
Abstract
We seek to determine a real algebraic variety from a fixed finite subset of points. Existing methods are studied and new methods are developed. Our focus lies on aspects of topology and algebraic geometry, such as dimension and defining polynomials. All algorithms are tested on a range of datasets and made available in a Julia package.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
This paper addresses a fundamental problem at the interface of data science and algebraic geometry. Given a sample of points \(\Omega =\{u^{(1)}, u^{(2)}, \ldots , u^{(m)}\}\) from an unknown variety V in \({\mathbb {R}}^n\), our task is to learn as much information about V as possible. No assumptions on the variety V, the sampling, or the distribution on V are made. There can be noise due to rounding, so the points \(u^{(i)}\) do not necessarily lie exactly on the variety from which they have been sampled. The variety V is allowed to be singular or reducible. We also consider the case where V lives in the projective space \({\mathbb {P}}^{n-1}_{\mathbb {R}}\). We are interested in questions such as:
-
1.
What is the dimension of V?
-
2.
Which polynomials vanish on V?
-
3.
What is the degree of V?
-
4.
What are the irreducible components of V?
-
5.
What are the homology groups of V?

Sample of 27 points from an unknown plane curve
Let us consider these five questions for the dataset with \(m=27\) and \(n=2\) shown in Fig. 1. Here the answers are easy to see, but what to do if \(n \ge 4\) and no picture is available?
-
1.
The dimension of the unknown variety V is one.
-
2.
The ideal of V is generated by one polynomial of the form \((x-\alpha )^2 + (y-\beta )^2 - \gamma \).
-
3.
The degree of V is two. A generic line meets V in two (possibly complex) points.
-
4.
The circle V is irreducible because it admits a parametrization by rational functions.
-
5.
The homology groups are \(\,H_0(V,{\mathbb {Z}}) = H_1(V,{\mathbb {Z}}) = {\mathbb {Z}}^1\,\) and \(\,H_i(V,{\mathbb {Z}}) = 0 \) for \(i \ge 2\).
There is a considerable body of literature on such questions in statistics and computer science. The general context is known as manifold learning. One often assumes that V is smooth, i.e. a manifold, in order to apply local methods based on approximation by tangent spaces. Learning the true nature of the manifold V is not a concern for most authors. Their principal aim is dimensionality reduction, and V only serves in an auxiliary role. Manifolds act as a scaffolding to frame question 1. This makes sense when the parameters m and n are large. Nevertheless, the existing literature often draws its inspiration from figures in 3-space with many well-spaced sample points. For instance, the textbook by Lee and Verleysen [38] employs the “Swiss roll” and the “open box” for its running examples (cf. [38, §1.5]).
One notable exception is the work by Ma et al. [41]. Their Generalized Principal Component Analysis solves problems 1–4 under the assumption that V is a finite union of linear subspaces. Question 5 falls under the umbrella of topological data analysis (TDA). Foundational work by Niyogi, Smale and Weinberger [46] concerns the number m of samples needed to compute the homology groups of V, provided V is smooth and its reach is known.
The perspective of this paper is that of computational algebraic geometry. We care deeply about the unknown variety V. Our motivation is the riddle: what is V? For instance, we may be given \(m=800\) samples in \({\mathbb {R}}^9\), drawn secretly from the group \(\mathrm{SO}(3)\) of \(3 {\times } 3\) rotation matrices. Our goal is to learn the true dimension, which is three, to find the 20 quadratic polynomials that vanish on V, and to conclude with the guess that V equals \(\mathrm{SO}(3)\).
Our article is organized as follows. Section 2 presents basics of algebraic geometry from a data perspective. Building on [16], we explain some relevant concepts and offer a catalogue of varieties V frequently seen in applications. This includes our three running examples: the Trott curve, the rotation group \(\mathrm{SO}(3)\), and varieties of low rank matrices.
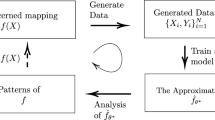
Section 3 addresses the problem of estimating the dimension of V from the sample \(\Omega \). We study nonlinear PCA, box counting dimension, persistent homology curve dimension, correlation dimension and the methods of Levina–Bickel [40] and Diaz–Quiroz–Velasco [22]. Each of these notions depends on a parameter \(\epsilon \) between 0 and 1. This determines the scale from local to global at which we consider \(\Omega \). Our empirical dimensions are functions of \(\epsilon \). We aggregate their graphs in the dimension diagram of \(\Omega \), as seen in Fig. 2.
Section 4 links algebraic geometry to topological data analysis. To learn homological information about V from \(\Omega \), one wishes to know the reach of the variety V. This algebraic number is used to assess the quality of a sample [1, 46]. We propose a variant of persistent homology that incorporates information about the tangent spaces of V at points in \(\Omega \).
A key feature of our setting is the existence of polynomials that vanish on the model V, extracted from polynomials that vanish on the sample \(\Omega \). Linear polynomials are found by Principal Component Analysis (PCA). However, many relevant varieties V are defined by quadratic or cubic equations. Section 5 concerns the computation of these polynomials.
Section 6 utilizes the polynomials found in Sect. 5. These cut out a variety \(V'\) that contains V. We do not know whether \(V' = V\) holds, but we would like to test this and certify it, using both numerical and symbolic algorithms. The geography of \(\Omega \) inside \(V'\) is studied by computing dimension, degree, irreducible decomposition, real degree, and volume.
Section 7 introduces our software package LearningAlgebraicVarieties. This is written in Julia [6], and implements all algorithms described in this paper. It is available at

To compute persistent homology, we use Henselman’s package Eirene [30]. For numerical algebraic geometry we use Bertini [5] and HomotopyContinuation.jl [9]. We conclude with a detailed case study for the dataset in [2, § 6.3]. Here, \(\Omega \) consists of 6040 points in \({\mathbb {R}}^{24}\), representing conformations of the molecule cyclo-octane \(C_8 H_{16}\), shown in Fig. 10.
Due to space limitations, many important aspects of learning varieties from samples are not addressed in this article. One is the issue of noise. Clearly, already the slightest noise in one of the points in Fig. 1 will let no equation of the form \((x-\alpha )^2 + (y-\beta )^2 - \gamma \) vanish on \(\Omega \). But some will almost vanish, and these are the equations we are looking for. Based on our experiments, the methods we present for answering questions 1-5 can handle data that is approximate to some extent. However, we leave a qualitative stability analysis for future work. We also assume that there are no outliers in our data. Another aspect of learning varieties is optimization. We might be interested in minimizing a polynomial function f over the unknown variety V by only looking at the samples in \(\Omega \). This problem was studied by Cifuentes and Parrilo in [15], using the sum of squares (SOS) paradigm [8].
2 Varieties and data
The mathematics of data science is concerned with finding low-dimensional needles in high-dimensional haystacks. The needle is the model which harbors the actual data, whereas the haystack is some ambient space. The paradigms of models are the d-dimensional linear subspaces V of \({\mathbb {R}}^n\), where d is small and n is large. Most of the points in \({\mathbb {R}}^n\) are very far from any sample \(\Omega \) one might ever draw from V, even in the presence of noise and outliers.
The data scientist seeks to learn the unknown model V from the sample \(\Omega \) that is available. If V is suspected to be a linear space, then she uses linear algebra. The first tool that comes to mind is Principal Component Analysis (PCA). Numerical algorithms for linear algebra are well-developed and fast. They are at the heart of scientific computing and its numerous applications. However, many models V occurring in science and engineering are not linear spaces. Attempts to replace V with a linear approximation are likely to fail.
This is the point where new mathematics comes in. Many branches of mathematics can help with the needles of data science. One can think of V as a topological space, a differential manifold, a metric space, a Lie group, a hypergraph, a category, a semi-algebraic set, and lots of other things. All of these structures are useful in representing and analyzing models.
In this article we focus on the constraints that describe V inside the ambient \({\mathbb {R}}^n\) (or \({\mathbb {P}}_{\mathbb {R}}^{n-1}\)). The paradigm says that these are linear equations, revealed numerically by feeding \(\Omega \) to PCA. But, if the constraints are not all linear, then we look for equations of higher degree.
2.1 Algebraic geometry basics
Our models V are algebraic varieties over the field \({\mathbb {R}}\) of real numbers. A variety is the set of common zeros of a system of polynomials in n variables. A priori, a variety lives in Euclidean space \({\mathbb {R}}^n\). In many applications two points are identified if they agree up to scaling. In such cases, one replaces \({\mathbb {R}}^n\) with the real projective space \({\mathbb {P}}^{n-1}_{\mathbb {R}}\), whose points are lines through the origin in \({\mathbb {R}}^n\). The resulting model V is a real projective variety, defined by homogeneous polynomials in n unknowns. In this article, we use the term variety to mean any zero set of polynomials in \({\mathbb {R}}^n\) or \({\mathbb {P}}^{n-1}_{\mathbb {R}}\). The following three varieties serve as our running examples.
Example 2.1
(Trott Curve) The Trott curve is the plane curve of degree four defined by
This curve is compact in \({\mathbb {R}}^2\) and has four connected components (see Fig. 3). The equation of the corresponding projective curve is obtained by homogenizing the polynomial (1). The curve is nonsingular. The Trott curve is quite special because all of its bitangent lines are all fully real. Plücker showed in 1839 that every plane quartic has 28 complex bitangents, Zeuthen argued in 1873 that the number of real bitangents is 28, 16, 8 or 4; see [49, Table 1].
Example 2.2
(Rotation Matrices) The group \(\mathrm{SO}(3)\) consists of all \(3 {\times } 3\)-matrices \(X= (x_{ij})\) with \(\mathrm{det}(X) = 1\) and \(X^T X = \mathrm{Id}_3\). The last constraint translates into 9 quadratic equations:
These quadrics say that X is an orthogonal matrix. Adding the cubic \(\mathrm{det}(X)-1\) gives 10 polynomials that define \(\mathrm{SO}(3)\) as a variety in \({\mathbb {R}}^9\). Their ideal I is prime. In total, there are 20 linearly independent quadrics in I: the nine listed in (2), two from the diagonal of \(XX^T-\mathrm{Id}_3\), and nine that express the right-hand rule for orientation, like \( x_{22} x_{33} - x_{23} x_{32} - x_{11}\).
Example 2.3
(Low Rank Matrices) Consider the set of \(m \times n\)-matrices of rank \(\le r\). This is the zero set of \(\left( {\begin{array}{c}m\\ r+1\end{array}}\right) \left( {\begin{array}{c}n\\ r+1\end{array}}\right) \) polynomials, namely the \((r+1)\)-minors. These equations are homogeneous of degree \(r+1\). Hence this variety lives naturally in the projective space \({\mathbb {P}}^{mn-1}_{\mathbb {R}}\).
A variety V is irreducible if it is not a union of two proper subvarieties. The above varieties are irreducible. A sufficient condition for a variety to be irreducible is that it has a parametrization by rational functions. This holds in Example 2.3 where V consists of the matrices \(U_1^T U_2\) where \(U_1\) and \(U_2\) have r rows. It also holds for the rotation matrices
However, smooth quartic curves in \({\mathbb {P}}^2_{\mathbb {R}}\) admit no such rational parametrization.
The two most basic invariants of a variety V are its dimension and its degree. The former is the length d of the longest proper chain of irreducible varieties \(V_1 \subset V_2 \subset \cdots \subset V_d \subset V\). A general system of d linear equations has a finite number of solutions on V. That number is well-defined if we work over \({\mathbb {C}}\). It is the degree of V, denoted \(\mathrm{deg}(V)\). The Trott curve has dimension 1 and degree 4. The group \(\mathrm{SO}(3)\) has dimension 3 and degree 8. In Example 2.3, if \(m=3,n=4\) and \(r=2\), then the projective variety has dimension 9 and degree 6.
There are several alternative definitions of dimension and degree in algebraic geometry. For instance, they are read off from the Hilbert polynomial, which can be computed by way of Gröbner bases. We refer to Chapter 9, titled Dimension Theory, in the textbook [16].
A variety that admits a rational parametrization is called unirational. Smooth plane curves of degree \(\ge 3\) are not unirational. However, the varieties V that arise in applications are often unirational. The reason is that V often models a generative process. This happens in statistics, where V represents some kind of (conditional) independence structure. Examples include graphical models, hidden Markov models and phylogenetic models.
If V is a unirational variety with given rational parametrization, then it is easy to create a finite subset \(\Omega \) of V. One selects parameter values at random and plugs these into the parametrization. For instance, one creates rank one matrices by simply multiplying a random column vector with a random row vector. A naive approach to sampling from the rotation group \(\mathrm{SO}(3)\) is plugging four random real numbers a, b, c, d into the parametrization (3). Another method for sampling from \(\mathrm{SO}(3)\) will be discussed in Sect. 7.
Given a dataset \(\Omega \subset {\mathbb {R}}^n\) that comes from an applied context, it is reasonable to surmise that the underlying unknown variety V admits a rational parametrization. However, from the vantage point of a pure geometer, such unirational varieties are rare. To sample from a general variety V, we start from its defining equations, and we solve \(\mathrm{dim}(V)\) many linear equations on V. The algebraic complexity of carrying this out is measured by \(\mathrm{deg}(V)\). See Dufresne et al. [25] for recent work on sampling by way of numerical algebraic geometry.
Example 2.4
One might sample from the Trott curve V in Example 2.1 by intersecting it with a random line. Algebraically, one solves \(\,\mathrm{dim}(V)=1\,\) linear equation on the curve. That line intersects V in \(\,\mathrm{deg}(V) = 4\,\) points. Computing the intersection points can be done numerically, but also symbolically by using Cardano’s formula for the quartic. In either case, the coordinates computed by these methods may be complex numbers. Such points are simply discarded if real samples are desired. This can be a rather wasteful process.
At this point, optimization and real algebraic geometry enter the scene. Suppose that upper and lower bounds are known for the values of a linear function \(\ell \) on V. In that case, the equations to solve have the form \(\ell (x) = \alpha \), where \(\alpha \) is chosen between these bounds.
For the Trott curve, we might know that no real points exist unless \(|x| \le 1\). We choose x at random between \(-1\) and \(+1\), plug it into the Eq. (1), and then solve the resulting quartic in y. The solutions y thus obtained are likely to be real, thus giving us lots of real samples on the curve. Of course, for arbitrary real varieties, it is a hard problem to identify a priori constraints that play the role of \(|x| \le 1\). However, recent advances in polynomial optimization, notably in sum-of-squares programming [8], should be quite helpful.
At this point, let us recap and focus on a concrete instance of the riddles we seek to solve.
Example 2.5
Let \(n=6\), \(m=40\) and consider the following forty sample points in \({\mathbb {R}}^6\):
Where do these samples come from? Do the zero entries or the sign patterns offer any clue?
To reveal the answer we label the coordinates as \((x_{22},x_{21},x_{13},x_{12},x_{23},x_{11})\). The relations
hold for all 40 data points. Hence V is the variety of \(2 \times 3\)-matrices \((x_{ij})\) of rank \(\le 1\). Following Example 2.3, we view this as a projective variety in \({\mathbb {P}}^5_{\mathbb {R}}\). In that ambient projective space, the determinantal variety V is a manifold of dimension 3 and degree 3. Note that V is homeomorphic to \({\mathbb {P}}^1_{\mathbb {R}}\times {\mathbb {P}}^2_{\mathbb {R}}\), so we can write its homology groups using the Künneth formula.
In data analysis, proximity between sample points plays a crucial role. There are many ways to measure distances. In this paper we restrict ourselves to two metrics. For data in \({\mathbb {R}}^n\) we use the Euclidean metric, which is induced by the standard inner product \({\langle u,v \rangle = \sum _{i=1}^n u_i v_i }\). For data in \({\mathbb {P}}^{n-1}_{\mathbb {R}}\) we use the Fubini–Study metric. Points u and v in \({\mathbb {P}}^{n-1}_{\mathbb {R}}\) are represented by their homogeneous coordinate vectors. The Fubini–Study distance from u to v is the angle between the lines spanned by representative vectors u and v in \({\mathbb {R}}^n\):
This formula defines the unique Riemannian metric on \({\mathbb {P}}^{n-1}_{\mathbb {R}}\) that is orthogonally invariant.
2.2 A variety of varieties
In what follows we present some “model organisms” seen in applied algebraic geometry. Familiarity with a repertoire of interesting varieties is an essential prerequisite for those who are serious about learning algebraic structure from the datasets \(\Omega \) they might encounter.
Rank constraints: Consider \(m \times n\)-matrices with linear entries having rank \(\le r\). We saw the \(r=1\) case in Example 2.3. A rank variety is the set of all tensors of fixed size and rank that satisfy some linear constraints. The constraints often take the simple form that two entries are equal. This includes symmetric matrices, Hankel matrices, Toeplitz matrices, Sylvester matrices, etc. Many classes of structured matrices generalize naturally to tensors.
Example 2.6
Let \(n = \left( {\begin{array}{c}s\\ 2\end{array}}\right) \) and identify \({\mathbb {R}}^n\) with the space of skew-symmetric \(s \times s\)-matrices \(P= (p_{ij}) \). These satisfy \(P^T = - P\). Let V be the variety of rank 2 matrices P in \({\mathbb {P}}^{n-1}_{\mathbb {R}}\). A parametric representation is given by \(p_{ij} = a_i b_j - a_j b_i\), so the \(p_{ij}\) are the \(2 \times 2\)-minors of a \(2 \times s\)-matrix. The ideal of V is generated by the \(4 \times 4\) pfaffians \(\, p_{ij} p_{kl} - p_{ik} p_{jl} + p_{il} p_{jk}\). These \(\left( {\begin{array}{c}s\\ 4\end{array}}\right) \) quadrics are also known as the Plücker relations, and V is the Grassmannian of 2-dimensional linear subspaces in \({\mathbb {R}}^s\). The r-secants of V are represented by the variety of skew-symmetric matrices of rank \(\le 2r\). Its equations are the \((2r{+}2) \times (2r{+}2)\) pfaffians of P. We refer to [29, Lectures 6 and 9] for an introduction to these classical varieties.
Example 2.7
The space of \(3 \times 3 \times 3 \times 3\) tensors \((x_{ijkl})_{1 \le i,j,k,l \le 3}\) has dimension 81. Suppose we sample from its subspace of symmetric tensors \(m = (m_{rst})_{0 \le r \le s \le t \le 3}\). This has dimension \(n=20\). We use the convention \(m_{rst} = x_{ijkl}\) where r is the number of indices 1 in (i, j, k, l), s is the number of indices 2, and t is the number of indices 3. This identifies tensors m with cubic polynomials \(m = \sum _{i+j+k \le 3} m_{ijk} x^i y^j z^k\), and hence with cubic surfaces in 3-space. Fix \(r \in \{1,2,3\}\) and take V to be the variety of tensors m of rank \(\le r\). The equations that define the tensor rank variety V are the \((r+1) \times (r+1)\)-minors of the \(4 \times 10\) Hankel matrix
See Landsberg’s book [37] for an introduction to the geometry of tensors and their rank.
Example 2.8
In distance geometry, one encodes finite metric spaces with p points in the Schönberg matrix \(\,D \,=\, \bigl (d_{ip}+d_{jp}-d_{ij} \bigr )\,\) where \(d_{ij}\) is the squared distance between points i and j. The symmetric \((p{-}1) \times (p{-}1)\) matrix D is positive semidefinite if and only if the metric space is Euclidean, and its embedding dimension is the rank r of D. See [20, §6.2.1] for a textbook introduction and derivation of Schönberg’s esults. Hence the rank varieties of the Schönberg matrix D encode the finite Euclidean metric spaces with p points. A prominent dataset corresponding to the case \(p=8\) and \(r=3\) will be studied in Sect. 7.
Matrices and tensors with rank constraints are ubiquitous in data science. Make sure to search for such low rank structures when facing vectorized samples, as in Example 2.5.
Hypersurfaces: The most basic varieties are defined by just one polynomial. When given a sample \(\Omega \), one might begin by asking for hypersurfaces that contain \(\Omega \) and that are especially nice, simple and informative. Here are some examples of special structures worth looking for.
Example 2.9
For \(s=6, r=2\) in Example 2.6, V is the hypersurface of the \(6 \times 6\)-pfaffian:
The 15 monomials correspond to the matchings of the complete graph with six vertices.
Example 2.10
The hyperdeterminant of format \(2 \times 2 \times 2 \) is a polynomial of degree four in \(n=8\) unknowns, namely the entries of a \(2 \times 2 \times 2\)-tensor \(X = (x_{ijk})\). Its expansion equals
This hypersurface is rational and it admits several nice parametrizations, useful for sampling points. For instance, up to scaling, we can take the eight principal minors of a symmetric \(3 \times 3\)-matrix, with \(x_{000} = 1\) as the \(0 \times 0\)-minor, \(x_{100},x_{010},x_{001}\) for the \(1 \times 1 \)-minors (i.e. diagonal entries), \(x_{110},x_{101}, x_{011}\) for the \(2 \times 2\)-minors, and \(x_{111} \) for the \(3 \times 3\)-determinant.
Example 2.11
Let \(n=10\), with coordinates for \({\mathbb {R}}^{10}\) given by the off-diagonal entries of a symmetric \(5 \times 5\)-matrix \((x_{ij})\). There is a unique quintic polynomial in these variables that vanishes on symmetric \(5 \times 5\)-matrices of rank \(\le 2\). This polynomial, known as the pentad, plays a historical role in the statistical theory of factor analysis [24, Example 4.2.8]. It equals
We can sample from the pentad using the parametrization \(\,x_{ij} = a_i b_j + c_i d_j \,\) for \( 1 \le i < j \le 5\).
Example 2.12
The determinant of the \( (p{-}1) \times (p{-}1) \) matrix in Example 2.8 equals the squared volume of the simplex spanned by p points in \({\mathbb {R}}^{p-1}\). If \(p=3\) then we get Heron’s formula for the area of a triangle in terms of its side lengths. The hypersurface in \({\mathbb {R}}^{\left( {\begin{array}{c}p\\ 2\end{array}}\right) }\) defined by this polynomial represents configurations of p points in \({\mathbb {R}}^{p-1}\) that are degenerate.
One problem with interesting hypersurfaces is that they often have a very high degree and it would be impossible to find that equation by our methods in Sect. 5. For instance, the Lüroth hypersurface [4] in the space of ternary quartics has degree 54, and the restricted Boltzmann machine [17] on four binary random variables has degree 110. These hypersurfaces are easy to sample from, but there is little hope to learn their equations from those samples.
Secret linear spaces: This refers to varieties that become linear spaces after a simple change of coordinates. Linear spaces V are easy to recognize from samples \(\Omega \) using PCA.
Toric varieties become linear spaces after taking logarithms, so they can be learned by taking the coordinatewise logarithm of the sample points. Formally, a toric variety is the image of a monomial map. Equivalently, it is an irreducible variety defined by binomials.
Example 2.13
Let \(n=6, m=40\) and consider the following dataset in \({\mathbb {R}}^6\):
Replace each of these forty vectors by its coordinate-wise logarithm. Applying PCA to the resulting vectors, we learn that our sample comes from a 4-dimensional subspace of \({\mathbb {R}}^6\). This is the row space of a \(4 \times 6\)-matrix whose columns are the vertices of a regular octahedron:
Our original samples came from the toric variety \(X_A\) associated with this matrix. This means each sample has the form (ab, ac, ad, bc, bd, cd), where a, b, c, d are positive real numbers.
Toric varieties are important in applications. For instance, in statistics they correspond to exponential families for discrete random variables. Overlap with rank varieties arises for matrices and tensors of rank 1. Those smallest rank varieties are known in geometry as the Segre varieties (for arbitrary tensors) and the Veronese varieties (for symmetric tensors). These special varieties are toric, so they are represented by an integer matrix A as above.
Example 2.14
Let \(n=6\) and take \(\Omega \) to be a sample of points of the form
The corresponding variety \(V \subset {\mathbb {P}}^5_{\mathbb {R}}\) is a reciprocal linear space V; see [36]. In projective geometry, such a variety arises as the image of a linear space under the classical Cremona transformation. From the sample we can learn the variety V by replacing each data point by its coordinate-wise inverse. Applying PCA to these reciprocalized data, we learn that V is a surface in \({\mathbb {P}}_{\mathbb {R}}^5\), cut out by ten cubics like \(\,2 x_3 x_4 x_5-x_3 x_4 x_6-2 x_3 x_5 x_6+x_4 x_5 x_6 \).
Algebraic statistics and computer vision: Model selection is a standard task in statistics. The models considered in algebraic statistics [24] are typically semi-algebraic sets, and it is customary to identify them with their Zariski closures, which are algebraic varieties.
Example 2.15
Bayesian networks are also known as directed graphical models. The corresponding varieties are parametrized by monomial maps from products of simplices. Here are the equations for a Bayesian network on 4 binary random variables [24, Example 3.3.11]:
The coordinates \(x_{ijkl}\) represent the probabilities of observing the 16 states under this model.
Computational biology is an excellent source of statistical models with interesting geometric and combinatorial properties. These include hidden variable tree models for phylogenetics, and hidden Markov models for gene annotation and sequence alignment.
In the social sciences and economics, statistical models for permutations are widely used:
Example 2.16
Let \(n=6\) and consider the Plackett-Luce model for rankings of three items [51]. Each item has a model parameter \(\theta _i\), and we write \(x_{ijk}\) for the probability of observing the permutation ijk. The model is the surface in \({\mathbb {P}}^5_{\mathbb {R}}\) given by the parametrization
The prime ideal of this model is generated by three quadrics and one cubic:
When dealing with continuous distributions, we can represent certain statistical models as varieties in moment coordinates. This applies to Gaussians and their mixtures.
Example 2.17
Consider the projective variety in \({\mathbb {P}}_{\mathbb {R}}^6\) given parametrically by \(m_0 = 1\) and
These are the moments of order \(\le 6\) of the mixture of two Gaussian random variables on the line. Here \(\mu \) and \(\nu \) are the means, \(\sigma \) and \(\tau \) are the variances, and \(\lambda \) is the mixture parameter. It was shown in [3, Theorem 1] that this is a hypersurface of degree 39 in \({\mathbb {P}}^6\). For \(\lambda = 0\) we get the Gaussian moment surface which is defined by the \(3 \times 3\)-minors of the \(3 \times 6\)-matrix
Example 2.18
Let \(n=9\) and fix the space of \(3 \times 3\)-matrices. An essential matrix is the product of a rotation matrix times a skew-symmetric matrix. In computer vision, these matrices represent the relative position of two calibrated cameras in 3-space. Their entries \(x_{ij}\) serve as invariant coordinates for pairs of such cameras. The variety of essential matrices is defined by ten cubics. These are known as the Démazure cubics [35, Example 2.2].
The article [35] studies camera models in the presence of distortion. For example, the model described in [35, Example 2.3] concerns essential matrices plus one focal length unknown. This is the codimension two variety defined by the \(3 \times 3\)-minors of the \(3 \times 4\)-matrix
Learning such models is important for image reconstruction in computer vision.
3 Estimating the dimension
The first question one asks about a variety V is “What is the dimension?”. In what follows, we discuss methods for estimating \( \mathrm{dim}(V)\) from the finite sample \(\Omega \), taken from V. We present six dimension estimates. They are motivated and justified by geometric considerations. For a manifold, dimension is defined in terms of local charts. This is consistent with the notion of dimension in algebraic geometry [16, Chapter 9]. The dimension estimates in this section are based on \(\Omega \) alone. Later sections will address the computation of equations that vanish on V. These can be employed to find upper bounds on \(\mathrm{dim}(V)\); see (23). In what follows, however, we do not have that information. All we are given is the input \(\Omega =\{u^{(1)},\ldots , u^{(m)}\}\).
3.1 Dimension diagrams
There is an extensive literature (see e.g. [12, 13]) on computing an intrinsic dimension of the sample \(\Omega \) from a manifold V. The intrinsic dimension of \(\Omega \) is a positive real number that approximates the Hausdorff dimension of V, a quantity that measures the local dimension of a space using the distances between nearby points. It is a priori not clear that the algebraic definition of \(\mathrm{dim}(V)\) agrees with the topological definition of Hausdorff dimension that is commonly used in manifold learning. However, this will be true under the following natural hypotheses. We assume that V is a variety in \({\mathbb {R}}^n\) or \({\mathbb {P}}^{n-1}_{\mathbb {R}}\) such that the set of real points is Zariski dense in each irreducible component of V. If V is irreducible, then its singular locus \(\mathrm{Sing}(V)\) is a proper subvariety, so it has measure zero. The regular locus \(V \backslash \mathrm{Sing}(V)\) is a real manifold. Each connected component is a real manifold of dimension \(\,d = \mathrm{dim}(V)\).
The definitions of intrinsic dimension can be grouped into two categories: local methods and global methods [13, 34]. Definitions involving information about sample neighborhoods fit into the local category, while those that use the whole dataset are called global.
Instead of making such a strict distinction between local and global, we introduce a parameter \(0\le \epsilon \le 1\). The idea behind this is that \(\epsilon \) should determine the range of information that is used to compute the dimension from the local scale (\(\epsilon =0\)) to the global scale (\(\epsilon =1\)).
To be precise, for each of the dimension estimates, locality is determined by a notion of distance: the point sample \(\Omega \) is a finite metric space. In our context we restrict extrinsic metrics to the sample. For samples \(\Omega \subset {\mathbb {R}}^n\) we work with the scaled Euclidean distance
For samples \(\Omega \) taken in projective space \({\mathbb {P}}^{n-1}_{\mathbb {R}}\) we use the scaled Fubini–Study distance
Two points \(u^{(i)}\) and \(u^{(j)}\) in \(\Omega \) are considered \(\epsilon \)-close with respect to the parameter \(\epsilon \) if \({\mathrm {dist}}_{{\mathbb {R}}^{n}}(u,v)\le \epsilon \) or \({\mathrm {dist}}_{{\mathbb {P}}^{n-1}_{\mathbb {R}}}(u,v)\le \epsilon \), respectively. Given \(\epsilon \) we divide the sample \(\Omega \) into clusters \(\Omega _1^\epsilon ,\ldots ,\Omega _l^\epsilon \), which are defined in terms of \(\epsilon \)-closeness, and apply the methods to each cluster separately, thus obtaining dimension estimates whose definition of being local depends on \(\epsilon \). In particular, for \(\epsilon =0\) we consider each sample point individually, while for \(\epsilon = 1\) we consider the whole sample. Intermediate values of \(\epsilon \) interpolate between the two.
Many of the definitions of intrinsic dimension are consistent. This means that it is possible to compute a scale \(\epsilon \) from \(\Omega \) for which the intrinsic dimension of each cluster converges to the dimension of V if m is sufficiently large and \(\Omega \) is sampled sufficiently densely. By contrast, our paradigm is that m is fixed. For us, m does not tend to infinity. Our standing assumption is that we are given one fixed sample \(\Omega \). The goal is to compute a meaningful dimension from that fixed sample of m points. For this reason, we cannot unreservedly employ results on appropriate parameters \(\epsilon \) in our methods. The sample \(\Omega \) will almost never satisfy the assumptions that are needed. Our approach to circumvent this problem is to create a dimension diagram. Such diagrams are shown in Figs. 2, 6, 8 and 11.
Definition 3.1
Let \({\mathrm {dim}}(\Omega ,\epsilon )\) be one of the subsequent dimension estimates. The dimension diagram of the sample \(\Omega \) is the graph of the function \(\,(0,1]\rightarrow {\mathbb {R}}_{\ge 0},\, \epsilon \mapsto {\mathrm {dim}}(\Omega ,\epsilon )\).
Remark 3.2
The idea of using dimension diagrams is inspired by persistent homology. Our dimension diagrams and our persistent homology barcodes in Sect. 4 both use \(\epsilon \) in the interval [0, 1] for the horizontal axis. This uniform scale for all samples \(\Omega \) makes comparisons across different datasets easier.
The true dimension of a variety is an integer. However, we defined the dimension diagram to be the graph of a function whose range is a subset of the real numbers. The reason is that the subsequent estimates do not return integers. A noninteger dimension can be meaningful mathematically, such as in the case of a fractal curve which fills space densely enough that its dimension could be considered closer to 2 than 1. By plotting these diagrams, we hope to gain information about the true dimension d of the variety V from which \(\Omega \) was sampled.

Dimension diagrams for 600 points on the variety of \(3 \times 4\) matrices of rank 2. This is a projective variety of dimension 9. Its affine cone has dimension 10. The top picture shows dimension diagrams for the estimates in Euclidean space \({\mathbb {R}}^{12}\). The bottom picture shows those for projective space \({\mathbb {P}}^{11}_{\mathbb {R}}\). The projective diagrams yield better estimates. The 600 data points were obtained by independently sampling pairs of \(4\times 2\) and \(2\times 3\) matrices, each with independent entries from the normal distribution, and then multiplying them
One might be tempted to use the same dimension estimate for \({\mathbb {R}}^n\) and \({\mathbb {P}}^{n-1}_{\mathbb {R}}\), possibly via the Euclidean distance on an affine patch of \({\mathbb {P}}_{\mathbb {R}}^{n-1}\). However, the Theorema Egregium by Gauss implies that any projection from \({\mathbb {P}}_{\mathbb {R}}^{n-1}\) to \({\mathbb {R}}^{n-1}\) must distort lengths. Hence, because we gave the parameter \(\epsilon \) a metric meaning, we must be careful and treat real Euclidean space and real projective space separately.
Each of the curves seen in Fig. 2 is a dimension diagram. We used six different methods for estimating the dimension on a fixed sample of 600 points. For the horizontal axis on the top we took the distance (6) in \({\mathbb {R}}^{12}\). For the diagram on the bottom we took (7) in \({\mathbb {P}}^{11}_{\mathbb {R}}\).
3.2 Six dimension estimates
In this section, we introduce six dimension estimates. They are adapted from the existing literature. Figures 2, 6, 8 and 11 show dimension diagrams generated by our implementation. Judging from those figures, the estimators CorrSum, PHCurve, MLE and ANOVA all perform well on each of the examples. By contrast, NPCA and BoxCounting frequently overestimate the dimension. In general, we found it useful to allow for a “majority vote” for the dimension. That is, we choose as dimension estimate the number which is closest to most of the estimators for a significant (i.e. “persistent”) range of \(\epsilon \)-values in [0, 1].
NPCA dimension: The gold standard of dimension estimation is PCA. Assuming that V is a linear subspace of \({\mathbb {R}}^n\), we perform the following steps for the input \(\Omega \). First, we record the mean \(\,\overline{u} := \frac{1}{m} \sum _{i=1}^m u^{(i)}\). Let M be the \(m \times n\)-matrix with rows \(u^{(i)} - \overline{u}\). We compute \(\sigma _1\ge \cdots \ge \sigma _{\min \{m,n\}}\), the singular values of M. The PCA dimension is the number of \(\sigma _i\) above a certain threshold. For instance, this threshold could be the same as in the definition of the numerical rank in (21) below. Following [38, p. 30], another idea is to set the threshold as \(\sigma _k\), where \({k = \mathrm{argmax}_{1\le i \le \min \{m,n\}-1} \vert \log _{10}(\sigma _{i+1}) - \log _{10}(\sigma _{i})\vert }\). In our experiments we found that this improved the dimension estimates. In some situations it is helpful to further divide each column of M by its standard deviation. This approach is explained in [38, p. 26].
Using PCA on a local scale is known as Nonlinear Principal Component Analysis (NPCA). Here we partition the sample \(\Omega \) into l clusters \(\Omega _1^\epsilon ,\ldots ,\Omega _l^\epsilon \subset \Omega \) depending on \(\epsilon \). For each \(\Omega _i^\epsilon \) we apply the usual PCA and obtain the estimate \(\mathrm{dim}_\mathrm{pca}(\Omega _i^\epsilon )\). The idea behind this is that the manifold \(V \backslash \mathrm{Sing}(V)\) is approximately linear locally. We take the average of these local dimensions, weighted by the size of each cluster. The result is the nonlinear PCA dimension
Data scientists have many clustering methods. For our study we use single linkage clustering. This works as follows. The clusters are the connected components in the graph with vertex set \(\Omega \) whose edges are the pairs of points having distance at most \(\epsilon \). We do this either in Euclidean space with metric (6), or in projective space with metric (7). In the latter case, the points come from the cone over the true variety V. To make \(\Omega \) less scattered, we sample a random linear function l and scale each data point \(u^{(i)}\) such that \(l(u^{(i)})=1\). Then we use those affine coordinates for NPCA. We chose this procedure because NPCA detects linear spaces and the proposed scaling maps projective linear spaces to affine-linear spaces.
We next introduce the notions of box counting dimension, persistent homology curve dimension and correlation dimension. All three of these belong to the class of fractal-based methods, since they rest on the idea of using the fractal dimension as a proxy for \(\mathrm{dim}(V)\).
Box counting dimension: Here is the geometric idea in \({\mathbb {R}}^2\). Consider a square of side length 1 which we cover by miniature squares. We could cover it with 4 squares of side length \(\frac{1}{2}\), or 9 squares of side length \(\frac{1}{3}\), etc. What remains constant is the log ratio of the number of pieces over the magnification factor. For the square: \(\frac{\log (4)}{\log (2)}=\frac{\log (9)}{\log (3)}=2\). If \(\Omega \) only intersects 3 out of 4 smaller squares, then we estimate the dimension to be between 1 and 2.
In \({\mathbb {R}}^n\) we choose as a box the parallelopiped with lower vertex \(u^{-} = \mathrm{min}(u^{(1)},\ldots ,u^{(m)})\) and upper vertex \({u^{+}= \mathrm{max}(u^{(1)},\ldots ,u^{(m)})}\), where “min” and “max” are coordinatewise minimum and maximum. Thus the box is \(\{ x \in {\mathbb {R}}^n\,: \, u^- \le x \le u^+ \}\). For \(j=1,\ldots ,n\), the interval \([u^-_j,u^+_j]\) is divided into \(R(\epsilon )\) equally sized intervals, whose length depends on \(\epsilon \). A d-dimensional object is expected to capture \(R(\epsilon )^d\) boxes. We determine the number \(\nu \) of boxes that contain a point in \(\Omega \). Then the box counting dimension estimate is
How to define the function \(R(\epsilon )\)? Since the number of small boxes is very large, we cannot iterate through all boxes. It is desirable to decide from a data point \(u\in \Omega \) in which box it lies. To this end, we set \(R(\epsilon ) = \lfloor \frac{\lambda }{\epsilon } \rfloor + 1\), where \(\lambda := \max _{1\le j\le n} \vert u^+_j - u^-_j \vert \). Then, for \(u\in \Omega \) and \(k=1,\ldots ,n\) we compute the largest \(q_k\) such that \(\frac{q_k}{R(\epsilon )} \vert u^+_k - u^-_k\vert \le \vert u_k-u^-_k\vert \). The n numbers \(q_1,\ldots ,q_n\) completely determine the box that contains the sample u.
For the box counting dimension in real projective space, we represent the points in \(\Omega \) on an affine patch of \({\mathbb {P}}^{n-1}_{\mathbb {R}}\). On this patch we do the same construction as above, the only exception being that “equally sized intervals” is measured in terms of scaled Fubini–Study distance (7).
Persistent homology curve dimension: The underlying idea was proposed by the Pattern Analysis Lab at Colorado State University [52]. First we partition \(\Omega \) into l clusters \(\Omega _1^\epsilon ,\ldots ,\Omega _l^\epsilon \) using single linkage clustering with \(\epsilon \). On each subsample \(\Omega _i\) we construct a minimal spanning tree. Suppose that the cluster \(\Omega _i\) has \(m_i\) points. Let \(l_i(j)\) be the length of the j-th longest edge in a minimal spanning tree for \(\Omega _i\). For each \(\Omega _i\) we compute
The persistent homology curve dimension estimate \(\,\dim _\mathrm{PHCurve}(\Omega ,\epsilon )\,\) is the average of the local dimensions, weighted by the size of each cluster:
In the clustering step we take the distance (6) if the variety is affine and (7) if it is projective.
Correlation dimension: This is motivated as follows. Suppose that \(\Omega \) is uniformly distributed in the unit ball. For pairs \(u,v\in \Omega \), we have \({\mathrm {Prob}}\{{\mathrm {dist}}_{{\mathbb {R}}^n}(u,v) < \epsilon \} = \epsilon ^d\), where \(d = {\mathrm {dim}}(V)\). We set \(C(\epsilon ) := (1/\genfrac(){0.0pt}1{m}{2})\cdot \sum _{1\le i<j\le m} \mathbf {1}({\mathrm {dist}}_{{\mathbb {R}}^n}(u^{(i)},u^{(j)}) < \epsilon )\) , where \(\mathbf {1}\) is the indicator function. Since we expect the empirical distribution \(C(\epsilon )\) to be approximately \(\epsilon ^d\), this suggests using \(\,\frac{\log (C(\epsilon ))}{ \mathrm{log}(\epsilon )}\,\) as dimension estimate. In [38, §3.2.6] it is mentioned that a more practical estimate is obtained from \(C(\epsilon )\) by selecting some small \(h>0\) and putting
In practice, we compute the dimension estimates for a finite subset of parameters \(\epsilon _1,\ldots , \epsilon _k\) and put \(h = \min _{i\ne j} \vert \epsilon _i -\epsilon _j\vert \). The ball in \({\mathbb {P}}^{n-1}_{\mathbb {R}}\) defined by the scaled Fubini–Study distance (7) is a spherical cap of radius \(\epsilon \). Its volume relative to a cap of radius 1 is \(\int _0^\epsilon (\sin \alpha )^{d-1} {\mathrm {d}}\alpha /\int _0^1 (\sin \alpha )^{d-1} {\mathrm {d}}\alpha \), which we approximate by \(\,\bigl (\frac{\sin (\epsilon )}{\sin (1)} \bigr )^{d}\). Hence, the projective correlation dimension estimate is
with the same h as above and where \( C(\epsilon )\) is now computed using the Fubini–Study distance.
We next describe two more methods. They differ from the aforementioned in that they derive from estimating the dimension of the variety V locally at a distinguished point \(u^{(\star )}\).
MLE dimension: Levina and Bickel [40] introduced a maximum likelihood estimator for the dimension of an unknown variety V. Their estimate is derived for samples in Euclidean space \({\mathbb {R}}^n\). Let k be the number of samples \(u^{(j)}\) in \(\Omega \) that are within distance \(\epsilon \) to \(u^{(\star )}\). We write \(T_i(u^{(\star )})\) for the distance from \(u^{(\star )}\) to its i-th nearest neighbor in \(\Omega \). Note that \(T_k(u^{(\star )}) \le \epsilon < T_{k+1}(u^{(\star )})\). The Levina-Bickel formula around the point \(u^{(\star )}\) is
This expression is derived from the hypothesis that \(k = k(\epsilon )\) obeys a Poisson process on the \(\epsilon \)-neighborhood \({\{u\in \Omega : {\mathrm {dist}}_{{\mathbb {R}}^n}(u,u^{(\star )}) \le \epsilon \}}\), in which u is uniformly distributed. The formula (11) is obtained by solving the likelihood equations for this Poisson process.
In projective space, we model \(k(\epsilon )\) as a Poisson process on \(\{u\in \Omega : {\mathrm {dist}}_{{\mathbb {P}}_{\mathbb {R}}^{n-1}}(u,u^{(\star )}) \le \epsilon \}\). However, instead of assuming that u is uniformly distributed in that neighborhood, we assume that the orthogonal projection of u onto the tangent space \({\mathrm {T}}_{u^{(\star )}} {\mathbb {P}}_{\mathbb {R}}^{n-1}\) is uniformly distributed in the associated ball of radius \(\sin {\epsilon }\). Then, we derive the formula
where \(\widehat{T}_i(u^{(\star )})\) is the distance from \(u^{(\star )}\) to its i-th nearest neighbor in \(\Omega \) measured for (7).
It is not clear how to choose \(u^{(\star )}\) from the given \(\Omega \). We chose the following method. Fix the sample neighborhood \(\,\Omega _i^\epsilon := \{u\in \Omega : {\mathrm {dist}}_{{\mathbb {R}}^n}(u,u^{(i)}) \le \epsilon \}\). For each i we evaluate the formula (11) for \(\Omega _i^\epsilon \) with distinguished point \(u^{(i)}\). With this, the MLE dimension estimate is
ANOVA dimension: Diaz, Quiroz and Velasco [22] derived an analysis of variance estimate for the dimension of V. In their approach, the following expressions are important:
The quantity \(\beta _d\) is the variance of the random variable \(\Theta _d\), defined as the angle between two uniformly chosen random points on the \((d-1)\)-sphere. We again fix \(\epsilon > 0\), and we relabel so that \(u^{(1)},\ldots ,u^{(k)}\) are the points in \(\Omega \) with distance at most \(\epsilon \) from \(u^{(\star )}\). Let \(\theta _{ij} \in [0,\pi ]\) denote the angle between \(u^{(i)} - u^{(\star )}\) and \(u^{(j)}- u^{(\star )}\). Then, the sample covariance of the \(\theta _{ij} \) is
The analysis in [22] shows that, for small \(\epsilon \) and \(\Omega \) sampled from a d-dimensional manifold, the angles \(\theta _{ij}\) are approximately \(\Theta _d\)-distributed. Hence, S is expected to be close to \(\beta _{\dim V}\). The ANOVA dimension estimate of \(\Omega \) is the index d such that \(\beta _d\) is closest to S:
As for the MLE estimate, we average (14) over all \(u\in \Omega \) being the distinguished point.
To transfer the definition to projective space, we revisit the idea behind the ANOVA estimate. For u close to \(u^{(\star )}\), the secant through u and \(u^{(\star )}\) is approximately parallel to the tangent space of V at \(u^{(\star )}\). Hence, the unit vector \((u^{(\star )}-u)/ \Vert u^{(\star )}-u\Vert \) is close to being in the tangent space \({\mathrm {T}}_{u^{(\star )}}(V)\). The sphere in \({\mathrm {T}}_{u^{(\star )}}(V)\) has dimension \({\mathrm {dim}} \,V - 1\) and we know the variances of the random angles \(\Theta _{d}\). To mimic this construction in \({\mathbb {P}}_{\mathbb {R}}^{n-1}\) we use the angles between geodesics meeting at \(u^{(\star )}\). In our implementation, we orthogonally project \(\Omega \) to the tangent space \({\mathrm {T}}_{u^{(\star )}} {\mathbb {P}}_{\mathbb {R}}^{n-1}\) and compute (13) using coordinates on that space.
We have defined all the mathematical ingredients inherent in our dimension diagrams. Figure 2 now makes sense. Our software and its applications will be discussed in Sect. 7.
4 Persistent homology
This section connects algebraic geometry and topological data analysis. It concerns the computation and analysis of the persistent homology [14] of our sample \(\Omega \). Persistent homology of \(\Omega \) contains information about the shape of the unknown variety V from which \(\Omega \) originates.
4.1 Barcodes
Let us briefly review the idea. Given \(\Omega \), we associate a simplicial complex with each value of a parameter \(\epsilon \in [0,1]\). Just like in the case of the dimension diagrams in the previous section, \(\epsilon \) determines the scale at which we consider \(\Omega \) from local (\(\epsilon = 0\)) to global (\(\epsilon = 1\)). The complex at \(\epsilon =0\) consists of only the vertices and at \(\epsilon =1\) it is the full simplex on \(\Omega \).
Persistent homology identifies and keeps track of the changes in the homology of those complexes as \(\epsilon \) varies. The output is a barcode, i.e. a collection of intervals. Each interval in the barcode corresponds to a topological feature which appears at the value of a parameter given by the left hand endpoint of the interval and disappears at the value given by the right hand endpoint. These barcodes play the same role as a histogram does in summarizing the shape of the data, with long intervals corresponding to strong topological signals and short ones to noise. By plotting the intervals we obtain a barcode, such as the one in Fig. 3.

Persistent homology barcodes for the Trott curve
The most straightforward way to associate a simplicial complex to \(\Omega \) at \(\epsilon \) is by covering \(\Omega \) with open sets \(\,U(\epsilon )=\bigcup _{i=1}^m U_i(\epsilon )\) and then building the associated nerve complex. This is the simplicial complex with vertex set \([m] = \{1,2,\ldots ,m\}\), where a subset \(\sigma \) of [m] is a face if and only if \(\bigcap _{i \in \sigma } U_i(\epsilon ) \not = \emptyset \). If all nonempty finite intersections of \(U_i(\epsilon )\) are contractible topological spaces, then the Nerve Lemma guarantees that the homology groups of \(U(\epsilon )\) agree with those of its nerve complex. When \(U_i(\epsilon )\) are \(\epsilon \)-balls around the data points, i.e.
the nerve complex is called the Čech complex at \(\epsilon \). Here \({\mathrm {dist}}_{{\mathbb {R}}^n}\) and \({\mathrm {dist}}_{{\mathbb {P}}_{\mathbb {R}}^n}\) are the distances from (6) and (7), respectively. Theorem 4.2 gives a precise statement for a sufficient condition under which the Čech complex of \(U(\epsilon )\) built on \(\Omega \) yields the correct topology of V. However, in practice the hypotheses of the theorem will rarely be satisfied.
Čech complexes are computationally demanding as they require storing simplices in different dimensions. For this reason, applied topologists prefer to work with the Vietoris–Rips complex, which is the flag simplicial complex determined by the edges of the Čech complex. This means that a subset \(\sigma \subset [m]\) is a face of the Vietoris–Rips complex if and only if \(\,U_i(\epsilon ) \bigcap U_j(\epsilon ) \not = \emptyset \,\) for all \(i,j \in \sigma \). With the definition in (15), the balls \(\,U_i(\epsilon ) \) and \(U_j(\epsilon ) \) intersect if and only if their centers \(u^{(i)}\) and \(u^{(j)}\) are less than \(2 \epsilon \) apart.
Consider the sample from the Trott curve in Fig. 3. Following Example 2.4, we sampled by selecting random x-coordinates between \(-1\) and 1, and solving for y, or vice versa. The picture on the right shows the barcode. This was computed via the Vietoris–Rips complex. For dimensions 0 and 1 the six longest bars are displayed. The sixth bar in dimension 1 is so tiny that we cannot see it. In the range where \(\epsilon \) lies between 0 and 0.2, we see four components. The barcode for dimension 1 identifies four persisting features for \(\epsilon \) between 0.01 and 0.12. Each of these indicates an oval. Once these disappear, another loop appears. This corresponds to the fact that the four ovals are arranged to form a circle. So persistent homology picks up on both intrinsic and extrinsic topological features of the Trott curve.
The repertoire of algebraic geometry offers a fertile testing ground for practitioners of persistent homology. For many classes of algebraic varieties, both over \({\mathbb {R}}\) and \({\mathbb {C}}\), one has a priori information about their topology. For instance, the determinantal variety in Example 2.5 is the 3-manifold \({\mathbb {P}}_{{\mathbb {R}}}^1 \times {\mathbb {P}}_{{\mathbb {R}}}^2\). Using Henselman’s software Eirene for persistent homology [30], we computed barcodes for several samples \(\Omega \) drawn from varieties with known topology.
4.2 Tangent spaces and ellipsoids
We underscore the benefits of an algebro-geometric perspective by proposing a variant of persistent homology that performed well in the examples we tested. Suppose that, in addition to knowing \(\Omega \) as a finite metric space, we also have information on the tangent spaces of the unknown variety V at the points \(u^{(i)}\). This will be the case after we have learned some polynomial equations for V using the methods in Sect. 5. In such circumstances, we suggest replacing the \(\epsilon \)-balls in (15) with ellipsoids that are aligned to the tangent spaces.
The motivation is that in a variety with a bottleneck, for example in the shape of a dog bone, the balls around points on the bottleneck may intersect for \(\epsilon \) smaller than that which is necessary for the full cycle to appear. When V is a manifold, we design a covering of \(\Omega \) that exploits the locally linear structure. Let \(0<\lambda <1\). We take \(U_i(\epsilon )\) to be an ellipsoid around \(u^{(i)}\) with principal axes of length \(\epsilon \) in the tangent direction of V at \(u^{(i)}\) and principal axes of length \(\lambda \epsilon \) in the normal direction. In this way, we allow ellipsoids to intersect with their neighbors and thus reveal the true homology of the variety before ellipsoids intersect with other ellipsoids across the medial axis. The parameter \(\lambda \) can be chosen by the user. We believe that \(\lambda \) should be proportional to the reach of V. This metric invariant is defined in the next subsection.
In practice, we perform the following procedure. Let \(f = (f_1,\ldots ,f_k)\) be a vector of polynomials that vanish on V, derived from the sample \(\Omega \subset {\mathbb {R}}^n\) as in Sect. 5. An estimator for the tangent space \({\mathrm {T}}_{u^{(i)}}V\) is the kernel of the Jacobian matrix of f at \(u^{(i)}\). In symbols,
Let \(q_i\) denote the quadratic form on \({\mathbb {R}}^n\) that takes value 1 on \(\,\widehat{{\mathrm {T}}}_{u^{(i)}}V \cap {\mathbb {S}}^{n-1}\,\) and value \(\lambda \) on the orthogonal complement of \(\widehat{{\mathrm {T}}}_{u^{(i)}}V\) in the sphere \({\mathbb {S}}^{n-1}\). Then, the \(q_i\) specify the ellipsoids
The role of the \(\epsilon \)-ball enclosing the ith sample point is now played by \(U_i(\epsilon ) := u^{(i)} + \epsilon E_i\). These ellipsoids determine the covering \(\,U(\epsilon ) = \bigcup _{i=1}^m U_i(\epsilon )\,\) of the given point cloud \(\Omega \). From this covering we construct the associated Čech complex or Vietoris–Rips complex.
While using ellipsoids is appealing, it has practical drawbacks. Relating the smallest \(\epsilon \) for which \(U_i(\epsilon )\) and \(U_j(\epsilon )\) intersect to \({\mathrm {dist}}_{{\mathbb {R}}^n}(u^{(i)},u^{(j)})\) is not easy. For this reason we implemented the following variant of ellipsoid-driven barcodes. We use the simplicial complex on [m] where
In (17) we weigh the distance between \(u^{(i)}\) and \(u^{(j)}\) by the arithmetic mean of the radii of the two ellipsoids \(E_i\) and \(E_j\) in the direction \(u^{(i)} - u^{(j)}\). If all quadratic forms \(q_i\) were equal to \(\sum _{j=1}^n x_j^2\), then the simplicial complex of (17) would equal the Vietoris–Rips complex from (15).

The top picture shows the barcode constructed from the ellipsoid-driven simplicial complex (17) with \(\lambda = 0.01\), for the sample from the Trott curve used in Fig. 3. For comparison we display the barcode from Fig. 3 in the bottom picture. All relevant topological features persist longer in the top plot
Figure 4 compares the barcodes for the classical Vietoris–Rips complex with those obtained from ellipsoids. It seems promising to further develop variants of persistent homology that take some of the defining polynomial equations for \((\Omega ,V)\) into consideration.
4.3 Reaching the reach
The Čech complex of a covering \(U=\bigcup _{i=1}^m U_i\) has the homology of the union of balls U. But, can we give conditions on the sample \(\Omega \subset V\) under which a covering reveals the true homology of V? A result due to Niyogi, Smale and Weinberger (Theorem 4.2 below) offers an answer in some circumstances. These involve the concept of the reach, which is an important metric invariant of a variety V. We here focus on varieties V in the Euclidean space \({\mathbb {R}}^n\).
Definition 4.1
The medial axis of V is the set \(M_V\) of all points \(u \in {\mathbb {R}}^n\) such that the minimum distance from V to u is attained by two distinct points. The reach \(\tau (V)\) is the infimum of all distances from points on the variety V to any point in its medial axis \(M_V\). In formulas: \(\tau (V):=\inf _{u\in V, w \in M_V}\Vert u-w\Vert \). If \(M_V = \emptyset \), we define \(\tau (V) = +\infty \).
Note that \(\tau (V)=+\infty \) if and only if V is an affine-linear subspace. Otherwise, the reach is a non-negative real number. In particular, there exist varieties V with \(\tau (V)=0\). For instance, consider the union of two lines \(\,V=\{(x,y)\in {\mathbb {R}}^2 : xy=0\}\). All points in the diagonal \(D=\{(x,y)\in {\mathbb {R}}^2 : x=y, x\ne 0\}\) have two closest points on V. Hence, D is a subset of the medial axis \(M_V\), and we conclude that \(0\le \tau (V)\le \inf _{u\in V, w \in D} \Vert u-w\Vert =0\). In general, any singular variety with an “edge” has zero reach.
To illustrate the concept of the reach, let V be a smooth curve in the plane, and draw the normal line at each point of V. The collection of these lines is the normal bundle. At a short distance from the curve, the normal bundle is a product: each point u near V has a unique closest point \(u^*\) on V, and u lies on the normal line through \(u^*\). At a certain distance, however, some of the normal lines cross. If u is a crossing point of minimal distance to V, then u has no unique closest point \(u^*\) on V. Instead, there are at least two points on V that are closest to u and the distance from u to each of them is the reach \(\tau (V)\). Aamari et al. [1] picture this by writing that “one can roll freely a ball of radius \(\tau (V)\) around V”.
Niyogi, Smale and Weinberger refer to \(\tau (V)^{-1}\) as the “condition number of V”. Bürgisser et al. [11] relate \(\tau (V)^{-1}\) to the condition number of a semialgebraic set. For the purposes of our survey it suffices to understand how the reach effects the quality of the covering \(U(\epsilon )\). The following result is a simplified version of [46, Theorem 3.1], suitable for low dimensions. Note that Theorem 4.2 only covers those varieties \(V \subset {\mathbb {R}}^n\) that are smooth and compact.
Theorem 4.2
(Niyogi, Smale, Weinberger 2006) Let \(V \subset {\mathbb {R}}^n\) be a compact manifold of dimension \(d \le 17\), with reach \(\tau = \tau (V)\) and d-dimensional Euclidean volume \(\nu = \mathrm{vol}(V)\). Let \(\Omega = \{u^{(1)}, \ldots , u^{(m)} \}\) be i.i.d. samples drawn from the uniform probability measure on V. Fix \(\epsilon = \frac{\tau }{4}\) and \(\,\beta = 16^d \tau ^{-d} \nu \,\). For any desired \(\delta > 0\), fix the sample size at
With probability \(\ge 1-\delta \), the homology groups of the following set coincide with those of V:
A few remarks are in order. First of all, the theorem is stated using the Euclidean distance and not the scaled Euclidean distance (6). However, scaling the distance by a factor t means scaling the volume by \(t^d\), so the definition of \(\beta \) in the theorem is invariant under scaling. Moreover, the theorem has been rephrased in a manner that makes it easier to evaluate the right hand side of (18) in cases of interest. The assumption \(d\le 17\) is not important: it ensures that the volume of the unit ball in \({\mathbb {R}}^d\) can be bounded below by 1. Furthermore, in [46, Theorem 3.1], the tolerance \(\epsilon \) can be any real number between 0 and \(\tau /2\), but then \(\beta \) depends in a complicated manner on \(\epsilon \). For simplicity, we took \(\epsilon = \tau /4\).
Theorem 4.2 gives the asymptotics of a sample size m that suffices to reveal all topological features of V. For concrete parameter values it is less useful, though. For example, suppose that V has dimension 4, reach \(\tau = 1\), and volume \(\nu = 1000\). If we desire a 90% guarantee that \(U(\epsilon )\) has the same homology as V, so \(\delta = 1/10\), then m must exceed 1, 592, 570, 365. In addition to that, the theorem assumes that the sample was drawn from the uniform distribution on V. But in practice one will rarely meet data that obeys such a distribution. In fact, drawing from the uniform distribution on a curved object is a non-trivial affair [21].
In spite of its theoretical nature, the Niyogi-Smale-Weinberger formula is useful in that it highlights the importance of the reach \(\tau (V)\) for analyzing point samples. Indeed, the dominant quantity in (18) is \(\beta \), and this grows to the power of d in \(\tau (V)^{-1}\). It is therefore of interest to better understand \(\tau (V)\) and to develop tools for estimating it.
We found the following formula by Federer [27, Theorem 4.18] to be useful. It expresses the reach of a manifold V in terms of points and their tangent spaces:
This formula relies upon knowing the tangent spaces at each point of \(u\in V\).
Suppose we are given the finite sample \(\Omega \) from V. If some equations for V are also known, then we can use the estimator \(\widehat{{\mathrm {T}}}_{u^{(i)}}V\) for the tangent space that was derived in (16). From this we get the following formula for the empirical reach of our sample:
A similar approach for estimating the reach was proposed by Aamari et al. [1, eqn. (6.1)].
4.4 Algebraicity of persistent homology
It is impossible to compute in the field of real numbers \({\mathbb {R}}\). Numerical computations employ floating point approximations. These are actually rational numbers. Computing in algebraic geometry has traditionally been centered around exact symbolic methods. In that context, computing with algebraic numbers makes sense as well. In this subsection we argue that, in the setting of this paper, most numerical quantities in persistent homology, like the barcodes and the reach, have an algebraic nature. Here we assume that the variety V is defined over \({\mathbb {Q}}\).
We discuss the work of Horobeţ and Weinstein in [32] which concerns metric properties of a given variety \(V \subset {\mathbb {R}}^n\) that are relevant for its true persistent homology. Here, the true persistent homology of V, at parameter value \(\epsilon \), refers to the homology of the \(\epsilon \)-neighborhood of V. Intuitively, the true persistent homology of the Trott curve is the limit of barcodes as in Fig. 3, where more and more points are taken, eventually filling up the entire curve.
An important player is the offset hypersurface \({\mathcal {O}}_\epsilon (V)\). This is the algebraic boundary of the \(\epsilon \)-neighborhood of V. More precisely, for any positive value of \(\epsilon \), the offset hypersurface is the Zariski closure of the set of all points in \({\mathbb {R}}^n\) whose distance to V equals \(\epsilon \). If \(n=2\) and V is a plane curve, then the offset curve \({\mathcal {O}}_\epsilon (V)\) is drawn by tracing circles along V.

Offset curves (blue) and the evolute (light blue) of a conic (black) (colour figure online)
Example 4.3
In Fig. 5 we examine a conic V, shown in black. The light blue curve is its evolute. This is an astroid of degree 6. The evolute serves as the ED discriminant of V, in the context seen in [23, Figure 3]. The blue curves in Fig. 5 are the offset curves \({\mathcal {O}}_\epsilon (V)\). These have degree 8 and are smooth (over \({\mathbb {R}}\)) for small values of \(\epsilon \). However, for larger values of \(\epsilon \), the offset curves are singular. The transition point occurs at the cusp of the evolute.
It is shown in [32, Theorem 3.4] that the endpoints of bars in the true persistent homology of a variety V occur at numbers that are algebraic over \({\mathbb {Q}}\). The proof relies on results in real algebraic geometry that characterize the family of fibers in a map of semialgebraic sets.
Example 4.4
The bars of the barcode in Fig. 3 begin and end near the numbers
These algebraic numbers delineate the true persistent homology of the Trott curve V.
The reach \(\tau (V)\) of any real variety \(V \subset {\mathbb {R}}^n\) is also an algebraic number. This follows from Federer’s formula (19) which expresses \(\tau (V)\) as the optimal value of a polynomial optimization problem. In principle, the reach can be computed in exact arithmetic from the polynomials that define V. It remains an open problem how to do this effectively in practice. Eklund’s recent work on bottlenecks [26] represents an important step towards a solution.
At present we do not know a good formula or a tight bound for the algebraic degrees of the barcode and the reach in terms of the invariants of the variety V. Deriving such formulas will require a further development and careful analysis of the offset discriminant that was introduced in [32]. We hope to return to this topic in the near future, as it can play a fundamental link between topology and algebraic geometry in the context of data science.
5 Finding equations
Every polynomial in the ideal \(I_V\) of the unknown variety V vanishes on the sample \(\Omega \). The converse is not true, but it is reasonable to surmise that it holds among polynomials of low degree. The ideal \(I_\Omega \) of the finite set \(\Omega \subset {\mathbb {R}}^n\) can be computed using linear algebra. All our polynomials and ideals in this section lie in the ring \(R = {\mathbb {R}}[x_1,x_2,\ldots ,x_n]\).
5.1 Vandermonde matrices
Let \({\mathcal {M}}\) be a finite linearly independent subset of R. We write \(R_{\mathcal {M}}\) for the \({\mathbb {R}}\)-vector space with basis \({\mathcal {M}}\) and generally assume that \({\mathcal {M}}\) is ordered, so that polynomials in \(R_{\mathcal {M}}\) can be identified with vectors in \({\mathbb {R}}^{\vert {\mathcal {M}}\vert }\). Two primary examples for \({\mathcal {M}}\) are the set of monomials \(\mathbf{x}^e= x_1^{e_1} x_2^{e_2} \cdots x_n^{e_n}\) of degree d and the set of monomials of degree at most d. We use the notation \(R_d\) and \(R_{\le d}\) for the corresponding subspaces of R. Their dimensions \(|{\mathcal {M}}|\) are
We write \(U_{\mathcal {M}}(\Omega )\) for the \(m \times |{\mathcal {M}}|\) matrix whose i-th row consists of the evaluations of the polynomials in \({\mathcal {M}}\) at the point \(u^{(i)}\). Instead of \(U_{\mathcal {M}}(\Omega )\) we write \(U_d(\Omega )\) when \({\mathcal {M}}\) contains all monomials of degree d and \(U_{\le d}(\Omega )\) when \({\mathcal {M}}\) contains monomials of degree \(\le d\).
For example, if \(n=1\), \(m=3\), and \(\Omega = \{u,v,w\}\) then \(U_{\le 3}(\Omega )\) is the Vandermonde matrix
For \( n \ge 2\), we call \(U_{\mathcal {M}}(\Omega )\) a multivariate Vandermonde matrix. It has the following property:
Remark 5.1
The kernel of the multivariate Vandermonde matrix \(U_{\mathcal {M}}(\Omega )\) equals the vector space \(\,I_\Omega \cap R_{\mathcal {M}}\,\) of all polynomials that are linear combinations of \({\mathcal {M}}\) and that vanish on \(\Omega \).
The strategy for learning the variety V is as follows. We hope to learn the ideal \(I_V\) by making an educated guess for the set \({\mathcal {M}}\). The two desirable properties for \({\mathcal {M}}\) are:
-
(a)
The ideal \(I_V\) of the unknown variety V is generated by its subspace \(I_V \cap R_{\mathcal {M}}\).
-
(b)
The inclusion of \(I_V \cap R_{\mathcal {M}}\) in its superspace \(\,I_\Omega \cap R_{\mathcal {M}} = \mathrm{ker} (U_{\mathcal {M}}(\Omega ))\) is an equality.
There is a fundamental tension between these two desiderata: if \({\mathcal {M}}\) is too small then (a) will fail, and if \({\mathcal {M}}\) is too large then (b) will fail. But, of course, suitable sets \({\mathcal {M}}\) do always exist, since the Hilbert’s Basis Theorem ensures that all ideals in R are finitely generated.
The requirement (b) imposes a lower bound on the size m of the sample. Indeed, m is an upper bound on the rank of \(U_{\mathcal {M}}(\Omega )\), since that matrix has m rows. The rank of any matrix is equal to the number of columns minus the dimension of the kernel. This implies:
Lemma 5.2
If (b) holds, then \(\,m \ge |{\mathcal {M}}| - \mathrm{dim}(I_V \cap R_{\mathcal {M}})\).
In practice, however, the sample \(\Omega \) is given and fixed. Thus, we know m and it cannot be increased. The question is how to choose the set \({\mathcal {M}}\). This leads to some interesting geometric combinatorics. For instance, if we believe that V is homogeneous with respect to some \({\mathbb {Z}}^r\)-grading, then it makes sense to choose a set \({\mathcal {M}}\) that consists of all monomials in a given \({\mathbb {Z}}^r\)-degree. Moreover, if we assume that V has a parametrization by sparse polynomials then we would use a specialized combinatorial analysis to predict a set \({\mathcal {M}}\) that works. A suitable choice of \({\mathcal {M}}\) can improve the numerical accuracy of the computations dramatically.
In addition to choosing the set of monomials \({\mathcal {M}}\), we face another problem: how to represent \(I_\Omega \cap R_{\mathcal {M}}\)? Computing a basis for the kernel of \(U_{\mathcal {M}}(\Omega )\) yields a set of generators for \(I_\Omega \cap R_{\mathcal {M}}\). But which basis to use and how to compute it? For instance, the right-singular vectors of \(U_{\mathcal {M}}(\Omega )\) with singular value zero yield an orthonormal basis of \(I_\Omega \cap R_{\mathcal {M}}\). But in applications one often meets ideals I that have sparse generators. This holds in Sect. 2.
Example 5.3
Suppose that we obtain a list of 20 quadrics in nine variables as the result of computing the kernel of a Vandermonde matrix and each quadric looks something like this:
This is the first element in an orthonormal basis for \(I_\Omega \cap R_{\le 2}\), where \(\Omega \) is a sample drawn from a certain variety V in \({\mathbb {R}}^9\). From such a basis, it is very hard to guess what V might be.
It turns out that V is \( \mathrm{SO}(3)\), the group of rotations in 3-space. After renaming the nine variables, we find the 20-dimensional space of quadrics mentioned in Example 2.2. However, the quadrics seen in (2) are much nicer. They are sparse and easy to interpret.
For this reason we aim to compute sparse bases of multivariate Vandermonde matrices. There is a trade-off between obtaining sparse basis vectors and stability of the computations. We shall discuss this issue in the next subsection. See Table 1 for a brief summary.
5.2 Numerical linear algebra
Computing kernels of matrices of type \(U_{{\mathcal {M}}}(\Omega )\) is a problem in numerical linear algebra. One scenario where the methodology has been developed and proven to work well is the Generalized Principal Component Analysis of Ma et al. [41], where V is a finite union of linear subspaces in \({\mathbb {R}}^n\). For classical Vandermonde matrices, the Bjoerck–Pereyra algorithm [7] accurately computes a LU-decomposition of the Vandermonde matrix; see [31, Section 22]. This decomposition may then be used to compute the kernel. A generalization of this for multivariate Vandermonde matrices of the form \(U_{\le d}(\Omega )\) is given in [47, Theorem 4.4]. To date such a decomposition for \(U_{\mathcal M}(\Omega )\) is missing for other subsets of monomials \(\mathcal M\). Furthermore, [47, Theorem 4.4] assumes that the multivariate Vandermonde matrix is square and invertible, but this is never the case in our situation.
In the literature on numerical algebraic geometry, it is standard to represent varieties by point samples, and there are several approaches for learning varieties, and even schemes, from such numerical data. See e.g. [18, 28] and the references therein. From the perspective of commutative algebra, our interpolation problem was studied in e.g. [44, 45].
We developed and implemented three methods based on classical numerical linear algebra:
-
1.
via the R from a QR-decomposition,
-
2.
via a singular value decomposition (SVD), or
-
3.
via the reduced row echelon form (RREF) of \(U_{\mathcal M}(\Omega )\).
The goal is to compute a (preferably sparse) basis for the kernel of \(\,U_{\mathcal M}(\Omega )\), with \(N = |{\mathcal {M}}|\). All three methods are implemented in our software. Their descriptions are given below.



Each of these three methods has its upsides and downsides. These are summarized in Table 1. The algorithms require a tolerance \(\tau \ge 0\) as input. This tolerance value determines the numerical rank of the matrix. Let \(\sigma _1 \ge \cdots \ge \sigma _{\min \{m,N\}}\) be the ordered singular values of the \(m\times N\) matrix U. As in the beginning of Sect. 3.2, the numerical rank of U is
Using the criterion in [19, §3.5.1], we can set \(\tau = \varepsilon \, \sigma _1\, \max \{m,N\}\), where \(\epsilon \) is the machine precision. The rationale behind this choice is [19, Corollary 5.1], which says that the round-off error in the \(\sigma _i\) is bounded by \(\Vert E\Vert \), where \(\Vert \cdot \Vert \) is the spectral norm and \(U+E\) is the matrix whose singular values were computed. For backward stable algorithms we may use the bound \(\Vert E\Vert = \mathcal O(\varepsilon ) \sigma _1\). On the other hand, our experiments suggest that an appropriate value for \(\tau \) is given by \(\frac{1}{2}(\sigma _i + \sigma _{i+1})\), for which the jump from \(\log _{10}(\sigma _i)\) to \(\log _{10}(\sigma _{i+1})\) is significantly large. This choice is particularly useful for noisy data (as seen in Sect. 7.3). In case of noise the first definition of \(\tau \) will likely fail to detect the true rank of \(U_{\le d}(\Omega )\). The reason for this lies in the numerics of Vandermonde matrices, discussed below.
We apply all of the aforementioned to the multivariate Vandermonde matrix \(U_{\mathcal {M}}(\Omega )\), for any finite set \({\mathcal {M}}\) in R that is linearly independent. We thus arrive at the following algorithm.

Remark 5.4
Different sets of quadrics can be obtained by applying Algorithm 4 to a set \(\Omega \) of 200 points sampled uniformly from the group \({\mathrm {SO}}(3)\). The dense equations in Example 5.3 are obtained using Algorithm 2 (SVD) in Step 4. The more desirable sparse equations from (2) are found when using Algorithm 1 (with QR). In both cases the tolerance was set to be \(\tau \approx 4 \cdot 10^{-14}\, \sigma _1\,\), where \(\sigma _1\) is the largest singular value of the Vandermonde matrix \(U_{\le 2}(\Omega )\).
Running Algorithm 4 for a few good choices of \({\mathcal {M}}\) often leads to an initial list of non-zero polynomials that lie in \(I_\Omega \) and also in \(I_V\). Those polynomials can then be used to infer an upper bound on the dimension and other information about V. This is explained in Sect. 6. Of course, if we are lucky, then we obtain a generating set for \(I_V\) after a few iterations.
If m is not too large and the coordinates of the points \(u^{(i)}\) are rational, then it can be preferable to compute the kernel of \(U_{{\mathcal {M}}}(\Omega )\) symbolically. Gröbner-based interpolation methods, such as the Buchberger-Möller algorithm [44], have the flexibility to select \({\mathcal {M}}\) dynamically. With this, they directly compute the generators for the ideal \(I_\Omega \), rather than the user having to worry about the matrices \(U_{\le d}(\Omega )\) for a sequence of degrees d. In short, users should keep symbolic methods in the back of their minds when contemplating Algorithm 4.
In the remainder of this section, we discuss numerical issues associated with Algorithm 4. The key step is computing the kernel of the multivariate Vandermonde matrix \(U_{\mathcal M}(\Omega )\). As illustrated in (20) for samples \(\Omega \) on the line \((n=1)\), and \(\mathcal M\) being all monomials up to a fixed degree, this matrix is a Vandermonde matrix. It is conventional wisdom that Vandermonde matrices are severely ill-conditioned [48]. Consequently, numerical linear algebra solvers are expected to perform poorly when attempting to compute the kernel of \(U_d(\Omega )\).
One way to circumvent this problem is to use a set of orthogonal polynomials for \({\mathcal {M}}\). Then, for large sample sizes m, two distinct columns of \(U_{{\mathcal {M}}}(\Omega )\) are approximately orthogonal, implying that \(U_{{\mathcal {M}}}(\Omega )\) is well-conditioned. This is because the inner product between the columns associated to \(f_1,f_2\in {\mathcal {M}}\) is approximately the integral of \(f_1\cdot f_2\) over \({\mathbb {R}}^n\). However, a sparse representation in orthogonal polynomials does not yield a sparse representation in the monomial basis. Hence, to get sparse polynomials in the monomials basis from \(U_{{\mathcal {M}}}(\Omega )\), we must employ other methods than the ones presented here. For instance, techniques from compressed sensing may help to compute sparse representations in the monomial basis.
We are optimistic that a numerically-reliable algorithm for computing the kernel of matrices \(U_{\le d}(\Omega )\) exists. The Bjoerck–Pereyra algorithm [7] solves linear equations \(Ua=b\) for an \(n \times n\) Vandermonde matrix U. There is a theoretical guarantee that the computed solution \(\hat{a}\) satisfies \(\vert a-\hat{a}\vert \le 7 n^5 \epsilon + \mathcal O(n^4\epsilon ^2)\); see [31, Corollary 22.5]. Hence, \(\hat{a}\) is highly accurate – despite U being ill-conditioned. This is confirmed by the experiment mentioned in the beginning of [31, Section 22.3], where a linear system with \(\kappa (U) \sim 10^9\) is solved with a relative error of \(5\epsilon \). We suspect that a Bjoerck–Pereyra-like algorithm together with a thorough structured-perturbation analysis for multivariate Vandermonde matrices would equip us with an accurate algorithm for finding equations. For the present article, we stick with the three methods above, while bearing in mind the difficulties that ill-posedness can cause.
6 Learning from equations
At this point we assume that the methods in the previous two sections have been applied. This means that we have an estimate d of what the dimension of V might be, and we know a set \({\mathcal {P}}\) of polynomials that vanish on the finite sample \(\Omega \subset {\mathbb {R}}^n\). We assume that the sample size m is large enough so that the polynomials in \({\mathcal {P}}\) do in fact vanish on V. We now use \({\mathcal {P}}\) as our input. Perhaps the unknown variety V is one of the objects seen in Sect. 2.2.
6.1 Computational algebraic geometry
A finite set of polynomials \({\mathcal {P}}\) in \({\mathbb {Q}}[x_1,\ldots ,x_n]\) is the typical input for algebraic geometry software. Traditionally, symbolic packages like Macaulay2, Singular and CoCoA were used to study \({\mathcal {P}}\). Buchberger’s Gröbner basis algorithm is the workhorse underlying this approach. More recently, numerical algebraic geometry has emerged, offering promise for innovative and accurate methods in data analysis. We refer to the textbook [5], which centers around the excellent software Bertini. Next to using Bertini, we also employ the Julia package HomotopyContinuation.jl [9]. Both symbolic and numerical methods are valuable for data analysis. The questions we ask in this subsection can be answered with either.
In what follows we assume that the unknown variety V is equal to the zero set of the input polynomials \({\mathcal {P}}\). We seek to answer the following questions over the complex numbers:
-
1.
What is the dimension of V?
-
2.
What is the degree of V?
-
3.
Find the irreducible components of V and determine their dimensions and degrees.
Here is an example that illustrates the workflow we imagine for analyzing samples \(\Omega \).
Example 6.1
The variety of Hankel matrices of size \(4 \times 4\) and rank 2 has the parametrization
Suppose that an adversary constructs a dataset \(\Omega \) of size \(m=500\) by the following process. He picks random integers \(s_i\) and \(t_j\), computes the \(4 \times 4\)-Hankel matrix, and then deletes the antidiagonal coordinate x. For the remaining six coordinates he fixes some random ordering, such as (c, f, b, e, a, d). Using this ordering, he lists the 500 points. This is our input \(\Omega \subset {\mathbb {R}}^6\).
We now run Algorithm 4 for the \(m \times 210 \)-matrix \(U_{\le 4}(\Omega )\). The output of this computation is the following pair of quartics which vanishes on the variety \(V \subset {\mathbb {R}}^6\) that is described above:
Not knowing the true variety, we optimistically believe that the zero set of \({\mathcal {P}}\) is equal to V. This would mean that V is a complete intersection, so it has codimension 2 and degree 16.
At this point, we may decide to compute a primary decomposition of \(\langle {\mathcal {P}} \rangle \). We then find that there are two components of codimension 2, one of degree 3 and the other of degree 10. Since \(3 + 10 \not = 16\), we learn that \(\langle {\mathcal {P}} \rangle \) is not a radical ideal. In fact, the degree 3 component appears with multiplicity 2. Being intrigued, we now return to computing equations from \(\Omega \).
From the kernel of the \(m \times 252\)-matrix \(U_5(\Omega )\), we find two new quintics in \(I_\Omega \). These only reduce the degree to \(3+10= 13\). Finally, the kernel of the \(m \times 452\)-matrix \(U_6(\Omega )\) suffices. The ideal \(I_V\) is generated by 2 quartics, 2 quintics and 4 sextics. The mystery variety \(V\subset {\mathbb {R}}^6\) has the same dimension and degree as the rank 2 Hankel variety in \({\mathbb {R}}^7\) whose projection it is.
Our three questions boil down to solving a system \({\mathcal {P}}\) of polynomial equations. Both symbolic and numerical techniques can be used for that task. Samples \(\Omega \) seen in applications are often large, are represented by floating point numbers, and have errors and outliers. In those cases, we use Numerical Algebraic Geometry [5, 9]. For instance, in Example 6.1 we intersect (22) with a linear space of dimension 2. This results in 13 isolated solutions. Further numerical analysis in step 3 reveals the desired irreducible component of degree 10.
In the numerical approach to answering the three questions, one proceeds as follows:
-
1.
We add s random (affine-)linear equations to \({\mathcal {P}}\) and we solve the resulting system in \({\mathbb {C}}^n\). If there are no solutions, then \(\mathrm{dim}(V) < s\). If the solutions are not isolated, then \(\mathrm{dim}(V) > s\). Otherwise, there are finitely many solutions, and \(\mathrm{dim}(V) = s\).
-
2.
The degree of V is the finite number of solutions found in step 1.
-
3.
Using monodromy loops (cf. [5]), we can identify the intersection of a linear space L with any irreducible component of \(V_{{\mathbb {C}}}\) whose codimension equals \(\mathrm{dim}(L)\).
The dimension diagrams from Sect. 3 can be used to guess a suitable range of values for the parameter s in step 1. However, if we have equations at hand, it is better to determine the dimension s as follows. Let \({\mathcal {P}} = \{f_1,\ldots ,f_k\}\) and u be any data point in \(\Omega \). Then, we choose the s from step 1 as the corank of the Jacobian matrix of \(f=(f_1,\ldots ,f_k)\) at u; i.e,
Note that \(s={\mathrm {dim}}\, V({\mathcal {P}})\) as long as u is not a singular point of \(V({\mathcal {P}})\). In this case, s provides an upper bound for the true dimension of V. That is why it is important in step 3 to use higher-dimensional linear spaces L to detect lower-dimensional components of \(V({\mathcal {P}})\).
Example 6.2
Take \(m=n=3\) in Example 2.3. Let \({\mathcal {P}}\) consist of the four \(2 \times 2\)-minors that contain the upper-left matrix entry \(x_{11}\). The ideal \(\langle {\mathcal {P}} \rangle \) has codimension 3 and degree 2. Its top-dimensional components are \(\langle x_{11}, x_{12}, x_{13} \rangle \) and \( \langle x_{11}, x_{21}, x_{31} \rangle \). However, our true model V has codimension 4 and degree 6: it is defined by all nine \(2 \times 2\)-minors. Note that \(\langle {\mathcal {P}} \rangle \) is not radical. It also has an embedded prime of codimension 5, namely \(\langle x_{11}, x_{12}, x_{13} , x_{21}, x_{31} \rangle \).
6.2 Real degree and volume
The discussion in the previous subsection was about the complex points of the variety V. The geometric quantity \(\mathrm{deg}(V)\) records a measurement over \({\mathbb {C}}\). It is insensitive to the geometry of the real points of V. That perspective does not distinguish between \({\mathcal {P}} = \{x^2+y^2-1\}\) and \({\mathcal {P}} = \{x^2+y^2+1\}\). That distinction is seen through the lens of real algebraic geometry.
In this subsection we study metric properties of a real projective variety \(V \subset {\mathbb {P}}^{n}_{\mathbb {R}}\). We explain how to estimate the volume of V. Up to a constant depending on \(d={\mathrm {dim}}\, V\), this volume equals the real degree \(\mathrm{deg}_{\mathbb {R}}(V)\), by which we mean the expected number of real intersection points with a linear subspace of codimension \(\mathrm{dim}(V)\); see Theorem 6.3 below.
To derive these quantities, we use Poincaré’s kinematic formula [33, Theorem 3.8]. For this we need some notation. By [39] there is a unique orthogonally invariant measure \(\mu \) on \({\mathbb {P}}_{\mathbb {R}}^n\) up to scaling. We choose the scaling in a way compatible with the unit sphere \({\mathbb {S}}^{n}\):
This makes sense because \({\mathbb {P}}_{\mathbb {R}}^n\) is doubly covered by \({\mathbb {S}}^n\). The n-dimensional volume \(\mu \) induces a d-dimensional measure of volume on \({\mathbb {P}}^n_{\mathbb {R}}\) for any \(d = 1,2,\ldots ,n-1\). We use that measure for \(d = \mathrm{dim}(V)\) to define the volume of our real projective variety as \({\mathrm {vol}}(V):=\mu (V)\).
Let \({\mathrm {Gr}}(k,{\mathbb {P}}_{\mathbb {R}}^n)\) denote the Grassmannian of k-dimensional linear spaces in \({\mathbb {P}}_{\mathbb {R}}^n\). This is a real manifold of dimension \((n-k)(k+1)\). Because of the Plücker embedding it is also a projective variety. We saw this for \(k=1\) in Example 2.6, but we will not use it here. Again by [39], there is a unique orthogonally invariant measure \(\nu \) on \({\mathrm {Gr}}(k,{\mathbb {P}}_{\mathbb {R}}^n)\) up to scaling. We choose the scaling \(\nu ({\mathrm {Gr}}(k,{\mathbb {P}}_{\mathbb {R}}^n))=1\). This defines the uniform probability distribution on the Grassmannian. Poincaré’s Formula [33, Theorem 3.8] states:
Theorem 6.3
(Kinematic formula in projective space) Let V be a smooth projective variety of codimension \(k=n-d\) in \({\mathbb {P}}^n_{\mathbb {R}}\). Then its volume is the volume of \(\,{\mathbb {P}}^d_{\mathbb {R}}\) times the real degree:
Note that in case of V being a linear space of dimension d, we have \(\#(L\cap V) = 1\) for all \(L\in {\mathrm {Gr}}(n-d,{\mathbb {P}}_{\mathbb {R}}^n)\). Hence, \({\mathrm {vol}}(V) = {\mathrm {vol}}({\mathbb {P}}_{\mathbb {R}}^d)\), which verifies the theorem in this instance.
The theorem suggests an algorithm. Namely, we sample linear spaces \(L_1,L_2,\ldots ,L_N\) independently and uniformly at random, and compute the number r(i) of real points in \(V\cap L_i\) for each i. This can be done symbolically (using Gröbner bases) or numerically (using homotopy continuation). We obtain the following estimator for \(\mathrm{vol}(V)\):
We can sample uniformly from \({\mathrm {Gr}}(k,{\mathbb {P}}_{\mathbb {R}}^n)\) by using the following lemma:
Lemma 6.4
Let A be a random \((k{+}1) \times (n {+} 1)\) matrix with independent standard Gaussian entries. The row span of A follows the uniform distribution on the Grassmannian \({\mathrm {Gr}}(k,{\mathbb {P}}_{\mathbb {R}}^n)\).
Proof
The distribution of the row space of A is orthogonally invariant. Since the orthogonally invariant probability measure on \({\mathrm {Gr}}(k,{\mathbb {P}}_{\mathbb {R}}^n)\) is unique, the two distributions agree. \(\square \)
Example 6.5
Let \(n=2\), \(k=1\), and let V be the Trott curve in \({\mathbb {P}}^2_{\mathbb {R}}\). The area of the projective plane \({\mathbb {P}}^2_{\mathbb {R}}\) is half of the surface area of the unit circle: \( \mu ({\mathbb {P}}^1_{\mathbb {R}}) \,= \, \frac{1}{2} \cdot \mathrm{vol}({\mathbb {S}}^1) \,=\, \pi \). The real degree of V is computed with the method suggested in Lemma 6.4: \(\mathrm{deg}_{\mathbb {R}}(V) \,=\,1.88364\). We estimate the length of the Trott curve to be the product of these two numbers: \(\, 5.91763\). Note that 5.91763 does not estimate the length of the affine curve depicted in Fig. 3, but it is the length of the projective curve defined by the homogenization of the polynomial (1).
Remark 6.6
Our discussion in this subsection focused on real projective varieties. For affine varieties \(V\subset {\mathbb {R}}^n\) there is a formula similar to Theorem 6.3. By [50, (14.70)],
where \({\mathrm {d}} L\) is the density of affine \((n-d)\)-planes in \({\mathbb {R}}^n\) from [50, Section 12.2], \({\mathrm {vol}}(\cdot )\) is Lebesgue measure in \({\mathbb {R}}^n\) and \(O_m:={\mathrm {vol}}\,({\mathbb {S}}^m)\). The problem with using this formula is that in general we do not know how to sample from the density \({\mathrm {d}}L\) given \(L\cap V \ne \emptyset \). The reason is that this distribution depends on \({\mathrm {vol}}(V)\)–which we were trying to compute in the first place.
Suppose that the variety V is the image of a parameter space over which integration is easy. This holds for \(V = {\mathrm {SO}}(3)\), by (3). For such cases, here is an alternative approach for computing the volume: pull back the volume form on V to the parameter space and integrate it there. This can be done either numerically or –if possible– symbolically. Note that this method is not only applicable to smooth varieties, but to any differentiable manifold.
7 Software and experiments
In this section, we demonstrate how the methods from previous sections work in practice. The implementations are available in our Julia package LearningAlgebraicVarieties. We offer a step-by-step tutorial. To install our software, start a Julia session and type

After the installation, the next command is

This command loads all the functions into the current session. Our package accepts a dataset \(\Omega \) as a matrix whose columns are the data points \(u^{(1)},u^{(2)},\ldots ,u^{(m)}\) in \({\mathbb {R}}^n\).
To use the numerical algebraic geometry software Bertini, we must first download it from https://bertini.nd.edu/download.html. The Julia wrapper for Bertini is installed by

The code HomotopyContinuation.jl accepts input from the polynomial algebra package MultivariatePolynomials.jl.Footnote 1 The former is described in [9] and it is installed using

We apply our package to three datasets. The first comes from the group \({\mathrm {SO}}(3)\), the second from the projective variety V of \(2\times 3\)-matrices \((x_{ij})\) of rank 1, and the third from the conformation space of cyclo-octane.
In the first two cases, we draw the samples ourselves. The introduction of [21] mentions algorithms to sample from compact groups. However, for the sake of simplicity we use the following algorithm for sampling from \({\mathrm {SO}}(3)\). We use Julia’s
 -command to compute the QR-decomposition of a random real \(3\times 3\) matrix with independent standard Gaussian entries and take the Q of that decomposition. If the computation is such that the diagonal entries of R are all positive then, by [43, Theorem 1], the matrix Q is uniformly distributed in \({\mathrm {O}}(3)\). However, in our case, \(Q\in {\mathrm {SO}}(3)\) and we do not know its distribution.
-command to compute the QR-decomposition of a random real \(3\times 3\) matrix with independent standard Gaussian entries and take the Q of that decomposition. If the computation is such that the diagonal entries of R are all positive then, by [43, Theorem 1], the matrix Q is uniformly distributed in \({\mathrm {O}}(3)\). However, in our case, \(Q\in {\mathrm {SO}}(3)\) and we do not know its distribution.
Our sample from the Segre variety \(V = {\mathbb {P}}^1_{\mathbb {R}}\times {\mathbb {P}}^2_{\mathbb {R}}\) in \({\mathbb {P}}^5_{\mathbb {R}}\) is drawn by independently sampling two standard Gaussian matrices of format \(2\times 1\) and \(1\times 3\) and multiplying them. This procedure yields the uniform distribution on V because the Segre embedding is an isometry under the Fubini–Study metrics on \({\mathbb {P}}^1_{\mathbb {R}}, {\mathbb {P}}^2_{\mathbb {R}}\) and \({\mathbb {P}}^5_{\mathbb {R}}\). The third sample, which is 6040 points from the conformation space of cyclo-octane, is taken from Adams et al. [2, §. 6.3].
We provide the samples used in the subsequent experiments in the JLDFootnote 2 data format. After having installed the JLD package in Julia (
 ),
load the datasets by typing
),
load the datasets by typing

7.1 Dataset 1: a sample from the rotation group \({\mathrm {SO}}(3)\)
The group \({\mathrm {SO}}(3)\) is a variety in the space of \(3 \times 3\)-matrices. It is defined by the polynomial equations in Example 2.2. A dataset containing 887 points from \({\mathrm {SO}}(3)\) is loaded by typing

Now the current session should contain a variable
 that is a \(9\times 887\) matrix. We produce the dimension diagrams by typing
that is a \(9\times 887\) matrix. We produce the dimension diagrams by typing

In this command,
 is our dataset, the Boolean value is
is our dataset, the Boolean value is
 if we suspect that our variety is projective and
if we suspect that our variety is projective and
 otherwise, and
otherwise, and
 is any of the dimension estimates
is any of the dimension estimates
 ,
,

 ,
,
 ,
,
 , and
, and
 . We can leave this unspecified and type
. We can leave this unspecified and type

This command plots all six dimension diagrams. Both outputs are shown in Fig. 6.

Dimension diagrams for 887 points in \(\mathrm{SO}(3)\). The bottom picture shows all six diagrams described in Sect. 3.2. The top picture shows correlation sum and persistent homology curve dimension estimates
Three estimates are close to 3, so we correctly guess the true dimension of \(\mathrm{SO}(3)\). In our experiments we found that NPCA and Box Counting Dimension often overestimate.
We proceed by finding polynomials that vanish on the sample. The command we use is

where
 is one of :with_svd, :with_qr, :with_rref. The degree
is one of :with_svd, :with_qr, :with_rref. The degree
 refers to the polynomials in R we are looking for. If homogeneous_eqnarrays is set to
refers to the polynomials in R we are looking for. If homogeneous_eqnarrays is set to
 , then we search in \(R_{\le d}\). If we look for a projective variety then we set it to
, then we search in \(R_{\le d}\). If we look for a projective variety then we set it to
 , and \(R_d\) is used. For our sample from \(\mathrm{SO}(3)\) we use the
, and \(R_d\) is used. For our sample from \(\mathrm{SO}(3)\) we use the
 option. Our sample size \(m=887\) is large enough to determine equations up to \(d=4\). The following results are found by the various methods:
option. Our sample size \(m=887\) is large enough to determine equations up to \(d=4\). The following results are found by the various methods:
d | Method | Number of linearly independent equations |
|---|---|---|
1 | SVD | 0 |
2 | SVD | 20 |
2 | QR | 20 |
2 | RREF | 20 |
3 | SVD | 136 |
4 | SVD | 550 |
The correctness of these numbers can be verified by computing (e.g. using Macaulay2) the affine Hilbert function [16, §9.3] of the ideal with the generators in Example 2.2. If we type

then we get a list of 20 polynomials that vanish on the sample.
The output is often difficult to interpret, so it can be desirable to round the coefficients:

The precision can be specified, the default being to the nearest integer. We obtain the output
Let us continue analyzing the 20 quadrics saved in the variable
 . We use the following command in Bertini to determine whether our variety is reducible and compute its degree:
. We use the following command in Bertini to determine whether our variety is reducible and compute its degree:

Here
 is the path to the Bertini binary. Bertini confirms that the variety is irreducible of degree 8 and dimension 3 (cf. Fig. 6).
is the path to the Bertini binary. Bertini confirms that the variety is irreducible of degree 8 and dimension 3 (cf. Fig. 6).
Using Eirene we construct the barcodes depicted in Fig. 7. We run the following commands to plot barcodes for a random subsample of 250 points in \(\mathrm{SO}(3)\):

The first array
 of the
of the
 function specifies the desired dimensions. The second array
function specifies the desired dimensions. The second array
 selects the 8 largest barcodes for each dimension. If the user does not pass the last array to the function, then all the barcodes are plotted. To compute barcodes arising from the complex specified in (17), we type
selects the 8 largest barcodes for each dimension. If the user does not pass the last array to the function, then all the barcodes are plotted. To compute barcodes arising from the complex specified in (17), we type

Here,
 is the vector of 20 quadrics. The third argument of
is the vector of 20 quadrics. The third argument of
 is the parameter \(\epsilon \) from (17). It is here set to \(10^{-5}\).
is the parameter \(\epsilon \) from (17). It is here set to \(10^{-5}\).

Barcodes for a subsample of 250 points from \( {\mathrm {SO}}(3)\). The top picture shows the standard Vietoris–Rips complex, while that on the bottom comes from the ellipsoid-driven complex (17). Neither reveals any structures in dimension 3, though \(V = {\mathrm {SO}}(3)\) is diffeomorphic to \({\mathbb {P}}^{3}_{\mathbb {R}}\) and has a non-vanishing \(H_3(V, {\mathbb {Z}})\)
Our subsample of 250 points is not dense enough to reveal features except in dimension 0. Instead of randomly selecting the points in the subsample, one could also use the sequential maxmin landmark selector [2, §5.2]. Subsamples chosen in this way tend to cover the dataset and to be spread apart from each other. One might also improve the result by constructing different complexes, for example, the lazy witness complexes in [2, §5]. However, this is not implemented in Eirene at present.
7.2 Dataset 2: a sample from the variety of rank one \(2\times 3\)-matrices
The second sample consists of 200 data points from the Segre variety \({\mathbb {P}}^1_{\mathbb {R}}\times {\mathbb {P}}^2_{\mathbb {R}}\) in \({\mathbb {P}}^5_{\mathbb {R}}\), that is Example 2.3 with \(m=n=3,\, r=1\). We load our sample into the Julia session by typing

We try the
 command once with the Boolean value set to
command once with the Boolean value set to
 (Euclidean space) and once with the value set to
(Euclidean space) and once with the value set to
 (projective space). The diagrams are depicted in Fig. 8. As the variety V naturally lives in \({\mathbb {P}}^5_{\mathbb {R}}\), the projective diagrams yield better estimates and hint that the dimension is either 3 or 4. The true dimension in \({\mathbb {P}}^5_{\mathbb {R}}\) is 3.
(projective space). The diagrams are depicted in Fig. 8. As the variety V naturally lives in \({\mathbb {P}}^5_{\mathbb {R}}\), the projective diagrams yield better estimates and hint that the dimension is either 3 or 4. The true dimension in \({\mathbb {P}}^5_{\mathbb {R}}\) is 3.

Dimension diagrams for 200 points on the variety of \(2 \times 3\) matrices of rank 1. The top picture shows dimension diagrams for the estimates in \({\mathbb {R}}^{6}\). The bottom picture shows those for projective space \({\mathbb {P}}^{5}_{\mathbb {R}}\)
The next step is to find polynomials that vanish. We set homogeneous_eqnarrays to
 and \(d=2\): f = FindEquations(data, method, 2,
and \(d=2\): f = FindEquations(data, method, 2,
 . All three methods, SVD, QR and RREF, correctly report the existence of three quadrics. The equations obtained with QR after rounding are as desired:
. All three methods, SVD, QR and RREF, correctly report the existence of three quadrics. The equations obtained with QR after rounding are as desired:
Running Bertini we verify that V is an irreducible variety of dimension 3 and degree 3.
We next estimate the volume of V using the formula in Theorem 6.3. We intersect V with 500 random planes in \({\mathbb {P}}^5_{\mathbb {R}}\) and count the number of real intersection points. We must initialize 500 linear functions with Gaussian entries involving the same variables as
 :
:

Now, we compute the real intersection points using HomotopyContinuation.jl.

The command
 reports an estimate of 19.8181 for the volume of V. The true volume of V is the length of \( {\mathbb {P}}^1_{\mathbb {R}}\) times the area of \( {\mathbb {P}}^2_{\mathbb {R}}\), which is \(\pi \cdot (2 \pi ) = 19.7392\).
reports an estimate of 19.8181 for the volume of V. The true volume of V is the length of \( {\mathbb {P}}^1_{\mathbb {R}}\) times the area of \( {\mathbb {P}}^2_{\mathbb {R}}\), which is \(\pi \cdot (2 \pi ) = 19.7392\).

Barcodes for 200 points on the Segre variety of \(2\times 3\) matrices of rank 1. The true mod 2 Betti numbers of \({\mathbb {P}}^1_{\mathbb {R}} \times {\mathbb {P}}^2_{\mathbb {R}}\) are 1, 2, 2, 1. The top picture shows the barcodes for the usual Vietoris–Rips complex computed using scaled Fubini–Study distance. The bottom picture is computed using the scaled Euclidean distance. Using the Fubini–Study distance yields better results
Using Eirene, we construct the barcodes depicted in Fig. 9. The barcodes constructed using Fubini–Study distance detect persistent features in dimensions 0, 1 and 2. The barcodes using Euclidean distance only have a strong topological signal in dimension 0.
7.3 Dataset 3: conformation space of cyclo-octane
Our next variety V is the conformation space of the molecule cyclo-octane \(C_8 H_{16}\). We use the same sample \(\Omega \) of 6040 points that was analyzed in [2, §.6.3]. Cyclo-octane consists of eight carbon atoms arranged in a ring and each bonded to a pair of hydrogen atoms (see Fig. 10). The location of the hydrogen atoms is determined by that of the carbon atoms due to energy minimization. Hence, the conformation space of cyclo-octane consists of all possible spatial arrangements, up to rotation and translation, of the ring of carbon atoms.

A cyclo-octane molecule
Each conformation is a point in \({\mathbb {R}}^{24} = {\mathbb {R}}^{8\cdot 3}\), which represents the coordinates of the carbon atoms \(\{z_0, \ldots , z_7\}\subset {\mathbb {R}}^3\). Every carbon atom \(z_i\) forms an isosceles triangle with its two neighbors with angle \(\frac{2\pi }{3}\) at \(z_i\). By the law of cosines, there is a constant \(c>0\) such that the squared distances \(\,d_{i,j}=\Vert z_i-z_j\Vert ^2\,\) satisfy
Thus we expect to find 16 quadrics from the given data. In our sample we have \(c\approx 2.21\).
The conformation space is defined modulo translations and rotation; i.e., modulo the 6-dimensional group of rigid motions in \({\mathbb {R}}^3\). An implicit representation of this quotient space arises by substituting (24) into the Schönberg matrix of Example 2.8 with \(p=8\) and \(r=3\).
However, the given \(\Omega \) lives in \({\mathbb {R}}^{24} = {\mathbb {R}}^{8\cdot 3}\), i.e. it uses the coordinates of the carbon atoms. Since the group has dimension 6, we expect to find 6 equations that encode a normal form. That normal form is a distinguished representative from each orbit of the group action.

Dimension diagrams for 420 points from the cyclo-octane dataset
Brown et al. [10] and Martin et al. [42] show that the conformation space of cyclo-octane is the union of a sphere with a Klein bottle, glued together along two circles of singularities. Hence, the dimension of V is 2, and it has Betti numbers 1, 1, 2 in mod 2 coefficients.
To accelerate the computation of dimension diagrams, we took a random subsample of 420 points. The output is displayed in Fig. 11. A dimension estimate of 2 seems reasonable:

The dataset \(\Omega \) is noisy: each point is rounded to 4 digits. Direct use of
 yields no polynomials vanishing on \(\Omega \). The reason is that our code sets the tolerance with the numerical rank in (21). For noisy samples, we must set the tolerance manually. To get a sense for adequate tolerance values, we first compute the multivariate Vandermonde matrix \(U_{\le d}(\Omega )\) and then plot the base 10 logarithms of its singular values. We start with \(d=1\).
yields no polynomials vanishing on \(\Omega \). The reason is that our code sets the tolerance with the numerical rank in (21). For noisy samples, we must set the tolerance manually. To get a sense for adequate tolerance values, we first compute the multivariate Vandermonde matrix \(U_{\le d}(\Omega )\) and then plot the base 10 logarithms of its singular values. We start with \(d=1\).

This code produces the top plot in Fig. 12. This graph shows a clear drop from \(-0.2\) to \(-2.5\). Picking the in-between value \(-1\), we set the tolerance at \(\tau = 10^{-1}\). Then, we type

where
 is one of our three methods. For this tolerance value we find six linear equations. Computed using :with_qr and rounded to three digits, they are:
is one of our three methods. For this tolerance value we find six linear equations. Computed using :with_qr and rounded to three digits, they are:
We add the second and the fifth equation, and we add the first, third and sixth, by typing
 and
and
 respectively. Together with
respectively. Together with
 we get the following:
we get the following:

We learned that centering is the normal form for translation. We also learned that the columns in (25) represent the eight atoms. Since we found 6 linear equations, we believe that the three 3 remaining equations determine the normal form for rotations. However, we do not yet understand how the three degrees of rotation produce three linear constraints.

Logarithms (base 10) of the singular values of the matrices \(U_{\le 1}(\Omega )\) (top) and \(U_{\le 2}(\Omega )\) (bottom)
We next proceed to equations of degree 2. Our hope is to find the 16 quadrics in (24). Let us check whether this works. Figure 12 on the bottom shows the logarithms of the singular values of the multivariate Vandermonde matrix \(U_{\le 2}(\Omega )\). Based on this we set \(\tau = 10^{-6}\).
The command
 reveals 21 quadrics. However, these are the pairwise products of the 6 linear equations we found earlier. An explanation for why we cannot find the 16 distance quadrics is as follows. Each of the 6 linear equations evaluated at the points in \(\Omega \) gives about \(10^{-3}\) in our numerical computations. Thus their products equal about \(10^{-6}\). The distance quadrics equal about \(10^{-3}\). At tolerance \(10^{-6}\), we miss them. Their values are much larger than the \(10^{-6}\) from the 21 redundant quadrics. By randomly rotating and translating each data point, we can manipulate the dataset such that
reveals 21 quadrics. However, these are the pairwise products of the 6 linear equations we found earlier. An explanation for why we cannot find the 16 distance quadrics is as follows. Each of the 6 linear equations evaluated at the points in \(\Omega \) gives about \(10^{-3}\) in our numerical computations. Thus their products equal about \(10^{-6}\). The distance quadrics equal about \(10^{-3}\). At tolerance \(10^{-6}\), we miss them. Their values are much larger than the \(10^{-6}\) from the 21 redundant quadrics. By randomly rotating and translating each data point, we can manipulate the dataset such that
 together with a tolerance value \(\tau = 10^{-1}\) gives the 16 desired quadrics. The fact that no linear equation vanishes on the manipulated dataset provides more evidence that 3 linear equations are determining the normal form for rotations.
together with a tolerance value \(\tau = 10^{-1}\) gives the 16 desired quadrics. The fact that no linear equation vanishes on the manipulated dataset provides more evidence that 3 linear equations are determining the normal form for rotations.

Barcodes for a subsample of 500 points from the cyclo-octane dataset. The top plot shows the barcodes for the usual Vietoris–Rips complex. The bottom picture shows barcodes for the ellipsoid-driven simplicial complex in (17). The bottom barcode correctly captures the homology of the conformation space
The cyclo-octane dataset was used in [2, §.6.3] to demonstrate that persistent homology can efficiently recover the homology groups of the conformation space. We confirmed this result using our software. We determined the barcodes for a random subsample of 500 points. In addition to computing with Vietoris–Rips complexes, we use the 6 linear equations and the 16 distance quadrics to produce the ellipsoid-driven barcode plots. The results are displayed in Fig. 13. The barcodes from the usual Vietoris–Rips complex do not capture the correct homology groups, whereas the barcodes arising from our new complex (17) do.
References
Aamari, E., Kim, J., Chazal, F., Michel, B., Rinaldo, A., Wasserman, L.: Estimating the reach of a manifold. arXiv:1705.04565
Adams, H., Tausz, A.: JavaPlex tutorial. http://www.math.colostate.edu/~adams/research/javaplex_tutorial.pdf. Accessed 24 February 2018
Améndola, C., Faugère, J.-C., Sturmfels, B.: Moment varieties of Gaussian mixtures. J. Algebr. Stat. 7, 14–28 (2016)
Basson, R., Lercier, R., Ritzenthaler, C., Sijsling, J.: An explicit expression of the Lüroth invariant. ISSAC 2013. Proceedings of the 38th International Symposium on Symbolic and Algebraic Computation, pp. 31–36. ACM, New York (2013)
Bates, D., Hauenstein, J., Sommese, A., Wampler, C.: Numerically Solving Polynomial Systems with Bertini, Software, Environments, and Tools. SIAM, Philadelphia, PA (2013)
Bezanson, J., Edelman, A., Karpinski, S., Shah, V.: Julia: a fresh approach to numerical computing. SIAM Rev. 59, 65–98 (2017)
Bjoerck, A., Pereyra, V.: Solutions of Vandermonde systems of equations. Math. Comput. 24, 893–903 (1970)
Blekherman, G., Parrilo, P., Thomas, R.: Semidefinite Optimization and Convex Algebraic Geometry, MOS-SIAM Series on Optimization, vol. 13 (2012)
Breiding, P., Timme, S.: HomotopyContinuation.jl—a package for solving systems of polynomial equations in Julia. arXiv:1711.10911
Brown, M.W., Martin, S., Pollock, S.N., Coutsias, E.A., Watson, J.P.: Algorithmic dimensionality reduction for molecular structure analysis. J. Chem. Phys. 129, 064118 (2008)
Bürgisser, P., Cucker, F., Lairez, P.: Computing the homology of basic semialgebraic sets in weak exponential time. arXiv:1706.07473
Camastra, F.: Data dimensionality estimation methods: a survey. Pattern Recogn. 36, 2945–2954 (2003)
Camastra, F., Staiano, A.: Intrinsic dimension estimation: advances and open problems. Inf. Sci. 328, 26–41 (2016)
Carlsson, G.: Topology and data. Bull. Am. Math. Soc. 46, 255–308 (2009)
Cifuentes, D., Parrilo, P.: Sampling algebraic varieties for sum of squares programs. SIAM J. Optim. 27, 2381–2404 (2017)
Cox, D., Little, J., O’Shea, D.: Ideals, Varieties, and Algorithms: An Introduction to Computational Algebraic Geometry and Commutative Algebra, Undergraduate Texts in Mathematics, 4th edn. Springer, Berlin (2015)
Cueto, M.A., Morton, J., Sturmfels, B.: Geometry of the restricted Boltzmann machine. Algebraic Methods in Statistics and Probability. Contemporary Mathematics, vol. 516, pp. 135–153. AMS, Providence (2010)
Daleo, N., Hauenstein, J.: Numerically deciding the arithmetically Cohen-Macaulayness of a projective scheme. J. Symb. Comput. 72, 128–146 (2016)
Demmel, J.W.: Applied Numerical Linear Algebra. SIAM, Philadelphia (1997)
Deza, M., Laurent, M.: Geometry of Cuts and Metrics, Algorithms and Combinatorics, vol. 15. Springer, Berlin (1997)
Diaconis, P., Holmes, S., Shahshahani, M.: Sampling from a manifold. Inst. Math. Stat. Collect. 10, 102–125 (2013)
Díaz, M., Quiroz, A., Velasco, M.: Local angles and dimension estimation from data on manifolds. arXiv:1805.01577
Draisma, J., Horobeţ, E., Ottaviani, G., Sturmfels, B., Thomas, R.: The Euclidean distance degree of an algebraic variety. Found. Comput. Math. 16, 99–149 (2016)
Drton, M., Sturmfels, B., Sullivant, S.: Lectures on Algebraic Statistics, Oberwolfach Seminars, vol. 39. Birkhäuser, Basel (2009)
Dufresne, E., Edwards, P., Harrington, H., Hauenstein, J.: Sampling real algebraic varieties for topological data analysis. arXiv:1802.07716
Eklund, D.: The numerical algebraic geometry of bottlenecks. arXiv:1804.01015
Federer, H.: Curvature measures. Trans. Am. Math. Soc. 93, 418–491 (1959)
Griffin, Z., Hauenstein, J., Peterson, C., Sommese, A.: Numerical computation of the Hilbert function and regularity of a zero dimensional scheme. Connections Between Algebra. Combinatorics, and Geometry, Springer Proceedings in Mathematics and Statistics, vol. 76, pp. 235–250. Springer, New York (2014)
Harris, J.: Algebraic Geometry. A First Course, Graduate Texts in Mathematics, vol. 133. Springer, New York (1992)
Henselman, G., Ghrist, R.: Matroid filtrations and computational persistent homology. arXiv:1606.00199
Higham, N.: Accuracy and Stability of Numerical Algorithms, 2nd edn. SIAM, Philadelphia (2002)
Horobeţ, E., Weinstein, M.: Offset hypersurfaces and persistent homology of algebraic varieties. arXiv:1803.07281
Howard, R.: The kinematic formula in Riemannian homogeneous spaces. Mem. Am. Math. Soc. 106(509) (1993)
Jain, A., Dubes, R.: Algorithms for Clustering Data. Prentice-Hall, Upper Saddle River, NJ (1998)
Kileel, J., Kukelova, Z., Pajdla, T., Sturmfels, B.: Distortion varieties. Found. Comput. Math. 18, 1043–1071 (2018)
Kummer, M., Vinzant, C.: The Chow form of a reciprocal linear space. Michigan Math. J. arXiv:1610.04584
Landsberg, J.M.: Tensors: Geometry and Applications, Graduate Studies in Mathematics, vol. 128. American Mathematical Society, Providence, RI (2012)
Lee, J.A., Verleysen, M.: Nonlinear Dimensionality Reduction. Information Science and Statistics. Springer, New York (2007)
Leichtweiss, K.: Zur Riemannschen Geometrie in Grassmannschen Mannigfaltigkeiten. Math. Z. 76, 334–366 (1961)
Levina, E., Bickel, P.: Maximum likelihood estimation of intrinsic dimension. Adv. Neural Inf. Process. Syst. 17, 777–784 (2004)
Ma, Y., Yang, A., Derksen, H., Fossum, R.: Estimation of subspace arrangements with applications in modeling and segmenting mixed data. SIAM Rev. 50, 413–458 (2008)
Martin, S., Thompson, A., Coutsias, E.A., Watson, J.P.: Topology of cyclo-octane energy landscape. J. Chem. Phys. 132, 234115 (2010)
Mezzadri, F.: How to generate matrices from the classical compact groups. Not. AMS 54, 592–604 (2007)
Möller, H., Buchberger, B.: The construction of multivariate polynomials with preassigned zeros. Computer Algebra (Marseille 1982). Lecture Notes in Computer Science, vol. 144, pp. 24–31. Springer, Berlin (1982)
Mustaţǎ, M.: Graded Betti numbers of general finite subsets of points on projective varieties. Pragmat. 1997 Mat. (Catania) 53, 53–81 (1998)
Niyogi, P., Smale, S., Weinberger, S.: Finding the homology of submanifolds with high confidence from random samples. Discrete Comput. Geom. 39, 419–441 (2008)
Olver, P.J.: On multivariate interpolation. Stud. Appl. Math. 116, 201–240 (2006)
Pan, V.Y.: How bad are Vandermonde matrices? SIAM J. Matrix Anal. Appl. 37(2), 676–694 (2016)
Plaumann, D., Sturmfels, B., Vinzant, C.: Quartic curves and their bitangents. J. Symb. Comput. 46, 712–733 (2011)
Santalo, L.: Integral Geometry and Geometric Probability. Addison-Wesley, Reading (1976)
Sturmfels, B., Welker, V.: Commutative algebra of statistical ranking. J. Algebra 361, 264–286 (2012)
The Pattern Analysis Lab at Colorado State University: A fractal dimension for measures via persistent homology (Preprint) (2018)
Acknowledgements
Open access funding provided by Max Planck Society. We thank Henry Adams, Mateo Díaz, Jon Hauenstein, Peter Hintz, Ezra Miller, Steve Oudot, Benjamin Schweinhart, Elchanan Solomon, and Mauricio Velasco for helpful discussions. Bernd Sturmfels and Madeleine Weinstein acknowledge support from the US National Science Foundation.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Breiding, P., Kališnik, S., Sturmfels, B. et al. Learning algebraic varieties from samples. Rev Mat Complut 31, 545–593 (2018). https://doi.org/10.1007/s13163-018-0273-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13163-018-0273-6