
Abstract
Spatial analysis studies in Palaeolithic archaeology arise as indispensable research tools for understanding archaeopalaeontological sites. In general terms, spatial studies have been specialised in the description of the distribution of materials and in the definition of accumulation areas, with the aim of distinguishing intentional activities or studying postdepositional processes. In recent decades, the development of GIS tools has enabled huge strides forward in the field of spatial archaeology research, such as spatial inferential statistics. These tools are particularly useful in the identification and location of clustering from statistical criteria, facilitating the subsequent analysis of accumulations through other archaeological, taphonomic and spatial techniques, such as fabric analysis or directional distribution. The cluster analysis, and its contextualisation considering all the archaeological and stratigraphical variables, allows the inference of some of the processes and factors that could have taken part in the accumulation of materials, as well as assessing how this affected the composition and preservation of the archaeological assemblage. The present article reviews the more traditional and innovative methods for studying horizontal distribution patterns and the objective definition of clusters, highlighting the parameters, uses and limitations of these techniques. We present an application of these methods to different Palaeolithic sites, going through different scenarios, such as location (open-air vs. cave), context, scale (large vs. small area), excavation methodology and spatial record methods.
Similar content being viewed by others

Introduction
Spatial horizontal studies focussing on defining clusters and distributional patterns are coming to the fore again as helpful tools to interpret archaeopalaeontological assemblages. These methods, combined with a prior characterisation of the site stratigraphy, provide spatial and statistical criteria to identify, characterise and differentiate activity areas and the influence of postdepositional processes in the formation of these distributions. The first spatial studies applied to Palaeolithic archaeology can be traced to interrogating human behaviour through studying the location of the materials found at a site, and the idea that the position of the archaeological materials could reflect a past moment frozen in time (Laplace & Méroc, 1954a, 1954b; Leroi-Gourhan, 1950). This idea evolved and increased the interest in the identification and interpretation of accumulation areas, giving rise to some articles focussing on understanding the spatial arrangement of materials and its possible meaning in human evolution. These publications were accompanied by plans and drawings that helped analysis and interpretation of the spatial disposition of the excavated materials (Baker, 1977; Carandini, 1979, 1981; Harris, 1979; Isaac et al., 1971), a trend that has continued to the present day and has turned out to be a very useful tool for spatial analysis.
Ethnographic analogies were also decisive in spatial archaeology studies, as well as in the interpretation of Palaeolithic sites (Yellen, 1977a, 1977b; Binford, 1978, 1983; O’Connell, 1987, O'Connell et al., 1988, 1990; Enloe et al., 1994). The results obtained in such work have been relevant to refining and tackling the most suitable spatial analyses for getting an approximation to the ways of life of human groups during the Palaeolithic. More recent work has applied spatial statistics and geostatistics in ethnoarchaeology (Lancelotti et al., 2017), revealing these techniques to be powerful tools to get for extracting as much information as possible in ethnoarchaeological contexts (Biagetti et al., 2016; Carrer, 2017; Maximiano, 2012; Negre, 2015), and therefore aiding better comprehension of Palaeolithic activities and their social organisation. The interpretation and analysis of the spatial arrangement of materials and anthropic structures have allowed organisational patterns to be investigated, which may furnish clues about important aspects of social organisation, like the structuration of activities in the occupation space, identifying zones of processing and exploitation of resources (Alperson-Afil et al., 2009; Blasco et al., 2016; Goren-Inbar et al., 2004; Martínez & Rando, 2001; Mora et al., 2020; Sánchez-Romero et al., 2020), as well as domestic or dumping areas (Bourguignon et al., 2002; Vaquero et al., 2004; Vaquero & Pastó, 2001). Additionally, these analyses allow evaluating the impact of other agents on the archaeological record, like the action of carnivores (Arilla et al., 2020; Camarós et al., 2013) or the degree of influence of postdepositional processes (Benito-Calvo & De la Torre, 2011; García-Moreno et al., 2016; Jia et al., 2019; Sánchez-Romero et al., 2016).
The first works focussing on the study of spatial patterns emerged in the 1970s, with mainly visual approaches (Dacey, 1963; Davis, 1975; Hietala & Stevens, 1977; Hodder & Orton, 1976; Whallon, 1973, 1974), and the application of quantitative methods that were more commonly used to analyse spatial patterning in ecology and botany (Clark & Evans, 1954; Thompson, 1958; Kershaw, 1961; Morisita, 1962; Pielou, 1969; inter alia). These first approaches to the identification of spatial distribution patterns were applied in Palaeolithic archaeology through innovative techniques, like nearest neighbour analysis (Dacey, 1963; Whallon, 1974), the analysis of distributional patterns by squares or quadrats (Davis, 1975; Haberman, 1974) or the application of chi-square tests to discriminate accumulation zones (Carbonell et al., 1980). However, density analysis started to be applied in Palaeolithic archaeology from the 1950s (Clark & Evans, 1954; Clarke, 1968; Davis, 1975), but was a manual and laborious process that restricted its application and interpretation. Later, besides density analysis, other studies also related to horizontal distribution of materials and unsupervised classification methods appeared, such as k-means. The first applications of this method in archaeology date to the 1980s, reaching their zenith with the use of k-means, a method widely used for classifying and grouping archaeological assemblages (Kintigh & Ammerman, 1982; Ammerman et al., 1983; Simek & Larick, 1983; Simek, 1984; Vaquero, 1999; Vaquero & Pastó, 2001; Mitchell et al., 2006; inter alia). Although these methods provide a useful and quantitative base, and are therefore reproducible, they are somewhat limited by subjective parameters, like setting up the number of groups in k-means or the search radius and classification in density analysis. Besides, these methods do not give statistical significance values for discriminating discrete areas. Nevertheless, recent years have borne witness to a renewed interest in spatial horizontal patterns in Palaeolithic contexts, which includes more detailed studies of the identification of material clustering and anthropic structures, a point being addressed through the application of Geographic Information Systems (GIS) tools. Current trends in spatial distribution analysis in archaeology incorporate tools that identify main accumulations of materials according to spatial statistical criteria, the so-called hotspots methods (Caruana et al., 2014; De la Torre et al., 2020; Domínguez-Rodrigo & Cobo-Sánchez, 2017a, 2017b; Mora et al., 2020; Sánchez-Romero et al., 2016, 2020; Shipton et al., 2018). These methods identify statistically significant accumulations according to a given quantitative variable and the spatial relationship among data. Thus, it is possible to discriminate concentrations not only by the clustering ratio (distance between items) but also according to the characteristics of the materials, such as length or weight. Discretising horizontal patterns not only provides new criteria for interpreting sites, but also increases the resolution of other spatial techniques through their application to specific accumulations (Sánchez-Romero et al., 2016, 2020).
The present work reviews these different techniques applied up to now in the horizontal identification of distributional patterns of materials, comparing methods and highlighting their limitations in relation to Palaeolithic data directly and indirectly derived from cave and open-air sites. Methodological novelties are also presented in terms of using and combining specific tools for performing a more efficient and solid analysis of horizontal distribution patterns.
Materials and methods
Materials
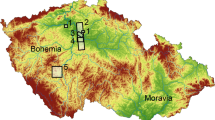
The data employed for this work, which will serve to illustrate the applications, advantages and limitations of each of the different tests and analytical methods, come from the sites of Ambrona, Amalda I and Aranbaltza II (Fig. 1). These three sites are very different in terms of context, scale, chronology and excavation method (Table 1), and turn out to be an excellent case set against which to test the feasibility, limits and advantages of the wide range of tools used to perform a complete spatial analysis. The open-air site of Ambrona was systematically excavated for the first time in the 1960s, with discontinuous excavation projects up to today (Howell, 1963, 1965; Howell et al., 1995; Sánchez-Romero et al., 2016; Santonja et al., 2018). This site was dated to 350 ka BP (AS6) (Falguères et al., 2006) and contains a large number of Palaeoloxodon antiquus bones and Acheulean lithic industry (Units AS1-AS5), as well as Equus remains and Early Middle Palaeolithic lithic industry pieces (Unit AS6) (Pérez-González et al., 2005; Santonja et al., 2005). The excavation methods used at this site have been varied, from plan drawings to data collection with total station. In this way, all the registration methods were tested in order to evaluate their effectiveness and limitations in terms of post-excavation data processing and to perform a complete spatial analysis. Another of the sites is the Amalda I cave, where its Level VII was recently dated between 44.5 and 42.6 ka uncal BP (Marín-Arroyo et al., 2018), and on which the present study is focussed. This site was excavated in the 1980s (Altuna, 1990) using measuring tape and a theodolite as a recording method for larger materials. Thus, we had to combine this XYZ information with that obtained after applying random XY coordinates according to information about the square of provenance and excavation spit (Rios-Garaizar, 2012; Sánchez-Romero et al., 2020). Lastly, the Châtelperronian open-air site of Aranbaltza II has allowed us to work with more advanced recording methods, since this site was excavated between 2013 and 2016 and the materials were recorded exclusively by total station. This site has provided a large amount of lithic materials in a relatively reduced area, where there is no presence of bone remains.

Material dispersion plans of the three sites analysed for this study: a Ambrona, b Amalda I and c Aranbaltza II
Thus, the fact that these three sites are very different has allowed us to compare results considering several constraints, such as different scales, contexts, techniques and excavation methodologies, size and type of materials or data collection methods. This work presents a review of the effectiveness, limitations and possible errors and difficulties that can be found when some methods and analytical tools are applied, as well as the type of results obtained.
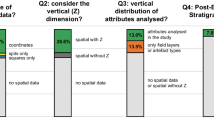
The input data have been classified by categories, according to whether they proceed from direct data collection in the field, or are indirect data from secondary or derived sources:
-
Category 1: Direct data with coordinates collected in the field, either with total station or according to the grid/square. In this case, we have handled data from the sites of Amalda I and Aranbaltza II.
-
Category 2: Data derived from secondary sources, such as photographs or planimetries (Benito-Calvo & De la Torre, 2011; Boschian & Saccà, 2010; De la Torre & Benito-Calvo, 2013; Sánchez-Romero et al., 2016; Walter & Trauth, 2013), or modelling to recover the position of non-coordinated materials (Rios-Garaizar, 2012; Blasco et al., 2016; Sánchez-Romero et al., 2020). By applying these methods, all the entities without spatial references can be located precisely, whether they are from raster (such as drawings or photographs) or discrete information (points, lines or polygons). The data for this category are from Ambrona and also partially from Amalda I and Aranbaltza II. On this point, it is important to remark that most sites combine both categories, since recording all the remains is quite complicated, especially at those sites where there is a high density of small or very small size remains. Thus, these methods that we proceed to describe allow the recovery, incorporation and interpretation of all remains, even those that are usually discarded from this kind of studies due to their size, recording method or because they were recovered during older excavations.
Methods of identification and classification
Defining general distributional patterns
The step preceding the identification of singular clusters should be a definition of horizontal distribution patterns, through evaluation of the general pattern of the assemblage by defining whether the materials are dispersed, clustered or randomly distributed. The type of distribution is measured by the quotient D = variance (S2) / average (m). A random distribution shows a variance higher than the average, where there are no patterns, but this is due to chance and there are no elements that determine the position of the materials. In a clustered distribution, the variance is equal to the average, and here the items are grouped due to a factor that has notionally caused that grouping. In spatial analysis, we study which factors could be responsible for that clustering of materials, since there are several anthropic and postdepositional processes that can produce these patterns. Lastly, in dispersed distributions, the variance is null, showing a uniform distribution of items within the study area. Most of the methods devoted to categorisation of the general pattern are based on the identification of a null hypothesis, but depending on the data in question, different methods and approaches can be applied. In this regard, several methods are available according to the type of data:
-
Applicable methods by quadrats: These methods evaluate the distributional patterns according to the number of points (items) contained in each square and their distribution along the surface (Quadrat Method, Lee & Wong, 2000). The most widely used statistical tests for quadrat sampling are chi-square (Pearson, 1900) and Kolmogorov-Smirnov (K-S) (Daniel, 1990; Conover, 1999; Senger, 2013), which allow us to infer whether the materials are clustered, dispersed or randomly distributed (Krauth, 1993; Lee & Wong, 2000; Sánchez-Romero et al., 2020).
-
Applicable methods based on distance between remains: These methods use the XY coordinates of each item to calculate the distance and relation between them, evaluating their distributional patterns. Among these methods are Average Nearest Neighbour (ANN), Ripley’s K Function (De la Torre et al., 2018; Giusti et al., 2018; Sánchez-Romero et al., 2020; Spagnolo et al., 2019, 2020), General G, Getis-Ord Gi*, Global Moran’s or Anselin Local Moran’s I (Sánchez-Romero et al., 2016, 2020; Shipton et al., 2018).
Regarding the methods that can be applied to points with XY data, these can be divided into global and local methods. The former (Table 2) are useful to evaluate whether the general pattern is dispersed, clustered or random. This is a preliminary step before the application of additional local methods, since it determines whether the general pattern is indeed clustered. General methods identify clustering patterns in relation to a given quantitative variable. However, these analyses do not detect specificities in heterogeneous scenarios. Thus, they do not provide the identification of subzones where there are clustering or dispersion phenomena (Siabato & Guzmán-Manrique, 2019). The evaluation of general associations within the assemblage is the main characteristic that distinguishes global analyses from local ones.
Identifying and defining local clusters
Density analysis is probably the most common method used in spatial archaeology (Sañudo et al., 2012; Sánchez-Romero et al., 2016, 2017; Blasco et al., 2016; Pop et al., 2016; Spagnolo et al., 2016, 2020; Alperson-Afil, 2017; Villaverde et al., 2017; Giusti et al., 2018; Coil et al., 2020; inter alia) since it shows graphically where the entities are more or less concentrated. The use of this kind of map was introduced in the analysis of archaeological data in the 1980s (Carbonell et al., 1980; Hodder & Orton, 1976; Hodder, 1988)—drawn by hand—but it was not until the late 1990s that it experienced an increase in its application. This change could be due to the availability of this method as a tool in GIS, very useful for two-dimensional estimation of density in spatial patterns (Baxter, 2003). One of the most common methods is kernel density estimation (KDE), which differs from normal density estimation in the application of a kernel function to calculate the magnitude per unit area of line or point features. KDE requires an input value corresponding to the search radius that varies depending on the analysed surface and the amount and size of the materials under study, and this parameter determines the detail and accuracy of the density analysis. Graphical density representations provide a continuous map of the materials’ concentrations, which on many occasions need to be segmented or classified to identify and study homogeneous groups. In order to delimit the zones of highest concentration objectively, statistical classifications can be performed. This task can be undertaken using unsupervised classification methods, such as natural breaks classification (Jenks, 1967). This unsupervised method is based on the natural groupings inherent in the data, maximising the differences between classes, without intermediate classifications and establishing the limits where the differences among the data values become more significant (De la Torre & Wehr, 2018; Sánchez-Romero et al., 2016, 2020). A widely used unsupervised method to classify horizontal distributions is k-means, where the characteristics of the classes are initially unknown (Forgy, 1965; Hartigan & Wong, 1979; Kintigh & Ammerman, 1982; Kintigh, 1990; Rios-Garaizar, 2012; Sánchez-Romero et al., 2016). In this method, the classification is automatic, with practically no intervention by the user, forcing the classification of the dataset into a selectable number of groups. The number of classes or groups must be set at the beginning and the results do not furnish statistical significance for the clustering. K-means has been largely applied in the first studies related to the intra-site spatial archaeology (Blankholm, 1991; Kintigh, 1990; Lemke, 2013; Simek, 1984; Vaquero, 1999), providing a fast method to classify the whole assemblage, but lately this is being superseded by other methods. On the other hand, unsupervised classification methods considering training areas and statistical values of classes have not been tested on Palaeolithic maps, as far as we know.
The different methods explained above show limitations in the identification of isolated clusters, mainly derived from a lack of objectivity or statistical criteria to identify and establish the boundaries of the clusters. These limitations can be addressed through different local analyses that have been little applied in spatial archaeology so far. These methods (Table 3) allow the individual identification of levels of clustering, random or dispersion distribution of each variable in relation to the rest of the units through neighbourhood criteria. During recent years, these methods are starting to be applied to confer statistical significance on the cluster mapping (De la Torre et al., 2018, 2020; Giusti et al., 2018; Mora et al., 2020; Sánchez-Romero et al., 2016, 2020; Spagnolo et al., 2019, 2020), with the aim of getting a more objective identification of the clusters in clustered distributions. These techniques can be applied to any quantitative variable, in order to assess different factors that could have boosted the concentration of materials at this point of the site. These methods are mainly represented by the Getis-Ord Gi* and Anselin Local Moran’s I spatial statistical tests (Table 3), which identify statistically significant concentrations from the spatial relationship among individual items, which are defined by a quantitative variable (length, weight or frequency). However, the parameters and limitations controlling hotspots methods have scarcely been tested to date.
Characterising clusters
The identification of clusters opens up a new research avenue into the spatial distribution patterns of Palaeolithic sites. Through the spatial and archaeological study of each of the clusters individually, and their relationship with the rest of the identified clusters, new questions can be addressed from different perspectives in relation to the possible causes of material clustering. The clusters have to be analysed individually in order to know their composition and features, such as raw materials, technology, typology, function, taxa, skeletal parts, cutmarks, toothmarks or digested bones, among others. In addition, information like the shape, length and fabrics of remains (Sneed & Folk, 1958; Schiffer, 1987; Benn, 1994; Bertran & Texier, 1995; Bertran et al. 1997; Dibble et al., 1997; Ringrose & Benn, 1997; Lenoble et al., 2000; Benn & Ringrose, 2001; Bertran & Lenoble, 2002; Lenoble & Bertran, 2004; McPherron, 2005; Jia et al., 2019; De la Torre et al., 2020) comprises very valuable data about the cluster composition (Roy Sunyer et al., 2014; Sánchez-Romero et al., 2020), and on whether there was any selection or reorganisation of materials (Benito-Calvo et al., 2009; Benito-Calvo & De la Torre, 2011; García-Moreno et al., 2016; Sánchez-Romero et al., 2016; Spagnolo et al., 2019).
The cluster definition also allows evaluating the position, shape, size and orientation of the concentrations. These methods have been applied to use-wear characterisation (De la Torre et al., 2013), but they are also appropriate to be performed in spatial analyses, to assess the cluster distribution in relation to the site structure and its local environment (Sánchez-Romero et al., 2020). One of these techniques is the directional distribution, which, through the standard deviational ellipse (Mitchell, 2005), compares the position, size, eccentricity and orientation of clusters (Benito-Calvo et al., 2015; De la Torre et al., 2013; Sánchez-Romero et al., 2020).
Discussion
Application and limits of the methods and their suitability according to the available data
The spatial analysis of Palaeolithic sites allows a vast amount of information to be put together, which needs to be homogenised, classified and spatially correlated. In this work, we aim to review the different analytical methods and go one step further in the identification of clusters, as a way of segmenting horizontal palimpsests, identifying, characterising and interpreting the archaeological accumulations found at Palaeolithic sites.
To this end, we work with spatial databases from different contexts that require a good understanding of the data handled, their origin, limitations and the methodology applied to collect them. Working with data taken directly in the field (or category 1) is preferable, since this provides detailed information about the spatial position of the materials under study (Dibble, 1987; Dibble & McPherron, 1988; McPherron, 2005; McPherron et al., 2005) and confers great versatility upon the analyses. As an example, the work performed at Aranbaltza II, where materials are recorded with total station, offered great precision in tackling spatial analysis of the distributional patterns (Fig. 1). In this particular case, because it is a small area (around 18 m2), the precision in data recording gains even more importance, since the margin is much tighter than for larger sites, such as Ambrona or Amalda I (Fig. 1). To do this, accuracy in bringing all the data together is critical to detecting significant archaeological clusters. As an example, the area of the main clusters in Ambrona varies from 10 to 45 m2 approximately (Sánchez-Romero et al., 2016), while in Amalda they are 1–6 m2 (Sánchez-Romero et al., 2020) and < 1m2 at Aranbaltza II.
However, not all sites present these characteristics in their data, especially for old excavations, when these techniques were not available or not in wide use. In addition, as mentioned above, most sites cannot offer a complete field record with XYZ data for all excavated materials. In these cases, indirect data sources (or category 2) are a good alternative, since they allow a large amount of information (De la Torre & Benito-Calvo, 2013; Sánchez-Romero et al., 2016) to be recovered and give these data a second life, as otherwise they would have been passed over and probably not fully taken into consideration. The Ambrona site, where data from the 1960s to the 1980s excavations were combined with data from the 2000s (Sánchez-Romero et al., 2016), is a good example of recovering information that would have not been used (Fig. 2), since it was unpublished or serving as merely as illustrations (Howell, 1963, 1965).

Plan on paper (a) and materials already georeferenced and integrated with the other elements georeferenced from other plans (b)
The recovery of this type of information implies the application of techniques such as georeferencing of plans (Benito-Calvo & De la Torre, 2011; Sánchez-Romero et al., 2016), which allows combining and scaling maps with the aim of obtaining complete information about the excavated materials and their position, not only individually but also in relation to the site and the remaining materials. This kind of work with preexisting plans allows the spatial analysis of large pieces that were drawn in the field (Boschian & Saccà, 2010; De la Torre & Benito-Calvo, 2013; Sánchez-Romero et al., 2016; Walter & Trauth, 2013). Unfortunately, these maps usually show the larger materials, not lithic pieces, which are smaller and normally represented by points. Spatial distribution analysis in drawings where items are represented by both points and polygons requires special considerations, since the transformation of all geometries to points could produce an underestimation of the distribution pattern at the study scale. Thus, the representation of large pieces with points at bigger scales does not provide the real occupation of the space by that piece, causing subsequent errors when analysing density, clusters or in other spatial analysis.
After working with a large number of spatial datasets, from different methods of data collection and excavation methodologies, we can establish that the most important point is the systematisation of the method, both in the field and the data treatment at the lab. It is essential that the data handling protocol is properly followed and maintained, with the aim of minimising the errors and uncertainties to the extent possible (Martínez-Moreno et al., 2016). Errors are inevitable, but with this systematisation they can be reduced or their accumulation avoided, which is critical, especially in those cases in which the data quality and accuracy are unknown. When the data from older excavations is dealt with, it is important to highlight that a new database is being created combining old data (such as drawings) with new data (such as the coordinate method where the material is being integrated) (Benito-Calvo & De la Torre, 2011; Sánchez-Romero et al., 2016). In this way, a new lease of life can be given to old documents or information, thus providing valuable new information for the interpretation of site formation processes and the activities performed at the site (Fig. 2).
To recover the spatial position of materials only represented by points, especially when the information is incomplete or comes from old excavations (Blasco et al., 2016; Rios-Garaizar, 2012), spatial modelling through random models has proved to be a useful resource. In the case of Amalda I, Rios-Garaizar (2012) modelled the spatial position of the pieces without XYZ data, using their positions in the square and a random distribution model (Rios-Garaizar, 2012; Sánchez-Romero et al., 2020). This XY coordinate assignment was evaluated using the unsupervised k-means method, which allowed the present authors to evaluate whether the same clusters persisted, and this was checked for each modelling performed. Random techniques are also applied to distribute the smallest pieces (e.g. debris) that are not usually coordinated during the excavation process. In the case of Aranbaltza II, random coordinates were generated for the smallest pieces according to the number of pieces and a neighbourhood determined by the collection radius (Blasco et al., 2016; Rios-Garaizar, 2012; Sánchez-Romero et al., 2020) (Fig. 3).

Modelling of pieces without XY information considering the radius where they were collected (a). Distribution resulting from this modelling (b), and together with the rest of the materials with XY information (c and d)
The generation of random coordinates in the Amalda I and Aranbaltza II sites has allowed incorporating information that would otherwise have been relegated to the background, or even excluded from a spatial analysis study. In both cases, we were able to verify that there were no variations of any kind in the number of clusters, their extension or location (Rios-Garaizar, 2012; Sánchez-Romero et al., 2020). The possible variations that could exist in terms of the location of the remains within the radius do not influence the cluster definition at all. However, taking this into consideration, it is important to highlight that if the area were larger and the material collection radius were also larger, the interpretation of the site might be affected. In the latter case, there could be variations in the location of the clusters and their extension, which could affect in some ways interpretation of the factors that could have affected the formation of the site and the accumulation of materials. Thus, and taking the cases of Amalda I and Aranbaltza II as contrasted examples, when a spatial study is undertaken with random coordinates, it is important to keep in mind the following: (1) defining the radius of collection of materials exactly and accurately is essential, and (2) awareness of the area where this method is being applied, since the greater the area and the greater the radius where we apply this random distribution of remains, the greater the error range and, therefore, the lower the precision. Above all, as we previously mentioned, adhering to exhaustive criteria in data collection is key, since the variations that may exist in the method will be added as accumulated errors, affecting the data postprocessing, and therefore rendering spatial study and interpretation of the site even more difficult.
Data preparation determines the accuracy and limitations of the spatial analysis. These techniques were tested on the sites of Ambrona, Amalda I and Aranbaltza II using different databases at different scales, and hence verifying their effectiveness in diverse scenarios (Sánchez-Romero et al., 2016, 2020). In all cases, the distributional general pattern could be inferred through chi-square and Kolmogorov-Smirnov tests (Fig. 4), pinpointing the clustered nature of all assemblages. These procedures allow an approximation to the general distribution pattern of the site, although recently these tests have been applied for predicting archaeological information from unexcavated areas (Domínguez-Rodrigo et al., 2017). Besides, these techniques are also applicable to providing general relationships between materials, such as, for example, the relationship between the raw materials and the type of tools. In this way, these tests are applied not only to learn the distribution type of the materials, but also to evaluate any correlation between them. This last use is the most common in archaeology, in order to reveal the correlation between variables and the statistical significance of the data handled (Simek & Leslie, 1983; Brantingham et al., 2007; Sisk & Shea, 2008; Bernatchez, 2010; Vaquero et al., 2017; De la Torre & Wehr, 2018; De la Torre et al., 2018; Giusti et al., 2018; inter alia). Because these tests, at spatial analysis scale, only indicate the random, clustered or dispersed general pattern of the materials, other analyses are necessary to locate the clusters, and hence to assess them more thoroughly.

Example of Amalda distribution plan and the frequency table elaborated from the number of quadrats, number of points and number of points contained in each quadrat. With these data and table, it is possible to calculate the chi-square and Kolmogorov-Smirnov values, which allow the distribution of the materials to be known
The widespread use of computers and spatial analysis software, such as GIS, permitted density analyses to be broadly applied in archaeology. This technique requires a search radius whose use depends on the data and site extension, determining the accuracy and representativeness of the density results (Fig. 5). In general, the selection of this parameter is not usually tested or assessed, which could affect the interpretation of the results. As an example, at Ambrona, several radii were tested, with a search radius of 2 m being selected due to the dimensions of the analysis area and the size of the materials (Sánchez-Romero et al., 2016). However, for Amalda I, the selected search radius was 0.5 m, while at Aranbaltza II it was 0.30 m (Sánchez-Romero et al., 2020). In these cases, the areas are much smaller than Ambrona, as is the size of the analysed materials, so in consequence the selected radius is smaller than the one chosen for larger areas. In all cases, density results were tested with other statistical methods (such as hotspots), in order to provide a cross-validation of the results and to add statistical criteria to the cluster identification (Fig. 6). Density analyses are applicable to point and line entities, generating a continuous raster distribution, but do not provide any segmentation of the space for separating clusters. This method is usually used to observe the occurrence of materials, although other quantitative variables can also be selected, such as size or weight.

Different search radii applied to the same distribution of materials at Ambrona: 1 m (a), 4 m (b) and 2 m (c)

Comparison between different methods of classification and identification of clusters at Ambrona: a hotspots (Getis-Ord Gi*) by points, b hotspots (Getis-Ord Gi*) by quadrats, c K-means and d Kernel density analysis
In this sense, this method has been recently combined with other unsupervised classification methods, such as the Jenks method (Sánchez-Romero et al., 2016, 2020). For Ambrona, the identification and comparison of large accumulations of materials were performed using these techniques, highlighting the clusters of faunal remains (Sánchez-Romero et al., 2016), which were also cross-validated with hotspot methods (Fig. 6). The identification of these clusters and their individual study, together with their correlation with the stratigraphic units, facilitated the identification of processes related to different sedimentological areas in a wetland environment. In Amalda, the unsupervised classification method of k-means allowed the verification of clustering patterns through modelling the spatial distribution of random points (Rios-Garaizar, 2012). However, this method has several limitations that can skew the identification of clusters if the analysis is solely founded upon it. The classification of k-means is mainly based on the number of groups, chosen previously by the user, and normally selected without objective criteria. Besides, the classification is forced, not supported by the criteria of significance, something that also is not detected by this method. Through the application of k-means, we cannot obtain statistical significance for the clustering, but rather the grouping of materials according to their proximity, and the number of groups will vary with the number determined by the user. The step preceding the classification of point distributions should be an objective definition of the number of groups, either through a previous plot with sum-of-squares errors that helps the number of clusters to be understood (Kintigh & Ammerman, 1982), or through the Ward hierarchical classification, which enables appraising the number of groups into which the distribution seems to be organised. In general, unsupervised methods ease the identification of uncertain clustering areas, especially by means of the limits established between groups. We tested some of these methods in the studied cases, like Ambrona (Fig. 6) or Aranbaltza II (Fig. 7), good examples of very different open-air sites.

Comparison between some of the same methods used in Ambrona but in the smaller area of Aranbaltza II: a Kernel density analysis and b K-means
More recently, these studies are being complemented with techniques that enable more thorough investigations into material distribution patterns, providing data reinforced by statistical significance. These methods are proving themselves very useful for estimating distributional patterns, but they are also applied as complementary tests to verify the results obtained by previous analyses. De la Torre and Wehr (2018) used them to discover the artifact density and clustering pattern using this function as a complementary analysis to ANN analysis, while Giusti et al. (2018) also used ANN to estimate the cumulative distribution, with Ripley’s K function as a correction to reduce the edge effect bias. However, Spagnolo et al. (2019) applied Ripley’s K function to verify the variations of clustering or dispersion rate, pinpointing the sensitivity of this method to study-area variations. This having said, other global methods, like General G or Global Moran’s I, have barely been used in comparison with the application of others, like Ripley’s K function, for example. In the case of Amalda I, we applied different global methods, such as ANN, Global Moran’s I, incremental spatial autocorrelation and the Ripley’s K function (Sánchez-Romero et al., 2020) to evaluate the clustering nature of the distribution pattern and its characteristics, like the statistically significant clustering or dispersion according to the distance range or the distance where the maximum clustering of materials was found.
However, global methods cannot identify the position, extent and statistical significance of the clusters. Nevertheless, such characteristics are provided by local methods, which identify the clusters and their statistical significance in the context of the whole assemblage. The first work using these methods in Palaeolithic archaeology applied them to use-wear analysis of lithic tools (Caruana et al., 2014) and intra-site spatial analysis (Sánchez-Romero et al., 2016), revealing their effectiveness at detecting statistically significant clusters of high and low values (De la Torre et al., 2020; Domínguez-Rodrigo & Cobo-Sánchez, 2017a, 2017b; Mora et al., 2020; Sánchez-Romero et al., 2016; Shipton et al., 2018). The application of these methods to the analysis of distributional patterns in Ambrona defined the main accumulation areas (Sánchez-Romero et al., 2016), both at individual level and by squares. These tools were also applied in Amalda I to assess the spatial organisation of the activities and the use of space by Neanderthals, as well as the accumulations caused by carnivores in inner and more protected zones (Sánchez-Romero et al., 2020). In this case, this method allowed testing the number of elements per square according to different variables (burnt remains, cutmarks, toothmarks, etc.), which yielded complete information about the distribution and clustering patterns of Amalda I with variables that are not themselves quantitative. These techniques produce a valuable picture and assessment of clustering, but they are controlled by several parameters which have been little tested so far. Hotspots are mainly controlled by the quantitative variable and the spatial relationship employed to perform the analysis. Thus, data characteristics and the area of the site are essential features for selecting the spatial relationships (fixed, inverse and inverse squared), since the results vary with these. We can verify the importance of the spatial relationships and the differences between the obtained results (Sánchez-Romero et al., 2020) (Fig. 8), highlighting the suitability of one spatial relationship or another according to the data in question. All these spatial relationships were tested, in order to evaluate the suitability of each according to the data. The application of Getis-Ord Gi* and Anselin Local Moran’s I to Amalda I was conducted using the length of the lithic pieces and faunal remains. The fixed relationship enabled a solid definition of clusters, while the inverse and inverse squared distance relationships only detected some scattered points.

Application of Getis-Ord Gi* to lithic materials of Amalda II by length, and comparison between the different spatial relationships: a fixed, b inverse and c inverse squared. Same comparison but considering the number of remains per quadrat: d fixed, e inverse and f inverse squared
In the case of Aranbaltza II, this method was applied according to the length of the lithic pieces and some clusters composed of few materials were detected, both high and low values (Fig. 9). Although the distribution of the assemblage is clearly clustered, the clusters detected were dispersed and composed of just a few elements, which provide no clear evidence for explaining the site formation processes. This happens because the tool detects the clustering of high or low values (in this case, length), but if there are no such clusters, the distribution turns out to be “not significant” in terms of statistically significant clustering. This happens for all the spatial relationships applied to the Aranbaltza II assemblage. However, as we noted in the rest of the cases analysed, the fixed relationship usually provides well-defined clusters, which is due to the fact that the distance band employed by this relation ensures that each element has at least one neighbour. In the inverse and inverse squared distances, all elements influence all others, but the further away they are, the smaller the impact. Apart from this, the weight of the distance bands is critical, as the definition of a correct distance will determine the influence of neighbours, and hence the results obtained. In the cases analysed, we observed that the extent of the study area influences the application of one spatial relationship or another, and therefore the interpretation, which enables the processes that took part in the formation of the site to be inferred, is also affected.

Samples of application of FDR in Getis-Ord Gi* analyses according to the length of lithic materials (a, b) and to the number of remains per quadrat (c, d) in Aranbaltza II
Additionally, it is important to consider the application of the FDR correction, which adjusts the statistical significance by reducing the error thresholds of p-values. This yields more solid detection of the statistically significant clusters but can also eliminate or reduce relevant values for the study, and hence bias the results (Fig. 9). The single use of the FDR correction should be applied cautiously and always as a complement to other analyses, since it may lead to the loss of relevant information. The functioning of this parameter was tested in Amalda I and Aranbaltza II, and we were able to verify that the results of this correction are conditioned by the type of distribution and number of elements, as well as the size of the analysed area. For Amalda I and Aranbaltza II, where the studied areas are smaller and more enclosed, its application simplifies the results excessively. In the case of Amalda I, the application of FDR reduced the statistical significance of the clusters when the fixed spatial relationship was applied, making delimitation of the clusters more difficult. However, in this case, this correction did not entail a great change with respect to not applying it (Sánchez-Romero et al., 2020). On the contrary, at Aranbaltza II, the FDR correction eliminates the high-significance spots of high and low values (Fig. 9a, b), blocking any identification and definition of clusters. In the case of its application to the frequency by squares (Fig. 9c, d), FDR reduces the extent of hotspot clusters and eliminates the coldspot ones. The FDR correction indicates which clusters are more robust according to their statistical significance, but the results should not be relied on alone for the final identification of the most significant clusters.
Regarding the application of local methods, Anselin Local Moran’s I and Getis-Ord Gi* are the most common ones. The main difference between them is that Anselin Local Moran’s I detects atypical values, while Getis-Ord Gi* allows the clustering degree (statistical significance) of low and high values to be known, excluding the analysis of atypical values (Getis & Ord, 1992; Ord & Getis, 1995; Anselin, 1995, 2019; Siabato & Guzmán-Manrique, 2019). In the case of spatial studies in archaeology, we have tested both methods in the identification and definition of clusters, verifying the advantages and disadvantages of each (Fig. 10). In these two examples (Fig. 10), both methods recognise the same clusters, identifying accumulations of low and high values. However, for spatial analysis in archaeology, knowing the statistical significance of the clusters proves a more useful resource than the presence or absence of atypical values, since it enables the clusters of materials to be delimited more accurately. A good example is observed with Aranbaltza II (Fig. 10c, d), where if only the clusters detected by Anselin Local Moran’s I are considered, numerous small concentrations of materials would be classified as statistically significant, although they are composed of just a few pieces. In reality, though, these clusters do not provide information that helps elucidate the formation processes or the presence of, for example, certain activity areas, since these concentrations are formed only of a few elements and, in most of the cases, are of low statistical significance. At this point, and as we have been indicating throughout this work, it is important to highlight that these methods should be supported by other analyses and we should not base all the spatial analysis results only on statistical data. It is necessary to evaluate to what extent these clusters made up of just a few pieces are decisive, since these pieces could be important to shedding light on the performance of a specific activity.

Comparison between the results obtained applying Getis-Ord Gi* in Amalda I (a) and Aranbaltza II (c), and Anselin Local Moran’s I (b, d) according to the length of the lithic materials.
Getis-Ord Gi* is the most widely used method (Sánchez-Romero et al., 2016, 2020; De la Torre et al., 2018, 2020; Spagnolo et al., 2019, 2020; Mora et al., 2020; Giusti et al., 2018; inter alia). In spatial archaeology, we mainly work on analysing the distribution of materials in relatively small and limited areas (in comparison with other surfaces, such as those dealt with by geography or ecology), trying to understand the relationships of the different elements that make up the site as a whole, not only considering lithic and bone assemblages, but also structures (like hearths) or natural elements (like large blocks), and the space itself, such as cave walls. Therefore, the evaluation of the distribution patterns and the clustering degree of the analysed variable provided by Getis-Ord Gi* acquires greater relevance for interpretations at the work scale and the studied distributions. However, when the analysis is performed at smaller scales and where great detail is required for knowing the clustering and distributional patterns of values, Anselin Local Moran’s I enables the variation among values and the possible existence of atypical values in relatively homogeneous distributions to be observed. Regarding spatial analysis in Palaeolithic archaeology, the same clusters are identified by both methods, although the concentration degree and its statistical significance become more useful in terms of identifying and pinpointing clusters of high and low values, rather than the presence or not of atypical values.
Thus, the combination of data and analytical methods is key to defining clusters or accumulations robustly, beyond mere visual identification. As we have previously seen, the methods and techniques for the identification analysis of clusters are numerous, so their use and combination prove to be a good method for correct identification of the main concentrations of materials. In the case of hotspots, although they are a useful and powerful tool, it is important to underline that these methods are also determined by parameters whose selection should be based on previous analysis and supported by other kind of identification methods. In order to achieve a solid identification of clusters, the combination of techniques and disciplines shows itself to be the best method, since this entails a more complete understanding of the site spatial distribution.
From clusters to the interpretation of site formation processes and human activity patterns
The cluster definition is the basic first step that allows the analysis of the processes that caused them to accumulate, as well as evaluation and understanding of the distributional patterns detected at Palaeolithic sites. From the spatial analysis point of view, several techniques are currently applied to explain the existence and location of clusters. Indeed, studies such as palaeogeographic reconstructions (Oliver, 1990) can turn out decisive for estimating the possible causes of material accumulations and their location, since the same process that modelled the palaeosurface could also be responsible for the material distribution. The possibility of gaining an approximate idea of the context in which materials were deposited is important, since it will allow carrying out a more exhaustive study evaluating other kinds of elements that could have been also involved in the accumulation process. Although intra-site palaeogeographic reconstructions are starting to be seen in the last few years (De la Torre & Wehr, 2018; Giusti et al., 2018; Bargalló et al., 2020; Sánchez-Romero et al., 2020), they are still scarce, since in many cases there is not enough information to infer the palaeosurfaces on which the excavated materials were deposited. At Amalda I, the palaeogeographic reconstruction made it possible to observe that the main accumulations were independent of the palaeotopography of the level, and the lithic and faunal remains clusters were located in regular areas with a gentle slope (Sánchez-Romero et al., 2020).
When it comes to characterising the identified clusters, there are some widely used spatial techniques that enable the processes that could have affected the materials contained in each to be evaluated, such as analyses of orientation, slope and 3D-fabric (Benn, 1994; Bertran & Lenoble, 2002; Lenoble & Bertran, 2004; McPherron, 2005, 2018; Benito-Calvo & De la Torre, 2011; Benito-Calvo et al., 2009; García-Moreno et al., 2016; Sánchez-Romero et al., 2016; Spagnolo et al., 2020; inter alia). The isolation of the main clusters and their analysis permits the clustering features to be detailed, and therefore zooming in on the possible processes that could generate these accumulations. The characterisation of the main clusters at Ambrona made it possible to establish the correlation between the georeferenced materials and their stratigraphic attribution, even when data about the units were not available in the plans (Sánchez-Romero et al., 2016). In this case, the data extracted from the identified clusters were orientation and size patterns, which were cross-referenced with the information obtained from stratigraphic studies of each Ambrona unit. There are other examples, similar to Ambrona, such as Neumark Nord (García-Moreno et al., 2016), where these techniques have also been also applied to understand formation processes.
The directional patterns allow testing whether the clusters are conditioned by the space where they are located, such as cave walls or the limits of an open-air excavation, or if they are independent of this type of factor. If the clusters are distributed according to the limits of the site, it is possible that this accumulation could have been constrained at the moment of the deposition of the materials, the geometry and the walls of the cave being the conditioning factors for the direction of the flow. In the case of Amalda I, the identified clusters showed independent patterns, different from the pattern identified for the whole assemblage. Thus, through the application of the directional distribution method, together with the other analyses performed, it was inferred that the accumulation patterns of the main clusters did not seem to reflect natural accumulation processes (Sánchez-Romero et al., 2020). However, other factors should be considered that might not be dependent on the limits of the site, such as random accumulations distributed according to the needs or activities at that time. Certain activities can generate accumulations that are also somewhat constrained, especially if the intention is to concentrate the materials at specific points of the site (dumping areas) or to use the site’s own structural elements, such as boulders or cave walls, for certain activities (Leroi-Gourhan & Brézillon, 1972; Martínez & Rando, 2001; Meignen, 1994; Sañudo et al., 2012; Vaquero et al., 2015; Vaquero, Chacón, Cuartero, et al., 2012a; Vaquero, Chacón, García-Antón, et al., 2012b). Thus, directional distribution ellipses can be helpful for offering deeper understanding of the accumulation dynamics and spatial relationship in the context of the whole site, not just in terms of spatial location but also regarding the site boundaries.
Throughout this article, different analytical methods for the detection of clusters and their subsequent interpretation have been mentioned, showing the strengths and weaknesses of each. To do this, we presented different sites, from a large open-air site to a small cave, with different data, excavation and data collection methods. As has been seen, the effectiveness of the methods mostly depends on the data employed and the question to be answered. Additionally, and as was mentioned above, the use of these methods in isolation will not enable inference of what happened on the site, since other disciplines are necessary for interpreting the results. Methods such as Getis-Ord Gi* and Anselin Local Moran’s I allow significant accumulations of materials according to quantitative variables over the whole site to be detected, but the relevance of these accumulations needs to be explained from an archaeological and stratigraphic point of view. This means it is necessary to evaluate whether, considering the number of remains, composition, context and extension of the site, these accumulations are really significant, or not, like in the case of those detected at Aranbaltza II. On the other hand, palaeotopographic reconstructions of the study levels where the spatial analysis is being performed may be essential to understanding the presence of certain accumulations and characteristics of the materials, such as orientation and/or slope patterns. This is a very useful resource for all types of sites, but its use depends on the availability of the data and how the data collection was compiled. The incorporation of data from old excavations, their amalgamation with new data and the subsequent spatial analysis depend on (1) whether such data are available and (2) the type of information about them to hand. Therefore, and trying to answer the question of which methods work better for one or another site, or which are more suitable for different types of sites, we cannot give a definitive response since it all depends on the data employed and available, and the question the researcher wants to answer.
Conclusions
This work is intended to offer an overview of the most widespread methods for identifying horizontal distribution patterns, and the tools that have emerged in recent years. It establishes that there is not just one tool valid for cluster detection, identification and analysis, but rather the combination of several analytical methods, thorough control over the data and exchanging data with other disciplines are key to conducting a complete study of the distributional patterns in Palaeolithic spatial archaeology.
The application of all the methods described here to data from different origins (plans, total station, random modelling) and sites (context, area, chronology, materials) has allowed us to test the spatial analysis method on a wide range of possibilities. The results, both at individual level and when compared mutually, have brought out the advantages and limitations of each of the methods, and how these limitations can be overcome by combination and application of other analytical techniques and methods. Thus, the detection of clusters using hotspots may provide objectivity and accuracy, helping to infer the possible processes responsible for these accumulations. However, this method is also dependent on testing and on existing detailed knowledge of the site and the materials composing the assemblage.
Cluster identification is a key step in segmenting horizontal accumulations and analysing their formation, so the application of different and varied methods and techniques acquires even greater importance. This approach offers the opportunity of testing the agency of these concentrations of material to rule out naturally driven processes, as a mandatory procedure prior to interpreting a given spatial distribution in terms of human activity. This article has demonstrated that practically all the available data can be useful for spatial studies, bringing order and putting everything together for deeper investigation of what happened at the site.
References
Alperson-Afil, N. (2017). Spatial analysis of fire: archaeological approach to recognizing early fire. Current Anthropology, 58(suppl. 16), 258–266.
Alperson-Afil, N., Sharon, G., Kislev, M., Melamed, Y., Zohar, I., Ashkenazi, R., Biton, R., Werker, E., Hartman, G., Feibel, C., & Goren-Inbar, N. (2009). Spatial organization of hominin activities at Gesher Benot Ya'aqov, Israel. Science, 326(5960), 1677–1680.
Altuna, J. (Ed.) (1990). La cueva de Amalda (Zestoa, País Vasco). Ocupaciones paleolíticas y postpaleolíticas. Monografía. Colección Barandiarán 4.
Ammerman, A., Kintigh, K., & Simek, J. (1983). Recent developments in the application of the k-means approach to spatial analysis. IV International Flint Symposium.
Anselin, L. (1995). Local Indicators of Spatial Association – LISA. Geographical Analysis, 27(2), 93–115. https://doi.org/10.1111/j.1538-4632.1995.tb00338.x.
Anselin, L. (2019). A local indicator of multivariate spatial association: extending Geary’s c. Geographical Analysis., 51(2), 133–150. https://doi.org/10.1111/gean.12164.
Arilla, M., Rosell, J., & Blasco, R. (2020). A neo-taphonomic approach to human campsites modified by carnivores. Scientific Reports, 10(1), 6659. https://doi.org/10.1038/s41598-020-63431-8.
Baker, P. (1977). Techniques of archaeological excavation. Batsford.
Bargalló, A., Gabucio, M. J., Gómez de Soler, B., Chacón, M. G., & Vaquero, M. (2020). A snapshot of a short occupation in the Abric Romaní rock shelter: Archaeo-level Oa. In J. Cascalheira & A. Picin (Eds.), Short-term occupation in Paleolithic Archaeology. Definition and interpretation (pp. 217–235). Springer.
Baxter, M. J. (2003). Statistics in archaeology. Arnold.
Benito-Calvo, A., & De la Torre, I. (2011). Analysis of orientation patterns in Olduvai Bed I assemblages using GIS techniques: implications for site formation processes. Journal of Human Evolution, 61(1), 50–60.
Benito-Calvo, A., Martínez-Moreno, J., Jordá Pardo, J. F., De la Torre, I., & Mora Torcal, R. (2009). Sedimentological and archaeological fabrics in Palaeolithic levels of the South-Eastern Pyrenees: Cova Gran and Roca dels Bous sites (Lleida, Spain). Journal of Archaeological Science, 36(11), 2566–2577.
Benito-Calvo, A., Carvalho, S., Arroyo, A., Matsuzawa, T., & De la Torre, I. (2015). First GIS analysis of modern stone tools used by wild Chimpanzees (Pan troglodytes verus) in Bossou, Guinea, West Africa. PLoS ONE, 10(3), e0121613. https://doi.org/10.1371/journal.pone.0121613.
Benn, D. I. (1994). Fabric shape and the interpretation of sedimentary data. Journal of Sedimentary Research A64, 4, 910–915.
Benn, D. I., & Ringrose, T. J. (2001). Random variation of fabric eigenvalues: implications for the use of a-axis fabric data to differentiate till facies. Earth Surface Processes and Landforms, 26(3), 295–306.
Bernatchez, J. A. (2010). Taphonomic implications of orientations of plotted finds from Pinnacle Point 13B (Mossel Bay, Western Cape Province, South Africa). Journal of Human Evolution, 59(3-4), 274–288.
Bertran, P., & Lenoble, A. (2002). Fabriques des niveaux archeologiques: methode et premier bilan des apports a l’etude taphonomique des sites paleolithiques. Paleo, 14, 13–28.
Bertran, P., & Texier, J. P. (1995). Fabric analysis: application to Paleolithic sites. Journal of Archaeological Science, 22(4), 521–535.
Bertran, P., Hétu, B., Texier, J. P., & Steijn, H. (1997). Fabric characteristics of subaerial slope deposits. Sedimentology, 44(1), 1–16.
Biagetti, S., Alcaina-Mateos, J., & Crema, E. (2016). A matter of ephemerality. The study of Kel Tadrart Tuareg (SW Libya) campsites via quantitative spatial analysis. Ecology and Society, 21(1), 42. https://doi.org/10.5751/ES-08202-210142.
Binford, L. R. (1978). Nunamiut ethnoarchaeology. Academic Press.
Binford, L. R. (1983). In Pursuit of the Past. Decoding the Archaeological Record. Thames and Hudson.
Blankholm, H. P. (1991). Intrasite spatial analysis in theory and practice. Aarhus University Press.
Blasco, R., Rosell, J., Sañudo, P., Gopher, A., & Barkai, R. (2016). What happens around a fire: faunal processing sequences and spatial distribution at Qesem Cave (300 ka), Israel. Quaternary International, 398, 190–209.
Boschian, G., & Saccà, D. (2010). Ambiguities in human and elephant interactions? Stories of bones, sand and water from Castel di Guido (Italy). Quaternary International, 214(1-2), 3–16.
Bourguignon, L., Sellami, F., Deloze, V., Sellier-Segard, N., Beyries, S., & Emery- Barbier, A. (2002). L’habitat moustérien de La Folie (Poitiers, Vienne): Synthèse des premiers résultats. Paléo, 14, 29–48.
Brantingham, P. J., Surovell, T. A., & Waguespack, N. M. (2007). Modeling post- depositional mixing of archaeological deposits. Journal of Anthropological Archaeology, 26(4), 517–540.
Camarós, E., Cueto, M., Teira, L. C., Tapia, J., Cubas, M., Blasco, R., Rosell, J., & Rivals, F. (2013). Large carnivores as taphonomic agents of space modification: an experimental approach with archaeological implications. Journal of Archaeological Science, 30, 1361–1368.
Carandini, A. (1979). Archeologia a cultura materiale. De Donato.
Carandini, A. (1981). Storie dalla terra. Manuale dello scavo archeologico.
Carbonell, E., Mora, R., & Canal, J. (1980). Sota Palou: un campament estacional-climàtic de caçadors prehistòrics. IV Col·loqui internacional d’arqueologia de Puigcerdà. Estat actual de la recerca arqueològica a l’istme pirinenc. Institut d’Estudis Ceretans.
Carrer, F. (2017). Interpreting intra-site spatial patterns in seasonal contexts: an ethnoarchaeological case study from the Western Alps. Journal of Archaeological Method and Theory, 24(2), 303–327. https://doi.org/10.1007/s10816-015-9268-5.
Caruana, M. V., Carvalho, S., Braun, D. R., Presnyakova, D., Haslam, M., Archer, W., Bobe, R., & Harris, J. W. K. (2014). Quantifying traces of tool use: a novel morphometric analysis of damage patterns on percussive tools. PLoS ONE, 9(11), e113856. https://doi.org/10.1371/journal.pone.0113856.
Clark, P. J., & Evans, F. C. (1954). Distance to Nearest Neighbor as a measure of spatial relationships in populations. Ecology, 35(4), 445–453.
Clarke, D. L. (1968). Analytical archaeology. London
Coil, R., Tappen, M., Ferring, R., Bukhsianidze, M., Noriadze, M., & Lordkipanidze, D. (2020). Spatial patterning of the archaeological and paleontological assemblage of Dmanisi, Georgia: an analysis of site formation and carnivore-hominin interaction in Block 2. Journal of Human Evolution, 143, 102773. https://doi.org/10.1016/j.jhevol.2020.102773.
Conover, W. J. (1999). Practical Nonparametric Statistics, 3rd edition. New York: John Wiley & Sons, Inc
Dacey, M. F. (1963). Order neighbor statistics for a class of random patterns in multidimensional space. Annals of the Association of American Geographers, 53(4), 505–515.
Daniel, W. W. (1990). Applied nonparametric statistics, 2nd edition. Duxbury Classic Series
Davis, D. D. (1975). Spatial organization and subsistence technology of Lower and Middle Pleistocene hominid sites at Olduvai Gorge, Tanzania. Yale University.
De la Torre, I., & Benito-Calvo, A. (2013). Application of GIS methods to retrieve orientation patterns from imagery: a case study from Beds I and II, Olduvai Gorge (Tanzania). Journal of Archaeological Science, 40, 1–12.
De la Torre, I., & Wehr, K. (2018). Site formation processes of the early Acheulean assemblage at EF-HR (Olduvai Gorge, Tanzania). Journal of Human Evolution, 120, 298–328.
De la Torre, I., Benito-Calvo, A., Arroyo, A., Zupancich, A., & Proffitt, T. (2013). Experimental protocols for the study of battered stone anvils from Olduvai Gorge (Tanzania). Journal of Archaeological Science, 40(1), 313–332.
De la Torre, I., Albert, R. M., Arroyo, A., Macphail, R., McHenry, L. J., Mora, R., Njau, J. K., Pante, M. C., Rivera-Rondón, C. A., Rodríguez-Cintas, Á., Stanistreet, I. G., Stollhofen, H., & Wehr, K. (2018). New excavations at the HWK EE site: archaeology, paleoenvironment and site formation processes during late Oldowan times at Olduvai Gorge, Tanzania. Journal of Human Evolution, 120, 140–202.
De la Torre, I., Benito-Calvo, A., Martín-Ramos, C., McHenry, L. J., Mora, R., Njau, J. K., Pante, M. C., Stanistreet, I. G., & Stollhofen, H. (2020). New excavations in the MNK Skull site, and the last appearance of the Oldowan and Homo habilis at Olduvai Gorge. Journal of Anthropological Archaeology.
Dibble, H. L. (1987). Measurement of artifact provenience with an electronic theodolite. Journal of Field Archaeology, 14, 249–254.
Dibble, H. L., & McPherron, S. P. (1988). On the computerization of archaeological projects. Journal of Field Archaeology, 15(4), 431–440.
Dibble, H. L., Chase, P. G., McPherron, S. P., & Tuffreau, A. (1997). Testing the reality of a “living floor” with archaeological data. American Antiquity, 62(4), 629–651.
Domínguez-Rodrigo, M., & Cobo-Sánchez, L. (2017a). A spatial analysis of stone tools and fossil bones at FLK Zinj 22 and PTK I (Bed I, Olduvai Gorge, Tanzania) and its bearing on the social organization of early humans. Palaeogeography, Palaeoclimatology, Palaeoecology, 488, 21–34.
Domínguez-Rodrigo, M., & Cobo-Sánchez, L. (2017b). The spatial patterning of the social organization of modern foraging Homo sapiens: a methodological approach for understanding social organization in prehistoric foragers. Palaeogeography, Palaeoclimatology, Palaeoecology, 488, 113–125.
Domínguez-Rodrigo, M., Cobo-Sánchez, L., Uribelarrea, D., Arriaza, M. C., Yravedra, J., Gidna, A., Organista, E., Sistiaga, A., Martín-Perea, D., Baquedano, E., Aramendi, J., & Mabulla, A. (2017). Spatial simulation and modelling of the early Pleistocene site of DS (Bed I, Olduvai Gorge, Tanzania): a powerful tool for predicting potential archaeological information from unexcavated areas. Boreas, 46(4), 805–815. https://doi.org/10.1111/bor.12252.
Enloe, J. G., Francine, D., & Hare, T. S. (1994). Patterns of fauna processing at Section 27 of Pincevent: the use of spatial analysis and ethnoarchaeological data in the interpretation of archaeological site structure. Journal of Anthropological Archaeology, 13(2), 105–124.
Falguères, C., Bahain, J.-J., Pérez-González, A., Mercier, N., Santonja, M., & Dolo, J.- M. (2006). The Lower Acheulian site of Ambrona, Soria (Spain): ages derived from a combined ESR/U-series model. Journal of Archaeological Science, 33(2), 149–157.
Forgy, E. W. (1965). Cluster analysis of multivariate data: efficiency vs interpretability of classifications. Biometrics, 21, 768–769.
García-Moreno, A., Smith, G. M., Kindler, L., Pop, E., Roebroeks, W., & Gaudzinski- Windheuser, S. & Klinkenberg, V. (2016). Evaluating the incidence of hydrological processes during site formation through orientation analysis. A case study of the Middle Palaeolithic Lakeland site of Neumark-Nord 2 (Germany). Journal of Archaeological Science: Reports, 6, 82–93.
Getis, A. (1964). Temporal land-use pattern analysis with the use of Nearest Neighbor and Quadrat Methods. Annals of the Association of American Geographers, 54(3), 391–399.
Getis, A., & Ord, J. K. (1992). The analysis of spatial association by use of distance statistics. Geographical Analysis, 24, 3.
Giusti, D., Tourloukis, V., Konidaris, G. E., Thompson, N., Karkanas, P., Panagopoulou, E., & Harvati, K. (2018). Beyond maps: pattern of formation processes at the Middle Pleistocene open-air site of Marathousa 1, Megalopolis basin, Greece. Quaternary International, 497, 137–153.
Goren-Inbar, N., Alperson, N., Kislev, M. E., Simchoni, O., Melamed, Y., Ben-Nun, A., & Werker, E. (2004). Evidence of hominin control of fire at Gesher Benot Ya’aqov, Israel. Science, 304(5671), 725–727.
Haberman, S. J. (1974). Log-linear models for frequency tables with ordered classifications. Biometrics, 30(4), 589–600.
Harris, E. C. (1979). Principles of archaeological stratigraphy. Academic Press.
Hartigan, J. A., & Wong, M. A. (1979). A K-means clustering algorithm. Applied Statistics, 28(1), 100–108.
Hietala, H. J., & Stevens, D. E. (1977). Spatial analysis: multiple procedures in pattern recognition studies. American Antiquity, 42(4), 539–559.
Hodder, I. (1988). Interpretación en Arqueología, Corrientes actuales. Barcelona: Ed. Critica
Hodder, I. & Orton, C. (1976). New studies in Archaeology. Spatial analysis in archaeology. Cambridge University Press
Howell, F.C. (1963). Yacimiento achelense de Ambrona. Noticiario Arqueológico Hispánico, VII. pp. 7–23. Madrid
Howell, F. C. (1965). Early Man. Time-Life Books.
Howell, F. C., Freeman, L. G., & Klein, R. G. (1995). Observations on the Acheulean occupation site of Ambrona (Soria Province, Spain), with particular reference to recent investigations (1980-1983) and the Lower Occupation. Jahrbuch des Römisch-Germanischen Zentralmuseum, 38, 33–82.
Isaac, G., Leakey, R. E. F., & Behrensmeyer, A. K. (1971). Archaeological traces of Early Hominid activities, East of Lake Rudolf, Kenya. Science, 173(4002), 1129–1134. https://doi.org/10.1126/science.173.4002.1129.
Jenks, G. F. (1967). The data model concept in statistical mapping. International Yearbook of Cartography, 7, 186–190.
Jia, Z., Pei, S., Benito-Calvo, A., Ma, D., Sánchez-Romero, L., & Wei, Q. (2019). Site formation processes at Donggutuo: a major Early Pleistocene site in the Nihewan Basin, North China. Journal of Quaternary Science, 34(8), 621–632. https://doi.org/10.1002/jqs.3151.
Kershaw, K. A. (1961). Association and co-variance analysis of plant communities. Journal of Ecology, 49(3), 643–654.
Kintigh, K. W. (1990). Intrasite spatial analysis: a commentary on major methods. In A. Voorrips (Ed.), Mathematics and information science in archaeology: A flexible framework (Vol. 3, pp. 165–200). Studies in Modern Archaeology.
Kintigh, K. W., & Ammerman, A. J. (1982). Heuristic approaches to spatial analysis in archaeology. American Antiquity, 47(1), 31–63.
Krauth, J. (1993). Spatial clustering of species based on quadrat sampling. In O. Opitz, B. Lausen, & R. Klar (Eds.), Information and classification. Concepts, methods, and applications proceedings of the 16th Annual Conference of the “Gesellschaft für Klassifikation e.V.”. University of Dortmund April 1–3, 1992.
Lancelotti, C., Negre, J., Alcaina-Mateos, J., & Carrer, F. (2017). Intra-site spatial analysis in ethnoarchaeology. Environmental archaeology, 22(4), 354–364. https://doi.org/10.1080/14614103.2017.1299908.
Laplace, G., & Méroc, L. (1954a). Application des coordonnées cartésiennes à la fouille d’un gisement (pp. 58–66). Bulletin de la Société Préhistorique Française.
Laplace, G., & Méroc, L. (1954b). Complément á notre note sur l’application des coordennées cartésiennes à la fouille d’un gisement (pp. 291–293). Bulletin de la Société Préhistorique Française.
Lee, J., & Wong, D. W. S. (2000). Statistical analysis with ArcView GIS. Wiley.
Lemke, A. K. (2013). Cutmark systematics: analyzing morphometrics and spatial patterning at Palangana. Journal of Anthropological Archaeology, 32(1), 16–27.
Lenoble, A., & Bertran, P. (2004). Fabric of Palaeolithic levels: methods and implications for site formation processes. Journal of Archaeological Science, 31(4), 457–469.
Lenoble, A., Ortega, I., & Bourguignon, L. (2000). Processus de formation du site mousterien de Champs-de-Bossuet (Gironde). Paleo, 12(1), 413–425.
Leroi-Gourhan, A. (1950). Les fouilles préhistoriques (techique et méthodes). Picard.
Leroi-Gourhan, A., & Brézillon, M. (1972). Fouilles de Pincevent. Essai d'analyse ethnographique d'un habitat Magdalénien (la Section 36) (pp. 263–385). Paris: Editions du CNRS.
Marín-Arroyo, A. B., Rios-Garaizar, J., Straus, L. G., Jones, J. R., De la Rasilla, M., González Morales, M. R., Richards, M., Altuna, J., Mariezkurrena, K., & Ocio, D. (2018). Chronological reassessment of the Middle to Upper Paleolithic transition and Early Upper Paleolithic cultures in Cantabrian Spain. PLoS ONE, 13(4), e0194708. https://doi.org/10.1371/journal.pone.0194708.
Martínez, K., & Rando, J. M. (2001). Organización y funcionalidad de la producción lítica en un nivel del Paleolítico Medio del Abric Romaní. Nivel Ja (Capellades, Barcelona). Trabajos de Prehistoria, 58(1), 51–70.
Martínez-Moreno, J., Mora Torcal, R., Roy Sunyer, M., & Benito-Calvo, A. (2016). From site formation processes to human behaviour: towards a constructive approach to depict palimpsests in Roca dels Bous. Quaternary International, 417, 82–93.
Maximiano, A. (2012). Geoestadística y arqueología: Una nueva perspectiva analítico-interpretativa en el análisis espacial intra-site. Analitika, Revista de análisis estadístico, 4(2), 83–95.
McPherron, S. P. (2005). Artefact orientation and site formation processes from total station proveniences. Journal of Archaeological Science, 32(7), 1003–1014.
McPherron, S. P. (2018). Additional statistical and graphical methods for analyzing site formation processes using artifact orientations. PLoS ONE, 13(1). https://doi.org/10.1371/journal.pone.0190195.
McPherron, S. J. P., Dibble, H. L. & Goldberg, P. (2005). Z. Geoarchaeology 20(3), 243-262, doi:https://doi.org/10.1002/gea.20048
Meignen, L. (1994). L'analyse de l'organisation spatiale dans les sites du Paléolithique Moyen: Structures évidentes, structures latentes. Prehistoire Anthropologie Méditerranéennes, 3, 7–23.
Mitchell, A. (2005). La guía de ESRI para el análisis SIG. ESRI Press, vol. 2.
Mitchell, P., Plug, I., & Bailey, G. (2006). Spatial patterning and site occupation at Likoaeng, an open-air hunter-gatherer campsite in the Lesotho Highlands, Southern Africa. Archeological Papers of the American Anthropological Association, 16, 81–94.
Mora, R., Roy Sunyer, M., Martínez-Moreno, J., Benito-Calvo, A., & Samper Carro, S. (2020). Inside the palimpsest: identifying short occupations in the 497D Level of Cova Gran (Iberia). In J. Cascalheira & A. Picin (Eds.), Short-term occupation in Paleolithic Archaeology. Definition and interpretation (pp. 39–69). Springer.
Moran, P. A. P. (1950). Notes on continuous stochastic phenomena. Biometrika, 37(1-2), 17–23.
Morisita, M. (1962). Iδ-index, a measure of dispersion of individuals. Research of Population Ecology IV, pp. 1-7. Kyushu University, Fukuoka
Negre, J. (2015). Non-Euclidean distances in point pattern analysis: anisotropic measures for the study of settlement networks in heterogeneous regions. In J. A. Barceló & I. Bogdanovic (Eds.), Mathematics and Archaeology (pp. 369–382). CRC Press.
O’Connell, J. F. (1987). Alyawara site structure and its archaeological implications. American Antiquity, 52(1), 74–108.
O’Connell, J. F., Hawkes, K., & Blurton Jones, N. (1988). Hadza hunting, butchering, and bone transport and their archaeological implications. Journal of Anthropological Research, 44(2), 113–161.
O’Connell, J. F., Hawkes, K., & Blurton Jones, N. (1990). Reanalysis of large mammal body part transport among the Hadza. Journal of Archaeological Science, 17(3), 301–316.
Oliver, M. A. (1990). Kriging: a method of interpolation for geographical information systems. International Journal of Geographic Information, 4(4), 313–332.
Ord, K., & Getis, A. (1995). Local spatial autocorrelation statistics: distributional issues and an application. Geographical Analysis, 27(4), 286–306. https://doi.org/10.1111/j.1538-4632.1995.tb00912.x.
Pearson, K. (1900). On the criterion that a given system of deviations from the probable in the case of a correlated system of variables is such that it can be reasonably supposed to have arisen from random sampling. The Philosophical Magazine: A Journal of Theoretical Experimental and Applied Physics, 5(50), 157–175.
Pérez-González, A., Santonja, M., & Benito-Calvo, A. (2005). Secuencias litoestratigráficas del Pleistoceno medio del yacimiento de Ambrona. In M. Santonja & A. Pérez-González (Eds.), Los yacimientos paleolíticos de Ambrona y Torralba (Soria) (Vol. 5, pp. 176–188). Un siglo de investigaciones arqueológicas.
Pielou, E. C. (1969). An introduction to Mathematical Ecology. Wiley-Interscience.
Pop, E., Kuijper, W., Van Hees, E., Smith, G., García-Moreno, A., Kindler, L., Gaudzinski-Windheuser, S., & Roebroeks, W. (2016). Fires at Neumark-Nord 2, Germany: an analysis of fire proxies from a Last Interglacial Middle Palaeolithic basin site. Journal of Field Archaeology, 41(5), 603–617. https://doi.org/10.1080/00934690.2016.1208518.
Ringrose, T. J., & Benn, D. I. (1997). Confidence regions for fabric shape diagrams. Journal of Structural Geology, 19(12), 1527–1536.
Rios-Garaizar, J. (2012). Industria lítica y sociedad del Paleolítico Medio al Superior en torno al Golfo de Bizkaia. Universidad de Cantabria.
Ripley, B. D. (1976). The second-order analysis of stationary point processes. Journal of Applied Probability, 13(2), 255–266.
Roy Sunyer, M., Roda Gilabert, X., Benito-Calvo, A., Martínez-Moreno, J., & Mora Torcal, R. (2014). Verificando la integridad del registro arqueológico: Análisis de fábricas en las unidades arqueológicas del paleolítico medio/superior de la Cova Gran (Santa Linya, Lleida). Treballs d’Arqueologia, 20, 55–77.
Sánchez-Romero, L., Benito-Calvo, A., Pérez-González, A., & Santonja, M. (2016). Assessment of accumulation processes at the Middle Pleistocene site of Ambrona (Soria, Spain). Density and orientation patterns in spatial datasets derived from excavations conducted from the 1960s to the present. PLoS ONE, 11(12). https://doi.org/10.1371/journal.pone.0167595.
Sánchez-Romero, L., Canals, A., Pérez-González, A., Márquez, B., Mosquera, M., Karampaglidis, T., Arsuaga, J. L., & Baquedano, E. (2017). Breaking the palimpsest: an approach to the cultural sequence of Neanderthal occupation at the Navalmaíllo rockshelter, Pinilla del Valle (Spain). Trabajos de Prehistoria, 74(2), 225–237.
Sánchez-Romero, L., Benito-Calvo, A., Marín-Arroyo, A. B., Agudo-Pérez, L., Karampaglidis, T., & Rios-Garaizar, J. (2020). New insights for understanding spatial patterning and formation processes of the Neanderthal occupation in the Amalda I cave (Gipuzkoa, Spain). Scientific Reports, 10(1), 8733. https://doi.org/10.1038/s41598-020-65364-8.
Santonja, M., Panera, J., Rubio-Jara, S., & Pérez-González, A. (2005). La industria lítica de Ambrona. Características generales y contexto estratigráfico. In M. Santonja & A. Pérez-González (Eds.), Los yacimientos paleolíticos de Ambrona y Torralba (Soria) (Vol. 5, pp. 307–332). Un siglo de investigaciones arqueológicas.
Santonja, M., Rubio-Jara, S., Panera, J., Sánchez-Romero, L., Tarriño, A. & A Pérez - González. (2018). Ambrona revisited: the Acheulean lithic industry in the Lower Stratigraphic Complex. Quaternary International, 1-23.
Sañudo, P., Vallverdú-Poch, J. & Canals, A. (2012). Spatial patterns in Level J. In Carbonell, E. (Ed.): High resolution. Archaeology and Neanderthal behavior. Time and space in Level J of Abric Romaní (Capellades, Spain), Vertebrate Paleobiology and Paleoanthropology Series. Springer, pp. 47-76
Schiffer, M. B. (1987). Formation Processes of the Archaeological Record. University of New Mexico Press.
Senger, O. (2013). A statistical power comparision of the Kolmogorov-Smirnov two-sample test and the Wald Wolfowitz test in terms of Fixed Skewness and Fixed Kurtosis in large sample sizes. Chinese Business Review, 12(7), 469–476.
Shipton, C., Blinkhorn, J., Breeze, P. S., Cuthbertson, P., Drake, N., Groucutt, H. S., Jennings, R. P., Parton, A., Scerri, E. M. L., Alsharekh, A., & Petraglia, M. D. (2018). Acheulean technology and landscape use at Dawadmi, central Arabia. PLoS ONE, 13(7), e0203488. https://doi.org/10.1371/journal.pone.0203488.
Siabato, W., & Guzmán-Manrique, J. (2019). La autocorrelación espacial y el desarrollo de la geografía cuantitativa. Cuadernos de geografía. Revista colombiana de Geografía, 28(1), 1–22. https://doi.org/10.15446/rcdg.v28n1.76919.
Simek, J. F. (1984). Integrating pattern and context in spatial archaeology. Journal of Archaeology Science, 11(5), 405–420.
Simek, J., & Larick, R. (1983). The recognition of multiple spatial patterns: a case study from the French Upper Palaeolithic. Journal of Archaeological Science, 10(2), 165–180.
Simek, J., & Leslie, P. (1983). Partitioning Chi-square for the analysis of frequency table data: an archaeological application. Journal of Archaeological Science, 10(1), 79–85.
Sisk, M. L., & Shea, J. J. (2008). Intrasite spatial variations of the Omo Kibish Middle Stone Age assemblages: artifact refitting and distribution patterns. Journal of Human Evolution, 55(3), 486–500.
Sneed, E. D., & Folk, R. L. (1958). Pebbles in the lower Colorado River, Texas, a study in particle morphogenesis. Journal of Geology, 66(2), 114–150.
Spagnolo, V., Marciani, G., Aureli, D., Berna, F., Boscato, P., Ranaldo, F., & Ronchitelli, A. (2016). Between hearths and volcanic ash: The SU 13 palimpsest of the Oscurusciuto rock shelter (Ginosa – Southern Italy): Analytical and interpretative questions. Quaternary International, 417, 105–121.
Spagnolo, V., Marciani, G., Aureli, D., Berna, F., Toniello, G., Astudillo, F., Boschin, F., Boscato, P., & Ronchitelli, A. (2019). Neanderthal activity and resting areas from stratigraphic unit 13 at the Middle Palaeolithic site of Oscurusciuto (Ginosa-Taranto, Southern Italy). Quaternary Science Reviews, 217, 169–193. https://doi.org/10.1016/j.quascirev.2018.06.024.
Spagnolo, V., Crezzini, J., Marciani, G., Capecchi, G., Arrighi, S., Aureli, D., Ekberg, I., Scaramucci, S., Tassoni, L., Boschin, F., & Moroni, A. (2020). Neandertal camps and hyena dens. Living floor 150ª at Grotta dei Santi (Monte Argentario, Tuscany, Italy). Journal of Archaeological Science: Reports, 30, 102249. https://doi.org/10.1016/j.jasrep.2020.102249.
Thompson, H. R. (1958). The statistical study of plan distribution patterns using a grid of quadrats. Australia Journal of Botany, 6(4), 322–342.
Vaquero, M. (1999). Intrasite spatial organization of lithic production in the Middle Paleolithic: the evidence of the Abric Romaní (Capellades, Spain). Antiquity, 73(281), 493–504.
Vaquero, M., & Pastó, I. (2001). The definition of spatial units in Middle Palaeolithic sites: the hearth-related assemblages. Journal of Archaeological Science, 28(11), 1209–1220.
Vaquero, M., Rando, J. M., & Chacón, M. G. (2004). Neanderthal spatial behavior and social structure: hearth-related assemblages from the Abric Romaní Middle Palaeolithic site. In N. J. Conard (Ed.), Settlement Dynamics of the Middle Paleolithic and Middle Stone Age (Vol. 2, pp. 367–392). Kerns Verlag.
Vaquero, M., Chacón, M. G., Cuartero, F., García-Antón, M. D., Gómez de Soler, B., & Martínez, K. (2012a). The lithic assemblage of Level J. In E. Carbonell (Ed.), High Resolution Archaeology and Neanderthal Behavior, Vertebrate Paleobiology and Paleoanthropology Series (pp. 189–311). Springer.
Vaquero, M., Chacón, M. G., García-Antón, M. D., Gómez de Soler, B., Martínez, K., & Cuartero, F. (2012b). Time and space in the formation of lithic assemblages: the example of Abric Romaní Level J. Quaternary International, 247, 162–181.
Vaquero, M., Bargalló, A., Chacón, M. G., Romagnoli, F., & Sañudo, P. (2015). Lithic recycling in a Middle Paleolithic expedient context: Evidence from the Abric Romaní (Capellades, Spain). Quaternary International, 361, 212–228.
Vaquero, M., Fernández-Laso, M. C., Chacón, M. G., Romagnoli, F., Rosell, J., & Sañudo, P. (2017). Moving things: comparing lithic and bone refits from a Middle Paleolithic site. Journal of Anthropological Archaeology, 48, 262–280.
Villaverde, V., Eixea, A., Zilhao, J., Sanchis, A., Real, C., & Bergadà, M. (2017). Diachronic variation in the Middle Paleolithic settlement of Abrigo de la Quebrada (Chelva, Spain). Quaternary International, 435, 164–179.
Walter, M. J., & Trauth, M. H. (2013). A MATLAB based orientation analysis of Acheulean handaxe accumulations in Olorgesailie and Kariandusi, Kenya Rift. Journal of Human Evolution, 64(6), 569–581.
Whallon, R. (1973). Spatial analysis of occupation floors I. Application of dimensional analysis of variance. American Antiquity, 38(3), 266–278.
Whallon, R. (1974). Spatial analysis of occupation floors II. Application of nearest neighbor analysis. American Antiquity, 39(1), 16–34.
Yellen, J. E. (1977a). Archaeological Approaches to the Present. Academic Press.
Yellen, J. E. (1977b). Cultural patterning in faunal remains: Evidence from the !Kung Bushmen. In D. Ingersoll, J. E. Yellen, & W. MacDonald (Eds.), Experimental Archaeology (pp. 271–331). Columbia University Press.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Sánchez-Romero, L., Benito-Calvo, A. & Rios-Garaizar, J. Defining and Characterising Clusters in Palaeolithic Sites: a Review of Methods and Constraints. J Archaeol Method Theory 29, 305–333 (2022). https://doi.org/10.1007/s10816-021-09524-8
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10816-021-09524-8