
Abstract
This work describes the convergence of the misalignment square norm (MSN) of the NLMS and LMS algorithms. It is shown that the MSN decrease is almost proportional to the mean square error (MSE). This allows obtaining simple expressions for the steady-state MSE. Also, it allows limiting the amount of time that the MSE takes large values and a curve that limits the MSE of LMS at any given time, independent of the input and background noise signals’ properties. Finally, it is also shown that many complications in the analysis of the LMS and NLMS algorithms can come from variations in the input vector square norm. The proposed analysis becomes very simple for long filters or constant power signals.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
The theory on the least mean square (LMS) [1, 2] algorithm dates back to the 1960s [3, 4], but comprehensive analyses of the algorithm using the independence assumption seem to have been published in the 1980s [5, 6]. The independence assumption [1, 7] states that the input data vector is statistically independent or that the filter weights are independent of the input data vectors. It has been shown that using this assumption and for moderate step sizes, the theoretical results agree very well with experiments. The convergence of the NLMS was also studied at that time [8]. After this, some results were obtained for non-Gaussian signals [9], and an exact analysis has been published [10]. The exact analysis uses mathematical software to obtain complex expressions for the convergence of the algorithm, resulting in results that agree with experiments also for large step s sizes. One work [11] shows that the LMS and NLMS algorithms are \(H^\infty \) optimum and limit the error signal’s power given the disturbances.
More recently, several efforts have been made to analyze the LMS algorithm without the independence assumption with a less complex theory than the presented in [10], namely using Butterweck iterative procedure [12,13,14,15,16,17]. Moreover, there is ongoing work to generalize the previous analysis to non-stationary and non-Gaussian inputs [7, 18,19,20]. There is also LMS algorithm variants analysis [21, 22]. This work proposes an analysis that allows obtaining some of the known results and new results easily.
2 The LMS and NLMS algorithms
Given a input signal x(n) and a desired response signal d(n), the LMS algorithm can be used to adapt a size N finite impulse response filter \(\textbf{w}(n)=[w_0, w_1, \dots w_{N-1}]^\textrm{T}\) to minimize the error between the filter output, \(y(n)={\textbf{x}^{\textrm{T}}}(n)\textbf{w}(n)\) and d(n), where \(\textbf{x}(n)=[x(n),x(n-1),\dots ,x(n-N+1)]^\textrm{T}\). The LMS algorithm is then described by [1, 2],
where \(\mu \) is the step size and e(n) is the error signal
Let, \(\textbf{w}_\textrm{o}\) be the filter that minimizes the mean square error (MSE) \({E}[e^2(n)]\) given by the Wiener filter [1], then e(n) can also be written by
where v(n) is the background noise and is uncorrelated to \(\textbf{x}(n)\). In the NLMS algorithm [1, 2], \(\mu \) is replaced by \(\mu /(\textbf{x}^\textrm{T}(n) \textbf{x}(n)+q)\) where q is a small regularization factor [23], resulting in:
The NLMS algorithm is stable for \(\mu <2\) [1]. In the following analysis, q is taken to be small or zero.
3 Variation of the misalignment square norm of the LMS
Let the misalignment be the vector formed by the error in the filter weights, \(\Delta (n)=\textbf{w}(n) - \textbf{w}_o\) then for both the LMS and NLMS algorithms
where \(\mu _\textrm{x}(n)=\mu \) for the LMS and \(\mu _\textrm{x}(n)=\mu /(\textbf{x}^\textrm{T}(n) \textbf{x}(n))\) for the NLMS, and
resulting in
This equation, although simple, is the main result of this work. It will be useful to get other results. Making \(e(n)=\epsilon (n)+v(n)\) where \(\epsilon (n)=-\textbf{x}^\textrm{T}(n)\Delta (n)\) results in,
From this equation, it is possible to obtain one first result. It is not possible to guarantee the stability of the LMS and NLMS algorithm for any input signal. In fact if \(\textbf{x}(n)\) is selected orthogonal to \(\Delta (n)\) so that \(\epsilon (n)=0\), both algorithms diverge since \({\Vert \Delta (n)\Vert }^2\) will in general increase. Of course, this condition is very unlikely to happen in practice since, generally, x(n) is independent of \(\Delta (n)\).
4 LMS with Gaussian signals
The following assumptions are used in this section:
-
1.
all signals will be taken to be Gaussian;
-
2.
x(n) is a stationary process;
-
3.
\(\textbf{x}(n)\) is independent of \(\Delta (n)\) that corresponds to the independence assumption of the LMS [1, 5, 7];
-
4.
v(n) is an independent identically distributed (i.i.d.) process.
Taking expected values on both sides of (8) results in,
where \(\delta (n)^2={E}[{\Vert \Delta (n)\Vert }^2]\), \(q_{\epsilon }(n)={E}[\epsilon ^2(n)]\), \(q_\textrm{v}={E}[v^2(n)]\), \(P_\textrm{T}(n)={\Vert \textbf{x}(n)\Vert }^2\) and \({\bar{P_\textrm{T}}}={E}[P_\textrm{T}(n)]\). Also, let \(q_\textrm{e}(n)={E}[e^2(n)]\) and \(q_\textrm{x}={E}[x^2(n)]\). Now,
and using the Gaussian moment factoring theorem [1] results in
where \(\textbf{R}={E}[\textbf{x}(n) \textbf{x}^\textrm{T}(n)]\), \(\textbf{K}(n)={E}[\Delta (n) \Delta ^\textrm{T}(n)]\) and noting that \(q_{\epsilon }(n)=\textrm{tr}\{\textbf{K}(n)\textbf{R}\}\) and \({\bar{P_\textrm{T}}}=\textrm{tr}\{\textbf{R}\}\). And, finally,
where
For the case of white noise \(\textbf{R}=q_\textrm{x}\textbf{I}\) results in \(\beta =1+2/N\). Also, note that \(\beta (n)\) is always less than three.
4.1 Steady-state mean square error and stability
It is known from LMS theory [1] that the convergence of \(\delta (n)\) does not exhibit oscillations. So, at steady state \(\delta (n+1)-\delta (n)=0\) and from (12) results in that,
; this result agrees with the results from [5, 6] for the Gaussian white noise case. Since, for stability, \(\delta (n+1)-\delta (n)\le 0\), the following limit for the step results in,
4.2 Limit on convergence time
Given a value for the excess noise power \(q_{\epsilon \mathrm{{x}}}\), one can limit the maximum time that \(q_{\epsilon }(n)\ge q_{\epsilon \mathrm{{x}}}\) by the time it would take to \(\delta (n)\) become zero using (12). Namely,
where \(\beta _\textrm{M}\) is the maximal value for \(\beta (n)\), resulting in
and the maximum excess noise at time n is obtained by merely rewriting the same equation as
5 NLMS with Gaussian signals
This section analyzes the NLMS using the same assumptions as in the previous section for the LMS. For the NLMS, taking expected values on both sides (8) results in
where \(\gamma _0(n)\) is such that
and \(\gamma _1\) is such that
Closed-form expressions for \(\gamma _0(n)\) and \(\gamma _1\) were obtained for white input signals. Using the independence assumption,
Diagonalizing \(\textbf{K}(n)\) (note that \(\textbf{K}(n)\) is symmetric \(\textbf{K}(n)=\textbf{K}^\textrm{T}(n)\) so the diagonalization matrix \(\textbf{Q}(n)\) is orthogonal \(\textbf{Q}(n)\textbf{Q}^\textrm{T}(n)=\textbf{I}\)) results in
where \(\textbf{K}(n)\textbf{Q}(n)=\varvec{\Lambda }(n)\textbf{Q}(n)\) and \(\varvec{\Lambda }(n)\) is a diagonal matrix with entries \(\lambda _i(n)\) and \(\textbf{u}(n)=\textbf{Q}(n)\textbf{x}(n)\). Now, since \(\textbf{x}(n)\) is Gaussian and white, \(\textbf{u}(n)\) is also Gaussian and white, and the expectation does not depend on i. Also,
Finally, this implies \(\gamma _0(n)=1\) since \(q_{\epsilon }(n)=q_\textrm{x}\textrm{tr}\{\textbf{K}(n)\}\) and \({\bar{P_\textrm{T}}}=q_\textrm{x}M\). To calculate \(\gamma _1\), note that (for white noise) \(P_\textrm{T}(n)\) has a chi-square distribution with N degrees of freedom with probability density function (PDF) \(\rho (x)\). Next,
and \(\gamma _1 = M/(M-2)\). Finally, [9] gets the following approximation for non-Gaussian signals \({E}\left[ 1/P_\textrm{T}(n)\right] = 1/(M+1-\kappa _\textrm{x})/q_\textrm{x}\) where \(\kappa _\textrm{x}\) is the kurtosis of x(n). It is also possible to obtain similar limits using the results in [11], for instance, (65), but these are looser bonds.
5.1 Steady-state mean square error and stability
Proceeding in the same way as for the LMS algorithm, one gets for NLMS,
Moreover, the algorithm is stable for \(\mu <2\). For the white noise case, \(\gamma _1/\gamma _0=M/(M-2)\). This is the same result as obtained in [8].
5.2 Limit on convergence time
For the NLMS,
where \(\gamma _{0\text {m}}\) is minimal value for \(\gamma _0(n)\). This gives the maximal time to reach an excess noise of \(q_{\epsilon \mathrm{{x}}}\),
and for the maximum excess noise at time n,
Similar but less general results appear in [9].
6 Constant input vector square norm signals
Most of the complications in the previous sections’ calculations come from the dependence between \(e^2(n)\) and \(P_\textrm{T}(n)\). If these signals are independent, then the analysis simplifies considerably. One such case is when \(P_\textrm{T}(n)\) is mostly constant. This can happen if \(x(n)^2\) is constant, for instance, in communications signals, or if the filter size N is large, making the fluctuations in \(P_\textrm{T}(n)\) small. In the previous sections, it was already shown that in the white noise case, the values of \(\beta (n)\), \(\gamma _0(n)\), and \(\gamma _1(n)\) become close to one for large N.
This section presents the same results as the previous sections but for constant \(P_\textrm{T}(n)=P_\textrm{T}\). These results are the same for the LMS and NLMS (with \(\mu =\mu _\textrm{x}=\mu _\text {LMS}=\mu _\text {NLMS}/P_\textrm{T}\)) and correspond in making \(\beta (n)\), \(\gamma _0(n)\) and \(\gamma _1(n)\) equal to one in the previous expressions. The previous results show that this approximation is fair even for moderate N.
Taking expected values on both sides of (7) results simply in
The steady-state MSE is
and the maximal MSE at time n is
7 LMS with the Cauchy–Schwarz inequality
In the case of the LMS algorithm, obtaining (9) requires v(n) to be i.i.d. However, it does not require the independence assumption, and it is possible to obtain a maximal value for \({E}[P_\textrm{T}(n)\epsilon ^2(n)]\) without using it. Namely, using the Cauchy–Schwarz inequality,
resulting that \(\beta (n)\) in (12) becomes
where \(\kappa _\textrm{x}= {E}[P_\textrm{T}^2(n)]/{E}[P_\textrm{T}(n)]^2\) and \(\kappa _{\epsilon }(n) = {E}[\epsilon ^4(n)]/ {E}[\epsilon ^2(n)]^2\) is the kurtosis of \(\epsilon (n)\). When x(n) and \(\epsilon (n)\) are Gaussian signals
\(\kappa _\textrm{x}\le 3\), \(\kappa _\textrm{x}= 1+2/N\) for white Gaussian signals and \(\kappa _{\epsilon }= 3\). Note, however, that in general \(\epsilon (n)\) is not Gaussian even with Gaussian input and background noise v(n). It is straightforward to obtain expression for the maximum MSE and other using these values. A value for the step that assures stability is \(\mu \le 2/({\bar{P_\textrm{T}}}\beta ) \le 2/({\bar{P_\textrm{T}}}\sqrt{\kappa _\textrm{x}\kappa _{\epsilon }})\).
8 Simulations
This section presents simulation results to confirm the theoretical findings from the previous sections. Simulations were run for the LMS and NLMS algorithms with a filter size of \(N=10\) and a Gaussian input signal with unit power. The charts result from 100 Monte Carlo runs with different optimal filters and signals during 1000 samples, unless stated otherwise.
The simulation of Fig. 1 shows the variation of the LMS algorithm misalignment square norm ensemble average \(\delta ^2(n) = {E}[{\Vert \Delta (n)\Vert }^2]\) with the squared error signal, more precisely \({E}[e^2(n)(2-\mu P_\textrm{T}(n))]\). The measurement noise signal power was \(q_\textrm{v}=0.1\). It can be seen that both quantities are linear dependent as predicted by (7). The chart shows three lines for three values for the step size \(\mu \).

The variation of the LMS algorithm misalignment square norm expected value with the squared error signal expected value: \({E}[-({\Vert \Delta (n+1)\Vert }^2-{\Vert \Delta (n)\Vert }^2)]\) versus \({E}[(2-\mu P_\textrm{T}(n))e^2(n)]\). The expected value is calculated using the values of 100 simulations. The data are for three values of \(\mu \): 0.01, 0.03, and 0.05

Theoretical (red) and experimental (blue) lines of the steady-state MSE of the LMS algorithm as a function of the step size. Lines for three values of \(q_\textrm{v}\) are shown: 0.01, 0.1, and 1. The input signal is colored noise (color figure online)

Theoretical (red) and experimental (blue) lines of the steady-state MSE of the LMS algorithm as a function of the step size for a long filter with \(N=100\). Lines for three values of \(q_\textrm{v}\) are shown: 0.01, 0.1, and 1. The input signal is colored noise (color figure online)
Figures 2 and 4 compare theoretical and experimental curves for the MSE of the LMS and NLMS algorithms as a function of the step size and different values of the measurement noise \(q_\textrm{v}\). Both charts use a colored input signal that results from filtering a white noise signal by a size ten filter with impulse response \(s(n)=\sin (2\pi n/5)\). The theoretical curves were obtained assuming a white noise input signal. The actual input is colored, but the difference in theoretical curves is not high for this power spectrum. They are all close to the long filter case, even for \(N=10\). The curves differ for very small steps because the experiments did not have time to reach a steady state.

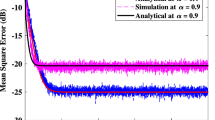
Theoretical (red) and experimental (blue) lines of the steady-state MSE of the NLMS algorithm as a function of the step size. Lines for three values of \(q_\textrm{v}\) are shown: 0.01, 0.1, and 1. The input signal is colored noise (color figure online)
In the LMS algorithm, the experimental curves agree with theory up to about \(\mu =0.04\), while the theoretical maximum step is 0.2. From this point forward, the independence assumption is no longer valid. It is worth noting that the validity range for the theoretical curves increases and decreases as the signal becomes less or more colored in agreement with [13]. In the NLMS algorithm, the experimental curves are very close to theory for all values of the step size. Figure 3 shows the same plot as in Fig. 2 but for a long filter with \(N=100\). It can be seen that the range of values of the step that the experimental values agree with the theory is much larger. Namely, in Fig. 2 this range is about \(20\% = 0.04/0.2\) of 2/M the theoretical maximum and in Fig. 3, the range is \(40\%\). For \(M=1000\), this range grows to \(70\%\).
Finally, Fig. 5 compares theoretical values for the maximal MSE as a function of the time n, and simulation results with the worst values for the expected value of \(e^2(n)\) using 10,000 Monte Carlo runs. Each run used a random optimal filter and a random input signal coloring filter of size 10. The figure confirms that the theoretical curves limit the MSE at any given time.

Theoretical (red) and experimental (blue) lines for the worst case performance of the NLMS algorithm (color figure online)
9 Conclusion
This work shows that the LMS misalignment square norm mean–variation is close to proportional to the error signal power. This allows obtaining formulas for the steady-state MSE of the LMS and NLMS in a simple way. It also allows obtaining formulas for the maximum MSE of the LMS and NLMS at any given time and any input signal. There are still some difficulties in the calculation due to the dependence between the error noise signal and the input signal vector norm. Simulation results confirm the theoretical findings.
Availability of data and materials
Data sharing is not applicable to this article as no datasets were generated or analyzed during the current study.
References
Haykin, S.: Adaptive Filter Theory. Prentice-Hall, Hoboken (1996)
Sayed, A.H.: Fundamentals of Adaptive Filtering. Wiley, Hoboken (2003)
Widrow, B.: Aspects of Network and System Theory, vol. 687. Holt, Rinehart, and Winston, Austin (1971)
Widrow, B., Mantey, P., Griffiths, L., Goode, B.: Adaptive antenna systems. Proc. IEEE 55(12), 2143–2159 (1967)
Gardner, W.A.: Learning characteristics of stochastic-gradient-descent algorithms: a general study, analysis, and critique. Signal Process. 6(2), 113–133 (1984)
Feuer, A., Weinstein, E.: Convergence analysis of LMS filters with uncorrelated Gaussian data. IEEE Trans. Acoust. Speech Signal Process. 33(1), 222–230 (1985)
Bershad, N.J., Eweda, E., Bermudez, J.C.: Stochastic analysis of the LMS algorithm for cyclostationary colored gaussian and non-gaussian inputs. Digit. Signal Process. 88, 149–159 (2019)
Bershad, N.: Analysis of the normalized LMS algorithm with Gaussian inputs. IEEE Trans. Acoust. Speech Signal Process. 34(4), 793–806 (1986)
Slock, D.T.: On the convergence behavior of the LMS and the normalized LMS algorithms. IEEE Trans. Signal Process. 41(9), 2811–2825 (1993)
Douglas, S.C., Pan, W.: Exact expectation analysis of the LMS adaptive filter. IEEE Trans. Signal Process. 43(12), 2863–2871 (1995)
Hassibi, B., Sayed, A.H., Kailath, T.: \({H}^\infty \) optimality of the LMS algorithm. IEEE Trans. Signal Process. 44(2), 267–280 (1996)
Butterweck, H.J.: In: 1995 International Conference on Acoustics, Speech, and Signal Processing, vol. 2 IEEE, pp. 1404–1407 (1995)
Butterweck, H.J.: A wave theory of long adaptive filters. IEEE Trans. Circuits Syst. I: Fund. Theory Appl. 48(6), 739–747 (2001)
Rupp, M., Butterweck, H.J.: In: The Thrity-Seventh Asilomar Conference on Signals, Systems and Computers, 2003, IEEE, vol. 1, pp. 607–611 (2003)
Haykin, S.: Adaptive Filter Theory. Prentice-Hall, Hoboken (2002)
Haykin, S.: Adaptive Filter Theory. Prentice-Hall, Hoboken (2005)
Butterweck, H.: Steady-state analysis of the long LMS adaptive filter. Signal Process. 91(4), 690–701 (2011)
Bershad, N.J., Bermudez, J.C.: In: 2011 IEEE Statistical Signal Processing Workshop (SSP) IEEE, pp. 57–60 (2011)
Bershad, N.J., Eweda, E., Bermudez, J.C.: Stochastic analysis of the LMS and NLMS algorithms for cyclostationary white Gaussian inputs. IEEE Trans. Signal Process. 62(9), 2238–2249 (2014)
Zhang, S., Zhang, J., So, H.C.: Mean square deviation analysis of LMS and NLMS algorithms with white reference inputs. Signal Process. 131, 20–26 (2017)
Eweda, E., Bershad, N.J., Bermudez, J.C.: Stochastic analysis of the least mean fourth algorithm for non-stationary white gaussian inputs. SIViP 8(1), 133–142 (2014)
Yazdanpanah, H., Diniz, P.S., Lima, M.V.: Improved simple set-membership affine projection algorithm for sparse system modelling: analysis and implementation. IET Signal Proc. 14(2), 81–88 (2020)
Lopes, P.A.C., Tavares, G., Gerald, J.B.: In: IEEE International Conference on Acoustics, Speech and Signal Processing, 2007. ICASSP 2007, vol. 3, pp. 1345–1348 (2007)
Funding
Open access funding provided by FCT|FCCN (b-on). This work was supported by national funds through Fundação para a Ciência e a Tecnologia (FCT) with reference UIDB/50021/2020.
Author information
Authors and Affiliations
Contributions
Not applicable.
Corresponding author
Ethics declarations
Conflict of interest
The authors have no financial or proprietary interests in any material discussed in this article.
Ethical approval
Not applicable.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Lopes, P.A.C. Analysis of the LMS and NLMS algorithms using the misalignment norm. SIViP 17, 3623–3628 (2023). https://doi.org/10.1007/s11760-023-02588-x
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11760-023-02588-x