
Abstract
Precipitation forecast is key for water resources management in semi-arid climates. The traditional hybrid models simulate linear and nonlinear components of precipitation series separately. But they do not still provide accurate forecasts. This research aims to improve hybrid models by using an ensemble of linear and nonlinear models. Preprocessing configurations and each of the Gene Expression Programming (GEP), Support Vector Regression (SVR), and Group Method of Data Handling (GMDH) models were used as in the traditional hybrid models. They were compared against the proposed hybrid models with a combination of all these three models. The performance of the hybrid models was improved by different methods. Two weather stations of Tabriz and Rasht in Iran with respectively annual and monthly time steps were selected to test the improved models. The results showed that Theil’s coefficient, which measures the inequality degree to which forecasts differ from observations, improved by 9% and 15% for SVR and GMDH relative to GEP for the Tabriz station. The applied error criteria indicated that the proposed hybrid models have a better representation of observations than the traditional hybrid models. Mean square error decreased by 67% and Nash Sutcliffe increased by 5% in the Rasht station when we combined the three machine learning models using genetic algorithm instead of SVR. Generally, the representation of the nonlinear models within the improved hybrid models showed better performance than the traditional hybrid models. The improved models have implications for modeling highly nonlinear systems using the full advantages of machine learning methods.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
1 Introduction
Accurate precipitation forecast remains challenging despite enormous attempts to improve weather and climate models (e.g., Adhikari and Agrawal 2014; Faramarzzadeh et al. 2023), which is partly due to the nonlinear nature of precipitation. Stochastic models were extensively used for precipitation forecasting. The models such as auto-regressive integrated moving average (ARIMA), seasonal ARIMA (SARIMA), and periodic moving average (PMA) are among the common stochastic models (Wang et al. 2013; Murthy et al. 2018; Bouznad et al. 2020; Zarei and Mahmoudi 2020a, b). Despite the popularity of these models, their applications in representing a nonlinear characteristic of precipitation were unsuccessful. It is expected that linear models cannot capture complex phenomena (Chen and Wang 2007). Alternatively, some machine learning techniques such as SVR were used to solve nonlinear problems such as precipitation forecasting (Hamidi et al. 2015; Shenify et al. 2016), streamflow forecasting (Rasouli et al. 2020; Aoulmi et al. 2023), and groundwater level estimation (Moravej et al. 2020). Machine learning techniques also require a rigorous search algorithm to obtain optimal hyperparameters (Zeynoddin et al. 2018). Because each of the linear and nonlinear models has their own advantages, it is reasonable to use a combination of them in forecasting problems. Hybrid models were introduced in the literature to assess the forecast accuracy compared to individual models (Chen and Wang 2007). A hybrid model, which is defined as a combination of linear and nonlinear models, performs better than each of the compounding models. The nonlinear component of the hybrid models can be obtained from the difference between observations and the output of a linear model, also called error series or residual time series (Chen et al. 2021). It has been shown that a combination of SARIMA and SVR improved the forecast errors relative to individual SARIMA or SVR (Chen and Wang 2007). Another example of the hybrid models is a combination of ARIMA and artificial neural network (ANN) models for particulate matter forecasting in urban areas introduced by Díaz-Robles et al. (2008).
A combination of SARIMA and ANN models was used to forecast monthly inflow, and the combined model had a high coefficient of determination relative to these two composing models (Moeeni et al. 2017). Another hybrid model was developed based on ARIMA coupled with ANN using GA to forecast the production value of the mechanical industry (Liang 2009). GA was used to optimize the ANN parameters, such as number of hidden neurons. The improvement of traditional hybrid models, especially in representing nonlinear part of time series, can significantly affect the accuracy of forecasts. The decomposed time series from observed time series are often highly nonlinear and the use of a single nonlinear model for accurate forecasting of those time series may not be adequate. Also, forecasting residuals with large errors increases the uncertainty of the forecasts (Mo et al. 2018). Therefore, there is a need to combine the forecast of nonlinear time series and avoid the large errors in some of the subseries by giving less weights to them. For example, the GMDH neural network was used to combine the nonlinear models (e.g., SVR, back-propagation (BP) ANN and GEP). The performance of the more recently improved hybrid models was better than the individual models such as SARIMA or previously used hybrid models such as SARIMA-SVR and SARIMA-BP (Mo et al. 2018). Another approach to couple nonlinear time series is to use a weighted combination of the forecasts. In this method, the combination is based on assigning proper weights to each model to better extract the information from the time series of the individual models (Song and Fu 2020).
One of the important challenges related to forecasting combination is the precise selection of weights (Wang et al. 2019), which affects the accuracy of the forecasts. The simple average (Timmermann 2006), the error-based methods (Adhikari and Agrawal 2014; Song and Fu 2020), the least square regression method (Frietas and Rodrigues 2006), and the differential weighting method (Winkler and Makridakis 1983; Chan et al. 2004) are a few examples of weighted combination methods. The main objective of this research is to improve precipitation forecasting in the data scarce, humid, and semi-arid climates with emphasis on the nonlinear part of time series across two annual and monthly temporal scales. In this study, the nonlinear component of time series in the hybrid model, which is misestimated by machine learning or neural network models, was improved with using an ensemble of machine learning. This is particularly important in the field of precipitation forecast in data scarce regions where there are not any national or regional physically based weather prediction systems. Rigorous metrics and configurations were provided for evaluating model performance to clearly show the novelty and efficiency of the proposed models. Two preprocessing configurations were used, one with only residuals and one with a combination of observations, linear model simulations, and residuals. ARIMA and SARIMA were used to simulate the linear part of the time series. Individual models such as SVR, GMDH and GEP were applied to model nonlinear patterns of time series. To capture the complexity of nonlinear patterns of precipitation, an ensemble of three models were used instead of each model outputs. The error-based methods, the least square regression method, optimization with GA, and artificial intelligence techniques such as SVR and ANN were used to combine the individual models.
2 Materials and Methods
2.1 Case Studies
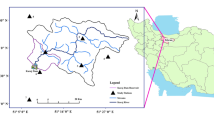
To evaluate the performance of the proposed improved hybrid model, precipitation data of two weather stations in Iran, namely Tabriz, East Azerbaijan and Rasht, Gilan were used over 1992–2019. The mean annual precipitation is 279 mm in Tabriz and 1278 mm in Rasht. The coefficient of variation for precipitation is 0.25 and 0.2 in Tabriz and Rasht, respectively. Based on the hythergraphs, monthly precipitation is more variable in Rasht than Tabriz (Fig. 1b, d). The climate in Tabriz and Rasht is categorized as semi-arid and very humid, respectively based on De Martonne (1925), or cold dry and wet based on Emberger (1952).

a Location and b hythergraph of Tabriz weather station in the East Azerbaijan province and c location and d hythergraph of Rasht weather station in the Gilan province in Iran over the 1992–2019 period
2.2 Traditional Hybrid Models Based on Two Linear and Nonlinear Models
One of the main concepts in time series analysis is separating them into two linear and nonlinear components, as in Eq. (1) (Chen and Wang 2007). The performance of the hybrid model depends on the estimated residuals, defined as the difference between observations and the linear ARIMA or SARIMA model outputs (Eq. 2). The nonlinear component, therefore, can be estimated using machine learning techniques such as SVR or ANN with different configurations. The forecasted time series are obtained by summing estimated linear and nonlinear components (Zhang 2003).
where Lt is the linear component; Nt denotes the nonlinear component; and \(e_{t}\) is the error term or the residual component.
2.2.1 Modeling the Linear Component of Time Series
ARIMA and its extension to represent seasonal variations (SARIMA) models can be expressed as in Eqs. (3) and (4) (Box and Jenkins 1976).
where ap(B), eq(B) and Ap(Bs) and EQ(Bs) are polynomials with orders p, q and P,Q for autoregressive and moving average terms, non-seasonal and seasonal terms, respectively. (1-B) and (1-Bs) are the regular and seasonal differencing operate, respectively. d is the number of differencing operations; D is the number of seasonal differencing. Yt is the observed value at time t; θ0 is a fixed term; and rt is a random error (Nwokike et al. 2020).
2.2.2 Individual Models for Modeling Nonlinear Components of Time Series
Support Vector Regression
SVR is a machine learning methodology (Vapnik 1999), which is widely used in classification problems, regression estimation, pattern recognition and probability density function estimation. The general form of SVR is expressed as:
where w is the weight coefficients vector; \(\varphi (x)\) is the map or kernel function to transform xi to a high-dimensional feature space; and b is an adjustable factor (Liu et al. 2014; Ghanbari and Goldani 2021). In other words, w and b act in the form of adjustable factors. The optimization problem was used to estimate w and b as Eq. (6).
where w is the weight coefficients vector; C is the penalty parameter; ε is the insensitive loss function; \(\xi_{i} ,\xi_{i}^{*} \,\) are the slack variables; and n is the number of training data (Ghanbari and Goldani 2021).
The penalty parameter in SVR can control the tolerance of the systematic outliers. One step in training a SVR model is to select the best kernel functions. Usually, radial basis and sigmoid functions perform better than linear kernels (Xu et al. 2019; Zhu et al. 2018).
Group Method of Data Handling
GMDH, a polynomial neural network, is a self-organization technique (Jeddi and Sharifian 2020). The model has a set of neurons in which different pairs in each layer are connected through a polynomial. In each layer, new neurons are built up for the next layer. The discrete form of the Volterra functional series (Volterra 1959) were applied for general connection between the inputs and outputs (Eq. 7). For modeling nonlinear input/output relationships, the Volterra series can be used (Marzocca et al. 2008).
where y is output variables; x is input variables; and a is a coefficient.
Gene Expression Programming
GEP was introduced by Ferreira (2001), and it is a data mining algorithm based on Darwin’s theory of evolution. GEP superiority to GA and GP is in its convergence speed and capability in solving complex problems. Chromosomes and expression tress are the main components of GEP. The start of GEP is based on the random generation of chromosomes that form one or more genes in the sub-expression tree (sub-ET). The best solution is to link the sub-ETs through algebraic or Boolean (AND, OR, NOT) functions. Each sub-ET provides information about the given process less than the corresponding expression tree. Finally, the power of GP blocks is applied with GEP to model nonlinear pattern of a complex system through a multi gene structure (Yousefi et al. 2017; DanandehMehr et al. 2019).
2.3 Improved Hybrid Model Based on One Linear Model and an Ensemble of Nonlinear Models
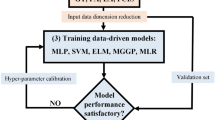
One approach to increase the efficiency of the traditional hybrid model in simulating the nonlinear component is to utilize a combination of individual models to forecast residuals instead of using a single model. In this study, GEP, SVR and GMDH were used to model the residuals with two configurations, discussed below. The model forecasts were given weights and combined. The steps of the improved hybrid model structure proposed include (Fig. 2):
-
1.
Applying stochastic models (i.e., ARIMA for annual and SARIMA for monthly time series) to simulate linear patterns of the precipitation (\(\hat{L}_{t}\)).
-
2.
Calculating residual subseries (\({e}_{t}\)) based on Eq. (2) with observed values (yt) and estimated linear time series in step 1 (\(\hat{L}_{t}\)).
-
3.
Determining two configurations to simulate residual subseries for annual (yan) and monthly (ymon) precipitation series. In these configurations, \({\varepsilon }_{t}\) denotes the random error.
-
The first configuration is based on residual subseries with different antecedent time steps (t-1), (t-2), (t-3), as the following:
$$e_{t} = f(e_{t - 1} ,e_{t - 2} ,e_{t - 3} ) + \varepsilon_{t}$$ -
The second configuration is based on the linear component (\({\widehat{L}}_{t}\)), the original observed time series with antecedent time steps (yt-1 or yt-12), and the residual sub series with different antecedent time intervals from step 1 as follows:
$$y_{t - an} = f(y_{t - 1} ,y_{t - 2} ,\hat{L}_{t}^{{}} ,e_{t - 1} ,e_{t} ) + \varepsilon_{t}$$$$y_{t - mon} = f(y_{t - 1} ,y_{t - 12} ,\hat{L}_{t}^{{}} ,e_{t - 1} ,e_{t} ) + \varepsilon_{t}$$
-
-
4.
Forecasting residual subseries with the configurations in step 3 by each of GEP, SVR, and GMDH nonlinear models. The final output is obtained in the first configuration by summing up the estimated linear and nonlinear components derived from individual models such as GEP.
-
5.
Obtaining weighted forecasts \({\widehat{y}}_{t}^{n, c}\). We combine the forecasts of the three nonlinear models with the most reasonable weights (Song and Fu 2020). The general structure of weighted forecasts is expressed as in Eq. (8):
$${\widehat{y}}_{t}^{n, c}= {\sum}_{i =1}^{m}{{w}_{i} .\widehat{y}}_{t}^{n, i, c}$$(8)
where n is the indicative of time step; 1 for monthly and 2 for annual; i represents type of the models, 1, 2 and 3 for GEP, SVR and GMDH, respectively; c represents the number of the configuration, 1 and 2;\({w}_{i}\) is the weight coefficient of ith individual model; and m is the total number of the models (\(\sum_{i=1}^{m}{w}_{i}=1\)).

The structure of hybrid model with linear and nonlinear components and improved hybrid model with combined weighted forecasts instead of using one single model to represent the nonlinear component
The inverse variance method (Iv) is one of the weighted combining methods that are based on the inversion of the forecast errors of the corresponding models (Eq. 9). A similar method is the mean square error inverse (MSEI), which can be categorized as an error-based method (Eq. 10, Adhikari and Agrawal 2014). The errors in Eqs. (9) and (10) are the sum of squared errors (SSE) as in Eq. (11) and the symmetric mean absolute percentage error (SMAPE) as in Eq. (12).
The least-square regression (LSR) method is used in this study to minimize the sum of squared errors for a linear combination of weighted forecasts. The matrix form of Eq. (8) can be written as in Eq. (13). Therefore, sum of squared errors between observed and simulated (\(y_{i}\),\(\hat{y}_{i}\)) values can be described as in Eq. (14). At the end, the weights vector can be obtained by minimizing SSE as in Eq. (15) (Frietas and Rodrigues 2006; Adhikari and Agrawal 2014).
The GA optimization method was used to find the weights so that the error between observed and simulated precipitation was minimized. The objective function and constraints are expressed as below (Prudêncio and Ludermir 2006).
Additionally, forecasted precipitation by GEP, SVR, and GMDH are used as inputs to SVR to further improve the forecasts (Eq. 18). A sensitivity analysis is carried out based on the type of kernel functions and penalty parameters.
An ANN model was also used to improve the forecasts by GEP, SVR, and GMDH models (Eq. 19). A sensitivity analysis was carried out to obtain optimal number of neurons in the hidden layer and type of activation function.
2.4 Evaluation of the Model Performance
The evaluation metrics are used in this study to compare the performance of the proposed improved hybrid models against the previous hybrid models. These metrics are mean square error (RMSE), relative root mean square error (RRMSE), mean absolute error (MAE), mean square error (MSE), Theil’s coefficient of U1, U2, residual predictive deviation (RPD), absolute percentage bias (APB), modified index of agreement(dm), adapted mean absolute percentages error (AMAPE), accuracy improved (AI), and geometric mean error ratio (GMER).
where Pi is the predicted value, Oi is the observed value,\(\overline{O }\) is the mean of observed value, S is MAE of the hybrid model, Sh is MAE of the improved hybrid model. Minimum values of RMSE, RRMSE, MAE, MSE, APB, and AMAPE indicate the similarity between forecasted and observed values (Ruiz-Aguilar et al. 2014; del Carmen Bas et al. 2017). Theil’s coefficient (Theil 1961, 1966) were used for evaluating models forecasting accuracy (U1) and quality of forecasting (U2). U1 = 0 and U2 = 0 are indicative of perfect forecasts. AI greater than 0 indicates the superior performance of the hybrid model, whereas AI less or equal to 0 shows that the hybrid model does not outperform any individual model (Chen and Zhu 2013). The NSE equal one indicates a perfect forecast. The RPD values less than 1.5 and greater than two show poor and high performance, respectively. The range of dm is between 0 and 1, where 1 is an indicative of high performance of the model (Duveiller et al. 2016). GMER > 1 indicates overestimation and GMER < 1 shows underestimation (Abdelbaki 2016). We used numerous evaluation criteria, which can confirm the reliability of the forecasted values as each metric shows specific aspects and characteristics of forecasts against observations.
3 Results
The observation period for precipitation data was 1964–2019 for annual and 2000–2019 for monthly time series. The investigated dataset was split into three subsets, 80% for calibration, 10% for validation, and 10% for verification. To check the sufficiency of data length for modeling, the Hurst coefficient (Hurst et al. 1965) was determined 0.8 and 0.6 in two Tabriz and Rasht stations, respectively above 0.5, the threshold for data length sufficiency.
3.1 Modeling Linear Component of Precipitation Time Series
The presence of seasonality in precipitation time series was checked and assured using autocorrelation function and partial autocorrelation function. The autocorrelation function had intervals of 12, clearly proving that there is a seasonal cycle in the Rasht precipitation. Thus, seasonal differencing in SARIMA is required. Preprocessing steps in precipitation analysis were shown in Table 1. The tests of Kolmogorov–Smirnov (Kolmogorov 1933) and Shapiro and Wilk (1965) confirmed the normality of the precipitation time series in Tabriz. The significance level of the normality tests was less than the critical value for the Rasht precipitation time series. Therefore, a transformation of the time series was necessary. After transformation, the significance level of the normality tests improved to reach about 0.2. Furthermore, the Augmented Dickey-Fuller (ADF) test (Said and Dickey 1984) was used to check the stationarity of the time series. The statistics tα was greater than the critical values (-3.6 and -2.57 for Tabriz and Rasht at 1% level), suggesting that both time series were non-stationary (Table 1). The Mann–Kendall test showed a significant decreasing trend in the observed precipitation for both stations. The ADF test was checked once again to assure the precipitation values to become stationarity. To find the orders of the models, a range of them was examined, p from 0 to 6, \(q\) from 0 to 5 for ARIMA and \(p, P, q, Q\) from 0 to 3 for SARIMA.
Out of many optional models, SARIMA(0,1,1) × (0,1,1)12 and ARIMA(0,1,2) had the minimum values of SBC and BIC for Rasht and Tabriz precipitation (Table 1). The SBC decreased from ARIMA(4,1,1) to ARIMA(0,1,2) by 6.6% and from SARIMA(1,1,0)(0,1,0)12 to SARIMA(0,1,2)(0,1,1)12 by 28.5%.
3.2 Modeling Nonlinear Component of Precipitation Time Series
A proper parameter estimation has an important role in the accuracy of precipitation forecasts. Therefore, a sensitivity analysis was conducted to identify the optimal parameters and kernel function types (e.g., Fig. 3). The parameters of models were summarized in Table 2. The GEP model parameters include addition (+), mutation rate (0.06), one-point recombination rate (0.2), two-point recombination rate (0.3), gene recombination rate (0.2), and IS transposition rate (0.2).

Sensitivity analysis of SVR model for two time series with respect to kernel function and penalty parameter
RMSE decreased by 15% when we switched the kernel function from sigmoid to radial basis function with C = 0.5 and by 8.8% when we changed the C parameter of the radial basis function from 2 to 0.5 in the Tabriz station and for the configuration one. Another comparison was conducted to show the performance of single individual models with two residual configurations (Fig. 4).

Comparison of the performance of two configurations for the nonlinear component of time series with single individual models and error criteria of a) Theil’s coefficient of U1 and U2 and b) RMSE and MAE. T1, T2, R1 and R2 denote Tabriz and Rasht station for the two configurations (Table 2)
As shown in Fig. 4, the error criteria decreased from configuration one to two. For instance, the Theil’s coefficient of U2 decreased by 56% for GEP and 62% for GMDH from configuration one to two in Rasht. By considering all models and all error criteria the average percent decreasing in Tabriz was greater than Rasht (46%). The error criteria increased by using GEP model. For instance, MAE decreased by 5% when GEP was replaced by SVR and by 24% when GEP was replaced by GMDH in the first configuration of Tabriz. In Rasht, U1 decreased by 42% when GEP was replaced by SVR and by 25% when GEP was replaced by GMDH in the second configuration. In general, the performance of GMDH and SVR for Tabriz and Rasht precipitation forecasting was reasonably well, and the difference between the error values of SVR and GMDH for Rasht time series in the first configuration is low.
3.3 Improved Hybrid Models
The performance of improved hybrid models with different combinations and weighting methods was compared against the traditional hybrid models, in which one linear is composed with only one nonlinear model (Table 3 and Fig. 5).

Performance of the hybrid models for the first configuration and the Rasht and Tabriz stations
As illustrated in Fig. 5, the error criteria degraded for the hybrid model using GEP as a single model (ARIMA + GEP in Table 3), relative to other single nonlinear hybrid models or combined nonlinear hybrid models. The forecast accuracy was improved when the nonlinear models were combined in the form of the hybrid model. For instance, in the second configuration for Tabriz station, RMSE improved and reached 43% decreasing when the ARIMA + GMDH hybrid model was replaced by the proposed multi-nonlinear hybrid models such as Iv + SSE (Table 3). The three improved hybrid models with the highest performance in different stations and configurations are those combined with:1) Iv + SMAPE, GA and SVR methods for Tabriz station and the first configuration; 2) SVR, MSEI + SSE and ANN methods for Tabriz station and the second configuration; 3) SVR, MSEI + SMAPE and GA for Rasht station and the first configuration; and 4) GA, SVR and LSR methods for Rasht station and the second configuration.
In general, the hybrid models combined with SVR, GA, and the error-based methods performed better than the other methods. The average RPD criteria were 0.42 and 4.33 in the traditional hybrid model for Tabriz precipitation series in the first and second configurations. These values were 1.17 and 3.11 for the Rasht station. The average of RPD criteria in proposed hybrid models combined with one linear and multiple nonlinear methods were improved and reached 0.58 and 6.83 for Tabriz station and 1.26 and 4.9 for Rasht station in the first (Fig. 5) and second (Table 3) configurations.
For evaluating the performance of improved hybrid models, an AI criterion (Eq. 31) was calculated for the three best models. This calculation was compared with the best model of the traditional hybrid model. AI of Tabriz precipitation in the first configuration for the hybrid models combined with Iv + SMAPE and SVR methods was 44% and 19.3%, respectively. AI in the second configuration for the hybrid models combined with SVR was 41%. AI of Rasht time series in the first configuration for the hybrid model combined with SVR was 6.7%. In the second configuration, AI was 35% for the hybrid models combined with SVR. Like other performance criteria, AI values for the proposed hybrid models were improved compared to the other traditional hybrid models. Among the error-based combinations of three nonlinear methods, Iv + SMAPE and MSEI + SMAPE outperformed for Tabriz and Rasht stations for the first configuration and MSEI + SSE and Iv + SSE for the second configuration. The observed and forecasted precipitation series are shown in Fig. 6 for the verification period and traditional and proposed hybrid models.

Comparison of observed and forecasted precipitation by 11 hybrid models for the second configuration in the a Tabriz and b Rasht weather stations in Iran during the verification period
The maximum and minimum annual precipitation were observed in 2018 and 2017 in Tabriz (Fig. 6a), which were preserved with all improved hybrid models combined with multiple error based and other combination methods. The observed monthly average of precipitation was 107 mm in Rasht, which was close to the monthly average forecasted by the hybrid model combined with GA (110 mm). The mean annual precipitation observed was 1279 mm in Rasht and its associated forecasted value was 1317 mm according to the hybrid model combined with GA (Fig. 6b). The scatter plots of the two best improved hybrid models with the highest performance are illustrated in Fig. 7. These model outputs were compared against observations and the traditional hybrid models of ARIMA + GMDH and SARIMA + SVR.

A scatter plot of observations against forecasted precipitation values in the a Tabriz and b Rasht weather stations with traditional hybrid models (ARIMA + GMDH and SARIMA + SVR) and two weighted hybrid models combined using support vector regression (SVR) and genetic algorithm (GA)
The R-square of the lines fitted to ARIMA + GMDH as a hybrid model and SVR and MSEI + SSE as improved hybrid model outputs were respectively 0.96, 0.99 and 0.96 in Tabriz and the R-square of the lines fitted to SARIMA + SVR as a hybrid model, and SVR and GA as improved hybrid models were respectively 0.87, 0.99 and 0.95 in Rasht. The R-square of the fitted line was increased using improved hybrid models 3 to 14%.
The forecasts of the hybrid (e.g., ARIMA + GMDH) and improved hybrid models (e.g., MESI + SSE, SVR, GA, and LSR) were compared in Fig. 8. These plots showed that observed precipitation matches with forecasts of the improved hybrid models (Fig. 8). From the point of lower and upper whisker view, a high similarity was observed between observed and the hybrid models combined with SVR. The median boxplot of observed and proposed hybrid models matched well. The same were true for observations and forecasts by the hybrid model combined with GA for the Rasht time series (Fig. 8).

Boxplot of observed and forecasted precipitation in the a Tabriz and b Rasht weather stations with traditional hybrid model (ARIMA + GMDH) and four weighted hybrid models combined using an error based MESI + SSE method, support vector regression (SVR), genetic algorithm (GA) and least square regression (LSR)
4 Discussion
The purpose of this study was to improve the accuracy of the traditional hybrid models. To achieve this, the following items must be considered: 1) a proper model of the linear component of time series using ARIMA or SARIMA; 2) a precise selection of the structures of the two configurations, respectively with antecedent residual subseries; and with antecedent observations and residual subseries and linear model simulations; 3) a proper selection of a model to represent residual subseries using an artificial intelligence technique (Liang 2009; Chen et al. 2010; Moeeni et al. 2017); and 4) an accurate estimation of the parameters of the selected models. The average RMSE, MAE, U1, and U2 decreased from first to second configuration in GEP model for Tabriz and Rasht time series. The performance of SVR and GMDH was better than GEP model, consistent with a previous study on estimation of monthly reference evapotranspiration in Iran (Ahmadi et al. 2021). A study investigates the performance of the multivariate regression spline, least-square support vector regression, GEP and ANN for estimation of monthly long-term rainfall and the best model was least square support vector regression (Mirabbasi et al. 2019). SVR model improved the forecasted error compared to ANN in the internal process of time variation analysis related to precipitation forecasting (Parviz 2020). The RMSE of the GEP model forecasts decreased by 44% and 4% for the first configuration when we decreased generation number from 1000 to 100 was and head size from 8 to 7.
The hybrid models increased forecasting efficiency by combining two types of models and capturing linear and nonlinear patterns of time series. For example, in the first configuration, MSE decreased by 8.5% when we replaced SARIMA with the hybrid model combined with SVR, by 44% when we replaced ARIMA with the hybrid model combined with GMDH. Improvement of precipitation forecasting by the monthly and annual hybrid models, relative to SARMIA model was observed in Rasht and Gorgan stations in Iran with 48% and 24% improvements in RMSE scores (Parviz and Rasouli 2019). Furthermore, the hybrid model structure was more important in forecasting. For instance, in a previous study, we showed that the two monthly hybrid models with a decomposition of precipitation time series into linear and nonlinear components had the minimum error (Parviz 2020). Incorporation of neural networks models to the ARIMA model by Pérez-Alarcón et al. (2022) showed improvement of rainfall forecast.
The hybrid model performance in capturing the complex phenomena has drawbacks as the nonlinearity of the decomposed time series may be high, and one model is insufficient to capture all variabilities (Mo et al. 2018). Furthermore, the error series may have high volatility and irregularity (Chen et al. 2021). Therefore, the improvement of hybrid models is necessary. The main direction of the improved hybrid model was to combine the forecasts of single models with different methods instead of using one model in the nonlinear part of time series modeling. The combined methods for the integration of forecasts outperform individual models (Wang et al. 2020). All used combined methods improved the efficiency of the hybrid model. Adhikari and Agrawal (2014) indicated that the combination procedure significantly outperformed all individual methods based on the evaluation scores of the weighting schemes. But it is hard to select one combination method as an inclusive method. The integration of SARIMA for the linear component of time series with a combination of SVR, GEP and BP for nonlinear components improved the results of the forecasts (Mo et al. 2018). The forecasts combination aims to integrate the competing forecasts to produce an ensemble of forecasts, which is superior to each of the composing individual models (Wang et al. 2020). By combining all the forecasts with a proper function, forecast combinations can fully use the information from each forecast model to improve the prediction accuracy and stability (Wang et al. 2019). The accuracy of combined forecasts depends on the weight of each forecast model. According to the evaluation metrics, the improved hybrid models with SVR, GA and error-based models had high performance. In the error-based methods, performance the type of error equation and the inversion method were different for each configuration. Therefore, there is a need to define a comprehensive error equation and an inversion method of the forecast errors from the corresponding models.
The average geometric standard deviation of the error for all improved hybrid models and all configurations in the Tabriz and Rasht time series was 1.4 and 2, respectively, which indicates forecasts overestimation.
5 Conclusion
Analysis of precipitation time series can provide insight into its spatial and temporal complexity. This study introduced improved hybrid models, which first separate linear and nonlinear components of precipitation time series and then extract the temporal patterns. High-performing machine learning methods were used for representing the nonlinear component of the precipitation in two weather stations in humid and semi-arid climates in Iran. We found that the improved hybrid models combined by SVR and GMDH showed a better performance than GEP in the Rasht and Tabriz weather stations.
In contrast to the traditional hybrid models of precipitation forecast, a combination of forecasts by multiple nonlinear models was applied in the structure of improved hybrid models in this study instead of using only one nonlinear model. An ensemble of forecasts with an appropriate weighting method and artificial intelligence techniques improved precipitation forecast accuracy at annual and monthly time steps. The high performance was shown by all the improved hybrid methods. Among combination methods, the artificial intelligence techniques (e.g., SVR), the optimization methods (e.g., GA), and the error-based methods showed the highest performance. In the error-based methods, the type of error formulation and the structure of the inversion method had the most crucial role. In general, three factors have the main control on the precipitation ensemble forecast with data-driven methods used in this study: separating linear and nonlinear components and appropriately modeling the nonlinear component; assigning appropriate weights to each ensemble member of the nonlinear modeling; and finally, the type of nonlinear models. One of the advantages of the improved hybrid model is that it can extract the nonlinear information from the original observations with high confidence. It uses an accurate forecast combination method embedded in its structure that can overcome the challenges in modeling the nonlinear processes in observed time series. The proposed improved hybrid model can be a powerful tool to increase precipitation forecast confidence across time scales by combining forecasts from sophisticated machine learning methods instead of relying on only individual models.
Availability of Data and Material
The data that support the findings of this study is available from the corresponding author upon request.
Abbreviations
- GEP:
-
Gene Expression Programming
- GMDH:
-
Group Method of Data Handling
- ARIMA:
-
Auto-Regressive Integrated Moving Average
- MSEI:
-
Mean Square Error Inverse
- SSE:
-
Sum of Squared Error
- RRMSE:
-
Relative Root Mean Square Error
- AMAPE:
-
Adapted Mean Absolute Percentage Error
- SVR:
-
Support Vector Regression
- GA:
-
Genetic Algorithm
- SARIMA:
-
Seasonal ARIMA
- Iv:
-
Inverse variance
- SMAPE:
-
Symmetric Mean Absolute Percentage Error
- RPD:
-
Residual Predictive Deviation
- GMER:
-
Geometric Mean Error Ratio
References
Abdelbaki AM (2016) Using automatic calibration method for optimizing the performance of pedotransfer functions of saturated hydrolic conductively. Ain Shams Eng J 7:653–662. https://doi.org/10.1016/j.asej.2015.05.012
Adhikari R, Agrawal RK (2014) Performance evaluation of weights selection schemes for linear combination of multiple forecasts. ArtifIntell Rev 42(4):529–548. https://doi.org/10.1007/s10462-012-9361-z
Ahmadi F, Mehdizadeh S, Mohammadi B, Pham QB, Doan TNC, Vo ND (2021) Application of an artificial intelligence technique enhanced with intelligent water drops for monthly reference evapotranspiration estimation. Agric Water Manag 244:106622. https://doi.org/10.1016/j.agwat.2020.106622
Aoulmi Y, Marouf N, Rasouli K, Panahi M (2023) Runoff prediction across spatial scales by convolutional neural network integrated with metaheuristic algorithms using reanalysis and climate data. J Hydrol Eng (In press)
Bouznad IE, Guastaldi E, Zirulia A, Brancale M, Barbagli A, Bengusmia D (2020) Trend analysis and spatiotemporal prediction of precipitation, temperature, and evapotranspiration values using the ARIMA models: case of the Algerian Highlands. Arab J Geosci 13(24):1–17. https://doi.org/10.1007/s12517-020-06330-6
Box GEP, Jenkins GM (1976) Times series analysis-forecasting and control. Prentice-Hall, Englewood Cliffs, NJ
Chan CK, Kingsman BG, Wong H (2004) Determining when to update the weights in combined forecasts for product demand–an application of the CUSUM technique. Eur J Oper Res 153(3):757–768. https://doi.org/10.1016/S0377-2217(02)00528-3
Chen KY, Wang CH (2007) A hybrid SARIMA and support vector machines in forecasting the production values of the machinery industry in Taiwan. Expert Syst Appl 32(1):254–264. https://doi.org/10.1016/j.eswa.2005.11.027
Chen S, Pao-Shan Y, Yi-Hsuan T (2010) Statistical downscaling of daily precipitation using support vector machines and multivariate analysis. J Hydrol 385(1–4):13–22. https://doi.org/10.1016/j.jhydrol.2010.01.021
Chen W, Xu H, Chen Z, Jiang M (2021) A novel method for time series prediction based on error decomposition and nonlinear combination of forecasters. Neurocomputing 426:85–103. https://doi.org/10.1016/j.neucom.2020.10.048
Chen X, Zhu S (2013) Improved hybrid model based on support vector regression machine for monthly precipitation forecasting. J Comput 8(1):232–238. https://doi.org/10.4304/jcp.8.1.232-239
DanandehMehr A, Nourani V, Karimi Khosrowshahi V et al (2019) A hybrid support vector regression–firefly model for monthly rainfall forecasting. Int J Environ Sci Technol 16:335–346. https://doi.org/10.1007/s13762-018-1674-2
De Martonne E (1925) TraitéGéographie. Physique: 3 tomes. Max leclcrc and H. Bourrclier, proprietors of Librairic Armard Colin: Paris
del Carmen Bas M, Ortiz J, Ballesteros L, Martorell S (2017) Evaluation of a multiple linear regression model and SARIMA model in forecasting 7Be air concentrations. Chemosphere 177:326–333. https://doi.org/10.1016/j.chemosphere.2017.03.029
Díaz-Robles LA, Ortega JC, Fu JS, Reed GD, Chow JC, Watson JG, Moncada-Herrera JA (2008) A hybrid ARIMA and artificial neural networks model to forecast particulate matter in urban areas: The case of Temuco. Chile Atmos Environ 42(35):8331–8340. https://doi.org/10.1016/j.atmosenv.2008.07.020
Duveiller G, Fasbender D, Meroni M (2016) Revisiting the concept of a symmetric index of agreement for continuous datasets. Sci Rep 6(1):1–14. https://doi.org/10.1038/srep19401
Emberger L (1952) Sur le quotient pluviothermique. Comptesrendushebdomadaires Des Séances De L’académie Des Sciences 234(26):2508–2510
Faramarzzadeh M, Ehsani MR, Akbari M et al (2023) Application of machine learning and remote sensing for gap-filling daily precipitation data of a sparsely gauged basin in East Africa. Environ Process 10:8. https://doi.org/10.1007/s40710-023-00625-y
Ferreira C (2001) Gene expression programming: a new adaptive algorithm for solving problems. Complex Syst 13(2):87–129
Frietas PSA, Rodrigues AJL (2006) Model combination in neural-based forecasting. Eur J Oper Res 173(3):801–814. https://doi.org/10.1016/j.ejor.2005.06.057
Ghanbari M, Goldani M (2021) Support vector regression parameters optimization using Golden Sine algorithm and its application in stock market. arXiv preprint arXiv:2103.11459. https://doi.org/10.48550/arXiv.2103.11459
Hamidi O, Poorolajal J, Sadeghifar M, Abbasi H, Maryanaji Z, Faridi HR, Tapak L (2015) A comparative study of support vector machines and artificial neural networks for predicting precipitation in Iran. Theor Appl Climatol 119(3):723–731. https://doi.org/10.1007/s00704-014-1141-z
Hurst H, Black R, Simaik Y (1965) Long-term storage: an experimental study. Constable, London
Jeddi S, Sharifian S (2020) A hybrid wavelet decomposer and GMDH-ELM ensemble model for Network function virtualization workload forecasting in cloud computing. Appl Soft Comput 88:105940. https://doi.org/10.1016/j.asoc.2019.105940
Kolmogorov AN (1933) Sulla determinazione empirica di una legge di distribuzione. Giornale Dell Instituto ItalianodegliAttuaru 4:83–91
Liang YH (2009) Combining seasonal time series ARIMA method and neural networks with genetic algorithms for predicting the production value of the mechanical industry in Taiwan. Neural Comput Appl 18(7):833–841. https://doi.org/10.1007/s00521-008-0216-0
Liu Y, Lian J, Bartolacci MR, Zeng QA (2014) Density-based penalty parameter optimization on C-SVM. Sci World J. https://doi.org/10.1155/2014/851814
Marzocca P, Nichols JM, Molanese A, Seaver M, Trickey ST (2008) Second-order spectra for quadratic nonlinear systems by Volterra functional series: Analytical description and numerical simulation. Math Control Signals Syst 22:1882–1895. https://doi.org/10.1016/j.ymssp.2008.02.002
Mirabbasi R, Kisi O, Sanikhani H, Meshram SG (2019) Monthly long-term rainfall estimation in Central India using M5Tree, MARS, LSSVR, ANN and GEP models. Neural Comput Appl 31(10):6843–6862. https://doi.org/10.1007/s00521-018-3519-9
Mo L, Xie L, Jiang X, Teng G, Xu L, Xiao J (2018) GMDH-based hybrid model for container throughput forecasting: Selective combination forecasting in nonlinear subseries. Appl Soft Comput 62:478–490. https://doi.org/10.1016/j.asoc.2017.10.033
Moeeni H, Bonakdari H, Fatemi SE, Zaji AH (2017) Assessment of stochastic models and a hybrid artificial neural network –genetic algorithm method in forecasting monthly reservoir inflow. INAE Lett 2:13–23. https://doi.org/10.1007/s41403-017-0017-9
Moravej M, Amani P, Hosseini-Moghari SM (2020) Groundwater level simulation and forecasting using interior search algorithm-least square support vector regression (ISA-LSSVR). Groundw Sustain Dev 11:100447. https://doi.org/10.1016/j.gsd.2020.100447
Murthy KV, Narasimha R, Saravana A, Vijaya Kumar K (2018) Modeling and forecasting rainfall patterns of southwest monsoons in North-East India as a SARIMA process. Meteorol and Atmos Phys 130(1):99–106. https://doi.org/10.1007/s00703-017-0504-2
Nwokike CC, Offorha BC, Obubu M, Ugoala CB, Ukomah HI (2020) Comparing SANN and SARIMA for forecasting frequency of monthly rainfall in Umuahia. Sci Afr 10:e00621. https://doi.org/10.1016/j.sciaf.2020.e00621
Parviz L (2020) Comparative evaluation of hybrid SARIMA and machine learning techniques based on time varying and decomposition of precipitation time series. J Agric Sci Technol 22(2):563–578
Parviz L, Rasouli K (2019) Development of precipitation forecasts model based on artificial intelligence and subseasonal clustering. J HydrolEngin 24(12):04019053. https://doi.org/10.1061/(ASCE)HE.1943-5584.0001862
Pérez-Alarcón A, Garcia-Cortes D, Fernández-Alvarez JC, Martínez-González Y (2022) Improving monthly rainfall forecast in a watershed by combining neural networks and autoregressive models. Environ Process 9(3):53. https://doi.org/10.1007/s40710-022-00602-x
Prudêncio R, Ludermir T (2006) A machine learning approach to define weights for linear combination of forecasts. In International Conference on Artificial Neural Networks (Springer, Berlin, Heidelberg) 274–283
Rasouli K, Nasri BR, Soleymani A, Mahmood TH, Hori M, Haghighi AT (2020) Forecast of streamflows to the Arctic Ocean by a Bayesian neural network model with snowcover and climate inputs. Hydrol Res 51(3):541–561. https://doi.org/10.2166/nh.2020.164
Ruiz-Aguilar JJ, Turias IJ, Jiménez-Come MJ, Cerbán MM (2014) Hybrid approaches of support vector regression and SARIMA models to forecast the inspections volume. Int Conf Hybrid Artif Intell Syst 502–514
Said ES, Dickey DA (1984) Testing for unit roots in autoregressive-moving average models of unknown order. Biometrika 71(3):599–607. https://doi.org/10.1093/biomet/71.3.599
Shapiro SS, Wilk MB (1965) An analysis of variznce test for normality (complete samples). Biometrika 52(3–4):591–611. https://doi.org/10.1093/biomet/52.3-4.591
Shenify M, Danesh AS, Gocić M, Taher RS, Wahab AWA, Gani A, Shamshirband S, Petković D (2016) Precipitation estimation using support vector machine with discrete wavelet transform. Water Resour Manag 30(2):641–652. https://doi.org/10.1007/s11269-015-1182-9
Song C, Fu X (2020) Research on different weight combination in air quality forecasting models. J Clean Prod 261:121169. https://doi.org/10.1016/j.jclepro.2020.121169
Theil H (1961) Economic forecasts and policy. North –Holland Pub. Co., Amsterdam, Netherland
Theil H (1966) Applied economic forecasting. North- Holland Pub. Co., Amsterdam, Netherland
Timmermann A (2006) Forecast combinations. In: Elliott G, Granger C, Timmermann A (eds) Handbook of Economic Forecasting. Elsevier, pp 135–196
Vapnik V (1999) The nature of statistical learning theory. Springer science & business media
Volterra V (1959) Theory of functionals and of integral and integro-differential equations. Dover, Inc., New York, 1959 Reprint of 1930
Wang J, Wang Z, Li X, Zhou H (2019) Artificial bee colony-based combination approach to forecasting agricultural commodity prices. Inter J Forecast. https://doi.org/10.1016/j.ijforecast.2019.08.006
Wang J, Zhou H, Hong T, Li X, Wang S (2020) A multi-granularity heterogeneous combination approach to crude oil price forecasting. Energy Econ 91:104790. https://doi.org/10.1016/j.eneco.2020.104790
Wang S, Feng J, Liu G (2013) Application of seasonal time series model in the precipitation forecast. Math Comput Model 58(3–4):677–683. https://doi.org/10.1016/j.mcm.2011.10.034
Winkler RL, Makridakis S (1983) The combination of forecasts. J R Stat Soc Ser A Stat Soc 146(2):150–157. https://doi.org/10.2307/2982011
Xu S, Chan HK, Zhang T (2019) Forecasting the demand of the aviation industry using hybrid time series SARIMA-SVR approach. Transp Res E: Logist Transprew 122:169–180. https://doi.org/10.1016/j.tre.2018.12.005
Yousefi P, Shabani S, Mohammadi H, Naser G (2017) Gene expression programing in long term water demand forecasts using wavelet decomposition. Procedia Eng 186:544–550. https://doi.org/10.1016/j.proeng.2017.03.268
Zarei AR, Mahmoudi MR (2020a) Ability assessment of the stationary and cyclostationary time series models to predict drought indices. Water Resour Manag 34:5009–5029. https://doi.org/10.1007/s11269-020-02710-5
Zarei AR, Mahmoudi MR (2020b) Investigating the ability of periodically correlated (PC) time series models to forecast the climate index. Stoch Environ Res Risk Assess 34:121–137. https://doi.org/10.1007/s00477-019-01751-6
Zeynoddin M, Bonakdari H, Azari A, Ebtehaj I, Gharabaghi B, Madavar HR (2018) Novel hybrid linear stochastic with non-linear extreme learning machine methods for forecasting monthly rainfall a tropical climate. J Environ Manag 222:190–206. https://doi.org/10.1016/j.jenvman.2018.05.072
Zhang GP (2003) Time series forecasting using a hybrid ARIMA and neural network model. Neurocomputing 50:159–175. https://doi.org/10.1016/S0925-2312(01)00702-0
Zhu S, Lian X, Wei L, Che J, Shen X, Yang L, Qiu X, Liu X, Gao W, Ren X, Li J (2018) PM2.5 forecasting using SVR with PSOGSA algorithm based on CEEMD, GRNN and GCA considering meteorological factors. Atmos Environ 183:20–32. https://doi.org/10.1016/j.atmosenv.2018.04.004
Funding
Open Access funding provided by University of Oulu including Oulu University Hospital. L.P. received in-kind financial support from the Azarbaijan Shahid Madani University for this research.
Author information
Authors and Affiliations
Contributions
L.P. and K.R. analyzed the data and wrote the paper. A.T.H., L.P. and K.R. Research conceptualization and methodology, supervision, reviewing and editing A.T.H.
Corresponding author
Ethics declarations
Consent for Publication
All authors have consented to publish this manuscript.
Research Involving Human and Animal Participants
This article does not contain any studies with human participants or animals performed by any of the authors.
Competing Interests/Conflict of Interest
No potential conflict of interest was reported by the authors. The authors have no relevant financial or non-financial interests to disclose.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Parviz, L., Rasouli, K. & Torabi Haghighi, A. Improving Hybrid Models for Precipitation Forecasting by Combining Nonlinear Machine Learning Methods. Water Resour Manage 37, 3833–3855 (2023). https://doi.org/10.1007/s11269-023-03528-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11269-023-03528-7