
Abstract
Background
Pectoral muscle removal is a fundamental preliminary step in computer-aided diagnosis systems for full-field digital mammography (FFDM). Currently, two open-source publicly available packages (LIBRA and OpenBreast) provide algorithms for pectoral muscle removal within Matlab environment.
Purpose
To compare performance of the two packages on a single database of FFDM images.
Methods
Only mediolateral oblique (MLO) FFDM was considered because of large presence of pectoral muscle on this type of projection. For obtaining ground truth, pectoral muscle has been manually segmented by two radiologists in consensus. Both LIBRA’s and OpenBreast’s removal performance with respect to ground truth were compared using Dice similarity coefficient and Cohen-kappa reliability coefficient; Wilcoxon signed-rank test has been used for assessing differences in performances; Kruskal–Wallis test has been used to verify possible dependence of the performance from the breast density or image laterality.
Results
FFDMs from 168 consecutive women at our institution have been included in the study. Both LIBRA’s Dice-index and Cohen-kappa were significantly higher than OpenBreast (Wilcoxon signed-rank test P < 0.05). No dependence on breast density or laterality has been found (Kruskal–Wallis test P > 0.05). Conclusion: Libra has a better performance than OpenBreast in pectoral muscle delineation so that, although our study has not a direct clinical application, these results are useful in the choice of packages for the development of complex systems for computer-aided breast evaluation.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Worldwide, breast cancer is the second most commonly diagnosed cancer, with approximately 2.1 million new diagnoses and almost 627,000 breast cancer-related deaths estimated to have occurred in 2018 [1, 2]. Breast cancer is a biologically and clinically heterogeneous disease, with several accepted histotypes, profiles of risk factors, responses to treatments and prognoses [1, 2]. The risk of developing breast cancer varies among women. Genetic susceptibility, factors affecting levels of endogenous hormones or exogenous hormone intake, lifestyle patterns, anthropometric characteristics, a high mammographic breast density and benign breast diseases are all associated with an increased risk of breast cancer [1, 2].
Screening mammography, with full-filed digital mammography (FFDM), is the method most commonly used worldwide for the detection of early tumor in asymptomatic women, and it is the only imaging modality proven to significantly lower cancer-related mortality [3]. Today, mammograms are evaluated by dedicated radiologists; however, during screening program, the high number of examinations to be evaluated and the complexity of the mammography features to be analyzed are elements that can influence the accuracy of the test. So, in this context, it has generated the necessity for systems for computer-aided diagnosis (CAD) to support radiologists in breast cancer detection and diagnosis [4,5,6].
Mammogram preprocessing is one of the primary steps in a CAD system. In the preprocessing step, the unnecessary elements are removed from the mammograms, which include annotations, labels, and background noises. The preprocessing allows the localization of region for abnormality search. In mammogram preprocessing, one of the major challenges is to accurately define the pectoral muscle (PM) boundary from the rest of the breast region. In fact, pixel intensities from pectoral muscle can be quite similar to masses and breast tissues and can affect lesion detection [7,8,9].
Several approaches have been proposed in the literature for pectoral muscle removal. Mainly, these algorithms have been based upon some kind of thresholding (adaptive histogram, region-growing) together with straight/curve line detection (Hough transform, Radon transform, wavelet transform, Euclidean regression) [8, 9, 16, 17, 24, 25]. Due to the specific appearance of pectoral muscle on MLO images (usually the pectoral muscle appears within MLO mammograms as a triangular region), the most spread approaches tried to exploit some a priori anatomical information and have been based on the Hough transform, an algorithm capable of detecting straight lines onto an image [7,8,9]. However, none of the above mentioned algorithms achieved optimal performance because of the precise shape of the pectoral border that is often curved (not straight) and because of the intensity levels which, as mentioned, often superimpose over the breast tissue intensities. Moreover, pectoral muscles are not always clearly visible in mammograms, especially of dense breasts, due to a poor contrast between pectoral muscle and breast parenchyma. Therefore, research is still active in this area. When developing complex pipelines for CAD breast evaluation or mass detection, researchers often should address the pectoral muscle removal as a first task; the availability of off-the-shelf tools for this task might greatly improve and simplify the overall design of a CAD system.
In this context, the Laboratory for Individualized Breast Radiodensity Assessment (LIBRA) [8] and OpenBreast [9] are two open-source packages available in Matlab environment (The MathWorks, Inc., Natik, MA, USA) [10]. In particular, these tools have been specifically developed for breast density evaluation, including pectoral muscle removal as a preprocessing step. However, each package performance has been evaluated on proprietary database of images acquired on different machines with different parameters. As a consequence, performance is not directly comparable since the different characteristics of the images might affect the results. Therefore, it could be interesting to evaluate the performance of available tools on a common database.
The primary endpoint of this study is to compare the performance of LIBRA and OpenBreast in pectoral muscle removal compared to radiologist manual segmentation. As secondary endpoint, we assessed the performance variability according to breast density and image laterality.
Methods
Women population
This retrospective study was approved by the ethic committee of University “Luigi Vanvitelli”, Naples, Italy, as an observational retrospective spontaneous study (Deliberation n. 469 of 23/07/2019). All methods were carried out in accordance with relevant guidelines and regulations. Informed consent was waived by the same ethic committee that approved the study.
We retrieved bilateral full-field digital mammograms (FFDMs) from consecutive women, who underwent mammography for breast cancer screening programs, at the Breast Unit of the University Hospital “Luigi Vanvitelli,” Naples, from June 2020 to November 2020. Moreover, we retrieved breast composition categories A, B, C, D (according to BI-RADS 5th edition published in 2013 [11]) that have been assessed by two expert radiologists in consensus (GG, MPB).
All examinations were performed according to the American College of Radiology (ACR) and the European Commission (EU) guidelines, [1]. We included only images satisfying quality/correctness criteria according to current best practices [1], although about 20% of images were considered not correct by the radiologist and have been repeated.
As the aim of the study was to assess pectoral muscle removal on routinely acquired images, no women inclusion/exclusion criteria were used. Breast composition has been retrieved to evaluate whether it could affect performance.
Image characteristics
Women have been assessed in both mediolateral oblique (MLO) and craniocaudal views (CC) using the system Giotto Class produced by IMS Giotto S.p.A. (Sasso Marconi (BO), Italy).
Although both MLO and CC were available, we analyzed only MLO images due the larger presence of pectoral muscle on this kind of projection.
Manual segmentation of pectoral muscle
According to the DICOM standard [20], mammographic images might be stored as both “For Processing” and “For Presentation.” In this study, for manual drawing purposes, “For Presentation” images, processed with algorithm "Deep View 1.0" embedded in Raffaello software by IMS Giotto S.p.A, have been used. Two expert radiologists in consensus (10 years in mammograms reviewing) have manually drawn contours of pectoral muscle on each MLO using Horos Medical image viewer v 2.0.2 [12]. A free-hand closed line has been drawn consisting of the outline of the pectoral muscle itself.
Packages to be compared
We have compared performance of two off-the-shelf Matlab open-source packages publicly available for breast assessment: LIBRA [8] and OpenBreast [9]. These two packages differ in the detection of the pectoral muscle as briefly described in 2.4.1 and 2.4.2. Although the ultimate goal of the two packages is to provide an automatic breast density estimation, in this study we considered only data on pectoral muscle removal.
Both algorithms assume that MLO-view mammograms can be roughly subdivided into three regions: the chest wall, including the pectoral muscle; the breast tissue, comprised primarily of adipose and fibroglandular tissues; and the background air region. Thus, they perform first breast area segmentation to identify the tissue-air interface and subsequently they identify the boundary between breast tissue and the pectoral muscle.
Both packages have been run on Matlab R2017b (The MathWorks, Inc., Natik, MA, USA) [10]).
LIBRA
The Laboratory for Individualized Breast Radiodensity Assessment (LIBRA) [8] is an algorithm for fully automated quantification of breast percentage density (PD%) performing for both raw and processed digital mammography images. LIBRA’s breast region and pectoral muscle segmentation, which represents one of the key computational steps constituting the algorithm, employs textural features in dense-tissue segmentation. The body‐air interface boundary is determined by a threshold based on the gray‐level intensity histogram, independent of any prior assumptions. The boundary between the pectoral muscle and breast tissue areas use a previously validated algorithm based on a straight line Hough transform [13]. In this study, we used LIBRA version 1.0.4 available at the link https://www.nitrc.org/projects/cbica_libra/ provided by Perelman School of Medicine University of Pennsylvania website—SBIA participating with CBICA.
OpenBreast
OpenBreast [9] is a fully automatic computerized framework for mammographic image analysis implemented in three steps: breast segmentation, region of interest (ROI) detection, and feature extraction. The first phase of the breast segmentation is similar to that of LIBRA. The second phase, represented by the identification of the boundary between breast tissue and the pectoral muscle, consists of the chest wall and nipple detection, respectively. More precisely, for the detection of the chest wall a Hough-based line detector is used [14]. The line detector works by first applying an edge detector to the input image. Subsequently, each edge pixel is represented into a parametric Hough accumulator space. Lines are detected as local maxima of the space histogram. Finally, the nipple is detected as the further contour point from the chest wall [15]. OpenBreast v1.0 has been developed at Universidad Industrial de Santander, School of Electrical, Electronics and Telecommunications Engineering, Bucaramanga, Colombia, and has been downloaded at the link https://github.com/spertuz/openbreast, GitHub.
Comparison between pectoral muscle removal
Performance of the two packages has been compared with respect to the manually segmented pectoral muscle by means of two commonly used indices for segmentation accuracy: Dice-index and Cohen-kappa [16]. Manually delineated pectoral muscle region has been considered the “ground truth” identification.
In order to perform the comparison between the segmented pectoral muscle and manually delineated pectoral muscle, we computed the number of pixels correctly identified as pectoral or breast (respectively true positive TP, true negative TN) and the number of pixels wrongly identified as pectoral or breast (respectively false positive FP, false negative FN).
Dice-index is defined as:
and it measures the overlap between two segmentations [16]. However, Dice-index does not included TN and another index was used to take into account TN: the Cohen’s kappa which is defined as:
where N is the total number of pixels on the image and:
Statistical analysis
Statistical differences between packages performance have been tested using non parametric Wilcoxon signed-rank test for paired groups; possible dependence of performance with breast density has been also assessed via Kruskal–Wallis test. Everywhere, P-values lower than 0.05 were considered significant. Given the small number of pre-planned tests, no p-value correction has been applied [26]. Statistical analysis has been performed using the R environment (https://www.R-project.org/).
Results
Women population and image characteristics
168 women have been included in the study, corresponding to 336 FFDM images. Women characteristics are summarized in Table 1. The detailed operative setting of mammographic image acquisition is reported in Table 2.
Table 1 reports main characteristics of our sample. Most women were between 45 and 64 years old. Moreover, a small proportion of women had A level of BI-RADS breast density. An inverse relationship between age and breast density was found (P < 0.05).
Comparison between packages
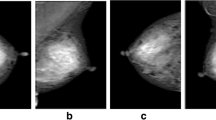
Figure 1 reports a few illustrative examples of pectoral muscle removal obtained by manual delineation (red), LIBRA (green) and OpenBreast (yellow). One example per each breast density and an example of different laterality have been reported. It can be observed that neither LIBRA nor OpenBreast can achieve very accurate approximation to the manual removal of the pectoral muscle.

Illustrative examples of pectoral muscle delineation. Manual (red), LIBRA (green) and OpenBreast (yellow). Breast parenchyma contour is also reported for comparison. Breast density is indicated below each image
For illustrative purposes, Fig. 2a and b reports the complete distributions of Dice-index and Cohen-kappa across the sample population (336 images). The Wilcoxon signed-rank test between LIBRA and OpenBreast revealed significant differences (P < 0.05): both Dice and Cohen performance indices were higher on LIBRA than OpenBreast.

a Dice-index of LIBRA and OpenBreast versus gold truth has been reported per each combination of breast density (A,B,C,D) and laterality (left, right); each subject is identified by a colored circle, and the measurements on the same subject but with different packages are connected by lines. b Cohen’s kappa of LIBRA and OpenBreast versus gold truth has been reported per each combination of breast density (A,B,C,D) and laterality (left, right); each subject is identified by a colored circle, and the measurements on the same subject but with different packages are connected by lines
Table 3 reports average values of Dice-index and Cohen-kappa, and TP, TN, FP, FN fractions. Moreover, Table 3 synthesizes TP, FP, TN, FN fractions, Dice-index and Cohen-kappa across breast density type.
Average values for LIBRA are higher than corresponding values for OpenBreast (P < 0.05). Results suggest that LIBRA can achieve better performances: in fact, both LIBRA’s Dice-index and Cohen-kappa were significantly higher than those of OpenBreast (P < 0.05). Average values do not depend upon breast density level. In fact, no differences statistically significance was observed among two algorithms respect to breast density value (P > 0.05 at Kruskal–Wallis test).
In addition, no statistically significant differences were observed among two algorithms respect to laterality (P > 0.05 at Wilcoxon paired test for laterality).
Discussion
There are two issues for the detection of breast cancer at an early stage: the proper acquisition of mammogram images and, secondly, precise analysis of the images for the breast cancer diagnosis. The manual segmentation is time consuming and could delay the processing process. Accurate viewing of images is a difficult assignment, especially with a large dataset. This challenge can be overcome by using a computational method such as image processing techniques or the breast cancer analysis algorithm. These algorithms lead to rapid analysis and reduce the radiologist job of medical experts. However, it is crucial to assess the nature of mammography images before using the algorithm based on the image process to detect tumor [5,6,7]. The pectoral muscle, which is commonly shown in MLO viewed mammograms, is usually removed before analysis as it can be easily misclassified as fibroglandular tissues. Additionally, artifacts that are accidentally produced during image acquisition may show in pectoral muscle areas of mammography images. Moreover, pectoral muscle regions can be examined by radiologists for auxiliary lymph abnormalities.
The aim of this work was to evaluate the performance in terms of pectoral muscle removal of two open-source Matlab packages (LIBRA and OpenBreast) publicly available. The comparison was made on a single database of FFDM images from a population of consecutively assessed women. Our results indicate that LIBRA has achieved higher performance than OpenBreast in terms of both Dice-index and Cohen-kappa. No dependence of results upon breast density or laterality has been found.
The main purpose of analyzing these tools is to support the development of computerized breast cancer detection systems whose aim is to detect mammographic lesions with poor visibility: low contrast regions with small abnormalities are mostly hidden in the tissue of mammogram images, which makes it challenging to analyze the abnormal region and also provides false detection. As outlined in the introduction the task of pectoral muscle removal is an important preliminary step for computer-aided diagnosis on FFDM, because the intensity levels of pectoral muscle might affect the detection of masses, microcalcifications etc. Moreover, pectoral boundaries identification might improve and simplify breast bi-laterality evaluation tasks. As a consequence, this is still an active area of research. However, many algorithms have been proposed and no definitive results have yet been achieved, also because of the specific anatomical difficulties in delineating pectoral boundaries on FFDM.
In this context, our results provide information on the performances of two open-source packages for pectoral muscle boundary delineation in the Matlab environment. The latter is a widely used software environment for development of computer-aided diagnosis systems. Our results might allow improvements in CAD development.
As far as the authors’ knowledge, our study is the only one comparing those two packages. Moreover, in contrast to many previous studies [17,18,19], our study has been performed on a large database of full-field digital mammograms: at the time of writing a public database of FFDM, in the order of thousands of images, is not yet available, and many studies used databases with digitized film mammograms [20,21,22,23,24,25,26,27,28,29,30,31]. In fact, one main issue concerning breast pectoral removal is the lack of large-scale well-annotated datasets for training of high performance models. In recent years, considerable effort has been devoted to develop intelligent and robust methods for breast pectoral removal. However, the majority of the methods are evaluated on self-annotated public datasets or even private datasets due to the limited availability of datasets. To give a flavor of the type of algorithms that have been used in recent literature, we briefly describe two algorithms that have been developed using such databases. Maitra et al. [32] implemented a method based on a triangular region to isolate the pectoral muscle from the rest of the tissue. Then, a region-growing technique was used to identify and remove the pectoral muscle. Kaitouni et al. [33] implemented breast tumor identification by pectoral muscle removal based on hidden Markov and region-growing method. The purpose of the method was to separate the pectoral muscle from the mammographic image. The method involved Otsu thresholding and k-means based for pixel classification.
The need for a full-tested preprocessing tool is strong in the research community of FFDM analysis, especially as texture radiomics and deep-learning approaches have entered into the field. As a matter of fact, important issues with deep models for pectoral removal are the robustness of the methods and the training phase. Before the advent of deep learning, feature-based methods dominated the field [34,35,36,37]. The robustness of these kinds of systems remains to be improved as variations in the images could lead to wrong removal. In this sense, the advantage of deep-learning-based methods is such that the robustness has been drastically enhanced [30,31,32, 38,39,40,41,42,43]. However, deep-learning approach requires a very large number of images to be properly trained. Therefore, their development still remains problematic due to the lack of large FFDM databases properly manually annotated, as mentioned above. On the contrary, although not based on deep-learning approach, the two packages analyzed have been proven to be robust against various situations and turned out to be suitable for pectoral muscle removal.
This study has several limitations. First, the simple size assessed. However, the sample size analyzed in this study was justified statistically. In fact, typical values for accuracy differences among different algorithms can be expected to be a few percentage points and the expected standard deviation is form 2 to 4 times the differences [2, 3]: this yields a standardized mean difference of 0.2. Applying standard power samples size computation [4] for paired test and considering a power of 80% and alpha level of 5%, a sample size of about 150 subjects can be considered adequate. Moreover, manual accurate free-hand delineation of the pectoral muscle is a very time-consuming task which puts a fundamental limit on the size of the database which can be analyzed in a limited frame of time. Second, the population is imbalanced considering that the prevalence of women had a breast density of B type; however, no statistically significant dependence of pectoral removal performance was found respect the breast density.
Conclusions
In summary, we compared the performance of pectoral muscle removal for the two Matlab packages LIBRA and OpenBreast on a single FFDM database with respect to manual delineation. Results indicated that both packages showed high values of agreement with manual segmentation. However, statistical tests suggest that, on average, LIBRA can achieve higher performance. Although this study has not a direct clinical application, our results are useful in the choice of packages for the development of complex systems for computer-aided breast evaluation.
References
Taylor K, Parashar D, Bouverat G, Poulos A, Gullien R, Stewart E, Aarre R, Crystal P, Wallis M (2017) Mammographic image quality in relation to positioning of the breast: A multicentre international evaluation of the assessment systems currently used, to provide an evidence base for establishing a standardised method of assessment. Radiography (Lond) 23(4):343–349. https://doi.org/10.1016/j.radi.2017.03.004
Ganesan K, Acharya UR, Chua KC, Min LC, Abraham KT (2013) Pectoral muscle segmentation: a review. Comput Methods Programs Biomed 110(1):48–57. https://doi.org/10.1016/j.cmpb.2012.10.020
Suganthi GV, Sutha J, Parvathy M, Devi CD (2020) Pectoral Muscle Segmentation in Mammograms. Biomed Pharmacol J 13(3):1357–1365
Murphy M (2004) Statistical power analysis. Lawrence Erlbaum Associates Publishers, London
Ohashi Y, Takashima H, Ohmori G, Harada K, Chiba A, Numasawa K, Imai T, Hayasaka S, Itoh A (2020) Efficacy of non-rigid registration technique for misregistration in 3D-CTA fusion imaging. Radiol Med 125(7):618–624. https://doi.org/10.1007/s11547-020-01164-4
He W, Juette A, Denton ER, Oliver A, Martí R, Zwiggelaar R (2015) A review on automatic mammographic density and parenchymal segmentation. Int J Breast Cancer 2015:276217. https://doi.org/10.1155/2015/276217
Juneja P, Evans P, Harris E (2013) A method for validating breast tissue segmentation in radiotherapy using multiple expert outlines. In: Long M (eds) World congress on medical physics and biomedical engineering May 26–31, 2012, Beijing, China. IFMBE Proceedings, vol 39. Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-642-29305-4_484
Keller BM, Nathan DL, Wang Y, Zheng Y, Gee JC, Conant EF, Kontos D (2012) Estimation of breast percent density in raw and processed full field digital mammography images via adaptive fuzzy c-means clustering and support vector machine segmentation. Med Phys 39(8):4903–4917. https://doi.org/10.1118/1.4736530
Pertuz S, Torres GF, Tamimi R and Kamarainen J (2019) open Framework for Mammography-based Breast Cancer Risk Assessment. In: 2019 IEEE EMBS international conference on biomedical and health informatics (BHI), Chicago, IL, USA, pp 1–4, https://doi.org/10.1109/BHI.2019.8834599.
Matlab [Internet]. Available: https://www.mathworks.com/downloads/
American College of Radiology (2013) ACR BI-RADS Atlas - Mammography. 5th ed. Reston, Va: American College of Radiology. https://doi.org/10.1118/1.4736530
Horos [Internet]. Available: https://www.horosproject.org/
Karssemeijer N (1998) Automated classification of parenchymal patterns in mammograms. Phys Med Biol 43(2):365–378. https://doi.org/10.1088/0031-9155/43/2/011.P
Ballard D (1981) Generalizing the Hough transform to detect arbitrary shapes. Pattern Recogn 13(2):111–122. https://doi.org/10.1016/0031-3203(81)90009-1
Torres GF, Pertuz S (2016) Automatic detection of the retroareolar region in x-ray mammography images. In: Torres I, Bustamante J, Sierra D (eds) VII Latin American congress on biomedical engineering CLAIB 2016, Bucaramanga, Santander, Colombia, October 26th–28th, 2016. IFMBE Proceedings, vol 60. Springer, Singapore. https://doi.org/10.1007/978-981-10-4086-3_40
Taha AA, Hanbury A (2015) Metrics for evaluating 3D medical image segmentation: analysis, selection, and tool. BMC Med Imaging 15:29. https://doi.org/10.1186/s12880-015-0068-x
Mughal B, Muhammad N, Sharif M, Rehman A, Saba T (2018) Removal of pectoral muscle based on topographic map and shape-shifting silhouette. BMC Cancer 18(1):778. https://doi.org/10.1186/s12885-018-4638-5
Yoon WB, Oh JE, Chae EY, Kim HH, Lee SY, Kim KG (2016) Automatic detection of pectoral muscle region for computer-aided diagnosis using MIAS mammograms. Biomed Res Int 2016:5967580. https://doi.org/10.1155/2016/5967580
Shen R, Yan K, Xiao F, Chang J, Jiang C, Zhou K (2018) Automatic Pectoral muscle region segmentation in mammograms using genetic algorithm and morphological selection. J Digit Imaging 31(5):680–691. https://doi.org/10.1007/s10278-018-0068-9
Digital Imaging and Communication in Medicine, https://www.dicomstandard.org
Reverberi C, Marinelli L, Campanella B, Scalabrino G, Nicosia L, Anzellini D, De Sanctis V, Valeriani M, Osti MF (2020) Post-mastectomy immediate breast reconstruction and adjuvant radiotherapy: long term results of a mono institutional experience. Radiol Med 125(9):887–893. https://doi.org/10.1007/s11547-020-01161-7
Zhang Y, Zhu Y, Zhang K, Liu Y, Cui J, Tao J, Wang Y, Wang S (2020) Invasive ductal breast cancer: preoperative predict Ki-67 index based on radiomics of ADC maps. Radiol Med 125(2):109–116. https://doi.org/10.1007/s11547-019-01100-1
Fiorini F, Granata A, Battaglia Y, Karaboue MAA (2019) Talking about medicine through mass media. G Ital Nefrol 36(1):2019 (Italian)
Bora VB, Kothari AG, Keskar AG (2016) Robust automatic pectoral muscle segmentation from mammograms using texture gradient and euclidean distance regression. J Digit Imaging 29:115–125
Wei CH, Gwo CY, Huang PJ (2016) Identification and segmentation of obscure pectoral muscle in mediolateral oblique mammograms. Br J Radiol 89:20150802
Armstrong RA (2014) When to use the Bonferroni correction. Ophthalmic Physiol Opt 34:502–508. https://doi.org/10.1111/opo.12131
Nori J, Bicchierai G, Amato F, De Benedetto D, Boeri C, Vanzi E, Di Naro F, Bianchi S, Miele V (2021) A new technique for the histological diagnosis of Paget’s disease of the breast using a semiautomated core needle biopsy with a 14-gauge needle. Radiol Med 126(7):936–945. https://doi.org/10.1007/s11547-021-01358-4
Deandrea S, Cavazzana L, Principi N, Luconi E, Campoleoni M, Bastiampillai AJ, Bracchi L, Bucchi L, Pedilarco S, Piscitelli A, Sfondrini MS, Silvestri AR, Castaldi S (2021) Screening of women with aesthetic prostheses in dedicated sessions of a population-based breast cancer screening programme. Radiol Med 126(7):946–955. https://doi.org/10.1007/s11547-021-01357-5
Bellardita L, Colciago RR, Frasca S, De Santis MC, Gay S, Palorini F, La Rocca E, Valdagni R, Rancati T, Lozza L (2021) Breast cancer patient perspective on opportunities and challenges of a genetic test aimed to predict radio-induced side effects before treatment: analysis of the Italian branch of the REQUITE project. Radiol Med 126(10):1366–1373. https://doi.org/10.1007/s11547-021-01395-z
Girometti R, Linda A, Conte P, Lorenzon M, De Serio I, Jerman K, Londero V, Zuiani C (2021) Multireader comparison of contrast-enhanced mammography versus the combination of digital mammography and digital breast tomosynthesis in the preoperative assessment of breast cancer. Radiol Med 126(11):1407–1414. https://doi.org/10.1007/s11547-021-01400-5
Sezgin G, Coskun M, Apaydin M, Akder SA (2021) The role of rare breast cancers in the false negative strain elastography results. Radiol Med 126(3):349–355. https://doi.org/10.1007/s11547-020-01270-3
Maitra IK, Nag S, Bandyopadhyay SK (2012) Technique for preprocessing of digital mammogram. Comput Methods Programs Biomed 107:175–188
Kaitouni SEIE, Abbad A, Tairi H (2018) A breast tumors segmentation and elimination of pectoral muscle based on hidden Markov and region growing. Multimed Tools Appl 77:31347–31362
Yu X, Wang SH, Górriz JM, Jiang XW, Guttery DS, Zhang YD (2022) PeMNet for pectoral muscle segmentation. Biology (Basel) 11(1):134. https://doi.org/10.3390/biology11010134
Zhou K, Li W, Zhao D (2022) Deep learning-based breast region extraction of mammographic images combining pre-processing methods and semantic segmentation supported by Deeplab v3. Technol Health Care 30(S1):173–190. https://doi.org/10.3233/THC-228017
Almalki YE, Soomro TA, Irfan M, Alduraibi SK, Ali A (2022) Impact of image enhancement module for analysis of mammogram images for diagnostics of breast cancer. Sens (Basel) 22(5):1868. https://doi.org/10.3390/s22051868
Gómez KAH, Echeverry-Correa JD, Gutiérrez ÁÁO (2021) Automatic pectoral muscle removal and microcalcification localization in digital mammograms. Healthc Inform Res 27(3):222–230. https://doi.org/10.4258/hir.2021.27.3.222
Carbonaro LA, Rizzo SS, Schiaffino S, Pisani Mainini A, Berger N, Trimboli RM, Sardanelli F (2021) Biennial screening mammography: How many women ask for more? Estimate of the interval mammogram rate in an organised population-based screening programme. Radiol Med 126(2):200–205. https://doi.org/10.1007/s11547-020-01238-3
Brunetti N, De Giorgis S, Zawaideh J, Rossi F, Calabrese M, Tagliafico AS (2020) Comparison between execution and reading time of 3D ABUS versus HHUS. Radiol Med 125(12):1243–1248. https://doi.org/10.1007/s11547-020-01209-8
Schiaffino S, Gristina L, Tosto S, Massone E, De Giorgis S, Garlaschi A, Tagliafico A, Calabrese M (2021) The value of coronal view as a stand-alone assessment in women undergoing automated breast ultrasound. Radiol Med 126(2):206–213. https://doi.org/10.1007/s11547-020-01250-7
Pediconi F, Galati F, Bernardi D, Belli P, Brancato B, Calabrese M, Camera L, Carbonaro LA, Caumo F, Clauser P, Girardi V, Iacconi C, Martincich L, Panizza P, Petrillo A, Schiaffino S, Tagliafico A, Trimboli RM, Zuiani C, Sardanelli F, Montemezzi S (2020) Breast imaging and cancer diagnosis during the COVID-19 pandemic: recommendations from the Italian College of Breast Radiologists by SIRM. Radiol Med 125(10):926–930. https://doi.org/10.1007/s11547-020-01254-3
Gregucci F, Fozza A, Falivene S, Smaniotto D, Morra A, Daidone A, Barbara R, Ciabattoni A (2020) Italian Society of Radiotherapy and Clinical Oncology (AIRO) Breast Group. Present clinical practice of breast cancer radiotherapy in Italy: a nationwide survey by the Italian Society of Radiotherapy and Clinical Oncology (AIRO) Breast Group. Radiol Med 125(7):674–682. https://doi.org/10.1007/s11547-020-01147-5
Boyd NF, Guo H, Martin LJ, Sun L, Stone J, Fishell E, Jong RA, Hislop G, Chiarelli A, Minkin S, Yaffe MJ (2007) Mammographic density and the risk and detection of breast cancer. N Engl J Med 356(3):227–236. https://doi.org/10.1056/NEJMoa062790
Acknowledgements
This study has been conducted in the framework of a wider study (“Senologia per te”) promoted by SIRM (Italian Society of Medical Radiology) approved by the Ethical Committee of University “Luigi Vanvitelli” (prot. N 469 of 23/07/2019). This study has been partially funded by GIOTTO IMS S.p.A. Sasso Marconi (BO), Italy. Special thanks go to PhD Sara Vecchio at IMS for useful discussions.
Funding
Open access funding provided by Università degli Studi di Napoli Federico II within the CRUI-CARE Agreement.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
On behalf of all authors, the corresponding author states that there is no conflict of interest.
Research involving human participants and/or animals
Approval was obtained from the ethics committee of University “Luigi Vanvitelli,” Naples, Italy. The procedures used in this study adhere to the tenets of the Declaration of Helsinki.
Informed consent
As this work is included within a larger project, informed consent was obtained from all individual participants included in the study.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Sansone, M., Marrone, S., Di Salvio, G. et al. Comparison between two packages for pectoral muscle removal on mammographic images. Radiol med 127, 848–856 (2022). https://doi.org/10.1007/s11547-022-01521-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11547-022-01521-5