
Abstract
We propose a novel method for drift estimation of multiscale diffusion processes when a sequence of discrete observations is given. For the Langevin dynamics in a two-scale potential, our approach relies on the eigenvalues and the eigenfunctions of the homogenized dynamics. Our first estimator is derived from a martingale estimating function of the generator of the homogenized diffusion process. However, the unbiasedness of the estimator depends on the rate with which the observations are sampled. We therefore introduce a second estimator which relies also on filtering the data, and we prove that it is asymptotically unbiased independently of the sampling rate. A series of numerical experiments illustrate the reliability and efficiency of our different estimators.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Learning models from data is a problem of fundamental importance in modern applied mathematics. The abundance of data in many application areas such as molecular dynamics, atmosphere/ocean science makes it possible to develop physics-informed data driven methodologies for deriving models from data (Raissi et al. 2019; Yang et al. 2021; Zhang et al. 2019). Naturally, most problems of interest are characterised by a very high-dimensional state space and by the presence of many characteristic length and time scales. When it is possible to decompose the state space into the resolved and unresolved degrees of freedom, then one is usually interested in the derivation of a model for the resolved degrees of freedom, while treating the unresolved scales as noise. Clearly, these reduced models are stochastic, often described by stochastic differential equations (SDEs). The goal of this paper is to derive rigorous and systematic methodologies for learning coarse-grained models that accurately describe the dynamics at macroscopic length and time scales from noisy observations of the full, unresolved dynamics. We apply the proposed methodologies to simple models of fast/slow SDEs for which the theory of homogenization exists, that enables us to study the inference problem in a rigorous and systematic manner.
In many applications, the available data are noisy, not equidistant and certainly not compatible with the coarse-grained model. The presence of observation noise and of the model-data mismatch renders the problem of learning macroscopic models from microscopic data highly ill-posed. Several examples from econometrics (market microstructure noise) (Aït-Sahalia et al. 2006) and molecular dynamics show that standard algorithms, e.g. maximum likelihood or quadratic variation for the diffusion coefficient, are asymptotically biased and they fail to estimate correctly the parameters in the coarse-grained model. In a series of earlier works, this problem was studied using maximum likelihood techniques with subsampled data (Pavliotis and Stuart 2007; Papavasiliou et al. 2009), methodologies based on the method of moments (Krumscheid et al. 2013; Kalliadasis et al. 2015; Krumscheid et al. 2015), quadratic programming approaches (Crommelin and Vanden-Eijnden 2006a) as well as Bayesian approaches (Abdulle and Di Blasio 2020; Abdulle et al. 2020). We also mention the pioneering work on estimating the integrated stochastic volatility in the presence of market microstructure noise (Aït-Sahalia et al. 2006; Zhang et al. 2005). In particular, in Aït-Sahalia and Jacod (2014) the authors analyse the correct interplay between the intensity of the microstructure noise and the optimal rates of convergence.
The main observation in Pavliotis and Stuart (2007); Papavasiliou et al. (2009) is that when the maximum likelihood estimator (MLE) of the fast/slow system is evaluated at the full data, then the MLE becomes asymptotically biased; in fact, the original data are not compatible with the homogenized equation, and therefore data need to be preprocessed, for instance under the form of subsampling. On the other hand, when the MLE is evaluated at appropriately subsampled data, then it becomes asymptotically unbiased. Although this is an interesting theoretical observation (see also later developments in Spiliopoulos and Chronopoulou (2013)), it does not lead to an efficient algorithm. The reason for this is that the performance of the estimator depends very sensitively on the choice of the sampling rate. In addition, the optimal sampling rate is not known and is strongly dependent on the problem under investigation. Furthermore, subsampling naturally leads to an increase in the variance, unless appropriate variance reduction methodologies are used.
In a recent work (Abdulle et al. 2021), we addressed the problem of lack of robustness of the MLE with subsampling algorithm by introducing an appropriate filtering methodology that leads to a stable and robust algorithm. In particular, rather than subsampling the original trajectory, we smoothed the data by applying an appropriate linear time-invariant filter from the exponential family and we modified the MLE by inserting the new filtered data. This new estimator was thus independent of the subsampling rate and also asymptotically unbiased and robust with respect to the parameters of the filter.
However, the assumption that the full path of the solution is observed is not realistic in most applications. In fact, in all real problems one can only obtain discrete measurements of the diffusion process. Hence, in this paper we focus on the problem of learning the coarse-grained homogenized model assuming that we are given discrete observations from the microscopic model. In this paper, we use the martingale estimating functions that were introduced in Bibby and Sø rensen (1995), where the authors study drift estimation for discrete observations of one-scale processes and show that estimators based on the discretized continuous-version likelihood function can be strongly biased. They therefore propose martingale estimating functions obtained by adjusting the discretized continuous-version score function by its compensator which leads to unbiased estimators. Moreover, in Kessler and Sørensen (1999) a different type of martingale estimating function, which is dependent on the eigenvalues and eigenfunctions of the generator of the stochastic process, is introduced and asymptotic unbiasedness and normality are proved. Furthermore, another inference methodology that uses spectral information is proposed in Crommelin and Vanden-Eijnden (2006b). Their approach consists of inferring the drift and diffusion functions of a diffusion process by minimizing an objective function which measures how close the generator is to having a reference spectrum which is obtained from the time series through the construction of a discrete-time Markov chain. This idea has been further expanded in several directions in Crommelin and Vanden-Eijnden (2011).
In this paper, we propose a new estimator for learning homogenised SDEs from noisy discrete data that is based on the martingale estimators that were introduced in Kessler and Sørensen (1999). The main idea is to consider the eigenvalues and eigenfunctions of the generator of the homogenized process. This new estimator is asymptotically unbiased only if the distance between two consecutive observations is not too small compared with the multiscale parameter describing the fastest scale, i.e. if data are compatible with the homogenized model. Therefore, in order to obtain unbiased approximations independently of the sampling rate with which the observations are obtained, we propose a second estimator which, in addition to the original observations, relies also on filtered data obtained following the filtering methodology presented in Abdulle et al. (2021). We observe that smoothing the original data makes observations compatible with the homogenized process independently of the rate with which they are sampled and hence this second estimator gives a black-box tool for parameter estimation.
1.1 Our main contributions
The main goal of this paper is to propose new algorithms based on martingale estimating functions and filtered data for which we can prove rigorously that they are asymptotically unbiased and not sensitive with respect to, e.g. the sampling rate and the observation error. In particular, we combine two main ideas:
-
the use of martingale estimating functions for discretely observed diffusion processes based on the eigenvalues and the eigenfunctions of the generator of the homogenized process, which was originally presented for one-scale problems in Kessler and Sørensen (1999);
-
the filtering methodology for smoothing the data in order to make them compatible with the homogenized model, which was introduced in Abdulle et al. (2021).
We prove theoretically and observe numerically that the estimator without filtered data is asymptotically unbiased if:
-
the observations are taken at the homogenized regime, i.e. the sampling rate is independent of the parameter measuring scale separation;
-
the observations are taken at the multiscale regime, i.e. the sampling rate is dependent on the fastest scale, and the sampling rate is bigger than the multiscale parameter.
Moreover, we show that the estimator with filtered data corrects the bias caused by a sampling rate smaller than the multiscale parameter, and therefore, it is asymptotically unbiased independently of the sampling rate.
Outline. The rest of the paper is organized as follows. In Sect. 2, we present the Langevin dynamics and its corresponding homogenized equation and we introduce the two proposed estimators based on eigenvalues and eigenfunctions of the generator with and without filtered data. In Sect. 3, we present the main results of this work, i.e. the asymptotic unbiasedness of the two estimators, and in Sect. 4 we perform numerical experiments which validate the efficacy of our methods. Section 4.1 is devoted to the proof of the main results which are presented in Sect. 3. Finally, in Appendix, we show some technical results which are employed in the analysis and we explain some details about the implementation of the proposed methodology.
2 Problem setting
In this work, we study the following class of multiscale diffusion processes. Consider the following two-scale SDE, observed over the time interval [0, T]
where \(\varepsilon >0\) describes the fast scale, \(\alpha \in \mathbb {R}^M\) and \(\sigma >0\) are, respectively, the drift and diffusion coefficients and \(W_t\) is a standard one-dimensional Brownian motion. The functions \(V:\mathbb {R}\rightarrow \mathbb {R}^M\) and \(p:\mathbb {R}\rightarrow \mathbb {R}\) are the slow-scale and fast-scale parts of the potential, and they are assumed to be smooth. Moreover, we also assume p to be periodic with period \(L>0\). We remark that our setting can be considered as a semi-parametric framework similar to the one of Krumscheid et al. (2013). The components of the potential function V, in fact, can be viewed as basis functions for a truncated expansion (e.g. Taylor series or Fourier expansion) of the unknown slow-scale potential \(V(\cdot ;\alpha ) :\mathbb {R}\rightarrow \mathbb {R}\), where the components of the unknown drift term \(\alpha \) contain the generalized Fourier coefficients, i.e.
We also mention that assuming a parametric form for the potential V is a technique usually employed in the statistics literature in order to regularize the likelihood function and obtain a parametric approximation of the actual MLE of V, which does not exist in general (Pokern et al. 2009).
Remark 2.1
For clarity of the presentation, we focus our analysis on scalar multiscale diffusions with a finite number of parameters in the drift that have to be learned from data. Nevertheless, we remark that all the following theory can be generalized to the case of multidimensional diffusion processes in \(\mathbb {R}^d\), for which we provide further details in Appendix C and an example in Sect. 4.5. However, the problem becomes more complex and computationally expensive from a numerical viewpoint and it can be prohibitive if the dimension d is too large, since the methodology proposed in this paper requires the solution of the eigenvalue problem for the generator of a d-dimensional diffusion process.
The theory of homogenization (see, for example, Bensoussan et al. 2011, Chapter 3 or Pavliotis and Stuart 2008, Chapter 18) guarantees the existence of the following homogenized SDE whose solution \(X_t^0\) is the limit in law of the solutions \(X_t^\varepsilon \) of (2.1) as random variables in \(\mathcal C^0([0,T]; \mathbb {R})\)
where \(A=K\alpha \), \(\Sigma =K\sigma \). The coefficient \(0<K<1\) has the explicit formula
with
and where the function \(\Phi \) is the unique solution with zero-mean with respect to the measure \(\mu \) of the differential equation
endowed with periodic boundary conditions. In particular, for one-dimensional diffusion processes, we have
which implies
Our goal is to derive estimators for the homogenized drift coefficient A based on multiscale data originating from (2.1). In this work, we consider the same setting as Abdulle et al. (2021), which is summarized by the following assumption.
Assumption 2.2
The potentials p and V satisfy
-
(i)
\(p \in \mathcal C^\infty (\mathbb {R}) \cap L^\infty (\mathbb {R})\) and is L-periodic for some \(L > 0\),
-
(ii)
\(V \in \mathcal C^\infty (\mathbb {R};\mathbb {R}^M)\) and each component is polynomially bounded from above and bounded from below, and there exist \(b_1,b_2 > 0\) such that
$$\begin{aligned} - b_1 + b_2 x^2 \le \alpha \cdot V'(x) x, \end{aligned}$$ -
(iii)
\(V'\) is Lipschitz continuous, i.e. there exists a constant \(C > 0\) such that
$$\begin{aligned} \left\| V'(x) - V'(y)\right\| \le C\left|x - y\right|. \end{aligned}$$
Let us remark that, under Assumption 2.2, it has been proved in Pavliotis and Stuart (2007) that both processes (2.1) and (2.2) are geometrically ergodic and their invariant measure has a density with respect to the Lebesgue measure. In particular, let us denote by \(\varphi ^\varepsilon \) and \(\varphi ^0\) the densities of the invariant measures of \(X_t^\varepsilon \) and \(X_t^0\), respectively, defined by
and
Remark 2.3
The value of the initial condition \(X_0^\varepsilon \) in the SDE (2.1) is important neither for the numerical experiments nor for the following analysis and can be chosen arbitrarily. In fact, the process \(X_t^\varepsilon \) is geometrically ergodic and therefore it converges to its invariant distribution with density \(\varphi ^\varepsilon \) exponentially fast for any initial condition.
Drift estimation problem. Consider \(N+1\) uniformly distributed observation times \(0 = t_0< t_1< t_2< \dots , < t_N = T\), set \(\Delta = t_n - t_{n-1}\) and let \((X_t^\varepsilon )_{t\in [0,T]}\) be a realization of the solution of (2.1). We then assume to know a sample \(\{ \widetilde{X}_n^\varepsilon \}_{n=0}^N\) of the realization where \(\widetilde{X}_n^\varepsilon = X_{t_n}^\varepsilon \), and we aim to estimate the drift coefficient A of the homogenized equation (2.2). First, since we deal with discrete observations of stochastic processes, we employ martingale estimating functions based on eigenfunctions, which have already been studied for problems without a martingale structure in Kessler and Sørensen (1999). Second, by observing that if the time-step \(\Delta \) is too small with respect to the multiscale parameter \(\varepsilon \), then the data could be compatible with the full dynamics rather than with the coarse-grained model, we also adopt the filtering methodology presented in Abdulle et al. (2021), which has been proved to be beneficial for correcting the behaviour of the maximum likelihood estimator (MLE) in the setting of continuous observations.
2.1 Martingale estimating functions based on eigenfunctions
We first remark that a general theory for martingale estimating functions exists and is thoroughly outlined in Bibby and Sø rensen (1995). They appear to be appropriate for multiscale problems due to their robustness properties. In this paper, we develop martingale estimating functions based on the eigenfunctions of the generator of the process, since the theory of the eigenvalue problem for elliptic differential operators and the multiscale analysis of this eigenvalue problem are well developed. Let \(\mathcal A \subset \mathbb {R}^M\) be the set of admissible drift coefficients for which Assumption 2.2(ii) is satisfied. To describe our methodology, we consider the solution \(X_t(a)\) of the homogenized process (2.2) with a generic parameter \(a\in \mathcal A\) instead of the exact drift coefficient A:
which, according to (2.6), has invariant measure
The generator \(\mathcal L_a\) of (2.7) is defined for all \(u \in C^2(\mathbb {R})\) as:
where the subscript denotes the dependence of the generator on the unknown drift coefficient a. From the well-known spectral theory of diffusion processes and under our assumptions on the potential V, we deduce that \(\mathcal L_a\) has a countable set of eigenvalues (see, for example, Hansen et al. 1998). In particular, let \(\{(\lambda _j(a),\phi _j(\cdot ;a))\}_{j=0}^\infty \) be the sequence of eigenvalue-eigenfunction couples of the generator which solve the eigenvalue problem
which, due to (2.9), is equivalent to
and where the eigenvalues satisfy \(0=\lambda _0(a)<\lambda _1(a)<\dots <\lambda _j(a)\uparrow \infty \) and the eigenfunctions form an orthonormal basis for the weighted space \(L^2(\varphi _a^0)\). We mention in passing that, by making a unitary transformation, the eigenvalue problem for the generator of the Langevin dynamics can be transformed to the standard Sturm–Liouville problem for Schrödinger operators (Pavliotis 2014, Chapter 4). We now state a formula, which has been proved in Kessler and Sørensen (1999) and will be fundamental in the rest of the paper
where \(\Delta = t_n - t_{n-1}\) is the constant distance between two consecutive observations. We now discuss how this eigenvalue problem can be used for parameter estimation. Let J be a positive integer and let \(\{ \beta _j(\cdot ;a) \}_{j=1}^J\) be J arbitrary functions \(\beta _j(\cdot ;a) :\mathbb {R}\rightarrow \mathbb {R}^M\) possibly dependent on the parameter a, which satisfy Assumption 2.5(i)(ii) stated below, and define for \(x,y,z \in \mathbb {R}\) the martingale estimating function
Then, given a set of observations \(\{ \widetilde{X}_n^\varepsilon \}_{n=0}^N\), we consider the score function \(\widehat{G}_{N,J}^\varepsilon :\mathcal A \rightarrow \mathbb {R}^M\) defined by
This function can be seen as an approximation in terms of eigenfunctions of the true score function, i.e. the gradient of the log-likelihood function with respect to the unknown parameter. The full derivation of a martingale estimating function as an approximation of the true score function is given in detail in Bibby and Rensen (1995, Sect. 2). The first step is a discretization of the gradient of the continuous-time log-likelihood, which yields a biased estimating function. Hence, the next step is adjusting this function by adding its compensator in order to obtain a zero-mean martingale. Moreover, by using the eigenfunctions of the generator, it is shown in Kessler and Sørensen (1999) that this approach is suitable for scalar diffusion processes with no multiscale structure, i.e. processes with a single characteristic length/time scale. In fact, by a classical result for ergodic diffusion processes (Pavliotis 2014, Sect. 4.7), any function in the \(L^2\) space weighted by the invariant measure can be written as an infinite linear combination of the eigenfunctions of the generator of the diffusion process.
Remark 2.4
In the construction of the martingale estimating function \(\widehat{G}^\varepsilon _{N,J}(a)\), we omitted the first index \(j = 0\) because, for ergodic diffusion processes, the first eigenvalue is zero, \(\lambda _0(a) = 0\), and its corresponding eigenfunction is constant, \(\phi _0(a) = 1\), and hence, they would give \(g_0(x,y,z;a) = 0\) independently of the function \(\beta _0(z;a)\). Therefore, it would not provide us with any information about the unknown parameters in the drift.
The estimator \(\widehat{A}^\varepsilon _{N,J}\). The first estimator we propose for the homogenized drift coefficient A is given by the solution \(\widehat{A}^\varepsilon _{N,J}\) of the M-dimensional nonlinear system
An intuition on why \(\widehat{G}^\varepsilon _{N,J}\) is a good score function is given by the following result. Let \(\widehat{G}^0_{N,J}\) be the score function where the observations of the slow variable of the multiscale process are replaced by the homogenized ones, then due to equation (2.12)
which means that the zero of the expectation of the score function with homogenized observations is exactly the drift coefficient of the effective equation. In Algorithm 1, we summarize the main steps for computing the estimator \(\widehat{A}^\varepsilon _{N,J}\) and further details about the implementation can be found in Appendix B. We finally introduce the following technical assumption which will be employed in the analysis.
Assumption 2.5
The following hold for all \(a\in \mathcal A\) and for all \(j=1,\dots ,J\):
-
(i)
\(\beta _j(z;a)\) is continuously differentiable with respect to a for all \(z\in \mathbb {R}\);
-
(ii)
all components of \(\beta _j(\cdot ;a)\), \(\beta _j'(\cdot ;a)\),
 ,
,  are polynomially bounded;
are polynomially bounded; -
(iii)
the slow-scale potential V is such that \(\phi _j(\cdot ;a)\), \(\phi _j'(\cdot ;a)\), \(\phi _j''(\cdot ;a)\), and all components of
 ,
,  ,
, 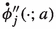 are polynomially bounded;
are polynomially bounded;
 ,
,  are polynomially bounded;
are polynomially bounded; ,
,  ,
, 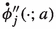 are polynomially bounded;
are polynomially bounded;where the dot denotes either the Jacobian matrix or the gradient with respect to a.
Remark 2.6
In Kessler and Sørensen (1999) the authors propose a method to choose the functions \(\{ \beta _j(\cdot ;a) \}_{j=1}^J\) in order to obtain optimality in the sense of Godambe and Heyde (1987): This optimal set of functions can be seen as the projection of the score function onto the set of martingale estimating functions obtained by varying the function \(\{ \beta _j(\cdot ;a) \}_{j=1}^J\). For the class of diffusion processes for which the eigenfunctions are polynomials, the optimal estimating functions can be computed analytically. In fact, they are related to the moments of the transition density, which can be computed explicitly. Moreover, another procedure is to choose functions which depend only on the unknown parameter and which minimize the asymptotic variance. This approach is strongly related to the asymptotic optimality criterion considered by Heyde and Gay (1989). For further details on how to choose these functions we refer to Kessler and Sørensen (1999), and we remark that their calculation requires additional computational cost. Nevertheless, the theory we develop is valid for all functions which satisfy Assumptions 2.5(i) and 2.5(ii) and we observed in practice that choosing simple functions independent of the unknown parameter, e.g. monomials of the form \(\beta _j(z;a) = z^k\) with \(k \in \mathbb {N}\), is sufficient to obtain satisfactory estimations. We also remark that in one dimension we can characterize completely all diffusion processes whose generator has orthogonal polynomials as eigenfunctions (Bakry et al. 2014, Sect. 2.7). Partial results in this directions also exist in higher dimensions.
2.2 The filtering approach
We now go back to our multiscale SDE (2.1) and, inspired by Abdulle et al. (2021), we propose a second estimator for the homogenized drift coefficient by filtering the data. In particular, we modify \(\widehat{A}_{N,J}^\varepsilon \) by filtering the observations and inserting the new data into the score function \(\widehat{G}_{N,J}^\varepsilon \) in order to take into account the case when the step size \(\Delta \) is too small with respect to the multiscale parameter \(\varepsilon \). Let us consider the exponential kernel \(k :\mathbb {R}^+ \rightarrow \mathbb {R}\) defined as
for which a rigorous theory has been developed in Abdulle et al. (2021). We remark that this exponential kernel is a low-pass filter, which cuts the high frequencies and highlights the slowest components. We then define the filtered observations \(\{ \widetilde{Z}_n^\varepsilon \}_{n=0}^N\) choosing \(\widetilde{Z}_0^\varepsilon = 0\) and computing the weighted average for all \(n = 1,\dots ,N\)
where the fast-scale component of the original multiscale trajectory is eliminated, and we define the new score function as a modification of (2.14), i.e.
Remark 2.7
Notice that the filtered data only partially replace the original data in the definition of the score function. This idea is inspired by Abdulle et al. (2021) where the same approach is used with the maximum likelihood estimator. The importance of keeping also the original observations becomes apparent in the proofs of the main results. However, a simple intuition is provided by equation (2.12). This equation is essential in order to obtain the unbiasedness of the estimators when the sampling rate \(\Delta \) is independent of the multiscale parameter \(\varepsilon \), but it is not valid for the filtered process.
The estimator \(\widetilde{A}^\varepsilon _{N,J}\). The second estimator \(\widetilde{A}^\varepsilon _{N,J}\) is given by the solution of the M-dimensional nonlinear system
The main steps to compute the estimator \(\widetilde{A}^\varepsilon _{N,J}\) are highlighted in Algorithm 2 and additional details about the implementation can be found in Appendix B. Note that (2.16) can be rewritten as
We introduce its continuous version \(Z_t^\varepsilon \) which will be employed in the analysis
We remark that the joint process \((X_t^\varepsilon ,Z_t^\varepsilon )\) satisfies the system of multiscale SDEs
and, using the theory of homogenization, when \(\varepsilon \) goes to zero it converges in law as a random variable in \(\mathcal C^0([0,T];\mathbb {R}^2)\) to the two-dimensional process \((X_t^0,Z_t^0)\), which solves
Moreover, it has been proved in Abdulle et al. (2021) that the two-dimensional processes \((X_t^\varepsilon ,Z_t^\varepsilon )\) and \((X_t^0,Z_t^0)\) are geometrically ergodic and their respective invariant measures have densities with respect to the Lebesgue measure denoted respectively by \(\rho ^\varepsilon = \rho ^\varepsilon (x,z)\) and \(\rho ^0 = \rho ^0(x,z)\). Let us finally remark that given discrete observations \(\widetilde{X}_n^\varepsilon \) we can only compute \(\widetilde{Z}^\varepsilon _n\), but the theory, which has to be employed for proving the convergence results, has been studied for the continuous-time process \(Z^\varepsilon _t\).
Remark 2.8
The only difference in the construction of the estimators \(\widehat{A}^\varepsilon _{N,J}\) and \(\widetilde{A}^\varepsilon _{N,J}\) is the fact that the latter requires filtered data, which are obtained from discrete observations, and thus, it is computationally more expensive. Therefore, when it is possible to use the estimator without filtered data, it is preferable to employ it.
3 Main results
In this section, we present the main results of this work, i.e. the asymptotic unbiasedness of the proposed estimators. We first need to introduce the following technical assumption, which is a nondegeneracy hypothesis related to the use of the implicit function theorem for the functions (2.14) and (2.17) in the limit as \(N \rightarrow \infty \).
Assumption 3.1
Let A be the homogenized drift coefficient of equation (2.2). Then, the following hold
-
(i)
 ,
, -
(ii)
 ,
, -
(iii)
 ,
, -
(iv)
 ,
,
 ,
, ,
, ,
, ,
,where \(\widetilde{\rho }^0\) is the invariant measure of the couple \((\widetilde{X}_n^0, \widetilde{Z}_n^0)\), whose existence is guaranteed by Lemma A.2, and \(\nabla _a X_t(a)\) is the gradient of the stochastic process \(X_t(a)\) in (2.7) with respect to the drift coefficient a.
Remark 3.2
The nondegeneracy Assumption 3.1, which is analogous to Condition 4.2(a) in Kessler and Sørensen (1999), holds true in all nonpathological examples and does not constitute an essential limitation on the range of validity of the results proved in this paper. Further details about the necessity of this assumption for the analysis of the proposed estimator will be given in Sect. 5.2.
The proofs of the following two main theorems are the focus of Sect. 5.
Theorem 3.3
Let J be a positive integer. Under Assumptions 2.2, 2.5, 3.1 and if \(\Delta \) is independent of \(\varepsilon \) or \(\Delta = \varepsilon ^\zeta \) with \(\zeta \in (0,1)\), there exists \(\varepsilon _0 > 0\) such that for all \(0<\varepsilon <\varepsilon _0\) , an estimator \(\widehat{A}_{N,J}^\varepsilon \) which solves the system \(\widehat{G}_{N,J}^\varepsilon (\widehat{A}_{N,J}^\varepsilon ) = 0\) exists with probability tending to one as \(N\rightarrow \infty \). Moreover,
where A is the homogenized drift coefficient of equation (2.2).
Theorem 3.4
Let J be a positive integer. Under Assumptions 2.2, 2.5, 3.1 and if \(\Delta \) is independent of \(\varepsilon \) or \(\Delta = \varepsilon ^\zeta \) with \(\zeta >0\) and \(\zeta \ne 1\), \(\zeta \ne 2\), there exists \(\varepsilon _0 > 0\) such that for all \(0<\varepsilon <\varepsilon _0\) an estimator \(\widetilde{A}_{N,J}^\varepsilon \) which solves the system \(\widetilde{G}_{N,J}^\varepsilon (\widetilde{A}_{N,J}^\varepsilon ) = 0\) exists with probability tending to one as \(N\rightarrow \infty \). Moreover,
where A is the homogenized drift coefficient of equation (2.2).
Remark 3.5
Notice that in both Theorem 3.3 and Theorem 3.4 the order of the limits is important and they cannot be interchanged. In fact, we first consider the large data limit, i.e. the number of observations N tends to infinity, and then we let the multiscale parameter \(\varepsilon \) vanish. Moreover, in Theorem 3.4 the values \(\zeta = 1\) and \(\zeta = 2\) are not allowed because of technicalities in the proof, but we observe numerically that the estimator works well also in these two particular cases.
These two theorems show that both estimators based on the multiscale data from (2.1) converge to the homogenized drift coefficient A of (2.2). Since the analysis is similar for the two cases, we will mainly focus on the second score function with filtered observations and at the end of each step we will state the differences with respect to the estimator without pre-processed data.
Remark 3.6
Since the main goal of this work is the estimation of the effective drift coefficient A, in the numerical experiments and in the following analysis we will always assume the effective diffusion coefficient \(\Sigma \) to be known. Nevertheless, we remark that our methodology can be slightly modified in order to take into account the estimation of the effective diffusion coefficient too. In fact, the parameter a can be replaced by the parameter \(\theta = (a,s) \in \mathbb {R}^{M+1}\) where a stands for the drift and s stands for the diffusion, yielding nonlinear systems of dimension \(M+1\) corresponding to (2.15) and (2.18). The proofs of the asymptotic unbiasedness of the new estimators \(\widehat{\theta }^\varepsilon _{N,J}\) and \(\widetilde{\theta }^\varepsilon _{N,J}\) can be adjusted analogously. For completeness, we provide a more detailed explanation and a numerical experiment illustrating this approach in Sect. 4.6.
3.1 A particular case
Before analysing the general framework, let us consider the simple case of the Ornstein–Uhlenbeck process, i.e. let the dimension of the parameter \(N=1\) and let \(V(x) = x^2/2\). Then, the multiscale SDE (2.1) becomes
and its homogenized version is
Letting \(a\in \mathcal A\), then the eigenfunctions \(\phi _j(\cdot ;a)\) and the eigenvalues \(\lambda _j(a)\) satisfy
The solution of the eigenvalue problem can be computed explicitly (see Pavliotis 2014, Sect. 4.4); we have
and \(\phi _j(\cdot ;a)\) satisfies the recurrence relation
with \(\phi _0(x;a) = 1\) and \(\phi _1(x;a) = x\). It is also possible to prove by induction that
Let us consider the simplest case with only one eigenfunction, i.e. \(J=1\), and \(\beta _1(z;a) = z\), which implies
Then, the score functions (2.14) and (2.17) become
The solutions of the equations \(\widehat{G}_{N,1}^\varepsilon (a) = 0\) and \(\widetilde{G}_{N,1}^\varepsilon (a) = 0\) can be computed analytically and are given by
and
Comparing these estimators with the discrete MLE defined in Pavliotis and Stuart (2007) without filtered data as
and the discrete MLE with filtered data
we notice that they coincide in the limit as \(\Delta \) vanishes. We remark that we are comparing our estimator with the discrete MLE instead of the analytical formula for the MLE in continuous time since we assume that we are observing our process at discrete times. Therefore, the continuous time MLE has to be approximated using the available discrete data (Pavliotis 2014, Sect. 5.3). In the following theorems we show the asymptotic limit of the estimators. We do not provide a proof for these results since Theorem 3.7 and Theorem 3.9 are particular cases of Theorem 3.3 and Theorem 3.4 respectively, and Theorem 3.8 follows from the proof of Theorem 3.3 as highlighted in Remark 5.11.
Theorem 3.7
Let \(\Delta \) be independent of \(\varepsilon \) or \(\Delta = \varepsilon ^\zeta \) with \(\zeta \in (0,1)\). Then, under Assumption 2.2, the estimator (3.1) satisfies
where A is the drift coefficient of the homogenized equation (2.2).
Theorem 3.8
Let \(\Delta \) be independent of \(\varepsilon \) or \(\Delta = \varepsilon ^\zeta \) with \(\zeta >2\). Then, under Assumption 2.2, the estimator (3.1) satisfies
where \(\alpha \) is the drift coefficient of the homogenized equation (2.1).
Theorem 3.9
Let \(\Delta \) be independent of \(\varepsilon \) or \(\Delta = \varepsilon ^\zeta \) with \(\zeta \ne 1\), \(\zeta \ne 2\). Then, under Assumption 2.2, the estimator (3.2) satisfies
where A is the drift coefficient of the homogenized equation (2.2).
Remark 3.10
Notice that it is possible to write different proofs for Theorems 3.7, 3.8 and 3.9, which take into account the specific form of the estimators, and thus show stronger results. In fact, if the distance \(\Delta \) between two consecutive observations is independent of the multiscale parameter \(\varepsilon \), then the convergences in the statements do not only hold in probability, but also almost surely. We expect that almost sure convergence can be proved for a larger class of equations, but are neither aware of related literature showing such a stronger result, nor have been able to prove it.

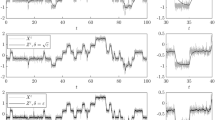
Sensitivity analysis with respect to the number N of observations for different values of \(\Delta \le 1\), for the estimator \(\widetilde{A}^\varepsilon _{N,J}\) with \(J=1\)

Sensitivity analysis with respect to the number N of observations for different values of \(\Delta > 1\), for the estimator \(\widetilde{A}^\varepsilon _{N,J}\) with \(J=1\)
4 Numerical experiments
In this section, we present numerical experiments which confirm our theoretical results and show the power of the martingale estimating functions based on eigenfunctions and filtered data to correct the unbiasedness caused by discretization and the fact that we are using multiscale data to fit homogenized models. Moreover, we present a sensitivity analysis with respect to the number N of observations and the number J of eigenvalues and eigenfunctions taken into account. In the experiments that we present data are generated employing the Euler–Maruyama method with a fine time step h, in particular we set \(h = \varepsilon ^3\). Letting \(\Delta ,T>0\), we generate data \(X_t^\varepsilon \) for \(0 \le t \le T\) and we select a sequence of observations \(\{ \widetilde{X}^\varepsilon _n \}_{n=0}^N\), where \(N=T/\Delta \) and \(\widetilde{X}^\varepsilon _n = X^\varepsilon _{t_n}\) with \(t_n = n\Delta \). In view of Remark 2.3, we do not require stationarity of the multiscale dynamics; hence, we always set the initial condition to be \(X_0^\varepsilon = 0\). Notice that the time step h is only used to generate numerically the original data and has to be chosen sufficiently small in order to have a reliable approximation of the continuous path. However, the distance between two consecutive observations \(\Delta \) is the rate at which we sample the data, which we assume to know, from the original trajectory. In order to compute the filtered data \(\{ \widetilde{Z}^\varepsilon _n \}_{n=1}^N\), we employ equation (2.19). We repeat this procedure for \(M = 15\) different realizations of Brownian motion and we plot the average of the drift coefficients computed by the estimators. We finally remark that in order to compute our estimators we need the value of the diffusion coefficient \(\Sigma \) of the homogenized equation. In all the numerical experiments, we compute it exactly using the formula for the coefficient K given by the theory of homogenization, but we also remark that its value could be estimated employing the subsampling technique presented in Pavliotis and Stuart (2007) or modifying the estimating function as explained in Remark 3.6.

Sensitivity analysis with respect to the number J of eigenvalues and eigenfunctions for different slow-scale potentials, for the estimators \(\widehat{A}^\varepsilon _{N,J}\) and \(\widetilde{A}^\varepsilon _{N,J}\)
4.1 Sensitivity analysis with respect to the number of observations
We consider the multiscale Ornstein–Uhlenbeck process, i.e. equation (2.1) with \(V(x)=x^2/2\), and we take \(p(y)=\cos (y)\), the multiscale parameter \(\varepsilon =0.1\), the drift coefficient \(\alpha = 1\) and the diffusion coefficient \(\sigma = 1\). Notice that for this choice of the slow-scale potential the technical assumptions required in the main Theorems 3.3, 3.4 can be easily checked. We plot the results computed by the estimator \(\widetilde{A}_{N,J}^\varepsilon \) with \(J=1\) and \(\beta (x;a) = x\) and we then divide the analysis in two cases: \(\Delta \) “small” and \(\Delta \) “big”.
Let us first consider \(\Delta \) “small”, i.e. \(\Delta = \varepsilon ^\zeta \) with \(\zeta = 0, 0.5, 1, 1.5\), and take \(T = 400\). In Fig. 1, we plot the results of the estimator as a function of the number of observations N. We remark that in this case the number of observations needed to reach convergence is strongly dependent and inversely proportional to the distance \(\Delta \) between two consecutive observations. This means that in order to reach convergence we need the final time T to be sufficiently large independently of \(\Delta \). In fact, when the distance \(\Delta \) is small, the discrete observations are a good approximation of the continuous trajectory and therefore what matters most is the length T of the original path rather than the number N of observations.
In order to study the case \(\Delta \) “big”, i.e. \(\Delta > 1\), we set \(\Delta = 2^\zeta \) with \(\zeta = 1, 2, 3, 4\), and take \(T = 2^{15}\). Figure 2 shows that in this case the number of observations needed to reach convergence is an increasing function of \(\Delta \). Therefore, in order to have a reliable approximation of the drift coefficient of the homogenized equation, the final time T has to be chosen depending on \(\Delta \). This is justified by the fact that, differently from the previous case, the discrete data are less correlated and therefore they do not well approximate the continuous trajectory. In particular, when the distance \(\Delta \) between two consecutive observations is very large, then in practice we need a huge amount of data because a good approximation of the unknown coefficient is obtained only if the final time T is very large.
4.2 Sensitivity analysis with respect to the number of eigenvalues and eigenfunctions
Let us now consider equation (2.1) with four different slow-scale potentials
The other functions and parameters of the SDE are chosen as in the previous subsection, i.e. \(p(y)=\cos (y)\), \(\alpha =1\), \(\sigma =1\) and \(\varepsilon =0.1\). Moreover, we set \(\Delta =\varepsilon \) and \(T=500\) and we vary \(J = 1, \dots , 10\). The functions \(\{ \beta _j \}_{j=1}^{10}\) appearing in the estimating function are given by \(\beta _j(x;a) = x\) for all \(j = 1, \dots , J\).
In Fig. 3, where we plot the values computed by \(\widehat{A}_{N,J}^\varepsilon \) and \(\widetilde{A}_{N,J}^\varepsilon \), we observe that the number J of eigenvalues and eigenfunctions slightly improve the results, in particular for the fourth potential, but the estimation stabilizes when the number of eigenvalues J is still small, e.g. \(J = 3\). Therefore, in order to reduce the computational cost, it seems to be preferable not to take large values of J. This is related to how quickly the eigenvalues grow and, therefore, how quickly the corresponding exponential terms decay. The rigorous study of the accuracy of the spectral estimators as a function of the number of eigenvalues and eigenfunctions that we take into account will be investigated elsewhere.
4.3 Verification of the theoretical results
We consider the same setting as in the previous subsection, i.e. equation (2.1) with slow-scale potentials given by (4.1) and \(p(y)=\cos (y)\), \(\alpha =1\), \(\sigma =1\) and \(\varepsilon =0.1\). Moreover, we set \(J=1\), \(\beta (x;a) = x\) and \(T=500\), and we choose the distance between two successive observations to be \(\Delta = \varepsilon ^\zeta \) with \(\zeta =0,0.1,0.2,\dots ,2.5\).

Comparison between the discrete maximum likelihood estimator \(\widehat{\mathrm {MLE}}_{N,\Delta }^\varepsilon \) presented in Pavliotis and Stuart (2007) and our estimator \(\widehat{A}_{N,J}^\varepsilon \) with \(J=1\) without filtered data as a function of the distance \(\Delta \) between two successive observations for different slow-scale potentials
In Fig. 4, we compare our martingale estimator \(\widehat{A}_{N,J}^\varepsilon \) without filtered data with the discrete maximum likelihood estimator denoted \(\widehat{\mathrm {MLE}}_{N,\Delta }^\varepsilon \). The MLE does not provide good results for two reasons:
-
if \(\Delta \) is small, more precisely if \(\Delta = \varepsilon ^\zeta \) with \(\zeta > 1\), sampling the data does not completely eliminate the fast-scale components of the original trajectory; therefore, since we are employing data generated by the multiscale model, the estimator is trying to approximate the drift coefficient \(\alpha \) of the multiscale equation, rather than the one of the homogenized equation;
-
if \(\Delta \) is relatively big, in particular if \(\Delta = \varepsilon ^\zeta \) with \(\zeta \in [0,1)\), then we are taking into account only the slow-scale components of the original trajectory, but a bias is still introduced because we are discretizing an estimator which is usually used for continuous data.
Nevertheless, as observed in these numerical experiments and investigated in greater detail in Pavliotis and Stuart (2007), there exists an optimal value of \(\Delta \) such that \(\widehat{\mathrm {MLE}}_{N,\Delta }^\varepsilon \) works well, but this value is not known a priori and is strongly dependent on the problem, hence this technique is not robust. Figure 4 shows that the second issue, i.e. when \(\Delta \) is relatively big, can be solved employing \(\widehat{A}_{N,J}^\varepsilon \), an estimator for discrete observations, and that filtering the data is not needed as proved in Theorem 3.3.

Comparison between our two estimators \(\widehat{A}_{N,J}^\varepsilon \) without filtered data and \(\widetilde{A}_{N,J}^\varepsilon \) with filtered data with \(J=1\) as a function of the distance \(\Delta \) between two successive observations for different slow-scale potentials
Then, in order to solve also the first problem, in Fig. 5 we compare \(\widehat{A}_{N,J}^\varepsilon \) with our martingale estimator \(\widetilde{A}_{N,J}^\varepsilon \) with filtered data. We observe that inserting filtered data in the estimator allows us to disregard the fast-scale components of the original trajectory and to obtain good approximations of the drift coefficient A of the homogenized equation independently of \(\Delta \), as already shown in Theorem 3.4. In particular, we notice that the results still improve even for big values of \(\Delta \) if we employ the estimator based on filtered data. Finally, as highlighted in Remark 5.11, we observe that the limiting value of the estimator \(\widehat{A}_{N,J}^\varepsilon \) as the number of observations N goes to infinity and the multiscale parameter \(\varepsilon \) vanishes is strongly dependent on the problem and cannot be computed theoretically. However, if we consider the slow-scale potential \(V_1(x) = x^2/2\), i.e. the multiscale Ornstein-Uhlenbeck process, then the limit, as proved in Theorem 3.8, is the drift coefficient \(\alpha \) of the multiscale equation.
4.4 Multidimensional drift coefficient
In this experiment, we consider a multidimensional drift coefficient, in particular we set \(N=2\). We then consider the bistable potential, i.e.
and the fast-scale potential \(p(y) = \cos (y)\). We choose the exact drift coefficient of the multiscale equation (2.1) to be \(\alpha = \begin{pmatrix} 1.2&0.7\end{pmatrix}^\top \) and the diffusion coefficient to be \(\sigma = 0.7\). We also set the number of eigenfunctions \(J = 1\), the function \(\beta (x;a) = \begin{pmatrix} x^3&x \end{pmatrix}^\top \), the distance between two consecutive observations \(\Delta = 1\) and the final time \(T = 1000\). We then compute the estimator \(\widehat{A}^\varepsilon _{N,J}\) after \(N = 100, 200, \dots , 1000\) observations and in Fig. 6 we plot the result of the experiment for the cases \(\varepsilon = 0.1\) and \(\varepsilon = 0.05\). Since we are analysing the case \(\Delta \) independent of \(\varepsilon \), filtering the data is not necessary and therefore we consider the estimator \(\widehat{A}^\varepsilon _{N,J}\) which is computationally less expensive to compute.

Evolution in time of the estimator \(\widehat{A}_{N,J}^\varepsilon \) with \(J=1\) for a two-dimensional drift coefficient
We observe that the estimation is approaching the exact value A of the drift coefficient of the homogenized equation as the number of observations increases, until it starts oscillating around the true value \(A = \begin{pmatrix} 0.48&0.28\end{pmatrix}^\top \). Moreover, we notice that the time needed to reach a neighbourhood of A is smaller when the multiscale parameter \(\varepsilon \) is closer to its vanishing limit. In Table 1, we report the absolute error \(\widehat{e}^\varepsilon _N\) defined as
where \(\left\| \cdot \right\| _2\) denotes the Euclidean norm, varying the number of observations N for the two values of the multiscale parameter.

Evolution in time of the estimator \(\widehat{A}_{N,J}^\varepsilon \) with \(J = 1\) for a d-dimensional system of interacting particles with sampling rate \(\Delta = 1\)

Evolution in time of the estimator \(\widetilde{A}_{N,J}^\varepsilon \) with \(J = 1\) for a d-dimensional system of interacting particles with sampling rate \(\Delta = \varepsilon \)
4.5 Multidimensional stochastic process: interacting particles
In this section, we consider a system of d interacting particles in a two-scale potential, a problem with a wide range of applications which has been studied in Gomes and Pavliotis (2018). For \(t \in [0,T]\) and for all \(i = 1, \dots , d\), consider the system of SDEs
In this paper we fix the number of particles and study the performance of our estimators as \(\varepsilon \) vanishes. The very interesting problem of inference for mean field SDEs, obtained in the limit as \(d \rightarrow \infty \), will be investigated elsewhere. It can be shown (see, for example, Gomes and Pavliotis 2018, Sect. 2.1 and Duncan and Pavliotis (2016); Delgadino et al. (2021)) that \((X_1^\varepsilon , \dots X_d^\varepsilon )\) converges in law as \(\varepsilon \) goes to zero to the solution \((X_1^0, \dots , X_d^0)\) of the homogenized system
where \(\Theta = K \theta \) and K is defined in (2.3). Moreover, the first eigenvalue and eigenfunction of the generator of the homogenized system can be computed explicitly and they are given, respectively, by
Hence, letting \(\Delta >0\) independent of \(\varepsilon \), given a sequence of observations \(( (\widetilde{X}_1^\varepsilon )_n, \dots (\widetilde{X}_d^\varepsilon )_n)_{n=0}^N\), we can express the estimators analytically
Let us now set \(p(y) = \cos (y)\), \(\alpha = 1\), \(\sigma = 1\) and \(\theta = 1\). We then simulate system (4.3) for different final times \(T = 100, 200, \dots , 1000\) and approximate the drift coefficient A of the homogenized system (4.4) for \(d = 2\) and \(d = 5\). In Figs. 7 and 8, we plot the results, respectively, of the estimators \(\widehat{A}^\varepsilon _{N,J}\) with \(\Delta = 1\) and \(\widetilde{A}^\varepsilon _{N,J}\) with \(\Delta = \varepsilon \) for two different values of \(\varepsilon = 0.1, 0.05\). As expected, we observe that our estimator provides a better approximation of the unknown coefficient A when the time T increases and that this value stabilizes after approximately \(T = 500\).

Simultaneous inference of drift and diffusion coefficient for the estimator \(\widehat{A}^\varepsilon _{N,J}\) with \(J = 2\)
4.6 Simultaneous inference of drift and diffusion coefficients
As highlighted by Remark 3.6, a small modification of our methodology allows us to estimate the diffusion coefficient, in addition to drift coefficients. Define the parameter \(\theta = \begin{pmatrix} a^\top&s \end{pmatrix}^\top \in \mathbb {R}^{M+1}\), whose exact value is given by \(\theta _0 = \begin{pmatrix} A^\top&\Sigma \end{pmatrix}^\top \in \mathbb {R}^{M+1}\), where A and \(\Sigma \) are the drift and diffusion coefficients of the homogenized equation, respectively. Then, the eigenvalue problem reads for all \(j \in \mathbb {N}\)
where the eigenvalues and eigenfunctions are now dependent on the new parameter \(\theta \). Accordingly, also the functions \(\{ \beta _j \}_{j=1}^J\) can be chosen dependent on both the drift and diffusion coefficients and, moreover, they have to take values in \(\mathbb {R}^{M+1}\), i.e. \(\beta _j(\cdot ;\theta ) :\mathbb {R}\rightarrow \mathbb {R}^{M+1}\). Therefore, the new score functions \(\widehat{G}^\varepsilon _{N,J}\) and \(\widetilde{G}^\varepsilon _{N,J}\) are defined from \(\Theta = \mathcal A \times \mathcal S \subset \mathbb {R}^{M+1}\), which is the set of admissible parameters \(\theta \), to \(\mathbb {R}^{M+1}\) and thus give nonlinear systems of dimension \(M+1\). Finally, the solutions \(\widehat{\theta }_{N,J}^\varepsilon \) and \(\widetilde{\theta }_{N,J}^\varepsilon \) of the systems are the estimators of both the drift and diffusion coefficients of the homogenized equation. In fact, small modifications in the proofs of the main results, in particular in the notation, yield the asymptotic unbiasedness of the estimators under the same conditions, i.e.
Consider now the same setting of Sect. 4.1, i.e. the multiscale Ornstein–Uhlenbeck potential with \(V(x) = x^2/2\), \(p(y) = \cos (y)\), \(\alpha = 1\), \(\sigma = 1\) and let us assume that both the drift and diffusion coefficients are unknown. We remark that in this case we have \(M = 1\). Then, set the final time \(T = 1000\), the sampling rate \(\Delta = 1\) and the number of eigenfunctions and eigenvalues \(J = 2\). Moreover, we choose the functions \(\beta _1(x;\theta ) = \beta _2(x;\theta ) = \begin{pmatrix} x^2&x \end{pmatrix}^\top \). Since the distance between two consecutive observations is independent of the multiscale parameter \(\varepsilon \), we consider the estimator \(\widehat{A}^\varepsilon _{N,J}\) without filtered data. In Fig. 9, we plot the evolution of our estimator varying the number of observations N for two different values of \(\varepsilon \), in particular \(\varepsilon = 0.1\) and \(\varepsilon = 0.05\). We observe that if the multiscale parameter is smaller, then the number of observations needed to obtain a reliable approximation of the unknown parameters is lower.
5 Asymptotic unbiasedness
In this section, we prove our main results. The plan of the proof is the following:
-
we first study the limiting behaviour of the score functions \(\widehat{G}_{N,J}^\varepsilon \) and \(\widetilde{G}_{N,J}^\varepsilon \) defined in (2.14) and (2.17) as the number of observations N goes to infinity, i.e. as the final time T tends to infinity;
-
we then show the continuity of the limit of the score functions obtained in the previous step and we compute their limits as the multiscale parameter \(\varepsilon \) vanishes (Sect. 5.1);
-
we finally prove our main results, i.e. the asymptotic unbiasedness of the drift estimators (Sect. 5.2).
We first define the Jacobian matrix of the function \(g_j\) introduced in (2.13) with respect to a:

which will be employed in the following and where \(\otimes \) denotes the outer product in
\(\mathbb {R}^M\) and the dot denotes either the Jacobian matrix or the gradient with respect to a, e.g.
 . Then note that, under Assumption 2.2, due to ergodicity and stationarity and by Bibby and Rensen (1995, Lemma 3.1) we have
. Then note that, under Assumption 2.2, due to ergodicity and stationarity and by Bibby and Rensen (1995, Lemma 3.1) we have
and
where
 and
and  denotes, respectively, that \(X_0^\varepsilon \) and
denotes, respectively, that \(X_0^\varepsilon \) and  are distributed according to their invariant distribution. We remark that the invariant distribution \(\widetilde{\rho }^\varepsilon \) exists due to Lemma A.2. By equation (5.1) the Jacobian matrices of \(\widehat{\mathcal G}_J(\varepsilon ,a)\) and \(\widetilde{\mathcal G}_J(\varepsilon ,a)\) with respect to a are given by
are distributed according to their invariant distribution. We remark that the invariant distribution \(\widetilde{\rho }^\varepsilon \) exists due to Lemma A.2. By equation (5.1) the Jacobian matrices of \(\widehat{\mathcal G}_J(\varepsilon ,a)\) and \(\widetilde{\mathcal G}_J(\varepsilon ,a)\) with respect to a are given by
and
5.1 Continuity of the limit of the score function
In this section, we first prove the continuity of the functions \(\widehat{\mathcal G}_J, \widetilde{\mathcal G}_J :(0,\infty ) \times \mathcal A \rightarrow \mathbb {R}^M\) and \(\widehat{\mathcal H}_J, \widetilde{\mathcal H}_J, :(0,\infty ) \times \mathcal A \rightarrow \mathbb {R}^{M \times M}\). We then study the limit of these functions for \(\varepsilon \rightarrow 0\). As the proof for the filtered and the non-filtered are similar, we will concentrate on the filtered case and comment on the non-filtered case. Before entering into the proof, we give two preliminary technical lemmas which will be used repeatedly and whose proof can be found, respectively, in Appendix A.1 and Appendix A.3.
Lemma 5.1
Let \(\widetilde{Z}^\varepsilon \) be defined in (2.16) and distributed according to the invariant measure \(\widetilde{\rho }^\varepsilon \) of the process \((\widetilde{X}_n, \widetilde{Z}_n)\). Then, for any \(p\ge 1\) there exists a constant \(C>0\) uniform in \(\varepsilon \) such that
Lemma 5.2
Let \(f :\mathbb {R}\rightarrow \mathbb {R}\) be a \(\mathcal C^\infty (\mathbb {R})\) function which is polynomially bounded along with all its derivatives. Then,
where \(R(\varepsilon ,\Delta )\) satisfies for all \(p\ge 1\) and for a constant \(C>0\) independent of \(\Delta \) and \(\varepsilon \)
We start here with a continuity result for the score function and its Jacobian matrix with respect to the unknown parameter.
Proposition 5.3
Under Assumption 2.5, the functions \(\widetilde{\mathcal G}_J : (0,\infty ) \times \mathcal A \rightarrow \mathbb {R}^M\) and \(\widetilde{\mathcal H}_J, :(0,\infty ) \times \mathcal A \rightarrow \mathbb {R}^{M \times M}\) defined in (5.2) and (5.3), where \(\Delta \) can be either independent of \(\varepsilon \) or \(\Delta =\varepsilon ^\zeta \) with \(\zeta >0\), are continuous.
Proof
We only prove the statement for \(\widetilde{\mathcal G}_J\), then the argument is similar for \(\widetilde{\mathcal H}_J\). Letting \(\varepsilon ^*\in (0,\infty )\) and \(a^*\in \mathcal A\), we want to show that
By the triangle inequality, we have
then we divide the proof in two steps and we show that the two terms vanish.
Step 1: \(Q_1(\varepsilon ,a) \rightarrow 0\) as \((\varepsilon ,a) \rightarrow (\varepsilon ^*,a^*)\).
Since \(\beta _j\) and \(\phi _j\) are continuously differentiable with respect to a for all \(j=1,\dots ,J\), respectively, due to Assumption 2.5 and Lemma A.4, then also \(g_j\) is continuously differentiable with respect to a. Therefore, by the mean value theorem for vector-valued functions, we have
Then, letting \(C>0\) be a constant independent of \(\varepsilon \), since \(\beta _j\) and \(\phi _j\) are polynomially bounded still by Assumption 2.5 and \(X_0^\varepsilon \), \(X_\Delta ^\varepsilon \) and \(\widetilde{Z}_0^\varepsilon \) have bounded moments of any order by Pavliotis and Stuart (2007, Corollary 5.4) and Lemma 5.1, we obtain
which implies that \(Q_1(\varepsilon ,a)\) vanishes as \((\varepsilon ,a)\) goes to \((\varepsilon ^*,a^*)\) both if \(\Delta \) is independent of \(\varepsilon \) and if \(\Delta =\varepsilon ^\xi \).
Step 2: \(Q_2(\varepsilon ) \rightarrow 0\) as \(\varepsilon \rightarrow \varepsilon ^*\).
If \(\Delta \) is independent of \(\varepsilon \), then we have
and the right-hand side vanishes due to the continuity of \(g_j\) for all \(j=1,\dots ,J\) and the continuity of the solution of a stochastic differential equation with respect to a parameter (see Krylov 2009, Theorem 2.8.1). Let us now consider the case \(\Delta = \varepsilon ^\zeta \) with \(\zeta >0\) and let us assume, without loss of generality, that \(\varepsilon >\varepsilon ^*\). Denoting \(\Delta ^* = (\varepsilon ^*)^\zeta \) and applying Itô’s lemma we have for all \(j=1,\dots ,J\)
then we can write
where \(R(\varepsilon )\) is given by
Let \(C>0\) be independent of \(\varepsilon \) and notice that since \(p'\) is bounded, \(\beta _j,\phi _j',\phi _j'',V'\) are polynomially bounded and \(X_t^\varepsilon \) and \(\widetilde{Z}_0^\varepsilon \) have bounded moments of any order by Pavliotis and Stuart (2007, Corollary 5.4) and Lemma 5.1, applying Hölder’s inequality we obtain
Therefore, by the continuity of the solution of a stochastic differential equation with respect to a parameter (see Mishura et al. 2010) and due to the bound (5.4), we deduce that
which implies that \(Q_2(\varepsilon )\) vanishes as \(\varepsilon \) goes to \(\varepsilon ^*\) and concludes the proof.
Remark 5.4
Notice that the proof of Proposition 5.3 can be repeated analogously for the functions \(\widehat{\mathcal G}_J :(0,\infty ) \times \mathcal A \rightarrow \mathbb {R}^M\) and \(\widehat{\mathcal H}_J :(0,\infty ) \times \mathcal A \rightarrow \mathbb {R}^{M \times M}\) without filtered data in order to prove their continuity.
Next we study the limit as \(\varepsilon \) vanishes and we divide the analysis in two cases. In particular, we consider \(\Delta \) independent of \(\varepsilon \) and \(\Delta =\varepsilon ^\zeta \) with \(\zeta >0\). In the first case (Proposition 5.5), data are sampled at the homogenized regime ignoring the fact that the they are generated by a multiscale model, while in the second case (Proposition 5.7) the distance between two consecutive observations is proportional to the multiscale parameter and thus, data are sampled at the multiscale regime preserving the multiscale structure of the full path.
Proposition 5.5
Let the functions \(\widetilde{\mathcal G}_J :(0,\infty ) \times \mathcal A \rightarrow \mathbb {R}^M\) and \(\widetilde{\mathcal H}_J, :(0,\infty ) \times \mathcal A \rightarrow \mathbb {R}^{M \times M}\) be defined in (5.2) and (5.3) and let \(\Delta \) be independent of \(\varepsilon \). Under Assumption 2.5 and for any \(a^* \in \mathcal A\), we have
Proof
We only prove the statement for \(\widetilde{\mathcal G}_J\), then the argument is similar for \(\widetilde{\mathcal H}_J\). By the triangle inequality, we have
where
which vanishes due to the first step of the proof of Proposition 5.3 and
Let us remark that the convergence in law of the joint process \(\{(\widetilde{X}^\varepsilon _n, \widetilde{Z}^\varepsilon _n)\}_{n=0}^N\) to the joint process \(\{(\widetilde{X}^0_n, \widetilde{Z}^0_n)\}_{n=0}^N\) by Lemma A.2 implies the convergence in law of the triple \((X_0^\varepsilon , X_\Delta ^\varepsilon , \widetilde{Z}_0^\varepsilon )\) to the triple \((X_0^0, X^0_\Delta , \widetilde{Z}^0_0)\) since \(\widetilde{X}_0^\varepsilon = X_0^\varepsilon \), \(\widetilde{X}_1^\varepsilon = X_\Delta ^\varepsilon \) and \(\widetilde{X}_0^0 = X_0^0\), \(\widetilde{X}_1^0 = X_\Delta ^0\). Therefore, we have
which implies the desired result.
Remark 5.6
Similar results to Proposition 5.3 and Proposition 5.5 can be shown for the estimator without filtered data. In particular we have that \(\widehat{\mathcal G}_J(\varepsilon ,a)\) and \(\widehat{\mathcal H}_J(\varepsilon ,a)\) are continuous in \((0,\infty ) \times \mathcal A\) and
Since the proof is analogous, we do not report here the details.
Proposition 5.7
Let the functions \(\widetilde{\mathcal G}_J :(0,\infty ) \times \mathcal A \rightarrow \mathbb {R}^M\) and \(\widetilde{\mathcal H}_J, :(0,\infty ) \times \mathcal A \rightarrow \mathbb {R}^{M \times M}\) be defined in (5.2) and (5.3) and let \(\Delta =\varepsilon ^\zeta \) with \(\zeta >0\) and \(\zeta \ne 1\), \(\zeta \ne 2\). Under Assumption 2.5 and for any \(a^* \in \mathcal A\), we have
-
(i)
\(\lim _{(\varepsilon ,a) \rightarrow (0,a^*)} \widetilde{\mathcal G}_J(\varepsilon ,a) = \widetilde{\mathfrak g}_J^0(a^*)\), where
$$\begin{aligned} \widetilde{\mathfrak g}_J^0(a) :=\sum _{j=1}^J \mathbb {E}^{\rho ^0} \left[ \beta _j(Z_0^0;a) \left( \mathcal {L}_A \phi _j(X_0^0;a) + \lambda _j(a) \phi _j(X_0^0;a) \right) \right] ,\nonumber \\ \end{aligned}$$ -
(ii)
\(\lim _{(\varepsilon ,a) \rightarrow (0,a^*)} \widetilde{\mathcal H}_J(\varepsilon ,a) = \widetilde{\mathfrak h}_J^0(a^*)\), where


where the generator \(\mathcal {L}_A\) is defined in (2.9).
Proof
We only prove the statement for \(\widetilde{\mathcal G}_J\), then the argument is similar for \(\widetilde{\mathcal H}_J\). By the triangle inequality, we have
then we need to show that the two terms vanish and we distinguish two cases.
Case 1: \(\zeta \in (0,1)\).
Applying Lemma 5.2 to the functions \(\phi _j(\cdot ;a^*)\) for all \(j=1,\dots ,J\) and noting that
since
is a martingale with \(M_0=0\), we have
where \(R(\varepsilon ,\Delta )\) satisfies for a constant \(C>0\) independent of \(\varepsilon \) and \(\Delta \) and for all \(p\ge 1\)
We now study the three terms separately. First, by Cauchy–Schwarz inequality, since \(\beta _j(\cdot ;a^*)\) is polynomially bounded, \(\widetilde{Z}_0^\varepsilon \) has bounded moments of any order by Lemma 5.1 and due to (5.5) we obtain
Let us now focus on \(I_1^\varepsilon \) for which we have
where \(Z_0^\varepsilon \) is distributed according to the invariant measure \(\rho ^\varepsilon \) of the continuous process \((X_t^\varepsilon ,Z_t^\varepsilon )\) and
By the mean value theorem for vector-valued functions, we have
and since \(\beta _j'(\cdot ;a^*),\phi _j(\cdot ;a^*)\) are polynomially bounded, \(X_0^\varepsilon \), \(Z_0^\varepsilon \), \(\widetilde{Z}_0^\varepsilon \) have bounded moments of any order, respectively, by Pavliotis and Stuart (2007, Corollary 5.4), Abdulle et al. (2021, Lemma C.1) and Lemma 5.1 and applying Hölder’s inequality and Corollary A.3 we obtain
Moreover, notice that by homogenization theory (see Abdulle et al. 2021, Sect. 3.2) the joint process \((X_0^\varepsilon , Z_0^\varepsilon )\) converges in law to the joint process \((X_0^0, Z_0^0)\) and therefore
which together with (5.7) and (5.8) yields
We now consider \(I_3^\varepsilon \) and we follow an argument similar to \(I_2^\varepsilon \). We first have
where the first term in the right-hand side converges due to homogenization theory and the second one is bounded by
Therefore, we obtain
which together with (5.6) and (5.9) implies
which shows that \(Q_2(\varepsilon )\) vanishes as \(\varepsilon \) goes to zero. Let us now consider \(Q_1(\varepsilon ,a)\). Following the first step of the proof of Proposition 5.3, we have
where \(\widetilde{a}\) assumes values in the line connecting a and \(a^*\), and repeating the same computation as above we obtain
which together with (5.10) gives the desired result.
Case 2: \(\zeta \in (1,2) \cup (2,\infty )\).
Let \(Z_0^\varepsilon \) be distributed according to the invariant measure \(\rho ^\varepsilon \) of the continuous process \((X_t^\varepsilon ,Z_t^\varepsilon )\) and define
Then, we have
and we first bound the remainder \(\widetilde{R}(\varepsilon ,\Delta )\). Applying Itô’s lemma to the process \(X_t^\varepsilon \) with the functions \(\phi _j(\cdot ;a^*)\) for each \(j=1,\dots ,J\) we have
and observing that
since
is a martingale with \(M_0=0\), we obtain
By the mean value theorem for vector-valued functions, we have
and since \(\beta _j'(\cdot ;a^*),\phi _j(\cdot ;a^*)\) are polynomially bounded, \(X_0^\varepsilon \), \(Z_0^\varepsilon \), \(\widetilde{Z}_0^\varepsilon \) have bounded moments of any order, respectively, by Pavliotis and Stuart (2007, Corollary 5.4), Abdulle (2021, Lemma C.1) and Lemma 5.1 and applying Hölder’s inequality, we obtain
for a constant \(C>0\) independent of \(\varepsilon \) and \(\Delta \). We repeat a similar argument for \(\widetilde{R}_2(\varepsilon ,\Delta )\) and \(\widetilde{R}_3(\varepsilon ,\Delta )\) to get
which together with (5.14) yield
Moreover, applying Lemma 5.2 and proceeding similarly to the first part of the first case of the proof, we have
which together with (5.15) and Corollary A.3 implies
Let us now consider \(Q_j^\varepsilon \). Replacing equation (5.12) into the definition of \(Q_j^\varepsilon \) in (5.11) and observing that similarly to (5.13), it holds
we obtain
We rewrite \(\beta _j(Z_0^\varepsilon ;a^*)\) inside the integrals employing equation (2.21) and Itô’s lemma
hence due to stationarity we have
where
and
Since \(\phi _j'(\cdot ;a^*), \phi _j''(\cdot ;a^*)\) and \(\beta _j'(\cdot ;a^*)\) are polynomially bounded, \(p'\) is bounded and \(X_t^\varepsilon \) and \(Z_t^\varepsilon \) have bounded moments of any order, respectively, by Pavliotis and Stuart (2007, Corollary 5.4) and Abdulle et al. (2021, Lemma C.1), \(Q_{j,2}^\varepsilon \) is bounded by
Let us now move to \(Q_{j,1}^\varepsilon \) and let us define the functions

where \(\rho ^\varepsilon \) and \(\rho ^0\) are, respectively, the densities with respect to the Lebesgue measure of the invariant distributions of the joint processes \((X_t^\varepsilon ,Z_t^\varepsilon )\) and \((X_t^0,Z_t^0)\) and \(\varphi ^\varepsilon \) and \(\varphi ^0\) are their marginals with respect to the first component. Integrating by parts we have
which implies
Employing the last equation in the proof of Lemma 3.5 in Abdulle et al. (2021) with \(\delta =1\) and \(f(x,z) = \beta _j(z;a^*) \phi _j'(x;a^*)\), we have
and thus we obtain
Letting \(\varepsilon \) go to zero and due to homogenization theory, it follows
then applying formula (5.19) for the homogenized equation, i.e. with \(p(y)=0\) and \(\alpha \) and \(\sigma \) replaced by A and \(\Sigma \), and integrating by parts we have
Therefore, we obtain
which together with (5.11), (5.17) and bounds (5.16) and (5.18) implies that \(Q_2(\varepsilon )\) vanishes as \(\varepsilon \) goes to zero. Finally, analogously to the first case we can show that also \(Q_1(\varepsilon ,a)\) vanishes, concluding the proof.
Remark 5.8
A similar result to Proposition 5.7 can be shown for the estimator without filtered data only if \(\zeta \in (0,1)\), i.e. the first case in the proof. In particular, we have
-
(i)
\(\lim _{(\varepsilon ,a) \rightarrow (0,a^*)} \widehat{\mathcal G}_J(\varepsilon ,a) = \widehat{\mathfrak g}_J^0(a^*)\), where
$$\begin{aligned}&\widehat{\mathfrak g}_J^0(a) :=\sum _{j=1}^J \mathbb {E}^{\varphi ^0}\left[ \beta _j(X_0^0;a) \left( \mathcal {L}_A \phi _j(X_0^0;a) + \lambda _j(a) \phi _j(X_0^0;a) \right) \right] ,\nonumber \\ \end{aligned}$$ -
(ii)
\(\lim _{(\varepsilon ,a) \rightarrow (0,a^*)} \widehat{\mathcal H}_J(\varepsilon ,a) = \widehat{\mathfrak h}_J^0(a^*)\), where


where the generator \(\mathcal {L}_A\) is defined in (2.9). Since the proof is analogous, we do not report here the details. On the other hand, if \(\zeta > 2\), we can show that
-
(i)
\(\lim _{(\varepsilon ,a) \rightarrow (0,a^*)} \widehat{\mathcal G}_J(\varepsilon ,a) = \mathfrak g_J^0(a^*)\), where
$$\begin{aligned}&\mathfrak g_J^0(a) :=\sum _{j=1}^J \mathbb {E}^{\varphi ^0} \left[ \beta _j(X_0^0;a) \left( \sigma \phi _j''(X_0^0;a) - \alpha \cdot V'(X_0^0) \phi _j'(X_0^0;a) \right. \right. \nonumber \\&\quad \left. \left. + \lambda _j(a) \phi _j(X_0^0;a) \right) \right] , \end{aligned}$$(5.20) -
(ii)
\(\lim _{(\varepsilon ,a) \rightarrow (0,a^*)} \widehat{\mathcal H}_J(\varepsilon ,a) = \mathfrak h_J^0(a^*)\), where
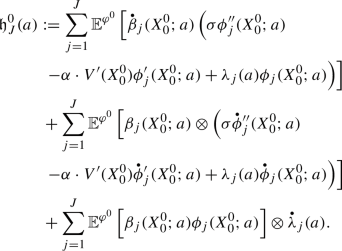
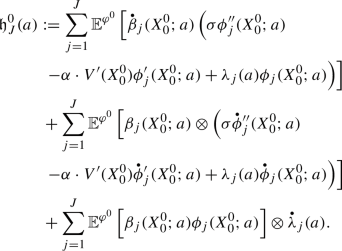
The proof is omitted since it is similar to the second case of the proof of Proposition 5.7.
5.2 Proof of the main results
Let us remark that we aim to prove the asymptotic unbiasedness of the proposed estimators, i.e. their convergence to the homogenized drift coefficient A as the number of observations N tends to infinity and the multiscale parameter \(\varepsilon \) vanishes. Therefore, we study the limit of the score functions and their Jacobian matrices as \(N\rightarrow \infty \) and \(\varepsilon \rightarrow 0\) evaluated in the desired limit point A.
We first analyse the case \(\Delta \) independent of \(\varepsilon \) and we consider the limit of Proposition 5.5 and Remark 5.6 evaluated in \(a^* = A\). Then, due to equation (2.12) we get
and similarly we obtain
On the other hand, if \(\Delta \) is a power of \(\varepsilon \), we study the limit of Proposition 5.7 and Remark 5.8 evaluated in \(a^* = A\) and by (2.10) we have
Moreover, differentiating equation (2.12) with respect to a, we get

where the process \(\nabla _a X_t(a)\) satisfies
Therefore, due to (2.12) and (5.23), we have
and
Then, due to Lemma A.4, we can differentiate the eigenvalue problem (2.11) with respect to a and deduce that

where the dot denotes the gradient with respect to a and which together with (2.11) implies
and
Before showing the main results, we need two auxiliary lemmas, which in turn rely on the technical Assumption 3.1, which can now be rewritten as:
-
(i)
\(\det \left( \frac{1}{\Delta }\sum _{j=1}^J \mathbb {E}^{\widetilde{\rho }^0} \left[ h_j \left( X_0^0, X_\Delta ^0, \widetilde{Z}_0^0; A \right) \right] \right) \ne 0\),
-
(ii)
\(\det \left( \frac{1}{\Delta }\sum _{j=1}^J \mathbb {E}^{\varphi ^0} \left[ h_j \left( X_0^0, X_\Delta ^0, X_0^0; A \right) \right] \right) \ne 0\),
-
(iii)
\(\det \left( \widetilde{\mathfrak h}_J^0(A) \right) \ne 0\),
-
(iv)
\(\det \left( \widehat{\mathfrak h}_J^0(A) \right) \ne 0\).
Since the proofs of the two lemmas are similar, we only write the details of the first one.
Lemma 5.9
Under Assumption 2.5 and Assumption 3.1, there exists \(\varepsilon _0>0\) such that for all \(0<\varepsilon <\varepsilon _0\) there exists \(\widetilde{\gamma }= \widetilde{\gamma }(\varepsilon )\) such that if \(\Delta \) is independent of \(\varepsilon \) or \(\Delta =\varepsilon ^\zeta \) with \(\zeta >0\) and \(\zeta \ne 1\), \(\zeta \ne 2\)
Moreover
Proof
Let us first extend the functions \(\widetilde{\mathcal G}_J\) and \(\widetilde{\mathcal H}_J\) by continuity in \(\varepsilon =0\) with their limit given by Proposition 5.5 and Proposition 5.7 depending on \(\Delta \) and note that due to (5.21) if \(\Delta \) is independent of \(\varepsilon \) and (5.22) otherwise, we have
Moreover, by (5.24), (5.25) and Assumption 3.1, we know that
Therefore, since the functions \(\widetilde{\mathcal G}_J\) and \(\widetilde{\mathcal H}_J\) are continuous by Proposition 5.3, the implicit function theorem (see Hurwicz and Richter 2003, Theorem 2) gives the desired result.
Lemma 5.10
Under Assumption 2.5 and Assumption 3.1, there exists \(\varepsilon _0>0\) such that for all \(0<\varepsilon <\varepsilon _0\) there exists \(\widehat{\gamma }= \widehat{\gamma }(\varepsilon )\) such that if \(\Delta \) is independent of \(\varepsilon \) or \(\Delta = \varepsilon ^\zeta \) with \(\zeta \in (0,1)\)
Moreover,
We are now ready to prove the asymptotic unbiasedness of the estimators, i.e. Theorems 3.3 and 3.4. We only prove Theorem 3.4 for the estimator \(\widetilde{A}^\varepsilon _{N,J}\) with filtered data. The proof of Theorem 3.3 for the estimator \(\widehat{A}^\varepsilon _{N,J}\) without filtered data is analogous and is omitted here.
Proof of Theorem 3.4
We need to show for a fixed \(0< \varepsilon < \varepsilon _0\):
-
(i)
the existence of the solution \(\widetilde{A}^\varepsilon _{N,J}\) of the system \(\widetilde{G}^\varepsilon _{N,J}(a) = 0\) with probability tending to one as \(N \rightarrow \infty \);
-
(ii)
\(\lim _{N \rightarrow \infty } \widetilde{A}^\varepsilon _{N,J} = A + \widetilde{\gamma }(\varepsilon )\) in probability with \(\lim _{\varepsilon \rightarrow 0} \widetilde{\gamma }(\varepsilon ) = 0\).
We first note that by Lemma 5.9 we have
We then follow the steps of the proof of Bibby and Rensen (1995, Theorem 3.2). Due to Barndorff–Nielsen and Sorensen (1994, Theorem A.1), claims (i) and (ii) hold true if we verify that

and as \(N \rightarrow \infty \)
where \(\Lambda ^\varepsilon \) is a positive definite covariance matrix and
for \(C>0\) small enough such that \(B_{C,1} \subset \mathcal A\). Result (5.27) is a consequence of Florens–Zmirou (1989, Theorem 1). We then have

where the right-hand side vanishes by Bibby and Rensen (1995, Lemma 3.3) and the continuity of \(\widetilde{\mathcal H}\) (Proposition 5.3), implying result (5.26). Hence, we proved (i) and (ii), which conclude the proof of the theorem.
Remark 5.11
Notice that if \(\Delta =\varepsilon ^\zeta \) with \(\zeta >2\) and we do not employ the filter, in view of (5.20) and following the same proof of Theorem 3.4, we could compute the asymptotic limit of \(\widehat{A}_{N,J}^\varepsilon \) as N goes to infinity and \(\varepsilon \) vanishes if we knew \(a^*\) such that
The value of \(a^*\) cannot be found analytically since it is, in general, different from the drift coefficients \(\alpha \) and A of the multiscale and homogenized equations (2.1) and (2.2). Nevertheless, we observe that in the simple scale of the multiscale Ornstein–Uhlenbeck process we have \(a^* = \alpha \).
6 Conclusion
In this work, we presented new estimators for learning the effective drift coefficient of the homogenized Langevin dynamics when we are given discrete observations from the original multiscale diffusion process. Our approach relies on a martingale estimating function based on the eigenvalues and eigenfunctions of the generator of the coarse-grained model and on a linear time-invariant filter from the exponential family, which is employed to smooth the original data. We studied theoretically the convergence properties of our estimators when the sample size goes to infinity and the multiscale parameter describing the fastest scale vanishes. In Theorem 3.3 and Theorem 3.4, we proved, respectively, the asymptotic unbiasedness of the estimators with and without filtered data. We remark that the former is not robust with respect to the sampling rate at finite multiscale parameter, while the estimator with filtered data is robust independently of the sampling rate. We analysed numerically the dependence of our estimators on the number of observations and the number of eigenfunctions employed in the estimating function noticing that the first eigenvalues in magnitude are sufficient to approximate the drift coefficient. Moreover, we performed several numerical experiments, which highlighted the effectiveness of our approach and confirmed our theoretical results. We believe that eigenfunction estimators can be very useful in applications, for example to multiparticle systems and their mean field limit (Gomes and Pavliotis 2018), since the eigenvalue problem for the generator of a reversible Markov process is a very well-studied problem. This means, in particular, that it is possible to study rigorously the proposed estimators and to prove asymptotic unbiasedness and asymptotic normality. Furthermore, in order to be able to assess the accuracy of the estimators, we could analyse its rate of convergence with respect to both the number of observations and the fastest scale. This is a highly nontrivial problem since it first requires the development of a fully quantitative periodic homogenization theory and we will return to this problem in future work. Finally, we think that it would be interesting to extend our estimators to the nonparametric framework and consider more general multiscale models.
References
Abdulle, A., Garegnani, G., Zanoni, A.: Ensemble Kalman filter for multiscale inverse problems. Multiscale Model. Simul. 18, 1565–1594 (2020)
Abdulle, A., Di Blasio, A.: A Bayesian numerical homogenization method for elliptic multiscale inverse problems. SIAM/ASA J. Uncertain. Quantif. 8, 414–450 (2020)
Abdulle, A., Garegnani, G., Pavliotis, G.A., Stuart, A.M., Zanoni, A.: Drift estimation of multiscale diffusions based on filtered data. Found. Comput. Math. (2021)
Aït-Sahalia, Y., Jacod, J.: High-Frequency Financial Econometrics. Princeton University Press, Princeton (2014)
Ait-Sahalia, Y.A., Mykland, P.A., Zhang, L.: How often to sample a continuous-time process in the presence of market microstructure noise. In: Shiryaev, A.N., Grossinho, M.R., Oliveira, P.E., Esquível, M.L. (eds.) Stochastic Finance, pp. 3–72. Springer, Boston (2006)
Bakry, D., Gentil, I., Ledoux, M.: Analysis and Geometry of Markov Diffusion Operators. Fundamental Principles of Mathematical Sciences, vol. 348. Springer, Cham (2014)
Barndorff-Nielsen, O.E., Sørensen, M.: A review of some aspects of asymptotic likelihood theory for stochastic processes. Int. Stat. Rev. 62, 133–165 (1994)
Bensoussan, A., Lions, J.L., Papanicolaou, G.: Asymptotic Analysis for Periodic Structures. AMS Chelsea Publishing, Providence (2011) (Corrected reprint of the 1978 original [MR0503330])
Bibby, B.M., Rensen, M.S.: Martingale estimation functions for discretely observed diffusion processes. Bernoulli 1, 17–35 (1995)
Brandt, A.: The stochastic equation \(Y_{n+1}=A_nY_n+B_n\) with stationary coefficients. Adv. Appl. Probab. 18, 211–220 (1986)
Crommelin, D., Vanden-Eijnden, E.: Fitting timeseries by continuous-time Markov chains: a quadratic programming approach. J. Comput. Phys. 217, 782–805 (2006a)
Crommelin, D., Vanden-Eijnden, E.: Reconstruction of diffusions using spectral data from timeseries. Commun. Math. Sci. 4, 651–668 (2006b)
Crommelin, D., Vanden-Eijnden, E.: Diffusion estimation from multiscale data by operator eigenpairs. Multiscale Model. Simul. 9, 1588–1623 (2011)
Delgadino, M.G., Gvalani, R.S., Pavliotis, G.A.: On the diffusive-mean field limit for weakly interacting diffusions exhibiting phase transitions. Arch. Ration. Mech. Anal. 241, 91–148 (2021)
Duncan, A.B., Pavliotis, G.A.: Brownian motion in an n-scale periodic potential (2016). Preprint arXiv:1605.05854
Florens-Zmirou, D.: Approximate discrete-time schemes for statistics of diffusion processes. Statistics 20, 547–557 (1989)
Godambe, V.P., Heyde, C.C.: Quasi-likelihood and optimal estimation. Int. Stat. Rev. 55, 231–244 (1987)
Gomes, S.N., Pavliotis, G.A.: Mean field limits for interacting diffusions in a two-scale potential. J. Nonlinear Sci. 28, 905–941 (2018)
Hansen, L.P., Scheinkman, J.A., Touzi, N.: Spectral methods for identifying scalar diffusions. J. Econom. 86, 1–32 (1998)
Heyde, C.C., Gay, R.: On asymptotic quasi-likelihood estimation. Stoch. Process. Appl. 31, 223–236 (1989)
Hurwicz, L., Richter, M.K.: Implicit functions and diffeomorphisms without \(C^1\). In: Advances in Mathematical Economics, Volume. 5 of Advanced Mathematics Econmics, pp. 65–96. Springer, Tokyo (2003)
Kalliadasis, S., Krumscheid, S., Pavliotis, G.A.: A new framework for extracting coarse-grained models from time series with multiscale structure. J. Comput. Phys. 296, 314–328 (2015)
Kessler, M., Sørensen, M.: Estimating equations based on eigenfunctions for a discretely observed diffusion process. Bernoulli 5, 299–314 (1999)
Krumscheid, S., Pavliotis, G.A., Kalliadasis, S.: Semiparametric drift and diffusion estimation for multiscale diffusions. Multiscale Model. Simul. 11, 442–473 (2013)
Krumscheid, S., Pradas, M., Pavliotis, G.A., Kalliadasis, S.: Data-driven coarse graining in action: modeling and prediction of complex systems. Phys. Rev. E 92, 042139 (2015)
Krylov, N.V.: Controlled diffusion processes, volume 14 of Stochastic Modelling and Applied Probability. Springer, Berlin (2009) [Translated from the 1977 Russian original by A. B. Aries, Reprint of the 1980 edition]
Mishura, Y.S., Posashkova, S. V., Posashkov, S.V.: Continuous dependence of solutions of stochastic differential equations controlled by standard and fractional Brownian motions on a parameter. Teor. Imovir. Mat. Stat. 92–105 (2010)
Papavasiliou, A., Pavliotis, G.A., Stuart, A.M.: Maximum likelihood drift estimation for multiscale diffusions. Stoch. Process. Appl. 119, 3173–3210 (2009)
Pavliotis, G.A.: Stochastic Processes and Applications. Texts in Applied Mathematics, vol. 60. Springer, New York (2014)
Pavliotis, G.A., Stuart, A.M.: Parameter estimation for multiscale diffusions. J. Stat. Phys. 127, 741–781 (2007)
Pavliotis, G.A., Stuart, A.M.: Multiscale Methods. Texts in Applied Mathematics, vol. 53. Springer, New York (2008)
Pokern, Y., Stuart, A.M., Vanden-Eijnden, E.: Remarks on drift estimation for diffusion processes. Multiscale Model. Simul. 8, 69–95 (2009)
Raissi, M., Perdikaris, P., Karniadakis, G.E.: Physics-informed neural networks: a deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. J. Comput. Phys. 378, 686–707 (2019)
Scheffler, T.B.: Analyticity of the eigenvalues and eigenfunctions of an ordinary differential operator with respect to a parameter. Proc. Roy. Soc. Lond. Ser. A 336, 475–486 (1974)
Spiliopoulos, K., Chronopoulou, A.: Maximum likelihood estimation for small noise multiscale diffusions. Stat. Inference Stoch. Process. 16, 237–266 (2013)
Yang, L., Meng, X., Karniadakis, G.E.: B-PINNs: Bayesian physics-informed neural networks for forward and inverse PDE problems with noisy data. J. Comput. Phys. 425, 109913 (2021)
Zhang, L., Mykland, P.A., Aït-Sahalia, Y.: A tale of two time scales: determining integrated volatility with noisy high-frequency data. J. Am. Stat. Assoc. 100, 1394–1411 (2005)
Zhang, D., Lu, L., Guo, L., Karniadakis, G.E.: Quantifying total uncertainty in physics-informed neural networks for solving forward and inverse stochastic problems. J. Comput. Phys. 397, 108850 (2019)
Acknowledgements
We thank the anonymous referees for useful comments and suggestions. AA and AZ are partially supported by the Swiss National Science Foundation, under grant No. 200020_172710. The work of GAP was partially funded by the EPSRC, grant number EP/P031587/1, and by JPMorgan Chase & Co. Any views or opinions expressed herein are solely those of the authors listed, and may differ from the views and opinions expressed by JPMorgan Chase & Co. or its affiliates. This material is not a product of the Research Department of J.P. Morgan Securities LLC. This material does not constitute a solicitation or offer in any jurisdiction.
Author information
Authors and Affiliations
Corresponding author
Additional information
Dedicated to the memory of Assyr Abdulle.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Technical results
In this section, we prove some technical results which are used to show the unbiasedness of the estimators \(\widehat{A}^\varepsilon _{N,J}\) and \(\widetilde{A}^\varepsilon _{N,J}\). We first study the properties of the filter applied to discrete data, and then, we focus on the regularity of the eigenfunctions and eigenvalues of the generator. We finally prove a formula which can be interpreted as an approximation of the Itô’s lemma.
1.1 Application of the filter to discrete data
The following result quantifies the expected distance among the continuous process \(Z^\varepsilon _t\) and the filtered observations \(\widetilde{Z}^\varepsilon _n\).
Lemma A.1
Let \(0<\Delta <1\), N be a positive integer and let \(\widetilde{Z}_n^\varepsilon \) and \(Z_t^\varepsilon \) be defined, respectively, in (2.16) and (2.20) with \(\widetilde{X}^\varepsilon _0 = X^\varepsilon _0\) distributed according to its invariant measure \(\varphi ^\varepsilon \). Then, there exists a constant \(C>0\) independent of \(\varepsilon \), \(\Delta \) and N such that for all \(n = 0, \dots , N\) and for all \(p\ge 1\)
where \(\mathbb {E}^{\varphi ^\varepsilon }\) denotes the expectation with respect to the Wiener measure and the fact that \(X^\varepsilon _0\) is distributed according to \(\varphi ^\varepsilon \).
Proof
In order to simplify the notation, let us define the quantity
which is equivalent to
Then, by Jensen’s inequality applied to the convex function \(y \mapsto \left|y\right|^p\) and since \(X^\varepsilon _{k\Delta } = \widetilde{X}^\varepsilon _k\), we have
We now study the two terms separately. Applying Abdulle et al. (2021, Lemma B.1), we first get
and, in order to bound the term inside the integral, we can follow two different procedures. Either we employ (Pavliotis and Stuart 2007, Lemma 6.1), which gives
where \(C > 0\) is a constant independent of \(\varepsilon \) and \(\Delta \) or we notice that, since \(X_t^\varepsilon \) has bounded moments of any order by Pavliotis and Stuart (2007, Corollary 5.4) and p is bounded, it holds for all \(s \in [k\Delta , (k+1)\Delta )\)
Therefore, due to (A.2), (A.3) and (A.4), we obtain
Let us now consider \(E_2\), which can be first bounded by
and note that
Therefore, applying Jensen’s inequality and due to the fact that \(\widetilde{X}_k^\varepsilon \) has bounded moments of any order by Pavliotis and Stuart (2007, Corollary 5.4) we have
which, together with (A.1) and (A.5), gives the desired result.
We now show the ergodicity of the process \((\widetilde{X}^\varepsilon _n, \widetilde{Z}^\varepsilon _n)\), where the first component is a sample from the continuous-time process, i.e. \(\widetilde{X}^\varepsilon _n = X_{n\Delta }^\varepsilon \), while the second component is computed starting from the discrete observations \(\widetilde{X}^\varepsilon _n\).
Lemma A.2
Let \(\Delta >0\) and let Assumption 2.2 hold. Then, the couple \((\widetilde{X}_n^\varepsilon , \widetilde{Z}_n^\varepsilon )\), where \(\widetilde{X}_n^\varepsilon \) is a sample from the continuous process (2.1) and \(\widetilde{Z}_n^\varepsilon \) is defined in (2.16), admits a unique invariant measure with density with respect to the Lebesgue measure denoted by \(\widetilde{\rho }^\varepsilon = \widetilde{\rho }^\varepsilon (x,z)\). Moreover, if \(\Delta \) is independent of \(\varepsilon \), it converges in law to the two-dimensional process \((\widetilde{X}_n^0, \widetilde{Z}_n^0)\) with \(\widetilde{\rho }^0 = \widetilde{\rho }^0(x,z)\) as density of the invariant measure.
Proof
By definition (2.19), we obtain the following stochastic difference equation
where \(\widetilde{X}^\varepsilon _n\) is a stationary and ergodic sequence. Observing that \(\log e^{-\Delta } = -\Delta < 0\), applying Theorem 1 and in view of Remark 1.3 in Brandt (1986) we deduce the existence of a unique invariant measure for the couple \((\widetilde{X}_n^\varepsilon , \widetilde{Z}_n^\varepsilon )\). Let us notice that in the theorem the sequence \(\widetilde{X}_n^\varepsilon \) must be defined for all \(n\in \mathbb {Z}\) while in our framework \(n\in \mathbb {N}\), but let us also remark that any stationary process indexed by \(\mathbb {N}\) can be extended to one indexed by \(\mathbb {Z}\) in an essentially unique way. Moreover, if \(\Delta \) is independent of \(\varepsilon \), the same reasoning can be repeated to get the existence of a unique invariant measure for the couple \((\widetilde{X}_n^0, \widetilde{Z}_n^0)\). Finally, standard homogenization theory implies the weak convergence of \(\widetilde{\rho }^\varepsilon \) to \(\widetilde{\rho }^0\), which concludes the proof.
Let us now denote the marginal invariant distributions of \(Z^\varepsilon , \widetilde{Z}^\varepsilon \) and \(Z^0, \widetilde{Z}^0\), respectively, by \(\psi ^\varepsilon = \psi ^\varepsilon (z), \widetilde{\psi }^\varepsilon = \widetilde{\psi }^\varepsilon (z)\) and \(\psi ^0 = \psi ^0(z), \widetilde{\psi }^0 = \widetilde{\psi }^0(z)\).
Corollary A.3
Let \(Z^\varepsilon \) and \(\widetilde{Z}^\varepsilon \) be distributed, respectively, according to \(\psi ^\varepsilon \) and \(\widetilde{\psi }^\varepsilon \). Then, there exists a constant \(C>0\) independent of \(\varepsilon \) and \(\Delta \) such that
Proof
The result follows directly from Lemma A.1 by letting n go to infinity, noting that the constant C is independent of n and employing ergodicity given by Lemma A.2.
It directly follows that \(\widetilde{Z}_n^\varepsilon \) has bounded moments of all order and, in particular, we can prove Lemma 5.1.
Proof of Lemma 5.1
Applying Jensen’s inequality to the function \(x\mapsto \left|x\right|^p\), we have
then bounding the two terms in the right-hand side, respectively, with Abdulle et al. (2021, Lemma C.1) and Corollary A.3 gives the desired result.
1.2 Properties of eigenfunctions and eigenvalues of the generator
Let us now consider the eigenvalue and the eigenfunctions of the generator of SDE (2.7).
Lemma A.4
Let \(\{(\lambda _j(a),\phi _j(\cdot ;a))\}_{j=0}^\infty \) be the solutions of the eigenvalue problem (2.10). Then, \(\phi _j(x;a)\) and \(\lambda _j(a)\) are continuously differentiable with respect to a for all \(x\in \mathbb {R}\) and for all \(j\in \mathbb {N}\). Moreover, \(\phi _j(\cdot ;a)\) and  belong to \(\mathcal C^\infty (\mathbb {R})\).
belong to \(\mathcal C^\infty (\mathbb {R})\).
Proof
The first result follows from Sects. 2 and 6 in Scheffler (1974). Let us remark that the fact that the spectrum is discrete and non-degenerate is guaranteed by Pavliotis and Stuart (2014, Sect. 4.7). Finally, the second result in the statement is a direct consequence of the elliptic regularity theory.
1.3 Approximation of the Itô formula
In this section, we prove Lemma 5.2, which is an approximation of the Itô’s lemma applied to the stochastic process \(X_t^\varepsilon \). Let us introduce the process \(S_t^\varepsilon \) defined by the following SDE with initial condition \(S_0^\varepsilon = X_0^\varepsilon \)
where \(Y_t^\varepsilon = X_t^\varepsilon /\varepsilon \) and \(\Phi \) is the cell function which solves equation (2.5), and notice that
Therefore, due to Eq. (5.7) in Pavliotis and Stuart (2007), we have
and, since \(\Phi \) is bounded by Pavliotis and Stuart (2007, Lemma 5.5), we get for a constant \(C>0\) independent of \(\Delta \) and \(\varepsilon \)
Before showing the main formula, we need two preliminary estimates which will be employed later in the analysis. The proofs of Lemma A.5 and Lemma A.6 are inspired by the proof of Proposition 5.8 in Pavliotis and Stuart (2007).
Lemma A.5
Let \(f :\mathbb {R}\rightarrow \mathbb {R}\) be a continuously differentiable function such that \(f,f'\) are polynomially bounded. Then,
where the remainder satisfies for all \(p\ge 1\) and for a constant \(C>0\) independent of \(\Delta \) and \(\varepsilon \)
Proof
To obtain the remainder \(R_1(\varepsilon ,\Delta )\) we decompose suitably the difference between the left-hand side and the right-hand side of (A.8). Applying Jensen’s inequality to the function \(z\mapsto \left|z\right|^p\), we have
Letting \(C>0\) be a constant independent of \(\varepsilon \) and \(\delta \), we now bound the three terms separately. First, applying Hölder inequality and since \(V'\) is Lipschitz, \(\Phi '\) is bounded, f is polynomially bounded and \(X_t^\varepsilon \) has bounded moments of any order by Pavliotis and Stuart (2007, Corollary 5.4), we have
then applying Pavliotis and Stuart (2007, Lemma 6.1) we obtain
We then rewrite \(I_2(\varepsilon ,\Delta )\) employing the mean value theorem
where \(\widetilde{X}_t^\varepsilon \) assumes values between \(X_0^\varepsilon \) and \(X_t^\varepsilon \), and we repeat the same reasoning as for \(I_1(\varepsilon ,\Delta )\) to get
We now consider the function
which by definition of A and due to (2.3) has zero mean with respect to \(\mu \) defined in (2.4). Therefore, since f and \(V'\) are polynomially bounded and \(X_0^\varepsilon \) has bounded moments of any order by Pavliotis and Stuart (2007, Corollary 5.4), applying Pavliotis and Stuart (2007, Lemma 5.6) we obtain
Finally, for \(\varepsilon \) and \(\Delta \) sufficiently small, the desired result follows from (A.9) and from estimates (A.10), (A.11) and (A.12).
Lemma A.6
Let \(f :\mathbb {R}\rightarrow \mathbb {R}\) be a continuously differentiable function such that \(f,f'\) are polynomially bounded. Then,
where the remainder satisfies for all \(p\ge 1\) and for a constant \(C>0\) independent of \(\Delta \) and \(\varepsilon \)
Proof
To obtain the remainder \(R_2(\varepsilon ,\Delta )\), we decompose suitably the difference between the left-hand side and the right-hand side of (A.13). Applying Jensen’s inequality to the function \(z\mapsto \left|z\right|^p\), we have

Letting \(C>0\) be a constant independent of \(\varepsilon \) and \(\Delta \), we now bound the two terms separately. First, we rewrite \(I_1(\varepsilon ,\Delta )\) employing the mean value theorem
where \(\widetilde{X}_t^\varepsilon \) assumes values between \(X_0^\varepsilon \) and \(X_t^\varepsilon \), then applying Hölder inequality and since \(\Phi '\) is bounded, \(f'\) is polynomially bounded and \(X_t^\varepsilon \) has bounded moments of any order by Pavliotis and Stuart (2007, Corollary 5.4), we have
and applying Pavliotis and Stuart (2007, Lemma 6.1) we obtain
We now consider the function
which by definition of \(\Sigma \) and due to (2.3) has zero mean with respect to \(\mu \) defined in (2.4). Therefore, since f is polynomially bounded and \(X_0^\varepsilon \) has bounded moments of any order by Pavliotis and Stuart (2007, Corollary 5.4), applying Pavliotis and Stuart (2007, Lemma 5.6) we obtain
Finally, for \(\varepsilon \) and \(\Delta \) sufficiently small, the desired result follows from (A.14) and from estimates (A.15) and (A.16).
We can now prove the main formula, which is employed repeatedly in the proof of the asymptotic unbiasedness of the drift estimators.
Proof of Lemma 5.2
Applying Itô’s lemma to the process \(S_t^\varepsilon \) defined in (A.6) with the function f, we have
and due to Lemma A.5 and Lemma A.6 we obtain
Then, we write
and, in order to conclude, it only remains to bound the expectation of \(R_3(\varepsilon ,\Delta )\). Applying the mean value theorem and the Cauchy-Schwarz inequality and due to (A.7), the hypotheses on f and the fact that \(X_t^\varepsilon \) has bounded moments of any order by Pavliotis and Stuart (2007, Corollary 5.4), we obtain
where \(\widetilde{X}\) takes values between \(X_\Delta ^\varepsilon \) and \(S_\Delta ^\varepsilon \), and which together with the estimates for \(R_1\) and \(R_2\) implies the desired result.
Implementation details
In this section, we present the main techniques that we employed in the implementation of the proposed method. The most important steps in the algorithm are the computation of the eigenvalues and eigenfunctions of the eigenvalue problem (2.11)
and the solution of the nonlinear system (2.15) or (2.18) with filtered data. Let us first focus on the eigenvalue problem. We note that the domain of the eigenfunctions is the whole real line \(\mathbb {R}\) and need to be truncated for numerical computations. We first consider the variational formulation of equation (2.11), i.e. we multiply it by \(v \varphi _a\), where v is a test function and \(\varphi _a\) is the invariant distribution defined in (2.8), and integrating by parts we obtain for all \(j \in \mathbb {N}\) the following eigenvalue problem
Since \(\varphi _a\) decays to zero exponentially fast, for all \(\delta > 0\) there exists \(r>0\) such that
Hence, letting \(R > 0\) we assume that \(\varphi _a(\pm R) \simeq 0\) and we solve the truncated problem
Notice that R must be chosen big enough and such that

and we take \(R = \max \{ \bar{R} + 0.1, 1.7 \}\). Moreover, in order to have a unique solution for the eigenvector \(\phi _j(\cdot ;a)\) we impose the additional conditions
We then introduce a partition \(\mathcal T_h\) of \([-R,R]\) in \(N_h\) subintervals \(K_i = [x_{i-1}, x_i]\) with
and \(h = 2R/N_h\), and we construct the discrete space
which is constituted by continuous piecewise linear functions. Note that the discretization parameter h is chosen to be \(h = 0.1\) or \(h = 0.05\). We pick the characteristic Lagrangian basis \(\{ \psi _k \}_{k=0}^{N_h}\) of \(X_h^1\) characterized by the following property
where \(\delta _{ik}\) is the Kronecker delta. We want to find \(\phi _j(\cdot ;a) \in X_h^1\) such that equation (B.1) holds true for all \(v \in X_h^1\). Therefore, in equation (B.1) we substitute
and we obtain the discrete formulation
where \(\Theta _j(a) \in \mathbb {R}^{N_h+1}\) is such that \((\Theta _j(a))_k = \theta _j^{(k-1)}(a)\) and the components of the matrices \(S,M \in \mathbb {R}^{N_h+1 \times N_h+1}\) are given by
where the integrals are approximated through the composite Simpson’s quadrature rule. Equation (B.3) is a generalized eigenvalue problem which can be solved in Matlab using the function eigs or in Phython using the function scipy.sparse.linalg.eigsh. Then, we normalize \(\Theta _j(a)\) or change its sign in order to impose the conditions (B.2), which can be rewritten as:
Once we compute \(\lambda _j(a)\) and \(\Theta _j(a)\), we have an approximation of the eigenvalues and eigenfunctions and we can construct the function \(\widehat{G}^\varepsilon _{N,J}(a)\) in (2.14) or \(\widetilde{G}^\varepsilon _{N,J}(a)\) in (2.17) with filtered data. Hence, it only remains to solve systems (2.15) or (2.18), i.e.
To solve these equations, we can follow two approaches:
-
find the zero of \(\widehat{G}^\varepsilon _{N,J}(a)\) or \(\widetilde{G}^\varepsilon _{N,J}(a)\);
-
find the minimum of \(\left\| \widehat{G}^\varepsilon _{N,J}(a)\right\| \) or \(\left\| \widetilde{G}^\varepsilon _{N,J}(a)\right\| \).
In practice, for the first approach the function fsolve in Matlab or the function scipy.optimize.fsolve in Python can be used, while for the second one the function fmincon in Matlab or the function scipy.optimize.minimize in Python can be used. Finally, note that the functions implemented in Matlab or Python have been employed with their default parameters.
Multidimensional diffusion processes
In this section, we present how our methodology for estimating the drift coefficient of the homogenized equation can be extended to the case of multidimensional multiscale diffusion processes in \(\mathbb {R}^d\). In the d-dimensional case, the multiscale SDE (2.1) reads
where \(W_t\) is a standard d-dimensional Brownian motion. The theory of homogenization (see, for example, Bensoussan et al. 2011, Chapter 3) or Pavliotis and Stuart (2008, Chapter 18) then guarantees the existence of the homogenized SDE
where \(A_m,\Sigma \in \mathbb {R}^{d \times d}\) are given by \(A_m = \alpha _m K\) and \(\Sigma = \sigma K\). The matrix \(K \in \mathbb {R}^{d \times d}\) is defined by
where
and where the function \(\Phi :[0,L]^d \rightarrow \mathbb {R}^d\) is the unique solution with zero-mean with respect to the measure \(\mu \) of the cell problem in \([0,L]^d\)
endowed with periodic boundary conditions. Using the tensor notation, we can then define the drift coefficient \(A \in \mathbb {R}^{M \times d \times d}\), which collects together the M matrices \(A_m\) for \(m = 1, \dots , M\). Our goal is now to estimate the tensor A and thus we need to define the score functions. First, the d-dimensional eigenvalue problem for \(j = 1, \dots , J\) corresponding to (2.11) is
where : denotes the Frobenius inner product, \(\nabla ^2\) the Hessian matrix and the parameter \(a \in \mathbb {R}^{M \times d \times d}\) collects together the M matrices \(a_m\) for \(m = 1, \dots , M\). Then, in order to define the martingale estimating functions \(g_j\) for \(j = 1, \dots , J\), we take a collection \(\{ \beta _j \}_{j=1}^J\) of functions \(\beta _j(\cdot ; a) :\mathbb {R}^d \rightarrow \mathbb {R}^{M \times d \times d}\) and we use equation (2.13). Finally, we construct the score functions \(\widehat{G}^\varepsilon _{N,J}\) and \(\widetilde{G}^\varepsilon _{N,J}\) in the same way as we did in the one dimensional case, i.e. employing equations (2.14) and (2.17). We remark that the filtered data are obtained as in equation (2.16) by applying the filter component-wise. We can now compute the estimators \(\widehat{A}^\varepsilon _{N,J}\) and \(\widetilde{A}^\varepsilon _{N,J}\) by solving the nonlinear systems
which have dimension \(Md^2\). From a theoretical point of view, slight modifications of the proofs allow to conclude that analogous results to the main theorems hold true, i.e. that the estimators are asymptotically unbiased in the limit of infinite observations and when the multiscale parameter vanishes. However, the problem becomes more complex and computationally expensive from a numerical viewpoint, in particular when the dimension d is large. In fact, the final nonlinear system, which has to be solved, has dimension \(Md^2\) instead of M and, most importantly, it is required to solve the eigenvalue problem for the generator of a diffusion process in d dimensions.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Abdulle, A., Pavliotis, G.A. & Zanoni, A. Eigenfunction martingale estimating functions and filtered data for drift estimation of discretely observed multiscale diffusions. Stat Comput 32, 34 (2022). https://doi.org/10.1007/s11222-022-10081-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11222-022-10081-7
Keywords
- Langevin dynamics
- Diffusion process
- Homogenization
- Parameter estimation
- Discrete observations
- Eigenvalue problem
- Filtering
- Martingale estimators