
Abstract
This research work intends to enhance the stepped double-slope solar still performance through an experimental assessment of combining linen wicks and cobalt oxide nanoparticles to the stepped double-slope solar still to improve the water evaporation and water production. The results illustrated that the cotton wicks and cobalt oxide (Co3O4) nanofluid with 1wt% increased the hourly freshwater output (HP) and instantaneous thermal efficiency (ITE). On the other hand, this study compares four machine learning methods to create a prediction model of tubular solar still performance. The methods developed and compared are support vector regressor (SVR), decision tree regressor, neural network, and deep neural network based on experimental data. This problem is a multi-output prediction problem which is HP and ITE. The prediction performance for the SVR was the lowest, with 70 (ml/m2 h) mean absolute error (MAE) for HP and 4.5% for ITE. Decision tree regressor has a better prediction for HP with 33 (ml/m2 h) MAE and almost the same MAE for ITE. Neural network has a better prediction for HP with 28 (ml/m2 h) MAE and a bit worse prediction for ITE with 5.7%. The best model used the deep neural network with 1.94 (ml/m2 h) MAE for HP and 0.67% MAE for ITE.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
In the last decades, freshwater supplies have become seriously insufficient because of the excessive use and the increasing pollution of natural water resources (Elkadeem et al. 2021; Kotb et al. 2021). Also, the global drinking water demand increases because of population density and industrial growth, but the amount of freshwater is fixed (Shannon et al. 2010). Therefore, improving the performance of the cleaning water technologies to produce freshwater has become crucial for the twenty-first century (Elimelech 2006; Elmaadawy et al. 2020). There has been considerable effort made worldwide to prevent this issue while retaining the limited drinking water supply and converting the huge quantities of non-potable water obtained through various desalination methods into potable water. Recently, solar stills (SSs) have become one of the best efficient ways and solutions used for solar desalination to get fresh water in arid regions and have large advantages such as simplicity in contraction and eco-friendly. However, the SS still faces a problem due to its low freshwater production (Sharshir et al. 2017a).
Researchers have focused on different modifications to enhance the performance of SSs (Arunkumar et al. 2019; Sharshir et al. 2017a). Several design improvements were proposed and examined in order to improve the SS performance such as flat SS (Peng et al. 2021a), pyramid SS (Nayi and Modi 2018; Sharshir et al. 2020a), inclined SS (Kalidasa Murugavel et al. 2013; Kaviti et al. 2016), tubular SS (Kabeel et al. 2019b; Sharshir et al. 2019a; Wang et al. 2021), multi-basin (Shanazari and Kalbasi 2018), double-slope SS with rubber scrapers (Elsheikh and Abd Elaziz 2018), trapezoidal pyramid SS(Sharshir et al. 2022c), double-slope SS (Elmaadawy et al. 2021; Kandeal et al. 2021a, b; Raj Kamal et al. 2021; Sharshir et al. 2020e; Tuly et al. 2021), and stepped SS (Alaudeen et al. 2014; Kabeel et al. 2015). On the other hand, the most widely used methods for solar still modifications, nanofluids (Elsheikh et al. 2018; Sharshir et al. 2017c), wick material (Sharshir et al. 2020c; Sharshir et al. 2022a; Sharshir et al. 2020f; Sharshir et al. 2021d) nano-coating (Thakur et al. 2022), thin film evaporation (Elsheikh et al. 2019b; Peng et al. 2018, 2021b; Sharshir et al. 2022a), phase change materials (AbuShanab et al. 2022; Al-Harahsheh et al. 2022, 2018; Javadi et al. 2020; Shalaby et al. 2016), basin water depth (Khalifa and Hamood 2009; Muthu Manokar et al. 2020; Phadatare and Verma 2007), hydrogel materials (Sharshir et al. 2020b), v-corrugated aluminum basin (Abdelaziz et al. 2021a), carbonized wood with nano (Sharshir et al. 2022b) reflectors (Elmaadawy et al. 2020), energy storage (El-Shafai et al. 2022; Sharshir et al. 2021a, 2019b; Thakur et al. 2021b), nano-based mushrooms (Sharshir et al. 2021b), heat localization materials (Sharshir et al. 2020e), cover cooling (Elsheikh et al. 2021; Sharshir et al. 2016a, 2022a, 2017c), evacuated tubes (Mevada et al. 2022), graphene nano-ratchet (Ding et al. 2017), solar collector (Abu-Arabi et al. 2020, 2018; Sharshir et al. 2019c; Thakur et al. 2021c), porous absorber (Abdelaziz et al. 2021d), and hybrid systems (ABDELAZIZ et al. 2021b; Abdelaziz et al. 2021e; Sharshir et al. 2016b; Sharshir et al. 2016c).
Pyramid still coated with TiO2 nano black paint (Kabeel et al. 2019a), inserting internal or external condensers (El-Bahi and Inan 1999), inserting internal or external reflectors, cooling the glass cover (Sharshir et al. 2017c), using silica nanocomposites which are fumed in black paint (Sathyamurthy et al. 2020), as a porous absorber, using activated carbon (Abdelaziz et al. 2021c), using nanomaterials (Sharshir et al. 2020d; Sharshir et al. 2018), the use of phase change materials or gravels (Sharshir et al. 2017b), humidification-dehumidification solar still (Sharshir et al. 2016b, 2016c), atomizer with ultrasonic waves (El-Said and Abdelaziz 2020), the use of airing multifunctional textile (Peng et al. 2020), chips made of wick metal (Sharshir et al. 2020f), and absorber made of graphene oxide (Thakur et al. 2021a). SS integrated with nanoparticles (Elsheikh et al. 2019b, 2018; Sharshir et al. 2018), energy storage (Yousef and Hassan 2019), sponges (Sellami et al. 2017), wick (Pal et al. 2018), painted the still basin with nanomaterials (Kabeel et al. 2019a), and so on.
It is illustrated that the saline water depth in the SS basin inversely affects the freshwater yield. The water depth control to maintain it at a minimum value in the SS is a cumbersome problem. Many modifications were proposed to achieve this purpose, such as cubes made of sponge material in the water basin (Sharshir et al. 2016d). The tentative performance of a SS combined with a small stratum of thermal material storage beneath the absorber plate to produce freshwater during sunset was investigated (El-Sebaii et al. 2009).
Using the wick materials which act through the capillary action improved the evaporation rate. This is because it does not need high energy to heat the whole water; on the other hand, solar irradiance focuses on the water in thin wick material. In addition, using these wick layers solved the problem of the dry spots appearing due to the decrease in water depth, thus increasing the evaporation rate. Also, Murugavel and Srithar (2011) employed several wick materials such as waste cotton pieces, coir mate, sponge sheet, and light cotton cloth to increase the area of evaporation to enhance the SS production. The light black cotton cloth proved to be the most effective wick material. Alaian et al. (2016) used a pin-finned wick to increase the solar still’s water productivity. The daily output of water rose by 13% over the traditional solar, still demonstrating the influence of the solar reflector. Hansen et al. (2015) examined how several wick materials (wicking water coral fleece fabric and wood pulp paper wick) affected various plate absorbers (stepped absorber, flat absorber, and stepped absorber with wire mesh). The result showed that when utilizing a wire mesh-stepped absorber with water coral fleece, the highest water output was 4.28 L/day.
However, in an experimental and simulation study, other researchers improved water evaporation by adding various thin-film nanostructures and heat localization with water desalination (Peng et al. 2020; Sharshir et al. 2020d). It was found that, at 1000 W/m2 irradiance, the thermal efficiency was 78% (Ghasemi et al. 2014). The effects of expanded carbon foam and graphite on evaporation rate and efficiency were explored using a double-layer structure, which achieved 67% at 1000 W/m2. Otherwise, employing a polystyrene and graphene oxide double-layer structure increased the efficiency of evaporation by 80% (Li et al. 2016). However, it should be noted that more investigations are needed for the real application of this material, and its usage remains very difficult.
Metallic surfaces are vital for enhancing the process of heat transfer in solar stills. On the other hand, nanofluid may promote corrosion and erosion on a metallic surface by both physical and chemical mechanisms (Celata et al. 2014). The metallic surface will be consumed noticeably and rapidly when the typical chemical corrosion range is available. The fluid’s characteristics fall in it—even if within a limited time interval (Bubbico et al. 2015). At the same time, the collision between the metallic surface and particles when using nanofluid will erode the bent pipes (Shamshirband et al. 2015; Shinde et al. 2019). So that, before using nanofluid in desalination systems, the erosion and corrosion must be examined to avoid any undesirable interactions between components (Celata et al. 2014). It is also useful to benefit from nanofluid’s advantage for decreasing corrosion and erosion by forming a compact protective film on the metallic surface (Sha et al. 2019). Proper system design and maintenance are necessary to reduce the effects of corrosion and erosion (Muthanna et al. 2019).
Nanofluid stability and pressure drop are other problems besides erosion and corrosion phenomena. Utilizing nanofluids in solar desalination is still one of the biggest long-term nanofluids’ issues that require more research. Poor stability causes particles to accumulate and settle in addition to chemical dissolution, and thus the nanofluids fail (Sezer et al. 2019). In addition, there will be a high accumulation of nanoparticles for passive devices, especially at high temperatures, due to the lack of a pump to circulate and move the nanoscale fluids (Taylor et al. 2012). When using nanoparticles, pressure drop and passive solar still pumping problems will arise. On the other hand, as the concentration of nanoscale fluids increased, the pressure drop under the turbulent system increased accordingly (Duangthongsuk and Wongwises 2010). Also, the rise in the pressure drop will necessarily raise the system operation cost.
Because of the need for precise and dependable modeling of solar energy systems, ANN models have been used to replace conventional models (Delfani et al. 2019; Elsheikh et al. 2019a; Kumar et al. 2019; Motahar and Bagheri-Esfeh 2020; Nasruddin et al. 2018). They have been successfully utilized because of their ability to deal with the extreme uncertainty of these data. ANN has been described as a robust tool for modeling various engineering systems (Babikir et al. 2019; Essa et al. 2020; Shehabeldeen et al. 2020, 2019). Santos et al. (2012) predicted the distillate production of a conventional SS using ANN and the local weather data in Las Vegas and the USA, using different parameters such as solar radiation, average daily air velocity, and the air direction, cloud cover, and air temperature. The results illustrated that with enough input data, the prediction of the SS performance using the ANN method works very effectively at various condition parameters. Hamdan et al. (2013) conducted three different ANN models, namely, nonlinear autoregressive exogenous, feed-forward ANN, and Elman NN, to predict a triple SS performance. The experiments were conducted under weather conditions in Jordan. The input data were air temperature; solar radiation time; glazier temperature; the water temperature in the upper, middle, and lower basins; freshwater output; and plate temperature. Results illustrated that the feed-forward ANN is a good tool for getting the wanted performance (Mashaly and Alazba 2017). The inclined SS immediate efficiency, water yield, and operating recovery ratio were predicted using an ANN model. The findings showed that the ANN model was accurate and effective in predicting SS performance with minor mistakes. Most of the operational and meteorological parameters that affect evaporation and condensation processes in the desalination unit were not addressed according to Hamdan et al. (2013) and Santos et al. (2012). Moreover, the contribution of all components is not determined in the modeling process.
Because of the need for a reliable and accurate simulation of the wick SS productivity every hour, ANN models were used. ANN can be trained using a few experimental data and then study the input and output nonlinear relationship. Once the training process is accomplished, ANN can predict the productivity for any inputs (conditions) that it has not seen before without involving in conducting more experiments or solving complicated mathematical models. Despite the generalization capabilities and robustness of ANN, the traditional ANN still faces some limitations related to the determination of the ANN model parameters. As the determination of ANN model parameters has a significant effect on the ANN performance, many methods have been reported in the literature to determine these parameters, such as backpropagation (Chen 1990), conjugate gradient (Saini and Soni 2002a), and Quasi-Newton’s method (Saini and Soni 2002b). However, these traditional methods are easy to stick to local solutions, which affects the final quality of the ANN.
According to the literature analysis, multiple designs with different amendments were carried out to improve solar performance further. Several approaches need extra components such as condensers, collectors, and reflectors to increase the area exposed to insolation. Although the yield of fresh water was greater, this led to high costs and poor efficiency. Very little research examines the influence of carbon black cobalt oxide (Co3O4) on SDSS performance paired with cotton wicks. Furthermore, four different machine learning models were used, i.e., support vector regressor (SVR), decision tree regressor, neural network, and deep neural network. The results showed that the neural network gave the worst results, especially for validation and test data, which means it failed to generalize. Hence, the neural network is almost out of comparison.
To conclude and summarize the related work, one may suppose that ANN gives the best prediction accuracy that can be achieved. However, no single study was investigated using SVM, decision tree, or deep neural network to predict the stepped double-slope solar. On the other hand, ANN can achieve good accuracy for the two outputs of our system simultaneously. That is why we investigated using more recent and stronger machine learning models, namely SVM, decision tree, and deep neural network.
The main contribution of this research paper is achieving a very high accuracy for the prediction of the two outputs of the stepped double-slope solar still system, namely the HP and the ITE, simultaneously. Moreover, we executed a comparative and statistical analysis of the deep learning model against other states of the art ML methods. Furthermore, we studied the importance and ranking of features w.r.t the outputs’ prediction.
The organization of the research paper is as follows: the “Experimental setup” section covers the experimental setup of the stepped double-slope solar still. The “Instantaneous thermal efficiency calculation and error estimation methods” section covers definitions and formulas of error metrics. The “Methods” section briefly explains the ML methods used for the prediction and introduces the idea of feature selection. The “Results and discussions” section covers the results for each of the previously explained methods in the “Methods” section and compares the results of these methods. The “Results and discussions” section also covers the feature selection results. Finally, the “Conclusions” section covers the conclusion and determines the best model for predicting the stepped double-slope solar still system.
Experimental setup
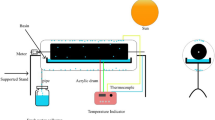
The experiment was carried out in the open air of Al-Burullus City in Kafrelsheikh, Egypt. (latitude 31.07° N and longitude 30.57° E) from 9 am to 5 pm (GMT + 2) during 5 days in May, 2020 (10th, 15th, 25th, 28th, and 30th) and 4 days in June, 2020 (5th, 12th, 18th, and 25th). All experiments were conducted with saline water from Burullus Lake. The sample had a total dissolved solid of 1400 ppm, and a pH value of 8.7 in the northern part of the Nile River Delta, near the Mediterranean Sea, Kafrelsheikh, Egypt. Figure 1(a, b) illustrates pictorial and schematic views of the experimental setup, respectively.

Experimental setup. (a) Photograph, and (b) schematic
The setup of the experiment consisted of a stepped double-slope solar still (SDSSS). The still was made of a sheet of iron with a thickness of 1.5 mm. All inner surfaces were painted black to absorb as much solar energy as possible. All outer surfaces (basin and sidewalls) of solar stills were suitably insulated to reduce heat losses to the ambient. The space bounded by the backside of steps in SDSSS, the wall of the water basin located inside SDSSS, and the frame of SDSSS were filled with wood shavings, as shown in Fig. 2. Wood shavings were an insulation material that prevents heat transfer from the steps’ bottom surfaces to space. A transparent glass cover of 3-mm thickness and inclined with ~ 30° horizontally was used to cover the SDSSS (almost the latitude angle of the location of the experiment). The saline water depth in the SSs was conserved at 1 cm. The projected area of SDSSS steps was 0.975 m2 (0.75 m × 1.3 m), and the area of the glass cover was 0.56 m2 (0.75 m × 0.75 m) for each side. The SDSSS was oriented in the East–West direction to absorb the maximum possible insolation. The nanofluid was obtained by mixing Co3O4 with the feed water at 1 wt%. The utilized Co3O4 nanoparticles had average grain size of 14 nm. The thermophysical properties of the Co3O4 particles are given in Table 1 and the cotton black wick was used.

Illustration of the training dependent input data variables SR, ambient temperature, air velocity
The experimental setup was equipped with a suitable measuring instrument to record several parameters’ variations at hourly intervals, such as temperatures of vapor, water inside the stills, glass covers, and the ambient air. K-type thermocouples (the range was from − 50 to 180 °C, and the accuracy was ± 1 °C) were used to evaluate these parameters which are connected to a digital temperature indicator (Manufacturer TES Electrical Electronic Corp., Model 305P). Solar irradiance in the East and West directions was measured by the solar meter of Manufacturer TES Electrical Electronic Corp., model TES-1333R (the range was from 0 to 2000 W/m2, and the accuracy was ± 10 W/m2). The wind velocity was measured using a vane-type digital anemometer manufacturer BENETECH, Model GM816 (the range was from 0.1 to 30 m/s, and the accuracy was ± 0.1 m/s). Freshwater productivity was measured using a graded cylinder, and the accuracy was ± 2 ml. Uncertainty in length, width, diameter, and thickness measurements were ± 0.5 mm.
The uncertainty of an estimated value derived from the uncertainty of observed parameters is known as a propagation of uncertainty. To calculate this function, the following equation was used (Cohen 1998; Dhivagar and Mohanraj 2021):
where \(w\) is the measured parameter uncertainty, \(x_{n}\) is the parameter of interest, and \(w_{x}\) is the uncertainty propagation for \(X\) value.
Instantaneous thermal efficiency calculation and error estimation methods
The immediate thermal efficiency is one of the most essential factors in estimating the distiller’s performance (Sharshir et al. 2017a). It represents the useful energy \(\left(\frac{{\dot{m}}_{d}}{3600} \times {h}_{fg}\right)\), divided by the energy input \(\left(I\left(t\right)\times {A}_{s}\right)\).
Instantaneous thermal efficiency \({\eta }_{\mathrm{ite}}\) calculated as follows:
where \({\dot{m}}_{d}\) is the freshwater production (kg/h); \({A}_{s}\) is the distiller basin area (m2); I(t) is the solar intensity (W/m.2); and \({h}_{fg}\) is the latent heat (J/kg) calculated as (Kabeel et al. 2018)
This section provides the verbal definitions, and mathematical formulas for mean absolute error (MAE), root mean square error (RMSE), mean relative error (MRE), and R-squared score.
MAE is the sum of the absolute values of errors for all samples divided by the number of these samples.
RMSE is the root of the division of the sum of the errors squared of all samples by the number of these samples.
MRE is the sum of the division of the absolute error by the actual measurement for all samples divided by the number of these samples.
The R-squared score is the goodness of the model’s fit such that one is the superior value. R-squared score equals one minus the division of the residual sum of squares by the total sum of squares. The residual sum of squares, SSres, is the sum of the square of the difference between the actual value and the predicted value for all samples. The total sum of squares, SStot, is the sum of the square of the difference between the actual value and the average of all the actual values for all samples.
For SVR, decision tree, and deep neural network, the sklearn library in python language has been used to obtain R-squared score, RMSE, and MAE. However, MRE has been calculated manually using a simple for loop. On the other hand, for neural network, RMSE and MAE has been obtained using RMS and MAE MATLAB functions. However, R-squared and MRE have been calculated manually using simple MATLAB code that implements the equations of each score.
Methods
Support vector regression
Since our data may have outliers due to faults in measurement equipment, we chose to build our first model using SVR.
SVR is a supervised machine learning algorithm that works on finding a line, hyperplane, or curve when using kernels such that all data points exist within the decision boundaries of the SVR (Ahmad et al. 2018). Hence, we use a road or street instead of a line or curve. This road can be linear, polynomial, or nonlinear, depending on whether we use kernels. We can also control the width of this road using hyperparameter C. Wider road means that some predictions are accepted despite some errors. On the other hand, the narrower road leads us to regular regression (Ma and Guo 2014). Support vector machines generally have a good reputation for dealing with data outliers (Géron 2019). The python language was chosen since it has many reliable libraries in machine learning. We used the sklearn library within python since it offers a wide range of options regarding the hyper-parameters of the SVR (Parbat et al. 2020).
Decision tree regressor
After that, we decided to test the decision tree regressor so that our model prioritizes the eight input features (Karax et al. 2019). The decision tree is a tree-like modeling method that can be used for classification and regression. After proper training, it can be reconfigured to be expressed in only a few conditional control statements. It is a white box machine learning technique (Ray 2019). Decision tree uses Gini impurity to determine which feature to check first, which helps to separate the most repeated class in its branch inside the tree (Daniya et al. 2020). Using the Gini impurity technique within the decision tree allows for determining the input features priorities that can be used to predict the desired output (Yuan et al. 2021). One node is pure with Gini impurity equals zero if all training data belonging to this node are from the same class. However, we must be careful about overfitting problems that are very common when using a decision tree (Suthaharan 2016).
Python language and sklearn library were chosen for the same reason as SVR. Besides very good documentation, sklearn provides a wide range of options and examples for the decision tree algorithm like SVR (Mohagaonkar et al. 2019).
Artificial neural network
Neural networks are adaptive systems that can learn from given data to simulate the real model that generated these data (Jani et al. 2017). The neural network structure is based on interconnected neurons in layers to resemble the human brain (Delfani et al. 2019). The neural network is a set of connected input/output relationships with weight on each connection. The standard structure consists of one input layer, one output layer, and one or zero hidden layer [80]. The learning procedure is based on updating the weight of connections to decrease the error until convergence. Iteratively updating the weights leads to increased network performance.
We used nntool, which is a part of the MATLAB Deep Learning toolbox in MATLAB software [81]. MATLAB nntool divided the 90 rows of data into 62 as training data, 14 as validation data, and 14 as testing data. More sophisticated machine learning models have been experimented with because our system has eight input features and two outputs to predict.
Deep neural network
Deep neural network is an advanced topic of machine learning. Experiments admitted that deep neural network has more capabilities in the prediction process than any other method in machine learning (Ramsundar and Zadeh 2018). That is why our main prediction model is based on a deep neural network. The deep neural network is only a multi-layer neural network. It is based on the neural network method but with many hidden layers between input and output layers. A deep neural network can model complex nonlinear data (Shridhar 2017). Python language was chosen for the same reason as SVR and decision tree. Regarding deep neural network, the TensorFlow library with keras API was chosen since TensorFlow is an open-source library for deep learning algorithms, and keras provides the high-level API that simplifies the coding procedure (Gulli and Pal 2017). Keras supports all models of deep neural networks.
Our deep neural network model comprises a flatten layer, five dense layers with 50 neurons each, and an output layer with only two neurons because we have two outputs. For the training procedure, the Adam optimizer was used.
Feature selection
In raw data, features are properties measurable with their corresponding class ownership information. Unfortunately, the curse of dimensionality limits current methods; too few subjects are available for training compared with large features. Furthermore, feature vectors of high dimension generally contain redundant or irrelevant information, which can lead to overfitting and reduced generalizability of the algorithm (Shi et al. 2022). The dataset is an important factor directly influencing machine learning performance(Turkoglu et al. 2022). According to researchers, machine learning relies more on clean data than on better algorithms. Training the model becomes more difficult with more features in the dataset. It worsens the model’s performance when unnecessary features are included in the dataset. The goal of feature selection is to eliminate these unnecessary features from the model before training to increase the model’s success. Many redundant or irrelevant features increase the computational burden (Tiwari and Chaturvedi 2022), resulting in the “curse of dimensionality.” Feature selection (FS) helps select the optimal classifier by choosing the most relevant features to decision-making (Qaraad et al. 2022). The number of possible solutions exponentially increases as the number of features increases in FS, which is an NP-hard combinatorial problem. Many different approaches have been put forward for feature selection in the literature. Feature selection methods fall into three main categories: (1) filters, (2) wrappers, and (3) hybrid or embedded methods (Hancer et al. 2022; Tiwari and Chaturvedi 2022). In conjunction with statistical data analysis metrics such as correlation and distance, filter-based methods such as principal component analysis, F-scores, and information gains identify subsets of features in the data (Qaraad et al. 2022). Despite their speed, the methods do not depend on the learning algorithm. Despite this, they neglect the importance of various dimensions when choosing the features to include in a subset. Wrapper-based algorithms, on the other hand, seek to find a near-optimal solution from an exponential set of possible solutions. In wrapper-based strategies, the subsets are identified based on the predictability of the classifiers. Filtering and wrapping are combined in different ways through hybrid methods. Their first step is to combine selected features with their learning algorithm. In addition, since the optimal feature set is not evaluated repeatedly, they are less expensive than wrapper methods (Tiwari and Chaturvedi 2022). Each input feature is given a priority value in this work using a random forest regressor as a wrapper method. Random forest regression was implemented using the Python package Sklearn.
Computing environment
Regarding computing results for SVR, decision tree regressor, and deep neural network, Python language has been used and run on the Google Colaboratory service, Colab. Colab is a Jupyter notebook environment completely free of charge that stores users’ notebooks on Google Drive and runs in the cloud. Google Colab CPU service provides 12.68 GB of RAM and 107.72 GB of temporary disk storage. However, regarding the neural network model, MATLAB has been used and run on a laptop Dell Inspiron n5520 with Intel(R) Core (TM) i5-3210 M CPU @ 2.5 GHz, 8 GB RAM, and operating system Windows 10 Pro 64-bit.
Results and discussions
Every hour from 9:00 to 17:00 (GMT + 2) throughout the day, the results were measured and repeated for 9 days. Figure 2 illustrates the sample of the experimental input variables data, which depends on the weather conditions and cannot be controlled, namely insolation, ambient temperature, inlet water temperature, and air velocity for the suggested model. Figure 2 demonstrates a sample of insolation data every hour; the mean insolation was 827.35 W/m2. Figure 2 demonstrates an example of ambient temperature; the mean value of the air temperature was 29.86 °C, respectively. Furthermore, Fig. 2 illustrates air velocity in meter/second; the mean air velocity was 2.36 m/s.
Furthermore, Fig. 3 illustrates samples of the dependent variables used as inputs during the training process of the suggested model. Figure 3 shows the water temperature, glass temperature (in and out), and vapor temperature for SDSSS, respectively. The maximum and minimum water temperature was about 69 and 33 °C, respectively, while the average vapor temperature was about 54.61 °C. Also, the average glass inlet temperature was about 52.69 °C, and the average glass outlet temperature was about 46.73 °C. Furthermore, the comparison between the accumulated efficiency and freshwater production of present results with other available works is illustrated in Table 2.

Samples of the dependent variables of SDSS were extracted from the training data set: (a) wick, (b) water, (c) vapor, and (d) glass temperatures for the proposed ANN and ANN-TSA model
Furthermore, the experimental data were divided into training data and testing data using k-fold cross-validation such that the data was split into ninefold. Hence, each epoch contains nine runs. Each run, a different part of data, is considered testing data. At the end of the nine runs, each fold was considered testing data.
The training and testing sets have been used to train and validate ANN, SVR, decision tree regressor (DTR), and deep neural network models. First, however, all the dataset has been used with the random forest regressor to obtain the percentage importance of each input feature. Figure 4 shows a flow diagram for the whole training process.

Flow diagram for the training procedure
Support vector regression
After proper training until convergence, the SVR gave good performance results for ITE output but not for HP output. Regarding SVR results, the MAE score was 70.35 (ml/m2 h) for HP output and 4.52% for ITE output. The R-squared score was 0.82 for HP output and 0.79 for ITE output, while the RMSE score was 98.23 (ml/m2 h) for HP output and 6.07% for ITE output. MRE score was 0.245 (ml/m2 h) for HP output and 0.155% for ITE output. Figure 5 a and b show actual vs. predicted for HP output and ITE output, respectively. Figure 6 a and b plot actual and predicted w.r.t time for HP and ITE outputs, respectively. It can be seen that the model gives a good prediction for the ITE output but not for the HP output. Hence, we will work on another model. Also, the R-squared values for both outputs are not good enough, 0.82 and 0.79.

a Actual vs. predicted figure for HP output with SVR, b actual vs. predicted figure for ITE output with SVR

a Actual and predicted w.r.t. time for HP output with SVR, b actual and predicted w.r.t. time for ITE output with SVR
Decision tree regressor
The decision tree algorithm gave better performance results than the SVR method. Regarding decision tree results, the MAE score was 33.67 (ml/m2 h) for HP output, and 4.63% for ITE output, which is better than SVR results only for HP output. The R-squared score was 0.94 for HP output and 0.74 for ITE output, while the RMSE score was 55.35 (ml/m2 h) for HP output and 6.76% for ITE output. MRE score was 0.109 (ml/m2 h) for HP output and 0.136% for ITE output. Figure 7a and b show actual vs. predicted HP output and ITE output, respectively. Figure 8a and b plot actual and predicted w.r.t time for HP and ITE outputs, respectively. It can be seen that the model gives a good prediction for the HP output but not for the ITE output. Hence, we will work on another model. Also, the R-squared values for ITE output are not good enough, 0.74.

a Actual vs. predicted figure for HP output with DTR; b actual vs. predicted figure for ITE output with DTR

a Actual and predicted w.r.t. time for HP output with DTR; b actual and predicted w.r.t. time for ITE output with DTR
Artificial neural network
Regarding the ANN method, the results were not much different from decision tree results. Regarding ANN results, the MAE score was 27.98 (ml/m2 h) for HP output and 5.72% for ITE output, which is a bit better than decision tree results for HP output, and a bit worse for ITE output as expected [87]. The R-squared score was 0.965 for HP output and 0.676 for ITE output, while the RMSE score was 43.5 (ml/m2 h) for HP output and 7.54% for ITE output. MRE score was 0.087 (ml/m2 h) for HP output and 0.205% for ITE output. Figure 9 shows that the best validation performance is achieved at epoch five; after that, it starts to diverge away. Figure 10a and b show actual vs. predicted HP output and ITE output, respectively. Figure 11a and b plot actual and predicted w.r.t time for HP and ITE outputs, respectively. It can be seen that we need a better model.

MATLAB training performance convergence plot

a Actual vs. predicted figure for HP output with ANN; b actual vs. predicted figure for ITE output with ANN

a Actual and predicted w.r.t. time for HP output with ANN; b actual and predicted w.r.t. time for ITE output with ANN
Deep neural network
The deep neural network gave the best performance results within all tested algorithms, including SVR, decision tree, and neural network. regarding deep neural network results; the MAE score was 1.94 for HP output and 0.67 for ITE output, which is much better than neural network, decision tree, and SVR results for both HP and ITE output. The R-squared score was 0.9998 for HP output and 0.995 for ITE output which is a great result, while the RMSE score was 3.3 for HP output and 0.9 for ITE output. MRE score was 0.0047 for HP output and 0.0185 for ITE output. Figure 12a and b show actual vs. predicted HP output and ITE output, respectively. Figure 13a and b plot actual and predicted w.r.t time for HP and ITE outputs, respectively. It can be seen that HP predicted output is almost the same as the actual output with almost no error. Obviously, actual and predicted w.r.t time have a complete match for the HP output and very close for the ITE output.

a Actual vs. predicted figure for HP output with DNN; b actual vs. predicted figure for ITE output with DNN

a Actual and predicted w.r.t. time for HP output with DNN; b actual and predicted w.r.t. time for ITE output with DNN
Comparison between SVR, decision tree, and deep neural network
Figures 14 and 15 show a plot of comparison between actual vs. predicted HP output and ITE output, respectively, for four models: SVR, decision tree, neural network, and deep neural network. First, the deep neural network gives the best prediction results, then the neural network, then the decision tree, then SVR for the HP output. After that, however, the deep neural network gives the best prediction results for the ITE output, SVR, decision tree, and neural network.

Actual vs. predicted for HP output (SVR vs. DT vs. NN vs. DNN)

Actual vs. predicted for ITE output (SVR vs. DT vs. NN vs. DNN)
Table 3 compares SVR, decision tree, neural network, and deep neural network using R-squared, RMSE, MAE, and MRE scores beside mean and Std.
Feature selection
The arrangement of the features’ importance parameters had been in decreasing logical sequence. From straight to indirect impact on productivity, the percentage importance of each input characteristic had been calculated, according to the data displayed in Fig. 16. The most important parameters were SR and Tw by about 40.22% and 27.62% because they directly influenced the rate of evaporation and, consequently, the freshwater production. Also, the vapor had a feature importance of about 24.34% followed by the glass out and inlet, which had 3.5 and 2.6% respectively. Additionally, the air speed and air temperature had the same feature importance values of about 0.75 and 0.7% respectively. Finally, the lower feature importance was related to a relative humidity of 0.18%.

Percentage importance for each input feature
Conclusions
The effects of employing a stepped double-slope solar still (SDSSS) with a cotton wick and cobalt oxide (Co3O4) nanofluid with 1wt% on its steps are shown in this research. Every hour from 9:00 to 17:00 (GMT + 2), the results were measured and repeated for 9 days. Furthermore, four different machine learning models: support vector regressor (SVR), decision tree, neural network, and deep neural network. The results showed that the neural network gave the worst results, especially for validation and test data, which means it failed to generalize. Hence, the neural network is almost out of comparison.
-
The results demonstrated that the deep neural network gives the best results for both outputs, which can be verified from comparison plots and the values of R-squared, RMS, MAE, and MRE scores, which outweigh the favor of the deep neural network with big differences.
-
The next best model depends on which output we consider since regarding HP output, it can be seen that the neural network is the next best model, then the decision tree comes after it. However, regarding the ITE output, it can be seen that the next best model is the SVR then the decision tree comes after it.
-
Regarding the feature importance, it can be noted that the most important input feature is SR, Tw, and Tv.
Data availability
Not applicable.
Abbreviations
- ANN :
-
Artificial neural network
- HP :
-
Hourly productivity
- SDSSS :
-
Stepped double-slope solar still
- SS :
-
Solar still
- RMSE :
-
Root mean square error
- R :
-
Regression
- R-squared :
-
Coefficient of determination
- MRE :
-
Mean relative error
- MAE :
-
Mean absolute error
- COV :
-
Coefficient of variance
- EC :
-
Efficiency coefficient
- OI :
-
Overall index of model performance
- CRM :
-
Coefficient of residual mass
References
Abdelaziz GB, Algazzar AM, El-Said EMS, Elsaid AM, Sharshir SW, Kabeel AE, El-Behery SM (2021a) Performance enhancement of tubular solar still using nano-enhanced energy storage material integrated with v-corrugated aluminum basin, wick, and nanofluid. Journal of Energy Storage 41:102933
Abdelaziz GB, El-Said EMS, Bedair AG, Sharshir SW, Kabeel AE, Elsaid AM (2021d) Experimental study of activated carbon as a porous absorber in solar desalination with environmental, exergy, and economic analysis. Process Saf Environ Prot 147:1052–1065
Abdelaziz GB, El-Said E, Dahab M, Omara M, Sharshir SW (2021b) Recent developments of solar stills and humidification de-humidification desalination systems: a review. J Pet Mining Eng 23(2):57-69
Abdelaziz GB, El-Said EMS, Bedair AG, Sharshir SW, Kabeel AB, Elsaid AM (2021c) Experimental study of activated carbon as a porous absorber in solar desalination with environmental, exergy, and economic analysis. Process Saf Environ Prot.
Abdelaziz GB, El-Said EMS, Dahab MA, Omara MA, Sharshir SW (2021e) Hybrid solar desalination systems review. Energy Sources, Part A: Recovery, Utilization, and Environmental Effects, 1–31
Abu-Arabi M, Al-harahsheh M, Mousa H, Alzghoul Z (2018) Theoretical investigation of solar desalination with solar still having phase change material and connected to a solar collector. Desalination 448:60–68
Abu-Arabi M, Al-harahsheh M, Ahmad M, Mousa H (2020) Theoretical modeling of a glass-cooled solar still incorporating PCM and coupled to flat plate solar collector. J Energy Storage 29:101372
AbuShanab WS, Elsheikh AH, Ghandourah EI, Moustafa EB, Sharshir SW (2022) Performance improvement of solar distiller using hang wick, reflectors and phase change materials enriched with nano-additives. Case Stud Therm Eng 31:101856
Ahmad MW, Reynolds J, Rezgui YJJocp (2018) Predictive modelling for solar thermal energy systems: a comparison of support vector regression, random forest, extra trees and regression trees. 203:810–821
Alaian W, Elnegiry E, Hamed AM (2016) Experimental investigation on the performance of solar still augmented with pin-finned wick. Desalination 379:10–15
Alaudeen A, Johnson K, Ganasundar P, Syed Abuthahir A, Srithar K (2014) Study on stepped type basin in a solar still. J King Saud Univ Eng Sci 26(2):176–183
Al-harahsheh M, Abu-Arabi M, Mousa H, Alzghoul Z (2018) Solar desalination using solar still enhanced by external solar collector and PCM. Appl Therm Eng 128:1030–1040
Al-Harahsheh M, Abu-Arabi M, Ahmad M, Mousa H (2022) Self-powered solar desalination using solar still enhanced by external solar collector and phase change material. Appl Therm Eng 206:118118
Arunkumar T, Raj K, Dsilva Winfred Rufuss D, Denkenberger D, Tingting G, Xuan L, Velraj R (2019) A review of efficient high productivity solar stills. Renew Sustain Energy Rev 101:197-220
Babikir HA, Elaziz MA, Elsheikh AH, Showaib EA, Elhadary M, Wu D, Liu Y (2019) Noise prediction of axial piston pump based on different valve materials using a modified artificial neural network model. Alex Eng J 58(3):1077–1087
Bubbico R, Celata GP, D’Annibale F, Mazzarotta B, Menale C (2015) Experimental analysis of corrosion and erosion phenomena on metal surfaces by nanofluids. Chem Eng Res Des 104:605–614
Celata GP, D’Annibale F, Mariani A, Sau S, Serra E, Bubbico R, Menale C, Poth H (2014) Experimental results of nanofluids flow effects on metal surfaces. Chem Eng Res Des 92(9):1616–1628
Chen F-C (1990) Back-propagation neural networks for nonlinear self-tuning adaptive control. IEEE Control Syst Mag 10(3):44–48
Cohen ER (1998) An introduction to error analysis: the study of uncertainties in physical measurements. IOP Publishing
Daniya T, Geetha M, Kumar K.S.J.A.i.M.S.J (2020) Classification And regression trees with Gini Index 9(10):8237–8247
Delfani S, Esmaeili M, Karami M (2019) Application of artificial neural network for performance prediction of a nanofluid-based direct absorption solar collector. Sustainable Energy Technol Assess 36:100559
Dhivagar R, Mohanraj M (2021) Performance improvements of single slope solar still using graphite plate fins and magnets. Environmental Science and Pollution Research.
Ding H, Peng G, Mo S, Ma D, Sharshir SW, Yang N (2017) Ultra-fast vapor generation by a graphene nano-ratchet: a theoretical and simulation study. Nanoscale 9(48):19066–19072
Duangthongsuk W, Wongwises S (2010) An experimental study on the heat transfer performance and pressure drop of TiO2-water nanofluids flowing under a turbulent flow regime. Int J Heat Mass Tran 53(1):334–344
El-Bahi A, Inan D (1999) A solar still with minimum inclination, coupled to an outside condenser. Desalination 123(1):79–83
Elimelech M (2006) The global challenge for adequate and safe water. J Water Supply Res Technol AQUA 55(1):3–10
Elkadeem MR, Kotb KM, Elmaadawy K, Ullah Z, Elmolla E, Liu B, Wang S, Dán A, Sharshir SW (2021) Feasibility analysis and optimization of an energy-water-heat nexus supplied by an autonomous hybrid renewable power generation system: An empirical study on airport facilities. Desalination 504:114952
Elmaadawy K, Kotb KM, Elkadeem MR, Sharshir SW, Dán A, Moawad A, Liu B (2020) Optimal sizing and techno-enviro-economic feasibility assessment of large-scale reverse osmosis desalination powered with hybrid renewable energy sources. Energy Convers Manage 224:113377
Elmaadawy K, Kandeal AW, Khalil A, Elkadeem MR, Liu B, Sharshir SW (2021) Performance improvement of double slope solar still via combinations of low cost materials integrated with glass cooling. Desalination 500:114856
El-Said EMS, Abdelaziz GB (2020) Experimental investigation and economic assessment of a solar still performance using high-frequency ultrasound waves atomizer. J Clean Prod 256:120609
El-Sebaii A, Yaghmour S, Al-Hazmi F, Faidah AS, Al-Marzouki F, Al-Ghamdi A (2009) Active single basin solar still with a sensible storage medium. Desalination 249(2):699–706
El-Shafai NM, Shukry M, Sharshir SW, Ramadan MS, Alhadhrami A, El-Mehasseb I (2022) Advanced applications of the nanohybrid membrane of chitosan/nickel oxide for photocatalytic, electro-biosensor, energy storage, and supercapacitors. J Energy Storage 50:104626
Elsheikh AH, Sharshir SW, Mostafa ME, Essa FA, Ahmed Ali MK (2018) Applications of nanofluids in solar energy: a review of recent advances. Renew Sustain Energy Rev 82:3483–3502
Elsheikh AH, Sharshir SW, Abd Elaziz M, Kabeel AE, Guilan W, Haiou Z (2019a) Modeling of solar energy systems using artificial neural network: a comprehensive review. Sol Energy 180:622–639
Elsheikh AH, Sharshir SW, Ahmed Ali MK, Shaibo J, Edreis EMA, Abdelhamid T, Du C, Haiou Z (2019b) Thin film technology for solar steam generation: a new dawn. Sol Energy 177:561–575
Elsheikh AH, Sharshir SW, Kabeel AE, Sathyamurthy R (2021) Application of Taguchi method to determine the optimal water depth and glass cooling rate in solar stills. J Scientia Iranica 28(2):731–742
Elsheikh AH, Abd Elaziz M (2018) Review on applications of particle swarm optimization in solar energy systems. Int J Environ Sci Technol
Essa FA, Abd Elaziz M, Elsheikh AH (2020) An enhanced productivity prediction model of active solar still using artificial neural network and Harris Hawks optimizer. Appl Therm Eng 170:115020
Géron A (2019) Hands-on machine learning with Scikit-Learn, Keras, and TensorFlow: Concepts, tools, and techniques to build intelligent systems. O'Reilly Media
Ghasemi H, Ni G, Marconnet AM, Loomis J, Yerci S, Miljkovic N, Chen G (2014) Solar steam generation by heat localization. Nat Commun 5:4449
Gulli A, Pal S (2017) Deep learning with Keras. Packt Publishing Ltd.
Hamdan M, Khalil HR, Abdelhafez E (2013) Comparison of neural network models in the estimation of the performance of solar still under Jordanian climate. J Clean Energy Technol 1(3):238–242
Hancer E, Xue B, Zhang M (2022) Fuzzy filter cost-sensitive feature selection with differential evolution. Knowl-Based Syst 241:108259
Hansen RS, Narayanan CS, Murugavel KK (2015) Performance analysis on inclined solar still with different new wick materials and wire mesh. Desalination 358:1–8
Jani D, Mishra M, Sahoo PJR, Reviews SE (2017) Application of artificial neural network for predicting performance of solid desiccant cooling systems–a review 80:352–366
Javadi FS, Metselaar HSC, Ganesan P (2020) Performance improvement of solar thermal systems integrated with phase change materials (PCM), a review. Sol Energy 206:330–352
Kabeel AE, Omara ZM, Younes MM (2015) Techniques used to improve the performance of the stepped solar still—a review. Renew Sustain Energy Rev 46:178–188
Kabeel AE, Abdelgaied M, Eisa A (2018) Enhancing the performance of single basin solar still using high thermal conductivity sensible storage materials. J Clean Prod 183:20–25
Kabeel AE, Sathyamurthy R, Sharshir SW, Muthumanokar A, Panchal H, Prakash N, Prasad C, Nandakumar S, El Kady MS (2019a) Effect of water depth on a novel absorber plate of pyramid solar still coated with TiO2 nano black paint. J Clean Prod 213:185–191
Kabeel AE, Sharshir SW, Abdelaziz GB, Halim MA, Swidan A (2019b) Improving performance of tubular solar still by controlling the water depth and cover cooling. J Clean Prod 233:848–856
Kalidasa Murugavel K, Anburaj P, Samuel Hanson R, Elango T (2013) Progresses in inclined type solar stills. Renew Sustain Energy Rev 20:364–377
Kandeal AW, El-Shafai NM, Abdo MR, Thakur AK, El-Mehasseb IM, Maher I, Rashad M, Kabeel AE, Yang N, Sharshir SW (2021b) Improved thermo-economic performance of solar desalination via copper chips, nanofluid, and nano-based phase change material. Sol Energy 224:1313–1325
Kandeal AW, An M, Chen X, Algazzar AM, Kumar Thakur A, Guan X, Wang J, Elkadeem MR, Ma W, Sharshir SW (2021a) Productivity modeling enhancement of a solar desalination unit with nanofluids using machine learning algorithms integrated with Bayesian optimization. 9(9):2100189
Karax JAP, Malucelli A, Barddal JP (2019) Decision tree-based feature ranking in concept drifting data streams, Proceedings of the 34th ACM/SIGAPP Symposium on Applied Computing, pp. 590–592
Kaviti AK, Yadav A, Shukla A (2016) Inclined solar still designs: a review. Renew Sustain Energy Rev 54:429–451
Khalifa AJN, Hamood AM (2009) On the verification of the effect of water depth on the performance of basin type solar stills. Sol Energy 83(8):1312–1321
Kotb KM, Elkadeem MR, Khalil A, Imam SM, Hamada MA, Sharshir SW, Dán A (2021) A fuzzy decision-making model for optimal design of solar, wind, diesel-based RO desalination integrating flow-battery and pumped-hydro storage: Case study in Baltim, Egypt. Energy Convers Manag 235:113962
Kumar R, Agrawal HP, Shah A, Bansal HO (2019) Maximum power point tracking in wind energy conversion system using radial basis function based neural network control strategy. Sustain Energy Technol Assess 36:100533
Li X, Xu W, Tang M, Zhou L, Zhu B, Zhu S, Zhu J (2016) Graphene oxide-based efficient and scalable solar desalination under one sun with a confined 2D water path. Proc Natl Acad Sci 113(49):13953–13958
Ma Y, Guo G (2014) Support vector machines applications. Springer
Mashaly AF, Alazba AA (2017) Thermal performance analysis of an inclined passive solar still using agricultural drainage water and artificial neural network in arid climate. Sol Energy 153:383–395
Mevada D, Panchal H, ElDinBastawissi HA, Elkelawy M, Sadashivuni K, Ponnamma D, Thakar N, Sharshir SW (2022) Applications of evacuated tubes collector to harness the solar energy: a review. Int J Ambient Energy 43(1):344–361
Mohagaonkar S, Rawlani A, Saxena A (2019) Efficient decision tree using machine learning tools for acute ailments, 2019 6th International Conference on Computing for Sustainable Global Development (INDIACom). IEEE, pp. 691–697
Motahar S, Bagheri-Esfeh H (2020) Artificial neural network based assessment of grid-connected photovoltaic thermal systems in heating dominated regions of Iran. Sustain Energy Technol Assess 39:100694
Murugavel KK, Srithar K (2011) Performance study on basin type double slope solar still with different wick materials and minimum mass of water. Renew Energy 36(2):612–620
Muthanna BGN, Amara M, Meliani MH, Mettai B, Božić Ž, Suleiman R, Sorour AA (2019) Inspection of internal erosion-corrosion of elbow pipe in the desalination station. Eng Fail Anal 102:293–302
Muthu Manokar A, Taamneh Y, Kabeel AE, Prince Winston D, Vijayabalan P, Balaji D, Sathyamurthy R, Padmanaba Sundar S, Mageshbabu D (2020) Effect of water depth and insulation on the productivity of an acrylic pyramid solar still – an experimental study. Groundw Sustain Dev 10:100319
Nasruddin S, Idrus Alhamid M, Saito K (2018) Hot water temperature prediction using a dynamic neural network for absorption chiller application in Indonesia. Sustain Energy Technol Assess 30:114–120
Nayi KH, Modi KV (2018) Pyramid solar still: a comprehensive review. Renew Sustain Energy Rev 81:136–148
Pal P, Yadav P, Dev R, Singh D (2017) Performance analysis of modified basin type double slope multi–wick solar still. Desalination 422:68–82
Pal P, Dev R, Singh D, Ahsan A (2018) Energy matrices, exergoeconomic and enviroeconomic analysis of modified multi–wick basin type double slope solar still. Desalination 447:55–73
Parbat D, Chakraborty MJC, Solitons Fractals (2020) A python based support vector regression model for prediction of COVID19 cases in India 138:109942
Peng G, Ding H, Sharshir SW, Li X, Liu H, Ma D, Wu L, Zang J, Liu H, Yu W, Xie H, Yang N (2018) Low-cost high-efficiency solar steam generator by combining thin film evaporation and heat localization: Both experimental and theoretical study. Appl Therm Eng 143:1079–1084
Peng G, Deng S, Sharshir SW, Ma D, Kabeel AE, Yang N (2020) High efficient solar evaporation by airing multifunctional textile. Int J Heat Mass Transf 147:118866
Peng G, Sharshir SW, Hu Z, Ji R, Ma J, Kabeel AE, Liu H, Zang J, Yang N (2021a) A compact flat solar still with high performance. Int J Heat Mass Transf 179:121657
Peng G, Sharshir SW, Wang Y, An M, Ma D, Zang J, Kabeel AE, Yang N (2021b) Potential and challenges of improving solar still by micro/nano-particles and porous materials - A review. J Clean Prod 311:127432
Phadatare MK, Verma SK (2007) Influence of water depth on internal heat and mass transfer in a plastic solar still. Desalination 217(1):267–275
Qaraad M, Amjad S, Hussein NK, Elhosseini MA (2022) Large scale salp-based grey wolf optimization for feature selection and global optimization. Neural Comput Appl 34(11):8989–9014
Raj Kamal MD, Parandhaman B, Madhu B, Magesh Babu D, Sathyamurthy R (2021) Experimental analysis on single and double basin single slope solar still with energy storage material and external heater. Materials Today: Proceedings
Ramsundar B, Zadeh RB (2018) TensorFlow for deep learning: from linear regression to reinforcement learning. " O'Reilly Media, Inc."
Ray S (2019) A quick review of machine learning algorithms, 2019 International conference on machine learning, big data, cloud and parallel computing (COMITCon). IEEE, pp. 35–39
Saini L, Soni M (2002a) Artificial neural network based peak load forecasting using Levenberg–Marquardt and quasi-Newton methods. IEE Proc, Gener Transm Distrib 149(5):578–584
Saini LM, Soni MK (2002b) Artificial neural network-based peak load forecasting using conjugate gradient methods. IEEE Trans Power Syst 17(3):907–912
Santos NI, Said AM, James DE, Venkatesh NH (2012) Modeling solar still production using local weather data and artificial neural networks. Renew Energy 40(1):71–79
Sathyamurthy R, Kabeel AE, Balasubramanian M, Devarajan M, Sharshir SW, Manokar AM (2020) Experimental study on enhancing the yield from stepped solar still coated using fumed silica nanoparticle in black paint. Mater Lett 272:127873
Sellami MH, Belkis T, Aliouar ML, Meddour SD, Bouguettaia H, Loudiyi K (2017) Improvement of solar still performance by covering absorber with blackened layers of sponge. Groundw Sustain Dev 5:111–117
Sezer N, Atieh MA, Koç M (2019) A comprehensive review on synthesis, stability, thermophysical properties, and characterization of nanofluids. Powder Technol 344:404–431
Sha J-Y, Ge H-H, Wan C, Wang L-T, Xie S-Y, Meng X-J, Zhao Y-Z (2019) Corrosion inhibition behaviour of sodium dodecyl benzene sulphonate for brass in an Al2O3 nanofluid and simulated cooling water. Corros Sci 148:123–133
Shalaby SM, El-Bialy E, El-Sebaii AA (2016) An experimental investigation of a v-corrugated absorber single-basin solar still using PCM. Desalination 398:247–255
Shamshirband S, Malvandi A, Karimipour A, Goodarzi M, Afrand M, Petković D, Dahari M, Mahmoodian N (2015) Performance investigation of micro- and nano-sized particle erosion in a 90° elbow using an ANFIS model. Powder Technol 284:336–343
Shanazari E, Kalbasi R (2018) Improving performance of an inverted absorber multi-effect solar still by applying exergy analysis. Appl Therm Eng 143:1–10
Shannon MA, Bohn PW, Elimelech M, Georgiadis JG, Marinas BJ, Mayes AM (2010) Science and technology for water purification in the coming decades, Nanoscience And Technology: A Collection of Reviews from Nature Journals. World Scientific, pp. 337–346
Sharshir SW, El-Samadony MOA, Peng G, Yang N, Essa FA, Hamed MH, Kabeel AE (2016a) Performance enhancement of wick solar still using rejected water from humidification-dehumidification unit and film cooling. Appl Therm Eng 108:1268–1278
Sharshir SW, Peng G, Yang N, El-Samadony MOA, Kabeel AE (2016b) A continuous desalination system using humidification – dehumidification and a solar still with an evacuated solar water heater. Appl Therm Eng 104:734–742
Sharshir SW, Peng G, Yang N, Eltawil MA, Ali MKA, Kabeel AE (2016c) A hybrid desalination system using humidification-dehumidification and solar stills integrated with evacuated solar water heater. Energy Convers Manage 124:287–296
Sharshir SW, Yang N, Peng G, Kabeel AE (2016d) Factors affecting solar stills productivity and improvement techniques: a detailed review. Appl Therm Eng 100:267–284
Sharshir SW, Elsheikh AH, Peng G, Yang N, El-Samadony MOA, Kabeel AE (2017a) Thermal performance and exergy analysis of solar stills – a review. Renew Sustain Energy Rev 73:521–544
Sharshir SW, Peng G, Wu L, Essa FA, Kabeel AE, Yang N (2017b) The effects of flake graphite nanoparticles, phase change material, and film cooling on the solar still performance. Appl Energy 191:358–366
Sharshir SW, Peng G, Wu L, Yang N, Essa FA, Elsheikh AH, Mohamed SIT, Kabeel AE (2017c) Enhancing the solar still performance using nanofluids and glass cover cooling: Experimental study. Appl Therm Eng 113:684–693
Sharshir SW, Peng G, Elsheikh AH, Edreis EMA, Eltawil MA, Abdelhamid T, Kabeel AE, Zang J, Yang N (2018) Energy and exergy analysis of solar stills with micro/nano particles: a comparative study. Energy Convers Manage 177:363–375
Sharshir SW, Ellakany YM, Algazzar AM, Elsheikh AH, Elkadeem MR, Edreis EMA, Waly AS, Sathyamurthy R, Panchal H, Elashry MS (2019a) A mini review of techniques used to improve the tubular solar still performance for solar water desalination. Process Saf Environ Prot 124:204–212
Sharshir SW, Kandeal AW, Ismail M, Abdelaziz GB, Kabeel AE, Yang N (2019c) Augmentation of a pyramid solar still performance using evacuated tubes and nanofluid: Experimental approach. Appl Therm Eng 160:113997
Sharshir SW, Abd Elaziz M, Elkadeem MR (2020a) Enhancing thermal performance and modeling prediction of developed pyramid solar still utilizing a modified random vector functional link. Sol Energy 198:399–409
Sharshir SW, Algazzar AM, Elmaadawy KA, Kandeal AW, Elkadeem MR, Arunkumar T, Zang J, Yang N (2020b) New hydrogel materials for improving solar water evaporation, desalination and wastewater treatment: a review. Desalination 491:114564
Sharshir SW, Elkadeem MR, Meng A (2020c) Performance enhancement of pyramid solar distiller using nanofluid integrated with v-corrugated absorber and wick: an experimental study. Appl Therm Eng 168:114848
Sharshir SW, Ellakany YM, Eltawil MA (2020d) Exergoeconomic and environmental analysis of seawater desalination system augmented with nanoparticles and cotton hung pad. J Clean Prod 248:119180
Sharshir SW, Elsheikh AH, Ellakany YM, Kandeal AW, Edreis EMA, Sathyamurthy R, Thakur AK, Eltawil MA, Hamed MH, Kabeel AE (2020e) Improving the performance of solar still using different heat localization materials. Environ Sci Pollut Res 27(11):12332–12344
Sharshir SW, Eltawil MA, Algazzar AM, Sathyamurthy R, Kandeal AW (2020f) Performance enhancement of stepped double slope solar still by using nanoparticles and linen wicks: energy, exergy and economic analysis. Appl Therm Eng 174:115278
Sharshir SW, Peng G, Elsheikh AH, Eltawil MA, Elkadeem MR, Dai H, Zang J, Yang N (2020g) Influence of basin metals and novel wick-metal chips pad on the thermal performance of solar desalination process. J Clean Prod 248:119224
Sharshir SW, El-Shafai NM, Ibrahim MM, Kandeal AW, El-Sheshtawy HS, Ramadan MS, Rashad M, El-Mehasseb IM (2021a) Effect of copper oxide/cobalt oxide nanocomposite on phase change material for direct/indirect solar energy applications: Experimental investigation. Journal of Energy Storage 38:102526
Sharshir SW, Hamada MA, Kandeal AW, El-Said EMS, Mimi Elsaid A, Rashad M, Abdelaziz GB (2021b) Augmented performance of tubular solar still integrated with cost-effective nano-based mushrooms. Sol Energy 228:27–37
Sharshir SW, Ismail M, Kandeal AW, Baz FB, Eldesoukey A, Younes MM (2021c) Improving thermal, economic, and environmental performance of solar still using floating coal, cotton fabric, and carbon black nanoparticles. Sustain Energy Technol Assess 48:101563
Sharshir SW, Salman M, El-Behery SM, Halim MA, Abdelaziz GB (2021d) Enhancement of solar still performance via wet wick, different aspect ratios, cover cooling, and reflectors. Int J Energy Environ Eng 12(3):517–530
Sharshir SW, Joseph A, Kandeal AW, Hussien AA (2022a) Performance improvement of tubular solar still using nano-coated hanging wick thin film, ultrasonic atomizers, and cover cooling. Sustain Energy Technol Assess 52:102127
Sharshir SW, Kandeal AW, Ellakany YM, Maher I, Khalil A, Swidan A, Abdelaziz GB, Koheil H, Rashad M (2022b) Improving the performance of tubular solar still integrated with drilled carbonized wood and carbon black thin film evaporation. Sol Energy 233:504–514
Sharshir SW, Elsheikh AH, Edreis EMA, Ali MKA, Sathyamurthyi R, Kabeel Ae, Zang J, Yang NJD, TREATMENT W (2019b) Improving the solar still performance by using thermal energy storage materials: a review of recent developments
Sharshir SW, Rozza MA, Joseph A, Kandeal AW, Tareemi AA, Abou-Taleb F, Kabeel AE (2022c) A new trapezoidal pyramid solar still design with multi thermal enhancers. Appl Therm Eng 118699
Shehabeldeen TA, Elaziz MA, Elsheikh AH, Zhou J (2019) Modeling of friction stir welding process using adaptive neuro-fuzzy inference system integrated with harris hawks optimizer. J Market Res 8(6):5882–5892
Shehabeldeen TA, Elaziz MA, Elsheikh AH, Hassan OF, Yin Y, Ji X, Shen X, Zhou J (2020) A novel method for predicting tensile strength of friction stir welded AA6061 aluminium alloy joints based on hybrid random vector functional link and Henry gas solubility optimization. IEEE Access 8:79896–79907
Shi Y, Zu C, Hong M, Zhou L, Wang L, Wu X, Zhou J, Zhang D, Wang Y (2022) ASMFS: Adaptive-similarity-based multi-modality feature selection for classification of Alzheimer’s disease. Pattern Recogn 126:108566
Shinde SM, Kawadekar DM, Patil PA, Bhojwani VK (2019) Analysis of micro and nano particle erosion by the numerical method at different pipe bends and radius of curvature. Int J Ambient Energy 1–18
Shridhar A (2017) A beginner’s guide to deep learning
Suthaharan S.J.I.S.I.S (2016) Machine learning models and algorithms for big data classification 36:1–12
Taylor RA, Phelan PE, Adrian RJ, Gunawan A, Otanicar TP (2012) Characterization of light-induced, volumetric steam generation in nanofluids. Int J Therm Sci 56:1–11
Thakur AK, Sathyamurthy R, Sharshir SW, Elnaby Kabeel A, Shamsuddin Ahmed M, Hwang J-Y (2021a) A novel reduced graphene oxide based absorber for augmenting the water yield and thermal performance of solar desalination unit. Mater Lett 286:128867
Thakur AK, Sathyamurthy R, Velraj R, Lynch I, Saidur R, Pandey AK, Sharshir SW, Ma Z, GaneshKumar P, Kabeel AE (2021b) Sea-water desalination using a desalting unit integrated with a parabolic trough collector and activated carbon pellets as energy storage medium. Desalination 516:115217
Thakur AK, Sharshir SW, Ma Z, Thirugnanasambantham A, Christopher SS, Vikram MP, Li S, Wang P, Zhao W, Kabeel AE (2021c) Performance amelioration of single basin solar still integrated with V- type concentrator: energy, exergy, and economic analysis. Environ Sci Pollut Res 28(3):3406–3420
Thakur AK, Sathyamurthy R, Velraj R, Saidur R, Lynch I, Chaturvedi M, Sharshir SW (2022) Synergetic effect of absorber and condenser nano-coating on evaporation and thermal performance of solar distillation unit for clean water production. Sol Energy Mater Sol Cells 240:111698
Tiwari A, Chaturvedi A (2022) A hybrid feature selection approach based on information theory and dynamic butterfly optimization algorithm for data classification. Expert Syst Appl 196:116621
Tuly SS, Rahman MS, Sarker MRI, Beg RA (2021) Combined influence of fin, phase change material, wick, and external condenser on the thermal performance of a double slope solar still. J Clean Prod 287:125458
Turkoglu B, Uymaz SA, Kaya E (2022) Binary artificial algae algorithm for feature selection. Appl Soft Comput 120:108630
Wang Y, Kandeal AW, Swidan A, Sharshir SW, Abdelaziz GB, Halim MA, Kabeel AE, Yang N (2021) Prediction of tubular solar still performance by machine learning integrated with Bayesian optimization algorithm. Appl Therm Eng 184:116233
Wassouf P, Peska T, Singh R, Akbarzadeh A (2011) Novel and low cost designs of portable solar stills. Desalination 276(1):294–302
Yousef MS, Hassan H (2019) An experimental work on the performance of single slope solar still incorporated with latent heat storage system in hot climate conditions. J Clean Prod 209:1396–1410
Yuan Y, Wu L, Zhang X.J.I.T.o.I.F., Security (2021) Gini-impurity index analysis 16:3154–3169
Funding
Open access funding provided by The Science, Technology & Innovation Funding Authority (STDF) in cooperation with The Egyptian Knowledge Bank (EKB).
Author information
Authors and Affiliations
Contributions
Swellam Wafa Sharshir: software, conceptualization, resources, writing original draft, writing review editing. Ahmed Elhelow: formal analysis, review editing, visualization, supervision, Funding acquisition, project administration. Ahmed Kabeel: resources, writing original draft, writing review editing. Aboul Ella Hassanien: software, formal analysis, writing review editing, visualization, funding acquisition. Abd Elnaby Kabeel: validation, writing review editing, visualization, supervision. Mostafa Elhosseini: software, conceptualization, resources, writing original draft, writing review editing.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Not applicable.
Consent for publication
All the authors have approved the manuscript and agreed with the submission to your esteemed journal.
Competing interests
The authors declare no competing interests.
Additional information
Responsible Editor: Philippe Garrigues
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Sharshir, S.W., Elhelow, A., Kabeel, A. et al. Deep neural network prediction of modified stepped double-slope solar still with a cotton wick and cobalt oxide nanofluid. Environ Sci Pollut Res 29, 90632–90655 (2022). https://doi.org/10.1007/s11356-022-21850-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11356-022-21850-2