
Abstract
It has been proven repeatedly in psychology and behavioural decision theory that the complexity of the choice sets affects the consistency of the responses in choice experiments. A handful of studies can be found in the discrete choice literature that take this dependency explicitly into account at the estimation stage. But there is only limited research that investigates how the choice complexity affects the efficiency of the choice design. In this research we propose choice designs in order to estimate the heteroscedastic mixed logit model which is parametrized to model the preference heterogeneity as well as the scale heterogeneity due to the choice complexity. The heteroscedastic model assumes that the scale factor is an exponentiated linear function of some complexity measures. An increase in choice complexity leads to an increase of the error variance, hence of the choice inconsistency. We generate sequential designs, heterogeneous semi-Bayesian designs and homogeneous semi-Bayesian designs considering and ignoring the choice complexity. This way we can examine the advantage of taking the choice complexity into account at the design stage in each design approach. Simulation results show that the proposed sequential design which takes the choice complexity into account outperforms all other designs we considered. It turns out that the sequential approach generates choice sets with a constant, relatively low complexity level. As the respondents can easily cope with these choice sets, they give consistent choices and these choice sets appear to be most informative about the individual preferences.






Similar content being viewed by others


References
Allenby, G.M., & Ginter, J.L. (1995). The effects of in-store displays and feature advertising on consideration sets. International Journal of Research in Marketing, 12, 67–80.
Arora, N., & Huber, J. (2001). Improving parameter estimates and model prediction by aggregate customization in choice experiments. Journal of Consumer Research, 28(2), 273–283.
Bliemer, M.C., & Rose, J.M. (2010). Construction of experimental designs for mixed logit models allowing for correlation across choice observations. Transportation Research Part B: Methodological, 44(6), 720–734.
Danthurebandara, V., Yu, J., Vandebroek, M. (2011a). Sequential choice designs to estimate the heterogeneity distribution of willingness-to-pay. Quantitative Marketing and Economics, 9, 429–448.
Danthurebandara, V.M., Yu, J., Vandebroek, M. (2011b). Effect of choice complexity on design efficiency in conjoint choice experiments. Journal of Statistical Planning and Inference, 141(7), 2276–2286.
Dellaert, B.G., Donkers, B., Soest, A.V. (2012). Complexity effects in choice experiment-based models. Journal of Marketing Research In press.
Dellaert, B.G.C., Brazell, J.D., Louviere, J.J. (1999). The effect of attribute variation on consumer choice consistency. Marketing Letters, 10(2), 139–147.
DeShazo, J., & Fermo, G. (2002). Designing choice sets for stated preference methods: The effects of complexity on choice consistency. Journal of Environmental Economics and Management, 44(1), 123–143.
Kampstra, P. (2008). Beanplot:A boxplot alternative for visual comparison of distributions. Journal of Statistical Software, Code Snippets, 28(1), 1–9.
Keller, K.L., & Staelin, R. (1987). Effects of quality and quantity of information on decision effectiveness. Journal of Consumer Research, 14(2), 200–213.
Kessels, R., Goos, P., Vandebroek, M. (2006). A comparison of criteria to design efficient choice experiments. Journal of Marketing Research, 43(3), 409–419.
Mazzotta, M.J., & Opaluch, J.J. (1995). Decision making when choices are complex: A test of heiner’s hypothesis. Land Economics, 71(4), 500–515.
Palma, A. d., Myers, G.M., Papageorgiou, Y.Y. (1994). Rational choice under an imperfect ability to choose. The American Economic Review, 84(3), 419–440.
Payne, J.W., Bettman, J.R., Johnson, E.J. (1988), 14(3), 534–552.
Sándor, Z., & Franses, P. (2009). Consumer price evaluations through choice experiments. Journal of Applied Econometrics, 24(3), 517–535.
Sándor, Z., & Wedel, M. (2005). Heterogeneous conjoint choice designs. Journal of Marketing Research, 42(2), 210–218.
Sonnier, G., Ainslie, A., Otter, T. (2007). Heterogeneity distributions of willingness-to-pay in choice models. Quantitative Marketing and Economics, 5(3), 313–331.
Swait, J., & Adamowicz, W. (2001). Choice environment, market complexity, and consumer behavior: A theoretical and empirical approach for incorporating decision complexity into models of consumer choice. Organizational Behavior and Human Decision Processes, 86(2), 141–167.
Toubia, O., Hauser, J.R., Garcia, R. (2007). Probabilistic polyhedral methods for adaptive choice-based conjoint analysis: Theory and applications. Marketing Science, 26, 596–610.
Toubia, O., Hauser, J.R., Simester, D.I. (2004). Polyhedral methods for adaptive choice-based conjoint analysis. Journal of Marketing Research, 41(1), 116–131.
Train, K. (2003). Discrete Choice Methods with Simulation. SUNY-Oswego, Department of Economics.
Wilkie, W.L. (1974). Analysis of effects of information load. Journal of Marketing Research, 11(4), 462–466.
Yu, J., Goos, P., Vandebroek, M. (2008). Model-robust design of conjoint choice experiments. Communications in Statistics - Simulation and Computation, 37(8), 1603–1621.
Yu, J., Goos, P., Vandebroek, M. (2011). Individually adapted sequential bayesian conjoint-choice designs in the presence of consumer heterogeneity. International Journal of Research in Marketing, 28(4), 378–388.
Yu, J., Goos, P., Vandebroek, M. (2012). A comparison of different bayesian design criteria for setting up stated preference studies. Transportation Research Part B: Methodological, 46(79), 789–807.
Acknowledgments
This work was supported by the KU Leuven, Belgium.
Author information
Authors and Affiliations
Corresponding author
Appendices
Appendix A: The sequential design approach
To generate the sequential designs we use the Bayesian D-optimality criterion which is based on the generalized Fisher information matrix (GFIM) (Yu et al. 2012). The GFIM is obtained by taking the negative expectation of the second derivative of the log-posterior density:
where γ n =(β n ,𝜃 n ) is a combined parameter vector and q(γ n |y n ,x n ) is the individual posterior density corresponding to the individual design x n and responses y n . This posterior density is proportional to the product of the likelihood and the priors:
The GFIM can be derived from the Fisher information matrix (FIM) which is the negative expectation of the second derivative of the log-likelihood function. Following Yu et al. (2012), under the multivariate normal prior distribution, the expression (2.12) can be written as:
For a given respondent and a choice set, the Fisher information matrix is given by
where c is the vector of complexity measurements of the given choice set, \(\textbf {M} = [\textbf {P} - \textbf {p}\textbf {p}^{\prime }]\textbf {x}\), \(\textbf {B} = [\textbf {P} - \textbf {p}\textbf {p}^{\prime }]\textbf {x}\boldsymbol {\beta }\textbf {c}^{\prime }\), p = (p 1, ..., p K ) is the vector of choice probabilities for each of the alternatives in the choice set and P = diag(p 1, ..., p K ). To assess the design efficiency we use the Bayesian D-error which is calculated using the determinant of the inverse of the GFIM. Assuming that γ n =(β n ,𝜃 n ) follows a multivariate normal distribution with mean μ γ and covariance Σ γ , the Bayesian D-error can be written as
The sequential design approach consist of two stages. In the first stage, each respondent is assigned to an initial D-optimal design with S 1 choice sets of size K generated using a common design prior. For a given respondent n, this initial design and the corresponding responses are denoted by \(\textbf {x}^{S_{1}}_{n}\) and \(\textbf {y}^{S_{1}}_{n}\), respectively. The initial choices \(\textbf {y}^{S_{1}}_{n}\) are analysed in a Bayesian way, specifically, by optimizing the log-posterior density \(\log q(\boldsymbol {\beta }_{n}, \boldsymbol {\theta }_{n} | \textbf {y}^{S_{1}}_{n}, \textbf {x}^{S_{1}}_{n})\) numerically. In the second stage, the posterior distribution obtained from the initial stage is used as the design prior to generate the next choice set \(\textbf {x}^{S_{1}+1}_{n}\). This choice set is chosen by minimizing the Bayesian D-error in expression (16) for the combine design \((\textbf {x}^{S_{1}}_{n}, \textbf {x}^{S_{1}+1}_{n})\). Once the new choice set is evaluated, the design prior is updated with all S 1+1 choices and the posterior distribution \(q(\boldsymbol {\beta }_{n}, \boldsymbol {\theta }_{n} | \textbf {y}^{S_{1} + 1}_{n}, \textbf {x}^{S_{1}}_{n}, \textbf {x}^{S_{1}+1}_{n})\) is obtained.The updated posterior is used to generate the next choice set. This process is repeated until a pre-specified number of choice sets is attained. The Bayesian modified Fedorov algorithm, also called the profile exchange algorithm, which is introduced by Kessels et al. (2006) is used as the design construction algorithm.
Appendix B: population-level and individual-level parameters under different design approaches
Appendix C: Simulation study with correlation between utility and complexity parameters
The simulation study we present here considers a full covariance matrix that allows correlations between preference and complexity coefficients. We generate designs with three continuous attributes, three alternatives per choice set and nine choice sets and therefore in this simulation study we estimate three utility coefficients and three complexity coefficients. We assume that the combined parameter vector γ n = (β n , 𝜃 n ) follows a multivariate normal distribution, that is \(\boldsymbol {\gamma }_{n}\thicksim \) N(μ γ , Σ γ ) where μ γ = [3.054, 0.922, 0.019, -0.194, -1.062, -1.948] and covariance matrix
We obtained this mean and covariance matrix based on the Swiss-metro data that we introduced in Section 2.2. The six designs presented in Table 3 were constructed. To construct the sequential designs, four initial choice sets are used and five choice sets are generated sequentially. To generate semi-Bayesian designs a common prior \(\boldsymbol {\gamma }_{n}\thicksim \) N(μ γ , Σ γ ) is used. Design performance is assessed by the RMSE of population and individual-level parameter estimates. Table 5 presents the RMSE values we obtained from this simulation study.
The results show similar patterns as in the previous study. The sequential design with complexity effects yields the smallest RMSE values for all parameters. The heterogeneous semi-Bayesian design now shows little better performance in estimating the population mean and the individual-level utility coefficients than the sequential design without complexity effects. In estimating the population covariance, these two designs perform equally well. To visualize the estimation accuracy of the preference heterogeneity distribution we generate a beanplot similar to Fig. 1.
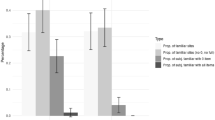
Figure 7 shows that the sequential approach that takes the complexity into account allows estimation of the true preference heterogeneity distribution more accurately than the other designs. Similar to the previous results, the homogeneous semi-Bayesian designs show the worst results regardless whether it considers the choice complexity at the design stage or not.

The estimated heterogeneity distribution of the first utility coefficient with the different designs in the simulation study with full covariance matrix
Appendix D: Robustness of the designs against misspecified prior distributions
In the simulation studies we conducted, the assumption that we can use the true heterogeneity distribution as prior in the design stage is not realistic. The true heterogeneity distribution of the model parameters will normally be different from the prior distribution we use to generate the design. We relax this assumption of perfect information and assess the estimation accuracy of the utility coefficients. We consider the simulation setting with the full covariance matrix presented in Appendix C and the design prior \(\boldsymbol {\gamma }_{n}\thicksim \) N(μ γ , Σ γ ) and the population parameters as defined in Appendix C. We generate choice data based on \(\boldsymbol {\widetilde {\gamma }}_{n}\thicksim \) N(\(\boldsymbol {\widetilde {\mu }}_{\gamma }\), \(\boldsymbol {\widetilde {\Sigma }}_{\gamma }\)) where \(\boldsymbol {\widetilde {\mu }}_{\gamma }\) = μ γ + δ 1 6 and \(\boldsymbol {\widetilde {\Sigma }}_{\gamma }\) = α Σ γ . The parameters δ and α quantify the degree of deviation of the inference prior from the design prior and set equal to 0.5 and 2. Table 6 lists the different cases that we consider. Remark that there is no misspecification in the first case which corresponds to the situation considered in Appendix C.
The estimation error as measured by the RMSE for the population mean μ β , the heterogeneity in the population Σ β and the individual part-worths β n are shown in Fig. 8 for the different cases and the different designs.

Prediction accuracy in case of different degrees of prior misspecification as listed in Table 6
Figure 8 clearly shows shows that the sequential designs still outperform the other designs for all levels of misspecification. These are clearly also most robust to the misspecification which is expected since the sequential approach updates the prior information repeatedly over the survey. It can also be derived that taking the complexity into account in the design is most benefical for estimating the population mean and the individual part worths.
To assess the efficiency loss in case one designs for complexity effects when there are none, we repeated the simulation study with the same designs as before but now the choices are generated without complexity effects, using \(\boldsymbol {\widetilde {\beta }}_{n}\thicksim \) N(\(\boldsymbol {\widetilde {\mu }}_{\beta }\), \(\boldsymbol {\widetilde {\Sigma }}_{\beta }\)) where \(\boldsymbol {\widetilde {\mu }}_{\beta }\) = μ β + δ 1 3 and \(\boldsymbol {\widetilde {\Sigma }}_{\beta }\) = α Σ β . The parameters δ and α again quantify the degree of misspecification and are also given in Table 6. The corresponding results are in Fig. 9 for the different cases and the different designs.

Prediction accuracy in case the true datagenerating model contains no complexity effects and with different degrees of prior misspecification as listed in Table 6
From Fig. 9 it can be seen, as expected, that the designs that were derived for the homoscedastic models are more efficient than their heteroscedastic counterparts but for the sequential designs the efficiency loss is smaller than for the other designs and these designs still outperform the other designs in all cases.
Appendix E: Validation of the significance of the differences between designs using 100 datasets
Considering the simulation setting presented in Appendix C with the full covariance matrix, we simulate 100 data sets and calculate the variance of RMSE for each design approach. Table 6 shows the results. The standard deviations confirm the significance of the results we obtained in the previous simulation studies. As such the conclusions we drew from the above analyses are validated.
Rights and permissions
About this article

Cite this article
Danthurebandara, V., Yu, J. & Vandebroek, M. Designing choice experiments by optimizing the complexity level to individual abilities. Quant Mark Econ 13, 1–26 (2015). https://doi.org/10.1007/s11129-014-9152-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11129-014-9152-8