
Abstract
Purpose
Using data from a randomized controlled trial for treatment of prescription-type opioid use disorder in Canada, this study examines sensitivity to change in three preference-based instruments [EQ-5D-3L, EQ-5D-5L, and the Health Utilities Index Mark 3 (HUI3)] and explores an oft-overlooked consideration when working with contemporaneous responses for similar questions—data quality.
Methods
Analyses focused on the relative abilities of three instruments to capture change in health status. Distributional methods were used to categorize individuals as ‘improved’ or ‘not improved’ for eight anchors (seven clinical, one generic). Sensitivity to change was assessed using area under the ROC (receiver operating characteristics) curve (AUC) analysis and comparisons of mean change scores for three time periods. A ‘strict’ data quality criteria, defined a priori, was applied. Analyses were replicated using ‘soft’ and ‘no’ criteria.
Results
Data from 160 individuals were used in the analysis; 30% had at least one data quality violation at baseline. Despite mean index scores being significantly lower for the HUI3 compared with EQ-5D instruments at each time point, the magnitudes of change scores were similar. No instrument demonstrated superior sensitivity to change. While six of the 10 highest AUC estimates were for the HUI3, ‘moderate’ classifications of discriminative ability were identified in 12 (of 22) analyses for each EQ-5D instrument, compared with eight for the HUI3.
Conclusion
Negligible differences were observed between the EQ-5D-3L, EQ-5D-5L, and HUI3 regarding the ability to measure change. The prevalence of data quality violations—which differed by ethnicity—requires further investigation.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Increases in non-medical use of prescription opioids in North America through the early 2000s paralleled the rise in adverse consequences including opioid use disorder, illicit drug use, overdose deaths, and associated societal costs [1, 2]. More recently, these trends have been exacerbated by the availability (through illicit/unregulated sources) of highly potent synthetic opioids such as fentanyl and fentanyl analogue [3]. Within the context of substance use disorders, there is a growing focus on quality of life as an outcome of interest because of the potential to capture the complexities of treatment and recovery [4]. Generic, preference-based health-related quality of life (HRQoL) instruments provide an approach to outcome measurement that can describe health status across person-centered dimensions and incorporate societal valuations of health states. These instruments also allow for the estimation of quality-adjusted life years (QALYs)—the unit of health benefit for economic evaluation recommended by multiple health technology assessment agencies [5, 6].
All preference-based HRQoL instruments comprise a fixed set of items and response options (the classification system), ensuring an individual’s set of responses correspond to one of a finite number of health states. Each instrument has its own scoring procedure (the valuation system)—sometimes multiple, country-specific scoring procedures [7, 8]—providing a set of preference weights that represent the relative value that society places on living in each of the instrument-defined states. While these fundamental components of preference-based HRQoL instruments are alike, differences exist regarding the incorporated dimensions and response options and the methods employed to estimate societal valuations.
The EQ-5D-3L, one of the most widely used preference-based instruments [6, 7], has been used to examine HRQoL trajectories among people with opioid use disorder. Multiple studies have found stable trajectories regardless of retention in opioid agonist treatment [9, 10]. Other work has shown that while initial improvements in HRQoL following initiation of opioid agonist therapy were sustained for some participants, a subpopulation was characterized by an initial improvement that diminished over time [11]. Similar findings have been reported with another preference-based HRQoL instrument, the SF-6D [12]. The EQ-5D-3L has also been shown to be somewhat responsive to decreases in illicit drug use among opioid-dependent patients [13].
Improving the sensitivity of the EQ-5D-3L was part of the rationale when the EuroQol Group embarked on a project that culminated in the EQ-5D-5L [14]. While the composite dimensions remained the same (see ‘Methods’), the EQ-5D-5L expanded the number of response levels per dimension from three to five. It was hypothesized that an increased number of response options would result in a more sensitive instrument, compared with EQ-5D-3L, although evidence across clinical and non-clinical settings is mixed [15–22]. Specific to the context of opioid use disorder, there have been no head-to-head comparisons of preference-based HRQoL instruments that include the EQ-5D-5L. The psychometric performance of the EQ-5D-5L (compared with a capability wellbeing instrument) in a sample of heroin users in opiate substitution treatment was explored in a UK study [23]. Regarding sensitivity to change, there was evidence of a ‘weak’ effect, with the assessment of sensitivity hampered by a ceiling effect, with 26.5% of participants reporting full health at the initial measurement point.
Assessment of psychometric criteria in a head-to-head comparison of preference-based instruments provides valuable insight into the relative performance of the instruments [24]. However, the concurrent administration of instruments comprising similar questions increases the cognitive burden for respondents and the potential for response bias, which may compromise data quality. In this study, we examined sensitivity to change in three preference-based instruments [EQ-5D-3L, EQ-5D-5L, and the Health Utilities Index Mark 3 (HUI3)] in the context of treatment for people with prescription-type opioid use disorder in Canada, incorporating data quality criteria to examine the consistency of participant responses across similar questions.
Methods
Data Source & Outcomes
This study is a secondary analysis of data from an open-label, pragmatic, noninferiority randomized controlled trial [25]. The trial was designed to determine whether flexible take-home buprenorphine/naloxone was as effective as supervised methadone in reducing opioid use in people with prescription-type opioid use disorder (where opioids could come from prescriptions or illicit sources). Full details of the trial design and procedures and the clinical and cost-effectiveness results are reported elsewhere [25–27]. Briefly, the clinical report found the buprenorphine/naloxone model of care to be a safe and noninferior alternative to methadone to decrease opioid use, while the economic evaluation concluded buprenorphine/naloxone was not a cost-effective treatment option when evaluated over a lifetime time horizon.
A battery of outcome measures was used in the trial, with data collected at baseline and at follow-up visits every two weeks for 24 weeks (not all instruments were administered at all time points) [26]. Assessments were conducted in-person between October 2017 and March 2020, then via telephone because of the COVID-19 pandemic. Details of the three generic, preference-based HRQoL instruments pertinent to this study (EQ-5D-3L, EQ-5D-5L and HUI3) are provided in Table 1. In addition to the five-dimension classification systems of EQ-5D instruments, the EQ-5D-3L and EQ-5D-5L include a visual analogue scale (EQ VAS), with anchors at 0 (“The worst health you can imagine”) and 100 (“The best health you can imagine”). Responses to the EQ VAS are not used in the derivation of EQ-5D-3L and EQ-5D-5L index scores. The preference-based instruments were administered in a fixed order: EQ-5D-5L was immediately followed by HUI3 and, later in the survey (after completing another 60+ questions), participants completed the EQ-5D-3L.
Other standardized measures used in the analyses (see ‘Statistical Analysis’) assess aspects of mental health, stress, and pain; signs and symptoms of opiate withdrawal; and substance cravings. The Beck Anxiety Inventory and Beck Depression Inventory-II are 21-item self-report inventories for measuring the severity of anxiety and depression, respectively [32, 33]. Each item describes one symptom and responses are provided on a four-point scale, resulting in a scoring range from 0 to 63. Higher scores indicate more severe symptoms. The short form version of the Brief Pain Inventory is a 14-item inventory used to assess pain intensity and the impact of pain on functioning, with a recall period of 24 h [34, 35]. The pain intensity subscale score is the mean of four items, each with responses ranging from 0 (“no pain”) to 10 (“pain as bad as you can imagine”). The pain interference subscale score is the mean of seven items, where participants are asked to rate the degree to which pain has interfered with listed functions, ranging from 0 (“does not interfere”) to 10 (“completely interferes”). The first item of the Brief Pain Inventory asks, “Throughout our lives, most of us have had pain from time to time (such as minor headaches, sprains, and toothaches). Have you had pain other than these everyday kinds of pain today?” In the trial, participants answering ‘no’ were assigned subscale scores of zero. The Brief Substance Craving Scale assesses the intensity, frequency, and duration of a craving (each on a five-point scale, where higher scores indicate higher-level cravings) and records the number of times a participant had a craving in the past 24 h [36]. Participants answer the four questions with respect to a primary drug (questions can be repeated for a second craved substance). For each drug/substance, scores for the first three questions can be summed to generate a score from 0 to 12 [37]. In the trial, the primary drug was specified as prescription opioids. Only responses for the primary drug were used in the analysis reported here. The Clinical Opiate Withdrawal Scale is an 11-item clinician-administered assessment tool for measuring withdrawal symptoms [38, 39]. The number of response levels and the scores ascribed to the levels of response vary by item. Total scores range from 0 to 48, with higher scores reflecting more severe withdrawal symptoms. The Kessler Psychological Distress Scale comprises 10 questions about emotional states, each with a five-level response scale, scored from one (“none of the time”) to five (“all of the time”) [40, 41]. Sum scores range from 10 to 50, where higher scores indicate higher levels of psychological distress.
Defining the Study Sample
Analyses focused on the subset of trial participants who provided complete data (i.e., no missing item-level data) for the preference-based instruments at baseline and at least one of the 12-week or 24-week follow-up points. These data defined the maximum number of participants included in the analyses described below, examining change over three time periods: (i) baseline to 12 weeks, (ii) 12 weeks to 24 weeks, and (iii) baseline to 24 weeks. The dataset was further restricted following the application of data quality criteria to identify and remove respondents providing inconsistent (or ‘unreliable’ [42]) responses. A detailed description of the conditions used to define data quality is provided in Supplementary Material 1. To summarize, two conditions (one related to EQ VAS scores, one related to dimension-level EQ-5D-3L and EQ-5D-5L responses) were used to define ‘strict’ and ‘soft’ data quality criteria. Under the strict criteria, a single data quality violation (using either condition) was sufficient to exclude a participant from relevant analyses, whereas the soft criteria excluded participants if there was more than one relevant dimension-level data quality violation. The primary analyses reported here focuses on the dataset created after applying the strict data quality criteria. As a sensitivity analysis, to assess the impact of different ways of defining data quality, all analyses were repeated when applying the soft criteria and no criteria.
Statistical Analysis
To examine the implications of imposing restrictions on the analytic sample, baseline characteristics for three groups were compared: (i) all trial participants, (ii) the study sample when applying no data quality criteria, and (iii) those in the study sample with at least one data quality violation. Statistical tests (Student’s t-test for age, Pearson’s chi-squared test for nominal variables) were conducted to compare participant characteristics between those with and without at least one data quality violation. Prior to looking at sensitivity to change, descriptive analyses were conducted for the preference-based instruments, comprising descriptive statistics (for index scores and change scores; two-sided paired t-tests for comparisons) and inspection of dimension-level response patterns.
An anchor-based approach was used to examine sensitivity to change. For eight external anchors (seven clinical, one generic), defined using the standardized outcome measures described above, participants were categorized as ‘improved’ or ‘not improved’ in each of the three time periods. None of the measures used as anchors has a published minimum clinically important difference (MCID) estimate in the context of opioid use disorder or substance use. In this study, distributional methods were used to classify changes in the anchor instruments. Based on the observations of Norman and colleagues [43, 44], participants were classified as ‘improved’ if their anchor change score improved by more than half a standard deviation of the sample’s score at the initial time point. ‘Sensitivity to change’ is the chosen term throughout this paper, as opposed to responsiveness or a form of construct validity. Some authors have used such terms interchangeably [21], while others have differentiated between them [45]. Similar to the approach by Goranitis and colleagues [23], our choice of term was driven by the absence of MCID estimates for the anchors used to categorize individuals as ‘improved’ or ‘not improved’.
Each instrument’s ability to discriminate between ‘improved’ and ‘not improved’ groups was assessed in two ways: (i) comparison of group mean change scores (Student’s t-tests) and (ii) area under the ROC (receiver operating characteristics) curve (AUC) analysis. An ROC curve plots the sensitivity (true positive rate) against 1–specificity (1–true negative rate) of classifying participants into binary categories according to varying thresholds of a continuous score. Here, the continuous score is the change in preference-based index score and the binary categories are the two groups defined by the respective anchor. In this context, the AUC represents the ability of the continuous variable to discriminate between groups, with values ranging from zero (perfect incorrect discrimination, where the classifier always predicts the incorrect choice) to 1.00 (perfect correct discrimination). An AUC of 0.50 indicates random detection of change, with no discriminative ability. The AUC was calculated for each instrument/anchor pair, in all three time periods; 95% confidence intervals were generated from 2000 nonparametric, stratified bootstrap samples. Comparisons between instruments were drawn using rule of thumb classifications for AUC estimates (low, between 0.50 and 0.70; moderate, between 0.70 and 0.90; or high, above 0.90) [46, 47] and identification of the 10 highest and 10 lowest estimates.
Analyses were completed using R software version 4.0.5. Statistical tests were interpreted using a significance level of 0.05.
Results
One hundred sixty (58.8%) of 272 trial participants provided complete data for the EQ-5D-3L, EQ-5D-5L, and HUI3 at baseline and at least one of the 12-week or 24-week follow-up points. Baseline characteristics are reported in Table 2. Ethnicity was the only characteristic that was statistically different between participants in the study sample with (n = 90) and without (n = 70) at least one data quality violation, where there was a smaller proportion of white participants in the group with at least one violation (see Supplementary Material 2). A breakdown of the number of participants satisfying data quality criteria, by time point, and the frequency of increasing numbers of violations is provided in Supplementary Material 1 (SM1 Table E and SM1 Table D, respectively). Adopting the strict data quality criteria, the maximum sample sizes for analyses at each time point were 112 (baseline), 111 (12 weeks), and 100 (24 weeks); and, for the time periods, 80 (baseline to 12 weeks), 69 (12 weeks to 24 weeks), and 77 (baseline to 24 weeks).
Dimension-level response patterns for the EQ-5D-3L, EQ-5D-5L, and HUI3, by time point, are reported in Supplementary Material 3 (SM3 Table A). Consistent observations were that the dimensions with the highest proportions of no impairment (i.e., a level 1 response) were Mobility and Self-care for EQ-5D instruments, and Hearing, Speech, and Dexterity for the HUI3. At all three time points, the highest levels of impairment were reported most frequently for the respective pain and mental health dimensions (Pain/Discomfort and Anxiety/Depression for EQ-5D instruments, Pain and Emotion for the HUI3). The baseline proportions of responses in the highest level of impairment for the pain and mental health dimensions (level 3 for the EQ-5D-3L, level 5 for the EQ-5D-5L and HUI3) were markedly different: 17.9% (EQ-5D-3L), 3.6% (EQ-5D-5L), and 1.8% (HUI3) for the pain items, and 18.8% (EQ-5D-3L), 9.8% (EQ-5D-5L), and 3.6% (HUI3) for the mental health items.
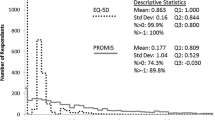
Figure 1 shows the frequency distributions of index scores, by time point. Descriptive statistics for index scores and change scores are reported in Table 3. At each time point, the HUI3 had the lowest individual value, the lowest mean value (statistically significantly lower than those of EQ-5D instruments) and the widest interquartile range. The magnitudes of change scores across the three time periods were similar. For example, between baseline and 12 weeks, mean change scores were 0.117 (EQ-5D-3L), 0.111 (EQ-5D-5L), and 0.124 (HUI3). There were no statistically significant differences between EQ-5D-3L, EQ-5D-5L, and HUI3 change scores.

Frequency distributions for EQ-5D-3L, EQ-5D-5L, and HUI3 index scores, by time point, for participants satisfying the strict data quality criteria (baseline, n = 112; 12-week follow-up, n = 111; 24-week follow-up, n = 100). Dashed lines indicate mean values
Figure 2 illustrates the results of the mean change score comparisons for the eight anchors (corresponding statistics are provided in Supplementary Material 4). The only anchor with directional inconsistencies, where the change score for the ‘not improved’ group was greater than the change score for the ‘improved’ group, was the Brief Substance Craving Scale. This result was observed for the EQ-5D instruments in the baseline to 24-week time period. The difference in mean change scores for the Brief Substance Craving Scale anchor was non-significant in eight of the nine analyses. For all other anchors—spanning 57 analyses—the differences in change scores were positive and statistically significantly different from zero in 53 analyses. Exceptions were observed for all three preference-based instruments: the Clinical Opiate Withdrawal Scale for the EQ-5D-3L (baseline to 12 weeks), the Beck Anxiety Inventory and EQ VAS for the EQ-5D-5L (baseline to 12 weeks), and the pain intensity subscale of the Brief Pain Inventory for the HUI3 (12 weeks to 24 weeks). Based solely on point estimates, the difference in mean change scores was highest for the HUI3 in 18 of 22 (82%) comparisons.

Differences in EQ-5D-3L, EQ-5D-5L, and HUI3 change scores between ‘improved’ and ‘not improved’ groups, by external criterion, for participants satisfying the strict data quality criteria. Results are presented for three time periods. Change scores are calculated as the participant’s index score at the latter time point minus the index score at the former time point. The difference in change scores is calculated as the mean value in the ‘improved’ group minus the mean value in the ‘not improved’ group. The number of participants in each group, for each criterion, is reported in Supplementary Material 4
The 10 lowest AUC estimates mirrored the non-significant change score comparisons, including seven for the Brief Substance Craving Scale anchor (see Table 4). Six of the 10 highest AUC estimates were for the HUI3, three for the EQ-5D-5L and one for the EQ-5D-3L. Six different anchors were present in the highest 10 estimates, with five of the estimates for subscales of the Brief Pain Inventory. There were no ‘high’ classifications of AUC estimates; ‘moderate’ classifications were identified in 12 (of 22) analyses for each of the EQ-5D instruments and eight for the HUI3. Using the lower bound of the confidence intervals as the statistic of interest, no estimates would be classified as ‘moderate’.
Sensitivity analyses
All results obtained after applying the soft criteria and no criteria are reported in the Supplementary Material: dimension-level response patterns (SM3); change scores for ‘improved’ and ‘not improved’ groups, by anchor (SM4); descriptive statistics (SM5); and AUC analysis (SM6). There were no directional inconsistencies in the comparisons of group means. Statistically significant differences were observed in 56 (of 66) analyses using the soft data quality criteria and 55 when using no data quality criteria; in both instances, the Brief Substance Craving Scale anchor accounted for five of the non-significant comparisons. Unlike analyses under the strict data quality criteria, there were statistically significant differences between change scores. The mean HUI3 change score from baseline to 24 weeks was significantly higher than the mean EQ-5D-3L and EQ-5D-5L change scores under the soft criteria, and significantly higher than the mean EQ-5D-3L change score when applying no criteria. Regarding AUC estimates, no ‘high’ classifications were observed in the sensitivity analysis. The number of ‘moderate’ classifications was lower in the sensitivity analyses compared with the strict data criteria for the EQ-5D instruments, and higher for the HUI3. Similar to the strict data criteria analysis, no single instrument dominated the highest 10 AUC estimates.
Discussion
This study assessed sensitivity to change in the EQ-5D-3L, EQ-5D-5L, and HUI3, over three different time periods, in a sample of people with prescription-type opioid use disorder. Whether comparing group mean estimates or using methods that employ the full distribution of responses, no instrument consistently outperformed the others.
Our finding of no superior instrument aligns with the mixed conclusions from previous comparative analyses that focus on changes in health status [15–22]. Even in studies where authors have identified a ‘better’ instrument—such as a 2022 study by Janssen and colleagues [21]—summary statements are cautious. It should not be unexpected that established instruments, which have each undergone extensive validation in numerous clinical and population samples, perform similarly when measuring change. Contemporaneous, point-in-time estimates can vary widely between preference-based instruments (as seen in Fig. 1) [48, 49], yet such differences between instruments may be negligible when change scores are examined. This emphasizes the need to consider multiple measurement attributes when assessing the relative merits of an instrument (face validity, content validity, construct validity, reliability, etc.)—and, almost inevitably, consideration of ‘better performing instruments’ will require people to make context-specific value judgments. For example, in the context of treatment for prescription-type opioid use disorder, the differences in the distribution of baseline responses to the respective pain and mental health items may discourage further use of the EQ-5D-3L.
Non-significant differences between ‘improved’ and ‘not improved’ groups were more frequent for the condition-specific anchors—eight of nine analyses for the Brief Substance Craving Scale, one of three analyses for the Clinical Opiate Withdrawal Scale—which likely reflects less of a conceptual overlap with the preference-based instruments (compared with domain-specific and generic anchors). The observation of weaker sensitivity of the index scores to changes in the two condition-specific anchors may also be due, partly, to the misaligned administration of measures. For example, Brief Substance Craving Scale scores at week 10 and week 22 were paired with week 12 and week 24 index scores, respectively (exploratory analyses of the trial data has shown the stability of Brief Substance Craving Scale scores from week 6 onward [50]).
The inclusion of near-identical items provided an opportunity to apply data quality checks. At each time point, at least 24% of participants violated a data quality condition; when adopting the strict data quality criteria, sample sizes for analyses by time period were reduced by over 40%. Specific to this study, data quality violations did not impact the key findings (i.e., findings were similar across the primary and sensitivity analyses). Definitions of data quality violations—or what other authors have referred to as ‘inconsistencies’ [15, 51, 52, 53] or ‘unreliable answers’ [42]—and the method of reporting violations differ across studies, as do the proportion of individuals or observations failing to satisfy quality/consistency criteria. For example, in a study with cognitively impaired patients living with dementia, Michalowsky and colleagues found at least one dimension-level inconsistency in 64 (49%) of 131 assessments [53]. In the current study, data quality violations were, typically, one-off occurrences for participants (see SM1 Table D), which aligns with similar findings in the contexts of multimorbidity [15] and atopic dermatitis [52].
The observation that data quality violations were more common in racialized participants warrants further investigation. While this statistically significant finding may be spurious—a consequence of multiple testing [54] —it raises questions about acceptance and accessibility of generic standardized instruments. Systematic differences between participants regarding comprehension, cultural relevance and/or communication with research staff are all potential reasons for the observation. Issues of acceptance and accessibility for EQ-5D instruments have been explored in groups such as the Deaf population and people living with aphasia [55, 56]. More broadly, a research program in Australia is developing a preference-based wellbeing measure for Aboriginal and Torres Strait Islander adults, acknowledging that understandings of health and wellbeing are culturally rooted [57]. A common theme across such methodological research is the desire to have instruments that are accessible to a wider community of users, thus improving representation of societal preferences in health care decision making. Further research to investigate the causes and consequences (and definition) of data quality violations, in different clinical and demographic contexts, is complementary to these endeavors.
Strengths of the study include the use of responses to three widely used preference-based HRQoL instruments (including the first use of the HUI3 in the context of opioid use disorder), all with preference weights derived from individuals from the same country (Canada); examination of instruments’ ability to capture change using different methodological approaches (ROC curves and group mean comparisons) across three time periods; and comprehensive consideration of data quality. As with all studies, there are limitations, and caution is advised when generalizing findings beyond the study population. For example, the data-intensive nature of examining change resulted in a significant proportion of participants from the data source (the trial) being excluded from the analysis. The primary limitation was the absence of relevant published MID estimates for the anchors (or questions about self-perceived changes in general health in the study surveys). Instead, distribution-based methods were used, which ensure there are differences in the degree of change between groups but make no judgment about whether these differences are clinically meaningful. In extolling the universality of the ‘half a standard deviation’ distribution-based approach, Norman and colleagues state that it “could be viewed as a default value [for reflecting minimal change that matters to patients] unless other evidence comes to light” [43]. Another limitation was the administration of instruments in a fixed order, although steps were taken to mitigate question-order bias concerns (i.e., 60 + questions between the EQ-5D instruments). The similarity in participant characteristics between the trial participants (n = 272) and the study sample (n = 160) (see Table 2) suggests the repetition of questions did not lead to any systematic dropout due to some form of response bias. Finally, as is typical when using data from pragmatic randomized controlled trials, the directionality of changes in health precluded separate examination of sensitivity to positive and negative change.
Conclusion
Negligible differences were observed between the EQ-5D-3L, EQ-5D-5L, and HUI3 regarding the ability to measure change. While the importance of comparative assessments of ‘similar’ questions/instruments is not in dispute, findings from this study highlight the need for further investigation into the definition, causes, and consequences of data quality violations.
References
Fischer, B., Jones, W., Tyndall, M., & Kurdyak, P. (2020). Correlations between opioid mortality increases related to illicit/synthetic opioids and reductions of medical opioid dispensing: Exploratory analyses from Canada. BMC Public Health, 20(1), 143. https://doi.org/10.1186/s12889-020-8205-z
Fischer, B., Gooch, J., Goldman, B., Kurdyak, P., & Rehm, J. (2014). Non-medical prescription opioid use, prescription opioid-related harms and public health in Canada: an update 5 years later. Canadian Journal of Public Health, 105(2), e146–e149.
Krausz, R. M., Westenberg, J. N., Mathew, N., Budd, G., Wong, J. S. H., Tsang, V. W. L., Vogel, M., King, C., Seethapathy, V., Jang, K., & Choi, F. (2021). Shifting North American drug markets and challenges for the system of care. Int J Ment Health Syst, 15(1), 86. https://doi.org/10.1186/s13033-021-00512-9
Miller, P. G., & Miller, W. R. (2009). What should we be aiming for in the treatment of addiction? Addiction, 104(5), 685–686. https://doi.org/10.1111/j.1360-0443.2008.02514.x
Canadian Agency for Drugs and Technologies in Health. (2017). Guidelines for the economic evaluation of health technologies: Canada (4th ed.). Canadian Agency for Drugs and Technologies in Health. Retrieved October 26, 2022, from https://www.cadth.ca/guidelines-economic-evaluation-health-technologies-canada-4th-edition.
National Institute for Health and Care Excellence. (2022). NICE health technology evaluations: the manual. National Institute for Health and Care Excellence. Retrieved October 26, 2022, from https://www.nice.org.uk/process/pmg36/resources/nice-health-technology-evaluations-the-manual-pdf-72286779244741.
Devlin, N. J., & Brooks, R. (2017). EQ-5D and the EuroQol group: Past, present and future. Applied Health Economics and Health Policy, 15(2), 127–137. https://doi.org/10.1007/s40258-017-0310-5
Poder, T. G., & Gandji, E. W. (2016). SF6D value sets: A systematic review. Value Health, 19(3), A282. https://doi.org/10.1016/j.jval.2016.03.1931
Krebs, E., Kerr, T., Wood, E., & Nosyk, B. (2016). Characterizing long-term health related quality of life trajectories of individuals with opioid use disorder. Journal of Substance Abuse Treatment, 67, 30–37. https://doi.org/10.1016/j.jsat.2016.05.001
Nosyk, B., Guh, D. P., Sun, H., Oviedo-Joekes, E., Brissette, S., Marsh, D. C., Schechter, M. T., & Anis, A. H. (2011). Health related quality of life trajectories of patients in opioid substitution treatment. Drug and Alcohol Dependence, 118(2–3), 259–264. https://doi.org/10.1016/j.drugalcdep.2011.04.003
Jalali, A., Ryan, D. A., Jeng, P. J., McCollister, K. E., Leff, J. A., Lee, J. D., Nunes, E. V., Novo, P., Rotrosen, J., Schackman, B. R., & Murphy, S. M. (2020). Health-related quality of life and opioid use disorder pharmacotherapy: A secondary analysis of a clinical trial. Drug and Alcohol Dependence, 215, 108221. https://doi.org/10.1016/j.drugalcdep.2020.108221
Nosyk, B., Bray, J. W., Wittenberg, E., Aden, B., Eggman, A. A., Weiss, R. D., Potter, J., Ang, A., Hser, Y.-I., Ling, W., & Schackman, B. R. (2015). Short term health-related quality of life improvement during opioid agonist treatment. Drug and Alcohol Dependence, 157, 121–128. https://doi.org/10.1016/j.drugalcdep.2015.10.009
Nosyk, B., Sun, H., Guh, D. P., Oviedo-Joekes, E., Marsh, D. C., Brissette, S., Schechter, M. T., & Anis, A. H. (2010). The quality of eight health status measures were compared for chronic opioid dependence. Journal of Clinical Epidemiology, 63(10), 1132–1144. https://doi.org/10.1016/j.jclinepi.2009.12.003
Herdman, M., Gudex, C., Lloyd, A., Janssen, M. F., Kind, P., Parkin, D., Bonsel, G., & Badia, X. (2011). Development and preliminary testing of the new five-level version of EQ-5D (EQ-5D-5L). Quality of Life Research, 20(10), 1727–1736. https://doi.org/10.1007/s11136-011-9903-x
Bhadhuri, A., Kind, P., Salari, P., Jungo, K. T., Boland, B., Byrne, S., Hossmann, S., Dalleur, O., Knol, W., Moutzouri, E., O’Mahony, D., Murphy, K. D., Wisselink, L., Rodondi, N., & Schwenkglenks, M. (2020). Measurement properties of EQ-5D-3L and EQ-5D-5L in recording self-reported health status in older patients with substantial multimorbidity and polypharmacy. Health and Quality of Life Outcomes, 18(1), 317. https://doi.org/10.1186/s12955-020-01564-0
Breheny, K., Hollingworth, W., Kandiyali, R., Dixon, P., Loose, A., Craggs, P., Grzeda, M., & Sparrow, J. (2020). Assessing the construct validity and responsiveness of Preference-Based Measures (PBMs) in cataract surgery patients. Quality of Life Research, 29(7), 1935–1946. https://doi.org/10.1007/s11136-020-02443-3
Buchholz, I., Thielker, K., Feng, Y. S., Kupatz, P., & Kohlmann, T. (2015). Measuring changes in health over time using the EQ-5D 3L and 5L: A head-to-head comparison of measurement properties and sensitivity to change in a German inpatient rehabilitation sample. Quality of Life Research, 24(4), 829–835. https://doi.org/10.1007/s11136-014-0838-x
Gandhi, M., Ang, M., Teo, K., Wong, C. W., Wei, Y. C., Tan, R. L., Janssen, M. F., & Luo, N. (2019). EQ-5D-5L is more responsive than EQ-5D-3L to treatment benefit of cataract surgery. Patient, 12(4), 383–392. https://doi.org/10.1007/s40271-018-00354-7
Golicki, D., Niewada, M., Karlińska, A., Buczek, J., Kobayashi, A., Janssen, M. F., & Pickard, A. S. (2015). Comparing responsiveness of the EQ-5D-5L, EQ-5D-3L and EQ VAS in stroke patients. Quality of Life Research, 24(6), 1555–1563. https://doi.org/10.1007/s11136-014-0873-7
Janssen, M. F., Bonsel, G. J., & Luo, N. (2018). Is EQ-5D-5L better than EQ-5D-3L? A head-to-head comparison of descriptive systems and value sets from seven countries. PharmacoEconomics, 36(6), 675–697. https://doi.org/10.1007/s40273-018-0623-8
Janssen, M. F., Buchholz, I., Golicki, D., & Bonsel, G. J. (2022). Is EQ-5D-5L better than EQ-5D-3L over time? A head-to-head comparison of responsiveness of descriptive systems and value sets from nine countries. PharmacoEconomics, 40(11), 1081–1093. https://doi.org/10.1007/s40273-022-01172-4
Jia, Y. X., Cui, F. Q., Li, L., Zhang, D. L., Zhang, G. M., Wang, F. Z., Gong, X. H., Zheng, H., Wu, Z. H., Miao, N., Sun, X. J., Zhang, L., Lv, J. J., & Yang, F. (2014). Comparison between the EQ-5D-5L and the EQ-5D-3L in patients with hepatitis B. Quality of Life Research, 23(8), 2355–2363. https://doi.org/10.1007/s11136-014-0670-3
Goranitis, I., Coast, J., Day, E., Copello, A., Freemantle, N., Seddon, J., Bennett, C., & Frew, E. (2016). Measuring health and broader well-being benefits in the context of opiate dependence: The psychometric performance of the ICECAP-A and the EQ-5D-5L. Value Health, 19(6), 820–828. https://doi.org/10.1016/j.jval.2016.04.010
Whitehurst, D. G., & Bryan, S. (2011). Another study showing that two preference-based measures of health-related quality of life (EQ-5D and SF-6D) are not interchangeable. But why should we expect them to be? Value Health, 14(4), 531–538. https://doi.org/10.1016/j.jval.2010.09.002
Jutras-Aswad, D., Le Foll, B., Ahamad, K., Lim, R., Bruneau, J., Fischer, B., Rehm, J., Wild, T. C., Wood, E., Brissette, S., Gagnon, L., Fikowski, J., Ledjiar, O., Masse, B., Socias, M. E., OPTIMA Research Group within the Canadian Research Initiative in Substance Misuse. (2022). Flexible buprenorphine/naloxone model of care for reducing opioid use in individuals with prescription-type opioid use disorder: An open-label, pragmatic, noninferiority randomized controlled trial. American Journal of Psychiatry, 179(10), 726–739. https://doi.org/10.1176/appi.ajp.21090964
Socias, M. E., Ahamad, K., Le Foll, B., Lim, R., Bruneau, J., Fischer, B., Wild, T. C., Wood, E., & Jutras-Aswad, D. (2018). The OPTIMA study, buprenorphine/naloxone and methadone models of care for the treatment of prescription opioid use disorder: Study design and rationale. Contemporary Clinical Trials, 69, 21–27. https://doi.org/10.1016/j.cct.2018.04.001
Enns, B., Krebs, E., Whitehurst, D. G. T., Jutras-Aswad, D., Le Foll, B., Socias, M.E., & Nosyk, B. (2023). OPTIMA Research Group within the Canadian Research Initiative in Substance Misuse. Cost-effectiveness of flexible take-home buprenorphine-naloxone versus methadone for treatment of prescription-type opioid use disorder. Under Review
Bansback, N., Tsuchiya, A., Brazier, J., & Anis, A. (2012). Canadian valuation of EQ-5D health states: preliminary value set and considerations for future valuation studies. PLoS ONE, 7(2), e31115. https://doi.org/10.1371/journal.pone.0031115
Xie, F., Pullenayegum, E., Gaebel, K., Bansback, N., Bryan, S., Ohinmaa, A., Poissant, L., Johnson, J. A., Canadian EQ-5D-5L Valuation Study Group. (2016). A time trade-off-derived value set of the EQ-5D-5L for Canada. Medical Care, 54(1), 98–105. https://doi.org/10.1097/MLR.0000000000000447
Feeny, D., Furlong, W., Torrance, G. W., Goldsmith, C. H., Zhu, Z., DePauw, S., Denton, M., & Boyle, M. (2002). Multiattribute and single-attribute utility functions for the health utilities index mark 3 system. Medical Care, 40(2), 113–128. https://doi.org/10.1097/00005650-200202000-00006
Richardson, J., Iezzi, A., & Maxwell, A. (2012). Cross-national comparison of twelve quality of life instruments. MIC paper 1: Background, questions, instruments. Research paper 76. Centre for Health Economics, Monash University. Retrieved October 26, 2022, from https://www.aqol.com.au/index.php/mic-papers.
Beck, A. T., Epstein, N., Brown, G., & Steer, R. A. (1988). An inventory for measuring clinical anxiety: Psychometric properties. Journal of Consulting and Clinical Psychology, 56(6), 893–897. https://doi.org/10.1037//0022-006x.56.6.893
Beck, A. T., Steer, R. A., & Brown, G. K. (1996). Manual for the beck depression inventory-II. Psychological Corporation.
Cleeland, C. S., & Ryan, K. M. (1994). Pain assessment: Global use of the brief pain inventory. Ann Acad Med Singap, 23(2), 129–138.
Cleeland, C. S. The brief pain inventory user guide. Retrieved October 26, 2022, from https://www.mdanderson.org/content/dam/mdanderson/documents/Departments-and-Divisions/Symptom-Research/BPI_UserGuide.pdf.
Somoza, E., Dyrenforth, A., Goldsmith, J., Mezinskis, J., & Cohen, M. (1995). In search of a universal drug craving scale. Paper presented at the Annual Meeting of the American Psychiatric Association, Miami, Florida.
Malcolm, B. J., Polanco, M., & Barsuglia, J. P. (2018). Changes in withdrawal and Craving Scores in participants undergoing opioid detoxification utilizing Ibogaine. Journal of Psychoactive Drugs, 50(3), 256–265. https://doi.org/10.1080/02791072.2018.1447175
Wesson, D. R., & Ling, W. (2003). The Clinical Opiate Withdrawal Scale (COWS). Journal of Psychoactive Drugs, 35(2), 253–259. https://doi.org/10.1080/02791072.2003.10400007
Tompkins, D. A., Bigelow, G. E., Harrison, J. A., Johnson, R. E., Fudala, P. J., & Strain, E. C. (2009). Concurrent validation of the Clinical Opiate Withdrawal Scale (COWS) and single-item indices against the Clinical Institute Narcotic Assessment (CINA) opioid withdrawal instrument. Drug and Alcohol Dependence, 105(1–2), 154–159. https://doi.org/10.1016/j.drugalcdep.2009.07.001
Andrews, G., & Slade, T. (2001). Interpreting scores on the Kessler Psychological Distress Scale (K10). Australian and New Zealand Journal of Public Health, 25, 494–497. https://doi.org/10.1111/j.1467-842x.2001.tb00310.x
Kessler, R. C., Andrews, G., Colpe, L. J., Hiripi, E., Mroczek, D. K., Normand, S. L., Walters, E. E., & Zaslavsky, A. M. (2002). Short screening scales to monitor population prevalences and trends in non-specific psychological distress. Psychological Medicine, 32(6), 959–976. https://doi.org/10.1017/s0033291702006074
Richardson, J., Iezzi, A,, Khan, M. A., & Maxwell, A. (2012). Cross-national comparison of twelve quality of life instruments: MIC paper 2: Australia. Research paper 78. Centre for Health Economics, Monash University. Retrieved October 26, 2022, from https://www.aqol.com.au/index.php/mic-papers
Norman, G. R., Sloan, J. A., & Wyrwich, K. W. (2003). Interpretation of changes in health-related quality of life: The remarkable universality of half a standard deviation. Medical Care, 41(5), 582–592. https://doi.org/10.1097/01.MLR.0000062554.74615.4C
Norman, G. R., Sloan, J. A., & Wyrwich, K. W. (2004). The truly remarkable universality of half a standard deviation: Confirmation through another look. Expert Review of Pharmacoeconomics & Outcomes Research, 4(5), 581–585. https://doi.org/10.1586/14737167.4.5.581
Liang, M. H. (2000). Longitudinal construct validity: Establishment of clinical meaning in patient evaluative instruments. Medical Care, 38(9I), 84–90.
Fischer, J. E., Bachmann, L. M., & Jaeschke, R. (2003). A readers’ guide to the interpretation of diagnostic test properties: Clinical example of sepsis. Intensive Care Medicine, 29(7), 1043–1051. https://doi.org/10.1007/s00134-003-1761-8
Streiner, D. L., & Cairney, J. (2007). What’s under the ROC? An introduction to receiver operating characteristics curves. Canadian Journal of Psychiatry, 52(2), 121–128. https://doi.org/10.1177/070674370705200210
Whitehurst, D. G., Bryan, S., & Lewis, M. (2011). Systematic review and empirical comparison of contemporaneous EQ-5D and SF-6D group mean scores. Medical Decision Making, 31(6), E34-44. https://doi.org/10.1177/0272989X11421529
Whitehurst, D. G. T., Mittmann, N., Noonan, V. K., Dvorak, M. F., & Bryan, S. (2016). Health state descriptions, valuations and individuals’ capacity to walk: A comparative evaluation of preference-based instruments in the context of spinal cord injury. Quality of Life Research, 25(10), 2481–2496. https://doi.org/10.1007/s11136-016-1297-3
McAnulty, C., Bastien, G., Socias, M. E., Bruneau, J., Foll, B. L., Lim, R., Brissette, S., Ledjiar, O., Marsan, S., Talbot, A., & Jutras-Aswad, D. (2022). Buprenorphine/naloxone and methadone effectiveness for reducing craving in individuals with prescription opioid use disorder: Exploratory results from an open-label, pragmatic randomized controlled trial. Drug and Alcohol Dependence, 239, 109604. https://doi.org/10.1016/j.drugalcdep.2022.109604
Garratt, A. M., Furunes, H., Hellum, C., Solberg, T., Brox, J. I., Storheim, K., & Johnsen, L. G. (2021). Evaluation of the EQ-5D-3L and 5L versions in low back pain patients. Health and Quality of Life Outcomes, 19(1), 155. https://doi.org/10.1186/s12955-021-01792-y
Koszorú, K., Hajdu, K., Brodszky, V., Bató, A., Gergely, L. H., Kovács, A., Beretzky, Z., Sárdy, M., Szegedi, A., & Rencz, F. (2022). Comparing the psychometric properties of the EQ-5D-3L and EQ-5D-5L descriptive systems and utilities in atopic dermatitis. European Journal of Health Economics. https://doi.org/10.1007/s10198-022-01460-y
Michalowsky, B., Hoffmann, W., & Xie, F. (2021). Psychometric properties of EQ-5D-3L and EQ-5D-5L in cognitively impaired patients living with dementia. Journal of Alzheimer’s Disease, 83(1), 77–87. https://doi.org/10.3233/JAD-210421
Austin, P. C., Mamdani, M. M., Juurlink, D. N., & Hux, J. E. (2006). Testing multiple statistical hypotheses resulted in spurious associations: A study of astrological signs and health. Journal of Clinical Epidemiology, 59(9), 964–969. https://doi.org/10.1016/j.jclinepi.2006.01.012
Rogers, K. D., Pilling, M., Davies, L., Belk, R., Nassimi-Green, C., & Young, A. (2016). Translation, validity and reliability of the British Sign Language (BSL) version of the EQ-5D-5L. Quality of Life Research, 25(7), 1825–1834. https://doi.org/10.1007/s11136-016-1235-4
Whitehurst, D. G. T., Latimer, N. R., Kagan, A., Palmer, R., Simmons-Mackie, N., Victor, J. C., & Hoch, J. S. (2018). Developing accessible, pictorial versions of health-related quality-of-life instruments suitable for economic evaluation: A report of preliminary studies conducted in Canada and the United Kingdom. Pharmacoecon Open, 2(3), 225–231. https://doi.org/10.1007/s41669-018-0083-2
Howard, K., Anderson, K., Cunningham, J., Cass, A., Ratcliffe, J., Whop, L. J., Dickson, M., Viney, R., Mulhern, B., Tong, A., & Garvey, G. (2020). What Matters 2 Adults: A study protocol to develop a new preference-based wellbeing measure with Aboriginal and Torres Strait Islander adults (WM2Adults). BMC Public Health, 20(1), 1739. https://doi.org/10.1186/s12889-020-09821-z
Acknowledgements
The authors thank the study participants for their contribution to the research, as well as current and past researchers and staff of the OPTIMA Research Group within the Canadian Research Initiative in Substance Misuse. The authors would also like to thank the EuroQol Research Foundation for funding to cover the Open Access fee. This funding was applied for after the manuscript had been accepted for publication; the EuroQol Research Foundation had no involvement in any other aspect of the study.
Funding
The OPTIMA study was supported by the Canadian Institutes of Health Research (CIHR) through the Canadian Research Initiative in Substance Misuse (CRISM; Grant Numbers CIS-144301, CIS-144302, CIS-144303, CIS-144304). The four nodes of CRISM received independent funding through CIHR priority-driven initiatives (Grant Numbers SMN-139148, SMN-139149, SMN-139150, SMN-139151). The funders had no role in the design and conduct of the study; collection, management, analysis, and interpretation of the data; preparation, review, or approval of the manuscript; and decision to submit the manuscript for publication. M. Eugenia Socias is supported by a MSFHR/St. Paul’s Foundation Scholar Award. Didier Jutras-Aswad holds a research scholar award from the Fonds de Recherche du Québec en Santé. Bernard Le Foll is supported by a clinician scientist award from the Department of Family and Community Medicine and by the Addiction Psychiatry Chair of the Department of Psychiatry, University of Toronto. Bohdan Nosyk is supported by a MSFHR Scholar Award.
Author information
Authors and Affiliations
Consortia
Contributions
Funding was obtained by MES, DJA, and BLF. DGTW, CM, and EK contributed to the study conception and design. DJA and BLF contributed to the acquisition of data. Data analysis was performed by CM. DGTW, CM, EK, BE, MES, and BN contributed to the interpretation of results. The first draft of the manuscript was written by DGTW and CM. All authors critically reviewed the paper for important intellectual content. All authors have read and approved the paper for submission.
Corresponding author
Ethics declarations
Competing interests
David GT Whitehurst is a member of the EuroQol Group Association. The opinions expressed in this paper do not necessarily reflect the opinions of the EuroQol Group, or those of the EuroQol Research Foundation. M Eugenia Socias and Bernard Le Foll report grants from Indivior, outside the work described in this paper. Didier Jutras-Aswad reports grants from the Canadian Institutes of Health Research and Health Canada, related to the work described in this paper; and non-financial support from Cardiol Rx and Tetra Bio Pharma, outside the work described in this paper. The remaining authors (Cassandra Mah, Emanuel Krebs, Benjamin Enns, and Bohdan Nosyk) declare they have nothing to disclose.
Ethical approval
Each clinical site’s ethics committee approved the study. The randomized controlled trial was registered at ClinicalTrials.gov (NCT03033732) prior to enrollment.
Informed consent
Informed consent was obtained from all individual participants included in the randomized controlled trial.
Consent to publish
Not applicable. No individuals are identifiable based on the information reported in this manuscript.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Whitehurst, D.G.T., Mah, C., Krebs, E. et al. Sensitivity to change of generic preference-based instruments (EQ-5D-3L, EQ-5D-5L, and HUI3) in the context of treatment for people with prescription-type opioid use disorder in Canada. Qual Life Res 32, 2209–2221 (2023). https://doi.org/10.1007/s11136-023-03381-6
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11136-023-03381-6