
Abstract
Preference data are a particular type of ranking data where some subjects (voters, judges,...) express their preferences over a set of alternatives (items). In most real life cases, some items receive the same preference by a judge, thus giving rise to a ranking with ties. An important issue involving rankings concerns the aggregation of the preferences into a “consensus”. The purpose of this paper is to investigate the consensus between rankings with ties, taking into account the importance of swapping elements belonging to the top (or to the bottom) of the ordering (position weights). By combining the structure of \(\tau _x\) proposed by Emond and Mason (J Multi-Criteria Decis Anal 11(1):17–28, 2002) with the class of weighted Kemeny-Snell distances, a position weighted rank correlation coefficient is proposed for comparing rankings with ties. The one-to-one correspondence between the weighted distance and the rank correlation coefficient is proved, analytically speaking, using both equal and decreasing weights.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Ranking is one of the most effective cognitive processes used by people to handle many aspects of their lives. When some subjects are asked to indicate their preferences over a set of alternatives (items), ranking data are called preference data. Therefore, ranking data arise when a group of n individuals (e.g., judges, experts, voters, raters, etc.) show their preferences for a finite set of items (m different alternatives of objects, e.g., movies, activities and so on). Preference data can be expressed in two forms: by ordering the items, or giving them a rank. Every ordering can be transformed into a ranking and vice-versa. If the m items, labeled \(1,\ldots , m\), are ranked in m distinguishable ranks, a complete (full) ranking or linear ordering is achieved (Cook 2006): this ranking a is a mapping from the set of items \(\{1,\ldots , m\}\) to the set of ranks \(\{1,\ldots , m\}\), endowed with the natural ordering of integers, where a(i) is the rank given by the judge to item i. For example, given 5 items, say \(\{i_1, i_2, i_3, i_4, i_5\}\), the ordering \((i_2, i_3, i_4, i_1, i_5)\) corresponds to the ranking \(a = (4,1,2,3,5)\). Ranking a is, in this case, one of the 5! (or m! with m items) possible permutations of 5 elements. When some items receive the same preference, then a tied ranking or a weak ordering is obtained. For example, given 5 items, say \(\{i_1, i_2, i_3, i_4, i_5\}\), the ordering \((i_2, <i_1, i_3>, i_4, i_5)\), where \(i_1 \) and \(i_3\) are tied, corresponds to the ranking \(a = (2,1,2,4,5)\). Finally, in real situations, sometimes not all items are ranked: we observe partial rankings, when judges are asked to rank only a subset of the whole set of items (for example only 3 over 6 items), and incomplete rankings, when judges can freely choose to rank only some items. As already said, every ordering can be transformed into a ranking and vice-versa, therefore in the following the two words will be used interchangeably.
An important issue involving rankings concerns the aggregation of the preferences in order to identify a compromise or a “consensus” (Kemeny and Snell 1962; Fligner and Verducci 1990) (Kemeny and Snell 1962). The same problem is known in the literature as the social choice problem, the rank aggregation problem, the median ranking problem, the central ranking detection, or the Kemeny problem, depending on the reference framework (D’Ambrosio et al. 2019). Different approaches have been proposed in the literature to cope with this problem, but probably the most popular is the one related to distances/correlations (Kemeny and Snell 1962; Cook et al. 1986; Fagot 1994; D’Ambrosio and Heiser 2016). As a matter of fact, in order to obtain homogeneous groups of subjects with similar preferences, it is common to measure the spread between rankings through dissimilarity or distance measures. In this sense, a consensus is defined as the ranking that is closest (i.e. with the minimum distance) to the whole set of preferences. Another possible way for measuring (dis)-agreement between rankings is in terms of a correlation coefficient: rankings in full agreement are assigned a correlation of \(+1\), those in full disagreement are assigned a correlation of \(-1\), and all others lie in between. A distance d between two rankings, instead, is a non-negative value, ranging in \([0 - \mathrm{Dmax}]\), where 0 is the distance between a ranking and itself. Considering the (finite) set S of all weak orderings of m objects, any rank correlation coefficient on S is also a distance metric on S, and vice versa. A distance metric d can be transformed into a correlation coefficient c (and vice-versa) using the linear transformation \(c = 1- \frac{2d}{D_{\mathrm{max}}}\). Distances between rankings have received a growing consideration in the past few years. Within this framework, the usual examples include Kendall’s and Spearman’s rank correlation coefficient. In 1962, Kemeny and Snell introduced a metric defined on linear and weak orders, known as Kemeny distance (or metric), later generalized to the framework of partial orders by Cook et al. (1986), which satisfies the constraints of a distance measure suitable for rankings.
Among the several axiomatic approaches proposed in the literature, here we consider the Kemeny’s axiomatic framework (Kemeny and Snell 1962) and, since the possibility of ties is admitted, we refer to a generalized permutation polytope as the geometrical space of preference rankings (Heiser and D’Ambrosio 2013; D’Ambrosio et al. 2017), for which the natural distance measure is the Kemeny distance. The generalized permutation polytope was defined by Thompson (1993) as the convex hull of a finite set of points in \(\mathcal {R}^m\) whose coordinates are the permutations of m items. It will be inscribed in a \(m-1\) dimensional subspace, hence a graphical visualization is only possible with \(m\le 4\). The case of a space from 4 items, involving ties, is shown in Fig. 1 and represents the truncated octahedron.

Permutation polytope for full and weak rankings of 4 items
Cook (2006) highlights the intractability of the Kemeny metric, an issue already underlined by Emond and Mason (2002) and connected to the mathematical formulation using absolute values [see Eq. (1)]. For this reason, the latter introduced a new correlation coefficient, strictly related to the Kemeny distance, and proposed the use of this coefficient as a basis for deriving a consensus among a set of rankings.
Distances between rankings are not sensitive toward where the disagreement occurs. Kumar and Vassilvitskii (2010) introduced two essential concepts for many applications involving distances between rankings: positional weights and element weights. We enter positional weights if we want to emphasize the disagreement between two rankings when it occurs in a particular position in the ranking, i.e., for example, if we consider swapping elements near the head of a ranking more important than swapping elements in the tail of the ranking. Conversely, element weights refer to the role played by the objects that judges are ranking: in certain situations swapping some particular objects should be less penalizing than swapping some others. As noted by Henzgen and Hüllermeier (2015), weighted versions of rank correlation measures have been studied in many fields other than statistics. For example, “in information retrieval, important documents are supposed to appear in the top, and a swap of important documents should incur a higher penalty than a swap of unimportant ones”. In the context of the web, when comparing the query results of different search engines, the distance should emphasize the difference of the top elements more than the bottom ones, since people may be interested in the first few items (Chen et al. 2014). A short review of solutions proposed in the literature to cope with this issue can be found in (Yilmaz et al. 2008).
In 2010 García-Lapresta and Pérez-Román introduced a position weighted Kemeny distance, which is suitable for both full and weak orderings, while Plaia et al. (2019) introduced the corresponding correlation coefficient that is suitable for linear orders only.
This paper aims to introduce a weighted correlation coefficient that accommodates both linear and weak orderings. A new weighted rank correlation can be derived by combining the weighted Kemeny distance proposed by García-Lapresta and Pérez-Román (2010) and the extension of Kendall’s \(\tau \), \(\tau _x\), provided by Emond and Mason (2002). This correlation coefficient works like the one proposed by Plaia et al. (2019) but asks for a generalization to weak orderings (i.e. tied rankings) that is anything but trivial since it needs for a new definition of the score matrices. The exact correspondence, under a particular configuration of weights, between the proposed correlation coefficient and the one proposed by Emond and Mason’s is shown and its relation to the García-Lapresta and Pérez-Román distance through the linear transformation \(\tau = 1- \frac{2d}{D_{\mathrm{max}}}\) is derived. Moreover, in the paper, the proposed weighted correlation coefficient will be used to deal with a consensus ranking problem, i.e. to find the ranking which best represents the rankings/preferences expressed by a group of judges: to this aim, a suitable branch and bound algorithm will be introduced.
2 Distances and correlations for rankings
The Kemeny distance (\(d_K\)) between two rankings a and b is a city-block distance defined as:
where \(a_{ij}\) and \(b_{ij}\) are the generic elements of the \(m \times m\) score matrices associated to a and b respectively, assuming the following values:
Note that the score matrix (2) is the same as the score matrix that defines Kendall’s \(\tau _b\).
Considering the usual relation between a distance d and its corresponding correlation coefficient \(\tau =1-2d/D_{\mathrm{max}}\), where \(D_{\mathrm{max}}\) is the maximum distance, \(d_K\) is in a one-to-one correspondence to the rank correlation coefficient \(\tau _x\) proposed by (Emond and Mason 2002), defined as:
where \(a^{'}_{ij}\) and \(b^{'}_{ij}\) are the generic elements of the \(m \times m\) score matrices associated to a and b respectively, assuming the following values
\(\tau _x\) reduces to Kendall’s \(\tau _b\) with linear orderings and differs from the last in that ties are given a score of 1 instead of 0: this allows to solve the known problems with Kendall’s \(\tau _b\) with weak orderings (Emond and Mason 2002).
Distances and correlations are the two possible measures used to cope with the consensus ranking problem; given n rankings, full or weak, of m items, what best represents the consensus opinion? This consensus is the ranking that shows maximum correlation, or equivalently minimum distance, with the whole set of n rankings.
3 Weighted distances
Distances between rankings are not sensitive to the point of disagreement: i.e. if the disagreement between two rankings relates to a particular position or a specific item. As already said in the Introduction, in this case we can introduce positional or element weights in the distance/correlation. In this paper, we deal with positional weights and consider the weighted version of the Kemeny metric since the Kemeny metric is not sensitive to the point of disagreement between two rankings. The non-increasing weighting vector \(w=(w_1,w_2,\ldots ,w_{m-1})\) is used to measure the weighted distances, where \(w_i\) is the weight given to position i in the ranking. Note that weights can be given at most \(m-1\) positions, since the \(m-th\) is univocally determined.
Given two generic rankings of m elements, a and b, the weighted Kemeny distance is defined by García-Lapresta and Pérez-Román (2010) as follows:
where (\(\sigma _1\)) states to follow the a ranking and (\(\sigma _2\)) states to follow the orders according to b. More specifically, \(b^{(\sigma _1)}_{ij}\) is the score matrix of the ranking b reordered according to a, \( a^{(\sigma _2)}_{ij}\) is the score matrix of the ranking a reordered according to b and \(a^{(\sigma _1)}_{ij} = b^{(\sigma _2)}_{ij}=c \) is the score matrix of the linear order \(\{1, 2,\ldots , m\}\) (for more details see Plaia and Sciandra (2019)).
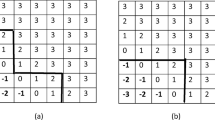
Let’s see a small example that shows how to compute the weighted Kemeny distance. Given the ranking vectors \(a=(3,1,1,4)\) and \(b=(1,3,2,2)\), we can easily define their orderings: \(\sigma _1=(2,3,1,4)\) and \(\sigma _2=(1,3,4,2)\). Then we have: \(a^{\sigma _1}=(1,1,3,4)\), \(a^{\sigma _2}=(3,1,4,1)\), \(b^{\sigma _1}=(3,2,1,2)\) and \(b^{\sigma _2}=(1,2,2,3)\). The score matrices of \(a^{\sigma _1}\), \(b^{\sigma _1}\), \(a^{\sigma _2}\) and \(b^{\sigma _2}\), computed according to (2), are respectively:
Through simple algebraic operations it can be easily found that:
Now we can compute the weighted Kemeny distance. Let’s assume equal weights, \(w=(1/3,1/3,1/3)\), the distance between a and b is:
If we change the vector of weights, with a decreasing structure \(w=(2/3,1/3,0)\), the value of the distance is:
4 A new weighted rank correlation coefficient for weak orders
Recently, Plaia et al. (2019) proposed a new rank correlation coefficient, that is suitable for position weighted rankings and handles linear orders. In this paper, a generalization is proposed to cope with the presence of ties. In particular, combining the weighted Kemeny distance proposed by García-Lapresta and Pérez-Román (2010) and the extension of \(\tau _x\) provided by Emond and Mason (2002), Plaia et al. (2019) proposed a weighted rank correlation defined as:
where the denominator represents the maximum value of the Kemeny weighted distances (García-Lapresta and Pérez-Román 2010):
For linear orderings (i.e. without ties), \(a^{\sigma _1}\) and \(b^{\sigma _2}\) represent the natural ascending orderings. Let \(a^{\sigma _1}=b^{\sigma _2}=o\), with \(o=\{1,2,\ldots ,m\}\), the new rank correlation coefficient reduces to:
where the score matrix \(O=\{o_{ij}\}\) of the ranking o has the form:
The correspondence between the weighted rank correlation coefficient and the weighted Kemeny distance holds, whichever the weighting vector assigned to the item’s positions (Plaia et al. 2019); moreover, the weighted rank correlation coefficient holds the main property of a generic correlation coefficient, i.e. it takes values between \(-1\), and 1 and, when equal importance is assigned to the item’s position, i.e. \(w_i=\frac{1}{(m-1)}\) \(\forall i=1,2,\ldots ,m-1\), the weighted rank correlation coefficient is equivalent to the rank correlation coefficient defined by Emond and Mason:
4.1 An extension to weak orders
Combining the weighted Kemeny distance proposed by García-Lapresta and Pérez-Román (2010) and the extension of \(\tau _x\) provided by Emond and Mason (2002), we propose an extension of the rank correlation coefficient in Eq. (6) suitable for weak orderings: this new rank correlation coefficient, \( \tau _x^w\), is based on a couple of score matrices.
Let’s define the generic (i, j) element of the score matrices \(A^+=\{a_{ij}^{+}\}\) and \(A^-=\{a_{ij}^{-}\}\) related to a ranking a as follows:
Following the observations in Emond and Mason (2002, secc 38, 39), both “+1” in \(A^+\) and “-1” in \(A^-\) are associated to ties. The new rank correlation coefficient, now, uses both these score matrices and is defined as:
where the denominator represents twice the maximum value of the Kemeny weighted distances (7). In short, the new rank correlation coefficient (8) generalizes Eq. (6) by duplicating the numerator, considering once the elements of the score matrices \(A^+\) and \(B^+\), and once the elements of the score matrices \(A^-\) and \(B^-\).
A question that arises immediately is: what weight or weights are used when two items occupy the same position in a ranking? Eq. (8), based on the two newly introduced score matrices, associates the same weight, as the next example shows. Let’s consider \(b = (1,2,3,4)\), and \(a_1 = (1,3,2,4)\), \(a_2 = (1,2,2,3)\), \(a_3 = (1,1,2,3)\) and \(w = (w_1,0,0)\). By weighting the first position only, the correlation between \(a_1\) and b, as well as the one between \(a_2\) and b must be maximum, while the correlation between \(a_3\) and b must not. And it is: \(\tau _x^w(a_1,b) = \tau _x^w(a_2,b)= 1\), while, \(\tau _x^w(a_3,b) < 1\).
4.1.1 Correspondence between distance and correlation
We will demonstrate that Eq. (8) is the correlation coefficient corresponding to the distance (5) through the straightforward linear transformation:
or equivalently
where \(\mathrm{Max}[d_K^w]\) and \(d_K^w\) are defined in Eq. (7) and in Eq. (5) respectively.
According to Emond and Mason (2002), if two rankings a and b agree except for a set S of k objects, which is a segment of both, then \(d_K^w(a,b)\) may be computed as if these k objects were the only objects being ranked. As a consequence, to prove the equality in (9) we will show that for each pair of objects i and j:
In Eq. (10), the weights \(w_i\) have been omitted on both sides. There are nine possible combinations of orderings for item i and j between judges a and b (i.e. rankings a and b), but only four distinct cases must be considered. The other five are equivalent to one of these four through a simple relabeling of the rankers and/or the objects (Emond and Mason 2002).
Case 1 Both judges a and b prefer object i to j. The Kemeny-Snell matrix values are: \(a_{ij}^{\sigma _1}=b_{ij}^{\sigma _1}=a_{ij}^{\sigma _2}=b_{ij}^{\sigma _2}=1\). The \(\tau _x^w\) score matrix values are: \(a_{ij}^{+\sigma _1}=b_{ij}^{+\sigma _1}=a_{ij}^{+\sigma _2}=b_{ij}^{+\sigma _2}=a_{ij}^{-\sigma _1}=b_{ij}^{-\sigma _1}=a_{ij}^{-\sigma _2}=b_{ij}^{-\sigma _2}=1\).
Hence, the equality in Eq. (10) holds:
Case 2 Judge a prefers object i to j and judge b prefers the two objects as tied. The Kemeny-Snell matrix values are: \(a_{ij}^{\sigma _1}=a_{ij}^{\sigma _2}=1\) and \(b_{ij}^{\sigma _1}=b_{ij}^{\sigma _2}=0\). The \(\tau _x^w\) score matrix values are: \(a_{ij}^{+\sigma _1}=b_{ij}^{+\sigma _1}=a_{ij}^{+\sigma _2}=b_{ij}^{+\sigma _2}=a_{ij}^{-\sigma _1}=a_{ij}^{-\sigma _2}=1\) and \(b_{ij}^{-\sigma _1}=b_{ij}^{-\sigma _2}=-1\).
Hence, the equality in Eq. (10) holds:
Case 3 Judge a prefers object i to j and judge b prefers object j to object i. The Kemeny-Snell matrix values are: \(a_{ij}^{\sigma _1}=b_{ij}^{\sigma _2}=1\) and \(a_{ij}^{\sigma _2}=b_{ij}^{\sigma _1}=-1\). The \(\tau _x^w\) score matrix values are: \(a_{ij}^{+\sigma _1}=b_{ij}^{+\sigma _2}=a_{ij}^{-\sigma _1}=b_{ij}^{-\sigma _2}=1\) and \(a_{ij}^{+\sigma _2}=b_{ij}^{+\sigma _2}=a_{ij}^{-\sigma _2}=b_{ij}^{-\sigma _1}=-1\).
Hence, the equality in Eq. (10) holds:
Case 4. Both judges a and b rank the objects i and j as tied. The Kemeny-Snell matrix values are: \(a_{ij}^{\sigma _1}=b_{ij}^{\sigma _2}=a_{ij}^{\sigma _2}=b_{ij}^{\sigma _1}=0\). The \(\tau _x^w\) score matrix values are: \(a_{ij}^{+\sigma _1}=b_{ij}^{+\sigma _1}=a_{ij}^{+\sigma _2}=b_{ij}^{+\sigma _2}=1\) and \(a_{ij}^{-\sigma _1}=b_{ij}^{-\sigma _1}=a_{ij}^{-\sigma _2}=b_{ij}^{-\sigma _2}=-1\).
Hence, the equality in Eq. (10) holds:
4.1.2 Minimum and maximum values of \(\tau _x^w\)
From the demonstrations in Sect. 4.1.1, \(\tau _x^w\) assumes its maximum value, equal to 1, if and only if, for all i and j, only Case 1 or only Case 4 are observed. Therefore, contrary to what happens with Kendall’s \(\tau _b\) (see Emond and Mason 2002, sect 3.3), \(\tau _x^w\) assumes the maximum value even when a generic all tied ranking is compared with itself.
Analogously, \(\tau _x^w\) can be minimum, and equal to \(-1\), if and only if for all i and j only Case 3 occurs.
4.1.3 Correspondence between weighted and unweighted measures
For equal weights assigned to the items (\(w_i=\frac{1}{m-1}\), for each \(i=1,2,\ldots ,m-1\)), we will demonstrate that the weighted distance is proportional to the classical Kemeny distance, on the basis of the number of items:
Proof
Referring to the cases listed in Sect. 4.1.1:
- Case 1:
-
\(d_x^w=\frac{1}{2}[|1-(1)|+|1-(1)|]w_i=0\) and \(d_x=\frac{1}{2}[|0-0|+|0-0|]=0\)
- Case 2:
-
\(d_x^w=\frac{1}{2}[|1-0|+|1-0|]w_i=\frac{1}{m-1}\) nd \(d_x=\frac{1}{2}[|1-0|+|1-0|]=1\)
- Case 3:
-
\(d_x^w=\frac{1}{2}[|1-(-1)|+|1-(-1)|]w_i=\frac{2}{m-1}\) nd \(d_x=\frac{1}{2}[|1-(-1)|+|1-(-1)|]=2\)
- Case 4:
-
\(d_x^w=\frac{1}{2}[|0-0|+|0-0|]w_i=0\) and \(d_x=\frac{1}{2}[|0-0|+|0-0|]=0\)
Corollary Since \(\tau _x\leftrightarrow d_K\) and \(\tau _x^w\leftrightarrow d_K^w\), the weighted rank correlation coefficient is equivalent to the rank correlation coefficient defined by Emond and Mason when equal importance is given to the positions occupied by the items:
4.1.4 A small numerical example
Considering the two ranking vectors \(a=(3,1,1,4)\) and \(b=(1,3,2,2)\), the score matrices defined by Emond and Mason [See Eq. (4)] are:
For computing \(\tau _x^w\) in (8) we need to compute the maximum value of the distance in (7), which needs a vector of weights. In case of equal weights (1/3, 1/3, 1/3) or decreasing weights (2/3, 1/3, 0) the maximum distance is, respectively, equal to:
After identifying \(\sigma _1=(2,3,1,4)\) and \(\sigma _2=(1,3,4,2)\), it is easy to compute the vectors \(a^{\sigma _1}=(1,1,3,4)\), \(a^{\sigma _2}=(3,1,4,1)\), \(b^{\sigma _1}=(3,2,1,2)\) and \(b^{\sigma _2}=(1,2,2,3)\) with score matrices defined in Sect. 4.1 corresponding to:
For the sake of completeness, we add the algebraic operations needed for computing \(\tau _x^w\):
Through simple algebra it is possible to show that computing \(\tau _x^w\) as defined in (8) or as a linear transformation of the weighted Kemeny distance, leads to the same outcome and this result validates the equality in (9).
In case of decreasing weights with \(w=(2/3,1/3,0)\):
5 The consensus ranking problem and a suitable branch-and-bound BB algorithm
The proposed weighted correlation coefficient can be used to deal with a consensus ranking problem: given n (full or weak) rankings of m items, which best represents the consensus opinion? This consensus will be the ranking that shows the maximum correlation with the whole set of n rankings.
Given a \(n \,\text {x}\, m\) matrix \( \mathbf {X} \), whose lth row, \(_lx \), represents the ranking associated to the lth judge, the consensus ranking, i.e. the ranking r (a candidate within the universe of the permutations with ties of m elements) that best represents matrix \( \mathbf {X} \), is that ranking that maximizes the following expression:
where \(\mathrm{Max}[d_K^w(X, r)]\) is \(2n\sum _{i=1}^{m-1}(m-i)w_i\).
Changing the order of the summations leads to work under another perspective:
where \(c_{ij}^w\) is an element of the combined input matrix C (Emond and Mason 2002). In a few words, it is an \(m\times m\) matrix obtained by aggregating the score matrices of all the individual orderings.
The maximization problem reduces to maximizing only the numerator because the denominator is a fixed quantity depending on the number of subjects, the number of items and the positional weights fixed at the beginning of the process.
A synthetic and exhaustive definition of the Branch-and-Bound algorithm (BB) can be found in (Cook 2012); he defines the BB procedure as a “method that consists of the repeated application of a process for splitting a space of solutions into two or more subspaces and adopting a bounding mechanism to indicate if it is worthwhile to explore any or all of the newly created subproblems”. The splitting phase is called branching, and it is followed by a bounding phase in which a value B is determined such that each solution in a subspace has an objective value no larger (for maximization problems) than B. It can be applied to many different types of problems, and several are applications in literature aimed to solve discrete programming problems (Tanaka and Tierney 2018; Brusco and Stahl 2006). Emond and Mason (2002) proposed a BB algorithm to deal with the consensus ranking problem: it starts with a splitting step in which three mutually exclusive branches are derived by comparing the relative positions of the first two objects (one branch with rankings such that i is preferred to j, one branch with rankings in which i is not preferred to j and the last one in which i and j are tied). Then a penalty P is computed, and every branch whose incremental penalty is greater than the penalty evaluated in the initial solution is cut off and not further considered in the procedure. The procedure goes on with the definition of new branches, and the process is repeated until all the objects are allocated and the median ranking is derived. As it is easy to understand and is highlighted by Brusco and Stahl (2006), one of the BB algorithm’s main limits is its slowness.
Within the framework of the Kemeny approach, D’Ambrosio et al. (2015) and Amodio et al. (2016) proposed two algorithms, they called QUICK and FAST, for identifying the median ranking when dealing with weak and partial rankings. They demonstrated the equivalence between the QUICK and FAST and the Emond and Mason’s branch-and-bound algorithms, and also showed a really remarkable saving of their proposal in computational time, by starting by a ‘good’ initial solution. These algorithms are faster than Emond and Mason’s BB, but still accurate: the solution they find is optimal even if they are not able to find all the solutions if multiple solutions are present. The procedure proposed in this paper is based on their approach, but \(\tau _x\) is replaced with \(\tau ^w_x\); in particular, following Emond and Mason, the maximum possible value \(P^*\) of the numerator in Eq. (12) is calculated. It is represented by the denominator of the equation itself, since a rank correlation coefficient has a maximum value equal to \(|\pm 1|\):
and taking a candidate ranking within the universe of the permutations with ties of the items, we evaluate the numerator in Eq. (12):
The two quantities, \(P^*\) and p, are used to establish an initial penalization, in the consensus ranking process, in the following way:
The purpose of the algorithm is to find, among all the possible weak rankings, the ranking that gives the minimum penalty. To this aim, the universe of permutations with ties is divided into three mutually exclusive branches, according to the position of the first two items (named i and j) in the ordering, used as the initial solution. After that, an incremental penalty for each branch can be computed, taking into account the \(c_{ij}^w\) and \(c_{ji}^w\) of the entire \(C^w\) input matrix:
BRANCH 1
-
Object i is preferred to object j:
-
(a)
If \(c^w_{ij}>c^w_{ji}>0\), then \(\delta P=0\)
-
(b)
If \(c^w_{ij}=c^w_{ji}=0\), then \(\delta P=[(w_{i}+w_{j})\cdot (m-1)\cdot n]/2\)
-
(c)
If \(c^w_{ij}<c^w_{ji}<0\), then \(\delta P=|c^w_{ij}+c^w_{ji}|\)
-
(a)
BRANCH 2
-
Object i is tied to object j:
-
(a)
If \(c^w_{ij}=c^w_{ji}=0\), then \(\delta P=[(w_{i}+w_{j})\cdot (m-1)\cdot n]/2 \)
-
(b)
If \(c^w_{ij}>0\) and \(c^w_{ji}<0\), then \(\delta P=0\)
-
(c)
If \(c^w_{ij}=c^w_{ji}=0\), then \(\delta P=[(w_{i}+w_{j})\cdot (m-1)\cdot n]/2\)
-
(a)
BRANCH 3
-
Object j is preferred to object i:
-
(a)
If \(c^w_{ij}<c^w_{ji}<0\), then \(\delta P=|c^w_{ij}+c^w_{ji}|\)
-
(b)
If \(c^w_{ij}=c^w_{ji}=0\), then \(\delta P=[(w_{i}+w_{j})\cdot (m-1)\cdot n]/2\)
-
(c)
If \(c^w_{ij}>c^w_{ji}>0\), then \(\delta P=0\)
-
(a)
where \(\delta P\) is the incremental penalty. When the incremental penalty computed from a branch is higher than the initial penalty, the rankings belonging to that branch are cut out from the search process. Otherwise, when the penalty of a branch is smaller than (or equal to) the initial one, then the next object in the initial solution is considered, and other new branches are built up, by moving this object to all possible positions with respect to the objects considered before. The incremental penalty produced by the new branches is again the tool used for cutting useless branches and for keeping only the useful ones until a solution is reached. Actually, following Amodio et al. (2016) QUICK algorithm, the penalty is evaluated by considering all items in the input ranking, while in the original BB formulation, the penalty was computed by considering only the elements of the combined input matrix associated with the processed objects, adding up these partial values.
The description of the BB algorithm step by step is the following:
1. Given \(P^*\) \(=\mathrm{Max}[d_K^w(X,b)]=2n\sum _{k=1}^{m-1}(m-k)w_k\); |
2. A candidate ranking Q is selected in \(S_m\) and its score matrix \(\{q_{ks}\}\) is derived; |
3. p \(=\bigg [\sum _{k<s}^{m}c_{ks}^w\bigg ]\); |
4. Penalty: P \(=P^*-p\); |
5. Branch : the universe of rankings (with ties) is divided in three starting mutually |
exclusive branches according to the position of the two first items; |
6. Incremental penalty \( \delta P_B\) for each branch (B=1,2,3) is computed; |
7. Bound \( \left\{ \begin{array}{ll} \text {if} \quad \delta P_{B}> P \quad \text {rankings in branch B are excluded from the search process};\\ \text {if} \quad \delta P_{B} \le P \quad \text {new branches are derived};\end{array} \right. \) |
8. \(\delta P_B\) produced by the new branches is again used for cutting useless branches and for keeping only the useful ones until a solution is reached. |
The introduction of the weights makes the algorithm slower, and this is especially true as the number of items increases. This is not a real problem because the higher the number of items the higher the number of weights equal to zero (i.e., usually, with many items, we are not interested in all the positions; therefore we assign a zero weight to all the positions we are not interested in) and this reduces the computational time.
6 Experimental evaluation
Both a simulation study and real datasets will be considered to assess the performance of the proposed procedure. Data analysis is performed using our code written in R language (available upon request). The proposed BB algorithm has been implemented in R environment by suitably modifying the corresponding functions of the ConsRank package (D’Ambrosio 2021).
6.1 Simulations
Ranking data in the simulation study were generated according to a Mallows model (Irurozki et al. 2016) which is an exponential model specified by a central permutation \(\alpha \) and a spread (or dispersion) parameter \(\theta \). When \(\theta > 0\) (with \(\theta = 0\) we obtain the uniform distribution), the central permutation \(\alpha \) is the permutation with the highest probability, while the probability of any other permutation S decays exponentially as its distance d to \(\alpha \) increases, according to the model
where \(C(\theta )\) is a normalization constant. The distance d can be any type of distance between rankings, including the Kendall, Cayley, Hamming and Ulam distances: in this paper, we consider (and implemented in R, (R Core Team 2020)) the Kemeny distance.
We consider \(m = 5\) and \(m = 9\) items, while four different values of \(\theta \) are used: 0.42, 0.6, 1.2 and 3.5. The full space of both complete and tied rankings was considered. The position weighting vectors were employed according to a precise structure: for example, for 5 items we consider \(w_1=(1/4,1/4,1/4,1/4)\), \(w_2=(4/10,3/10,2/10,1/10)\), \(w_3=(1/2,1/2,0,0)\), \(w_4=(2/3,1/3,0,0)\) and \(w_5=(1,0,0,0)\). In brief, equal and decreasing weightings were considered, at first involving all the weights and then only half of the total number of the positions and, finally, only the first position was weighted. The sample size used for all the datasets generated was 50, and for each combination of \(\theta \) and number of items, 100 samples were generated. For each sample, we estimated the consensus ranking and the corresponding \(\tau _x^w\) (12) by using all the weighting vectors. Figure 2 compares the true distribution (i.e., computed with reference to the true mode \(\alpha \) used to generate the data according to model (14)) of \(\tau _x^w\), always shown in white color, and \(\tau _x^w\) computed with respect to the estimated consensus.

Real (white color) and estimated \(tau_x^w\) distribution vs \(\theta \) and weighting vectors for rankings of 5 items (left) and 9 items (right)

Real (white color) and estimated \(tau_x^w\) distribution vs \(\theta \) and weighting vectors for rankings of 5 items and \(n = 200\) (left) and \(n = 500\) (right)
As it appears, the implemented procedure always finds the correct consensus, since the distributions of true and estimated \(\tau _x^w\) are comparable. Both with 5 (left plot of Fig. 2) and with 9 items (right plot of Fig. 2) the higher \(\theta \) the higher \(\tau _x^w\) and the simpler the weighting vector (few positions involved) the higher \(\tau _x^w\).
In order to verify the effect of the sample size, we consider two more sizes, \(n = 200\) and \(n = 500\), considering all the values of \(\theta \) and all the weighting vectors again. The results are shown in Fig. 3. It is interesting to observe that, in the presence of low values of the spread parameter \(\theta \), the consensus ranking returned by the algorithm is even “better” (higher values of the correlation coefficient) than the central permutation \(\alpha \) used to generate the samples. Of course, the higher \(\theta \), the more similar are the real (white coloured) and the estimated distributions of \(\tau _x^w\). This further simulation relates only to 5 items. The extension to the case of 9 items would require a more efficient implementation of the procedure, that is still an open issue we are working on.
6.2 Real data
The first data set is comprised of ranks of seven different sports made by 130 students from a large midwestern university. The ranks were made according to their preferences to participate in the sports. The sports considered were: A=baseball, B=football, C=basketball, D=tennis, E=cycling, F=swimming and G=jogging.
As previously considered in the simulations, 5 different weighting vectors are considered (shown in Table 1), in order to assess their effect on the estimated consensus.: with \(w_1\) we give the same importance to each position, which means that we do not weight positions (see Sect. 4.1.3); with \(w_5\) we give importance to the first position only.
The Consensus estimated for each weighting vector is shown in Table 2. With the first two weighting vectors, we obtain the same consensus, which corresponds to the one obtained by Amodio et al. (2016). With the other 3 weighting structures we obtained different consensuses, and with \(w_5\) 2 different solutions corresponding to the same value of \(\tau _x^w\), always with the sport “E” in first position.
The second real data example is reported by Emond and Mason (2000). In this dataset, 112 experts were asked to rank 15 Departmental initiatives (A to Q), competing for limited funds. In this example, some ties occur, and some rankings are not complete. This dataset has also been analyzed by Amodio et al. (2016). Table 3 shows the results corresponding to the five weighting structures (conceptually equivalent to the ones shown in the Table 1, but extended to 15 items). Note that items within the less and greater signs are tied. The first Consensus, as expected, is the one found by Emond and Mason, while it changes as soon as the weighting structure changes, although D is always in first position.
The third and, probably, more appropriate example relates to APA Election Data (available at http://www.preflib.org/data/election/apa/). These datasets contain the results of the elections of the American Psychological Association between 1998 and 2009. The voters are allowed to rank any number of the five candidates without ties. The “PrefLib: A Library for Preferences” provides for data that have been imbued with extra information. In these data, all incomplete, partial orders have been extended by placing all unranked candidates tied at the end. Each of these elections has 5 candidates and between 13,318 and 20,239 voters. In particular, the 2008 and 2009 datasets are considered here (candidates are indicated as C1, C2, C3, C4 and C5).
These two years have been chosen because they are useful to show that, if one candidate is clearly preferred over the others, weights cannot change these condition (see the year 2009 dataset results); on the other side, the introduction of weights, or better, giving a higher weight to the first position, can resolve some not so evident situation (see the year 2008 dataset results). In particular, the results for the 2008 dataset (Table 5) with different weighing vectors (Table 4) show that the candidates C1 and C2 are tied at the first position when all the positions are equally weighed (\(w_1\)), while, when a higher weight is given to position 1, candidate C2 is the only winner. With 2009 dataset (Table 6), the candidate C1 is clearly preferred over the others and, even changing the weights, he always stays, alone, in the first position.
7 Concluding remarks
In this paper, we provided a weighted rank correlation coefficient \(\tau _x^w\) for weak orderings, as an extension of \(\tau _x^w\) for linear orderings (Plaia et al. 2019). This extension ensures greater applicability, since in many real cases rankings with ties are observed and, with the methodology available up to now, they could only be ignored or eliminated.
We demonstrated the correspondence between \(\tau _x^w\) and the weighted Kemeny distance and, finally, we showed that, in the case of tied rankings and \(w_i=\frac{1}{m-1} \; \text {for all}\; i\), the weighted rank correlation coefficient \(\tau _x^w\) is equal to the Emond and Mason’s rank correlation coefficient \(\tau _x\). Moreover, we modified appropriately Amodio et al. (2016) QUICK and FAST algorithms by including positional weights. A simulation study was carried out to demonstrate that, through the use of these modified algorithms, it is possible to find the consensus rankings that maximizes the weighted rank correlation coefficient \(\tau _x^w\). The effect of different weighting vectors has also been studied. Three real datasets were analyzed to show how the solutions usually change with the weighting structure; in particular, more simple the weighting structure is more unstable is the resulting solution, except when one item is strongly preferred over the others. Some points are still open: to adapt the procedure to partial and incomplete rankings. Moreover, we are looking for a more efficient implementation of the algorithms in R language, and these will allow us to consider a much larger number of items. For now, to cope with a larger number of items, two different approaches can be considered: introducing position weights with some elements equal to 0, that reduces the size of the rankings, or, alternatively, since the research of the consensus ranking requires searching the space of all possible rankings of m objects, we can reduce the space cardinality by considering the full space of linear rankings only, following the idea in Amodio et al. (2016).
References
Amodio S, D’Ambrosio A, Siciliano R (2016) Accurate algorithms for identifying the median ranking when dealing with weak and partial rankings under the Kemeny axiomatic approach. Eur J Oper Res 249(2):667–676
Brusco M, Stahl S (2006) Branch-and-bound applications in combinatorial data analysis. Psychometrika 71:411–413
Chen J, Li Y, Feng L (2014) On the equivalence of weighted metrics for distance measures between two rankings. J Inf Comput Sci 11(13):4477–4485
Cook W (2012) Markowitz and manne + eastman + land and doig = branch and bound
Cook WD (2006) Distance-based and ad hoc consensus models in ordinal preference ranking. Eur J Oper Res 172(2):369–385. https://doi.org/10.1016/j.ejor.2005.03.048
Cook WD, Kress M, Seiford LM (1986) An axiomatic approach to distance on partial orderings. RAIRO-Oper Res 20(2):115–122
D’Ambrosio A (2021) ConsRank: Compute the Median Ranking(s) According to the Kemeny’s Axiomatic Approach. https://CRAN.R-project.org/package=ConsRank, r package version 2.1.1
D’Ambrosio A, Amodio S, Iorio C (2015) Two algorithms for finding optimal solutions of the Kemeny rank aggregation problem for full rankings. Electron J Appl Stat Anal 8(2):198–213
D’Ambrosio A, Iorio C, Staiano M, Siciliano R (2019) Median constrained bucket order rank aggregation. computational statistics. Comput Stat 34:787–802
D’Ambrosio A, Heiser WJ (2016) A recursive partitioning method for the prediction of preference rankings based upon Kemeny distances. Psychometrika 81(3):774–794
D’Ambrosio A, Mazzeo G, Iorio C, Siciliano R (2017) A differential evolution algorithm for finding the median ranking under the Kemeny axiomatic approach. Comput Oper Res 82:126–138
Emond EJ, Mason DW (2000) A new technique for high level decision support. ORD Project Report PR2000/13
Emond EJ, Mason DW (2002) A new rank correlation coefficient with application to the consensus ranking problem. J Multi-Criteria Decis Anal 11(1):17–28
Fagot R (1994) An ordinal coefficient of relational agreement for multiple judges. Psychometrika 59:241–251
Fligner M, Verducci J (1990) Posterior probabilities for a consensus ordering. Psychometrika 55:53–63
García-Lapresta JL, Pérez-Román D (2010) Consensus measures generated by weighted Kemeny distances on weak orders. In: 2010 10th international conference on intelligent systems design and applications, IEEE, pp 463–468
Heiser WJ, D’Ambrosio A (2013) Clustering and prediction of rankings within a Kemeny distance framework. In: Lausen B, Van den Poel D, Ultsch A (eds) Algorithms from and for Nature and Life. Springer, Berlin, pp 19–31
Henzgen S, Hüllermeier E (2015) Weighted rank correlation: a flexible approach based on fuzzy order relations. In: Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Springer, pp 422–437
Irurozki E, Calvo B, Lozano JA et al (2016) Permallows: An r package for mallows and generalized mallows models. J Stat Softw 71(i12):1–30
Kemeny JG, Snell L (1962) Preference ranking: an axiomatic approach. In: Mathematical models in the social sciences, MIT press, pp 9–23
Kumar R, Vassilvitskii S (2010) Generalized distances between rankings. In: Proceedings of the 19th international conference on World wide web, ACM, pp 571–580
Plaia A, Sciandra M (2019) Weighted distance-based trees for ranking data. Adv Data Anal Classif 13:427–424
Plaia A, Buscemi S, Sciandra M (2019) A new position weight correlation coefficient for consensus ranking process without ties. Stat 8(1):e236
R Core Team (2020) R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing, Vienna, Austria, https://www.R-project.org/
Tanaka S, Tierney K (2018) Solving real-world sized container pre-marshalling problems with an iterative deepening branch-and-bound algorithm. Eur J Oper Res 264(1):165–180. https://doi.org/10.1016/j.ejor.2017.05.046
Thompson GL (1993) Generalized permutation polytopes and exploratory graphical methods for ranked data. Ann Stat 21(3):1401–1430. https://doi.org/10.1214/aos/1176349265
Yilmaz E, Aslam JA, Robertson S (2008) A new rank correlation coefficient for information retrieval. In: Proceedings of the 31st annual international ACM SIGIR conference on Research and development in information retrieval, ACM, pp 587–594
Funding
Open access funding provided by Università degli Studi di Palermo within the CRUI-CARE Agreement.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Plaia, A., Buscemi, S. & Sciandra, M. Consensus among preference rankings: a new weighted correlation coefficient for linear and weak orderings. Adv Data Anal Classif 15, 1015–1037 (2021). https://doi.org/10.1007/s11634-021-00442-x
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11634-021-00442-x