
Abstract
The main objectives of this study are analysis of spatial behavior of the porosity and permeability, presenting direction of anisotropy for each variable and describing variation of these parameters in Shurijeh B gas reservoir in Khangiran gas field. Porosity well log data of 32 wells are available for performing this geostatistical analysis. A univariate statistical analysis is done on both porosity and permeability to provide a framework for geostatistical analysis and modeling. For spatial analysis of these parameters, the experimental semivariogram of each variable in different direction as well as their variogram map plotted to find out the direction of anisotropy and their geostatistical parameters such as range, sill, and nugget effect for later geostatistical work and finally for geostatistical modeling, two approaches kriging and Sequential Gaussian Simulation are used to get porosity and permeability maps through the entire reservoir. All of statistical and geostatistical analysis has been done using GSLIB and PETREL software. Maximum and minimum direction of continuity are found to be N75W and N15E, respectively. Geostatistical parameters of calculated semivariogram in this direction like range of 7000 m and nugget of 0.2 are used for modeling. Both kriging and SGS method used for modeling but kriging tends to smooth out estimates but on the other hand SGS method tends to show up details. Cross-validation also used to validate the generated modeling.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Geostatistics is a branch of applied statistics that deals with spatially correlated data based on the theory of the regionalized variables. It was initially addressed by George Matheron of the Centre de Morophologie Mathematicque in Fontainebleau, France in 1960s. The original purpose of geostatistics is centered on estimating changes in ore grade within a mine. However, the principles have been applied to a variety of areas in geology and other scientific disciplines. The geostatistical models can provide interesting solutions to the two important challenges. These include: the construction of 3-D geologically realistic representations of heterogeneity and the quantification of uncertainty through the generation of variety of possible models (or realizations). The attempts of quantifying and constructing numerical models that describe the heterogeneity of the reservoir properties started as early as the 1978 when Journel and Huijbregts tried to use Markov chain analysis to quantify one-dimensional lithological sequences along wells, but this study was not mature enough to gain publicity. Speer (1976) introduced the comprehensive theory of estimating the regionalized variables. He found that the estimation of results could be improved after the lognormal transformation before using the kriging technique. In the early Eighties, Issaks and Srivastava (1989) renewed the interest in the approach used at Hass-Messaoud. Later this was further perused by Haldorsen and Davis (1987) that lead with the fast progress in computing facilities, to generate the models in three dimensions. Dowd (1994) emphasized the importance of using the non-linear geostatistics in case of non-normally distributed data. In 1989, Issaks and Srivastava published the most comprehensive geostatistical book that had been written to that date. Damsleth and Omre (1997) added a voice in the debate by promoting the use of fractals geostatistics. In the early nineties, Hohn (1999) published the GSLIB library that enable the user to choose the suitable geostatistical technique based on the depositional setting and the scale of the problem. Since then, the use of petroleum geostatistics has grown rapidly. Reservoir engineers were the fastest to adopt the new techniques as shown in the large number of publications in the SPE literatures since the Eighties (Wang and et al. 1999). The current research emphasizes aspects related to multidisciplinary data integration, or uncertainty quantification. The goal of this study is to characterize the distributions of porosity and permeability in Shurijeh-B reservoir of Khangiran gas field. Spatial distributions of porosity and permeability estimated using the ordinary kriging and nineteen realizations of porosity and permeability distributions determined by means of conditional Gaussian simulation.
Area of study
Location
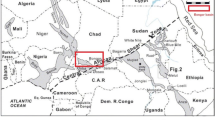
Khangiran gas field is located in Sarakhs area at a distance of about 180 km. N. E. of city of Mashhad (Hosseini et al. 2015). This gas field actually located in Kopet–Dagh basin (Fig. 1). Khangiran structure is an asymmetric anticline, having approximately a NW–SE trend. The dips of north flank is steeper than south flank and it has a very low dip plunges. According to the seismic structural contour map, near top of Mozduran formation, Khangiran structure has a maximum length of 20 km, and a width of a about 8 km. The aerial closure of the structure is about 115 km2 and the vertical closure is about 500 m. The thickness of the Shurijeh gas bearing zone is about 60 m in KG-l well.

Location map of the Kopet-Dagh basin in northeastern Iran
Structure
Khangiran structure is an asymmetrical anticline with NW–SE trending axis therefore main traps will be structural traps. The structure has affected the Khangiran shale, and it is partly covered by alluvial deposits, consisting of loess, sand dunes, and Quaternary Terraces. Based on the seismic data the northern flank of the structure is steeper than its southern flank. The structure has low plunges with a vertical closure of about 2200′ and an areal closure of about 600 km2. There is a vertical fault which has trend parallel to axis of anticline but it is located in northern flunk of anticline far from its axis so that it does not affect the trap (Fig. 2).

Structure contour map of top of Shurijeh formation
Known and potential reservoirs
The major reservoir in the giant Khangiran gas field is the highly porous and permeable dolomitic unit of the Middle Jurassic (Oxfordian–Kimmeridgian) Mozduran Formation. In the Khangiran gas field, this formation has a thickness that exceeds 1000 m (e.g., 1380 m in Khangiran well 1–3). The reservoir properties are related to dolomitization, and the dolomitic interval is not as well developed in the central and western parts of the basin as it is in the east. The cap rock for this reservoir in the Khangiran gas field is the gypsum, gypsiferous claystone, and shales of the lower Shurijeh formation (Neocomian) in the eastern Kopet-Dagh basin. The second and youngest gas-producing reservoir is the sandstone member of the Shurijeh formation (Neocomian) that was deposited in the fluvial systems. The porosity in the sandstone unit is mainly secondary and formed during the time that these strata were at their maximum burial depth in the early tertiary, prior to uplift of the Kopet-Dagh basin. The cap for this reservoir is also the gypsiferous shale of the upper Shurijeh formation in Sarakhs area. What is going to be discussed in this project about geostatistical modeling and geostatistical analysis will be on Shurijeh reservoir.
Geology of Shurijeh reservoir
As it is apparent in Fig. 3, the Shurijeh formation geologically can be divided in five zones namely zones A, B, C, D and E. Lithologically zones B and D are sandstone and have capability of being a reservoir other zones are mainly consists of very tight layers of lime. Therefore in Shurijeh formation there are two reservoir zones (zones B and D) and other zones do not have capability of being reservoirs (very low porosity and permeability). These facts can be readily shown in Fig. 4 which shows well log porosity of three wells (well no. 3, 5, 6). Here in this figure zones B and D have relatively good porosities but in other zones the amount of porosity is near to zero. Location map of the wells in the Khangiran gas field shown in Fig. 5. In this study, the Shurijeh B reservoir has been investigated.

The five zones of Shurijeh formation in Khangiran

Porosity well log of wells no. 3, 5 and 6

Location map of the wells in the Khangiran gas field
Methodology
Data description
This study was based on a variety of data that are listed below:
-
a.
Wireline logs: Wireline logs for 42 wells are used for this work the data were in digital format (i.e., LAS format) and include gamma ray, SP, resistivity logs, porosity logs curves, etc.... Some of these wells did not have any information about zone of interest; however 32 vertical wells that penetrate the reservoir body and have porosity data were selected for the current geostatistical modeling.
-
b.
Official reports: Several official reports were utilized to establish the geological and structural settings of the study areas.
-
c.
Core description reports: Core analysis data of just well no. 3 are available which is used for generation permeability data in entire reservoir.
Figure 6 shows the flowchart of the procedure in this study. The steps of procedure have been explained below.

Flowchart of the procedure of this study
Geostatistical analysis methods
Kriging
Kriging is a statistically based estimation technique that was initially introduced by Matheron (1963) and was named after Dr. D. G. Krige of South Africa as geostatistical estimation procedure that produces the best unbiased linear estimates (referred as kriging estimate) with minimum estimation variance (referred as kriging variance). There are several kriging themes including ordinary kriging (OK), simple kriging (SK), universal kriging (UK), indicator kriging (IK), probability kriging (PK), cokriging (CK), etc. (Basbug and Karpyn 2007). In theory, no other method of grid generation can produce better estimates (in the sense of being unbiased and having minimum error) of the form of a mapped surface than kriging. In practice, the effectiveness of the technique depends on the correct specification of several parameters that describe the semivariogram (Hasanipak and Sharafoddin 2005). However, because kriging is robust, even with a naive selection of parameters the method will do no worse than conventional grid estimation procedures. Kriging is best linear unbiased estimator (Hassanipak 1998). This estimator is defined as follows:
where Z (xi) and λi represent the value of sample (here porosity) and the weighting factor at point i, respectively, and Z∗k is the kriged estimator. The weights λi are calculated according to the criteria.
Conditional simulations
One of the geostatistical simulation algorithms is the conditional simulation approach which is defined as a geostatistical method used to create unknown data sets which have the same variability of the original data (Hosseini and Gholami 2011). The generated data do not only have the same histograms and semivariogram of the original data but also honor the data values at sampling location (Doligez and et al. 2007). It provides several possible equally probable numerical models (or realizations) for the reservoir attributes (Kamali and et al. 2013). Theoretically the number of these realizations is boundless, but practically only some realizations can be used to simulate the flow problem. These models are subsequently used to assess the uncertainty of the attribute under investigation while testing the efficiency of the production schemes (Brown and Falade 2003). In this part for geostatistical modeling, we use two methods one Sequential Gaussian Simulation and the other ordinary kriging. A comparison of these two methods will be done and finally validation of each method with the available data is done using cross plot validation.
Variography (spatial structural analysis tool)
The semivariogram is a mathematical function for quantifying the similarity or dissimilarity between sample values as a function of the distance between sample locations (Meddaugh and et al, 2011). It can also be defined as the half of the mean squared difference between sample values separated by vector h (Kelkar 2002). The theoretical expression for semivariogram is given as follows:
the experimental semivariogram IS computed from the samples using the following mathematical expression (Deutch and Journel 1998):
where Z (Xi) and Z (Xi + h) are sample values at locations Xi and Xi + h separated by a vector h and n (h) is the total number of sample pairs. The final step in variography is modeling the variogram. The goal of the modeling is to determine the sill, slope, range and nugget effect by the use of specific functions (Yarus and Chambers 2006). The models that usually used are spherical, exponential, Gaussian, linear or pure nugget effect, cubic, power, De Wijs and Cauchy (Dubrule 2003). In this study, the spatial analysis will be carried out with the following steps:
-
At the first step, the experimental semivariogram for each variable were calculated and plotted in several directions (azimuth). These directions include 0, 10, 20, 30, 40, 50, 60, 70, 80, 90, − 10, − 20, − 30, − 40, − 50, − 60, − 70, − 80, and − 90. This step was required to find in which directions the variable samples have more continuity (anisotropy). The variogram maps were also plotted to ensure the correct pick up of the continuity directions.
-
Also the experimental semivariograms for each variable were calculated in the vertical direction (dip angle 90°). This step was used to control the theoretical model fitting and to find the vertical range for which the variable samples have more continuity.
-
The geostatistical parameters including the range (a), the sill variance (C), and the nugget variance (Co) were calculated in the two continuous directions for each variable.
Data preparation and statistical analysis
Calculating permeability from core data
The only reliable way for finding permeability values is permeability test which is done on core samples in the laboratory. Therefore by using different methods and tests we will find values for horizontal and vertical permeability. But getting core sample in all of reservoir in all wells and doing permeability tests on them is very expensive. Instead of doing so, usually relationship between porosity and permeability is used for finding permeability in area in which we do not have any core sample. In this method, they get core sample from limited number of wells in even small intervals depending on degree of heterogeneity of reservoir and degree of accuracy needed and by using a plot of porosity versus permeability a formula describing their relationship will be estimated. Only core data and consequently permeability data of well no. 3 in Shurijeh-B which is our zone of interest are available so as mentioned above a plot of porosity and permeability is made (Fig. 7) and by using this graph a general formula describing their relationship is estimated.

Relationships between porosity and permeability (zone B) in Shurijeh formation
As you can see from above figure the regression coefficient R2 = 0.61 which is not statistically very good and acceptable. An alternative method is used to generate permeability data. In petrophysics, there are a variety of empirical formula describing general relation between porosity and permeability each of them applicable just in a particular condition. Here in this project the Remy (2004) equation is used for generating permeability data in Shurijeh B reservoir which is highly compatible with the condition requirement of this empirical equation. Based on the work of Kozeny, Wyllie and Rose, Remy proposed a generalized equation in the form:
He analyzed data obtained by laboratory measurements conducted on 155 sandstone samples from three different oil fields in North America. Based on the highest correlation coefficient and on the lowest standard deviation, Remy has chosen from five alternative relationships the following formula for permeability (Babadagli and Al-saimi 2004):
The procedure is that with using formula (5) irreducible water saturation and porosity are correlated and then a general formula for residual saturation based on porosity through entire reservoir is estimated. Residual saturation and porosity show excellent correlation with highly reliable from statistical point of view. The trendline and its equation and also regression equation are shown in Fig. 8.

Irreducible water saturation and porosity
So by using this correlation and available porosity data, irreducible water saturation is estimated with reasonable accuracy and finally having porosity and residual water saturation and Eq. (5) we can generate permeability values. In this part, all of data that are related to zone B of Shurijeh formation are separated and extracted from all available porosity well log data and after doing this, we find permeability values by using both formula which we have found in last section. At this moment we are ready to start our statistical analysis.
Statistical analysis
It is not an easy task, if not impossible, to visualize or to describe raw data when it is in a digital form. This is, especially, true for data sets from oil reservoirs because of the large number of points. Therefore, raw data must be organized and presented in the form of charts, diagrams or tables in order to give a clear picture of the phenomena it represents. Statistics is the science which deals with the collection, organization, presentation, and summary of data. Therefore, statistical analysis is considered as an essential step in any geostatistical study. The univariate statistical analysis provides several parameters and helps to determine the type of distribution of the data set. Statistical parameters including mean, median, minimum, maximum, variance, standard deviation, lower and upper quartiles and coefficient of variation were computed for each well and for zone B of the Shurijeh formation which is under consideration. These parameters are very useful for determining the general behavior of the data distribution. Parameters like the mean and the median provide information about the location of center of mass for distribution. The variance and the standard deviation quantify the variability of the data values and indicate how the data are distributed around the mean. In addition to these parameters, the coefficient of variation (CV), which is the ratio of the standard deviation to the mean, was also calculated. This parameter provides a measure of the relative variability of the data.
Interpretation of statistical parameters for porosity values
The statistical parameters of the well-log porosity data were calculated for each well and for each zone of the reservoir. The list of the statistical parameters, together with the total number of sample points, for each well used in this study is given in Table 1. The mean porosity values for the individual wells range between 0.01 and 0.08. The problem of outlier data should be taken into account because some of them inversely affect the statistical parameters especially mean so that in this situation the median is more reliable. In fact, an outlier is an observation that lies an abnormal distance from other values in a random sample from a population. There are many ways to define a margin beyond of which data are defined as outlier. In one of these methods the outlier is found by using upper quartile, lower quartile and a box plot. A box plot is a convenient way of graphically depicting groups of numerical data through their five-number summaries the smallest observation, lower quartile (Q1), median (Q2), upper quartile (Q3), and largest observation. The following quantities (called fences) are needed for identifying extreme values in the tails of the distribution: (IQR stands for inter quartile range which is equal to Q3–Q1).
-
1.
Lower inner fence: Q1 − 1.5 × IQR.
-
2.
Upper inner fence: Q3 + 1.5 × IQR.
-
3.
Lower outer fence: Q1 − 3 × IQR.
-
4.
Upper outer fence: Q3 + 3 × IQR.
A point beyond an inner fence on either side is considered a mild outlier. A point beyond an outer fence is considered an extreme outlier. At first, we analyze all data without trimming any data so we have
Q1 = 0.02, Q2 = median = 0.04, Q3 = 0.06.
So the upper inner fence that is mild outlier is 0.12 and the upper outer fence that is extreme outlier is 0.18 (Fig. 9).

Box plot for all of porosity data in Shurijeh B
Statistical parameters for whole of the reservoir body in Shurijeh B are as follows:

The histogram plot for all of data available in whole of reservoir is shown in Fig. 10 showing some statistical parameters describing porosity data when the trimming limit has been put 0.12. As it is apparent from the below histogram the porosity distribution is positively skewed and its value is 0.5691.

Histogram plot of well-log porosity for the whole reservoir
Histogram plots are valuable tools in determining the type of distribution. The knowledge of the type of distribution is required in selecting geostatistical technique to be employed. Many geostatistical techniques require the data to be in a particular distribution form (i.e., normal distribution). Therefore, if the given data show other distribution than normal, it is required to perform an appropriate transformation of the data to normality before applying such technique. When the histogram has a long tail of higher values, the data are said to be positively skewed. On the other hand, when there is a long tail of lower values, the histogram is said to be negatively skewed. The cumulative frequency plot shows a straight line if the data are normally distributed. Also for normal distribution, the coefficient of skewness is equal to zero. As it is apparent in Fig. 10, the distribution of porosity data is not normal so it should be transferred into normal distribution. This transformation can be easily done by using GSLIB software. Figure 11 shows histogram plot of data which are transferred to normal distribution.

Histogram plot of porosity data which are transferred to normal distribution
Interpretation of statistical parameters for permeability values
In this part, we do the same procedure on permeability values as in the case of porosity well log values. Analysis of permeability data has been divided into two parts; firstly we will analyze permeability data generated by using a linear regression discussed in previous section and finally analysis of permeability data generated by using empirical equation will be done. During these two analyses, histogram plots of permeability data will be drawn and also a table describing different statistical parameters as we did on porosity values. Type of distribution also will be checked whether is normal or not and if we face a non-normal distribution by using GSLIB software make them normally distributed for doing further geostatistical analysis and modeling. In the first part for statistical analysis of data generated by linear regression we should define boarder for finding outlier values so we need to know what Q1 and Q3 are for permeability values. The calculated values of Q1 and Q3 are 0.4247 and 0.5471, respectively, and now we can find outlier boarders as follows:
Lower inner fence: Q1 − 1.5 × IQR = 0.2411.
Upper inner fence: Q3 + 1.5 × IQR = 0.7307.
Lower outer fence: Q1 − 3 × IQR = − 0.1251.
Upper outer fence: Q3 + 3 × IQR = 1.0979.
Q1 and Q3 values can also be estimated from box plot diagram shown in Fig. 12. In this type of plot min, max, median of data are depicted.

Box plot for all of permeability data
Histogram plot of permeability data both before and after removing outlier data is shown in Fig. 13a, b.

a Histogram plot of permeability data before removing outlier data. b Histogram plot of permeability data after removing outliers
Distribution of permeability data as it is obvious from upper histogram is non-normal so as mentioned before doing geostatistical modeling this distribution should be transferred into a normal one. This transformation has been done by using GSLIB software and the resulting histogram is depicted in Fig. 14. In the last part for data generated by using empirical formula (Remy 2004), we will do the same analysis as we have done before that is finding Q1and Q3 and consequently determining outlier fences, plotting histogram of data both before and after removing outliers. Q1and Q3 are found to be 0.1099 and 0.1503, respectively, and consequently lower and upper fences for outliers are 0.0493 and 0.2146, respectively.

Histogram showing permeability data transferred into normal distribution
In Fig. 15a, b histogram plot of permeability both after and before removing outlier data generated in second method has been plotted. Most important statistical parameters are present in histogram plots describing data. As you can see after removing outliers mean and median become closer to each other.

a Histogram plot of permeability data (empirical methods) before outlier removing. b Histogram plot of permeability data (empirical methods) after outlier removing
Finally in this part all the statistical parameters for permeability data that are generated by second method (empirical equation) will be summarized in a table. In this table analysis of each well will be done separately as we did for porosity data (Table 2).
Spatial analysis
Analysis plan
The analysis will be carried out with the following steps:
-
At the first step, the experimental semivariogram for each variable was calculated and plotted in several directions (azimuth). These directions include 0, 10, 20, 30, 40, 50, 60, 70, 80, 90, − 10, − 20, − 30, − 40, − 50, − 60, − 70, − 80, and − 90. This step was required to find in which directions the variable samples have more continuity (anisotropy). The variogram maps were also plotted to ensure the correct pick up of the continuity directions.
-
Also the experimental semivariograms for each variable were calculated in the vertical direction (dip angle 90°). This step was used to control the theoretical model fitting and to find the vertical range for which the variable samples have more continuity.
-
The geostatistical parameters including the range (a), the sill variance (C) and the nugget variance (Co) were calculated in the two continuous directions for each variable.
Because the well distribution is irregular, a tolerance angle should be encountered in the calculation (Najafzadeh and Riahi 2010). This angle should be large enough to provide adequate number of pairs to compute the semivariogram at each lag, yet small enough to sustain the directional character of the semivariogram. In the current study, the tolerance angle of 30° yielded satisfactory results. Another consideration for lag distance must be taken into account. The lag distance for the irregular well distribution should the average spacing between wells. In the current study, a lag distance of 2800 m, which was found to be the best to reveal the structural extend, was chosen. On the other hand, the tolerance distance of half the lag distance was the optimal choice for both regular and irregular well distribution the lag distance. Number of lags of 10 was chosen to cover the study area.
Porosity
Determination of anisotropy
As discussed earlier, some variables are more continuous along a particular direction than others. The only approach to identify the anisotropy direction is to calculate several semivariograms and determine the maximum and minimum continuity ranges or it is possible to create a variogram map and find the general trend of anisotropy which is the direction at which the variogram map is elongated (Fig. 16). The semivariograms for the porosity in the horizontal directions were calculated in 19 directions. These semivariograms have almost the same sill value which is equal to one because sill is identical to square of variance and as the data have been normalized before. Therefore, the variograms have to show sill values more or less equal to one but they have different ranges in different directions showing structural anisotropy in the case of porosity. It also shows that the directions of continuity are toward N75W for the maximum range and N15E direction for the minimum range as confirmed by the variogram map of porosity. The experimental variogram parameters, their directions, and the best fitting theoretical model are listed in Table 3, some of them (direction 0, 45, 90, 135) are shown in Fig. 17a–d.

Variogram map, direction of elongation shows direction of max of continuity; counters represent variance

a Semivariogram in direction of 0°. b Semivariogram in direction of 45°. c Semivariogram in direction of 90°. d Semivariogram in direction of 135°
In this figure, histogram shows the number of sample pairs in each Lag and the grey points, showing that the semi-variance in each lag is sample variogram and gray line is regression curve that is a best fit variogram model for the sample variogram (grey curve). As obvious from the above figures, in all cases the best fitting theoretical model is the simple spherical model with varying values for nugget effect. Also vertical semivariogram for the entire reservoir is calculated and plotted in Fig. 18. In vertical direction as in horizontal directions, the simple spherical model was found to be the best to fit the experimental semivariogram. The nugget effect for vertical direction is 0.043 and its range is 70 m.

Vertical semivariogram of all of reservoir body
It is obvious from the above table that the major and minor directions of continuity are N75W and N15E, respectively. In Fig. 19a, b, their experimental variogram and best fitting theoretical model are presented.

a Semivariogram in maximum direction of continuity. b Semivariogram in minimum direction of continuity
Finally having completed the spatial analysis of porosity and also constructed the semivariogram models, the following remarks can be made:
-
All of the semivariograms were fitted with simple spherical models with nugget effects ranging between 0 and 0.38.
-
The vertical semivariograms of the selected wells do not show the hole affect. The hole effect is a response of zonality of the horizon under investigation. The absence of the hole effect in the subset area illustrates the absence of the zonality in the current study area. Generally, a hole-effect variogram typically exhibits sinusoidal waves that form peaks and troughs.
-
The range of the vertical semivariogram representing the entire reservoir was found to be approximately identical to average thickness of reservoir that is 70 m.
-
The porosity data revealed geometrical anisotropy with a linear continuity behavior.
Permeability
As mentioned earlier, we generated permeability data by two methods; one of which is by using a linear regression from porosity data. So each porosity value is linearly transferred to permeability values by general formula, such as \({y_i}=\alpha {x_i}+\beta\). Generally, from statistics, we know that whenever all of data multiplied by a constant such as α and then added to a constant such as β then for the mean, transformation will be exactly the same as one by which values transferred (i.e., \(\bar {y}=\alpha \bar {x}+\beta\)). The variance will change by square of multiplier α. During the spatial analysis, data should be normally distributed and if not, they should be transferred into normal one; this transformation makes the spatial analysis exactly the same as the analysis with the porosity data, and we will have exactly identical variogram map and also experimental variogram in all direction therefore in this part we will do spatial analysis and geostatistical modeling on permeability data generated by Remy equation.
Determination of anisotropy
For determination, the direction of anisotropy that is the direction of maximum and minimum continuity we do the same procedure as with the porosity data are taken. Using variogram map, the direction of anisotropy, which is direction of elongation of map, can be easily determined. In Fig. 20 variogram map of permeability data has been depicted. The direction of elongation, which is direction of anisotropy, is approximately N75W.

Variogram map, direction of elongation shows direction of max of continuity; counters represent variance
Geostatistical parameters of variograms in different directions are listed in Table 4. Nugget effect ranges from 0 to 0.7. In all directions, best fitting model which completely describes variability of the data is spherical. Major and minor axes of anisotropy also have been shown. In Fig. 21a–d, some of the experimental semivariograms and best fitting theoretical model are illustrated, indicating sill, range, and nugget values.

a Semivariogram in direction of 0°. b Semivariogram in direction of 45°. c Semivariogram in direction of 90°. d Semivariogram in direction of 135°
The vertical semivariograms for the entire reservoir were calculated and plotted (Figs. 22, 23, 24). The vertical semivariogram has a nugget effect of about 0 and range of 71 m. The simple spherical model is the best fit to the experimental semivariograms.

Vertical variogram for entire reservoir

Semivariogram in maximum direction of continuity

Semivariogram in minimum direction of continuity
It is obvious from comparison of spatial analysis between porosity and permeability values that the spatial variability of these two variables more or less is close to each other. One important reason for this claim is that the major and minor axes of anisotropy are almost equal and also their variogram maps have very good similarity in shape and structure. The most important reason for this phenomenon is that both the regionalized variables are derived from wells located in the same area and generally are affected by the same depositional and digenetic processes because geological and depositional aspects are the most important parameters that affect spatial variability of these variables. In the area under study, the spatial analysis of permeability demonstrates a geometrical anisotropic behavior in which various ranges exist in different directions. The different ranges for both variables may be due to the diagenetic processes that affect the permeability to a different degree to that of porosity. This issue by itself is an interesting subject and requires an elaborate future study.
Final remarks
The following remarks and conclusions are made from the analysis of the permeability data in the subset area:
-
All the semivariograms were fitted with simple spherical models, having different amount of nugget.
-
The vertical semivariograms of the selected wells do not show the hole affect. The absence of the hole effect in the subset area illustrates the absence of the zonality in the current study area.
-
The range of the vertical semivariogram for both porosity and permeability values is found to be approximately 70 m but they represent different amounts of nugget value. This may be due to the fact that two variables have been affected by the diagenetic processes to different degrees.
-
The permeability data revealed geometrical anisotropy with both linear continuity and nugget type behavior in different directions.
Geostatistical modeling
In this section, the spatial analysis described in proceeding sections was employed to conduct the geostatistical modeling of the porosity and permeability values. For geostatistical modeling generally data should meet two vital requirements: regionalized variable should be stationary (i.e., the area of under study should not show any trend and it should be removed if there is any) and the data should be normally distributed (otherwise, as discussed earlier, they should be transferred into normal distribution). The Sequential Gaussian Simulation that is used in property modeling requires that the input data have a mean of zero and a standard deviation of one. The algorithm generates a property with a standard normal distribution, and if the input data were not standard normally distributed then the results will not agree with the input. In the case of presence of a trend in the study area, the data points are represented as anomalies in the property maps which are smoothed and disappeared during the modeling. This smoothing effect is stronger for larger ranges used for modeling. In this part for geostatistical modeling, we use two methods one Sequential Gaussian Simulation and the other ordinary kriging. A comparison of these two methods will be done and finally validation of each method with the available data is done using cross plot validation.
Porosity
As mentioned at the beginning of this section the first steps for modeling of porosity are removing trends and transforming data into normal distribution. Figure 25a–c is cross plot of porosity data in three orthogonal coordinates x, y and z, it is obvious from this figure that both porosity and permeability values represent no trend in any direction.

a Porosity scatter plot versus Z coordinate. b Porosity scatter plot versus Y coordinate. c Porosity scatter plot versus X coordinate
For making non-normally distributions normalized, the Petrel software has itself an algorithm that make any distribution normalized. Making the data normally distributed and stationary, now it is time to do modeling with SGS and kriging. Direction of major and minor anisotropy, their ranges and variogram characteristics in major direction of anisotropy are essential parameters for producing a property model. Final result for SGS modeling is shown in Fig. 26. Porosity modeling also is done based on kriging interpolation (Fig. 27). As it can be inferred by comparison between these two modeling, model generated by kriging is smoother than SGS. Distribution of data into cells is so that they have much lower variation with respect to adjacent cells compared with the real data distribution.

Porosity map after SGS modeling

Modeling based on kriging interpolation
Permeability
Modeling of permeability data has exactly the same algorithm and processes with what is done for porosity modeling (i.e., checking whether regionalized variable is stationary and normally distributed). From statistical analysis on permeability data, we know that permeability data are not normally distributed and they should be transferred into normal distribution. Presence of trend is checked by plotting scattergram of permeability data versus each of the three orthogonal Cartesian axes.
From Fig. 28a–c, it is easily inferred that there is no statistically considerable trend for permeability data in different directions. For all directions, the best passing regression line has very small correlation coefficient which is statistically not reliable. For permeability modeling, we should use statistical and spatial parameters which we got during the analysis especially those belonging to direction of anisotropy. Modeling is done by using both SGS and kriging methods. The resulting maps are depicted in Figs. 29 and 30.

a Permeability scatter plot versus Z axis. b Permeability scatter plot versus Y axis. c Permeability scatter plot versus X axis

Map of permeability data generated by SGS method

Map of permeability data generated by kriging interpolation method
Cross validation of models
This step is essential for validating the produced modeling. The procedure is that before doing modeling we remove two or three random wells and then a new model is produced with the remaining upscaled wells. After the model is produced, we compare estimated and simulated data in the location of missing wells with the real data from upscaled well logs in a cross plot. The more the closer points into the line (Fig. 31a–d) the more valid the model we have made. For achieving the above task, we randomly remove three wells namely well number: 3, 23, and 36. After that, we generate model based on both approaches (SGS and kriging) and then compare the result of models in exact location of missing wells with original well data. The results of comparison are presented in a cross plot shown in Fig. 31a–d. Both kriging and SGS models show relatively good compatibility with original data. Generally the closer the dots to the line the higher the degree of compatibility of data and then consequently the more valid the modeling generated. As it is obvious from cross validation plots that models generated by SGS method are more compatible with the original data for both porosity and permeability.

a Cross plot validation between original porosity data and SGS-based modeled data. b Cross plot validation between original porosity data and kriging-based modeled data. c Cross plot validation between original permeability data and SGS-based modeled data. d Cross plot validation between original permeability and kriging-based modeled data
Conclusion
The main conclusions drawn from this study are listed as follows:
-
Statistical analysis of well-log porosity and permeability values in the Shurijeh-B reservoir revealed that the porosity and permeability distribution is non-normal. Porosity values range between 0 and 0.12 and its mean through the entire reservoir is equal to 0.04. Permeability values also range between zero and one md and their mean through entire reservoir is 0.48 after removing outlier data.
-
Both statistical porosity and permeability analysis show that the variable distribution is inversely affected by outliers. These outliers have to be removed before doing any further analysis.
-
Regression coefficient in linear relation between porosity and permeability values is almost equal to 0.6 which is not statistically reliable for generating permeability values.
-
An alternative method based on Remy equation is used. Remy equation is an empirical equation which relates porosity, permeability and irreducible water saturation to each other. Using this method and plotting scattergram of porosity and residual water saturation give us excellent correlation coefficient of 0.996 which is highly reliable.
-
The spatial analysis reveals that porosity and permeability experimental variograms are best represented by simple spherical theoretical model with different values for nugget ranging between zero and 0.6 for both variables.
-
Direction of elongation in both permeability and porosity variogram map shows major and minor directions of continuity (anisotropy). The major direction of continuity is N75W and the minor direction of continuity is N15E.
-
Vertical semivariogram of both variables has nugget effect of zero and range of 70 m that approximately shows the thickness of reservoir.
-
Geostatistical modeling of porosity and permeability is done using two approaches: Sequential Gaussian Simulation (SGS) and kriging interpolation. The results confirmed that kriging tends to produce smoother distribution of the variables, whereas conditional simulation tends to represent more details as in actual data. In kriging, it makes the best possible estimate at the un-sampled location by minimizing the error variance. On the other hand, simulation allows coming up with theoretically an infinite number of realizations of the map each of which has approximately the same variogram and variance of the original data.
-
Results of geostatistical modeling using both approaches are validated with actual well log data using cross validation methods. Results show that SGS models have better match with the actual data than kriging models
References
Babadagli M, Al-saimi S (2004) A review of permeability-prediction methods for carbonate reservoirs using well-log data. SPE Reserv Eval Eng. https://doi.org/10.2118/87824-PA
Basbug B, Karpyn ZT (2007) Estimation of permeability from porosity, specific surface area, and irreducible water saturation using an artificial neural network. In: Latin American and Caribbean petroleum engineering conference, society of petroleum engineers, Buenos Aires, Argentina, 2007, pp 1–10. https://doi.org/10.2118/107909-MS
Brown PC, Falade GK (2003) A quick look kriging technique for reservoir characterization. In 27th Annual SPE technical conference and Nigeria SPE 85679, August 4–6. https://doi.org/10.2118/85679-MS
Damsleth E, Omre H (1997) Geostatistical approach in reservoir evaluation. J Pet Technol 49:498–501. https://doi.org/10.2118/37681-JPT
Davis B (1987) Uses and abuses of cross-validation in geostatistics. Math Geosci 19(3):241–248. https://doi.org/10.1007/BF00897749
Delfiner P, Delhomme JP, Pelissier J (1983) Application of geostatistical analysis to the evaluation of petroleum reservoirs with well logs. In: SPE 1983-WW, SPWLA 24th annual logging symposium, 27–30 June, Calgary, Alberta
Deutsch C, Journel A (1998) Geostatistical software library and user’s guide. Oxford University Press, Oxford
Doligez B, Beucher H, Lerat O, Souza O (2007) Use of a seismic derived constraint: different steps and joined uncertainties in the construction of a realistic geological model. Oil Gas Sci Technol Rev IFP 62(2):237–248. https://doi.org/10.2516/ogst:2007020
Dowd PA (1994) Geological controls in the geostatistical simulation of hydrocarbon reservoirs. Arabian J Sci Eng 19:237
Dubrule O (1998) Geostatistics in petroleum geology. AAPG Course Note Series, Tulsa
Dubrule O (2003) Geostatistics for seismic data integration in earth models. Distinguished instructor short course. Society of Exploration Geophysics
Hasanipak A, Sharafoddin M (2005) Exploration data analysis. Tehran University Press, Tehran
Hassanipak AA (1998) Geostatistics, 1st edn. Tehran University Press, Tehran
Hohn ME (1999) Geostatistics and petroleum geology, 2nd edn. Kluwer Academic, Dordrecht
Hosseini A, Gholami R (2011) Artificial intelligence for prediction of porosity from seismic attributes: case study in the Persian Gulf. Iran J Earth Sci 3:167–174
Hosseini E, Habibnia B, Hajheydari A (2015) Geochemical analysis for the source rock evaluation in oil field region of Kopeh Dagh Basin in Eastern Iran. In: The 4th hydrocarbon reservoir engineering and related upstream industry conference, Tehran, Iran, 28th May 2015
Issaks EH, Srivastava RM (1989) An introduction to applied geostatistics. Oxford University Press Inc, Oxford
Journel AG, Huijbregts CJ (1978) Mining geostatistics. Academic Press, London
Kamali MR, Omidvar A, Kazemzadeh E (2013) 3D geostatistical modeling and uncertainty analysis in a carbonate reservoir, SW Iran. J Geol Res 12:36–48. https://doi.org/10.1155/2013/687947
Kelkar M, Perez G (2002) Applied geostatistics for reservoir characterization, 1st edn. Society of Petroleum Engineers, Dallas
Matheron G (1963) Principles of geostatistics. Econ Geol 58:1246–1266. https://doi.org/10.2113/gsecongeo.58.8.1246
Meddaugh WS, Champenoy N, Osterloh WT, Tang H (2011) Reservoir forecast optimism-impact of geostatistics, reservoir modeling, heterogeneity, and uncertainty. In: SPE annual technical conference and exhibition, society of petroleum engineers, Denver, 30 October–2 November 2011, p 18. https://doi.org/10.2118/145721-MS
Najafzadeh K, Riahi MA (2010) Optimized combination of seismic attribute in porosity estimation by means of co-kriging. In: Paper 192, 14th Iranian geophysics conference, Tehran, Iran, May 11–13
Official Geologic Reports of Khangiran Gas Field (1977) Iranian Central Oil Field Company (ICOFC) library
Remy N (2004) SGEMS, the Stanford geostatistical earth modeling software. User’s manual. http://sgems.sourceforge.net/doc/sgems manual.pdf
Speer A (1976) Geology of Bangestan reservoir in Ab-Tymur and Mansuri. Technical report in NISOC-Iran, report no. P-(3021)
Wang L, Wong PM, Shibli SAR (1999) Modeling porosity distribution in the A’nan oilfield: use of geological quantification, neural networks, and geostatistics. SPE Res Eval Eng 2:527–532. https://doi.org/10.2118/59090-PA
Yarus JM, Chambers RL (2006) Practical geostatistics: an armchair overview for petroleum reservoir engineers. J Pet Technol 58:78–86. https://doi.org/10.2118/103357-JPT
Acknowledgements
We are grateful to the companies of Oil Industries Engineering and Construction (OIEC) and Sarvak Azar Engineering and Development (SAED) for financial support.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Hosseini, E., Gholami, R. & Hajivand, F. Geostatistical modeling and spatial distribution analysis of porosity and permeability in the Shurijeh-B reservoir of Khangiran gas field in Iran. J Petrol Explor Prod Technol 9, 1051–1073 (2019). https://doi.org/10.1007/s13202-018-0587-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13202-018-0587-4