
Abstract
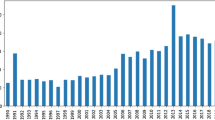
Formal epistemology is a growing field of philosophical research. It is also evolving, with the subject matter of formal epistemology papers changing considerably over the past two decades. To quantify the ways in which formal epistemology is changing, I generate a stochastic block topic model of the abstracts of papers classified by PhilPapers.org as pertaining to formal epistemology. This model identifies fourteen salient topics of formal epistemology abstracts at a first level of abstraction, and four topics at a second level of abstraction. I then study diachronic trends in the degree to which formal epistemology abstracts written in a given year are likely to contain words associated with a particular topic, beginning in 2000 and continuing to 2020. My findings suggest that there has been a marked decline in the likelihood of a given formal epistemology abstract being about logical approaches to belief revision (e.g., AGM belief-revision theory). On the other hand, over the past two decades, the salience of probabilistic techniques in formal epistemology has increased, as has the salience of work at the intersection of formal epistemology and some areas of philosophy of science.




Similar content being viewed by others

Notes
In a paper written at the same time as this one, and recently accepted by this journal, Fletcher et al. (forthcoming) hand-coded a sample of papers from the journal Philosophical Studies to detect the use of formal methods and investigate the specific formal methods used in each paper. Their findings cohere in with mine in several respects. They show a significant increase in the use of probabilistic methods in formal philosophy papers over the course of the twenty-first century. While their analysis detected no significant change in the use of logical methods within formal philosophy as a whole, it did detect a decline in the proportion of epistemology papers making use of logical methods. Similarly, my analysis here indicates a decline in the salience of logical approaches within formal epistemology in particular. Ultimately, while there is clearly some connection between my results and theirs, our studies are different in several important respects. Most saliently, their paper and this one use very different techniques for gathering data, and analyze corpora that are constructed using very different principles.
For full details of PhilPapers’ categorization policy, see https://philpapers.org/help/categorization.html.
For all code and data used in this paper, see https://github.com/davidbkinney/formalepistemologySBM.
While there is room for disagreement about how any topic is to be interpreted, with respect to Topics 16 and 17 there is an especially strong case to be made that the high probabilities assigned to words like ‘functional’, ‘brain’, ‘mental’, ‘disease’, and ‘physical’ suggest an association with philosophy of mind or psychology. At the same time, words like ‘scientists’, ‘treatment’, ‘confirm’, ‘caused’, and ‘estimation’, which are also assigned high probability by these topics, do not have any special relevance to philosophy of mind, but are relevant to scientific practice. For this reason, I have chosen the topic title ‘Applications to Scientific Practice,’ but flag here that “scientific practice” should be taken to include the practice of neuroscience, cognitive science, and psychology.
References
Alchourrón, C. E., Gärdenfors, P., & Makinson, D. (1985). On the logic of theory change: Partial meet contraction and revision functions. Journal of Symbolic Logic, 50, 510–530.
Ball, B., Karrer, B., & Newman, M. E. (2011). Efficient and principled method for detecting communities in networks. Physical Review E, 84(3), 036103.
Blei, D. M., Ng, A. Y., & Jordan, M. I. (2003). Latent dirichlet allocation. The Journal of machine Learning research, 3, 993–1022.
Buchak, L. (2014). Belief, credence, and norms. Philosophical Studies, 169(2), 285–311.
Collins, J. (2020). Simple belief. Synthese, 197(11), 4867–4885. https://doi.org/10.1007/s11229-018-1746-3.
Fletcher, S. C., Knobe, J., Wheeler, G., & Woodcock B. A. Changing use of formal methods in philosophy: Late 2000s vs. late 2010s. Synthese, forthcoming.
Gerlach, M., Peixoto, T. P., & Altmann, E. G. (2018). A network approach to topic models. Science Advances, 4(7), eaaq1360.
Griffiths, T. L., Steyvers, M., Blei, D. M., & Tenenbaum, J. B. (2004). Integrating topics and syntax. NIPS, 4, 537–544.
Hansson, S. O. (2017). Logic of Belief Revision. In E. N. Zalta, editor, The Stanford Encyclopedia of Philosophy. Metaphysics Research Lab, Stanford University, winter 2017 edition.
Jackson, E. (2018). Belief, credence, and evidence. Synthese, 197, 1–20.
Malaterre, C., Chartier, J.-F., & Pulizzotto, D. (2019). What is this thing called philosophy of science? A computational topic-modeling perspective, 1934–2015. HOPOS: The Journal of the International Society for the History of Philosophy of Science, 9(2), 215–249.
Malaterre, C., Lareau, F., Pulizzotto, D., & St-Onge, J. (2020). Eight journals over eight decades: A computational topic-modeling approach to contemporary philosophy of science. Synthese, 199, 1–41.
Peixoto, T. P. (2015). Model selection and hypothesis testing for large-scale network models with overlapping groups. Physical Review X, 5(1), 011033.
Peixoto, T. P. (2017). Nonparametric bayesian inference of the microcanonical stochastic block model. Physical Review E, 95(1), 012317.
Pettigrew, R. (2015). Accuracy and the credence-belief connection. Philosopher’s Imprint,15(16).
Ross, J., & Schroeder, M. (2014). Belief, credence, and pragmatic encroachment. Philosophy and Phenomenological Research, 88(2), 259–288.
Spirtes, P., Glymour, C. N., & Scheines, R. (2000). Causation, prediction, and search. MIT press.
Staffel, J. (forthcoming). Probability without tears. Teaching Philosophy. https://philpapers.org/rec/STAPWT
Weatherson, B. (2021a). A history of philosophy journals. volume 1: Evidence from topic modelling, 1876–2013. http://www-personal.umich.edu/~weath/lda/
Weatherson, B. (2021b). Tweet on 8 february. https://twitter.com/bweatherson/status/1358813210741264386?s=20
Weisberg, J. (2021). Tweet on 8 february. https://twitter.com/jweisber/status/1358809726079885315?s=20
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This article belongs to the topical collection “Metaphilosophy of Formal Methods”, edited by Samuel Fletcher.
Forthcoming in Synthese: I am grateful to Julia Lefkowitz and two anonymous reviewers for their insightful comments on early drafts of this manuscript.
Appendices
Appendix A: LDA and SBM approaches to topic modeling
This appendix presents a more detailed comparison of the LDA and SBM approaches to topic modelling than would be appropriate in the main body of the paper, although there is some conceptual overlap between the presentation of SBM given here and that given in Sect. 2.2. Specifically, I give an exegetical overview of the LDA and SBM approaches to topic modelling, highlighting the differences between the two approaches where appropriate.
1.1 A1: LDA topic modelling
As is done above, consider a corpus \(\mathcal {D}=\{d_{1},\dots ,d_{z}\}\) of documents in which each document is a sequence of words \(d_{i}=(w_{i,1},\dots ,w_{i,m_{i}})\) from a vocabulary \(\mathcal {W}=\{w_{1},\dots ,w_{m}\}\). In an LDA topic model, we must also pre-specify a number of topics K to be discovered. We then assume that each document \(d_{i}\) in the corpus is generated via the following process (Blei et al. 2003, p. 996):
-
1.
Obtain the number \(m_{i}\) of words in the document by sampling from a Poisson distribution with parameter \(\xi \).
-
2.
Obtain a document-specific probability distribution \(p(\cdot |d_{i})\) over topics \(\mathcal {T}\) by sampling from a Dirichlet distribution with \(\varvec{\alpha }\) as its concentration parameter and K as the parameter fixing the number of elements in \(\mathcal {T}\). Note that the Dirichlet distribution is a unimodal distribution, meaning that in an LDA the distribution over topics \(p(\cdot |d_{i})\) is always “either concentrated around the mean value, or spread away uniformly from it towards pure components” (Gerlach et al. 2018, p. 5).
-
3.
To determine each word \(w_{i,j}\) in the document \(d_{i}\):
-
(a)
Choose a topic \(t_{j}\) by sampling from a single-trial multinomial distribution that takes as its parameter the topic mixture \(p(\cdot |d_{i})\).
-
(b)
Choose a word \(w_{i,j}\) by sampling from a single-trial multinomial distribution whose parameter is a mixture of the topic \(t_{j}\) and a distribution \(\varvec{\beta }\).
-
(a)
Inferring an LDA topic model involves finding settings for the parameters \(\varvec{\alpha }\) and \(\varvec{\beta }\) that produce topics and topic distributions that render the corpus \(\mathcal {D}\) maximally likely while avoiding over-fitting, where parameters are said to avoid over-fitting if they not only render the corpus \(\mathcal {D}\) highly likely but also render corpora that are similar but not identical to \(\mathcal {D}\) sufficiently likely. While solving this inference problem exactly is computationally intractable, there are several algorithms for efficient approximation of suitable LDA parameters for a given input corpus.
1.2 A2: SBM topic modelling
As stated in the main body of the paper, an SBM represents a corpus as a multigraph in which nodes represent either documents or words, such that all documents and words in the corpus are represented, and the adjacency matrix \(\mathbf {A}\) is such that if two nodes \(n_{i}\) and \(n_{j}\) both represent documents or both represent words, then \(A_{ij}=0\). Otherwise, \(A_{ij}\) represents the number of times that word \(w_{j}\) appears in document \(d_{i}\), or the number of times word \(w_{i}\) appears in document \(d_{j}\), depending on whether \(n_{i}\) and \(n_{j}\) represent a word or a document, respectively. We group the set of nodes \(\mathcal {N}_{\mathcal {W}}\) representing words in the vocabulary into v groups \(\mathcal {N}^{\uparrow }_{\mathcal {W}}=\{N^{\uparrow 1}_{\mathcal {W}},\dots ,N^{\uparrow v}_{\mathcal {W}}\}\) (in Gerlach et al.’s presentation of their technique they also group the documents, but I dispense with this part of their model here as it is not used in my analysis). This yields a high-level adjacency matrix \(\mathbf {A}^{\uparrow }\) such that whenever node \(n^{\uparrow }_{i}\) represents a document and \(n^{\uparrow }_{r}\) represents a document group, the matrix entry \(A^{\uparrow }_{ir}\) represents the number of words in \(N^{\uparrow r}_{\mathcal {W}}\) included in \(d_{i}\). Inferring an SBM topic model involves finding a set of groups of word nodes \(\mathcal {N}^{\uparrow }_{\mathcal {W}}\) and the upper-level adjacency matrix \(\mathbf {A}^{\uparrow }\) such that the observed lower-level adjacency matrix \(\mathbf {A}\) is maximally likely while avoiding over-fitting.
To describe this inference process, I follow the presentation in Peixoto (2017) and Gerlach et al. (2018), with some adjustments for the topic modelling context. I begin by introducing some notation. Let \(\mathcal {N}^{l}_{\mathcal {W}}\) be the grouping of word nodes at the l-th level of abstraction, so that \(\mathcal {N}^{0}_{\mathcal {W}}=\mathcal {N}_{\mathcal {W}}\), \(\mathcal {N}^{1}_{\mathcal {W}}=\mathcal {N}^{\uparrow }_{\mathcal {W}}\), \(\mathcal {N}^{2}_{\mathcal {W}}=\mathcal {N}^{\uparrow \uparrow }_{\mathcal {W}}\), and so on. Let \(\mathbf {A}^{l}\) be the adjacency matrix for the multigraph with nodes \(\mathcal {N}_{D}\cup \mathcal {N}^{l}_{\mathcal {W}}\). Let \(\{\mathcal {N}^{l}_{\mathcal {W}}\}\) denote the set of word groupings at all levels of abstraction \(l\in \{0,\dots ,L\}\). We aim to find the set of world groupings \(\{\mathcal {N}^{l}_{\mathcal {W}}\}\) that maximizes the joint probability \(P(\mathbf {A}^{0},\{\mathcal {N}^{l}_{\mathcal {W}}\})\). To do this, we aim to minimize the description length \(\Sigma \), which is defined via the equation:
To do this, we note first that \(P(\mathbf {A}^{0},\{\mathcal {N}^{l}_{\mathcal {W}}\})\) can be expanded as follows (recall that \(\mathbf {k}\) is still the degree vector for the lowest-level multigraph \(\mathcal {G}\)):
We then proceed by defining each of the components of this expansion of \(P(\mathbf {A}^{0},\{\mathcal {N}^{l}_{\mathcal {W}}\})\).
We begin with each \(P(\mathcal {N}^{l}_{\mathcal {W}})\), which can be defined as follows:
where \(N^{l,r}_{\mathcal {W}}\) is the r-th element of the level-l grouping \(\mathcal {N}^{l}_{\mathcal {W}}\). The RHS of this equation is the proportion of possible groupings of word nodes at level l that are consistent with the size of the grouping \(\mathcal {N}^{l-1}_{\mathcal {W}}\). Sampling each grouping of the vocabulary from this hierarchical prior at each level allows us to avoid the unimodality constraint on topic distributions imposed under the LDA framework.
Next, we move to the probabilities of the form \(P(\mathbf {A}^{l}|\mathbf {A}^{l+1},\mathcal {N}^{l+1}_{\mathcal {W}})\), which can be defined as follows:

where  . The RHS of this equation is a fraction with 1 as its numerator and the number of adjacency matrices \(\mathbf {A}^{l}\) consistent with the higher-level adjacency matrix and higher-level grouping \(\mathbf {A}^{l+1}\) and \(\mathcal {N}^{l+1}_{\mathcal {W}}\) as its denominator.
. The RHS of this equation is a fraction with 1 as its numerator and the number of adjacency matrices \(\mathbf {A}^{l}\) consistent with the higher-level adjacency matrix and higher-level grouping \(\mathbf {A}^{l+1}\) and \(\mathcal {N}^{l+1}_{\mathcal {W}}\) as its denominator.
Moving to the probability \(P(\mathbf {k}|\mathbf {A}^{1},\mathcal {N}^{1}_{\mathcal {W}})\), let \(\eta ^{r}_{k}\) be the number of nodes in \(N^{1,r}_{\mathcal {W}}\) with degree \(k\in \{1,\dots ,\kappa \}\). We define the probability as follows:
where q(m, n) is the number of ways of writing m as the sum of n positive integers. Although q(m, n) is computationally intractable for larger m and n, efficient approximations are given in Peixoto (2017, p. 6). The RHS of this equation is the ratio between the number of lowest-level multigraphs with degree vector \(\mathbf {k}\) and the number of lowest-level multigraphs that are consistent with the higher-level adjacency matrix and grouping \(\mathbf {A}^{1}\) and \(\mathcal {N}^{1}_{\mathcal {W}}\).
Finally, to define \(P(\mathbf {A}^{0}|\mathbf {k},\mathbf {A}^{1},\mathcal {N}^{1}_{\mathcal {W}})\), we begin by calculating the number \(\Omega (\mathbf {A}^{1},\mathcal {N}^{1}_{\mathcal {W}})\) of lower-level multigraphs consistent with \(\mathbf {A}^{1}\) and \(\mathcal {N}^{1}_{\mathcal {W}}\):
For any given lowest-level adjacency matrix \(\mathbf {A}^{0}\) and degree vector \(\mathbf {k}\), the number \(\Xi (\mathbf {A}^{0},\mathbf {k})\) of higher-level multigraphs consistent with \(\mathbf {A}^{0}\) and \(\mathbf {k}\) is given by the equation:
Thus, the probability of observing a multigraph with the lower-level adjacency matrix \(\mathbf {A}^{0}\), given parameter settings \(\mathcal {N}^{\uparrow }_{\mathcal {W}}\), \(\mathbf {k}\), and \(\mathbf {A}^{1}\), is given by the following ratio:
Taking stock, we see that the RHS of the equations for all the component probabilities in the product in the RHS of (5) can be calculated using either the observed lowest-level adjacency matrix \(\mathbf {A}^{0}\) for the corpus, or from the set of groupings \(\{\mathcal {N}^{l}_{\mathcal {W}}\}\). This entails in turn that one can infer the SBM at all levels of abstraction by finding the set of groupings \(\{\mathcal {N}^{l}_{\mathcal {W}}\}\) that minimizes the description length \(\Sigma \) of the probability \(P(\mathbf {A}^{0},\{\mathcal {N}^{l}_{\mathcal {W}}\})\). In Gerlach et al. (2018), and in the code used in the analysis in this paper, this is done through Markov Chain Monte Carlo simulation. Said inference algorithms do not require pre-specification of the cardinality of the grouping of the word nodes at each level of abstraction. Instead, this can learned from data; this is another advantage of the SBM methodology over LDA methods.
Appendix B: Formal epistemology topics
1.1 B1: Level 1
In this appendix, I list the twenty words with highest probability according to each of the twenty-one first-level topics discovered in this analysis. The probability of each word in that topic is given in parenthesis next to the word in question. Note that for the purpose of this study, topics 2 and 13, 16 and 17, and 18 and 19 were deemed to be sufficiently similar that each pair was combined into a single topic. Note also that in topic 19, the five words listed are the only five words that had positive probability with respect to that topic.
-
0.
Evidence
-
Evidence (.129)
-
Disagreement (.021)
-
Response (.018)
-
Correct (.015)
-
Right (.014)
-
Thought (.014)
-
Law (.014)
-
Think (.013)
-
Always (.013)
-
Procedure (.013)
-
Positive (.011)
-
Procedures (.011)
-
Lead (.011)
-
Seem (.011)
-
Consensus (.011)
-
Majority (.010)
-
Legal (.009)
-
Act (.008)
-
Significance (.008)
-
Confidence (.008)
-
-
1.
No Clear Interpretation
-
Information (.024)
-
Results (.018)
-
Set (.016)
-
Terms (.013)
-
View (.012)
-
Important (.011)
-
Notion (.010)
-
Conditions (010)
-
Principle (.009)
-
Certain (.009)
-
Second (.008)
-
Number (.008)
-
States (.008)
-
Standard (.008)
-
Relation (.008)
-
Order (.008)
-
Kind (.008)
-
Role (.008)
-
Often (.007)
-
Rather (.007)
-
-
2.
Logical Approaches to Belief Revision I
-
Belief (.214)
-
Epistemic (.121)
-
Beliefs (.093)
-
Revision (.082)
-
Change (.067)
-
Agent (.052)
-
Agents (.046)
-
State (.037)
-
AGM (.028)
-
Postulates (.017)
-
Iterated (.017)
-
Operators (.014)
-
Doxastic (.014)
-
Epistemically (.013)
-
Minimal (.011)
-
Operator (.011)
-
Update (.010)
-
Base (.010)
-
Operations (.009)
-
Inconsistent (.009)
-
-
3.
Logical Approaches to Knowledge
-
Knowledge (.062)
-
Logic (.045)
-
Common (.031)
-
Logical (.025)
-
Truth (.019)
-
System (.017)
-
Context (.014)
-
Normative (.013)
-
Attitudes (.012)
-
Without (.011)
-
Inquiry (.011)
-
Dynamic (.011)
-
Language (.011)
-
Action (.009)
-
Level (.009)
-
Available (.009)
-
Prior (.008)
-
Appropriate (.008)
-
Logics (.008)
-
Full (.008)
-
-
4.
Probability and Rationality
-
Probability (.044)
-
Rational (.042)
-
Probabilistic (.026)
-
Rationality (.022)
-
Group (.020)
-
Principles (.018)
-
True (.017)
-
Functions (.017)
-
Rule (.016)
-
Individual (.016)
-
Propositions (.016)
-
Rules (.016)
-
Aggregation (.016)
-
Function (.015)
-
Justification (.015)
-
Thesis (.015)
-
Probabilities (.015)
-
Proposition (.015)
-
Credences (.014)
-
Norms (.013)
-
-
5.
Inductive Risk
-
Error (.014)
-
Risk (.013)
-
Core (.011)
-
Practical (.010)
-
Hume (.010)
-
Glymour (.009)
-
Nonmonotonic (.008)
-
Published (.008)
-
Failure (.008)
-
Fails (.008)
-
Drawing (.007)
-
Parameter (.007)
-
Program (.007)
-
Warrant (.007)
-
Deductive (.007)
-
Chance (.006)
-
Agency (.006)
-
QCA (.006)
-
Efficacy (.006)
-
Reading (.005)
-
-
6.
Applications to General PhilSci
-
Science (.043)
-
Explanation (.028)
-
Scientific (.027)
-
Causal (.017)
-
Philosophers (.013)
-
Explanatory (.013)
-
Explanations (.012)
-
Practice (.010)
-
Author (.010)
-
Psychology (.009)
-
Thinking (.009)
-
Ideas (.008)
-
Psychological (.008)
-
Cognition (.008)
-
Power (.007)
-
Authors (.007)
-
Diversity (.007)
-
Domain (.007)
-
Tools (.007)
-
Property (.006)
-
-
7.
No Clear Interpretation
-
Social (.024)
-
Question (.022)
-
Research (.021)
-
Philosophical (.018)
-
Philosophy (.018)
-
Well (.016)
-
Decision (.015)
-
Cognitive (.014)
-
Questions (.013)
-
Empirical (.012)
-
Book (.012)
-
Idea (.012)
-
Concept (.011)
-
Among (.011)
-
Alternative (.011)
-
Interpretation (.011)
-
Value (.011)
-
Choice (.010)
-
Issues (.010)
-
Explain (.009)
-
-
8.
Abstracts not in English
-
de (.043)
-
la (.023)
-
que (.012)
-
en (.011)
-
un (.009)
-
die (.009)
-
John (.008)
-
der (.007)
-
und (.007)
-
las (.006)
-
es (.005)
-
el (.005)
-
una (.004)
-
se (.004)
-
testimonio (.004)
-
los (.004)
-
des (.004)
-
como (.003)
-
del (.003)
-
En (.003)
-
-
9.
Judgment
-
Judgments (.027)
-
People (.024)
-
Features (.016)
-
Judgment (.015)
-
Influence (.014)
-
Multiple (.013)
-
Actual (.013)
-
Networks (.012)
-
Moral (.012)
-
Factors (.012)
-
Temporal (.011)
-
Found (.011)
-
Behavior (.011)
-
Considerations (.010)
-
Ability (.010)
-
Likely (.010)
-
Identify (.010)
-
Children (.009)
-
Across (.009)
-
Network (.008)
-
-
10.
Coherence and Conditionalization
-
coherence (.063)
-
Bayesian (.045)
-
Measure (.027)
-
Version (.022),
-
Measures (.020)
-
Changes (.016)
-
Coherent (.013)
-
Mind (.010)
-
External (.009)
-
Intuitive (.009)
-
Illustrate (.009)
-
Dutch (.009)
-
Foundations (.009)
-
Sequence (.008)
-
Updating (.007)
-
Acceptance (.007)
-
Pragmatic (.007)
-
Internal (.007)
-
Conditionalization (.007)
-
Components (.006)
-
-
11.
Applications to Scientific Modelling
-
Model (.102)
-
Models (.066)
-
Inference (.046)
-
Possible (.033)
-
Methods (.031)
-
Method (.025)
-
Conditional (.023)
-
World (.022)
-
Time (.022)
-
Relevant (.020)
-
Modeling (.020)
-
Assumption (.017)
-
Inferences (.016)
-
Constraints (.016)
-
Allows (.015)
-
Consistent (.014)
-
Test (.014)
-
Relevance (.013)
-
Strong (.012)
-
Apply (.012)
-
-
12.
Hypothesis Testing and Confirmation
-
Condition (.032)
-
Hypothesis (.024)
-
Confirmation (.020)
-
Bayes (.014)
-
Markov (.014)
-
Assessment (.014)
-
Evaluation (.014)
-
Prediction (.013)
-
Performance (.012)
-
Opinion (.012)
-
Correlations (.012)
-
Quantum (.011)
-
Nets (.011)
-
Discussions (.010)
-
Deterministic (.008)
-
Systematic (.008)
-
Counterexamples (.007)
-
Universal (.007)
-
Intended (.007)
-
Mechanics (.007)
-
-
13.
Logical Approaches to Belief Revision II
-
Contraction (.054)
-
Sets (.029)
-
Class (.019)
-
Partial (.017)
-
Meet (.016)
-
Conditionals (.016)
-
Represented (.016)
-
Sentences (.015)
-
& (.013)
-
et (.013)
-
Gärdenfors (.012)
-
Equivalent (.012)
-
Entrenchment (.011)
-
Sentence (.011)
-
Operation (.011)
-
al (.011)
-
Semantic (.010)
-
Accepted (.010)
-
Obtained (.010)
-
Theorems (.010)
-
-
14.
No Clear Interpretation
-
informal (.003)
-
Foundational (.003)
-
Price (.002),
-
2013 (.002)
-
Written (.002)
-
Suggestion (.002)
-
Paul (.001)
-
Disjunction (.001)
-
Keith (.001)
-
Essence (.001)
-
Advancing (.001)
-
Time (.001)
-
Defeasibility (.001)
-
Machinery (.001)
-
Substitute (.001)
-
Depart (.001)
-
Pervasive (.001)
-
Raising (.001)
-
Basic (.001)
-
Thoroughly (.001)
-
-
15.
Data Science Applications
-
Data (.034)
-
Structure (.030)
-
Cause (.029)
-
Effect (.028)
-
Variables (.028)
-
Effects (.026)
-
Learning (.024)
-
Relations (.022)
-
Studies (.020)
-
Assumptions (.019)
-
Statistical (.016)
-
Structural (.015)
-
Experimental (.012)
-
Structures (.012)
-
Outcome (.011)
-
Discovery (.010)
-
Selection (.010)
-
Independence (.010)
-
Distribution (.010)
-
Underlying (.010)
-
-
16.
Applications to Scientific Practice I
-
Treatment (.033)
-
Functional (.016)
-
Select (.014)
-
Personal (.013)
-
Brain (.013)
-
Confirm (.012)
-
Policies (.011)
-
Toward (.011)
-
Agree (.010)
-
Sharing (.009)
-
Balance (.009)
-
Formats (.009)
-
Find (.008)
-
Asked (.008)
-
Estimation (.008)
-
Robust (.008)
-
Simulation (.008)
-
Articles (.008)
-
Format (.007)
-
Processing (.007)
-
-
17.
Applications to Scientific Practice II
-
Mental (.0470)
-
Scientists (.044)
-
Difference (.024)
-
Disease (.023)
-
Physical (.022)
-
Challenges (.016)
-
Pooling (.015)
-
Already (.014)
-
Helps (.014)
-
Caused (.013)
-
Seek (.013)
-
nt (.012)
-
Intermediate (.010)
-
Try (.010)
-
Communication (.010)
-
Looks (.010)
-
Fixed (.010)
-
Needs (.010)
-
Assigned (.009)
-
Care (.009)
-
-
18.
Causal Modelling I
-
Causation (.064)
-
Causes (.030)
-
Mechanisms (.025)
-
Counterfactual (.022)
-
Causality (.022)
-
Events (.019)
-
Sciences (.019)
-
Semantics (.018)
-
Mechanism (.018)
-
Relationships (.016)
-
Interventionist (.014)
-
Counterfactuals (.013)
-
Lewis (.011)
-
Event (.011)
-
Dependence (.010)
-
Modelling (.008)
-
Policy (.009)
-
Pearl (.008)
-
Definitions (.008)
-
Trials (.008)
-
-
19.
Causal Modelling II
-
Causal (.875)
-
Experiments (.048)
-
Interventions (.030)
-
Intervention (.028)
-
Cartwright (.010)
-
Net (.009)
-
-
20.
No Clear Interpretation
-
th (.010 )
-
Pain (.006)
-
Variance (.004)
-
Futurium (.003)
-
Crisis (.003)
-
Semmelweis (.003)
-
Deaths (.003)
-
Observe (.003)
-
Convincing (.003)
-
Creature (.003)
-
Continuing (.003)
-
Aufbau (.003)
-
Digital (.003)
-
COVID (.003)
-
Reductions (.002)
-
KCIT (.002)
-
Neglects (.002)
-
J-revision (.002)
-
Implausibility (.002)
-
ca (.002)
-
1.2 B2: Level 2
Here I list the twenty words with highest probability according to each of five second-level topics discovered in this analysis.
-
0.
Belief and Belief Revision
-
Belief (.033)
-
Evidence (.019)
-
Epistemic (.019)
-
Beliefs (.014)
-
Revision (.013)
-
Change (.0102)
-
Coherence (.008)
-
Agent (.008)
-
Agents (.007)
-
Contraction (.007)
-
Bayesian (.006)
-
State (.006)
-
AGM (.004)
-
Measure (.004)
-
Sets (.004)
-
Condition (.004)
-
Disagreement (.003)
-
Version (.003)
-
Measures (.003)
-
Hypothesis (.003)
-
-
1.
No Clear Interpretation
-
Information (.015)
-
Results (.011)
-
Set (.010)
-
Social (.009)
-
Terms (.008)
-
Question (.008)
-
Research (.008)
-
View (.008)
-
Important (.007)
-
Philosophical (.007)
-
Notion (.007)
-
Philosophy (.007)
-
Conditions (.006)
-
Well (.006)
-
Principle (.006)
-
Certain (.005)
-
Decision (.005)
-
Number (.005)
-
Second (.005)
-
Cognitive (.005)
-
-
2.
Applications to Scientific Modelling
-
Model (.014)
-
Knowledge (.010)
-
Models (.009)
-
Causation (.007)
-
Logic (.007)
-
Probability (.007)
-
Rational (.007)
-
Science (.007)
-
Inference (.006)
-
Common (.005)
-
Data (.005)
-
Possible (.004)
-
Structure (.004)
-
Probabilistic (.004)
-
Cause (.004)
-
Explanation (.004)
-
Effect (.004)
-
Methods (.004)
-
Scientific (.004)
-
Variables (.004)
-
-
3.
Abstracts not in English
-
de (.043)
-
la (.023)
-
que (.012)
-
en (.011)
-
un (.009)
-
die (.009)
-
John (.008)
-
der (.007)
-
und (.007)
-
las (.006)
-
es (.005)
-
el (.005)
-
una (.004)
-
se (.004)
-
testimonio (.004)
-
los (.004)
-
des (.004)
-
como (.003)
-
del (.003)
-
En (.003)
-
-
4.
Causal Modelling
-
Causal (.204)
-
Experiments (.011)
-
Treatment (.011)
-
Mental (.010)
-
Scientists (.010)
-
Interventions (.007)
-
Intervention (.007)
-
Functional (.005)
-
Difference (.005)
-
Disease (.005)
-
Physical (.005)
-
Select (.005)
-
Personal (.004)
-
Brain (.004)
-
Confirm (.004)
-
Policies (.004)
-
Challenges (.004)
-
Toward (.004)
-
Agree (.004)
-
Pooling (.003)
-
Rights and permissions
About this article

Cite this article
Kinney, D. Diachronic trends in the topic distributions of formal epistemology abstracts. Synthese 200, 10 (2022). https://doi.org/10.1007/s11229-022-03466-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11229-022-03466-8