
Abstract
Artificial Intelligence techniques based on Machine Learning algorithms, Neural Networks and Naïve Bayes can optimise the diagnostic process of the SARS-CoV-2 or Covid-19. The most significant help of these techniques is analysing data recorded by health professionals when treating patients with this disease. Health professionals' more specific focus is due to the reduction in the number of observable signs and symptoms, ranging from an acute respiratory condition to severe pneumonia, showing an efficient form of attribute engineering. It is important to note that the clinical diagnosis can vary from asymptomatic to extremely harsh conditions. About 80% of patients with Covid-19 may be asymptomatic or have few symptoms. Approximately 20% of the detected cases require hospital care because they have difficulty breathing, of which about 5% may require ventilatory support in the Intensive Care Unit. Also, the present study proposes a hybrid approach model, structured in the composition of Artificial Intelligence techniques, using Machine Learning algorithms, associated with multicriteria methods of decision support based on the Verbal Decision Analysis methodology, aiming at the discovery of knowledge, as well as exploring the predictive power of specific data in this study, to optimise the diagnostic models of Covid-19. Thus, the model will provide greater accuracy to the diagnosis sought through clinical observation.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The Covid -19 pandemic has increased dramatically since the first reported cases in China in December 2019 (Aggarwal 2018; World Health Organization 2020). Since then, more than 160 million cases of Covid-19 have been reported worldwide, with characteristics of Severe Acute Respiratory Syndrome by Coronavirus two infection (SARS-CoV-2). They were also causing more than 3.3 million deaths. The news in this context is that more than 1.38 million people in the world have already been vaccinated (Johns Hopkins University2021). The disease spectrum can range from asymptomatic infection to severe pneumonia with Acute Respiratory Distress Syndrome (ARDS) and death. The estimated incubation period is up to 14 days from the time of exposure, with an average incubation period of 4–5 days (Cao et al. 2020; Kucharski et al. 2020; Lauer et al. 2020). Anyone who has symptoms consistent with Covid-19 should be tested for SARS-CoV-2 infection (Liang 2020).
In a report on more than 373,000 confirmed Covid-19 cases with reported symptoms in the United States, 70% of patients experienced fever, cough, shortness of breath, 36% had muscle aches, and 34% reported headaches (Stokes et al. 2020). Other reported symptoms have included, but are not limited to, diarrhoea, dizziness, rhinorrhea, anosmia, dysgeusia, sore throat, abdominal pain, anorexia, and vomiting. More accurate clinical diagnoses and more effective treatments have driven computational methodologies based on Artificial Intelligence (A.I.). Activities such as remote monitoring, telemedicine, symptom association, epidemiological status alerts, exchange of clinical information, analysis of test results and treatment recommendations can use the A.I. The ability of machines to perform complex tasks and make decisions independently can improve outcomes be more efficient in establishing diagnoses and implementing treatments.
Algorithms based on Machine Learning (ML), one of the fields of A.I. study, have transformed medicine and its use, resulting in benefits for patients, doctors, and healthcare managers. Artificial Intelligence can help guide medical analysis, aiming to solve decision-making problems more realistically using relevant criteria and evaluation of several symptoms and risk factors, such as those existing in the cases of Covid-19. The early detection of the disease is essential to prevent the spread of the SARS-CoV-2 and the correct treatment in the initial phase, avoid the evolution of the cases, perform systematic monitoring in each stage of the disease, and improve the chances of hospital discharge. It is essential to highlight that the clinical diagnosis can vary from asymptomatic infections to extremely severe conditions. Within the database of the present study, approximately 80% of patients with Covid-19 were asymptomatic or had mild symptoms. Of the 20% of cases that presented moderate and severe symptoms, 43% required hospital care due to breathing difficulties, and 56% needed ventilatory support inside or outside the ICUs.
Additionally, to diagnose Covid-19, the association of the following signs and symptoms should be evaluated: fever, cough, dyspnea, runny nose, respiratory distress, sore throat, loss, or reduction of smell and or taste. Other risk factors are also observed, such as chronic cardiovascular diseases, myalgia, gastrointestinal disorders, diabetes mellitus and dyspnea. Its most common transmission is contact with another person who already has the virus through droplets of saliva and respiratory secretions.
Given the above, it is essential to emphasise that the present study proposes a hybrid approach model, structured in the juxtaposition of Artificial Intelligence techniques associated with the methodology of multicriteria decision analysis (MCDA). Regarding A.I., Machine Learning algorithms were used by the study. The choice for ML was due to its great potential in generating knowledge from large databases (Andrade et al. 2021b). In turn, about the MCDA methodology, the study was based on Verbal Decision Analysis methods, such as Ordinal Classification (ORCLASS) and ZAPROS-IIIi (Andrade et al. 2021a). The use of VDA is related to the need for decisions that involve subjective knowledge used in qualitative choices. Thus, the model proposed in this research aimed to discover expertise and explore the predictive power of study-specific data from a large set of well-defined information to optimise Covid-19 diagnostic protocols. In addition, the model provides greater accuracy to the diagnosis sought through clinical observation as a result.
The article is organised as follows: in addition to the Introduction Section, Sect. 2 presents details of the methods that make up the proposed model of this study. Next, the relationship between symptoms and diagnoses of the International Classification of Diseases (ICD) is presented in Sect. 3. In turn, in Sect. 4, the application of Verbal Decision Analysis methods is explained in detail. In Sect. 5, the analysis and results of the study are discussed. Finally, in Sect. 6, the conclusions are presented, and some future works related to the theme of this research are proposed. Additionally, the study shows the research limitations in the brief Sect. 7.
2 The model structure proposed
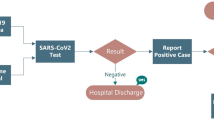
The construction of the proposed model used in this research used Verbal Decision Analysis (VDA) methods associated with Machine Learning (ML) techniques. Through VDA, the main criteria and respective alternatives were defined to formulate a questionnaire submitted to health professionals, aiming at a valuable validation of the model. Figure 1 shows the operation process of the model proposed for this study. In line with similar research, (Andrade et al. 2021a) conducted a study to obtain the main characteristics for the diagnosis of autism, as well as proposed a comparative study between ML algorithms and a hybrid model with Verbal Decision Analysis applied to the diagnosis of autism and optimisation of medical expertise (Andrade 2020).

Process of functioning of the proposed hybrid model structure
The present research used the quantitative research method based on the responses to the questionnaire on Covid-19, which had been submitted to evaluate health professionals. In addition, a qualitative approach was used to interpret the results of the mentioned assessments in the context of the effects of treatments applied to patients infected with SARS-CoV-2 in hospitals in Brazil. In the following subsections, there is a summary of the methods and techniques used in this research.
2.1 Machine learning
Considered a subset of Artificial Intelligence, Machine Learning allows a machine to have complete autonomy and control to learn on its own from previous data. Tom M. Mitchell, the principal exponent in ML, explains: “Machine learning is the study of computer algorithms that allow computer programs to improve with the experience” (Turban et al. 2011; Mitchell 2011) automatically. Machine Learning leads to Artificial Intelligence and depends on working with data sets, examining common patterns, and exploring complaints (Beğenilmiş and Uskudarl 2018; Mitchell 1997). The learning of the algorithms happens autonomously over time, according to the analysis of the training data. Its principal function is to guide computers to learn independently to improve their performance in the face of specific problems (Wilmott 2019).
Moreover, Machine Learning can recognise and extract patterns from a large volume of data with its learning characteristics, thus building a learning model. This learning is based on observing data, such as examples, direct experience or instruction. Once learning is done, it is possible to perform complex and dynamic tasks, predict more accurately, react in different situations, and behave intelligently (Delsentoth et al. 2020). According to well-defined objectives and known results, this study chose to use the Supervised Machine Learning methods to obtain knowledge and classification, identify trends and even predict outcomes based on historical data.
2.2 Machine learning algorithm considerations: logistic regression
Logistic Regression (L.R.), also known in the literature as logit regression, maximum-entropy classification (MaxEnt) or log-linear classifier, is a Machine Learning algorithm for classification problems and predictive analysis based on the concept of probability and used to assign observations to a discrete set of classes (Beğenilmiş and Uskudarl 2018; Hosmer and Lemeshow 2013). L.R. is one of the most popular AM algorithms for binary classification, given a set of independent variables to predict a binary result (1/0, Yes/No, True/False). It has simple complexity, and its application is successful in several areas, such as medicine, finance, and economics. In this model, the probabilities that describe the possible results of a single trial are modelled using a logistic function: a logical relationship between a dichotomous response variable and a series of numerical explanatory variables (continuous, discrete) “and”/“or” categorical.
Logistic Regression is a type of linear regression, when the result variable is categorical, in which the log of probabilities is used as a dependent variable. In simple words, it predicts the probability of an event occurring by adjusting data to a logit function (Hilbe 2016; Pant 2019). The algorithm makes various assumptions, such as independence responses (logits) at all subpopulation levels, where the explanatory variable is usually distributed. The variance is constant between the reactions and all the explanatory variable values. Intuitively, a transformation for the response variable is applied to produce a continuous probability distribution over output classes bounded between 0 and 1; this transformation is called the “logistic” or “sigmoid” function, where “z” corresponds to the logarithmic probabilities divided by the logit (Hoffman 2021). A logistic function or logistic curve is a standard S-shaped curve (sigmoid curve) with the equation (Bacaer 2011):
\({{\varvec{x}}}_{0}\) = x value of the sigmoid midpoint,L = maximum value of the curve,k = the logistic growth rate or slope of the curve.
L.R. is more of a classifier than a regression technique despite the name. Also, it is especially true in the scientific field, in medicine or the psychosocial sciences, where the focus is on prediction and explanation (Shmueli 2010).
2.3 Machine learning algorithm considerations: random forest
The random forest consists of random decision trees capable of predicting the expected values of regressions and classifications. Since its publication in 1996, the Breiman model (Breiman 1996) has become an important data analysis tool, quite versatile and with few adjustment parameters. The method is generally recognised for its precision and ability to handle small sample sizes, large resource spaces and complex data structures (Scornet et al. 2015). Several practical issues have successfully involved Random Forest, for example, air quality forecasting, chemoinformatics, ecology, 3D object recognition and bioinformatics. Many have proposed valid variations on the original algorithm to improve calculation times while maintaining good forecasting accuracy. Breiman's Random Forests were also extended to quantile estimation, survival analysis, and ranking forecast (Scornet et al. 2015). Theoretically, the analyses are less conclusive, and, regardless of their extensive use in practical contexts, little is known about the mathematical properties of Random Forests. Most studies have focused on isolated parts or simplified versions of the procedure. The most famous theoretical result is Breiman (1996), which offers an upper limit to the error of generalising forests in terms of the correlation and strength of individual trees. A critical step proposed by Jeon and Lin established lower limits for non-adaptive forests, independent of the training set (Jeon and Lin 2006).
The main computational procedures embedded in this algorithm are bagging and the criterion for classification and regression trees (CART) (Breiman et al. 1985). Bagging consists of a general aggregation scheme that generates subsamples of the original data set, building a predictor for each resampling and deciding on the mean. It improves unstable estimates, especially for extensive data and large data sets. In turn, the CART algorithm and its CART-split derivative are used to construct individual trees to choose the best cuts perpendicular to the axes. The best amount is selected in each tree node, optimising the CART split criterion based on the notion of Gini impurity (classification) and quadratic regression error (Breiman et al. 1985). Scornet, Biau and Vert studied some asymptotic properties of the Breiman algorithm in additive regression models. They proved the consistency of Random Forest, which provides a first basic theoretical guarantee of efficiency for this algorithm. This finding was the first consistent result for Breiman’s original procedure. The approach was based on a detailed analysis of the cell behaviour generated by selecting the CART-split as the sample size increased. The study also showed that Random Forest could adapt to a sparse structure when the dimension is large, but only a smaller number of coordinates makes the information.
The general structure consists of the regression in which a random input vector X ∈ [0, 1]p is observed—with “p” being the dimension of the vector. The objective is to predict the integrable random response square Y ∈ \(R\) by estimating the function of regression \(m\left(x\right)=E\left[Y|X=x\right]\). Therefore, it is assumed that the training sample is given by \({D}_{n}=\left({X}_{1},{Y}_{1}\right),\dots ,\left({X}_{n},{Y}_{n}\right) de{ \left[\mathrm{0,1}\right]}^{p}\times R\), independently distributed as the independent pair (X, Y). The objective is to use the data set Dn to construct an estimate \({m}_{n}:{\left[\mathrm{0,1}\right]}^{p}\to R\) of the function “m”. Thus, it is said that an estimated regression function \({m}_{n}\) is consistent if \(E{\left[{m}_{n}\left(X\right)-m\left(X\right)\right]}^{2}\to \infty \) where the expectation E is more significant than X and Dn (Scornet et al. 2015). A random forest is a predictor that consists of a collection of M trees of random regression. For the j-th family tree, the predicted value at query point x is indicated by, \({m}_{n}\left(x,{\Theta }_{j},{D}_{n}\right)\), where \({\Theta }_{1},\dots ,{\Theta }_{M}\) are independent random variables, distributed as a generic random variable Θ and independent of Dn. The trees are combined to form the finite estimate of the forest (Scornet et al. 2015).
Since one can choose, in practice, M as large as possible, Scornet, Biau, and Vert (2015) demonstrated the property according to which the infinite forest estimate obtained as the limit of Eq. (1) is verified as follows when the number of M trees grows to infinity (Scornet et al. 2015):
where \({E}_{\Theta }\) denotes expectation concerning the random parameter Θ, conditional on Dn. The law of large numbers, which states that it almost certainly depends on Dn, justifies this operation (Scornet et al. 2015):
See Breiman (Breiman 1996) for more details. From now on, to simplify the notation, \({m}_{n}\left(x\right)\) will be written instead of \({m}_{n}\left(x;{D}_{n}\right)\) (Scornet et al. 2015). In the original forests of Breiman (1996), each node of a single tree is associated with a hyper rectangular cell. At each stage of the tree's construction, the set of cells forms a partition [0, 1]p. The tree's root is [0, 1]p itself, and each tree grows, as explained in Algorithm 1. This algorithm has three parameters (Scornet et al. 2015):
-
(1)
\({m}_{try}\in \{1,...,p\}\), which is the number of preselected directions for the tree’s dividing.
-
(2)
\({a}_{n}\in \{1,...,n\}\), which is the number of data points sampled in each tree.
-
(3)
\({t}_{n}\in \{1,...,{a}_{n}\}\), which is the number of leaves in each tree.
By default, in the original procedure, the parameter \({m}_{tinytry}\) is set to p/3, \({a}_{n}\) is set to \(n\) (resampling is done with substitution) and \({t}_{n}={a}_{n}\). However, resampling is done without replacing this approach, and the parameters \({a}_{n}\) and \({t}_{n}\) may differ from their default values (Scornet et al. 2015). The algorithm works by growing M different trees as follows: For each tree, data points are drawn at random without replacing the original data set; then, in each cell of each tree, a division is chosen maximising the CART criterion; finally, the construction of each tree is interrupted when the total number of cells in the tree reaches the value \({t}_{n}\). Therefore, each cell contains exactly one point in the case \({t}_{n}={a}_{n}\) (Scornet et al. 2015).
2.4 Machine learning algorithm considerations: naïve bayes
Bayesian networks can be applied to classification problems using Bayesian classifiers. The simplest Bayesian Network structure constitutes a classification algorithm called Naïve Bayes, also known as the Bayesian classifier with k-dependency and the structure of Simple Bayesian Networks with K-Dependency (Castro et al. 2011; Sahami 1996). Therefore, Naïve Bayes is a simple probabilistic algorithm based on Bayes’ theorem. This algorithm uses training data to form a probabilistic model based on the evidence of specific characteristics in an extensive database. The algorithm assumes independence between the model's features, implying the absence of relations between a given quality and the other attributes in the database. A Naïve Bayes classifier is structured in the calculation of the posterior probability distribution P(Y|X), where \(\user2{Y = }\left( {y_{1} ,y_{2} , \ldots y_{k} } \right)\) is the random variable to be classified presenting “k” categories and \(\user2{X = }\left( {x_{1} ,\,x_{2} ,\, \ldots ,x_{p} } \right)\) is a set of “p” discrete explanatory variables. For the calculation of conditional probability P(Y|X), this method assumes probabilistic independence between the explanatory variables, facilitating the application of the technique computationally, the result of this calculation being obtained by the following formula:
Therefore, a Naïve Bayes classifier calculates the probability that a given observation belongs to each category and classifies that observation in the most appropriate variety.
2.5 Machine learning algorithm considerations: neural networks
Artificial neural networks are Machine Learning techniques that simulate learning in biological organisms. The human nervous system contains cells, which are referred to as neurons. Synapses connect the neurons. The strengths of synaptic connections often change in response to external stimuli. This change is how learning takes place in living organisms. This biological mechanism is simulated in artificial neural networks containing neurons or “perceptrons” units. Neurons are connected employing weights, which play the same role as synaptic connections in biological organisms.
Neural Networks have some advantages over traditional Machine Learning. The first advantage is that Neural Networks provides a top-level abstraction to express semantic insights about data domains through architectural design options in the computational graph. The second advantage is that Neural Networks offer a simple way to adjust the complexity of a model, adding or removing neurons from the architecture according to training data or computational power availability. In the recent success of Neural Networks, the increased availability of data and the processing power of modern computers have exceeded the limits of traditional Machine Learning algorithms. The performance of conventional Machine Learning sometimes remains better for smaller data sets due to more options, more accessible interpretation of the model under analysis and the tendency to create hand-interpretable resources incorporating domain-specific perceptions. With limited data, the best of a wide variety of models in Machine Learning will generally outperform a single class of Neural Networks models.
As for the type of learning, Neural Networks can be categorised as follows: Supervised Learning, Unsupervised or Hybrid Learning.
2.6 Verbal decision analysis methods
Verbal Decision Analysis (VDA) is an approach introduced in 1997 by Larichev and Moshkovich (1997, 1994, 1995). VDA seeks to express the decision-maker’s assessments and preferences verbally and qualitatively. In this approach, natural language forms the questions, and verbal evaluations include the scales of criteria (Machado et al. 2014).
2.6.1 The ZAPROS method family
ZAPROS consists of Russian words meaning “locked procedures close to reference situations”. The first version added the creators’ first names initials “L.M.” (Larichev and Moshkovich) to the name, forming ZAPROS-LM (Larichev and Moshkovich 1995). This method is destined to aid in resolving problems that need to classify and sort a large number of alternatives with sets capable of changing the decision rules. The ZAPROS method presents the decision-maker's preferences by comparing hypothetical alternatives pairs of any set close to so-called “landmarks”: the better or worse possible values. These alternatives compose only two criteria, and the decision-maker must indicate the preference for one of the indifferences among both.
O method evaluates information’s consistency through the preferences’ transitivity and compares it to the same criteria values at two landmarks. As a result of these comparisons' complete set, the Joint Ordinal Scale (JOS) is formed in the scope of the criteria. This scale sorts the different criteria and is not linked to a specific set of alternatives. Therefore, the Joint Ordinal Scale (JOS) enables partial comparisons of natural alternatives pairs. These form the basis for partisan sorting of valid alternatives and constitute the ZAPROS method’s focus (Larichev and Moshkovich 1995).
2.7 Orange canvas framework considerations
The present study used the Orange Canvas framework to obtain the best possible results when comparing the algorithms referenced in this work. Demsar et al. (2013) designed a framework called Orange, whose structure consists of a set of machine learning and data mining tools for data analysis using Python coding language scripts, in addition to visual programming. Orange is aimed at experienced users and programmers, students, and data scientists who constantly use data mining techniques. This framework is based on the C + + language; however, it allows code developers to work with Python. In addition, (Andrade et al. 2021b) used Machine Learning (ML) algorithms and their concepts through the Orange tool in a data volume of 51,560 (fifty thousand five hundred and sixty) Covid-19 cases registered in Brazil by “SIVEP Influenza—Sistema de Epidemiological Surveillance of Influenza”. This study classified the main symptoms and risk factors from a minor symptomatic perspective, identified by the Logistic Regression algorithm when applied in the SIPEV database. Table 1 presents these main symptoms and risks.
Using the Orange tool, with the same data as the study to obtain symptoms and risk factors, the Neural Networks algorithm was added to analyse its performance concerning the others used in the previous study.
2.8 Performance analysis
The authors made some comparisons using the software Orange, between the Logistic Regression (L.R.), Random Forest (R.F.), Naïve Bayes (N.B.), and Neural Network (N.N.) algorithms to identify which could improve, for example, in the list of symptoms or even in the performance and precision in obtaining this data. The proposed model was refined from several test bases, one for each learning cycle. The origin of each test base of each cycle counted on the exploration of a large and varied amount of data structured in rows and columns. In this way, it is understood that there is no trend bias in the model, given the magnitude and variety of the data source for each test base. In addition to the test cycles, there is a horizon based on the experience and common sense of the professionals who validated the model. The metrics presented in Tables 2 and 3 show the best performing Logistic Regression algorithm in almost all measures, concerning Neural Network, Random Forest, and Naïve Bayes. Additionally, it offers a better Classification Accuracy (C.A.,) indicating that many are correctly classified among all the classifications of Covid-19 cases performed.
Finding an algorithm with better performance is very relative, according to the idea of The No Free Lunch theorem for supervised algorithms (Wolper April 1997). After completing the comparison of the algorithms, we chose to follow the studies with the same symptoms and risk factors previously classified by Logistic Regression, Table 2, because even in comparison with Neural Networks (algorithm included in this study), it presented the best accuracy and precision above the studied data.
3 The relationship: symptoms, international classification of disease and possible sequelae
The International Classification of Disease (ICD) was obtained through the identified symptoms and risk factors, referring to each (ICD 2019). Based on these ICDs, the authors prepared a table, with the help of a health professional, containing the symptoms, risk factors, their related ICDs and the possible sequelae or need for post-Covid-19 treatment, as shown in Fig. 2 and Fig. 3.

Symptoms and possible sequels

Risk factors and possible sequels
3.1 Application phase
Through the identified symptoms and risk factors, the International Classification of Disease (ICD) was obtained from the collection of data from Fig. 3 and Fig. 4. The evaluation criteria were defined according to the chapter of the manual of the International Classification of Functioning, Disability and Health—ICF (World Health Organization 2001), using the broadest classification of the category (chapter), as shown in Table 4. Each criterion is registered to consider the recurrence of the symptom or risk factor, with possible sequelae or need for treatment related to the analysed criterion. Also, Table 4 below shows the qualifiers that specify this recurrence.

Possible sequelae/need for treatments in the post-disease period
Health professionals created an online survey to validate the symptoms identified by the machine learning algorithm and the sequelae (Andrade et al. 2021b). Fourteen possible relationships between symptoms and sequelae were addressed in the questionnaire. The professional qualified the questions based on the criteria and qualifiers (recurrence) when answering the questions and assessing them. Twenty individual specialists working in the health area were interviewed. Nurses, physiotherapists, doctors, occupational therapists, phono audiologists, psychologists, dentists, pharmacists, and researchers responded to the survey in the interview.
In addition to collecting data that meets the concept, obtaining it is extremely important so that the necessary treatment can be applied later to test the hypotheses. Therefore, it is essential to pay attention to the design of the collection instrument, the type of information it will provide and the type of analysis that can be done after obtaining the responses to the form. From the data collection of useful or pertinent data for testing the hypotheses, the analysis model was compared with the collected data, considering the requirements to correctly put the chosen method into practice and obtaining elements to achieve the objectives proposed in this research. After obtaining the survey responses, the result was applied to the Aranau tool that implements ZAPROS-IIIi.
4 Application of the verbal decision analysis methods
The results were obtained through the hybrid model using Machine Learning, with Logistic Regression and the ZAPROS-IIIi method of the Verbal Decision Analysis methodology, to determine the relationship between symptoms/risk factors and possible sequelae/treatment. After the application phase, in which the evaluations of each professional were obtained through responses to the online questionnaire, a table was created with the 14 (fourteen) symptoms/risk factors and their respective relationship alternatives (low, moderate, and high). The most significant response is highlighted for each relationship between symptom/risk factor with possible sequelae or need for treatment after the disease, as shown in Fig. 4. For example, each question was evaluated, the first question: Regarding criterion A, fourteen professionals answered that there might be a high relationship between the symptom and the sequel under the analysed criterion. Likewise, all research questions and their answers were analysed.
According to the evaluation carried out for each question, the result was recorded in the Aranau tool. Figure 5 exemplifies the first 3 (three) alternatives to be evaluated by the decision-maker, using the Aranau tool, which implements ZAPROS-IIIi. On the other hand, following the first question's application, it was included in the tool according to the number of responses for each criterion and qualifier: A1—High / B1—High/C2—Moderate.

Defined alternatives
After defining the relationships, Elicitation of Preferences was initiated. The qualifiers A1 (High), B1 (High) and C1 (High) are considered the ideal result, or the one that would have the most significant impact on the relationship between symptom X/risk factor X with the possible sequel Y or the need for post-treatment disease. Having defined the ideal reference situation, the ZAPROS-IIIi method, based on the concept of Quality Variations (Q.V), presents the minimum number of qualifying pairs needed to be compared by the decision-maker. The process uses the measurement of the distances between the evaluations of the two alternatives and the Formal Index Quality (F.I.Q). The Aranau tool presents the Q.V.s for comparison of the decision-maker. The question “What is the recurrence of sequel X or the need for treatment X to occur for a symptom Y?” is considered. The tool performed the sum of the assessments for each character, according to the comparison of the V.Q.s. The best alternatives obtained in the comparison received a lower Formal Index Quality. These data allowed the combination of vectors formed by the “Qualifiers X Alternatives”, that is, “rows X columns” of Fig. 4. Figure 6, in turn, shows the final order of preference for the central relationships between symptoms/risk factors and their possible sequelae or need for post-disease treatment, established by the ZAPROS-IIIi method, implemented in the Aranau tool for the cases of COVID-19. Figure 7 shows this order graphically.

Preferred order

Alternatives graph
5 Analysis and discussion of results
The post-COVID-19 syndrome is a set of symptoms that persisted in patients infected with SARSCOV-2, both in the manifestation of the disease in its mild/moderate form and its critical condition leading to hospitalisation for intensive long-term care infection (Irwin et al. 2018). Thus, patients surviving COVID-19 even after hospital discharge need immediate and long-term care related to psychomotor and social care. Persistent fatigue is one of the symptoms identified in the long term. When associated with depressive symptoms, anxiety, and diffuse myalgia, they are characterised as chronic fatigue syndrome (CFS), which can be caused due to the febrile reaction and the immunodepression associated with viral status (Perrin et al. 2020). According to research carried out by Carfi et al. (2020), among the symptoms analysed by patients who were discharged from hospital after the cure of COVID-19, 53.1% of the people still revealed to have cognitive dysfunction, anxiety, depression, in addition to fatigue and muscle weakness, due to prolonged hospitalisation in the Intensive Care Unit (ICU).
As predictors of persistent pulmonary fibrosis are the constant high inflammatory load, the PaO2/FiO2 ratio < 324 and Body Mass Index (BMI) > 33 kg/m2 at hospital admission. The increase in anti-inflammatory cytokine (Interleukin-4) and macrophages are triggered by blocking the conversion of angiotensin-2 to angiotensin, inducing a pro-inflammatory state. The viral protein composed of a single RNA chain can be expressed in the bronchial and parenchymal pathways, corroborating lung injury and vascular endothelium, glial, renal, and enteric cells (Santana et al. 2021). The binding of the virus to the receptors of the Angiotensin-2 converting enzyme (ACE2) favours viral penetration into cardiac cells, triggering sequelae and a high risk of thrombogenesis, which persist after infection SARS-CoV2 (Santana et al. 2021). Studies indicate a high prevalence of COVID-19 patients with damage to the cardiovascular system, such as acute cardiac injury of 7.2%, cardiogenic shock 8.7% and cardiac arrhythmia of 16.7%, which were caused due to the systemic inflammatory response by the overproduction of inflammatory cytokines, IL-6 and TNF-α. Disorders of the immune system during the progression of the disease can lead to hypercoagulability, a high mortality rate and the need for cardiovascular protection during drug therapy for COVID-19 (Ferrari 2020).
After clinical discharge, due to the context of respiratory failure and immunological deficiency, hypoperfusion of the frontal lobe can be evidenced, and encephalopathy, which involves the rupture of the blood–brain barrier by the indirect invasion of the virus through cytokines (Mao et al. 2020). In addition to pulmonary involvement in patients with SARS-CoV-2, other organs can suffer complications such as the development of Acute Kidney Injury (AKI). Research infers those patients with dialysis Chronic Kidney Disease (CKD) affected by COVID-19 may develop severe immune dysregulation and exaggerated production of cytokines of acute infection, causing lymphopenia, anaemia, gastric or intestinal bleeding, bone and joint pain, myalgia, acidosis metabolic, malnutrition and alteration of the metabolism of calcium and phosphorus (Pecly et al. 2021).
Thus, the early detection of renal abnormalities is essential to ensure a better evolution of these patients during hospitalisation by planning excellent hemodynamic support when indicated and avoiding nephrotoxic drugs through medical risk judgment (Pecly et al. 2021). Another point to be discussed during the COVID-19 pandemic is the risk factor Diabetes Mellitus, a chronic disease capable of causing cellular and vascular metabolism changes. As a result, diabetic people are at high risk since hyperglycemia and insulin resistance that may be present in this public promote a more remarkable synthesis of glycation products, pro-inflammatory cytokines and oxidative stress capable of stimulating the adhesion of inflammatory mediators and carry a higher risk of pulmonary infection (Marinho et al. 2021). According to World Health Organization (WHO), the initial signs and symptoms of the disease are similar to the flu condition. They can vary from each individual, manifested in mild form as pneumonia and Severe Acute Respiratory Syndrome (SARS). Most infected people experience headaches early in the disease, which can persist due to activation of the nociceptive system by the inflammatory cascade; cough; sore throat; diarrhoea; abdominal pain; nausea and vomiting. Hyposmia is also a common symptom in COVID-19 in the first eight days of the disease since the viral contamination of the olfactory bulb is considered the gateway of the virus to the Central Nervous System, reaching the olfactory cortex and structures of the diencephalon. Thus, the SARS-CoV-2 invasion process can cause an axonal lesion, affecting the individual, even when cured, a change in sensitivity secondary to inflammatory microangiopathy of the nasal epithelium (Waheed et al. 2020).
6 Conclusions and future works
Complex problems are usually solved by breaking them into less complicated parts. Therefore, hybrid models are heavily used, as this facilitates the implementation of methodologies with their methods in each piece. The model proposed in the present study shows that this form of execution was perceived in stages of the decomposition of the problem studied. Thus, the hybrid approach model structured in the composition of Artificial Intelligence techniques (Machine Learning) associated with the Multicriteria Decision Analysis Methodology (Verbal Decision Analysis) ordered the main symptoms and factors of COVID-19 with their respective persistent changes after clinical discharge and cured the disease. With the application of Machine Learning, Logistic Regression was obtained as the best performing algorithm with an accuracy of 60.4%; Neural Network (57.6%), Random Forest (56.4%), Bayesian Naïve (31.7%). In turn, in the qualitative solution sought for the order of preference of the characteristics according to the Verbal Decision Analysis with the evaluation of specialist professionals in the first place, presented the symptom "fatigue" with the respective sequelae: lack of strength, muscle weakness, depression, anxiety and cognitive changes. Lastly, he showed the sign "abdominal pain", whose sequelae were: prostration, diarrhoea, and inability to drink water and eat properly. The research theme has shown outstanding interest according to Gupta et al. (2021); Verma and Rathi 2022).
Therefore, hybrid models, such as the one proposed in this research, provide the resolution of complex problems as described in the Introduction Section. Next, some future work and possible refinements presented in this research are suggested, in addition to some new ideas that emerged during the development of the study: seek to identify treatments for potential sequelae of the disease involved in the study; use machine learning algorithms to rank drugs with the best results for COVID-19; seek to use machine learning algorithms to organise the best treatments for the symptoms of said disease, listed in this study. Developing other hybrid models will help discover proactive solutions to prevent similar or even more severe pandemic events and combat them. Such models can use Data Science techniques based on Artificial Neural Networks, Deep Learning, Data Mining. All these techniques may be associated with methods from the MCDA family.
7 Limitations
The present study was limited to developing a protocol structured in a hybrid model of Machine Learning and Verbal Decision Analysis, identifying the possible sequelae or necessary treatments related to the main symptoms and risk factors of COVID -19.
References
Aggarwal CC (2018) Neural networks and deep learning. Springer International Publishing AG Springer Nature, New York
Andrade E (2020) Um Modelo Híbrido em Aprendizagem de Máquina e Análise Verbal de Decisão Aplicado ao Diagnóstico de Autismo, Masters Dissertation, University of Fortaleza
Andrade E, Portela S, Pinheiro, PR, Nunes LC, Simão Filho M, Costa, WS, Pinheiro MCD (2021a) A protocol for the diagnosis of autism spectrum disorder structured in machine learning and verbal decision analysis. Comput Math Methods Med 2021:1628959. https://doi.org/10.1155/2021/1628959
Andrade E, Pinheiro PR, Nunes LC, Pinheiro MCD, HolandaFilho R, Abreu W, SimãoFilho M, Pinheiro LICC, Pereira MLD (2021b) Application of machine learning to infer symptoms and risk factors of Covid-19, research, and innovation forum. Springer, New York
Bacaer N (2011) Verhulst and the logistic equation (1838), A short history of mathematical population dynamics. Springer, London, pp 35–39
Beğenilmiş E, Uskudarl S (2018) Organised behavior classification of tweet sets using supervised learning methods. In: Proceedings of the 8th International Conference on Web Intelligence, Mining and Semantics (WIMS '18). ACM
Breiman L (1996) Bagging predictors. Mach Learn 24:123–140. https://doi.org/10.1023/A:1018054314350
Breiman L, Friedman J, Olshen R, Stone EC (1985) Classification, and regression trees. The Wadsworth Statistics/Probability Series, Wadsworth
Cao Z, Li T, Liang LL, Wang H, Wei F, Meng S, Cai M, Zhang Y, Xu H, Zhang J, Jin R (2020) Clinical characteristics of coronavirus disease 2019 in Beijing China. PLoS ONE 15(6):e0234764
Carfi A, Bernabei R, Landi F (2020) Persistent symptoms in patients after acute COVID-19. JAMA 324(6):603–605. https://doi.org/10.1001/jama.2020.12603
Castro AKA, Pinheiro PR, Pinheiro MCD, Tamanini I (2011) Towards the applied hybrid model in decision making: a neuropsychological diagnosis of Alzheimer’s disease study case. Int J of Comp Intell Syst 4(1):89–99
Delsentoth MP, Falsal AA, Soon C (2020) Mathematics for machine learning. Cambridge University Press, Cambridge
Demsar J, Curk T, Erjavec A (2013) Orange: data mining toolbox in Python. J Mach Learn Res 14:2349–2353
Ferrari F (2020) COVID-19: updated data and its relation to the cardiovascular system. Arq Bras Cardiol 114(5):823
Gupta A, Jain V, Singh A (2021) Stacking ensemble-based intelligence machine learning model for predicting post-COVID-19 complications. N Gener Comput. https://doi.org/10.1007/s00354-021-00144-0
Hilbe JM (2016) Practical guide to logistic regression. Chapman & Hall/CRC, Boca Raton
Hoffman JP (2021) Linear regression models: applications in R. Chapman & Hall/CRC, Boca Raton
Hosmer DW, Lemeshow S (2013) Applied logistic regression. John Wiley & Sons, New York
ICD-10 (2019), https://www.icd.who.int/browse10/2019/en, Accessed 15 Apr 2021
Irwin RS, Lilly CM, Mayo PH, Rippe JM (2018) Intensive care medicine, 8th edn. Wolters Kluwer, Alphen aan den Rijn
Jeon Y, Lin Y (2006) An effective method for high-dimensional log-density anova estimation, with application to nonparametric graphical model building. Stat Sin 16:353–374
Johns Hopkins University—COVID-19 Map—Johns Hopkins Coronavirus Resource Center (jhu.edu)—2021/05/12
Kucharski AJ, Russell TW, Diamond C, Liu Y, Edmunds J, Funk A, Eggo RM (2020) Early dynamics of transmission and control of coviD-19: a mathematical modelling study. Lancet Infect Dis 20(5):553–558
Larichev OI, Moshkovich HM (1994) An approach to ordinal classification problems. Int Trans Oper Res 1(3):375–385
Larichev OI, Moshkovich HM (1995) ZAPROS-LM—a method and system for ordering multiattribute alternatives. Eur J Oper Res 82:503–521
Larichev OI, Moshkovich HM (1997) Verbal decision analysis for unstructured problems. Kluwer Academic Press, Dordrecht
Lauer AS, Grantz KH, Bi Q, Jones FK, Zheng Q, Meredith HR, Azman AS, Reich NG, Lessler J (2020) The incubation period of coronavirus disease 2019 (COVID-19) from publicly reported confirmed cases: estimation and application. Ann Intern Med 172(9):577–582
Liang T (2020) Handbook of Covid-19 prevention and treatment. Zhejiang University School of Medicine, Hangzhou
Machado TCS, Pinheiro PR, Tamanini I (2014) OrclassWeb: a tool based on the classification methodology ORCLASS from verbal decision analysis framework. Math Probl Eng 2014:238168. https://doi.org/10.1155/2014/238168
Mao L, Jin H, Wang M, Hu Y, Chen S, He Q, Chang J, Hong C, Zhou Y, Wang D, Miao X, Li Y (2020) Neurologic manifestations of hospitalised patients with coronavirus disease 2019 in Wuhan China. JAMA Neurol 77(6):683–690
Marinho FP, Loyola IS, Monteiro IOF, Carvalho MGS, Garcia JAD, Silvério ACP, Santos GB (2021) Interrelationship between COVID-19 and diabetes mellitus: a syst review. Res Soc Dev 10(2):e4810212191
Mitchell T (1997) Machine Learning Definition, McGraw-Hill Science/Engineering/Math, http://www.cs.cmu.edu/afs/cs.cmu.edu/user/mitchell/ftp/mlbook.html
Mitchell T (2011) For pioneering contributions and leadership in the methods and applications of machine learning. National Academy of Engineering
Pant A, Introduction to Logistic Regression. Medium. Towards Data Science. 2019. 685 https://www.towardsdatascience.com/introduction-to-logistic-regression-66248243c148. Accessed Oct 2021
Pecly IMD, Azevedo RB, Muxfeldt ES, Botelho BG, Albuquerque GG, Diniz PHP, Silva R, Rodrigues CIS (2021) COVID-19 and chronic kidney disease: a comprehensive review. Braz J Nephrol 43:383
Perrin R, Riste L, Hann M, Walther (2020) Into the looking glass: post-viral syndrome post-Covid-19. Med Hypotheses 144:110055. https://doi.org/10.1016/j.mehy.2020.110055
Sahami M (1996) Learning Limited Dependence Bayesian Classifiers. In KDD-96: Proceedings of the Second International Conference on Knowledge Discovery and Data Mining, 335–338, Menlo Park, CA: AAAI Press
Santana AV, Fontana AD, Pitta F (2021) Pulmonary rehabilitation after COVID-19. Jornal Bras. de Pneumologia, 47(1)
Scornet E, Biau G, Vert J (2015) Consistency of random florests. Ann Stat 43(4):1716–1741
Shmueli G (2010) To explain or to predict? Stat Sci 25(3):289–310. https://doi.org/10.1214/10-sts330
Stokes EK, Zambrano LD, Anderson KN, Marder EP, Raz KM, Felix SEB, Tie Y, Fullerton KE (2020) Coronavirus disease 2019 case surveillance. Morb Mortal Wkly Rep 69(24):759–765
Turban E, Sharda R, Dursun D (2011) Decision support and business intelligence syst. Prentice-Hall, Hoboken
Verma A, Rathi B (2022) Machine learning based predictive model and systems-level network of host-microbe interactions in post-COVID-19 Mucormycosis. Microb Pathog 162(1):105324. https://doi.org/10.1016/j.micpath.2021.105324
Waheed A, Goyal M, Gupta D, Khanna A, Al-Turjman F, Pinheiro PR (2020) CovidGAN: data augmentation using auxiliary classifier GAN for improved Covid-19 detection. IEEE Access. https://doi.org/10.1109/access.2020.2994762
Wilmott P (2019) Machine learning: an applied mathematics introduction. Panda Ohana Publishing, Oxford
Wolper DH (1997) No free lunch theorems for optimisation. IEEE Trans Evol Comput 1(1):67–82. https://doi.org/10.1109/4235.585893
World Health Organization (2001) International classification of functioning, disability and health. World Health Organization, Geneva, p 302
World Health Organization. Coronavirus disease (COVID-2019) situation reports. 2020. Available at: https://www.who.int/emergencies/diseases/novel-coronavirus-2019/situation-reports/
Acknowledgements
To all health professionals and diagnosed patients who fought or fought an arduous battle against COVID-19. The third, sixth and eighth authors are grateful to the Brazilian National Council for Scientific and Technological Development (CNPq).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
We have no conflict of interest to declare.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
de Andrade, E.C., Pinheiro, L.I.C.C., Pinheiro, P.R. et al. Hybrid model for early identification post-Covid-19 sequelae. J Ambient Intell Human Comput 14, 14739–14752 (2023). https://doi.org/10.1007/s12652-023-04555-3
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12652-023-04555-3