
Abstract
Permeability is a property of rocks which refers to the ability of fluids to flow through each substance. It depends on several factors as pore shape and diameter. Also the presence and type of clay has a large influence on the permeability value. Permeability can be measured on rock sample in the laboratory by injecting fluid through the rock under known condition, but this provides only point information. Due to the dependence of the parameter on many factors, the deterministic estimation of permeability based on laboratory measurement and well logs is problematic. Many empirical methods for determining permeability are available in the literature and interpretation systems. An interesting approach to the problem is the use of artificial neural networks based on laboratory measurement and modern, high-resolution logging tools. The authors decided to use MLP artificial neural networks, which allow permeability estimation and can be used both in the test well and applied to neighbouring wells. The network was checked in several variants. Obtained results show the legitimacy of using artificial neural networks in the issue of estimating permeability. However, they also show limitations resulting from the lack of accurate data or influence of geological setting and processes.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Permeability is one of the most difficult properties of rocks to estimate. It refers to the ability of fluids to flow through the substance. Permeability of a rock for oil, gas or water is a function of the absolute permeability and the fluid viscosity.
Permeability is influenced, the same as porosity, by many depositional and diagenetic factors. The most important factors that depend on the permeability of the rock is shape, pore diameter and pore connection (Schön 2011). Moreover, among the depositional factors affecting permeability, size and sorting of the grains should be mentioned (Beard and Weyl 1973; Bloch 1991; Lucia 1995). Coarse and well-sorted grains ensure better flows in the reservoir. Diagenetic factors such as compaction and cementation cause a reduction in permeability. Also, the type of minerals, which build the rock, affects this parameter. The presence of quartz increases the absolute permeability, despite the smaller porosity, while clay minerals due to their properties and distribution in rock significantly affect its reduction (Neuzil 1994).
The permeability is related to the productivity of the rock formation. Occurrence of oil or gas saturation in low-permeability reservoirs requires additional activities such as hydraulic fracturing or drilling of horizontal wells to obtain the hydrocarbon flow. Determination of the absolute permeability is crucial in order to properly identify the reservoir parameters and determine the profitability of possible hydrocarbon production.
Permeability can be estimated in many different methods. The most reliable method is laboratory measurements, which mainly are based on injecting fluid to the core sample under known condition (Tiab and Donaldson 2000; Jarzyna and Puskarczyk 2009) and are carried out on liquid permeameters. Laboratory measurements provide only point information and are mainly used to calibrate deterministic calculations based on well logging (Iturrarán-Viveros and Parra 2014; Wawrzyniak-Guz 2016).
Absolute permeability of materials is described by Darcy’s equation. Nevertheless, deterministic calculation of permeability in rocks is very difficult due to its dependence on many factors, which are problematic in determination in laboratory measurements and interpretation of well logs. Despite this, many methods of permeability estimation are available in the literature and interpretation systems (Asquith and Krygowski 2004). Most of the equations are based on the relationship between permeability and porosity. This is due to the fact that the permeability mainly depends on the structure and specific surface of the pore space (Such and Leśniak 2006). Kozeny (1927) and Carman (1937), using the Darcy equation, proposed a formula (Eq. 1) combining these two parameters, but it is challenging to correctly determine all the factors present in the formula (Amaefule et al. 1993):
where \(K\)—absolute permeability, \(\phi_{{\text{e}}}\)—effective porosity, \(F_{{\text{s}}}\)—shape factor, \(\tau\)—tortuosity, \(S_{{{\text{gv}}}}\)—surface area per unit grain volume.
Equations based on porosity are also available, which additionally use such quantities as irreducible water saturation or shale volume. In Poland, the empirical equation suggested by Zawisza (1993) is often used, which includes porosity and irreducible water saturation (Eq. 2):
where \(a\)—regional factor, \(\phi\)—porosity, \(S_{{{\text{wir}}}}\)—irreducible water saturation.
An interesting approach to the problem of permeability determination is the use of artificial neural networks based on laboratory measurement on core samples, modern, high-resolution logging tools or results of their qualitative interpretation.
Method
The precursor to the emergence of artificial neural networks was the development of the model of the neuron in the human brain and explained the mechanism of memorizing information via the biological network in the 1940s by McCulloch and Pitts (1943) (Tadeusiewicz 1992). The first designed and constructed neural network was the perceptron developed by Rosenblatt (1958). Initially, neural networks have not gained much interest because the use of single-layer networks is limited. Further work demonstrating that multilayer, nonlinear networks have unlimited possibilities caused a significant increase in their use. Neural networks are widely used also in geophysical and petrophysical problems (Huang et al. 1996; Aminzade and De Groot 2006; Bhatt and Helle 2002; Sudakov et al. 2019).
Artificial neural networks (ANNs) with the ability to reproduce complicated functions are used to reduce interference, classification or prediction of data and parameters. Neural networks have the ability to learn, memorize and generalize calculations based on the training data set. They cope very well with inconsistent, distorted data. ANN are stable and resistant to damage. Calculations using the network in relation to the structure are very efficient, even operating on large data sets.
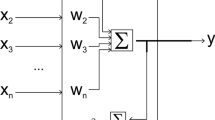
In the case of the parameter prediction task, feedforward, multilayer networks stand out, which guarantee very good results, and are relatively easy to design and use. Multilayer Perceptron (MLP) is built from at least three layers: the input layer, the hidden layers and the output layer (Fig. 1).

Scheme of a multilayer perceptron (Tutak and Brodny 2019; modified)
During the design of neural networks, the most important stages are the selection process and the learning stage, because they project on the network and obtained results. Romeo (1994) distinguishes three main causes resulting in bad network performance: bad network configuration, algorithm suspension in the minimum and wrong learning set. The key moment is choosing the number of neurons in the hidden layer. There are no clearly defined rules for their number. However, the number of layers should not be too large because it can cause the network to be overly adapted to the test data. The best method to select the right number of layers is trial and error, starting with a small number of layers. In the case of selecting a training sample, it should be ensured that they are as representative as possible and possibly free from measurement errors. Avoiding the above-mentioned errors, it is possible to design networks that are capable of solving complex problems and predicting parameters whose relationship with measurements is not easy to describe using simple mathematical functions. One of such parameters used in petrophysics is the absolute permeability.
An important element of creating a network is the validation process. It allows to evaluate the quality of the solution obtained by the network. For this process, a certain sample of the output data is used, usually random, which is not used in the network learning process. The error function is minimized during the network learning process. Its drop is definitely faster for the learning sample and slower for validation. Changing the validation error is also an indicator for proper network construction, because its increase during the learning process may suggest too many hidden layers (Krogh and Vedelsby 1994). While the network is being designed for the learning process and its evaluation, the error function is used. The task of the network is to minimize it, in each subsequent iteration. To calculate the error, various functions are used, such as mean absolute error function, the cross-entropy or maximum likelihood function; and the most frequently used is sum of squares (Falas and Stafylopatis 1999) (Eq. 3):
where \(N\)—number of cases used for learning, \(y_{i}\)—network prediction result, \(t_{i}\)—measured parameter value.
Presented analysis was performed in Statistica software (version 13) using Multilayer Perceptron algorithm with exponential activation function for the hidden and output neurons (StatSoft 2011).
Materials
Research was made on data from three wells located on Lublin Syncline in Poland. The analysis covered the Silurian and Ordovician shale and mudstone formations, which are potential unconventional shale gas deposits. These formations are characterized by poor reservoir properties, in particular low permeability (Krakowska and Puskarczyk 2015). Due to the location of the wells within various geological regions, analogous formations are buried at various depths. The distance and complex tectonics of the area can affect the differences in petrophysical parameters between the layers.
The basis for the training of neural networks was the results of laboratory measurements of absolute permeability from gas permeameter and effective porosity from mercury porosimetry measured on core samples from one of the wells. For each well, there were also available results of well logging and the logs interpretation, the summary of which is presented in Table 1.
Results
The first, but very important step in the process of using neural networks is the appropriate selection of the data used. According to the assumption, the output data being tested, and training and validation data should be associated with the input data. In the case of creating neural networks, it is not entirely true to say that the more the better, because variables unrelated to the output data may cause deterioration of the network (StatSoft 2011).
The implemented input data for the creation of artificial neural networks were the following well logs: RHOB, NPHI, DT, LLD, LLS, MSFL, THOR, URAN, POTA, PE and the results of their interpretation: VCL, VANH, VDOL, VLIM, VSAN, VPYR, VTOC, PHI, K, SWI. As the qualitative input for the training wells, absolute permeability from laboratory measurements was applied. Before performing the data selection for all wells, the basic statistics and histograms for reservoir parameters were calculated (Table 2).
Basic statistics of laboratory data indicate that the studied formations exhibit very poor reservoir parameters, in particular absolute permeability, which is typical for unconventional hydrocarbon resources, such as tight gas or shale gas (Xiao et al. 2014). For the training well A, the absolute permeability is very low, mostly not exceeding 0.01 mD, as evidenced by the median, i.e. the value that prevents the flow of hydrocarbons. The network learning process was carried out on the basis of trial and error, both checking the various functions of activation of input and output neurons and observing the behaviour of the error function for individual network dimensions. Network design was carried out using automated algorithms in which a random selection of data for learning, testing and validation sets was applied.
At the beginning, for the well A, the networks were designed based on well logs, for the whole available depth interval. In the second step, division into stratigraphic units (periods: Silurian and Ordovician) was implemented as qualitative input. In the third step, based on the same data, the division into stratigraphic units was provided with details, taking into consideration Polish informal stratigraphic units: Ludlow, Wenlock, Llandovery, Ashgill, Caradoc. The absolute permeabilities, which are equal to the minimum detected value (K = 0.0001 mD) in gas permeameter, were not considered, as not informative for the ANN. The total number of permeability values from laboratory measurements was equal to 109. Thanks to this procedure, three absolute permeabilities were obtained: K_ANN—no stratigraphic units were applied, K_ANN1—stratigraphic units were applied, and K_ANN2—informal stratigraphic units were applied.
Table 3 presents the results of probe quality using three different constructions of the Multilayer Perceptron in the form of determination coefficient for the estimated absolute permeabilities from ANN and from gas permeameter. The best results were obtained for the Multilayer Perceptron: MLP 16-10-1 (ANN3), which is revealed by the highest determination coefficient for the learning, test and validation procedure.
Calculated absolute permeabilities were compared quantitatively and qualitatively with laboratory data (K_LAB) and permeability determined from the Zawisza (K_ZAWISZA) and Wyllie–Rose (K_WYLLIE–ROSE) formula using scatterplots (Fig. 2) and basic statistics (Table 4). Figure 2 presents the comparison between the absolute permeability from laboratory measurements and from ANN at the depth available from the laboratory measurements on the core samples. Absolute permeability from ANN is in the form of the log, so the values are available for each 0.1 m. ANN2 network was used on the other wells because it presented the best validation, which indicated the ability to implement network to other data. Determination coefficient for the absolute permeability from gas permeameter (K_LAB) and absolute permeability from the artificial neural network ANN2 is 0.72.

Comparison of laboratory data with estimated and calculated absolute permeabilities
Permeabilities from Zawisza (available from the interpretation data set) and Wyllie–Rose (calculated by authors) formula were estimated in order to check the quality of the ANN results. Results obtained for Wyllie–Rose equation were better but similar to the Zawisza equation. The determination coefficient for K_LAB and K_Wyllie–Rose is 0.26. During the analysis, an attempt was made to learn the network applied to the division created using XRMI tool measurements, based on resistivity contrast between layers. Nevertheless, due to the small number of samples, the obtained results were unsatisfactory.
Analysing the calculated statistics, the parameter variability with the depth and the qualitative fit between the estimated permeability (K_ANN, K_ANN1, K_ANN2) and the input permeability (K_LAB, K_ZAWISZA), it was decided that the best match appears in the networks created for the most detailed stratigraphy (K_ANN2), even if the calculated matching factors are not the best.
Using the estimated permeability based on the formula (Eq. 4), the FZI (Flow Zone Index) parameter was calculated, which was then used as an input parameter in the creation of artificial neural networks based only on interpretation data from well logs. Interpretation logs were available for the whole Silurian depth interval and partially in Ordovician. The FZI parameter characterizes the rock ability to move media in the pore space. The determination of FZI classes allows classification of the formation according to intervals of similar hydraulic properties.
The calculated parameter FZI served as one of the parameters for the calculation of neural networks using the data obtained in the petrophysical interpretation. When training the network, a similar procedure was used as in the case of well logging data. Multilayer Perceptron had the form of MLP 9-6-1 with determination coefficient for the input, hidden and output layers: 0.79, 0.70 and 0.28, respectively. The result, in the form of absolute permeability K_ANN3, was obtained and is presented in the chart (Fig. 3) and in Table 5. Again, the best match was obtained for more detailed stratigraphy: K_ANN2.

Comparison between estimated absolute permeability (K_ANN3) and from laboratory measurements (K_LAB)
The estimated absolute permeabilities were compiled on the track, to which the results of laboratory measurements were superimposed (Fig. 4).

Results of absolute permeability estimation by artificial neural network in well A. Symbols of Polish informal stratigraphic units: A—Ludlow, B—Wenlock, C—Llandovery, D—Ashgill, E—Caradoc
The analysis of logs shows that, as indicated by the calculated statistics, the differences between the permeabilities, in which the input data were well logs, are not too high and the best fit was considered for K_ANN. Nevertheless, ANN2 network was used on the other wells because it presented the best validation statistics and differences in fit between K_LAB and K_ANN were slightly lower. The other wells have also implemented networks, taught on the basis of interpretation data. However, the obtained results were not satisfactory. The results of the implemented networks were presented on the track (Fig. 5). Unfortunately, due to the lack of data from laboratory measurements on core samples, it was not possible to compare them. Only the comparison with the permeability calculated from the Zawisza formula was used.

Results of absolute permeability estimation by artificial neural network in well B and C. Symbols of Polish informal stratigraphic unit as in Fig. 4
The correlation coefficient between the absolute permeability from the artificial neural networks and the Zawisza equation will be lower than 0.5 for both wells. Nevertheless, due to the lack of data from laboratory measurements on core samples, it is not possible to accurately assess this parameter. In particular, in the case of absolute permeability from the Zawisza formula calculated for the well C, it seems to be overestimated in relation to the actual parameters for the formation in the studied area. Lack of success in the application of the best ANN for wells B and C is caused by the strong heterogeneity of reservoir parameters for Silurian and Ordovician deposits and active tectonic in the research area. Even small changes in the diagenesis process for the thin-layered mudstone and shale deposits reveal enormous change in the petrophysical parameters, such as effective porosity and absolute permeability.
Conclusions
The presented work aimed at checking the legitimacy of using artificial neural networks to determine the absolute permeability parameter. Tests were carried out on data from Silurian and Ordovician shale and mudstone formations. These formations are characterized by poor reservoir parameters, such as effective porosity and absolute permeability, which additionally hampered the assumed task.
Attempts were made in providing the different sets of variables as the input data. The best results were obtained for well logs and the data from the well log interpretation, given as follows: RHOB, NPHI, DT, LLD, LLS, MSFL, THOR, URAN, POTA, PE, VCL, VANH, VDOL, VLIM, VSAN, VPYR, VTOC, PHI, K, SWI.
The best ANN was ANN2 with MLP 16-10-1 characteristic, using Polish informal stratigraphic units, as an input division. In both cases, learned networks for smaller depths intervals worked better. Determination coefficient for the relationship between the absolute permeabilities derived from ANN2 and from absolute permeability from gas permeameter is R2 = 0.72.
Unfortunately, due to the lack of data from laboratory measurements on core samples in the remaining B and C wells, it was impossible to make an unambiguous and objective assessment of their quality. A possible poor fit may result from the complicated tectonic structure of the research area. An attempt in learning the network using measurements from the XRMI tool, which seems to be an interesting issue, was made and failed also due to the small number of samples.
Artificial neural networks can be used in petrophysical analysis because they give the possibility to get the information in the form of the log, from larger amount of data and calibrated with the laboratory measurements. Calculations of ANN are fast and quite cheap in comparison with the measurements and give good results for the parameters with nonlinear characteristic such as permeability in reference to well logs.
Abbreviations
- ANN:
-
Artificial neural network
- MLP:
-
Multilayer perceptron
- GR:
-
Natural radioactivity, gamma ray log (API)
- RHOB:
-
Bulk density, density log (g/cm3)
- NPHI:
-
Neutron porosity in limestone unit, neutron porosity log (frac)
- DT:
-
Sonic transit time, sonic log (μs/ft)
- LLD:
-
Electrical resistivity, deep resistivity laterolog (\({\Omega }\;{\text{m}}\))
- LLS:
-
Electrical resistivity, shallow resistivity laterolog (\({\Omega }\;{\text{m}}\))
- MSFL:
-
Electrical resistivity, micro-spherically focused resistivity log (\({\Omega }\;{\text{m}}\))
- SP:
-
Spontaneous potential log (mV)
- THOR:
-
Thorium content, spectral gamma ray log (ppm)
- URAN:
-
Uranium content, spectral gamma ray log (ppm)
- POTA:
-
Potassium content, spectral gamma ray log (%)
- PE:
-
Photoelectric factor, litho-density log (barn/electron)
- XRMI:
-
Electrical resistivity, X-tended Range Micro Imager (\({\Omega }\;{\text{m}}\))
- VCL:
-
Volume of clay, result of petrophysical interpretation of well logs (frac)
- VANH:
-
Volume of anhydrite, result of petrophysical interpretation of well logs (frac)
- VDOL:
-
Volume of dolomite, result of petrophysical interpretation of well logs (frac)
- VLIM:
-
Volume of calcite, result of petrophysical interpretation of well logs (frac)
- VSAN:
-
Volume of quartz, result of petrophysical interpretation of well logs (frac)
- VPYR:
-
Volume of pyrite, result of petrophysical interpretation of well logs (frac)
- VTOC:
-
Volume of total organic carbon, result of petrophysical interpretation of well logs (frac)
- PHI:
-
Effective porosity, result of petrophysical interpretation of well logs (frac)
- K :
-
Absolute permeability, result of petrophysical interpretation of well logs (mD)
- SWI:
-
Irreducible water saturation, result of petrophysical interpretation of well logs (frac)
- PHSW:
-
Volume of rock occupied by water, result of petrophysical interpretation of well logs (frac)
- K_LAB:
-
Absolute permeability from laboratory measurements (mD)
- K_ANN:
-
Absolute permeability from artificial neural network MLP 10-7-1 (mD)
- K_ANN1:
-
Absolute permeability from artificial neural network MLP 12-9-1 (mD)
- K_ANN2:
-
Absolute permeability from artificial neural network MLP 16-10-1 (mD)
- K_ANN3:
-
Absolute permeability from artificial neural network MLP 9-6-1 (mD)
- K_ZAWISZA:
-
Absolute permeability from Zawisza equation (mD)
- K_WYLLIE–ROSE:
-
Absolute permeability from Wyllie–Rose equation (mD)
- Φ:
-
Porosity from laboratory measurements (frac)
- FZI:
-
Flow zone indicator (μm)
References
Amaefule JO, Altunbay M, Tiab D, Kersey DG, Keelan DK (1993) Enhanced reservoir description: using core and log data to identify hydraulic (flow) units and predict permeability in uncored intervals/wells. SPE Paper 26436:1–16. https://doi.org/10.2118/26436-MS
Aminzade F, de Groot P (2006) Neural networks and other soft computing techniques with application in the oil industry. EAGE Publications, Houten, p 129
Asquith G, Krygowski D (2004) Basic well log analysis. AAPG, Oklahoma, https://doi.org/10.1306/Mth16823
Beard DC, Weyl PK (1973) Influence of texture on porosity and permeability of unconsolidated sand. Am Assoc of Petrol Geol Bull 57(2):349–369
Bhatt A, Helle HB (2002) Committee neural networks for porosity and permeability prediction from well logs. Geophys Prospec 50(6):645–660. https://doi.org/10.1046/j.1365-2478.2002.00346.x
Bloch S (1991) Empirical prediction of porosity and permeability in sandstones. Am Assoc Petrol Geol Bull 75(7):1145–1160
Carman PC (1937) Fluid flow through granular beds. Trans Inst Chem Eng 15:150–167. https://doi.org/10.1016/S0263-8762(97)80003-2
Falas T, Stafylopatis AG (1999) The impact of the error function selection in neural network-based classifiers. In Proceedings of the international joint conference on neural networks, Washington, DC, USA, pp 1799–1804, DOI: 10.1109/IJCNN.1999.832651
Huang Z, Shimeld J, Williamson M, Katsube J (1996) Permeability prediction with artificial neural network modeling in the Venture gas field, offshore Eastern Canada. Geophys 61(2):422–436. https://doi.org/10.1190/1.1443970
Iturrarán-Viveros U, Parra JO (2014) Artificial Neural Networks applied to estimate permeability, porosity and intrinsic attenuation using seismic attributes and well-log data. J Appl Geophys 107:45–54
Jarzyna J, Puskarczyk E (2009) Permeability of rocks on the basis of mercury porosimetry and NMR measurements. Geologia 35(2/1):599–606 (in Polish)
Kozeny J (1927) Uber Kapillare Letung des Wassers im Boden, Sitzungsberichte: Royal Academy of Science, Vienna. Proc Class I 136:271–306
Krakowska P, Puskarczyk E (2015) Tight reservoir properties derived by nuclear magnetic resonance, mercury porosimetry and computed microtomography laboratory techniques: case study of Palaeozoic clastic rocks. Acta Geophys 63(3):789–814. https://doi.org/10.1515/acgeo-2015-0013
Krogh A, Vedelsby J (1994) Neural network ensembles, cross validation and active learning. In: NIPS'94 proceedings of the 7th international conference on neural information processing systems, pp 231–238
Lucia FJ (1995) Rock-fabric/petrophysical classification of carbonate pore space for reservoir characterization. Am Assoc Petrol Geol Bull 79(9):1275–1300
McCulloch WS, Pitts J (1943) A logical calculus of the ideas immanent in nervous activity. Bull of Math Biophys 5:115–133. https://doi.org/10.1007/BF02478259
Neuzil CE (1994) How permeable are clays and shales? Water Resour Res 30(2):145–150
Romeo G (1994) Seismic signals detection and classification using artificial neural networks. Ann Geofis 37:343–353. https://doi.org/10.4401/ag-4211
Rosenblatt F (1958) The perceptron: a probabilistic model for information storage and organization in the brain. Psychol Rev 65(6):386–408. https://doi.org/10.1037/h0042519
Schön J (2011) Physical properties of rocks: a workbook. Elsevier, Amsterdam
Statistica Tutorial (2011) StatSoft Polska, EPS
Such P, Leśniak G (2006) Warunki konieczne i wystarczające do up-scalingu danych petrofizycznych. Nafta-Gaz 11:565–570 (in Polish)
Sudakov O, Burnaev E, Koroteev D (2019) Driving digital rock towards machine learning: Predicting permeability with gradient boosting and deep neural networks. Comput Geosci 127:121–136
Tadeusiewicz R (1993) Sieci neuronowe. Akademicka Oficyna Wydawnicza, Warsaw, Poland (in Polish)
Tiab D, Donaldson EC (2000) Petrophysics, theory and practice of measuring reservoir rock and fluid transport properties. Elsevier, N.Y., 899 s. (sec. ed.)
Tutak M, Brodny J (2019) Predicting methane concentration in longwall regions using artificial neural networks. Int J Environ Res Public Health 16(8):1406. https://doi.org/10.3390/ijerph16081406
Wawrzyniak-Guz K (2016) Acoustic full waveforms as a bridge between seismic data and laboratory results in petrophysical interpretation. Acta Geophys 64:2356–2381
Węgrzyn H, Huk-Skiba A, Dubiel J, Karapeta M, Byś I, Cieśla M, Polak J (2015) Unpublished documentation of the results of measurements. Polish Oil Gas Company Archive, Warsaw, Poland (in Polish)
Xiao L, Liu XP, Zou CC, Hu XX, Mao ZQ, Shi YJ, GuoHP Li GR (2014) Comparative study of models for predicting permeability from nuclear magnetic resonance (NMR) logs in two Chinese tight sandstone reservoirs. Acta Geophys 62(1):11–141. https://doi.org/10.2478/s11600-013-0165-6
Zawisza L (1993) Określanie współczynnika przepuszczalności absolutnej oraz przepuszczalności względnych skał na podstawie pomiarów geofizycznych w otworach wiertniczych. AGH Publishing, Kraków, Poland (in Polish)
Acknowledgements
Data are ownership of POGC, Warsaw, Poland. Paper was financially supported from the research subsidy nr 16.16.140.315 at the Faculty of Geology Geophysics and Environmental Protection of the AGH University of Science and Technology, Krakow, Poland, 2019.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Waszkiewicz, S., Krakowska-Madejska, P. & Puskarczyk, E. Estimation of absolute permeability using artificial neural networks (multilayer perceptrons) based on well logs and laboratory data from Silurian and Ordovician deposits in SE Poland. Acta Geophys. 67, 1885–1894 (2019). https://doi.org/10.1007/s11600-019-00347-6
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11600-019-00347-6