
Abstract
Characterizing thermally sprayed coatings remains challenging due to the interplay between different operating and process parameters. Currently, no general framework exists for accurately predicting the coating characteristics under specific operating conditions. In this paper, artificial intelligence models were employed to investigate a case study of generating superhydrophobic coatings by suspension plasma spray (SPS), an emerging thermal spray process that can produce coatings with micro and nano-scale features. The approach aimed to relate key thermal spray process parameters such as plasma torch nozzle diameter, plasma power, standoff distance, grit-blast effect, and suspension solvent type to different coating characteristics such as water contact angle, sliding angle, and surface roughness. Machine learning (ML) algorithms of both tree-based (ranging from linear regression and random forest to improved gradient boost) and deep-neural network models were investigated using a recent dataset of SPS experiments. Following the training of the ML models, selected algorithms were tested on unseen SPS data points at different operating conditions. The ML models were able to predict the sliding angles with good accuracy of over 80% based on a limited dataset. Finally, a state-of-the-art generative adversarial network (GAN) was employed to generate realistic scanning electron microscope (SEM) images of SPS coatings with specific sliding angles. These GAN-generated SEM images were qualitatively and visually satisfactory, paving the way for a machine-learning approach to controlling thermally sprayed coating microstructures.
Similar content being viewed by others
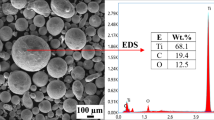

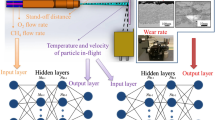
Introduction
Thermal spray is a common method of applying coatings on surfaces to improve their functional performance. It works by heating and spraying molten or semi-molten particles onto the substrates to form coatings, where particles form bonds with the surface and impair the desired mechanical and thermal properties and has direct applications in aerospace, renewable energy, and healthcare (Ref 1, 6).
This process can coat various materials and components to increase their resistance to heat, corrosion, erosion, or wear.
A liquid feedstock in the suspension spray plasma (SPS) process can generate sub-micron molten droplets, resulting in nanometer-scale microstructures, as seen in Fig. 1.

Schematic of the Suspension Plasma Spray process. Reprinted from Surface and Coatings Technology, Vol. 329, Navid Sharifi, Fadhel Ben Ettouil, Christian Moreau, Ali Dolatabadi, Martin Pugh, Engineering surface texture and hierarchical morphology of suspension plasma sprayed TiO2coatings to control wetting behavior and superhydrophobic properties, pages no. 139–148, Copyright 2017, with permission from Elsevier (Ref 12)
Due to the significantly smaller splats produced by SPS compared to conventional atmospheric plasma spray (APS), it is possible to create entirely new or significantly improved coating structures (Ref 7, 9, 12). SPS is currently an active research topic in thermal spray technology with applications in thermal barrier coatings (TBCs), fuel cell component manufacturing, and, more recently, superhydrophobic SPS coatings (Ref 10, 12).
The current techniques of fabricating superhydrophobic coatings involve roughening the low-energy surface with low-energy materials and necessitating complex methods to enhance microstructure properties. This is where SPS coatings outperform alternatives, as the microstructure properties of the coating can be modified by adjusting process parameters such as plasma torch nozzle diameter, plasma power, standoff distance, grit-blast effect, and suspension solvent type (Ref 12). For instance, when water and ethanol are used separately as suspension solvents in an application, the water-based suspension coating lacks the columnar texture observed with the ethanol-based suspension. This could be due to a variety of factors, including differences in atomization, heat capacity, or latent heat of vaporization, all of which result in a higher proportion of unmelted particles in the water-based suspension (Ref 12). These are just a few of the possible causes of the varied textures; the true cause may be just one of them or a combination of all. Altering process and operating parameters such as injection speed, temperature, and nozzle diameter can achieve different coating characteristics. And slightly changing any of these parameters may result in completely different coating properties. Thus, quantifying these variables in a theoretical formula is a daunting task, as it would require physically producing and recording the coatings each time a variable is altered.
Despite the wide range of applications and studies, the control and build-up of SPS coating, which involves many processes and operating parameters, has yet to be fully understood. This is because the acceleration of coating particles at high speeds onto the surface can result in numerous different coating thickness, porosity, or columnar structures. Subsequently, the resulting coating can be characterized in terms of thermal or mechanical properties, and its microstructure can be examined using a scanning electron microscope (SEM) image.
Traditionally, coating analysis is associated with physically spraying the coatings and then capturing and characterizing the coating microstructure properties using a microscopic imaging system. However, one limitation of this approach is that it is time-consuming and requires expert knowledge of the process. In addition, setting up a thermal spray workstation requires costly equipment, such as an industrial robotic arm and a high-power ventilation system. To complement the physical approaches, a thermal spray digital-twin system can be an interesting alternative to potentially reduce costs while also allowing extensive control over the properties of the coating generated. In practice, this system could simulate the thermal spraying process to provide the desired coating characteristics. Since this process occurs entirely in a simulation environment, it can be run numerous times while modifying the operating conditions or process parameters to generate and potentially optimize functional coatings.
Machine learning and predictive analytics are currently one of the most active research areas within artificial intelligence (AI) and have advanced rapidly in recent years. Machine learning has been successfully applied to the analysis of complex interactions from engineering applications to healthcare (Ref 2, 8, 14). However, there have been few studies devoted to the application of AI to thermal spray processes. It is worth noting the recent work by (Ref 11, 13), which used regression-based ML models to infer single output, such as the coating hardness or critical velocity for the cold spray process. However, neither the relative importance of the input features nor the coating generation was addressed.
By introducing AI-based prediction models and computer-generated images, one may be able to provide an alternative to the traditional approach of physical testing and characterization of coatings. Particularly, because SPS coatings do not follow a predictable sequence when operating conditions are changed, they are an ideal candidate for using AI to predict coating characteristics. Incorporating Prediction models allow for estimating coating characteristics based on spray parameters. Furthermore, generative adversarial networks (GAN) could enable the production of computer-generated images of SEM coating surfaces based on operating conditions. Thus, using AI in thermal-spray applications would save time and reduce operating costs while providing accurate predictions.
Due to the process's complexity, most studies can only analyze a subset of thermal spray process variables without optimization. This paper aims to use machine learning and deep learning techniques to predict the properties and characteristics of thermally sprayed coatings. As a proof of concept, we will focus on the recent application of SPS for generating SHS coatings, which involves numerous material and process parameters, the impact of which on the coating characteristics is traditionally unclear.
Methodology
We investigate a machine and deep learning approach mapping SPS process parameters to the coating properties. An overview of the workflow is depicted in Fig. 2. Following data collection, analysis, and processing, several machine learning regression models were used to predict coating wetting characteristics, and subsequently, a deep learning technique was employed to generate SEM micrographs of the corresponding process parameters.

Machine and deep learning workflow to estimate SPS coating properties
Sample Description and Dataset Selection
The current study employs data from the author's previous work on engineering superhydrophobic coatings using the SPS process (Ref 12). The data set includes about 27 distinct experimental samples with three different suspension compositions, and the coating was applied to substrates that had previously been grit-blasted with alumina particles. The summary of the process parameters is illustrated in Table 1. The actual data points and parameter combinations are included in Table 2.
There are a few requirements for selecting a training dataset for ML prediction. The first step is to ensure that the dataset is complete and that no data that could be critical to our application is missing. We must also look for diversity in the dataset to maximize learning and ensure a correct fit. Finally, we need consistency in the data recording, which in our case means ensuring that all experimental data was obtained under similar operating conditions using the same setup. Lastly, numerous (over 100) SEM micrograph images of coatings subjected to different spraying conditions and scales exhibiting diverse surface textures and wetting behavior were utilized.
We aimed to improve these predictions by incorporating a wide range of process parameters as inputs. In contrast, the outputs were based on the sliding angle and water contact angle, two measures of the coating’s wettability. These values quantify surface wettability and are particularly useful for identifying the coating microstructure, such as the column-like structures. Experimental observation qualitatively suggests that the water contact angle decreases as the sliding angle increases. In addition, as the sliding angle decreases, the columnar structure becomes well defined, as illustrated in Fig. 3 by the three SEM images, where the first image represents a surface of sliding angle of 13.3˚, the second 7.1˚, and the third 3.4˚. Using computer vision to analyze images, a detailed quantitative assessment of the mapping between columnar structures and sliding angles will be provided in Sect. "Microstructure Analysis Using Computer Vision".

SEM micrographs illustrating deviations obtained in coating structure with differing sliding angles and water contact angle
Data Pre-processing and Analysis
The statistics on the dataset collected from the experiment are shown in Table 3, which is subsequently used for ML analysis. The statistics in Table 3 correspond to the mean, median, maximum, and percentiles of the different process variables. This is a preprocessing step to ensure that the data are consistent, which is necessary for large datasets that cannot be displayed all at once. In addition, this showcases the diversity in our dataset.
Before applying ML models, the features (X) were scaled using standardization as follows:
where µ is the mean and σ is the standard deviation of the feature values. The standardization of input data is performed so that features with a variance that differs from the others by orders of magnitude, would not skew the algorithm’s estimation ability.
For certain features, such as the solvent used for the plasma spray application, the labels were either one kind of solvent or the other. Since these values were not numerical, we had to convert them to a computer-readable format. This was accomplished by converting the choice between water and ethanol into a binary selection, with water being 1 and ethanol 0 in the same feature. This approach would be ideal for all practical purposes; however, we aim for this work to be a proof of concept that can be extended to other process parameters, including different solvents. As a result, the binary approach would be inadequate in accounting for different solvent compositions. Consequently, we adopted the one-hot encoding representation by creating two new feature groups, water and ethanol. Here, one is true (or 1) when the corresponding feature is used, and all the others would be false (or 0). This allows us to potentially account for additional types of solvents as new features in the future, as depicted in Table 4.
Given the limited dataset, increasing features may result in reduced accuracy; however, we consider adaptability more critical to developing our workflow at this point in time.
Microstructure Analysis Using Computer Vision
We employed computer vision using python and the scikit-image image processing library to characterize the microstructure of coatings based on ‘column (blob) detection’ algorithms. Every sliding angle value had corresponding images, around 800 images each which were cropped to the same magnification. In the present case, the model was able to identify the columnar structures of the coating and quantify the effect of sliding angle on the columns. To quantify the microstructure of the coatings based on image processing, we used pixel intensity clustering algorithms to detect pixel clusters referred to as blobs, which in our case represent the pillar or column structures of the SEM micrograph of the coating. To identify these blobs, we segmented the images by thresholding. Thresholding enables the identification of blobs; after selecting a threshold value, images with pixel values less than that threshold are set to 0, while the others are set to 1. This provides a clear distinction between the background and the foreground. For our use case, choosing a constant thresholding value was not very efficient, as we would be working with images taken from different angles with varying exposures and lighting. We thus employed adaptive thresholding with Otsu’s binarization algorithm after applying a Gaussian blur to remove noise. Otsu's method chooses a threshold value automatically for each image from the image histogram, which not only avoids manually choosing a global threshold value for each image but also increases the accuracy of threshold value selection. We thus do not use a constant global thresholding value; Otsu’s automatic segmentation technique is employed for adaptive thresholding.
After image thresholding, we used the Difference of Gaussian (DoG) method (Ref 19) for blob detection. This method entails blurring the images with increasing standard deviations and layering up the differences in two successive blurs in a cube. The local maxima observed are the blobs in the image. This allows the algorithm to work faster than one of its counterparts, the Laplace of Gaussian (LoG) method, which calculates the Laplacian instead of the difference from the successive images. The LoG operator works by initially convoluting an image say f (x, y) by a Gaussian kernel g as:
Such that L(x, y; t) is defined as f (x, y)·g (x, y, t), then using the convoluted image we define the scale normalized Laplacian operator.
The DoG algorithm operator is mathematically defined as:
where L (x; y; t) satisfies \(\partial_{t} L = \frac{1}{2}\nabla^{2} L\); the diffusion equation.
In addition, DoG is more accurate than its other counterpart, the Determinant of Hessian (DoH), as it can identify much smaller blobs (smaller pillar-like microstructures in our case).
The DoH operator works as follows:
One downside of DoG is that it can only identify light blobs on a dark background, unlike the DoH, which can also identify dark blobs on a light background. However, this fact works to our advantage in this specific case since the features we wish to identify are the column-like structures, which are light peaks on a dark background of valleys.
Figure 4(a) depicts a sample SEM coating micrograph; its binarized form highlighting the columns and providing contrast for computer recognition is shown in Fig. 4(b). Finally, blobs were identified using the DoG algorithm in Fig. 4(c).

Computer Vision Analysis to obtain structural properties from SEM micrographs
Machine and Deep Learning Workflow
For the machine learning aspect, we employed both supervised and unsupervised learning techniques. In the proposed workflow, supervised learning was used to estimate the coating wetting characteristics, while the unsupervised learning technique was applied to automatically cluster coating SEM images based on microstructure analysis for the GAN. Additional information on the ML algorithms, training, and hyperparameters used is provided below.
Supervised Learning
Supervised learning in the form of regression algorithms was used to predict surface properties such as the sliding angle and water contact angle. Regression algorithms were trained on input data and were used to estimate the outputs. Algorithms such as linear regression, decision trees, random forest and XGBoosting were used. All the algorithms used showed promise; however, some appeared prone to overfitting. This was corrected by tuning and optimizing their hyperparameters using GridSearch: for XGB, especially, max_depth (the maximum depth of a tree), subsample (the fraction of observations needed to be sampled for each tree), min_child_weight (minimum sum of weights of total observations required in a child) were considered. Their performance was then evaluated based on their mean squared error and coefficient of determination or R2 score.
Unsupervised Learning
We applied unsupervised learning based on K-means clustering algorithms on our data to determine how to use the GAN to generate accurate images efficiently. Since the GAN was trained on a dataset of images, it would produce a computer-generated image with similar coating properties. The task of the clustering algorithm was to find the best split in the dataset of the images to train the GAN on a subdivision based on the sliding angle. The reasoning behind having separate datasets is that it allows for the generation of images with distinctive properties that can more accurately produce the desired coating microstructure.
For this task, we used the K-means clustering algorithm and its elbow method to find the best split in terms of the sliding angle, allowing for a more diverse and representative dataset and hence more accurate results. The K-means algorithm was trained by using as features the number of blobs or column structures for each sliding angle, the average diameter, and the average area for each of the blobs. This was done since a larger blob diameter implies thicker column structures, and larger average areas imply higher column density in the region. This helped to give a kind of physical consistency to our workflow since feeding information about the structural properties of the columnar structures is what helps it create distinct clusters. These clusters formed using the K-Means clustering algorithm and were made based not only on the blobs' physical characteristics but also on the sliding angle for the SEM images. Figure 5 shows the K-Means clustering algorithm, with the red dot representing the optimum number of clusters using the elbow method—in this case, three. With this information, we created three classes of SEM images based on their sliding angle, each containing about 3500 images.

K-Means Algorithm and Elbow Method to determine the ideal number of clusters for our dataset
Generative Adversarial Network (GAN)
The GAN consists of two adversarial neural networks: the generator, which tries to replicate the original image, and the discriminator, which assesses whether the replication is comparable to the original images.
As illustrated in Fig. 6, a GAN works as follows: a random noise is fed into the generator, which is then forced to produce an image. The generated image from the generator is then compared to the actual image using the discriminator. The neural network in the generator learns from this comparison and produces another image with the data it has just learned. This process is repeated over and over, and the generator improves at producing realistic-looking images to the point that the discriminator cannot differentiate between the generated and real images. In the instance where the discriminator cannot differentiate between the original dataset and the produced images, the GAN has succeeded in producing realistic images.

General overview of the GAN architecture
In this work, we used state-of-the-art StyleGAN3 ADA neural network architecture (Ref 18) to improve the quality of our images. StyleGAN3 offers changes to the GAN generator and introduces a mapping network in addition to the synthesis network. This mapping network allows control of the intermediate latent vector and hence control over the ‘style’ of the image produced by the generator. This capability allowed for the exploration of the latent space as well as the generation of different visual variations of the same image. However, latent vector space exploration is beyond the scope of this paper, so we instead focused on the outputs without altering their latent space.
The main differences between traditional GAN architecture and a style-based one, as illustrated in Fig. 7, are as follows.

Copyright 2021 IEEE. Reprinted, with permission from IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol 43, Issue 12, Tero Karras, Samuli Laine, Timo Aila, A Style-Based Generator Architecture for Generative Adversarial Networks, pp. 4217–4228. (Ref 18)
Difference between a traditional and style-based GAN Generator architecture.
The style-based architecture employs a baseline progressive growing method in which the generator and discriminator are built with small-sized images, and after stability is established, the dimensions are doubled until the desired output size is reached. The AdaIN layers standardize the outputs of the feature maps and add the style vector as bias. Finally, noise is added to the final output as a stochastic deviation to make it appear more photo realistic.
We trained the GAN on three datasets of images and developed the associated trained models to represent all possible predicted sliding angle values. Since each dataset of images corresponds to an interval of sliding angles, hence each sliding angle estimated by the regression model will be mapped to a certain dataset. The datasets included around 3500 images, each with a resolution of 1024 × 1024 pixels and obtained from the original SEM micrographs by sliding windows method. Each image was operated on by a window of a specific size that would crop out that portion, producing multiple images of the same magnification from a single image. It is worth noting that no other data augmentations apart from the sliding window method were made.
A GAN usually produces an image from a random latent vector, also known as the seed value. Each seed is unique and reproducible; we used this property to generate a consistent yet unique SEM coating image corresponding to its sliding angle, another property which will be distinctive to the coating. When a sliding angle is estimated, it produces a unique seed which is then used to generate an image from the GAN. Figure 8 shows the images produced by the GAN at different stages of its training cycle.

GAN training cycle producing images at intervals of every 80 epochs clockwise. Higher epochs signify longer training
Fréchet Inception Distance (FID) (Ref 17) is used to measure the similarity in the quality of images produced by a generative model. In our case, the FID measures the distribution of the produced images from the generator of our GAN with the distribution of real images. The FID score is the current standard for image quality comparison because it imitates human pattern recognition. The lower the FID score, the higher quality of the produced images. Figure 9 shows the FID score of our generator model as a function of its training. We can see that even with a limited working dataset, the FID score converges and hence shows that image quality is improving over time.

Fréchet Inception Distance metric values from our GAN's training as a function of training epochs over time
Results and Discussion
As discussed in Sect. "Methodology", our workflow consists majorly of two aspects: the coating characteristic prediction and the consequent image generation and validation.
To assess coating wetting characteristics, we used regression models to predict the sliding angle. Specifically, during the application of these models, 80% of our dataset was utilized as the training set, while 20% was used as the test set. This is important to note since the available dataset is on the smaller side for regression algorithms, and further segmenting it does not provide highly accurate results.
Table 5 shows that XGBoosting has the highest accuracy (R2-score over 0.85) and the lowest error, while the k-nearest neighbors algorithm (kNN) has the lowest. This is attributed to the fact that XGBoosting employs advanced regularization algorithms that improves gradient boosting’s generalizability. Since regression algorithms are generally designed for large datasets, they tend to overfit on smaller (or limited) datasets, as in the current work (Ref 15).
However, we can see an R2 score of over 0.70 and an MSE under 0.2 from a few algorithms, which indicates that our learning workflow performs works.
It is worth noting that our prediction algorithm performs ‘reasonably well,’ given a small dataset which shows potential for future applications. The notion of ‘reasonably well’ comes from the R2 score and MSE values. According to the R2 score, we infer that 70% of the variability of the output variable (Sliding Angle: SA) can be accounted for by the prediction model, whereas only the remaining 30% cannot be. This provides an indication of the ‘goodness of fit’ of our prediction model. However, we may encounter the case when we obtain similar R2 scores using distinct prediction models that produce different errors. Although the R2 score might be high in one case, the errors and residuals may indicate that from the fit that the model is biased. This raises the need for our second metric, the Mean square error or MSE. The MSE provides us with an account for the average squared errors such that the positive and negative errors do not cancel each other, thereby avoiding ambiguity due to bias in the R2 score. Thus, we obtain the following primitive convention for our understanding: prediction is unbiased and accurate when we encounter a high R2 score and low MSE.
This completes the discussion of the first part of our workflow. For the second part, we investigate the images generated after the predictions of our regressor model.
As illustrated in Fig. 10, the images produced by the GAN, while being completely artificial, look realistic. We verify this not only through looking at the images, but also running the blob detection algorithm as explained in Sect. "Microstructure Analysis Using Computer Vision". The blob detection algorithm validates the GAN generated images for each seed value and outputs it. In case, the unique seed received from the prediction model produces an image that has different coating characteristics (differing column structures in terms of number, shape, or size) as compared to the image class belonging to the specific cluster, it produces the image corresponding to the mathematically subsequent seed value. This process is repeated till we obtain a seed with a corresponding coating image whose properties match the bounds set by our clustering algorithm. This is the final image produced, thereby maintaining accuracy and reproducibility.

Original image from our dataset compared to synthetic image generated by the GAN
These results demonstrate the capability of our workflow to estimate coating characteristics of an SPS process based on its process parameters. Further, it generates an image that looks identical to the one we obtain after imaging the coating. But, since our GAN model uses the outputs from our prediction model, the accuracy of the image produced by the GAN is bound by the accuracy of the prediction it uses. Thus, the better the prediction of the regressors, the more accurate the image generated will be.
We show in Fig. 11 the prediction of our model from the operating conditions to coating generation by combining the regression algorithm (XGBoosting) and the GAN model. Our learning model's capability to map process variables to coating microstructure is distinctive, and the workflow can be enhanced with additional data. Further, the ability to work with images could be used to better describe the coatings' pore space, pore connectivity, tortuosity or to perform blobs analysis, which appears to better describe the SHS coating roughness. Finally, the impact of operating conditions could be evaluated based on the deposited coatings. Such a technique could be used to quantify digitally unmolten particles, cracks, or oxidized particles in coating images.

Comparison of various operating conditions and its effect on the coating microstructure
Summary and Conclusion
In this paper, we explored the use of machine learning algorithms and neural networks to predict suspension plasma spray coating characteristics. We used supervised learning algorithms on existing datasets to predict the properties of any new coating. Using the sliding angle as one of the major differentiating factors between coatings, we used computer vision algorithms and identified the correlation between the sliding angle and the columnar structures in the coating. This suggests that the column density decreases as the sliding angle increases. We further concluded that for the extent of this paper, the estimated sliding angle is unique, and one coating can only have one sliding angle, as it is constrained to a specific geometry and a specific number of columnar structures. This was determined when we explored the possibility of roughly classifying coating microstructure properties based on the sliding angle.
Feeding the unique sliding angle to the GAN, in turn, generates a unique image from scratch using our images training dataset. The images of the coating are then explored within the latent space of the GAN to improve upon the image to resemble the properties of the real image with a similar sliding angle value. This process is completely automated, and the effects of changing parameters of the SPS operating conditions instantaneously produce the resulting sliding angle and an SEM image of the coating.
We observe an accuracy of over 80% in our regression algorithms, which validates our method of predicting coating characteristics.
The next steps include performing more physical experiments to generate more data, enabling higher accuracy in our predicting algorithms. However, even now, current results show promise and can be used as a preliminary indicator of the properties of an SPS coating without performing a physical spray application.
References
M. Aghasibeig, F. Tarasi, R.S. Lima, A. Dolatabadi, and C. Moreau, A Review on Suspension Thermal Spray Patented Technology Evolution, J. Therm. Spray Technol., 2019, 28(7), p 1579-1605. https://doi.org/10.1007/S11666-019-00904-X/FIGURES/27
A. Diaz-Pinto, N. Ravikumar, R. Attar, A. Suinesiaputra, Y. Zhao, E. Levelt, E. Dall’Armellina, M. Lorenzi, Q. Chen, T.D.L. Keenan, E. Agrón, E.Y. Chew, Z. Lu, C.P. Gale, R.P. Gale, S. Plein, and A.F. Frangi, Predicting Myocardial Infarction Through Retinal Scans and Minimal Personal Information, Nat. Mach. Intell., 2022, 4(1), p 55-61. https://doi.org/10.1038/s42256-021-00427-7
S. Guessasma, G. Montavon, P. Gougeon et al., Designing Expert System Using Neural Computation in View of the Control of Plasma Spray Processes, Mater. Des., 2003, 24, p 497-502.
S. Guessasma and Z. Salhi, Artificial Intelligence Implementation in the APS Process Diagnostic, Mater. Sci. Eng. B, 2004, 110, p 285-295.
A.-F. Kanta, G. Montavon, M. Vardelle et al., Artificial Neural Networks vs. Fuzzy Logic: Simple Tools to Predict and Control Complex Processes-Application to Plasma Spray Processes, J. Therm. Spray Technol., 2008, 17, p 365-376.
P.L. Fauchais, J.V.R. Heberlein, and M.I. Boulos, Overview of Thermal Spray, Therm. Spray Fundam., 2014 https://doi.org/10.1007/978-0-387-68991-3_2
J. Fiebig, E. Bakan, T. Kalfhaus, G. Mauer, O. Guillon, and R. Vaßen, Thermal Spray Processes for the Repair of Gas Turbine Components, Adv. Eng. Mater., 2020, 22(6), p 1901237. https://doi.org/10.1002/ADEM.201901237
A. Gupta, A. Anpalagan, L. Guan, and A.S. Khwaja, Deep Learning for Object Detection and Scene Perception in Self-driving Cars: Survey, Challenges and Open Issues, Array, 2021, 10, p 100057. https://doi.org/10.1016/J.ARRAY.2021.100057
R. Jaworski, L. Pawlowski, F. Roudet, S. Kozerski, and A.L. Maguer, Influence of Suspension Plasma Spraying Process Parameters on TiO2 Coatings Microstructure, J. Therm. Spray Technol., 2007, 17(1), p 73-81. https://doi.org/10.1007/S11666-007-9147-Z
H. Kassner, R. Siegert, D. Hathiramani, R. Vassen, and D. Stoever, Application of Suspension Plasma Spraying (SPS) for Manufacture of Ceramic Coatings, J. Therm. Spray Technol., 2007, 17(1), p 115-123. https://doi.org/10.1007/S11666-007-9144-2
M. Razavipour, J.G. Legoux, D. Poirier, B. Guerreiro, J.D. Giallonardo, and B. Jodoin, Artificial Neural Networks Approach for Hardness Prediction of Copper Cold Spray Laser Heat Treated Coatings, J. Therm. Spray Technol., 2022 https://doi.org/10.1007/s11666-021-01311-x
N. Sharifi, F. Ben Ettouil, C. Moreau, A. Dolatabadi, and M. Pugh, Engineering Surface Texture and Hierarchical Morphology of Suspension Plasma Sprayed TiO2 Coatings to Control Wetting Behavior and Superhydrophobic Properties, Surf. Coat. Technol., 2017, 329, p 139-148. https://doi.org/10.1016/j.surfcoat.2017.09.034
Z. Wang, S. Cai, W. Chen, R.A. Ali, and K. Jin, Analysis of Critical Velocity of Cold Spray Based on Machine Learning Method with Feature Selection, J. Therm. Spray Technol., 2021 https://doi.org/10.1007/s11666-021-01198-8
A. Yala, C. Lehman, T. Schuster, T. Portnoi, and R. Barzilay, A Deep Learning Mammography-Based Model for Improved Breast Cancer Risk Prediction, Radiology, 2019, 292(1), p 60-66. https://doi.org/10.1148/radiol.2019182716
D.G. Jenkins and P.F. Quintana-Ascencio, A Solution to Minimum Sample Size for Regressions, PLOS ONE, 2020, 15(2), p e0229345. https://doi.org/10.1371/journal.pone.0229345
M. Borenstein, L.V. Hedges, J.P. Higgins, and H.R. Rothstein, A Basic Introduction to Fixed-Effect and Random Effects Models for Meta-Analysis, Res. Synth. Methods, 2010, 1, p 97-111.
M. Heusel, H. Ramsauer, T. Unterthiner, N. Nessler, S. Hochreiter, GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium. Adv. Neural Inf. Process. Syst. 30. arXiv:1706.08500. (2017)
T. Karras, S. Laine, and T. Aila, A Style-Based Generator Architecture for Generative Adversarial Networks, IEEE Trans. Pattern Anal. Mach. Intell., 2021, 43(12), p 4217-4228. https://doi.org/10.1109/TPAMI.2020.2970919
T. Lindeberg, Image matching using generalized scale-space interest points, Scale space and variational methods in computer vision. SSVM 2013. Lecture notes in computer science, Vol 7893, A. Kuijper, K. Bredies, T. Pock, H. Bischof Ed., Springer, Berlin, 2013
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This article is an invited paper selected from presentations at the 2022 International Thermal Spray Conference, held May 4–6, 2022 in Vienna, Austria, and has been expanded from the original presentation. The issue was organized by André McDonald, University of Alberta (Lead Editor); Yuk-Chiu Lau, General Electric Power; Fardad Azarmi, North Dakota State University; Filofteia-Laura Toma, Fraunhofer Institute for Material and Beam Technology; Heli Koivuluoto, Tampere University; Jan Cizek, Institute of Plasma Physics, Czech Academy of Sciences; Emine Bakan, Forschungszentrum Jülich GmbH; Šárka Houdková, University of West Bohemia; and Hua Li, Ningbo Institute of Materials Technology and Engineering, CAS
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Mahendru, P., Tembely, M. & Dolatabadi, A. Artificial Intelligence Models for Analyzing Thermally Sprayed Functional Coatings. J Therm Spray Tech 32, 388–400 (2023). https://doi.org/10.1007/s11666-023-01554-w
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11666-023-01554-w