
Abstract
The key problem in oil exploration and engineering is the lack of accurate and reliable data about the reservoir parameters of a field. Having a precise assessment of petrophysical properties can provide the ability to make decisions with a high degree of confidence about planning for production, exploitation, and further field development scenario. In this research, an artificial intelligence (AI)-based approach was developed to improve the estimation of reservoir parameters including porosity and volume of shale, which has a significant role in different stages of hydrocarbon exploration, in the Kashafrud Gas Reservoir in the northeast of Iran. For this purpose, we measured the petrophysical properties of 27 samples of the Kashafrud Formation. To increase the amount of data for employing a multilayer perceptron (MLP) artificial neural network (ANN), a geostatistical algorithm was used to increase the amount of laboratory measured data of porosity and volume of shale to 686 and 702, respectively. In addition, 2263 well-logging data from the same well were provided. The optimal MLP network with the topology of 6-7-1, and 6-8-1 was selected to estimate the porosity and shale volume with mean squared error (MSE) of 2.78731E−4, and 1.28701E−9, respectively. The training process was performed using two different sets of input data. In the first approach, all available well-logging data were used as input, ending up in high MSE. In the second approach, some selected well logs were used based on the results of sensitivity analysis which clearly improved the estimations. The ability of MLP networks made great improvements in the estimation of the both parameters up to 99.9%. The presence of valuable core data in this study significantly improved the process of comparison and conclusion. The final results prove that AI is a trusted method, also the potential of the ANN method for the reservoir characterization and evaluation associated problems should be taken into consideration. Due to the unavailability of core data along the whole wells, the application of intelligent methods, such as machine learning (ML) can be used to estimate the parameters in other oil or gas fields and wells.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
The reservoir properties including porosity and volume of shale play important roles in the reservoir production (Cheng and Pan 2020). Engineers design the best plans for the further reservoir development stages, also optimize the hydrocarbon recovery with the help of precise knowledge of these petrophysical parameters (Solanki et al. 2021). The porosity (\(\mathrm{\varnothing }\)) is greatly affected by the amount of clay minerals inside the reservoir known as volume of shale (\({V}_{\mathrm{sh}}\)) (Iqbal and Rezaee 2020). One of the most crucial stages in the characterization of reservoirs is the estimation of the shale volume (Balaky et al. 2023). It can be very challenging to determine the amount of shale in many areas accurately (Hussain et al. 2023). Its overestimation causes the effective water saturation (\({\mathrm{S}}_{{\mathrm{w}}_{\mathrm{e}}}\)) to be estimated very low, and this eventually leads to the wrong assumption of productivity. On the other hand, in the case of underestimation of shale volume, the water saturation will be estimated more than its actual value and this makes a productive zone to be overlooked. Moreover, the underestimation or overestimation of this parameter can cause some miscalculation in the estimation of effective porosity which is used for the determination of net pay (Iltaf et al. 2023).
ANNs can efficiently solve nonlinear problems. The ANN combines connected units including the artificial nodes (neurons), input, output, and processing layers. Each node is able to receive or transmit a pulse from or to the other nodes. A weight is assigned to each neuron and updated during the learning process. Typically, there are one or several hidden (processing) layers of nodes in an ANN model. Each of these layers has input and output values, gives and receives data to or from the next and pervious layers, respectively. Eventually, data are weighted and mixed together to make a new input for the upcoming layer (Gong et al. 2019). The ANN is considered as algorithms with two crucial functions, i.e., classification and regression. The outputs or responses generated by regression are normally continuous values, and the regression application in the oil industry is to estimate the porosity (∅), permeability (k), volume of shale (\({V}_{\mathrm{sh}}\)), and water saturation (\({S}_{\mathrm{w}}\)) (Gong et al. 2019). The ANNs have played a significant role in the accurate estimation of reservoir parameters including porosity, permeability, water saturation (Okon et al. 2021), and volume of shale (Taheri et al. 2021; Hong and Tien 2022). The implementation of the intelligence models enables the reservoir engineers to tackle the challenging and time-consuming tasks more successfully. The ANNs help to fuse different data and acquire complete and accurate information (Saikia et al. 2020).
The development of shale formations has had a transformative effect, especially in the USA, leading to notable improvements in the industry (Alessa et al. 2022). Over the last decade, shale reservoirs have been the major focus of extensive discussion and research on hydrocarbon exploration and exploitation globally. The development of shale formations has been a turning point, particularly in the USA, resulting in significant improvements. Simultaneously, ML and artificial intelligence (AI) have been instrumental in driving rapid development across all industries by automating routine operations (Syed et al. 2022). Shale gas reservoirs have been explored at various depths, ranging from as shallow as 1000 ft to as deep as 12,000 ft, with a variable range of total organic content (TOC) from 1 to 12%. The quality of the shale formation is characterized based on a variety of factors, including petrophysical properties like TOC, thermal maturity, saturation, and geo-mechanical properties such as the percentage of quartz or carbonate in mineralogy, differential stress, and friability, (Sondergeld et al. 2010). Since the early 1980s, petroleum engineers have been using computer-aided petrophysical and geo-mechanical studies such as log analysis, interpretation, and integration (Doveton 1986). However, ML-based and AI geo-mechanical and petrophysical analyses have become more prominent over the past decade, resulting in faster and more successful development than ever before in the history of the oil industry. As an unconventional reservoir, shale formations’ geo-mechanical properties are affected by diagenetic changes resulting from the depositional environment, temperature, and pressure. These changes cause mineralogical alterations, leading to changes in rock composition that directly impact sediment compaction and lithification. This makes it challenging to predict the geo-mechanical properties of shale (Syed et al. 2022).
In a study focused on the gas permeability of shale, Sakhaee-Pour & Bryant (2012) demonstrated that the narrowness of pore throats in shale is predominantly below 10nm and is situated within organic material where \({\mathrm{CH}}_{4}\) is absorbed. Consequently, the gas permeability of these rock formations is notably influenced by the gas that is absorbed, along with the movement of gas sliding along the pore walls. This effect is particularly pronounced at higher pressures (such as the initial pressures) found in typical shale gas reservoirs. In such conditions, the impact of the absorbed gas layer takes precedence over the influence of gas slipping through the pore spaces. Besides, it was projected that the permeability of the reservoir matrix can experience a substantial increase over the well operation, potentially growing by a factor of 4.5 as production continues and pressure decreases. According to Sakhaee-Pour and Steven (2015), non-random spatial distributions of throat sizes in acyclic void models offer more accurate portrayals of the void space within samples. These models are particularly suited for cases where drainage experiments demonstrate a capillary pressure versus saturation trend that deviates from the plateau-like pattern. Furthermore, they made successful permeability predictions that aligned well with laboratory measurements. The models they developed may find utility in other porous media where drainage data do not display a plateau-like variation.
The examination carried out by Sakhaee-Pour and Li (2016), with potential far-reaching effects on comprehending hydrocarbon movement in shale formations, scrutinized drainage experiments conducted on core samples to elucidate the interconnected pathway topology within the pore space on a core-scale level. Their investigation across various shale varieties revealed that the path traversed within the pore space by the nonwetting phase, measured as the length of the pore space, adheres to a fractal pattern. This is in contrast to the pore volume, which does not inherently exhibit fractal characteristics. While the assessment of matrix permeability through mercury injection capillary pressure measurements is a customary procedure in the petrophysical analysis of rock formations, it remains unachievable for shale formations due to the absence of a practical and reliable model. In 2018, Tran et al. (2018) introduce a straightforward correlation, rooted in the acyclic pore model, to approximate shale permeability. This uncomplicated relation was subjected to testing using seven samples drawn from three distinct formations.
Tran and Sakhaee-Pour (2018a, b) asserted that their research holds significant implications for the characterization of reservoirs using conventional petrophysical measurements. The results of numerical simulations revealed that the gas flow’s effective pore-throat size is influenced by pore pressure. Furthermore, the measured permeability in the presence of liquid surpassed the nominal permeability, commonly known as the Hagen–Poiseuille model, without accounting for slippage effects. Tran and Sakhaee-Pour (2018a, b) utilized the acyclic pore model to incorporate the effective interconnections among shale samples on the core scale. Their research, focused on exploring the core-scale critical properties (\({\mathrm{T}}_{\mathrm{c}}, {\mathrm{P}}_{\mathrm{c}}\)) of shale gas, holds significant potential for advancing a practical reservoir model tailored to shale formations. The findings indicated substantial alterations in displacement-critical properties, while modifications were unnecessary for storage-critical properties.
Yu et al. (2018) established a study about pore size of shale based on acyclic pore model. Their investigation into diverse shale types revealed that the average size of pore bodies typically exceeds 20nm. As a result, there is no necessity to consider pore proximity or confinement. In contrast, the pore-throat size distributions across different shales generally lie below 20nm, necessitating adjustments to a transport property that pertains to the formation’s resistance against fluid flow. Another study conducted by Alessa et al. (2021), they investigated the comprehensive characterization of pore sizes within Midra shale. The research established that pore-throat and pore-body sizes exhibit both narrow and wide distributions, with average measurements approximately 22nm and 18nm, respectively. As a result, modifications are needed for transport properties influenced by pore-throat sizes in order to accurately represent subsurface conditions. Notably, properties like density, which are tied to the volume of pores in the matrix, can be reasonably estimated based on gas composition within broader channels. These findings hold relevance for advancing unconventional gas development, which is regarded as one of the cleaner fossil fuel alternatives.
In 2022, Alipour et al. (2022) introduced an empirical correlation designed to account for the nonplateau-like pattern and the estimated capillary pressure observed in shale formations. By a dataset of mercury capillary pressure measurements from 30 samples extracted from various US shale formations, their proposed model holds potential for analyzing two-phase displacement phenomena within shale environments. Alessa et al. (2022) introduced a simple formula to precisely ascertain the entry pressure. This relationship, offering a novel method of determination, was employed on real measurements from seven shale samples. Enhancements to its effectiveness were achieved through the integration of k-nearest neighbors (KNN), locally selective combination in parallel outlier ensembles (LSCP), and Savitzky–Golay (SG) filters. The optimal outcome emerged from the sequential amalgamation of the basic formula with unsupervised machine learning and noise-filtering techniques.
The conventional well-logging data which are used to estimate the volume of shale, namely, are gamma ray (GR) and its spectral components, SP log, density (RHOB) log, resistivity logs (LLD, LLS, ILD, MSFL), neutron (NPHI), and sonic (DT) log. Moreover, a combination of gamma ray-density, neutron-density, and sonic-density logs can be used in formulas to estimate the \({V}_{\mathrm{sh}}\) (Ehsan et al. 2019; Tali and Farman, 2021; Mohavvel and Jozanikohan 2022). The decrease in porosity due to the presence of clay minerals will lead in a poor reservoir quality (Zhou et al. 2022). The presence of shale has an effect on the petrophysical properties and logging tool responses, thereby it causes a significant reduction in the effectiveness of the reservoir porosity (Radwan et al. 2020; El-Gendy, 2022; Ismail et al., 2023; Saleh et al. 2023). Using the factor index, a linear relationship between a special factor and shale content can be obtained with the natural gamma ray index (Szabó 2011). To have the best prediction of the hydrocarbon accumulations, one needs to know the reservoir quality distribution factors such as (\(\varnothing\)) and \({V}_{\mathrm{sh}}\) (Mohammed 2020). Gamal and Elkatatny (2021) implemented a new approach developed by the machine learning techniques (ANN) to predict the porosity of the reservoir rock. Their approach overcomes all of the conventional problems in the domain of porosity estimation using empirical correlations, measurements of the core samples, and logging tools.
Taheri et al. (2021) conducted a study by seismic data from the Hendijan oil field to establish a correlation between seismic properties and shale volume values. The researchers employed three distinct methods, namely, the sparse spike inversion, model-based inversion, and band-limited inversion methods to select the seismic line between the wells. The results indicated that the model-based method yielded the most favorable outcomes. Besides, they utilized ANNs in conjunction with seismic properties to estimate the shale volume. In another research, Ali (2021) employed traditional petrophysical techniques, such as linear gamma ray, nonlinear gamma ray, and spontaneous potential with the aim of creating a dataset for training ML algorithms, including random forest (RF), extreme gradient boost (XGBoost), and k-nearest neighbor (KNN). Ultimately, the nonlinear gamma ray method was identified as the most effective among the classical approaches, while the XGBoost algorithm demonstrated superior performance, achieving a mean squared error (MSE) of 0.078 (Ali 2021).
The findings obtained from the study of Jozanikohan and Abarghooei (2022) offer valuable advantages for geoscientists in the upstream petroleum sector. They proved that by the conducted method, samples can be assessed before resorting to intricate and time-consuming chemical and mineralogical analyses, as the Fourier transform infrared spectroscopy (FTIR) method efficiently accomplishes both tasks with greater ease and reduced expenses. This technique proves especially beneficial for evaluating clastic reservoirs, shale oil, and shale gas targets, enabling a rapid evaluation of their potential. The study demonstrates the practicality of the approach using a set of Shurijeh core samples as an illustrative example. In recent years, there has been a noticeable trend in utilizing machine learning (ML) algorithms for shale volume estimation, marking a novel area of interest in the petrophysical evaluation stage. This development is evident from studies conducted in the past decade, such as the research by Syed et al. in the year 2022, wherein they observed an increasing application of ML in various shale-related investigations. In a separate study conducted by Mohammadinia et al. (2023), the aim was to propose simplified techniques for shale volume estimation in a reservoir located in southern Iran. Furthermore, they sought to compare the performance of various ML methods in estimating shale volume. The conventional methods employed for comparison included gamma ray (GR), density-neutron (DN), and density-sonic (DS), while the ML methods consisted of ANN, support vector machine (SVM), and RF. The authors deduced that ANN, SVM, and RF methods estimated the shale volume with much better performance.
Since there are no detailed published data of the Kashafrud reservoir studies, the current research has been performed to investigate and evaluate its reservoir parameters including the shale content (\({V}_{\mathrm{sh}}\)), and porosity (\(\varnothing\)) by the laboratory, and petrophysical methods, as well as the intelligent methods (such as ANN). The aim of this paper was to shed light on the possible role of machine learning to estimate two critical parameters of reservoir quality assessment, porosity and volume of shale, in the Kashafrud Formation. During this process, the high accuracy of estimated parameters by artificial intelligence was carefully evaluated. The performance of the artificial neural network was measured using a criterion of comparing the results of calculations obtained for both results obtained from conventional petrophysical methods and artificial neural network methods. The presence of valuable core data in this study significantly improved the process of comparison and conclusion.
Geological setting
The Kashafrud Formation is in the northeastern of Iran in a sedimentary basin of Kopet-Dagh (Fig. 1). The Kashafrud Formation was characterized as a reservoir by sedimentological and geochemical studies (Ershadinia et al. 2023). This sandstone formation, aging Aalenian-Bathonian (Middle Jurassic) mostly consists of the sedimentary rocks such as shale, sandstone, and conglomerate. A large area in the Kopet-Dagh basin, across the northeastern of Iran has been widespread by the Kashafrud Formation (Poursoltani & Gibling 2011).

The geographic location map of the studied area and well (Revised from Miri et al. 2018)
The Khangiran anticline is approximately located at 180 km northeast of Mashhad and 25 km west of Sarakhs city. Based on the geophysical information, the general trend of the structure is northwest-southeast and it is asymmetric. Also, the northern edge has a steeper slope than the southern edge. In the mentioned anticline, the existence of three separate gas reservoirs including two sweet ones in the Shurijeh Formation, and one sour gas reservoir in the Mozdoran Formation has been confirmed (Mashayekhi et al. 2022). The Khangiran Formation, aging Lower–Middle Eocene with a thickness of 500 m is mainly consisted of succession of olive green, silty, calcareous and clay shales of gray, green-gray, silty, sticky, and calcareous rocks (Ghorbanpour et al. 2023). The stratigraphic column of the studied well (Well A) in the Khangiran gas field has been drawn by Strater software ver. 5 (Fig. 2).

The stratigraphic column of the studied well in the Khangiran gas field, plotted by Strater software ver. 5
The sandstones of Kashafrud Formation are mostly from the arkosic and lithic arenite types, rich of the fragments from the volcanic and sedimentary sources (Poursoltani and Gibling 2011). The thickness of drilled Kashafrud Formation is 433 m. The drilled thickness in the upper parts includes succession of light gray, light brown, gray, medium to coarse sandstones, hard to slightly porous bituminous, calcareous and gray, green-gray, silty and slightly pyrite. The lower drilled parts mainly consist of light gray, brownish gray, light brown, silty, sandy, calcareous, soft and thin layers of light gray sandstone, medium grain, semi-hard to hard (Ghorbanpour 2023).
Materials and methods
Core data
In the present research, the dataset was collected from one well, i.e., well A (Fig. 1) in the Khangiran gas field, NE Iran. This well was drilled to investigate the hydrocarbon status of the bottom formations under Mozdoran (especially Kashafrud Formation) as well as the hydrocarbon production from the Mozdoran, and Kashafrud Formation. This well is drilled up to Kashafrud Formation (with a drilled thickness of 433 m).
Additionally, nine intervals were cored between depths of 3080.5 and 4397.5 m. During the drilling operation, nine core boxes of 0.9 m length were obtained. 10 core samples were then carefully selected and cut from the core #9 of well A. The laboratory measurements of the porosity (mercury prosimetry) and volume of shale (XRD test and densitometry) were performed on these 10 core samples.
Wireline logging data
In this study, 2263 petrophysical data were provided with a depth interval of 0.061 m. One set of well-logging data from an eastern Kopet-Dagh field’s gas producing well, including natural gamma ray (GR), sonic (DT), photoelectric (PEF), density (RHOB), neutron (NPHI), caliper (CALI), spontaneous potential (SP), and shallow & deep laterolog (LLS & LLD) were available from wireline logging process. Since there was a discrepancy between the depths of core samples and well logs, the depth matching was conducted by averaging between the upper and lower depths for each depth whose well-logging data was absent.
Methods
Core analyses
To analyze 10 core samples, the X-ray diffraction (XRD) was used to determine how much clay content existed in the Kashafrud Formation. The analysis was performed to fully identify the type of clay minerals and to calculate the laboratory shale weight percent. The results indicated that the constituent minerals in order of abundance in the studied samples were quartz, clay minerals, alkali feldspars, plagioclase, ankerite, and pyrite, respectively. In Fig. 3, the average weight percentage of each mineral in all samples is plotted separately.

The average weight percentage of samples’ minerals, obtained from the XRD analysis
The result of the XRD experiments is generally based on the weight percent and since it is necessary to make a comparison with the petrophysical data based on the volume percentage, one needs to have the density of each sample to convert the weight percent to the volume percent of clay minerals. The densitometry of the samples was performed by a 25-cc standard pycnometer by means of an organic fluid such as acetone. Therefore, the densitometry tests the samples were performed and each total weight percent of clay minerals were converted to the volume percent. The relevant information is listed in Table 1.
The mercury porosimetry can detect the nanopores and macropores up to the size of 400 \(\mathrm{\mu m}\). The mercury porosimetry remained the preferred method for analyzing the microporous materials (Schlumberger & Thommes 2021). Using the mercury porosimetry method, the porosity of 10 samples was precisely measured in the laboratory.
The conventional petrophysical methods for porosity and volume of shale estimation
The most well-logging data can detect the clay minerals. Therefore, the estimation of the shale volume is possible from any logs. The definition of volume of shale in the literature is the ratio of the volume of fine grain particles such as silt and clay to the total volume of the rock (Shah et al. 2021). It has been proven that the gamma ray log and its spectral components (potassium, thorium, and uranium) are the best logs for the volume of shale estimation (Al Al-Azazi and Albaroot 2022; Khamees et al. 2022).
To determine the quantity of the clay minerals, the estimated volume of shale needs to be corrected. Below, Eqs. (1)–(6) illustrate the conventional petrophysical relationships to estimate the shale volume from the natural gamma ray log including Bhuyan and Passey (1994), Stieber (1973), Clavier (1971), Larionov-1 (according to the age of the Kashafrud Formation) (1969), and combination of gamma density logs. The symbols, values, and parameters used in the formulas are listed in List of symbols section.
After calculating the volume of shale using petrophysical and laboratory relationships, to measure the accuracy of the data, the values obtained from these two methods were compared. The results obtained from the petrophysical methods with error were calculated. Through this method, it is possible to match the volume percentages achieved in the laboratory with the values obtained through the experimental relationships and validation. According to the curve of the average percentage of errors (Fig. 4), the natural gamma ray (GR) was the criterion for further petrophysical studies and analytical methods such as the neural network.

The curve of average errors percentages for volume of shale. (1) Stieber/\({\text{I}}_{{{\text{GR}}}}\), (2) Stieber/\(I_{{{\text{SGR}}}}\), (3) Stieber/\(I_{{{\text{CGR}}}}\), (4) Clavier/\(I_{{{\text{GR}}}}\), (5) Clavier/\(I_{{{\text{SGR}}}}\), (6) Clavier/\(I_{{{\text{CGR}}}}\), (7) Larionov/\({\text{I}}_{{{\text{GR}}}}\), (8) Larionov/\({\text{I}}_{{{\text{SGR}}}}\), (9) Larionov/\(I_{{{\text{CGR}}}}\), (10) Gamma-Density logs/\(I_{{{\text{GR}}}}\), (11) Gamma-Density logs/\(I_{{{\text{SGR}}}}\), (12) Gamma-Density logs/\({\text{I}}_{{{\text{CGR}}}}\)
After the calculations, it was observed that the average error rate was considerably high due to the laboratory validations (89.46%). Thus, the intelligent methods (ANN) became the basis of the next step.
In the porosity calculation segment, to compare the performance and results of both conventional petrophysical and laboratory methods, the average errors percentages obtained from these two methods were calculated (Table 2). It was observed that the average error rate was high, standing at 58.3%. Thereby to reduce the error rate, the ANN was chosen to accurately calculate the porosity at different depths.
The estimation of the \(\varnothing\) and \({V}_{\mathrm{sh}}\), using the multilayer perceptron (MLP) artificial neural network (ANN)
The neural network is a simulation of the human brain in the form of an artificial system that consists of a myriad of processor organs which are known as neurons with a special order that is similar to the human mind. A neural network consists of an input layer to the apply features of problem, a hidden layer to process, and an output layer to provide the answer(s). All of the training algorithms aim to minimize the mean squared error (MSE) between the outputs of the predicted model and the observed outputs with respect to the training dataset (Adegbite et al. 2021). The methods based on the artificial intelligence proved their effectiveness and ability to provide robustness modeling on the basis of their high correlation coefficient between the actual and estimated volume of shale.
The application of MLP network for the porosity estimation
In the well under study, the core laboratory measured porosity contains 10 data. Since the artificial intelligence-based methods needs a large number of data to well train the network, the number of data has been increased to 686 based on the geostatistical algorithms. The selection of input data was performed in two ways. In the first approach, all the available logs were inserted to the MATLAB software ver. 2021 (Rajabi et al. 2021, 2023; Radwan et al. 2022; Abdelghany et al. 2023). In the other approach, some selected well-logging information chosen from the sensitivity analysis were inserted to the mentioned software as input data. In the both approaches, the input data was standardized to avoid one variable dominates the model.
In general, 70%, 15%, and 15% of the data were assigned for the training, validation, and testing, respectively. The Levenberg–Marquardt algorithm was used to train the MLP neural network. During several trainings, the main criteria for evaluation of the most appropriate network, was chosen to be the mean squared error (MSE) and the correlation coefficient (R). The structure of the network consists of nine and six neurons (for the both approaches) in the input layer, one and two hidden layers, and one output layer. The input, output, parameters of the network, and their symbols are summarized in Table 3.
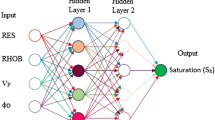
An outline of the optimal MLP network model for estimating porosity in the Kashafrud Formation can be seen in Fig. 5. All the possible mathematical functions for generation of the output were tested, and the results are listed in Table 4. There are several characteristics distinguishing each of neurons in the network, including the input weights, and the activation functions. Compared to the rest of the functions, the Tan-Sigmoid transfer function showed a better performance.

The outline of the optimal MLP network model for estimating porosity in the Kashafrud Formation
Since the input data ranged between 0 and 1, having a function that computes the output between zero and one was a logical reason for choosing the Tan-Sigmoid function. Therefore, the Tan-Sigmoid (tansig) was assumed as one of the most commonly used activation functions in the MLP networks. Equation (7) describes the Tan-Sigmoid function in which \(\upbeta\) indicates the slope parameter:
First, all available well-logs data were entered into the ANN (Table 5). As the proposed MLP network had a low R-value and a high MSE, it did not capture the laboratory data successfully. To improve the results, it was decided to limit the input data to the most relevant parameters. To find the most correlated parameters with the porosity, a sensitivity analysis in the form of a Pearson matrix (Table 6) was performed.
To calculate the correlation coefficient (R), and the MSE (Eq. (8), the resulting estimates were compared to the actual measurements of the porosity in the laboratory.
In which \(x_{{i_{{{\text{meas}}}} }}\) is the measured values, \(x_{{i_{{{\text{est}}}} }}\) is the estimated values, and N is the total number of observations. The input and output data were normalized as follows:
The porosity estimation results illustrated that when both all and selected well logs were put into the network, 288, 62, and 62 data were assigned for training, validation, and testing, respectively. It was also observed that the estimation when all logs were inserted into model as the input, has high MSE and also low R-values (Table 5). Considering all other tested topologies, 6-7-1 was the chosen architecture, having the highest R-value and the lowest MSE (Table 7). The MSE and R values were the best model at epoch 103 (Fig. 6), when the optimal MLP model was gained for estimation of the porosity in the Kashafrud Formation. Table 8 compares the results of networks’ trainings with one and two hidden layers. MSE and R values of 2.78731 \({\mathrm{E}}^{-4}\) (Fig. 6) and 0.9999 (Fig. 7), respectively, were found with an optimal MLP model for the porosity estimation in the Kashafrud Formation.

Training, validation, and testing curves of the samples with the chosen topology 6–7-1

The estimation error curves for the samples with the chosen topology 6–7-1
Finally, as a major step, to estimate the porosity in the whole interval of the Kashafrud Formation from the core data that were not used since this step (10 samples), the optimal MLP network was employed. The average output which indicates the estimated porosity was equal to 0.13%.
The application of MLP network for the volume of shale estimation
The core laboratory measured \({\mathrm{V}}_{\mathrm{sh}}\) contains 10 data. Since the artificial intelligence-based methods needs a large number of data to well train the network, the number of data has been increased to 702 based on the geostatistical algorithms. It was observed that the \({\mathrm{V}}_{\mathrm{sh}}\) estimation when all logs were inserted into model as the input has high MSE and also low R-values (Table 11). In the selection of proper inputs for the ANN model, the Pearson Correlation Coefficient (Table 8) has been used extensively. An outline of the optimal MLP network model for estimating volume of shale is shown in Fig. 8. The input, output, parameters of the network, and their symbols are summarized in Table 9. Compared to the rest of the different transfer functions, the Tan-Sigmoid function showed a better performance (Table 10).

The outline of the optimal MLP network model for estimating \(V_{{{\text{sh}}}}\) in the Kashafrud Formation
Similar to the previous estimation, before using the results of the Pearson correlation matrix, the values of R and MSE had significant errors (Table 11). However, after considering the sensitivity analysis, a significant improvement was seen in the trains (Table 12). The conventional methods for the estimation of \({\mathrm{V}}_{\mathrm{sh}}\) are used which produce inconsistent results. Though, comparing all the tested networks, 6-8-1 had the least mean squared error and the highest correlation coefficient (Table 12). Through this, MSE and R-values of 1.28701 \({\mathrm{E}}^{-9}\) (Fig. 9) and 0.9999 (Fig. 10), respectively, were found at epoch 1000 with an optimal MLP model for the \({V}_{\mathrm{sh}}\) estimation in the Kashafrud Formation.

Training, validation, and testing curves of the samples with the chosen topology 6-8-1

The estimation error curves for the samples with the chosen topology 6-8-1
Finally, as a major step, to estimate the \({V}_{\mathrm{sh}}\) in the whole interval of the Kashafrud Formation from the core data that were not used since this step (10 samples), the optimal MLP network was employed. The average output which indicates the estimated \({\mathrm{V}}_{\mathrm{sh}}\) was equal to 8.34%.
Results and discussion
In this study, the laboratory analyses including the Powder X-ray diffraction (PXRD), and densitometry were performed. Based on the results of XRD analysis, the minerals in order of abundance are quartz, clay minerals, alkali feldspars, plagioclase, ankerite, and pyrite. Since the percentage of the clay minerals in the XRD test is weight percentage, this result should be compared with petrophysical data expressed in terms of volume percentage. To calculate the volume percent, a densitometry test was performed and its results showed that the highest and lowest amounts of clay minerals were 12.8 and 6.7 volume percent, respectively (Table 1). Then, having the density, the laboratory \({\mathrm{V}}_{\mathrm{sh}}\) of all samples was obtained. The results are presented in Table 13.
Figure 11 plots the data from the density log in terms of the natural gamma ray. The lowest amount of the natural GR of the studied well was chosen as the clean sand baseline, and the highest amount of the natural GR was chosen as the clay baseline, based on the data of the natural GR of the studied field. The range of all samples lead to the clay baseline, and most core samples have a density between 2.68 and 2.72 g/cm3 and subsequently, their radioactivity is relatively high. Thus, this indicates a high amount of the clay minerals, and this was confirmed in the laboratory studies.

Density vs. natural gamma-ray
Furthermore, SEM studies were performed to determine the distribution pattern of the clay minerals. Based on these studies, the distribution pattern of clay minerals was mainly of pore filling type and in some limited cases, pore coating type was identified. The size of clay minerals varied from 1.4 μm to 40 μm. The performed EDAX analysis confirmed the minerals identified by XRD method. The most important achievements of this research include the following findings:
The results of volume of shale estimation showed that the natural gamma ray can be used as a criterion for further petrophysical studies and mathematical analytical methods (such as neural network) due to the lower error rate. Stieber calibration and combination of gamma-density logs also had the lowest mean error. The MLP neural network recorded an acceptable and appropriate performance for estimating the \(\varnothing\) and \({V}_{\mathrm{sh}}\) based on the selected logs. Though, when all the logs were imported as input, the error values prevented the appropriate topology from being selected as the best performance.
The challenge with the utilized method is the effort required to carefully select the appropriate training data, which is a common requirement for all models that use real well-logging data. However, the ANN helps to fuse different data and acquire complete and accurate information. Furthermore, this approach minimizes computing time, saving both time and money that would have been spent on core sampling without any prior knowledge of the matrix material or pore fluid.
The most important results of this study including following:
-
1.
The average laboratory value of \({V}_{\mathrm{sh}}\) for all the core samples was %8.88.
-
2.
The average value of \({V}_{\mathrm{sh}}\) based on the petrophysical relationships in the entire under-studied well was %0.88.
-
3.
The average value of \({V}_{\mathrm{sh}}\) based on the conducted MLP-ANN in the entire under-studied well was %8.34.
-
4.
The average value of \(\varnothing\) based on the conducted MLP-ANN in the entire under-studied well was %0.13.
The aim of this study was to estimate the porosity and volume of shale in the Kashfrud gas reservoir in the Khangiran field. The validation conducted in the research was highly valuable as it compared the results obtained from two distinct approaches, enabling authors to accurately and reliably calculate the percentages of improvement in estimating the two parameters. The superiority of the present investigation compared to other similar published studies in the field of oil exploration is the integration of conventional petrophysical methods (calculation of parameters methods using traditional relationships), and intelligent ML methods (MLP—ANN) to improve the accuracy of reservoir parameters estimation.
The ANN developed in the study can be employed and examined to estimate porosity and volume of shale values in other wells within the gas field with reliable accuracy, when real well log or core samples data are not available. Given the high expenses associated with exploration operations in the oil industry, the method in this article presents a golden opportunity to save time and money by intelligent and modern techniques like ANNs to quickly and accurately estimate reservoir parameters using initial data from the target field. This approach can greatly assist petroleum engineers in tackling time-consuming and challenging problems related to the petroleum engineering field.
Conclusions
Traditionally, the porosity and volume of shale are estimated with a very high error rate, which was the main reason that the multilayer perceptron (MLP) artificial neural network (ANN) was conducted to reduce the error. The application of MLP resulted in the significant error percentage decrease in the estimation of two parameters including \(\mathrm{\varnothing }\) and \({\mathrm{V}}_{\mathrm{sh}}\) from 58.3% and 89.46% in the traditional petrophysical method to 2.78731 \({\mathrm{E}}^{-4}\) and 1.28701 \({\mathrm{E}}^{-9}\), respectively. According to the validation of obtained results from the application of the MLP method with the core analysis data, the porosity and volume of shale in the understudy field has been assessed to be highly accurate.
The correlation coefficient (R-value) and mean squared error (MSE) in the estimation process were improved considerably in comparison with conventional methods. Furthermore, the correlation coefficient for the both estimations were 0.9999, using the MLP method. Besides, the ability of MLP-ANN made great percentage of improvements, which were 99.95% for \(\varnothing\), and 99.99% for \({\mathrm{V}}_{\mathrm{sh}}\). The obtained results of this investigation using MLP-ANN made great percentage of improvements (99.95% for \(\varnothing\), and 99.99% for \({V}_{\mathrm{sh}}\)), which has greatly impacted the estimation of in place hydrocarbon.
Abbreviations
- CALI:
-
Caliper, IN
- CGR:
-
Corrected gamma ray, API
- DT:
-
Sonic, US/F
- GR:
-
Natural gamma ray, API
- \({\text{GR}}_{{{\text{log}}}}\) :
-
Total ray reading in the zone of interest, API or wt%
- \({\text{GR}}_{{{\text{max}}}}\) :
-
Average ray response in dirty (clay rich) zone, API or wt%
- \({\text{GR}}_{{{\text{min}}}}\) :
-
Average ray response in clean (clay free) zone, API or wt%
- \(I_{{{\text{GR}}}}\) :
-
Natural gamma ray index
- \(I_{{{\text{SGR}}}}\) :
-
Standardized natural gamma ray index
- K:
-
Permeability, mD
- LLS:
-
Shallow resistance radius, Ohmm
- MSFL:
-
Micro spherically, Ohmm
- NPHI:
-
Neutron, V/V
- PEF:
-
Photoelectric, B/E
- RHOB:
-
Density, g/cm3
- SCR:
-
SUM gamma ray, API
- SP:
-
Spontaneous, mV
- \(S_{{{\text{w}}_{{\text{e}}} }}\) :
-
Effective water saturation
- \(V_{{{\text{sh}}}}\) :
-
Shale volume, %
- \(\rho_{{{\text{b}}_{{{\text{sh}}}} }}\) :
-
Bulk density in dirty (clay rich) zone, g/\({\text{cm}}^{3}\)
- \(\rho_{b}\) :
-
Density log data (RHOB), g/\({\text{cm}}^{3}\)
- \(\emptyset_{{{\text{ND}}}}\) :
-
Neutron–density log porosity, V/V
- \(\emptyset_{{\text{N}}}\) :
-
Neutron log porosity, V/V
- \(\emptyset\) :
-
Porosity, V/V
- AI:
-
Artificial intelligence
- ANN:
-
Artificial neural network
- FTIR:
-
Fourier transform infrared spectroscopy
- KNN:
-
K-nearest neighbor
- ML:
-
Machine learning
- MLP:
-
Multilayer perceptron
- MSE:
-
Mean squared error
- R :
-
Correlation coefficient
- RF:
-
Random forest
- SVM:
-
Support vector machine
- XGBoost:
-
Extreme gradient boost
- XRD:
-
X-ray diffraction
References
Abdelghany WK, Hammed MS, Radwan AE (2023) Implications of machine learning on geomechanical characterization and sand management: a case study from Hilal field, Gulf of Suez, Egypt. J Pet Explor Prod Technol 13(1):297–312. https://doi.org/10.1007/s13202-022-01551-9
Adegbite JO, Belhaj H, Bera A (2021) Investigations on the relationship among the porosity, permeability and pore throat size of transition zone samples in carbonate reservoirs using multiple regression analysis, artificial neural network and adaptive neuro-fuzzy interface system. Pet Res 6(4):321–332. https://doi.org/10.1016/j.ptlrs.2021.05.005
Al Al-Azazi NA, Albaroot M (2022) Effect evaluation of shale types on hydrocarbon potential using well logs and cross plot approach, Halewah oilfield, Sab’atayn Basin, Yemen. Energy Geosci 3(2):202–210. https://doi.org/10.55699/ijogr.2023.0301.1037
Alessa S, Sakhaee-Pour A, Sadooni FN, Al-Kuwari HA (2021) Comprehensive pore size characterization of Midra shale. J Petrol Sci Eng 203:108576. https://doi.org/10.1016/j.petrol.2021.108576
Alessa S, Sakhaee-Pour A, Sadooni FN, Al-Kuwari HA (2022) Capillary pressure correction of cuttings. J Petrol Sci Eng 217:110908. https://doi.org/10.1016/j.petrol.2022.110908
Ali M (2021) Machine learning based shale volume prediction from the Norwegian North Sea (Master's thesis, uis)
Alipour KM, Kasha A, Sakhaee-Pour A, Sadooni FN, Al-Kuwari HAS (2022) Empirical relation for capillary pressure in shale. Petrophysics 63(05):591–603. https://doi.org/10.30632/PJV63N5-2022a2
Balaky SM, Al-Dabagh MM, Asaad IS, Tamar-Agha M, Ali MS, Radwan AE (2023) Sedimentological and petrophysical heterogeneities controls on reservoir characterization of the Upper Triassic shallow marine carbonate Kurra Chine Formation, Northern Iraq: Integration of outcrop and subsurface data. Mar Pet Geol 149:106085. https://doi.org/10.1016/j.marpetgeo.2022.106085
Bhuyan K, Passey QR (1994) Clay estimation from GR and neutron-density porosity logs. In: SPWLA 35th Annual Logging Symposium. Tulsa, Oklahoma, OnePetro. SPWLA-1994-DDD
Cheng Y, Pan Z (2020) Reservoir properties of Chinese tectonic coal: a review. Fuel 260:116350. https://doi.org/10.1016/j.fuel.2019.116350
Clavier C, Hoyle W, Meunier D (1971) Quantitative interpretation of thermal neutron decay time logs: part I. Fundamentals and techniques. J Pet Technol 23(06):743–755. https://doi.org/10.2118/2658-A-PA
Doveton JH (1986). Log analysis of subsurface geology: concepts and computer methods
Ehsan M, Gu H, Ahmad Z, Akhtar MM, Abbasi SS (2019) A modified approach for volumetric evaluation of shaly sand formations from conventional well logs: A case study from the talhar shale, Pakistan. Arab J Sci Eng 44(1):417–428. https://doi.org/10.1007/s13369-018-3476-8
El-Gendy NH, Radwan AE, Waziry MA, Dodd TJ, Barakat MK (2022) An integrated sedimentological, rock typing, image logs, and artificial neural networks analysis for reservoir quality assessment of the heterogeneous fluvial-deltaic Messinian Abu Madi reservoirs, Salma field, onshore East Nile Delta. Egypt Mar Pet Geol 145:105910. https://doi.org/10.1016/j.marpetgeo.2022.105910
Ershadinia M, Ghaemi F, Homam SM (2023) Permian to recent tectonic evolution of the Palaeotethys suture zone in NE Iran. J Asian Earth Sci. https://doi.org/10.1016/j.jseaes.2023.105658
Gamal H, Elkatatny S (2021) Prediction model based on an artificial neural network for rock porosity. Arab J Sci Eng. https://doi.org/10.1007/s13369-021-05912-0
Ghorbanpour Yami H, Naqibi A, Alaviyan SM, Bahari A (2023) Different qualities of cement banding in geological formations of khangiran Gas Field NE, Iran. J Pet Res. https://doi.org/10.22078/PR.2022.4901.3191
Gong B, Keele D, Toumelin E, Clinch S (2019) Estimating net sand from borehole images in laminated deepwater reservoirs with a neural network. Petrophys SPWLA J Form Eval Reserv Descr 60(05):596–604. https://doi.org/10.30632/PJV60N5-2019a4
Hong DV, Tien HN (2022) Using artificial neural network to predict volume of shale from well logging data. Moлoдыe-Hayкaм o Зeмлe. https://doi.org/10.46326/JMES.2021.62(3).06
Hussain W, Ehsan M, Pan L, Wang X, Ali M, Din SU, Liang L (2023) Prospect evaluation of the cretaceous yageliemu clastic reservoir based on geophysical log data: A case study from the Yakela Gas Condensate Field, Tarim Basin, China. Energies 16(6):2721. https://doi.org/10.3390/en16062721
Iltaf KH, Butt SEH (2023) Energy geoscience. Energy 4:100143. https://doi.org/10.1016/j.engeos.2022.100143
Iqbal MA, Rezaee R (2020) Porosity and water saturation estimation for shale reservoirs: an example from Goldwyer formation Shale, Canning Basin. Western Austr Energ 13(23):6294. https://doi.org/10.3390/en13236294
Ismail A, Zeinel-Din MY, Radwan AE, Gabr M (2023) Rock typing of the Miocene Hammam Faraun alluvial fan delta sandstone reservoir using well logs, nuclear magnetic resonance, artificial neural networks, and core analysis, Gulf of Suez, Egypt. Geol J. https://doi.org/10.1002/gj.4747
Jozanikohan G, Abarghooei MN (2022) The Fourier transform infrared spectroscopy (FTIR) analysis for the clay mineralogy studies in a clastic reservoir. J Pet Explor Prod Technol. https://doi.org/10.1007/s13202-021-01449-y
Khamees LA, Alrazzaq AAAA, Humadi JI (2022) Different methods for determination of shale volume for Yamama formation in an oil field in southern Iraq. Mater Today Proc. https://doi.org/10.1016/j.matpr.2022.01.455
Larionov VV (1969) Borehole radiometry. Nedra, Moscow 127:813
Mashayekhi Z, Kadkhodaei A, Solgi A, Baba Zadeh A, Aleali M (2022) Facies analysis, diagenesis processes and sedimentary environment of Shurijeh Formation in Khangiran gas field. J Pet Res 32:36–59. https://doi.org/10.22078/PR.2022.4650.3090
Miri M, Bagheri R, Akhlaghi MR, Sotohian F (2018) Geochemical evolution of saline formation water of the Mozduran gas reservoir. J Stratigr Sedimentol Res 34(4):39–56. https://doi.org/10.22108/jssr.2019.114104.1074
Mohammadinia F, Ranjbar A, Kafi M, Shams M, Haghighat F, Maleki M (2023) Shale volume estimation using ANN, SVR, and RF algorithms compared with conventional methods. J Afr Earth Sci. https://doi.org/10.1016/j.jafrearsci.2023.104991
Mohammed AKA (2020) A review: controls on sandstone permeability during burial and its measurements comparison—example, Permian Rotliegend Sandstone. Model Earth Syst Environ 6(2):591–603. https://doi.org/10.1007/s40808-019-00704-w
Mohavvel S, Jozanikohan G (2022) The application of neural network method in petrophysical evaluation of asmari formation in a producing well in southwest of Iran. J Min Eng 17(54):1–13. https://doi.org/10.22034/ijme.2021.113997.1751
Okon AN, Adewole SE, Uguma EM (2021) Artificial neural network model for reservoir petrophysical properties: porosity, permeability and water saturation prediction. Model Earth Syst Environ 7(4):2373–2390. https://doi.org/10.1007/s40808-020-01012-4
Poursoltani MR, Gibling MR (2011) Composition, porosity, and reservoir potential of the Middle Jurassic Kashafrud Formation, northeast Iran. Mar Pet Geol 28(5):1094–1110. https://doi.org/10.1016/j.marpetgeo.2010.11.004
Radwan AE, Abudeif AM, Attia MM (2020) Investigative petrophysical fingerprint technique using conventional and synthetic logs in siliciclastic reservoirs: a case study, Gulf of Suez basin. Egypt J Afr Earth Sci 167:103868. https://doi.org/10.1016/j.jafrearsci.2020.103868
Radwan AE, Wood DA, Radwan AA (2022) Machine learning and data-driven prediction of pore pressure from geophysical logs: a case study for the Mangahewa gas field, New Zealand. J Rock Mech Geotech Eng 14(6):1799–1809. https://doi.org/10.1016/j.jrmge.2022.01.012
Rajabi M, Beheshtian S, Davoodi S, Ghorbani H, Mohamadian N, Radwan AE, Alvar MA (2021) Novel hybrid machine learning optimizer algorithms to prediction of fracture density by petrophysical data. J Pet Explor Prod Technol 11:4375–4397. https://doi.org/10.1007/s13202-021-01321-z
Rajabi M, Hazbeh O, Davoodi S, Wood DA, Tehrani PS, Ghorbani H, Radwan AE (2023) Predicting shear wave velocity from conventional well logs with deep and hybrid machine learning algorithms. J Pet Explor Prod Technol 13(1):19–42. https://doi.org/10.1007/s13202-022-01531-z
Saikia P, Baruah RD, Singh SK, Chaudhuri PK (2020) Artificial Neural Networks in the domain of reservoir characterization: a review from shallow to deep models. Comput Geosci 135:104357. https://doi.org/10.1016/j.cageo.2019.104357
Sakhaee-Pour A, Bryant SL (2012) Gas permeability of shale. SPE Reserv Eval Eng 15(04):401–409. https://doi.org/10.2118/146944-PA
Sakhaee-Pour A, Bryant SL (2015) Pore structure of shale. Fuel 143:467–475. https://doi.org/10.1016/j.fuel.2014.11.053
Sakhaee-Pour A, Li W (2016) Fractal dimensions of shale. J Nat Gas Sci Eng 30:578–582. https://doi.org/10.1016/j.jngse.2016.02.044
Saleh AH, Hemimey WAE, Leila M (2023) Integrated geological and petrophysical approaches for characterizing the pre-cenomanian nubian sandstone reservoirs in ramadan oil field, Central Gulf of Suez, Egypt. Arab J Sci Eng. https://doi.org/10.1007/s13369-023-07743-7
Schlumberger C, Thommes M (2021) Characterization of hierarchically ordered porous materials by physisorption and mercury porosimetry—A tutorial review. Adv Mater Interfaces 8(4):2002181. https://doi.org/10.1002/admi.202002181
Shah MS, Khan MHR, Rahman A, Islam MR, Ahmed SI, Molla MI, Butt S (2021) Petrophysical evaluation of well log data for reservoir characterization in Titas gas field, Bangladesh: a case study. J Nat Gas Sci Eng 95:104129. https://doi.org/10.1016/j.jngse.2021.104129
Solanki P, Baldaniya D, Jogani D, Chaudhary B, Shah M, Kshirsagar A (2021) Artificial intelligence: new age of transformation in petroleum upstream. Pet Res. https://doi.org/10.1016/j.ptlrs.2021.07.002
Sondergeld, C. H., Newsham, K. E., Comisky, J. T., Rice, M. C., & Rai, C. S. (2010, February). Petrophysical considerations in evaluating and producing shale gas resources. In SPE unconventional gas conference. OnePetro. https://doi.org/10.2118/131768-MS
Steiber RG (1973) Optimization of shale volumes in open hole logs. J Petrol Technol 31(1973):147–162
Syed FI, AlShamsi A, Dahaghi AK, Neghabhan S (2022) Application of ML & AI to model petrophysical and geomechanical properties of shale reservoirs–a systematic literature review. Petroleum 8(2):158–166. https://doi.org/10.1016/j.petlm.2020.12.001
Szabó NP (2011) Shale volume estimation based on the factor analysis of well-logging data. Acta Geophys 59(5):935–953. https://doi.org/10.2478/s11600-011-0034-0
Taheri M, Ciabeghodsi AA, Nikrouz R, Kadkhodaie A (2021) Modeling of the shale volume in the hendijan oil field using seismic attributes and artificial neural networks. Acta Geolog Sin English Edition 95(4):1322–1331. https://doi.org/10.1111/1755-6724.14739
Tali AH, Farman GM (2021) Use conventional and statistical methods for porosity estimating in carbonate reservoir in southern Iraq, Case study. Iraqi Geol J. https://doi.org/10.46717/igj.54.2D.3Ms-2021-10-22
Tran H, Sakhaee-Pour A (2018a) Slippage in shale based on acyclic pore model. Int J Heat Mass Transf 126:761–772. https://doi.org/10.1016/j.ijheatmasstransfer.2018.05.138
Tran H, Sakhaee-Pour A (2018b) Critical properties (Tc, Pc) of shale gas at the core scale. Int J Heat Mass Transf 127:579–588. https://doi.org/10.1016/j.ijheatmasstransfer.2018.08.054
Tran H, Sakhaee-Pour A, Bryant SL (2018) A simple relation for estimating shale permeability. Transp Porous Media 124:883–901. https://doi.org/10.1007/s11242-018-1102-6
Yu C, Tran H, Sakhaee-Pour A (2018) Pore size of shale based on acyclic pore model. Transp Porous Media 124:345–368. https://doi.org/10.1007/s11242-018-1068-4
Zhou Y, Yang W, Yin D (2022) Experimental investigation on reservoir damage caused by clay minerals after water injection in low permeability sandstone reservoirs. J Pet Explor Prod Technol 12(4):915–924. https://doi.org/10.1007/s13202-021-01356-2
Acknowledgements
The authors would like to acknowledge the X-ray laboratory, School of Mining Engineering, College of Engineering, University of Tehran for kind participation and collaborations made throughout the present study.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ardebili, P.N., Jozanikohan, G. & Moradzadeh, A. Estimation of porosity and volume of shale using artificial intelligence, case study of Kashafrud Gas Reservoir, NE Iran. J Petrol Explor Prod Technol 14, 477–494 (2024). https://doi.org/10.1007/s13202-023-01729-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13202-023-01729-9