
Abstract
Assuming that the wealth process \(X^u\) is generated self-financially from the given initial wealth by holding its fraction u in a risky stock (whose price follows a geometric Brownian motion with drift \(\mu \in \mathbb {R}\) and volatility \(\sigma >0\)) and its remaining fraction \(1 -u\) in a riskless bond (whose price compounds exponentially with interest rate \(r \in \mathbb {R}\)), and letting \(\mathsf{P}_{t,x}\) denote a probability measure under which \(X^u\) takes value x at time t, we study the dynamic version of the nonlinear mean-variance optimal control problem

where t runs from 0 to the given terminal time \(T>0\), the supremum is taken over admissible controls u, and \(c>0\) is a given constant. By employing the method of Lagrange multipliers we show that the nonlinear problem can be reduced to a family of linear problems. Solving the latter using a classic Hamilton-Jacobi-Bellman approach we find that the optimal dynamic control is given by
where \(\delta = (\mu -r)/\sigma \). The dynamic formulation of the problem and the method of solution are applied to the constrained problems of maximising/minimising the mean/variance subject to the upper/lower bound on the variance/mean from which the nonlinear problem above is obtained by optimising the Lagrangian itself.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Imagine an investor who has an initial wealth which he wishes to exchange between a risky stock and a riskless bond in a self-financing manner dynamically in time so as to maximise his return and minimise his risk at the given terminal time. In line with the mean-variance analysis of Markowitz [11] where the optimal portfolio selection problem of this kind was solved in a single period model (see e.g. Merton [12] and the references therein) we will identify the return with the expectation of the terminal wealth and the risk with the variance of the terminal wealth. The quadratic nonlinearity of the variance then moves the resulting optimal control problem outside the scope of the standard optimal control theory (see e.g. [5]) which may be viewed as dynamic programming in the sense of solving the Hamilton–Jacobi–Bellman (HJB) equation and obtaining an optimal control which remains optimal independently from the initial (and hence any subsequent) value of the wealth. Consequently the results and methods of the standard/linear optimal control theory are not directly applicable in this new/nonlinear setting. The purpose of the present paper is to develop a new methodology for solving nonlinear optimal control problems of this kind and demonstrate its use in the optimal mean-variance portfolio selection problem stated above. This is done in parallel to the novel methodology for solving nonlinear optimal stopping problems that was recently developed in [13] when tackling an optimal mean-variance selling problem.
Assuming that the stock price follows a geometric Brownian motion and the bond price compounds exponentially, we first consider the constrained problem in which the investor aims to maximise the expectation of his terminal wealth \(X_T^u\) over all admissible controls u (representing the fraction of the wealth held in the stock) such that the variance of \(X_T^u\) is bounded above by a positive constant. Similarly the investor could aim to minimise the variance of his terminal wealth \(X_T^u\) over all admissible controls u such that the expectation of \(X_T^u\) is bounded below by a positive constant. A first application of Lagrange multipliers implies that the Lagrange function (Lagrangian) for either/both constrained problems can be expressed as a linear combination of the expectation of \(X_T^u\) and the variance of \(X_T^u\) with opposite signs. Optimisation of the Lagrangian over all admissible controls u thus yields the central optimal control problem under consideration. Due to the quadratic nonlinearity of the variance we can no longer apply standard/linear results of the optimal control theory to solve the problem.
Conditioning on the size of the expectation we show that a second application of Lagrange multipliers reduces the nonlinear optimal control problem to a family of linear optimal control problems. Solving the latter using a classic HJB approach we find that the optimal control depends on the initial point of the controlled wealth process in an essential way. This spatial inconsistency introduces a time inconsistency in the problem that in turn raises the question whether the optimality obtained is adequate for practical purposes. We refer to this optimality as the static optimality (Definition 1) to distinguish it from the dynamic optimality (Definition 2) in which each new position of the controlled wealth process yields a new optimal control problem to be solved upon overruling all the past problems. This in effect corresponds to solving infinitely many optimal control problems dynamically in time with the aim of determining the optimal control (in the sense that no other control applied at present time could produce a more favourable value at the terminal time). While the static optimality has been used in the paper by Strotz [21] under the name of ‘pre-commitment’ as far as we know the dynamic optimality has not been studied in the nonlinear setting of optimal control before. In Sect. 4 below we give a more detailed account of the mean-variance results and methods on the static optimality starting with the paper by Richardson [19]. Optimal controls in all these papers are time inconsistent in the sense described above. This line of papers ends with the paper by Basak and Chabakauri [1] where a time-consistent control is derived that corresponds to the Strotz’s approach of ‘consistent planning’ [21] realised as the subgame-perfect Nash equilibrium (the optimality concept refining Nash equilibrium proposed by Selten in 1965).
We show that the dynamic formulation of the nonlinear optimal control problem admits a simple closed-form solution (Theorem 3) in which the optimal control no longer depends on the initial point of the controlled wealth process and hence is time consistent. Remarkably we also verify that this control yields the expected terminal value which (i) coincides with the expected terminal value obtained by the statically optimal control (Remark 4) and moreover (ii) dominates the expected terminal value obtained by the subgame-perfect Nash equilibrium control (in the sense of Strotz’s ‘consistent planning’) derived in [1] (Sect. 4). Closed-form solutions to the constrained problems are then derived using the solution to the unconstrained problem (Corollaries 5 and 7). These results are of both theoretical and practical interest. In the first problem we note that the optimal wealth exhibits a dynamic compliance effect (Remark 6) and in the second problem we observe that the optimal wealth solves a meander type equation of independent interest (Remark 8). In both problems we verify that the expected terminal value obtained by the dynamically optimal control dominates the expected terminal value obtained by the statically optimal control.
The novel problems and methodology of the present paper suggest a number of avenues for further research. Firstly, we work within the transparent setting of one-dimensional geometric Brownian motion in order to illustrate the main ideas and describe the new methodology without unnecessary technical complications. Extending the results to higher dimensions and more general diffusion/Markov processes appears to be worthy of further consideration. Secondly, for similar tractability reasons we assume that (i) unlimited short-selling and borrowing are permitted, (ii) transaction costs are zero, (iii) the wealth process may take both positive and negative values of unlimited size. Extending the results under some of these constraints being imposed is also worthy of further consideration. In both of these settings it is interesting to examine to what extent the results and methods laid down in the present paper remain valid under any of these more general or restrictive hypotheses.
2 Formulation of the problem
Assume that the riskless bond price B solves
with \(B_0=b\) for some \(b>0\) where \(r \in \mathbb {R}\) is the interest rate, and let the risky stock price S follow a geometric Brownian motion solving
with \(S_0=s\) for some \(s>0\) where \(\mu \in \mathbb {R}\) is the drift, \(\sigma >0\) is the volatility, and W is a standard Brownian motion defined on a probability space \((\Omega ,\mathcal{F},\mathsf{P})\). Note that a unique solution to (2.1) is given by \(B_t = b\; e^{rt}\) and recall that a unique strong solution to (2.2) is given by \(S_t = s\, \exp ( \sigma W_t +(\mu -(\sigma ^2/2))\, t )\) for \(t \ge 0\).
Consider the investor who has an initial wealth \(x_0 \in \mathbb {R}\) which he wishes to exchange between B and S in a self-financing manner (with no exogenous infusion or withdrawal of wealth) dynamically in time up to the given horizon \(T>0\). It is then well known (see e.g. [2, Chapter 6]) that the investor’s wealth \(X^u\) solves
with \(X_{t_0}^u = x_0\) where \(u_t\) denotes the fraction of the investor’s wealth held in the stock at time \(t \in [t_0,T]\) for \(t_0 \in [0,T)\) given and fixed. Note that (i) \(u_t<0\) corresponds to short selling of the stock, (ii) \(u_t>1\) corresponds to borrowing from the bond, and (iii) \(u_t \in [0,1]\) corresponds to a long position in both the stock and the bond.
To simplify the exposition we will assume that the control u in (2.3) is given by \(u_t = u(t,X_t^u)\) where \((t,x) \mapsto u(t,x) \cdot x\) is a continuous function from \([0,T] \times \mathbb {R}\) into \(\mathbb {R}\) for which the stochastic differential equation (2.3) understood in Itô’s sense has a unique strong solution \(X^u\) (meaning that the solution \(X^u\) to (2.3) is adapted to the natural filtration of W and if \(\tilde{X}^u\) is another solution to (2.3) of this kind then \(X^u\) and \(\tilde{X}^u\) are equal almost surely). We will call controls of this kind admissible in the sequel. Recalling that the natural filtration of S coincides with the natural filtration of W we see that admissible controls have a natural financial interpretation as they are obtained as deterministic (measurable) functionals of the observed stock price. Moreover, adopting the convention that \(u(t,0) \cdot 0 := \lim _{\,0 \ne x \rightarrow 0} u(t,x) \cdot x\) we see that the solution \(X^u\) to (2.3) could take both positive and/or negative values after passing through zero when the latter limit is different from zero (as is the case in the main results below). This convention corresponds to re-expressing (2.3) in terms of the total wealth \(u_t X_t^u\) held in the stock as opposed to its fraction \(u_t\) which we follow throughout (note that the essence of the wealth equation (2.3) remains the same in both cases). We do always identify u(t, 0) with \(u(t,0) \cdot 0\) however since \(x \mapsto u(t,x)\) may not be well defined at 0.
Note that the results to be presented below also hold if the set of admissible controls is enlarged to include discontinuous and path dependent controls u that are adapted to the natural filtration of W, or even controls u which are adapted to a larger filtration still making W a martingale so that (2.3) has a unique weak solution \(X^u\) (meaning that the solution \(X^u\) to (2.3) is adapted to the larger filtration and if \(\tilde{X}^u\) is another solution to (2.3) of this kind then \(X^u\) and \(\tilde{X}^u\) are equal in law). Since these extensions follow along the same lines and needed modifications of the arguments are evident, we will omit further details in this direction and focus on the set of admissible controls as defined above.
For a given admissible control u we let \(\mathsf{P}_{t,x}\) denote the probability measure (defined on the canonical space) under which the solution \(X^u\) to (2.3) takes value x at time t for \((t,x) \in [0,T] \times \mathbb {R}\). Note that \(X^u\) is a (strong) Markov process with respect to \(\mathsf{P}_{t,x}\) for \((t,x) \in [0,T] \times \mathbb {R}\).
Consider the optimal control problem

where the supremum is taken over all admissible controls u such that \(\mathsf{E\,}_{t,x}[(X_T^u)^2]<\infty \) for \((t,x) \in [0,T] \times \mathbb {R}\) and \(c>0\) is a given and fixed constant. A sufficient condition for the latter expectation to be finite is that \(\mathsf{E\,}_{t,x} \big [ \int _t^T (1 +u_s^2)\, (X_s^u)^2\; ds \big ] < \infty \) and we will assume in the sequel that all admissible controls by definition satisfy that condition as well.
Due to the quadratic nonlinearity of the second term in the expression  it is evident that the problem (2.4) falls outside the scope of the standard/linear optimal control theory for Markov processes (see e.g. [5]). Moreover, we will see below that in addition to the static formulation of the nonlinear problem (2.4) where the maximisation takes place relative to the initial point (t, x) which is given and fixed, one is also naturally led to consider a dynamic formulation of the nonlinear problem (2.4) in which each new position of the controlled process \(((t,X_t^u))_{t \in [0,T]}\) yields a new optimal control problem to be solved upon overruling all the past problems. We believe that this dynamic optimality is of general interest in the nonlinear problems of optimal control (as well as nonlinear problems of optimal stopping as discussed in [13]).
it is evident that the problem (2.4) falls outside the scope of the standard/linear optimal control theory for Markov processes (see e.g. [5]). Moreover, we will see below that in addition to the static formulation of the nonlinear problem (2.4) where the maximisation takes place relative to the initial point (t, x) which is given and fixed, one is also naturally led to consider a dynamic formulation of the nonlinear problem (2.4) in which each new position of the controlled process \(((t,X_t^u))_{t \in [0,T]}\) yields a new optimal control problem to be solved upon overruling all the past problems. We believe that this dynamic optimality is of general interest in the nonlinear problems of optimal control (as well as nonlinear problems of optimal stopping as discussed in [13]).
The problem (2.4) seeks to maximise the investor’s return identified with the expectation of \(X_T^u\) and minimise the investor’s risk identified with the variance of \(X_T^u\) upon applying the control u. This identification is done in line with the mean-variance analysis of Markowitz [11]. Moreover, we will see in the proof below that the problem (2.4) is obtained by optimising the Lagrangian of the constrained problems


respectively, where u is any admissible control, and \(\alpha \in (0,\infty )\) and \(\beta \in \mathbb {R}\) are given and fixed constants. Solving (2.4) we will therefore be able to solve (2.5) and (2.6) as well. Note that the constrained problems have transparent interpretations in terms of the investor’s return and the investor’s risk as discussed above.
We now formalise definitions of the optimalities alluded to above. Recall that all controls throughout refer to admissible controls as defined/discussed above.
Definition 1
(Static optimality). A control \(u_*\) is statically optimal in (2.4) for \((t,x) \in [0,T] \times \mathbb {R}\) given and fixed, if there is no other control v such that

A control \(u_*\) is statically optimal in (2.5) for \((t,x) \in [0,T] \times \mathbb {R}\) given and fixed, if  and there is no other control v satisfying
and there is no other control v satisfying  such that
such that
A control \(u_*\) is statically optimal in (2.6) for \((t,x) \in [0,T] \times \mathbb {R}\) given and fixed, if \(\mathsf{E\,}_{t,x}(X_T^{u_*}) \ge \beta \) and there is no other control v satisfying \(\mathsf{E\,}_{t,x}(X_T^v) \ge \beta \) such that

Note that the static optimality refers to the optimality relative to the initial point (t, x) which is given and fixed. Changing the initial point may yield a different optimal control in the nonlinear problems since the statically optimal controls may and generally will depend on the initial point in an essential way (cf. [21]). This stands in sharp contrast with standard/linear problems of optimal control where in view of dynamic programming (the HJB equation) the optimal control does not depend on the initial point explicitly. This is a key difference between the static optimality in nonlinear problems of optimal control and the standard optimality in linear problems of optimal control (cf. [5]).
Definition 2
(Dynamic optimality). A control \(u_*\) is dynamically optimal in (2.4), if for every given and fixed \((t,x) \in [0,T] \times \mathbb {R}\) and every control v such that \(v(t,x) \ne u_*(t,x)\), there exists a control w satisfying \(w(t,x) = u_*(t,x)\) such that

A control \(u_*\) is dynamically optimal in (2.5), if for every given and fixed \((t,x) \in [0,T] \times \mathbb {R}\) and every control v such that \(v(t,x) \ne u_*(t,x)\) with  , there exists a control w satisfying \(w(t,x) = u_*(t,x)\) with
, there exists a control w satisfying \(w(t,x) = u_*(t,x)\) with  such that
such that
A control \(u_*\) is dynamically optimal in (2.6), if for every given and fixed \((t,x) \in [0,T] \times \mathbb {R}\) and every control v such that \(v(t,x) \ne u_*(t,x)\) with \(\mathsf{E\,}_{t,x}(X_T^v) \ge \beta \), there exists a control w satisfying \(w(t,x) = u_*(t,x)\) with \(\mathsf{E\,}_{t,x}(X_T^w) \ge \beta \) such that

Dynamic optimality above is understood in the ‘strong’ sense. Replacing the strict inequalities in (2.10)–(2.12) by inequalities would yield dynamic optimality in the ‘weak’ sense.
Note that the dynamic optimality corresponds to solving infinitely many optimal control problems dynamically in time where each new position of the controlled process \(((t,X_t^u))_{t \in [0,T]}\) yields a new optimal control problem to be solved upon overruling all the past problems. The optimal decision at each time tells us to exert the best control among all possible controls. While the static optimality remembers the past (through the initial point) the dynamic optimality completely ignores it and only looks ahead. Nonetheless it is clear that there is a strong link between the static and dynamic optimality (the latter being formed through the beginnings of the former as shown below) and this will be exploited in the proof below when searching for the dynamically optimal controls. In the case of standard/linear optimal control problems for Markov processes it is evident that the static and dynamic optimality coincide under mild regularity conditions due to the fact that dynamic programming (the HJB equation) is applicable. This is not the case for the nonlinear problems of optimal control considered in the present paper as it will be seen below.
3 Solution to the problem
In this section we present solutions to the problems formulated in the previous section. We first focus on the unconstrained problem.
Theorem 3
Consider the optimal control problem (2.4) where \(X^u\) solves (2.3) with \(X_{t_0}^u=x_0\) under \(\mathsf{P}_{t_0,x_0}\) for \((t_0,x_0) \in [0,T] \times \mathbb {R}\) given and fixed. Recall that B solves (2.1), S solves (2.2), and we set \(\delta = (\mu -r)/\sigma \) for \(\mu \in \mathbb {R}\), \(r \in \mathbb {R}\) and \(\sigma >0\). We assume throughout that \(\delta \ne 0\) and \(r \ne 0\) (the cases \(\delta =0\) or \(r=0\) follow by passage to the limit when the non-zero \(\delta \) or r tends to 0).
(A) The statically optimal control is given by
for \((t,x) \in [t_0,T] \times \mathbb {R}\). The statically optimal controlled process is given by
for \(t \in [t_0,T]\). The static value function  is given by
is given by
for \((t_0,x_0) \in [0,T] \times \mathbb {R}\).
(B) The dynamically optimal control is given by
for \((t,x) \in [t_0,T] \times \mathbb {R}\). The dynamically optimal controlled process is given by
for \(t \in [t_0,T]\). The dynamic value function  is given by
is given by
for \((t_0,x_0) \in [0,T] \times \mathbb {R}\).
Proof
We assume throughout that the process \(X^u\) solves the stochastic differential equation (2.3) with \(X_{t_0}^u=x_0\) under \(\mathsf{P}_{t_0,x_0}\) for \((t_0,x_0) \in [0,T] \times \mathbb {R}\) given and fixed where u is any admissible control as defined/discussed above. To simplify the notation we will drop the subscript zero from \(t_0\) and \(x_0\) in the first part of the proof below.
(A): Note that the objective function in (2.4) reads

where the key difficulty is the quadratic nonlinearity of the middle term on the right-hand side. To overcome this difficulty we will condition on the size of \(\mathsf{E\,}_{t,x}(X_T^u)\). This yields

Hence to solve (3.8) and thus (2.4) we need to solve the constrained problem
for \(M \in \mathbb {R}\) given and fixed where u is any admissible control.
1. To tackle the problem (3.9) we will apply the method of Lagrange multipliers. For this, define the Lagrangian as follows
for \(\lambda \in \mathbb {R}\) and let \(u_*^\lambda \) denote the optimal control in the unconstrained problem
upon assuming that it exists. Suppose moreover that there is \(\lambda = \lambda (M,t,x) \in \mathbb {R}\) such that
It then follows from (3.10)–(3.12) that
for any admissible control u such that \(\mathsf{E\,}_{t,x}(X_T^u)=M\). This shows that \(u_*^\lambda \) satisfying (3.11) and (3.12) is optimal in (3.9).
2. To tackle the problem (3.11) with (3.12) we consider the optimal control problem
where u is any admissible control. This is a standard/linear problem of optimal control (see e.g. [5]) that can be solved using a classic HJB approach. For the sake of completeness we present key steps in the derivation of the solution.
From (3.14) combined with (2.3) we see that the HJB system reads
on \([0,T] \times \mathbb {R}\). Making the ansatz that \(V_{xx}^\lambda > 0\) and minimising the quadratic function of u over \(\mathbb {R}\) in (3.15) we find that
Inserting (3.17) back into (3.15) yields
Seeking the solution to (3.18) of the form
and making use of (3.16) we find that
on [0, T] with \(a(T)=1\), \(b(T) = -\lambda \) and \(c(T)=0\). Solving (3.20) under these terminal conditions we obtain
Inserting (3.21) into (3.19) and calculating (3.17) we find that
Applying Itô’s formula to the process Z defined by
where we set \(K := (\lambda /2)\; e^{-r(T-t_0)}\) and making use of (2.3) we find that
with \(Z_{t_0} = K -x_0\) under \(\mathsf{P}_{t_0,x_0}\). Solving the linear equation (3.24) explicitly we obtain the following closed form expression
for \(t \in [t_0,T]\). The process \(X^u\) defined by (3.25) is a unique strong solution to the stochastic differential equation (2.3) obtained by the control u from (3.22) and yielding the value function \(V^\lambda \) given in (3.19) combined with (3.21) above. It is then a matter of routine to apply Itô’s formula to \(V^\lambda \) composed with \((t,X_t^v)\) for any admissible control v and using (3.15)+(3.16) verify that the candidate control u from (3.22) is optimal in (3.14) as envisaged (these arguments are displayed more explicitly in (3.36)–(3.37) below).
3. Having solved the problem (3.14) we still need to meet the condition (3.12). For this, we find from (3.25) that
To realise (3.12) we need to identify (3.26) with M. This yields
for \(\delta \ne 0\). Note that the case \(\delta =0\) is evident since in this case \(u_*^\lambda =0\) is optimal in (3.14) for every \(\lambda \in \mathbb {R}\) and hence the inequality in (3.13) holds for every admissible control u while from (2.3) we also easily see that (3.26) (with \(\delta =0\)) holds for every admissible control u so that we only have one M possible in (3.8) and that is the one given by (3.26) (with \(\delta =0\)). This shows that (3.1)–(3.3) are valid when \(\delta =0\) and we will therefore assume in the sequel that \(\delta \ne 0\). Moreover, from (3.25) we also find that
Note that this expression can also be obtained from (3.14) and (3.26) upon recalling (3.19) with (3.21) above. Inserting (3.27) into (3.28) and recalling (3.13) we see that (3.9) is given by
for \(\delta \ne 0\). Inserting (3.29) into (3.8) we get
for \(\delta \ne 0\). Note that the function of M to be maximised on the right-hand side is quadratic with the coefficient in front of \(M^2\) strictly negative when \(\delta \ne 0\). This shows that there exists a unique maximum point in (3.30) that is easily found to be given by
Inserting (3.31) into (3.27) we find that
Inserting (3.32) into (3.22) we establish the existence of the optimal control in (2.4) that is given by (3.1) above. Moreover, inserting (3.32) into (3.25) we obtain the first identity in (3.2). The second identity in (3.2) then follows upon recalling the closed form expressions for B and S stated following (2.2) above. Finally, inserting (3.31) into (3.30) we obtain (3.3) and this completes the first part of the proof.
(B): Identifying \(t_0\) with t and \(x_0\) with x in the statically optimal control \(u_*^s\) from (3.1) we obtain the control \(u_*^d\) from (3.4). We claim that this control is dynamically optimal in (2.4). For this, take any other admissible control v such that \(v(t_0,x_0) \ne u_*^d(t_0,x_0)\) and set \(w=u_*^s\). Then \(w(t_0,x_0) = u_*^d(t_0,x_0)\) and we claim that

upon noting that \(V_w(t_0,x_0)\) equals \(V(t_0,x_0)\) since w is statically optimal in (2.4).
4. To verify (3.33) set \(M_v := \mathsf{E\,}_{t_0,x_0}(X_T^v)\) and first consider the case when \(M_v \ne M_*\) where \(M_*\) is given by (3.31) above. Using (3.9) + (3.29) and (3.30) + (3.31) we then find that
for \(\delta \ne 0\) where the strict inequality follows since \(M_*\) is the unique maximum point of the quadratic function as pointed out following (3.30) above. The case \(\delta =0\) is excluded since then as pointed out following (3.27) above we only have \(M_*\) possible in (3.8) so that \(M_v\) would be equal to \(M_*\). This shows that (3.33) is satisfied when \(M_v \ne M_*\) as claimed.
Next consider the case when \(M_v = M_*\). We then claim that
where \(V^{\lambda _*}\) is defined in (3.14) and \(\lambda _*\) is given by (3.32) above. For this, note that using (3.16) and applying Itô’s formula we get
where \(M_t := \int _{t_0}^t \sigma \; v(s,X_s^v)\, X_s^v \, V_x^{\lambda _*}(s,X_s^v)\, dW_s\) is a continuous local martingale under \(\mathsf{P}_{t_0,x_0}\) for \(t \in [t_0,T]\). Using that \(\mathsf{E\,}_{t_0,x_0} \big [ \int _{t_0}^T (1 +v_t^2)\, (X_t^v)^2\; dt \big ] < \infty \) it is easily seen from (2.3) by means of Jensen’s and Burkholder–Davis–Gundy’s inequalities that \(\mathsf{E\,}_{t_0,x_0} [ \max _{\,t_0 \le t \le T} (X_t^v)^2 ] < \infty \) and hence upon recalling (3.19) + (3.21) above (with \(\lambda _*\) in place of \(\lambda \)) it follows by Hölder’s inequality that \(\mathsf{E\,}_{t_0,x_0} \sqrt{\langle M,M \rangle _T} < \infty \) so that M is a martingale. Taking \(\mathsf{E\,}_{t_0,x_0}\) on both sides of (3.36) we therefore get
where the integrand is non-negative due to (3.15) (with \(\lambda _*\) in place of \(\lambda \)). Since \(u_*^d(t_0,x_0) = u_*^s(t_0,x_0)\) and \(v(t_0,x_0) \ne u_*^d(t_0,x_0)\) we see that \(v(t_0,x_0) \ne w(t_0,x_0)\). Assuming \(x_0 \ne 0\) by the continuity of v and w it then follows that \(v(s,x) \ne w(s,x)\) for all \((s,x) \in R_\varepsilon := [t_0,t_0 +\varepsilon ] \times [x_0 -\varepsilon ,x_0 +\varepsilon ]\) for some \(\varepsilon >0\) small enough such that \(t_0 +\varepsilon \le T\) as well. Moreover, since w(t, x) is the unique minimum point of the continuous function on the left-hand side of (3.15) (with \(\lambda _*\) in place of \(\lambda \)) evaluated at (t, x) for every \((t,x) \in [0,T] \times \mathbb {R}\), we see that this \(\varepsilon >0\) can be chosen small enough so that
on \(R_\varepsilon \) for some \(\beta >0\) given and fixed. Setting \(\tau _\varepsilon := \inf \, \{\, s \in [t_0,t_0 +\varepsilon ]\; \vert \; (s,X_s^v) \notin R_\varepsilon \, \}\) we see by (3.37) and (3.38) that
where in the first inequality we use that the integrand in (3.37) is non-negative as pointed out above and in the final (strict) inequality we use that \(\tau _\varepsilon > t_0\) with \(\mathsf{P}_{t_0,x_0}\)-probability one due to the continuity of \(X^v\). The arguments remain also valid when \(x_0 = 0\) upon recalling that \(v(t_0,0)\) and \(w(t_0,0)\) are identified with \(v(t_0,0) \cdot 0\) and \(w(t_0,0) \cdot 0\) in this case. From (3.39) we see that (3.35) holds as claimed.
Recalling from (3.10)–(3.13) that \(V^{\lambda _*}(t_0,x_0) = V_{M_*}(t_0,x_0) -\lambda _*\, M_*\) as well as that \(M_v=M_*\) by hypothesis we see from (3.35) that
It follows therefore from (3.8) that

This shows that (3.33) holds when \(M_v = M_*\) as well and hence we can conclude that the control \(u_*^d\) from (3.4) is dynamically optimal as claimed.
5. Applying Itô’s formula to \(e^{r(T-t)} X_t^d\) where we set \(X^d := X^{u_*^d}\) and making use of (2.3) we easily find that the first identity in (3.5) is satisfied. Integrating by parts and recalling the closed form expressions for B and S stated following (2.2) above we then establish that the second identity in (3.5) also holds. From the first identity in (3.5) we get

From (3.42) and (3.43) we obtain (3.6) and this completes the proof. \(\square \)
Remark 4
The dynamically optimal control \(u_*^d\) from (3.4) by its nature rejects any past point \((t_0,x_0)\) to measure its performance so that although the static value \(V_s(t_0,x_0)\) by its definition dominates the dynamic value \(V_d(t_0,x_0)\) this comparison is meaningless from the standpoint of the dynamic optimality. Another issue with a plain comparison of the values \(V_s(t,x)\) and \(V_d(t,x)\) for \((t,x) \in [t_0,T] \times \mathbb {R}\) is that the optimally controlled processes \(X^s\) and \(X^d\) may never come to the same point x at the same time t so that the comparison itself may be unreal. A more dynamic way that also makes more sense in general is to compare the value functions composed with the controlled processes. This amounts to look at \(V_s(t,X_t^s)\) and \(V_d(t,X_t^d)\) for \(t \in [t_0,T]\) and pay particular attention to t becoming the terminal value T. Note that \(V_s(T,X_T^s) = X_T^s\) and \(V_d(T,X_T^d) = X_T^d\) so that to compare \(E_{t_0,x_0} \big [ V_s(T,X_T^s) \big ]\) and \(E_{t_0,x_0} \big [ V_d(T,X_T^d) \big ]\) is the same as to compare \(E_{t_0,x_0}(X_T^s)\) and \(E_{t_0,x_0}(X_T^d)\). It is easily seen from (3.2) and (3.5) that the latter two expectations coincide. We can therefore conclude that
for all \((t_0,x_0) \in [0,T] \times \mathbb {R}\). This shows that the dynamically optimal control \(u_*^d\) is as good as the statically optimal control \(u_*^s\) from this static standpoint as well (with respect to any past point \((t_0,x_0)\) given and fixed). In addition to that however the dynamically optimal control \(u_*^d\) is time consistent while the statically optimal control \(u_*^s\) is not.
Note also from (3.4) that the amount of the dynamically optimal wealth \(u_*^d(t,x) \cdot x\) held in the stock at time t does not depend on the amount of the total wealth x. This is consistent with the fact that the risk/cost in (2.4) is measured by the variance (applied at a constant rate c) which is a quadratic function of the terminal wealth while the return/gain is measured by the expectation (applied at a constant rate too) which is a linear function of the terminal wealth. The former therefore penalises stochastic movements of the large wealth more severely than what the latter is able to compensate for and the investor is discouraged to hold larger amounts of his wealth in the stock. Thus even if the total wealth is large (in modulus) it is still dynamically optimal to hold the same amount of wealth \(u_*^d(t,x) \cdot x\) in the stock at time t as when the total wealth is small (in modulus). The same optimality behaviour has been also observed for the subgame-perfect Nash equilibrium controls (cf. Sect. 4).
We now turn to the constrained problems. Note in the proofs below that the unconstrained problem above is obtained by optimising the Lagrangian of the constrained problems.
Corollary 5
Consider the optimal control problem (2.5) where \(X^u\) solves (2.3) with \(X_{t_0}^u=x_0\) under \(\mathsf{P}_{t_0,x_0}\) for \((t_0,x_0) \in [0,T] \times \mathbb {R}\) given and fixed. Recall that B solves (2.1), S solves (2.2), and we set \(\delta = (\mu -r)/\sigma \) for \(\mu \in \mathbb {R}\), \(r \in \mathbb {R}\) and \(\sigma >0\). We assume throughout that \(\delta \ne 0\) and \(r \ne 0\) (the cases \(\delta =0\) or \(r=0\) follow by passage to the limit when the non-zero \(\delta \) or r tends to 0).
(A) The statically optimal control is given by
for \((t,x) \in [t_0,T] \times \mathbb {R}\). The statically optimal controlled process is given by
for \(t \in [t_0,T]\). The static value function \(V_s^1 := \mathsf{E\,}(X_T^s)\) is given by
for \((t_0,x_0) \in [0,T] \times \mathbb {R}\).
(B) The dynamically optimal control is given by
for \((t,x) \in [t_0,T] \times \mathbb {R}\). The dynamically optimal controlled process is given by
for \(t \in [t_0,T)\). The dynamic value function \(V_d^1 := \lim _{\,t \uparrow T} \mathsf{E\,}(X_t^d)\) is given by
for \((t_0,x_0) \in [0,T) \times \mathbb {R}\).
Proof
We assume throughout that the process \(X^u\) solves the stochastic differential equation (2.3) with \(X_{t_0}^u=x_0\) under \(\mathsf{P}_{t_0,x_0}\) for \((t_0,x_0) \in [0,T] \times \mathbb {R}\) given and fixed where u is any admissible control as defined/discussed above. To simplify the notation we will drop the subscript zero from \(t_0\) and \(x_0\) in the first part of the proof below.
(A): Note that we can think of (3.7) as (the essential part of) the Lagrangian for the constrained problem (2.5) defined by

for \(c>0\). By the result of Theorem 3 we know that the control \(u_*^s\) given in (3.1) is optimal in unconstrained problem
for \(c>0\). Suppose moreover that there exists \(c = c(\alpha ,t,x) > 0\) such that

It then follows that

for any admissible control u such that  . This shows that the control \(u_*^c\) from (3.1) with \(c = c(\alpha ,t,x) > 0\) is statically optimal in (2.5).
. This shows that the control \(u_*^c\) from (3.1) with \(c = c(\alpha ,t,x) > 0\) is statically optimal in (2.5).
To realise (3.53) note that taking \(\mathsf{E\,}_{t_0,x_0}\) in (3.2) and making use of (3.3) we find that

Setting this expression equal to \(\alpha \) yields
By (3.53) and (3.54) we can then conclude that the control \(u_*^c\) is statically optimal in (2.5). Inserting (3.56) into (3.1) and (3.2) we obtain (3.45) and (3.46) respectively. Taking \(\mathsf{E\,}_{t_0,x_0}\) in (3.46) we obtain (3.47) and this completes the first part of the proof.
(B): Identifying \(t_0\) with t and \(x_0\) with x in the statically optimal control \(u_*^s\) from (3.45) we obtain the control \(u_*^d\) from (3.48). We claim that this control is dynamically optimal in (2.5). For this, take any other admissible control v such that \(v(t_0,x_0) \ne u_*^d(t_0,x_0)\) and set \(w=u_*^s\). Then \(w(t_0,x_0) = u_*^d(t_0,x_0)\) and (3.33) holds with c from (3.56). Using that  by (3.55) and (3.56) we see that (3.33) yields
by (3.55) and (3.56) we see that (3.33) yields

whenever  . This shows that the control \(u_*^d\) from (3.48) is dynamically optimal in (2.5) as claimed.
. This shows that the control \(u_*^d\) from (3.48) is dynamically optimal in (2.5) as claimed.
Applying Itô’s formula to \(e^{r(T-t)} X_t^d\) where we set \(X^d := X^{u_*^d}\) and making use of (2.3) we easily find that the first identity in (3.49) is satisfied. Integrating by parts and recalling the closed form expressions for B and S stated following (2.2) above we then establish that the second identity in (3.49) also holds. From the first identity in (3.49) we get
for \(t \in [t_0,T)\). Letting \(t \uparrow T\) in (3.58) we obtain (3.50) and this completes the proof. \(\square \)
Remark 6
(A dynamic compliance effect). From (3.47) and (3.50) we see that the dynamic value \(V_d^1(t_0,x_0)\) strictly dominates the static value \(V_s^1(t_0,x_0)\). To see why this is possible note that using (3.49) we find that

for \(t \in [t_0,T)\) with \(\delta \ne 0\). This shows that  as \(t \uparrow T\) so that the static value \(V_s^1(t_0,x_0)\) can indeed be exceeded by the dynamic value \(V_d^1(t_0,x_0)\) since the set of admissible controls is virtually larger in the dynamic case. It amounts to what we refer to as a dynamic compliance effect where the investor follows a uniformly bounded risk (variance) strategy at each time (and thus complies with the adopted regulation rule imposed internally/externally) while the resulting static strategy exhibits an unbounded risk (variance). Denoting the stochastic integral (martingale) in (3.49) by \(M_t\) we see that \(\langle M,M \rangle _t = \int _{t_0}^t e^{2 \delta ^2(T-s)}/(e^{2 \delta ^2(T-s)} -1)\, ds \rightarrow \infty \) as \(t \uparrow T\). It follows therefore that \(M_t\) oscillates from \(-\infty \) to \(\infty \) with \(\mathsf{P}_{t_0,x_0}\)-probability one as \(t \uparrow T\) and hence the same is true for \(X_t^d\) whenever \(\delta \ne 0\) (for similar behaviour arising from the continuous-time analogue of a doubling strategy see [9, Example 2.3]). We also see from (3.46) and (3.49) that unlike in (3.44) we have the strict inequality
as \(t \uparrow T\) so that the static value \(V_s^1(t_0,x_0)\) can indeed be exceeded by the dynamic value \(V_d^1(t_0,x_0)\) since the set of admissible controls is virtually larger in the dynamic case. It amounts to what we refer to as a dynamic compliance effect where the investor follows a uniformly bounded risk (variance) strategy at each time (and thus complies with the adopted regulation rule imposed internally/externally) while the resulting static strategy exhibits an unbounded risk (variance). Denoting the stochastic integral (martingale) in (3.49) by \(M_t\) we see that \(\langle M,M \rangle _t = \int _{t_0}^t e^{2 \delta ^2(T-s)}/(e^{2 \delta ^2(T-s)} -1)\, ds \rightarrow \infty \) as \(t \uparrow T\). It follows therefore that \(M_t\) oscillates from \(-\infty \) to \(\infty \) with \(\mathsf{P}_{t_0,x_0}\)-probability one as \(t \uparrow T\) and hence the same is true for \(X_t^d\) whenever \(\delta \ne 0\) (for similar behaviour arising from the continuous-time analogue of a doubling strategy see [9, Example 2.3]). We also see from (3.46) and (3.49) that unlike in (3.44) we have the strict inequality
satisfied for all \((t_0,x_0) \in [0,T) \times \mathbb {R}\). This shows that the dynamic control \(u_*^d\) from (3.48) outperforms the static control \(u_*^s\) from (3.45) in the constrained problem (2.5).
Corollary 7
Consider the optimal control problem (2.6) where \(X^u\) solves (2.3) with \(X_{t_0}^u=x_0\) under \(\mathsf{P}_{t_0,x_0}\) for \((t_0,x_0) \in [0,T] \times \mathbb {R}\) given and fixed. Recall that B solves (2.1), S solves (2.2), and we set \(\delta = (\mu -r)/\sigma \) for \(\mu \in \mathbb {R}\), \(r \in \mathbb {R}\) and \(\sigma >0\). We assume throughout that \(\delta \ne 0\) and \(r \ne 0\) (the cases \(\delta =0\) or \(r=0\) follow by passage to the limit when the non-zero \(\delta \) or r tends to 0).
(A) The statically optimal control is given by
if \(x_0\, e^{r(T-t_0)} < \beta \) and \(u_*^s(t,x)=0\) if \(x_0\, e^{r(T-t_0)} \ge \beta \) for \((t,x) \in [t_0,T] \times \mathbb {R}\). The statically optimal controlled process is given by
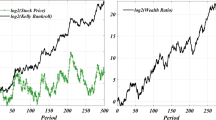
if \(x_0\, e^{r(T-t_0)} < \beta \) and \(X_t^s = x_0\, e^{r(t-t_0)}\) if \(x_0\, e^{r(T-t_0)} \ge \beta \) for \(t \in [t_0,T]\) (see Fig. 1 below). The static value function  is given by
is given by
if \(x_0\, e^{r(T-t_0)} < \beta \) and \(V_s^2(t_0,x_0) = 0\) if \(x_0\, e^{r(T-t_0)} \ge \beta \) for \((t_0,x_0) \in [0,T] \times \mathbb {R}\).

The dynamically optimal wealth \(t \mapsto X_t^d\) and the statically optimal wealth \(t \mapsto X_t^s\) in the constrained problem (2.6) of Corollary 7 obtained from the stock price \(t \mapsto S_t\) when \(t_0=0\), \(x_0=1\), \(S_0=1\), \(\beta =2\), \(r=0.1\), \(\mu =0.5\), \(\sigma =0.4\) and \(T=1\). Note that the expected value of \(S_T\) equals \(e^{\mu T} \approx 1.64\) which is strictly smaller than \(\beta \)
(B) The dynamically optimal control is given by
if \(x_0\, e^{r(T-t_0)} < \beta \) and \(u_*^d(t,x)=0\) if \(x_0\, e^{r(T-t_0)} \ge \beta \) for \((t,x) \in [t_0,T) \times \mathbb {R}\). The dynamically optimal controlled process is given by
with \(X_t^d\, e^{r(T-t)} < \beta \) for \(t \in [t_0,T)\) and \(X_T^d := \lim _{\,t \uparrow T} X_t^d = \beta \) with \(\mathsf{P}_{t_0,x_0}\)-probability one if \(x_0\, e^{r(T-t_0)} < \beta \), and \(X_t^d = x_0\, e^{r(t-t_0)}\) for \(t \in [t_0,T]\) if \(x_0\, e^{r(T-t_0)} \ge \beta \) (see Fig. 1 above). The dynamic value function  is given by
is given by
for \((t_0,x_0) \in [0,T) \times \mathbb {R}\).
Proof
We assume throughout that the process \(X^u\) solves the stochastic differential equation (2.3) with \(X_{t_0}^u=x_0\) under \(\mathsf{P}_{t_0,x_0}\) for \((t_0,x_0) \in [0,T] \times \mathbb {R}\) given and fixed where u is any admissible control as defined/discussed above. To simplify the notation we will drop the subscript zero from \(t_0\) and \(x_0\) in the first part of the proof below.
(A): Note that the Lagrangian for the constrained problem (2.6) is defined by

for \(c>0\). To connect to the results of Theorem 3 observe that

which shows that the control \(u_*^{1/c}\) given in (3.1) is optimal in the unconstrained problem
for \(c>0\). Suppose moreover that there exists \(c=c(\beta ,t,x)>0\) such that
It then follows that

for any admissible control u such that \(\mathsf{E\,}_{t,x} (X_T^u) \ge \beta \). This shows that the control \(u_*^{1/c}\) from (3.1) with \(c=c(\beta ,t,x)>0\) is statically optimal in (2.6).
To realise (3.70) note that taking \(\mathsf{E\,}_{t_0,x_0}\) in (3.2) we find that
Setting this expression equal to \(\beta \) yields
From (3.73) we see that \(c>0\) if and only if \(x_0\, e^{r(T-t_0)} < \beta \). If \(x_0\, e^{r(T-t_0)} \ge \beta \) then clearly we can invest all the wealth in B and receive zero variance at T. This shows that the control \(u_*^s(t,x)=0\) for \((t,x) \in [t_0,T] \times \mathbb {R}\) is statically optimal in this case with \(V_s^2(t_0,x_0) = 0\) as claimed. Let us therefore assume that \(x_0\, e^{r(T-t_0)} < \beta \) in the sequel. Then by (3.70) and (3.71) we can conclude that the control \(u_*^{1/c}\) is statically optimal in (2.6). Inserting (3.73) into (3.1) and (3.2) we obtain (3.61) and (3.62) respectively. Inserting (3.73) into (3.55) we obtain (3.63) and this completes the first part of the proof.
(B): Identifying \(t_0\) with t and \(x_0\) with x in the statically optimal control \(u_*^s\) from (3.61) we obtain the control \(u_*^d\) from (3.64). We claim that this control is dynamically optimal in (2.6) when \(x_0\; e^{r(T-t_0)} < \beta \). For this, take any other admissible control v such that \(v(t_0,x_0) \ne u_*^d(t_0,x_0)\) and set \(w=u_*^s\). Then \(w(t_0,x_0) = u_*^d(t_0,x_0)\) and (3.33) holds with c from (3.73). Using that \(\mathsf{E\,}_{t_0,x_0}(X_T^w) = \beta \) by (3.72) and (3.73) we see that (3.33) yields

whenever \(\mathsf{E\,}_{t_0,x_0} (X_T^v) \ge \beta \). This shows that the control \(u_*^d\) from (3.64) is dynamically optimal in (2.6) when \(x_0\, e^{r(T-t_0)} < \beta \)
as claimed. If \(x_0\, e^{r(T-t_0)} \ge \beta \) then both \(u_*^s(t,x)=0\) and \(u_*^d(t,x)=0\) so that by (2.3) we see that \(X_t^d := X_t^{u_*^d} = x_0\, e^{r(t-t_0)}\) for \(t \in [t_0,T]\) as claimed. Dynamic optimality then follows from the fact (singled out in Remark 9 below) that zero control is the only possible admissible control that can move a given deterministic wealth \(x_0\) at time \(t_0 \in [0,T)\) to another deterministic wealth (of zero variance) at time T. Let us therefore assume that \(x_0\, e^{r(T-t_0)} < \beta \) in the sequel.
Applying Itô’s formula to the process Z defined by
where we set \(X^d := X^{u_*^d}\)and making use of (2.3) we easily find that
with \(Z_{t_0} = \beta - e^{r(T-t_0)} x_0\) under \(\mathsf{P}_{t_0,x_0}\). Solving the linear equation (3.76) explicitly we obtain the closed form expression
for \(t \in [t_0,T)\) under \(\mathsf{P}_{t_0,x_0}\). Inserting (3.77) into (3.75) we easily find that the first identity in (3.65) is satisfied. Integrating by parts and recalling the closed form expressions for B and S stated following (2.2) above we then establish that the second identity in (3.65) also holds.
From (3.75) and (3.77) we see that \(Z_t = \beta - e^{r(T-t)} X_t^d > 0\) so that \(X_t^d\, e^{r(T-t)} < \beta \) for \(t \in [t_0,T)\) as claimed. Moreover, by the Dambis-Dubins-Schwarz theorem (see e.g. [18, p. 181]) we know that the continuous martingale M defined by \(M_t = -\delta \int _{t_0}^t e^{\delta ^2(T-s)}/(e^{\delta ^2(T-s)} -1)\, dW_s\) for \(t \in [t_0,T)\) is a time-changed Brownian motion \(\bar{W}\) in the sense that \(M_t = \bar{W}_{\langle M,M \rangle _t}\) for \(t \in [t_0,T)\) where we note that \(\langle M,M \rangle _t = \delta ^2 \int _{t_0}^t e^{2\delta ^2(T-s)}/(e^{\delta ^2(T-s)} -1)^2\, ds \uparrow \infty \) as \(t \uparrow T\). It follows therefore by the well-known sample path properties of \(\bar{W}\) that \(M_t - \tfrac{1}{2} \langle M,M \rangle _t = \bar{W}_{\langle M,M \rangle _t} - \tfrac{1}{2} \langle M,M \rangle _t \rightarrow -\infty \) as \(t \uparrow T\) with \(\mathsf{P}_{t_0,x_0}\)-probability one. Making use of this fact in (3.65) we see that \(X_t^d \rightarrow \beta \) with \(\mathsf{P}_{t_0,x_0}\)-probability one as \(t \uparrow T\) if \(x_0\, e^{r(T-t_0)} < \beta \) as claimed. From the preceding facts we also see that (3.66) holds and the proof is complete. \(\square \)
Remark 8
Note from the proof above that \(X_t^d < \beta \) with \(\mathsf{P}_{t_0,x_0}\)-probability one for all \(t \in [t_0,T)\) if \(x_0\, e^{r(T-t_0)} < \beta \) so that \(X^d\) is not a bridge process but a time-reversed meander process. The result of Corollary 7 shows that it is dynamically optimal to keep the wealth \(X_t^d\) strictly below \(\beta \) for \(t \in [t_0,T)\) with achieving \(X_T^d = \beta \). This behaviour is different from the statically optimal wealth \(X_t^s\) which can go above \(\beta \) on \([t_0,T)\) and end up either above or below \(\beta \) at T (see Fig. 1 above). Moreover, it is easily seen from (3.62) that \(\mathsf{P}_{t_0,x_0}(X_T^s < \beta ) > 0\) from where we find that
if \(x_0 e^{r(T-t_0)} < \beta \) using (3.63) and (3.66) respectively. This shows that the dynamic control \(u_*^d\) from (3.64) outperforms the static control \(u_*^s\) from (3.61) in the constrained problem (2.6).
Remark 9
Note that no admissible control u can move a given deterministic wealth \(x_0\) at time \(t_0 \in [0,T)\) to any other deterministic wealth at time T apart from \(x_0\, e^{r(T-t_0)}\) in which case u equals zero. This is important since otherwise the optimal control problem (2.6) would not be well posed. Indeed, this can be seen by a standard martingale measure change \(d \tilde{\mathsf{P}}_{t_0,x_0} = \exp ( -\delta (W_T -W_{t_0}) -(\delta ^2/2) (t -t_0))\, d \mathsf{P}_{t_0,x_0}\) making \(\tilde{W}_t := W_t -W_{t_0} +\delta (t -t_0)\) a standard Brownian motion for \(t \in [t_0,T]\). It then follows from (2.3) using integration by parts that
where \(M_t := \int _{t_0}^t \sigma \; e^{-r(s-t_0)}\; u_s X_s^u\, d \tilde{W}_s\) is a continuous local martingale under \(\tilde{\mathsf{P}}_{t_0,x_0}\) for \(t \in [t_0,T]\). Moreover, by Hölder’s inequality we see that
since \(\mathsf{E\,}_{t_0,x_0} \big [\int _{t_0}^T (1 +u_t^2)\, (X_t^u)^2 \; dt \big ] < \infty \) by admissibility of u. This shows that M is a martingale under \(\tilde{\mathsf{P}}_{t_0,x_0}\). Hence if \(X_T\) is constant then it follows from (3.79) and the martingale property of M that \(M_t=0\) for all \(t \in [t_0,T]\). But this means that \(X_t^u = x_0\, e^{r(T-t_0)}\) for \(t \in [t_0,T]\) with u being equal to zero as claimed.
Remark 10
Note from (3.65) that \(\mathsf{E\,}_{t_0,x_0}(X_t^d) \rightarrow \beta \) as \(t \uparrow T\) if \(x_0\, e^{r(T-t_0)} < \beta \), however, this convergence fails to extend to the variance. Indeed, using (3.65) it can be verified that

for \(t \in [t_0,T)\) from where we see that  as \(t \uparrow T\) if \(x_0\, e^{r(T-t_0)} < \beta \). To connect to the comments on the sample path behaviour made in Remark 6 note that \(t \mapsto X_t^d\) is not bounded from below on \([t_0,T)\). Both of these consequences are due partly to the fact that we allow the wealth process to take both positive and negative values of unlimited size (recall the end of Sect. 1 above). Another reason is that the dynamic optimality by its nature pushes the optimal controls to their limits so that breakdown points are possible.
as \(t \uparrow T\) if \(x_0\, e^{r(T-t_0)} < \beta \). To connect to the comments on the sample path behaviour made in Remark 6 note that \(t \mapsto X_t^d\) is not bounded from below on \([t_0,T)\). Both of these consequences are due partly to the fact that we allow the wealth process to take both positive and negative values of unlimited size (recall the end of Sect. 1 above). Another reason is that the dynamic optimality by its nature pushes the optimal controls to their limits so that breakdown points are possible.
4 Static versus dynamic optimality
In this section we address the rationale for introducing the static and dynamic optimality in the nonlinear optimal control problems under consideration and explain their relevance for applications of both theoretical and practical interest. We also discuss relation of these results with the existing approaches to similar problems in the literature.
-
1.
To simplify the exposition we focus on the unconstrained problem (2.4) and similar arguments apply to the constrained problems (2.5) and (2.6) as well. Recall that (2.4) represents the optimal portfolio selection problem for an investor who has an initial wealth \(x_0 \in \mathbb {R}\) which he wishes to exchange between a risky stock S and a riskless bond B in a self-financing manner dynamically in time so as to maximise his return (identified with the expectation of his wealth) and minimise his risk (identified with the variance of his wealth) at the given terminal time T. Due to the quadratic nonlinearity of the variance (as a function of the expectation) the optimal portfolio strategy (3.1) depends on the initial wealth \(x_0\) in an essential way. This spatial inconsistency (not present in the standard/linear optimal control problems) introduces the time inconsistency in the problem because the investor’s wealth process moves from the initial value \(x_0\) in t units of time to a new value \(x_1\) (different from \(x_0\) with probability one) which in turn yields a new optimal portfolio strategy that is different from the initial strategy. This time inconsistency repeats itself between any two points in time and the investor may be in doubt which optimal portfolio strategy to use unless already made up his mind. To tackle these inconsistencies we are naturally led to consider two types of investors and consequently introduce the two notions of optimality as stated in Definitions 1 and 2 respectively. The first investor is a static investor who stays ‘pre-committed’ to the optimal portfolio strategy evaluated initially and does not re-evaluate the optimality criterion (2.4) at later times. This investor will determine the optimal portfolio strategy at time \(t_0\) and follow it blindly to the terminal time T. The second investor is a dynamic investor who remains ‘non-committed’ to the optimal portfolio strategy evaluated initially as well as subsequently and continuously re-evaluates the optimality criterion (2.4) at each new time. This investor will determine the optimal portfolio strategy at time \(t_0\) and continue doing so at each new time until the terminal time T. Clearly both the static investor and the dynamic investor embody realistic economic behaviour (see below for a more detailed account coming from economics) and Theorem 3 discloses their optimal portfolio selection strategies in the unconstrained problem (2.4). Similarly Corollary 5 and Corollary 7 disclose their optimal portfolio selection strategies in the constrained problems (2.5) and (2.6). Given that the financial interpretations of these results are easy to draw directly and somewhat lengthy to state explicitly we will omit further details. It needs to be noted that although closely related the three problems (2.4)–(2.6) are still different and hence it is to be expected that their solutions are also different for some values of the parameters. Difference between the static and dynamic optimality is best understood by analysing each problem on its own first as in this case the complexity of the overall comparison is greatly reduced.
-
2.
Apart from the paper [13] where the dynamic optimality was used in a nonlinear problem of optimal stopping, we are not aware of any other paper on optimal control where nonlinear problems were studied using this methodology. The dynamic optimality (Definition 2) appears therefore to be original to the present paper in the context of nonlinear problems of optimal control. There are two streams of papers on optimal control however where the static optimality (Definition 1) has been used. The first one belongs to the economics literature and dates back to the paper by Strotz [21]. The second one belongs to the finance literature and dates back to the paper by Richardson [19]. We present a brief review of these papers to highlight similarities/differences and indicate the applicability of the present methodology in these settings.
-
3.
The stream of papers in the economics literature starts with the paper by Strotz [21] who points out a time inconsistency arising from the presence of the initial point in the time domain when the exponential discounting in the utility model of Samuelson [20] is replaced by a non-exponential discounting. For an illuminating exposition of the problem of intertemporal choices (decisions involving tradeoffs among costs and benefits occurring at different times) lasting over hundred years and leading to the Samuelson’s simplifying model containing a single parameter (discount rate) see [7] and the references therein. To tackle the issue of the time inconsistency Strotz proposed two strategies in his paper: (i) the strategy of ‘pre-commitment’ (where the individual commits to the optimal strategy derived initially) and (ii) the strategy of ‘consistent planning’ (where the individual rejects any strategy which he will not follow through and aims to find the optimal strategy among those that he will actually follow). Note in particular that Strotz coins the term ‘pre-committed’ strategy in his paper and this term has since been used in the literature including most recent papers too. Although his setting is deterministic and his time is discrete on closer look one sees that our financial analysis of the static investor above is fully consistent with his economic reasoning and moreover the statically optimal portfolio strategy derived in the present paper may be viewed as the strategy of ‘pre-commitment’ in Strotz’s sense as already indicated above. The dynamically optimal portfolio strategy derived in the present paper is different however from the strategy of ‘consistent planning’ in Strotz’s sense. The difference is subtle still substantial and it will become clearer through the exposition of the subsequent development that continues to the present time. The next to point out is the paper by Pollak [16] who showed that the derivation of the strategy of ‘consistent planning’ in the Strotz paper [21] was incorrect (one cannot replace the individual’s non-exponential discount function by the exponential discount function having the same slope as the non-exponential discount function at zero). Peleg and Yaari [14] then attempted to find the strategy of ‘consistent planning’ by backward recursion and concluded that the strategy could exist only under too restrictive hypotheses to be useful. They suggested to look at what we now refer to as a subgame-perfect Nash equilibrium (the optimality concept refining Nash equilibrium proposed by Selten in 1965). Goldman [8] then pointed out that the failure of backward recursion does not disprove the existence as suggested in [14] and showed that the strategy of ‘consistent planning’ does exist under quite general conditions. All these papers deal with problems in discrete time. A continuous-time extension of these results appear more recently in the paper by Ekeland and Pirvu [6] and the paper by Björk and Murgoci [3] (see also the references therein for other unpublished work). The Strotz’s strategy of ‘consistent planning’ is being understood as a subgame-perfect Nash equilibrium in this context (satisfying the natural consumption constraint at present time).
-
4.
The stream of papers in the finance literature starting with the paper by Richardson [19] deals with optimal portfolio selection problems under mean-variance criteria similar/analogous to (2.4)–(2.6) above. Richardson’s paper [19] derives a statically optimal control in the constrained problem (2.6) using the martingale method suggested by Pliska [15] who makes use of the Legendre transform (convex analysis) rather than the Lagrange multipliers. For an overview of the martingale method based on Lagrange multipliers see e.g. [2, Sect. 20]. This martingale method can be used to solve the auxiliary optimal control problem (3.14) in the proof of Theorem 3 above. Moreover on closer look it is possible to see that the dynamically optimal control is obtained by setting the Radon-Nikodym derivative of the equivalent martingale measure with respect to the original measure equal to one. Given that the martingale method is applicable to more general problems of optimal control including those in non-Markovian settings as well this observation provides a lead for finding the dynamically optimal controls when a classic HJB approach may not be directly applicable. Returning to the stream of papers in the finance literature, the paper by Li and Ng [10, Theorems 1&2] in discrete time and the paper by Zhou and Li [24, Theorem 3.1] in continuous time show that if there is statically optimal control in the unconstrained problem (2.4) then this control can be found by solving a linear-quadratic optimal control problem (which in turn also yields statically optimal controls in the constrained problems (2.5) and (2.6)). The methodology in these papers relies upon the results on multi-index optimisation problems from the paper by Reid and Citron [17] and is more involved (in comparison with the simple conditioning combined with a double application of Lagrange multipliers as done in the present paper). In particular, the results of [10] and [24] do not establish the existence of statically optimal controls in the problems (2.4)–(2.6) although they do derive their closed form expressions in discrete and continuous time respectively. In this context it may be useful to recall that the first to point out that nonlinear dynamic programming problems may be tackled using the ideas of Lagrange multipliers was White in his paper [23]. He also considered the constrained problem (2.6) in discrete time (his Sect. 3) and using Lagrange multipliers derived some conclusions on the statically optimal control (without realising its time inconsistency). In his setting the conditioning on the size of the expected value is automatic since he assumed that the expected value in (2.6) equals \(\beta \). For this reason his first Lagrangian associated with (2.6) was a linear problem and hence there was no need to untangle the resulting nonlinearity by yet another application of Lagrange multipliers as done in the present paper. All papers in the finance literature reviewed above (including others not mentioned) study statically optimal controls which in turn are time inconsistent. Thus all of them deal with ‘pre-committed’ strategies in the sense of Strotz. This was pointed out by Basak and Chabakauri in their paper [1] where they return to the Strotz’s approach of ‘consistent planning’ and study the subgame-perfect Nash equilibrium in continuous time. The paper by Björk and Murgoci [3] merges this with the stream of papers from the economics literature (as already stated above) and studies general formulations of time inconsistent problems based on the Strotz’s approach of ‘pre-commitment’ vs ‘consistent planning’ in the sense of the subgame-perfect Nash equilibrium. A recent paper by Czichowsky [4] studies analogous formulations and further refinements in a general semimartingale setting. For applications of statically optimal controls to pension schemes see the paper by Vigna [22].
-
5.
We now return to the question of comparison between the Strotz’s definition of ‘consistent planning’ which is interpreted as the subgame-perfect Nash equilibrium in the literature and the ‘dynamic optimality’ as defined in the present paper. The key conceptual difference is that the Strotz’s definition of ‘consistent planning’ is relative (constrained) in the sense that the ‘optimal’ control at time t is best among all ‘available’ controls (the ones which will be actually followed) while the present definition of the ‘dynamic optimality’ is absolute (unconstrained) in the sense that the optimal control at time t is best among all ‘possible’ controls afterwards. To illustrate this distinction recall that the subgame-perfect Nash equilibrium formulation of the Strotz ‘consistent planning’ optimality can be informally described as follows. Given the present time t and all future times \(s>t\) one identifies the control \(c_s\) applied at time \(s \ge t\) with an action of the s-th player. The Strotz ‘consistent planning’ optimality is then obtained through the subgame-perfect Nash equilibrium at a given control \((c_r)_{r \ge 0}\) if the action \(c_t\) is best when the actions \(c_s\) for \(s>t\) are given and fixed, i.e. no other action \(\tilde{c}_t\) in place \(c_t\) would do better when the actions \(c_s\) for \(s>t\) are given and fixed (the requirement is clear in discrete time and requires some right-hand limiting argument in continuous time). Clearly this optimality is different from the ‘dynamic optimality’ where the optimal control at time t is best among all ‘possible’ controls afterwards. To make a more explicit comparison between the two concepts of optimality, recall from [1] (see also [3]) that a subgame-perfect Nash optimal control in the problem (2.4) is given by
$$\begin{aligned} u_*^n(t,x) = \frac{\delta }{2\; c\; \sigma }\; \frac{1}{x}\, e^{-r(T-t)} \end{aligned}$$(4.1)for \((t,x) \in [t_0,T] \times \mathbb {R}\), the subgame-perfect Nash optimal controlled process is given by
$$\begin{aligned} X_t^n = x_0\, e^{r(t-t_0)} + \frac{\delta }{2c}\, e^{-r(T-t)} \Big [\, \delta (t -t_0) + W_t -W_{t_0} \Big ] \end{aligned}$$(4.2)for \(t \in [t_0,T]\), and the subgame-perfect Nash value function is given by
$$\begin{aligned} V_n(t_0,x_0) = x_0\, e^{r(T-t_0)} + \frac{\delta ^2}{4c}\, (T -t_0) \end{aligned}$$(4.3)for \((t_0,x_0) \in [t_0,T] \times \mathbb {R}\) (compare these expressions with those given in (3.4)–(3.6) above). Returning to the analysis from the first paragraph of Remark 4 above, one can easily see by direct comparison that the subgame-perfect Nash value \(V_n(t_0,x_0)\) dominates the dynamic value \(V_d(t_0,x_0)\) (and is dominated by the static value \(V_s(t_0,x_0)\) due to its definition). Given that the optimally controlled processes \(X^n\) and \(X^d\) may never come to the same point x at the same time t we see (as pointed out in Remark 4) that this comparison may be unreal and a better way is to compare the value functions composed with the controlled processes. Noting that \(V_n(T,X_T^n) = X_T^n\) and \(V_d(T,X_T^d) = X_T^d\) it is easy to verify using (3.5) and (4.2) that
$$\begin{aligned} E_{t_0,x_0} \big [ V_n(T,X_T^n) \big ] = E_{t_0,x_0}(X_T^n) < E_{t_0,x_0} (X_T^d) = E_{t_0,x_0} \big [ V_d(T,X_T^d) \big ] \end{aligned}$$(4.4)for all \((t_0,x_0) \in [0,T) \times \mathbb {R}\). This shows that the dynamically optimal control \(u_*^d\) from (3.4) outperforms the subgame-perfect Nash optimal control \(u_*^n\) from (4.1) in the unconstrained problem (2.4). A similar comparison in the constrained problems (2.5) and (2.6) is not possible since subgame-perfect Nash optimal controls are not available in these problems at present.
References
Basak, S., Chabakauri, G.: Dynamic mean-variance asset allocation. Rev. Financ. Stud. 23, 2970–3016 (2010)
Björk, T.: Arbitrage Theory in Continuous Time. Oxford University Press, Oxford (2009)
Björk, T., Murgoci, A.: A general theory of Markovian time inconsistent stochastic control problems. Preprint SSRN (2010)
Czichowsky, C.: Time-consistent mean-variance portfolio selection in discrete and continuous time. Financ. Stoch. 17, 227–271 (2013)
Fleming, W.H., Rishel, R.W.: Deterministic and Stochastic Optimal Control. Springer, Berlin (1975)
Ekeland, I., Pirvu, T.A.: Investement and consumption without commitment. Math. Financ. Econ. 2, 57–86 (2008)
Frederick, S., Loewenstein, G., O’Donoghue, : Time discounting and time preferences: a critical review. J. Econ. Lit. 40, 351–401 (2002)
Goldman, S.M.: Consistent plans. Rev. Econ. Stud. 47, 533–537 (1980)
Karatzas, I., Shreve, S.E.: Methods of Mathematical Finance. Springer, Berlin (1998)
Li, D., Ng, W.L.: Optimal dynamic portfolio selection: multiperiod mean-variance formulation. Math. Financ. 10, 387–406 (2000)
Markowitz, H.M.: Portfolio selection. J. Financ. 7, 77–91 (1952)
Merton, R.C.: An analytic derivation of the efficient portfolio frontier. J. Financ. Quant. Anal. 7, 1851–1872 (1972)
Pedersen, J.L., Peskir, G.: Optimal mean-variance selling strategies. Math. Finan. Econ. 10, 203–220 (2016)
Peleg, B., Yaari, M.E.: On the existence of a consistent course of action when tastes are changing. Rev. Econ. Stud. 40, 391–401 (1973)
Pliska, S.R.: A stochastic calculus model of continuous trading: optimal portfolios. Math. Oper. Res. 11, 370–382 (1986)
Pollak, R.A.: Consistent planning. Rev. Econ. Stud. 35, 201–208 (1968)
Reid, R.W., Citron, S.J.: On noninferior performance index vectors. J. Optim. Theory Appl. 7, 11–28 (1971)
Revuz, D., Yor, M.: Continuous Martingales and Brownian Motion. Springer, Berlin (1999)
Richardson, H.R.: A minimum variance result in continuous trading portfolio optimization. Manag. Sci. 35, 1045–1055 (1989)
Samuelson, P.: A note on measurement of utility. Rev. Econ. Stud. 4, 155–161 (1937)
Strotz, R.H.: Myopia and inconsistency in dynamic utility maximization. Rev. Econ. Stud. 23, 165–180 (1956)
Vigna, E.: On efficiency of mean-variance based portfolio selection in defined contribution pension schemes. Quant. Finance 14, 237–258 (2014)
White, D.J.: Dynamic programming and probabilistic constraints. Oper. Res. 22, 654–664 (1974)
Zhou, X.Y., Li, D.: Continuous-time mean-variance portfolio selection: a stochastic LQ framework. Appl. Math. Optim. 42, 19–33 (2000)
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Pedersen, J.L., Peskir, G. Optimal mean-variance portfolio selection. Math Finan Econ 11, 137–160 (2017). https://doi.org/10.1007/s11579-016-0174-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11579-016-0174-8
Keywords
- Nonlinear optimal control
- Static optimality
- Dynamic optimality
- Mean-variance analysis
- The Hamilton–Jacobi–Bellman equation
- Martingale
- Geometric Brownian motion
- Markov process