
Abstract
In modeling survival data with a cure fraction, flexible modeling of covariate effects on the probability of cure has important medical implications, which aids investigators in identifying better treatments to cure. This paper studies a semiparametric form of the Yakovlev promotion time cure model that allows for nonlinear effects of a continuous covariate. We adopt the local polynomial approach and use the local likelihood criterion to derive nonlinear estimates of covariate effects on cure rates, assuming that the baseline distribution function follows a parametric form. This approach ensures that the model is identifiable and we adopt a flexible method to estimate the cure rate locally, the important part in cure models, and a convenient way to estimate the baseline function globally. An algorithm is proposed to implement estimation at both the local and global scales. Asymptotic properties of local polynomial estimates, the nonparametric part, are investigated in the presence of both censored and cured data, and the parametric part is shown to be root-n consistent. The proposed methods are illustrated by simulated and real data with discussions on the practical applications of the proposed method, including the selections of the bandwidths in the local polynomial approach and the parametric baseline distribution family. Extension of the proposed method to multiple covariates is also discussed.




Similar content being viewed by others
References
Berkson J, Gage RP (1952) Survival curve for cancer patients following treatment. J Am Stat Assoc 47:501–515. https://doi.org/10.2307/2281318
Farewell V (1982) The use of mixture models for the analysis of survival data with long-term survivors. Biometrics 38:1041–1046. https://doi.org/10.2307/2529885
Kuk AYC, Chen CH (1992) A mixture model combining logistic regression with proportional hazards regression. Biometrika 79:531–541. https://doi.org/10.2307/2336784
Lu W, Ying Z (2004) On semiparametric transformation cure models. Biometrika 91:331–343. https://doi.org/10.1093/biomet/91.2.331
Mao M, Wang JL (2010) Semiparametric efficient estimation for a class of generalized proportional odds cure models. J Am Stat Assoc 105:302–311. https://doi.org/10.1198/jasa.2009.tm08459
Jiang C, Zhao W, Zhao H (2019) A prediction-driven mixture cure model and its application in credit scoring. Eur J Oper Res 277(1):20–31. https://doi.org/10.1016/j.ejor.2019.01.072
Li P, Peng Y, Jiang P, Dong Q (2020) A support vector machine based semiparametric mixture cure model. Comput Stat 35:931–945. https://doi.org/10.1007/s00180-019-00931-w
Pal S, Peng Y, Aselisewine W (2023) A new approach to modeling the cure rate in the presence of interval censored data. Comput Stat. https://doi.org/10.1007/s00180-023-01389-7
Tsodikov AD, Ibrahim JG, Yakovlev AY (2003) Estimating cure rates from survival data: an alternative to two-component mixture models. J Am Stat Assoc 98:1063–1078. https://doi.org/10.1198/01622145030000001007
Tsodikov A (1998) A proportional hazards model taking account of long-term survivors. Biometrics 54:1508–1516. https://doi.org/10.2307/2533675
Chen MH, Ibrahim JG, Sinha D (1999) A new Bayesian model for survival data with a surviving fraction. J Am Stat Assoc 94:909–919. https://doi.org/10.2307/2670006
Zeng D, Yin G, Ibrahim JG (2006) Semiparametric transformation models for survival data with a cure fraction. J Am Stat Assoc 101:670–684. https://doi.org/10.1198/016214505000001122
Ma Y, Yin G (2008) Cure rate model with mismeasured covariates under transformation. J Am Stat Assoc 103:743–756. https://doi.org/10.1198/016214508000000319
Bertrand A, Legrand C, Carroll RJ, de Meester C, Van Keilegom I (2017) Inference in a survival cure model with mismeasured covariates using a simulation-extrapolation approach. Biometrika 104:31–50. https://doi.org/10.1093/biomet/asw054
Chen T, Du P (2018) Promotion time cure rate model with nonparametric form of covariate effects. Stat Med 37(10):1625–1635. https://doi.org/10.1002/sim.7597
Lin LH, Huang LS (2019) Connections between cure rates and survival probabilities in proportional hazards models. Statistics 8:e255. https://doi.org/10.1002/sta4.255
Li CS, Taylor JMG, Sy JP (2001) Identifiability of cure models. Stat Probab Lett 54(4):389–395. https://doi.org/10.1016/S0167-7152(01)00105-5
Hanin L, Huang LS (2014) Identifiability of cure models revisited. J Multivariate Anal 130:261–274. https://doi.org/10.1016/j.jmva.2014.06.002
Yakovlev AY, Tsodikov AD (1996) Stochastic models of tumor latency and their biostatistical applications. World Scientific, Singapore
Xie Y, Yu Z (2020) Promotion time cure rate model with a neural network estimated nonparametric component. Stat Med 40(15):3516–3532. https://doi.org/10.1002/sim.8980
Pal S, Aselisewine W (2023) A semi-parametric promotion time cure model with support vector machine. Ann Appl Stat 17:2680–2699. https://doi.org/10.1214/23-AOAS1741
Rodrigues J, de Castro M, Cancho VG, Balakrishnan N (2009) COM-Poisson cure rate survival models and an application to a cutaneous melanoma data. J Stat Plann Inference 139:3605–3611. https://doi.org/10.1016/j.jspi.2009.04.014
Balakrishnan N, Pal S (2013) Lognormal lifetimes and likelihood-based inference for flexible cure rate models based on COM-Poisson family. Comput Stat Data Anal 67:41–67. https://doi.org/10.1016/j.csda.2013.04.018
Fan J, Gijbels I (1996) Local polynomial modelling and its applications. Chapman and Hall, London
Klein JP, Moeschberger ML (1997) Survival analysis techniques for censored and truncated data. Springer, New York
He K, Ashby VB, Schaubel DE (2019) Evaluating center-specific long-term outcomes through differences in mean survival time: Analysis of national kidney transplant data. Stat Med 38(11):1957–1967. https://doi.org/10.1002/sim.8076
Sawinski D, Poggio ED (2021) Introduction to kidney transplantation: long-term management challenges. Clin J Am Soc Nephrol 16(8):1262–1263. https://doi.org/10.2215/CJN.13440820
Fan J, Gijbels I, King M (1997) Local likelihood and local partial likelihood in hazard regression. Ann Stat 25:1661–1690. https://doi.org/10.1214/aos/1031594736
Laska EM, Meisner MJ (1992) Nonparametric estimation and testing in a cure model. Biometrics 48:1223–1234. https://doi.org/10.2307/2532714
Murphy SA, van der Vaart AW (2000) On profile likelihood. J Am Stat Assoc 95:449–465. https://doi.org/10.2307/2669386
Eguchi S, Kim TY, Park BU (2003) Local likelihood method: a bridge over parametric and nonparametric regression. J Nonparametric Stat 15:665–683. https://doi.org/10.1080/10485250310001624756
Cai J, Fan J, Jiang J, Zhou H (2007) Partially linear hazard regression for multivariate survival data. J Am Stat Assoc 102:538–551. https://doi.org/10.1198/016214506000001374
Huang J (1999) Efficient estimation of the partly linear additive Cox model. Ann Stat 27:1536–1563. https://doi.org/10.1214/aos/1017939141
Tian L, Zucker D, Wei L (2005) On the Cox model with time-varying regression coefficients. J Am Stat Assoc 100:172–183. https://doi.org/10.1198/016214504000000845
Balakrishnan N, Pal S (2015) An EM algorithm for the estimation of parameters of a flexible cure rate model with generalized gamma lifetime and model discrimination using likelihood- and information-based methods. Comput Stat 30:151–189. https://doi.org/10.1007/s00180-014-0527-9
Wang P, Pal S (2022) A two-way flexible generalized gamma transformation cure rate model. Stat Med 41:2427–2447. https://doi.org/10.1002/sim.9363
Fan J, Heckman NE, Wand MP (1995) Local polynomial kernel regression for generalized linear models and quasi-likelihood functions. J Am Stat Assoc 90:141–150. https://doi.org/10.2307/2291137
Mondal S, Subramanian S (2016) Simultaneous confidence bands for Cox regression from semiparametric random censorship. Lifetime Data Anal 22:122–144. https://doi.org/10.1007/s10985-015-9323-2
Horn RA, Rhee NH, So W (1998) Eigenvalue inequalities and equalities. Linear Algebra Appl 279:29–44
Acknowledgements
We are grateful to the Editor-in-Chief Joan Hu, an associate editor, and three anonymous reviewers for the constructive comments and suggestions. The National Science and Technology Council, TAIWAN, provided funding for this study in the form of grants awarded to author LSH (NSTC 103-2118-M-007-001-MY2 and 111-2118-M-007-004-MY2). LSH is very grateful to the late Professor Andrei Yakovlev for his encouragements and advice to study cure rate models under US NIH grant R21 CA131603 while at the University of Rochester.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors have declared that no Conflict of interest exist.
Appendix
Appendix
I. Derivation of the log likelihood function (4)
II. Proofs of the Lemmas and Theorems in Section 2
The conditions used in the Lemmas and Theorems are given first, followed by the details of their proofs.
Conditions (A)
-
(A1)
The kernel function \(K(\cdot ) \ge 0\) is a bounded density with compact support.
-
(A2)
The function \(m(\cdot )\) has a continuous \((p+1)\)-th derivative around grid point x.
-
(A3)
The second derivative of the baseline function \(F(\cdot )\) exists.
-
(A4)
The density of X, \(f_X(x) >0\), is continuous on a compact support.
-
(A5)
For estimating the k-th derivative of \(m(\cdot )\), \(k=0, \dots , p\), \(h \rightarrow 0\) and \(nh^{2k+1} \rightarrow \infty\), as \(n \rightarrow \infty\).
-
(A6)
The true value of \(\gamma\), \(\gamma _0\), in the baseline function \(F(\cdot )\) is an interior point of its parameter space.
-
(A7)
There exists an \(\eta > 0\) such that \(E\{|\Delta - \theta (x)F(Y;\gamma _{0})|^{2+\eta }\}\) is finite and continuous at point \(X=x\) for \(0<\eta <1\).
-
(A8)
The functions \(E\{\Delta |X\}\), \(E\{F(Y; \gamma _{0})|X\}, E\{F^{'}(Y; \gamma _{0})|X\}\), \(E\{F^{''}(Y; \gamma _{0})|X\}, E\{\xi (Y; \gamma _{0})|X\}\), \(E\{\xi ^{'}(Y; \gamma _{0})|X\},\) and \(E\{\xi ^{''}(Y;\gamma _{0})|X\}\) are continuous at point \(X=x\), where \(\xi (Y; \gamma ) = \log f(Y; \gamma )\).
-
(A9)
There exists a function M(y) with \(EM(Y) < \infty\) such that
$$\begin{aligned} \left| \frac{\partial ^{3}}{\partial \beta _{j}\partial \beta _{k}\partial \beta _{l}} \xi (y; \gamma ) \right| < M(y). \end{aligned}$$
Proof of Lemma 1
The log likelihood function (4) is the data version of the population log likelihood function
With \(\gamma =\gamma _0\), at point x, taking the derivative of \(\ell _1\) with respect to \(\theta (\cdot )\) and then taking the conditional expectation,
which is 0 at the true value of \(\theta (x)\). Thus Lemma 1 is obtained. \(\square\)
Proof of Theorem 1
For simplicity, the subscript of \(\beta _x\) is neglected in this proof. Recall that \(\beta ^{0}\) is the true value of \(\beta\). Given \(\gamma = \gamma _{0}\), let \(\alpha = H(\beta - \beta ^{0})\) with the true value of \(\alpha =0\), where H is defined in Theorem 1. Then \(\tilde{\text{ x }}_i^{T}\beta = \tilde{\text{ x }}_i^{T}\beta ^{0}+U_i^{T}\alpha\), where \(U_{i} = H^{-1}\tilde{\text{ x }}_{i}\). The local likelihood (6) is rewritten as
Taking the derivative of (15) with respect to \(\alpha\) yields
Then it is equivalent to show that there exists a maximizer \(\hat{\alpha }\) to the likelihood equation (16) such that \(\hat{\alpha } {\mathop {\rightarrow }\limits ^{p}} 0\).
Let \(B(0,\epsilon )\) be an open ball which centered at 0 with radius \(\epsilon > 0\). Denote by \(\alpha _j\) the j-th element of \(\alpha\). By a Taylor expansion around the true \(\alpha =0\), \(\ell _{x}(\alpha ) = \ell _{x}(0) + \ell ^{'}_{x}(0)^{T}\alpha + \frac{1}{2}\alpha ^{T}\ell ^{''}_{x}(0)\alpha + R_{n}(\alpha ^{\star }),\) where \(R_{n}(\alpha ) = \frac{1}{3!}\sum _{j,k,l} \alpha _{j} \alpha _{k} \alpha _{l} \frac{\partial ^{3}}{\partial \alpha _{j}\partial \alpha _{k}\partial \alpha _{l}}\ell _{x}(\alpha )\) and \(\alpha ^{*}\) is between \(\alpha\) and 0. For the term \(\ell ^{'}_{x}(0)^{T}\alpha\),
where \(\text{ u }\) is defined in Theorem 2. Based on Lemma 1, \(\ell ^{'}_{x}(0)=0\). Thus for any \(\epsilon > 0\), with probability tending to 1,
For \(\alpha ^{T}\ell ^{''}_{x}(0) \alpha\), taking the second derivative of (15) with respect to \(\alpha\) yields \(\ell _x^{''}\),
Plugging in \(\alpha =0\), the expectation of \(\ell _x^{''}(0)\) is
where \(S_{1}(x)\) is defined in Theorem 2. Thus for any \(\epsilon > 0\),
where \(\eta _{1}\) is the minimum eigenvalue of \(S_{1}(x)\) (Horn et al. [39]).
Under condition (A9), \(|R_{n}(\alpha )| \le C\epsilon ^{3}\frac{1}{n}\sum ^{n}_{i=1}M(Y_{i})=C\epsilon ^{3}\{E(M(Y))+o_{p}(1)\}\) for some constant \(C > 0\). As a result, when \(\epsilon\) is small enough, for any \(\alpha \in B(0,\epsilon )\),
which implies
Thus \(\ell _x(\alpha )\) has a local maximum in \(B(0, \epsilon )\) so that the likelihood equation has a maximizer \(\hat{\alpha }(\epsilon )\) and \(||\hat{\alpha }|| \le \epsilon\) with probability tending to 1. This completes the proof of Theorem 1. \(\square\)
Proof of Theorem 2
We prove part (a) first. Following the proof of Theorem 1, from (15) with \(\gamma =\gamma _0\), since \(0 = \ell _x^{'}(\hat{\alpha }) \approx \ell _x^{'}(0) + \ell _x^{''}(0)\hat{\alpha },\)
We next derive the asymptotic expressions of \(\ell _x^{'}(0)\) and \(Var\{\ell _x^{'}(0)\}\).
Taking the expectation of (16) and using Lemma 1,
By a Taylor expansion,
and by a change of variables \(X-x = hu\), (19) is
Applying Lemma 1 again, the last expression is
By (17), (18), and (20), \(b_n(x)\) is obtained.
For \(Var\{\ell _x^{'}(0)\}\), it can be decomposed into two parts, the quadratic term, and the cross-product terms minus the squared of \(E\{\ell _x^{'}(0)\}\). For the quadratic term,
where \(S_{2}(x; \gamma _{0})\) is defined in Theorem 2. Based on (20), the cross-product terms minus the squared of \(E\{\ell _x^{'}(\beta ^0)\}\) is of order \(n^{-1}h^{2(p+1)} (1+o_p(1))\). Hence
Based on (17), (18), and (21), \(Var(H \hat{\beta })\) in Theorem 2 is obtained.
To prove asymptotic normality, by the Cramer-Wold device, for any non-zero constant vector \(b \in R^{p+1}\), we will show that
Consider \(\sqrt{nh}\{b^{T} \ell ^{'}_x(0)- b^{T}E(\ell ^{'}_x(0))\}\) at first. We verify the Lyapounov condition as follows. For \(0< \eta <1\) and by condition (A7),
Then the asymptotic normality of \(\sqrt{nh}\{b^{T} \ell ^{'}_{x}(0)- b^{T} E( \ell ^{'}_{x}(0))\}\) is shown; that is,
Finally, by (17), (18), and (22),
This completes the proof of Theorem 2(a).
To show Theorem 2(b), note that the results in (a) depend on \(\gamma _0\) only through \(S_2(x; \gamma _0)\). From the definition of \(S_2(x; \gamma _0)\), it is clear that if \(\hat{\gamma }\) is \(\sqrt{n}\)-consistent, then \(F(Y; \hat{\gamma })\) is \(\sqrt{n}\)-consistent and the results in (21) and (22) continue to hold. \(\square\)
Proof of Theorem 3
(a) Given that \(\theta (\cdot )\) is known, the poof is similar to proofs for standard maximum likelihood estimators. First,
Then \(\sqrt{n} (\hat{\gamma }-\gamma _{0}) \approx -\sqrt{n}(\ell ^{*''}(\gamma _{0}))^{-1} \ell ^{*'}(\gamma _{0}).\) From (7), the first derivative of \(\ell ^{*}\) with respect to \(\gamma\) is
where \(\xi (Y; \gamma )\) is defined in condition (A8), \(\bar{F}(\cdot )= 1-F(\cdot )\), and \(F^{'}(\cdot )\) and \(\xi ^{'}(\cdot )\) are the first derivatives of F and \(\xi\) respectively with respect to \(\gamma\). Since \(E\{ \ell ^{*'}(\gamma _{0}) \}=0\), the bias of \(\hat{\gamma }\) is 0. We know that \(\ell ^{*''}(\gamma _{0}) = {n}^{-1}\sum ^{n}_{i=1}\ell ^{*''}_i(\gamma _{0}) \rightarrow _{p} E\{ \ell ^{*''}_i(\gamma _{0})\}\equiv T_1(\gamma _0)\). The expression of \(T_1(\gamma )\) is obtained by deriving \(\frac{\partial ^{2}\ell ^{*}}{\partial \gamma ^{2} }\) from (24) and then taking expectation,
For \(Var(\hat{\gamma }-\gamma _{0})\), based on (23), it is approximately \(T_{1}(\gamma _{0})^{-1} E\{(\ell ^{*'}(\gamma _0))^2 \} T_{1}(\gamma _{0})^{-1}.\) For \(E\{(\ell ^{*'}(\gamma _{0}))^2\}\), it is dominated by \(n^{-2}\sum ^{n}_{i=1}E\{ (\ell _i^{*'}(\gamma _{0}))^2\} \equiv n^{-1} T_{2}(\gamma _0),\) where
Moreover \(\sqrt{n}\ell ^{*'}(\gamma _{0})\) converges in distribution to \(N(0, T_2(\gamma _0))\). By Slutsky’s theorem, Theorem 3(a) is proved.
(b) When \(\theta (\cdot )\) is estimated at the rate in Theorem 2, the difference between the expected values of (24) with true \(\theta (x)\) and \(\hat{\theta }(x)\) for x evaluated at a data point \(X_{i}\) is of rate \(h^{(p+1)}\). The conditions \(nh^{2p+2} \rightarrow 0\) and \(nh \rightarrow \infty\) ensure that the asymptotic normality in (a) continues to hold. \(\square\)
III. Additional simulation results
This example is the same as Example 1 with \(n=200\) except that the censoring time \(C \sim U(0, 0.4)\), to increase the censoring rate. Then the censoring and cure rates are 26.8\(\%\) and 13.5\(\%\), respectively, which means \(13.3\%\) observations are censored but not cured. We want to examine whether the performance seen in Example 1 is affected after increasing the censoring rate. We first try the bandwidth \(h=\)0.2, 0.4, and 0.6 in step 2 of the proposed algorithm. When \(h=0.2\), the average \(\hat{\gamma }\) (sd) in step 2 is 7.293 (1.049), which is not as good as in Example 1. For \(h= 0.4\) and 0.6, the average \(\hat{\gamma }\)’s are 7.56 and 7.60 respectively, which shows a sizable difference from the true value 7. Hence we choose a smaller \(h=0.2\) in step 2 and the corresponding \(\widehat{se}\) and the average coverage probability are 1.398 and 96\(\%\) respectively. Then \(h=0.4\) and 0.6 are used in step 5 for estimating \(m(\cdot )\) and the average MSE (sd) are 0.062 (0.043) and 0.041 (0.032) respectively when \(\gamma\) is estimated. It is seen that \(\hat{m}\) has larger MSEs generally as compared to those in Example 1, and in step 5, using \(h=0.6\) has a smaller average MSE than that of \(h=0.4\). The estimated functions and their cure rates (not shown) were examined. Overall, the estimated curves exhibit more variability than those of Example 1. From this example, it is seen that increasing the censoring rate affects the choice of h and estimation of both \(m(\cdot )\) and \(\gamma\).
IV. Computation Time Discussion
The computation time of the proposed method is discussed in this section. We have recorded the time of (1) data generation, (2) parameter tuning using the CV method (Section 3.2 of the main paper), and (3) the estimation by using Algorithm 1. The results are summarized in Table 6 below. It shows that the computation time are in a reasonable range. The time for parameter tuning is around 9 times of the estimation time since we consider 9 candidate bandwidths. The parameter tuning process may be time-consuming but note that it can be further reduced by incorporating parallel algorithm to compute the CV scores for each bandwidth candidates and to compute the estimates of \(m(X_{i})\)’s in step 2 of Algorithm 1.
V. Additional Data Analysis Results
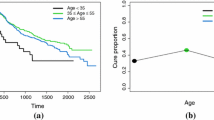
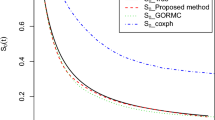
Although we have implemented an AIC based approach to select the baseline distribution family, it will be an interesting exploration to visualize the estimating curves using a different baseline distribution and to see if the resulting curves look different. The Weibull distribution family has been implemented in the Kidney transplant data analysis and the resulting curves with those from the exponential distribution (Fig. 3) are presented in Fig. 5. We observe that the results are only affected slightly and it does not affect our interpretations for this dataset.

Comparison of the Estimated Curves Using Two Baseline Distributions. a the estimated cure rates with exponential baseline (blue solid line) as in Fig. 3a, and with Weibull baseline (red long dashed line); b the corresponding \(\hat{m}(\cdot )\). The point symbols are the same as in the caption of Fig. 3
Rights and permissions
About this article

Cite this article
Lin, LH., Huang, LS. Promotion Time Cure Model with Local Polynomial Estimation. Stat Biosci (2024). https://doi.org/10.1007/s12561-024-09423-y
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s12561-024-09423-y