
Abstract
Spatial statistical analysis is almost absent from research on underwater archaeological contexts. However, the information obtained using this approach would allow the reconstruction of depositional dynamics and the exploration of distribution patterns related to the ships’ on-board organization. This paper proposes a six-step methodology that will contribute to reducing the current gap in the use of spatial statistical analysis of shipwreck sites. This methodology will be tested in two distinct case studies, the Uluburun and the Tortugas wrecks, showing that the same protocol can be useful in the interpretation of different shipwrecks, in sites with a coherent distribution during their formation process. Using statistical tools, this methodology will strengthen context awareness, confirming, refuting, or adding new perspectives to previous interpretations. Finally, the way the framework was built will allow its replication in other sites.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
From its beginnings, the development of underwater archaeology took into serious consideration documenting and interpreting the distribution of artifacts and the relationship between contexts. These were important advances in underwater archaeological methodologies (Bass 2012), amongst which the pioneering work of Keith Muckelroy (a student of Grahame Clark and David Clarke at the University of Cambridge) stood out. Muckelroy, probably influenced by these processualist thinkers, developed a highly analytical approach to shipwreck sites. His works included several methods that still constitute a very important reference for the study of shipwreck sites today. As an example, he saw the definition of a central point of distribution in several functional categories as sufficient for understanding patterns of on-board organization at coherent sites (Muckelroy 1978). Conversely, at dispersed sites the study would be based on multivariate statistics, which Muckelroy explored in his research on the 1664 Dutch East Indiaman Kennemerland. This work raised new analytical perspectives and focused on the study of distribution patterns and underwater formation processes, which, unfortunately, were little explored in the following decades.
Nevertheless, results from spatial data recorded in several projects continued to be represented largely through graphics. For example, some monographs concerning underwater studies often show thematic maps with the distribution of points related to diverse categories (material or functional), e.g., the studies on the Serge Limani wreck (Bass et al. 2004), on the Mary Rose (Gardiner 2005), on the La Belle (Bruseth et al. 2017) or on the Almere cog-like vessel (Hocker and Vlierman 1996). In other cases, when it was not possible to record the positions of individual objects, the density of materials was represented using squares categorized by artifact quantity, as in the study of Cala Culip I (Nieto Prieto 1989); or the distribution was illustrated through the drawing of several layered maps, as in the Roman shipwreck Culip VIII (Carreras et al. 2004) or the 18th-century La Natière ships (L’Hour and Veyrat 2000, 2001, 2002, 2003, 2004).
Nowadays, the use of GIS has become increasingly common as a method of representation and visualization of spatial data, and as a basis for the production of maps. These maps are then interpreted based on visual analyses and as a starting point for interpretations of the on-board organization (Nicolardi 2011; Beltrame and Manfio 2014). However, the use of spatial statistical analysis is almost absent from research produced in nautical and underwater contexts in recent decades. This is quite different from what occurs in the study of terrestrial contexts, where the use of spatial statistics is prolific (Bevan et al. 2013; Theunissen et al. 2014; Carrer 2015; Rodriguez-Rellan and Valcarce 2015; Thacher et al. 2017; Salgueiro et al. 2018; Verbrugghe et al. 2020). This lack of statistical methods in underwater archaeology is surely a methodological issue, when compared with terrestrial archaeology, where accurate spatial data recording has been greatly helped by methods such as total station or DGPS. However, recent advances in underwater documentation have enabled the more routine collection of 3D geospatial digital data (McCarthy et al. 2019) which is precisely the type of data needed as input for statistical methods. Thus, with more and better data being obtained in recent years, there is a need to consider more advanced analytical methods in order to take advantage of these new data.
Spatial analysis of shipwreck sites is important for several reasons (not unlike terrestrial sites). Firstly, it contributes to the analysis of the formation processes of the underwater archaeological record. Secondly, it allows the validation of archaeological information, confirming and/or refuting associations between objects and their cultural significance—patterns of human use of inboard space or the result of post-depositional processes. Finally, the investigation of the spatial dimension adds value to the overall archaeological information, justifying investment in exhaustive documentation, highlighting the importance of context and the preservation of heritage; all these values have been adopted by the archaeological community in an unequivocal way.Footnote 1
The objective of this paper is to develop and test a shipwreck spatial analysis protocol incorporating statistical tools, using Geographic Information Systems (GIS) combined with the R statistical computing and graphics software. This method is used to reconstruct depositional dynamics and explore the distribution patterns through collected data related to a ship’s on-board organization. The process was tested on two different case studies, which allowed us to compare the statistical results with preliminary visual renderings, mathematically confirming, refuting, or adding new information to the qualitative interpretation of the archaeological data. The sites were selected because they represent two distinct case studies, the Uluburun and the Tortugas wrecks. The former was systematically excavated, published, and studied, providing the possibility of testing our methodology in a case where the distribution of the evidence is coherent and has already been visually analyzed. The latter is the other way around, corresponding to a salvaged site, at great depth, where the available spatial data are of lower quality and where the distribution of the evidence has never been systematically analyzed.
Methodology
Case Studies
The first case, the Ulubrurun, is a Late Bronze Age shipwreck (late fourteenth century BC), an icon of international underwater archeology. The site was discovered off the Grand Cape, 6 miles due southeast of Kaş, Turkey, in the Mediterranean Sea, and was visited and disturbed by sponge divers before it was systematically studied. It was excavated between 1984 and 1994 by a team from the INA (Institute of Nautical Archeology), led by George F. Bass and Cemal Pulak (Bass et al. 1989; Pulak 1998, 2005). The site is well-preserved and shows a more or less continuous distribution over some 250 square meters on a rocky seabed with occasional pockets of sand and a steep slope falling eastward, averaging 30 degrees and ranging from 42 to 61 m in depth. The hull probably listed 15 degrees to starboard in an approximately east–west orientation, with the stern on the western end and the bow at the deeper end of the site. The wooden hull gradually collapsed and disintegrated and some artifacts settled into level areas of the seabed, while others tumbled down the slope. Nevertheless, the distribution of artifacts was very coherent, allowing the reconstruction of the cargo’s original placement within the ship’s hold through systematic study (Shih-Han 2003; Pulak 2005). Shih-Han (2003) carried out a systematic study of the material distribution, based only on visual analysis, without resorting to spatial statistics. According to the research, the Uluburun wreck was an eastern Mediterranean cargo vessel involved in the east–west transport of copper, tin, and other raw materials (Pulak 1998).
The second case study is a shipwreck from the beginning of the seventeenth century discovered in 1989 near the Dry Tortugas Islands, the westernmost of the Florida Keys, at a depth of 405 m. This site, probably disturbed by fishermen's nets and by treasure hunters prior to the salvage work, was explored in 1990 and 1991 using a Remotely Operated Vehicle (ROV). The recovered assemblage is indicative of an Atlantic operating area, possibly corresponding to the vessel Buen Jesús y Nuestra Señora del Rosario. This 106-ton vessel, probably of Portuguese construction, with a 17.4 m-long keel, captained by Manuel Diaz, was traveling to Nueva Cordoba in present-day Venezuela when it sank in 1622. Unlike other low-depth shipwrecks from the same period, such as the Nuestra Señora de Atocha or the Santa Margarida, the Tortugas site vessel featured an apparently coherent and continuous distribution. The available spatial data is based on the photomosaics produced during excavation (Stemm et al. 2013). Although the original investigation of the in situ remains was limited due to the adopted strategy, this site was selected because it is one of the few known shipwrecks sitting at a great depth and because it will allow us to test the proposed methodology on a partially published site. The available publications show several maps with the distribution of points indicating which quantities of various categories are associated, such as bottles, kitchenware, gold bars, beads, and silver coins. The published data regarding the quantities, attributes and position of the various objects are incomplete, but it was nevertheless possible to evaluate the potential of the methodology proposed in this paper, as it will be demonstrated.
Methodology
The methodology was similar for both case studies, inspired by terrestrial works that, albeit different, used the same formulation and similar statistical analyses, applied mostly to pre- and proto-historical contexts (Rodriguez-Rellan and Valcarce 2015; Salgueiro et al. 2018). These terrestrial investigations sought to answer the same basic question: ‘Would it be possible to understand what happened within the boundaries of a site through the use of spatial statistical analyses?’.
The GIS tools used are available in Quantum GIS (v. 3.18), which was integrated with the free R (v. 4.04) software environment for statistical computing and graphics. The methodology followed the steps shown in Fig. 1.

Shipwreck analytical methodology using spatial statistics
The first step involves the creation of vector layers (polygons, lines, or points) in order to define the wreck in its quantitative and spatial dimensions through the identification of the different categories of objects (and their attributes). This virtual construction of the wreck aims to facilitate successive analyses and was achieved by georeferencing the various maps and plans available from publications, using local coordinates, which allowed the analyzed data to maintain the correct scale and coherence. The vector used was the point format, which allowed for successive statistical analyses.
The second step involves an initial exploratory analysis of the plots generated in the previous step through the use of Kernel Density Estimation (KDE). This analysis facilitates a preliminary evaluation of the general distribution of the artifacts and hypothesizing the depositional processes and patterns, which will be tested successively through a Point Pattern Analysis (PPA). KDE is used to create a raster (heatmap), and the resulting density is calculated on the basis of the number of points at a given location. Therefore, the greater the number of points in a given zone of the plot, the greater the perception of density. A quantitative attribute can be used to reinforce the weight of each point. This tool used pre-existing QGIS processes (‘qgis:heatmapkerneldensityestimation’).
The next step, PPA, aims to carry out tests of Complete Spatial Randomness (CSR) in order to understand whether the objects in the wreck follow a random or patterned distribution in the overall archaeological context. There are several types of CSR tests, such as the Quadrat Method, the Nearest Neighbor Method, or Ripley’s K function (Baddeley 2008). In our study, we chose the Monte Carlo statistical test for Ripley’s K function. This tool used pre-existing QGIS R scripts (‘r:Montecarlo spatial analysis’).
The fourth step is applied when the distribution is not random. The objective is to identify statistically significant groups of objects (clusters) in order to understand which ones were likely grouped together and how each cluster was connected to a certain part of the vessel or site. These analyses were based on the density-based spatial clustering of applications with noise (DBSCAN), a non-parametric algorithm for density-based clustering: after taking a set of points in a demarcated space, it groups those within a certain distance and marks those isolated in regions of low density as outliers. The “distance” attribute used for the DBSCAN was calculated based on the Average Nearest Neighbor. Both tools were applied using pre-existing QGIS processes (‘native:dbscanclustering’ and ‘native:nearestneighbouranalysis’).
Finally, correlation tests were carried out. These tests sought to identify whether different types of objects have spatial correlations with each other in order to understand whether their dispersion across the wreck was eventually impacted by the same variables (for example, whether they were transported in the same part of the vessel). The correlation tests were performed on raster data through the use of three correlation coefficients—Pearson, Spearman, and Kendall—seeking to define the degree of relationship between two distinct variables. For this tool, we developed a specific script in R.
During our investigation, it was necessary to use other analytical frameworks that were not foreseen in the initial plan. This necessity derived from questions that emerged during our interpretations in the previous steps. An example is the Points Average Coordinate, an algorithm that transforms a layer of points with certain attributes (that can be used to weigh each point’s contribution) into a single coordinate (average). This tool used pre-existing QGIS processes (‘native:meancoordinates’).
Case Study 1—Uluburun Shipwreck
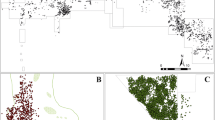
Since the material culture recovered from the Uluburun shipwreck is very diverse, we decided to test the methodology on three distinct artifact typologies: stone anchors, Canaanite jars and oxhide ingots. The vector rendering of the points was based on the maps published in Pulak 1998 and Shih-Han 2003 (see example in Fig. 2a).

a Example of plan published in Pulak (1998, 192) (kindly authorized by the author), b Point layer representation of the Uluburun shipwreck artifacts; KDE plots from the Uluburun shipwreck, weighed by the quantity attribute of: c all artifacts, d stone anchors, e oxhide ingots, f Canaanite jars
The points representing artifacts were configured with the following attributes: Id (artifact identification number), Number (object reference, if any), Type (Canaanite jars, oxhide ingots, or stone anchors), Quantity (all types have a quantity of one), Stone (stone anchor stone type), Apical Hole (stone anchor hole type), Markings (stone anchor number of marks), and Size (Canaanite jar size—small, medium or large). Four hundred and sixty-six points were created and the final result is shown in Fig. 2b.
The first preliminary analysis, using KDE, was performed for all artifacts, weighed with a quantity equal to one. This analysis requires defining a parameter called radius. This parameter determines the circular neighborhood around each point where that point will have an influence. The small size of the wreck (the estimated length of the vessel is 15 m) recommended the use of a reduced radius for these tests, which was set at 1 m (see Fig. 2c).
This first analysis indicates that the three selected typologies of materials were found throughout the whole context, with a large concentration in the central part of the vessel and a less significant one at the stern. We know that the sea floor slopes between 30 and 45 degrees eastwards, with the bow facing downwards. The concentration of artifacts in the center and stern of the vessel, when contrasted with the bow, seems to indicate that the vessel held a greater cargo load at the center and stern, an organization that was not displaced by the sinking and gravity. While the ship had tilted to starboard upon sinking, the artifact distribution seems to have maintained a level of consistency with the original on-board organization.
This hypothesis seems to be confirmed when analyzing the KDE plot of the stone anchors, which, if considered alone, are the heaviest objects (Fig. 2d). The density plot shows a large concentration at the bow and a lower one at the stern. The concentration at the bow extends beyond the location of the greatest density, which matches the slope of the bottom and was probably the result of some anchors having rolled along the seabed. This leads to the question of whether the stone anchors were being transported in two different places aboard.
Finally, Fig. 2e and f show the representation of the remaining artifact types (Oxhide ingots and Canaanite jars). The ingots (Fig. 2e) have a density that covers the entire wreck from stern to bow, although greater in the center of the vessel, where they are concentrated in three north–south lines. The alignment closer to the bow shows a stronger density for only half of the line, with the density extending along the seabed, probably due to the slope. This alignment was probably affected by gravity during the sinking.
The Canaanite jars (Fig. 2f) have a higher density at the stern, decreasing as we move down the seabed. This last observation suggests that the jars were originally transported at the stern and would have rolled some distance along the seabed during and after the vessel’s sinking.
After the preliminary analysis, it was time to test the distribution pattern of the materials, statistically validating the visual interpretation.
The CSR tests show three trends. One is related to objects that show a non-random distribution relative to all r distances, which can be seen in Fig. 3a–c. These three cases indicate that their deposition was not accidental and could have been influenced by how they were transported. In these cases, we should look for possible clusters (see next step).

Ripley’s K function applied to; a all artifacts, b oxhide ingots, c all Canaanite jars, d Stone anchors, e large Canaanite jars, f medium Canaanite jars, g small Canaanite jars
A second trend is related to objects that initially show a tendency towards randomness when smaller r distances are tested, but as the r distance increases, the distribution is no longer random. This is exemplified by the distribution of stone anchors (Fig. 3d). This trend may indicate that we should look for influencing factors on a larger scale. In this case, and not unlike the objects addressed in the previous paragraph, we should look for possible clusters at a larger scale.
Finally, a third trend concerns objects with an apparently random distribution. At Uluburun, this is observable after sorting the Canaanite jars according to their size—large (Fig. 3e), medium (Fig. 3f), and small (Fig. 3g). The small jars maintain a non-random pattern (Fig. 3g), while the large and medium jars, despite having a very wide confidence interval (the gray color in the graph) and a relatively small total sample, clearly demonstrate the trailing of the theoretical line of randomness (dashed red line). These large and medium Canaanite jars were probably ‘spread out’ from the point where they were being transported in the ship. This point can be defined through the ‘average coordinates’, which must be successively corrected due to the slope of the seabed, although we do not have enough information to do it in a definite way. The final result would help to understand the possible location of these objects during the voyage.
Having assessed whether object distribution was random or not, the next step intends to examine, in the case of non-random distribution, how many and which object clusters can be identified.
The DBSCAN algorithm was used for identifying the clusters. This algorithm needs an input variable, the ‘Maximum distance between clustered points’, meaning the maximum allowed distance between points in the cluster. To calculate this distance, a Nearest Neighbor Analysis (NNA) was performed, which, among other results, provided the ‘expected mean difference’ between points. After several iterations and tests, the ‘Maximum distance between clustered points’ was set at the triple value of the ‘expected mean difference.’
In Fig. 4a, two stone anchor clusters (yellow and cyan points) were identified, which statistically confirm the two distinct deposition zones that were already perceptible after combining the KDE plots with the CSR testing. The application of Ripley’s K function for each of the two clusters in Fig. 4a resulted in a random distribution for both. Applying the average coordinates to each of the clusters (see the blue and red points in Fig. 4a, a possible position for the stone anchors during the voyage was identified, which should be slightly corrected by taking into account the slope of the seabed for which, as stated above, we do not have enough information.

a Stone anchor clusters, b small Canaanite jar clusters, c oxhide ingot clusters, d Cluster 2 oxhide ingot sub-clusters
Since the large and medium Canaanite jars showed random distributions in the previous step (Fig. 3e and f), the DBSCAN algorithm was only applied to the small jars (Fig. 4b), which resulted in one cluster (Cluster 1) concentrated at the stern. Successive iterations (NNA and DBSCAN) searching for possible clusters within Cluster 1 were unsuccessful, even though the CSR analysis continued to provide non-random results. The small Canaanite jars were probably transported all together at the stern and the slope of the seabed impacted the distribution resulting in a non-random situation. The average coordinate (red point in Fig. 4b) used to identify their possible stowage location should be corrected due to the slope of the seabed.
Finally, regarding the oxhide ingots the proposed methodology was applied with additional steps. In Fig. 4c, it is possible to observe the identification of three clusters. Subsequently, the previous steps were performed for Clusters 1 and 3 (CSR, NNA Analysis, and DBSCAN algorithm) and the result confirmed the existence of these two clusters without further changes. The weight and shape of the oxhide ingots led to the hypothesis that these two clusters were being transported at the section of the vessel where they were found, with small adjustments due to the slope of the seabed.
However, when the previous methodology was applied to Cluster 2, the results were refined. The DBSCAN algorithm identified the existence of three sub-clusters within Cluster 2 (see Fig. 4d). Applying the methodology followed so far, these three clusters did not change with successive calculations. As described above, the weight and shape of the oxhide ingots suggest they were being transported in the section of the vessel where they were found, always with small adjustments due to the slope of the seabed. This correction should also be applied to the outliers (green points), such as the ones near Cluster 2 (Fig. 4d), which probably were part of that cluster, having lost their former organization due to the slope of the seabed.
We can conclude that the oxhide ingots were probably organized into five different rows—three sequential in the center of the ship and two along with other cargo at the stern.
The final step was answering the question regarding the possibility of any spatial relationship between different artifact types by using correlation tests. If different types of objects are identified as having a high correlation with each other, this would probably mean that these different types of objects were transported in the same areas of the ship, as noted in their deposition at the wreck site. Among the various possible approaches to test correlation, we have chosen to use the rasters produced by the KDE plots.
First, we tested the correlation between all object types (oxhide ingots, stone anchors, and Canaanite jars), and no correlations were identified (Fig. 5a).

a Correlation tests of all objects (oxhide ingots, stone anchors and Canaanite jars) using the Spearman Coefficient. b Correlation tests of the Canaanite jars (large, medium and small) using the Spearman Coefficient. c Canaanite jar (large, medium and small) KDE plots to which the correlation tests were applied
However, when correlation tests were applied to the various typologies of Canaanite jars (Fig. 5b and c), the scenario changed. High correlations were identified between medium and large jars, but also between medium and small jars.
These results indicate that all the jars irrespective of size were probably traveling in the same area of the vessel, with medium-sized jars being transported between the large and small ones. Such a hypothesis was not considered in the previous studies (Shih-Han 2003, p. 191).
Case Study 2—Tortugas Shipwreck
Concerning the Tortugas wreck, the artifact vector layers were produced based on maps published in Stemm et al. (2013) (Fig. 6a). All the points in the figure represent artifacts with the following attributes: ID (artifact identification number), Type (bead, gold bar, silver coins, kitchenware, olive jars, and miscellaneous), Sub-Type (only for kitchenware and miscellaneous objects) and Quantity (equals 1 for all types except beads and silver coins). A total of three hundred and forty-nine points were generated.

a Point layer representation of the Tortugas shipwreck artifacts. b Tortugas shipwreck vector layer showing the silver coins weighed by quantity. c Tortugas shipwreck vector layer showing the beads weighed by quantity
The two object types with a quantity attribute different from ‘one’ (silver coins and beads) had the quantity attribute highlighted to simplify visualization, in this specific case according to size (Fig. 6b and c).
As for the previous case study, the approach chosen for the preliminary visual analysis of the Tortugas wreck were KDE plots. The first KDE plot was performed for all artifacts, weighed by the quantity attribute. Due to the size of the wreck (vessel length—c. 22 m) and the high dispersion (see Fig. 6a) of the artifacts the radius was set at 5 m (see Fig. 7a).

Tortugas shipwreck KDE plots of: a total artifact distribution weighed by quantity, b cannon ball distribution, c olive jar distribution, d bead distribution, weighed by quantity, e gold bar distribution, f silver coin distribution, weighed by quantity, g kitchenware distribution, h tortoiseshell distribution
Looking at the plan in Fig. 7a, it can be immediately seen that there is a concentration of artifacts on the starboard side, closer to the stern. Although with a lower density, the concentration of artifacts is maintained across the stern and port side. In the bow area, there are light clouds denoting the presence of artifacts and these are much less dense than in other areas of the wreck.
The first interpretation considers the tilt of the ship during the depositional process. The high density of artifacts on the starboard side of the vessel seems to indicate that the vessel tilted to starboard, which seems to be confirmed when we apply KDE to specific artifacts. For example, the KDE of the cannon balls is marked only on the starboard side (Fig. 7b), and because they are very heavy cargo, usually loaded in the hold along the central axis of the hull (see green dashed line), this confirms the starboard tilt of the ship.
The other artifacts—olive jars, beads, gold bars, silver coins, kitchenware, and tortoiseshell—have distinct KDE plots that require individual interpretation. The olive jar KDE plot (Fig. 7c) has a density that covers the entire wreck, although more concentrated on the starboard side, which seems to confirm the hypothesis of the vessel’s starboard tilt. The olive jars were supposed to be one of the main containers in the overall cargo, which explains their widespread distribution across the wreck.
The KDE plot for beads (Fig. 7d) has two large zones with higher density—one at the stern, wider and tending more towards starboard, and another more concentrated at the bow and port. Was the cargo therefore divided into two zones on the vessel? This is a question that will be answered below.
The gold bars (Fig. 7e) are highly concentrated at the bow, in the middle of the vessel. The reason why they did not disperse to starboard like many of the other artifacts discussed here is unknown, and a further question to be addressed below.
Silver coins (Fig. 7f) show two very high-density zones with a very low dispersion—one at the stern and another at the bow and port side. Does this suggest that they were transported in two different areas of the vessel?
Finally, we have the kitchenware (Fig. 7g), which is represented by a greater number of artifacts at the stern, with a tendency towards a greater concentration on the starboard side; and another smaller concentration at the bow, also mainly on the starboard side. Was the kitchenware therefore used in two different places on the vessel, as well?
The tortoiseshell does not allow for in-depth analysis and firm conclusions (Fig. 7h) owing to the small sample (six pieces), although it also seems to be concentrated in a single area. Stemm et al. (2013) mentions 64 samples, which are not reflected on the maps. Most likely, each point has an invisible quantity attribute.
The CSR randomness tests, applying Ripley’s K function, show three types of trends at the Tortugas wreck, depending on the object type (Fig. 8a–h).

Ripley’s K function applied: a all objects, b the olive jars, c the beads, d the kitchenware, e the silver coins, f the gold bars, g the tortoiseshell, h the cannon balls
The first trend shows objects with an apparently random distribution, which is only demonstrated by the gold bars (Fig. 8f). Although having a very wide confidence interval and a total sample that is quite small, they clearly fall within the interval, something that becomes even clearer when outliers are eliminated from the CSR test (Fig. 9a).

a Ripley’s K function applied to gold bars (without outliers). b Tortugas shipwreck KDE plot showing the gold bars (with outliers in white)
Figure 9b shows the gold bars without outliers (gold bars in green and outliers in white) and we can see a clear concentration at the stern. These calculations, therefore, lead us to consider that the gold bars were stored in a single container during transportation (a box, for example) that was probably opened or broken after reaching the seabed, possibly scattering its contents randomly. And, since gold is heavy, unless sufficient forces were exerted during the sinking it is unlikely they’d have moved much from their original on-board position. Applying the calculation of the average coordinates (see the yellow point in Fig. 9b) provides an idea of the possible location of that single container or the place on the vessel where such valuables would have been stored.
The second trend identified by CSR tests concerns objects that initially showed a tendency towards random distribution (the beads and silver coins—Fig. 8c and e respectively), when testing smaller r distances, but which, as the r distance increases, show a distribution that is not random. This statistical trend echoes the two situations that had been clearly identified in the previous step as having two possible zones with high point densities. The search for possible clusters will be analyzed in the next step using the DBSCAN algorithm.
Finally, a third trend is related to objects that show non-random distribution for CSR tests regarding all r distances. This is the case for all objects when analyzed together, for the kitchenware, and for the olive jars (Fig. 8a, b, and d). Regarding these three instances, there is no doubt that these objects were grouped in some way. The clustering of objects for this third trend will be examined in more depth in the next step, using the DBSCAN algorithm. It is important to note that the trend towards non-random distribution observed for the tortoiseshell and cannonballs cannot be considered significant due to the very small sample (see Fig. 8g and h); in these cases, the only possible considerations were the ones already made in the initial visual analysis.
The identification of clusters (through the DBSCAN algorithm) was only performed for objects that show non-random distribution for CSR tests regarding all r distances. The maximum distance between points was calculated following the same method as in the previous case study using NNA.
The two kitchenware clusters obtained using the DBSCAN algorithm statistically confirm the existence of two distinct deposition zones (Fig. 10a), something that was ‘previewed’ in the KDE plots and CSR tests. The application of Ripley’s K function in the clusters of Fig. 10a shows a random distribution for Cluster 1 (Fig. 10b), which seems to indicate that its deposition, not unlike the gold bars, happened while the vessel was sinking and dispersing across the seabed. The application of average coordinates (see the blue point in Fig. 10a shows a possible position for kitchenware Cluster 1 slightly to starboard. One plausible interpretation could be the starboard tilt of the vessel at the depositional moment, as already mentioned, or perhaps the location of a galley on the starboard side of the stern. The application of Ripley’s K function to Cluster 2 showed few statistically significant results due to the small sample size.

a Kitchenware clusters, b Ripley’s K function applied to kitchenware Cluster 1 (white points in a)
When exploring the kitchenware sub-types in each of the clusters, we found that the dishes were only in Cluster 1 (stern), while jugs and bowls were concentrated at the bow. Were there really two distinct zones with kitchen wares? Did they have different features? For example, was food eaten at the stern location (denoted by the presence of the dishes) and does the smaller number of artifacts and their typology mean a less formal use at the bow? Or were these two cargos loaded onto different areas of the ship? The data presented in the article do not support more in-depth conclusions.
Application of the DBSCAN algorithm to the olive jars showed different results. The quantity of artifacts and their distribution throughout the shipwreck suggests that the olive jars were one of the main containers of the overall cargo. Would it be possible to identify where they were originally transported? In Fig. 11a and b we can see the result of clustering with and without outliers. The high number of olive jars allowed configuring the use of the DBSCAN algorithm for a minimum number of 15 elements per cluster. The successive application of Ripley’s K function to the various clusters (see Fig. 12a–c) showed a random tendency of the objects in Cluster 1 (white dots in Fig. 11b), a trend at the limit of the confidence interval between randomness and clustering for Cluster 3 objects, red dots in Fig. 11b) and a non-random trend for Cluster 2 objects (salmon dots in Fig. 11b). Using the same logic for the objects of Cluster 2 and applying the DBSCAN algorithm once again, the result was a new division that can be seen in Fig. 13a and in the application of Ripley’s K function to the two new clusters (Fig. 13b and c).

a Olive jar clusters (with outliers), b Olive jar clusters (without outliers)

Ripley’s K function applied to: a olive jar Cluster 1, b olive jar Cluster 2, c olive jar Cluster 3

a Total olive jar clusters (without outliers), b Ripley’s K function applied to Sub-cluster 1 of the initial olive jar Cluster 2, c Ripley’s K function applied to Sub-cluster 2 of the initial olive jar Cluster 2
The new results show a trend towards randomness in the two new clusters, more pronounced in Sub-cluster 2 (blue dots in Fig. 13a) than in Sub-cluster 1 (violet dots in Fig. 13a), which is at the limit of the confidence interval. These four clusters can be interpreted as four possible zones for the location of the olive jars, although it is necessary to underline the importance of knowing the ship’s internal organization to facilitate further interpretation. If that were the case, we would have two areas at each end of the hull—one at the stern and another at the bow, and a large amidships area–, which could have been divided into goods carried on the starboard side and the port side respectively.
The correlation tests performed between all object types resulted in a single positive correlation—between the silver coins and beads (see Fig. 14a and b). As an example, Fig. 14a also shows correlation tests with the olive jars. Silver coins and beads seem to have the same distribution at the site. Were they being transported in the same area? As we have seen already, the two artifact density zones may be interpreted as closer to their places on-board, where they probably were transported. However, irrespective of the interpretation that may or may not be correct, what appears to be clear is that these two types of objects seem to have been impacted by the same depositional and post-depositional processes.

a Correlation tests of three object types (olive jars, silver coins, and gold bars), using the Spearman Coefficient, b KDE plots to which the correlation tests were applied (olive jars, silver coins, and gold bars)
Final Considerations
The methodological model presented in this paper is meant to be a contribution aimed at extracting more information from available underwater archaeological sites, highlighting the importance of context and systematic collection of spatial data. It is a preliminary approach to an underwater statistical analysis and is intended to be an intuitive and easily usable tool, even if it is not a closed model.
The first results presented in this paper allow us to assume that the model works. The preliminary analysis, through the production of Kernel Density Estimation (KDE) plots, allowed us to assess the artifact distribution at the Uluburun and Tortugas sites holistically. If these plots are interpreted by taking into consideration the overall ship organization and the data gathered during excavation, they can contribute to understanding the depositional processes, ship functions, and cargo distribution. They are, however, just a different way of representing the observed distribution. On coherent (or partially coherent) sites, like Uluburun and Tortugas, the KDE plots do not replace interpretation based on the visual analysis of traditional archaeological maps, but do strengthen it.
The other analytical approaches are different. PPA supports the validation of these interpretations through the statistical dimension. This is a fundamental step to understanding the eventual patterns of object distribution in the archaeological context. Accordingly, we are able to gain a deeper understanding of the depositional and post-depositional processes. This step was essential to the ensuing ones in the cluster analysis, by validating or ruling out the distribution documented during the archaeological work. The cluster analysis itself enabled the identification of statistically significant groups of objects, contributing to understanding which objects were grouped together and their overall distribution on the ship.
Finally, in some specific cases the correlation tests allowed the detection of object categories with the same distribution patterns, which might indicate that these objects were stowed together or, at least, that they were affected by similar processes.
In both case studies, the methodology allowed us to confirm or add new information to previous results, thus corroborating its utility.
Concerning Uluburun, it was possible to confirm previous propositions about the on-board organization, regarding the stone anchors and the oxhide ingots—which were stored in a very particular way (Shih-Han 2003; Pulak 2005). However, the methodology allowed us to make a new proposal regarding the Canaanite jars, which was not hypothesized in previous studies (Shih-Han 2003, p. 191).
The Tortugas wreck did not have the same previously in-depth analysis so, besides confirming the starboard tilting of the vessel during the deposition, all the results obtained through the methodology had not been proposed yet. The on-board organization of the olive Jars (the main cargo), the kitchenware, the correlation between the silver coins and the beads (probably stored at two different places, as was the kitchenware), and the location of the gold bars in the vessel are just some examples.
Those results clearly confirm the potential of spatial statistics on underwater sites. The GIS tools combined with statistical tools are a useful means, even for the analysis of coherent archaeological sites, that can be also interpreted through a visual interpretation of the available data. The importance of these methods will probably be even greater in the analysis of scattered sites or partial archaeological excavations. Therefore, it is important to pursue this research path by testing it in other situations, namely in shipwrecks where the interpretations derived solely from visual analysis and knowledge of the culture under study is not as substantial as in the two case studies presented herein. We look forward to seeing the use of other approaches and other statistical tools to complement what we have published here.
However, this work does not intend to replace an archaeologist’s personal analytical capacity. On the contrary, it aims to provide tools and facilitate the archaeologists’ decision making. The proposed sequence of steps is an ordering of fundamental questions for the understanding of depositional and post-depositional processes, but also for the identification and analysis of patterns related to the organization of goods on board. Some research questions may include the following: ‘Was the deposition of the objects random or was it influenced by some factor?’; ‘What kind of clusters can possibly be envisaged?’; ‘Where on the vessel was this material stored or used?’; ‘Are there any objects that, from a statistical point of view, could be traveling in the same part of the vessel and in association?’; ‘Is it possible to deduce the tilt of the vessel during deposition?’. These are some questions for which statistical analyses can help archaeologists in their interpretations and the construction of historical knowledge. Many other questions will naturally arise once the initial answers are obtained. It seems, looking at the two different case studies, that it is possible, with the correct information, to statistically answer these questions.
Unlike in a judicial setting, where one can prepare a sequence of initial questions and after a certain point the subsequent questions will depend on the preceding answers, the archaeologist has the benefit of having time to prepare the successive questions. Nevertheless, there is also a substantial limitation—the collection of data in the field is of fundamental importance. The questions are not necessarily the problem, but rather the detail of data collection, which will dictate the answers we will be able to provide. The positioning of objects, their classification, their contextualization in relation to the site features, the bathymetry of the wreck site, tides, currents, and fishing activities are some of the many factors that can make a difference when collecting and interpreting spatial data. At a time when widespread use of georeferenced photogrammetry makes it possible to easily position any discovered materials, the use of the methods presented herein can also be a powerful analytical tool capable of highlighting the scientific potential of underwater cultural heritage for archaeological knowledge.
Notes
See, for example, the Convention on the Protection of the Underwater Cultural Heritage—https://unesdoc.unesco.org/ark:/48223/pf0000126065
References
Baddeley A (2008) Analysing spatial point patterns in R-2. CSIRO. (https://research.csiro.au/software/wp-content/uploads/sites/6/2015/02/Rspatialcourse_CMIS_PDF-Standard.pdf)
Bass GF (2012) The development of maritime archaeology. In: Ford B, Hamilton DL, Catsambis A (eds) The Oxford handbook of maritime archaeology. Oxford University Press, Oxford
Bass G, Pulak C, Collon D, Weinstein J (1989) The bronze age shipwreck at Ulu Burun: 1986 campaign. Am J Archaeol 93(1):1–29
Bass GF, Matthews S, Steffy JR, Doorninck FHV (2004) Serçe Limanı: an eleventh-century Shipwreck.Volume I: the ship and its anchorage, crew, and passengers. Texas A&M University Press, College Station
Beltrame C, Manfio S (2014) Alcune proposte metodologiche per l’impiego di un GIS intra-site nella documentazione di un relitto: l’applicazione sul brick Mercurio (Punta Tagliamento, Italia). Archeologia e Calcolatori 25:113–129
Bevan A, Crema ER, Xiuzhen JL, Palmisano A (2013) Intensities, interactions, and uncertainties: some new approaches to archaeological distributions. In: Bevan A, Lake M (eds) Computational Approaches to archaeological spaces. Left Coast Press, Walnut Creek, pp 27–52
Bruseth JE, Borgens AA, Jones BM, Ray ED (eds) (2017) La Belle: the archaeology of a seventeenth-century ship of new world colonization. Texas A&M University Press, College Station
Carrer F (2015) Interpreting intra-site spatial patterns in seasonal contexts: an ethnoarchaeological case study from the Western Alps. J Archaeol Method Theory 24:303–327
Carreras C, Aguilera A, Berni P, Garrote E, Marimon P, Morais R, Moros J, Nieto X, Puig A, Ramesal J, Rovira R, Vivar G (2004) Culip VIII y les Àmfores Haltern 70. Girona: CASC [Centre d’Arqueologia Subaquàtica de Catalunya], Museu d’Arqueologia de Catalunya.
Gardiner J (ed) (2005) Before the mast: life and death aboard the Mary Rose. Portsmouth, Mary Rose
Hocker FM, Vlierman K (1996) A small cog, wrecked on the Zuiderzee in the early fifteenth century. Nederlands Instituut voor Scheeps en OnderwaterArcheologie/ROB (NISA), Lelystad
L’Hour M, Veyrat É (2000) Un corsaire sous la mer. Les épaves de la Natière, archéologie sous-marine à Saint-Malo. Campagne de fouille 1999. Édition Adramar, Paris
L’Hour M, Veyrat É (2001) Un corsaire sous la mer. Les épaves de la Natière, archéologie sous-marine à Saint-Malo. Volume 2. Campagne de fouille 2000. Édition Adramar, Paris
L’Hour M, Veyrat É (2002) Un corsaire sous la mer. Les épaves de la Natière, archéologie sous-marine à Saint-Malo. Volume 3. Campagne de fouille 2001. Édition Adramar, Paris
L’Hour, M. and Veyrat, É. (2003). Un corsaire sous la mer. Les épaves de la Natière, archéologie sous-marine à Saint-Malo. Volume 4. Campagne de fouille 2002. Édition Adramar, Paris
L’Hour M, Veyrat É (2004) Un corsaire sous la mer. Les épaves de la Natière, archéologie sous-marine à Saint-Malo. Volume 5. Campagne de fouille 2003. L’épave Natière 1. Bilan intermédiaire. Édition Adramar, Paris
McCarthy J, Benjamin J, Winton T, Van Duivenvoorde W (2019) The rise of 3D in maritime archaeology. Coast Res Libr 31
Muckelroy K (1978) Maritime archaeology. Cambridge University Press, Cambridge
Nicolardi M (2011) Interpreting a coherent post-medieval shipwreck: a qualitative spatial approach supported by GIS. Bull Australas Inst Mar Archaeol 34:9–19
Nieto Prieto FJ (1989) (ed) Excavacions arqueològiques subaquàtiques a Cala Culip. Girona, Museu d'Arqueologia de Catalunya - Centre d'Arqueologia Subaquàtica de Catalunya
Pulak C (1998) The Uluburun shipwreck: an overview. Int J Naut Archaeol 27(3):188–224
Pulak C (2005) Discovering a royal ship from the age of King Tut: Uluburun, Turkey. In: Bass GF (ed) Beneath the Seven Seas. Thames & Hudson Inc., New York, pp 34–47
Rodriguez-Rellan C, Valcarce RF (2015) Arte rupestre galaica: unha achega dende a estatística espacial e os SIX [Galician Rock Art: an approach from Spatial Statistics and GIS]. In: Rodríguez Casal AA, Blanco Chao R (eds) SÉMATA. Sistemas de Información Geográfica, gestión del territorio y conocimiento histórico. Universidade de Santiago de Compostela, vol 27, pp 323–348
Salgueiro CL, Rodriguez-Rellan C, Valcarce RF (2018) Análise microespacial do asentamento prehistórico de Monte dos Remedios (Moaña, Pontevedra): achegas preliminares. Gallaecia Revista De Arqueoloxía Antigüidades 36:73–102
Shih-Han L (2003) Lading of the late bronze age ship at Ulubrurun. Master thesis, Texas A&M University
Stemm G, Gerth E, Flow J, Guerra-Librero CL, Kingsley S (2013) The deep-sea Tortugas shipwreck, Florida: a Spanish-operated Navio of 1622 Tierra Firme Fleet. Part 1, the Site”. In: Stemm G, Kingsley S (eds) Ocean odyssey III chapter: I publisher. Oxbow, pp 1–37
Thacher D, Brooke Milne S, Parka R (2017) Applying GIS and statistical analysis to assess the correlation of human behaviour and ephemeral architectural features among Palaeo-Eskimo sites on Southern Baffin Island, Nunavut. J Archaeol Sci Rep 14:21–30
Theunissen EM, Brinkkemper O, Lauwerier RCGM, Smit BI, van der Jagt IMM (eds) (2014) A mosaic of habitation at Zeewijk (the Netherlands). Late neolithic behavioural variability in a dynamic landscape. Cultural Heritage Agency of the Netherlands, Amersfoort
Verbrugghe G, Saey T, De Clercq W (2020) Lost but revived. Revisiting the medieval village of Nieuw-Roeselare (Flanders) using large-scale frequency domain multi-receiver EMI and landscape archaeological prospection. Archaeol Prospect 27:239–252
Author information
Authors and Affiliations
Contributions
Both authors contributed integrally to the paper
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Santos, J., Bettencourt, J. Spatial Statistical Analysis of Shipwreck Sites: A Methodological Proposal. J Mari Arch 18, 297–319 (2023). https://doi.org/10.1007/s11457-023-09364-5
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11457-023-09364-5