
Abstract
We consider the problem of minimizing a function that is a sum of convex agent functions plus a convex common public function that couples them. The agent functions can only be accessed via a subgradient oracle; the public function is assumed to be structured and expressible in a domain specific language (DSL) for convex optimization. We focus on the case when the evaluation of the agent oracles can require significant effort, which justifies the use of solution methods that carry out significant computation in each iteration. To solve this problem we integrate multiple known techniques (or adaptations of known techniques) for bundle-type algorithms, obtaining a method which has a number of practical advantages over other methods that are compatible with our access methods, such as proximal subgradient methods. First, it is reliable, and works well across a number of applications. Second, it has very few parameters that need to be tuned, and works well with sensible default values. Third, it typically produces a reasonable approximate solution in just a few tens of iterations. This paper is accompanied by an open-source implementation of the proposed solver, available at https://github.com/cvxgrp/OSBDO.







Similar content being viewed by others
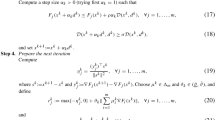

References
Agrawal A, Verschueren R, Diamond S, Boyd S (2018) A rewriting system for convex optimization problems. J Control Decis 5(1):42–60
Atkinson D, Vaidya P (1995) A cutting plane algorithm for convex programming that uses analytic centers. Math Program 69:1–43
Bacaud L, Lemaréchal C, Renaud A, Sagastizábal C (2001) Bundle methods in stochastic optimal power management: a disaggregated approach using preconditioners. Comput Optim Appl 20:227–244
Belloni A (2005) Lecture notes for IAP 2005 course introduction to bundle methods. Operation Research Center, MIT, Version of February, 11
Ben Amor H, Desrosiers J, Frangioni A (2009) On the choice of explicit stabilizing terms in column generation. Discret Appl Math 157(6):1167–1184
Birgin E, Martínez J, Raydan M (2003) Inexact spectral projected gradient methods on convex sets. IMA J Numer Anal 23(4):539–559
Boyd, S, Duchi J, Pilanci M, Vandenberghe L (2022) Stanford EE 364b, lecture notes on subgradients. URL: https://web.stanford.edu/class/ee364b/lectures/subgradients_notes.pdf
Boyd S, Vandenberghe L (2004) Convex optimization. Cambridge University Press, Cambridge
Boyd S, Parikh N, Chu E (2011) Distributed optimization and statistical learning via the alternating direction method of multipliers. Found Trends Mach Learn 3(1):1–122
Bradley A (2010) Algorithms for the equilibration of matrices and their application to limited-memory Quasi-Newton methods. PhD thesis, Stanford University, CA
Bruck R (1975) An iterative solution of a variational inequality for certain monotone operators in Hilbert space. Bull Am Math Soc 81:890–892
Burachik R, Martínez-Legaz J, Rezaie M, Théra M (2015) An additive subfamily of enlargements of a maximally monotone operator. Set-Valued Variat Anal 23:643–665
Burke J, Qian M (2000) On the superlinear convergence of the variable metric proximal point algorithm using Broyden and BFGS matrix secant updating. Math Program 88:157–181
Chen X, Fukushima M (1999) Proximal quasi-Newton methods for nondifferentiable convex optimization. Math Program 85(2):313–334
Chen G, Rockafellar R (1997) Convergence rates in forward-backward splitting. SIAM J Optim 7(2):421–444
Cheney E, Goldstein A (1959) Newton’s method for convex programming and Tchebycheff approximation. Numer Math 1:253–268
Choi Y, Lim Y (2016) Optimization approach for resource allocation on cloud computing for IoT. Int J Distrib Sens Netw 12(3):3479247
Combettes P, Pesquet J-C (2011) Proximal splitting methods in signal processing. Fixed-point algorithms for inverse problems in science and engineering. Springer, Berlin, pp 185–212
Concus P, Golub G, Meurant G (1985) Block preconditioning for the conjugate gradient method. SIAM J Sci Stat Comput 6(1):220–252
Correa R, Lemaréchal C (1993) Convergence of some algorithms for convex minimization. Math Program 62:261–275
de Oliveira W, Solodov M (2016) A doubly stabilized bundle method for nonsmooth convex optimization. Math Program 156(1):125–159
de Oliveira W, Solodov M (2020) Bundle methods for inexact data. Numerical nonsmooth optimization. Springer, Berlin, pp 417–459
de Oliveira W, Sagastizábal C, Lemaréchal C (2014) Convex proximal bundle methods in depth: a unified analysis for inexact oracles. Math Program 148:241–277
de Oliveira W, Eckstein J (2015) A bundle method for exploiting additive structure in difficult optimization problems. Optimization Online
Dem’yanov V, Vasil’ev L (1985) Nondifferentiable optimization. Translations series in mathematics and engineering. Springer, New York
Diamond S, Boyd S (2016) CVXPY: a Python-embedded modeling language for convex optimization. J Mach Learn Res 17(83):1–5
Díaz M (2021) proximal-bundle-method. Julia software package available at https://github.com/mateodd25/proximal-bundle-method
Díaz M, Grimmer B (2023) Optimal convergence rates for the proximal bundle method. SIAM J Optim 33(2):424–454
Duchi J, Hazan E, Singer Y (2011) Adaptive subgradient methods for online learning and stochastic optimization. J Mach Learn Res 12(7):2121–2159
Elzinga J, Moore T (1975) A central cutting plane algorithm for the convex programming problem. Math Program 8:134–145
Emiel G, Sagastizábal C (2010) Incremental-like bundle methods with application to energy planning. Comput Optim Appl 46(2):305–332
Fischer F (2022) An asynchronous proximal bundle method. Optimization Online
Frangioni A (2002) Generalized bundle methods. SIAM J Optim 13(1):117–156
Frangioni A (2020) Standard bundle methods: untrusted models and duality. Numerical nonsmooth optimization. Springer, Berlin, pp 61–116
Frangioni A, Gorgone E (2014) Bundle methods for sum-functions with “easy’’ components: applications to multicommodity network design. Math Program 145:133–161
Frangioni A, Gorgone E (2014) Generalized bundle methods for sum-functions with “easy’’ components: applications to multicommodity network design. Math Program 145:133–161
Fuduli A, Gaudioso M, Giallombardo G (2004) Minimizing nonconvex nonsmooth functions via cutting planes and proximity control. SIAM J Optim 14(3):743–756
Gonzaga C, Polak E (1979) On constraint dropping schemes and optimality functions for a class of outer approximations algorithms. SIAM J Control Optim 17(4):477–493
Grant M, Boyd S, Ye Y (2006) Disciplined convex programming. Global optimization. Springer, Berlin, pp 155–210
Haarala M, Miettinen K, Mäkelä M (2004) New limited memory bundle method for large-scale nonsmooth optimization. Optim Methods Softw 19(6):673–692
Haarala N, Miettinen K, Mäkelä M (2007) Globally convergent limited memory bundle method for large-scale nonsmooth optimization. Math Program 109:181–205
Han Z, Liu K (2008) Resource allocation for wireless networks: basics, techniques, and applications. Cambridge University Press, Cambridge
Hare W, Sagastizábal C, Solodov M (2016) A proximal bundle method for nonsmooth nonconvex functions with inexact information. Comput Optim Appl 63(1):1–28
Helmberg C, Rendl F (2000) A spectral bundle method for semidefinite programming. SIAM J Optim 10(3):673–696
Helmberg C, Pichler A (2017) Dynamic scaling and submodel selection in bundle methods for convex optimization. https://www.tu-chemnitz.de/mathematik/preprint/2017/PREPRINT_04.pdf
Hestenes M, Stiefel E et al (1952) Methods of conjugate gradients for solving linear systems. J Res Natl Bur Stand 49(6):409–436
Hintermüller M (2001) A proximal bundle method based on approximate subgradients. Comput Optim Appl 20(3):245–266
Hiriart-Urruty J-B, Lemaréchal C (1996) Convex analysis and minimization algorithms II: advanced theory and bundle methods. Grundlehren der mathematischen Wissenschaften. Springer, Berlin Heidelberg
Hiriart-Urruty J-B, Lemaréchal C (2013) Convex analysis and minimization algorithms I: fundamentals, vol 305. Springer Science & Business Media, Berlin
Iutzeler F, Malick J, de Oliveira W (2020) Asynchronous level bundle methods. Math Program 184:319–348
Jacobi C (1845) Ueber eine neue auflösungsart der bei der methode der kleinsten quadrate vorkommenden lineären gleichungen. Astron Nachr 22(20):297–306
Kairouz P, McMahan H, Avent B, Bellet A, Bennis M, Bhagoji A, Bonawitz K, Charles Z, Cormode G, Cummings R et al (2021) Advances and open problems in federated learning. Found Trends Mach Learn 14(1–2):1–210
Karmitsa N (2016) Proximal bundle method. http://napsu.karmitsa.fi/proxbundle/
Karmitsa N (2007) LMBM—FORTRAN subroutines for large-scale nonsmooth minimization: user’s manual. TUCS Tech Rep 77:856
Karmitsa N, Mäkelä M (2010) Limited memory bundle method for large bound constrained nonsmooth optimization: convergence analysis. Optim Methods Softw 25(6):895–916
Kelley J (1960) The cutting-plane method for solving convex programs. J Soc Ind Appl Math 8(4):703–712
Kim K, Petra C, Zavala V (2019) An asynchronous bundle-trust-region method for dual decomposition of stochastic mixed-integer programming. SIAM J Optim 29(1):318–342
Kim K, Zhang W, Nakao H, Schanen M (2021) BundleMethod.jl: Implementation of Bundle Methods in Julia
Kiwiel K (1983) An aggregate subgradient method for nonsmooth convex minimization. Math Program 27:320–341
Kiwiel K (1985) An algorithm for nonsmooth convex minimization with errors. Math Comput 45(171):173–180
Kiwiel K (1990) Proximity control in bundle methods for convex nondifferentiable minimization. Math Program 46(1–3):105–122
Kiwiel K (1995) Approximations in proximal bundle methods and decomposition of convex programs. J Optim Theory Appl 84(3):529–548
Kiwiel K (1996) Restricted step and Levenberg–Marquardt techniques in proximal bundle methods for nonconvex nondifferentiable optimization. SIAM J Optim 6(1):227–249
Kiwiel K (1999) A bundle Bregman proximal method for convex nondifferentiable minimization. Math Program 85(2):241–258
Kiwiel K (2000) Efficiency of proximal bundle methods. J Optim Theory Appl 104(3):589–603
Kiwiel K (2006) A proximal bundle method with approximate subgradient linearizations. SIAM J Optim 16(4):1007–1023
Lemaréchal C (1978) Nonsmooth optimization and descent methods. IIASA Research Report, 78-4
Lemaréchal C (1975) An extension of Davidon methods to non differentiable problems. Math Program Study 3:95–109
Lemaréchal C (2001) Lagrangian relaxation. Computational combinatorial optimization. Springer, Berlin, pp 112–156
Lemaréchal C, Sagastizábal C (1994) An approach to variable metric bundle methods. System modelling and optimization. Springer, Berlin, pp 144–162
Lemaréchal C, Sagastizábal C (1997) Variable metric bundle methods: from conceptual to implementable forms. Math Program 76:393–410
Lemaréchal C, Nemirovskii A, Nesterov Y (1995) New variants of bundle methods. Math Program 69(1):111–147
Lemaréchal C, Ouorou A, Petrou G (2009) A bundle-type algorithm for routing in telecommunication data networks. Comput Optim Appl 44:385–409
Lemaréchal C, Sagastizábal C, Pellegrino F, Renaud A (1996) Bundle methods applied to the unit-commitment problem. In: System modelling and optimization: proceedings of the seventeenth IFIP TC7 conference on system modelling and optimization, 1995. Springer, Berlin, pp 395–402
Li T, Sahu AK, Talwalkar A, Smith V (2020) Federated learning: challenges, methods, and future directions. IEEE Signal Process Mag 37(3):50–60
Lions P, Mercier B (1979) Splitting algorithms for the sum of two nonlinear operators. SIAM J Numer Anal 16(6):964–979
Liu Y, Zhao S, Du X, Li S (2005) Optimization of resource allocation in construction using genetic algorithms. In: 2005 International conference on machine learning and cybernetics, vol 6, pp 3428–3432. IEEE
Lukšan L, Vlček J (1998) A bundle-Newton method for nonsmooth unconstrained minimization. Math Program 83:373–391
Lukšan L, Vlček J (1999) Globally convergent variable metric method for convex nonsmooth unconstrained minimization. J Optim Theory Appl 102:593–613
Lv J, Pang L, Meng F (2018) A proximal bundle method for constrained nonsmooth nonconvex optimization with inexact information. J Global Optim 70(3):517–549
Mäkelä M (2003) Multiobjective proximal bundle method for nonconvex nonsmooth optimization: Fortran subroutine MPBNGC 2.0. Reports of the Department of Mathematical Information Technology, Series B. Sci Comput B 13:2003
Mäkelä M, Karmitsa N, Wilppu O (2016) Proximal bundle method for nonsmooth and nonconvex multiobjective optimization. Math Model Optim Complex Struct, 191–204
Marsten R, Hogan W, Blankenship J (1975) The boxstep method for large-scale optimization. Oper Res 23(3):389–405
Mifflin R (1977) Semismooth and semiconvex functions in constrained optimization. SIAM J Control Optim 15(6):959–972
Mifflin R (1996) A quasi-second-order proximal bundle algorithm. Math Program 73(1):51–72
Nesterov Y (1983) A method for solving the convex programming problem with convergence rate \({\cal{O} }(1/k^2)\). Proc USSR Acad Sci 269:543–547
Nocedal J, Wright S (1999) Numerical Optimization. Springer, Berlin
Ouorou A, Mahey P, Vial J-Ph (2000) A survey of algorithms for convex multicommodity flow problems. Manage Sci 46(1):126–147
Parikh N, Boyd S et al (2014) Proximal algorithms. Found Trends Optim 1(3):127–239
Passty G (1979) Ergodic convergence to a zero of the sum of monotone operators in Hilbert space. J Math Anal Appl 72(2):383–390
Rey P, Sagastizábal C (2002) Dynamical adjustment of the prox-parameter in bundle methods. Optimization 51(2):423–447
Rey P, Sagastizábal C (2002) Dynamical adjustment of the prox-parameter in bundle methods. Optimization 51(2):423–447
Rockafellar R (1981) The theory of subgradients and its applications to problems of optimization. Heldermann Verlag
Schechtman S (2022) Stochastic proximal subgradient descent oscillates in the vicinity of its accumulation set. Optim Lett, 1–14
Schramm H, Zowe J (1992) A version of the bundle idea for minimizing a nonsmooth function: conceptual idea, convergence analysis, numerical results. SIAM J Optim 2(1):121–152
Shor N (2012) Minimization methods for non-differentiable functions, vol 3. Springer Science & Business Media, Berlin
Sinkhorn R (1964) A relationship between arbitrary positive matrices and doubly stochastic matrices. Ann Math Stat 35(2):876–879
Sra S, Nowozin S, Wright S (2012) Optimization for machine learning. MIT Press, Cambridge
Takapoui R, Javadi H (2016) Preconditioning via diagonal scaling. arXiv preprint arXiv:1610.03871
Teo C, Vishwanathan S, Smola A, Le Q (2010) Bundle methods for regularized risk minimization. J Mach Learn Res, 11(1)
Trisna T, Marimin M, Arkeman Y, Sunarti T (2016) Multi-objective optimization for supply chain management problem: a literature review. Decis Sci Lett 5(2):283–316
van Ackooij W, Frangioni A (2018) Incremental bundle methods using upper models. SIAM J Optim 28:379–410
van Ackooij W, Frangioni A, de Oliveira W (2016) Inexact stabilized Benders’ decomposition approaches with application to chance-constrained problems with finite support. Comput Optim Appl 65:637–669
van Ackooij W, Berge V, de Oliveira W, Sagastizábal C (2017) Probabilistic optimization via approximate \(p\)-efficient points and bundle methods. Comput Oper Res 77:177–193
Wei F, Zhang X, Xu J, Bing J, Pan G (2020) Simulation of water resource allocation for sustainable urban development: an integrated optimization approach. J Clean Prod 273:122537
Westerlund T, Pettersson F (1995) An extended cutting plane method for solving convex MINLP problems. Comput Chem Eng 19:131–136
Yin P, Wang J (2006) Ant colony optimization for the nonlinear resource allocation problem. Appl Math Comput 174(2):1438–1453
Zhou B, Bao J, Li J, Lu Y, Liu T, Zhang Q (2021) A novel knowledge graph-based optimization approach for resource allocation in discrete manufacturing workshops. Robot Comput Integr Manuf 71:102160
Acknowledgements
We thank Parth Nobel, Nikhil Devanathan, Garrett van Ryzin, Dominique Perrault-Joncas, Lee Dicker, and Manan Chopra for very helpful discussions about the problem and formulation. The supply chain example was suggested by van Ryzin, Perrault-Joncas, and Dicker. The communication layer for the implementation with structured variables, to be described in a future paper, was designed by Parth Nobel and Manan Chopra. We thank Mateo Díaz for pointing us to some very relevant literature that we had missed in an early version of this paper. We thank three anonymous reviewers who gave extensive and helpful feedback on an early version of this paper. We gratefully acknowledge support from Amazon, Stanford Graduate Fellowship, Office of Naval Research, and the Oliger Memorial Fellowship. This research was partially supported by ACCESS – AI Chip Center for Emerging Smart Systems, sponsored by InnoHK funding, Hong Kong SAR.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix A: Convergence proof
Appendix A: Convergence proof
In this section we give a proof of convergence of the bundle method for oracle-structured optimization. Our proof uses well known ideas, and borrows heavily from Belloni (2005). We will make one additional (and traditional) assumption, that f and g are Lipschitz continuous on \(\mathop \textbf{dom}g\).
We say that the update was accepted in iteration k if \(x^{k+1}={\tilde{x}}^{k+1}\). Suppose this occurs in iterations \(k_1< k_2< \cdots \). We let \(K=\{k_1, k_2, \ldots \}\) denote the set of iterations where the update was accepted. We distinguish two cases: \(|K| = \infty \) and \(|K| < \infty \).
1.1 Infinite updates
We assume \(|K| = \infty \). First we establish that \(\delta ^{k_s}\rightarrow 0\) as \(s\rightarrow \infty \). Since \(k=k_s\) is an accepted step, from step 6 of the algorithm we have
Summing this inequality from \(s=1\) to \(s=l\) and dividing by \(\eta \) gives
which implies that \(\delta ^{k_s}\) is summable, and so converges to zero as \(s \rightarrow \infty \).
Since \({\tilde{x}}^{k_s+1}\) minimizes \({\hat{h}}^{k_s}(x)+(\rho /2)\Vert x-x^{k_s}\Vert _2^2\), we have
Using \({\tilde{x}}^{k_s+1} = x^{k_s+1} = x^{k_{s+1}}\), we have
It follows that
We first rewrite this as
and then in the form we will use below,
Now we use a standard subgradient algorithm argument. We have
Summing this inequality from \(s=1\) to \(s=l\) and re-arranging yields
It follows that the nonnegative series \(h(x^{k_s}) - h^\star \) is summable, and therefore, \(h(x^{k_s})\rightarrow h^\star \) as \(s \rightarrow \infty \).
1.2 Finite updates
We assume \(|K| < \infty \), with \(p = \max K\) its largest entry. It follows that for any \(k>p\), we have \( h(x^k) - h\left( \tilde{x}^{k+1}\right) <\eta \delta ^k \). Note that \(x^k=x^p\) for all \(k\ge p+1\). Moreover, using
with \(\rho (x^p - \tilde{x}^{k+1}) \in \partial \hat{h}^k\left( \tilde{x}^{k+1} \right) \) and \(\hat{h}^{k+1}(\tilde{x}^{k+2})\ge \hat{h}^k(\tilde{x}^{k+2})\), we get
Therefore, \(\delta ^k \ge \delta ^{k+1}+ (\rho /2)\left\| \tilde{x}^{k+2} - \tilde{x}^{k+1}\right\| _2^2\) for all \(k \ge p+1\). Then from
it follows that \(\left\| x^p - \tilde{x}^{k+1}\right\| _2^2\le 2\delta ^k/\rho \le 2\delta ^p/\rho \).
Now we use the assumption that f and g are Lipschitz continuous with Lipschitz constant L for all \( x \in \mathop \textbf{dom}g\). Every \(q\in \partial \hat{f}^k(x)\) has the form \(q= \sum _{t \le k} \theta _t q^t\), with \(\theta _t \ge 0\) and \(\sum _t \theta _t=1\), a convex combination of normal vectors of active constraints at x, where \(q^t \in \partial f(x^t)\). Therefore, \(\hat{h}^k(x)=\hat{f}^k (x)+g(x)\) is 2L-Lipschitz continuous.
Combining this with
we have
Therefore, from
we can establish that \(\delta ^{k}\) converges to zero as \(k \rightarrow \infty \). This implies
Also from \(\underset{k\rightarrow \infty }{\lim }\ \left( h(x^p) - h\left( \tilde{x}^{k+1}\right) \right) = 0\) and \(\left\| {x}^{p} - \tilde{x}^{k+1}\right\| _2^2 \le \frac{2\delta ^k}{\rho }\), it follows that
Hence, we get \(0 \in \partial h(x^p)\), which implies \(h(x^p)=h^\star \).
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Parshakova, T., Zhang, F. & Boyd, S. Implementation of an oracle-structured bundle method for distributed optimization. Optim Eng (2023). https://doi.org/10.1007/s11081-023-09859-z
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11081-023-09859-z