
Abstract
The longitudinal dispersion coefficient (LDC) of river pollutants is considered as one of the prominent water quality parameters. In this regard, numerous research studies have been conducted in recent years, and various equations have been extracted based on hydrodynamic and geometric elements. LDC’s estimated values obtained using different equations reveal a significant uncertainty due to this phenomenon’s complexity. In the present study, the crow search algorithm (CSA) is applied to increase the equation’s precision by employing evolutionary polynomial regression (EPR) to model an extensive amount of geometrical and hydraulic data. The results indicate that the CSA improves the performance of EPR in terms of R2 (0.8), Willmott’s index of agreement (0.93), Nash–Sutcliffe efficiency (0.77), and overall index (0.84). In addition, the reliability analysis of the proposed equation (i.e., CSA) reduced the failure probability (Pf) when the value of the failure state containing 50 to 600 m2/s is increasing for the Pf determination using the Monte Carlo simulation. The best-fitted function for correct failure probability prediction was the power with R2 = 0.98 compared with linear and exponential functions.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Monitoring the contaminants of natural rivers is a fundamental part of environmental monitoring and assessment (Jeon et al. 2007; Rolsky et al. 2020). Developing novel methods for evaluating and accurately estimating water quality of rivers, as one of the fundamental freshwater recourses, has been an active research domain of environmental modeling and assessment (Parsaie and Haghiabi 2015). Urban and industrial sewages are globally known as the principal sources of rivers’ pollution (Sercu et al. 2009; Cheng 2003). Therefore, the study of mixing flow for reducing contamination level has drawn many researchers’ attention for water quality assessment (Hu et al. 2013; Haghiabi 2016). However, modeling the pollutant composition due to several uncertainties and irregularities regarding the formation of dead zones, recirculation mechanism, bed configuration, velocity, and secondary flow development is considered highly complex (Jeon et al. 2007). Modifying the longitudinal dispersion coefficient (LDC) has been used to specify the pollution density distribution (Li et al. 2020).
Various mixing stages influence a pollutant due to flow turbulence and molecular motion. As illustrated in Fig. 1, which is an illustration adapted from (Baek and Seo 2010), the pollutants gradually diffuse in the river and infect the downstream’s water. During the pollutant mixing process, firstly, vertical mixing rapidly occurs near the field (Seo and Cheong 1998). Afterward, a mixture occurs in the intermediate field in both longitudinal and transverse directions (Baek and Seo 2010). After completing the transverse mixing in natural rivers, the longitudinal mixing only is indefinitely maintained in the far field without any boundaries (Baek and Seo 2010). The dispersion coefficients are usually investigated using the concentration data collected from a tracer test. However, in the absence of any concentration dataset, the dispersion coefficients are determined by theoretical or empirical approaches based on the geometric and hydraulic parameters (Baek and Seo 2010). Empirical approaches and experimental datasets require time-consuming and expensive research; thus, there is an essential demand for professional tools for estimating this coefficient in rivers (Alizadeh et al. 2017c). Several studies (e.g., Elder 1959; Seo and Cheong 1998; Deng et al. 2001; Kashefipour and Falconer 2002; Disley et al. 2014; Zeng and Huai 2014; Sahin 2014; Wang and Huai 2016) estimate the LDC using the experimental methods and field measurements where the LDC of rivers represents the mixture’s intensity in the rivers (Alizadeh et al. 2017b). Among the parameters used for the prediction of LDC, hydraulic and geometrical river features, including channel width (B), flow depth (H), shear velocity (U*), and mean velocity (U), play prominent roles. However, the LDC estimations vary remarkably. Nevertheless, determining the environmental problems and evaluating the pollutant transport in rivers are important; consequently, it is important to estimate the LDC with a high accuracy (Alizadeh et al. 2017a). Generally, LDC measurement approaches have been divided into three categories: statistical equations, mathematical solutions, and artificial intelligence (AI) procedures. Mathematical solutions (e.g., numerical and analytical models) use the geomorphology and the channel’s geometry to estimate LDC. Statistical models apply the accessible measurement dataset for correlating the LDC based on the efficient parameters (regression analysis (RA) methods known as the most popular subcategories of statistical approaches). Because of the assumptions regarding the normality and linearity of this type of intricate phenomenon, these equations may not yield sufficiently accurate and valid results (Alizadeh et al. 2017c).

Conceptual diagram of dispersion mechanism in rivers
On the other hand, AI techniques have been recruited to overcome the disadvantage of regression-based methods in predicting various problems. In particular, machine learning methods, e.g., artificial neural networks (ANNs), support vector machine (SVM), model tree (MT), as well as metaheuristic algorithms, have recently shown promising results (Li et al. 2016; Wang et al. 2016; Zounemat-Kermani et al. 2016; Rezaie-Balf et al. 2017; Deo et al. 2018; Horton et al. 2018; Kisi et al. 2019; Najafzadeh and Ghaemi 2019; Fallah et al. 2019; Ghaemi et al. 2019; Maroufpoor et al. 2019; Bozorg-Haddad et al. 2019). In the case of LDC, although many studies (e.g., Adarsh 2010; Etemad-Shahidi and Taghipour 2012; Li et al. 2013; Najafzadeh and Tafarojnoruz 2016; Alizadeh et al. 2017b; Noori et al. 2017; Seifi and Riahi-Madvar 2019; Riahi-Madvar et al. 2019) have been performed during the last decades in order to predict this complicated phenomenon with high precision, the estimation results have not been adequately accurate or reliable. Consequently, this research aims to improve prediction performance by proposing the crow search algorithm (CSA) and evolutionary polynomial regression (EPR).
Theoretical background
Despite describing the pollutant behavior in natural streams as a three-dimensional advection–diffusion equation (3D-ADE), which was obtained from a Fickian diffusion law, in the far downstream of the mixing zone where concentration variations in the horizontal and vertical directions have been insignificant, the 3D-ADE over width and depth yields
where C denotes the average cross-sectional concentration, t is time (seconds-based), and U and x are the average velocities of the cross-sectional and the longitudinal coordinate along the direction of mean flow, respectively (Noori et al. 2017; Rezaie-Balf et al. 2018).
Equation (1), which is taken into account as 1D advection–dispersion equation, has been highly recruited to evaluate the behavior of pollutants originating downstream from nonsteady point resources and is a balance between the advection and dispersion. The LDC is based on the river geometries, hydraulic condition, as well as fluid properties. The government parameters influencing the LDC are expressed as
where ρ and μ are fluid density and dynamic viscosity, respectively; the width of cross section and flow depth are shown by W and H, respectively; Sn is the sinuosity of the river, Sf is the longitudinal bed shape, and U* denotes the shear velocity. To reach the dimensionless parameter in the LDC, the Buckingham theory was employed, and the dimensionless parameter was derived, as shown in Eq. (3) (Seo and Cheong 1998; Alizadeh et al. 2017a).
Since the river flow is turbulent, the Reynolds number \( \rho \frac{UH}{\mu } \) can be omitted and the measurement of the bed form and sinusitis path parameters cannot be clear. Consequently, their effectiveness can be selected as flow resistant, which can be observed in the flow depth. The nondimensional parameters that have been measured are
Developing a plethora of AI models and empirical formulas is mostly based on these nondimensionless parameters. Table 1 provides some well-known empirical formulas proposed by the researchers (Seo and Cheong 1998; Alizadeh et al. 2017c).
State of the art
This section employed various state-of-the-art scholarly studies on empirical and AI approaches for LDC prediction collected from the existing literature. A list of studies adopting empirical and AI techniques is presented in Table 1, which is arranged as an extensive overview of the prediction methods developed so far. It should be mentioned that in Table 1, the ratios of channel width to flow depth (B/H) and velocity to shear velocity (U/U*) are presented by A and C, respectively.
Elder (1959) proposed the first extension of Taylor’s approach for an open channel with infinite width using a laboratory dataset. He recruited a logarithmic velocity profile in the vertical direction and introduced an equation (Alizadeh et al. 2017b). Fischer (1967) suggested a simplified integral equation which presented the advantage of LDC estimation in the nondimensional form of accessible parameters. Liu (1977) considered lateral velocity gradients’ role in the LDC and suggested an expression in natural streams.
Seo and Cheong (1998) suggested an empirical equation with respect to the one-step technique developed by Huber (1981); it was a sturdy regression approach with a permissible estimating even at the presence of moderately bad leverage points. They used 59 sets of data from 26 U.S. streams to implement their equation. Their findings revealed that their equation had outperformed in comparison with other existing expressions. Deng et al. (2001) derived expressions for LDC prediction by assuming the importance of the transverse turbulent mixing (e). Based on the dimensional and regression analysis, Kashefipour and Falconer (2002) developed a predictive equation to estimate the LDC in natural rivers using 81 datasets collected from 30 rivers in the USA.
Disley et al. (2014) presented a predictive equation for a LDC using combined datasets from 29 rivers. Based on the outcomes, they concluded that their proposed equation was far superior to other empirical equations. Additionally, they found that the Froude number played a key role in capturing the effect of slope of the reach. Furthermore, Zeng and Huai (2014) established an empirical formula to estimate the LDC based on the 116 datasets of width, depth, cross-sectional averaged velocity, and bed shear velocity. Based on the results, their formula was as an effective method for LDC prediction. The evaluation performed by a couple of empirical approaches concerning 128 field datasets collected from 41 natural rivers in the USA revealed that the empirical equation obtained by Sahin (2014) was more valid and reliable than other predictive methods for LDC estimation in rivers.
In a research by Hamidifar et al. (2015), the examination of longitudinal dispersion in a compound open channel was performed for both vegetated and smooth floodplains and various flow conditions. They concluded that the magnitude of LDC had an increasing trend by implanting vegetation over the floodplain as well as increasing the relative flow depth. Outcomes of two studies by Farzadkhoo et al. 2018, 2019a) indicated that roughening the floodplain with stems was one of the important factors in increasing the longitudinal flow velocity and the Reynolds shear stress in the main channel. The maximum value of nondimension (LDC/U⁎H) was also found at the bend apex. Moreover, by increasing the relative flow depth, the nondimensional LDC (LDC/U⁎H) values decreased in the compound meandering channel for all the vegetated cases.
Furthermore, Farzadkhoo et al. (2019b) investigated the effect of rigid vegetation on the LDC estimation in a compound open channel. According to the results, floodplain vegetation caused the depth-averaged longitudinal velocity and LDC values to decrease and increase, respectively, compared with nonvegetated conditions. The results of a study by Shin et al. (2020) indicated that the cross-sectional averaged values of the dimensionless LDC, determined by the velocity profile data in a range of 4.1–6.5, had a behavior corresponding to the theoretical values, whereas this value, by a concentration data between 14.7 and 35.5, was 4–6 times greater than the velocity-based coefficient.
In terms of artificial intelligence, Tayfur and Singh (2005) used AI methods in LDC prediction for the first time. They employed an artificial neural network to model the LDC by 71 data of geometric and hydraulic parameters. The results showed that ANN could predict this target better than the empirical methods. Moreover, fuzzy, ANN, as well as MLR were applied by Tayfur (2006) to estimate the LDC based on 92 datasets of field dataset. He demonstrated that the fuzzy approach had higher performance compared to the other predictive methods.
Adarsh (2010) evaluated the degree of precision of data-driven models, including SVM and genetic programming (GP) in LDC estimation. The results indicated the superiority of the GP model to SVM and empirical methods. MT was employed by Etemad-Shahidi and Taghipour (2012) to estimate the LDC. In their study, for developing the proposed model, 149 distinctive hydraulic and geometrical field datasets of several rivers were applied. The error criteria confirmed that MT demonstrated a significantly good performance in capturing the relationship between input and output variables for LDC prediction than empirical approaches. The accuracy of the GP expression implemented by Sahay (2013) indicated that the GP model outperformed the empirical methods (e.g., Fisher and Liu) to predict LDC. They also found that the channel sinuosity was considered as a critical input variable for LDC prediction.
Sattar and Gharabaghi (2015) used 150 geometric and hydraulic datasets at hand for LDC prediction. Their study illustrated that the gene expression programming (GEP) model yielded the best performance. Najafzadeh and Tafarojnoruz (2016) evaluated the performance of the neuro-fuzzy–based group method of data handling (NF-GMDH)–particle swarm optimization (PSO) compared to some of the approaches such as MT, genetic algorithm (GA), and DE in LDC prediction. In their study, NF-GMDH had better accuracy than other alternative methods. They performed sensitivity analysis (SA) to select the important variables in LDC prediction. They also concluded that the flow depth had the most effective performance on the target variable. In a study by Alizadeh et al. (2017a), a multi-objective PSO algorithm was applied to derive a new expression in order to prognosticate the LDC. Based on the results, PSO methodology could increase the precision of the predictive equations by considering the optimum coefficient values.
Rezaie-Balf et al. (2018) developed evolutionary polynomial regression to estimate the LDC. According to statistical measures, EPR was an appropriate tool in comparison to the other alternative methods (e.g., PSO, GA, and MT). In addition, the result of sensitivity analysis demonstrated that channel width played a prominent role in LDC estimation. Evaluation of support vector regression (SVR), M5P, Gaussian process regression (GPR), and random forest (RF) was performed by Kargar et al. (2020) to estimate the LDC in the natural streams. Their findings illustrated that the applied M5P model outperformed the other alternative methods. Whale optimization algorithm (WOA) was applied by Memarzadeh et al. (2020) to improve the accuracy of the LDC predictive equation. Their outcomes illustrated that the proposed method could be considered as a useful method to estimate LDC.
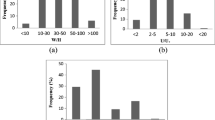
In general, in recent years, the LDC prediction has been performed using AI (67%) and empirical (33%) methods (Fig. 2). In terms of AI techniques, approximately 39% of the utilized methods have the formula to predict the LDC. Additionally, only few studies in LDC prediction (30% of equation-based models) have been carried out on the basis of the evolutionary algorithms.

Different techniques applied in LDC estimation
Objective
Since the LDC is considered as a complicated phenomenon, obtaining a predictive model with an acceptable level of accuracy has attracted many researchers’ attention. As a result, a number of predictive approaches based on the empirical and AI methods have been reviewed to find the best approach. As the first attempt, this study aims to provide a comprehensive overview of applied LDC estimation techniques. Secondly, the main contribution of the present research is to improve one of the LDC equations (Rezaie-Balf et al. 2018) by using a kind of metaheuristic algorithm called CSA. It can be said that there is no published study related to employing this algorithm in LDC prediction. The accuracy of the proposed model is evaluated with other existing equations that are provided for LDC predictions. Thirdly, after selecting the best-fitted model in LDC estimation using conventional metrics, the partial derivative sensitivity analysis (PDSA) is applied for evaluating the pattern of input variables by the superior model. Afterward, the failure limit of a phenomenon is defined as a permissible domain for its safety. Different items (e.g., number of input variables) may influence the appropriate failure limits. One of the reliability evaluation techniques is Monte Carlo simulation (MCS) which is recruited in this study to determine the failure probability of the best LDC predictive equation in different failure states. Eventually, the variations of failure probabilities regarding the average and standard deviation corresponding to the suitable distribution of input variables are investigated.
Proposed models
Crow search algorithm
Among different types of animals and birds, crows are the most intelligent, and despite the small size of their brains, they have longer memories. They can communicate in sophisticated ways, memorize faces using tools, hide foods, and remember their positions during the various seasons. These features cause crows to discover and steal other crows’ hidden foods when they are not there. If a crow finds out that it is being followed by another one, it attempts to misguide the follower by flying to another area. Considering this, Askarzadeh (2016) introduced the CSA as a novel evolutionary algorithm to solve sophisticated optimization difficulties. This approach follows four principles as follows:
-
(1)
Their lives are as herd form
-
(2)
They maintain the location of the hidden food
-
(3)
They pursue each other for robbery
-
(4)
Crows memorize their caches from being pilfered using a probability
Like other algorithms, the optimization process begins with a dimensional environment containing the crow number (or population size). Suppose x denotes the position of crow i at each time (iteration) in the search area, which is calculated using a vector \( {x}^{i,\mathrm{iter}}=\left[{x}_1^{i,\mathrm{iter}},{x}_2^{i,\mathrm{iter}},\dots, {x}_d^{i,\mathrm{iter}}\right] \) where i = (1, 2, …, N) and i = (1, 2, …, N). Each crow keeps in mind the position of its hidden location. It can be said that the best place of the hidden food experienced by each crow is preserved in its memory. Therefore, the crow’s hiding position i in iteration iter is the crow memory, which is illustrated by mi, iter. In each iteration, two states can occur, crow j flies to its hiding position (mj, iter), and crow i follows crow j to discover the hidden place of crow (Askarzadeh 2016; Díaz et al. 2018):
-
(1)
If crow j does not recognize that it is followed by crow i, crow i finds out the hidden place of crow j. Hence, the new position of crow i is expressed as
where fli, iter is the flight length for crow i in iteration iter and ri presents a random number of the uniform distribution in an interval of 0 and 1. If fl value is considered less than 1, it brings about a local search and provides other situation of crow i between xi, iter and mj, iter; otherwise, a global search will be anticipated, which causes the next situation of crow i gained away from xi, iter and may exceed mj, iter.
-
(2)
If crow j becomes aware that crow i is pursuing it to get its hidden food, it will deceive crow i by changing the food situation. States 1 and 2 are written briefly as
where APi, iter indicates the awareness possibility of crow j at iteration iter. The function of this parameter is balancing the exacerbation and variety for increasing the exacerbation by minor quantity for awareness probability by searching a local space and rising the probability value of the awareness, and CSA tends to investigate the searching space on the global scale. In sum, crow search algorithm implementation in solving the optimization problems can be expressed as (Askarzadeh 2016; Rezaie-Balf et al. 2019):
-
1.
Defining the optimization problem and its constraints, selecting the CSA flock size (N), decision variables, the awareness probability (AP), the number of iteration (itermax), as well as the length of flight (fl).
-
2.
Randomly finding the memory and position in a d-dimensional search space for proposed crows based on Eqs. (7) and (8). Each crow is considered as a conceivable solution for a specific problem, and d reveals the values for decision variables.
-
3.
Fitness function evaluation of each crow using the decision variables putting into the objective function.
-
4.
Generating a new position by crow i which one crow (crow j) selects randomly and chasing it for finding crow j’s hidden food resource (Eq. (5)).
-
5.
Evaluating the possibility of the new situation by all crows. If the possibility of a new position of each crow is confirmed, updating the position of that crow is conducted. Otherwise, the crow stays in that situation and does not generate a new position.
-
6.
Afterwards, the fitness function is assessed for the new position of each crow.
-
7.
Eventually, the memory of crows is updated using Eq. (9)
where the objective function is represented by f (.), and xi, iter and mi, iter are the position and memory of crow i in iteration iter, respectively. The termination benchmark is evaluated (repeating steps 4–7 until itermax). Ultimately, the optimum solution is the best memory position calculated based on the objective function (Askarzadeh 2016; Rezaie-Balf et al. 2019).
Geometry and hydraulic parameters influencing LDC
In this research, in order to implement CSA for estimating the LDC, a comprehensive field dataset including flow velocity, flow depth, channel width, and shear velocity was collected from the previous literature (e.g., Etemad-Shahidi and Taghipour 2012). This dataset has been applied to predict LDC in a wide range of the former studies with access to a huge number of natural streams. Moreover, it is obvious that these parameters have remarkably influence the LDC estimation (Noori et al. 2016). In general, 149 distinctive data records containing various hydraulic and geometric parameters have been applied in the model implementation (Etemad-Shahidi and Taghipour 2012). Moreover, in this study, among the defined distributions in MATLAB software, the proper distribution of each input variable based on the Kolmogorov–Smirnov test has been calculated. Hence, results of the statistical analysis of the data used (average (mean), maximum (max), minimum (min), standard deviation (SD), and their suitable distributions) are shown in Table 2.
It is clear that the largest maximum value of LDC (1486.5 m2/s) is roughly twice the second largest value. Therefore, removing these values is a convenient way (Tayfur and Singh 2005; Li et al. 2013; Disley et al. 2014). Despite the fact that omitting the largest LDC value may improve the model precision, it limits the implemented model usage. Accordingly, this study aims to improve the existing LDC equation provided by the EPR model using CSA.
Development of CSA in the prediction of the LDC
As for the artificial intelligence methods (e.g., ANN, GEP, and MT), parameter selection is one of the prominent processes for getting better performance of the methods. For illustration, in terms of ANN, the weight and the number of hidden layers are used to optimize this model. Even an incorrect selection of optimized parameters leads to worse performance of the model in comparison to what expected. As a result, applying the metaheuristic approaches can be a worthwhile way for one has no longer count on a deep experience on the application of each method to the problem.
On the other hand, as mentioned above, in the recent decades, the LDC prediction has drawn the attention of lots of researchers. Thus, various methods have been recruited to estimate the LDC accurately. Among the applied approaches, most of which are presented in Table 1, EPR is considered as one of the successful tools in LDC prediction. In this regard, the principal aim of this study is to exhibit the usage of CSA to optimize the LDC equation gained from EPR.
EPR, as one of the artificial intelligence techniques, is the nonlinear global stepwise regression, which presents mathematical expressions according to the evolutionary calculation. EPR also applied GA along with numerical regression for improving the mathematical equations to calculate optimum parameters. The common form of EPR mathematical equations is written as (Giustolisi and Savic 2009; Kakoudakis et al. 2017)
where y indicates the estimated value; ai and X are the constant coefficient and input variables, respectively; m is the sample number; F creates model structures in the process; and f is the user-defined function.
Finally, EPR expression can be presented based on one of the general forms as below
where ES(j, K) indicates a function exponent which is related to the Kth input of the jth term, and its bound is assigned by user (Khosravi and Javan 2019; Balacco and Laucelli 2019).
By assuming dimensional analysis in LDC estimation on the basis of the hydraulic (including velocity (U) and shear velocity (U∗)) and geometric (including channel width (B) and flow depth (H)) parameters, Eq. (15) is obtained
Additionally, the EPR mathematical equation that is provided for LDC estimation is written as
By considering Eq. (16), the general expression of the LDC is written as follows:
where a, b, and c until n are constant values of the equation. Therefore, the major purpose of this research is to use the CSA to gain the constant optimum values. The adjustable CSA parameters are shown in Table 3. These parameters included the flock size (N), maximum number of iterations (itermax), flight length (fl), and AP, which are determined using trial and error methodology and demonstrated optimum values of this study. In addition, LDC estimation diagram using EPR-CSA model is illustrated in Fig. 3.

LDC estimation diagram using the EPR-CSA model
Model assessment criteria
In the current study, the performance of the predictive methods is assessed by a couple of conventional benchmarks consisting of determination coefficient (R2), root mean square error (RMSE), Willmott’s index of agreement (WI), mean absolute error (MAE), Nash–Sutcliffe efficiency (NSE), overall index (OI), and objective function (OBJ), which are written as
where LDCPre and LDCObs are the estimated and observed values of LDC, respectively; LDCmean indicates the average estimated values; and N is the length of observation dataset (Gandomi et al. 2010; Ghaemi et al. 2019).
LDC prediction result and discussion
Comparison of different models
In this paper, the accuracy of a new equation that was obtained by CSA (EPR-CSA) is evaluated for the prediction of LDC. The inputs employed in the proposed model are velocity, shear velocity, channel width, and flow depth. The models were calibrated (i.e., trained) by using 103 datasets (about 70% of total dataset) while the remaining data (46 data) were utilized for validating the proposed model. The extracted equation is as follows:
In the present study, the results corresponding to the abovementioned benchmarks of 16 regression and AI-based equations were initially compared with the predictive equation obtained by EPR-CSA, and this can be difficult to have a comprehensive and comparable assessment. As asserted by Henseler et al. (2009) and Hair et al. (2013), the acceptance condition of models’ performance is determination coefficient (R2) ≥0.75, and it means that the response variable can be perfectly explained with insignificant error by the predictor variables. In this sense, eight equations provided by Seo and Cheong (1998), Deng et al. (2001), Li et al. (2013), Zeng and Huai (2014), Disley et al. (2014), Wang and Huai (2016), EPR (2018), and CSA are selected based on their determination coefficients calculated (higher than 0.75 (Table 4)).
To confirm the robustness of the proposed approach, EPR-CSA, this section presents the performances of the selected methods to estimate LDC. To evaluate the merits of the proposed method, a plethora of evaluation metrics, as expressed by Eqs. (18)–(24), is selected to illustrate the predictive performance criteria achieved in the calibration and validation stages. The predictive capability of the EPR-CSA and equations provided by previous research in LDC prediction is shown concisely in Tables 5 and 6.
Conventional benchmarks (R2, RMSE, NSE, WI, OI, as well as MAE) were applied for LDC prediction in the calibration stage, and the quantitative comparison of performances is shown in Table 5. Accordingly, by performing a comparison between the eight selected equations, the LDC prediction equation, which was observed by using the EPR model (proposed by Rezaie-Balf et al. 2018), had the highest level of accuracy with respect to statistical metrics (e.g., highest WI = 0.945 and R2 = 0.80, lowest RMSE = 88.71) in comparison with other predictive equations. After that, Eq. (25) achieved by EPR-CSA with minor difference from the EPR model in terms of RMSE (88.75), NSE (0.776), and R2 (0.787) ranked second.
In the case of validation dataset, it is apparent from Table 6 that Eq. (25) provided with EPR-CSA yielded the greatest precision (i.e., generally largest R2, OI, WI, and lowest RMSE) compared to the other approaches illustrating the crow search algorithm as a sturdy technique to enhance the EPR accuracy. For instance, as seen in Table 5, contrary to the results of the validation stage, the EPR-CSA model with lower MAE (11.41%) and higher OI (1.69%) in comparison with the EPR model with MAE = 48.52 and OI = 0.827 outperformed the EPR model. Moreover, Seo and Cheong’s (1998) equation with respect to NSE (0.659), MAE (60.25), and OI (0.772) could not estimate the LDC values compared to that of other methods, such as Wang and Huai (2016) (NSE = 0.688, MAE = 49.83, and OI = 0.789) and Disley et al. (2014) (NSE = 0.677, MAE = 48.99, and OI = 0.782)
Furthermore, to gain more meticulous comprehension of the EPR-CSA model’s performance, the goodness-of-fit and Pearson’s correlation coefficients (R) of the observed LDC values versus the predicted ones are demonstrated by Fig. 4 for the validation dataset. Scatterplots confirm the best agreement between the output and predicted values. The determination coefficient (R2) with a linear fit equation y = px + t (p and t are taken into account as the gradient and the intercept on the y-axis, respectively) and a least squares regression (LSR) line have been presented in each sub-panel (Deo et al. 2016). As it is specified in Fig. 4, most of the LDC values predicted by the eight proposed equations were underestimated, and the estimated LDC values using EPR-CSA were closest to the perfect line and were in better agreement with corresponding observed values than others.

Scatterplot of LDC values of the predicted versus the observed
Further analysis with the relative estimated error as presented on polar plots (Fig. 5) verifies the EPR-CSA model’s worthiness. As for the polar plots, the radial axis from origin illustrates the magnitude of the appraising benchmark calculated. Accordingly, it is obvious from Fig. 5a that the maximum values of evaluation metrics (R2, WI, NSE, and OI) generated by Eq. (25) were obtained by EPR-CSA. Moreover, the calculated values of RMSE, MAE, and OBJ for EPR-CSA were closer to the center of the regular octagon. These determined metrics, however, indicated the incapacitation of Seo and Cheong’s (1998) equation owing to the far distance from the regular octagon center in comparison with other alternative approaches (Fig. 5b).

Polar plots related to the selected approaches a DC, WI, NSE, OI b RMSE, MAE, OBJ
To determine the error concentration in LDC estimation, the error histograms of the proposed approaches are plotted in Fig. 6. It can be seen that the error density for EPR-CSA aggregated around the zero roughly in an interval of −3 and 3, whereas this error density related to the EPR model is almost gathered around zero between −10 and 10. Consequently, the EPR-CSA performs more appropriately compared to the other equations.

Relative forecasting error generated using proposed predictive equations for LDC prediction
Partial derivative sensitivity analysis
The PDSA is considered one of the most prominent techniques to determine the pattern of changes in predictors by the superior approach (Azimi et al. 2017). It should be noted that the positive and negative values of PDSA denote the increasing and decreasing of the objective function, respectively. On the other hand, based on the PDSA, influence of decreasing or increasing of input variables on the output variable can be found. The positive PDSA value indicates the increasing trend of the LDC. In this technique, the relative derivative of the proposed equation is conducted for each input parameter (Rashki Ghaleh Nou et al. 2019).
The results of PDSA for the input parameters (B, H, U, U*) for EPR-CSA, which could predict LDC values with a maximum level of accuracy, are shown in Fig. 7. In Fig. 7, all regression variables were plotted by means of a second-order polynomial. Accordingly, in the case of U, the calculated PDSA was positive, and by growing the U values, the sensitivity increased. Moreover, U*, B, and H versus sensitivity parameter’s behaviors were complicated and do not follow a particular trend.

The results obtained by PDSA for LDC prediction using EPR-CSA
Reliability analysis
A major problem with the reliability of the predictive approach is calculating the multifold probability integral as a failure probability (Pf) expressed as
where X = [x1, x2, …, xn]T and T and X are transposed and a vector of random variables, respectively, indicating the uncertainty of the structural quantities. The functions P(X) and f(X) represent the failure state and joint probability density function (PDF) of X, respectively. The negative values of P(ξ) (P(x) ≤ 0) reveal the integration domain which covers the failure set. As argued by Cardoso et al. (2008), the assessment of Eq. (26) is too difficult owing to some difficulties (Cardoso et al. 2008) including
-
(1)
Determining P(X),
-
(2)
Conducting the multidimensional integration of P(X) in the domain, and
-
(3)
Evaluating Eq. (26) either when the number of random variables rises or when the shape of failure regions is complicated (Cardoso et al. 2008).
These problems for calculating Eq. (26) can be essential factors to implement different approximation techniques. Generally, simulation is taken into account as a useful approach to perform experiments in a laboratory or on a digital computer to model the system behavior. Usually, simulation models output simulated data, which must be treated statistically for estimating the future treatment of that system. MCS is one of the appropriate tools that is usually applied for a number of problems, including random variables with proposed suitable probability distribution. By means of statistical sampling methods, random variables are generated based on the corresponding probability distribution. These values are treated similar to experimental datasets and are recruited to determine a sample solution. By repeating this process and generating various sample datasets, dozens of sample solutions can be obtained. Following this, the statistical analysis of the sample solutions is conducted. Thus, it can be said that the result of MCS approach depends on the length of the samples used.
In this study, the fundamental idea is that random values corresponding to the original variables, which are based on their appropriate probability distribution, are sampled, and the number of failure samples (Nf) is determined. Afterward, the failure probability (Pf) is calculated as follows (Mahadevan 1997; Cardoso et al. 2008):
where N is the length of the samples and Nf indicates failure samples, and the failure probability is written as follows:
where I(.) denotes the failure area identifier, and the values of 0 and 1 show the safe and failure regions, respectively
else
In this section, the main aim is to determine the best distribution for the input variable. To gain this aim, since there are different probability distributions for the dataset with specific features, one of them defined in MATLAB was used to determine the proper distribution in the current study (Table 2). As mentioned earlier in Table 2, among the input variables, except the variable B that follows the lognormal distribution, the generalized extreme value distribution was selected as the best probability distribution for the remaining variables, namely H, U, and U*. Additionally, 1,000,000 samples for each of the input variables, based on their own distributions, were produced in order to estimate LDC values using Eq. (25). Eventually, the failure probability for a couple of failure-state values, including 50 to 600 m2/s, has been calculated, which is demonstrated in Fig. 8. Based on Fig. 8, by increasing the value of failure state, Pf decreased. It should be noted that a power-fitted function by R2 = 0.98 for the prediction of correct failure probability is more suitable than the other fitted functions, such as linear and exponential functions.

Failure probability in various failure states
Furthermore, changes in average (μ) and standard deviation (σ) corresponding to each predictor variable’s appropriate distribution may have impact on the failure probability. On the other hand, this analysis evaluates each input variable’s influence on failure probability behavior of the proposed technique. Thus, in this research, the influence of changes in B, H, U, and U* on the failure probability of LDC predictive equation is investigated. To achieve this target, values for each predictor’s average and standard deviation separately varied in the interval of their own 0.75 and 1.25 values. Moreover, three LDC values, including 50 m2/s, 100 m2/s, as well as 150 m2/s, were considered as failure states of failure probability.
Channel width effect
Results of the failure probability changes versus the μ and σ of channel width (B) are presented in Fig. 9. Regarding Fig. 9, increasing the average of B leads to a decrease in failure probability. For instance, in the failure state 50 m2/s, the Pf value for μ = 2.64 m was equal to 0.016, and by increasing μ to 4 m, the calculated Pf had a decreasing trend by 0.002. In the case of standard deviation, Pf had an ascending trend when the σ values increased. In addition, the rising slope of the failure state 50 m2/s was roughly higher than that of the failure state 150 m2/s.

Failure probability changes for the different μ and σ values of B
Flow depth effect
Figure 10 illustrates the Pf changes versus the μ and σ of flow depth (H). As shown, Pf varies almost within the range of μ = 0.75 and μ = 1, which indicates that μ changing in this interval may have more impact on Pf in comparison to the range of μ = 1 and μ = 1.25. In contrast, the increasing value of σ caused failure probability to have a rising trend and obtained its highest value for all failure states such as having a Pf value of 0.0017 at a point with H = 1.25 for the failure state 50 m2/s.

Failure probability changes for the different μ and σ values of H
Velocity effect
The Pf changes versus the μ and σ of velocity (U) are shown in Fig. 11. Accordingly, in terms of U, it is obvious that increasing both values of μ and σ causes the failure probability to have a rising trend. However, the influence of increasing σ on the Pf was greater than μ. Additionally, for the failure state 100, the variation Pf in an interval of 75% and 125% of μ and σ was limited.

Failure probability changes for the different μ and σ values of U
Shear velocity effect
Similar to other input variables, the evaluation of Pf changes based on the μ and σ of shear velocity (U*) was performed. According to Fig. 12, an increase in the μ and σ values results in the descending and ascending trend of Pf value.

Failure probability changes for the different μ and σ values of U*
It is clear that the highest values of failure probability in different μ and σ values of input variables belonged to the failure state 50 m2/s. Therefore, this failure state was selected to assess the maximum influence of input variables with respect to their average and standard deviation in this section. The Pf variation for different average values of input variables (B, H, U, U*) is shown in Fig. 13. From Fig. 13, it can be concluded that by increasing the average values of input variables, channel width (B) has the highest importance with respect to failure probability. In case of increasing σ between 75 and 115% of standard deviation for input variables, the Pf changes for B was more than those for U*. Additionally, the σ and μ variations of H and U had relatively the lowest Pf effect compared with B and U*.

Failure probability variation for the different μ and σ input variables
Conclusion
Accurate estimation of the LDC is one of the challenges in finding the distribution of pollution density. Due to this phenomenon’s nonlinearity and complexity, it is crucial to develop more accurate predictive approaches. To this end, this research implements and evaluates the efficiency of a kind of nature-inspired metaheuristic algorithm called crow search algorithm (CSA) to optimize the LDC equation coefficients provided using the EPR model. Outcomes of this comparison with respect to some evaluation metrics indicated that, among the existing equations, the proposed model EPR-CSA with a slight difference from the EPR model in terms of RMSE and WI had an acceptable accuracy in the calibration stage. In the case of validation dataset, recruiting the obtained equations by CSA illustrated that Eq. (25) could provide an acceptable estimation of LDC values for natural rivers with the lowest RMSE (77.57) and MAE (42.987). Eventually, comparing the results of LDC equations by applied evaluation benchmarks and diagnostic plots confirms the efficiency and robustness of the EPR-CSA versus other existing equations.
As a result, it can be concluded that CSA can be an alternative and promising estimation approach for complicated problems such as LDC prediction. Evaluating the pattern of input variables in LDC prediction reveals that the calculated value of PDSA related to U was positive, and increasing the value of U has an outstanding influence on growing the PDSA value. In addition, reliability analysis of the propose equation was performed by applying MCS. Determining the failure probability for several failure states containing 50 to 600 m2/s showed that, by increasing the value of the failure state, Pf is decreasing. Moreover, the influence of the input variables on the failure probability was assessed. According to the results, σ and μ changes for channel width (B) had the most effect on the Pf compared to those of other input variables.
Data availability
The datasets used during the current study are available from the corresponding author on reasonable request.
Abbreviations
- AI:
-
Artificial intelligence
- ANFIS:
-
Adaptive neuro-fuzzy inference system
- ANN:
-
Artificial neural network
- ARE:
-
Average relative error
- B :
-
Channel width
- BA:
-
Bee algorithm
- BN:
-
Bayesian network
- CSA:
-
Crow search algorithm
- DE:
-
Differential evolution
- DR:
-
Discrepancy ratio
- EPR:
-
Evolutionary polynomial regression
- H :
-
Flow depth
- GA:
-
Genetic algorithm
- GC:
-
Granular computing
- GEP:
-
Gene expression programming
- GP:
-
Genetic programming
- GPR:
-
Gaussian process regression
- ICA:
-
Imperialist competitive algorithm
- LDC:
-
Longitudinal dispersion coefficient
- LMA:
-
Levenberg–Marquardt algorithm
- MAE:
-
Mean absolute error
- MARS:
-
Multivariate adaptive regression splines
- MCS:
-
Monte Carlo simulation
- ME:
-
Mean of the absolute error
- MER:
-
Mean error rate
- MLR:
-
Multivariate linear regression
- MT:
-
Model tree
- NE:
-
Normalized error
- NF-GMDH:
-
Neuro-fuzzy–based group method of data handling
- NSE:
-
Nash–Sutcliffe efficiency
- NLR:
-
Nonlinear regression
- P f :
-
Failure probability
- RAE:
-
Relative absolute error
- RMSE:
-
Root mean square error
- SE:
-
Standard error
- SVM:
-
Support vector machine
- SVR:
-
Support vector regression
- U :
-
Velocity
- U ∗ :
-
Shear velocity
References
Adarsh, S. (2010). Prediction of longitudinal dispersion coefficient in natural channels using soft computing techniques.
Alizadeh MJ, Shahheydari H, Kavianpour MR, Shamloo H, Barati R (2017a) Prediction of longitudinal dispersion coefficient in natural rivers using a cluster-based Bayesian network. Environ Earth Sci 76(2):86
Alizadeh MJ, Shabani A, Kavianpour MR (2017b) Predicting longitudinal dispersion coefficient using ANN with metaheuristic training algorithms. Int J Environ Sci Technol 14(11):2399–2410
Alizadeh MJ, Ahmadyar D, Afghantoloee A (2017c) Improvement on the existing equations for predicting longitudinal dispersion coefficient. Water Resour Manag 31(6):1777–1794
Antonopoulos VZ, Georgiou PE, Antonopoulos ZV (2015) Dispersion coefficient prediction using empirical models and ANNs. Environ Proc 2(2):379–394
Askarzadeh A (2016) A novel metaheuristic method for solving constrained engineering optimization problems: crow search algorithm. Comput Struct 169:1–12
Azamathulla HM, Ghani AA (2011) Genetic programming for predicting longitudinal dispersion coefficients in streams. Water Resour Manag 25(6):1537–1544
Azamathulla HM, Wu FC (2011) Support vector machine approach for longitudinal dispersion coefficients in natural streams. Appl Soft Comput 11(2):2902–2905
Azimi H, Bonakdari H, Ebtehaj I (2017) A highly efficient gene expression programming model for predicting the discharge coefficient in a side weir along a trapezoidal canal. Irrig Drain 66(4):655–666
Baek KO, Seo IW (2010) Routing procedures for observed dispersion coefficients in two-dimensional river mixing. Adv Water Resour 33(12):1551–1559
Balacco G, Laucelli D (2019) Improved air valve design using evolutionary polynomial regression. Water Supply 19(7):2036–2043
Bozorg-Haddad O, Delpasand M, & Loáiciga HA (2019). Self-optimizer data-mining method for aquifer level prediction. Water Supply.
Cardoso JB, de Almeida JR, Dias JM, Coelho PG (2008) Structural reliability analysis using Monte Carlo simulation and neural networks. Adv Eng Softw 39(6):505–513
Cheng S (2003) Heavy metal pollution in China: origin, pattern and control. Environ Sci Pollut Res 10(3):192–198
Deng ZQ, Singh VP, Bengtsson L (2001) Longitudinal dispersion coefficient in straight rivers. J Hydraul Eng 127(11):919–927
Deo RC, Samui P, Kim D (2016) Estimation of monthly evaporative loss using relevance vector machine, extreme learning machine and multivariate adaptive regression spline models. Stoch Env Res Risk A 30(6):1769–1784
Deo RC, Salcedo-Sanz S, Carro-Calvo L, & Saavedra-Moreno B (2018). Drought prediction with standardized precipitation and evapotranspiration index and support vector regression models. In: Integrating disaster science and management (pp. 151-174). Elsevier.
Díaz P, Pérez-Cisneros M, Cuevas E, Avalos O, Gálvez J, Hinojosa S, Zaldivar D (2018) An improved crow search algorithm applied to energy problems. Energies 11(3):571
Disley T, Gharabaghi B, Mahboubi AA, McBean EA (2014) Predictive equation for longitudinal dispersion coefficient. Hydrol Process 29(2):161–172
Elder J (1959) The dispersion of marked fluid in turbulent shear flow. J Fluid Mech 5(4):544–560
Etemad-Shahidi A, Taghipour M (2012) Predicting longitudinal dispersion coefficient in natural streams using M5′ model tree. J Hydraul Eng 138(6):542–554
Fallah H, Kisi O, Kim S, Rezaie-Balf M (2019) A new optimization approach for the least-cost design of water distribution networks: improved crow search algorithm. Water Resour Manag 33(10):3595–3613
Farzadkhoo M, Keshavarzi A, Hamidifar H, Javan M (2018) A comparative study of longitudinal dispersion models in rigid vegetated compound meandering channels. J Environ Manag 217:78–89
Farzadkhoo M, Keshavarzi A, Hamidifar H., & Ball J (2019a). Flow and longitudinal dispersion in channel with partly rigid floodplain vegetation. In Proceedings of the Institution of Civil Engineers-Water Management (Vol. 172, No. 5, pp. 229-240). Thomas Telford Ltd.
Farzadkhoo M, Keshavarzi A, Hamidifar H, Javan M (2019b) Sudden pollutant discharge in vegetated compound meandering rivers. Catena 182:104155
Fischer HB (1967) The mechanics of dispersion in natural streams. J Hydraul Div 93(HY6):187–216
Gandomi AH, Alavi AH, Sahab MG, Arjmandi P (2010) Formulation of elastic modulus of concrete using linear genetic programming. J Mech Sci Technol 24(6):1273–1278
Ghaemi A, Rezaie-Balf M, Adamowski J, Kisi O, Quilty J (2019) On the applicability of maximum overlap discrete wavelet transform integrated with MARS and M5 model tree for monthly pan evaporation prediction. Agric For Meteorol 278:107647
Giustolisi O, Savic DA (2009) Advances in data-driven analyses and modelling using EPR-MOGA. J Hydroinf 11(3-4):225–236
Haghiabi AH (2016) Prediction of longitudinal dispersion coefficient using multivariate adaptive regression splines. J Earth SystSci 125(5):985–995
Hair JF, Ringle CM, Sarstedt M (2013) Partial least squares structural equation modeling: rigorous applications, better results and higher acceptance. Long Range Plan 46(1-2):1–12
Hamidifar H, Omid MH, Keshavarzi A (2015) Longitudinal dispersion in waterways with vegetated floodplain. Ecol Eng 84:398–407
Henseler J, Ringle CM, & Sinkovics RR (2009). The use of partial least squares path modeling in international marketing. In New challenges to international marketing. Emerald Group Publishing Limited.
Horton P, Jaboyedoff M, Obled C (2018) Using genetic algorithms to optimize the analogue method for precipitation prediction in the Swiss Alps. J Hydrol 556:1220–1231
Hu Y, Liu X, Bai J, Shih K, Zeng EY, Cheng H (2013) Assessing heavy metal pollution in the surface soils of a region that had undergone three decades of intense industrialization and urbanization. Environ Sci Pollut Res 20(9):6150–6159
Huber PJ (1981) Robust statistics. John Wiley and Sons, Inc., New York
Iwasa Y, Aya S (1991) Predicting longitudinal dispersion coefficient in open channel flows. In: Proceedings of the international symposium on environmental hydraulics, Hong Kong, pp 505–510
Jeon TM, Baek KO, Seo IW (2007) Development of an empirical equation for the transverse dispersion coefficient in natural streams. Environ Fluid Mech 7(4):317–329
Kakoudakis K, Behzadian K, Farmani R, Butler D (2017) Pipeline failure prediction in water distribution networks using evolutionary polynomial regression combined with K-means clustering. Urban Water J 14(7):737–742
Kargar K, Samadianfard S, Parsa J, Nabipour N, Shamshirband S, Mosavi A, Chau KW (2020) Estimating longitudinal dispersion coefficient in natural streams using empirical models and machine learning algorithms. Eng Appl Comp Fluid Mech 14(1):311–322
Kashefipour SM, Falconer RA (2002) Longitudinal dispersion coefficients in natural channels. Water Res 36(6):1596–1608
Khosravi M, Javan M (2019) Prediction of side thermal buoyant discharge in the cross flow using multi-objective evolutionary polynomial regression (EPR-MOGA). J Hydroinf 21(6):980–998
Kisi O, Heddam S, Yaseen ZM (2019) The implementation of univariable scheme-based air temperature for solar radiation prediction: new development of dynamic evolving neural-fuzzy inference system model. Appl Energy 241:184–195
Koussis AD, Rodríguez-Mirasol J (1998) Hydraulic estimation of dispersion coefficient for streams. J Hydraul Eng 124(3):317–320
Li ZH, Huang J, Li J (1998) Preliminary study on longitudinal dispersion coefficient for the gorges reservoir. In: Proceedings of the seventh international symposium environmental hydraulics 16e18 December, Hong Kong, China
Li X, Liu H, Yin M (2013) Differential evolution for prediction of longitudinal dispersion coefficients in natural streams. Water Resour Manag 27(15):5245–5260
Li X, Sha J, Wang ZL (2016) A comparative study of multiple linear regression, artificial neural network and support vector machine for the prediction of dissolved oxygen. Hydrol Res 48(5):1214–1225
Li Q, Zhang H, Guo S, Fu K, Liao L, Xu Y, Cheng S (2020) Groundwater pollution source apportionment using principal component analysis in a multiple land-use area in southwestern China. Environ Sci Pollut Res 27(9):9000–9011
Liu H (1977) Predicting dispersion coefficient of streams. J. Environ. Eng Div 103(1):59–69
Mahadevan S (1997). Monte Carlo simulation. Mech Eng-New York and Basel-Marcel Dekker, 123-146.
Maroufpoor S, Sanikhani H, Kisi O, Deo RC, Yaseen ZM (2019) Long-term modelling of wind speeds using six different heuristic artificial intelligence approaches. Int J Climatol 39:3543–3557
McQuivey RS, Keefer TN (1974) Simple method for predicting dispersion in streams. J Environ Eng Div 100(4):997–1011
Memarzadeh R, Zadeh HG, Dehghani M, Riahi-Madvar H, Seifi A, Mortazavi SM (2020) A novel equation for longitudinal dispersion coefficient prediction based on the hybrid of SSMD and whale optimization algorithm. Sci Total Environ 716:137007
Mohamed HI, Hashem M (2006) Estimation of longitudinal dispersion coefficient in rivers using artificial neural networks. J Eng Sci: Assiut University 34(5):1341–1352
Najafzadeh M, Ghaemi A (2019) Prediction of the five-day biochemical oxygen demand and chemical oxygen demand in natural streams using machine learning methods. Environ Monit Assess 191(6):380
Najafzadeh M, Tafarojnoruz A (2016) Evaluation of neuro-fuzzy GMDH-based particle swarm optimization to predict longitudinal dispersion coefficient in rivers. Environ Earth Sci 75(2):157
Noori R, Karbassi A, Farokhnia A, Dehghani M (2009) Predicting the longitudinal dispersion coefficient using support vector machine and adaptive neuro-fuzzy inference system techniques. Environ Eng Sci 26(10):1503–1510
Noori R, Karbassi AR, Mehdizadeh H, Vesali-Naseh M, Sabahi MS (2011) A framework development for predicting the longitudinal dispersion coefficient in natural streams using an artificial neural network. Environ Prog Sustain Energy 30(3):439–449
Noori R, Deng Z, Kiaghadi A, Kachoosangi FT (2016) How reliable are ANN, ANFIS, and SVM techniques for predicting longitudinal dispersion coefficient in natural rivers? J Hydraul Eng 142(1):04015039
Noori R, Ghiasi B, Sheikhian H, Adamowski JF (2017) Estimation of the dispersion coefficient in natural rivers using a granular computing model. J Hydraul Eng 143(5):04017001
Parsaie A, Haghiabi AH (2015) Predicting the longitudinal dispersion coefficient by radial basis function neural network. Model Earth Syst Environ 1(4):34
Parsaie A, Emamgholizadeh S, Azamathulla HM, Haghiabi AH (2018) ANFIS-based PCA to predict the longitudinal dispersion coefficient in rivers. Int J Hydrol Sci Technol 8(4):410–424
Rashki Ghaleh Nou M, Azhdary Moghaddam M, Shafai Bajestan M, Azamathulla HM (2019) Estimation of scour depth around submerged weirs using self-adaptive extreme learning machine. J Hydroinf 21(6):1082–1101
Rezaie-Balf M, Naganna SR, Ghaemi A, Deka PC (2017) Wavelet coupled MARS and M5 model tree approaches for groundwater level forecasting. J Hydrol 553:356–373
Rezaie-Balf MR, Noori R, Berndtsson R, Ghaemi A, Ghiasi B (2018) Evolutionary polynomial regression approach to predict longitudinal dispersion coefficient in rivers. J Water Supply Res Technol AQUA 67(5):447–457
Rezaie-Balf M, Maleki N, Kim S, Ashrafian A, Babaie-Miri F, Kim NW, Chung IM, Alaghmand S (2019) Forecasting daily solar radiation using CEEMDAN decomposition-based MARS model trained by crow search algorithm. Energies 12(8):1416
Riahi-Madvar H, Ayyoubzadeh SA, Khadangi E, Ebadzadeh MM (2009) An expert system for predicting longitudinal dispersion coefficient in natural streams by using ANFIS. Expert Syst Appl 36(4):8589–8596
Riahi-Madvar H, Dehghani M, Seifi A, Singh VP (2019) Pareto optimal multigene genetic programming for prediction of longitudinal dispersion coefficient. Water Resour Manag 33(3):905–921
Rolsky C, Kelkar V, Driver E, Halden RU (2020) Municipal sewage sludge as a source of microplastics in the environment. Curr Opin Environ Sci Health 14:16–22
Sahay RR, Dutta S (2009) Prediction of longitudinal dispersion coefficients in natural rivers using genetic algorithm. Hydrol Res 40(6):544–552
Sahay RR (2011) Prediction of longitudinal dispersion coefficients in natural rivers using artificial neural network. Environ Fluid Mech 11(3):247–261
Sahay RR (2013) Predicting longitudinal dispersion coefficients in sinuous rivers by genetic algorithm. J Hydrol Hydromech 61(3):214–221
Sahin S (2014) An empirical approach for determining longitudinal dispersion coefficients in rivers. Environ Proc 1(3):277–285
Sattar AM, Gharabaghi B (2015) Gene expression models for prediction of longitudinal dispersion coefficient in streams. J Hydrol 524:587–596
Seifi A, Riahi-Madvar H (2019) Improving one-dimensional pollution dispersion modeling in rivers using ANFIS and ANN-based GA optimized models. Environ Sci Pollut Res 26(1):867–885
Seo IW, Cheong TS (1998) Predicting longitudinal dispersion coefficient in natural streams. J Hydraul Eng 124(1):25–32
Sercu B, Werfhorst LCVD, Murray J, Holden PA (2009) Storm drains are sources of human fecal pollution during dry weather in three urban southern California watersheds. Environ Sci Technol 43(2):293–298
Shin J, Seo IW, Baek D (2020) Longitudinal and transverse dispersion coefficients of 2D contaminant transport model for mixing analysis in open channels. J Hydrol 583:124302
Tayfur G (2006) Fuzzy, ANN, and regression models to predict longitudinal dispersion coefficient in natural streams. Hydrol Res 37(2):143–164
Tayfur G (2009) GA-optimized model predicts dispersion coefficient in natural channels. Hydrol Res 40(1):65–78
Tayfur G, Singh VP (2005) Predicting longitudinal dispersion coefficient in natural streams by artificial neural network. J Hydraul Eng 131(11):991–1000
Toprak ZF, Cigizoglu HK (2008) Predicting longitudinal dispersion coefficient in natural streams by artificial intelligence methods. Hydrol Proc: An International Journal 22(20):4106–4129
Toprak ZF, Savci ME (2007) Longitudinal dispersion coefficient modeling in natural channels using fuzzy logic. CLEAN–Soil, Air, Water 35(6):626–637
Toprak ZF, Hamidi N, Kisi O, Gerger R (2014) Modeling dimensionless longitudinal dispersion coefficient in natural streams using artificial intelligence methods. KSCE J Civ Eng 18(2):718–730
Tutmez B, Yuceer M (2013) Regression kriging analysis for longitudinal dispersion coefficient. Water Resour Manag 27(9):3307–3318
Wang Y, Huai W (2016) Estimating the longitudinal dispersion coefficient in straight natural rivers. J Hydraul Eng 142(11):04016048
Wang L, Kisi O, Zounemat-Kermani M, Salazar GA, Zhu Z, Gong W (2016) Solar radiation prediction using different techniques: model evaluation and comparison. Renew Sust Energ Rev 61:384–339
Zeng Y, Huai W (2014) Estimation of longitudinal dispersion coefficient in rivers. J Hydro Environ Res 8(1):2–8
Zounemat-Kermani M, Kişi Ö, Adamowski J, Ramezani-Charmahineh A (2016) Evaluation of data driven models for river suspended sediment concentration modeling. J Hydrol 535:457–472
Funding
Open Access funding provided by Óbuda University. This work received financial support from the Hungarian State and the European Union under the EFOP-3.6.1-16-2016-00010 project and the 2017-1.3.1-VKE-2017-00025 project. This research has been in part supported by the Alexander von Humboldt Foundation.
Author information
Authors and Affiliations
Contributions
Conceptualization: AG, TZ, BP, SAHM, and AM; methodology: AG, TZ, BP, SAHM, and AM; software: AG, TZ, BP, SAHM, and AM; validation: AG, TZ, BP, SAHM, and AM; formal analysis: AG, TZ, BP, SAHM, and AM; investigation: AG, TZ, BP, SAHM, and AM; resources: AG, TZ, BP, SAHM, and AM; data curation: AG, TZ, BP, SAHM, and AM; writing—original draft preparation: AG, TZ, and BP; writing—review and editing: AG, TZ, BP, SAHM, and AM; visualization: AG, TZ, BP, SAHM, and AM; supervision: AG, TZ, BP, SAHM, and AM; project administration: A.M.; funding acquisition: A.M. All authors have read and agreed to the published version of the manuscript.
Corresponding authors
Ethics declarations
Ethics approval and consent to participate
This manuscript does not report on or involve the use of any animal or human data or tissue.
Consent for publication
This manuscript also does not contain data from any individual person, and therefore, consent to publish is not applicable.
Competing interests
The authors declare no competing interests.
Additional information
Responsible Editor: Marcus Schulz
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ghaemi, A., Zhian, T., Pirzadeh, B. et al. Reliability-based design and implementation of crow search algorithm for longitudinal dispersion coefficient estimation in rivers. Environ Sci Pollut Res 28, 35971–35990 (2021). https://doi.org/10.1007/s11356-021-12651-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11356-021-12651-0