
Abstract
This paper deals with the geometric numerical integration of gradient flow and its application to optimization. Gradient flows often appear as model equations of various physical phenomena, and their dissipation laws are essential. Therefore, dissipative numerical methods, which are numerical methods replicating the dissipation law, have been studied in the literature. Recently, Cheng, Liu, and Shen proposed a novel dissipative method, the Lagrange multiplier approach, for gradient flows, which is computationally cheaper than existing dissipative methods. Although their efficacy is numerically confirmed in existing studies, the existence results of the Lagrange multiplier approach are not known in the literature. In this paper, we establish some existence results. We prove the existence of the solution under a relatively mild assumption. In addition, by restricting ourselves to a special case, we show some existence and uniqueness results with concrete bounds. As gradient flows also appear in optimization, we further apply the latter results to optimization problems.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
In this paper, we consider the numerical integration of the gradient flow
where \(x_0 \in {\mathbb {R}}^n\) is an initial condition, \(V :{\mathbb {R}}^n \rightarrow {\mathbb {R}}\) is a differentiable function, and the matrix \(D\in {\mathbb {R}}^{n \times n}\) is positive definite but not necessarily symmetric.
Gradient flows (1) are important class of ordinary differential equations (ODEs) that describe various physical phenomena. Consequently, numerical methods for gradient flow (1) have also been intensively studied. In particular, specialized numerical schemes that replicate the dissipation law \(\frac{\textrm{d}}{\textrm{d}t} V(x(t)) \le 0\) have been devised and investigated. Techniques devising and analyzing such a specialized numerical scheme replicating a geometric property of ODEs are known as “geometric numerical integration” techniques (cf. [1]).
The discrete gradient method [2] (see also [3]) is the most popular specialized numerical method for gradient flows. Schemes based on the discrete gradient method are often superior to general-purpose methods, particularly for numerically difficult differential equations.
Although these schemes allow us to employ a larger step size than general-purpose methods, they are usually more expensive per step. Most of these schemes require solving an n-dimensional nonlinear equation per step.
Consequently, several techniques to enhance the computational efficiency have been studied in the literature (see, e.g., [4] and references therein). In particular, Cheng, Liu, and Shen [5] proposed the Lagrange multiplier approach, which replicates the dissipation law. Their proposed method is based on splitting the function V in the form
where \(Q \in {\mathbb {R}}^{n\times n}\) is symmetric, and \(E :{\mathbb {R}}^n \rightarrow {\mathbb {R}}\) is a differentiable function. Note that the splitting is not unique (E may contain a quadratic term); however, when we consider physical problems, the function V often includes a quadratic term so that we can naturally obtain a splitting (see, e.g., [6]).
Then, we can construct a numerical scheme preserving the dissipation law by using the implicit midpoint rule for the quadratic term and special treatment for the nonlinear term E, respectively (see Sect. 2.1 for details). The resulting scheme requires solving a scalar nonlinear equation (and n-dimensional linear equations) per step, which is quite cheap.
Unfortunately, however, the existence of a solution of the scalar nonlinear equation is not known in the literature. Therefore, in this paper, we establish some existence results. First, we prove the existence of the solution under a relatively mild assumption (Sect. 3.1). Second, by restricting ourselves to a case where Q is the zero matrix, we establish several existence and uniqueness results with concrete bounds on the solution (Sect. 3.2).
The latter results are useful in the application of the Lagrange multiplier method to optimization problems because the gradient flow (1) also appears in the context of optimization. Investigations on the relationship between optimization methods and the discretization of ordinary differential equations (ODEs) have been reported in the 1980s (e.g., [7,8,9]). In addition, inspired by the pioneering work of Su, Boyd, and Candès [10] on Nesterov’s accelerated gradient method, research in this direction has been active again in recent years (see [11] and the references therein).
When considering the optimization, the dissipation law is also important: it is not merely a guarantee of the monotonic decrease of the function value, but can also be used to prove its convergence rate. Indeed, the discrete gradient method has recently been applied to optimization problems [12,13,14].
Because the Lagrange multiplier method is much cheaper than the discrete gradient method per step, we consider its application to optimization problems. Indeed, when Q is the zero matrix and \(D\) is the identity matrix, the resulting scheme can be regarded as the well-known steepest descent method, adopting a new step size criterion. For the scheme, we show the convergence rates for several function classes: (i) general L-smooth functions, (ii) convex functions, and (iii) functions that satisfy the Polyak–Łojasiewicz inequality (Sect. 4). We also introduce a relaxation technique to further enhance the computational efficiency (Sect. 5).
It may seem as though the scheme is merely a variant of the basic existing method; moreover, as shown in numerical experiments later, the actual behavior is almost the same as that of the existing method.
However, the optimization methods proposed in this paper have the advantage that the relationship between continuous and discrete systems is clear in the proof of convergence rates (see, e.g., Theorems 2 and 10). In existing research considering the correspondence between continuous and discrete systems, although the discussion on continuous systems is simple, it is often very complicated to prove the corresponding property in discrete systems. A limitation of this paper is that we deal with the simplest gradient flows; however, it suggests that the above issues can be overcome by geometric numerical integration techniques even when we are dealing with more complicated ODEs that appear in optimization.
The remainder of this paper is organized as follows. Section 2 presents the Lagrange multiplier approach and the relation between gradient flow and optimization. We show several existence results in Sect. 3 and convergence rates as an optimization method in Sect. 4. In Sect. 5, we introduce a relaxation technique. These results are confirmed by numerical experiments in Sect. 6. Finally, Sect. 7 concludes this paper.
2 Preliminaries
2.1 Lagrange multiplier approach
In this section, we review the numerical method proposed by Cheng et al. [5], which preserves the dissipation law.
By introducing an auxiliary variable \(\eta :{\mathbb {R}}_{\ge 0} \rightarrow {\mathbb {R}}\), we consider the following ODE based on the splitting (2):
In view of the chain rule, the auxiliary variable \(\eta\) satisfies \(\eta (t) = 1\) such that the ODE above is equivalent to the gradient flow (1).
Based on the reformulated ODE (3), we consider the following scheme (\(x_k \approx x \left( {kh}\right)\), \(\eta _k \approx \eta \left( {kh}\right)\)):
Here, \(x_{k+1/2}^{*}\) is a numerical approximation of \(x\left( {(k+1/2)h}\right)\), which can be computed without the unknown variables \(x_{k+1}\) and \(\eta _k\). For example, Cheng et al. [5] employed \(x_{k+1/2}^{*} {:=} \left( {3x_k - x_{k-1}}\right) /2\), and we employ \(x_{k+1/2}^{*} {:=} x_k\) later.
Remark 1
The setting \(x_{k+1/2}^{*} = \left( {3x_k - x_{k-1}}\right) /2\) is to achieve the second order accuracy, whereas the setting \(x_{k+1/2}^{*} = x_k\) only achieves the first order accuracy. Although the former setting is better in terms of accuracy, the latter setting is easier to deal with in mathematical analysis. In addition, when we employ the latter, the Lagrange multiplier approach can be regarded as a special case of the discrete gradient method [2, 3, 15]: \(Q\left( {\frac{x_{k+1} + x_k}{2}}\right) + \eta _k \nabla E \left( {x_k}\right)\) satisfies the conditions of the discrete gradient.
From this point on, we always assume \(x_{k+1/2}^{*} {:=} x_k\).
Theorem 1
[5] A solution \(x_{k+1}\) of the scheme (4) satisfies the discrete dissipation law \(f\left( {x_{k+1}}\right) \le f\left( {x_k}\right)\).
By introducing
we can rewrite (4a) as follows: \(x_{k+1} = p_k - h \eta _k q_k\). Here, \(p_k\) and \(q_k\) can be computed by solving the linear equations with the same coefficient matrix \(I+\frac{h}{2} DQ\), which is invertible for sufficiently small h. Thus, we can compute \(\eta _k\) by solving
The scheme (4) requires solving two linear equations with n variables and a scalar nonlinear equation; moreover, because the coefficient matrix is constant, we can solve them quite efficiently. However, existence results for the nonlinear equation \(F_h (\eta _k; x_k) = 0\) have not been established in the literature.
2.2 Gradient flow and optimization
In this section, we consider the unconstrained optimization problem
where the function \(f :{\mathbb {R}}^n \rightarrow {\mathbb {R}}\) is assumed to be L-smooth (see Definition 1) and satisfies \(\mathop {\mathrm {arg\,min}}\limits f \ne \emptyset\). Under this assumption, there is an optimal solution \(x^\star\) and an optimal value \(f^\star {:=} f ( x^\star )\). In particular, we consider the relationship between the problem and gradient flow (5):
which is a special case of the general gradient flow (1).
First, we introduce the following definitions.
Definition 1
Let \(f :{\mathbb {R}}^n \rightarrow {\mathbb {R}}\) be a function.
-
A function f is called L-smooth for \(L > 0\) if its gradient \(\nabla f\) is L-Lipschitz continuous, that is, \(\left\Vert \nabla f(x) - \nabla f (y) \right\Vert \le L \left\Vert x-y\right\Vert\) holds for all \(x, y \in {\mathbb {R}}^n\).
-
A function f is called \(\mu\)-strongly convex for \(\mu > 0\) if \(f - \frac{\mu }{2} \left\Vert \cdot \right\Vert ^2\) is convex.
-
A function f is called strictly convex if \(f(\lambda x + (1-\lambda ) y) < \lambda f(x) + (1-\lambda ) f(y)\) holds for all \(\lambda \in (0,1)\) and all \(x, y \in {\mathbb {R}}^n\) such that \(x \ne y\).
-
A function f is said to satisfy the Polyak–Łojasiewicz (PŁ) inequality with parameter \(\mu >0\) (cf. [16]) if
$$\begin{aligned} \frac{1}{2} \left\Vert \nabla f (x) \right\Vert ^2 \ge \mu \left( { f(x) - f^\star }\right) . \end{aligned}$$(6)holds for all \(x \in {\mathbb {R}}^n\).
L-smooth functions satisfy the following inequalities.
Lemma 1
If f is L-smooth, the following inequalities hold for all \(x, y \in {\mathbb {R}}^n\) :
Note that a \(\mu\)-strongly convex function satisfies the PŁ inequality with parameter \(\mu\). In addition, if a function is L-smooth and satisfies the PŁ inequality with parameter \(\mu\), \(L\ge \mu\) holds [17].
When the objective function f is strictly convex, the gradient flow (5) satisfies the following proposition.
Proposition 1
(cf. [18]) Let f be a strictly convex function. Then, f is a Lyapunov function of the gradient flow (1), that is, the solution x satisfies \(\frac{\textrm{d}}{\textrm{d}t} f(x(t)) \le 0\) for all \(t \in {\mathbb {R}}_{\ge 0}\), and
holds for any initial condition \(x_0 \in {\mathbb {R}}^n\).
Based on the above fact, some researchers have posited the idea of using a numerical method for gradient flow as an optimization method. For example, the explicit Euler method
coincides with the steepest descent method. However, we should carefully choose the step size h to ensure the convergence of this method.
Here, because the convergence in continuous time, such as in Proposition 1, is based on the dissipation law, the numerical method replicating the dissipation law can be regarded as an optimization method (see, e.g., [14]). Before stepping into the property in discrete systems, we review the convergence in continuous systems in this section. The gradient flow (5) satisfies the following three theorems.
Theorem 2
[11] The solution x of the gradient flow (1) satisfies
Proof
Since \(f^\star\) is an optimal value,
holds. \(\square\)
Theorem 3
[10] If f is convex, the solution x of the gradient flow (5) satisfies
Proof
Let \({\mathcal {E}}\) be a function defined by
Then, \({\mathcal {E}}(t)\) decreases along time:
where the last inequality is due to convexity. Therefore,
holds, which proves the theorem. \(\square\)
Theorem 4
(cf. [19]) If f satisfies the Polyak–Łojasiewicz inequality (6) with parameter \(\mu > 0\), the solution x of the gradient flow (5) satisfies
Proof
Let \({\mathcal {L}}\) be a function defined by \({\mathcal {L}}(t) {:=} f(x) - f^\star\). Then,
therefore, \({\mathcal {L}}(t) \le \exp \left( {-2\mu t}\right) {\mathcal {L}}(0)\) holds, which proves the theorem. \(\square\)
Ehrhardt et al. [14] showed that the discrete gradient method with several known constructions of the discrete gradient satisfies \(f(x_k) - f^\star = O\left( {1/k}\right)\) for convex functions, and \(f(x_k) - f^\star = O\left( {\exp (-Ck)}\right)\) for functions satisfying PŁ inequality (6) (\(C > 0\) is a constant).
3 Existence theorems
In this section, we establish existence theorems for the Lagrange multiplier method (4) under the assumption \(x_{k+1/2}^{*} = x_k\). First, we establish an existence result for general splitting in Sect. 3.1. Then, we restrict ourselves to a special case and obtain existence results with bounds on the solution \(\eta _k\).
3.1 Existence results in general setting
In this section, we prove the existence of the solution \(\eta\) of the nonlinear equation \(F_h (\eta ; x_k) = 0\) for sufficiently small h by using the intermediate value theorem. For this purpose, we first prove that \(F_h (\eta ; x_k) > 0\) holds for sufficiently large \(\eta\) (Lemma 2). Then, we prove that there exists \(\eta\) satisfying \(F_h (\eta ; x_k) < 0\) when \(\left\langle \nabla E \left( {x_k}\right) , D\nabla V \left( {x_k}\right) \right\rangle \ne 0\) (Lemma 3). These lemmas imply the desired existence theorem (Theorem 5) on the case \(\left\langle \nabla E \left( {x_k}\right) , D\nabla V \left( {x_k}\right) \right\rangle \ne 0\). In addition, even in the case \(\left\langle \nabla E \left( {x_k}\right) , D\nabla V \left( {x_k}\right) \right\rangle = 0\), by introducing a small perturbation to the splitting, we can return to the case \(\left\langle \nabla E \left( {x_k}\right) , D\nabla V \left( {x_k}\right) \right\rangle \ne 0\).
Let us denote the minimum value of the Rayleigh quotient of matrix A by \(\omega _{\min }(A)\). Note that, if matrix A is symmetric, \(\omega _{\min }(A)\) coincides with the minimum eigenvalues of A. Moreover, since the matrix \(D\) is positive definite, \(\omega _{\min }(D) > 0\) and \(\omega _{\min }\left( { D^{-1} }\right) > 0\) hold.
Lemma 2
Let \(E :{\mathbb {R}}^n \rightarrow {\mathbb {R}}\) be an \(L_E\)-smooth function. Suppose that \(\nabla E (x_k) \ne 0\) holds and h satisfies \(h \left( { \omega _{\min }(Q) - L_E }\right) > - 2 \omega _{\min }\left( { D^{-1} }\right)\). Then, there exits \({\overline{\eta }} \in {\mathbb {R}}\) such that \(F_h ({\overline{\eta }}; x_k) > 0\) holds.
Proof
Because of the assumption on h, the matrix \(I + (h/2) DQ\) is invertible. Therefore, the assumption \(\nabla E \left( {x_k}\right) \ne 0\) implies \(q_k \ne 0\).
Since E is \(L_E\)-smooth, we use Lemma 1 and obtain
The right-hand side is a quadratic function with respect to \(\eta\), whose coefficient of the highest degree is positive:
Therefore, \(F_h \left( { \eta ; x_k }\right)\) is positive for sufficiently large \(\eta\). \(\square\)
Lemma 3
Suppose that \(\left\langle \nabla E \left( {x_k}\right) , D\nabla V \left( {x_k}\right) \right\rangle \ne 0\) holds. Then, there exist \({\underline{\eta }} \in {\mathbb {R}}\) and \({\overline{h}} > 0\) such that \(F_h \left( { {\underline{\eta }}; x_k }\right) < 0\) holds for any \(h < {\overline{h}}\).
Proof
Since
holds, we see
The right-hand side is a quadratic function with respect to \(\eta\) such that its coefficient of the highest degree is positive. In addition, under the assumption of the lemma, the quadratic function has two distinct real roots. Therefore, for any \(\eta\) between these two real roots, \(\left. \frac{ \partial }{ \partial h } F_h \left( { \eta ; x_k }\right) \right| _{h=0} < 0\) holds. This implies the lemma because \(F_0 \left( {\eta ; x_k }\right) = 0\) holds and \(F_h \left( { \eta ; x_k }\right)\) is continuous with respect to h for sufficiently small h. \(\square\)
Combining Lemmas 2 and 3, we obtain the following existence theorem because of the intermediate value theorem.
Theorem 5
Let \(E :{\mathbb {R}}^n \rightarrow {\mathbb {R}}\) be an \(L_E\)-smooth function. If \(x_k\) satisfies \(\left\langle \nabla E \left( {x_k}\right) , D\nabla V \left( {x_k}\right) \right\rangle \ne 0\), then, for all sufficiently small h, there exists a solution of the scheme (4).
Remark 2
The above argument implies that the scalar nonlinear equation \(F_h (\eta ;x_k) = 0\) has at least two solutions. In this sense, the usual uniqueness does not hold for the schemes. However, roughly speaking, the proof of Lemma 3 implies that, for sufficiently small h, the two solutions are close to 1 and \(- \left\langle \nabla E (x_k),DQ x_k\right\rangle /\left\langle \nabla E (x_k),D\nabla E ( x_k) \right\rangle\), two distinct roots of \(\left. \frac{ \partial }{ \partial h } F_h \left( { \eta ; x_k }\right) \right| _{h=0}\), respectively (see Appendix A for details). Since the solution of the continuous system (4) is \(\eta (t) = 1\), the solution that is closest to 1 should be used in numerical computation.
Finally, we consider the case \(\left\langle \nabla E \left( {x_k}\right) , D\nabla V \left( {x_k}\right) \right\rangle = 0\). If \(\nabla V \left( { x_k }\right) = 0\) holds, \(x_k\) is an equilibrium point of the system. Therefore, we focus on the case \(\nabla V \left( { x_k }\right) \ne 0\) hereafter. In this case, by introducing a small perturbation to the splitting (2), we can use Theorem 5.
For an arbitrary \(\epsilon \ne 0\), we consider the splitting
Then, we see
where the most right-hand side is nonzero because D is positive definite and \(\nabla V(x) = Q x + \nabla E(x)\). Therefore, Theorem 5 implies that the Lagrange multiplier scheme with the splitting (8) has a solution. Consequently, by using the perturbed scheme only when \(\left\langle \nabla E \left( {x_k}\right) , D\nabla V \left( {x_k}\right) \right\rangle = 0\), we can continue to compute numerical solutions.
3.2 Existence results in a special case
In this section, we further assume \(D= I\) and Q is the zero matrix. The results in this section can be extended to the case with general \(D\) (see Appendix B); however, here we focus on the simple gradient flow (5) because the existence results in this case can be utilized in optimization (see Sects. 2.2 and 4).
In this case, the scheme can be written in the form
Then, \(x_{k+1}\) can be computed by solving a scalar nonlinear equation:
This equation has a trivial solution \(\eta _k = 0\) (cf. Remark 2), and we prove an existence theorem below for a nontrivial solution.
Theorem 6
Let \(f :{\mathbb {R}}^n \rightarrow {\mathbb {R}}\) be an L-smooth function satisfying \(\mathop {\mathrm {arg\,min}}\limits f \ne \emptyset\). Then, for any \(x_k \in {\mathbb {R}}^n\), there exists an \(\eta _k\) that satisfies \(F_h (\eta _k; x_k) = 0\) and
Proof
In this proof, we use the notation \(d_k {:=} -\nabla f(x_k)\) for brevity. If \(d_k = 0\), \(F_h(\eta _k; x_k) = 0\) holds for any \(\eta _k \in {\mathbb {R}}\) so that the theorem holds. Therefore, we focus on the case \(d_k \ne 0\) hereafter. Then, because \(\mathop {\mathrm {arg\,min}}\limits f \ne \emptyset\), f is bounded from below so that \(\lim _{\eta \rightarrow \infty } F_h ( \eta ; x_k ) = \infty\) holds.
Because we assume that f is L-smooth, the second inequality of Lemma 1 implies
Therefore, \(F_h \left( {\eta _{\textrm{LB}}; x_k}\right) \le 0\) holds, which proves the theorem due to the intermediate value theorem. \(\square\)
The theorem above gives the lower bound of the nontrivial solution, and the following theorem gives the upper bound for a sufficiently small step size h.
Theorem 7
Let \(f :{\mathbb {R}}^n \rightarrow {\mathbb {R}}\) be an L-smooth function satisfying \(\mathop {\mathrm {arg\,min}}\limits f \ne \emptyset\). Assume that \(\nabla f(x_k) \ne 0\) and \(h \le {2}/{L}\) hold. If \(\eta _k > 0\) satisfies \(F_h(\eta _k; x_k) = 0\), then
holds.
Proof
From (10), \(F_h (\eta _k; x_k) < 0\) holds for any \(\eta _k \in \left( { 0,\eta _{\textrm{LB}}}\right)\). Then, by using the first inequality in Lemma 1, we see
(the proof is similar to the proof of Theorem 6). Therefore, \(F_h (\eta _k; x_k) > 0\) holds for any \(\eta _k > \left( {1 - \frac{Lh}{2}}\right) ^{-1}\), which proves the theorem. \(\square\)
Moreover, if f is convex or satisfies the PŁ inequality (6), there is an upper bound that is valid for any step size h.
Theorem 8
Let \(f :{\mathbb {R}}^n \rightarrow {\mathbb {R}}\) be an L-smooth function satisfying \(\mathop {\mathrm {arg\,min}}\limits f \ne \emptyset\). If f is convex and \(\nabla f(x_k) \ne 0\) holds, then there exists a unique nontrivial solution \(\eta _k\) of the nonlinear equation \(F_h(\eta _k; x_k) = 0\) such that \(\eta _{\textrm{LB}}\le \eta _k \le 1\) holds.
Proof
The convexity of f implies that \(F_h (\eta _k; x_k )\) is strictly convex with respect to \(\eta _k\) such that the nontrivial solution is unique.
Since f is convex, we see that
which proves the theorem owing to the intermediate value theorem. \(\square\)
Theorem 9
Let \(f :{\mathbb {R}}^n \rightarrow {\mathbb {R}}\) be an L-smooth function satisfying \(\mathop {\mathrm {arg\,min}}\limits f \ne \emptyset\). If f satisfies the PŁ inequality (6) with parameter \(\mu > 0\) and \(\nabla f(x_k) \ne 0\) holds, there exists a nontrivial solution \(\eta _k\) of the nonlinear equation \(F_h (\eta _k; x_k) = 0\) such that \(\eta _{\textrm{LB}}\le \eta _k \le \left( { 2 \mu h }\right) ^{-\frac{1}{2}}\) holds.
Proof
By introducing \({\overline{\eta }} = \left( { 2 \mu h }\right) ^{-\frac{1}{2}}\) and \({\overline{x}} = x_k + h {\overline{\eta }} d_k\), we obtain
which proves the theorem. \(\square\)
4 Convergence rates of the Lagrange multiplier method as an optimization method
The scheme (9) described in the previous section can be interpreted as the steepest descent method with a new step-size criterion (9b). In this section, we show the convergence rates corresponding to Theorems 2 to 4. Hereafter, we assume f is L-smooth and \(\mathop {\mathrm {arg\,min}}\limits f \ne \emptyset\) holds.
First, we establish the discrete counterpart of Theorem 2 as follows.
Theorem 10
Let \(\mathop {\{(x_k,\eta _k)\}}\nolimits _{k=1}^\infty\) be a sequence satisfying (9). Suppose that \(\{\eta _k\}_{k=1}^{\infty }\) is the solution guaranteed by Theorem 6, i.e., \(\eta _k \ge \eta _{\textrm{LB}}\) holds for all non-negative integer k. Then, the following inequalities hold:
Proof
Similar to the proof of Theorem 2, we see that
By the definition of \(\eta _{\textrm{LB}}\), the estimation above proves the theorem. \(\square\)
From the theorem above, we obtain the following result when f is coercive.
Theorem 11
Assume that f is coercive. Let \(\mathop {\{(x_k,\eta _k)\}}\nolimits _{k=1}^{\infty }\) be a sequence satisfying (9). Suppose that \(\{\eta _k\}_{k=1}^{\infty }\) is the solution guaranteed by Theorem 6, i.e., \(\eta _k \ge \eta _{\textrm{LB}}\) holds for all non-negative integer k. Then, the sequence \(\mathop {\{x_k\}}\nolimits _{k=0}^\infty\) has an accumulation point; moreover, \(\nabla f(x^{*}) = 0\) holds for any accumulation point \(x^{*}\).
Proof
The set \(\{ x \in {\mathbb {R}}^n | f(x) \le f(x_0) \}\) is compact because f is coercive. Since the discrete dissipation law implies \(\mathop {\{x_k\}}\nolimits _{k=0}^\infty \subset \{ x\in {\mathbb {R}}^n | f(x) \le f(x_0) \}\), \(\mathop {\{x_k\}}\nolimits _{k=0}^\infty\) has an accumulation point.
For an accumulation point \(x^{*}\), there exists a convergent subsequence \(\mathop {\{x_{k(i)}\}}\nolimits _{i=0}^\infty\). The first equation of Theorem 10 implies that \(\lim _{k \rightarrow \infty }\left\Vert \nabla f(x_k)\right\Vert = 0\). Due to the continuity of the norm and \(\nabla f\), we see
which proves the theorem. \(\square\)
Moreover, if f is convex or satisfies the PŁ inequality, we show the discrete counterparts of Theorems 3 and 4.
Theorem 12
Suppose that f is convex. Let \(\mathop {\{(x_k,\eta _k)\}}\nolimits _{k=1}^\infty\) be a sequence satisfying (9). Suppose that \(\{\eta _k\}_{k=1}^{\infty }\) is the solution guaranteed by Theorem 8, i.e., \(\eta _{\textrm{LB}} \le \eta _k \le 1\) holds for all non-negative integer k. Then, the sequence \(\mathop {\{x_k\}}\nolimits _{k=0}^\infty\) satisfies \(f(x_k) - f^\star = O\left( {\frac{1}{k}}\right)\). In particular, if \(h \le \frac{2}{L}\), then
holds.
Proof
Let us introduce the discrete counterpart
of \({\mathcal {E}}\) defined by (7). Then, we see
Here, the last term on the right-hand side can be evaluated as follows:
Using this evaluation, we see that
Because \(\eta _k \ge \left( \frac{Lh}{2} + 1\right) ^{-1}\), there exists \(k_0 \in {\mathbb {N}}\) such that \(\frac{1}{2} - \sum _{i=0}^{k} \eta _i \le 0\) holds for any \(k \ge k_0\). Therefore, we see that
which implies \(f(x_k) - f^\star = O\left( \displaystyle \frac{1}{k}\right)\). Moreover, if \(h \le \frac{2}{L}\), then \(\eta _k \ge \left( {\frac{Lh}{2} + 1}\right) ^{-1} \ge \frac{1}{2}\) holds. Since \({\mathcal {E}}_{k+1} \le {\mathcal {E}}_k\) holds for any k,
holds. \(\square\)
Theorem 13
Suppose that f satisfies the Polyak–Łojasiewicz inequality (6) with parameter \(\mu > 0\). Let \(\mathop {\{(x_k,\eta _k)\}}\nolimits _{k=1}^\infty\) be a sequence satisfying (9). Suppose that \(\{\eta _k\}_{k=1}^{\infty }\) is the solution guaranteed by Theorem 9, i.e., \(\eta _{\textrm{LB}} \le \eta _k \le (2\mu h)^{-\frac{1}{2}}\) holds for all non-negative integer k. Then, the sequence \(\mathop {\{x_k\}}\nolimits _{k=0}^\infty\) satisfies
Proof
We introduce the discrete counterpart \({\mathcal {L}}_k {:=} f(x_k) - f^\star\) of \({\mathcal {L}}\) in the proof of Theorem 4. Then, we see that
and
Because \(1 + r \le \textrm{e}^r\) holds for any real number r, we obtain
\(\square\)
5 Some relaxations of the Lagrange multiplier method
As an optimization method, the scheme (9) is still more expensive than the standard optimization methods. Note that, the computational cost of the scheme (9) is similar to that of the steepest descent method with the exact line search, which is sometimes regarded as impractical and usually replaced by backtracking in actual computation. Therefore, in this section, we propose a relaxation of the scheme (9) that allows us to use a backtracking technique. Throughout this paper, we assume that the backtracking parameter \(\alpha\) satisfies \(0< \alpha < 1\).
In view of the dissipation law (Theorem 1), condition (9b) can be relaxed to
Finding the solution of this inequality is easier than finding a solution of the scheme (9). For example, if f is convex, and the unique nonzero solution of the scheme (9) is \(\eta _k^{*}\), then all \(\eta _k \in [0, \eta _k^{*} ]\) satisfy (11).
Theorem 14
A solution \(x_{k+1}\) of the scheme (11) satisfies the discrete dissipation law \(f(x_{k+1}) \le f(x_k)\).
Proof
We see that
which proves the theorem. \(\square\)
Because the discrete dissipation law is crucial in the discussion in the previous section, we can prove the convergence rates even after this relaxation (Sect. 5.1); moreover, we propose another method to adaptively change h at every step, and also show convergence rates for it in Sect. 5.2.
5.1 A relaxation of the Lagrange multiplier method
In this section, we consider Algorithm 1.

Because Theorems 10, 12 and 13 rely on the lower bound of \(\eta _k\) as well as the discrete dissipation law, we establish the following lemma.
Lemma 4
The number of iterations of backtracking in Algorithm 1 is at most \(\lceil \log _{\alpha } \eta _{\textrm{LB}}\rceil\). In addition, when the backtracking stops, \(\eta _k \ge \alpha \eta _{\textrm{LB}}\) holds.
Proof
As shown in the proof of Theorem 6, \(F_h ( \eta ; x_k ) \le 0\) holds for any \(\eta \le \eta _{\textrm{LB}}\). Because \(\alpha ^{ \lceil \log _{\alpha } \eta _{\textrm{LB}}\rceil } \le \alpha ^{ \log _{\alpha } \eta _{\textrm{LB}}} = \eta _{\textrm{LB}}\), the iteration stops at most \(\lceil \log _{\alpha } \eta _{\textrm{LB}}\rceil\) times. Therefore, we see that \(\eta _k \ge \alpha ^{ \lceil \log _{\alpha } \eta _{\textrm{LB}}\rceil } \ge \alpha ^{ \log _{\alpha } \eta _{\textrm{LB}}+ 1 } = \alpha \eta _{\textrm{LB}}\). \(\square\)
By using the lemma, we obtain the following convergence results. We omit the proof because it can be proved in a manner similar to that in Theorems 10, 12 and 13.
Theorem 15
The sequence \(\{ x_k \}_{k=0}^{\infty }\) obtained by Algorithm 1 satisfies
Moreover, if f is convex,
holds. If f satisfies the Polyak–Łojasiewicz inequality (6) with parameter \(\mu > 0\),
holds.
5.2 Adaptive step size
In this section, we consider adaptively changing the step size \(h_k\) in every step. Here, instead of \(F_h ( \eta _k; x_k ) \le 0\), we use the condition \(F_{h_k} (\eta _k; x_k ) \le 0\). Then, \(h_{k+1}\) is defined by \(h_{k+1} = h_k \eta _k / \eta ^{*}\), which is intended to maintain \(\eta _{k+1}\) around a fixed constant \(\eta ^{*}\). As shown in the numerical experiments in the next section, this simple strategy reduces the number of backtracking iterations, and the numerical result does not depend significantly on the choice of \(h_0\).

In view of Lemma 4, we see \(\eta _k \ge \frac{ 2 \alpha }{ L h_k + 2 }\). The assumption \(\eta ^{*} < \alpha\) ensures that \(\{ h_k \}_{k=0}^{\infty }\) is bounded from below, as shown in the lemma below. This lower bound of \(\{ h_k \}_{k=0}^{\infty }\) will be used in the proof of convergence rates.
Lemma 5
If \(h_0 \ge h_{\textrm{LB}} {:=} \frac{2 (\alpha - \eta ^{*})}{ \eta ^{*} L }\), then \(h_k \ge h_{\textrm{LB}}\) holds for any positive integer k.
Proof
We prove the lemma by induction. Suppose that \(h_k \ge h_{\textrm{LB}}\) holds. Then, we see that
which proves the lemma. \(\square\)
5.2.1 Convex functions
In this section, we deal with convex functions.
Theorem 16
We assume that \(h_0 \ge h_{\textrm{LB}}\) and \(\eta ^{*} \ge \frac{1}{2}\) hold. If f is convex, the sequence \(\mathop {\{x_k\}}\nolimits _{k=0}^\infty\) obtained by Algorithm 2 satisfies
Proof
Let us introduce the discrete counterpart
of \({\mathcal {E}}\) defined by (7). Then, similar to the proof of Theorem 12, we see that
Since
holds owing to the assumption \(\eta ^{*} \ge \frac{1}{2}\), we see that \({\mathcal {E}}_{k+1} - {\mathcal {E}}_k \le 0\). Therefore, we see that
which proves the theorem. \(\square\)
5.2.2 Functions satisfying PŁ inequality
In this section, we deal with functions satisfying PŁ inequality. In this case, we need the upper bound of \(\{ h_k \}_{k=0}^{\infty }\) as well as the lower bound.
Lemma 6
Assume that f satisfies the Polyak–Łojasiewicz inequality (6) with parameter \(\mu > 0\), and \(h_0 \le h_{\textrm{UB}} {:=} \frac{1}{ 2 \mu (\eta ^{*})^2 }\) holds. Then, \(h_k \le h_{\textrm{UB}}\) holds for any positive integer k.
Proof
In a manner similar to the proof of Theorem 9, we see that \(\eta _k \le \sqrt{\frac{1}{2 \mu h_k}}\). Then, we prove the lemma by induction. Suppose that \(h_k \le h_{\textrm{UB}}\) holds. Then, we see that
which proves the lemma. \(\square\)
Theorem 17
Assume that \(h_0 \in [h_{\textrm{LB}},h_{\textrm{UB}}]\) holds. If f satisfies the Polyak–Łojasiewicz inequality (6) with parameter \(\mu > 0\), the sequence \(\mathop {\{x_k\}}\nolimits _{k=0}^\infty\) obtained by Algorithm 2 satisfies
where \(\kappa {:=} L / \mu\) is the condition number.
Proof
We introduce the discrete counterpart \({\mathcal {L}}_k {:=} f(x_k) - f^\star\) of \({\mathcal {L}}\) in the proof of Theorem 4. Then, we see that
By using \(h_k (\eta _k)^2 = \eta ^{*} h_{k+1} \eta _k \ge \eta ^{*} h_{\textrm{LB}} \frac{2\alpha }{Lh_{\textrm{UB}}+2} = \frac{8 \alpha \mu (\alpha - \eta ^{*}) (\eta ^{*})^2 }{ L \left( { L + 4 \mu (\eta ^{*})^2 }\right) }\), we obtain
which proves the theorem. \(\square\)
6 Numerical experiments
The efficacy of the Lagrange multiplier method for differential equations is well described by Cheng et al. [5]. Therefore, in this section, we focus on the application for optimization: we compare Algorithms 1 and 2 with the steepest descent method with a fixed step size \(h = 1/L\) and the step size satisfying the standard Armijo rule:
where \(c \in (0,1)\) is a parameter, and \(h_k\) is obtained by a standard backtracking line search with the parameter \(\alpha \in (0,1)\).
Throughout the numerical experiment in this section, the parameter \(\alpha\) in the Armijo rule and Algorithms 1 and 2 is fixed at \(\alpha = 0.8\). Because we investigate the difference in the results depending on the step size criteria in this experiment, we choose the parameter \(\alpha\) corresponding to a relatively precise line search. In addition, we fix the parameter \(\eta ^{*} = 0.5\) in view of Theorem 16.
6.1 Quadratic function
First, we consider the quadratic function
where \(A \in {\mathbb {R}}^{n \times n}\) and \(b \in {\mathbb {R}}^{n}\). In this section, we fix \(n = 500\) and \(b \in {\mathbb {R}}^{n}\), whose elements are independently sampled from the normal distribution \({\mathcal {N}} (0,5)\). We also fix the symmetric positive definite matrix \(A \in {\mathbb {R}}^{ n \times n }\), defined as \(A = Q^{\top } \Lambda Q\) by using a diagonal matrix \(\Lambda\), whose elements are sampled from a uniform distribution on [0.001, 1], and an orthogonal matrix Q that was sampled from the Haar measure on the orthogonal group. The resulting matrix A has the maximum eigenvalue of \(L \approx 0.998\) and minimum eigenvalue of \(\mu \approx 0.0022\). We set the initial step size of the backtracking line search for the Armijo rule to 10.

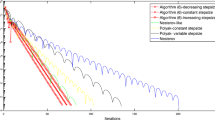
Evolution of function values for the quadratic function (12)
Figure 1 summarizes the evolution of function values and Table 1 summarizes the average step size and the average number of backtracking iterations. Here, the average step size is the average of \(h_k\) for the Armijo rule, \(h\eta _k\) for Algorithm 1, and \(h_k \eta _k\) for Algorithm 2, respectively. Note that, for each method, the number of backtracking iterations in each step is the same as the number of function value evaluations.
In Fig. 1, we omit the Armijo rule with \(c = 0.1\), Algorithm 1 with \(h=100\), and Algorithm 2 with \(h_0 = 1, 100\) because they are very similar to the Armijo rule with \(c = 10^{-4}\), Algorithm 1 with \(h=10\), and Algorithm 2 with \(h_0 = 10\), respectively.
The results of Algorithm 1 with an appropriate h and Algorithm 2 are similar to those of the Armijo rule with a small c. Because the Armijo rule with \(c = 0.5\) is similar to the exact line search for quadratic functions, it overwhelms the other methods.
6.2 Log-Sum-Exp function
Second, we consider the Log-Sum-Exp function:
where \(a_i \in {\mathbb {R}}^n \ (1 \le i \le m)\), \(b_i \in {\mathbb {R}}\ (1 \le i \le m)\) and \(\rho > 0\). In this section, we fix \(n = 50\), \(m = 200\), and \(\rho = 20\). We also fix \(a_i\) and \(b_i\), whose elements are independently sampled from the normal distribution \({\mathcal {N}} (0,1)\) and \({\mathcal {N}} (0,\sqrt{2})\), respectively. The resulting \(a_i\) satisfies \(\max _{ 1 \le k \le m } \left\Vert a_k\right\Vert ^2 \approx 42.687\), and the Lipschitz constant L satisfies \(L \le \max _{ 1 \le k \le m } \left\Vert a_k\right\Vert ^2\). We set the initial step size of the backtracking line search for the Armijo rule to 100.

Evolution of function values for the Log-Sum-Exp function (13)
Figure 2 summarizes the evolution of function values and Table 2 summarizes the average step size and the average number of backtracking iterations. The results of Algorithm 1 with an appropriate h and Algorithm 2 are similar to those of the Armijo rule with a small c. Although the Armijo rule with \(c = 0.5\) converges faster than the other methods, the rate itself is similar to Algorithm 1 with an appropriate h and Algorithm 2.
6.3 A nonconvex function satisfying PŁ inequality
Finally, we consider the function
used in [14], where \(b \in {\mathbb {R}}^n\) is a vector that satisfies \(\left\Vert b\right\Vert = 1\). This function is 8-smooth, nonconvex, and satisfies the Polyak–Łojasiewicz inequality 6 with parameter \(\mu = 1/32\). In this section, we fix \(n = 50\) and \(b = v / \left\Vert v\right\Vert \in {\mathbb {R}}^{n}\), where the elements of \(v \in {\mathbb {R}}^n\) are independently sampled from the normal distribution \({\mathcal {N}} (0,1)\). We set the initial step size of the backtracking line search for the Armijo rule to 10.

Evolution of function values for the nonconvex function (14)
Figure 3 summarizes the evolution of function values and Table 3 summarizes the average step size and the average number of backtracking iterations. The results of Algorithm 1 with an appropriate h and Algorithm 2 are similar to those of the Armijo rule.
7 Conclusion
In this paper, we established existence results on the Lagrange multiplier approach, a recent geometric numerical integration technique, for the gradient system. In addition, we showed that, when Q is the zero matrix, the Lagrange multiplier approach reads a new step-size criterion for the steepest descent method. Thanks to the discrete dissipation law, the convergence rates of the proposed method for several cases can be proved in a form similar to the discussions on ODEs. In this paper, we focused only on the simplest gradient flow, but the results suggest that geometric numerical integration techniques can be effective for other ODEs appearing in optimization problems.
Several issues remain to be investigated. First, it would be interesting to investigate the application of geometric numerical integration techniques to other ODEs that appear during optimization. Second, the existence results in this paper are only for a special case of the Lagrange multiplier approach. Because the assumption \(x_{k+1/2}^{*}:= x_k\) is a bit restrictive in the usual numerical integration of ODEs and PDEs, it is important to generalize the existence results.
Data availability
Data sharing not applicable to this article as no datasets were generated or analyzed during the current study.
References
Hairer, E., Lubich, C., Wanner, G.: Geometric Numerical Integration. Structure-Preserving Algorithms for Ordinary Differential Equations. Springer, Heidelberg (2010)
Gonzalez, O.: Time integration and discrete Hamiltonian systems. J. Nonlinear Sci. 6, 449–467 (1996). https://doi.org/10.1007/978-1-4612-1246-1_10
McLachlan, R.I., Quispel, G.R.W., Robidoux, N.: Unified approach to Hamiltonian systems, Poisson systems, gradient systems with Lyapunov functions or first integrals. Phys. Rev. Lett. 81, 2399–2403 (1998). https://doi.org/10.1103/PhysRevLett.81.2399
Kemmochi, T., Sato, S.: Scalar auxiliary variable approach for conservative/dissipative partial differential equations with unbounded energy functionals. BIT 62, 903–930 (2022). https://doi.org/10.1007/s10543-021-00904-w
Cheng, Q., Liu, C., Shen, J.: A new Lagrange multiplier approach for gradient flows. Comput. Methods Appl. Mech. Eng. 367, 113070 (2020). https://doi.org/10.1016/j.cma.2020.113070
Shen, J., Xu, J., Yang, J.: A new class of efficient and robust energy stable schemes for gradient flows. SIAM Rev. 61(3), 474–506 (2019). https://doi.org/10.1137/17M1150153
Brown, A., Bartholomew-Biggs, M.C.: Some effective methods for unconstrained optimization based on the solution of systems of ordinary differential equations. J. Optim. Theory Appl. 62(2), 211–224 (1989). https://doi.org/10.1007/BF00941054
Saupe, D.: Discrete versus continuous Newton’s method: a case study. In: Newton’s Method and Dynamical Systems, pp. 59–80. Springer, Dordrecht (1988). https://doi.org/10.1007/978-94-009-2281-5_2
Zufiria, P.J., Guttalu, R.S.: On an application of dynamical systems theory to determine all the zeros of a vector function. J. Math. Anal. Appl. 152(1), 269–295 (1990). https://doi.org/10.1016/0022-247X(90)90103-M
Su, W., Boyd, S., Candès, E.J.: A differential equation for modeling Nesterov’s accelerated gradient method: theory and insights. J. Mach. Learn. Res. 17, 1–43 (2016)
Wilson, A.: Lyapunov arguments in optimization. PhD thesis, University of California, Berkeley (2018)
Riis, E.S., Ehrhardt, M.J., Quispel, G., Schönlieb, C.-B.: A geometric integration approach to nonsmooth, nonconvex optimisation. Found. Comput. Math. 22, 1351–1394 (2022). https://doi.org/10.1007/s10208-020-09489-2
Ringholm, T., Lazic, J., Schönlieb, C.-B.: Variational image regularization with Euler’s elastica using a discrete gradient scheme. SIAM J. Imaging Sci. 11(4), 2665–2691 (2018). https://doi.org/10.1137/17M1162354
Ehrhardt, M.J., Riis, E.S., Ringholm, T., Schönlieb, C.-B.: A geometric integration approach to smooth optimisation: foundations of the discrete gradient method. arXiv:1805.06444 [math.OC] (2018)
McLachlan, R.I., Quispel, G.R.W., Robidoux, N.: Geometric integration using discrete gradients. Philos. Trans. R. Soc. Lond. A Math. Phys. Eng. Sci. 357, 1021–1045 (1999). https://doi.org/10.1098/rsta.1999.0363
Karimi, H., Nutini, J., Schmidt, M.: Linear convergence of gradient and proximal-gradient methods under the Polyak-Łojasiewicz condition. In: Joint European Conference on Machine Learning and Knowledge Discovery in Databases, pp. 795–811. Springer (2016)
Guille-Escuret, C., Girotti, M., Goujaud, B., Mitliagkas, I.: A study of condition numbers for first-order optimization. In: International Conference on Artificial Intelligence and Statistics, pp. 1261–1269. PMLR (2021)
Hirsch, M.W., Smale, S., Devaney, R.L.: Differential Equations, Dynamical Systems, and an Introduction to Chaos, 3rd edn. Elsevier/Academic Press, Cambridge (2013)
Scieur, D., Roulet, V., Bach, F., d’Aspremont, A.: Integration methods and accelerated optimization algorithms. Adv. Neural Inf. Process. Syst. 30 (2017)
Acknowledgements
The authors are grateful to Takayasu Matsuo and Naoki Marumo for their valuable comments.
Funding
Open access funding provided by The University of Tokyo. The second author was supported by a Japan Society for the Promotion of Science (JSPS) Grant-in-Aid for Research Activity Start-up (No. 19K23399) and a JSPS Grant-in-Aid for Scientific Research (B) (No. 20H01822), and a JSPS Grant-in-Aid for Early-Career Scientists (No. 22K13955).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors have no relevant financial or non-financial interests to disclose.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix A. Details on Remark 2
Let us consider the behavior of the solutions of the scalar nonlinear equation \(F_h (\eta ;x_k) = 0\) for sufficiently small h. We show the following proposition which reveals that a solution of the nonlinear equation is close to 1. (The same proposition holds for \(\xi {:=} - \frac{\left\langle \nabla E (x_k),DQ x_k\right\rangle }{\left\langle \nabla E (x_k),D\nabla E ( x_k) \right\rangle }\) instead of 1, which is another root of the quadratic function \(\left. \frac{ \partial }{ \partial h } F_h \left( { \eta ; x_k }\right) \right| _{h=0}\)).
Proposition 2
For any \(\varepsilon > 0\), there exits \(\delta > 0\) such that, for all \(h \in (0,\delta )\), there exists \(\eta _h\) satisfying \(F_h (\eta _h;x_k) = 0\) and \(| 1 - \eta _h | < \varepsilon\).
Proof
For given \(\varepsilon > 0\), we define \(\varepsilon ' {:=} \min \left\{ \varepsilon , \frac{1}{2} \left| 1 - \xi \right| \right\}\). Then, if \(1 > \xi\) holds,
is satisfied. Otherwise, the same relation holds with > and < interchanged. Since the discussion is essentially the same, we focus on the former case. In this case, due to the continuity of \(F_h (\eta ; x_k )\) with respect to h, there exists \(\delta > 0\) such that, for all \(h \in (0,\delta )\), \(F_h (\eta ; x_k) < 0\) holds for all \(\eta \in [1-\varepsilon ',1-\frac{1}{2} \varepsilon ']\) and \(F_h (\eta ; x_k) > 0\) holds for all \(\eta \in [1+\frac{1}{2}\varepsilon ',1 + \varepsilon ']\). Therefore, the intermediate value theorem implies that, for all \(h \in (0,\delta )\), there exists \(\eta _h \in ( 1 - \frac{1}{2} \varepsilon ', 1 + \frac{1}{2} \varepsilon ' )\) such that \(F_h (\eta _h; x_k ) = 0\) holds. This proves the proposition. \(\square\)
Appendix B. An extension of Sect. 3.2
In this section, we consider the scheme (4) with the assumption \(x^{*}_{k+1/2} = x_k\) and \(Q = 0\) (note that we further assume \(D= I\) in Sect. 3.2). In this case, the scheme can be written as
Then, \(x_{k+1}\) can be computed by solving a scalar nonlinear equation
Even in this case, the counterparts of Theorems 6 to 9 hold as follows. We omit their proofs because they are similar to those of the counterparts in Sect. 3.2.
Theorem 18
For any \(x_k \in {\mathbb {R}}^n\), there exists an \(\eta _k\) that satisfies \(F_h (\eta _k; x_k) = 0\) and
Theorem 19
Assume that \(\nabla f(x_k) \ne 0\) and \(h \le {2 \omega _{\min }\left( { D^{-1} }\right) }/{L}\) hold. If \(\eta _k > 0\) satisfies \(F_h (\eta _k; x_k) = 0\), then
holds.
Theorem 20
If f is a convex function and \(\nabla f(x_k) \ne 0\) holds, there exists a unique nontrivial solution \(\eta _k\) of the nonlinear equation \(F_h (\eta _k; x_k) = 0\) satisfying
Theorem 21
If f satisfies the PŁ inequality (6) with parameter \(\mu > 0\) and \(\nabla f(x_k) \ne 0\) holds, there exists a nontrivial solution \(\eta _k\) of the nonlinear equation \(F_h (\eta _k; x_k) = 0\) satisfying
Rights and permissions
This article is published under an open access license. Please check the 'Copyright Information' section either on this page or in the PDF for details of this license and what re-use is permitted. If your intended use exceeds what is permitted by the license or if you are unable to locate the licence and re-use information, please contact the Rights and Permissions team.
About this article

Cite this article
Onuma, K., Sato, S. Existence results on Lagrange multiplier approach for gradient flows and application to optimization. Japan J. Indust. Appl. Math. 41, 165–189 (2024). https://doi.org/10.1007/s13160-023-00595-6
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13160-023-00595-6
Keywords
- Ordinary differential equations
- Geometric numerical integration
- Lagrange multiplier approach
- Gradient flow
- Optimization