
Abstract
This study endeavors to assess and compare the efficacy of various modeling approaches, including statistical, machine learning, and physical-based models, in the creation of shallow landslide susceptibility maps within the Besikduzu district of Trabzon province, situated in the Black Sea Region of Türkiye. The landslide inventory data, spanning from 2000 to 2018, was acquired through meticulous field surveys and analysis of Google Earth satellite imagery. Key topographic and geologic input parameters, such as slope, aspect, topographic wetness index, stream power index, plan and profile curvature, and geologic units, were extracted from a high-resolution 10 m spatial DEM (Digital Elevation Model) and a 1:25,000 scaled digital geology map, respectively. Additionally, soil unit weight and shear strength parameters, critical for the physical-based model, were determined through field samples. To evaluate landslide susceptibility, logistic regression, random forest, and Shalstab were employed as the chosen methods. The accuracy of susceptibility maps generated by each method was assessed using the area under the curve method, yielding impressive values of 0.99 for the random forest model, 0.97 for the logistic regression model, and 0.93 for the Shalstab model. These results underscore the robust performance of all three methods, suggesting their applicability for generating shallow landslide susceptibility maps not only in the Black Sea Region but also in analogous areas with similar geological characteristics.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Landslides are one of the most common natural events in Türkiye, especially after earthquakes. Given Türkiye's active tectonic characteristics, earthquakes are expected to be an important triggering factor for landslide occurrence. However, it is well known that precipitation is also a significant factor contributing to landslides in Türkiye. The Black Sea Region of Türkiye is particularly susceptible to landslides due to the triggering effect of precipitation, as well as its geological, topographical, and environmental factors. As a result, both the western and eastern parts of the region have become attractive areas for landslide researchers in Türkiye (Baltacı et al. 2010; Akçalı 2011; Akçalı and Arman 2013; Dağ et al. 2020; Akinci et al. 2021; Keles and Nefeslioglu 2021; Kavzoglu and Teke 2022; Sahin 2022).
A review of the landslide susceptibility literature shows that a significant number of studies have been conducted in the last two decades (Chen et al. 2019; Chang et al. 2023; Liu et al. 2022; Pourghasemi et al. 2012; Pradhan 2010; Regmi et al. 2014; Sun et al. 2021; Wu et al. 2020; Yilmaz 2009; Yi et al. 2022; Zhang et al. 2023; Zhu et al. 2020). In these studies, researchers have concentrated their efforts in different parts of the world, especially in areas with steep geomorphology dominated by hydro-meteorological conditions and favorable predisposing geological and environmental factors. When an overview of these studies is provided, it is seen that they have carried out landslide susceptibility mapping for the relevant areas by using different modeling methods considering the mentioned conditions. Among these modeling tools, logistic regression (Bhardwaj and Singh 2023; Boussouf et al. 2023; Can et al. 2005; Chen and Yang 2023; Chen et al. 2016, 2017, 2019; Liu et al. 2022; Rai et al. 2022; Sun et al. 2021; Yilmaz 2009), artificial neural networks (Adnan Ikram et al. 2023; Can et al. 2019; Choi et al. 2010; Conforti et al. 2014; Ermini et al. 2005; Kalantar et al. 2018; Moayedi et al. 2023; Nefeslioglu et al. 2008; Selamat et al. 2022; Yi et al. 2022), fuzzy set membership rating (Kumar and Anbalagan 2015; Okoli et al. 2023; Pradhan 2010; Shahabi et al. 2015; Zhang et al. 2023; Zhu et al. 2020), decision tree (Miao et al. 2023; Nefeslioglu et al. 2010; Saygin et al. 2023; Tsangaratos and Ilia 2016; Wu et al. 2020), analytical hierarchy process (Bahrami et al. 2021; Cengiz and Ercanoglu 2022; El Jazouli et al. 2019; Hsekioğulları and Ercanoglu 2012; Okoli et al. 2023; Pourghasemi et al. 2012; Saygin et al. 2023), multivariate and bivariate statistics such as frequency ratio, expert opinion-based and heuristic methods have come to the fore to a considerable extent. However, when we look at the studies in the last decade, it is also seen that there has been a significant increase in the widespread use of machine learning methods (Al-Shabeeb et al. 2022; Chang et al.2023; Chen et al. 2018; Ganesh et al. 2023; Goetz et al. 2015; Kavzoglu et al. 2019; Liu et al. 2023; Merghadi et al. 2020; Nanehkaran et al. 2023; Pham et al. 2016). Of course, the main purpose of this methodological richness can be considered as the determination of the advantages or weaknesses of the methods, as well as the highest accuracy of the landslide susceptibility maps to be produced for the studied areas.
It should be emphasized that methods based on physical models such as Shalstab, Sinmap, TRIGRS (Akgun and Erkan 2016; Cabral and Reis 2021; Ciurleo et al. 2019, 2021; do Pinho and Augusto Filho 2022; Ji and Cui 2023; Michel et al. 2014; Nery and Vieira 2015; Pradhan and Kim 2015; Rana and Babu 2022; Vieira et al. 2018; Wei et al. 2023), which are not among the methods mentioned above, are used much less frequently compared to other methods. The main reason for this is that it takes relatively more time and effort to obtain the material parameters needed as a requirement of the method. However, it should be emphasized that these methods should also be taken into consideration since the results obtained fill an important gap such as the lack of material properties and hydrological-hydrometeorological parameters in the results obtained by probabilistic methods.
In this study, we focus on the eastern part of the Black Sea Region, specifically the Beşikdüzü district of Trabzon province. This region is highly susceptible to shallow slip and flow type mass failure and flood events, as evidenced by a large number of incidents that occurred on September 21, 2016. Due to the sensitivity of the region to similar processes and the frequency of such incidents, numerous susceptibility, hazard, and risk assessment studies have been carried out by researchers in the region (Akgun and Bulut 2007; Akgun et al. 2008; Nefeslioglu et al. 2011; Dağ and Bulut 2012; Kavzoglu et al. 2014).
Despite the previous studies (Akgun and Erkan 2016; Keles and Nefeslioglu 2021), however, most of these assessments were based on probabilistic models rather than physical data. This study seeks to address this gap by conducting a landslide susceptibility assessment based on physical data for the Besikduzu district. We compare our findings with previous studies to provide a more comprehensive understanding of the processes and better solutions for managing potential disasters in the future.
Study area
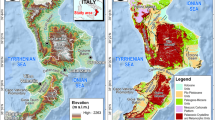
The study area, situated in the Eastern Black Sea part of the Black Sea Region, encompasses approximately 121 km2 (Fig. 1). This district exhibits the highest level of precipitation, with a long-term average (1927–2021) of 828.9 mm (URL 2020). The region's steep topographical characteristics, weathering conditions of lithological units, heavy precipitation, and misuse of land cover contribute to the frequent occurrence of shallow-seated landslides.

Location map of the study area by a digital elevation model
Analysis of lithological units in the study area (Fig. 2) reveals the presence of units with ages ranging from Middle-Upper Eocene to Quaternary. The oldest units are composed of Middle-Upper Eocene-aged basalt-andesites, their pyroclastics, and alternation of sedimentary rock units (Tek). The youngest units consist of Quaternary-aged alluviums (Qal) (Güven 1993; Akbaş et al. 2011).

Data and methods
The focus of this study was on spatial data, with an emphasis on two important facets: the mapping of shallow landslide inventory and the production of conditioning factors. These two facets together comprise the dataset for analyses and will be further discussed in the following sections.
Shallow landslide inventory mapping
The previous occurrences of landslides in a region play an important role in further landslide susceptibility analyses (Varnes 1984). Therefore, landslide inventory mapping is an essential step in landslide susceptibility assessments. However, carrying out field surveys to ascertain exact locations and the damage caused is challenging due to inaccessibility and time constraints. With advancements in remote sensing (RS) and geographic information system (GIS), mapping landslides has become relatively quick and easy (Sachdeva et al. 2020).
To produce the landslide inventory for the study area, temporal satellite images from the Google Earth application were utilized (Google Earth Pro 2020). The inventory includes shallow landslide locations that occurred between 2000 and 2018, and a total of 117 such locations were identified by inspecting the temporal satellite images of the study area using Google Earth Pro. 8 landslides locations taken from General Directorate of Mineral Research and Exploration landslide inventory (Duman et al. 2007). The visual interpretation focused mainly on changes in vegetation cover, which changes quickly in the region. To verify these landslide locations, newspaper articles, technical reports, and interviews with local people were also used.
The landslide inventory was randomly split into a training dataset comprising 88 landslide locations and a testing dataset with 37 shallow landslide locations. A sample of the training and testing landslide and non-landslide locations used in the study is shown in Fig. 3.

Landslide inventory map of the area
As a result of the inventory mapping study, a total of 125 shallow landslide locations were identified, with 8 occurring before 2005 and 117 mapped between 2000 and 2018 (Tezel 2021). The areal extent of these shallow seated landslides ranged from 53.28 to 902,809 m2. Given the absence of definitive records regarding the main triggering factors for these shallow landslides, precipitation is accepted as the unique triggering factor, given the high annual average precipitation rate of 828 mm in the area. This result is also consistent with field observations made in the area after heavy precipitation cases. These mapped shallow landslides were also checked on-site during field studies carried out in August 2017 and September 2018 (Fig. 3), and the approximate depths of the earthflows were determined to be between 3 and 10 m, with an average of 5 m, based on direct field measurements. Almost all of these shallow landslides were found to be located in hazelnut plantation areas, which are the most important agricultural product for the region (Fig. 4).

Some field views for the shallow landslides mapped in the study area
During the digitization of the shallow landslides on the satellite images obtained from Google Earth, both the depletion and accumulation zones were drawn as polygons. Although there is no consensus on the best landslide sampling strategy, a few studies have been carried out for this purpose (Suzen and Doyuran 2004; Gorum et al. 2008; Yilmaz 2010; Nefeslioglu et al. 2011; Dagdelenler et al. 2016). Dagdelenler et al. (2016) provided detailed explanations on this issue. Considering the suggestions made in this study, buffer zones of 50 m were drawn around the earthflow polygons. Then, only the main scarp portions of these buffered polygons, which are recognized as the landslide occurrence area, were distinguished for use in the modeling and validation stages of the predicted results.
Multicollinearity analysis of conditioning factors
According to Yange et al. (2020), the presence of multicollinearity, particularly among multiple variables in regression analysis, can lead to various issues such as instability in parameter estimates, counterintuitive parameter signs, elevated coefficient of determination (R2) diagnostics despite few or no significant parameters, and other challenges (Fotheringham and Oshan 2016). Given the intricate nature of landslide data and the complex interplay between geological and topographical factors, a careful consideration of multicollinearity is crucial in landslide susceptibility assessment (Yange et al. 2020).
To address this concern, a thorough multicollinearity analysis was conducted to examine the correlation among the landslide conditioning parameters. Multicollinearity, defined as a statistical scenario characterized by a high correlation between two or more predictor variables in a multiple regression model (O'brien 2007; Wang et al. 2019), was assessed in this study. Specifically, tolerance (TOL) and variance inflation factor (VIF) were employed to gauge the extent of multicollinearity among the conditioning parameters, focusing exclusively on DEM derivative parameters.
Let X = {X1, X2,…,XN} represent the given independent variable set, and Rj2 denote the coefficient of determination when the jth independent variable Xj is regressed on all other predictor variables in the model. The VIF value was computed using the formula:
The TOL value is the reciprocal of the VIF value and represents the degree of linear correlation between independent variables (Wang et al. 2019). If the VIF value is higher than 10 or the TOL value is lower than 0.1, the corresponding factors are multicollinearity and should be eliminated from the landslide susceptibility models.
The reciprocal of the VIF value is the TOL value, representing the degree of linear correlation between independent variables (Wang et al. 2019). If the VIF value exceeds 10 or the TOL value falls below 0.1, it indicates the presence of multicollinearity, prompting the need to eliminate the corresponding factors from the landslide susceptibility models.
The multicollinearity analysis yielded TOL and VIF values, which are presented in Table 1. Based on these values, it was determined that there was no evidence of multicollinearity among the DEM derivative parameters used in the models. This suggests that the selected parameters maintained sufficient independence in the regression analysis, ensuring the reliability of the landslide susceptibility assessment.
Conditioning factors
In this study, the main conditioning factors for shallow landslides were parameters such as lithology, slope gradient, slope aspect, stream power index (SPI), topographical wetness index (TWI), as well as plan and profile curvature (Fig. 5) (ArcGIS 2018; SAGA 2019).

Landslide conditioning factors considering for the study area
Lithology
The lithology map of the study area at a scale of 1:25.000, prepared by Güven (1993; Akbaş et al. 2011), was used in this study (Fig. 5a). The analysis of the spatial distribution of shallow landslides shows that all of the movements occurred in the study area are confined to Eocene-aged andesite-basalt and pyroclastics units, which are highly weathered.
Slope gradient
The study utilized a slope gradient map, produced using a 10 m resolution digital elevation model (DEM) (Fig. 5b), and categorized into different classes to determine gradient intervals.
The spatial distribution of these classes, including those with earthflow and slide occurrences, were determined and presented in Table 2. Low and moderate gradient values, ranging from 20 to 30°, were found to be the most abundant in the study area, making up approximately half of them with 47%. Analysis of past landslide occurrences revealed that 91% of landslides occurred on slopes with moderate gradient, ranging from 10° to 40°.
Slope aspect
The slope aspect map, an important parameter for an area prone to heavy rainfall, was generated using a numerical elevation model (Fig. 5c) and classified into nine different classes. Table 2 presents these classes and their corresponding spatial distribution of landslide studies.
Analysis of landslide distribution showed a proportionally similar distribution regarding general gradient aspect class.
Stream power index (SPI)
The stream power index (SPI) parameter, a secondary derivative of topographic data, was used to describe potential flow erosion and related landscape processes (Moore et al. 1991). The SPI was calculated using the equation given below (Eq. 2), taking into consideration the relationship between slope gradient and drainage area (Lee and Min 2001; Gokçeoglu et al. 2005).
whereas gives the specific basin area (m2/m) and β is the gradient value in degrees.
The SPI map in Fig. 5d, indicated that areas with a low SPI index comprised over half of the study area, while areas with high SPI index values had a spatial distribution of approximately 16%.
Analysis of landslide spatial distribution revealed that around 70% of landslides occurred in areas with SPI index values less than 222 (Table 2).
Topographical wetness index (TWI)
The topographic wetness index (TWI) is an important parameter for evaluating the probability of water content increase on slopes and determining lithological units susceptible to landslides. It is calculated using the specific basin area (As) and gradient value (β) in degrees according to the equation given by Beven and Kirkby (1979):
Using the numerical elevation model for the upper section of the study area, the TWI map was generated and divided into 5 classes as shown in Table 2 and Fig. 5g. The data indicate that the study area has landslide spatial distribution close to each other in all TWI classes.
Slope curvature
The slope curvature maps for the study area were generated based on the numerical land model and is presented in Fig. 5e, f. While negative values represent concave slopes, positive values represent convex slopes for profile curvature, the same representation is opposite for the plan profile. 0 represents flat surfaces both profile and plan curvatures. The data in Table 2 indicates that almost equal motion development was observed on concave and convex slopes on both maps in the study area.
Modeling methods
Logistic regression
Logistic regression is a statistical method that establishes a multivariate regression relationship between a dependent variable and several independent variables (Lee 2005). In landslide susceptibility mapping studies, the purpose of logistic regression is to find the most appropriate model to describe the relationship between the dependent variable (presence or absence of a landslide) and independent parameters such as slope and lithology (Ayalew and Yamagishi 2005). The relationship between occurrence and its dependence on multiple variables can be expressed numerically as follows (Hosmer and Lemeshow 1989):
Here, "p" represents the probability of landslide occurrence, and "z" is the linear combination of the independent variables. Logistic regression includes an equation shown in the form below, which corresponds to the "z" value given above:
Here, "b0" is the constant of the model, "bi" values (i = 0,1,2,…, n) are the slope coefficients of the logistic regression model, and "xi" values (i = 1,2, …, n) are the independent variables. This linear model shows the occurrence (yes/no) of the landslide based on the pre-occurrence conditions of the independent variables. The probability of landslide occurrence ranges from 0 to 1 and is expressed as an S-shaped curve.
Random forest
Random Forest is a popular ensemble method that combines multiple decision trees trained with different subsets of data to improve accuracy and reduce overfitting (Breiman 2001). Unlike traditional decision trees, which select the best split for each node based on all available features, Random Forest selects the best split based on a random subset of features. The trees are grown without pruning, and predictions are made by averaging the results of all trees in the forest (Archer 2008; Breiman 2001) (Fig. 6).

The basic working principle of the Random Forest algorithm (Şahin 2018)
The algorithm uses the Gini index method to measure the homogeneity of classes at each split. The Gini index measures the probability of misclassification, and a lower Gini index value indicates a more homogeneous split. The algorithm stops splitting a node when the Gini index reaches zero, or when a specified depth or minimum number of samples per leaf is reached.
The Random Forest algorithm requires two parameters to be specified: the number of variables used for each split (m) and the number of trees in the forest (N). The algorithm is flexible and can handle both continuous and categorical variables (Watts et al. 2011).
Shalstab mathematical model
The Shalstab model is a mathematical model that combines the infinite slope and stable hydrological models to predict the potential for slope failure (Dietrich and Montgomery 1998). The model is an add-on to ArcView 3.x Geographic Information Systems software and determines stability classes based on height, slope, and drainage network data from the Digital Elevation Model (see Table 3).
Equation 6 of the model is used to calculate the h/z value (saturated soil layer) required for mass failure development. The equation considers soil parameters, slope angle, and water table height. If h/z equals 0, then the slope is absolutely unstable, and if h/z is equal to 1, the slope is absolutely stable. Partial ground saturation leads to slope failure when the slope is neither absolutely unstable nor stable (see Table 4).
The Shalstab model combines the infinite slope and stable hydrological models to predict slope failure. The final formula of the model is produced by modifying Eq. 6 according to the q and T parameters. The model requires cohesion (c), internal friction angle (f), dry density (gs), and total soil thickness (z) as input parameters. Other variables such as slope drainage area, contour length, and slope gradient are determined through the digital elevation model.
The model classifies the area into seven classes of instability based on the hydrological ratio (q/T) required to ensure instability. The two extreme classes are absolutely unstable and absolutely stable, and the other five classes emerge as a function of q/T among them. Refer to Table 6 for more information on the classes of instability.
To fulfill the input requirements of the Shalstab mathematical model, it is necessary to ascertain certain physical properties of landslides. In identifying suitable locations for sampling, susceptibility maps were overlaid, focusing on areas categorized as "high" and "very high" sensitivity across all maps within slope units. Subsequently, following the removal of the overlying vegetable soil layer (approximately 0.10–0.20 m), samples were collected both in a disturbed manner using shovels and undisturbed using sampler tubes driven into the ground and then extracted. All tests were conducted at the Applied Geology Laboratory of the Department of Geological Engineering at KTU.
In the laboratory, the initial step involved determining the natural and dry densities of the samples, adhering to the ASTM (D7263-09 2018) test standard. Wet sieve analyses and hydrometer tests were then performed following the (ASTM D422-63 1998) standard. For disturbed samples, liquid limit values were assessed using the falling cone method (penetration) as per the BS (1377-2:4.3 1990) standard, while plastic limit values were determined in accordance with the ASTM (D4318-17e1 2017) standard.
To ascertain shear strength parameters, direct shear tests without consolidation and drainage (UU) were executed, aligning with ASTM D3080/D3080M–11 (2011) test standards. The choice of the UU test was motivated by the absence of soil consolidation and impractical groundwater drainage conditions in the field.
The Unified Soil Classification System (USCS) (ASTM D2487-11 2011) was used to classify the soil types, and the permeability coefficients were calculated. Transmissibility (T) values were then computed using the permeability coefficient (K) (m/s) and the average floor profile thickness (z) as shown in Eq. 8, where K is given in m/day:
The susceptibility classes obtained from the Shalstab model were reclassified into sensitivity classes (very low, low, medium, high, and very high) similar to those obtained by LR and RF methods. Akgün and Erkan (2016) approach was used to achieve this reclassification.
Results
To assess susceptibility, landslides were prepared using the "seed cell sampling strategy" method (Suzen and Doyuran 2004). This method aims to obtain the best undisturbed morphological conditions from the periphery of the landslide polygon by adding a buffer zone to the top and sides of the landslides. According to Suzen and Doyuran (2004), the buffer distance should be selected based on the distance between the slip boundary and the micro-catchment separation line, as well as the spatial resolution. Dagdelenler et al. (2016) used different buffer distances and spatial resolutions with this method in a landslide susceptibility study, and found that the optimal buffer distance was 50 m. Therefore, susceptibility assessments were carried out by drawing 50 m buffers on the top and sides of the landslides.
To prepare the landslide susceptibility map with the LR method, the GIS-based ArcGIS program and “ArcGIS tools created with the help of R programming language”, which were produced as a result of a “Tubitak Project” conducted and concluded by Sahin et al. (2021). The LR method was performed using 70% of the data for training and 30% for verification, randomly selected. According to the map produced by the LR method, the study area was classified as follows: 19.42% very low, 20.28% low, 20.98% medium, 19.22% high, and 20.11% very high susceptibility class (Fig. 7a).

Landslide susceptibility maps prepared by: a logistic regression, b random forest and c Shalstab mathematical models
The landslide susceptibility map obtained from the LR method showed that 19.77% of the mapped landslides were in very low, 20.46% in low, 19.65% in moderate, 20.50% in high, and 19.62% in very high susceptible areas. The statistical results of the model indicated that the beta coefficient for "lithology" was the highest, while the coefficient for "topographic wetness index" was the lowest (Table 5).
The regression equation of the LR model used in this study is presented below, where the dependent variable is the logarithm of the odds of landsliding, and the independent variables are various topographic and geological factors:
The RF method was also used to prepare a landslide susceptibility map in the same GIS environment and with the same data split ratio as the LR method (Sahin et al. 2021). According to the resulting map, 19.91% of the study area is very low, 19.61% is low, 20.1% is medium, 18.43% is high, and 21.95% is in the very high susceptibility class. Figure 7b shows the susceptibility map obtained with the RF method.
The Shalstab model was employed to assess landslide susceptibility based on the physical properties of the slope material and various terrain attributes derived from the digital elevation model (DEM). To this end, cohesion and dry density values of the slope material were determined through field sampling and laboratory experiments, while the DEM-based parameters (e.g., slope angle, contour length, drainage area) were extracted from the DEM data. The resulting map shows that 20.61% of the study area is very low, 24.56% is low, 11.58% is medium, 23.44% is high, and 19.81% is in the very high susceptibility class.
Validation of the results
In this study, various performance evaluation metrics, including Accuracy, AUC, RMSE, Kappa value, and F1 score, were employed to assess the models (Table 6). Accuracy measures were computed based on the Confusion Matrix, an N x N matrix where N represents the number of classes or predicted categories. It is important to note that the confusion matrix presupposes pre-labeled test data with 1 denoting landslide-prone areas and 0 indicating non-landslide-prone areas. True positive (TP) represents the number of positive values correctly predicted as actual positives, false positive (FP) is the count of negative values incorrectly predicted as positive, false negative (FN) signifies positive predictions incorrectly classified as negative, and true negative (TN) denotes the number of negative values correctly predicted as actual negatives. The accuracy assessment metrics obtained in this study are given in Table 6.
The validation evaluation was conducted using ArcGIS tools created with the "R" statistical software language, which was conducted and concluded by Sahin et al. (2020, 2021). The results indicate that all three methods exhibit a very high performance, with the random forest method having the highest value of 0.99 and the Shalstab model having the lowest value of 0.93, while the logistic regression model has a 0.97 value of AUC (Fig. 8).

Comparison of performance of the susceptibility maps with ROC curves
Conclusions
In this research, Geographic Information Systems (GIS) and remote sensing techniques were harnessed to generate medium-scale shallow landslide susceptibility maps for the central district of Besikduzu province in Türkiye. The following key findings and conclusions emerge:
-
1.
Utilizing high-resolution satellite images from Google Earth Pro, a multi-temporal inventory of earthflow-type shallow landslides was meticulously created for the study area.
-
2.
Earthflow susceptibility maps were developed using logistic regression, random forest, and the Shalstab mathematical model. These maps, classified into five categories (very low, low, moderate, high, and very high), revealed that approximately 60% of the study area exhibits a susceptibility ranging from moderate to very high. This underscores the high susceptibility of the Besikduzu province's central district to earthflow-type shallow landslides.
-
3.
Evaluation of model prediction performance through the Receiver Operating Characteristic (ROC) approach yielded AUC values of 0.99, 0.97, and 0.93 for random forest, logistic regression, and the Shalstab mathematical model, respectively. These high AUC values indicate a commendable level of predictive capability for the models.
-
4.
The study underscores the significance of creating earthflow inventories and susceptibility maps as crucial tools in minimizing the impact of mass movements on lives and property. The resulting database establishes a solid foundation for hazard and risk mapping, essential for planning new settlement areas and roads.
-
5.
Emphasizing the need for careful evaluation at an appropriate scale, the generated susceptibility maps should guide regional and local planning, discouraging construction in high or very high landslide susceptibility areas. Adequate precautions should also be implemented for existing settlements.
-
6.
In summary, the research advocates for nationwide landslide susceptibility mapping and inventory creation in Türkiye as essential components in mitigating the damages associated with mass movements. Such comprehensive maps can play a pivotal role in disaster risk reduction and management strategies across the country.
Data availability
No data availability.
References
Adnan Ikram R M, Khan I, Moayedi H, Ahmadi Dehrashid A, Elkhrachy I, Nguyen Le B (2023) Novel evolutionary-optimized neural network for predicting landslide susceptibility. In: Environment development and sustainability, pp 1–33
Akbaş B, Akdeniz N, Aksay A, Altun İ E, Balcı V, Bilginer E, Bilgiç T, Duru M, Ercan T, Gedik İ, Günay Y, Güven İ H, Hakyemez H Y, Konak N, Papak İ, Pehlivan Ş, Sevin M, Şenel M, Tarhan N, Turhan N, Türkecan A, Ulu Ü, Uğuz M F, Yurtsever A et al (2011) 1:1 250 000 Ölçekli Türkiye Jeoloji Haritası. Maden Tetkik ve Arama Genel Müdürlüğü Yayını, Ankara Türkiye
Akçalı E (2011) Heyelan Yağış İlişkisi Analizi ve Modellemesi; Trabzon İli Örneği, Ph.D. dissertation of Sakarya Üniversitesi Turkey, 213 pp (in Turkish)
Akçalı E, Arman H (2013) Yağış Eşiği Bazlı Heyelan Erken Uyarı Sistem Önerisi: Trabzon İli Örneği. İMO Teknik Dergi 396:6307–6332
Akgun A, Bulut F (2007) GIS-based Landslide Susceptibility for Arsin- Yomra (Trabzon, North Türkiye) Region. Environ Geol 51:1377–1387. https://doi.org/10.1007/s00254-006-0435-6
Akgun A, Erkan O (2016) Landslide Susceptibility Mapping by Geographical Information System-based Multivariate Statistical and Deterministic Models: In an Artificial Reservoir Area at Northern Türkiye. Arab J Geosci 9:165. https://doi.org/10.1007/s12517-015-2142-7
Akgun A, Dag S, Bulut F (2008) Landslide Susceptibility Mapping for a Landslide-Prone Area (Findikli, NE of Türkiye) by Likelihood-Frequency Ratio and Weighted Linear Combination Models. Environ Geol 54:1127–1143. https://doi.org/10.1007/s00254-007-0882-8
Akinci H, Zeybek M, Dogan S (2021) Evaluation of landslide susceptibility of Şavşat District of Artvin Province (Turkey) using machine learning techniques. Landslides. https://doi.org/10.5772/intechopen.99864
Al-Shabeeb AR, Al-Fugara AK, Khedher KM, Mabdeh AN, Al-Adamat R (2022) Spatial mapping of landslide susceptibility in Jerash governorate of Jordan using genetic algorithm-based wrapper feature selection and bagging-based ensemble model. Geomat Nat Haz Risk 13(1):2252–2282. https://doi.org/10.1080/19475705.2022.2112096
ArcGIS 10.6 (2018). Accessed Sep 2018
Archer KJ (2008) Emprical characterization of random forest variable ımportance measure. Comput Stat Data Anal 52(4):2249–2260. https://doi.org/10.1016/j.csda.2007.08.015
ASTM D2487-11 (2011) Standard Practice for Classification of Soils for Engineering Purposes (Unified Soil Classification System)1. ASTM International, West Conshohocken
ASTM D3080, D3080M-11 (2011M) Standard Test Method for Direct Shear Test of Soils Under Consolidated Drained Conditions1. West Conshohocken PA, USA
ASTM D422-63 (1998) Standard Test Method for Particle-Size Analysis of Soils1. ASTM International, West Conshohocken
ASTM D4318-17e1 (2017) Standard Test Method for Liquid Limit, Plastic Limit, and Plasticity Index of Soils. ASTM International, West Conshohocken
ASTM D7263-09 (2018) Standard test method for laboratory determination of density (Unit Weight) of soil specimens. ASTM International, West Conshohocken
Ayalew L, Yamagishi H (2005) The Application of GIS-based Logistic Regression for Landslide Susceptibility Mapping in the Kakuda-Yahiko Mountains Central Japan. Geomorphology 65:15–31. https://doi.org/10.1016/j.geomorph.2004.06.010
Bahrami Y, Hassani H, Maghsoudi A (2021) Landslide susceptibility mapping using AHP and fuzzy methods in the Gilan province, Iran. GeoJournal 86:1797–1816. https://doi.org/10.1007/s10708-020-10162-y
Baltacı H, Şen Ö L, Karaca M (2010) Doğu Karadeniz Bölgesi Heyelan-Yağış İlişkisinin İncelenmesi ve Minimum Eşik Değerlerin Belirlenmesi, Uluslararası Katılımlı 1. Meteoroloji Sempozyumu, Mayıs, Ankara, Bildiriler Kitabı 356–363.
Beven KJ, Kirkby MJ (1979) A physically based, variable contributing area model of basin hydrology/Un modèle à base physique de zone d’appel variable de l’hydrologie du bassin versant. Hydrol Sci J 24(1):43–69. https://doi.org/10.1080/02626667909491834
Bhardwaj V, Singh K (2023) Assessment of landslide susceptibility of Pithoragarh, Uttarakhand (India) using logistic regression and multi-criteria decision-based analysis by analytical hierarchy process. Appl Earth Sci 11:1–9. https://doi.org/10.1080/25726838.2023.2237370
Boussouf S, Fernández T, Hart AB (2023) Landslide susceptibility mapping using maximum entropy (MaxEnt) and geographically weighted logistic regression (GWLR) models in the Río Aguas catchment (Almería, SE Spain). Nat Hazards 117(1):207–235. https://doi.org/10.1007/s11069-023-05857-7
Breiman L (2001) Random forests. Mach Learn 45(1):5–32
BS 1377-2:4.3 (1990) Liquit Limit Cone Penetrometer Method, British Standard Institution, London.
Cabral VC, Reis FAGV (2021) Assessment of shallow landslides susceptibility using SHALSTAB and SINMAP at Serra Do Mar, Brazil. Understanding and Reducing Landslide Disaster Risk: Volume 2 From Mapping to Hazard and Risk Zonation 5th, 257–265.
Can T, Nefeslioglu HA, Gokceoglu C, Sonmez H, Duman TY (2005) Susceptibility assessments of shallow earthflows triggered by heavy rainfall at three catchments by logistic regression analyses. Geomorphology 72(1–4):250–271. https://doi.org/10.1016/j.geomorph.2005.05.011
Can A, Dagdelenler G, Ercanoglu M, Sonmez H (2019) Landslide susceptibility mapping at Ovacık-Karabük (Turkey) using different artificial neural network models: comparison of training algorithms. Bull Eng Geol Environ 78:89–102. https://doi.org/10.1007/s10064-017-1034-3
Cengiz LD, Ercanoglu M (2022) A novel data-driven approach to pairwise comparisons in AHP using fuzzy relations and matrices for landslide susceptibility assessments. Environ Earth Sci 81(7):222
Chang Z, Catani F, Huang F, Liu G, Meena SR, Huang J, Zhou C (2023) Landslide susceptibility prediction using slope unit-based machine learning models considering the heterogeneity of conditioning factors. J Rock Mech Geotech Eng 15(5):1127–1143. https://doi.org/10.1016/j.jrmge.2022.07.009
Chen W, Yang Z (2023) Landslide susceptibility modeling using bivariate statistical-based logistic regression, naïve Bayes, and alternating decision tree models. Bull Eng Geol Environ 82(5):190. https://doi.org/10.1007/s10064-023-03216-1
Chen T, Niu R, Jia X (2016) A comparison of information value and logistic regression models in landslide susceptibility mapping by using GIS. Environ Earth Sci 75:867. https://doi.org/10.1007/s12665-016-5317-y
Chen W, Pourghasemi HR, Zhao Z (2017) A GIS-based comparative study of Dempster-Shafer, logistic regression and artificial neural network models for landslide susceptibility mapping. Geocarto Int 32(4):367–385. https://doi.org/10.1080/10106049.2016.1140824
Chen W, Peng J, Hong H, Shahabi H, Pradhan B, Liu J et al (2018) Landslide susceptibility modelling using GIS-based machine learning techniques for Chongren County, Jiangxi Province, China. Sci Total Environ 626:1121–1135. https://doi.org/10.1016/j.scitotenv.2018.01.124
Chen W, Zhao X, Shahabi H, Shirzadi A, Khosravi K, Chai H et al (2019) Spatial prediction of landslide susceptibility by combining evidential belief function, logistic regression and logistic model tree. Geocarto Int 34(11):1177–1201. https://doi.org/10.1080/10106049.2019.1588393
Choi J, Oh HJ, Won JS, Lee S (2010) Validation of an artificial neural network model for landslide susceptibility mapping. Environ Earth Sci 60:473–483. https://doi.org/10.1007/s12665-009-0188-0
Ciurleo M, Mandaglio MC, Moraci N (2019) Landslide susceptibility assessment by TRIGRS in a frequently affected shallow instability area. Landslides 16:175–188. https://doi.org/10.1007/s10346-018-1072-3
Ciurleo M, Ferlisi S, Foresta V, Mandaglio MC, Moraci N (2021) Landslide susceptibility analysis by applying TRIGRS to a reliable geotechnical slope model. Geosciences 12(1):18. https://doi.org/10.3390/geosciences12010018
Conforti M, Pascale S, Robustelli G, Sdao F (2014) Evaluation of prediction capability of the artificial neural networks for mapping landslide susceptibility in the Turbolo River catchment (northern Calabria, Italy). CATENA 113:236–250. https://doi.org/10.1016/j.catena.2013.08.006
Dağ S, Bulut F (2012) Coğrafi Bilgi Sistemleri Tabanlı Heyelan Duyarlılık Haritalarının Hazırlanmasına Bir Örnek: Çayeli (Rize, KD Türkiye). Jeoloji Mühendisliği Dergisi 36(1):35–62
Dağ S, Akgün A, Kaya A, Alemdağ S, Bostancı HT (2020) Medium scale earthflow susceptibility modelling by remote sensing and geographical information systems based multivariate statistics approach: an example from Northeastern Turkey. Environ Earth Sci 79:1–21. https://doi.org/10.1007/s12665-020-09217-7
Dagdelenler G, Nefeslioglu HA, Gokceoglu C (2016) Modification of Seed Cell Sampling Strategy for Landslide Susceptibility Mapping: An Application From the Eastern Part of the Gallipoli Peninsula (Canakkale, Türkiye). Bull Eng Geol Environ 75:575–590. https://doi.org/10.1007/s10064-015-0759-0
Dietrich WE, Montgomery DR (1998) Shalstab: A digital terrain model for mapping shallow landslide potential, technical Report, Corvallis, OR: National Council of the Paper Industry for Air and Stream Improvement.
Duman T Y, Nefeslioğlu H A, Çan T, Olgun Ş, Durmaz S, Hamzaçebi S, Çörekçioğlu, Ş (2007) 1:500.000 Ölçekli Türkiye Heyelan envanter Haritası. Trabzon Paftası, MTA Özel Yayın Serisi-9.
El Jazouli A, Barakat A, Khellouk R (2019) GIS-multicriteria evaluation using AHP for landslide susceptibility mapping in Oum Er Rbia high basin (Morocco). Geoenviron Disasters 6(1):1–12. https://doi.org/10.1186/s40677-019-0119-7
Ermini L, Catani F, Casagli N (2005) Artificial neural networks applied to landslide susceptibility assessment. Geomorphology 66(1–4):327–343. https://doi.org/10.1016/j.geomorph.2004.09.025
Fotheringham AS, Oshan TM (2016) Geographically weighted regression and multicollinearity: dispelling the myth. J Geogr Syst 18:303–329. https://doi.org/10.1007/s10109-016-0239-5
Ganesh B, Vincent S, Pathan S, Garcia Benitez SR (2023) Machine learning based landslide susceptibility mapping models and GB-SAR based landslide deformation monitoring systems: GROWTH and evolution. Remote Sens Appl Soc Environ 29:100905. https://doi.org/10.1016/j.rsase.2022.100905
Goetz JN, Brenning A, Petschko H, Leopold P (2015) Evaluating machine learning and statistical prediction techniques for landslide susceptibility modeling. Comput Geosci 81:1–11. https://doi.org/10.1016/j.cageo.2015.04.007
Gokceoglu C, Sonmez H, Nefeslioglu HA, Duman TY, Can T (2005) The 17 March 2005 Kuzulu landslide (Sivas, Turkey) and landslide-susceptibility map of its near vicinity. Eng Geol 81(1):65–83. https://doi.org/10.1016/j.enggeo.2005.07.011
Google Earth Pro (2020) version 7.3.6.9796. Accessed Nov 2020
Gorum T, Gonencgil B, Gokceoglu C, Nefeslioglu HA (2008) Implementation of reconstructed geomorphologic units in landslide susceptibility mapping: the Melen Gorge (NW Turkey). Nat Hazards 46:323–351. https://doi.org/10.1007/s11069-007-9190-6
Güven İH (1993) Geology of the eastern pontides and compilation of it in scale 1:250000 (in Turkish). Unpublished report, General Directorate of Mineral Research & Exploration, Turkey.
Hasekioğulları GD, Ercanoglu M (2012) A new approach to use AHP in landslide susceptibility mapping: a case study at Yenice (Karabuk, NW Turkey). Nat Hazards 63:1157–1179. https://doi.org/10.1007/s11069-012-0218-1
Hosmer DW, Lemeshow S (1989) Applied regression analysis. Wiley, New York
Ji J, Cui H (2023) A GIS-based tool for probabilistic physical modelling and prediction of landslides: improved GIS-TRIGRS-FORM landslide prediction. In: Geo-Risk, pp 320–330.
Kalantar B, Pradhan B, Naghibi SA, Motevalli A, Mansor S (2018) Assessment of the effects of training data selection on the landslide susceptibility mapping: a comparison between support vector machine (SVM), logistic regression (LR) and artificial neural networks (ANN). Geomat Nat Haz Risk 9(1):49–69. https://doi.org/10.1080/19475705.2017.1407368
Kavzoglu T, Teke A (2022) Predictive Performances of ensemble machine learning algorithms in landslide susceptibility mapping using random forest, extreme gradient boosting (XGBoost) and natural gradient boosting (NGBoost). Arab J Sci Eng 47(6):7367–7385. https://doi.org/10.1007/s13369-022-06560-8
Kavzoglu T, Sahin EK, Colkesen I (2014) Landslide susceptibility mapping using GIS-based multi-criteria decision analysis, support vector machines, and logistic regression. Landslides 11(3):425–439. https://doi.org/10.1007/s10346-013-0391-7
Kavzoglu T, Colkesen I, Sahin E K (2019) Machine learning techniques in landslide susceptibility mapping: a survey and a case study. Landslides: Theory, practice and modelling, pp 283–301. https://doi.org/10.1007/978-3-319-77377-3_13
Keles F, Nefeslioglu HA (2021) Infinite slope stability model and steady-state hydrology-based shallow landslide susceptibility evaluations: the Guneysu catchment area (Rize, Türkiye). CATENA 200:1–18. https://doi.org/10.1016/j.catena.2021.105161
Kumar R, Anbalagan R (2015) Landslide susceptibility zonation in part of Tehri reservoir region using frequency ratio, fuzzy logic and GIS. J Earth Syst Sci 124:431–448. https://doi.org/10.1007/s12040-015-0536-2
Lee S (2005) Application of logistic regression model and its validation for landslide susceptibility mapping using GIS and remote sensing data. Int J Remote Sens 26(7):1477–1491. https://doi.org/10.1080/01431160412331331012
Lee S, Min K (2001) Statistical analysis of landslide susceptibility at Yongin, Korea. Environ Geol 40:1095–1113. https://doi.org/10.1007/s002540100310
Liu Y, Zhao L, Bao A, Li J, Yan X (2022) Chinese high resolution satellite data and GIS-based assessment of landslide susceptibility along highway G30 in Guozigou Valley using logistic regression and maxent model. Remote Sens 14(15):3620. https://doi.org/10.3390/rs14153620
Liu S, Wang L, Zhang W, He Y, Pijush S (2023) A comprehensive review of machine learning-based methods in landslide susceptibility mapping. Geol J 58(6):2283–2301. https://doi.org/10.1002/gj.4666
Merghadi A, Yunus AP, Dou J, Whiteley J, ThaiPham B, Bui DT et al (2020) Machine learning methods for landslide susceptibility studies: a comparative overview of algorithm performance. Earth Sci Rev 207:103225. https://doi.org/10.1016/j.earscirev.2020.103225
Miao F, Zhao F, Wu Y et al (2023) Landslide susceptibility mapping in Three Gorges Reservoir area based on GIS and boosting decision tree model. Stoch Environ Res Risk Assess 37:2283–2303. https://doi.org/10.1007/s00477-023-02394-4
Michel GP, Kobiyama M, Goerl RF (2014) Comparative analysis of SHALSTAB and SINMAP for landslide susceptibility mapping in the Cunha River Basin, Southern Brazil. J Soils Sediments 14:1266–1277. https://doi.org/10.1007/s11368-014-0886-4
Moayedi H, Dehrashid AA, Gholizadeh MH (2023) A novel hybrid based on nature-inspired and Stochastic Fractal Search algorithms for optimizing of artificial neural network model in landslide susceptibility. Eng Appl Artif Intell 117:105457. https://doi.org/10.1016/j.engappai.2022.105457
Moore ID, Grayson RB, Ladson AR (1991) Digital terrain modeling: a review of hydrological, geomorphological, and biological applications. Hydrol Process 5:3–30. https://doi.org/10.1002/hyp.3360050103
Nanehkaran YA, Chen B, Cemiloglu A, Chen J, Anwar S, Azarafza M, Derakhshani R (2023) Riverside landslide susceptibility overview: leveraging artificial neural networks and machine learning in accordance with the United Nations (UN) Sustainable Development Goals. Water 15(15):2707. https://doi.org/10.3390/w15152707
Nefeslioglu HA, Gokceoglu C, Sonmez H (2008) An assessment on the use of logistic regression and artificial neural networks with different sampling strategies for the preparation of landslide susceptibility maps. Eng Geol 97(3–4):171–191. https://doi.org/10.1016/j.enggeo.2008.01.004
Nefeslioglu HA, Sezer E, Gokceoglu C, Bozkir AS, Duman TY (2010) Assessment of landslide susceptibility by decision trees in the metropolitan area of Istanbul, Türkiye. Math Probl Eng 2010:1–15. https://doi.org/10.1155/2010/901095
Nefeslioglu HA, Gokceoğlu C, Sonmez H, Gorum T (2011) Medium-scale Hazard Mapping for Shallow Landslide Initiation: the Buyukkoy Catchment Area (Cayeli, Rize Türkiye. Landslides 8(4):459–483. https://doi.org/10.1007/s10346-011-0267-7
Nery TD, Vieira BC (2015) Susceptibility to shallow landslides in a drainage basin in the Serra do Mar, São Paulo, Brazil, predicted using the SINMAP mathematical model. Bull Eng Geol Envirom 74:369–378. https://doi.org/10.1007/s10064-014-0622-8
O’Brien RM (2007) A caution regarding rules of thumb for variance inflation factors. Qual Quant 41(5):673–690. https://doi.org/10.1007/s11135-006-9018-6
Okoli J, Nahazanan H, Nahas F, Kalantar B, Shafri HZM, Khuzaimah Z (2023) High-Resolution Lidar-Derived DEM for Landslide Susceptibility Assessment Using AHP and Fuzzy Logic in Serdang, Malaysia. Geosci 13(2):34. https://doi.org/10.3390/geosciences13020034
Pham BT, Pradhan B, Bui DT, Prakash I, Dholakia MB (2016) A comparative study of different machine learning methods for landslide susceptibility assessment: a case study of Uttarakhand area (India). Environ Model Softw 84:240–250. https://doi.org/10.1016/j.envsoft.2016.07.005
Pinho do TM, Augusto Filho O (2022) Landslide susceptibility mapping using the infinite slope, SHALSTAB, SINMAP, and TRIGRS models in Serra do Mar, Brazil. J Mt Sci 19(4):1018–1036. https://doi.org/10.1007/s11629-021-7057-z
Pourghasemi HR, Pradhan B, Gokceoglu C (2012) Application of fuzzy logic and analytical hierarchy process (AHP) to landslide susceptibility mapping at Haraz watershed. Iran Nat Hazards 63:965–996. https://doi.org/10.1007/s11069-012-0217-2
Pradhan B (2010) Application of an advanced fuzzy logic model for landslide susceptibility analysis. Int J Comput Intell Syst 3(3):370–381. https://doi.org/10.1080/18756891.2010.9727707
Pradhan AMS, Kim YT (2015) Application and comparison of shallow landslide susceptibility models in weathered granite soil under extreme rainfall events. Environ Earth Sci 73:5761–5771. https://doi.org/10.1007/s12665-014-3829-x
Rai DK, Xiong D, Zhao W, Zhao D, Zhang B, Dahal NM et al (2022) An investigation of landslide susceptibility using logistic regression and statistical index methods in Dailekh district, Nepal. Chin Geogr Sci 32(5):834–851. https://doi.org/10.1007/s11769-022-1304-2
Rana H, Babu GS (2022) Regional back analysis of landslide events using TRIGRS model and rainfall threshold: an approach to estimate landslide hazard for Kodagu, India. Bull Eng Geol Env 81(4):160. https://doi.org/10.1007/s10064-022-02660-9
Regmi AD, Devkota KC, Yoshida K, Pradhan B, Pourghasemi HR, Kumamoto T, Akgun A (2014) Application of frequency ratio, statistical index, and weights-of-evidence models and their comparison in landslide susceptibility mapping in Central Nepal Himalaya. Arab J Geosci 7:725–742. https://doi.org/10.1007/s12517-012-0807-z
Sachdeva S, Bhatia T, Verma AK (2020) A novel voting ensemble model for spatial prediction of landslides using GIS. Int J Remote Sens 41(3):929–952. https://doi.org/10.1080/01431161.2019.1654141
SAGA (2019) System for Automated Geoscientific Analyses version 8.4.0
Şahin EK (2018) Heyelan Duyarlılık Haritası İçin Adımsal Regresyona Dayalı Faktör Seçme Yönteminin Etkinliğinin Araştırılması. Harita Dergisi 159:1–15
Sahin EK (2022) Comparative analysis of gradient boosting algorithms for landslide susceptibility mapping. Geocarto Int 37(9):2441–2465. https://doi.org/10.1080/10106049.2020.1831623
Sahin EK, Colkesen I, Acmali SS, Akgun A, Aydinoglu AC (2020) Developing comprehensive geocomputation tools for landslide susceptibility mapping: LSM Tool Pack. Comput Geosci 144:104592. https://doi.org/10.1016/j.cageo.2020.104592
Sahin E K, Colkesen I, Akgun A, Aydınoglu A C (2021) Development of ArcGIS interfaces with the help of R programming language for the production of landslide susceptibility maps (Tubitak Project, Project No: 118Y090).
Saygin F, Şişman Y, Dengiz O, Şişman A (2023) Spatial assessment of landslide susceptibility mapping generated by fuzzy-AHP and decision tree approaches. Adv Space Res 71(12):5218–5235. https://doi.org/10.1016/j.asr.2023.01.057
Selamat SN, Majid NA, Taha MR, Osman A (2022) Landslide susceptibility model using artificial neural network (ANN) approach in Langat River basin, Selangor, Malaysia. Land 11(6):833. https://doi.org/10.3390/land11060833
Shahabi H, Hashim M, Ahmad BB (2015) Remote sensing and GIS-based landslide susceptibility mapping using frequency ratio, logistic regression, and fuzzy logic methods at the central Zab basin, Iran. Environ Earth Sci 73:8647–8668. https://doi.org/10.1007/s12665-015-4028-0
Sun D, Xu J, Wen H, Wang D (2021) Assessment of landslide susceptibility mapping based on Bayesian hyperparameter optimization: a comparison between logistic regression and random forest. Eng Geol 281:105972. https://doi.org/10.1016/j.enggeo.2020.105972
Suzen ML, Doyuran V (2004) data driven bivariate landslide susceptibility assessment using geographical information systems: a method and application to Asarsuyu Catchment, Türkiye. Eng Geol 71(3–4):303–321. https://doi.org/10.1016/S0013-7952(03)00143-1
Tezel K (2021) Landslide hazard analyses of Beşikdüzü (Trabzon) region, PhD Thesis, Karadeniz Technical University, institute of science and technology, Trabzon (in Turkish)
Tsangaratos P, Ilia I (2016) Landslide susceptibility mapping using a modified decision tree classifier in the Xanthi Perfection, Greece. Landslides 13:305–320. https://doi.org/10.1007/s10346-015-0565-6
URL (2020) www.mgm.gov.tr. Accessed 26 Jan 2020
Varnes DJ (1984) Landslide hazard zonation: a review of principles and practice. Unesco, Paris
Vieira BC, Fernandes NF, Augusto Filho O, Martins TD, Montgomery DR (2018) Assessing shallow landslide hazards using the TRIGRS and SHALSTAB models, Serra do Mar, Brazil. Environ Earth Sci 77:1–15. https://doi.org/10.1007/s12665-018-7436-0
Wang H, He Z, Lipton ZC, Xing EP (2019) Learning robust representations by projecting superficial statistics out. arXiv preprint arXiv:1903.06256
Watts JD, Powell SL, Lawrence RL, Hilker T (2011) Improved classification of conservation tillage adoption using high temporal and synthetic satellite imagery. Remote Sens Environ 115:66–75. https://doi.org/10.1016/j.rse.2010.08.005
Wei X, Zhang L, Gardoni P, Chen Y, Tan L, Liu D et al (2023) Comparison of hybrid data-driven and physical models for landslide susceptibility mapping at regional scales. Acta Geotech 18:4453–4476. https://doi.org/10.1007/s11440-023-01841-4
Wu Y, Ke Y, Chen Z, Liang S, Zhao H, Hong H (2020) Application of alternating decision tree with AdaBoost and bagging ensembles for landslide susceptibility mapping. CATENA 187:104396. https://doi.org/10.1016/j.catena.2019.104396
Yange L, Liu X, Han Z, Dou J (2020) Spatial proximity-based geographically weighted regression model for landslide susceptibility assessment: a case study of Qingchuan area, China. Appl Sci 10(1107):1–16. https://doi.org/10.3390/app10031107
Yi Y, Zhang W, Xu X, Zhang Z, Wu X (2022) Evaluation of neural network models for landslide susceptibility assessment. Int J Digit Earth 15(1):934–953. https://doi.org/10.1080/17538947.2022.2062467
Yilmaz I (2009) Landslide susceptibility mapping using frequency ratio, logistic regression, artificial neural networks and their comparison: a case study from Kat landslides (Tokat-Turkey). Comput Geosci 35(6):1125–1138. https://doi.org/10.1016/j.cageo.2008.08.007
Yilmaz I (2010) Comparison of landslide susceptibility mapping methodologies for Koyulhisar, Türkiye: conditional probability, logistic regression, artificial neural networks, and support vector machine. Environ Earth Sci 61:821–836. https://doi.org/10.1007/s12665-009-0394-9
Zhang Y, Zhang J, Dong L (2023) Fuzzy logic regional landslide susceptibility multi-field information map representation analysis method constrained by spatial characteristics of mining factors in mining areas. Processes 11(4):985. https://doi.org/10.3390/pr11040985
Zhu AX, Wang R, Qiao J, Qin CZ, Chen Y, Liu J et al (2014) An expert knowledge-based approach to landslide susceptibility mapping using GIS and fuzzy logic. Geomorphology 214:128–138. https://doi.org/10.1016/j.geomorph.2014.02.003
Acknowledgements
We extend our heartfelt appreciation to Karadeniz Technical University for their generous funding, which made this research possible under research project number (BAP06) FDK-2018-7368. Additionally, it is worth noting that this study originated from the doctoral thesis of the primary author.
Funding
Open access funding provided by the Scientific and Technological Research Council of Türkiye (TÜBİTAK). The authors have not disclosed any funding.
Author information
Authors and Affiliations
Contributions
All authors contributed to the study conception and design. Material preparation, data collection and analysis were performed by [Kübra Tezel] and [Aykut Akgün]. The first draft of the manuscript was written by [Kübra Tezel] and all authors commented on previous versions of the manuscript. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors have not disclosed any competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Tezel, K., Akgün, A. Comparing shallow landslide susceptibility maps in Northeastern Türkiye (Beşikdüzü, Trabzon): a multivariate statistical, machine learning, and physical data-based analysis. Environ Earth Sci 83, 335 (2024). https://doi.org/10.1007/s12665-024-11627-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s12665-024-11627-w