 5, N = number of data samples, \({y}_{{\text{actual}}}\) = the actual or experimental values, \({y}_{{\text{predicted}}}\) = values predicted by the developed model, \(\overline{y }\) = average of the actual or experimental values.
Results and discussion
This section presents the results obtained in the course of developing neural network models for the prediction of oil flow rate in an ESP operated well. First, the result from the method used for selecting the model architecture is presented. The result from the performance of the proposed model is presented next, while the mathematical representation of the model comes thereafter. The results from the parametric importance of the input variables, the models computational burden analysis as well as the field deployment of the model would be highlighted.
Optimal neural network architecture determination
The number of neurons in the network’s hidden layer influences the generalization ability of the ANN model. In order to find the appropriate architecture for the networks, the trial-and-error approach was adopted. In this regard, numerous network topologies were evaluated, wherein the number of neurons in the hidden layer was varied between 1 and 20. The error function chosen was the MSE. Decision on the optimum topology was based on the minimum error of the testing data. Each topology was tried for 25 times in order to get the best network from that topology. At the end of the trials, it was observed that a network having 10 neurons in the hidden layer gave the optimal performance oil flow rate prediction with test MSE values of 2.37E-05. Figure 6 illustrates the MSE obtained with different number of hidden neurons for the oil flow rate data. The essence of this figure is to highlight the magnitude of the errors obtained when a specified number of neurons is tried in the hidden layer.

MSE of model by varying the number of hidden layer neurons
The optimal architecture of the ANN network for the model is shown in Fig. 7. This figure aids in the interpretability of the neural network’s optimal topology. It equally helps experts and non-experts in the field of machine learning visualize the way and manner the different layers of the neural network are interconnected.

Optimal architecture of the neural network for oil flow rate estimation
Figure 8 presents the scatter plots of the proposed model for the training, validation and testing dataset. The predicted model is in agreement with the experimental values for the training, testing and validation sets as seen in their correlation coefficients (R). The reason for this assertion is that the closer the correlation coefficient is to 1, the better the model. However, using only the correlation coefficients as the basis for determining the predictive capability of a neural network model is not always recommended. This is because a model may have a good correlation coefficient but predicts poorly when subjected to new data sets that were not used during the ANN training process.

Scatter plots of ANN model for oil rate prediction
Furthermore, the blue, green, red and black coloured solid lines inclined at 45° in the regression plots in Fig. 8 are the best fit linear regression lines between the model outputs and the model targets. These plots are necessary in showing whether or not some of the data points have good or poor fits. In this instance, the training, testing and validation data all have good fits since the data points all lie on the 45° line.
Performance evaluation of developed neural network model for oil flow rate
The network’s performance with regard to its training, validation and testing capability is presented here. Given that the main objective of a trained neural network is its prediction capability, it is believed that the criteria for testing the predictive capability should be the model’s performance when exposed to the test dataset. Every neural network in this analysis was trained with 1000 iterations using the Levenberg–Marquardt algorithm. The performance of the models after being evaluated using three statistical error metrics is summarized in Table 4. From the table, the value for the coefficient of determination for the ANN model developed was 0.999965 for the test data indicating that 99% of the data fit the regression model. According to a categorization of R-values by Taylor (1990), a weak or low correlation has a value R ≤ 0.35; a moderate correlation ranges between 0.36 ≤ R ≤ 0.67 and high correlation ranges between 0.68 < R < 1.0 values. In like manner, Ozili (2023) opined that if the R2 value is more than 0.5, then, a strong correlation exists between the actual/experimental and predicted values. In addition, according to Alel et al. (2018), R2 value ranging between 0.7 and 0.9 can be interpreted as high positive correlation, while a range of 0.0 to 0.3 can be interpreted as negligible correlation. The R2 values obtained in respect of the proposed ANN models in this study indicate strong correlation between the ANN predicted values and the field data. With respect to the MSE, a small value of the MSE and RMSE indicates that it is close to finding the line of best fit. For a perfect model, the MSE and RMSE should have a numerical value of 0. In the case of the oil flow rate data used in developing the ANN model, reasonable values were obtained for the MSE and RMSE.
Figure 9 shows the plots of the field data against the predictions from the developed ANN model. This figure essentially enables one visualize how well the developed model matches the field data. From the figure, it can be seen that the model has the capacity to capture the nonlinearities associated with the prediction of oil flow rate.

Comparison of field data and neural network model predictions for oil flow rate
Neural network model weights and biases
The weights and biases of a neural network are essentially the most important parts of its development and functionality. The essence of including the crucial details (the weights and biases) of the models developed is to ensure that the models are reproducible (ability to recreate a model without the original code). Legendi et al. (2013) posited that model reproduction is scarcely carried out since successful reproductions do not seem to deliver new scientific results and the reasons of failed reproduction may be hard to discern. Table 5 lists the weights and the biases of the developed empirical correlation that can be used to predict oil flow rate in ESP operated wells. A description of these terms is presented as follows:
The neural network weights: During neural network training, it is initialized with a set of weights. The network weight values are essentially random numerical values generated by the network and used as coefficients to multiply the input parameter values. The neural network weights are similar to the slope in a linear regression model, where a weight is multiplied by the input to add up to produce the output. A weight essentially dictates how much influence the input will have on the output. For example, weights that are negative indicate that an increase in that input would lead to a decrease in the output and vice versa. Weights that are near zero imply that increasing or decreasing the input would not change the output. In order to get optimum results, during the training period, the weights are adjusted till the optimum weights are obtained. In this work, Wij (or IW) and W2 (or LW) are the nomenclatures used to represent the input layer to hidden layer weights and hidden layer to output layer weights, respectively.
Threshold or Bias: In the context of neural networks, threshold and bias are the same. Basically, the bias in a neural network plays the role that the intercept plays in a linear equation. The bias is an additional parameter which is used to adjust the output along with the weighted sum of the inputs to the neuron. The unique thing about the bias is that it does not interact with the actual input data. The biases for the input layer to the hidden layer and that from the hidden layer to the output layer are represented as b1 and b2, respectively.
Mathematical representation of developed models
The model generated by applying the Levenberg–Marquardt algorithm is given in Eq. 6.
Equation 6 is the representation of the trained feed-forward neural network model correlating the nine input parameters and the oil flow rate in MATLAB. Here, ‘purelin’ and ‘tansig’ are basically MATLAB functions. They are used in the computation of the output from the network’s input. Whereas tansig is equivalent to the hyperbolic tangent (tanh), purelin gives a linear outcome between the inputs and output parameters. The weights from the inputs to hidden layers and from the hidden layer to the output layer are represented by IW and LW, respectively.
Explicit representation of the developed ANN Model
Presenting the model in an explicit manner helps in enhancing the models’ replicability (ability to obtain the same results using the same data and code). The duo of reproducibility and replicability of machine learning models has been omitted in most studies applying machine learning (Miłkowski et al. 2018). Furthermore, Stroebe and Strack (2014) reported that the majority of published machine learning studies lack any source code, and that machine learning studies rarely include documentation of how precisely the model was created. For the neural network models to be explicitly presented, the weights and biases for the network were presented. These biases and weights are presented in Table 5. With these weights and biases, the model can be replicated and the results obtained therefrom can be reproduced. Equation 7 is the explicit representation of the neural network model for oil flow rate prediction. This explicit nature makes it easy for the model to be deployed in software and also makes it explainable.
where \({Q}_{n}\) is the denormalized value of the oil flow rate and is given by
\(Where:\)
where tanh = Hyperbolic Tangent, \({UP}_{p}\) = Upstream pressure, \({Down}_{P}\) = Downstream Pressure, \({P}_{i}\) = Pump intake pressure, \({P}_{d}\) = Pump discharge pressure, \({T}_{i}\) = Intake Temperature, \({T}_{m}\) = Discharge Temperature, CHP = Casing head pressure and GOR = Gas Oil Ratio. It should be noted that all input variables in parameters A1 to A10 are expressed as normalized values.
Relative importance of input parameters in the developed neural network model
A viable means of getting insight into a model is to assess its behaviour as one or more of its parameters are varied. This gives an idea as to the importance of the variable to the output of the model. The contribution of each input parameter to the output’s prediction defines the relative importance of that variable. Many methods abound in the literature for calculating the relative importance of input variables. Examples include: Garson’s algorithm, connection weights algorithm, use of partial derivatives, sensitivity plots, forward and backward stepwise addition and input perturbation (Olden et al. 2004). Garson’s algorithm was chosen for this research work (Garson 1991). Using this algorithm, the relative importance of a given input variable can be defined as shown in Eq. 8.
where RIx is the relative importance of input parameter x. \(\sum_{y=1}^{m}{w}_{xy}{w}_{yz}\) is the sum of the product of the connection weights from the input to the hidden neurons with the connection weights from the hidden neurons to the output neuron while y is the total number of hidden neurons and z is the output neurons.
Procedure for determining relative importance of input variables for ANN model using Garson’s algorithm
(a) Extract the absolute value of the connection weights (input layer weights and hidden layer weights) from the weights and biases in Table 5. The result is shown in Table 6.
(b) Multiply the hidden-input layer weight vectors by the hidden-output layer weight vector. Applying these results in the values we have in Table 7.
(c) The rows in Table 7 are added. This results in the values in column 11 of Table 7
(d) A quotient of each value in columns 2 – 10 of Table 7 and the value in column 11 of Table 7 is done. This results in Table 8. Thereafter, a sum of the absolute values in each of columns 2 to 10 is done. The relative importance of the parameters is based on absolute values of this sum.
The relative importance in percentage is calculated by finding the quotient of the sum of each column of Table 8 and the sum total of rows of Table 8 then multiplied by 100. The result is shown in Fig. 10.

Relative Importance of parameters used in developing the neural network model
As shown in Fig. 10, choke size and upstream pressure have the highest effect on oil flow rate estimation in ESP operated wells, while casing head pressure has the least effect on it.
Evaluation of the effects of dimensional reduction on the predictive ability of the neural network
Dimensionality reduction is a crucial stage in the process of obtaining relevant data from a high-dimensional dataset. The objective is to get this data set's dimensionality down to its intrinsic dimensionality, which is the fewest parameters necessary to model the data without sacrificing any relevant information for the application. In this instance, using the parametric importance analysis (which shows an input variable’s usefulness) carried out in this study, the dimensional reduction is implemented by excising the input variable, (in this case, the casing head pressure) which has the least contribution to the prediction of oil flow rate. Thus, the casing pressure would be dropped from the network and the effect of its removal would be assessed by developing a new network without it. After reducing the dimension of the inputs, the new model with 8 inputs had an optimal architecture of [8 – 8 – 1]. The explicit representation of the new model is as shown in Eq. 9:
where \({Q}_{n}\) is the denormalized value of the oil flow rate and is given by
\(where:\)
where tanh = Hyperbolic Tangent, \({UP}_{p}\) = Upstream pressure, \({Down}_{P}\) = Downstream Pressure, \({P}_{i}\) = Pump intake pressure, \({P}_{d}\) = Pump discharge pressure, \({T}_{i}\) = Intake Temperature, \({T}_{m}\) = Discharge Temperature, CHP = Casing head pressure and GOR = gas oil ratio. It should be noted that all input variables in parameters B1 to B8 are expressed as normalized values.
The performance of the new model with 8 inputs is as summarized in Table 9. From the table, it is observed that the performance of the new model with 8 inputs (i.e. excluding the casing head pressure) performs equally as good as the original model performance (shown in Table 4) with 9 inputs judging from the error metrics. This implies that the casing head pressure has minimal effect on the prediction of oil flow rate in ESP operated wells. It is crucial to emphasize that the developed model (Eq. 9) should be applied within the studied range of relevant parameters and caution must be taken when extending beyond this range.
Comparison of the performance of existing models with the developed model
A comparison of the performance of existing models for flow rate prediction and the developed model is presented in Table 10. From the table, it is observed that most of the existing models used a limited number of metrics to evaluate the performance of their models. Another point worth noting from the table is that the developed model performs better than the existing models. It must be said that since the model developed in this study is meant for flow rate estimation in ESP lifted wells, it is only natural to compare its performance with other models developed for ESP-lifted wells since the inputs variables for gas lift wells are radically different from those of ESP wells. However, two reasons why this is not possible include: first, there is a general lack or scarcity of flow rate data from ESP-assisted wells. Second, of the seven models in Table 10 meant for flow rate prediction in ESP wells, six were not presented in an explicit manner, thus making it difficult to fit experimental/field data to them.
Computational cost of the developed ANN models
A mathematical model must be implemented in software in order to be effective. The computational complexity of a model is one factor used to determine its effectiveness in software. This has to do with how quickly the model can compute and how much memory it uses. Khan Academy (2022) defines an efficient algorithm as one that produces the desired result with the least amount of memory usage and execution time. A crucial component of an algorithm's design is estimating its complexity because it provides vital information about the intended performance (INTERSOG 2020).
For a neural network, an increase in each hidden layer's node count directly affects how much memory is used. It follows that if the neural network size is extended horizontally, the memory usage will increase (Mahendran 2021). Therefore, a model's computational cost (memory and execution time) increases in direct proportion to its complexity and size. However, there is an effort to try and lessen the ever-increasing memory and computing costs that models incur as their number of parameters continues to expand (Bird et al. 2021).
The success of a software-intensive system in the real world depends on the non-functional software characteristics of quality parameters, such as dependability, computational cost, performance, and memory consumption. In this instance, two distinct costs are examined: (i) the computational cost, which depends on how quickly the resulting model can carry out computations, and (ii) the memory consumption cost, which gauges the eventual size of the model. Computing expenses are more commonly measured in computer science as "complexity".
Computational cost of the model: one way to get an idea of the computational cost of a model is to simply count how many computations it does. In neural network models, MACCs (Multiply-Accumulate Operations) are a measure of computational complexity and effectiveness. They estimate how many basic arithmetic operations are required to process data via the network. It goes to reason that if a model has a lot of computations to carry out, then it would definitely take a longer time to execute. Therefore, knowledge of MACCs aids in the prediction of a model's execution time on various hardware platforms. Generally, models with lower MACCs have a low computational workload (Lin and Yeh 2022). To compute the MACCs for a simple neural network, the formula in Eq. 10 is used.
Memory consumption: Usually a neural network gets represented by a matrix of weights and biases. Each weight can be represented using 64–bit floating point number (double precision). This uses 8 bytes of data since 8 bits is equal to 1 byte. Thus, the size in memory depends on the layers of the neural network. For instance, a neural network architecture of [3–5–1] requires 26 doubles, or 208 bytes of data to represent the network since the weights for the aggregation function are represented by [(3 × 5) + (5 × 1) + (5 + 1)] doubles. There are a total of 26 parameters for such a network that must be optimized in order to obtain the best result. With a huge number of parameters to be optimized, a huge amount of computing resources would be required. The memory consumption of existing models and the models developed in this study is presented in Table 11.
From Table 11, a comparison of the MACCs of the models developed for ESP operated wells with the models developed in this study for oil rate estimation; it is found that the models developed in this study occupied the least memory in terms of space requirements, while it has a small number of MACCs, implying that its speed of computation would be fast. This makes this model useful for real-time deployment in the field where oil flow rate data are required in real time.
Conclusions
This work aimed at developing an explicit, computationally efficient and accurate predictive tool useful for estimating oil flow rate in electrical submersible operated wells. Since oil flow rate is considered a challenging problem that depends on many variables and has high parameter interdependencies, neural network algorithm was chosen for this purpose. This methodology was applied successfully to this flow rate estimation process. A database sourced from the field was used to train the neural network structures and check the validity of the network’s algorithm. Predictive results showed good agreement with field data. Based on the findings of this work, the following conclusions are drawn:
-
i.
The uniqueness of this study lies in three features of the developed model namely: its explicit representation, its computational cost evaluation and memory consumption as well as its high predictive capacity. These combined attributes are uncommon in most AI models that aim to predict flow rates in ESP-lifted wells.
-
ii.
The performance of the developed model as demonstrated by its high predictive precision compared with the existing models indicates that the developed model is a viable alternative for flow rate prediction in ESP-lifted wells.
-
iii.
The explicit nature of the developed model coupled with the sensitivity analysis of the input variables helped in making the developed model explainable and easy to incorporate in a software application.
-
iv.
The computational cost analysis of the developed model in comparison with existing models indicates that the developed model would perform computations in a timely manner should it be deployed in a software application.
-
v.
It is recommended that the model be tried on other fields operated with ESPs to further assess its predictive strength.
Abbreviations
- AAPRE:
-
Average absolute percentage relative error
- AI:
-
Artificial intelligence
- ALS:
-
Artificial lift systems
- ANFIS:
-
Adaptive neuro-fuzzy inference system
- ANN:
-
Artificial neural network
- API:
-
American Petroleum Institute
- APRE:
-
Average per cent relative error
- BPD:
-
Barrel per day
- BS&W:
-
Basic sediments and water
- CHP:
-
Casing head pressure
- CNN:
-
Convolutional neural network
- EDA:
-
Exploratory data analysis
- ESP:
-
Electrical submersible pump
- FVF:
-
Formation volume factor
- GL:
-
Gas lift
- GLR:
-
Gas liquid ratio
- GOR:
-
Gas oil ratio
- GRNN:
-
Generalized regression neural network
- HJP:
-
Hydraulic jet pumps
- LSTM:
-
Long short-term memory
- MACC:
-
Multiply-accumulate operations
- MAPE:
-
Mean absolute percentage error
- MPa:
-
Megapascals
- MPFM:
-
Multiphase flow meters
- MSE:
-
Mean square error
- NMSE:
-
Normalized mean square error
- PCP:
-
Progressive cavity pump
- PI:
-
Productivity index
- PINN:
-
Physics-informed neural network
- PP:
-
Plunger pumps
- RMSE:
-
Root mean square error
- RPM:
-
Revolution per minute
- SRP:
-
Sucker rod pump
- SVR:
-
Support vector regression
- Tanh:
-
Hyperbolic tangent
- WHP:
-
Well head pressure
- WHT:
-
Well head temperature
- XGBoost:
-
Extreme gradient boosting
- \({P}_{{\text{d}}}\) :
-
Pump discharge pressure (psi)
- \({P}_{i}\) :
-
Pump intake pressure (psi)
- \({P}_{wf}\) :
-
Bottom hole flowing pressure (psi)
- \({T}_{{\text{bh}}}\) :
-
Bottom hole temperature (°F)
- \({T}_{{\text{i}}}\) :
-
Intake temperature (°F)
- \({T}_{m}\) :
-
Discharge temperature (°F)
- \({T}_{{\text{s}}}\) :
-
Surface temperature (°F)
- \(\text{{UP}}_{p}\) :
-
Upstream pressure, (psi)
- \({{\text{Down}}}_{{\text{P}}}\) :
-
Downstream pressure (psi)
- \(X\) :
-
Set of observed values of X
- \(Y\) :
-
The normalized value of X
- \({X}_{{\text{min}}}\) :
-
Minimum value of X
- \({X}_{{\text{max}}}\) :
-
Maximum value of X
- \({R}^{2}\) :
-
Coefficient of determination
- \({y}_{{\text{actual}}}\) :
-
The actual output values
- \({y}_{{\text{predicted}}}\) :
-
The predicted output values
- \(\overline{y }\) :
-
The average of actual values
- IW:
-
Input–Hidden layer weights
- LW:
-
Hidden–Output layer weights
- \(i\) :
-
Index used for number of neurons
- \(j\) :
-
Index used for number of inputs
- \({b}_{1}\) :
-
Bias vector between the input and the hidden layers
- \({b}_{2}\) :
-
Bias value between the hidden and the output layers
- Purelin:
-
Linear transfer function
- Tansig:
-
Tangent sigmoidal transfer function
- \(Q\) :
-
Oil flow rate (bpd)
- \({Q}_{n}\) :
-
Normalized oil flow rate
- RIx :
-
The relative importance of input parameter X
- \({w}_{xy}\) :
-
Connection weights between input–hidden neurons
- \({w}_{yz}\) :
-
Connection weights between hidden–output neurons
- Tanh:
-
Hyperbolic tangent
References
Abdalla R, Al-Hakimi W, Perozo N, Jaeger P (2023) Real-time liquid rate and water cut prediction from the electrical submersible pump sensors data using machine learning algorithms. ACS Omega 8(14):12671–12692. https://doi.org/10.1021/acsomega.2c07609
Abdollahi F, Hosseini S, Sabet M, Esmaeili-Faraj SH, Amiri F (2021) A novel study of the gas lift process using an integrated production/injection system using artificial neural network approach. Model Earth Syst Environ 7:2101–2112. https://doi.org/10.1007/s40808-020-00958-9
Khan Academy (2022). Measuring an algorithm's efficiency. https://www.khanacademy.org/computing/ap-computer-science-principles/algorithms-101/evaluating-algorithms/a/measuring-an-algorithms-efficiency (Retrieved 08/08/2023)
Adamowski J, Chan HF, Prasher SO, Sharda VN (2012) Comparison of multivariate adaptive regression splines with coupled wavelet transform artificial neural networks for runoff forecasting in Himalayan micro-watersheds with limited data. J Hydrodyn 14(3):731–744
Ajiboye AR, Abdullah-Arshah R, Qin H, Isah-Kebbe H (2015) Evaluating the effect of dataset size on predictive model using supervised learning technique. Int J Softw Eng Comput Sci 1:75–84
Al Selaiti, I., Mata, C., Saputelli,L., Badmaev, D., Alatrach,Y., Rubio, E. and Mohan,R., Quijada, D. (2020). Robust data driven well performance optimization assisted by machine learning techniques for natural flowing and gas-lift wells in Abu Dhabi. Paper SPE-201696-MS presented at the SPE Annual Technical Conference & Exhibition originally scheduled to be held in Denver, Colorado, USA, pp 5 – 7. https://doi.org/10.2118/201696-MS
Alel MMA, Upom MRA, Abdullah RA, Abidin MHZ (2018) Estimating SPT-N value based on soil resistivity using hybrid ANN-PSO algorithm. J Phys Conf Series 995(1):1–14
Ali A, Si Q, Wang B, Yuan J, Wang P, Rasool G, Shokrian A, Ali A, Zaman MA (2022) Comparison of empirical models using experimental results of electrical submersible pump under two-phase flow: numerical and empirical model validation. Phys Scr 97(6):065209
Ambade, A., Karnik, S., Songchitruksa, P., Sinha, R.R. and Gupta, S. (2021). Electrical submersible pump prognostics and health monitoring using machine learning and natural language processing. Paper SPE-208649-MS presented at the SPE Symposium: artificial intelligence - towards a resilient and efficient energy industry, Virtual, October 2021. https://doi.org/10.2118/208649-MS
Azim RA (2020) Prediction of multiphase flow rate for artificially flowing wells using rigorous artificial neural network technique. Flow Meas Instrum 76(15):1–9. https://doi.org/10.1016/j.flowmeasinst.2020.101835
Azim RA (2022) A new correlation for calculating wellhead oil flow rate using artificial neural network. Artif Intell Geosci 3:1–7. https://doi.org/10.1016/j.aiig.2022.04.001
Bafghi, M.H.B. and Vahedi, A. (2018). A comparison of electric motors for electrical submersible pumps used in the oil and gas industry. IOP conference series: materials science and engineering, Volume 433, 2nd international conference on engineering sciences 26–27 March 2018, Kerbala, Iraq. https://iopscience.iop.org/article/https://doi.org/10.1088/1757-899X/433/1/012091
Bahaa, M., Shokir, E. and Mahgoub, I. (2018). Soft computation application: utilizing artificial neural network to predict the fluid rate and bottom hole flowing pressure for gas-lifted oil wells. Paper SPE -193052-MS presented at the Abu Dhabi international petroleum exhibition and conference held in Abu Dhabi, UAE 12 – 15 November 2018. https://doi.org/10.2118/193052-MS
Ban, Z. and Pfeiffer, C. (2023). Physics-Informed Gas Lifting Oil Well Modelling using Neural Ordinary Differential Equations. 33rd Annual INCOSE International Symposium 15–20 July 2023 — Honolulu, HI. pp 689–703. https://doi.org/10.1002/iis2.13046
Behnoud P, Hosseini P (2017) Estimation of lost circulation amount occurs during under balanced drilling using drilling data and neural network. Egyptian J Petrol 26(3):627–634. https://doi.org/10.1016/j.ejpe.2016.09.004
Binder BJT., Pavlov A, Johansen TA (2015) Estimation of flow rate and viscosity in a well with an electric submersible pump using moving Horizon. IFAC-PapersOnLine. https://doi.org/10.1016/j.ifacol.2015.08.022
Bird, T., Kingma, F.H. and Barber, D. (2021). Reducing the computational cost of deep generative models with binary neural networks. Paper presented at the international conference on learning representations. ICLR 2021. Vienna, Austria May 04 2021
Brasil J, Maitelli C, Nascimento J, Chiavone-Filho O, Galvão E (2023) Diagnosis of operating conditions of the electrical submersible pump via machine learning. Sensors 23(1):279. https://doi.org/10.3390/s23010279
Breit, S. and Ferrier, N. (2011). Using ESP systems for artificial lift. Pumps & Systems, https://www.pumpsandsystems.com/electric-submersible-pumps-oil-and-gas-industry?oly_enc_id=1561D9053534G4F (Accessed 18 November 2023)
Camargo, E., Aguilar, J., Ríos, A., Rivas, F. and Aguilar-Martin, J. (2009). Parameters Estimation in petroleum wells using artificial intelligence. Proceedings of the 13th WSEAS International Conference on SYSTEMS, Rodos Greece July 22 - 24, 2009. pp. 173 – 178. https://dl.acm.org/doi/abs/https://doi.org/10.5555/1627575.1627612
Chen J, Li W, Yang P, Chen B, Li S (2022) Prediction and classification of faults in electric submersible pumps. AIP Adv 12:1–10. https://doi.org/10.1063/5.0065792
Chicco D, Warrens MJ, Jurman G (2021) The coefficient of determination R-squared is more informative than SMAPE, MAE, MAPE, MSE and RMSE in regression analysis evaluation. Peer J Comput Sci 7:1–24
Chu H, Dong P, Lee WJ (2023) A deep-learning approach for reservoir evaluation for shale gas wells with complex fracture networks. Adv Geo-Energy Res 7(1):49–65. https://doi.org/10.46690/ager.2023.01.06
Cortes B, Araujo LR, Penido DRR (2019) Electrical submersible pump system model to assist oil lifting studies. J Petrol Sci Eng 174:1279–1289. https://doi.org/10.1016/j.petrol.2018.11.055
Dachanuwattana, S., Ratanatanyong, S., Wasanapradit, T., Vimolsubsin, P. and Kulchanyavivat, S. (2022). The deployment of deep learning models for performance optimization and failure prevention of electric submersible pumps. Paper OTC-31612-MS presented at the Offshore Technology Conference Asia, Virtual and Kuala Lumpur, Malaysia, March 2022. https://doi.org/10.4043/31612-MS
Elgibaly AA, Ghareeb M, Kamel S, El-Bassiouny ME (2021) Prediction of gas-lift performance using neural network analysis. AIMS Energy 9(2):355–378. https://doi.org/10.3934/energy.2021019
El-Tantawy M, Elgibaly A, El-Noby M (2020) Prediction and optimization of gas lift performance using artificial neural network analysis. J Appl Sci Res 7(1):41–68
Fontes, R.; Costa, E.; Abreu, O.L.; Martins, M.; Schnitman, L. (2020). On application of a zone IHMPC to an ESP-lifted oil well system. In Proceedings of the Anais do Congresso Brasileiro de Automática 2020, Online, pp 23–26 November 2020. https://doi.org/10.48011/asba.v2i1.1700
Franklin TS, Souza LS, Fontes RM, Martins MAF (2022) A physics-informed neural networks (PINN) oriented approach to flow metering in oil wells: an ESP lifted oil well system as a case study. Digital Chem Eng 5:1–11. https://doi.org/10.1016/j.dche.2022.100056
Ganat TA, Hrairi M (2018) A new choke correlation to predict flow rate of artificially flowing wells. J Petrol Sci Eng 171:378–1389. https://doi.org/10.1016/j.petrol.2018.08.004
Garrouch AA, Al-Dousari MM, Al-Sarraf Z (2020) A pragmatic approach for optimizing gas lift operations. J Petrol Explor Product Technol 10:197–216. https://doi.org/10.1007/s13202-019-0733-7
Garson GD (1991) Interpreting neural-network connection weights. AI Expert 6(4):46–51
Ghareeb, M. and Shedid, S.A. (2007). A New Correlation for Calculating Wellhead Production Considering Influences of Temperature, GOR, and Water-Cut for Artificially Lifted Wells. Paper IPTC 11101 presented at the International Petroleum Technology Conference held in Dubai, U.A.E., pp 4–6 December 2007. https://doi.org/10.2523/IPTC-11101-MS
Guo B, Lyons WC, Ghalambor A (2007) Artificial lift methods in petroleum production engineering. Comput-Assist Approach. https://doi.org/10.1016/B978-075068270-1/50074-8
Hallo, M., Jaramillo, B., Aguilar, J., Lozada, H. and Camargo, E. (2017). Developing a Mathematical Model of Oil Production in a Well That Uses an Electric Submersible Pumping System. In Proceedings of the 14th International Conference on Informatics in Control, Automation and Robotics (ICINCO 2017) - Volume 1, pp 230–237. https://www.scitepress.org/papers/2017/64212/64212.pdf
Hodson TO (2022) Root-mean-square error (RMSE) or mean absolute error (MAE): when to use them or not. Geosci Model Dev 15:5481–5487
Hoffmann A, Stanko M (2017) Short-term model-based production optimization of a surface production network with electric submersible pumps using piecewise-linear functions. J Petrol Sci Eng 158:570–584
Huang F, Xiong H, Chen S, Lv Z, Huang J, Chang Z, Catani F (2023) Slope stability prediction based on a long short-term memory neural network: comparisons with convolutional neural networks, support vector machines and random forest models. Int J Coal Sci Technol. https://doi.org/10.1007/s40789-023-00579-4
Kimrays Inc. (2023). How Does an Electric Submersible Pump (ESP) Work? https://kimray.com/training/how-does-electric-submersible-pump-esp-work. (Date accessed: 21 November 2023)
INTERSOG (2020) Calculating Time Complexity of an Algorithm: What You Should Know. https://intersog.com/blog/algorithm-complexity-estimation-a-bit-of-theory-and-why-it-is-necessary-to-know/ (Retrieved 08/08/2023)
Jierula A, Wang S, Tae-Min OH, Wang P (2021) Study on accuracy metrics for evaluating the predictions of damage locations in deep piles using artificial neural networks with acoustic emission data. Appl Sci 11(5):2314
Khakimyanov, M.I., Shafikov, I.N. and Khusainov, F.F. (2016). Electric Submersible Pumps in Oil Production and Their Efficiency Analysis. Proceedings of the 4th international conference on applied innovations in IT, (ICAIIT), March 2016, 4p.
Khamehchi E, Rashidi F, Rasouli H (2009) Prediction of gas lift parameters using artificial neural networks. Iranian Chem Eng J 8(43):1–11
Khan MR, Tariq Z, Abdulraheem A (2020) Application of artificial intelligence to estimate oil flow rate in gas-lift wells. Nat Resour Res 29(06):1–13. https://doi.org/10.1007/s11053-020-09675-7
Khare M, Shiva SM (2007) Artificial neural networks in vehicular pollution modelling. Springer-Verlag, Berlin Heidelberg, New York, p 242p
Krishnamoorthy D, Bergheim EM, Pavlov A, Fredriksen M, Fjalestad K (2016) Modelling and robustness analysis of model predictive control for electrical submersible pump lifted heavy oil wells. IFAC-PapersOnLine 49–7:544–549. https://doi.org/10.1016/j.ifacol.2016.07.399
Legendi RO, Gulyás L, Mansury Y (2013) Model replication in the context of agent-based simulation: Lessons learnt from two case studies. Eur Q Polit Attit Mentalities 2(1):74–85
Lin WC, Yeh YR (2022) Efficient malware classification by binary sequences with one-dimensional convolutional neural networks. Mathematics 2022(10):608. https://doi.org/10.3390/math10040608
Livingstone DJ, Manallack DT, Tetko IV (1997) Data modelling with neural networks: advantages and limitations. J Comput Aided Mol Des 11:135–142
Lu, Z., Pu, H., Wang, F., Hu, Z., and Wang, L. (2017). The Expressive Power of Neural Networks: A View from the Width. 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA.
Luo S, Ding C, Cheng H, Zhang B, Zhao Y, Liu L (2022) Estimated ultimate recovery prediction of fractured horizontal wells in tight oil reservoirs based on deep neural networks. Adv Geo-Energy Res 6(2):111–122. https://doi.org/10.46690/ager.2022.02.04
Mahendran, N. (2021). Analysis of memory consumption by neural networks based on Hyperparameters. https://arxiv.org/pdf/2110.11424.pdf (Retrieved 07/04/2023)
Maier H, Dandy G (2000) Neural networks for the prediction and forecasting of water resources variables: a review of modelling issues and applications. Environ Model Softw 15(1):101–124. https://doi.org/10.1016/S1364-8152(99)00007-9
Marcu M (2022) Using the artificial neural network to approximate the gas-lift performance curve. Appl Math, Mech, Eng 65(3):1–6
Miłkowski M, Hensel WM, Hohol M (2018) Replicability or reproducibility? On the replication crisis in computational neuroscience and sharing only relevant detail. J Comput Neurosci 45:163–172
Mohammadzaheri M, Tafreshi R, Khanb Z, Franchekc M, Grigoriadis K (2016) An intelligent approach to optimize multiphase subsea oil fields lifted by electrical submersible pumps. J Comput Sci 15:50–59. https://doi.org/10.1016/j.jocs.2015.10.009
Mohammadzaheri M, Tafreshi R, Khan Z, Ziaiefar H, Ghodsi M, Franchek M, Grigoriadis K (2019) Modelling of electrical submersible pumps for petroleum multiphase fluids, an intelligent approach supported by a critical review and experimental results. J Eng Res [TJER] 16(2):77–86. https://doi.org/10.24200/tjer.vol16iss2pp77-86
Ng M-F, Zhao J, Yan Q, Conduit GJ, Seh ZW (2020) Predicting the state of charge and health of batteries using data-driven machine learning. Nat Mach Intell 2:161–170
Nguyen HT, Vu DH, To TH, Thi N (2022) Application of artificial neural network for predicting production flow rates of gaslift oil wells. J Mining Earth Sci 63(3):82–91
Odedele T. O. and Ibrahim H. D. (2016). Predicting Oil Well Gas Lift Performance and Production Optimization Using hybrid Particle Swarm Optimization and Fuzzy Support Vector Machines. Proceedings of the World Congress on Engineering 2016 Vol I, WCE 2016, June 29 - July 1, 2016, London, U.K. https://www.iaeng.org/publication/WCE2016/WCE2016_pp110-116.pdf
Okoro EE, Sanni SE, Okigbo A, Adeyemi F, Emetere ME, Obomanu T (2021) Predicting non-newtonian fluid electric submersible pump failure using deep learning and artificial neural network. In: IOP conference series: Earth and environmental science, vol 655, 4th International conference on science and sustainable development (ICSSD 2020), “Advances in sciences and technology for sustainable development”, Center for Research, Innovation and Discovery, Covenant University, Ota, 3–5 August 2020. https://doi.org/10.1088/1755-1315/655/1/012027
Okorocha IT, Chinwuko CE, Mgbemena CO, Godfrey OC, Mgbemena CE (2022) Production optimization using gas lift incorporated with artificial neural network. J Eng Appl Sci 21(1):842–858
Olden JD, Joy MK, Death RG (2004) An accurate comparison of methods for quantifying variable importance in artificial neural networks using simulated data. J Ecol Modell 178:389–397
Ozili, P. K. (2023). The acceptable R-square in empirical modelling for social science research. Munich Personal RePEc Archive, 115769. pp. 1–14. https://mpra.ub.uni-muenchen.de/115769/ (Date accessed: 18/07/2023)
Popa, A., Umbriaco, J. and Tirtawidjaja, A. (2022). Effective Neural Networks Models for Inferred Production Prediction in ESP Equipped Wells. Paper SPE 209266-MS presented at the SPE Western Regional Meeting held in Bakersfield, California, USA, 26 - 28 April, 2022. https://doi.org/10.2118/209266-MS
Ranjan, A., Verma, S. and Singh, Y. (2015). Gas lift optimization using artificial neural network. Paper SPE-172610-MS presented at the SPE Middle East Oil and Gas Show and Conference held in Manama, Bahrain, 8 – 11 March 2015. https://doi.org/10.2118/172610-MS
Ricardo DMM, Jiménez GEC, Ferreira JV, Meirelles PS (2018) Multiphase gas-flow model of an electrical submersible pump. Oil & Gas Science and Technology - Revue d’IFP Energies Nouvelles 2018(73):29. https://doi.org/10.2516/ogst/2018031
Ruz-Hernandez, J.A., Salazar-Mendoza, R., Jimenez de la C, G., Garcia-Hernandez, R. and Shelomov, E. (2010). An Approach Based on Neural Networks for Gas Lift Optimization. Soft Comp. for Recogn. Based on Biometrics, SCI 312, pp. 207–224. https://link.springer.com/chapter/https://doi.org/10.1007/978-3-642-15111-8_13
Sabaa A, Abu El Ela M, El-Banbi AH, Sayyouh MHM (2023) Artificial neural network model to predict production rate of electrical submersible pump wells. SPE Prod Oper 38(01):63–72. https://doi.org/10.2118/212284-PA
Shokir EME-M, Hamed MMB, Ibrahim AE, Mahgoub I (2017) Gas lift optimization using artificial neural network and integrated production modeling. Energy Fuels 31(9):9302–9307. https://doi.org/10.1021/acs.energyfuels.7b01690
Stroebe W, Strack F (2014) The alleged crisis and the illusion of exact replication. Perspect Psychol Sci 9(1):59–71
Syed FI, Alshamsi M, Dahaghi AK, Neghabhan S (2022) Artificial lift system optimization using machine learning applications. Petroleum 8(2):219–226. https://doi.org/10.1016/j.petlm.2020.08.003
Takacs, G. (2009). Electrical Submersible Pumps Manual: Design, Operations, and Maintenance, Gulf Professional Publishing, 425p. https://doi.org/10.1016/B978-1-85617-557-9.X0001-2
Taylor R (1990) Interpretation of the correlation coefficient: a basic review. J Diagnos Med Sonogr 6(1):35–39. https://doi.org/10.1177/875647939000600106
Torres-Huitzil C, Girau B (2017) Fault and error tolerance in neural networks: a review. IEEE Access 5:17322–17341. https://doi.org/10.1109/ACCESS.2017.2742698
Wang Y, Liu H, Zhou Y (2021a) Development of a deep learning-based model for the entire production process of steam-assisted gravity drainage (SAGD). Fuel 287:1–11. https://doi.org/10.1016/j.fuel.2020.119565
Wang Y, Liu H, Guo M, Shen X, Han B, Zhou Y (2021b) Image recognition model based on deep learning for remaining oil recognition from visualization experiment. Fuel 291:1–14. https://doi.org/10.1016/j.fuel.2021.120216
Zhou Y, Wang Y (2022) An integrated framework based on deep learning algorithm for optimizing thermochemical production in heavy oil reservoirs. Energy 253:1–15. https://doi.org/10.1016/j.energy.2022.124140
Zhou J, Lin H, Jin H, Li S, Yan Z, Huang S (2022) Cooperative prediction method of gas emission from mining face based on feature selection and machine learning. Int J Coal Sci Technol 9(51):1–12. https://doi.org/10.1007/s40789-022-00519-8
Funding
The authors received no funding for this work.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that there is no conflict of interest regarding the publication of this paper.
Ethical approval
On behalf of all the co-authors, the corresponding author states that there are no ethical statements contained in the manuscripts.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Agwu, O.E., Alkouh, A., Alatefi, S. et al. Utilization of machine learning for the estimation of production rates in wells operated by electrical submersible pumps. J Petrol Explor Prod Technol 14, 1205–1233 (2024). https://doi.org/10.1007/s13202-024-01761-3
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13202-024-01761-3