
Abstract
Purpose of Review
The length of telomeres, protective structures at the chromosome ends, is a well-established biomarker for pathological conditions including multisystemic syndromes called telomere biology disorders. Approaches to measure telomere length (TL) differ on whether they estimate average, distribution, or chromosome-specific TL, and each presents their own advantages and limitations.
Recent Findings
The development of long-read sequencing and publication of the telomere-to-telomere human genome reference has allowed for scalable and high-resolution TL estimation in pre-existing sequencing datasets but is still impractical as a dedicated TL test. As sequencing costs continue to fall and strategies for selectively enriching telomere regions prior to sequencing improve, these approaches may become a promising alternative to classic methods.
Summary
Measurement methods rely on probe hybridization, qPCR or more recently, computational methods using sequencing data. Refinements of existing techniques and new approaches have been recently developed but a test that is accurate, simple, and scalable is still lacking.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
Introduction
Telomeres are non-coding hexamer repeats located at the ends of eukaryotic chromosomes. They protect the genome from enzymatic degradation, and the loss of distal DNA that naturally occurs due to the end-replication problem, which would eventually lead to information loss due to the inability of the replication process to copy entire linear DNA molecules [1,2,3]. Average telomere length (TL) in humans ranges from 8 to 15 kb at birth and is reduced by 50 to 200 bp in healthy normal somatic cells after each cell division [1,2,3]. Once TL reaches a critical threshold (the Hayflick limit), cells become senescent and lose their capacity to replicate [3, 4]. TL has long been recognized as a biomarker for chronological cellular aging and over the ensuing years has also become a biomarker for a broad variety of diseases and conditions (e.g., cancer, infertility, diabetes, and cardiovascular disease) [1, 5,6,7,8]. Pathogenic variants in telomere maintenance genes may likewise result in abnormally shortened telomeres and cause multisystemic diseases collectively termed telomere biology disorders (TBD) that include idiopathic pulmonary and liver fibrosis, bone marrow failure and cancer predisposition among other manifestations [9,10,11,12,13].
Many approaches have been developed to measure TL, but no single method is at the same time accurate, simple and scalable [14, 15]. The terminal restriction fragment (TRF) assay is a southern blot-based method for measuring TL with high accuracy, but it is labor-intensive, technically difficult, and thus not suitable for large studies [16,17,18]. Fluorescence in situ hybridization (FISH) and its variation adapted to flow cytometry (flowFISH) is one of the most successful alternatives to TRF. FlowFISH measures average TL in blood samples and, in combination with different cell surface markers, can detect TL in different cell populations [19]. This method is scalable and easier to use than TRF, and it is the only test approved for clinical use according to the clinical laboratory improvement amendments (CLIA). Nevertheless, its broad implementation is limited by the need to identify enough control samples to define normal ranges, and therefore, it is only available in a small number of institutions (Johns Hopkins Laboratories and RepeatDx) [19]. Additionally, flowFISH is challenging to perform in non-hematological tissues, which can be an issue in some studies as TL in blood may not be representative of TL in other organs. Another approach uses qPCR to measure average TL [20, 21]. The latter are amongst the most commonly used, as they are simple to implement, scalable, and compatible with any tissue source [20, 21]. However, one limitation with these approaches is that they have proven to be irreproducible for TL accuracy from laboratory to laboratory due to the inherent variability of qPCR [20, 21]. Finally, with the increasing incorporation of sequencing data into research and clinical practice, several computational methods have been developed to estimate TL from this data [22]. Approaches using short read sequencing are scalable and compatible with DNA from any tissue source but are generally limited to reporting average TL only. Approaches using long read sequencing are capable of reporting the lengths of individual telomeres but are costly and still in their early developmental stages, requiring further research and validation to be translated into clinical practice.
In recent years, several refinements to these methods have been described; thus, it is critical to understand the advantages and limitations of these techniques in order to select the most appropriate for a given use case. In this review, we summarize the latest advances to measure TL using both bench-based and computational-based procedures (Fig. 1). We highlight the strengths and weaknesses of each technique (Table 1), provide guidance to select the most appropriate method, and describe how to interpret the different results.

Schematic representation of the different telomere measurement techniques described in the text, indicating targeted region of the telomere in each case. STAR: single telomere absolute-length assay; HT-STELA: high-throughput single telomere length assay; Ref: reference; TVR: telomere variant repeat
Telomere Structure and Considerations of Telomere Measurement
Healthy human cells contain 92 telomeres (23 chromosome pairs, 2 arms per chromosome) each with its own length [1,2,3]. This telomeric DNA is comprised of TTAGGG hexamer repeats, also referred to as “canonical” repeats. Adjacent to telomeres are subtelomeres, informally defined as the most distal 500 kb of each chromosome arm. Subtelomeres are highly variable regions with a high frequency of structural rearrangements observed across samples [1,2,3]. In between the telomeres and subtelomeres are telomere variant repeat (TVR) regions, which are typically 1–2 kb in length and contain variations of TTAGGG repeats, often modified by a single base substitution. The variable length of TVR regions introduces uncertainty in many methods for measuring TL and is often accounted for in the form of a corrective factor. Applying different TL measurement methods to the same sample may result in different TL estimations, as methods such as qPCR or FISH that estimate the length of the canonical sequence differ from approaches such as TRF that include the subtelomeric and TVR regions in their measurements, potentially overestimating TL. Finally, different measurement methods were designed to measure different features of telomeres. While most methods measure average length of all 92 telomeres (e.g., TRF and qPCR) [16,17,18, 20, 21], some techniques report the length distribution of all 92 telomeres (e.g., FISH), the number of shortened telomeres (e.g., TeSLA) [23], or telomere length of certain specific chromosome arms (e.g., STELA) [24].
Hybridization-Based Methodologies
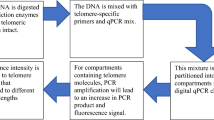
TRF was the first method developed to measure TL, and its usage has been foundational to studies of telomere biology since the 1990s. Its methodological details are described elsewhere [16,17,18], but in summary, genomic DNA is digested using restriction enzymes that retain telomeres intact; these fragments are then detected using a telomeric probe by southern blot. Telomeres are shown as a smear where average TL is identified by the most intense area in the lane. The main limitations of TRF are its requirements for high amounts of DNA (1–10 µg), a time-consuming and labor-intensive protocol, and low scalability. Additionally, TRF sensitivity decreases dramatically for very short telomeres (< 2 kb), and it is not able to identify the shortest telomeres in the sample [16,17,18]. Despite these limitations, TRF is still considered the “gold standard” for TL, and it has been the basis for later methods like single telomere length analysis (STELA) [24] and telomere shortest length assay (TeSLA) [23]. This section will describe recent improvements to this approach and will summarize other approaches that also depend on labeled telomeric probes to measure TL.
High-Throughput STELA
STELA was one of the first methods adapted from TRF [24]. It offered for the first time the ability to measure TL from specific chromosome arms, as opposed to other methods that were limited to reporting averages. STELA introduces a PCR step that uses telomere linkers and primers specific to a subtelomeric region of selected chromosome arm to amplify single telomeres that are then detected by southern blot. Thus, similar to TRF, STELA is labor intensive and not suitable to study a large number of samples. To overcome these limitations, Norris et al. adapted STELA as a high-throughput protocol (HT-STELA). [25] In this approach, specific chromosome arm telomeres (e.g., XpYp and 17p) are amplified through PCR, but samples are resolved using capillary gel electrophoresis instead of southern blot. Average telomere length is then determined using specialized software (e.g., PROSize and Agilent).
This approach has been used in studies including hundreds of samples across several use cases such as in TBD diagnosis or in predicting treatment response in patients with chronic lymphocytic leukemia [25, 26]. However, HT-STELA still has many of the limitations inherited from both TRF and STELA, including requiring large amounts of DNA and the fact that not all chromosome arms have unique sequences and thus cannot be analyzed with this approach, limiting its use to a small number of chromosome arms [25].
Telomere Combing Assay
The telomere length combing assay (TCA) measures TL using a telomere-specific peptide nucleic acid (PNA) probe over stretched DNA fibers on a glass cover slip [27]. Results can be analyzed manually or using an automated quantification software (provided by the Genomic Vision platform) for higher throughput testing. TCA measures individual telomeres and has a wide dynamic range (< 1 to > 80 kb) making it suitable for samples with both very short or very long telomeres (e.g., TBD and cancer, respectively) [27]. In this approach, absolute TL is estimated by using a constant stretching factor (2 kb/µm), and since individual telomeres are being measured, it also provides the distribution of TL [27]. TCA’s main advantages are simplicity, automation, and accuracy to measure all telomeres in the sample. However, it is limited by the need for specialized equipment, as well as its high cost and time-consuming protocol as compared to other methods.
High-Throughput Optical Genome Mapping
Optical genome mapping (OGM) was developed as an alternative to cytogenetics to detect copy number variation and structural anomalies in the genome [28]. This technique uses fluorescent labels that bind to specific sequence motifs, followed by uncoiling of the DNA molecules in nanochannels to analyze structural variations in a genome-wide manner. In more recent years, this technology has been applied to the analysis of telomeres and subtelomeres, where TL is measured via the intensity of TTAGGG-specific labels. The specific chromosome end from which a molecule originated is determined via its pattern of GCTCTTC motifs [29,30,31]. While this method has been able to provide an unprecedented characterization of subtelomere haplotypes, it requires specialized equipment and expertise in the use of these technologies. Additionally, the reported TL on benchmark samples exhibit high variance and telomeres of some chromosome arms can be missed if the sample preparation induces DNA breakage at fragile sites in subtelomere regions [32]. Additional validation of this technique is needed before it can be widely implemented in the field.
qPCR-Based Method for Telomere Length Measurement
Quantitative PCR approaches remain among the most cost-effective and scalable methods to measure average TL and thus are the most frequently used for large epidemiological studies [20, 21]. This method measures the quantity of telomeric DNA normalized to a single-copy gene, usually expressed as a T/S (telomere/standard) ratio that can be translated to absolute length using a reference sample with known TL [20, 21]. qPCR methods are flexible and can be used on any tissue source. Conversely, they exhibit high sensitivity to preanalytical (e.g., DNA isolation method) and analytical (e.g., PCR conditions) variables which lead to inconsistent results between laboratories and even between experiments within the same laboratory. Additionally, qPCR results can be confounded in situations where the copy number of the reference genes can vary (e.g., from aneuploidy or genetic instability). In order to address these limitations, some attempts have been made to develop guidelines on how to perform and report TL assessment by qPCR, as well as methodological refinements developed over the last years. In this section, we will present an overview of these guidelines as well as other recently developed qPCR-based techniques.
Standardized Guidelines for TL Reporting Using qPCR
There is growing interest in developing standardized guidelines to perform and report TL measurements through qPCR. One of the most significant standardizations was put forth by the Telomere Research Network (TRN), an initiative from the National Institute of Aging and National Institute of Environmental Health Sciences to establish best practices for the measurement of TL in population-based studies [33]. Other researchers have also published similar guidelines [21, 34]. All of them agree on three main areas for designing and reporting qPCR TL results: (A) report sample details including type, storage, DNA extraction method, and integrity; (B) qPCR assay employed; and (C) data analysis. Detailed criteria on each of these can be found on the TRN website (https://trn.tulane.edu/). Despite these efforts at standardization, these guidelines have not been widely adopted by the research community, and qPCR remains a highly sensitive approach potentially yielding variable results even when attempts are made to follow best practices.
Single Telomere Absolute-Length Rapid Assay
The single telomere absolute-length rapid (STAR) assay is a qPCR-based method to measure the absolute telomere length of single telomere molecules [35]. In this assay, telomeric repeat sequences in individual telomere molecules are measured using qPCR in nanoliter compartments in the presence of a double-stranded DNA binding dye. This allows real-time monitoring of the reaction kinetics in each individual compartment. Only compartments with telomere molecules show exponential increase in PCR product that is correlated to the TL of the initial telomere molecule. Different amplification kinetics in each compartment represent the heterogeneous distribution of TL in the tested sample [35]. This approach tackles several limitations of classic qPCR protocols like copy number variability of the standard genes or in the PCR reaction performance [35]. However, it requires specialized equipment, and to date, very few laboratories have used this approach, which makes difficult to predict its utility in practice.
Computational-Based Approaches to Estimate Telomere Length
As the costs of generating sequencing data continue to decline and its usage in research and clinical settings grows, there has been an increasing interest in using this type of data to estimate TL. “Short read” sequencing works by breaking the target DNA into short 50–300 bp fragments (“reads”) that are then amplified by PCR and aligned to a reference genome [36,37,38]. This approach is not suited to sequence highly repetitive sequences and therefore telomeres cannot be studied at nucleotide-resolution from short reads [36,37,38]. In addition to the length and sequence complexity of telomeres themselves, the variability of adjacent subtelomere regions that are not well represented in early versions of the human genome reference sequence (e.g., GRCh37 or GRCh38) also introduce uncertainty during read alignment. These issues have been improved by two recent developments: (A) The development of “long read” sequencing that generates reads from 10,000 to 100,000 bp, is improving the capacity to align reads to repetitive genomic regions, including telomeres [39,40,41,42] and (B) the release of the “telomere-to-telomere” (T2T) reference assembly [43]. A gapless human genome reference that resolved ~ 8% of the human genome still lacking from CRCh38. The T2T reference provides almost 200Mbp of novel sequence with high accuracy and included for the first time high-quality sequences for subtelomeres. In this section, we will describe the attempts to leverage short read and long read sequencing to estimate different aspects of TL, as well as a different approach using methylation sequencing data.
Short-Read Next-Generation Sequencing
TelSeq was one of the first methods developed to estimate TL from short read sequencing data. It has been extensively used in the field and methodological details have been described elsewhere [22]. TelSeq estimates TL by counting the number of reads with canonical telomere repeats (TTAGGG) and in some cases telomere variant repeats as well. Later methods designed around this principle differ primarily in how they discriminate reads originating from telomeres from other non-telomere regions such as interstitial telomere repeats [22, 44,45,46]. TelomereHunter [44] is a more recent tool that estimates average TL from counts of TTAGGG repeats, as well as telomere variant repeats TCAGGG, TGAGGG, and TTGGGG. Repeat composition and reference alignment position are used to categorize telomere repeats as intrachromosomal, subtelomeric and intratelomeric. Average TL is then computed from the intratelomeric repeats. These strategies were found to improve correlations of average TL with other methods such as qPCR and TRF. Other short read methods achieve similar filtering by using different combinations of repeats in tandem when querying reads for telomere sequences [47, 48].
Long-Read Next-Generation Sequencing
Long read sequencing, also referred to as third-generation sequencing, has been gaining attention in recent years due to significant improvements in throughput and affordability. The most frequently used long read sequencing technologies by Pacific Biosciences (PacBio) and Oxford Nanopore (ONT) produce high quality reads that are 10–20 kb in length [39,40,41,42], long enough to span the entirety of human telomeres in most use cases.
Among these methods, Telogator [49] is the first one to report chromosome-specific TL in human using long reads, building on earlier approaches that demonstrated the viability of clustering long reads at telomere boundaries [50, 51]. Telogator leverages the T2T reference genome and identifies reads that originate from telomere regions based on their pattern of canonical repeats. These reads are then “anchored” in the subtelomeres using a sequence alignment procedure. The major advantage of Telogator is its ability to estimate individual TLs for most of the 46 chromosome arms individually [49].
Approaches such as Telogator can estimate, from a single experiment, average TL, chromosome-arm specific TL, TL distribution, and potentially TL at the allele level [49]. It also opens the possibility of studying the biological significance of genomic variation in the subtelomeric regions. Long read sequencing is more costly than short read approaches, and it is impractical to generate long reads exclusively to measure TL. In this sense, selectively enriching telomere regions prior to sequencing [52] has shown promise in further reducing the cost of long read sequencing via sample multiplexing while also potentially capturing all telomere alleles. Though the read lengths generated by this approach are comparatively shorter and may not be viable for all studies. There are also considerations for read quality, as certain long read protocols can have systematic sequencing artifacts that affect telomeres [53]. Another approach recently developed for ONT (Telo-seq) [54] uses adapters that bind to the 3′ single stranded overhand at the end of the chromosome. The 5′ end of these telomere adapters is complementary to the sequencing adapter, allowing for the sequencing of the full telomere and the subtelomeric region. The lower cost of ONT makes this an attractive approach that is likely to become a preferred option in the early future.
All these technologies, however, are still in the early stages of development and the accuracy of determining from which chromosome end a read originated remains challenging even with long reads. The variability and homology between subtelomeres in different chromosomes can result in telomere alleles being misassigned to incorrect chromosome arms resulting in inaccurate measurements. The high rate of structural variation in subtelomeres may manifest as substantial differences between a sample’s sequence and the T2T reference. We expect that this limitation may be mitigated over time, either by further increases in the length of the reads, or as additional high quality subtelomere assemblies from different populations become publicly available, like the T2T-YAO [55] and T2T-Han [56] assembly or the pangenome references [57].
The advantage of methods that use sequencing data is that they are easy to run on existing datasets and are scalable for large studies. However, it is still impractical and costly to generate sequencing data with the sole purpose of measuring TL. Therefore, their application has largely been limited to datasets created for other purposes (e.g., genetic variant analysis). Despite these limitations, the high-resolution view enabled by long read approaches potentially facilitates broader comparative studies of individual telomere alleles and their relationship to senescence or telomere dysfunction. For example, applications to aging or aging-related disorders could provide insight into whether certain conditions are driven by the shortest telomeres, a subset of shortened telomeres, or reduced averaged TL.
DNA Methylation Estimator of Telomere Length (DNAmTL)
Similar to TL, methylation of cytosines in cytosine-phosphate-guanine dinucleotides (CpG) has emerged as an additional biomarker for aging. CpG methylation frequencies have formed the basis for machine learning algorithms to quantify “epigenetic clocks” with the goal of estimating the physiological age of any given sample. Using this approach, Dr. Lu et al. developed DNAmTL, an estimator that uses one of these biological clocks to estimate average TL in leukocytes using the methylation status of 140 CpGs [58, 59]. This method is very robust and outperformed leukocyte TL measured by TRF in several aspects, including correlation with age (r ~ − 0.75 for DNAmTL versus r ~ 0.35 for LTL), predicting time-to-death (p = 2.5E − 20), time to coronary heart disease (p = 6.6E − 5), time to congestive heart failure (p = 3.5E − 6), and association with smoking history (p = 1.21E − 17).
This method offers the clear advantage of using a single technique to measure at the same time two markers of aging (TL and CpG methylation). Nevertheless, this approach does not measure TL directly but, instead, offers an estimation of average TL using the predictive model developed by the authors [58, 59]. Therefore, in situations not resembling the training dataset, these estimations may not be completely accurate. For the same reason, these estimations are only valid for lymphocyte TL, needing to develop new models for TL estimation in other cell types.
Conclusions
Several options to measure TL have been developed and improved over recent years, but the search continues for a simple and scalable assay that achieves at the same time accurate results. Each technique has different strengths and limitations that need to be carefully considered to match the purpose of the research undertaken. New bioinformatic tools able to provide TL with a level of granularity not previously possible could provide an attractive alternative to the experimental techniques [60, 61] but are still costly and in need of further refinements. We anticipate that declining cost of long read sequencing and the use of telomere-enrichment approaches prior to sequencing will contribute to broader implementation of these techniques, shaping the future of telomere research.
Data Availability
Not applicable.
References
Turner KJ, Vasu V, Griffin DK. Telomere biology and human phenotype. Cells. 2019;8(1):73. https://doi.org/10.3390/cells8010073.
Harley CB, Futcher AB, Greider CW. Telomeres shorten during ageing of human fibroblasts. Nature. 1990;345(6274):458–60.
Liu J, Wang L, Wang Z, Liu JP. Roles of telomere biology in cell senescence, replicative and chronological ageing. Cells. 2019;8(1):54. https://doi.org/10.3390/cells8010054.
Gorgoulis V, Adams PD, Alimonti A, Bennett DC, Bischof O, Bishop C, et al. Cellular senescence: defining a path forward. Cell. 2019;179(4):813–27.
Rossiello F, Jurk D, Passos JF, d’Adda di Fagagna F. Telomere dysfunction in ageing and age-related diseases. Nat Cell Biol. 2022;24(2):135–47.
Fossel M, Bean J, Khera N, Kolonin MG. A unified model of age-related cardiovascular disease. Biol. 2022;11(12):1768.
Fasching CL. Telomere length measurement as a clinical biomarker of aging and disease. Crit Rev Clin Lab Sci. 2018;55(7):443–65.
Vasilopoulos E, Fragkiadaki P, Kalliora C, Fragou D, Docea AO, Vakonaki E, et al. The association of female and male infertility with telomere length (Review). Int J Mol Med. 2019;44(2):375–89.
Armanios M. The role of telomeres in human disease. Annu Rev Genomics Hum Genet. 2022;23:363–81.
Mangaonkar AA, Ferrer A, Pinto EVF, Cousin MA, Kuisle RJ, Klee EW, et al. Clinical correlates and treatment outcomes for patients with short telomere syndromes. Mayo Clin Proc. 2018;93(7):834–9.
Mangaonkar AA, Ferrer A, Vairo FPE, Hammel CW, Prochnow C, Gangat N, et al. Clinical and molecular correlates from a predominantly adult cohort of patients with short telomere lengths. Blood Cancer J. 2021;11(10):170.
Mangaonkar AA, Patnaik MM. Short telomere syndromes in clinical practice: bridging bench and bedside. Mayo Clin Proc. 2018;93(7):904–16.
Niewisch MR, Giri N, McReynolds LJ, Alsaggaf R, Bhala S, Alter BP, et al. Disease progression and clinical outcomes in telomere biology disorders. Blood. 2022;139(12):1807–19.
Dweck A, Maitra R. The advancement of telomere quantification methods. Mol Biol Rep. 2021;48(7):5621–7.
Lai TP, Wright WE, Shay JW. Comparison of telomere length measurement methods. Philos Trans R Soc Lond B Biol Sci. 2018;373(1741):20160451.
Mender I, Shay JW. Telomere restriction fragment (TRF) analysis. Bio Protoc. 2015;5(22). https://doi.org/10.21769/BioProtoc.1658
Lincz LF, Scorgie FE, Garg MB, Gilbert J, Sakoff JA. A simplified method to calculate telomere length from Southern blot images of terminal restriction fragment lengths. Biotechniques. 2020;68(1):28–34.
Kimura M, Stone RC, Hunt SC, Skurnick J, Lu X, Cao X, et al. Measurement of telomere length by the Southern blot analysis of terminal restriction fragment lengths. Nat Protoc. 2010;5(9):1596–607.
Alder JK, Hanumanthu VS, Strong MA, DeZern AE, Stanley SE, Takemoto CM, et al. Diagnostic utility of telomere length testing in a hospital-based setting. Proc Natl Acad Sci U S A. 2018;115(10):E2358–65.
Ferreira MSV, Kirschner M, Halfmeyer I, Estrada N, Xicoy B, Isfort S, et al. Comparison of flow-FISH and MM-qPCR telomere length assessment techniques for the screening of telomeropathies. Ann N Y Acad Sci. 2020;1466(1):93–103.
Lin J, Smith DL, Esteves K, Drury S. Telomere length measurement by qPCR - Summary of critical factors and recommendations for assay design. Psychoneuroendocrinology. 2019;99:271–8.
Ding Z, Mangino M, Aviv A, Spector T, Durbin R, Consortium UK. Estimating telomere length from whole genome sequence data. Nucleic Acids Res. 2014;42(9): e75.
Lai TP, Zhang N, Noh J, Mender I, Tedone E, Huang E, et al. A method for measuring the distribution of the shortest telomeres in cells and tissues. Nat Commun. 2017;8(1):1356.
Baird DM, Rowson J, Wynford-Thomas D, Kipling D. Extensive allelic variation and ultrashort telomeres in senescent human cells. Nat Genet. 2003;33(2):203–7.
Norris K, Walne AJ, Ponsford MJ, Cleal K, Grimstead JW, Ellison A, et al. High-throughput STELA provides a rapid test for the diagnosis of telomere biology disorders. Hum Genet. 2021;140(6):945–55.
Norris K, Hillmen P, Rawstron A, Hills R, Baird DM, Fegan CD, et al. Telomere length predicts for outcome to FCR chemotherapy in CLL. Leukemia. 2019;33(8):1953–63.
Kahl VFS, Allen JAM, Nelson CB, Sobinoff AP, Lee M, Kilo T, et al. Telomere length measurement by molecular combing. Front Cell Dev Biol. 2020;8:493.
Garcia-Heras J. Optical genome mapping: a revolutionary tool for “next generation cytogenomics analysis” with a broad range of diagnostic applications in human diseases. J Assoc Genet Technol. 2021;47(4):191–200.
Uppuluri L, Varapula D, Young E, Riethman H, Xiao M. Single-molecule telomere length characterization by optical mapping in nano-channel array: perspective and review on telomere length measurement. Environ Toxicol Pharmacol. 2021;82: 103562.
Young E, Abid HZ, Kwok PY, Riethman H, Xiao M. Comprehensive analysis of human subtelomeres by whole genome mapping. PLoS Genet. 2020;16(1): e1008347.
Young E, Pastor S, Rajagopalan R, McCaffrey J, Sibert J, Mak ACY, et al. High-throughput single-molecule mapping links subtelomeric variants and long-range haplotypes with specific telomeres. Nucleic Acids Res. 2017;45(9): e73.
Uppuluri L, Jadhav T, Wang Y, Xiao M. Multicolor whole-genome mapping in nanochannels for genetic analysis. Anal Chem. 2021;93(28):9808–16.
Lindrose ADS. Minimum reporting recommendations for pcr-based telomere length measurement [Internet]. OSF Preprints. 2020;93(28):9808–16. https://doi.org/10.1021/acs.analchem.1c01373.
Morinha F, Magalhaes P, Blanco G. Standard guidelines for the publication of telomere qPCR results in evolutionary ecology. Mol Ecol Resour. 2020;20(3):635–48.
Luo Y, Viswanathan R, Hande MP, Loh AHP, Cheow LF. Massively parallel single-molecule telomere length measurement with digital real-time PCR. Sci Adv. 2020;6(34):eabb7944.
Kumar KR, Cowley MJ, Davis RL. Next-generation sequencing and emerging technologies. Semin Thromb Hemost. 2019;45(7):661–73.
Hu T, Chitnis N, Monos D, Dinh A. Next-generation sequencing technologies: an overview. Hum Immunol. 2021;82(11):801–11.
Slatko BE, Gardner AF, Ausubel FM. Overview of next-generation sequencing technologies. Curr Protoc Mol Biol. 2018;122(1): e59.
Wang Y, Zhao Y, Bollas A, Wang Y, Au KF. Nanopore sequencing technology, bioinformatics and applications. Nat Biotechnol. 2021;39(11):1348–65.
Jain M, Koren S, Miga KH, Quick J, Rand AC, Sasani TA, et al. Nanopore sequencing and assembly of a human genome with ultra-long reads. Nat Biotechnol. 2018;36(4):338–45.
Hon T, Mars K, Young G, Tsai YC, Karalius JW, Landolin JM, et al. Highly accurate long-read HiFi sequencing data for five complex genomes. Sci Data. 2020;7(1):399.
Logsdon GA, Vollger MR, Eichler EE. Long-read human genome sequencing and its applications. Nat Rev Genet. 2020;21(10):597–614.
Mc Cartney AM, Shafin K, Alonge M, Bzikadze AV, Formenti G, Fungtammasan A, et al. Chasing perfection: validation and polishing strategies for telomere-to-telomere genome assemblies. Nat Methods. 2022;19(6):687–95.
Feuerbach L, Sieverling L, Deeg KI, Ginsbach P, Hutter B, Buchhalter I, et al. TelomereHunter - in silico estimation of telomere content and composition from cancer genomes. BMC Bioinformatics. 2019;20(1):272.
Nersisyan L, Arakelyan A. Computel: computation of mean telomere length from whole-genome next-generation sequencing data. PLoS ONE. 2015;10(4): e0125201.
Farmery JHR, Smith ML, Diseases NB-R, Lynch AG. Telomerecat: A ploidy-agnostic method for estimating telomere length from whole genome sequencing data. Sci Rep. 2018;8(1):1300.
Sun Q, Wang H, Tao S, Xi X. Large-scale detection of telomeric motif sequences in genomic data using TelFinder. Microbiol Spectr. 2023;11(2): e0392822.
Holmes O, Nones K, Tang YH, Loffler KA, Lee M, Patch AM, et al. qmotif: determination of telomere content from whole-genome sequence data. Bioinform Adv. 2022;2(1):vbac005.
Stephens Z, Ferrer A, Boardman L, Iyer RK, Kocher JA. Telogator: a method for reporting chromosome-specific telomere lengths from long reads. Bioinformatics. 2022;38(7):1788–93.
Grigorev K, Foox J, Bezdan D, Butler D, Luxton JJ, Reed J, et al. Haplotype diversity and sequence heterogeneity of human telomeres. Genome Res. 2021;31(7):1269–79.
Sholes SL, Karimian K, Gershman A, Kelly TJ, Timp W, Greider CW. Chromosome-specific telomere lengths and the minimal functional telomere revealed by nanopore sequencing. Genome Res. 2022;32(4):616–28.
Tham CY, Poon L, Yan T, Koh JYP, Ramlee MK, Teoh VSI, et al. High-throughput telomere length measurement at nucleotide resolution using the PacBio high fidelity sequencing platform. Nat Commun. 2023;14(1):281.
Tan KT, Slevin MK, Meyerson M, Li H. Identifying and correcting repeat-calling errors in nanopore sequencing of telomeres. Genome Biol. 2022;23(1):180.
Nanopore. 2023. https://nanoporetech.com/resource-centre/telo-seq-native-sequencing-of-individual-telomeres-on-r10-nanopores. Accessed 11/06/23
He Y, Chu Y, Guo S, Hu J, Li R, Zheng Y, et al. T2T-YAO: a telomere-to-telomere assembled diploid reference genome for Han Chinese. Genomics Proteomics Bioinformatics. 2023. https://doi.org/10.1016/j.gpb.2023.08.001
Yang C, Zhou Y, Song Y, Wu D, Zeng Y, Nie L, et al. The complete and fully-phased diploid genome of a male Han Chinese. Cell Res. 2023;33(10):745–61.
Liao WW, Asri M, Ebler J, Doerr D, Haukness M, Hickey G, et al. A draft human pangenome reference. Nature. 2023;617(7960):312–24.
Lu AT, Seeboth A, Tsai PC, Sun D, Quach A, Reiner AP, et al. DNA methylation-based estimator of telomere length. Aging (Albany NY). 2019;11(16):5895–923.
Pearce EE, Horvath S, Katta S, Dagnall C, Aubert G, Hicks BD, et al. DNA-methylation-based telomere length estimator: comparisons with measurements from flow FISH and qPCR. Aging (Albany NY). 2021;13(11):14675–86.
Castle JC, Biery M, Bouzek H, Xie T, Chen R, Misura K, et al. DNA copy number, including telomeres and mitochondria, assayed using next-generation sequencing. BMC Genomics. 2010;11:244.
Parker M, Chen X, Bahrami A, Dalton J, Rusch M, Wu G, et al. Assessing telomeric DNA content in pediatric cancers using whole-genome sequencing data. Genome Biol. 2012;13(12):R113.
Ethics declarations
Ethics Approval
Not applicable.
Competing Interests
The authors declare no competing interests.
Human and Animal Rights and Informed Consent
This article does not contain any studies with human or animal subjects performed by any of the authors.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ferrer, A., Stephens, Z.D. & Kocher, JP.A. Experimental and Computational Approaches to Measure Telomere Length: Recent Advances and Future Directions. Curr Hematol Malig Rep 18, 284–291 (2023). https://doi.org/10.1007/s11899-023-00717-4
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11899-023-00717-4