
Abstract
Cardiac-related disorders are rapidly growing throughout the world. Accurate classification of cardiovascular diseases is an important research topic in healthcare. During COVID-19, auscultating heart sounds was challenging as health workers and doctors wear protective clothing, and direct contact with patients can spread the outbreak. Thus, contactless auscultation of heart sound is necessary. In this paper, a low-cost ear contactless stethoscope is designed where auscultation is done with the help of a bluetooth-enabled micro speaker instead of an earpiece. The PCG recordings are further compared with other standard electronic stethoscopes like Littman 3 M. This work is made to improve the performance of deep learning-based classifiers like recurrent neural networks (RNN) and convolutional neural networks (CNN) for different valvular heart problems using tuning of hyperparameters like learning rate of optimizers, dropout rate, and hidden layer. Hyper-parameter tuning is used to optimize the performances of various deep learning models and their learning curves for real-time analysis. The acoustic, time, and frequency domain features are used in this research. The investigation is made on the heart sounds of normal and diseased patients available from the standard data repository to train the software models. The proposed CNN-based inception network model achieved an accuracy of 99.65 ± 0.06% on the test dataset with a sensitivity of 98.8 ± 0.05% and specificity of 98.2 ± 0.19%. The proposed hybrid CNN-RNN architecture attained 91.17 ± 0.03% accuracy on test data after hyperparameter optimization, whereas the LSTM-based RNN model achieved 82.32 ± 0.11% accuracy. Finally, the evaluated results were compared with machine learning algorithms, and the improved CNN-based Inception Net model is the most effective among others.
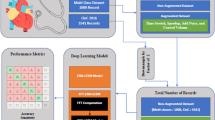
Graphical Abstract

Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The heart is the primary organ of the human circulatory system. The blood circulation within the heart makes the sound. The sounds come from the closing and opening of the atrioventricular valves. As these valves open and close, allowing blood flow to and from the Heart, it produces the heartbeat sound in this course. Analysis of heart sounds is fundamental to detecting any heart-related disorders. Under the investigation of heart sounds, the classification of heart-related disease is also crucial for quickly taking the correct preventive action. In practice, the background noise signals must be removed in the valvular heart disease [1, 2] analysis after receiving auscultation through an electronic acoustic stethoscope. Then the noise-free heart sound was digitized for computational needs. Convenient feature-extracting algorithms [1, 3] are applied in the computational intelligence to extract the essential features to classify the heart sound [1, 4] for diseases. As PCG signals are produced from the opening and closing of valves, they are repetitive and mechanical vibrations that occur at certain fixed time intervals and are analogous to an electrical signal. The heart sound can be analyzed in the conventional time and frequency domain using different developed algorithms and tools applied in various computational intelligence techniques. Artificial intelligence with computational intelligence plays a significant role in cardiac monitoring, early screening, and identification of valvular heart diseases. Inception networks and residual networks found suitable applications in heart sound analysis in terms of their accuracy and low screening time. Integration of squeeze and excitation blocks with these networks improved their performance depending on their respective connection positions. Detailed studies based on multiple hyperparameters are required to enhance the performance of the suitable deep-learning classifier on normal and abnormal heart sounds. Tuning hyperparameters in deep neural network models is necessary to avoid overfitting and underfitting issues. The study aims to search for the best cost-effective, simplified, and improved classifier tool for the early screening of heart diseases.
2 Paper organization
Section 3 provides a literature study of different deep learning methods used in heart sound analysis. Section 4 provides the objective of the research work. Section 5 details about techniques and materials used in this research paper. Section 6 explains the hardware development of the proposed system. Section 7 explains software based developed deep learning models for the proposed method and their improvements using hyperparameter tuning. Section 8 highlights the result analysis of the research work. Eventually, Section 9 summarizes the conclusions and future scope.
3 Related work
In this research, the signal classification of valvular heart diseases using a deep learning model is essential. According to a literature survey, many researchers have worked in this area. The authors [1] 2005 did work on different stages in heart sound signal for PCG signal analysis.
The authors [3] 2009 did work on heart sound analysis using an adaptive fuzzy inference system based on a Mamdani-type fuzzy inference classifier. The experiment was carried out on a standard heart sound repository. It was an offline method and not tested with human subjects. The authors [5] 2013 did work on heart sound analysis using different feature extraction techniques and methods. However, no artificial intelligence was involved in this. The authors [6] (2014) reviewed the papers on the classification of PCG signals. The authors [4] (2015) researched the analysis of second heart sounds, which involves computing the length and the energy of normalized heart sounds. However, they did not classify heart sounds. The authors [7] (2018) researched PCG signal sensing using several machine-learning methods for abnormal heart sound detection. However, it was used to discriminate between different types of heart sounds.
The authors [8] in 2018 and [9] in 2013 researched PCG signal analysis using the wavelet transform method. However, it had restrictions in real-time signal analysis. The authors [10] 2015 did work on the classification of heart sounds using multimodal features and obtained an accuracy of 85%. The authors [11] (2020) researched the classification of heart sound using CNN and achieved an accuracy of 88%. The authors [12] (2017) paper investigated PCG signal analysis for murmur diagnosing using Shannon energy and obtained an accuracy of 83%. The authors [13, 14] in 2017 and 2018 did work on a simple technique for heart sound detection and identification using the Kalman filter in real-time analysis, where various feature extraction techniques were discussed. Thus, improving data science models and artificial intelligence is necessary for PCG signal analysis. Table 1 shows some of the recent works that have been done on PCG signal analysis and classification methods.
4 Objective
The main objective of this paper is to design and develop an artificial intelligence-based ear-contactless electronic stethoscope that is low-cost, portable, and accurate. The developed stethoscope can also effectively diagnose various heart sound types where auscultation occurs through a bluetooth-enabled micro speaker.
5 Methods and materials
5.1 Heart sound dataset description
The research was based on four heart sound data repositories. A massive number of heart sound data (70,000 heart sound samples) are taken from these four heart sound data repositories for training and testing purposes of the modeling. The training and testing ratio is 80:20. Similar classes’ heart sounds are considered during training. The heart sound banks are the only source available on the internet used by many researchers, as the literature says. These sounds are highly authentic and reliable, as described in the following: https://github.com/yaseen21khan/Classification-of-Heart-Sound-Signal-Using-Multiple-Features [15].
Five categories of heart sound samples have been considered, as shown in Fig. 1: normal sound, mitral regurgitation, mitral stenosis, mitral valve prolapse, and atrial stenosis. Each heart sound lasts for a time duration of 5 s to 10 s and has a bandwidth of 65 Hz to 500 Hz.

Cardiac sound dataset 1
Heart sound dataset 2, as shown in Fig. 2, is obtained from the classification of heart sound recordings-pascal challenge dataset B [15, 16]. Three categories of heart sounds have been considered: normal, murmur, and extra–systole.

Cardiac sound dataset 2
Figure 3 details the physio net challenge training set [17, 18], comprising five training databases (A through E) containing 3126 heart sound samples.

Cardiac sound dataset 3
Kaggle heartbeat sounds [19, 20] dataset consisting of normal, abnormal, noisy normal, and noisy abnormal is also used for our heart sound analysis.
Mainly, two categories of heart sounds are used for analysis: normal and abnormal.
Features [21] of the heart sound considered for the whole study have been limited to:
-
1.
Acoustic features: MFCCs, Mel, Chroma, Contrast, and Tonnetz.
-
2.
Time domain features: RMS, Signal Energy, Signal Power, ZCR, THD, DWT, Skewness, and Kurtosis.
-
3.
Time and Frequency domain features: Hilbert Huang transform (HHT)
Figure 4 depicts a block diagram of PCG signal classification [21, 22]. Heart samples are given to a pre-processing module, which applies a bandpass filter with a bandwidth of 35 to 480 Hz to suppress the ambient error. A sample length of 3 s is considered and made constant for each heart sample recording undergoing pre-processing. Various features are collected from the pre-processed heart sound, and eventually, the heart sound sample is categorized for validation of the proposed developed system.
where x' (t) is the processed cardiac sound signal.

Block diagram of PCG signal classification
Each dataset is split into training data (85%) and test data (15%). Training data is further divided into validation data (15%) and the rest for training the model.
HHT is used as one of the feature extraction methods where the heart signal is decomposed into various intrinsic mode functions (IMFs) using empirical mode decomposition (EMD). The Hilbert transform is applied to the IMFs to obtain the time, and frequency distribution for Hilbert spectral analysis (HSA) to detect extra Heart sounds like S3 and S4.
The following algorithms are applied to classify heart sounds:
-
1.
Proposed SE-based Inception Network
-
2.
Proposed CNN-RNN architecture
-
3.
Proposed Recurrent Neural Network (RNN)
-
4.
Proposed CNN-based Inception Network
All deep learning-based algorithms are written in Python ver. 3.9.2 using Thorny python editor (Linux). The proposed algorithms mentioned above are briefly described under the software development of the proposed deep learning models.
The valvular heart sounds considered for the entire PCG signal analysis [23, 24] are divided into the following categories:
-
1.
Normal Heart Sounds
-
2.
Mitral Stenosis
-
3.
Aortic Stenosis
-
4.
Mitral Regurgitation
-
5.
Aortic Regurgitation
-
6.
Mitral Valve Prolapse
-
7.
Extra Systole
6 The hardware development of the proposed system
The schematic diagram of the data acquisition system and other interfaces is described in Figs. 5.

Schematic diagram of the proposed heart sound acquisition system
The hardware circuit for heart sound data acquisition and interface is described in Fig. 5, where it uses a chest piece for sensing real-time heart sound samples, an electret microphone for conversion of the real-time heart sounds into an electronic signal, a microphone pre-amplifier for amplification of the heart sound, a notch filter for removing the electrical interferences, an analog tunable band pass filter, a buffer amplifier for impedance matching, a Raspberry Pi 4B model acting as a CPU, a Bluetooth enabled micro speaker for listening to the captured heart sound, a power supply for the Raspberry Pi model, 7-inch touch screen for displaying the heart sound.
Heart sound in the chest generates pressure waves which the stethoscope diaphragm has picked up. The electret microphone fitted inside the chest piece and the stethoscope tube convert the heart sound signal to an electrical signal. This electrical signal is amplified by an audio amplifier based on a MAX 9812 IC chip of gain 20 and fed to the notch filter to remove electrical interferences. The processed signal is fed to an analog tunable band pass filter with a 35–470 Hz spectrum. The heart sound signal typically [25] belongs to 35–470 Hz for normal and abnormal sounds. Finally, the processed signal is converted to digital form in a USB sound card that contains a 16-bit ADC converter with a sampling frequency of 44.1 KHz. The output of the USB sound card is connected to the Raspberry Pi 4B computer. The heart sound samples are picked up in real-time by a stethoscope sensor and saved in WAV format for further processing through the Raspberry Pi 4B with developed deep learning models. A 7-inch LCD touch screen is used to display the processed data and AI-based prediction of the disease of heart sound sample picked from the chest through the developed system in real time.
Figure 6 highlights the prototype of the proposed system incorporating all the required elements. The Bluetooth-enabled micro speaker attached to the raspberry pi makes the stethoscope ear-contactless.

The prototype of the proposed system and its components. A The uninterruptible power supply. B The Raspberry Pi 4B (left) and uninterruptible power supply (right). C Combination of the Raspberry Pi and the power supply. D A 7-inch touch screen, Raspberry Pi with power supply, and micro speaker. E A fully assembled device containing the components in D
The stethoscopes are designed to meet specific parameters. The proposed stethoscope satisfies all these parameters better than others and thus can be considered an essential tool in cardiac monitoring of heart disease. Figure 7 provides the heart sounds captured in real-time through the proposed stethoscope and 3 M Littman digital stethoscope. Figure 8 provides how digital sound wav files are stored using the raspberry pi 4B model. Figure 9 shows a comparative study of the proposed stethoscope with the conventional stethoscope and 3 M Littman stethoscope based on the computation of these parameters. The third (S3) and fourth heart sounds (S4) are very low frequency and have low intensity. Thus, it can sometimes be heard using the bell of the stethoscope chest piece.

PCG recordings obtained through 3 M Littman stethoscope and proposed stethoscope

Digital heart sound wav files stored in Raspberry Pi using Thorny IDE environment and Python 3.9 version

Comparison of the proposed stethoscope based on the evaluation of specific parameters with a conventional stethoscope and 3 M Littman stethoscope
The developed system is ear contactless because heart sound plays through an external bluetooth speaker. There is no contact between the stethoscope chest piece and the ear. Therefore, it is hygienically safe during the COVID-19 chest examination. Auscultation of the heart is essential in patients with COVID-19. However, proper auscultation of these patients is difficult when medical workers wear personal protective suits.
Figure 9 highlights the parameters considered in comparing the three stethoscopes:
-
1.
Disinfection in use.
-
2.
Ease of handling the stethoscope.
-
3.
Safety for patients and health professionals in use.
-
4.
Ease of auscultation.
-
5.
Easy to afford.
-
6.
Digital storage of wav files.
-
7.
Compatibility with the wearing of personal protective clothing.
7 The software development of the proposed model
7.1 Squeeze and excitation networks applied to existing state of art architectures (SOTA)
The residual network and inception network work best for valvular heart sound analysis [26, 27]. However, their performances can be further improved by integrating squeeze and excitation (SE) blocks with the existing state of art models, as given in Figs. 10 and 11.

SE—ResNet Block

SE—Inception Net Block
Figure 12 provides various positions of attached SE blocks. Table 2 highlights and compares results based on the different positions of SE blocks connected with the existing CNN models. Table 2 also provides a standard SE block associated with the existing state of the model [28, 29], like inception net offers the best result among all others.

Various positions of squeeze and excitation blocks
In SE modules, there exist mainly three parts:
-
1.
Squeeze block
-
2.
Excitation block
-
3.
Scale block
In the squeeze block, a global average pooling operation is performed to reduce the C × H × W shape to C × 1 × 1 shape to get a global picture for each channel.
The excitation network contains two fully connected layers, first to reduce the dimensions and second to increase the dimensions back to the original. The dimensions are reduced by a reduction ratio of r = 16. Initially, the vector of length C is obtained in the squeeze operation, and the next stage is to generate a set of weights for each channel which is done with the help of the excitation operation.
Finally, the scaling operation is done with the help of a sigmoid layer where outputs of the excitation block are multiplied element-wise with the input feature to get the final output of the SE Module.
Various learning curves are obtained, as shown in Figs. 13 and 14.

Plot of accuracy vs. epoch during training and validation in SE-Inception Net

Plot of cossentropy loss vs. epoch during training and validation in SE-Inception Net
7.2 Proposed CNN-RNN architecture
A combination of CNN-RNN architecture has been proposed, where features are extracted with a CNN-based inception network, and classification is done by the RNN model, as given in Fig. 15. The hybrid CNN-based inception network model and LSTM-based RNN model use some of the acoustic features of the heart sound signal like Mel-frequency cepstrum coefficients (MFCCs), Mel, Chroma, Contrast, and Tonnetz. The proposed CNN-RNN model [28, 30], after hyper-parameter settings, achieved an accuracy of 91.17%. It produced better performance in terms of accuracy compared to the RNN model after optimizing its hyperparameters.

Functional block diagram of the proposed CNN-RNN model
Figure 16 depicts a plot of the accuracy of the proposed CNN-RNN model after hyper-parameter tuning with the number of epochs during the training and validation stage. It is found from the above plot that accuracy rises as the number of epochs grow.

Plot of accuracy vs. epoch during training and validation
Table 3 produces the hyper-parameter settings of the proposed model.
7.3 Proposed RNN Architecture
It is a special kind of deep neural network [13, 15] where the obtained result from the previous stage is used as input to the present stage, as explained in Fig. 17. In PCG signal analysis, it plays an important role.
where ht = present state in RNN network.

Steps involved in RNN
- ht-1:
-
= Previous state in RNN network
- xt:
-
= Input to RNN network
- Whh:
-
= Weight at recurrent neuron in RNN network
- Wxh:
-
= Weight at input neuron in RNN network
- ReLU:
-
= Activation function used in the hidden layer
- σ:
-
= Softmax Activation function used in the output layer
- yt:
-
= output of RNN network
- Why:
-
= Weight at output layer in RNN network.
Each dataset is grouped into training data (85%) and test data (15%), as shown in Fig. 18. Furthermore, training data is decomposed into validation data (15%) and the rest for training the model. Once the proposed RNN model [31, 32] gets trained using training data, it is then validated using the validation data to adjust the hyper-parameters to get better results and choose the best-selected model. Test data is commonly used to validate the performance of the proposed model. Eventually, statistical parameters are computed for the proposed model.

Functional block diagram of RNN
Figure 19 shows the architecture of the proposed RNN model applied to dataset 2. The input layer uses six neurons followed by two long short-term memory (LSTM) layers. The first LSTM layer [28, 33] comprises 50 neurons followed by a 35% dropout rate, whereas the second LSTM layer contains 20 neurons followed by a 35% dropout rate. In every LSTM layer, the ReLU activation function has been used. The softmax activation function has been used in the dense output layer, having several neurons depending on the dataset to which the proposed model is applied, as shown in Table 3.

Architecture of the proposed RNN using LSTM
Table 4 shows the proposed RNN model [34] summary using two LSTM layers with the ReLU activation function and a dense output layer with the Softmax function being used.
Figure 20 shows the cross-entropy loss [35] of the proposed RNN model under the training and validation phase. The plot of cross-entropy loss with the number of epochs indicates that loss reduces as the number of epochs rises in the training and validation stage for the proposed RNN model.

Plot of cossentropy loss vs. epoch during training and validation in RNN
Figure 21 depicts the accuracy of the proposed RNN model under the training and validation phase. The plot of accuracy with the number of epochs indicates that accuracy rises as the number of the epochs grows in the training and validation stage for the proposed RNN model.

Plot of accuracy vs. epoch during training and validation in RNN
The effect of various optimizers on the proposed RNN model applied on dataset 2 is shown in Fig. 22. The figure below shows that the Adam optimizer gives the best result among the others.

Comparison of different optimizers in RNN
Table 5 shows the effect of different dropout rates on the proposed RNN model. It is observed that on increasing the dropout rates, the model’s accuracy increases, and cross-entropy loss decreases. The tuning of hyperparameters thus helps to choose the best proposed RNN model at a dropout rate of 0.35. The performance evaluation of the proposed RNN model is carried out on the test data by considering a dropout rate of 35%, as shown in Table 6. After hyperparameter settings, the proposed RNN-based long short-term memory (LSTM) model achieved an accuracy of 82.32%.
Table 7 provides the block diagram of proposed Inception Net architecture. Table 8 shows the effect of adding inception blocks on the proposed inception net model. It is experimentally studied and found that increasing the number of blocks increases the model’s accuracy and cross-entropy loss decreases.
Figure 22 provides the comparative study of different optimizers used in deep learning methods like RNN. As it is clear from the above figure, the accuracy increases very steeply on implementing the said optimizer. The learning rate is a configurable and most important hyperparameter in the deep learning model. Figure 23 depicts the effect of the learning rate on the cross-entropy loss of the proposed RNN model under the training and validation phase. It shows that the optimal condition is obtained at a learning rate of 0.001. As the combined architecture of the CNN and RNN model [36, 37] has low accuracy and more training time, this hyperparameter optimization method can easily keep track of that.

Effect of learning rate during training and validation using ADAM optimizer
Various parameters used to judge any developed system’s performance are called accuracy, precision, recall, and F-measure. For the computation of these metrics, the count of true-positive (TP), false-positive (FP), true-negative (TN), and false-negative (FN) data are needed, as provided:
7.4 Proposed CNN-based inception network
Inception networks [9, 19, 38] are often used in classification problems related to medical imaging. An inception network responds to a set of Heart sounds, performs the required operations and analysis on them, and eventually predicts the type of heart sound for classification [39]. A CNN-based inception network [40, 41] has multiple convolutional layers and inception modules to learn the various features in a heart sound and predict the class labels accordingly. All inception network parameters and hyperparameters are adjusted during the training phase of the deep learning model. A Python-based Keras sequential model [42, 43] has been taken for implementation. The entire design of the deep learning model is shown in Fig. 24. This model summary was obtained after training and validation of the dataset.

Inception net block
Figure 25 provides the skeleton of an inception module used. It is a sparsely connected network with a max pool and multiple convolutions of kernel sizes 1, 3, and 5 at the same layer, followed by an application of concatenation operation from all filter outputs.

Proposed CNN-based inception net model summary
Table 6 shows the proposed inception net architecture using three inception blocks with a ReLU activation function, an input layer, and an output layer with a softmax activation function.
Table 7 reflects the architecture of the proposed inception net model applied to dataset1. In this model, the first hidden convolution layer contains 256 filters, each kernel size equal to 3 using the ReLU activation function, followed by the second hidden convolution layer containing the same number of filters and kernel size. The third hidden layer has three inception modules, followed by the fourth, fifth, and sixth hidden layers. They are the fully connected layer containing 1200, 600, and 150 nodes, respectively. The output layer contains five nodes using the Softmax activation function to classify five different types of heart sound [2, 44]. Learning curves are obtained for the proposed model developed with normal and abnormal heart sounds and plotted accordingly, as shown in Figs. 26 and 27.

Plot of cross entropy loss vs. epoch during training and validation in CNN-based Inception Net

Plot of accuracy vs. epoch during training and validation in CNN-based Inception Net
Figure 26 shows the cross-entropy loss of the proposed inception net model [45] under the training and validation phase. The plot of cross-entropy loss with the number of epochs indicates that loss reduces as the number of epochs rises in the training and validation phase for the proposed inception net model. Learning rate affects the cross-entropy loss and accuracy as a lower learning rate needs a large number of iterations, and a larger one needs a small number of iterations. Thus, choosing a proper learning rate value is a challenging and significant task, as shown in Fig. 28.

Effect of learning rate during training and validation using ADAM optimizer
Figure 27 highlights the accuracy of the proposed inception net model under the training and validation phase. The plot of accuracy with the number of epochs indicates that accuracy rises as the number of epochs grows in the training and validation stage for the proposed CNN model.
The proposed inception net model’s performance evaluation [46, 47] is carried out on the test data by selecting the number of inception blocks as six, as shown in Table 9. The best-proposed model has been chosen when the number of added blocks equals six.
Figure 28 shows the effect of the learning rate on the cross-entropy loss of the proposed inception net model under the training and validation phase. It shows that the optimal condition is obtained at a learning rate of 0.001.
After hyperparameter settings, the proposed CNN-based inception net model achieved an accuracy of 99.65%.
7.5 Comparison to machine learning methods
The proposed model gets compared with the available machine-learning methods. A similar set of feature learning methods is considered and then a perception is made about the proposed software base deep learning model.
Dataset 1, dataset 2, and dataset 3 have been used to compare all the machine learning algorithms, as shown in Fig. 29. All machine learning algorithms [14], like Support Vector Machine [43], K-Nearest Neighborhood, Naïve Bayes, and Random Forest, are written in Python ver. 3.8 using Keras and tensor flow. Datasets have been fed to these various machine learning models using fivefold cross-validation to evaluate their performance and statistical analysis [48, 49]. Different models have been assessed against three datasets and compared, as given in the figure below. It is found that the inception network works best among all other machine learning algorithms, as shown in Fig. 30.

The comparison of the machine learning performance between the proposed method (RNN and CNN) and other machine learning

Comparison of different machine learning methods with deep learning on various datasets
8 Result analysis
Table 10 shows the accuracy of the four proposed models. The proposed hybrid CNN-RNN model attained better accuracy after hyperparameter settings than the RNN model. It has been found that the SE-based inception network works the best of all.
Tables 11 and 12 depicts the comparison of performance metrics in terms of training time and testing time. After optimizing hyperparameters, the training time and testing time of the proposed hybrid CNN-RNN model are lower than the RNN model, and the SE-inception network achieved the most down screening time among them. Table 12 provides a detailed comparative study of the performance of different stethoscopes.
Table 13 describes the detail of the 30 volunteers of different age groups and genders considered for the entire experimental study. Table 14 analyzes PCG recordings obtained using the proposed contactless stethoscope by adapting SE-inception network. Different positions like upper left sternal border (ULSB), upper right sternal border (URSB), and lower left sternal borders (LLSB) are considered for this analysis under postures like sitting, standing, and supine. The recordings are finally compared with their past medical history.
For heart sound detection of valvular disease, the stethoscope diaphragm should be placed with good contact on the body over the heart at areas defined in Fig. 31. In the case of pulse rate measurement, the stethoscope diaphragm is placed over bronchial arteries. The almost 30 mm Hg pressure is higher than the systolic pressure during palpation. For every volunteer, nine PCG readings (3 readings from each posture) are obtained using the developed system. Table 15 shows the scores on a 1 to 5 scale by comparing the developed stethoscope readings with the volunteer’s medical history. The developed system works quite decently for most volunteers in terms of accuracy (Table 16).

Locations of heart for the acquisition of heart sound
9 Conclusion
Machine learning algorithms have certain restrictions in real-time valvular heart sound analysis applications. This research aimed to use a CNN-based deep learning classifier to develop a low-cost portable contactless stethoscope for valvular heart disease prediction in rural places. The hardware development provides an electronic stethoscope with ear contactless that has a bluetooth-enabled speaker. The cost of an echo ultrasound 2D/3D imaging machine for cardiac imaging is around 12,000 to 15,000 USD. Our total development cost of the AI-based prototype system for detecting and predicting heart diseases is about 2500 USD. The available echo machines for cardiac imaging are portable and easy to use in rural villages. However, the developed prototype cannot image the cardiac condition. However, it can predict valvular diseases cheaply and can be incorporated into rural village applications using artificial intelligence. The designed system was experimentally evaluated for its performance with 30 human volunteers having a medical history of 27 volunteers with normal heart, two with mitral stenosis, and one with mitral regurgitation, which the physician clinically assessed. On experimentation with those human volunteers, the developed system predicts the same results. The experimental studies aimed to find a suitable and improved deep learning classifier using Python-based convolutional neural network (CNN) and recurrent neural network (RNN) on verified normal and abnormal heart sounds of three datasets, as described in the text. Integration of SE blocks with the existing state of art architecture prevailed in better performance of the inception and residual networks where standard SE blocks produced the best results, among others. The training dataset trains the deep learning model, the validation dataset is used to validate the performance of hyperparameters of the model, and the test dataset computes the model’s overall performance. It has been found that the best results can be obtained from any deep learning model by tuning the hyperparameters. In this entire experiment, classifier accuracy, precision, recall, and F1-scores are evaluated with the different heart sound databases. It has also been experimentally studied and found that the CNN-based inception network model classifier can be chosen as the most effective deep learning classifier. However, it has some complexity in the computational part. A recurrent neural network (RNN) is also suitable as an AI classifier of heart sound though it takes much time in the learning phase. However, once learned, it gives a speedy result.
Data availability
Heart sound data samples used in the proposed research work are available in standard heart sound repositories like.
1. Yaseen et al. [50] https://github.com/yaseen21khan/Classification-of-Heart-Sound-Signal-Using-Multiple-Features-.
2. 2016 Physio Net heart sound recording challenge. [35] https://physionet.org/content/challenge-2016/1.0.0/
3. 2012 Pa heart sound recording challenge. [33] http://www.peterjbentley.com/heartchallenge/.
4. Kaggle heartbeat sounds [20] https://www.kaggle.com/datasets/kinguistics/heartbeat-sounds
References
CN Gupta, R Palaniappan, S Rajan, S Swaminathan, SM Krishnan (2005) “Segmentation and classification of heart sounds”. International Conference: Canadian Conference on Electrical and Computer Engineering. https://doi.org/10.1109/CCECE.2005.1557305
Anju SK et al (2014) Detection of cardiac murmur. Int J Comput Sci Mob Comput 3(7):76–80
Ahmad T, Ali H, Khan S (2009) Classification of phonocardiogram using an adaptive fuzzy inference system. Comput Sci 2:609–614
Barma S, Chen B-W, Ji W, Jiang F, Wang J-F (2015) Measurement of duration, the energy of instantaneous-frequencies, and splits of subcomponents of the second heart sound. IEEE Trans Instrum Meas 64(7):1958–1967. https://doi.org/10.1109/TIM.2014.2383071
Mandeep Singh, Amandeep Cheema, “Heart sounds classification using feature extraction of phonocardiography signal,” International Journal of Computer Applications, Volume 77– No.4, September 2013, ISSN NO:0975 – 8887
Ajay Kumar Roy, Abhishek Misal, G. R. Sinha, “Classification of PCG signals: a survey,” International Journal of Computer Applications, Recent Advances in Information Technology, 2014, ISSN No: 0975 – 8887
Latif S, Usman M, Rana R, Qadir J (2018) Phonocardiographic sensing using deep learning for abnormal heartbeat detection. Sens J IEEE 18(22):9393–9400
Dewangan NK, Shukla SP, Dewangan K (2018) PCG signal analysis using discrete wavelet transform. Int J Adv Manag, Technol, Eng Sci 8:2249–7455
Mishra G, Biswal K, Mishra AK (2013) Denoising of heart sound signal using wavelet transform. Int J Res Eng Technol 2(4):2319–1163
Randhawa SK, Singh M (2015) “Classification of heart sound signals using multimodal features” Second International Symposium on Computer Vision and the internet, Elsevier. Procedeia Comput Sci 58:165–171
Li F, Tang H, Shang S, Mathiak K, Cong F (2020) Classification of heart sounds using convolutional neural network. Appl Sci 10:3956. https://doi.org/10.3390/app10113956
Othman Matin Z, Khaleel Asmaa N (2017) Phono cardiogram signal analysis for murmur diagnosing using Shannon energy envelop and sequenced DWT decomposition. J Eng Sci Technol 12(9):2393–2402
JK Roy & TS Roy (2017) “A simple technique for heart sound detection and real-time analysis” Proceedings of ICST 2017 held at Macquarie University Sidney, Sensing Technology (ICST), 2017. Eleventh International Conference, 4–6. https://doi.org/10.1109/ICSensT.2017.8304502.
JK Roy, TS Roy, N Mandal & OA Postolache (2018) “A simple technique for heart sound detection and identification using Kalman filter in real-time analysis”. International Symposium Sensing And Instrumentation IoT Era (ISSI), 1-8
Mdhaffar A, Bouassida Rodriguez I, Charfi K, Abid L, Freisleben B (2017) CEP4HFP: complex event processing for heart failure prediction. IEEE Trans NanoBiosci 16(8):708–717. https://doi.org/10.1109/TNB.2017.2769671
Femir D, S¸engür A, Bajaj V, Polat K (2019) Towards the classification of Heart sounds based on convolutional deep neural network. Health Inf. Sci Syst 7:1–9
Your First Deep Learning Project in Python with Keras Step. https://machinelearningmastery.com/tutorial-first-neural-network-python-keras/
Xiao B, Xu Y, Bi X, Li W, Ma Z, Zhang J, Ma X (2020) Follow the sound of children’s heart: a deep-learning-based computer-aided pediatric CHDs diagnosis system. IEEE Internet Things J 7:1994–2004
Bhatikar SR, DeGroff C, Mahajan RL (2005) A classifier based on the artificial neural network approach for cardiologic Auscultation in pediatrics. Artificial intelligence in medicine 33(3):251–260
Kaggle heartbeat sounds. https://www.kaggle.com/datasets/kinguistics/heartbeat-sounds
Prasad GV, Kumar PR (2015) Analysis of various DWT methods for feature extracted PCG signals. Int J Eng Res Technol 4(04). https://doi.org/10.17577/IJERTV4IS041236
Cheng X, Huang J, Li Y, Gui G (2019) Design and application of a laconic heart sound neural network. IEEE Access 7:124417–124425
Alafif T, Boulares M, Barnawi A, Alafif T, Althobaiti H, Alferaidi A (2020) Normal and abnormal heart rates recognition using transfer learning. In Proceedings of the 2020 12th International Conference on Knowledge and Systems Engineering (KSE), 2020 275–280
Khan FA, Abid A, Khan MS (2020) Automatic heart sound classification from segmented/unsegmented phonocardiogram signals using time and frequency features. Physiol Meas 41:055006. https://doi.org/10.1088/1361-6579/ab8770
Raza A, Mehmood A, Ullah S, Ahmad M, Choi GS, On BW (2019) Heartbeat sound signal classification using deep learning. Sensors 19(21):4819. https://doi.org/10.3390/s19214819
Ryu H, Park J, Shin H (2016) Classification of heart sound recordings using convolution neural network. In Proceedings of the 2016 Computing in Cardiology Conference (CinC). 1153–1156
DB Springer, L Tarassenko, and GD Clifford (2014) Support vector machine hidden semi Markov model-based heart sound segmentation. Comput Cardiol, 625–628
El-Segaier M, Lilja O, Lukkarinen S, Sörnmo L, Seppanen R, Pesonen E (2005) Computer-based detection and analysis of heart sound and murmur. Ann Biomed Eng 33(7):937–42. http://www.ncbi.nlm.nih.gov/pubmed/16060534
Abduh Z, Nehary EA, Wahed MA, Kadah YM (2019) Classification of Heart sounds using fractional fourier transform based mel-frequency spectral coefficients and traditional classifiers. Biomed Signal Process Control 9:1–8
Deng M, Meng T, Cao J, Wang S, Zhang J, Fan H (2020) Heart sound classification based on improved MFCC features and convolutional recurrent neural networks. Neural Netw 130:22–32
Rubin J, Abreu R, Ganguli A, Nelaturi S, Matei I, Sricharan K (2016) Classifying heart sound recordings using deep convolutional neural networks and mel-frequency cepstral coefficients. In Proceedings of the 2016 Computing in Cardiology Conference (CinC), 813–816
Tang H, Dai Z, Jiang Y, Li T, Liu C (2018) PCG classification using multidomain features and SVM classifier. BioMed Res Int 2018:1–14. https://doi.org/10.1155/2018/4205027
Liu C, Springer D, Li Q, Moody B, Juan RA, Chorro FJ, Castells F, Roig JM, Silva I, Johnson AE, Syed Z, Schmidt SE, Papadaniil CD, Hadjileontiadis L, Naseri H, Moukadem A, Dieterlen A, Brandt C, Tang H, Samieinasab M, Samieinasab MR, Sameni R, Mark RG, Clifford GD (2016) An open-access database for the evaluation of heart sound algorithms. Physiol Meas 37(12):2181–2213. https://doi.org/10.1088/0967-3334/37/12/2181
Nygaard H et al (1993) Assessing the severity of aortic valve stenosis by spectral analysis of cardiac murmurs (spectral vibrocardiography) Part I: Technical aspects. J Heart Valve Dis. 2(4):454–467
Gomes EF, Bentley PJ, Coimbra M, Pereira E, Deng Y (2013) Classifying heart sounds: approaches to the PASCAL challenge. In Proceedings of the HEALTHINF 2013- Proceedings of the International Conference on Health Informatics, Barcelona, Spain, pp 337–340
Maknickas V, Maknickas A (2017) Recognition of normal, abnormal phonocardiographic signals using deep convolutional neural networks and mel-frequency spectral coefficients. Physiol Meas 38:1671–1684
Li F, Liu M, Zhao Y, Kong L, Dong L, Liu X, Hui M (2019) Feature extraction and classification of heart sound using 1D convolutional neural networks. EURASIP J Adv Signal Process 59:1–11. https://doi.org/10.1186/s13634-019-0651-3
Quiroz-Juárez MA, Jiménez-Ramírez O, Vázquez-Medina R, Ryzhii E, Ryzhii M, Aragón JL (2018) Cardiac conduction model for generating 12 lead ECG signals with realistic heart rate dynamics. IEEE Trans Nanobiosci 17(4):525–532. https://doi.org/10.1109/TNB.2018.2870331
Yang TC, Hsieh H (2016) Classification of acoustic physiological signals based on deep learning neural networks with augmented features. In Proceedings of the 2016 Computing in Cardiology Conference (CinC), 569–572
Javed F, Venkatachalam PA, Ahmad Fadzil MH (2006) A signal processing module for the analysis of heart sounds and heart murmurs. J Phys: Conf Ser 34(1):1098–1105. https://doi.org/10.1088/1742-6596/34/1/181
Lubaib P, Ahammed Muneer KV (2016) The heart defect analysis based on PCG signals using pattern recognition techniques. Procedia Technol 24:1024–1031. https://doi.org/10.1016/j.protcy.2016.05.225
Muruganantham. Methods for classification of phonocardiogram. TENCON, (2003)
Wu JB, Zhou S, Wu Z, Wu XM (2012) Research on the method of characteristic extraction and classification of Phonocardiogram. In: 2012 International Conference on Systems and Informatics. ICSAI 2012. https://doi.org/10.1109/ICSAI.2012.6223377
Cheema A, Singh M (2013) Steps involved in heart sound analysis- a review of existing trends. Int J Eng Trends Technol 4(7):2921–2925
Wu JM-T, Tsai M-H, Huang YZ, Islam SH, Hassan MM, Alelaiwi A, Fortino G (2019) Applying an ensemble convolutional neural network with Savitzky-Golay filter to construct a phonocardiogram prediction model. Appl Soft Comput 78:29–40
JK Roy, TS Roy, SC Mukhopadhyay (2019) “Heart sound: detection and analytical approach towards diseases”. Modern Sensing Technologies, 103–145. https://doi.org/10.1007/978-3-319-99540-3_7
Suo Q et al (2018) Deep patient similarity learning for personalized healthcare. IEEE Trans Nanobiosci 17(3):219–227. https://doi.org/10.1109/TNB.2018.2837622
S Romiti, M Vinciguerra, W Saade, I Ansocortajarena and E Cresco (2020) “Artificial intelligence and cardiovascular diseases: an unexpected alliance”. Cardiol Res Pract, 2020
Li D, Huang M, Li X, Ruan Y, Yao L (2018) MfeCNN: mixture feature embedding convolutional neural network for data mapping. IEEE Trans Nanobiosci 17(3):165–171. https://doi.org/10.1109/TNB.2018.2841053
Yaseen G-Y, Kwon S (2018) Classification of heart sound signal using multiple features. Appl Sci 8:2344. https://doi.org/10.3390/app8122344
Author information
Authors and Affiliations
Contributions
All authors contributed to the algorithm conception and design. All authors also performed the experimental evaluation. Eventually, all authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interest
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Roy, T.S., Roy, J.K. & Mandal, N. Design of ear-contactless stethoscope and improvement in the performance of deep learning based on CNN to classify the heart sound. Med Biol Eng Comput 61, 2417–2439 (2023). https://doi.org/10.1007/s11517-023-02827-w
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11517-023-02827-w