
Abstract
There is no final consensus regarding which covariates should be used (in addition to prior achievement) when estimating value-added (VA) scores to evaluate a school’s effectiveness. Therefore, we examined the sensitivity of evaluations of schools’ effectiveness in math and language achievement to covariate selection in the applied VA model. Four covariate sets were systematically combined, including prior achievement from the same or different domain, sociodemographic and sociocultural background characteristics, and domain-specific achievement motivation. School VA scores were estimated using longitudinal data from the Luxembourg School Monitoring Programme with some 3600 students attending 153 primary schools in Grades 1 and 3. VA scores varied considerably, despite high correlations between VA scores based on the different sets of covariates (.66 < r < 1.00). The explained variance and consistency of school VA scores substantially improved when including prior math and prior language achievement in VA models for math and prior language achievement with sociodemographic and sociocultural background characteristics in VA models for language. These findings suggest that prior achievement in the same subject, the most commonly used covariate to date, may be insufficient to control for between-school differences in student intake when estimating school VA scores. We thus recommend using VA models with caution and applying VA scores for informative purposes rather than as a mean to base accountability decisions upon.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
How can we find out how schools influence the development of students’ achievement? Drawing on statistical methods in agriculture agricultural analyses (e.g., Kupermintz, 2003) value-added (VA) models have been developed as a statistical tool to estimate educational effectiveness at different levels. An early reference to VA models can be found in Hanushek (1971) and one of the first educational VA model was the “Tennessee Value-Added Assessment System” (Sanders & Horn, 1994). Since then, various targets for VA models have been identified, involving teachers and schools, or less frequently also school principals. Common to all VA models is their aim to “make fair comparisons of the academic progress of pupils in different settings” (Tymms, 1999, p. 27). In particular, VA models targeting schools (to which we refer as school VA models) are applied to find the “value” (i.e., the school VA score) that was added by schools to students’ achievement, independent of students’ backgrounds (e.g., Amrein-Beardsley et al., 2013). Conceptually, this means that the actual achievement attained by students attending a certain school is juxtaposed with the achievement that is expected for students with the same starting characteristics (e.g., pretest scores). A positive effect of attending a certain school is suggested when actual achievement is better than expected achievement (i.e., a positive VA score is observed).
VA models are often used for accountability and high-stakes decisions, not only about teachers, but also to allocate financial or personal resources to schools. In other words, the use of VA models is often highly consequential. It is thus a highly political topic, especially in the USA, where many states have implemented VA-based evaluation systems, particularly on the teacher level (Amrein-Beardsley & Holloway, 2017; Kurtz, 2018) even though the consequential use of VA models seems to be decreasing again in many states (Close et al., 2018). Importantly, the application of VA models for high-stakes decisions at the school level is not restricted to the USA. Other countries, such as France or the UK, are also using school VA models for accountability purposes (e.g.; Duclos & Murat, 2014; Perry, 2016).
Given the far-reaching impact of VA scores, it is surprising that there is no final consensus on how to obtain the best estimate of school VA scores (Levy et al., 2019; Everson, 2017; but see Koedel et al., 2015 for a review on the consensus for the calculation of teacher VA). This lack of consensus can be observed for various aspects of the school VA model, including the applied statistical model, methodological adjustments, and the selection of covariates to compute the VA score. In particular, school VA scores are often interpreted as causal effects of (in)effective pedagogical practices within a certain school (for a critical discussion on causal inferences based on school VA scores, see, Reardon & Raudenbush, 2009). Conceptually speaking, as school VA scores represent the part of the variance in performance measures that cannot be explained by the covariates in the model, the question of which covariates should be included in the VA model is of utmost importance. Whereas there seems to be consensus that prior achievement is the primary choice for a covariate (e.g., Levy et al., 2019; Casillas et al., 2012; Hanushek, 1971; Ray, 2006), it is still not clear whether it should be the only covariate, or whether (and if so, which) other covariates could contribute to school VA scores to best approximate a school’s effectiveness without any bias. In the context of VA scores, “unbiased” means that differences in school VA scores between schools are—to the greatest possible extent—due to true differences in school effectiveness rather than to between-school differences in student intake, thus that the forecast is as unbiased as possible. For example, if a fictive School A selected only the most motivated students, the effectiveness of this school would be overrated if the school VA scores were only estimated with prior achievement as a predictor without considering students’ motivation. This would lead to wrong information on school report cards, which might lead to parents wrongfully wanting to send their children to this school. In high-stakes contexts, this might even mean that School A receives more resources than other schools. This example shows that the choice of covariates can have an immediate consequence on school development. The overarching goal of the present study is therefore to systematically analyze the extent to which school VA scores for mathematics and language achievement are sensitive to the selection of covariates in the applied VA models and which practical implications covariate selection can have for individual schools. This allows to investigate whether the current practices of school VA models can lead to biased estimates of school VA scores and in how far adding additional covariates can help reduce this bias in school VA scores.
1 Practical issues to obtain unbiased school VA scores
There is a broad literature on sources of bias when estimating school VA scores (see, e.g., Harris & Anderson, 2013; van de Grift, 2009; and see the Standards for Educational & Psychological Testing, 2014, for a general discussion in psychometrics). Importantly, VA models contain three parts: (a) the outcome, (b) the covariates that are used to predict the outcome, and (c) the residual term that depicts the school VA score. There is broad consensus that valid school VA scores can only be obtained when using valid and reliable outcome measures, such as standardized tests from educational large-scale assessment programs (Braun, 2015). However, there is some debate on the selection of covariates, as will be described in the following.
2 Covariate selection for school VA models
Covariate selection (i.e., the choice of “correct” covariates) is important in the estimation of causal effects in observational studies (Steiner et al., 2010). As the aim of covariate selection is to reduce bias in causal estimates, its importance is also evident for the estimation of school VA scores. The school VA score juxtaposes the actual level of achievement attained by students attending a certain school with the level of achievement that is expected from students who have the same background characteristics. If these background characteristics affect students’ achievement, including these variables as covariates in the VA model—thereby statistically controlling for them—will help to make the VA scores as unbiased as possible (e.g., Ehlert et al., 2014; Timmermans et al., 2011).
In order to estimate causal effects of school effectiveness (i.e., VA scores) based on observational data, we followed the suggestion from Steiner et al. (2010) for scenarios in which there is no complete knowledge of the covariates that might have an influence in the selection process (i.e., in our case, the process of how students are selected by or sorted to different schools). More specifically, they recommend to consider theoretical, empirical, and expert knowledge in the selection process in order to allow for an identification of the most crucial covariates that help to approximate the selection process while at the same time not wasting resources by contemplating covariates without any proven influence. Thus, on the basis of models of school learning (e.g., Haertel et al., 1983; Wang et al., 1993) and findings on predictors of students’ achievement (e.g., Casillas et al., 2012; Genesee et al., 2005; Jansen & Stanat, 2015; Sirin, 2005; Voyer & Voyer, 2014), we chose investigating four sets of covariates in 4: prior achievement in the same domain as the achievement outcome measure, prior achievement in a different domain, sociodemographic and sociocultural background, and motivational variables. In the following, for each of these sets of covariates, we will present an overview of empirical evidence that may support their use in school VA models (but see, e.g., Ehlert et al., 2016; Perry, 2016; Sloane et al., 2013 for discussions on covariate choice in school VA models from a more political point of view).
2.1 Prior academic achievement
Most authors seem to agree that prior academic achievement should be included in school VA models (e.g., Levy et al., 2019; Casillas et al., 2012; Hanushek, 1971; Ray, 2006). One exception is a study on 4- and 5-year-old students (Luyten et al., 2009) that suggested that it is possible to estimate school effects with cross-sectional data (i.e., without controlling for prior achievement).
Until now, most studies on school VA modeling have estimated VA models with prior achievement from the same domain as the outcome variable or used a composite score of achievement (e.g., Muñoz-Chereau & Thomas, 2016; Timmermans et al., 2011). One exception is a longitudinal study with data from 60,000 to 70,000 students from Australia (Marks, 2017). In that study, school VA models controlling for prior achievement in the same domain were compared with school VA models without prior achievement and school VA models with prior achievement in “all” domains (i.e., numeracy and four different subdomains of language). The author concluded that studies should control for prior achievement in different domains when estimating school VA scores in a language domain but that the school VA model controlling only for prior achievement in the same domain was the preferred one for math achievement. The latter recommendation is in contrast to the “medium function hypothesis” (Peng et al., 2020, p. 2) stating that language has a causal influence on mathematical learning. This hypothesis was supported by findings from a recent meta-analysis, indicating that prior language achievement is predictive for later math achievement and that prior math achievement is predictive for later language achievement (Peng et al., 2020).
2.2 Sociodemographic and sociocultural background variables
Most studies on sociodemographic and sociocultural variables in VA research have focused on socioeconomic status (SES), and the resulting conclusions have been mixed. In general, three different positions can be identified in the existing literature. First, some authors reported that across schools, the effect of SES is often encapsulated by prior achievement (Ferrão, 2009; Hægeland & Kirkebøen, 2008). Second, other research indicated that ignoring students’ backgrounds in school VA models may reward or punish the wrong schools (Dearden et al., 2011; Ehlert et al., 2014; Leckie & Goldstein, 2019; Timmermans et al., 2011) and that students’ learning gains were higher in schools with higher SES than in those with lower SES, also after controlling for prior achievement (De Fraine et al., 2003; Dumont et al., 2013). A third position is that the inclusion or exclusion of students’ background variables depends on the purpose of school VA scores (Muñoz-Chereau & Thomas, 2016; Tekwe et al., 2004). To the best of our knowledge, no studies have investigated the inclusion or exclusion of students’ language or migration background in school VA models, and only one study investigated the inclusion of students’ sex, reporting sex effects in favor of girls in some subjects (see Fitz-Gibbon, 1997).
2.3 Motivational variables
To the best of our knowledge, no previous studies have investigated the inclusion of motivational variables. Additionally, most prior studies on VA modeling did not include any motivational variables in their VA models (Levy et al., 2019). However, researchers and practitioners have begun to emphasize the importance of noncognitive skills in students, for example, by highlighting that “soft skills predict success in life, that they causally produce that success, and that programs that enhance soft skills have an important place in an effective portfolio of public policies” (Heckman & Kautz, 2012, p. 451). After the enactment of the Every Student Succeeds Act (Every Student Succeeds Act, 2015), which allowed for more “soft skills” in schools’ curricula (e.g., Gallup Inc., 2018; Pelletier, 2018), these noncognitive student variables might also become more important in accountability systems and more specifically in VA models.
3 The present study
There seems to be consensus that school VA models should include measures of prior achievement that come from the same domain as the achievement for which the VA score was estimated. However, it is still not clear whether it should be the only covariate, or whether (and if so, which) other covariates can contribute to school VA scores being as unbiased as possible. Only a few studies have sought to determine which variables should be included in or excluded from VA models on the school level. Most of these previous studies have reported strong positive correlations between school VA scores from different school VA models with different covariates. However, they stressed that strong correlations will not prevent individual schools being misclassified (e.g., Ehlert et al., 2014; Timmermans et al., 2011). The body of research on VA models is still growing, also within the last decade, even though not as fast as it was the case in the earlier 2000s (as reported in a systematic review; Levy et al., 2019). However, while previous studies have compared VA models with different covariates (e.g., Ehlert et al., 2014), to the best of our knowledge, no previous study has systematically investigated different combinations of covariates when estimating school VA scores by studying every possible combination of the chosen covariates. The present study takes important steps toward filling this gap by analyzing how different sets of covariates affect school VA scores for math and language achievement. This is based on the idea to combine theory- and data-driven approaches, by considering covariates that have previously been found to have an influence on students’ achievement and not only including them separately but systematically combine them with each other. This approach is similar to the “specification curve analysis” (e.g., Rohrer et al., 2017; Simonsohn et al., 2015), suggesting to consider every possible model specification and allowing for a systematic investigation.
As school VA scores are, by definition, everything that cannot be explained by the covariates included in the school VA model, higher amounts of explained variance (i.e., R2) will reduce the heterogeneity in school VA scores that can be attributed to between-school differences in student intake. Additionally, as VA scores are supposed to provide an estimate of a school’s effectiveness that is as unbiased as possible, independently of students’ backgrounds, an educational system with diverse student populations is best suited for a systematic comparison of VA models. One particularly diverse and multilingual school setting is situated in Luxembourg, a tiny country in the heart of Europe. Luxembourg seems to experience the increase in societal and student diversity even faster than other countries, which can be attributed to, among other factors, its small size, a traditional multilingualism, and an economic system based on immigration. For example, in the 2016–2017 school year, 64% of all newly enrolled students did not speak the first language of instruction (i.e., Luxembourgish) at home (Ministry of National Education, Children and Youth, 2018). This highly diverse school setting poses a challenge for students, teachers, and schools. On the other hand, it offers the opportunity to investigate this unique educational learning environment as an anticipatory model for other educational systems with an increase in student diversity.
Further, many scholars consider VA scores that are applied for consequential decision making to be subject to Campbell’s law (1976), which states that “the more any quantitative social indicator is used for social decision-making, the more subject it will be to corruption pressures and the more apt it will be to distort and corrupt the social processes it is intended to monitor” (p. 49). More concretely, some of the concerns when using school VA scores for high-stakes decisions include psychological consequences for all parties concerned (i.e., teachers, students, and parents) and a risk of attempts of gaming the system (e.g., Foley & Goldstein, 2012; Leckie & Goldstein, 2019). While some researchers still acknowledge the usefulness of teacher VA scores in accountability contexts (Loeb, 2013; Scherrer, 2011), others have indicated the usefulness of an informative use of school VA scores in order to inform teachers, parents, or schools and to learn from those schools that have been classified as “effective” (e.g., Ferrão, 2012; Leckie & Goldstein, 2019). In the present study, we thus use representative longitudinal achievement data obtained from the low-stakes Luxembourg School Monitoring Programme (LUCET, 2021) to circumvent these potential sources of bias that result from pressure due to accountability and explore a more informative use of school VA scores.
Capitalizing on this unique data, we examined school VA scores for two key outcome domains—math and language achievement—using four different sets of covariates that were systematically combined with each other: (a) prior achievement in the same outcome domain (e.g., a measure of prior math achievement to derive the school VA score for math achievement), (b) prior achievement in the other outcome domain (e.g., prior language achievement to derive the school VA score for math achievement), (c) sociodemographic and sociocultural background characteristics, and (d) motivational variables in the same domain (e.g., self-concept in math to derive the school VA score for math achievement). In doing so, we addressed two research questions:
-
1.
How do different covariate sets affect the amount of explained variance by the VA models that are used to calculate school VA scores for math and language achievement?
-
2.
How sensitive is the evaluation of schools to the selection of covariates in the VA model?
4 Method
4.1 Participants
For the analyses, we used longitudinal large-scale data obtained from the Luxembourg School Monitoring Programme ÉpStan (LUCET, 2021). The ÉpStan assesses students’ academic competencies (in math and languages), their achievement motivation, as well as information on their sociodemographic and sociocultural backgrounds at the beginning of Grades 1, 3, 5, 7, and 9, respectively. Every year, the entire student population in each of these grade levels participates in the ÉpStan. In the present paper, we used longitudinal data from the student cohort that participated in ÉpStan in Grade 1 in 2014. For our analyses, we included only the N = 3603 students attending 153 primary schools who took the math and/or language achievement tests in Grade 3 after participating in Grade 1 in 2014 (see Table 1 for details on the sample composition and excluded students). Excluded students (N = 1400) were either absent on the day of testing in third grade (N = 1068; e.g., due to illness, because they left the Luxembourgish school system, or because they repeated a grade between first and third grade), or they changed schools between Grades 1 and 3 (N = 332). Excluded students had lower achievement values in Grade 1 than included students, indicating that nonparticipation in Grade 3 could most likely be due to repeating a grade between first and third grade. Notably, the longitudinal sample on which the present VA models were based represents almost the entire student population that successfully progressed from Grade 1 in 2014 to Grade 3 in 2016 at the same school. All participating children and their parents or legal guardians were duly informed before data collection and had the opportunity to opt-out. To ensure students’ privacy and in accordance with the European General Data Protection Regulation, a so-called “Trusted Third Party” pseudonymized the data (for more information, see LUCET, 2021). For the present analysis, we used an anonymized data set.
4.2 Measures
4.2.1 Academic achievement
Achievement measures were used as outcome variables (i.e., math and language achievement in Grade 3) and as covariates (i.e., math and language achievement in Grade 1). While typically in VA research, the difference between prior and later achievement is only 1 year, the 2-year-gap in Luxembourg is necessary as the primary school system consists of learning cycles of 2 years. Thus, at the beginning of Grade 3, the knowledge gained in the first learning cycle of elementary school is tested, spanning Grade 1 and Grade 2. All achievement measures were assessed with standardized achievement tests, which were developed on the basis of the national curriculum standards (defined by the Ministry of National Education, Children and Youth, 2011) and are used as such in the national school monitoring. All achievement tests (i.e., listening comprehension, reading comprehension, and math) were developed and scaled as one-dimensional tests (Fischbach et al., 2014). The tests were administered in the classroom setting, given in a paper-and-pencil format, and mostly based on closed-format items. To scale the items, a unidimensional Rasch model was used (Fischbach et al., 2014; see Nagy & Neumann, 2010; Wu et al., 2007). Weighted likelihood estimates (Warm, 1989) were used as measures of students’ achievement (Fischbach et al., 2014). The reliability estimates of all achievement scales were calculated using the TAM package version 3.3.10 (Robitzsch et al., 2019).
4.2.2 Math achievement
The math tests in Grade 3 were constructed in German because the language of instruction in Grades 1 and 2 is German. Math items in Grade 3 assessed children’s competencies in three areas: “numbers and operations,” “space and form,” and “quantities and measures.” As it is typical for large-scale assessments, one global score for math competencies was used (e.g., PISA, OECD, 2018), designed with a mean of 500 and a standard deviation of 100. The reliability of the math test scores in Grade 3 was 0.90. Math achievement in Grade 1 was assessed in Luxembourgish (which is, although politically and culturally a language on its own, linguistically speaking a variety of German, see, Dalby, 1999) because the language of instruction in preschool is Luxembourgish. Mathematics items in Grade 1 assessed children’s competencies in the domains “numbers and operations,” “space and shape,” and “size and measurement.”.Footnote 1 The reliability of the math test scores in Grade 1 was 0.75.
4.2.3 Language achievement
Two scales were used to operationalize language achievement in Grade 3: children’s listening and reading comprehension in the German language, each on a scale designed with a mean of 500 and a standard deviation of 100. Listening comprehension was based on the subskills “identifying and applying information presented in a text” and “construing information and activating listening strategies.” Reading comprehension was assessed with the subskills “identifying and applying information presented in a text” and “construing information and activating reading strategies/techniques”.Footnote 2 The reliability of the listening comprehension/reading comprehension test scores in Grade 3 was 0.81/0.88. We computed a mean score across listening and reading comprehension in the German language to represent students’ language achievement in Grade 3. Language achievement in Grade 1 consists of the two scales “early literacy comprehension” and “listening comprehension” in Luxembourgish in Grade 1 because the language of instruction in preschool is Luxembourgish. Listening comprehension was assessed with the two subskills “identifying and applying information presented in a text” and “construing information and activating listening strategies” with different kinds of texts, which were played from an audio CD. Early literacy comprehension was assessed with the subskills “phonological awareness,” “visual discrimination,” and “understanding of the alphabetic principle”.Footnote 3 The reliability of the listening comprehension/reading comprehension test scores in Grade 1 was 0.70/0.70. As these scores were used as independent variables and as reading and listening comprehension cover different subdomains of language achievement (see, e.g., Elgart, 1978; van Zeeland & Schmitt, 2013), both test scores were included in the models.
4.2.4 Note on the reliability of achievement measures
As reported above, the weighted likelihood estimates representing students’ domain-specific achievement demonstrated score reliability ranging between 0.70 and 0.90. While depending on the purpose of the application of those measures, especially those reliability measures around 0.70 could be considered as rather low, it has been shown that they suffice research purposes (Schmitt, 1996). Other authors argue that for reliabilities above 0.60, the exact size of the reliability plays a less important role in reducing bias than the nature of the covariates (Steiner et al., 2011, 2015) and the importance of a covariate (i.e., an important variable with a reliability of 0.60 is still better than a perfectly measured poor variable; Cook et al., 2009). In addition, the present domain-specific tests were developed by expert panels (i.e., teachers, content-specialists on teaching and learning, psychometricians) to ensure content validity of all test items. Further, psychometric experts examined all test items for whether they exhibit differential item functioning across student cohorts attending the same grade level to allow for commensurable measures across time.
4.3 Sociodemographic and sociocultural background variables
To obtain information about children’s sociodemographic and sociocultural backgrounds, parents filled out a questionnaire when the students were in Grade 1. Parents were asked to locate their profession within given occupational categories; these categories were based on the International Standard Classification of Occupations. For each occupational category, the average value of the ISEI scale (International Socio-Economic Index of occupational status; see Ganzeboom, 2010) was computed to obtain a proxy for parents’ SES. ISEI values had a mean of 49.9 and a standard deviation of 15.4. Parents were also asked where they and their child were born to indicate their migration status. In the present analyses, migration status was dummy-coded with “native” as the reference category. On the student questionnaire in Grade 1, students were asked to indicate what language(s) they spoke with their father and their mother. As the first language of instruction is Luxembourgish, not speaking any Luxembourgish at home represents a challenge for the newly enrolled students. We thus created a dummy variable to differentiate between students who did not speak any Luxembourgish at home and those who spoke Luxembourgish with at least one parent (reference category). Students’ sex was retrieved from the official database of the Ministry of National Education, Children and Youth.
4.4 Motivational variables
Students in Grade 1 were asked about their domain-specific learning motivation (i.e., academic anxiety, self-concept, and interest) in math and in the German language (which is most closely related to Luxembourgish) on a 2-point rating scale (“agree” and “disagree”). Specifically, domain-specific anxiety was assessed with one item per domain (e.g., “I’m afraid of math,” derived from Gogol et al., 2014); academic self-concept and interest were each assessed with two items per domain (e.g., “I am good at math,” derived from Marsh, 1990, or “I’m interested in the subject of German language,” derived from Gogol et al., 2016). The reliabilities, measured with Cronbach’s alpha, were 0.53 for academic self-concept in math, 0.60 for academic self-concept in the German language, 0.66 in interest in math, and 0.71 for interest in the German language. Additional analyses on their convergent and discriminant validity showed that domain-specific achievement test scores in both Grade 1 and Grade 3 followed the theoretically predicted pattern to academic self-concepts in matching and non-matching domains (Niepel et al., 2017; van der Westhuizen et al., 2019), indicating that the motivational scales measure what they are purported to measure.
4.5 Analysis
We conducted all analyses with R version 3.6.1 (R Core Team, 2019).
4.5.1 Data preparation
Due to the inclusion criterion of students’ participation in the achievement tests in Grade 3, there were no missing data in the achievement data in Grade 3. Missing data on the covariates were imputed using multiple multilevel imputation with 20 imputations, 50,000 burn-in iterations, and 5000 iterations between imputations using the mitml package version 0.3–7 (Grund et al., 2019) as an interface for the jomo package version 2.6–9 (Quartagno & Carpenter, 2019).
4.5.2 Between-school differences in student intake
Intraclass correlations, measured with ICC(1) values, estimate how much of the total variance can be attributed to differences between schools in student intake (see, e.g., Bliese, 2000; Lüdtke et al., 2006). ICC(1) was computed with the rptR package version 0.9.22. (Stoffel et al., 2019).
4.5.3 Multicollinearity
Data was checked for multicollinearity by estimating the variance inflation factor (VIF), using the package performance version 0.9.0 (Lüdecke et al., 2021).
4.5.4 Estimation of VA scores
Multilevel models were used to estimate the VA scores (for more details, see, e.g., Doran & Lockwood, 2006). We chose them because on the one hand, they represent one of the two most commonly used model types in VA research (the other one being linear regressions; Levy et al., 2019; Kurtz, 2018). On the other hand, in a study with the same sample as the present study, multilevel models prevailed over other models, including linear and nonlinear “classical” and machine learning models, in the estimation of school VA scores (Levy et al., 2020). Thus, the model choice reflects current practices in VA research and applications, and at the same time seems to be the best choice given the present dataset.
Specifically, two-level models (with students located at Level 1 and schools located at Level 2; see Eqs. 1 and 2) with random intercepts were estimated using the lmer function from the lme4 package (Bates et al., 2015).
In Eq. 1, Aij is the achievement in math or language of student i in school j in Grade 3. Xij is a vector of the different covariates X of student i in school j as assessed in Grade 1. β0j is the intercept, β1 is a vector of regression coefficients linking the covariates to achievement in Grade 3, and eij is a residual term (assumed to be normally distributed with a mean of zero and a common variance of σ2 for all schools). Equation 2 represents between-school differences in the intercept (β0j) in Eq. 1. γ00 represents the intercept of the outcome variable A that is assumed to be constant across all students and schools (i.e., a fixed effect). μ0j is a random residual error term that can vary between schools and was assumed to be normally distributed with a mean of 0 and a variance specified as σμ02 (Hox, 2013). The VA score of a school j can be quantified in terms of an estimate of the random effect \(\widehat{\upmu }\) 0j for a particular school at Level 2 (i.e., the residual for a certain school; see Ferrão & Goldstein, 2009). School VA scores were estimated using the ranef function from the lme4 package (Bates et al., 2015).
4.5.5 Systematic combination of covariate sets in the VA models
The idea of systematically combining different covariate sets is based on specification curve analysis (Simonsohn et al., 2015; see Rohrer et al., 2017, for an application), which aims to calculate all “reasonable” specifications. Applied to our case, we estimated all school VA scores for math and language achievement that could be derived from all possible combinations of four covariate sets: (a) prior achievement in the same domain, (b) prior achievement in a different domain, (c) sociodemographic and sociocultural background variables, and (d) motivational variables in the same domain. Doing so resulted in 15 (24–1) covariate set combinations per domain, and thus 15 school VA scores in math achievement and 15 school VA scores for language achievement per school, respectively (see Table 2 for more detail).
Notably, each model was run for each imputed data set (i.e., resulting in 2 domains * 15 models * 20 imputed data sets = 600 analyses). To evaluate the school VA scores in further analyses, we pooled the domain-specific scores across the 20 imputed data sets to obtain a mean school VA score for each school for a certain combination of covariates.
To address research question 1, we evaluated the amount of explained variance of the underlying VA model in terms of the total amount of variance (R2s) explained by the covariates. The R2 values were computed in accordance with Snijders and Bosker (2012, p. 112). Further, we tackled research question 2 on how the evaluation of schools depends on the choice of covariates in the VA models by computing correlations of VA scores as obtained from various school VA models and by analyzing the implications of covariate selection on benchmark classifications. Specifically, we used benchmarks classifying schools below the 25th percentile as “needs improvement,” schools between the 25th and 75th percentiles as “moderately effective,” and schools above the 75th percentile as “highly effective” (e.g., Marzano & Toth, 2013). We calculated consistency scores based on the benchmark classifications from the school VA model that included all covariates, as this allowed to analyze the impact that the exclusion of the different covariate sets can have. More specifically, for every school VA model, the percentage of schools identified at the same benchmark classification as the one in the model that included all covariates was used as a measure of consistency, where higher values represented a higher concordance with the benchmark classifications from the school VA model that included all of the covariates. In addition, we calculated percentages of disagreement for benchmark classifications of all school VA scores with each other and “disagreement” was defined as schools being placed at a different benchmark (i.e., “needs improvement,” “moderately effective,” or “highly effective”). The practical implications on individual schools will additionally be illustrated on the example of five schools that were randomly chosen as examples for high ranges in VA scores (schools 1 and 2), and for constant high, low, or medium VA scores (schools 3, 4, and 5), respectively (see Table 8 for descriptive data on these schools). The same example schools were used in Levy et al., (2020).
5 Results
5.1 Preliminary analyses of between-school differences in student intake
Table 3 shows the intraclass correlations, computed as ICC(1) values, and variance inflation factors (VIF), as an estimate of multicollinearity. For all achievement variables, parents’ SES, and “Luxembourgish spoken at home,” the ICC(1) was greater than 0.1, indicating that a substantial proportion of the total variance could be attributed to mean differences between schools when students began primary school in Grade 1. Furthermore, all VIF values, exemplified in Table 3 based on the school VA model with math achievement as a dependent variable and all covariate sets included, were smaller than 5, indicating that no multicollinearity is present in the data (James et al., 2013).
5.2 Research question 1: how do the different covariate sets affect the amount of explained variance by the VA models?
Table 2 shows the amount of explained variance (R2) from the 15 different covariate sets for the school VA scores in math and language, respectively. In the following, results will be described and in the discussion section, they will be put into context and possible explanations will be discussed.
5.2.1 School VA models for math achievement
As expected, the highest amount of explained variance (R2 = 0.45) was obtained when all four covariate sets were included (model 15). Nevertheless, some covariates turned out to be more important than others. More specifically, the amount of explained variance was considerably higher when prior math achievement was included (i.e., models 1, 3, 5, 7, 9, 11, 13, 15), both when considering the range (from 0.40 to 0.45) and the median (0.43), as compared with its exclusion (i.e., models 2, 4, 6, 8, 10, 12, 14; ranging from 0.06 to 0.31; Mdn = 0.26). The R2s were higher and had a smaller range when prior language achievement was included (0.26 to 0.45) in comparison to its exclusion (0.06 to 0.43), even though the median was lower for the models with prior language achievement (0.37 vs. 0.40). The range in R2s was slightly higher (by 0.02) when the sociodemographic and sociocultural background variables were included (0.09 to 0.45), but the median was lower (0.37) in comparison to their exclusion (0.06 to 0.43; Mdn = 0.40). Both the range and the median for the R2 were lower when the motivational variables were included (0.06 to 0.45; Mdn = 0.36) as compared to their exclusion (0.09 to 0.45; Mdn = 0.40).
5.2.2 School VA models for language achievement
As expected, the highest amount of explained variance (R2 = 0.47) was obtained when all four covariate sets were included. The differences in R2s between the inclusion of prior language achievement (ranging from 0.35 to 0.47; Mdn = 0.41) and its exclusion (0.06 to 0.38; Mdn = 0.26) were substantial. However, the range and median of explained variance were only slightly higher when prior math achievement was included (0.16 to 0.47; Mdn = 0.37) than when it was excluded (0.06 to 0.46; Mdn = 0.35). Bigger differences in the range and median could be observed when the sociodemographic and sociocultural background variables were included (0.26 to 0.47; Mdn = 0.41) in comparison with when they were excluded (0.06 to 0.37; Mdn = 0.35). The amount of explained variance when the motivational covariates were included (0.06 to 0.47; Mdn = 0.37) was very similar to the amount of explained variance when they were excluded (0.16 to 0.46; Mdn = 0.36).
5.3 Research question 2: how sensitive is the evaluation of schools to the selection of covariates in the VA model?
5.3.1 Descriptives and correlations between school VA scores
School VA models for math achievement
Table 4 shows the minimum and maximum values, median, and standard deviation for VA scores resulting from the different VA models for math achievement. The mean is not depicted, as it is 0 by definition in any case. When interpreting the size of median and standard deviation, it should be considered that the scale on which the dependent variables for the calculation of VA scores are based was designed to have a mean of 500 and a standard deviation of 100.
In addition, Table 4 shows the correlations between the school VA scores resulting from the different models, ranging from.66 to 1.00 (Mdn = 0.91). When prior math achievement was included in the VA models, the correlations between the VA scores ranged from 0.94 to 1.00 (Mdn = 0.98). However, when prior math achievement was not included, the range of the correlations between the VA scores was considerably broader (0.74 ≤ r ≤ 1.00). Additionally, the only correlations that were equal to 1.00 were those between a model with motivational variables and the same model without the motivational variables (e.g., r = 1.00 for the correlation between model 9, which included prior math achievement and motivation, and model 1, which included only prior math achievement).
School VA models for language achievement
A similar pattern of results was obtained for school VA scores in the language domain (Table 5). Overall, the correlations ranged from 0.81 to 1.00 (Mdn = 0.92). When prior achievement in language was included in the VA models, the correlations between the VA scores ranged from 0.96 to 1.00 (Mdn = 0.98). When both prior language achievement and sociodemographic characteristics were included, the correlations between the school VA scores were even higher (0.99 ≤ r ≤ 1.00; Mdn = 1.00). Additionally, any correlations equal to 1.00 were observed either between a model with the motivational variables (e.g., model 9) and the same model without the motivational variables (e.g., model 1) or between a model with prior math achievement (e.g., model 3) and the same model without prior math achievement (e.g., model 2).
5.3.2 Implications on benchmark classifications
The benchmark classifications based on the school VA scores resulting from VA models with different covariate sets can be substantially different from each other, with percentages of disagreement ranging from 1.3 to 39.9% (Table 6, math achievement as a dependent variables) and from 1.3 to 33.3% (Table 7, language achievement as a dependent variable), respectively. A more detailed analysis of the number of schools classified at a certain benchmark by the different models, in comparison with the number of schools classified by the VA model with all four covariate sets included, can be found in the Online Resource 1 for the math VA models and Online Resource 2 for the language VA models.
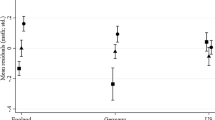
A more comprehensive overview of the most relevant comparison can be seen in Fig. 1, showing the consistency of the benchmark classifications in comparison to the model that included all four covariate sets (Table 8).

Consistency measures of benchmark classifications as compared with the classifications made by the model that included all of the covariates. Consistency measures for school VA scores in math are shown on the right and school VA scores for language on the left. Below the plots, the color of the dots indicates the inclusion (black) or exclusion (white) of the respective covariate sets
5.4 School VA models for math achievement
The right side of Fig. 1 shows that the highest consistency measures were reached when prior math and prior language achievement were included, and the lowest values of consistency were reached when neither of these covariate sets were included. In contrast, there seemed to be only small to not observable advantages of including the sociodemographic and sociocultural background variables or motivational variables.
5.5 School VA models for language achievement
The left side of Fig. 1 shows that the highest consistency values were reached when prior language achievement and students’ sociodemographic and sociocultural backgrounds were included, and the lowest values were reached without prior language achievement, whereas there seemed to be no observable advantage of including prior math achievement or motivational variables.
5.6 Real-life implications of choice of covariate for the school VA percentiles
Figure 2 illustrates the real-life implications that the use of different VA scores may have on the example of five schools. It shows the range of the VA percentiles for these schools and illustrates that the effectiveness of some schools may be evaluated quite differently depending on the model used to estimate the school VA scores, whereas other schools have VA scores within a more consistent range (e.g., School 4). The school VA model including all covariate sets is marked in black. For schools 1, 2, and 3, it can even be seen that the inclusion or exclusion of certain covariates can lead to different benchmark classifications. For example, School 1 would be classified as “highly effective” by VA percentiles resulting from those math VA models that included prior math and/or language achievement, whereas it would be classified as “moderately effective” without these covariates (see Online Resource 3 for detailed values of the percentiles that resulted from the respective school VA models).

Range of percentiles resulting from math (white) and language (gray) VA scores for five example schools. Every dot represents the school VA percentile as obtained from a certain VA model. The VA models with all the covariates included are marked in black. At the 25th and 75th percentiles, there are cut-off lines to define the border between schools classified as “needs improvement,” “moderately effective,” and “highly effective”
6 Discussion
The VA score of a certain school juxtaposes the actual level of achievement attained by students attending a certain school with the achievement level that is expected from students who have the same background characteristics (e.g., prior achievement or sociodemographic and sociocultural backgrounds). If these characteristics affect students’ achievement, including these variables as covariates in the VA model—thereby statistically controlling for them—may substantially contribute to improving the consistency of VA models (e.g., Ehlert et al., 2014; Timmermans et al., 2011). As there seems to be no final consensus on which covariates should be used in VA models, the aim of the present paper was to systematically analyze and compare different combinations of covariates in school VA models. Of course, not every combination of covariates is as likely to be used in practice. However, in order to conduct a systematic exhaustive comparison and contribute to a cumulative empirical body of knowledge, every possible combination of covariates was considered. In doing so, the present paper addressed two research questions:
-
1.
How do different covariate sets affect the amount of explained variance of the VA models that are used to calculate school VA scores for math and language achievement?
-
2.
How sensitive is the evaluation of schools to the selection of covariates in the VA model?
In the following, we discuss the implications from the results of the math and language school VA models together because the focus of the present paper is on the choice of covariates rather than on the dependent variables.
6.1 How do different covariate sets affect the amount of explained variance of VA models?
As school VA scores include, by definition, everything that cannot be explained by the covariates included in the school VA model, aiming to explain a large amount of variance will reduce the heterogeneity in school VA scores that can be attributed to between-school differences in student intake. More specifically, higher amounts of explained variance in the underlying model that is used to estimate school VA scores will result in less noise in VA scores and thus estimated VA scores that are closer to the “real” school VA score (which could of course be estimated only if all factors causing bias are known and controlled for). While complex models are prone to overfit, the risk is rather low in multilevel models with only a few covariates and a big sample size, as it is the case in 4, which is why we assume that higher amount of explained variance will lead to less bias in VA scores.
In line with previous research on academic achievement, we found that the best predictor of later achievement is prior achievement in the same domain (e.g., Aubrey et al., 2006; Hemmings & Kay, 2010; Reynolds, 1991; Yates, 2000). This supports one of the most prominent VA applications ( “Educational Value-Added Assessment System,” which was built on the Tenessee Value-Added Assessment System, Sanders & Horn, 1994).
Whether prior academic achievement in a different domain affects the amount of explained variance of school VA models depends on the outcome variable. On the one hand, prior achievement in language contributed to explaining additional variance in later math achievement, confirming that early language abilities are important for learning math (Peng et al., 2020), particularly in the multilingual and diverse context of Luxembourgish schools (e.g., Van Rinsveld et al., 2015). On the other hand, the inclusion or exclusion of prior math achievement did not make a substantial difference in explaining language achievement in Grade 3, contradicting findings from a recent meta-analysis (Peng et al., 2020).
Similarly, whether students’ sociodemographic and sociocultural backgrounds affect the amount of explained variance of school VA models depends on the outcome variable. Even though it was not the case in school VA models for math, including students’ sociodemographic and sociocultural background variables in the school VA models for language led to higher amounts of explained variance, which is in line with previous research on the relationship between achievement and sociodemographic variables (e.g., SES, Sirin, 2005; or sex, Voyer & Voyer, 2014). These findings suggest that students’ sociodemographic and sociocultural background variables play crucial roles in the development of language abilities, even when controlling for prior language achievement. It would be interesting for future research to investigate whether the importance of students’ sociodemographic and sociocultural background variables can be replicated in a linguistically more homogenous sample.
Motivational variables seem to incrementally explain variance in students’ achievement in addition to prior achievement (e.g., Marsh & Craven, 2006; Marsh et al., 2005; Valentine et al., 2004), even after cognitive ability was controlled for (Spinath et al., 2006; Steinmayr & Spinath, 2009). Our opposed findings could be explained by the fact that students in Grade 1 reported a high level of motivation in general and between-school differences in motivation (see Table 3) were rather small. Thus, this restriction of range in the between-school differences of motivational measures may have mitigated the possibility that these measures help to improve precision of VA scores. Further, a more recent study indicated that reciprocal effects between motivation (e.g., self-concepts) and achievement are not present in the early years of primary school (Weidinger et al., 2019). One reason may be that many students at that age may not have reached a sufficient level of self-reflection to provide accurate self-reports on how motivated they are in a certain school subject. Future research on VA is required to investigate whether motivational variables play a more important role in improving the amount of explained variance of school VA models in older students.
6.2 How sensitive is the evaluation of schools to the selection of covariates in the VA model?
The investigation of the sensitivity of schools’ evaluations to covariate selection was twofold. First, on a descriptive level, the range, median, standard deviation, and correlations between school VA scores resulting from the school VA models with different combinations of covariates were calculated. Second, implications for the benchmark classifications were investigated across all schools and on an illustrative example involving five schools.
Correlations from different school VA models were moderate to high (ranging from 0.66 to 1.00 in the math VA models and from 0.81 to 1.00 in the language VA models), which is in line with findings from previous studies on teacher and school VA (e.g., Ehlert et al., 2014). These correlations were even higher when considering only the school VA models that contained prior achievement in the same domain (0.94 ≤ r ≤ 1.00 for school VA models in math and 0.96 ≤ r ≤ 1.00 for school VA models in language). These high correlations between school VA scores could lead to the erroneous conclusion that, for the sake of specifying the most parsimonious school VA model, including prior achievement in the same domain should be enough to obtain consistency in the school VA models. However, as other authors have also stated (e.g., Ehlert et al., 2014 on teacher and school VA; Johnson et al., 2015 on teacher VA; and Timmermans et al., 2011 on school VA), strong correlations will not prevent misclassifications, a phenomenon that will be discussed in more detail below.
The same covariate sets as identified under Research Question 1 led to higher levels of consistency and lower levels of disagreements in the benchmark classifications of school VA scores. In line with most current VA practices (for an exception, see, Luyten et al., 2009), it was crucial to include prior academic achievement in the same domain to get high consistency measures in school VA scores. Further, recommendations from an Australian study on school VA (Marks, 2017) to only control for prior math achievement in the math VA models but to include prior achievement in different domains in the language VA models was not empirically supported in our study. This might be explained by the fact that the sample used by Marks (2017) is more homogenous than our sample and that language(s) spoken at home was never included in his models. The effect of students’ sociodemographic and sociocultural background variables seemed to be encapsulated by prior achievement in the school VA models for math (in line with, e.g., Ferrão, 2009; Hægeland & Kirkebøen, 2008). but not in the school VA models for language, indicating that the exclusion of students’ sociodemographic and sociocultural backgrounds could reward or punish the wrong schools (e.g., Dearden et al., 2011; Timmermans et al., 2011). In the school VA models for both math and language, motivational variables did seem to have an influence on the consistency of the school VA scores, empirically underscoring the decision of most previous studies not to include motivational variables in the VA models (Levy et al., 2019). However, these results might be different in data from the USA, which has added more “soft skills” to schools’ curricula and accountability systems after the enactment of the Every Student Succeeds Act (2015).
The implications on benchmark classifications were also illustrated with five example schools, showing that for individual schools, the range of VA percentiles could change so dramatically that they might be classified as “highly effective” or “needs improvement,” depending on which covariate sets were included. This indicates yet again how crucial covariate selection is when estimating school VA scores. However, it should be kept in mind that there are many more internal and external factors that could come into play but cannot be influenced by schools, such as summer learning losses or mental support at home (Braun, 2015; Darling-Hammond, 2015). Future research on VA models should even be more careful in this regard, as during the current COVID-19 pandemic children were being home schooled for months, which could lead to a higher proportion of influence of students’ backgrounds (see, e.g., Cachón-Zagalaz et al., 2020 for a systematic review on the effects of the pandemic on children).
6.3 Recommendations for educational practice
The findings from the present study support current practice in VA modeling in the sense that prior achievement is crucial in the inclusion of school VA models. However, the present results also indicate that evaluation systems that include only prior achievement from the same domain in school VA models may draw the wrong conclusions about schools’ effectiveness, highlighting the importance of adding additional covariates (e.g., sociodemographic background), as has already been concluded by research on teacher VA (Koedel et al., 2015). Most importantly, given the fluctuation of school VA scores depending on the chosen covariates, the awareness of model differences is essential when applying or interpreting school VA models. In other words, the present results cast further doubt on the use of VA scores for accountability purposes because the evaluation of a certain school’s effectiveness varied widely depending on the covariate set that was chosen, also calling for caution concerning a causal interpretation of school VA scores. Under the assumption that the size of school VA scores can be interpreted as a causal educational effectiveness of these schools, of course reducing the bias in VA scores is of utmost importance. However, previous authors argued that VA scores should not be seen as causal estimates (and rather as descriptives), “except under extreme and unrealistic assumptions” (Rubin et al., 2004, p. 113). As was also shown by Reardon & Raudenbush (2009), a causal interpretation of school VA scores would be based on assumptions, which are implausible in most educational contexts. More specifically, the assumptions that students could potentially be assigned to any school and that school assignments of other students do not have an influence on students’ achievement are both implausible for the present sample, as students usually go to the primary school closest to their home. Furthermore, even though the assumption that a school that is effective for a subgroup would be effective for any other subgroup of students cannot be empirically proven, a recent large-scale international study indicates that there are small but meaningful differences between schools concerning their students’ motivational-affective variables (Brunner et al., 2018). Additionally, an empirical verification of the causality of school VA scores would only be possible through the tautological investigation whether schools with high VA scores lead to higher growth in their students’ achievement, analogously to the commonly known definition of intelligence as “the tests test it” (Boring, 1923).
In line with these recommendations on descriptive rather than causal interpretations of school VA scores, we recommend using VA models with caution and applying VA scores for informative purposes rather than as a mean to base accountability decisions upon (see also, e.g., Floden, 2012; Leckie & Goldstein, 2019). For example, even though only a few schools have constant VA percentiles, these schools could be used as a starting point for further analyses, for example, by comparing the pedagogical strategies of those consistently classified as “highly effective” to those consistently classified as “needs improvement.” Furthermore, the model selection process should include different specifications in order to obtain ranges of potential VA scores instead of one single “true” value of effectiveness (as the one true value does not exist, e.g., Amrein-Beardsley & Holloway, 2017; Conaway & Goldhaber, 2018). In addition, as these estimations are based on human data, they can never be perfectly exact. There are so many more internal and external factors that could come into play but are usually not assessed and/or cannot be influenced by teachers or schools, such as, to name only a few, summer learning losses, mental support at home, medical care, or community environment (Braun, 2015; Darling-Hammond, 2015). School VA scores should thus be considered as one tool to evaluate schools, which are suited rather for pedagogical purposes than for summative evaluations.
7 Limitations
Given that so far there is no final consensus on the type of model that should be used to estimate VA scores, we used multilevel models, one of the two most common types of models (next to linear regressions) for calculating VA scores in the international literature (Levy et al., 2019; Kurtz, 2018). As multilevel models directly take into account the hierarchical structure of the data (the fact that students are nested in schools, meaning that students within the same school tend to be more similar to each other than students from different schools) when estimating VA scores, we decided to use multilevel models rather than linear regression models. Furthermore, in a study with the same sample as the present study, multilevel models prevailed over other models, including linear and nonlinear “classical” and machine learning models, in the estimation of school VA scores (Levy et al., 2020). Of course, other types of models would be possible, too. For example, Bayesian models have started to find their way into VA research (in VA research often called “empirical Bayes”; for an overview, see, Guarino et al., 2015). However, in the present paper, we decided against the use of empirical Bayes estimates, as Guarino et al. (2015) concluded that they do not perform well if no random assignment to classes is given (see also, e.g., Kruschke & Liddell, 2018 for an overview on Bayesian statistics; and Kane et al., 2013; or Rothstein, 2009 on random assignment of students and its effect on teacher VA). However, as the term “empirical Bayes” is used quite broadly, it could also be argued that the estimation process in the multilevel model can also be seen as an empirical Bayes technique (Bates, 2009). In addition, in classical models, measurement error cannot be separated from error variance, which is why latent models, such as structural equation models, might be better suited for measurement error in the variables included in the models (see, e.g., Pohl & Carstensen, 2012; and for VA literature on measurement error see, e.g., Ferrão & Goldstein, 2009; Koedel et al., 2012).
Furthermore, only the main effects of the covariates were part of the VA models. In future studies, including interaction effects between covariates in the VA models might allow deeper insights into differences between model specifications in the estimation of VA scores.
For the interpretation of our results, we assumed that higher amount of explained variance will lead to less bias in VA scores. However, it should be noted that, in order to quantify the amount of bias, a validation against credible causal estimates would be necessary, which is not possible given the data of the present study, as the “true” scores are impossible to be known (see, Angrist et al., 2017 for an investigation on bias in school VA scores).
In the present study, we used low-stakes data from the Luxembourg School Monitoring Programme (LUCET, 2021) to circumvent potential sources of bias that result from pressure due to accountability and explore a more informative use of school VA scores, which we would rather recommend. However, this also leads to a limited possibility of generalizing the findings for countries with a high-stakes use of school VA scores (e.g., the UK, France), as the present findings are for now limited to a country with high student diversity and low-stakes data. As the Luxembourgish school system consists of learning cycles, which usually take 2 years but can be extended to 3 years, the number of students who took part in Grade 1 in 2014 but not in Grade 3 in 2016 was quite high. This could have affected the results because the excluded students had lower achievement, lower SES values, and a higher percentage of students who did not speak the first language of instruction at home than those who met the inclusion criteria. However, students who repeated a grade or who switched schools were also excluded from the VA models in prior research, as this practice is typically applied for accountability purposes. Thus, our data and results largely reflect the reality of how school VA scores are typically estimated. Further research is necessary to investigate methods that have previously been suggested for accounting for co-teaching when estimating VA scores, as these methods sound promising to account for school switching (e.g., the “dosage” method, where a percentage of time spent with each of the teachers is used; Hock & Isenberg, 2017).
In addition, in terms of causality and in contrast to the work by Reardon & Raudenbush (2009), we only took into account one point of causal interpretation based on observed data, whereas other aspects, such as the functional form, were kept constant. Furthermore, the used variables were not centered on the mean (as in, e.g., Reardon & Raudenbush, 2009), which would have made the interpretability of VA scores more straightforward.
As the present study was conducted in a highly diverse and multilingual educational context, the present findings would have to be replicated in a more homogenous setting in order to determine whether the findings are only specific to the diverse setting in Luxembourg or can be generalized to other school systems. Additionally, the difference between time points was 2 years (representing one learning cycle in the Luxembourg school system), whereas in most applications of VA models, the difference between time points is only 1 year, which raises the question of whether these results can be replicated with a longitudinal data set with 1 year between measurement points.
The VA score of a certain school juxtaposes the actual level of achievement attained by students attending a certain school with the achievement level that is expected from students who have the same background characteristics. It is thus implicitly assumed that (in a perfect world) we can control for all relevant factors that affect students’ achievement except for differences in the effectiveness between schools. In this perfect world, the resulting VA score would represent a “pure” measure of a school’s effectiveness. However, as in every data set with human data, there are always unobserved relationships, measurement error, and the reliability of the covariates themselves (e.g., Cook et al., 2009), which may affect VA scores. Hence, the VA scores obtained from the various VA models specified in the present paper represent only an estimate of a school’s effectiveness. Yet, this is also the case in the VA models that are used in practice.
The present study only investigated differences in school VA scores within the same time period. However, previous research has indicated high variability in VA scores over time (e.g., Newton et al., 2010; Sass, 2008). Future research could thus extend the present study by including VA scores over a longer time period to investigate whether there are schools with stable VA scores across time within (or across) models and the extent to which the stability over time is related to the choice of covariates.
8 Conclusion
Our study empirically supports several conclusions: First, in line with previous research and common VA practices, prior achievement in the same domain is an important covariate for estimating school VA scores. Second, prior achievement in one domain cannot be replaced by prior achievement from another domain. Third, the amount of explained variance and the consistency of school VA scores may be substantially improved by additionally including covariates of between-school differences in student intake. Differential findings in relation to the outcome domain are (a) prior language achievement and sociodemographic and sociocultural background characteristics in the VA models for math, and (b) sociodemographic and sociocultural background characteristics in the VA models for language. Fourth, even though motivational variables have been highly discussed in models of school learning, they did not incrementally add to the quality of school VA scores. However, this might be different when considering higher grades. Fifth, these findings empirically underscore the idea that school VA scores are sensitive to the selection of covariates because the VA scores may vary considerably within individual schools depending on the covariates included in the school VA model. This in turn can lead to radically different assessments of the effectiveness of the same school, raising further doubts concerning causal interpretations of school VA scores when only prior achievement in the same domain is used as covariate to estimate these scores. We thus recommend using VA models with caution and applying VA scores for informative purposes rather than as a mean to base accountability decisions upon.
References
Amrein-Beardsley, A., & Holloway, J. (2017). Value-added models for teacher evaluation and accountability: Commonsense assumptions. Educational Policy, 33(3), 516–542. https://doi.org/10.1177/0895904817719519
Amrein-Beardsley, A., Collins, C., Polasky, S. A., & Sloat, E. F. (2013). Value-added model (VAM) research for educational policy: Framing the issue. Education Policy Analysis Archives, 21(4), 1–14. https://doi.org/10.14507/epaa.v21n4.2013
Angrist, J. D., Hull, P. D., Pathak, P. A., & Walters, C. R. (2017). Leveraging lotteries for school value-added: Testing and estimation. The Quarterly Journal of Economics, 132(2), 871–919. https://doi.org/10.1093/qje/qjx001
Aubrey, C., Godfrey, R., & Dahl, S. (2006). Early mathematics development and later achievement: Further evidence. Mathematics Education Research Journal, 18(1), 27–46. https://doi.org/10.1007/BF03217428
Bates, D., Mächler, M., Bolker, B., & Walker, S. (2015). Fitting linear mixed-effects models using lme4. Journal of Statistical Software, 67(1), 1–48. https://doi.org/10.18637/jss.v067.i01
Bates, D. (2009). Does lmer use empirical Bayes to estimate random effects. https://stat.ethz.ch/pipermail/r-sig-mixed-models/2009q4/002984.html. Accessed 2020-09-30
Bliese, P. D. (2000). Within-group agreement, non-independence, and reliabiltiy. In K. J. Klein & S. W. J. Kozlowski (Eds.), Multilevel theory, research, and methods in organizations (pp. 349–381). Jossey-Bass. https://www.kellogg.northwestern.edu/rc/workshops/mlm/Bliese_2000.pdf. Accessed 2019-12-10
Boring, E. G. (1923). Intelligence as the tests test it. New Republic, 35–37.
Braun, H. (2015). The value in value added depends on the ecology. Educational Researcher, 44(2), 127–131. https://doi.org/10.3102/0013189X15576341
Brunner, M., Keller, U., Wenger, M., Fischbach, A., & Lüdtke, O. (2018). Between-school variation in students’ achievement, motivation, affect, and learning strategies: Results from 81 countries for planning group-randomized trials in education. Journal of Research on Educational Effectiveness, 11(3), 452–478. https://doi.org/10.1080/19345747.2017.1375584
Cachón-Zagalaz, J., Sánchez-Zafra, M., Sanabrias-Moreno, D., González-Valero, G., Lara-Sánchez, A. J., & Zagalaz-Sánchez, M. L. (2020). Systematic review of the literature about the effects of the COVID-19 pandemic on the lives of school children. Frontiers in Psychology, 11. https://doi.org/10.3389/fpsyg.2020.569348
Campbell, D. T. (1976). Assessing the impact of planned social change. Occasional Paper Series, 8.
Casillas, A., Robbins, S., Allen, J., Kuo, Y.-L., Hanson, M. A., & Schmeiser, C. (2012). Predicting early academic failure in high school from prior academic achievement, psychosocial characteristics, and behavior. Journal of Educational Psychology, 104(2), 407–420. https://doi.org/10.1037/a0027180
Close, K., Amrein-Beardsley, A., & Collins, C. (2018). State-level assessments and teacher evaluation systems after the passage of the every student succeeds act: Some steps in the right direction. National Education Policy Center. http://nepc.colorado.edu/publication/state-assessment. Accessed 2019-10-16
Conaway, C., & Goldhaber, D. (2018). Appropriate Standards of evidence for education policy decision-making (No. 04032018–1–3; CEDR Policy Brief). University of Washington.
Cook, T. D., Steiner, P. M., & Pohl, S. (2009). How bias reduction is affected by covariate choice, unreliability, and mode of data analysis: Results from two types of within-study comparisons. Multivariate Behavioral Research, 44(6), 828–847. https://doi.org/10.1080/00273170903333673
Dalby, D. (1999). The linguasphere register of the world’s languages and speech communities / (Vol. 1–2). Linguasphere Press.
Darling-Hammond, L. (2015). Can value added add value to teacher evaluation? Educational Researcher, 44(2), 132–137. https://doi.org/10.3102/0013189X15575346
De Fraine, B., Van Damme, J., Van Landeghem, G., Opdenakker, M.-C., & Onghena, P. (2003). The effect of schools and classes on language achievement. British Educational Research Journal, 29(6), 841–859. https://doi.org/10.1080/0141192032000137330
Dearden, L., Miranda, A., & Rabe-Hesketh, S. (2011). Measuring school value added with administrative data: The problem of missing variables. Fiscal Studies, 32(2), 263–278. https://doi.org/10.1111/j.1475-5890.2011.00136.x
Doran, H. C., & Lockwood, J. R. (2006). Fitting value-added models in R. Journal of Educational and Behavioral Statistics, 31(2), 205–230. https://doi.org/10.3102/10769986031002205
Duclos, M., & Murat, F. (2014). Comment évaluer la performance des lycées? Un point sur la méthodologie des IVAL (Indicateurs de valeur ajoutée des lycées). Éducation & Formations, 85, 73–84.
Dumont, H., Neumann, M., Maaz, K., & Trautwein, U. (2013). Die Zusammensetzung der Schülerschaft als Einflussfaktor für Schulleistungen. Internationale und nationale Befunde. Psychologie in Erziehung Und Unterricht, 3, 163–183. https://doi.org/10.2378/peu2013.art14d
Ehlert, M., Koedel, C., Parsons, E., & Podgursky, M. J. (2014). The sensitivity of value-added estimates to specification adjustments: Evidence from school- and teacher-level models in Missouri. Statistics and Public Policy, 1(1), 19–27. https://doi.org/10.1080/2330443X.2013.856152
Ehlert, M., Koedel, C., Parsons, E., & Podgursky, M. (2016). Selecting growth measures for use in school evaluation systems: Should proportionality matter? Educational Policy, 30(3), 465–500. https://doi.org/10.1177/0895904814557593
Elgart, D. B. (1978). Oral reading, silent reading, and listening comprehension: A comparative study. Journal of Reading Behavior, 10(2), 203–207. https://doi.org/10.1080/10862967809547270
Everson, K. C. (2017). Value-added modeling and educational accountability: Are we answering the real questions? Review of Educational Research, 87(1), 35–70. https://doi.org/10.3102/0034654316637199
Every Student Succeeds Act, Pub. L. No. 114–95, S.1177—114th Congress (2015).
Ferrão, M. E. (2009). Sensivity of value added model specifications: Measuring socio-economic status. Revista De Educacin, 348, 137–152.
Ferrão, M. E. (2012). On the stability of value added indicators. Quality & Quantity, 46(2), 627–637. https://doi.org/10.1007/s11135-010-9417-6
Ferrão, M. E., & Goldstein, H. (2009). Adjusting for measurement error in the value added model: Evidence from Portugal. Quality & Quantity, 43(6), 951–963. https://doi.org/10.1007/s11135-008-9171-1
Fischbach, A., Ugen, S., & Martin, R. (2014). ÉpStan technical report. University of Luxembourg. http://hdl.handle.net/10993/15802
Fitz-Gibbon, C. T. (1997). The value added national project: Final report: Feasibility studies for a national system of value-added indicators. School Curriculum and Assessment Authority.
Floden, R. E. (2012). Teacher value added as a measure of program quality: Interpret with caution. Journal of Teacher Education, 63(5), 356–360. https://doi.org/10.1177/0022487112454175
Foley, B., & Goldstein, H. (2012). Mesuring success: League tables in the public sector. British Academy. Accessed 2022-03-19
Gallup, Inc. (2018). Assessing soft skills: Are we preparing students for successful futures? A Perceptions Study of Parents, Teachers, and School Administrators. https://www.nwea.org/content/uploads/2018/08/NWEA_Gallup-Report_August-2018.pdf
Ganzeboom, H. B. G. (2010). International Standard Classification of Occupations (ISCO) (pp. 3336–3336). Springer Netherlands. https://doi.org/10.1007/978-94-007-0753-5_102084
Genesee, F., Lindholm-Leary, K., Saunders, W., & Christian, D. (2005). English language learners in US schools: An overview of research findings. Journal of Education for Students Placed at Risk, 10(4), 363–385. https://doi.org/10.1207/s15327671espr1004_2
Gogol, K., Brunner, M., Goetz, T., Martin, R., Ugen, S., Keller, U., Fischbach, A., & Preckel, F. (2014). “My questionnaire is too long!” The assessments of motivational-affective constructs with three-item and single-item measures. Contemporary Educational Psychology, 39(3), 188–205. https://doi.org/10.1016/j.cedpsych.2014.04.002
Gogol, K., Brunner, M., Preckel, F., Goetz, T., & Martin, R. (2016). Developmental dynamics of general and school-subject-specific components of academic self-concept, academic interest, and academic anxiety. Frontiers in Psychology, 7, 356. https://doi.org/10.3389/fpsyg.2016.00356
Grund, S., Robitzsch, Alexander, & Luedtke, Oliver. (2019). mitml: Tools for multiple imputation in multilevel modeling (R package version 0.3–7) [Computer software]. https://CRAN.R-project.org/package=mitml. Accessed 2019-09-1
Guarino, C. M., Maxfield, M., Reckase, M. D., Thompson, P. N., & Wooldridge, J. M. (2015). An evaluation of empirical Bayes’s estimation of value-added teacher performance measures. Journal of Educational and Behavioral Statistics, 40(2), 190–222.
Hægeland, T., & Kirkebøen, L. J. (2008). School performance and value-added indicators—What is the effect of controlling for socioeconomic background (No. 2008/8). Statistics Norway. https://www.ssb.no/a/english/publikasjoner/pdf/doc_200808_en/doc_200808_en.pdf. Accessed 2020-03-04
Haertel, G. D., Walberg, H. J., & Weinstein, T. (1983). Psychological models of educational performance: A theoretical synthesis of constructs. Review of Educational Research, 53(1), 75–91. https://doi.org/10.3102/00346543053001075
Hanushek, E. A. (1971). Teacher characteristics and gains in student achievement: Estimation using micro data. The American Economic Review, 61(2), 280–288.
Harris, D. N. & Anderson, A. (2013). Does value-added work better in elementary than in secondary grades? (What We Know Series: Value-Added Methods and Applications) [Knowledge Brief]. Carnegie Knowledge Network. https://eric.ed.gov/?id=ED560139. Accessed 2017-02-22
Heckman, J. J., & Kautz, T. (2012). Hard evidence on soft skills. Labour Economics, 19(4), 451–464. https://doi.org/10.1016/j.labeco.2012.05.014
Hemmings, B., & Kay, R. (2010). Prior achievement, effort, and mathematics attitude as predictors of current achievement. The Australian Educational Researcher, 37(2), 41–58. https://doi.org/10.1007/BF03216921
Hock, H., & Isenberg, E. (2017). Methods for accounting for co-teaching in value-added models. Statistics and Public Policy, 4(1), 1–11. https://doi.org/10.1080/2330443X.2016.1265473
Hox, J. J. (2013). Multilevel regression and multilevel structural equation modeling. In The Oxford Handbook of Quantitative Methods in Psychology: Vol. 2: Statistical Analysis. Oxford University Press. https://doi.org/10.1093/oxfordhb/9780199934898.013.0014
James, G., Witten, D., Hastie, T., & Tibshirani, R. (2013). An introduction to statistical learning (Vol. 103). Springer, New York. https://doi.org/10.1007/978-1-4614-7138-7
Jansen, M., & Stanat, P. (2015). Achievement and motivation in mathematics and science: The role of gender and immigration background. International Journal of Gender, Science and Technology, 8(1), 4–18.
Johnson, M. T., Lipscomb, S., & Gill, B. (2015). Sensitivity of teacher value-added estimates to student and peer control variables. Journal of Research on Educational Effectiveness, 8(1), 60–83. https://doi.org/10.1080/19345747.2014.967898
Kane, T. J., McCaffrey, D. F., Miller, T., & Staiger, D. O. (2013). Have we identified effective teachers? Validating measures of effective teaching using random assignment. Research Paper. MET Project. Bill & Melinda Gates Foundation.
Koedel, C., Leatherman, R., & Parsons, E. (2012). Test measurement error and inference from value-added models. The B.E. Journal of Economic Analysis & Policy, 12(1), 1–37. https://doi.org/10.1515/1935-1682.3314
Koedel, C., Mihaly, K., & Rockoff, J. E. (2015). Value-added modeling: A review. Economics of Education Review, 47, 180–195. https://doi.org/10.1016/j.econedurev.2015.01.006
Kruschke, J. K., & Liddell, T. M. (2018). Bayesian data analysis for newcomers. Psychonomic Bulletin & Review, 25(1), 155–177. https://doi.org/10.3758/s13423-017-1272-1
Kupermintz, H. (2003). Teacher effects and teacher effectiveness: A validity investigation of the Tennessee value added assessment system. Educational Evaluation and Policy Analysis, 25(3), 287–298. https://doi.org/10.3102/01623737025003287
Kurtz, M. D. (2018). Value-added and student growth percentile models: What drives differences in estimated classroom effects? Statistics and Public Policy, 5(1), 1–8. https://doi.org/10.1080/2330443X.2018.1438938
Leckie, G., & Goldstein, H. (2019). The importance of adjusting for pupil background in school value-added models: A study of progress 8 and school accountability in England. British Educational Research Journal, 45(3), 518–537. https://doi.org/10.1002/berj.3511
Levy, J., Brunner, M., Keller, U., & Fischbach, A. (2019). Methodological issues in value-added modeling: An international review from 26 countries. Educational Assessment, Evaluation and Accountability, 31(3), 257–287. https://doi.org/10.1007/s11092-019-09303-w
Levy, J., Mussack, D., Brunner, M., Keller, U., Cardoso-Leite, P., & Fischbach, A. (2020). Contrasting classical and machine learning approaches in the estimation of value-added scores in large-scale educational data. Frontiers in Psychology, 11, Article 2190. https://doi.org/10.3389/fpsyg.2020.02190
Loeb, S. (2013). How can value-added measures be used for teacher improvement? (What We Know Series: Value-Added Methods and Applications). Carnegie Knowledge Network. Accessed 2017-05-03
LUCET. (2021). Épreuves Standardisées (ÉpStan). https://epstan.lu
Lüdecke, D., Ben-Shachar, M., Patil, I., Waggoner, P., & Makowski, D. (2021). performance: An R package for assessment, comparison and testing of statistical models. Journal of Open Source Software, 6(60), 3139. https://doi.org/10.21105/joss.03139
Lüdtke, O., Trautwein, U., Kunter, M., & Baumert, J. (2006). Reliability and agreement of student ratings of the classroom environment: A reanalysis of TIMSS data. Learning Environments Research, 9(3), 215–230. https://doi.org/10.1007/s10984-006-9014-8
Luyten, H., Tymms, P., & Jones, P. (2009). Assessing school effects without controlling for prior achievement? School Effectiveness and School Improvement, 20(2), 145–165. https://doi.org/10.1080/09243450902879779
Marks, G. N. (2017). Is adjusting for prior achievement sufficient for school effectiveness studies? Educational Research and Evaluation, 23(5–6), 148–162. https://doi.org/10.1080/13803611.2017.1455287
Marsh, H. W., & Craven, R. G. (2006). Reciprocal effects of self-concept and performance from a multidimensional perspective: Beyond seductive pleasure and unidimensional perspectives. Perspectives on Psychological Science, 1(2), 133–163. https://doi.org/10.1111/j.1745-6916.2006.00010.x
Marsh, H. W., Trautwein, U., Lüdtke, O., Köller, O., & Baumert, J. (2005). Academic self-concept, interest, grades, and standardized test scores: Reciprocal effects models of causal ordering. Child Development, 76(2), 397–416.
Marsh, H. W. (1990). Self-Description Questionnaire (SDQ) II: A theoretical and empirical basis for the measurement of multiple dimensions of adolescent selfconcept: An interim test manual and a research monograph.
Marzano, R. J., & Toth, M. D. (2013). Teacher evaluation that makes a difference: A new model for teacher growth and student achievement. ASCD.
Ministry of National Education, Children and Youth. (2011). Elementary School. Cycles 1 -4. The Levels of Competence. http://www.men.public.lu/catalogue-publications/fondamental/apprentissages/documents-obligatoires/niveaux-competences/en.pdf. Accessed 2019-05-06
Ministry of National Education, Children and Youth. (2018). L’enseignement luxembourgeois en chiffres: Année scolaire 2016–2017. MENJE. http://www.men.public.lu/catalogue-publications/themes-transversaux/statistiques-analyses/enseignement-chiffres/2016-2017-depliant/en.pdf. Accessed 2019-04-08
Muñoz-Chereau, B., & Thomas, S. M. (2016). Educational effectiveness in Chilean secondary education: Comparing different ‘value added’ approaches to evaluate schools. Assessment in Education: Principles, Policy & Practice, 23(1), 26–52. https://doi.org/10.1080/0969594X.2015.1066307
Nagy, G., & Neumann, M. (2010). Psychometrische Aspekte des Tests zu den voruniversitären Mathematikleistungen in TOSCA-2002 und TOSCA-2006: Unterrichtsvalidität, Rasch-Homogenität und Messäquivalenz. In U. Trautwein, M. Neumann, G. Nagy, O. Lüdtke, & K. Maaz (Eds.), Schulleistungen von Abiturienten. Die neu geordnete gymnasiale Oberstufe auf dem Prüfstand. (pp. 281–306). VS Verlag für Sozialwissenschaften.
Newton, X., Darling-Hammond, L., Haertel, E., & Thomas, E. (2010). Value-added modeling of teacher effectiveness: An exploration of stability across models and contexts. Education Policy Analysis Archives, 18(23), 1–24. https://doi.org/10.14507/epaa.v18n23.2010
Niepel, C., Greiff, S., Keller, U., & Fischbach, A. (2017). Dimensional comparisons in primary school. A validation of the generalized I/E model. 17th Conference of the EARLI, Tampere, Finland.
OECD. (2018). PISA for Development assessment and analytical framework: Reading, mathematics and science. OECD Publishing. https://doi.org/10.1787/9789264305274-en
Pelletier, M. (2018, March 16). Soft-Skills are Becoming a Stronger Component in School Accountability. MDR. https://mdreducation.com/2018/03/16/soft-skills-becoming-stronger-school-accountability/. Accessed 2019-05-28
Peng, P., Lin, X., Ünal, Z. E., Lee, K., Namkung, J., Chow, J., & Sales, A. (2020). Examining the mutual relations between language and mathematics: A meta-analysis. Psychological Bulletin, 146(7), 595–634. https://doi.org/10.1037/bul0000231
Perry, T. (2016). English value-added measures: Examining the limitations of school performance measurement. British Educational Research Journal, 42(6), 1056–1080. https://doi.org/10.1002/berj.3247
Pohl, S., & Carstensen, C. H. (2012). NEPS technical report—Scaling the data of the competence Tests (No. 14; NEPS Working Paper). Otto-Friedrich-Universität, Nationales Bildungspanel. https://www.neps-data.de/Portals/0/Working%20Papers/WP_XIV.pdf
Quartagno, M., & Carpenter, J. (2019). jomo: A package for multilevel joint modelling multiple imputation. https://CRAN.R-project.org/package=jomo. Accessed 2019-12-12
R Core Team. (2019). R: A language and environment for statistical computing. R Foundation for Statistical Computing. Accessed 2019-12-12
Ray, A. (2006). School value added measures in England (A Paper for the OECD Project on the Development of Value-Added Models in Education Systems).
Reardon, S. F., & Raudenbush, S. W. (2009). Assumptions of value-added models for estimating school effects. Education Finance and Policy, 4(4), 492–519. https://doi.org/10.1162/edfp.2009.4.4.492
Reynolds, A. J. (1991). The middle schooling process: Influences of science and mathematics achievement from the longitudinal study of American youth. Adolescence, 26(101), 133.
Robitzsch, A., Kiefer, T., & Wu, M. (2019). TAM: test analysis modules (3.3–10) [Computer software]. https://CRAN.R-project.org/package=TAM. Accessed 2019-12-02
Rohrer, J. M., Egloff, B., & Schmukle, S. C. (2017). Probing birth-order effects on narrow traits using specification-curve analysis. Psychological Science, 28(12), 1821–1832. https://doi.org/10.1177/0956797617723726
Rothstein, J. (2009). Student sorting and bias in value added estimation: Selection on observables and unobservables. Education Finance and Policy, 4(4), 537–571. https://doi.org/10.1162/edfp.2009.4.4.537
Rubin, D. B., Stuart, E. A., & Zanutto, E. L. (2004). A potential outcomes view of value-added assessment in education. Journal of Educational and Behavioral Statistics, 29(1), 103–116. https://doi.org/10.3102/10769986029001103
Sanders, W. L., & Horn, S. P. (1994). The Tennessee Value-added assessment system (TVAAS): Mixed-model methodology in educational assessment. Journal of Personnel Evaluation in Education, 8(3), 299–311. https://doi.org/10.1007/BF00973726
Sass, T. R. (2008). The stability of value-added measures of teacher quality and implications for teacher compensation policy. Brief 4 (Brief No. 4). National center for analysis of longitudinal data in education research. https://eric.ed.gov/?id=ED508273. Accessed 2017-02-08
Scherrer, J. (2011). Measuring teaching using value-added modeling: The imperfect panacea. NASSP Bulletin, 95(2), 122–140. https://doi.org/10.1177/0192636511410052
Schmitt, N. (1996). Uses and abuses of coefficient alpha. Psychological Assessment, 8(4), 350.
Simonsohn, U., Simmons, J. P., & Nelson, L. D. (2015). Specification curve: Descriptive and inferential statistics on all reasonable specifications. SSRN Electronic Journal. https://doi.org/10.2139/ssrn.2694998
Sirin, S. R. (2005). Socioeconomic status and academic achievement: A meta-analytic review of research. Review of Educational Research, 75(3), 417–453. https://doi.org/10.3102/00346543075003417
Sloane, F. C., Oloff-Lewis, J., & Kim, S. H. (2013). Value-added models of teacher and school effectiveness in Ireland: Wise or otherwise? Irish Educational Studies, 32(1), 37–67. https://doi.org/10.1080/03323315.2013.773233
Snijders, T. A. B., & Bosker, R. J. (2012). Multilevel analysis: An introduction to basic and applied multilevel analysis. SAGE Publications.
Spinath, B., Spinath, F. M., Harlaar, N., & Plomin, R. (2006). Predicting school achievement from general cognitive ability, self-perceived ability, and intrinsic value. Intelligence, 34(4), 363–374. https://doi.org/10.1016/j.intell.2005.11.004
Standards for educational and psychological testing. (2014). American educational research association. https://www.testingstandards.net/open-access-files.html. Accessed 2022-03-19
Steiner, P. M., Cook, T. D., Shadish, W. R., & Clark, M. H. (2010). The importance of covariate selection in controlling for selection bias in observational studies. Psychological Methods, 15(3), 250. https://doi.org/10.1037/a0018719
Steiner, P. M., Cook, T. D., & Shadish, W. R. (2011). On the importance of reliable covariate measurement in selection bias adjustments using propensity scores. Journal of Educational and Behavioral Statistics, 36(2), 213–236. https://doi.org/10.3102/1076998610375835
Steiner, P. M., Cook, T. D., Li, W., & Clark, M. H. (2015). Bias reduction in quasi-experiments with little selection theory but many covariates. Journal of Research on Educational Effectiveness, 8(4), 552–576. https://doi.org/10.1080/19345747.2014.978058
Steinmayr, R., & Spinath, B. (2009). The importance of motivation as a predictor of school achievement. Learning and Individual Differences, 19(1), 80–90. https://doi.org/10.1016/j.lindif.2008.05.004
Stoffel, M., Nakagawa, S., & Schielzeth, H. (2019). rptR: Repeatability estimation for Gaussian and non-Gaussian data (0.9.22) [Computer software]. https://CRAN.R-project.org/package=rptR. Accessed 2020-01-10
Tekwe, C. D., Carter, R. L., Ma, C.-X., Algina, J., Lucas, M. E., Roth, J., Ariet, M., Fisher, T., & Resnick, M. B. (2004). An empirical comparison of statistical models for value-added assessment of school performance. Journal of Educational and Behavioral Statistics, 29(1), 11–36. https://doi.org/10.3102/10769986029001011
Timmermans, A. C., Doolaard, S., & de Wolf, I. (2011). Conceptual and empirical differences among various value-added models for accountability. School Effectiveness and School Improvement, 22(4), 393–413. https://doi.org/10.1080/09243453.2011.590704
Tymms, P. (1999). Baseline assessment, value-added and the prediction of reading. Journal of Research in Reading, 22(1), 27–36. https://doi.org/10.1111/1467-9817.00066
Valentine, J. C., DuBois, D. L., & Cooper, H. (2004). The relation between self-beliefs and academic achievement: A meta-analytic review. Educational Psychologist, 39(2), 111–133.
van de Grift, W. (2009). Reliability and validity in measuring the value added of schools. School Effectiveness and School Improvement, 20(2), 269–285. https://doi.org/10.1080/09243450902883946
van der Westhuizen, L., Arens, K., Keller, U., Greiff, S., Fischbach, A., & Niepel, C. (2019). Dimensional and social comparison effects on domain-specific academic self-concepts and interests with first-and third-grade students. LuxERA Emerging Researchers’ Conference, Esch-sur-Alzette, Luxembourg.
Van Rinsveld, A., Brunner, M., Landerl, K., Schiltz, C., & Ugen, S. (2015). The relation between language and arithmetic in bilinguals: Insights from different stages of language acquisition. Frontiers in Psychology, 6, 265. https://doi.org/10.3389/fpsyg.2015.00265
van Zeeland, H., & Schmitt, N. (2013). Lexical coverage in L1 and L2 listening comprehension: The same or different from reading comprehension? Applied Linguistics, 34(4), 457–479. https://doi.org/10.1093/applin/ams074
Voyer, D., & Voyer, S. D. (2014). Gender differences in scholastic achievement: A meta-analysis. Psychological Bulletin, 140(4), 1174–1204. https://doi.org/10.1037/a0036620
Wang, M. C., Haertel, G. D., & Walberg, H. J. (1993). Toward a knowledge base for school learning. Review of Educational Research, 63(3), 249–294. https://doi.org/10.2307/1170546
Warm, T. A. (1989). Weighted likelihood estimation of ability in item response theory. Psychometrika, 54(3), 427–450. https://doi.org/10.1007/BF02294627
Weidinger, A. F., Steinmayr, R., & Spinath, B. (2019). Ability self-concept formation in elementary school: No dimensional comparison effects across time. Developmental Psychology, 55(5), 1005–1018. https://doi.org/10.1037/dev0000695
Wu, L. M., Adams, R. J., Wilson, M. R., & Haldane, S. A. (2007). ACER ConQuest version 2: Generalised item response modelling software [computer program]. Australian Council for Educational Research.
Yates, S. (2000). Task involvement and ego orientation in mathematics achievement: A three-year follow-up. Issues in Educational Research, 10(1), 77–91.
Acknowledgements
We want to thank Jane Zagorski for her thorough editing.
Funding
The present research was supported by a PRIDE grant (PRIDE/15/10921377) of the Luxembourg National Research Fund (FNR).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no conflict of interest.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Levy, J., Brunner, M., Keller, U. et al. How sensitive are the evaluations of a school’s effectiveness to the selection of covariates in the applied value-added model?. Educ Asse Eval Acc 35, 129–164 (2023). https://doi.org/10.1007/s11092-022-09386-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11092-022-09386-y