
Abstract
High-quality hydrocarbon source rocks are present in the upper Cretaceous layer in the western slope of the Songliao Basin. Oil and gas have accumulated in these rocks at the shallow edge of the basin, which has led to the formation of oil sand resources. This study uses the back-propagation (BP) neural network method to predict the distribution of oil sand reservoirs and is the first study of its kind in China. First, based on the basic data collected by core sample, well log and geochemical analyses, and the reasonable selection of samples, the cores are divided into mudstone, siltstone, fine sandstone, medium sandstone, and sand, according to lithology. Second, a three-layer BP neural network model is constructed with two hidden S-type layers and one linear output layer. Third, through a comparison of the effect of different numbers of training sessions of the sample data, we demonstrate that the accuracy of the model can be increased to 90% after training the network 100,000 times. Then, the log-derived data of rocks with unknown lithologies are input into the neural network to predict whether they contain oil sands. We show that the BP neural network method can predict the distribution of oil sand reservoirs in the target horizon of the study area, and the results are consistent with research results on the corresponding sand reservoirs and sedimentary facies. Thus, we conclude that it is feasible to use the BP neural network method to predict the distribution of oil sand reservoirs.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
Introduction
As an unconventional oil and gas reservoir, oil sands have great potential. The amount of oil resources in oil sand worldwide is approximately 3.74 × 1012 barrels (Kramers and Mcssop 1987). In recent years, the reserves of conventional oil and gas resources have begun to decline sharply with the continuous development of these oil and gas resources. To solve this problem, a large number of scholars have carried out research on unconventional energy resources, including oil sand resources. Zhao et al. and Jin et al. (Zhao et al. 2008; Jin et al. 2008) studied the formation of oil sand deposits and the source of crude oil. Different reservoir-forming models of oil sand deposits have been established. Shan et al. (Shan et al. 2007) established the distribution range of China’s oil sand resources and pointed out that the oil sands are mostly distributed in sandstone reservoirs associated with rivers, lakes, and deltas.
At present, the evaluation of sandstone reservoirs includes many aspects, such as petrology, petroleum geology, logging, and petroleum engineering. The geological techniques used to evaluate the reservoir mainly include microscope observations, SEM observations, and X-ray diffraction analysis. In petroleum engineering, the reservoir is evaluated by observing capillary pressure curves obtained during high-pressure mercury tests. Logging can achieve quantitative or semiquantitative evaluation of reservoirs by calculating the values of physical properties.
Although the geological causes, storage conditions, and distribution patterns of oil sands have been investigated, a breakthrough in the evaluation and prediction of oil sand reservoirs has not yet been made, and no relevant research results have been published. Oil sand, as a unique sedimentary rock, can be evaluated by referencing the evaluation method of sedimentary rock reservoirs.
With the increasing maturity of neural network technology, many kinds of neural networks have been used to automatically judge the lithology of a formation, with good results (Zhang and Pan 2009; Zhang 2010). This logging identification method is used in low porosity and low permeability, dense sandstone and volcanic rock reservoirs (Yang et al. 2013).
In addition, Wang et al. (Wang et al. 2008) identified and predicted the presence of carbonate rock reservoirs mainly through artificial neural networks. Their research focused on identifying the degree of crack development in the rock. Yin et al. (Yin et al. 2013) predicted coal seam gas penetration using BP neural networks. The results obtained by the BP neural network model matched measured data well. Zhu et al. (Zhu et al. 2015) used a simulation model based on an improved neural network to predict the permeability of tight sandstone reservoirs. Zhou et al. (Zhou et al. 2017) evaluated the gas content of the Upper Triassic continental shale reservoir in the western Sichuan Basin using a BP neural network model. An ideal application effect was also achieved.
In this study, the BP neural network method is used to identify oil sand reservoirs. The purpose of this study is to establish a fast and accurate oil sand layer identification method to guide oil sand exploration in less-explored areas.
Geological setting
The Songliao Basin is an important oil and gas basin in China. However, conventional oil and gas resources have begun to decrease sharply, while the area is rich in unconventional energy resources represented by oil sand resources. Jia (Jia 2007) showed that the western slope of the Songliao Basin is rich in oil sand resources and has potential for development. The calculated geological resource is approximately 4.75×108 t, making it an important oil sand resource distribution area in China. A large number of scholars have carried out oil sand research and accumulated a considerable amount of basic research findings in this basin. At present, we have elucidated the geological conditions, sedimentary environment, and sedimentary system of the research area, but no in-depth and systematic study on the evaluation and prediction of oil sand reservoirs has been performed yet.
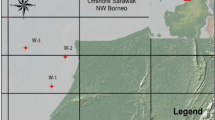
The chosen study area is located in an overlap zone on the western slope of the Songliao Basin. It is adjacent to the Taikang uplift zone in the northern Songliao Basin, the Taobao–Shuanggang high slope break zone in the southern Songliao Basin, and the Longhupao–Honggangzi terrace and the central sag (Fig. 1). In total, 100 wells were drilled in the study area before 2015 (Zhao 2015). The drilled formations mainly consist of Quaternary sediments, the Upper Cretaceous Nanjing Group (K2n), and the Yaojia Group (K2y). The oil and gas target layer is located in mainly the 2nd and 3rd sections of the Upper Cretaceous Yaojia Group (K2y2 and K2y3), which corresponds to the Salto oil layer. Oil accumulation in the study area mainly occurred during the subsidence period, and the mineral deposits were buried to depths of less than 220 m. The Yaojia Formation, which developed during the Upper Cretaceous (K2y) period, corresponds to delta front and pro-delta facies (Liu 2013; Luo 2013; Zhao 2015).

Location of the structure in the study area [modified from Zhao et al. 2017]
The highest-quality source rocks in the middle-shallow layer of the Qingshankou Formation (K2qn) in the central sag (Songliao Basin) reached the peak hydrocarbon generation stage in the middle and late stages of the subsidence period. In the late stage of the Yanshanian movement and early stage of the Himalayan movement (70–65 Ma), the generated oil and gas quickly and laterally migrated long distances via tectonic compression. This resulted in the formation of oil and gas migration channels in some shallow faults and along the sand bodies connected by faults. Oil and gas migrated to then accumulated in areas with good source-reservoir-cap assemblages. The evolution of the crude oil, including biodegradation, rinsing, and oxidation, changed its viscosity and resulted in a poorer fluidity, which in turn allowed it to accumulate in the shallow edge of the basin more easily (Luo 2013; Zhao 2015). Therefore, the distribution characteristics of the shallow oil and gas resources in the western slope of the Songliao Basin exhibit a pattern controlled by a far source (Liu 2013; Luo 2013).
There are mainly feldspar lithic sandstone and lithic feldspar sandstone and very little feldspathic quartz sandstone and arkosic sandstone in the study area. The rocks can be divided according to grain size into mudstone, siltstone, fine sandstone, medium sandstone, and some fine conglomerate. There are visible gas-liquid inclusions in some quartz particles, and some alteration is visible on the feldspar surfaces, resulting in a rough surface texture. Polysynthetic twinning is also visible, and the biodetritus mainly possesses an oolitic morphology (Fig. 2a), where the centers are felsic and the outer layers are ring calcite. There is a small amount of granular and flaky dark minerals and black mica particles with nonuniform particle sizes in a scattered distribution. A banded distribution of dark minerals is also visible (Fig. 2), which is mainly argillaceous cement between the particles; a small amount of this material is calcareous cement, and a small amount of the matrix is clay minerals (Fig. 2b). The particles are angular to subangular and exhibit moderate and poor sorting.

Thin-section photographs of samples from cores in the research area [modified from Zhao et al. (2017)]
There is a relatively low clay mineral content in the shallow oil sand reservoirs in the study area, and the clay minerals are mixed layers of illite, montmorillonite, and a small amount of kaolinite (Zhao 2015; Zhao et al. 2017) (Fig. 2c, d). There are mainly intergranular pores, secondary intragranular dissolved pores, and secondary enlargement pore types in the oil sand reservoirs in the study area. The measurement of the surface porosity and pore size is mainly based on thin section observations. In the laboratory microscopic imaging system, the pores and cracks are filled with dye, and the number and sizes of the dye-filled pores are identified and measured. Then, through the area ratio calculation, the calculated values of the pore face ratio and aperture can be obtained. The surface porosity is approximately 15%, the maximum pore size is 0.1–0.2 mm, the pore throat coordination number is 2–3, and the pores exhibit good connectivity.
Methodology
The BP neural network, which was proposed in 1986 by a group of scientists led by Rumelhart and McCelland (Rumelhart et al. 1986), is a neural network trained by the BP of errors. It is a type of feed-forward neural network, which is also known as a multilayer perceptron, and uses an error BP algorithm to perform the training.
There have been applications of this technique in the field of geology, as performed by foreign scholars (Murnion 1996; Suwansawat and Einstein 2006) and Chinese scholars (Xue and Pan 1999; Zhao and Gui 2005; Zou et al. 2006; Yan et al. 2008; Yang and Xia 2013; Zhang et al. 2017; Bi et al. 2019; Shi et al. 2019), but BP neural networks rarely have been used in oil sand reservoir distribution prediction.
Application
In this study, the BP neural network method was used to identify the oil sand layer. The BP neural network learns and trains the corresponding relationship between well logging data and core logging data to determine the implicit nonlinear correspondence pattern. By selecting the training samples of the typical wells in the study area, after sorting and screening, the most reasonable training samples are selected to establish the neural network training model. After the network training is completed, the oil sand layer prediction can be performed based on the unknown area of the existing logging data.
In the study area, there are five lithologies: mudstone, siltstone, fine sandstone, medium sandstone, and oil sand. Mudstone is often characterized by high natural gamma ray values, low resistivity values, and well diameter enlargement. Sandstone generally exhibits low natural gamma ray values, a variation in apparent resistivity, and small well diameters. In addition to sharing many general characteristics with sandstone, oil sand sometimes displays small increases in natural gamma.
There are 84 wells with logging data in the study area, and many types of logging data were collected. Among the data types, the natural gamma ray (GR, API), apparent resistivity (RT, Ω·m), density (DEN, g/cm3), neutron porosity (PORC, %), interval transit time (AC, μs/m), and calliper (CAL, mm) logging data best reflect the oil sand layer in the training samples. Other logging data types that are insensitive to the oil sand layer are eliminated.
Samples of each of the five lithologies were evaluated, and 4361 sets of well logging data in the study area were selected as the overall samples.
First, samples of the same type are merged. Samples of the same type have similar characteristics. The number of such samples will affect only the number of training sessions of the network and will not affect the convergence of the network. If a sample size is too large, the proportion of the training focused on that sample will increase, which will cause network overfitting, resulting in the insufficient training of other samples, which is not conducive to the stability of the network. When merging samples of the same type, the number of the different types of samples should be approximately equal. Because there are many mud rock samples from the study area, they are properly combined.
Second, the anomalous samples are deleted. Samples of the same lithology should have similar ranges of logging data (AC, CAL, GR, RT, DEN, and PORC). Some samples should be excluded because factors such as the logging instrument itself and the formation around the wellhead may cause the logging data to deviate from a reasonable range. Thus, the training samples are representative after the merging, eliminating and supplementing processes. Very few singular samples may be used in neural network training. They can be ignored if the proportion of such samples is less than 5% of the total number of training samples (Zhang and Pan 2009).
Finally, obvious samples are included. When an abnormal sample is deleted, it may result in an insufficient number of training samples of a certain type, and a sample with obvious lithology characteristics should be added to the training sample.
After the samples were merged, eliminated, and supplemented, there were 1287 sets of actual training samples (Table 1). The proportion of various types of rock samples in the training data was basically consistent with the proportion of formation lithology composition. Some of the data selected for the training samples are shown in Table 2. The normalized training sample data are shown in Table 3.
By considering the requirements of training accuracy and the computer configuration, we constructed a three-layer BP neural network model, which consisted of two S-type hidden layers and one linear output layer. Before network training, learning termination conditions were set, such as the maximum number of trainings, training accuracy, maximum number of failures, root mean square error, and minimum gradient requirements. The training process stops when any learning termination condition is met. The establishment process of the BP neural network is shown in Fig. 3.

The establishment process of the BP neural network in this study
Results
In this practical research, we carried out many tests, setting the training frequency to 10,000, 20,000, 50,000, and 100,000 times. By choosing reasonable training samples, after 100,000 network trainings, an accuracy rate of nearly 90% can be achieved (Fig. 4). The increased accuracy rate was not significant compared with the results from 50,000 training sessions (Table 4). Therefore, the training network was determined to be adequate. This network can meet the needs of research and can be used as a BP neural network to predict the distribution of oil sands in the study area. Figure 5 shows the result of the network prediction in a single well.

Accuracy of the network after 100,000 training iterations

Results of network prediction
After inputting the other (processed, screened, and normalized) logging data in the study area into the BP neural network, the predicted thickness of the oil sand at each well was obtained (Table 5). Then, a distribution map of oil sand thickness in the study area was drawn according to the predicted values (Fig. 6). Figure 6 shows that oil sand is widely distributed in the study area and that the areas with the thickest oil sand reservoirs are in the central, northern, and southern parts of the study area. The distribution trend is consistent with sedimentary facies research results (Luo 2013; Zhao 2015), which prove the feasibility of predicting the thicknesses of oil sand reservoirs by using a BP neural network.

The distribution of oil sand thicknesses obtained from the BP neural network
Discussion
-
(1)
The advantages and disadvantages of lithology prediction by using a BP neural network.
The BP neural network method obtains the recognition mode with its own unique sample training ability. Compared with the conventional logging interpretation method, the BP network model has great advantages in lithology prediction. As an effective method, the prediction results of the BP neural network can be used as a supplement to the conventional logging interpretation results or as a reference during interpretation. This method exhibits self-organization, self-learning, adaptation, fault tolerance, and anti-jamming characteristics. The input training data are unlimited in theory and can make full use of logging information. The calculation results are not related to the experience of interpreters; instead, the recognition results are objective and reliable. With learning, it is not necessary to establish a theoretical model in advance or to establish the mapping relationship between logging response and reservoir parameters adaptively by providing samples, overcoming the difficulty of nonlinear mathematical modelling in traditional logging interpretation methods.
The disadvantage of this method is that a large and extensive training sample is required. In the face of practical problems, there is often a situation in which there are too few training samples, which will directly affect the prediction effect of the network. Therefore, for neural network systems to have the desired effect, it is necessary to carefully select training samples based on the principles of extensiveness, representativeness, and comprehensiveness with respect to the geological patterns and remove samples with no geological significance.
-
(2)
Rationalizing the selection of training samples can help improve the compliance rate of forecast results.
A BP neural network is trained after it is built. The process of training is actually the process of adjusting the connections between neurons and the process of the neurons themselves adjusting to store information. These adjustments are entirely dependent on the training samples. Therefore, the representativeness and rationality of the training samples should not be ignored. Thus, in the training process of the neural network, a training sample should include some unreasonable samples. However, if too many unreasonable samples are included, the output of the neural network will deviate too much, resulting in a decrease in the prediction compliance rate.
-
(3)
The success rate of network training can be improved by appropriately increasing the number of training processes.
At the beginning of training, the information stored in each neuron and the connections between the neurons are randomly specified by the program. Although the initial value can be specified artificially, the initial values of different forecast networks are not the same. Through multiple training comparisons, a reasonable initial value can be derived. After artificial designation, the success rate of network training can be improved. In this study, it was concluded that 100,000 training sessions meet the requirements of neural network training by comparing the training effects of different training sessions.
-
(4)
The promotion of neural networks.
In this work, the ultimate goal of constructing a neural network is to predict the distribution of oil sand reservoirs in the uncored sections of the study area based on logging information. The vertical change in lithology of the uncored sections can be judged according to the observation data of a single well. The comparative analysis of many wells is often of practical significance to determine the horizontal change in lithology. For an oil region, the BP neural network method can be used to establish a suitable artificial neural network interpretation system. At the same time, attention should be paid to the impact of regional geological conditions. For the establishment and training of the network and the prediction of the results, geological factors should be used.
-
(5).
The comparison of lithology prediction between the BP neural network method and conventional lithology prediction method.
Compared with conventional lithology prediction methods, the prediction accuracy of the BP neural network method does not have outstanding advantages. However, from the point of view of the convenience of the method, the BP neural network method has the following advantages: the model is easily constructed, the number of learning samples can be conveniently changed at any time, and the network structure can be rapidly adjusted at any time. In addition, the BP neural network method requires less human interference. It makes full use of computational analysis and can greatly reduce the burden of researchers. In lithology prediction, the BP neural network method can be used as an effective method to supplement other manual prediction methods. With the development of computer technology and software technology, neural network methods are bound to continue improving, and the simulation of in situ formations will become increasingly detailed; thus, neural network methods may become widely used by oil exploration researchers.
-
(6).
The comparison with previous studies that used a BP neural network to predict other rock layers.
Some previous studies have indicated that the use of a BP neural network based on conventional logging data can accurately predict the distribution of sandstone and carbonate reservoir rock. The compliance rate can reach more than 90% in comparisons with core observation data and oil test data. In the prediction of the lithology of complex reservoirs such as igneous rock, some results are approximately 90% accurate, while some logging responses indicate a compliance rate of more than only 80% (Zhang et al. 2002, 2005; Zou et al. 2006; Zhao 2011; Yang et al. 2013). The results of this study show that the accuracy of the prediction results is close to 90% when using the BP neural network to predict the oil sand reservoirs. This application of oil sand reservoir prediction has achieved good results. The accuracy rate of oil sand reservoir prediction exceeds the accuracy rate of complex reservoir prediction.
Conclusions
-
1.
Through the selection of sample data and the construction and debugging of a BP neural network, the accuracy of the training samples in the BP neural network constructed by this research for identifying the oil sand reservoirs in the target layer in the study area is nearly 90%.
-
2.
After the other well logging data in the study area, which were processed, screened, and normalized, were input into the BP neural network, the predicted distribution map of oil sand thickness was obtained. The distribution trend was consistent with a regular sedimentary facies distribution pattern.
-
3.
The BP neural network method can accurately predict the distribution of oil sand reservoirs, which demonstrates that it may be a valuable tool for future studies.
References
Bi L, Xie W, Zhao JJ (2019) Automatic recognition and classification of multi-channel microseismic waveform based on DCNN and SVM. Comput Geosci 123:111–120. https://doi.org/10.1016/j.jappgeo.2018.09.022
Jia CZ (2007) Oil sand resources and evaluation methods of reserves. Petroleum Industry Press, Beijing (in Chinese)
Jin WH, Zhou W, Zhang YD, Yu L, Niu HL (2008) Mineralization factors of Baijiantan oil sand in northwest Junggar Basin. Spec Oil Gas Reserv 6(12-21):95 (in Chinese)
Kramers JW, Mcssop GD (1987) Geology and development of the Athabasca oil sand deposit. Can Min Metall Bull 69:92–99
Liu C (2013) The research on oil sand reservoir sedimentary microfacies and sandbody properties of Y2+3 on ZhenLai county in western slope of Songliao basin. Dissertation, Jilin University (in Chinese)
Luo HH (2013) The reservoir forming main control factors and distribution law of the Upper Cretaceous slope migration type oil sands in Songliao Basin. Dissertation, Jilin University (in Chinese)
Murnion DS (1996) Comparison of back propagation and binary diamond neural networks in the classification of a Landsat TM image. Comput Geosci 22:995–1001. https://doi.org/10.1016/S0098-3004(96)00037-4
Rumelhart DE, Hinton GE, McClelland JL (1986) A general framework for parallel distribution processing. In: Rumelhart DE, McClelland JL (eds) Parallel Distribution Processing, vol 1. MIT Press, Cambridge
Shan XL, Che CB, Li J, Fan YC, Zang CY, Wang QB (2007) Present status of oil sand resources at home and abroad. Glob Geol 4:459–464 (in Chinese)
Shi BB, Chang XC, Yin W, Li Y, Mao LX (2019) Quantitative evaluation model of tight sandstone reservoirs based on statistical methods - a case study of the Triassic Chang 8 tight sandstones, Zhenjing area, Ordos Basin, China. J Pet Sci Eng 173:601–616. https://doi.org/10.1016/j.petrol.2018.10.035
Suwansawat S, Einstein HH (2006) Artificial neural networks for predicting the maximum surface settlement caused by EPB shield tunneling. Tunn Undergr Space Technol 21:133–150. https://doi.org/10.1016/j.tust.2005.06.007
Wang ZD, Wang XH, Zhang W, Yang XM, Ping Y (2008) BP neural network model to recognize carbonate reservoir in Tazhong of Tarim Oilfield. J Oil Fas Technol 2:25+279–25+281 (in Chinese)
Xue LF, Pan BZ (1999) Identify lithofacies automatically using self-organizing neural network. J Changchun Univ Sci Technol 29:144–147 (in Chinese)
Yan B, Zhang QH, Wai Onyx WH (2008) Prediction of sand ripple geometry under waves using an artificial neural network. Comput Geosci 34:1655–1664. https://doi.org/10.1016/j.cageo.2008.03.002
Yang H, Huang JQ, Hu XT, Shi MY (2013) Application of BP neural net in lithologic identification of tight sandstone gas reservoirs. Pet Geophys 1:39–42 (in Chinese)
Yang WF, Xia XH (2013) Prediction of mining subsidence under thin bedrocks and thick unconsolidated layers based on field measurement and artificial neural networks. Comput Geosci 52:199–203. https://doi.org/10.1016/j.cageo.2012.10.017
Yin GZ, Li MH, Li WP, Cao J (2013) Model of coal gas permeability prediction based on improved bp neural network. J China Coal Soc 7:1179–1184
Zhang T (2010) Application of BP neural network in logging interpretation. Dissertation, Northwest University (in Chinese)
Zhang H, Zou LJ, Shen XH (2002) The application of BP neural network in well lithology identification. Geol Prospect 6:63–65 (in Chinese)
Zhang JL, Liu SS, Li JZ, Liu LL, Liu HM, Sun ZQ (2017) Identification of sedimentary facies with well logs: an indirect approach with multinomial logistic regression and artificial neural network. Arab J Geosci 10:247. https://doi.org/10.1007/s12517-017-3045-6
Zhang Y, Pan BZ (2009) Application of SOM neural network method to volcanic lithology recognition based on principal components analysis. Well Logging Technol 6:550–554 (in Chinese)
Zhang ZG, Yang YH, Xia LX (2005) Application of RPROP algorithm to well logging lithologic identification. J Jilin Univ (Earth Sci Ed) 3:389–393 (in Chinese)
Zhao C, Gui ZX (2005) Method and application of reservoir parameter prediction based on neural networks. J JPI 27:467–468 (in Chinese)
Zhao LC (2011) Application of BP neural network in identification of different lithology in logging interpretation. Dissertation, Zhejiang University (in Chinese)
Zhao Q, Wang HY, Liu RH, Bai WH, Zhang XW, Yang Z (2008) Oil sand mineralization mode and distribution features in Heiyoushan Area of the Junggar Basin. Nat Gas Ind 12:117–120 (in Chinese)
Zhao YT (2015) The Evaluation and Prediction of 0il Sands Reservoir in Western Slope, Songliao Basin: A case study in Zhenlai. Dissertation, Jilin University (in Chinese)
Zhao YT, Sun J, Shan XL (2017) Clay minerals in an oil-sand deposit and their effect on oil-bearing properties. Pet Sci Technol 35:578–585. https://doi.org/10.1080/10916466.2016.1266366
Zhou G, Li X, Huang B, Yu R, Sun W (2017) Application of optimized BP Neural Networks to gas content prediction of continental shale in upper Triassic of western Sichuan Basin. J Mineral Petrol 3:90–96
Zhu P, Lin C, Wu P, Fan R, Pu W (2015) Permeability prediction of tight sandstone reservoirs using improved bp neural network. Open Pet Eng J:288–292. https://doi.org/10.2174/1874834120150625E010
Zou W, Li R, Wang XW (2006) Application of BP neural network in the identification of tight sandstone reservoir on well logging data. PEG 29:428–432 (in Chinese)
Acknowledgements
We gratefully thank the anonymous reviewers for their thorough comments and constructive suggestions that helped to improve the manuscript.
Funding
The authors received financial support of the Shandong Provincial Natural Science Foundation (Grant No. ZR2020MD037) and the China Geological Survey Project (Grant Nos. DD20190211 and DD20160153).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no competing interests.
Additional information
Responsible Editor: Narasimman Sundararajan
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Sun, J., Zhao, Y., Yang, C. et al. Application of back-propagation neural networks in the distribution of oil sand reservoirs—a case study from the western slope of the Songliao Basin, China. Arab J Geosci 14, 290 (2021). https://doi.org/10.1007/s12517-021-06671-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s12517-021-06671-w