
Abstract
Studies with sensitive questions should include a sufficient number of respondents to adequately address the research interest. While studies with an inadequate number of respondents may not yield significant conclusions, studies with an excess of respondents become wasteful of investigators’ budget. Therefore, it is an important step in survey sampling to determine the required number of participants. In this article, we derive sample size formulas based on confidence interval estimation of prevalence for four randomized response models, namely, the Warner’s randomized response model, unrelated question model, item count technique model and cheater detection model. Specifically, our sample size formulas control, with a given assurance probability, the width of a confidence interval within the planned range. Simulation results demonstrate that all formulas are accurate in terms of empirical coverage probabilities and empirical assurance probabilities. All formulas are illustrated using a real-life application about the use of unethical tactics in negotiation.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Traditional direct questioning methods face limitations when socially sensitive topics are studied. Usually, respondents may refuse to answer, may conceal their true preferences, opinions or behaviors if the attribute in question is illegal, or may temper their responses to appear to be more socially acceptable (social desirability bias), especially if their responses can be observed by the third parties. These make data collection using surveys with sensitive questions challenging, as refusal to answer will result in nonresponse bias and offering untruthful answers will lead to response bias. Both sources of bias can negatively influence data quality and produce severely biased prevalence estimates (i.e., over- or under-estimation of the behavior under study) and inflated standard error estimates (i.e., probably wrong conclusion), which in turn jeopardize the usefulness of the data for both research and policy making (Chaudhuri & Mukerjee, 1988; Rasinski et al., 1999; Tourangeau & Yan, 2007).
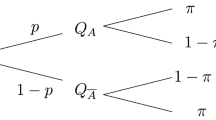
Randomized response techniques (RRTs), originally proposed by Warner (1965), aim to eliminate or at least minimize both response and nonresponse biases from survey respondents. By introducing random noise via employing a randomizing device, the RRT conceals individual responses and thus protects respondents’ privacy. Therefore, respondents may be more willing to answer truthfully. In Warner’s model, a respondent is presented with two mutually exclusive statements about the sensitive attributes, for example, (A): Have you ever made promises without an intention to deliver in a negotiation? and (\(A^c\)): Have you never made promises without an intention to deliver in a negotiation? The respondent is then instructed to provide an answer to statement A or \(A^c\), depending on the outcome from a randomizing device provided by the interviewer (e.g., spinning arrow, dice or coin), with the probability p of being assigned to answer A and \(1-p\) of being assigned to answer \(A^c\) (with \(p \ne 0.5\)). It should be noted that the interviewer does not know which question to be answered by the respondent, but he or she knows only the probability p. As a result, the privacy of the interviewee is protected (for details, see Fox & Tracy, 1986; Horvitz, Greenberg, & Abernathy, 1976). It is noteworthy that statements A and A\(^c\) are two related but mutually exclusive and complimentary questions. Most importantly, both questions are related to the sensitive attribute. Several revisions and modifications of Warner’s model have been proposed over the years (e.g., Greenberg et al., 1969; Mangat, 1994). One of these is the well-established unrelated question model (UQM) proposed by Greenberg et al. (1969). Briefly, UQM simply replaces statement \(A^c\) in Warner’s model by a neutral question, for example, "Were you born in the first quarter of a year?". Dowling and Shachtman (1975) proved that UQM usually yields a more reliable sensitive prevalence estimate than Warner’s estimate. Even though an unrelated question is introduced in the UQM, some respondents ("cheaters") will choose to answer a self-protective "No" to either of the two alternative questions in the survey. To take this behavior into consideration, another modification of the RRT known as cheater detection model (CDM) was proposed by Clark and Desharnais (1998). CDM is considered as an improvement over the forced-response procedure, which modifies Warner’s model by replacing the neutral question in the UQM by the forced instruction to say "yes" for the inverted sensitive question. In particular, it considers not only those carriers of the sensitive attribute who answer honestly and noncarriers who answer honestly but also a third class of respondents, namely cheaters who respond "No" regardless of the outcome of the randomization procedure. Clark and Desharnais (1998) referred to the latter class as cheaters. To provide a greater degree of privacy to respondents, Miller (1984) developed another indirect questioning technique, namely the item count technique (ICT), in which the respondents are randomly assigned to either the experiment group or control group. Respondents in the control group are presented with a list of k neutral questions with answers "Yes" or "No", those in the experiment group are given the same k neutral questions together with the sensitive item. In both groups, all respondents are asked to report only their total number of "Yes" answers but not the replies to the individual items. Note that the response to each question is a binary variable. The difference between the observed means in the experiment and control groups provides an estimate of the proportion of the sensitive attribute. The privacy of respondents is protected to a greater extent, because this approach allows respondents to mask their answers to the sensitive question. Therefore, a potentially less biased prevalence estimate of the sensitive attribute may be obtained using the item count procedure.
Sample size determination becomes a crucial step in every study design, since studies with an inadequate number of respondents may not yield significant conclusions, while those with an excess of respondents become a waste of investigators’ resources. Ulrich et al. (2012) derived the statistical powers for the aforementioned models (i.e., Warner’s RRT model, UQM, ICT and CDM) based on the Wald test statistic. As a result, their corresponding sample size requirements that can achieve a desired power for the Wald test with a predetermined Type I error rate can be readily obtained. However, it is well documented that confidence intervals are more informative than simple hypothesis tests (which simply yield a direct accept-or-reject conclusion) in terms of description of location and precision of the statistic, and confidence intervals should be the best reporting strategy, based on the recommendations of Wilkinson and the American Psychological Association Task Force on Statistical Inference (1999) and the Publication Manual of the American Psychological Association (2009). Indeed, several prominent educational and psychological journals stressed in their editorial guidelines and methodological recommendations that it is necessary to include some measures of effect size and confidence intervals for all primary outcomes (see, Alhija and Levy, 2009; Dunst and Hamby, 2012; Fritz, Morris and Richler, 2012; Odgaard and Fowler, 2010; and Sun, Pan and Wang, 2010). In this paper, we thus consider the sample size formulas that can control the width of a confidence interval for the prevalence of sensitive attributes with a pre-specified confidence level. Most importantly, our formulas explicitly incorporate an assurance probability of achieving pre-specified precision.
This article is organized as follows. Sample size formulas that control the width of a confidence interval with a pre-specified confidence level for the prevalence of a sensitive attribute for the aforementioned models (i.e., Warner’s RRT model, UQM, ICT and CDM) are derived in Sect. 1. Most importantly, our formulas explicitly incorporate a pre-specified probability of achieving the pre-specified width. We evaluate their performance in Sect. 2. In Sect. 3, a real example of how Kern and Chugh (2009) examined negotiators’ unethical behavior is used to illustrate the accuracy of the estimated sample size formulas. In this example, the sensitive question is: Have you ever made promises without an intention to deliver in a negotiation? In one of Kern and Chugh’s (2009) experiments, \(16.5\%\) of participants, on average, made false promises to their advantage. Suppose that an applied psychologist collects survey data and examines whether negotiators use this unethical tactic in order to increase the likelihood of reaching an agreement. We calculate the required sample size for a new study that can control the width of a confidence interval at a specified confidence level, with the assurance probability of achieving the pre-specified precision, for the various RRT models considered in this article. A brief conclusion and discussion will be given in Sect. 4.
1 Sample Size Determination
1.1 Sample Size Estimation Under Warner’s RRT Model
1.1.1 Confidence Intervals Under Warner’s RRT Model
Under Warner’s model, a randomizing device is used to determine if a respondent will answer the sensitive question A with probability p or the complement question A\(^c\) with probability \(1-p\) with p \(\ne \) 0.5. The parameter of interest is the proportion of subjects in the population who possess the sensitive attribute and is denoted by \(\pi _s\). Let \(\lambda \) \(=\) \(\pi _s p+(1-\pi _s)(1-p)\) (i.e., the probability of a respondent answering "Yes"), n the number of respondents participating in the survey and x the number of respondents answering "Yes." Obviously, x follows the binomial distribution \(B(n,\lambda )\) and the maximum likelihood estimate (MLE) of \(\lambda \) is given by \(\hat{\lambda }\) \(=\) x/n with expectation being \(\text{ E }(\hat{\lambda })\) \(=\) \(\lambda \) and variance being \(\text{ Var }(\hat{\lambda })\) \(=\) \(\lambda (1-\lambda )/n\). Since \(\pi _s\) \(=\) \((\lambda +p-1)/(2p-1)\) (p \(\ne \) 0.5), the MLE of \(\pi _s\) is given by \(\hat{\pi }_{s, WM}\) \(=\) \((\hat{\lambda }+p-1)/(2p-1)\). Therefore, the variance of \(\hat{\pi }_s\) is given by
As a result, the \((1-\alpha )100\%\) Wald confidence interval (CI) for \(\pi _s\) is given by
where \(z_{\alpha /2}\) is the \(1 -\alpha /2\) quantile of the standard normal distribution. As shown in Newcombe (1998) and Agresti and Coull (1998), a confidence interval based on Wilson method performs very well compared to the Wald interval, when sample size is not large. Therefore, we also apply the Wilson (1927) method to construct a \((1-\alpha )100\%\) confidence interval for \(\pi _s\) as
where
1.1.2 Sample Size Formula Based on Wald Confidence Interval \({{\varvec{[n_{WM, W}}}}\), \({{\varvec{n_{WM, W, 0.5}]}}}\)
The half width of the \((1-\alpha )100\%\) Wald CI for \(\pi _s\) is given by
Here, we control the half width no larger than \(\omega \) with probability \(1-\beta \). That is,
or equivalently
According to the delta method, it is easily shown that
If we let Z \(=\) \(\frac{\sqrt{\hat{\lambda }(1-\hat{\lambda })}-\sqrt{\lambda (1-\lambda )}}{|1-2\lambda |/(2\sqrt{n})}\), then we have
Therefore, the desired sample size n satisfies the following equation:
where \(z_\beta \) is the \(1-\beta \) quantile of a standard normal distribution.
Solving the above equation yields
In particular, when \(\beta \) \(=\) 0.5 the conventional sample size is given by
Given the values of n, p and \(\pi _s\), the assurance probability can be obtained by
where \(\Phi (\cdot )\) is the distribution function of the standard normal random variable.
1.1.3 Sample Size Formula Based on Wilson Confidence Interval \({{\varvec{[n_{WM, Wi}}}}\), \({{\varvec{n_{WM, Wi, 0.5}]}}}\)
Similarly, in order to control the half width of the Wilson CI to be no larger than \(\omega \) with probability \(1-\beta \), the sample size estimate needs to satisfy
i.e.,
According to the delta method, the asymptotic distribution of \(\hat{\lambda }(1-\hat{\lambda })\) is
Therefore,
i.e., the approximate sample size (denoted as \({{\varvec{n_{WM, Wi}}}}\)) can be obtained by solving the following equation:
where
The eigenvalue methods for finding roots of polynomials can be used to obtain the sample size estimate, based on Wilson method by solving Eq. (6) with respect to \(n+z_{\alpha /2}^2\). If \(m_\mathrm{max}\) is the maximum real root of Eq. (6), then the desired sample size \({{\varvec{n_{WM, Wi}}}}\) is the minimum integer that is not smaller than \(m_\mathrm{max}-z_{\alpha /2}^2\).
In particular, when \(\beta \) \(=\) 0.5, the approximate sample size n is given by
Given the values of n, p and \(\pi _s\), the assurance probability can be obtained by
1.2 Sample Size Estimation Under Unrelated Question Model
1.2.1 Confidence Intervals Under Unrelated Question Model
It should be noted that the unrelated question model (UQM) simply replaces question A\(^c\) in Warner’s model with a neutral question N (see, Greenberg et al., 1969). Similar to Warner’s model, a randomizing device is used to impel a respondent to answer A with a probability of p or the neutral question N with a probability of \(1 - p\). Let the probability of responding "yes" to statement N be \(\pi _N\). If \(\lambda \) \(=\) \(p\pi _s+(1-p)\pi _N\), then x follows binomial distribution B(n,\(\lambda \)). Again, the MLE of \(\lambda \) is given by \(\hat{\lambda }\) \(=\) x/n, and the expectation and variance of \(\hat{\lambda }\) are, respectively, E(\(\hat{\lambda }\)) \(=\) \(\lambda \) and Var(\(\hat{\lambda }\)) \(=\) \(\lambda (1-\lambda )/n\). Therefore, the MLE of \(\pi _{s, UQM}\) is \(\hat{\pi }_{s, UQM}\) \(=\) \((\hat{\lambda }-(1-p)\pi _N)/p\), E(\(\hat{\pi }_{s, UQM}\)) \(=\) \(\pi _s\) and Var(\(\hat{\pi }_{s, UQM}\)) \(=\) \(\lambda (1-\lambda )/(np^2)\).
The \((1-\alpha )100\%\) confidence interval for \(\pi _s\) based on Wald method is given by
Alternatively, a \((1-\alpha )100\%\) Wilson confidence interval for \(\lambda \) is given by
Hence, the \((1-\alpha )100\%\) Wilson confidence interval for \(\pi _s\) can be obtained as
where
and
1.2.2 Sample Size Formula Based on Wald Confidence Interval \({{\varvec{[n_{UQM, W}}}}\), \({{\varvec{n_{UQM, W, 0.5}]}}}\)
Again, we control the half width of the Wald CI to be no larger than \(\omega \) with probability \(1-\beta \). That is,
or,
It is shown that
Equation (10) becomes
Therefore,
i.e.,
By solving the above equation, we have
When \(\beta \) \(=\) 0.5, the approximate sample size is given by
1.2.3 Sample Size Formula Based on Wilson Confidence Interval \({{\varvec{[n_{UQM, Wi}}}}\), \({{\varvec{n_{UQM, Wi, 0.5}]}}}\)
To control the half width of the Wilson CI that is no larger than \(\omega \) with probability \(1-\beta \), the desired sample size should satisfy
i.e.,
It is thus shown that the sample size is the solution to the following equation:
where
Similarly, the eigenvalue methods can be used to find the solutions of the above equation with respect to \(n+z_{\alpha /2}^2\), and the approximate sample size n is denoted as \({{\varvec{n_{UQM, Wi}}}}\).
When \(\beta \) \(=\) 0.5, the formula reduces to
1.3 Sample Size Estimation Under Item Count Technique
1.3.1 Confidence Intervals Under Item Count Technique
Under the item count technique (ICT) model developed by Miller (1984), it was designed that the \(n_c\) respondents randomly assigned to the control group would receive a list of k neutral questions, while the \(n_e\) respondents randomly assigned to the experiment group would receive the same set of neutral questions as the control group together with the sensitive question. The probability of answering the ith neutral question with "yes" would be \(\pi _i\) (\(i=1,2,\ldots ,k\)). Let the expected numbers of total "yes" response of the control and experiment groups are \(T_c\) \(=\) \(\sum \nolimits _{i=1}^k\pi _i\) and \(T_e\) \(=\) \(\sum \nolimits _{i=1}^k\pi _i+\pi _s\), respectively. Let \(t_c\) be the total number of answering "Yes" in the control group and \(t_e\) be the total number of answering "Yes" in the experiment group, respectively. Therefore, \(\hat{T}_c\) \(=\) \(t_c/n_c\) and \(\hat{T}_e\) \(=\) \(t_e/n_e\), and the estimation of \(\pi _s\) is given by \(\hat{\pi }_s\) \(=\) \(\hat{T}_e\) − \(\hat{T}_c\) \(=\) \(t_e/n_e-t_c/n_c\).
Given that all items are statistically unrelated, it is shown that the sample variance of \(\hat{\pi }_s\) is given by
Therefore, the \((1-\alpha )100\%\) Wald confidence interval for \(\pi _s\) is given by
where
and
while the \((1-\alpha )100\%\) Wilson confidence interval for \(\pi _s\) is given by
where
and
1.3.2 Sample Size Formula Based on Wald Confidence Interval \({{\varvec{[n_{ICT, W}}}}\), \({{\varvec{n_{ICT, W, 0.5}]}}}\)
It is noted that the half width of the \((1-\alpha )100\%\) Wald CI is given by
To control the half width of the Wald CI that is no larger than \(\omega \) with a probability of \(1 - \beta \), the desired sample size should satisfy
i.e.,
It is clear that
Hence, we have
When \(n_c\) \(=\) \(n_e\) \(=\) \(\frac{1}{2}n\) and let c \(=\) \(2\sum \nolimits _{i=1}^k\pi _i(1-\pi _i)+\pi _s(1-\pi _s)\), the above equation can be simplified to
where
According to Cardans formula for solving the cubic equation, the desired sample size \(n_e\) (\(=\frac{1}{2}n\)) can be estimated to be the unique real root or the maximum root of three real roots. Therefore, the estimated sample size is given by \({{\varvec{n_{ICT, W}}}}=2n_e\).
When \(\beta \) \(=\) 0.5, the estimated sample size n is given by
1.3.3 Sample Size Formula Based on Wilson Confidence Interval \({{\varvec{[n_{ICT, Wi}}}}\), \({{\varvec{n_{ICT, Wi, 0.5}]}}}\)
The half width of the \((1-\alpha )100\%\) Wilson CI is given by
To control the half width of the Wilson CI to be no larger than \(\omega \) with probability \(1-\beta \), we have
i.e.,
Similarly, it is clear that
Therefore, we have
If \(n_c\) \(=\) \(n_e\), then
where
Similarly, the eigenvalue methods can be employed to find the solutions of the above equation with respect to \(n_e+z_{\alpha /2}^2\), and the desired sample size is denoted as \({{\varvec{n_{ICT, Wi}}}}\) (i.e., \({{\varvec{n_{ICT, Wi}}}}= 2n_e\)).
When \(\beta \) \(=\) 0.5, the estimated sample size n is given by
where f \(=\) \(2\sum \nolimits _{i=1}^k\pi _i(1-\pi _i)+\pi _s(1-\pi _s)\) and g \(=\) \(\omega ^2[4\pi _s(1-\pi _s)-1]\).
1.4 Sample Size Estimation Under Cheater Detection Model
1.4.1 Confidence intervals Under Cheater Detection Model
Assume that the true proportions of honest-yes respondents, honest-no respondents, and cheaters are \(\pi _s\), \(\beta _s\) and \(\gamma \), respectively (i.e., \(\pi _s\)+\(\beta _s\)+\(\gamma \)=1), and a total of n individuals participates in the interview under Cheater Detection Model (CDM). Following Clark & Desharnais (1998), the whole sample n is divided into two subsamples of sizes \(n_1\) and \(n_2\) to estimate parameters \(\pi _s\), \(\beta _s\) and \(\gamma \). The probabilities of a respondent being assigned by the randomizing device to answer the sensitive question are, respectively, \(p_1\) and \(p_2\) (\(p_1\) \(\ne \) \(p_2\)) for subsamples 1 and 2. Let \(\lambda _1\) and \(\lambda _2\) denote the true proportions of "yes" responses, and \(y_1\) and \(y_2\) the number of "Yes" answers for subsamples 1 and 2. Obviously, \(y_i\) follows B(\(n_i,\lambda _i\)) (i =1, 2). Then, we have \(\hat{\lambda }_i\) \(=\) \(y_i/n_i\) (i =1, 2), \(\hat{\pi }_s\) \(=\) \((p_2\hat{\lambda }_1-p_1\hat{\lambda }_2)/(p_2-p_1)\), \(\hat{\beta }_s\) \(=\) \((\hat{\lambda }_2-\hat{\lambda }_1)/(p_2-p_1)\) and \(\hat{\gamma }\) \(=\) \(1-\hat{\pi }_s-\hat{\beta }_s\). Therefore, the variance of \(\hat{\pi }_s\) is given by \(\frac{p_2^2}{(p_2-p_1)^2}\cdot \frac{\lambda _1(1-\lambda _1)}{n_1}\) + \(\frac{p_1^2}{(p_2-p_1)^2}\cdot \frac{\lambda _2(1-\lambda _2)}{n_2}\). As a result, the \((1-\alpha )100\%\) Wald confidence interval for \(\pi _s\) is given by
where
and
Alternately, since \(\pi _s\) \(=\) \((p_2\lambda _1-p_1\lambda _2)/(p_2-p_1)\), we can first construct the Wilson confidence intervals for \(\lambda _1\) and \(\lambda _2\) and subsequently obtain the confidence interval for \(\pi _s\) via the method of variance estimates recovery (MOVER) proposed by Zou & Donner (2008). It is shown that the \((1-\alpha )100\%\) Wilson confidence lower and upper limits for \(\lambda _i\) can be obtained by
for i = 1,2.
By using MOVER proposed by Zou & Donner (2008), the \((1-\alpha )100\%\) confidence interval for \(\pi _s\) is given by
where
and
1.4.2 Sample Size Formula Based on Wald Confidence Interval \({{\varvec{[n_{CDM, W}}}}\), \({{\varvec{n_{CDM, W, 0.5}]}}}\)
The half width of the \((1-\alpha )100\%\) Wald CI is given by
To control the half width of the Wald CI to be no larger than \(\omega \) with probability \(1-\beta \), we have
Let A \(=\) \(p_2^2/n_1\), B \(=\) \(p_1^2/n_2\) and C \(=\) \(\omega |p_2-p_1|/z_{\alpha /2}\), then we have
Similarly, it is clear that
Therefore, we have
If \(n_1\) \(=\) \(n_2\) \(=\) \(\frac{1}{2}n\), the above equation can be simplified as
where \(D=p_2^2\lambda _1(1-\lambda _1)+p_1^2\lambda _2(1-\lambda _2)\) and E \(=\) \(p_2^4\lambda _1(1-\lambda _1)(1-2\lambda _1)^2\) \(+\) \(p_1^4\lambda _2(1-\lambda _2)\) \((1-2\lambda _2)^2\). By using Cardans formula for solving the cubic equation, we can obtain the solutions and the desired sample size is the minimum integer that is not smaller than the unique real root or the maximum root of three real roots. The estimated sample size is denoted as \({{\varvec{n_{CDM, W}}}}\).
When \(\beta \) \(=\) 0.5, the formula reduces to be
1.4.3 Sample Size Formula Based on Wilson Confidence Interval \({{\varvec{[n_{CDM, Wi}}}}\), \({{\varvec{n_{CDM, Wi, 0.5}]}}}\)
The width of the \((1-\alpha )100\%\) Wilson CI is given by
To control the width of the Wilson CI to be no larger than \(2\omega \) with probability \(1-\beta \), we have
Let a \(=\) \(p_2^2(\bar{u}_1-\lambda _1)^2\) \(+\) \(p_1^2(\lambda _2-\bar{l}_2)^2\), b \(=\) \(p_2^2(\lambda _1-\bar{l}_1)^2\) \(+\) \(p_1^2(\bar{u}_2-\lambda _2)^2\) with
and c \(=\) \(n_1\lambda _1(1-\lambda _1)+z_{\alpha /2}^2/4\), d \(=\) \(n_2\lambda _2(1-\lambda _2)+z_{\alpha /2}^2/4\), e \(=\) \([p_2^2(u_1-\hat{\lambda }_1)^2+p_1^2(\hat{\lambda }_2-l_2)^2]^{1/2}\) \(+\) \([p_2^2(\hat{\lambda }_1-l_1)^2+p_1^2(u_2-\hat{\lambda }_2)^2]^{1/2}\). It is shown that the variance of e is given by
i.e.,
Equation (28) can be re-written as
Therefore, we have
When \(\beta \) \(=\) 0.5, the equation is given as
If \(n_1\) \(=\) \(n_2\) \(=\) \(\frac{1}{2}n\), the desired sample sizes can be obtained by solving Eqs. (29) or (30) via the secant method. The desired sample sizes are estimated to be the minimum integer that is not smaller than the maximum real root of Eqs. (29) or (30), respectively. The corresponding estimated sample sizes (i.e., the values of n) are denoted as \({{\varvec{n_{CDM, Wi}}}}\) and \({{\varvec{n_{CDM, Wi, 0.5}}}}\), respectively.
2 Evaluation
To evaluate the formulas proposed in this article, we consider the following parameter settings for different models:
(a) Warner model: (1) p \(=\) 0.3, 0.6, 0.8; (2) \(\pi _s\) \(=\) 0.04(0.04)0.16; (3) \(\omega \) \(=\) \(25\%\) or \(50\%\) of \(\pi _s\); i.e., a total of 3 \(\times \) 4 \(\times \) 2 \(=\) 24 parameter combinations.
(b) Unrelated question model: \(p=0.75\) and (1) \(\pi _N\) \(=\) 0.2(0.3)0.8; (2) \(\pi _s\) \(=\) 0.04(0.04)0.16; (3) \(\omega \) \(=\) \(25\%\) or \(50\%\) of \(\pi _s\); i.e., a total of 3 \(\times \) 4 \(\times \) 2 \(=\) 24 parameter combinations.
(c) Item count technique: (2) k \(=\) 4(2)8; (2) \(\pi _s\) \(=\) 0.04(0.04)0.16; (3) \(\pi _i=0.5\) for \(i=1,2,\ldots ,k\); (4) \(\omega \) \(=\) \(25\%\) or \(50\%\) of \(\pi _s\); i.e., a total of 3 \(\times \) 4 \(\times \) 2 \(=\) 24 parameter combinations.
(d) Cheater detection model: (1) \(p_1\) \(=\) 1/3, \(p_2\) \(=\) 2/3 or \(p_1\) \(=\) 1/4, \(p_2\) \(=\) 3/4; (2) \(\beta _s\) \(=\) 0.04(0.04)0.16; (3) \(\pi _s\) \(=\) 0.04(0.04)0.16; (4) \(\omega \) \(=\) \(25\%\) or \(50\%\) of \(\pi _s\); i.e., a total of 3 \(\times \) 4 \(\times \) 2 \(=\) 64 parameter combinations.
According to the formulas developed in Sect. 1, the desired sample sizes can be estimated for different RRT models. Given the estimated sample sizes, we can then consider their empirical coverage probabilities (ECPs), empirical assurance probabilities (EAPs), left noncoverage probabilities (LNCPs) and right noncoverage probabilities (RNCPs) of the \((1-\alpha )100\%\) Wald and Wilson CIs for evaluating the accuracy of various sample size formulas. For all models, the confidence level \(1-\alpha \) is set to be 0.95, and the number of replications is set to be \(K=10000\) when calculating the following evaluation indices:
(i) Empirical Assurance Probability (EAP)
where \((\pi _{l}^{(k)},\pi _{u}^{(k)})\) is the CI for \(\pi _s\) at the kth replication, and \(I(\cdot )\) is the indicator function of the event that \(\pi _{u}^{(k)}-\pi _{l}^{(k)}\le 2\omega \).
(ii) Empirical Coverage Probability (ECP)
(iii) Left and Right Noncoverage Probability (LNCP and RNCP)
Simulation results for assessing the accuracy of various sample size formulas under Warner’s model, unrelated question model, item count technique and cheater detection model are reported in Tables 1, 2, 3, 4 and 5.
When the assurance probability is 95%, results in Tables 1, 2, 3, 4 and 5 consistently show that all the empirical assurance probabilities (EAPs) are generally close to the pre-determined nominal level for both Wald and Wilson methods under the four RRT models. Only when assurance probability is 50%, EAPs of Wald method are slightly lower than the nominal in some cases (e.g., \(\pi _s\) \(=\) 0.08, 0.12 with p \(=\) 0.8 and \(\pi _s\) \(=\) 0.12 with \(\pi _N\) \(=\) 0.2, 0.8 for Warner’s RRT model). Based on the estimated sample sizes, all CIs perform well in the regard that their ECPs are pretty close to the pre-specified nominal level (i.e., \(95\%\)) and have satisfactory balance between left- and right-tailed errors. The results also show that the sample size estimates, using Wilson approach, are slightly smaller than those based on Wald approach. And, the estimates are more accurate in terms of actual assurance probabilities, coverage probabilities and balances between left- and right-tailed errors.
The above simulation studies are based on the assumption that the expected prevalence equals the true prevalence. We also conduct simulation studies to investigate the performance of the proposed methods in situations where this assumption does not hold true. For this purpose, we let \(\alpha =0.05\), \(\beta =0.05\), and assume the true prevalence \(\pi _s=0.165\), the expected prevalence \(\pi _{es}=r\pi _s\) with \(r=0.5,0.7,0.95,1.2\), and the half-widths of CI \(\omega =0.05,0.10\). In addition, for cheater detection model, we set the true prevalence \(\pi _s=0.165\) and the expected prevalence \(\pi _{es}=r_1\pi _s\) with \(r_1=0.6,0.95,1.2\). We also consider that the expected cheating parameter \(\gamma \) is different from the true parameter. Since \(\pi _s+\beta _s+\gamma =1.0\) (i.e., \(\gamma =1.0-\pi _s-\beta _s\)), we consider the following expected proportion of honest-no respondent (i.e.,\(\beta _{es}\)), which differs from the true proportion (i.e., \(\beta _s\)): the true proportion \(\beta _s=0.7\) and the expected proportion \(\beta _{es}=r_2\beta _s\) with \(r_2=0.6,0.95,1.1\). As shown in Tables 1, 2, 3, 4 and 5, the performances of the estimated sample sizes under various models are not affected by the settings of the other parameters (i.e., p, \(\pi _N\), k, \(p_1\), \(p_2\)). Therefore, we consider other settings of the parameters for each model: (i) Warner model: \(p=0.3\); (ii) unrelated question model: \(p=0.7\) and \(\pi _N=0.5\); (iii) item count technique: k \(=\) 4 and \(\pi _i=0.5\) for \(i=1,2,\cdots ,k\); (iv) cheater detection model: \(p_1\) \(=\) 0.2, \(p_2\) \(=\) 0.8. We conduct the simulation study as follows. First, given the expected prevalence \(\pi _{es}\), the expected proportion \(\beta _{es}\) and other parameters from each model, the estimated sample size for each model is obtained via the formulas illustrated in Sect. 1. Second, based on the estimated sample size for each model, 10000 random samples are generated under the true parameter values, and consequently 10000 confidence intervals for \(\pi _s\) are obtained. Third, based on the 10000 confidence intervals for each model, we calculate the proportion of these intervals that include the true prevalence \(\pi _s\) to obtain the ECP, and we calculate the proportion of the widths of the intervals being controlled within the pre-given value (i.e., \(\omega \)) to obtain the ACP. Simulation results are reported in Table 6.
According to Table 6, when the expected prevalence differs from the true prevalence, we have the following observations: (i) ECPs of all CIs are still very close to the nominal confidence level for each RRT model; (ii) most CIs have satisfactory balance between left- and right-tailed errors; (iii) the closer the expected prevalence rate (i.e., \(\pi _{es}\)) to the true prevalence rate (i.e., \(\pi _s\)), the closer the actual assurance probability to the pre-specified assurance probability; (iv) similar observations can be found when the expected cheating parameter differs from the true parameter for the cheater detection model.
3 Numerical Examples
To demonstrate the practicability and applicability of the proposed methods, we apply them to the study on unethical behavior in negotiation as discussed in Sect. 1. Suppose that an applied psychologist collects survey data and examines whether negotiators use this unethical tactic to increase the likelihood of reaching an agreement. He or she believes that approximately \(16.5\%\) of negotiators make false promises in negotiations (i.e., \(\pi _s\) \(=\) 0.165). We calculate the required sample size for a new study in which we have \(95\%\) chance (i.e., \(\beta \) \(=\) 0.05) that the half width of the \(95\%\) (i.e., \(1-\alpha \) \(=\) 0.95) confidence interval is no greater than \(25\%\) of the point estimate (i.e., \(\omega \) = \(0.25\pi _s\)), for the various RRT models considered in this article.
3.1 Warner’s RRT Model
Within Warner’s RRT model, two mutually exclusive questions about the sensitive attributes are: (A) Have you ever made promises without an intention to deliver in a negotiation? (A\(^c\)) Have you never made promises without an intention to deliver in a negotiation? These two questions are presented with probability p \(=\) 0.3 and \(1-p\) \(=\) 0.7, respectively. With \(\pi _s\) \(=\) 0.165, the approximate sample size n \(=\) 3326 is calculated from Eq. (4) based on Wald CI and n \(=\) 3322 is calculated from Eq. (6) based on Wilson CI, respectively. The corresponding ECPs (EAPs) are \(94.93\%\) (\(95.89\%\)) and \(95.03\%\) (\(95.73\%\)) for Wald and Wilson methods, respectively. In contrast, the conventional sample sizes (i.e., the assurance probability \(1-\beta =50\%\)) required for a two-sided \(95\%\) confidence interval with expected width \(\omega \) \(=\) \(0.25\pi _s\) are n \(=\) 3274 and 3271, respectively. The corresponding ECPs (EAPs) are \(94.87\%\) (\(50.95\%\)) and \(95.15\%\) (\(51.16\%\)) for the Wald and Wilson methods, respectively.
3.2 Unrelated Question Model
Within the unrelated question model, a neutral question N, for example, “Were you born in odd months?” is required in addition to the sensitive question (A): Have you ever made promises without an intention to deliver in a negotiation? Hence, \(\pi _N\) \(=\) 0.5. Assume that the sensitive question and the neutral question are presented with probabilities p \(=\) 0.7 and \(1-p\) \(=\) 0.3, respectively. With \(\pi _s\) \(=\) 0.165, the approximate sample size n \(=\) 950 is calculated from Equation (11) based on Wald CI and n \(=\) 946 is calculated from Equation (14) based on Wilson CI, respectively. The corresponding ECPs (EAPs) are \(94.77\%\) (\(96.13\%\)) and \(94.97\%\) (\(95.62\%\)) for Wald and Wilson methods, respectively. In contrast, when the conventional sample sizes (i.e., the assurance probability \(1-\beta =50\%\)) required for a two-sided \(95\%\) confidence interval with an expected width \(\omega \) \(=\) \(0.25\pi _s\) are n \(=\) 898 and 896, the corresponding ECPs (EAPs) are \(94.67\%\) (\(50.68\%\)) and \(94.94\%\) (\(49.17\%\)) for the Wald and Wilson methods, respectively.
3.3 Item Count Technique
Within the model of item count technique, assume that \(k=4\) neutral questions are used by a researcher and that the probability of answering each of these neutral question with “yes” is 0.5, i.e., \(\pi _i\) \(=\) 0.5 for i \(=\) 1, 2, 3, 4, the number of respondents in control group is the same as that in experiment group, i.e., \(n_c\) \(=\) \(n_e\) \(=\) \(\frac{1}{2}n\). With \(\pi _s\) \(=\) 0.165, the approximate sample size n \(=\) 9756 is calculated from Equation (18) based on Wald CI and n \(=\) 9748 is calculated from Equation (20) based on Wilson CI, respectively. The corresponding ECPs (EAPs) are \(95.04\%\) (\(95.83\%\)) and \(95.05\%\) (\(95.56\%\)) for Wald and Wilson methods, respectively. In contrast, when the conventional sample sizes (i.e., the assurance probability \(1-\beta =50\%\)) required for a two-sided \(95\%\) confidence interval only with an expected width \(\omega \) \(=\) \(0.25\pi _s\) are n \(=\) 9652 and 9646, the corresponding ECPs (EAPs) are \(94.78\%\) (\(49.03\%\)) and \(95.03\%\) (\(50.54\%\)) for the Wald and Wilson methods, respectively.
3.4 Cheater Detection Model
Within the cheater detection model, assume that participants in the experiment and control groups receive the sensitive question with probability \(p_1\) \(=\) 0.2 and \(p_2\) \(=\) 0.8, respectively. The numbers of participants in two groups are equal, i.e., \(n_1\) \(=\) \(n_2\) \(=\) \(\frac{1}{2}n\). With \(\beta _s\) \(=\) 0.7 and \(\pi _s\) \(=\) 0.165, the approximate sample size of n \(=\) 1878 is calculated from Equation (26) based on Wald CI and the approximate sample size of n \(=\) 1872 is calculated from Equation (29) based on Wilson CI, respectively. The corresponding ECPs (EAPs) are \(95.04\%\) (\(95.92\%\)) and \(94.78\%\) (\(95.95\%\)) for the Wald and Wilson methods, respectively. In contrast, when the conventional sample sizes (i.e., the assurance probability \(1-\beta =50\%\)) required for a two-sided \(95\%\) confidence interval with an expected width \(\omega \) \(=\) \(0.25\pi _s\) are n \(=\) 1800 and 1794, the corresponding ECPs (EAPs) are \(94.75\%\) (\(49.41\%\)) and \(95.00\%\) (\(49.07\%\)) for the Wald and Wilson methods, respectively.
It should be noted that the recommended sample sizes for all models are greater than the number of participants (i.e., 240) recruited to Kern and Chugh’s (2009) studies. In fact, with the sample size 240, the actual ECPs, ECWs and EAPs of CIs for \(\pi _s\) under the parameter settings being considered in the above studies for each model are reported in Table 7.
According to the results, the ECPs of CIs for \(\pi _s\) under all models are very close to the pre-assigned nominal confidence level (i.e., \(95\%\)). However, the probabilities of controlling the half width of the CI that are not larger than \(\omega =0.25\pi _s=0.04125\) are 0.0 for all models. In fact, the actual half widths of all CIs with sample size 240 are much greater than \(\omega =0.25\pi _s=0.04125\), as indicated in Table 7. Specifically, our findings suggest that when the assurance probability is not incorporated into the sample size estimation, the widths of CIs cannot be controlled even though the coverage probability is close to the nominal confidence level.
4 Conclusion and Discussion
For studying the prevalence of a sensitive attribute, determining the number of participants to be recruited to the survey is an important research aspect. In the context of survey sampling, sample size determination based on interval estimation is key objective. Therefore, the current research considers sample size determination using interval width control based on two CI types (i.e., Wald and Wilson CIs) for four different randomized response models (i.e., Warner’s model, UQM, ICT and CDM). The derived sample size formulas can control the width of a confidence interval at a specified confidence level with the assurance probability of achieving the pre-specified precision. Our simulation results demonstrate that all formulas derived from Wald and Wilson CIs are accurate in terms of empirical coverage probability (ECP) and empirical assurance probability (EAP). An important note is that sample size formulas based on Wilson CIs outperform those based on Wald CIs for various RRT models in the sense that the ECPs and EAPs of the former are closer to the pre-specified levels than those of the latter. Therefore, sample size formulas derived in this article may help researchers determine a sample size that can achieve pre-specified precision with an assurance probability in a survey study for detecting meaningful prevalence rates. As shown in Ulrich et al. (2012), the parameters of the four RRT models cannot be matched with each other; therefore, it is not realistic to compare the sample size formulas of the different RRT models in order to determine the most accurate one. Finally, the numerical examples regarding detecting negotiators’ use of unethical tactics in Sect. 3 clearly demonstrate how to better estimate the required sample size by using interval width control and carrying out a survey instead of conducting a full-scale experiment.
Generally, the two approaches that are employed to determine the desired sample size are, namely hypothesis testing and confidence interval estimation. It is well documented that the former involves both the type I error rate and power, while the latter does not explicitly involve power. In order that the sample size estimation based on expected confidence interval width can provide high assurance in achieving the desired precision, we incorporate an assurance probability for sample size determination to control the width of a confidence interval, i.e., sample size can be estimated by controlling the width of a confidence interval at a specified assurance probability. Ulrich et al. (2012) considered the sample size determination, in terms of hypothesis testing under four randomized response models. However, sample size formulas based on confidence interval width are not available in the extant literature. In this article, we derived such formulas for survey sampling of sensitive attributes. Note that most sample size estimates can be obtained by solving polynomial equation of degree not greater than four. Thus, no complicated computations are required in this article. We also developed program codes to compute the estimated sample sizes, and these program codes are available to readers as the supplementary material.
A restriction of our proposed sample size formulas relies on the specifications of relative accurate values of the prevalence rate (i.e., \(\pi _s\)) and other model parameters (e.g., \(\beta _s\) in CDM model). Researchers, who consider applying our proposed sample size formulas, should be aware that the actual confidence intervals could be wider than required if they cannot come up with accurate approximations of the true prevalence and other model parameters beforehand.
Recently, many variants of the RRT technique have been proposed. For example, Yu, Tian, & Tang (2008) developed a RRT variant (i.e., the crosswise model (CWM) with simple instructions. Specifically, the interviewee received a sensitive question (denoted as "S") and a neutral question (denoted as "N") simultaneously and was then asked to indicate whether the two answers given in "S" and "N" were the same or different. This model can be applied to both face-to-face personal interviews and mail questionnaire, because no randomization device is required. This also enables the interviewee to mask his or her answer to the sensitive question. Therefore, it has received considerable attention in the scientific community (e.g., Sagoe et al., 2021; Schnell & Thomas, 2021). It is clear that the crosswise model is mathematically equivalent as Warner’s model. As a result, the reported formulas and the results of the Warner model are equally valid for CWM. Ostapczuk et al. (2009) proposed a symmetric variant of CDM, but an iterative algorithm (e.g., expectation-maximization (EM) algorithm (Dempster, Laird, & Rubin, 1977)) is needed to obtain the maximum likelihood estimations (MLEs) of parameters \(\pi _s\), \(\beta _s\) and \(\gamma \). Therefore, we do not consider the sample size determination under the symmetric CDM in this article.
References
Agresti, A., & Coull, B. (1998). Approximate is better than exact for interval estimation of binomial proportions. American Statistician, 52, 119–126.
Alhija, F. N. A., & Levy, A. (2009). Effect size reporting practices in published articles. Educational and Psychological Measurement, 69, 245–265.
American Psychological Association. (2009). Publication manual of the American Psychological Association (6th ed.).
Chaudhuri, A., & Mukerjee, R. (1988). Randomized response: Theory and techniques. Marcel Dekker.
Clark, S. J., & Desharnais, R. A. (1998). Honest answers to embarrassing questions: Detecting cheating in the randomized response model. Psychological Methods, 3, 160–168. https://doi.org/10.1037/1082-989X.3.2.160
Dempster, A., Laird, N., & Rubin, D. (1977). Maximum likelihood from incomplete data via the EM algorithm. Journal of the Royal Statistical Society, Series B, 39, 1–38
Dowling, T. A., & Shachtman, R. H. (1975). On the relative efficiency of randomized response models. Journal of the American Statistical Association, 70, 84–87.
Dunst, C. J., & Hamby, D. W. (2012). Guide for calculating and interpreting effect sizes and confidence intervals in intellectual and developmental disability research studies. Journal of Intellectual & Developmental Disability, 37, 89–99.
Fox, J. F., & Tracy, P. E. (1986). Randomized response: A method for sensitive surveys.
Fritz, C. O., Morris, P. E., & Richler, J. J. (2012). Effect size estimates: Current use, calculations, and interpretation. Journal of Experimental Psychology General, 141, 2–18.
Greenberg, B. G., Abul-Ela, A.-L.A., Simmons, W. R., & Horvitz, D. G. (1969). The unrelated question randomized response model: Theoretical framework. Journal of the American Statistical Association, 64, 520–539. https://doi.org/10.1080/01621459.1969.10500991
Horvitz, D. G., Greenberg, B. G., & Abernathy, J. R. (1976). Randomized response: A data-gathering device for sensitive questions. International Statistical Review, 44, 181–196. https://doi.org/10.2307/1403276
Kern, M. C., & Chugh, D. (2009). Bounded ethicality: The perils of loss framing. Psychological Science, 20, 378–384.
Lensvelt-Mulders, G. J. L. M., Hox, J. J., van der Heijden, P. G. M., & Maas, C. J. M. (2005). Meta-analysis of randomized response research: Thirty-five years of validation. Sociological Methods and Research, 33, 319–348. https://doi.org/10.1177/0049124104268664
Mangat, N. S. (1994). An improved randomized-response strategy. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 56, 93–95.
Miller, J. (1984). A new survey technique for studying deviant behavior. Ph.D. dissertation, George Washington University.
Newcombe, R. G. (1998). Interval estimation for the difference between independent proportions: Comparison of eleven methods. Statistics in Medicine, 17, 873–890.
Odgaard, E. C., & Fowler, R. L. (2010). Confidence intervals for effect sizes: Compliance and clinical significance in the Journal of Consulting and Clinical Psychology. Journal of Consulting and Clinical Psychology, 78, 287–297.
Ostapczuk, M., Moshagen, M., Zhao, Z.M., & Musch, J. (2009). Assessing sensitive attributes using the randomized response technique: Evidence for the importance of response symmetry. Journal of Educational and Behavioral Statistics, 34(2), 267–287.
Rasinski, K. A., Willis, G. B., Baldwin, A. K., Yeh, W., & Lee, L. (1999). Methods of data collection, perceptions of risks and losses, and motivation to give truthful answers to sensitive survey questions. Applied Cognitive Psychology, 13, 465–481.
Sagoe, D., Cruyff, M., Spendiff, O., Chegeni, R., de Hon, O., van der Heijden, P., Saugy, M., & Petrczi, A. (2021). Functionality of the Crosswise model for assessing sensitive or transgressive behavior: A systematic review and meta-analysis. Frontiers in Psychology. https://doi.org/10.3389/fpsyg.2021.655592
Schnell, R., & Thomas, K. (2021). A meta-analysis of studies on the performance of the crosswise model. Sociological Methods & Research, Advance Online Publication. https://doi.org/10.1177/0049124121995520
Sun, S., Pan, W., & Wang, L. L. (2010). A comprehensive review of effect size reporting and interpreting practices in academic journals in education and psychology. Journal of Educational Psychology, 102, 989–1004.
Tourangeau, R., & Yan, T. (2007). Sensitive questions in surveys. Psychological Bulletin, 133, 859–883. https://doi.org/10.1037/0033-2909.133.5.859
Ulrich, R., Schröter, H., Striegel, H., & Simon, P. (2012). Asking sensitive questions: A statistical power analysis of randomized response models. Psychological Methods, 17(4), 623–641. https://doi.org/10.1037/a0029314
Warner, S. L. (1965). Randomized response: A survey technique for eliminating evasive answer bias. Journal of the American Statistical Association, 60, 63–66. https://doi.org/10.1080/01621459.1965.10480775
Wilkinson, L. (1999). The task force on statistical inference: Statistical methods in psychology journals: Guidelines and explanations. American Psychologist, 54, 594–604.
Wilson, E. B. (1927). Probable inference, the law of succession, and statistical inference. Journal of the American Statistical Association, 22, 209–212. https://doi.org/10.1080/01621459.1927.10502953
Yu, J. W., Tian, G. L., & Tang, M. L. (2008). Two new models for survey sampling with sensitive characteristic: Design and analysis. Metrika, 67, 251–263. https://doi.org/10.1007/s00184-007-0131-x
Zou, G. Y., & Donner, A. (2008). Construction of confidence limits about effect measures: A general approach. Statistics in Medicine, 27, 1693–1702. https://doi.org/10.1002/sim.3095
Acknowledgements
The work of Shi-Fang Qiu and Man-Lai Tang was supported by the grants from the National Natural Science Foundation of China (Grant No. 11871124). The work of Man-Lai Tang was also supported through grants from the Research Grant Council of the Hong Kong Special Administrative Region (Projects UGC/FDS14/P06/17 and UGC/FDS14/P02/18).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Qiu, SF., Tang, ML., Tao, JR. et al. Sample Size Determination for Interval Estimation of the Prevalence of a Sensitive Attribute Under Randomized Response Models. Psychometrika 87, 1361–1389 (2022). https://doi.org/10.1007/s11336-022-09854-w
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11336-022-09854-w