
Abstract
Increasingly, experimental economists, when eliciting risk preferences using a set of pairwise-choice problems (between two risky lotteries A and B), have given subjects a third choice (in addition to ‘I prefer A’ and ‘I prefer B’), namely that of saying, for example, ‘I am not sure about my preference’ or ‘I am not sure what to choose’. The implications for subjects of choosing this third option (which we call the ‘middle column’) vary across experiments depending upon the incentive structure. Some experiments provide no direct financial implications: what is ‘played out’ at the end of the experiment is not influenced by subjects choosing this middle column. In other experiments, if the middle column has been checked, then the payoff is determined by a randomisation of A and B. I report on an experiment, which adopts this latter incentive mechanism, and ask the question as to why people might choose this option, that is “why do they prefer randomisation?” I explore four distinct stories and compare their goodness-of-fit in explaining the data. My results show that the two of the four have the most empirical support. I conclude with a discussion of whether my results have anything to say about preference imprecision.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Increasingly, experimental economists, when eliciting risk preferences using a set of pairwise-choice problems (between two risky lotteries A and B), have given subjects a third choice (in addition to ‘I prefer A’ and ‘I prefer B’), namely, for example, that of saying ‘I am not sure about my preference’ or ‘I am not sure what to choose’. We call this choice ‘choosing the middle column’. Some experimental economists use this design to investigate the difficulty in making a straight choice (either Option A or Option B), while some use it to explore the possibility of a preference for randomisation.
The implications for subjects of choosing this middle column vary across experiments—it depends on the incentive mechanism. In some experiments, for example Cubitt et al. (2015), there are no financial implications: what is ‘played out’ at the end of the experiment is not influenced by subjects choosing this middle column. Cubitt et al. use this procedure to associate the subjects’ choice of the middle column with preference imprecision. In other experiments, for example, Cettolin and Riedl (2019), if the middle column has been checked, then the payoff is determined by randomisation of Option A and Option B (a mixture of A and B). Recent literature adopts this procedure to allow the investigation of a preference for randomisation (Dwenger et al. 2018) and stochastic choice (Agranov and Ortoleva 2017).
I report on an experiment that adopts this latter incentive mechanism, and ask the question as to why people might choose this option, that is “why do they prefer randomisation?” I explore four distinct stories and compare their goodness-of-fit in explaining the data: the random-convex preference story, the tremble story, the threshold story, and the delegation story. The first story is that the decision-maker (DM) has convex indifference curves within the Marschak–Machina Triangle (MMT) and actually prefers a mixture of A and B. To make it operational, this story is embedded in the Random Preferences Model (Loomes and Sugden 1995; Loomes et al. 2002) in which the risk-aversion parameter varies randomly from problem to problem. My second story is that the DM prefers a mixture of A and B only if it gives the highest utility; however, the DM simply makes a mistake in expressing their preferences. By this, the DM is assumed to be able to calculate the subjective utility of an alternative but that does not guarantee him or her choosing the optimal choice. This stochastic specification follows the tremble specification as in Harless and Camerer’s (1994), Moffatt, and Peters (2001). My third story is that the DM cannot distinguish between A and B unless their difference exceeds some threshold. This story follows the same logic as in Khrisnan (1977). Here the DM prefers an alternative if he or she subjectively perceives the utility of an alternative exceeding another one by at least some threshold (a minimum perceivable difference). Otherwise, the DM perceives that he or she is indifferent between the two alternatives. So the choice of a mixture A and B depends on the magnitude of the threshold—the higher is the threshold, the more likely is the choice of a mixture of A and B. I also add in a tremble. Lastly, the delegation story follows Vickers (1985) and Armstrong and Vickers (2010). The DM will delegate decisions if it gives the highest utility. Hence, I assume that the DM gets an additional utility when stating their preference with “I am not sure what to choose”—delegating the decision to the coin toss. Again, I add in a tremble.
I note that my incentive mechanism is different from that in Cubitt et al. The latter was concerned with preference imprecision; this paper is concerned with preference for randomisation. These are different things, but this paper may have something to tell us about preference imprecision—this depends upon how subjects view the choice problem and the incentive mechanism. We shall have more to say on this in Sects. 4.2 and 5.
This paper is organised as follows: the next section discusses the experimental design; Sect. 3 describes the four stories in detail; Sect. 4 presents the empirical results and analyses; Sect. 5 discusses and concludes.
2 Experimental design
I used 72 ‘response tables’. In each of these, subjects were presented with a number (which varied from table to table) of pairwise-choice problems (we refer this to problem) between a certainty and a (two- or three-outcome) lottery. In every response table, the lottery remained unchanged, while the certain amount varied from the highest amount in the lottery, in steps of 25 pence to the lowest amount in the lottery. This determines the number of rows or problems in each response table.
These tables were similar to those used in Cubitt et al. (giving subjects choices which spanned most possible preferences), though I duplicated the tables (to have a sufficient number of problems for estimation). There are seven lottery sequences: payoff scale (Seq. 1), mean preserving spread (Seq. 2), risky common consequence (Seq. 3), safe common consequence (Seq. 4), safe common ratio (Seq. 5), risky common ratio (Seq. 6) and betweenness (Seq. 7). Subjects were given three alternative answers to state their preference on a particular problem in each response table: (1) I choose Option A; (2) I am not sure what to choose; or (3) I choose Option B. Figure 1 illustrates a response table used in the experiment. In the Instructions, these were called ‘Preference Sheets’.

A response table in the experiment
As Fig. 1 shows, a short explanation of what subjects are asked to do is written at the top of the table. There is a description of Option A and Option B. Option A is always a sure amount of money whereas Option B is a fixed lottery in any one table. There were five columns in each table: the first column was the problem number in the particular response table; the second column was the certain amount of money in Option A; the third to the fifth columns are the three answer boxes.
The response table is implemented as follows. Subjects had to choose one answer in each row of the table. Unlike Cubitt et al. (who forced subjects not to switch between columns as they moved down the table). I did not restrict the subjects in any way. There were two buttons to confirm and to modify the answer. The confirm button became active after 10 s; before that it was inactive. However, there was no maximum time to complete the tasks, so subjects were free to think as long as they wished. Subjects were given the instructions (paper and on-screen) and two practice tables prior to the main tasks. The experimental software was written (mainly by Alfa Ryano) in Python 2.7.
Monetary incentives were provided to reveal the subjects’ true preferences. Subjects were told in the instructions that one of the problems from one of the tables would be the basis of their payment (additionally they were given a show-up fee of £2.50). The subject’s response in a randomly chosen problem would be played out for real. First, the subject drew a disk from a closed bag containing the numbered disks from 1 to 72—this identified a particular response table. Then, the subject drew another disk from a different closed bag to choose the problem in the selected table to play out—the number of disks depending upon the number of rows or problems in the randomly chosen table. For the selected problem, the following rules were used to determine the subjects’ payment: (1) if a subject chose Option A, then he or she would get the sure amount of money; (2) if a subject chose Option B, then he or she would play the lottery in that particular response table; (3) if a subject stated that he or she was unsure, then he or she would flip a coin to determine which option to play—then either rule (1) or rule (2) would be applied for the chosen option from the coin toss. This payment mechanism implied that the choice of the middle column was a choice for randomisation. Note that this is a different incentive mechanism than that used by Cubitt et al.Footnote 1 as we are specifically interested in a preference for randomisation.
The experiment was conducted in the EXEC Lab at the University of York. Invitation messages were sent through hroot (Hamburg registration and organization online tool) to all registered subjects in the system. There were 77 subjects who participated in the main experiment; this was preceded by a pilot experiment; I do not report its results here. They were all members of the University of York: 73 subjects were students and 4 subjects were staff members. The gender composition was such that 32 subjects were male and 45 subjects were female. Subjects read the instructions together and were free to ask anything about the experiment before starting the experiment. After subjects had completed all tasks, they were paid as previously explained. Then they were free to leave. The average payment to the subjects was £11.72 and the average duration of the experiment (including reading the instructions) was a little below one and a half hours. Communication was prohibited during the experiment.
3 Modelling the choice
I bring four stories to try to explain the subjects’ decisions: the random-convex preference story (henceforth the RCP story), the tremble story, the threshold story, and the delegation story. These four stories have different ways of interpreting a statement of choosing the middle column; hereafter we use A, B, and M to refer Option A, Option B and the mixture of A and B (the middle column), respectively. To model the stories in this paper I use either the Expected Utility (EU) or the Rank-Dependent Expected Utility (RDEU) functional as the DM’s preference function; so that the DM chooses the option with the highest expected (rank-dependent) utility. This is crucial as I put important assumptions on the DM’s preference within the MMT; these I describe later in this section. EU has a risk-aversion parameter (r) while RDEU has two parameters (risk aversion, r, and probability-weighting-function parameter, g). I use the Constant Absolute Risk Aversion (CARA) and the Constant Relative Risk Aversion (CRRA) to specify the DM’s utility function in both EU and RDEU. In addition, I use the Power functionFootnote 2 to specify the probability-weighting function in RDEU to rationalise the strictly convex preference, which is necessary for the RCP story.Footnote 3
All stories share the common assumption that the subjects answer each pairwise-choice problems independently.Footnote 4 So crucially, all stories can rationalise the DM’s decision to switch between columns as he or she moves down the table. We should notice that A first-order stochastically dominates B in the first problem in each table, and vice versa in the last problem in each table. Hence, these two problems are dominance problems, since, using either the EU or the RDEU, they should be chosen with certainty. I also assume that the DM perceives M as a single lottery through the use of the reduction of compound lotteries (ROCL). This may raise an issue as I use RDEU in some of my stories (the RCP story and the tremble story).Footnote 5 For example, Harrison et al. (2015) find the violation of ROCL as they assume RDEU preference and implement random lottery incentive mechanism. This violation occurs since their subjects attach additional value to the compound lottery hence evaluate it differently problem to problem. However, to keep my stories as simple as possible, I assume ROCL.
The first story is that the decision-maker (DM) has strictly convex indifference curves within the MMT—this can rationalise the choice of M. The second is that the DM simply makes a mistake though he or she is fully able to determine the best choice. The third is that the DM cannot distinguish between A and B unless their utility difference exceeds some threshold; if not, the DM chooses MFootnote 6; I specify the threshold in two ways, a random and a fixed threshold. The fourth is that the DM actually prefers to delegate the choice (to the coin), shifting the ‘responsibility’ to the coin; here the DM receives an extra utility from delegating the choice. The details will be explained later. In each story, there is inevitably some randomness (Table 1).
I apply RDEU to the RCP and the tremble stories as it allows the indifference curves (IC) in the MMT to be non-linear in probability, hence these stories can explain why randomising might be preferable. The DM prefers the mixture of A and B if it gives the highest utility. This may occur if the indifference curves are strictly convexFootnote 7 within the MMT (Starmer 2000). Figure 2 illustrates concave preferences (left panel) and convex preferences (right panel) within the MMT.Footnote 8 In the left panel, A and B are preferred to M, while in the right panel, M is preferred to both A and B.

Indifferences curve within MMT
I apply EU to the threshold story and to the delegation story; with EU the DM’s indifference curves are linear within the MMT. For the threshold story, in particular, one can assume other preference functions to calculate the utility, but I assume that the DM is an EU agent to have the simplest version of this story; I explain these in each story’s specification. Building on these four stories, I have sixteen variants depending upon the stochastic specification and the utility function. I fit the various stories using maximum likelihood.
3.1 The random-convex preference story
In this story, I assume that the DM’s preference function is that of RDEU and the DM has strictly convex indifference curves within the MMT. This convex preference implies the possibility that the DM prefers M. Given this, I assume that the DM always chooses the option with the highest expected rank-dependent utility. I also assume the Random Preference Model (Loomes and Sugden 1995) in which the DM’s preferences vary randomly from problem to problem. By this, I mean that the DM’s risk-aversion parameter varies randomly from problem to problem.
Let me explain how I implement this story. Let V(A) be the RDEU value of A, V(B) be the RDEU value of B and V(M) be the RDEU value of M. To proceed to a decision, the DM makes the following comparisons: (i) V(A, M) = V(A)–V(M) to compare A and M; (ii) V(B, M) = V(B)–V(M) to compare B and M. Therefore, the DM’s preferences on each comparison are given by:
I specify the r (risk-aversion parameter) in the RDEU to be random across problems, while the g (probability-weighting parameter) is fixed; that is why I call this the random-convex preference story. So there will be an r* in every comparison indicating that the DM is indifferent between two options for any given fixed g; V(A, M) = 0 and V(B, M) = 0. This setup is to simplify the estimation.Footnote 9 I arbitrarily assume that the r has a normal distribution with parameters (μ and σ)—mean and standard deviation.
Each comparison, V(A, M) and V(B, M), defines a function between r and g. Since I assume random r and fixed g, this implies a unique r for each comparison. I define r*1 and r*2 as follows: r*1 ⟺ V(B, M) = 0 and r*2 ⟺ V(A, M) = 0. These must satisfy r*1 ≤ r*2 since the DM must be less risk-averse to be indifferent between B and M than when he or she is indifferent between A and M. The implication is that the DM chooses A if r ≥ r*2; that the DM chooses B if r ≤ r*1; and that the DM chooses M if r*1 < r < r*2. As the preferences are convex, so that 0 < g < 1, there exists the solution for r*1 and r*2. However, I exclude the dominance problems, for which r*1 and r*2 do not exist. It follows that this story has fewer observations than the other stories by excluding the first and the last row in each response table since they are dominance problems.Footnote 10
Using these two ‘boundary’ risk attitudes (r*1 and r*2), I can now specify the log-likelihood function. Let y ϵ {1, 2, 3} be the DM’s decision in any problem; taking the value 1, 2 and 3 if the DM chooses A, M, and B, respectively. The contribution to the log-likelihood of the observation y in any problem is:
where Φ2 is the cumulative distribution function (cdf) of a normal distribution with parameters μ and σ given an observation r*2, and Φ1 is the cdf of a normal distribution with parameters μ and σ given an observation r*1.Footnote 11 However, I will report s = 1/σ, the precision. I implement this story with two variants—being the two utility functions CARA and CRRA.
3.2 The tremble story
As with the RCP story, I use RDEU to specify the DM’s preference function and assume that he or she always prefers the option that yields the highest expected rank-dependent utility. I assume that r and g are fixed across the problems. For this story, I assume that the DM is able to make a correct calculation but he or she sometimes trembles when expressing his or her preference. Hence, I involve a tremble parameter, which I denote by ω, in this story to capture the DM’s mistake.
I specify this story in two ways: the tremble 1 and the tremble 2. The former specification assumes that the tremble is the same in all possible non-optimal decisions. The tremble parameter for this specification takes a value 0 ≤ ω ≤ 0.5. The probability distribution of all decisions within this sub-story therefore is:
Optimal decisions (y*) | |||
|---|---|---|---|
A | M | B | |
Actual decisions (y) | |||
A | 1–2ω | ω | ω |
M | ω | 1–2ω | ω |
B | ω | ω | 1–2ω |
Following table above, the contribution to the log-likelihood of the observation y conditional to y* is:
The tremble 2 specification assumes that the error can be different across the non-optimal decisions. The probability distribution of all decisions within this sub-story therefore is:
Optimal decisions (y*) | |||
|---|---|---|---|
A | M | B | |
Actual decisions (y) | |||
A | 1–ω1–ω2 | ω1 | ω2 |
M | ω1 | 1–2ω1 | ω1 |
B | ω2 | ω1 | 1–ω1–ω2 |
It is not necessarily the case that ω1> ω2 in the tremble 2 specification. The tremble parameters in this particular specification take values 0 ≤ ω1, ω2≤ 0.5. I assume that the tremble is shared equally if the optimal decision is choosing M, otherwise, it is not necessary. As with the tremble 1 specification, this specification has two variants depending upon the utility function (CARA or CRRA) in the RDEU. Following the table above, the contribution to the log-likelihood of the observation y conditional to y* is:
This story has four variants from the implementation of the tremble specification and the utility function in the EU.
3.3 The threshold story
Unlike the two previous stories, I assume that the DM has a limitation in making a precise calculation of a straight option (either A or B). The implication is that the DM can clearly distinguish between A and B only if the difference in their evaluation exceeds some threshold, otherwise the DM’s optimal decision is to choose M. Here is a simple example: someone is shown two bars, they are similar in length with a difference of 0.5 mm. Those bars are seen from a distance of 1 m. It is highly likely that someone would say that those bars are exactly identical. So he or she thinks that those bars give the same level of utility.
For this story, I use the EU to specify the DM’s preference function. The DM prefers A if EU(A)–EU(B) > φ and prefers B if EU(B)–EU(A) > φ, where φ is the threshold of the EU difference. Additionally, I will have to involve a tremble (ω) to capture the DM’s mistake in expressing the EU when the DM is fully able to calculate the EU precisely; the DM cannot express the EU preference if the EU difference is less than the threshold.
I specify this story in two ways according to the DM’s threshold: a random and a fixed threshold. The random threshold specification assumes that the DM has a different calculation ability across problems because he or she may understand each problem differently—that the φ may be different across problems. Here I assume that the DM cannot distinguish A and B if he or she prefers M. So the choice of either A or B implies that the DM can clearly distinguish A and B. The fixed threshold specification assumes that the DM has fixed calculation ability across problems—that the φ is fixed across problems. I arbitrarily assume that the DM can choose any option when he or she cannot distinguish A and B with a probability of 1/3.
I involve tremble in both specifications to capture the DM’s mistake in expressing his or her preference. However, since the two specifications have key differences, they will have a different probability distribution of the DM’s decision. For the random threshold specification, the probability distribution of the DM’s decisions where he or she does not choose M is:
Optimal decisions (y*) | ||
|---|---|---|
A | B | |
Actual decisions (y) | ||
A | 1 − ω | ω |
B | ω | 1 − ω |
The tremble parameter takes value 0 ≤ ω ≤ 1 in this specification. To proceed to the estimation I have to assume the distribution of φ as it is assumed to be random across all problems. I use the exponential and log-normal distribution of φ. Both distributions take into account the non-negative nature of φ. The exponential distribution has a parameter of λ (the inverse of the mean), whereas the log-normal distribution has two parameters: log(μ) and log(σ). Instead, I will report the mean of φ (Λ = 1/λ) for the exponential distribution, and the mean (μ) and the precision (s = 1/σ) of φ to make it easy to read—the higher is the precision, the less is the noise. Following the decision matrix above, the contribution to the log-likelihood of the observation y conditional to y* is:
where Θ is cdf of the φ following either a log-normal or exponential distribution, and δ is a set of parameter(s) of either a log-normal or an exponential distribution. This random threshold specification has four variants from the implementation of the threshold distribution and the utility function in the EU. So I have: (i) the log-normal threshold combined with CRRA and CARA, and (ii) the exponential threshold combined with CRRA and CARA.
Move on to the fixed threshold specification, the probability distribution of all decisions within this sub-story therefore is:
Actual decisions (y) | |||
|---|---|---|---|
A | M | B | |
What the DM reveals (y*) | |||
EU(A)–EU(B) > φ | 1–2ω | ω | ω |
EU(A)–EU(B) ≤ φ and EU(B)–EU(A) ≤ φ | 1/3 | 1/3 | 1/3 |
EU(B)–EU(A) > φ | ω | ω | 1–2ω |
As in the decision matrix above, each option shares an equal probability to be optimal decision when the DM cannot distinguish A and B. I assume that ω is the same in all possible non-optimal decisions when the DM can distinguish A and B. This is to keep this story as simple as possible.Footnote 12 The tremble parameter takes value 0 ≤ ω ≤ 0.5. The contribution to the log-likelihood of the observation y conditional to y* is:
This fixed threshold story has two variants depending on the specification of the utility function: the fixed threshold with CRRA and the fixed threshold with CARA.
3.4 The delegation story
As in the threshold story, I assume that the DM is the EU agent so he or she always prefers the option that yields the highest expected utility. In addition, I assume that the DM receives an extra utility if he or she chooses M—delegating the decision to the coin toss. Therefore, the expected utility of M is defined as: EU(M) = 0.5{EU(A)} + 0.5{EU(B)} + a where EU(M) is the expected utility of M, and a is an extra utility. This setup differentiates this story from the tremble story.
Also, I involve a tremble to capture the DM’s mistake in expressing his or her preference. I specify the tremble in two ways: tremble 1 and tremble 2 as in the tremble story. Since there is always the best of all decisions in this story, the probability distribution of the DM’s decision in both tremble 1 and tremble 2 specifications is identical to that one in the tremble story; likewise the contribution to the log-likelihood. This story has four variants arising from variations of the tremble specification and of the utility function in the EU.
4 Results and analyses
I start with some simple descriptive statistics. Then I proceed to a more formal analysis.
4.1 Descriptive statistics
I have already noted that I allowed subjects to switch between columns as they moved down a table. We observed 253 (4.56%) such switches in 5544 tables from 27 subjects. This means that the entries in the middle column may not have been continuous. There are 114 (2.06%) of 5544 tables from 10 subjects see a non-continuous range in the choice of the middle column. However, in either case, I can measure the percentage of middle column responses in each table. This I call PROPMID. Note that this is not the same as INTSIZE as used in Cubitt et al., though it is closely related to it.
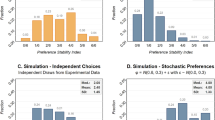
First, I report the subjects’ behaviour when they choose M. There are 14,761 cases (6.22%) out of 237,314 decisions in which subjects choose M—with 47 subjects choosing M at least once. Figure 3 below shows the histogram of PROPMID in all problems. It is clear that some subjects hardly ever choose the middle column, while a few choose it rather often.

The percentage of choosing M
Now we break down PROPMID by the lottery sequence—there are seven basic lottery sequences following the design in Cubitt et al. The percentage of choosing M is slightly different between the seven sequences, and there is a slight tendency for PROPMID to be lower when the problems are repeated: in the first half (problems 1–36) PROPMID averages 6.95% compared to 5.49% in the second half (problems 37–72).Footnote 13
Note that, not only does PROPMID decrease when the lottery sequences are repeated, but also the subjects show different pattern across lotteries within sequence. We can use this to see whether there is any connection between our subjects’ behaviour and those of Cubitt et al. Let us focus attention on Sequences 3–6 where Cubitt et al. find that the size of the imprecision decreases as the lotteries approach certainty. The left panel in Fig. 4, for problems 1–36, shows that only Sequences 3 and 6 have an apparent decrease in PROPMID as the lotteries approach certainty; however, Sequences 4 and 5 do not have a systematic pattern across lotteries. Different results are shown in the right panel, for problems 37–72, where there is an apparent decrease of PROPMID as the lotteries approach to certainty in Sequence 3–6. These findings are different from those in Cubitt et al, since subjects do not show a strong systematic pattern of in Sequences 3–6. The differences almost certainly arise because of the different incentive mechanism: a point that is reinforced by our regression results below.

The percentage of subjects choosing M by sequence in each half of the problem set
4.2 Formal analyses
Now I report formal results investigating my stories. There are sixteen variants of the four stories to try to explain why subjects choose M. I estimate subject-by-subject using maximum likelihood. Below is a summary of the stories. Following that are the results.
I separate the formal analysis into two parts. The first part is the main analysis of this paper where it tries to find the best story to account for the subjects’ behaviour. I do this subject-by-subject. For this, I run a horse-race between the four stories and their some descriptive statistics, before proceeding to some more formal analyses. Second, I perform a regression analysis that serves as a complement to the first part and tries to identify the connection between preference for randomisation and preference imprecision (Table 2).
To find the best-fitting variant and story, I compare the individual average-corrected log-likelihood in each model. Note that the RCP story has fewer observations than other stories due to exclusion of the dominance problems in this story.Footnote 14 So this compares the contribution of the corrected log-likelihood from each problem. I use the Akaike Information Criterion (AIC), the Bayesian Information Criterion (BIC), and Hannan-Quinn Information Criterion (HQC) for that.Footnote 15
Based on the variant comparisons, the RCP with CARA and the fixed threshold with CARA receive the most empirical support. These two variants best explain the choice of the majority of the subjects. Within the story comparison, it follows that the RCP story and the threshold story receive the most empirical support.Footnote 16 The results show that 38 subjects are best explained by the threshold story; 33 subjects are best explained with the RCP story.
Now I turn to the subjects’ risk aversion. All variants used involve risk aversion, and it is obvious that different subjects have different attitudes to risk.Footnote 17 All variants show that most of the subjects are risk-averse. The details of each variant can be seen in Appendix 6. I report the tremble (ω) from variants within those stories in Appendix 7 following the tremble parameter used in the tremble, the threshold, and the delegation stories to capture the mistake in expressing the subjects’ preference. I also report the extra utility parameter within the delegation story in Appendix 8.
4.3 Regression analyses of the choice on the mixture of A and B
This section’s main purpose is to see whether there is a connection between preference for randomisation and preference imprecision. I follow the regression model as in Cubitt et al. to explore what determines the choice of M. Since we saw switching amongst the subjects, I collect the percentage (PROPMID) of the choice of M in each response table—this differs from Cubitt et al. who use the range of the choice of M as measured in a monetary sum (INTSIZE). I use the lottery characteristics and the subjects’ experience as the determinant of PROPMID for each regression. Outcomes in the particular lottery are constructed through the MMT: each lottery has three outcomes with corresponding probabilities. x1 is the highest outcome with probability p1, x2 is the middle outcome with probability p2, and x3 is the lowest outcome with probability p3. For any lottery with two outcomes, I interpret it as having x3 zero with p3 zero. I also involve the ratio of the middle to the highest outcome (RATIO_x2x1), the expected value of each lottery (EV), and the range between the highest and the lowest outcome stated in the lottery (RANGE) as the lottery characteristics in the regression. To capture the subjects’ experience, I involve the number of response table that the subjects had completed (ORDER) and a dummy variable to indicate the repeated response table (REPEAT). I report the significant variables only from stepwise regression in Eq. 7 belowFootnote 18:
The regression model shows reasonable results as all coefficients are jointly different from zero.Footnote 19 The regression results show that both x1 and RATIO_x2x1 have a positive effect on PROPMID; the higher are x1 and RATIO_x2x1, the higher is PROPMID. Meanwhile, both p1 and ORDER have a negative effect on PROPMID; the higher are p1 and ORDER, the lower is the PROPMID. One interesting finding here is that of experience (ORDER) is negatively significant to PROPMID. This implies that randomising behaviour is a temporary phenomenon; there is a tendency of the choice of M to decrease as subjects continued to the next tables. This confirms the descriptive analysis in the previous sub-section where the subjects are found to have different behaviour of choosing M when the problems were repeated.
Below I reproduce the same regression from Cubitt et al. (the only difference being the definitionFootnote 20 of the dependent variable)Footnote 21:
Comparing these two equations (Eqs. 7 and 8), it is seen that, not only does significance change, but also the magnitudes of the coefficients. The conclusion seems to be that preference for randomisation and preference imprecision are two different things. The incentive mechanism would appear to be the key reason for these different results.
5 Discussion and conclusion
The motivation for this paper is to explore possible stories to help understand subjects’ behaviour when they are given an additional option when stating their preference between two options, namely, “I am not sure what to choose”, and when, if they chose this option, their payment would depend upon the tossing of a coin. It means that this choice has a direct financial implication through randomisation, and leads to the discussion of preference for randomisation.
The main contribution of this paper is to try to understand the nature of preference for randomisation. I propose four stories why someone may randomise the choice. This complements previous studies that rarely provide a formal model to account for this behaviour. My analysis shows, that of the four stories, the random-convex preference story and the threshold story receive the most empirical support in behaviour. Further research, of course, is necessary to disentangle these two since they have clearly different reasons for why the DM may randomise the choice.
The four stories in this paper consider that preference for randomisation is a deliberate choice. Cettolin and Riedl (2019) investigated if the subjects prefer to randomise the choice between risky and uncertain options, and between risky and sure options. They found that randomisation is a deliberate decision and is consistent across problems since their subjects’ behaviour does not change with the magnitude of the incentives. An investigation by Dwenger et al. (2018) shows a similar pattern; they conducted experiments where the subjects’ choice is implemented (in the payout rule) with a certain known probability. In one treatment, subjects were allowed to make a choice twice, the idea being that subjects with a strict preference will have the same choice in both attempts. However, the results show that a significant proportion of the subjects have choice reversals, indicating deliberate randomisation. A different approach was followed by Dominiak and Schnedler (2011) who tried to challenge the classical prediction in which an uncertainty-averse individual is supposed to prefer randomisation. The experiment elicited both randomisation and uncertainty attitudes, and identified their connection. Their findings show that randomisation and uncertainty attitude are not negatively associated; it is either that randomising-averse subjects are uncertainty-averse or vice versa.
An interesting exploration has been made by Agranov and Ortoleva (2017) that is related to one concern of my stories: the source of the stochastic process. They ran an experiment to find the relationship between preference for randomisation and stochastic choice. In their experiment, the subjects faced repeated problems in two treatments: far repetition and in-a-row repetition. The treatments differed in how the binary-problems were presented. The far repetition treatment repeated the same problems far apart and the subjects were not told about that, whereas the in-a-row repetition treatment repeated the same problems in a row and the subjects were told about that. Moreover, subjects were allowed to randomise the choice in both treatments at a fixed cost. They found that subjects who randomise the choice are significantly more likely to report inconsistent choice in both treatments. This indicates that the desire to randomise plays an important role in driving the stochastic choice.
One recent popular topic that may have a connection with a preference for randomisation is preference imprecision. This has been the main subject explored in Cubitt et al. (2015) and in Butler and Loomes (2007, 2011); these papers give an interpretation of the choice of the middle column despite there being no financial implication of subjects choosing it. I try to find a connection between these two topics, though they have different incentive mechanisms, by constructing a regression model following Cubitt et al. My regression estimation shows different results than that of Cubitt et al. since no explanatory variables have the same magnitude and significance. This suggests that there is no association between preference for randomisation and preference imprecision as defined by Cubitt et al.
However, it still might be possible to link these phenomena by having a different interpretation of what we mean by preference imprecision. As Loomes and Pogrebna (2014) recommend, eliciting preferences should take care of the context where it is elicited, and that it is necessary to develop a model engaging the inherently stochastic nature of human decision-making; though they avoid using some deterministic theory combined with the error term. This paper tries to address this issue by identifying the possible source of stochasticity given the elicitation procedure, that is, the two stories that receive most empirical support in this paper involve an imprecision element: in the threshold story, the imprecision occurs because of the DM’s (in)ability to calculate utility; surely this has an implication for the DM’s preference? In the random-convex preference story, the DM does not have a single preference since his or her risk attitude changes across problems. Perhaps we should pay more attention to defining what we mean by preference imprecision.
Notes
In that, there was no incentive for choosing the middle column: subjects were additionally asked to indicate the row on which their preference changed from A to B, and their payment depended on the position of this row relative to the randomly-chosen row.
f(p) = pg.
Other specifications, i.e. the Quiggin and Prelec functions, cannot rationalise a strictly convex preference within MMT as they produce an S-shape form. Detailed specifications can be found in the Appendix 2.
I have to assume this as I allowed subjects to switch between columns as they moved down a table: in fact, in 253 out of 5544 Tables (4.56%) from 27 subjects saw such switches.
Other evaluations are possible to used, for example the compound independence (Segal 1990), in the case of RDEU preference.
This idea is different than that of noisy preference; here I assume that the DM can calculate precisely if the utility difference between two alternatives exceeds some threshold.
Of course, one can assume other preference functions that allow for non-linear preference within MMT to explain why the mixture of A and B might be preferable.
I specify the MMT accordingly with p1 is the probability of the highest outcome and p3 is the probability of the lowest outcome.
However, it is possible to allow both r and g random, and find a combination of r* and g* on each V(A, M) and V(B, M)—when the DM is indifferent between A and M, and between B and M respectively. Thus, to make it operational, it needs a joint distribution to define the simultaneous relationship of r* and g*.
I could include these problems within the RCP story by involving a tremble in its specification, but I want to keep this story as simple as possible.
Strictly, Φ2 is the probability that a variable with the given distribution takes value less than r2.
Of course one can assume that the tremble can be different across non-optimal decisions when the DM can distinguish A and B.
Sequence 5 has six lotteries with lottery 2 is a slightly different kind of lottery 1 in this sequence. Lottery 1 is certain lottery while lottery 2 is close-to-certainty lottery.
This leaves the RCP story to have 2694 observations for each subject compared to 3082 observations for each subject in other stories.
AIC is given by 2 k – 2LL; BIC is given by ln(n)k – 2LL; HQC is given by -2LL + 2ln(ln(n))k; where k is the number of parameters, LL is the maximised log-likelihood and n is the number of observations.
The overall comparisons to find the best variant and the best story are in Appendix 3 and 4 respectively.
The detail results can be seen in Appendix 5.
Standard errors are in parentheses; * and ** denote significance at the 5% and 1% levels respectively.
Stepwise deletion (p value ≤ 0.2) and stepwise addition (p value ≥ 0.2) produce identical results. I also report results from simple regression. The detail of all regression results can be seen in Appendix 9.
My PROPMID is the percentage of responses using M; Cubitt et al’s INTSIZE is the interval size of the choice of M as measured in a monetary sum.
I reproduce the detail of regression results from Cubitt et al in Appendix 9.
There are several forms to specify the probability weighting function, such as Quiggin and Prelec weighting function. However, a power function is used due to a technical reason.
References
Agranov, M., & Ortoleva, P. (2017). Stochastic choice and preferences for randomization. Journal of Political Economy,125(1), 40–68.
Armstrong, M., & Vickers, J. (2010). A model of delegated project choice. Econometrica,78(1), 213–244.
Butler, D. J., & Loomes, G. C. (2007). Imprecision as an account of the preference reversal phenomenon. American Economic Review,97(1), 277–297.
Butler, D. J., & Loomes, G. C. (2011). Imprecision as an account of violations of independence and betweenness. Journal of Economic Behavior & Organization,80, 511–522.
Cettolin, E., & Riedl, A. (2019). Revealed preferences under uncertainty: Incomplete preferences and preferences for randomization. Journal of Economic Theory,181, 547–585.
Cubitt, R. P., Navarro-Martinez, D., & Starmer, C. (2015). On preference imprecision. Journal of Risk and Uncertainty,50(1), 1–34.
Dominiak, A., & Schnedler, W. (2011). Attitudes toward uncertainty and randomization: An experimental study. Journal of Economic Theory,48, 289–312.
Dwenger, N., Kubler, D., & Weizsacker, G. (2018). Flipping a coin: Evidence from university applications. Journal of Public Economics,167, 240–250.
Harless, D. W., & Camerer, C. F. (1994). The predictive utility of generalized expected utility theories. Econometrica,62(6), 1251–1289.
Khrisnan, K. S. (1977). Incorporating thresholds of indifference in probabilistic choice models. Management Science,23(11), 1224–1233.
Loomes, G. C., Moffatt, P. G., & Sugden, R. (2002). A microeconometric test of alternative stochastic theories of risky choice. Journal of Risk and Uncertainty,24(2), 103–130.
Loomes, G. C., & Pogrebna, G. (2014). Measuring individual risk attitudes when preferences are imprecise. The Economic Journal,124(576), 569–593.
Loomes, G. C., & Sugden, R. (1995). Incorporating a stochastic element into decision theories. European Economic Review,39(3), 641–648.
Segal, U. (1990). Two-stage lotteries without the reduction axiom. Econometrica,58(2), 349–377.
Starmer, C. (2000). Development in non-expected utility theory: The hunt for a descriptive theory of choice under risk. Journal of Economic Literature,38(2), 332–382.
Vickers, J. (1985). Delegation and the theory of firm. Management Science,23(11), 1224–1233.
Acknowledgements
I am thankful to John Hey, Robin Cubitt, Chris Starmer, Daniel Navarro-Martinez, Oben Bayrak, and participants at FUR York 2018, ASFEE Nice 2018 and WIEM Warsaw 2018 for helpful comments and feedback. I also thank three anonymous referees for their relevant remarks and suggestions. This paper was funded by Indonesia Endowment Fund for Education (Ref: S-4294/LPDP.3/2015) as a part of my doctoral scholarship. All errors and omissions are solely mine.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix 1
See Fig. 5 in Appendix.

On the screen example to complete the tasks in the particular response table
Appendix 2: Specification of the EU and the RDEU
The general form of EU is \( EU(.) = \sum\nolimits_{i}^{I} {p_{i} u_{i} } \) and of RDEU is \( RDEU(.) = \sum\nolimits_{i}^{I} {P_{i} u_{i} } \)—where (pi) is the set of true probabilities, (ui) is the utility indices and (Pi) is the set of weighted probabilities. For the RDEU specification, I assume that the DM ranks the outcomes from the highest to the lowest. So I can define Pi as: \( P_{i} = \sum\nolimits_{I}^{I} {w(p_{i} ) - w(p_{i - 1} )} \)—where w(.) is the probability-weighting function. I use the Power weighting function for w(.) that can formally be written as: w(p) = pg; g > 0—where g is a parameter of w(.).Footnote 22 Given this, P1 = w(p1) and RDEU will reduce to EU if w(pi) = pi everywhere. The w(pi) is monotonically increasing in the area of [0, 1] with w(0) = 0 and w(1) = 1.
To complete the specification of the EU and the RDEU, I use CARA and CRRA to specify the utility function. The general form of CARA and CRRA, and its application in this paper, are:
where x is the outcome received by the DM in a choice problem i, X is the highest outcome for all choice problems and r is the parameter of risk attitude. I normalise CARA so the utility index will always be 0 ≤ ui ≤ 1. For CRRA, I need to add e because CRRA does not fully accommodate the case when x = 0 and r < 0 otherwise the function is undefined.
Appendix 3
See Table 3 in Appendix.
Appendix 4
See Table 4 in Appendix.
Appendix 5
See Table 5 in Appendix.
Appendix 6
See Fig. 6 in Appendix.

Risk aversion of each model
Appendix 7
See Fig. 7 in Appendix.

Tremble parameter of the related model
Appendix 8
See Fig. 8 in Appendix.

Extra utility parameter of the related models
Appendix 9
See Table 6 in Appendix.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Permana, Y. Why do people prefer randomisation? An experimental investigation. Theory Decis 88, 73–96 (2020). https://doi.org/10.1007/s11238-019-09719-2
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11238-019-09719-2