
Abstract
Determining climatic and physiographic variables in Mexico's major ecoregions that are limiting to biodiversity and species of high conservation concern is essential for their conservation. Yet, at the national level to date, few studies have been performed with large data sets and cross-confirmation using multiple statistical analyses. Here, we used 25 endemic, rare and endangered species from 3610 sampling points throughout Mexico and 25 environmental attributes, including average precipitation for different seasons of the year, annual dryness index, slope of the terrain; and maximum, minimum and average temperatures to test our hypothesis that these species could be assessed with the same weight among all variables, showing similar indices of importance. Our results using principal component analysis, covariation analysis by permutations, and random forest regression showed that summer precipitation, length of the frost-free period, spring precipitation, winter precipitation and growing season precipitation all strongly influence the abundance of tropical species. In contrast, annual precipitation and the balance at different seasons (summer and growing season) were the most relevant variables on the temperate region species. For dry areas, the minimum temperature of the coldest month and the maximum temperature of the warmest month were the most significant variables. Using these different associations in different climatic regions could support a more precise management and conservation plan for the preservation of plant species diversity in forests under different global warming scenarios.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
The extinction risk of a species is linked, among other factors, to its limited plasticity and capacity to adapt to rapid changes in environmental factors (e.g., temperature or precipitation; Walther et al. 2002). Slow adaptation to change (i.e., physiological and genetic responses) could be yet another limitation of species included in some risk categories (Bradshaw 1965; IUCN 2017), because some environmental variables fluctuate faster than the generation period of many species (Clements et al. 2004), which could result in a late genetic response and restricted geographic distribution.
Identifying variables that limit or enhance the presence or abundance of species with high conservation or economic values is a valuable step in characterizing their habitat (Antúnez et al. 2017b), given the complex task of elucidating the behavior of each species in a multidimensional space (Hutchinson 1957; Zhu et al. 2021). Such information is essential for adequate monitoring of natural populations of high ecological, social, economic or any other value (NOM-059 2010), for designing and promoting rational use and conservation actions, such as assisted migration in the face of progressive changes in the environment (Rice and Emery 2003; Sáenz-Romero et al. 2012; Gómez-Ruiz et al. 2020).
At present, information concerning sensitivity of priority species for conservation (endemic, danger of extinction or rare) to the individual fluctuations of some covariates is insufficient. For example, it is not known which of the species listed in the Official Mexican Standard for native species in a given risk category (NOM-059 2010), or in the IUCN Red List, are the most vulnerable to changes in the precipitation regime of any specific period of the year (e.g., April–September, the growing season precipitation), or to the reduction of the global average precipitation, which seems to be up to 3% in subtropical land areas (Watson and Albritton 2001). Nor has the response of these species to the change of a temperature variable been described (e.g., the minimum or maximum temperature of the warmest month).
A methodological approach which reinforces the biogeographic knowledge of plants, including the fundamental ecological niche, is the correlational study between bioclimatic variates and an abundance indicator (Soberón et al. 2017). In this context, studies related to species distribution and abundance are often approached mainly from two perspectives: (i) physical-geographical space and (ii) non-physical space (Hutchinson 1957; Colwell and Rangel 2009), which correspond to the “area of distribution” and “ecological niche” in species distribution models (SDM) (Soberón et al. 2017).
In this study, we analyzed 25 species of trees and shrubs of high conservation priority in Mexico (endemic, rare, endangered or subject to special protection) and a total of 25 climatic and physiographic variables. The relative abundance relationships of each species and environmental variables were examined by identifying different statistical association indicators. To this, several analytical techniques were used, including covariation analysis by permutations, Boruta wrapper algorithm, multivariate analysis and regression analysis. The selected techniques provide quantitative indicators of the possible degree of individual incidence of the variables on the relative abundance of the species from different perspectives, including the strength and direction (positive or negative) of the relationship between the variables studied and an index or importance value of each predictor.
Materials and methods
Sampling area and data collection
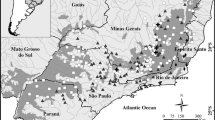
We utilized data from 3610 sampling units (clusters), which were collected by the National Forestry Commission (CONAFOR) during the National Inventory of Forests and Soils (INFyS) for the 2004 − 2009 period. These sampling units were stratified and systematically distributed, trying to cover the most important wooded areas of Mexico. Each main sampling unit (cluster) consisted of four subunits of 400 m2 each; the clusters were equidistantly distributed every 5 km in temperate zones and tropical and subtropical regions, every 10 km in semi-arid communities and every 20 km in dry regions (CONAFOR 2009). Sampling and data record details on the main units and subunits can be found in the National Forest Inventory manual (CONAFOR 2009) (Fig. 1).

Network of sampling units, where at least one of the 25 species studied were observed. This map is an adaptation of the potential vegetation map for Mexico by Rzedowski (1990), published by the National Commission for the Knowledge and Use of Biodiversity (CONABIO 2001)
Species and variables studied
A total of 25 species of high conservation value and classified in some risk category by the Official Mexican Standard (NOM-059-SEMARNAT) were selected (NOM-059 2010). Seventeen of the studied species (68%) appear also in one of the categories of the red list of the IUCN (2017) (Table 1).
Twenty-five explanatory variables were modeled, including maximum, minimum and average temperatures; precipitation at specific periods; freezing dates; and some physiographic variables (Table 2). We obtained the climatic variables for each sampling plot from the USDA Forest Service Rocky Mountain Research Station Modeler (Rehfeldt 2006; Rehfeldt et al. 2006), which uses climate data for a 30-year period (1961−1990), with records of over 6000 weather stations in Mexico, South America, Guatemala, Belize and Cuba (Rehfeldt 2006; Crookston et al. 2008; Sáenz-Romero et al. 2010). The average slope of the terrain, the geographic aspect and elevation, important factors in the species' distribution (Kebede et al. 2013), were registered in the field (CONAFOR 2009) (Table 2). To integrate geographic exposure into quantitative analyses, each geographic orientation of the main sampling plot was coded with numbers from one to nine: zenith = 1, north = 2, south = 3, east = 4, west = 5, northeast = 6, southeast = 7, northwest = 8 and southwest = 9. Numerical coding was done during the gathering of field information (CONAFOR 2009).
In this study, the relative population density per plot was used as an indicator of the abundance, whose value was obtained by dividing the number of individuals recorded in each plot of a given species by the total number of individuals of that species in all plots (Brower et al. 1998).
Data analyses
Pearson, Kendall and Spearman correlations analyses; principal component analysis (PCA); linear regression analyses (LRA); regression trees by random forest (RA-FOR); Boruta wrapper algorithm (BA); and a measure of covariation (C) were used as described by Gregorius et al. (2007) and Gillet and Gregorius (2008). In this last method, with 10,000 permutations, the abundance of each species was correlated with each of the variables, assuming the rest remained constant. The importance of the selected methods lies in (1) providing quantitative indicators on the strength and direction (positive or negative) of the relationships between the variables studied; (2) identifying those that explain the highest percentage of variability in the data of interest; and (3) providing values or indices of importance based on learning algorithm.
According to Kursa and Rudnicki (2010), the Boruta algorithm iteratively compares the importance of certain attributes with the importance of shadow attributes, which are created by shuffling the original ones. With the PCA, we identified the variables that explained the highest percentage of variability in the data (Dormann et al. 2007). We used a regression analysis to identify evidence of a causal relationship, but the results were not robust, and therefore, are not reported here. Likewise, the correlation coefficients of Pearson, Kendall and Spearman were excluded because they were not significant. All analyses were done using R ver. 3.4.0 (R Core Team 2017).
Selection in RA-FOR was based on values from a statistical dispersion measure called the Gini coefficient or Gini index (Cutler et al. 2007). This index is effective and simple to estimate, and its value not only focuses on the heterogeneity reduction produced by a given variable, but also makes a correction to the bias produced in the model (Sandri and Zuccolott 2008). High Gini index values indicate a greater contribution of a given independent variable to explain the variation of the dependent variable (Cutler et al. 2007; Sandri and Zuccolotto 2008; Breiman and Cutler 2017). In the Boruta algorithm, the variables were filtered by the variable importance measure (VIM) (Kursa and Rudnicki 2010).
For evaluating if the high importance variables are the same in different types of vegetation, they were categorized into four groups: (1) Variables with strong evidence; those occupying the first five places when sorted in descending order of importance in four analyses techniques. (2) Variables with medium evidence; those that, sorted in descending order, occupied the first five places according to the order of importance in three analyses techniques. (3) Variables with poor evidence; those occupying the first five places when sorting them in descending order in one or two techniques. (4) Variables with very poor evidence; those that did not appear among the first five places in order of importance in any of the techniques tested or that were not statistically significant.
Results
What variables showed the highest importance indexes?
The order of importance of the variables differs for each species and vegetation type. For example, according to the random forest method ELEV and ASL were detected as high-relevant variables for Cryosophila argentea (a tropical species), Olneya tesota (a dry region plant) and for Pseudotsuga menziesii (a temperate species) (Fig. 2; Table S1). In contrast, variables showing weak evidence of relationship to the relative abundance of these species were: MMINDD0, D100 and DD0 (Table S1). When removing ELEV from the analyses, assuming that it could dilute the contribution of other variables, very few changes in the order of importance were observed in most cases (Table S2). Most of the replacements or alterations were observed in the results of the random forest method. Even so, 76% of the species retained at least three of the first five variables that headed the order of importance (Tables S1 and S2).

The five variables with the highest values of importance according to random forest method for Cryosophila argentea, Olneya tesota and Pseudotsuga menziesii. The lines at the top of the bars are standard errors. ELEV is elevation above sea level; ASL, average slope of the terrain; GSDI, growing season dryness index; SDI, summer dryness index (GSDD5)0.5/GSP; MAP, mean annual precipitation; PRATIO, GSP/MAP; WINP, winter precipitation
What types of relationships were observed?
In most cases, poor linear relationships were observed among the variables and the relative abundance of the species, showing small coefficients or being not significant (P > 0.05). Regardless of the degree of correlation, most of the coefficients were positive. For example, the abundance of Carpinus caroliniana, Astronium graveolens and C. argentea were negatively correlated with GSP (Fig. 3a and b). However, in some species, such as Tilia americana (var. mexicana), P. menziesii or Thrinax radiata, a positive correlation was observed among the same variable and the relative abundance (Fig. 3a and b).

a Representation of the summer precipitation (SMRP), elevation above sea level (ELEV) and growing season precipitation (GSP) in the factorial plane for three species of temperate regions; b representation of the mean temperature in the coldest month (MTCM), growing season precipitation (GSP) and mean annual precipitation (MAP) in the factorial plane for three species of tropical regions, with their respective correlation coefficients based from the measure of covariation with 10,000 permutations
Was any pattern of response identified?
The individual effect of each variable changed in both intensity and magnitude, contrasting in many cases (Table S4), even when comparing among species of the same vegetation type, as in the case of C. caroliniana whose response was negative to variation in summer precipitation (SMRP), while P. menziesii showed a positive relation to SMRP (Fig. 3a; Table S4).
In a species-by-species assessment based on the PCA results, variables GSDD5 and DD5explained the highest percentage of variability in the data, followed by MAP, GSP and ELEV, which usually appear among the first five most important variables in the first dimension of the principal components, accounting for over 80% of the studied species (Fig. 4a and b; Table S3).

Two-dimensional PCA ordination of the first two principal components as a function of the explanatory variables: a results for Carpinus caroliniana, Pseudotsuga menziesii and Tilia americana, and b results for Astronium graveolens, Cryosophila argentea and Thrinax radiata. The ellipses show the covariance structure for each species, while the vectors show the projections of the original data
When valuing the results of all the analyses techniques applied in this work, excluding ELEV (an underlying climate factor), there is strong evidence that MAP, GSDI, SMRP, FFP, SPRP, WINP, GSP, GSDD5 and DD5 had influence more on the species that grow in the tropical and warm regions. The measure of heating degree-days above 5 °C, SMRP, GSP, MAP, MTCM, MMAX and SDAY showed medium evidence on the species belonging to the temperate forest, while MMIN and MMAX were the most relevant for species from dry regions, although for this latter case, the evidence was moderate (Tables S1, S2, S4).
Discussion
Response of the species to unitary change in variables
Considering the changing global climate, it is important to diagnose the spectrum of variables that will enhance or inhibit the decline in plant diversity, from a unitary and multivariate perspective. The results suggest that the variation of some variables can positively influence the abundance of a species and also affect other species of the same ecological affinity (Figs. 3 and 4a; Tables S1, S3 and S4). For example, with an increase in the precipitation from April to September (GSP), the most favorably affected tropical species, among those studied, would be Astronium graveolens, Avicennia germinans and Vatairea lundellii with absolute values of C equal to or greater than 0.94 (Table S4). On the contrary, the same variable has a poor correlation with the abundance of Guaiacum sanctum, Sideroxylon capiri or Olneya tesota (absolute values of C equal to or less than 0.22) (Table S4), which confirms that each climatic variable affects, in a different magnitude and intensity, the presence or abundance of a species (Thuiller et al. 2004; Toledo et al. 2012; Martínez-Antúnez et al. 2013).
Similarly, the correlation values of species abundances regarding the different temperature records (minimum, maximum and average) fluctuated, suggesting that, if a causal connection exists, it is irregular, heterogeneous without a defined single tendency (Table S4). For example, although most correlation coefficients were small, increasing MTCM would negatively affect A. graveolens, A. germinans or Bursera coyucensis (a negative and significant correlation was found), but would positively affect the relative abundance of V. lundellii, Lophocereus schottii or Cryosophila argentea (Table S4).
Role of variables from a multivariate perspective
When all the environmental variables were included in the analyses, we could not determine clearly whether the abundance increased or decreased as the value of a variable changed. Such was the case for the variables related to the amount of heat available (important for the growth and development of plants species) based on mean monthly temperature above 5 °C (GSDD5 and DD5), which appear in the first group of components of the PCA accounting for more than 95% of the species (Table S3), but their contributions in the random forest models and the correlation coefficients were not always significant (Tables S1, S4). Instead, winter precipitation (WINP), mean annual precipitation (MAP) and the physiographic variables, showed signs of a high causal relationship on at least 32% of the total species studied, according to the random forest.
Therefore, a single and categorical conclusion cannot be made from the multivariate analyses because their results do not always coincide. This result might be due to the fact that each method is based on different assumptions and that each method assesses a species’ response to variation in predictors from different perspectives. For example, PCA is designed to identify the variables that explain the highest percentage of variability of the data from a multivariate perspective excluding autocorrelation, and RA-FOR tries to detect the most relevant variables of a random vector whose selection is based on the degree of contribution of each variable to decrease the error, assuming that each one is independent of the other.
The negligible contribution of the values of the index of the amount of heat available calculated from the temperature above 5 °C in most of the random forest models (unlike PCA analysis), might suggest an indirect effect or a nonlinear relationship. In similar studies, using correlative models, DD5 has been reported as one of the most important climatic variables for several species of ecological or economic interest, such as Agave cupreata (Sáenz-Romero et al. 2010) or Pinus strobiformis, Pseudotsuga menziesii and Pinus arizonica (Martínez-Antúnez et al. 2013).
Other tools that may be applied are the regression techniques excluding the collinearity, spatial and temporal autocorrelation (Raxworthy et al. 2003; Martínez-Meyer and Peterson 2006), but it is very probable that each technique will continue to give different results. So, the methods where a single environmental variable is included (under a scenario of absence of spatial and temporal autocorrelation) could be more useful, in certain cases, to identify the degree of association or correspondence between two variables. Table S4 shows the variables that have high correlation (positive or negative) with each of the species. Certainly, combination of methods (univariate and multivariate) might give a broader and clearer panorama on the relationship among each of the most relevant environmental variables and the abundance of species (Ter Braak 1986; Thuiller et al. 2004; Martínez-Antúnez et al. 2015).
Considerations and possible applications
In this study, we tried to reduce the probability of a variable being misclassified as a high importance variable (Tables S1–S4) by contrasting the results of several techniques simultaneously, since all models have limitations and they each have a degree of uncertainty (Antúnez et al. 2017a). For example, a correlative model does not take into account variable interactions or human activities that are increasingly common (Hunter 2007; Crowther et al. 2015). In addition, the level of incidence that human activities have on each species (in quantitative terms) is unknown, making it difficult to include them in the models with the appropriate weighting.
Likewise, there are other factors not taken into account, such as the properties of the soil and other physiographic variables (Berg and Smalla 2009; Webb and Peart 2000) and the presence/absence of invasive plants, which in many cases also play an adverse role for native populations in danger of extinction (Mooney and Cleland 2001; Traveset and Richardson 2006), although the intensity of affectation varies by species (Gurevitch and Padilla 2004). Furthermore, the presence or absence of factors and elements can enhance or inhibit the impact of a variable and cause a chain reaction, like a change in the regional pluviometric regime as a result of fluctuations in continental precipitation (Watson and Albritton 2001).
At present, Mexico is home to globally significant biodiversity (Sarukhán et al. 2015). To sustain this biodiversity in the long term, the findings reported here could contribute to forming a scientific basis for strengthening the conservation actions and strategies implemented by the National Commission of Natural Protected Areas of Mexico. The inclusion of more taxa, listed in NOM-059 (2010) and IUCN red list, in the Action Programs for the Conservation of Species (PACE) is a pertinent action strategy, prioritizing those that are sensitive to extreme temperature variations, as they are most at risk in the face of climate change (Mo et al. 2019). For example, A. graveolens, A. germinans, V. lundellii, L. schottii and Guaiacum coulteri all showed signs of high sensitivity to changes in the average temperature in both the coldest month and the warmest month (Table S4).
Current action programs, in particular the Program for the Conservation of Species at Risk (PROCER), might also consider aspects like the most relevant variables based on the values or indices of importance, the types of associations (increasing, decreasing, linear or curvilinear), and environmental values where the maximum probability of abundance occurs (Antúnez et al. 2017b; Antúnez 2021) to characterize and delineate current habitats and identify places susceptible to be occupied in the future. In general, the identification of the most important variables for the abundance of plants classified in some risk category is an important step in defining their actual environmental tolerance (Table S1, S2, S4) and could be used as a preliminary indicator of species' sensitivity to climate change (Hannah et al. 2002).
Conclusions
Our findings reveal that, the most important variables for most species, regardless of the type of forest they belong to—and excluding altitudes—are the amount of precipitation in specific periods (mainly winter precipitation, growing season precipitation, and mean annual precipitation), the average slope of the terrain, and the dominant geographical aspect. We observed a significant change in the order of appearance of the variables (in their descending order), according to the values of importance of each method, but without a clear and conclusive pattern for each vegetation type, was because of the low number of species analyzed for some vegetation types (temperate forest and dry climate). Therefore, continuing and future efforts to find, conserve or enable suitable habitats (natural or artificial) for these species should focus on the variables with strong evidence of an impact on each species, taking into account both the analyses from a multiple perspective (Tables S1, S3) and the univariate results (Table S4).
References
Antúnez P (2021) Influence of physiography, soil and climate on Taxus globosa. Nordic J Bot 39(3):e03058
Antúnez P, Hernández-Díaz JC, Wehenkel C, Clark-Tapia R (2017a) Generalized models: An application to identify environmental variables that significantly affect the abundance of three tree species. Forests 8(3):59
Antúnez P, Wehenkel C, López-Sánchez CA, Hernández-Díaz JC (2017b) The role of climatic variables for estimating probability of abundance of tree species. Pol J Ecol 65:324–338
Berg G, Smalla K (2009) Plant species and soil type cooperatively shape the structure and function of microbial communities in the rhizosphere. FEMS Microbiol Ecol 68(1):1–13
Bradshaw AD (1965) Evolutionary significance of phenotypic plasticity in plants. Adv Genet 13:115–155
Breiman L, Cutler A (2017) Random Forest. http://www.stat.berkeley.edu/~breiman/RandomForests/cc_home.htm. Accessed 7 June 2017
Brower JE, Zar JH, Ende CV (1998) Field and laboratory methods for general Ecology. http://www.sisal.unam.mx/labeco/LAB_ECOLOGIA/Ecologia_de_Poblaciones_y_Comunidades_files/GeneralEcology.pdf Accessed 17 June 2017
Clements DR, DiTommaso A, Jordan N, Booth BD, Cardina J, Doohan D, Mohler CL, Murphy D, Swanton CJ (2004) Adaptability of plants invading North American cropland. Agric Ecosyst Environ 104(3):379–398
Colwell RK, Rangel TF (2009) Hutchinson’s duality: the once and future niche. Proc Natl Acad Sci 106(Supplement 2):19651–19658
CONABIO (National Commission for the Knowledge and Use of Biodiversity) (2001) In: Vegetación potencial propuesta por Rzedowski, (1990) Instituto de Geografía. Atlas Nacional de México Vol. II, IV.8.2. Universidad Nacional Autónoma de México. Catálogo de metadatos geográficos. Comisión Nacional para el Conocimiento y Uso de la Biodiversidad. Available online: http://conabio.gob.mx/informacion/metadata/gis/vpr4mgw.xml?_xsl=/db/metadata/xsl/fgdc_html.xsl&_indent=no. Accessed 12 February 2018
CONAFOR (Comisión Nacional Forestal) (2009) Manual y procedimientos para el muestreo de campo – Inventario Nacional Forestal y de Suelos [Manual and procedures for field sampling – National forest and soil inventory] – https://www.snieg.mx/DocumentacionPortal/iin/acuerdo_3_X/Manual_y_Procedimientos_para_el_Muestreo_de_Campo_INFyS_2004-2009.pdf, Accessed 7 November 2017
Crookston NL, Rehfeldt EG, Ferguson DE, Warwell M (2008) FVS and global warming: a prospectus for future development. In: R.N. Havis, N.L.Crookston (eds) Proceedings of the third forest vegetation simulator conference. Department of Agriculture, Forest Service, Rocky Mountain Research Station, Fort Collins, CO: U.S., pp. 7–16. Available online: https://www.fs.fed.us/rm/pubs/rmrs_p054/rmrs_p054_007_016.pdf. Accessed 13 February 2018.
Crowther TW, Glick HB, Covey KR et al (2015) Mapping tree density at a global scale. Nature 525:201–205
Cutler DR, Edwards TC, Beard KH, Cutler A, Hess KT, Gibson J, Lawler JJ (2007) Random forests for classification in ecology. Ecology 88:2783–2792
Dormann FC, McPherson JM, Araújo MB, Kühn I et al (2007) Methods to account for spatial autocorrelation in the analysis of species distributional data: A review. Ecography 30:609–628
Gillet EM, Gregorius HR (2008) Measuring differentiation among populations at different levels of genetic integration. BMC Genet 9(1):60
Gómez-Ruiz PA, Sáenz-Romero C, Lindig-Cisneros R (2020) Early performance of two tropical dry forest species after assisted migration to pine–oak forests at different altitudes: strategic response to climate change. J Forestry Res 31:1215–1223
Gregorius HR, Degen B, König A (2007) Problems in the analysis of genetic differentiation among populations A case study in Quercus robur. Silvae Genet 56:190–199
Gurevitch J, Padilla DK (2004) Are invasive species a major cause of extinctions? Trends Ecol Evol 19(9):470–474
Hannah L, Midgley GF, Millar D (2002) Climate change-integrated conservation strategies. Glob Ecol Biogeogr 11(6):485–495
Hunter P (2007) The human impact on biological diversity. EMBO Rep 8(4):316–331
Hutchinson GE (1957) Concluding remarks. Cold Spring Harb Symp Quant Biol 22:415–427
IUCN (2017). The IUCN red list of threatened species. Version 2017–3. https://www.iucnredlist.org. Accessed 16 August 2017
Kebede M, Kanninen M, Yirdaw E, Lemenih M (2013) Vegetation structural characteristics and topographic factors in the remnant moist Afromontane forest of Wondo Genet, south central Ethiopia. J Forestry Res 24:419–430
Kursa MB, Rudnicki WR (2010) Feature selection with the Boruta package. J Stat Softw 36(11):1–13
Martínez-Antúnez P, Wehenkel C, Hernández-Díaz JC, González-Elizondo M, Corral-Rivas JJ, Pinedo-Álvarez A (2013) Effect of climate and physiography on the density of tree and shrub species in Northwest Mexico. Pol J Ecol 61(2):283–295
Martínez-Antúnez P, Hernández-Díaz JC, Wehenkel C, López-Sánchez CA (2015) Estimación de la densidad de especies de coníferas a partir de variables ambientales. Madera Bosques 21:23–33
Martínez-Meyer E, Peterson AT (2006) Conservatism of ecological niche characteristics in North American plant species over the Pleistocene-to-Recent transition. J Biogeogr 33(10):1779–1789
Mo LC, Liu JK, Zhang H, Xie Y (2019) The predicted effects of climate change on local species distributions around Beijing. China J Forestry Res 31(5):1539–1550. https://doi.org/10.1007/s11676-019-00993-y
Mooney HA, Cleland EE (2001) The evolutionary impact of invasive species. Proc Nat Acad Sci 98(10):5446–5451
NOM-059 (Official Mexican Standard NOM-059-SEMARNAT-2010) (2010). https://www.gob.mx/cms/uploads/attachment/file/134778/35.-_NORMA_OFICIAL_MEXICANA_NOM-059-SEMARNAT-2010.pdf. Accessed 2 May 2017
R Core Team (2017) R: a language and environment for statistical computing – R Foundation for Statistical Computing. https://cran.r-project.org/doc/manuals/r-release/fullrefman.pdf. Accessed 1 May 2017
Raxworthy CJ, Martinez-Meyer E, Horning N, Nussbaum RA, Schneider GE, Ortega-Huerta MA, Peterson AT (2003) Predicting distributions of known and unknown reptile species in Madagascar. Nature 426:837–841
Rehfeldt GE, Crookston NL, Warwell MV, Evans JS (2006) Empirical analyses of plants climate relationships for the western United States. Int J Plant Sci 167:1123–1150
Rehfeldt GE (2006) A spline model of climate for the western United States. Gen. Tech. Rep. RMRS-GTR-165. Fort Collins, CO: US Department of Agriculture, Forest Service, Rocky Mountain Research Station. 21 p.165. https://doi.org/10.2737/RMRS-GTR-165. Accessed 26 October 2021
Rice KJ, Emery NC (2003) Managing microevolution: restoration in the face of global change. Front Ecol Environ 1(9):469–478
Sáenz-Romero C, Rehfeldt GE, Crookston NL, Duval P, St-Amant R, Beaulieu J, Richardson BA (2010) Spline models of contemporary, 2030, 2060 and 2090 climates for Mexico and their use in understanding climate-change impacts on the vegetation. Clim Change 102(3–4):595–623
Sáenz-Romero C, Martínez-Palacios A, Gómez-Sierra JM, Pérez-Nasser N, Sánchez-Vargas NM (2012) Estimación de la disociación de Agave cupreata a su hábitat idóneo debido al cambio climático. Rev Chapingo Ser Cie 18(3):291–301
Sandri M, Zuccolotto P (2008) A bias correction algorithm for the Gini variable importance measure in classification trees. J Comput Graph Stat 17(3):611–628
Sarukhán J, Urquiza-Haas T, Koleff P, Carabias J, Dirzo R, Ezcurra E, Cerdeira-Estrada S, Soberon J (2015) Strategic actions to value, conserve, and restore the natural capital of mega diversity countries: The case of Mexico. Bioscience 65(2):164–173
Soberón J, Osorio-Olvera L, Peterson T (2017) Diferencias conceptuales entre modelación de nichos y modelación de áreas de distribución. Rev Mex Biodivers 88(2):437–441
Ter Braak CJ (1986) Canonical correspondence analysis: a new eigenvector technique for multivariate direct gradient analysis. Ecology 67(5):1167–1179
Thuiller W, Araujo MB, Lavorel S (2004) Do we need land-cover data to model species distributions in Europe? J Biogeogr 31(3):353–361
Toledo M, Peña-Claros M, Bongers F, Alarcón A, Balcázar J, Chuviña J, Leaño C, Licona JC, Poorter L (2012) Distribution patterns of tropical woody species in response to climatic and edaphic gradients. J Ecol 100(1):253–263
Traveset A, Richardson DM (2006) Biological invasions as disruptors of plant reproductive mutualisms. Trends Ecol Evol 21(4):208–216
Walther GR, Post E, Convey P, Menzel A, Parmesan C, Beebee TJ, Fromentin JM, Guldberg OH, Bairlein F (2002) Ecological responses to recent climate change. Nature 416(6879):389–395
Watson RT, Albritton DL, Barker T. (2001) Climate change 2001: Synthesis report: Third assessment report of the Intergovernmental Panel on Climate Change. Summary for Policymakers pp. 43–44. Available online: https://www.ess.uci.edu/researchgrp/prather/files/2001ipcc_syr-watson.pdf . Accessed 16 September 2021.
Webb CO, Peart DR (2000) Habitat associations of trees and seedlings in a Bornean rain forest. J Ecol 88(3):464–478
Zhu H, Yi XG, Li YF, Duan YF, Wang XR, Zhang LB (2021) Limiting climatic factors in shaping the distribution pattern and niche differentiation of Prunus dielsiana in subtropical China. J Forestry Res 32:1467–1477. https://doi.org/10.1007/s11676-020-01194-8
Acknowledgements
The author thanks the National Council of Science and Technology of Mexico for the postdoc fellowship awarded. Thanks to Christoph Kleinn, Socorro González Elizondo, José Ciro Hernández Díaz and Christian Wehenkel for valuable suggestions and contributions to the research project from which this article was derived. The spelling and grammar check by John R. Perry is appreciated. Thanks to the National Forestry Commission (CONAFOR) for providing one part of the data in this study.
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Antúnez, P. Main environmental variables influencing the abundance of plant species under risk category. J. For. Res. 33, 1209–1217 (2022). https://doi.org/10.1007/s11676-021-01425-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11676-021-01425-6