
Abstract
In this study, we explore the citedness of research data, its distribution over time and its relation to the availability of a digital object identifier (DOI) in the Thomson Reuters database Data Citation Index (DCI). We investigate if cited research data “impacts” the (social) web, reflected by altmetrics scores, and if there is any relationship between the number of citations and the sum of altmetrics scores from various social media platforms. Three tools are used to collect altmetrics scores, namely PlumX, ImpactStory, and Altmetric.com, and the corresponding results are compared. We found that out of the three altmetrics tools, PlumX has the best coverage. Our experiments revealed that research data remain mostly uncited (about 85 %), although there has been an increase in citing data sets published since 2008. The percentage of the number of cited research data with a DOI in DCI has decreased in the last years. Only nine repositories are responsible for research data with DOIs and two or more citations. The number of cited research data with altmetrics “foot-prints” is even lower (4–9 %) but shows a higher coverage of research data from the last decade. In our study, we also found no correlation between the number of citations and the total number of altmetrics scores. Yet, certain data types (i.e. survey, aggregate data, and sequence data) are more often cited and also receive higher altmetrics scores. Additionally, we performed citation and altmetric analyses of all research data published between 2011 and 2013 in four different disciplines covered by the DCI. In general, these results correspond very well with the ones obtained for research data cited at least twice and also show low numbers in citations and in altmetrics. Finally, we observed that there are disciplinary differences in the availability and extent of altmetrics scores.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Recently, data citations have gained momentum (Piwowar and Chapman 2010; Borgman 2012; Torres-Salinas et al. 2013b). This is reflected, among others, in the development of data-level metrics (DLM), an initiative driven by PLOS, UC3 and DataONE,Footnote 1 to track and measure activity on research data, and the recent announcement of CERN to provide digital object identifier (DOIs) for each dataset they share through their novel Open Data portal.Footnote 2 In the latter case, the aim is “to make [data sets] citable objects in the scientific discourse”. Data citations are citations included in the reference list of a published article that formally cite either the data that led to a research result or a data paper.Footnote 3 Thereby, data citations indicate the influence and reuse of data in scientific publications.
First studies on data citations showed that certain well-curated data sets receive far more citations or mentions in other articles than many traditional articles (Belter 2014; Parsons et al. 2010; Piwowar et al. 2007, 2011). Citations, however, are used as a proxy for the assessment of impact primarily in the “publish or perish” community. To consider other disciplines and stakeholders of research, such as industry, government and academia, and in a much broader sense, the society as a whole, altmetrics (i.e. alternative, social media-based indicators) are emerging as a useful instrument to assess the “societal” impact of research data. It is assumed that altmetrics can provide a more complete picture of research uptake, besides more traditional usage and citation metrics (Bornmann 2014; Konkiel 2013). Previous work on altmetrics for research data has mainly focused on motivations for data sharing, creating reliable data metrics and effective reward systems (Costas et al. 2012).
The prerequisite to study the reuse of research data is clearly that the data has been made available to the scientific community and that it has been shared. Reuse of data can yet also mean that the creators of the data themselves, who then refer to their previous work, extensively use the data. Besides the provision and study of more technical prerequisites for data citations we argue that the processes underlying research data sharing and the attitudes towards these practice (e.g., advancing knowledge by sharing or misuse of shared data sets; Bauer et al. 2015; Fecher et al. 2015b; Tenopir et al. 2011) must also play an important role in the studies and interpretation of data citations.
Generally, Fecher et al. (2015b) found that 76 % of polled researchers believe that scientists should publish data; 88 % of respondents would actually use secondary data to perform original studies on its basis. In comparison to 2011 this is only a small increase in the results of Tenopir et al. In their survey, 83.3 % of scholars responded that they (somewhat) agree with “I would use other researchers’ datasets if their datasets were easily accessible”. In fact, the presumed visibility of research and increased reputation caused by data citations are strong drivers of data sharing practices and was stated by 79 % of respondents in the study of Fecher et al. (2015b). Tenopir et al. (2011) had 91.7 % of the researchers (somewhat) agreeing with “It is important that my data are cited when used by other researchers” and 95 % said that it is “fair to use other people’s data if there is formal citation of the data providers and/or funding agencies in all disseminated work making use of the data “(Tenopir et al. 2011, p. 10)”. Bauer et al. (2015) showed that 54 % of polled researchers consider citations to research data “as relevant scientific output in research documentation, intellectual capital report and evaluations”, although “the quality and traceability of the re-use of data” are not yet given (p. 49).
However, Fecher et al. (2015b) revealed that the majority of researchers have not shared data publicly yet (only 13 % had ever publicly shared data sets). The authors also showed that the degree of skills related to data sharing (i.e., retrieval and publication of data sets) plays a major role: “Researchers that know how to make data available to others are significantly more willing to make data available” (p. 11; see also Tenopir et al. 2011). It is not only the lack of knowledge on how to make research data available, but it is also missing information on adequate data repositories or other places to publish the data, which prevents researchers from sharing (Tenopir et al. 2011; Wallis et al. 2013).
The aforementioned studies mainly followed a qualitative approach by asking researchers about their opinions on and the frequency of data publication and sharing. Their results are therefore purely based on self-reporting. Hence, it is interesting to investigate whether the same tendencies are reflected by more quantitative evidence as provided by citation counts and altmetrics.
We consider the qualitative studies based on self-reporting as theoretical background, which will guide our interpretation of data citations and data-level metrics. The combination of both lines of research as well as the study of formal aspects of research data citations will add to the understanding of actual practices in sharing and referencing of research data, even across disciplines. It sheds light on what citation and altmetrics practices are currently in use, what types of data are actually cited and shared via social media platforms and which identifiers are popular for which data types and disciplines. Thus, the analyses will lay the foundation for the development of supporting processes and tools in research data sharing and referencing by learning, which properties make data sets successful (in terms of number of citations and altmetrics). Moreover, the study is a first approach to digging deeper into the nature and scope of Thomson Reuters Data Citation Index (DCI) as well as the research data landscape used for research assessment studies.
This study extends previous work (Peters et al. 2015) and contributes to the research on data citations in describing their characteristics as well as their impact in terms of citations and altmetrics scores. Specifically, we tackle the following research questions grouped into three thematic sets:
-
Coverage and intensity of references to research data in DCI and social media channels
-
How often and to what extent are research data cited?
-
How does citedness evolve over time?
-
Are there any differences in the results of the tools used for altmetrics scores aggregation?
-
-
Formal aspects of data citations in DCI and social media channels
-
Which identifiers are used for data citations and to what extent?
-
What are the characteristics of cited research data?
-
Which data types and disciplines are the most cited?
-
From which sources do research data originate?
-
-
Differences in databases: DCI versus altmetrics
-
Which preferences can be observed?
-
What characteristics do uncited research data have?
-
Data sources
On the Web, a large number of data repositories are available to store and disseminate research data. The Thomson Reuters Data Citation Index (DCI), launched in (2012), provides an index of high-quality research data from various data repositories across disciplines and around the world. It enables search, exploration and bibliometric analysis of research data through a single point of access, i.e. the Web of Science (Torres-Salinas et al. 2013b). The selection criteria are mainly based on the reputation and characteristics of the repositories.Footnote 4 Three document types are available in the DCI: data set, data study, and repository. The document type “repository” can distort bibliometric analyses, because repositories are mainly considered as a source, but not as a document type.
First coverage and citation analyses of the DCI have been performed April–June 2013 by the EC3 bibliometrics group of Granada (Torres-Salinas et al. 2014; Torres-Salinas et al. 2013a). According to these studies, the data is highly skewed: Science areas accounted for almost 80 % of records in the database and four repositories contained 75 % of all the records in the database. 88 % of all records remained uncited. In Science, Engineering and Technology, citations are concentrated among datasets, whereas in the Social Sciences and Arts and Humanities, citations normally refer to data studies.
Since these first analyses, DCI has been constantly growing, now indexing nearly two million records from high-quality repositories around the world. One of the most important enhancements of the DCI has undoubtedly been the inclusion of “figshare”Footnote 5 as new data source, which led to an increase of almost a half million of data sets and 40,000 data studies (i.e. about one-fourth of the total coverage in the database).
In contrast to the DCI, where citation information is already summarized, gathering altmetrics data is quite laborious since they are spread over a variety of social media platforms which each offer different applications programming interfaces (APIs). Tools, which collect and aggregate these altmetrics data come in handy and are now fighting for market shares since also large publishers increasingly display altmetrics for articles (e.g., WileyFootnote 6). There are currently three big altmetrics data providers: ImpactStory,Footnote 7 Altmetric.com, and PlumX.Footnote 8 Whereas Altmetrics.com and PlumX focus more on gathering and providing data for institutions (e.g., publishers, libraries, or universities), ImpactStory’s target group is the individual researcher who wants to include altmetrics information in her CV.
ImpactStory is a web-based tool which works with individually assigned permanent identifiers (such as DOIs, URLs, PubMed IDs) or links to ORCID, Figshare, Publons, Slideshare, or Github to auto-import new research outputs like e.g. papers, data sets, slides. Altmetric scores from a large range of social media platforms, including Twitter, Facebook, Mendeley, Figshare, Google + , and Wikipedia,Footnote 9 can be downloaded as.json or.csv (as far as original data providers allow data sharingFootnote 10). With Altmetric.com, users can search within a variety of social media platforms (e.g., Twitter, Facebook, Google+, or 8000 blogsFootnote 11) for keywords as well as for permanent identifiers (e.g., DOIs, arXiv IDs, RePEc identifiers, handles, or PubMed IDs). Queries can be restricted to certain dates, journals, publishers, social media platforms, and Medline Subject Headings. The search results can be downloaded as.csv from the Altmetric Explorer (web-based application) or via the API. Plum Analytics or PlumX (the fee-based altmetrics dashboard) offers article-level metrics for so-called artifacts, which include articles, audios, videos, book chapters, or clinical trials.Footnote 12 Plum Analytics works with ORCID and other user IDs (e.g., from YouTube, Slideshare) as well as with DOIs, ISBNs, PubMed-IDs, patent numbers, and URLs. Because of its collaboration with EBSCO Plum Analytics can provide statistics on the usage of articles and other artifacts (e.g., views to or downloads of html pages or pdfs), but also on, amongst others, Mendeley readers, GitHub forks, Facebook comments, and YouTube subscribers.
Methodology
In our work, we used DCI to retrieve records of cited research data. First, we conducted a general analysis of citedness among all items published in the last five and a half decades (1960–1969, 1970–1979, 1980–1989, 1990–1999, 2000–2009, and 2010–2014) (n = 3,984,028 items). Then, we downloaded and analysed all items with two or more citations (Sample 1, n = 10,934 records). Since the study’s focus was on the actual reuse of data, we limited our analysis to research data that have been cited at least twice in order to reduce the effect of self-citations generated by single papers produced on the basis of the particular data set (the DCI does not report the number of self-citations). In contrast to the work of Torres-Salinas et al. (2013b), the present study does not aim at making general conclusions about the entire DCI, but deliberately uses the subset of more frequently cited data sets. The following metadata fields were used in the analysis: available DOI or URL, document type, source, research area, publication year, data type, number of citations and ORCID availability.Footnote 13 Then, the citedness in the database was computed for each decade considered in this study and analysed in detail for each year since 2000. Afterwards, we analysed the distribution of document types, data types, sources and research areas with respect to the availability or non-availability of the permanent identifier DOI reported by DCI.
After this, all research data with two or more citations and with an available DOI (n = 2907 items) were analysed with PlumX, ImpactStory, and Altmetric.com. The coverage on social media platforms and the altmetric scores obtained from all three tools were analysed and compared. Finally, all other items with two or more citations and an available URL (n = 8027 items) were also analysed in PlumX, the only tool enabling analyses based on URLs, and the results were compared with the ones obtained for items with a DOI.
We also analysed the distribution of document types, data types, sources and research areas (i.e. disciplines) for all research data with two or more citations and at least one altmetric score (Sample 2; n = 301 items) with respect to the availability or non-availability of the permanent identifier DOI reported by DCI (items with DOI and URL or items with URL only).
Since several studies on research papers showed that citations do only moderately correlate with altmetric scores (i.a. Haustein et al. 2014a, b; Schlögl et al. 2014), we investigated the relationship between citations and altmetrics for research data as well. To this end, we examined whether uncited research data is better represented in PlumX or whether discipline specific differences in citation and altmetric counts exist. Hence, we analysed the availability of both citations and altmetrics for all research data published between 2011 and 2013 in four selected disciplines (Astronomy and Astrophysics, Chemistry, Mathematics, Sociology) to determine discipline-specific dependencies (Sample 3; n = 1276; 991, 125 and 1662 items respectively for each discipline, total = 4054 items) and to verify whether cited research data have more and higher altmetrics scores than uncited research data. The four disciplines were chosen because they are well comparable to the categories available in figshare, the largest research data provider in DCI. Since research showed (Haustein et al. 2014c) that recent publications are better covered on social media platforms, favour was given to the last full 3 years from time of data collection (i.e. December 2014) although this leaves us with a comparatively small citation window.
Results and discussion
Part 1: general results
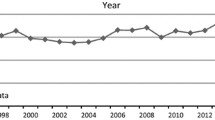
Table 1 gives an overview of the general results obtained in this study. The amount of research data available in the DCI as well as the total number of research data that has been cited at least once has increased over the last decades. Our analysis, however, revealed a high level of uncitedness of research data, which corresponds to the findings of Torres-Salinas et al. (2013b). A more detailed analysis for each year (see Fig. 1) shows, however, that the citedness is comparatively higher for research data published in recent years although the citation window is shorter. Many research data published after 2007 have been attracting citations.

Evolution of uncitedness in DCI in the last 14 years (n = 3,723,691 items)
The results also show a very low percentage of altmetrics scores available for research data with two or more citations (see Table 1). But in this case, two different trends can be observed: the percentage of data with DOI referred to on social media platforms is steadily increasing while the percentage of data with just a URL is steadily decreasing in the same time frame.
Interestingly, since 1990, there has been a strong rise in the number of research data, which can be referred to via URLs (mean = 320.24 items per year, min = 2 items, max = 3809 items in 2012). This URL-referenced research data also gained the most citations in total (58,285 citations, mean = 2331.4 citations per year, min = 4 citations, max = 15,868 citations for 2010). This corresponds to the results of Belter (2014) but, nevertheless, is surprising given extensive DOI promotion initiatives (e.g. the DataCite project), which resulted in a total of 2453 items (mean = 98.12 items, min = 2 items, max = 210 items in 2010) and of 47,190 citations for data sets published between 1990 and 2014 (mean = 1887.6 citations per year, min = 4, max = 7424 citations for 1999).
The percentage of research data with DOI and altmetrics scores in PlumX, the tool with the highest coverage of research data found in this study, is lower than expected (ranging between 4 and 9 %) but actually has doubled for data published in the last decades, which confirms the interest in younger research data and an increase in social media activity of the scientific community in recent years.
Part 2: results for Sample 1
Table 2 shows an overview on the citation distribution of Sample 1 (10,934 items with at least two citations in DCI) for items with a DOI or a URL separated according to the three main DCI document types (data set, data study, and repositoryFootnote 14). The results reveal that almost half of the data studies already have a DOI (48.9 %), but only few data sets do so. Data studies are on average more often cited than data sets (17.5 vs. 3.2 citations per item), and data studies with a DOI attract on average more citations than those with a URL (20 vs. 14 mean citations per item).
The number of repositories in the data set was low with a total number of 51. “Repository” is the document type, which attracts the most citations per item. This finding is in line with the results of Belter (2014) who also found aggregated data sets—Belter calls them “global-level data sets”—to be more cited. However, such citing behaviour has a negative side effect on repository content (i.e., the single data sets), since it is not properly attributed in favour of citing the repository as a whole.
The high values of SD and variance illustrate the skewness of the citation distribution (see Figure 1 in Peters et al. 2015). Almost half of the research data (4974 items; 45.5 %) have only two citations. Six items, two repositories and four data studies, from different decades (PY = 1981, 1984, 1995, 2002, 2011, and 1998 sorted by descending number of citations) attracted more than 1000 citations and were responsible for almost 30 % of the total number of citations.
Considering their origin, considerable differences were also reported in Sample 1 for items with or without a DOI (see Table 3). All twice or more frequently cited research data with a DOI are archived in only nine repositories, while 92 repositories are responsible for research data without a DOI.
Table 4 shows the top 10 repositories with regard to the number of items. Considering the number of citations, there are three other repositories, which account for more than 1000 citations each: Manitoba Centre for Health Policy Population Health Research Data Repository (29 items with a total of 1631 citations), CHILDES—Child Language Data Exchange System (one item with 3082 citations), and World Values Survey (one item with 3193 citations). Interestingly, although “figshare” accounts for almost 25 % of the DCI, no item from “figshare” was cited at least twice in DCI. For a more in-depth analysis of figshare see Kraker et al. (2015). We also noted that the categorization of figshare items is missing. All items are assigned to the Web of Science category (WC) “Multidisciplinary Sciences” or the Research Area (SU) “Science and Technology/Other Topics” preventing detailed topic-based citation analyses. Furthermore, only nine items from Sample 1 were related to an ORCID, three data sets with a DOI, and three data sets and data studies with a URL.
Table 4 also shows that there are big differences between the most cited data types when considering research data with a DOI or just a URL. Survey data, aggregate data, and clinical data are the most cited ones of the first group (with a DOI), while sequence data and numerical and individual level data are the most cited data types of the second group (with a URL). Apart from survey data, there is no overlap in the top 10 data types indexed in DCI. Similar results were obtained when considering data sets and data studies separately.
Disciplinary differences become apparent in the citations of DOIs and URLs as well as in the use of certain document types. As shown in Table 5, it is more common to refer to data studies via DOIs in the Social Sciences than in the Natural and Life Sciences, where the use of URLs for both data studies and data sets is more popular. These findings confirm the results from Torres-Salinas et al. (2014). The authors report that citations in Science, Engineering and Technology citations are concentrated on data sets, whereas the majority of citations in the Social Sciences and Arts and Humanities refer to data studies. The results of Table 5 suggest that these differences could be simply related to the availability of a DOI.
Part 3: results for Sample 2
Sample 2 comprises all items from DCI satisfying the following criteria: two or more citations in DCI, a DOI or a URL and at least one altmetrics score in PlumX (n = 301 items).
Table 6 shows the general results for this sample. The total number of altmetrics scores is lower than the number of citations for all document types with or without a DOI. Furthermore, the mean altmetrics score is higher for data studies than for data sets.
Tables 7 and 8 show the distributions of data types and subject areas in this sample. Most data with DOI are survey data, aggregate data, event over transaction data, whereas sequence data and images are most often referred to via URL only (see Table 6). Microdata with DOI and spectra with URL only are the data types with the highest altmetrics scores per item.
In terms of subject areas the results of Table 8 are very similar to the results of Table 5. Taking into account the small sample size, however, it is notable that in some subject areas (e.g. Archaeology or Cell Biology) research data receive more interest on social media platforms, reflected by altmetrics scores, than via citations in traditional publications. This is also confirmed by the missing correlation between citations and altmetrics scores for this sample (see Figure 2 in Peters et al. 2015). In both cases it becomes clearly apparent that altmetrics can complement traditional impact evaluation.
Nevertheless, coverage of research data on social media platforms is still low, e.g. from the nine repositories whose data studies and data sets were cited twice in DCI and had a DOI (see Table 3), only five items had altmetrics scores in PlumX, and only one DOI item of Sample 2 included an ORCID.
Part 4: selected altmetrics scores and comparison of the results of three altmetrics tools
Table 9 shows the general results obtained in PlumX according to the aggregation groups used in this tool (captures, social media, mentions, and usage) for all document types and with or without DOI.
While DOIs for data sets seem to be important in order to get captures (mainly in Mendeley), a URL is sufficient for an inclusion in social media tools like Facebook, Twitter, etc. In Peters et al. (2015), it has been shown that cited research data with DOI attracting two or more citations and with at least one entry in PlumX gain more citations than altmetrics scores, and that there is no correlation between highly cited and highly altmetrics-scored research data. Altmetrics scores as reported by PlumX for the top 10 research data-URLs with two or more citations are depicted in Table 10. Research data-URLs receive far more citations in total and also significantly higher altmetrics scores than research data with DOIs, especially when we compare mentions and social media.
The comparison of altmetrics aggregation tools also revealed that ImpactStory only found Mendeley reader statistics for research data: 78 DOIs had 257 readers. Additionally, ImpactStory found one other DOI in Wikipedia. ImpactStory found five items, which have not been found by PlumX, although they both relied on the same data source (Mendeley); the Mendeley data scores were exactly the same in PlumX and in ImpactStory.
PlumX found 18 items that were not available via ImpactStory. These research data were distributed on social media platforms (mostly shares in Facebook) and one entry has been used via click on a Bitly-URL. The tool Altmetric.com found only one of 194 items.
As already reported in previous analyses (Jobmann et al. 2014), PlumX is the tool with the highest coverage of research products found on social media platforms. Whereas Mendeley is well covered in ImpactStory, no other social media metrics were found for the data set used in this study.
Part 5: results for Sample 3
Table 11 presents the amount of and the citation numbers for different types of research data published between 2011 and 2013. Most of the research data is reported for Sociology, which is also the discipline with the most citations in total. Similar to the results reported above, the percentage of research data with DOI varies considerably between the disciplines covered by the DCI: in Astronomy and Astrophysics, <1 % of research data come with a DOI, whereas in Sociology and Mathematics the percentage ranges between 10 % and 14 %. DOIs are most prominent in Chemistry where 38 % of research data have a DOI. Also, disciplinary differences in the assignment of DOIs to research data types become apparent. In Astronomy and Astrophysics and in Chemistry only data studies have a DOI, while in Mathematics and Sociology, there are more data sets than data studies with a DOI.
The investigation of the citation activity reveals that the total number of citations, as well as the mean and maximum values, are very low across all disciplines. In Astronomy and Astrophysics, 94 % of the research data remain uncited, in Chemistry it is 98 %, in Mathematics 99 % and in Sociology 95 %. This is in line with the results of the analyses of the other samples in this study and may be due to the short citation window. Discipline-specific citation behaviour is also visible: in Mathematics and Chemistry only research data with DOIs are cited, whereas in the other disciplines both DOIs and URLs are used for citation of research data. Sociology shows the highest citation activity, where a particular data study has attracted more than 40 citations, despite the short citation window.
In terms of altmetrics scores, research data from Astronomy and Astrophysics have the greatest impact (see Table 12) and data sets receive far higher altmetrics scores than data studies—although we should consider that interpretation of altmetrics scores is only based on a very low number of research data available on social media platforms (see column “items with scores” in Table 12). Interestingly, research data without DOIs gain the highest altmetrics scores in all disciplines. Research data without DOIs from Sociology only receive mentions, which are exclusively derived from Facebook comments.
When comparing the results of Tables 11 and 12, the same tendencies are revealed as in research paper citations and altmetrics scores (e.g., Haustein et al. 2014a). For example, eight repositories in Astronomy and Astrophysics have not been cited at all, but three of them received together an altmetrics score of 213. On the other hand, data sets, data studies, and repositories from Sociology receive 193 citations in sum, but an altmetrics score of only 33. Mathematical research data are neither cited nor present on social media platforms.
General conclusions
Coverage and intensity of references to research data in DCI and social media channels
Most of the research data still remain uncited (approx. 86 %) and total altmetrics scores found via aggregation tools are even lower than the number of citations. However, research data published from 2007 onwards have gradually attracted more citations reflecting a bias towards more recent research data which might be due to the awareness of and demand for research data reuse (Fecher et al. 2015a).
The disciplinary analysis showed that altmetrics scores vary between disciplines at a low level; a very limited amount of research data (<1 % in each discipline) received any altmetrics scores in these disciplines at all. Only a number of research data from Astronomy and Astrophysics has received scores across various sources.
Formal aspects of data citations in DCI and social media channels
In the DCI, the availability of cited research data with a DOI is rather low. A reason for this may be the increase of available and indexed research data in recent years. Furthermore, the percentage of cited research data with a DOI has not increased as expected, which indicates that citations do not depend on this standard identifier in order to be processed by the DCI. Nevertheless, data studies with a DOI attract more citations than those with a URL. In a nutshell, the analyses showed that there is a low number of research data with a DOI in general and that there are considerable differences in the adoption of DOIs across disciplines as well as across research data types (e.g., data studies). Surprisingly, the DOI in cited research data has so far been more embraced in the Social Sciences than in the Natural Sciences.
Furthermore our study shows an extremely low number of research data with two or more citations (only nine out of around 10,000) related to an ORCID. Only three of them had a DOI likewise. This illustrates that we are still a far cry from the establishment of permanent identifiers and their optimal interconnectedness in a data source.
The qualitative studies on data sharing (Tenopir et al. 2011; Wallis et al. 2013) already showed that there are many uncertainties regarding sharing and reuse of research data on the researchers’ side. Hence, we may argue that differences in URL and DOI citation behaviour as well as the lack of data citations at all might be due to the lack of knowledge on how to formally refer to data sets as well as on how to find reusable data sets. The lack of standardized data citation practices is even more problematic considering that there is often more than one research product associated with a data set. There are, however, first approaches towards citation standards, e.g. the American Psychological Association (APA) recommends to use the DOI first and then the URL—depending on the availability.Footnote 15 They argue that the DOI is preferable to the URL since the DOI is a persistent identifier.Footnote 16 A more speculative explanation—which needs to be backed up with future research, but is informed by the disciplinary differences in URL-/DOI-use—is that the different practices of citing URLs or DOIs may point to the researchers’ different concepts of the referenced scientific products, in this case research data. This investigation might be especially useful by applying disciplinary lenses.
Differences in databases: DCI versus altmetrics
No correlation between citation and altmetrics scores could be observed in our preliminary analysis: neither the most cited research data nor the most cited sources (repositories) received the highest scores in the altmetrics aggregator PlumX. The low percentage of altmetrics scores for research data with two or more citations corroborates a threefold hypothesis: First, research data are either rarely published or not findable on social media platforms, because DOIs or URLs are not used in references thus resulting in a low coverage of items. Second, research data are not widely shared on social media by the scientific community so far which would result in higher altmetrics scores.Footnote 17 Third, the reliability of altmetrics aggregation tools is questionable as the results on the coverage of research data on social media platforms differ widely between tools. However, the steadily increasing percentage of cited research data with a DOI suggests that the adoption of this permanent identifier increases the online visibility of research data and may intensify inclusion in altmetrics tools (since they heavily rely on DOIs or other permanent identifiers for search) and in (automated) referencing practices on social media platforms.
The first finding is in line with other studies on correlations between altmetrics and citations to research papers (amongst others: Thelwall et al. 2013) resulting only in low or moderate values. It is possible, however, that this finding is an artefact of our initial data collection limiting the studied data set to research data with at least two citations. The analysis of cited and uncited research data in four different disciplines showed that certain research data can get high altmetrics scores when having no citations and no DOIs. It seems that at the moment two different types of referencing practices on social media platforms exist. Presumably, DOI referencing practices and social media-activities differ between communities (e.g., scientists who refer to research data via DOIs in their papers and laymen who refer to research data via URLs in their social media-posts). It is also possible that the altmetrics scores depend on the audiences of social media platforms.
Limitations
In our opinion, our work has two limitations. Firstly, the results rely on the indexing quality of the DCI. Our analysis showed that the categorisation in DCI is problematic at times. This is illustrated by the fact that all items from figshare, which is one of the top providers of records, are categorised in “Miscellaneous”. The category “repository” is rather a source than a document type. Such incorrect assignments of data types and disciplines can easily lead to wrong interpretations in citation analyses. Furthermore, it should be taken into account that citation counts are not always traceable.
Secondly, we only take into consideration data sets cited at least two times. Given that we cut the ‘long tail’ of uncited and barely cited research data, we excluded basic statistical computation such as means, SD, correlations and regressions from our study. Hence, the conclusions we have drawn necessarily refer to frequently cited data sets, which is in line with our overarching research question on the reuse of research data: What are the quantities, formal characteristics, and origins of successfully reused data sets (i.e. cited more than once) and which differences appear in formal citations and altmetrics? Accordingly, our study is a first step towards the understanding of research data reuse and citation practices and complements the work of Torres-Salinas et al. (2013b), which has shed light on the reliability of the DCI.
Still, citations of research data should be studied in more detail. They certainly differ from citations of papers relying on these data with regard to dimension and purpose. For example, we found that entire repositories are proportionally more often cited than single data sets, which was confirmed by a former study (Belter 2014). Therefore, it will be important to study single repositories (such as figshare) in more detail. It is crucial to further explore the real meaning and rationale of research data citations and how they depend on the nature and structure of the underlying research data, e.g., in terms of data curation and awarding of DOIs.
Notes
For example, Scopus’ citation data can be displayed on the ImpactStory-profile but not downloaded.
The DCI field “data type” was manually merged to more general categories; e.g. “survey data in social sciences” was merged with the category “survey data”.
Even if we consider repositories not really to be a document type, they were included in Table 2 to give a complete picture of the citation volume in DCI.
figshare recently announced a partnership with Altmetric.com which might increase the visibility of altmetrics with respect to data sharing: http://figshare.com/blog/The_figshare_top_10_of_2014_according_to_altmetric/142.
References
Bauer, B., Ferus, A., Gorraiz, J., Gründhammer, V., Gumpenberger, C., & Maly, N., et al. (2015). Researchers and their data. Results of an Austria survey—Report 2015. Version 1.2. doi:10.5281/zenodo.34005
Belter, C. W. (2014). Measuring the value of research data: A citation analysis of oceanographic data sets. PLoS One, 9(3), e92590. doi:10.1371/journal.pone.0092590.
Borgman, C. L. (2012). The conundrum of sharing research data. Journal of the American Society for Information Science and Technology, 63, 1059–1078.
Bornmann, L. (2014). Do altmetrics point to the broader impact of research? An overview of benefits and disadvantages of altmetrics. Journal of Informetrics, 8(4), 895–903. doi:10.1016/j.joi.2014.09.005.
Costas, R., Meijer, I., Zahedi, Z., & Wouters, P. (2012). The value of research data—Metrics for data sets from a cultural and technical point of view. a knowledge exchange report. http://www.knowledge-exchange.info/datametrics. Accessed July 11, 2015.
Fecher, B., Friesike, S., & Hebing, M. (2015a). What drives academic data sharing? PLoS One, 10(2), e0118053. doi:10.1371/journal.pone.0118053.
Fecher, B., Friesike, S., Hebing, M., Linek, S., & Sauermann, A. (2015b). A reputation economy: Results from an empirical survey on academic data sharing. DIW Discussion Papers. http://www.diw.de/discussionpapers. Accessed November 25, 2015.
Haustein, S., Larivière, V., Thelwall, M., Amyot, D., & Peters, I. (2014a). Tweets vs. Mendeley readers: How do these two social media metrics differ. IT-Journal, 56(5), 207–215. doi:10.1515/itit-2014-1048.
Haustein, S., Peters, I., Bar-Ilan, J., Priem, J., Shema, H., & Terliesner, J. (2014b). Coverage and adoption of altmetrics sources in the bibliometric community. Scientometrics, 101(2), 1145–1163. doi:10.1007/s11192-013-1221-3.
Haustein, S., Peters, I., Sugimoto, C. R., Thelwall, M., & Larivière, V. (2014c). Tweeting biomedicine: An analysis of tweets and citations in the biomedical literature. Journal of the American Society for Information Science and Technology, 65(4), 656–669. doi:10.1002/asi.23101.
Jobmann, A., Hoffmann, C.P., Künne, S., Peters, I., Schmitz, J., & Wollnik-Korn, G. (2014). Altmetrics for large, multidisciplinary research groups: Comparison of current tools. Bibliometrie-Praxis und Forschung, 3. http://www.bibliometrie-pf.de/article/viewFile/205/258. Accessed July 11, 2015.
Konkiel, S. (2013). Altmetrics. A 21st-century solution to determining research quality. Information Today, 37(4). http://www.infotoday.com/OnlineSearcher/Articles/Features/Altmetrics-A-stCentury-Solution-to-Determining-Research-Quality-90551.shtml. Accessed July 11, 2015.
Kraker, P., Lex, E., Gorraiz, J., Gumpenberger, C., & Peters, I. (2015). Research data explored II: The anatomy and reception of figshare. In Books of Abstracts of Research organizations under scrutiny: New indicators and analytical results. 20th International Conference on Science and Technology Indicators, Lugano, Switzerland (pp. 77–79). http://arxiv.org/abs/1503.01298. Accessed July 11, 2015.
Parsons, M. A., Duerr, R., & Minster, J. B. (2010). Data citation and peer review. Eos, Transactions American Geophysical Union, 91(34), 297–298. doi:10.1029/2010eo340001.
Peters, I., Kraker, P., Lex, E., Gumpenberger, C., & Gorraiz, J. (2015). Research data explored: Citations versus altmetrics. In A.A. Salah, Y. Tonta, A.A. Akdag Salah, C. Sugimoto, & U. Al (Eds.), Proceedings of the 15th International Conference on Scientometrics and Informetrics, Istanbul, Turkey (pp. 172–183). http://issi2015.org/files/downloads/all-papers/0172.pdf. Accessed November 25, 2015.
Piwowar, H. A., & Chapman, W. W. (2010). Public sharing of research datasets: A pilot study of associations. Journal of Informetrics, 4, 148–156.
Piwowar, H. A., Day, R. S., & Fridsma, D. B. (2007). Sharing detailed research data is associated with increased citation rate. PLoS One,. doi:10.1371/journal.pone.0000308.
Piwowar, H. A., Vision, T. J., & Whitlock, M. C. (2011). Data archiving is a good investment. Nature, 473, 285. doi:10.1038/473285a.
Schlögl, C., Gorraiz, J., Gumpenberger, C., Jack, K., & Kraker, P. (2014). Comparison of downloads, citations and readership data for two information systems journals. Scientometrics, 101(2), 1113–1128. doi:10.1007/s11192-014-1365-9.
Tenopir, C., Allard, S., Douglass, K., Aydinoglu, A. U., Wu, L., Read, E., et al. (2011). Data sharing by scientists: Practices and perceptions. PLoS One, 6(6), e21101. doi:10.1371/journal.pone.0021101.
Thelwall, M., Haustein, S., Larivière, V., Sugimoto, C. R. (2013). Do altmetrics work? Twitter and ten other social web services. PLoS One, 8(5), e64841. doi:10.1371/journal.pone.0064841.
Thomson Reuters. (2012). Repository evaluation, selection, and coverage policies for the Data Citation Index within Thomson Reuters Web of Knowledge. http://wokinfo.com/products_tools/multidisciplinary/dci/selection_essay. Accessed July 11, 2015.
Torres-Salinas, D., Jimenez-Contreras, E., & Robinson-Garcia, N. (2014). How many citations are there in the Data Citation Index? In Proceedings of the STI Conference, Leiden, The Netherlands. http://arxiv.org/abs/1409.0753. Accessed July 11, 2015.
Torres-Salinas, D., Martín-Martín, A., & Fuente-Gutiérrez, E. (2013a). An introduction to the coverage of the Data Citation Index (Thomson-Reuters): Disciplines, document types and repositories. EC3 Working Papers, 11, June 2013. http://arxiv.org/papers/1306/1306.6584.pdf. Accessed July 11, 2015.
Torres-Salinas, D., Robinson-Garcia, N., & Cabezas-Clavijo, Á. (2013b). Compartir los datos de investigación: Una introducción al ‘Data Sharing’. El profesional de la información, 21, 173–184.
Wallis, J. C., Rolando, E., & Borgman, C. L. (2013). If we share data, will anyone use them? Data sharing and reuse in the long tail of science and technology. PLoS One, 8(7), e67332. doi:10.1371/journal.pone.0067332.
Acknowledgments
The study is an extended version of the paper “Research Data Explored: Citations versus Altmetrics” which was presented at the 2015 ISSI Conference in Istanbul. We thank the ISSI committee for recognizing the conference paper with an outstanding paper award (http://issi2015.org/en/ISSI-2015Awards.html) and the anonymous reviewer for improving the manuscript for the Scientometrics special issue. Furthermore, this analysis was done within the scope of e-Infrastructures Austria (http://e-infrastructures.at/). The authors thank Dr. Uwe Wendland (Thomson Reuters) and Stephan Buettgen (EBSCO) for granted trial access to Data Citation Index resp. PlumX. The Know-Center is funded within the Austrian COMET program—Competence Centers for Excellent Technologies—under the auspices of the Austrian Federal Ministry of Transport, Innovation and Technology, the Austrian Federal Ministry of Economy, Family and Youth, and the State of Styria. COMET is managed by the Austrian Research Promotion Agency FFG.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Peters, I., Kraker, P., Lex, E. et al. Research data explored: an extended analysis of citations and altmetrics. Scientometrics 107, 723–744 (2016). https://doi.org/10.1007/s11192-016-1887-4
Received:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11192-016-1887-4