
Abstract
Landslides are a significant global hazard, especially prevalent in regions with high rainfall, active tectonic processes, and rugged topography, such as the Colombian Andean region. Therefore, it is crucial to identify areas prone to landslides in order to protect human lives and mitigate the adverse impacts on national economies, especially in developing countries situated in tropical and mountainous regions. Assessing landslide hazard and susceptibility is a fundamental step in comprehending the fundamental characteristics of slopes susceptible to failure, particularly under extreme rainfall conditions. Various researchers have devised methods and techniques to assess and map landslides, employing heuristic, statistical, and deterministic approaches. This study carried out a geographic information system-based approach for shallow landslides, with the objective to compare different methods for a landslide-event hazard mapping using the landslide records on May 18, 2015, triggered by a rainstorm in the La Liboriana basin (Colombia). In the first place, a fuzzy logic gamma model was applied using landslide conditioning factors. Then, the deterministic model TRIGRS was applied to assess shallow landslides. Finally, a support vector machine (SVM) model was used to obtain an intermediate scale solution. All models consider the rainfall that triggered the aforementioned landslide event. The results indicated that the SVM (radial basis function) model permits to obtain a better performance (AUC = 0.95) in landslide hazard zonation rather than quantitative heuristic fuzzy gamma model (AUC = 0.86) and the deterministic TRIGRS model (AUC = 0.60), obtaining best accurate at predicting the landslide hazard in the study area.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Identifying areas susceptible to landslides is a critical undertaking aimed at safeguarding human lives and avoiding negative effects on countries’ economies (Pradhan and Kim 2016). Developing countries located within tropical zones are significantly impacted by extreme climatic events. Also, active volcanic-seismic areas and instable areas produce significant higher levels of disaster risk arising from natural events (Frodella et al. 2022). Worldwide patterns on the loss of life caused by landslides clearly demonstrate that landslides pose a significant hazard, particularly in regions such as the Andean region. High rates of tectonic processes, complex relief, and intense rainfall patterns characterize this region, contributing to the heightened risk of landslides (Petley 2012).
The assessment of landslide hazards holds paramount importance in the Circum-Pacific region, encompassing tropical and mountainous countries, where rainfall-induced landslides are recognized as one of the most frequent causes of natural disasters (Ruiz-Vásquez and Aristizábal 2018), involving a complex problem, crucial to consider the associated economic impacts, including costs related to community relocation, reconstruction of damaged structures, and restoration of water quality in affected water sources (Vega and Hidalgo 2016). River or stream flooding caused by landslides in basins is a primary cause of both fatalities and significant economic losses in countries like Colombia (Hidalgo and Vega 2021).
On May 18, 2015, in the La Liboriana basin, a rainstorm triggered over 50 landslides followed by a devastating flash flood and debris flow. Tragically, these events claimed the lives of more than 100 residents and inflicted substantial economic losses and infrastructure damage. The repercussions extended far beyond the directly affected region, impacting distant areas as well.
Similar to the La Liboriana river, numerous regions of developing countries in the tropics, landslides-and-flash flood prone basins are usually located in inaccessible terrains of rural mountainous areas, with scarce or non-existent real-time hydro-meteorological information, imposing a challenge for their prediction, modeling, and, consequently, optimal risk management (Hoyos et al. 2019).
Landslide hazard assessment and landslide susceptibility analysis serve as essential tools for comprehending the fundamental characteristics of slopes prone to failure, particularly during episodes of intense rainfall. Consequently, numerous researchers have dedicated efforts to developing methods and techniques for evaluating landslide hazard and susceptibility. Typically, the assessment and mapping of these factors have relied on heuristic, statistical, and deterministic approaches.
Methods with heuristic approach employ direct mapping methodologies that establish correlations between landslide occurrences and the conditioning terrain factors. These methods rely on landslide inventories, typically conducted at large and medium scales. Furthermore, it implies that areas exhibiting similar conditions to those already affected by landslides are more susceptible to future events. Some studies have been conducted using knowledge-driven methods as fuzzy logic and multi-criteria decision-making methods (Kaur et al. 2018; Sur et al. 2020; Ali et al. 2021; Pham et al. 2021).
Deterministic models consider the influence of physico-mechanical properties of upslope deposit materials. They not only consider the influence of mechanical and hydraulic parameters such as soil cohesion, internal friction angle, soil hydraulic conductivity, and pore water pressure, but also specific triggering factors as rainfall (Si et al. 2020), which induce the landslide initiation, involving detailed site characterization, currently provide the highest prediction accuracy. The infinite slope method has gained significant popularity as a slope stability model in this type of approach, but it requires a notable simplification of the intrinsic variables to be suitable for local-area (i.e., sub-basin) scale mapping and analysis (Merghadi et al. 2020). Various studies have used deterministic models, as Transient Rainfall Infiltration and Grid-Based Regional Slope-Stability (TRIGRS) model (Marin et al. 2021a, b; Marin et al. 2021b), Shallow Slope Stability (SHALSTAB) model (Michel et al. 2014; Pradhan and Kim 2015; Si et al. 2020), Stability Index MAPping (SINMAP) model (Legorreta Paulin and Bursik 2009; Michel et al. 2014), SLIDE (Slope-Infiltration-Distributed Equilibrium) (Ortiz-Giraldo et al. 2023), and Steady-State Infinite Slope Method (SSIS) (Si et al. 2020) to measure the slope stability and assess the landslide hazard.
Regarding the statistical approach methods, these represent an indirect methodology for assessing susceptibility. It involves the statistical analysis of variable combinations that have historically contributed to landslide occurrences. All possible intrinsic variables or conditioning factors are entered and crossed into a geographic information system (GIS) for analysis with a landslide inventory map in a bivariate or multivariate way at large scale (Dahal et al. 2012). Obtaining precise and comprehensive historical landslide records, which serve as a crucial element for conducting appropriate susceptibility assessments, can often be challenging to acquire. With this approach, landslide susceptibility mapping (LSM) is initially assessed by considering the availability of the background information to reflect the influence of terrain on landslides, but the influence of the triggering mechanism is neglected. Such problems are responsible for a great component of the uncertainties in landslide susceptibility assessment (LSA) (Si et al. 2020).
Within this category can be included methods based on artificial intelligence using machine learning (ML) methods, although the margin between statistical modeling and ML is a matter of debate, since the association and differences between statistical modeling approaches and ML modeling approaches are not well explained in the LSA literature. Several ML approaches have been employed to obtain accurate landslide zonation maps for landslide identification and prevention (Gupta et al. 2018; Ma et al. 2021; Wang et al. 2021). The most common ML models correspond to random forest (RF), logistic regression (LR), artificial neural networks (ANN), support vector machine (SVM), and decision trees (DT).
This study carried out a GIS-based approach for shallow landslides, with the objective to compare different methods for a landslide-event hazard mapping using the landslide records on May 18, 2015, triggered by a rainstorm in the La Liboriana basin (Colombia). In the first place, a fuzzy logic gamma model was applied using landslide conditioning factors. Then, the deterministic model TRIGRS was applied to assess shallow landslides. Finally, a support vector machine (SVM) model was used to obtain an intermediate scale solution. All models consider the rainfall that triggered the aforementioned landslide event. Landslide studies using these models appropriately can support stakeholders’ decision-making processes to identify critical areas that need to be studied in more detail for protection purposes to achieve the United Nations’ 2030 Agenda for Sustainable Development. The methods used provide basic tools for landslide hazard analysis and their incorporation into basic land-use planning studies.
Landslide hazard assessment (LHA)
The term “landslide” refers to the downward movement of a mass of soil, debris, or rock along a slope. Conditioning and triggering factors play a primordial role in landslide formation and are typically incorporated into landslide maps. LHA methods permit to identify areas potentially affected by landslides, quantifies its likelihood of occurrence, and they permit to estimate the magnitude. Nevertheless, it is habitual that landslide hazard be represented by landslide susceptibility, which is the landslide probability of occurrence in a specific area, based on local terrain conditions by interaction of conditioning factors. Landslide hazard mapping can be defined as the mapping of areas with the same landslide occurrence probability considering a specified time.
Different comparison of methods for landslide hazard assessment and mapping and their limitations, assumptions, and applicability can be found in literature (Pradhan and Kim 2016; Sahana and Sajjad 2017; Huang et al. 2020; Ali et al. 2021; Pham et al. 2021). The existing methods can be categorized as either qualitative or quantitative. In the context of this study, a quantitative approach was adopted to represent hazard zoning. This involved establishing numerical relationships between landslide conditioning factors (LCF) and landslide occurrences.
Heuristic methods (HM) are subjective in nature as they rely on expert opinions regarding terrain properties that can potentially trigger instabilities. On the other hand, physically based models (PBM), often coupled with geo-hydrological modules, are commonly described by complex algorithms and heavily depend on a significant quantity of detailed geotechnical parameters. Statistically based models, as machine learning models (MLM), use empirical relationships between the observations and its underlying ground features instead of the complex physical relationships considered in the PBM (Lima et al. 2022).
Fuzzy gamma operator model
Zadeh (1965) was the first to introduce the fuzzy set theory to analyze mathematically non-discrete natural processes or phenomena (Sema et al. 2017). Fuzzy logic (FL) is a multivariate logic system that enables the representation of common knowledge using mathematical language. It achieves this through the utilization of fuzzy sets and associated characteristic functions. FL is very useful for handling complex problems, where conditioning factors are fuzzy by nature, showing complexity mechanism not fully understood (Zhang et al. 2022). The investigation of applying fuzzy set theory in GIS environments as a potential method for regional-scale landslide susceptibility assessment is being explored, because FL provides a way for handling spatial uncertainties and addressing the intricate relationships between conditioning factors and landslide occurrence (Kritikos and Davies 2015).
The concept of fuzzy logic (FL) involves spatial objects on a map as members of a set. In fuzzy set theory, membership is not limited to binary values but can take any value between 0 and 1, reflecting the degree of certainty of membership. The fundamental component of any FL model is related to obtain the membership function for associate the fuzzy linguistic terms to degrees of membership of a variable to a set (Kritikos and Davies 2015), and this specific function describes how landslide susceptibility varies regarding changes in a predisposing factor (Zhu et al. 2014). The critical step in the application of a FL model is to find the suitable fuzzy membership of conditioning factors (Zhang et al. 2022). In this work, the membership functions between landslide conditioning factors and landslide-event inventory data were derived using the landslide density derived from the frequency ratio in a GIS environment. Moreover, the linear, triangular, large, small, and gauss functions were implemented to obtain the fuzzified landslide conditioning factors (FLCF) with values ranging from 0 to 1.
Aggregation operations on fuzzy sets are employed to combine individual fuzzy sets into a unified one for the purpose of creating a hazard map by aggregating the FLCF. Bonham‐Carter (1994) shows and discusses the operators AND, OR, product, sum, and gamma. Also, sinus and cosines functions have been used considering direct or inverse proportionality between the value of the LCF and susceptibility to landslides (Salcedo et al. 2018). According to results of some papers in literature (Lee 2007; Kritikos and Davies 2015; Pradhan and Kim 2016; Zhang et al. 2022), the fuzzy gamma operator is more suitable, hence, in this study it was applied, establishing the relationships between the FLCF, and providing an approach between the increasing tendency of the sum operator and the decreasing effect of the product operator. Equation 1 defines the FL gamma operator using the fuzzy algebraic product and the fuzzy algebraic sum:
where “μx” is the aggregate membership value, “μi” is the fuzzy membership function for the ith parameter, “i” = 1, 2, 3…, n are the LCFs to be aggregate, and “γ” is a parameter ranged between 0 and 1. In the cases when γ is 1, the combination is the same as the fuzzy algebraic sum; and when γ is 0, the is the same as the fuzzy algebraic product. The parameter γ is usually based on expert opinion.
TRIGRS model
The TRIGRS model was specifically developed to simulate the potential occurrence of shallow rainfall-induced landslide by the use of the infinite slope method considering both transient pressure response and downward infiltration processes due to rainfall. The TRIGRS model has been widely published in many works of literature (Hsu and Liu 2019).
The TRIGRS model employs a 1D infinite slope stability approach, making it suitable for areas prone to shallow rainfall-induced landslides, including clay/silt planar slides or gravel/sand/debris slides, according to the update of the Varnes’ classification of landslide types proposed by Hungr et al. (2014). Uniformity is assumed in the slope within each soil type in terms of soil thickness and physical properties.
TRIGRS model is a coupled hydrological and geotechnical model to predict shallow rainfall-induced landslides by computing of the factor of safety (FOS) and the effect of transient pore-pressure changes at different depths (Baum et al. 2002). Equation 2 presents the formula for FOS calculation by measuring the ratio between the resisting basal Coulomb friction and the gravitationally induced downslope basal driving stress. When rainfall infiltration occurs (Inz/KZ > 0), it leads to an increase in the total pressure head of groundwater. This rise in pressure makes the slope prone to instability (FOS < 1).
where “ϕ” is the soil friction angle for effective stress [°]. “\(\delta\)” is the slope angle [°]. “c′” is the soil cohesion for effective stress [KPa]. “\(\psi \left(Z,t\right)\)” is a groundwater pressure head [m]. “t” is the elapsed time since the beginning of the rainstorm [s]. “γw” is unit weight of groundwater [kN/m3]. “γs” is soil unit weight [kN/m3]. “Z” is the vertical coordinate direction (positive downward) and depth below the ground surface [m] (Vieira et al. 2018).
Prediction of failure occurs when FOS < 1, while stability is maintained when FOS ≥ 1. The state of limiting equilibrium is reached when FOS = 1. Therefore, the depth Z at which the FOS first falls below 1 indicates the initiation depth of the landslide. This initiation depth depends on soil properties and the time and depth variation of pressure head, which, in turn, depends on rainfall history (Baum et al. 2002).
Support vector machine (SVM) model
Support vector machine (SVM) is an exceptionally robust, common, and promising supervised machine learning method widely used for classification and regression problems from the concept of structural risk minimization (Chang et al. 2020; Dou et al. 2020). It has become popular with the development of artificial intelligence and the widespread use of GIS and remote sensing (RS) (Huang and Zhao 2018).
SVM model has been recommended for its high accuracy in almost all cases (Pourghasemi et al. 2013; Lee et al. 2017) showing its better performance by a globally optimal solution, performing well with a small group of samples and a high dimensional classification problems in many studies (Huang and Zhao 2018; Zhou et al. 2018).
SVM is a highly effective classifier model that has been successfully applied to address numerous geohazard real-world problems, including landslide, flood, and forest fire prediction (Bui et al. 2019). SVM is framed on the basis of statistical learning theory minimization and can be resistant to overfitting (Dang et al. 2020).
In SVM modeling for discriminant-type statistical problems, two fundamental principles are employed, the determination of an optimal classification hyperplane that effectively separates data patterns, and the utilization of a kernel function to transform nonlinear patterns into a format that becomes linearly separable within a high-dimensional feature space (Fig. 1) (Lee et al. 2017; Huang and Zhao 2018). The aim of SVM classification is to find an optimal separating hyperplane that can distinguish between the two classes (i.e., landslides and non-landslides). The SVM has been used as a standard method in LSM.

© Larhmam, 2018, CC-BY-SA-4.0)
Support vector machine (SVM) model and different kernels considered in the study. Maximum-margin hyperplane and margins for an SVM trained with samples from two classes (in this study landslides and non-landslide). Samples on the margin are called the support vectors (adapted from SVM margin
SVM model uses a separating hyperplane to maximize the margin and enhance its generalization capability, addressing binary classification and regression problems in an effective way. The SVM’s decision function used to solve these tasks is expressed in Eq. 3.
where “\(\phi \left(x\right)\)” denotes the mapping of landslide sample “x” from the input space to a higher-dimensional feature space. By solving the optimization function, the optimal values of “w” (coefficient vector) and “b” (offset of the hyperplane from the origin) are determined (Eqs. 4 and 5).
Minimize:
Subject to the constraints following equation:
where “\({\xi }_{i}\)” denotes the slack variable. “C (> 0)” denotes the regularization variable of the errors, and a kernel function is computed by Eq. 6:
“k (.,.)” is a kernel function and “xi,j” are the training sample vectors. SVM encompasses four main categories of kernels: radial basis function (RBF), polynomial, linear, and sigmoid. These kernels provide a diverse range of options for capturing and modeling different types of relationships within the data. The two first kernels are the most used in the literature. Among these kernel functions, RBF is the most popular because it has fewer parameters and excellent ability to reflect the nonlinear relationship (Hu et al. 2020).
Study area, data, and processing
Study area characterization
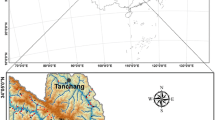
The La Liboriana basin served as a prime case study to showcase and implement the proposed comparison. This basin’s geological, geomorphological, and weather characteristics make it particularly prone to landslides and flash floods. Situated in the southwest of the Department of Antioquia, within the western branch of the Colombian Andes, the La Liboriana river basin is located in the municipality of Salgar. Figure 2 displays the elevation range within the study area, highlights the recorded landslide event on May 18, 2015, and indicates the location of the rainfall data point used in the analysis.

Location of the study area in the municipality of Salgar (Department of Antioquia), in the western branch of the Colombian Andean Mountain range. Landslides of 18th May 2015 are presented in cyan color
The mean elevation in the basin is 2487 m.a.s.l. with the highest elevation to Cerro Plateado (3609 m.a.s.l.). The outlet of the basin is at 1316 m.a.s.l. Almost a half of the total area of the basin presents slope gradients exceeding 30°. The Strahler-Horton order of the mainstream is 5, with a longitude and slope of 18.12 km and 8.1%, respectively. The longitudinal profile of the basin displays a pronounced steepness in the upper basin. These features are typical of Andean mountainous basins (Velásquez et al. 2018). The rainfall pattern exhibits significant variability at both inter-annual and inter-seasonal scales. The mean annual rainfall in the basin reaches 3073 mm.
From a geomorphological perspective, the basin is characterized by mountainous terrain featuring rugged morphology, narrow valleys, and highly steep forested hillslopes. Regarding vegetation and land use, the upper zone of the basin is dominated by a combination of crop fields and tropical deep forests. In the middle and lower zones, forested areas have been replaced by grasslands, coffee plantations, and banana plantations. Grazing areas and urban development are located in close proximity to the riverbanks.
The La Liboriana river basin is composed predominately by a Cretaceous sedimentary rock formation, an intrusive Miocene body, and Quaternary deposits. The sedimentary rocks found in the basin are classified as part of the Urrao member of the geological Penderisco formation. They constitute the primary component of a turbiditic succession, comprising approximately 5 km in thickness, consisting of arenites and mudstones. This geological unit encompasses roughly 93% of the total basin area. Additionally, there is a body of intrusive igneous rock known as Stock of Cerro Plateado composed of monzonite and monzodiorite rocks, and located in the westernmost part of the basin, accounting for approximately 2% of the basin’s total area. The site is in contact with sedimentary rocks, and at its boundary, it forms a contact aureole devoid of meta-sedimentary rocks (Marin et al. 2021a). Under the influence of the humid tropical climate, these rocks have undergone significant in situ weathering, forming well-developed saprolite and residual soils of different textures with a predominance of limes and clays (Ruiz-Vásquez and Aristizábal 2018). These soils are well-drained and characterized for a poor retention capacity. The first layer is predominantly composed of organic material, while the second layer consists mainly of clay loam soil. The depth of the soil is hillslope dependent (Velásquez et al. 2018). Finally, in relation to Quaternary deposits, they are closely associated with alluvial terraces and alluvial fans located in proximity to the La Liboriana river channel. These deposits predominantly consist of clay and silty-clay sediments.
Landslide conditioning factors (LCF)
Landslide factors can be categorized as causal or triggering factors. Causal factors play a significant role in enabling landslide occurrence, making it sensitive to triggering factors that initiate the mass movement (van Natijne et al. 2020). Under the assumption that past landslide occurrences provide insight into future events, it is believed that landslides are more prone to happen under similar conditions to those that triggered previous landslides, and various influencing factors and a landslide inventory map should be prepared before assessing the landslide risk (Chang et al. 2020). For this study, the landslide inventory in the La Liboriana basin, as documented by Ruiz-Vásquez and Aristizábal (2018), was used. The inventory was created by conducting a multi-temporal analysis of satellite images and aerial photographs, resulting in the identification of an area encompassing approximately 0.6 km2 of landslides. This area corresponds to approximately 1% of the total basin area. Nonetheless, only 33% of landslides in the used inventory correspond to landslides occurred on 18th May 2015 triggered by the rainstorm, which are shown in Fig. 2 (cyan color polygons). As landslide sampling strategy, multiple sample points throughout the whole landslide body were used (Lima et al. 2022). In some cases, using the whole extension of the landslide bodies might be an alternative to more complex coupled models (landslide release models with landslide propagation models) to identify potential landslide impact areas (Lima et al. 2023). In this work, and due to the limitations of the landslide inventory used as a reference, it is assumed that the landslide inventory polygons correspond to the affected area, without discretizing any of its interior parts as scarps or deposition zone.
In literature, various geo-environmental conditioning factors have been utilized to generate landslide susceptibility maps. However, selecting the appropriate factors is a crucial step due to the significant impact of pre-disposing (intrinsic) factor selection on the predictive capabilities of different models. The fundamental conditioning factors relate to the inherent characteristics of the terrain. In this work, the landslide conditioning factors (LCF) were primarily grouped into the following categories: terrain, drainage, soil, geological, coverage, and hydrological factors (Fig. 3). Subsequently, the frequency ratio (FR) method was employed to determine the non-linear correlations between landslide events and LCF, utilizing spatial analysis functions (Table 1).

Conditioning factors used for landslide analysis using a multi-approach of fuzzy logic, TRIGRS model, and support vector machine
The terrain and hydrological factors (excluding the antecedent rainfall index—ARI) were obtained from a high-resolution digital terrain model (DTM), 12.5-m spatial resolution. The DTM was obtained from ALOS PALSAR data provided by the Alaska Satellite Facility (https://asf.alaska.edu/data-sets/sar-data-sets/alos-palsar), through spatial analysis in ArcGIS Desktop 10.7 (https://desktop.arcgis.com) and SAGA GIS 7.7 (http://www.saga-gis.org) software.
Temperature and precipitation have a significant impact on soil moisture and exhibit variations with changes in elevation (Fig. 3A). Moreover, constructing roads at lower elevations in hilly or mountainous areas can contribute to an increased risk of landslides. The impact of elevation on landslides is not fixed and may vary depending on the geological and geographical context of the region under study (Nhu et al. 2020). When considering slope (Fig. 3B), it is important to note that all other factors being equal, steeper slopes are more susceptible to landslides. Therefore, slope plays a crucial role as a landslide conditioning factor (LCF) in landslide prediction modeling. Moreover, slope aspect (Fig. 3C) is associated with evapotranspiration patterns in hilly areas, making it another significant LCF in landslide susceptibility assessment.
Water infiltration and slope erosion are closely related to curvature (Fig. 3D), making it a commonly used factor in the development of landslide susceptibility models. Curvature also affects the flow of water across slopes. Topographic position and landform play a significant role in various physical processes, including landslides occurring on the landscape. These processes are often correlated with specific landforms such as hilltops, valley bottoms, exposed ridges, flat plains, and upper or lower slopes (Fig. 3E). Landforms were derived from the DTM using SAGA GIS software. Additionally, the terrain ruggedness index (TRI) captures small-scale features such as flanks of banks, boulder ridges, mud-draped gravel mounds, sand dunes, as well as gentle slopes of banks, valleys, and basins. TRI (Fig. 3F) was also obtained from the DTM using SAGA GIS software.
The frequency of landslides in mountainous regions is related to river’s density, partially through its effects on groundwater recharge (Nhu et al. 2020). Drainage density (Fig. 3G) is calculated using hydrological analysis methods applied to the DTM data. It represents the ratio of the total length (in kilometers) of the drainage network to the unit area (in square kilometers). Drainage density serves as an indicator of the balance between climate, geomorphology, and hydrology within the basin. A higher drainage density signifies increased sensitivity to rainfall, indicating that the basin is more prone to the effects of precipitation.
Soil depth (Zs) (Fig. 3H) was determined using a calculation procedure based on improved geomorphological relationships of the terrain, as outlined in Eq. 7 (Botero et al. 2015). This approach takes into account factors such as the distance from a given point to the streams and the distribution of slopes. It is observed that regions with flatter topography tend to have a higher sediment deposition rate, resulting in a greater accumulation of material and consequently a greater soil depth in these areas. Conversely, as the slope angle increases, the rate of sediment accumulation decreases, leading to a shallower soil depth and a tendency for rock outcrop. These geomorphological considerations contribute to understanding the spatial distribution of soil depth in the study area.
In addition to the factors mentioned earlier, the hypothesis takes into account the influence of the horizontal distance from a specific point to the nearest drainage. This interaction implies that as the horizontal distance increases, there is a greater tendency for the soil layer to grow, as expressed in Eq. 7. This relationship recognizes that the proximity to drainage networks plays a role in the accumulation and deposition of sediment, which contributes to the development of a thicker soil layer. By incorporating the distance from slopes into the analysis, the hypothesis acknowledges the combined influence of both topographic and hydrological factors in shaping the soil characteristics within the study area.
where “Zmin” and “Zmax” correspond to minimum and maximum values of soil depth (0.2 m and 2.5 m, respectively). “β” is the slope angle [°]. “βlim” is the assumed slope value as a limit of influence for altering the soil layer (in this study 45°). “\(a\)” is dimensionless parameter controlling the curvature (in this study 0.04 for tropical soils). “\(x\)” is the horizontal (Euclidean) distance from a point considered to the closest drainage [m].
The different characteristics inherent to the behavior of the lithological units such as strength, composition, and structure have a great effect on the stability of the slopes. Therefore, lithology plays an important role in assessing landslide susceptibility (Lee et al. 2017; Nhu et al. 2020). Lithological data (Fig. 3I) for the study area were obtained from 1:100,000 geology maps provided by the Colombian Geological Service (SGC) and digitized for the purpose of this study. These data have been previously utilized in other studies that employed physically based methods within the study basin (Marin et al. 2021a, b; Hidalgo and Vega 2021; Vega and Hidalgo 2021). The lithological information serves as a valuable input for understanding the geological composition and properties of the terrain, which are crucial factors in assessing landslide susceptibility and developing PBM.
The occurrence of landslides exhibits variations depending on the pattern of land-use, which serves as an indicator of the stability of hillslopes. The way in which land is utilized and modified can have a substantial impact on the stability of the terrain and contribute to the occurrence of landslides, and it influences the hydrological properties of hills such as water flow, which, in turn, is associated with triggering landslides (Lee et al. 2017; Oh et al. 2018). The landcover types were obtained by extracting information from the 1:100,000 land cover map provided by the Colombian Institute of Hydrology, Meteorology, and Environmental Studies (IDEAM) for the period 2005–2009. The land cover data were classified using the CORINE Land Cover Colombia (CLC) methodology, which provides a standardized classification system for land cover categories (Fig. 3J).
The normalized difference vegetation index (NDVI) is a widely used metric that quantifies the greenness and vegetation biomass in a given area. It is calculated based on the difference between the reflectance of near-infrared (NIR) and red-light wavelengths. Change in vegetation areas might lead to slope failures (Nhu et al. 2020). The normalized difference vegetation index (NDVI) data used in this study were derived from a Landsat 8 OLI sensor image captured on 11th January 2015, with a specific path and row (path 9, row 56) (Fig. 3K).
The stream power index (SPI) (Fig. 3L) is a valuable indicator for assessing the potential erosion caused by surface runoff, which can contribute to landslide occurrences. The SPI is calculated using Eq. 8, taking into account the slope gradient “β” [°] and the contributing area “A” [m2], both derived from the digital terrain model (DTM).
The terrain wetness index (TWI) (Fig. 3M) is a measure of water accumulation degree at a site (Eq. 9) (Nhu et al. 2020). The TWI provides valuable insights into the relationship between the characteristics of the terrain and the landslide occurrence. By considering the combined effects of topography and soil moisture content, the TWI helps to identify areas that are more susceptible to landslides. It is extensively employed in studies related to hydrology, soil science, and geomorphology.
To study the change in soil moisture over time for landslide hazard analysis, cumulative antecedent rainfall has been widely used in the literature, since it is a variable that is directly related to meteorological conditions and has greater availability compared to direct moisture data (not available in the study area). Short- and medium-term antecedent rainfall (the first days and up to 2 weeks before the event) are relevant for landslides (Gómez-García et al. 2023). The antecedent rainfall index (ARI) computes a weighted average of the most recent 7 days of rainfall, including the current date (Eq. 10). In this study, the used temporal windows for ARI calculation correspond to 7 days previous to 18th May 2015 landslide event (Fig. 3N) using satellite rainfall estimates between 11 and 17th May, which is detailed in the next section.
where “t” is the number of days before the present, “pt” is the precipitation [mm] at time t, and parameter wt = (t + 1)−2 (Kirschbaum and Stanley 2018).
Landslide triggering factor (LTF)
On May 18, 2015, the La Liboriana basin experienced a regional landslide event as a result of heavy rainfall. The rainfall intensity caused numerous landslides throughout the area, leading to the displacement of regolith and exposing underlying rock formations.
According to reports from the SIATA weather radar (early warning system for the city of Medellin and the Aburrá Valley), a significant rainfall event occurred between 10:00 pm on May 17 and 2:00 am on May 18. The western side of the basin was particularly affected, experiencing a very intense rainfall that covered approximately 30% of the total basin area. Over the course of 4 h, the rainfall accumulation reached 100 mm. Additional minor rainfall occurred until 7:00 pm on May 18, resulting in a total of 160 mm of rainfall in the upper part of the basin within a 24-h period. These continuous rains triggered around 160 shallow landslides in the area. However, in the La Liboriana basin, a total of 50 landslides were specifically identified and recorded (Ruiz-Vásquez and Aristizábal 2018). The combination of the heavy rainfall and the vulnerable geological conditions in the basin contributed to the occurrence of these landslides. The event served as a significant reminder of the susceptibility of the La Liboriana basin to such natural hazards and highlighted the need for effective monitoring and mitigation measures to ensure the safety of the area’s inhabitants and infrastructure.
NASA’s remotely sensed precipitation products, such as the Integrated Multi-satellitE Retrievals for Global Precipitation Measurements (IMERG) V06 Level 3 Final Run, provide valuable data for estimating rainfall accumulation worldwide in near real-time. For the analysis of the May 2015 rainfall in the La Liboriana basin, IMERG data at a spatial resolution of 0.1° and a temporal resolution of 30 min were utilized. The data were obtained from the NASA GPM (Global Precipitation Measurement) directory (https://gpm.nasa.gov/data/directory). The analyzed rainfall period extended from 9:00 pm on May 16 to 6:00 am on May 18, encompassing the time frame reported by SIATA for the main triggering event. This time interval was selected to ensure comprehensive coverage of the rainfall records during the critical period. The IMERG dataset provided valuable insights into the spatial and temporal distribution of rainfall in the study area.
To validate the IMERG data, records from two nearby rain gauge stations, La Mansa and Concordia, were also incorporated in the analysis. These rain gauge stations, operated by IDEAM, provided ground-based measurements of precipitation in proximity to the study area (as depicted in Fig. 2). Figure 4 visually presents the IMERG rainfall data for May 2015, alongside the recorded rainfall measurements from the La Mansa and Concordia rainfall gauge stations.

Rainfall data used for landslide assessment: rain gauge (IDEAM) and satellite-based (IMERG)
Processing of the conditioning factors and landslide inventory
Effective attribute selection is crucial in machine learning modeling as it not only reduces computation time but also enhances the overall performance of the models. By carefully choosing the relevant attributes, unnecessary noise and redundant information can be eliminated, allowing the models to focus on the most significant features. Various studies have demonstrated that there is not a standard number of LCF. Moreover, if its correlation increases, the prediction performance of a model can be reduced. Many LCF does not necessarily generate a better LSA. It could be associated to a high correlation between factors or a low correlation between the factors and the occurrence of landslides (Ruiz-Vásquez and Aristizábal 2018).
The accuracy of a machine learning model (MLM) can be significantly improved through a careful factor selection process. This is because certain landslide conditioning factors (LCFs) may introduce noise into the model, which can reduce its predictive capability. Therefore, it becomes essential to thoroughly examine and eliminate LCFs that exhibit low or negligible predictive power.
Multi-collinearity analysis
Before conducting the landslide susceptibility analysis, it is essential to assess the correlation between the fourteen conditioning factors and one triggering factor. This correlation analysis was performed using the IBM SPSS 25 software, which provided the necessary tools for statistical analysis (https://www.ibm.com/co-es/analytics/spss-statistics-software).
High correlation among independent variables can have a negative impact on the parameter estimates of the model and make it difficult to interpret the results accurately. To identify and address collinearity issues, several methods can be employed. One simple approach involves examining the correlation matrix, which provides an initial assessment of the relationships between variables. However, for a more reliable assessment, the variance inflation factor (VIF) and tolerance (TOL) can be used. A VIF value greater than 10 or a tolerance value less than 0.1 indicates a multi-collinearity issue in the LCF (Dou et al. 2020).
Frequency ratio analysis
Frequency ratio (FR) method is applied with the aim to determine the effects of landslide conditioning factors on its occurrence (Chang et al. 2020). FR method is utilized to assess the impact of conditioning factors on landslide hazard assessment (LHA). In this method, all the conditioning factors (LCF) are categorized into different classes, typically using classification methods like the natural break point method. Subsequently, the FR values are calculated by comparing the percentage of landslides to the percentage of the domain for each LCF. FR values greater than 1 indicate a higher correlation between landslide occurrence and the conditioning factors, implying a stronger influence. Conversely, FR values lower than 1 suggest a lesser effect on landslides. To standardize the FR values, they were derived based on landslide densities and then normalized to create new classes. These normalized FR classes served as input data for the machine learning modeling process.
In Table 1, a summary for each conditioning and triggering factor is presented. For numerical continuous LCF, an automatic reclassification process was undertaken considering a convenient manual interval reclassification method to produce classified data, because of the non-uniform distribution. Other authors have used different methods to determine the threshold values of the subclasses as Jenks natural break (Ye et al. 2022) and geometrical intervals (Merghadi et al. 2020). For categorical LCF, the classification remains the same as provided source data.
Figure 5 shows the fuzzy logic functions which were fitted considering the landslide density in the original classes of the landslide conditioning factors (LCF).

Landslide density and fuzzy functions of landslide conditioning factors (LCF)
Landslide inventory resampling
In landslide modeling studies, the first step involves collecting, mapping, and constructing a landslide inventory map (Merghadi et al. 2020). In this work, the landslide inventory documented in Ruiz-Vásquez and Aristizábal (2018) was used. About the inventory resampling procedure, random single holdout partitioning has been the most applied method in a literature review (Lima et al. 2022), and for this work, database entries for non-landslide areas have been obtained by random under sampling (RUS) method to obtain equal number of landslide occurrence samples (1:1 ratio). This ratio is recommended when the sampling area significantly exceeds the area impacted by landslides, and RUS can be used for achieving the best performance (Rodrigues et al. 2021). It was used by Ospina-Gutiérrez and Aristizábal-Giraldo (2021) in a similar geographical context in the Andean Mountain region. The balancing of this dataset is very important, since a machine learning method learns from the data provided and having the same number of samples in the classes (in this case landslide and non-landslide) is more convenient. Once the landslide dataset has been balanced, a feature selection (LCF) method was carried out.
Relief-F selection method
It is essential to assess the relevance of the conditioning factors (LCF) used for landslide hazard mapping. The Relief-F method, a probabilistic approach, is employed for this purpose as it assesses the conditional dependencies among variables and reveals the discriminative power of each variable for data classification.
This method quantifies the relevance of each variable by calculating a weight value known as “average merit” for each variable. Landslide conditioning factors with the weight values exceeding a certain threshold (in this study higher than 0) are selected for analysis. LCF assigned zero weight have no contribution to landslide occurrence and therefore, must be removed from further analysis (Hong et al. 2018; Dang et al. 2020). To assess the predictive ability of the conditioning factors, the Relief-F method was implemented using the WEKA open-source machine learning software (https://www.cs.waikato.ac.nz/ml/weka). In this study, a cross-validation strategy was employed, specifically the standard random fivefold cross-validation, for the Relief-F attribute selection method. This approach ensures robust evaluation and selection of the most relevant LCF for accurate landslide hazard assessment.
Landslide hazard modeling
This section outlines the methodology for landslide spatial modeling using the fuzzy gamma, TRIGRS, and SVM models. Figure 6 provides a comprehensive overview of all the phases involved in this process. The spatial modeling approach incorporates three main models: fuzzy gamma, TRIGRS, and SVM. Each model plays a crucial role in analyzing and predicting landslides within the study area. The combination of these models allows for a more comprehensive and accurate LSA. Figure 6 visually illustrates the step-by-step process of the landslide spatial modeling methodology. Each phase encompasses specific tasks, such as data preprocessing, feature selection, parameter calibration, model training, and validation. These phases are carefully designed to ensure a rigorous and reliable modeling process.

Methodology for landslide spatial modeling using fuzzy logic, physically based model, and machine learning approaches
Selecting best fuzzy gamma model
Using the LCF and landslide inventory, the relationships were calculated using the frequency ratio and landslide density. Next, the fuzzy membership values were computed as well. The fuzzy membership values of 13 LCF, excluding SPI, and the triggering factor were combined using the fuzzy gamma operator for landslide-hazard mapping. Five cases were modeling considering different values of γ parameter, between 0.70 and 0.90 (with steps of 0.05) to analyze its effect on the landslide hazard.
Parameterization of the TRIGRS model
Firstly, a 12.5-m resolution digital terrain model (DTM) was utilized to capture the topographic characteristics of the study area (Fig. 3A). From this DTM, slope and flow direction maps were generated, providing essential information for subsequent analyses. Based on the lithological map (see Fig. 3I), afterward, the study area was subdivided into three distinct property zones, with each zone representing the weathering soil of specific lithological units. These zones include Kaa and Tdt, characterized by silty clay soil; Qar, characterized by silty sand soil; and Tcf, characterized by sandy silt soil. To classify the soils accurately, the textural classes were assigned based on the US Department of Agriculture (USDA) textural triangle, which provides a standardized classification system for soil textures. This classification system, available on the USDA website (https://www.usda.gov), ensures consistency and compatibility in describing the different textural classes of soils within the study area.
The soil effective cohesion and soil internal friction angle were determined for each soil type according to used values by Marin et al. (2021a, b) and Vega and Hidalgo (2021). The average values of soil shear strength parameters were reviewed by comparing them with literature values for similar soil types. To calibrate these parameters, various combinations of mechanical properties were utilized, taking into account the analyzed rainfall events. The objective was to achieve the most accurate predictive results and simulate the observed landslides recorded in the reference landslide inventory. Through this calibration process, the mechanical properties were refined to ensure optimal alignment with the observed landslide behavior.
As established in accordance with Marin et al. (2021a, b), after evaluating various combinations of input parameters, the selection process focused on identifying the combinations that ensured stability results with FOS values greater than or equal to 1.0 (FOS ≥ 1) before the analyzed rainfall event. The optimal results were obtained when shallow landslides were predicted in the upper zone of the basin, while no landslides were anticipated in the remaining areas where no landslides were recorded in the landslide inventory.
The soil depth was adopted according to the soil depth map (Fig. 3H). This assumption considers the presence of a permeable surficial layer overlaying a less permeable substrate, such as regolith over bedrock. Additionally, the initial water table height was assumed at the same lower boundary of soil depth according to other authors running simulations with TRIGRS model (Marin and Velásquez 2020; Marin et al. 2021a, b; Aristizabal et al. 2022), who recently have obtained appropriate results in this study area and other areas of similar conditions in the Colombian Andean region.
The background rainfall rate at long term, referred to as the ILT, was determined by calculating the average multi-annual precipitation for the historically rainiest month (May) using the Climate Hazards Group InfraRed Precipitation with Station data (CHIRPS) (https://www.chc.ucsb.edu/data/chirps). The CHIRPS rainfall records from 1981 to 2016 in the La Liboriana basin were utilized to obtain an average precipitation value of 291 mm. This value was then used as the ILT constant (1.12 × 10−7 m/s) throughout the entire study area for all simulations.
The estimation of the saturated hydraulic diffusivity (D0) has been the subject of investigation by various researchers, who have found it to be a multiple of the soil hydraulic conductivity. The value of D0 is typically reported to range between 2 and 500 times the hydraulic conductivity (Ks). In this work, this parameter was defined with a value of 200 (D0 = 200Ks), according to other landslide susceptibility analysis using TRIGRS model (Hsu and Liu 2019).
A pedo-transfer function (PTF) is a mathematical function used to estimate indirectly soil hydraulic properties based on soil information, such as soil texture. These properties include the soil water retention curve (SWRC), representing the relationship between soil water content and matric suction. In this work, the estimation of soil hydraulic parameters for water flow simulation was performed using the van Genuchten model. This model is widely recognized as suitable for representing soil hydraulic behavior across various soil textures. TRIGRS model uses four hydrodynamic parameters to linearize Richards’ equation: saturated (θs) and residual (θr) water content, saturated hydraulic conductivity (Ks), and a parameter associated with pore size distribution according to Gardner model (αG).
Hodnett and Tomasella (2002) developed a pedo-transfer function (PTF) specifically for tropical soils to predict the parameters of the soil water retention curve (SWRC). They utilized regression techniques along with a non-linear least square fitting routine to adjust the van Genuchten parameters (θs, θr, αvG, n) based on water retention data. The PTFs were developed for different textural classes using readily available data, allowing for the prediction of hydraulic properties of tropical soils.
The hydraulic conductivity (Ks) exhibits significant spatial variability, even at small scales or within the same soil type (or textural class). Various pedo-transfer functions (PTFs) have been developed to estimate the equation parameters of the van Genuchten model, typically using indirect measurements based on the fractions of sand, silt, and clay. In this study, the hydrodynamic properties were predicted using the SPAW Hydrology software from the US Department of Agriculture (USDA), which considers soil grain size distribution. The adjustment process to the soil water retention curve (SWRC) was performed using the Gardner model, incorporating the mean, minimum, and maximum values of αvG and n, along with their respective standard deviations, based on the average values of θs and θr. The volumetric water contents were kept consistent between the van Genuchten and Gardner models, while the parameter αG was adjusted to ensure it fell within the limits of the van Genuchten curves. This process is documented in Marin et al. (2021a, b) and Marin and Velásquez (2020). The SWRC parameters determined by Marin et al. (2021a, b) were considered. Table 2 shows the hydrodynamic and geotechnical parameters used for TRIGRS modeling.
Three rainfall events were selected to characterize the rainfall parameters based on the analyzed rainfall interval. The first event occurred from 21:00 on 16th May to 10:00 on 17th May. The second event spanned from 11:00 to 21:00 on 17th May. The final event took place from 22:00 on 17th May to 6:00 on 18th May. Rainfall intensities were derived from the IMERG rainfall series and were spatially mapped in a raster format for each of the zones depicted in Fig. 3O.
Hyperparameters setting and sampling strategy for SVM models
To optimize the performance of the support vector machine (SVM) models in predicting landslide classes, an exhaustive grid search process was conducted. This process involved searching through a range of parameter values to identify the optimal combination. Table 3 provides the selected kernel parameters for each SVM model, which were determined through this optimization process.
The sampling strategy was a very important issue. For partitioning process of the training and testing samples, a randomly selected multiple times process was adopted, without a spatial component named “non-spatial cross validation” (Lima et al. 2022). The k-fold defines how many times the model is re-sampled and validated. The number of parameter k decides the ratio of training to testing ratio of validation, and, in most studies, the k value is randomly chosen as 5 (Abraham et al. 2021). For the purpose of training the models, a spatial fivefold cross-validation approach was used. This method involved dividing the data into 5 spatially distinct folds. In each iteration, the models were trained using data from four folds while the remaining fold was held out for testing. This process was repeated 5 times, ensuring that all data points were used for both training and testing. To maintain the balance of target classes in each fold, a stratified fivefold strategy was implemented using the Scikit Learn Library in Python (Pedregosa et al. 2011). This approach ensured that each fold contained a similar proportion of samples from each target class (0—non-landslide, 1—landslide), enabling a robust evaluation of the models’ performance. In this study, the used sampling strategy group landslides in two datasets, 70% for training and 30% for testing, and this process is repeated for each fold considered in the cross-validation process carried out. The cross-validation process was used with the aim to prevent overfitting issues, which occurs when a model performs well on the training data but fails to generalize to new, unseen data. The adopted process guided model selection, hyperparameter tuning, and other aspects of the modeling to improve the SVM model’s generalization performance.
Validation of landslide models
To assess the predictive capability of the three models, a ROC (receiver operating characteristic) analysis was conducted to carry out a validation process. The ROC analysis evaluates the performance of a classification model by plotting the true positive rate (TPR) against the false positive rate (FPR) at various classification thresholds. This method can be applied for the validation and evaluation of the performance of a model to predict classified values (Fawcett 2006), which allows to explain how well the model and the variables involved predict an event, in this case, a potential unstable zone leading to movement mass. Near to a half of the publications analyzed by Lima et al. (2022) included the area under the ROC curve (AUC), as one of the assessment quality evaluators. Although ROC method is commonly applied to the validation of statistical models of landslides susceptibility (Pourghasemi et al. 2013), it can also be applied to physically based models as TRIGRS model (Dikshit et al. 2019) and EPADYM (Evaluación Probabilística de Deslizamientos y Movimientos en Masa, in Spanish) model (Vega and Hidalgo 2021).
In the ROC analysis, the hit rate or TPR is calculated as a measure of the cells correctly classified as unstable, relative to the total number of positive cases (classified as landslide) in the inventory. Conversely, the false alarm rate or FPR is calculated as a measure of the cells incorrectly classified as unstable, relative to the total number of negative cases (classified as not landslide) in the inventory.
The area under the ROC curve (AUC) serves as a metric to assess the overall performance of the model. A higher AUC value indicates better performance. It quantifies the model’s ability to discriminate between landslide and non-landslide areas. In terms of accuracy classification, the rankings proposed by Hosmer and Lemeshow cited by Pradhan and Kim (2016) are considered as follows for the accuracy test: 0.90–1.0 (excellent), 0.80–0.90 (good), 0.70–0.80 (fair), 0.60–0.70 (poor), and 0.50–0.60 (fail). Overall, if the ROC (AUC) value is larger than 0.8, it indicates that the performance of the models is good (Hong et al. 2018).
The F1-score is a commonly metric for evaluating the performance of machine learning models which has been used in some landslide studies (Dias et al. 2021; Deng et al. 2022). In landslide susceptibility modeling, the F1-score is used to measure the balance between the model’s precision and recall. Precision refers to the proportion of predicted positive cases that are positive, while recall refers to the proportion of actual positive cases that are correctly predicted. The F1-score combines these two metrics into a single score that ranges from 0 to 1, with higher values indicating better performance. A high F1-score suggests that the model is achieving a good balance between identifying the locations that are likely to experience landslides while minimizing false positives. The F1-score can be calculated according to Eq. 11:
F1-score was used with the purpose to have other performance indicator for selecting the best SVM model according to each kernel.
Results
Landslide conditioning factor selection
A statistical analysis of landslide conditioning factors was carried out. Figure 7 shows the results of a correlation analysis of LCF and Table 4 shows the descriptive statistics of numerical conditioning factors. In general terms, a low correlation is notice between predictive variables, except for rainfall and ARI. All LCF present statistical significance to explain the landslide occurrences according to reported inventory in literature for study area, and therefore were good effective factors according to results of Pearson correlation coefficient. A considerable multicollinearity problem between LCF was not detected according to VIF results.

Correlation matrix of landslide conditioning factors (LCF)
The Relief-F method was used to inspect the conditional dependencies between LCF using a fivefold cross-validation process. SPI factor got an average merit equal to zero as hence it has no significant contribution to landslide occurrence, being excluded from ML modeling. Slope, curvature, soil depth, TWI, and TRI got a slightly average merit value, but it is considered that they have a slightly contribution to landslide occurrence. The elevation and landcover factor had the highest contribution according to Relief-F results.
Fuzzy gamma model
Regarding fuzzy γ parameter, values between 0.70 and 0.90 were considered to analyze its effect on the landslide-hazard map, but the case with gamma operator considering γ equal to 0.90 showed the best performance (AUC = 0.86). Across the range of γ values tested (0.70 to 0.85), the prediction accuracy showed consistent performance, with minimal variation. The choice of different γ values did not have a significant impact on the results. The resulting landslide-hazard maps generated with different γ values exhibited high similarity, and the prediction accuracy remained largely unchanged during the verification process. Figure 8 shows the results of landslide hazard assessment (LHA) using fuzzy gamma operator.

Landslide hazard map using fuzzy gamma model considering the analyzed rainfall event
TRIGRS model
A landslide hazard map in terms of FOS was obtained using the TRIGRS model (Fig. 9). Five hazard classes were considered for hazard zonation purpose. The performance rate of the TRIGRS model for the May 18th, 2015 event was just over the random prediction, it means, ROC (AUC) equal to 0.60.

Landslide hazard map (in terms of FOS) using TRIGRS model considering the analyzed rainfall event
SVM models
Several SVM models were tested using the Scikit Learn Library through a Python script for landslide analysis in the study area. Table 5 shows the results of each SVM classifier analyzed and its mean ROC (AUC) value. Using the RBF kernel function, the higher performance in terms of ROC analysis values was obtained (0.95), and for that reason this kernel was used for LSM in the study basin (Fig. 10) and five landslide susceptibility classes were adopted.

Landslide hazard map using the SVM RBF kernel considering the analyzed rainfall event
Discussion
Regarding landslide conditioning factor (LCF) selection process, other studies in this tropical region reported curvature and TWI as poor effective factors (Ruiz-Vásquez and Aristizábal 2018), and Ospina-Gutiérrez and Aristizábal-Giraldo (2021) consider slope as not adequate predictor variable since it does not differ in terms of landslide and exhibit different behavior when mass movement occurs in another tropical basin of Colombian Andean. Although the SVM simulations carried out considered the aforementioned three LCF, the results show acceptable prediction rates for unstable areas in the study tropical basin.
Fuzzy gamma model adopted for this research has been recommended for its high accuracy in different cases in literature (Sahana and Sajjad 2017; Zhang et al. 2022). It showed good performance and globally optimal solution in landslide susceptibility maps even though the subjectivity inherent of the heuristic methods, in this case of FL because the critical step finding the suitable fuzzy membership of landslide factors (Zhang et al. 2022). The issue is that there is no rule on which fuzzy membership values are assigned (Klai et al. 2020). So, the FR and landslide density approach were adopted to reduce the subjectivity of this issue. The results indicate that fuzzy gamma model is suitable to model landslide in the study area. Other studies also suggested its use in literature instead of other fuzzy operators (Kritikos and Davies 2015; Zhang et al. 2022).
As for the lower performance of TRIGRS model, we consider that the results were influenced by a deficit of accurate data inherent to the geomechanical and hydraulic properties of the soil. Several parameters were obtained from secondary sources. Also, the lower prediction rate is attributed to the accuracy of the landslide inventory map, particularly regarding the map’s completeness, especially of May 18th, 2015. Other aspect to consider is related to consideration of whole failure zone or landslide body registered in the inventory from Ruiz-Vásquez and Aristizábal (2018), and not only the landslide scar as other studies. In this way, it considers the cascade effect between adjacent failure cells assuming a stress transfer.
Special discussion deserves the topic of accurate of the rainfall, both spatially and temporal, with the purpose to incorporate it correctly in the slope stability models. In this regard, it is worth mentioning that the rainfall measured from satellite, in this case IMERG rainfall, tends to overestimate daily precipitation values in the region north-western of Colombia nearest to study area (Palomino-Ángel et al. 2019), and it has a low spatial resolution. Therefore, the study area was only represented in four rainfall zones, which do not reflect a completely variability of the complex rainfall patterns in the zone.
The model’s performance was influenced by additional factors related to rainfall, such as the initial water table height, antecedent rainfall, and soil moisture conditions. While some of these parameters were estimated based on existing studies, the influence of previous rainfall events on the water table and soil water content could not be considered due to data limitations.
Back analysis, a technique used by various researchers, was employed to determine input parameters for the TRIGRS model. This approach has yielded satisfactory results in previous studies conducted in the same basin. This kind of analysis is a good alternative to define the input parameters of physically based models in data-scarce environments such as the tropical mountain basin (Marin et al. 2021a, b) as the La Liboriana basin. However, the values obtained do not always faithfully represent the reality of the initial parameters of the models, and these are masked by other types of uncertainty.
The ROC (AUC) values obtained from the TRIGRS model fall within the range reported in some studies conducted in the same area, despite variations in the methodological workflow, input data values, level of detail, and the source of rainfall data used in the models. Marin et al. (2021a, b) obtained a performance close to AUC of 0.80 for the basin and an AUC of 0.55 for the upper part of the basin, considering FOS of the slopes as an indicator of stability and failure probability using TRIGRS, SLIP, and Iverson models. Hidalgo and Vega (2021) used EPADYM model to calculate the reliability index, failure probability, and FOS of a slope under dynamic and static conditions obtaining an AUC value of 0.56. In the aforementioned studies as well as in the present study, the scarcity of data derived from primary sources was a common factor that limited the applicability of the physical models especially at large scales.
Regarding the use of machine learning approaches in landslide assessment, comparing with other studies, SVM model provides good results in landslide susceptibility mapping (Achour and Pourghasemi 2020). In fact, same as other studies, the SVM-RBF model was the most suitable model for landslide assessment (Pourghasemi et al. 2013; Hong et al. 2017; Achour and Pourghasemi 2020). The SVM-RBF model demonstrated superior performance compared to previous studies conducted in the study area. In the research conducted by Ruiz-Vásquez and Aristizábal (2018), a multivariate statistical method (logistic regression) was employed to assess landslide susceptibility. The model was then validated using the May 18, 2015 landslide event through a ROC analysis, resulting in an AUC of 0.69. In contrast, our SVM-RBF model achieved higher accuracy and performance. This comparison suggests a better performance of kernel models over regression models under some similar considerations.
In other mountain regions with often intense rainfall have been carried out studies with similar AUC results using PBM (Pradhan and Kim 2015; Si et al. 2020). A case where the efficiency of MLM was better than the geomechanical model TRIGRS can be found in Liu et al. (2021), where the accuracy was about 82% against accuracies above 90% using random forest (RF), gradient boosted regression tree (GBRT), and multilayer perceptron neural network (MLP). In our study, the results indicate that the SVM-RBF model permits to obtain the better performance (AUC = 0.95) in landslide hazard zonation rather than quantitative heuristic fuzzy gamma model (AUC = 0.86) and the deterministic model TRIGRS model (AUC = 0.60), obtaining best accurate at predicting the landslide hazard in the study area. Also, it can be notice that fuzzy models permit to obtain results with an intermediate performance, outweighed statistical methods as bivariate frequency ratio or multivariate logistic regression and some machine learning models as other studies (Pham et al. 2021).
The method used to reclassify landslide map values was dependent on the histogram values. The landslides maps were obtained using the results of the models, which were categorized in five classes: very low, low, moderate, high, and very high classes, using natural break value distribution as is usual in other studies. Landslide-event hazard zones determined by the three models showed dissimilarities in very low, low, and moderate hazard zones, with standard deviation of 33.9%, 16.7%, and 25.5%, respectively. On the other hand, high and very high hazard zones had less difference between standard deviation values, 2.9% and 0.9%, respectively. Specifically, regarding the landslide map using SVM-RBF (Fig. 10), landslide inventory points fall into very low class in 10.2%, low 30.7%, moderate 16.8%, high 13.7%, and very high 28.6%. But at the basin level, a noticeable difference between very high (2.6%) and very low (91.0%) landslide hazard areas can be seen. Nonetheless, this is not due to an overfitting problem because to avoid overfitting issues, a stratified fivefold was implemented.
There is a lack of literature comparing different techniques, particularly multi-criteria evaluation, and machine learning algorithms, in the context of landslide mapping. Limited research has been conducted to directly compare the performance and effectiveness of these approaches in landslide mapping tasks. Recent studies showed higher accuracy and power of MLM in comparison to conventional statistical methods or heuristic approaches for landslide modeling (Ali et al. 2021). Nevertheless, in the past, very large areas were mostly assessed through HM due to the lack of computational resources to process large databases and the lack of comprehensive data to cover large territories (Lima et al. 2022).
In most cases, the selection of the modeling and mapping method considers the close relationship between study area size and data availability. Although site-specific analysis requires more locally detailed parameters assessments, some studies have tried to apply PBM for larger areas, but the spatial heterogeneity and variability of parameters still restrict its application to overly those areas, and consequently, data-driven approaches, as MLM, are more commonly applied at a regional scale using models with less restrictive data and complex physical requirements.
Conclusions
Landslides represent one of the most prevalent and complex natural geodynamic phenomena. In regions frequently impacted by landslides, such as tropical mountainous areas, there has been a noticeable increase in the number of landslide studies driven by researchers, as well as regional and local planners. This task is yet usually difficult because of terrain complexity, presence of vegetation, hydrometeorological conditions, and data scarcity.
Physically based models (PBM) necessitate thorough site characterization and demand substantial amounts of detailed data to yield reliable results, thereby incurring significant financial and computational costs. While PBMs currently offer the highest prediction accuracy and are well-suited for local-scale analyses, data-driven models such as machine learning models (MLM) are gaining popularity in environmental science research. MLMs can be integrated with geographic information systems (GIS) to enable large-scale analyses, effectively addressing non-linear and nonparametric problems like landslide hazard assessment (LHA).
In order to forecast potential shallow landslides in the La Liboriana basin, a comprehensive landslide hazard mapping exercise was conducted utilizing fuzzy logic, support vector machine (SVM), and the TRIGRS model. The fuzzy gamma operator and SVM models were employed, and the resulting combination of 14 conditioning factors and one triggering factor associated with landslide hazard was used to generate hazard maps. Additionally, the TRIGRS model was utilized to calculate five distinct instability classes based on the factor of safety (FOS) indicator. These calculations took into account the specific rainfall event that triggered the landslides and subsequent flash flood on May 18, 2015, in the upper zone of the basin. The results indicated that the SVM-RBF model permits to obtain a better performance (AUC = 0.95) in landslide hazard zonation rather than quantitative heuristic Fuzzy gamma model (AUC = 0.86) and the deterministic model TRIGRS model (AUC = 0.60), obtaining best accurate at predicting the landslide hazard in the study area.
This work contributes to the knowledge landslide hazard using ML by investigating the application of different kernel functions of SVM. According to this study, the SVM model with RBF function is the best kernel for the available scarce data, obtaining quite interesting results which indicate their suitability for predicting landslides comparably with a purely PBM approach using parameters obtained from secondary sources and a heuristic approach based in landslide density. The results of this research showed that used MLM approach is convenient delimiting landslide hazard areas for zonation purposes for land use planning and risk management.
Data Availability
The datasets generated and/or analyzed during the current comparison study are available from the corresponding author on reasonable request.
References
Abraham MT, Satyam N, Lokesh R, Pradhan B, Alamri A (2021) Factors affecting landslide susceptibility mapping: assessing the influence of different machine learning approaches, sampling strategies and data splitting. Land (Basel) 10. https://doi.org/10.3390/land10090989
Achour Y, Pourghasemi HR (2020) How do machine learning techniques help in increasing accuracy of landslide susceptibility maps? Geosci Front 11:871–883. https://doi.org/10.1016/j.gsf.2019.10.001
Ali SA, Parvin F, Vojteková J, Costache R, Linh NTT, Pham QB, Vojtek M, Gigović L, Ahmad A, Ghorbani MA (2021) GIS-based landslide susceptibility modeling: a comparison between fuzzy multi-criteria and machine learning algorithms. Geosci Front 12:857–876. https://doi.org/10.1016/j.gsf.2020.09.004
Aristizabal E, Garcia EF, Marin RJ, Gomez F, Guzman-Martinez J (2022) Rainfall-intensity effect on landslide hazard assessment due to climate change in north-western Colombian Andes. Rev Fac Ing: 51–66. https://doi.org/10.17533/udea.redin.20201215
Baum RL, Savage WZ, Godt JW (2002) TRIGRS — a Fortran program for transient rainfall infiltration and grid-based regional slope stability analysis, version 2.0. U.S. Geological Survey Open-File Report 02-0424 27. Retrieved from https://pubs.usgs.gov/of/2008/1159/downloads/pdf/OF08-1159.pdf
Bonham-Carter GF (1994) Geographic information systems for geoscientists: modelling with GIS, 1st edn. Pergamon, Ottawa, p 416
Botero EM, Azevedo GF, Souza HEMC, De Souza NM, Aristizabal EFG (2015) Estimativa da profundidade do solo pelo uso de técnicas de geoprocessamento, estudo de caso: Setor Pajarito, Colômbia. Anais XVII Simpósio Brasileiro de Sensoriamento Remoto - SBSR, João Pessoa-PB, Brasil, 25 a 29 de abril de 2015, INPE 4551–4558
Bui DT, Shirzadi A, Shahabi H, Geertsema M, Omidvar E, Clague JJ, Pham BT, Dou J, Asl DT, Ahmad BB, Lee S (2019) New ensemble models for shallow landslide susceptibility modeling in a semi-arid watershed. Forests 10. https://doi.org/10.3390/f10090743
Chang Z, Du Z, Zhang F, Huang F, Chen J, Li W, Guo Z (2020) Landslide susceptibility prediction based on remote sensing images and GIS: comparisons of supervised and unsupervised machine learning models. Remote Sens (Basel) 12. https://doi.org/10.3390/rs12030502
Dahal RK, Hasegawa S, Bhandary NP, Poudel PP, Nonomura A, Yatabe R (2012) A replication of landslide hazard mapping at catchment scale. Geomat Nat Haz Risk 3:161–192. https://doi.org/10.1080/19475705.2011.629007
Dang VH, Hoang ND, Nguyen LMD, Bui DT, Samui P (2020) A novel GIS-based random forest machine algorithm for the spatial prediction of shallow landslide susceptibility. Forests 11. https://doi.org/10.3390/f11010118
Deng N, Li Y, Ma J, Shahabi H, Hashim M, de Oliveira G, Chaeikar SS (2022) A comparative study for landslide susceptibility assessment using machine learning algorithms based on grid unit and slope unit. Front Environ Sci 10:1009433. https://doi.org/10.3389/fenvs.2022.1009433
Dias HC, Sandre LH, Satizábal Alarcón DA, Grohmann CH, Quintanilha JA (2021) Landslide recognition using SVM, random forest, and maximum likelihood classifiers on high-resolution satellite images: a case study of Itaóca, southeastern Brazil. Brazilian J Geol 51. https://doi.org/10.1590/2317-4889202120200105
Dikshit A, Satyam N, Pradhan B (2019) Estimation of rainfall-induced landslides using the TRIGRS model. Earth Syst Environ 3:575–584. https://doi.org/10.1007/s41748-019-00125-w
Dou J, Yunus AP, Bui DT, Merghadi A, Sahana M, Zhu Z, Chen CW, Han Z, Pham BT (2020) Improved landslide assessment using support vector machine with bagging, boosting, and stacking ensemble machine learning framework in a mountainous watershed, Japan. Landslides 17:641–658. https://doi.org/10.1007/s10346-019-01286-5
Fawcett T (2006) An introduction to ROC analysis. Pattern Recognit Lett 27:861–874. https://doi.org/10.1016/j.patrec.2005.10.010
Frodella W, Rosi A, Spizzichino D, Nocentini M, Lombardi L, Ciampalini A, Vannocci P, Ramboason N, Margottini C, Tofani V, Casagli N (2022) Integrated approach for landslide hazard assessment in the High City of Antananarivo, Madagascar (UNESCO tentative site). Landslides 19:2685–2709. https://doi.org/10.1007/s10346-022-01933-4
Gómez-García DE, Aristizábal E, García E (2023) Antecedent rainfall influence on landslides in the Colombian Andes. Revista De La Asociación Geológica Argentina, 80(2). Retrieved from https://revista.geologica.org.ar/raga/article/view/1658
Gupta SK, Shukla DP, Thakur M (2018) Selection of weightages for causative factors used in preparation of landslide susceptibility zonation (LSZ). Geomat Nat Haz Risk 9:471–487. https://doi.org/10.1080/19475705.2018.1447027
Hidalgo CA, Vega JA (2021) Probabilistic landslide risk assessment in water supply basins: La Liboriana River Basin (Salgar-Colombia). Nat Hazards 109:273–301. https://doi.org/10.1007/s11069-021-04836-0
Hodnett MG, Tomasella J (2002) Marked differences between van Genuchten soil water-retention parameters for temperate and tropical soils: a new water-retention pedo-transfer functions developed for tropical soils. Geoderma 108:155–180. https://doi.org/10.1016/S0016-7061(02)00105-2
Hong H, Pradhan B, Bui DT, Xu C, Youssef AM, Chen W (2017) Comparison of four kernel functions used in support vector machines for landslide susceptibility mapping: a case study at Suichuan area (China). Geomat Nat Haz Risk 8:544–569. https://doi.org/10.1080/19475705.2016.1250112
Hong H, Liu J, Bui DT, Pradhan B, Acharya TD, Pham BT, Zhu AX, Chen W, Ahmad BB (2018) Landslide susceptibility mapping using J48 decision tree with AdaBoost, bagging and rotation forest ensembles in the Guangchang area (China). Catena (Amst) 163:399–413. https://doi.org/10.1016/j.catena.2018.01.005
Hoyos CD, Ceballos LI, Pérez-Carrasquilla JS, Sepulveda J, López-Zapata SM, Zuluaga MD, Velasquez N, Herrera-Mejía L, Hernández O, Guzmán-Echavarría G, Zapata M (2019) Meteorological conditions leading to the 2015 Salgar flash flood: lessons for vulnerable regions in tropical complex terrain. Nat Hazard 19:2635–2665. https://doi.org/10.5194/nhess-19-2635-2019
Hsu YC, Liu KF (2019) Combining TRIGRS and DEBRIS-2D models for the simulation of a rainfall infiltration induced shallow landslide and subsequent debris flow. Water (Switzerland) 11. https://doi.org/10.3390/w11050890
Hu Q, Zhou Y, Wang S, Wang F (2020) Machine learning and fractal theory models for landslide susceptibility mapping: case study from the Jinsha River Basin. Geomorphology 351:106975. https://doi.org/10.1016/j.geomorph.2019.106975
Huang Y, Zhao L (2018) Review on landslide susceptibility mapping using support vector machines. Catena (Amst) 165:520–529. https://doi.org/10.1016/j.catena.2018.03.003
Huang F, Cao Z, Guo J, Jiang SH, Li S, Guo Z (2020) Comparisons of heuristic, general statistical and machine learning models for landslide susceptibility prediction and mapping. Catena (Amst) 191:104580. https://doi.org/10.1016/j.catena.2020.104580
Hungr O, Leroueil S, Picarelli L (2014) The Varnes classification of landslide types, an update. Landslides. https://doi.org/10.1007/s10346-013-0436-y
Kaur H, Gupta S, Parkash S, Thapa R (2018) Knowledge-driven method: a tool for landslide susceptibility zonation (LSZ). Geol Ecol Landsc 00:1–15. https://doi.org/10.1080/24749508.2018.1558024
Kirschbaum D, Stanley T (2018) Satellite-based assessment of rainfall-triggered landslide hazard for situational awareness. Earths Future 6:505–523. https://doi.org/10.1002/2017EF000715
Klai A, Haddad R, Bouzid MK, Rabia MC (2020) Landslide susceptibility mapping by fuzzy gamma operator and GIS, a case study of a section of the national road n°11 linking Mateur to Béja (Nortshern Tunisia). Arab J Geosci 13:1–10. https://doi.org/10.1007/s12517-019-5029-1
Kritikos T, Davies T (2015) Assessment of rainfall-generated shallow landslide/debris-flow susceptibility and runout using a GIS-based approach: application to western Southern Alps of New Zealand. Landslides 12:1051–1075. https://doi.org/10.1007/s10346-014-0533-6
Lee S (2007) Application and verification of fuzzy algebraic operators to landslide susceptibility mapping. Environ Geol 52:615–623
Lee S, Hong SM, Jung HS (2017) A support vector machine for landslide susceptibility mapping in Gangwon Province, Korea. Sustainability (Switzerland) 9:15–19. https://doi.org/10.3390/su9010048
Legorreta Paulin G, Bursik M (2009) Logisnet: a tool for multimethod, multiple soil layers slope stability analysis. Comput Geosci 35:1007–1016. https://doi.org/10.1016/j.cageo.2008.04.003
Lima P, Steger S, Glade T, Mergili M (2023) Conventional data-driven landslide susceptibility models may only tell us half of the story: potential underestimation of landslide impact areas depending on the modeling design. Geomorphology 430:108638. https://doi.org/10.1016/j.geomorph.2023.108638
Lima P, Steger S, Glade T (2022) Literature review and bibliometric analysis on data-driven assessment of landslide susceptibility landslide susceptibility. https://doi.org/10.1007/s11629-021-7254-9
Liu Z, Gilbert G, Cepeda JM, Lysdahl AOK, Piciullo L, Hefre H, Lacasse S (2021) Modelling of shallow landslides with machine learning algorithms. Geosci Front 12:385–393. https://doi.org/10.1016/j.gsf.2020.04.014
Ma Z, Mei G, Piccialli F (2021) Machine learning for landslides prevention: a survey. Neural Comput Appl 33:10881–10907. https://doi.org/10.1007/s00521-020-05529-8
Marin RJ, Velásquez MF, Sánchez O (2021a) Applicability and performance of deterministic and probabilistic physically based landslide modeling in a data-scarce environment of the Colombian Andes. J South Am Earth Sci. https://doi.org/10.1016/j.jsames.2021.103175
Marin RJ, Velásquez MF, García EF, Alvioli M, Aristizábal E (2021b) Assessing two methods of defining rainfall intensity and duration thresholds for shallow landslides in data-scarce catchments of the Colombian Andean Mountains. Catena (Amst) 206. https://doi.org/10.1016/j.catena.2021.105563
Marin RJ, Velásquez MF (2020) Influence of hydraulic properties on physically modelling slope stability and the definition of rainfall thresholds for shallow landslides. Geomorphology 351:106976. https://doi.org/10.1016/j.geomorph.2019.106976
Merghadi A, Yunus AP, Dou J, Whiteley J, ThaiPham B, Bui DT, Avtar R, Abderrahmane B (2020) Machine learning methods for landslide susceptibility studies: a comparative overview of algorithm performance. Earth Sci Rev 207:103225. https://doi.org/10.1016/j.earscirev.2020.103225
Michel GP, Kobiyama M, Goerl RF (2014) Comparative analysis of SHALSTAB and SINMAP for landslide susceptibility mapping in the Cunha River basin, southern Brazil. J Soils Sediments 14:1266–1277. https://doi.org/10.1007/s11368-014-0886-4
Nhu VH, Shirzadi A, Shahabi H, Singh SK, Al-Ansari N, Clague JJ, Jaafari A, Chen W, Miraki S, Dou J, Luu C, Górski K, Pham BT, Nguyen HD, Ahmad BB (2020) Shallow landslide susceptibility mapping: a comparison between logistic model tree, logistic regression, naïve Bayes tree, artificial neural network, and support vector machine algorithms. Int J Environ Res Public Health 17. https://doi.org/10.3390/ijerph17082749
Oh HJ, Kadavi PR, Lee CW, Lee S (2018) Evaluation of landslide susceptibility mapping by evidential belief function, logistic regression and support vector machine models. Geomat Nat Haz Risk 9:1053–1070. https://doi.org/10.1080/19475705.2018.1481147
Ortiz-Giraldo L, Botero B, Vega J (2023) An integral assessment of landslide dams generated by the occurrence of rainfall-induced landslide and debris flow hazard chain. Front Earth Sci Sec Geohazards Georisks 11. https://doi.org/10.3389/feart.2023.1157881
Ospina-Gutiérrez JP, Aristizábal-Giraldo EV (2021) Application of Artificial Intelligence and machine learning techniques for landslide susceptibility assessment. Rev Mex Ciencias Geológicas 38:43–54. https://doi.org/10.22201/cgeo.20072902e.2021.1.1605
Palomino-Ángel S, Anaya-Acevedo JA, Botero BA (2019) Evaluation of 3B42V7 and IMERG daily-precipitation products for a very high-precipitation region in northwestern South America. Atmos Res 217:37–48. https://doi.org/10.1016/j.atmosres.2018.10.012
Pedregosa F, Varoquaux G, Gramfort A, Michel V, Thirion B, Grisel O, Blondel M, Prettenhofer P, Weiss R, Dubourg V, Vanderplas J, Passos A, Cournapeau D, Brucher M, Perrot M, Duchesnay É (2011) Scikit-learn: machine learning in Python. J Mach Learn Res 12:2825–2830
Petley D (2012) Global patterns of loss of life from landslides. Geology 40:927–930. https://doi.org/10.1130/G33217.1
Pham QB, Achour Y, Ali SA, Parvin F, Vojtek M, Vojteková J, Al-Ansari N, Achu AL, Costache R, Khedher KM, Anh DT (2021) A comparison among fuzzy multi-criteria decision making, bivariate, multivariate and machine learning models in landslide susceptibility mapping. Geomat Nat Haz Risk 12:1741–1777. https://doi.org/10.1080/19475705.2021.1944330
Pourghasemi HR, Jirandeh AG, Pradhan B, Xu C, Gokceoglu C (2013) Landslide susceptibility mapping using support vector machine and GIS at the Golestan province, Iran. J Earth Syst Sci 122:349–369. https://doi.org/10.1007/s12040-013-0282-2
Pradhan AMS, Kim YT (2015) Application and comparison of shallow landslide susceptibility models in weathered granite soil under extreme rainfall events. Environ Earth Sci 73:5761–5771. https://doi.org/10.1007/s12665-014-3829-x
Pradhan AMS, Kim YT (2016) Evaluation of a combined spatial multi-criteria evaluation model and deterministic model for landslide susceptibility mapping. Catena (Amst) 140:125–139. https://doi.org/10.1016/j.catena.2016.01.022
Rodrigues SG, Silva MM, Alencar MH (2021) A proposal for an approach to mapping susceptibility to landslides using natural language processing and machine learning. Landslides 18:2515–2529. https://doi.org/10.1007/s10346-021-01643-3
Ruiz-Vásquez D, Aristizábal E (2018) Landslide susceptibility assessment in mountainous and tropical scarce-data regions using remote sensing data: a case study in the Colombian Andes. Geophysical Research Abstracts. 20th EGU General Assembly, EGU2018, Proceedings from the conference held 4-13 April, 2018 in Vienna, Austria, p 408. https://ui.adsabs.harvard.edu/abs/2018EGUGA..20.3408R
Sahana M, Sajjad H (2017) Evaluating effectiveness of frequency ratio, fuzzy logic and logistic regression models in assessing landslide susceptibility: a case from Rudraprayag district, India. J Mt Sci 14:2150–2167. https://doi.org/10.1007/s11629-017-4404-1
Salcedo D, Padilla Almeida O, Morales B, Toulkeridis T, (2018) Landslide susceptibility mapping using fuzzy logic and multi-criteria evaluation 1 techniques in the city of Quito Ecuador. https://doi.org/10.5194/nhess-2018-86
Sema HV, Guru B, Veerappan R (2017) Fuzzy gamma operator model for preparing landslide susceptibility zonation mapping in parts of Kohima Town, Nagaland. India. Model. Earth Syst Environ 3:499–514. https://doi.org/10.1007/s40808-017-0317-9
Si A, Zhang J, Zhang Y, Kazuva E, Dong Z, Bao Y, Rong G (2020) Debris flow susceptibility assessment using the integrated random forest based steady-state infinite slope method: a case study in Changbai Mountain, China. Water (Switzerland) 12. https://doi.org/10.3390/w12072057
Sur U, Singh P, Meena SR (2020) Landslide susceptibility assessment in a lesser Himalayan road corridor (India) applying fuzzy AHP technique and earth-observation data. Geomat Nat Haz Risk 11:2176–2209. https://doi.org/10.1080/19475705.2020.1836038
van Natijne AL, Lindenbergh RC, Bogaard TA (2020) Machine learning: new potential for local and regional deep-seated landslide nowcasting. Sensors (Switzerland) 20:1–18. https://doi.org/10.3390/s20051425
Vega JA, Hidalgo CA (2021) Methodology for landslides assessment causing river channel obstructions and the consequent water shortage in rural communities. In: Guzzetti F, Mihalić Arbanas S, Reichenbach P, Sassa K, Bobrowsky PT, Takara K (eds) Understanding and reducing landslide disaster risk. WLF 2020. ICL contribution to landslide disaster risk reduction. Springer, Cham, p 289–295 https://doi.org/10.1007/978-3-030-60227-7_32
Vega JA, Hidalgo CA (2016) Quantitative risk assessment of landslides triggered by earthquakes and rainfall based on direct costs of urban buildings. Geomorphology 273:217–235. https://doi.org/10.1016/j.geomorph.2016.07.032
Velásquez N, Hoyos C, Vélez J, Zapata E (2018) Reconstructing the Salgar 2015 flash flood using radar retrievals and a conceptual modeling framework: a basis for a better flood generating mechanisms discrimination. Hydrol Earth Syst Sci Discuss: 1–36. https://doi.org/10.5194/hess-2018-452
Vieira BC, Fernandes NF, Augusto Filho O, Martins TD, Montgomery DR (2018) Assessing shallow landslide hazards using the TRIGRS and SHALSTAB models, Serra do Mar, Brazil. Environ Earth Sci 77:1–15. https://doi.org/10.1007/s12665-018-7436-0
Wang H, Zhang L, Yin K, Luo H, Li J (2021) Landslide identification using machine learning. Geosci Front 12:351–364. https://doi.org/10.1016/j.gsf.2020.02.012
Ye Cm, Wei Rl, Ge Yg, Li Y, Junior JM, Li J (2022) GIS-based spatial prediction of landslide using road factors and random forest for Sichuan-Tibet Highway. J Mt Sci 19:461–476. https://doi.org/10.1007/s11629-021-6848-6
Zadeh L (1965) Fuzzy sets. Inf Control 8:338–353
Zhang Y, Chen J, Wang Q, Tan C, Li Y, Sun X, Li Y (2022) Geographic information system models with fuzzy logic for susceptibility maps of debris flow using multiple types of parameters: a case study in Pinggu District of Beijing, China. Nat Hazard 22:2239–2255. https://doi.org/10.5194/nhess-22-2239-2022
Zhou C, Yin K, Cao Y, Ahmed B, Li Y, Catani F, Pourghasemi HR (2018) Landslide susceptibility modeling applying machine learning methods: a case study from Longju in the Three Gorges Reservoir area, China. Comput Geosci 112:23–37. https://doi.org/10.1016/j.cageo.2017.11.019
Zhu AX, Wang R, Qiao J, Qin CZ, Chen Y, Liu J, Du F, Lin Y, Zhu T (2014) An expert knowledge-based approach to landslide susceptibility mapping using GIS and fuzzy logic. Geomorphology 214:128–138. https://doi.org/10.1016/j.geomorph.2014.02.003
Acknowledgements
Thanks to Valeria Madrid-Muñoz for her support on the tabulation of the rainfall data and fuzzy logic functions. As well to “High Level Training Program for Full-time Professors in their own Doctorates” of the Academic and Research Vice Rector’s Offices of the Universidad de Medellín, and the National Doctorate Program for Teachers of Higher Education Institutions of the Ministry of Science, Technology and Innovation. The research data for this study was provided by the research program “Vulnerability, Resilience, and Risk of Communities and Supplying Basins Affected by Landslides and Avalanches.” The program was assigned under the code 1118-852-71251, and it falls under the research project “Functions for Vulnerability Assessment due to Water Shortages by Landslides and Avalanches: Micro-basins of Southwest Antioquia.” The project was carried out through a contract 80740-492-2020 between Fiduprevisora and the Universidad de Medellín, with funding provided by the National Financing Fund for Science, Technology, and Innovation, known as the “Francisco José de Caldas” fund.
Funding
Open Access funding provided by Colombia Consortium
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no competing interests.
Additional information
Responsible Editor: Zeynal Abiddin Erguler
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Vega, J., Hidalgo, C. Comparison study of a landslide-event hazard mapping using a multi-approach of fuzzy logic, TRIGRS model, and support vector machine in a data-scarce Andes Mountain region. Arab J Geosci 16, 527 (2023). https://doi.org/10.1007/s12517-023-11627-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s12517-023-11627-3