
Abstract
Optimization problems with discrete–continuous decisions are traditionally modeled in algebraic form via (non)linear mixed-integer programming. A more systematic approach to modeling such systems is to use generalized disjunctive programming (GDP), which extends the disjunctive programming paradigm proposed by Egon Balas to allow modeling systems from a logic-based level of abstraction that captures the fundamental rules governing such systems via algebraic constraints and logic. Although GDP provides a more general way of modeling systems, it warrants further generalization to encompass systems presenting a hierarchical structure. This work extends the GDP literature to address two major alternatives for modeling and solving systems with nested (hierarchical) disjunctions: explicit nested disjunctions and equivalent single-level disjunctions. We also provide theoretical proofs on the relaxation tightness of such alternatives, showing that explicitly modeling nested disjunctions is superior to the traditional approach discussed in literature for dealing with nested disjunctions.
Similar content being viewed by others
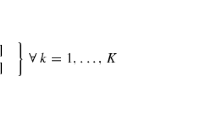


Avoid common mistakes on your manuscript.
1 Introduction
Discrete–continuous optimization is one of the main modeling approaches to address design, planning, and scheduling problems in process systems engineering (PSE) (Grossmann 2012). Raman and Grossmann (1994) present a powerful modeling paradigm that extends the work by Balas (1985) on disjunctive programming. This new paradigm, called generalized disjunctive programming (GDP), has been further developed by others in the PSE community over the years to account for additional features, such as nonlinearities and nonconvexities encountered in the problems (Grossmann and Trespalacios 2013). GDP relies on the intersection of disjunctions of algebraic constraints (equality and inequality constraints with continuous variables) to model the feasible space. Boolean variables are used as indicatr variables for each disjunct (set of algebraic constraints), enforcing the constraints in the disjunct when True. Logic constraints are also included to describe the relationships between the Boolean indicator variables via propositional logic.
GDP is a valuable modeling abstraction for optimization problems for two main reasons. Firstly, modeling systems from the basis of their underlying logical relationships aids the development and formulation of optimization models by making them easier to interpret, reducing the likelihood of modeling errors due to logical fallacies. Secondly, GDP makes available a broad array of solution methods, ranging from mixed-integer reformulations to logic-based search methods (Chen et al. 2022).
The present work extends the GDP theory to allow modeling hierarchical systems, which are commonly encountered in PSE, and more particularly in enterprise-wide optimization (EWO) (Grossmann 2012; van den Heever and Grossmann 1999), and flowsheet superstructure optimization (Türkay and Grossmann 1996a). Hierarchical systems involve multiple levels of decision making, which can be concisely modelled via nested disjunctions. However, traditional GDP does not consider such formulations. Existing GDP literature suggests reformulating nested disjunctions into equivalent single-level disjunctions (Vecchietti and Grossmann 2000). Such an approach requires introducing additional Boolean variables and logical propositions. Industrial examples of this approach in scheduling include that of Castro et al. (2014) and Castro (2017). An alternate approach is used in the work by van den Heever and Grossmann (1999), in which a direct or inside-out reformulation to MI(N)LP is performed. We formalize these two approaches and provide theoretical proofs on the tightness of their continuous relaxations. The model tightness and computational performance of the different approaches are compared. A series of examples are used to show the modeling and computational advantages obtained by explicitly modeling nested disjunctions.
The paper is organized as follows, Sect. 2 provides a background on the GDP modeling paradigm. Section 3 extends this formulation to account for hierarchical systems, and discusses the alternatives for modeling such systems. The equivalent mixed-integer programming reformulations for these alternatives are presented, along with two theorems on the tightness of the resulting models. Section 4 provides several numerical use cases for hierarchical GDPs. Section 5 presents concluding remarks.
2 Background: generalized disjunctive programming (GDP)
The classical GDP formulation is given below (GDP), where \(x\) is the set of continuous variables (bounded between \({x}^{LB}\) and \({x}^{UB}\)), \(f(x)\) is the objective function, \(r\left(x\right)\le 0\) is the set of global constraints, \({g}_{ij}\left(x\right)\le 0\) is the set of constraints applied when the indicator Boolean \({Y}_{ij}\) is True for disjunct \(j\) in disjunction \(i\). \(f(x)\), \(r(x)\), and \({g}_{ij}(x)\) are assumed to be continuous and differentiable over \(x\). \(\Omega (Y)\) defines the set of logic constraints, which are described via propositional logic on a subset of Boolean variables. These constraints describe the relations between the Boolean variables via clauses that contain with one or more of the following logic operators: AND (\(\wedge \)), OR (\(\vee \)), implication (\(\Rightarrow \)), equivalence (\(\iff \)), and negation (\(\neg \)). The set of logic constraints may also include cardinality clauses of the form choose exactly (or at least or at most) \(m\) Boolean variables from a subset of Booleans to be True (Yan and Hooker 1999). We leverage predicate logic to extend the notation used by Yan and Hooker for cardinality clauses by defining the following predicates: \({\varvec{\Xi}}\left(m,{Y}_{s} \quad \,\forall\, s\in S\right)\) enforces that exactly \(m\) of the Boolean variables \({Y}_{s}\) are True, \({\varvec{\Lambda}}\left(m, {Y}_{s} \quad \,\forall\, s\in S\right)\) enforces that at least \(m\) of the variables are True, and \({\varvec{\Gamma}}\left(m, {Y}_{s} \quad \,\forall\, s\in S\right)\) enforces that at most \(m\) are True.
GDP models typically include a cardinality clause to enforce that exactly 1 disjunct in each disjunction is selected, i.e., \({\varvec{\Xi}}\left(1,{Y}_{ij} \quad \,\forall\, j\in {J}_{i}\right) \quad \,\forall\, i\in I\). The GDP literature often uses the exclusive OR (XOR) operator, \(\underset{\_}{\vee }\), to define this constraint. However, such an operator is only correct for proper disjunctions (those with non-overlapping disjuncts) and poses issues in GDP when there are overlapping disjuncts (improper disjuncts). This is because XOR is an n-ary operator that returns True when an odd number of propositions in the operator are True. This can create problems when transforming the GDP into a MIP via the Hull reformulation because an odd number of disaggregated variables will be active (non-zero) for any feasible point at the intersection of an odd number of disjuncts. As a result, the projection of the disaggregated variables onto the original space will result in a value that is an odd integer multiple of the disaggregated variable values, which is incorrect and may exclude valid solutions by making them infeasible (see “Appendix A”). Thus, to avoid these issues, we use the predicate logic notation, \({\varvec{\Xi}}(1,Y)\), here instead.
To illustrate the elements of a GDP model, consider the model below (GDP-example). The projection of this model on the \({x}_{1},{x}_{2}\)-plane is given in Fig. 1, where the quadratic objective function is shown in the colored contours, the global constraints are given by the region under the black curves (one linear and the other nonlinear), and the disjunction constraint is given by the three colored rectangles. The feasible space of such a system is given by the disjoint regions in the orange, blue, and green rectangles that satisfy the global constraints.

Sample GDP graphical representation for GDP-example model.

One of the main advantages of modeling discrete–continuous problems using GDP is the collection of methods that are available for optimizing such systems. These include, (1) reformulating to mixed-integer (non)linear models (MI(N)LP) via either Big-M (Trespalacios and Grossmann 2015) or Hull reformulations (Agarwal 2015; Bernal and Grossmann 2021; Furman et al. 2020; Grossmann and Lee 2003), (2) logic-based decomposition methods such as Logic-based Outer Approximation (LOA) (Türkay and Grossmann 1996b), (3) disjunctive branch-and-bound (Lee and Grossmann 2000), (4) basic steps (Ruiz and Grossmann 2012), and (5) hybrid cutting planes (Sawaya and Grossmann 2005; Trespalacios and Grossmann 2016). The reader is referred to the above references for a detailed understanding of each of these solution methods.
3 Extended formulation for multi-level hierarchies
Decision hierarchies are present in most decision-making applications. These include for instance supply chain and enterprise-wide optimization, where different levels of decision-making exist depending on the time scales considered: planning (months/years), scheduling (hours/days), and control (seconds/minutes). According to Brunaud and Grossmann (2017), integrating different decision levels enables better coordination and communication between functional areas, which increases agility in response to disturbances and makes it possible to attain benefits for the company that are not possible with a siloed approach. Figure 2 illustrates the notion of the synergistic benefits that can be obtained by an integrated approach, rather than siloed or aggregated approaches. Accounting for the relationships between different levels of decision-making can aid in finding the true optimum, which differs from that of the aggregated model (i.e., the model obtained by summing the siloed costs). Integrated approaches to hierarchical decision-making systems have been addressed in the literature. Some examples of these integrations are the integration between design and planning (operational and expansion) (van den Heever and Grossmann 1999), planning and scheduling (Maravelias and Sung 2009), and scheduling and control (Muñoz et al. 2011; Sokoler et al. 2017). The following subsections formalize how GDP can be used to model hierarchical systems, along with theoretical proofs on the differences between the approaches.

Illustartion of the different optimas for siloed, aggregated, and integrated approaches.
3.1 Hierarchical GDP
We propose extending the GDP paradigm to include multi-level decisions by means of nested disjunctions. Although the notion of nesting disjunctions to represent hierarchical decisions is not new, the limitations in the traditional GDP notation have made it difficult to exploit the benefits of using such structures. One of the first references to nested disjunctions is found in the work by Vecchietti and Grossmann (2000), which describes the transformations required to conform to the current GDP notation. It is interesting to note that several works have relied on the nested GDP representation due to its compact representation. In one of these (Rodriguez and Vecchietti 2009), the following statement is made,
Although the expressiveness of the hierarchical decisions by means of nested disjunctions, they cannot be implemented directly. These disjunctions must be transformed into GDP form. For that purpose, the disjunctions…must be rewritten as single disjunctions, and some additional constraints must also be included in the model.
Therefore, from a model development point of view, the use of disjunction nesting is shown to add value. However, its implementation has often required breaking the explicit hierarchical structure. An exception is the work by van den Heever and Grossmann (1999), which does not transform the nested GDP into a logically equivalent single-level GDP, but rather suggests performing the Hull reformulation on the inner disjunction and then reformulating the outer disjunction. We now build upon this concept to formally extend the GDP notation for hierarchical systems that generalizes to multi-disjunct disjunctions, rather than the on/off disjunctions used by van den Heever and Grossmann (1999). We also provide theoretical proofs on the advantages of modeling system hierarchies via nested disjunctions, and highlight the computational performance gains obtained using this explicit notation.
The proposed extension to the classical GDP notation for hierarchical systems is given below for a 2-Level nested GDP (2L-GDP), where the upper-level decisions, \(Y\), enforce the constraints \(g\left(x\right)\le 0\) and the nested decisions, \(W\), which have constraints \(h\left(x\right)\le 0\). Here the cardinality clause of selecting exactly one disjunct from the upper-level decisions, \(Y\), is expressed explicitly, along with a new set of cardinality rules that enforce selecting exactly one of the lower-level decisions, \(W\), if and only if the upper-level decision has been selected, and selecting no lower-level decisions when the upper-level decision is not selected. This constraint is expressed as the conjunction of two cardinality rules: \(\left[{Y}_{ij}\Rightarrow{\varvec{\Xi}}\left(1,{W}_{ijkl} \quad \,\forall\, l\in {L}_{ijk}\right)\right]\wedge \left[{\neg Y}_{ij}\Rightarrow{\varvec{\Xi}}\left(0,{W}_{ijkl} \quad \,\forall\, l\in {L}_{ijk}\right)\right] \quad \,\forall\, i\in I,j\in {J}_{i},k\in {K}_{ij}\). In the GDP literature, this constraint has been traditionally written as \({Y}_{ij}\iff \underline{\vee}_{l\in {L}_{ijk}}{W}_{ijkl} \quad \,\forall\, i\in I,j\in {J}_{i},k\in {K}_{ij}\). However, such a logic proposition is incomplete because it would allow the following to occur: \({Y}_{ij}=False\) and \({W}_{ijkl}=True\) for more than 1 index \(l\in {L}_{ijk}\) (i.e., False \(\iff \) (True \(\underline{\vee }\) True) is valid because the exclusive OR makes the right-hand side False). If all disjunctions are proper, then this will not occur. However, since there can be a disjunction with overlapping disjuncts, the cardinality rule \({\varvec{\Gamma}}\left(1,{W}_{ijkl} \quad \,\forall\, l\in {L}_{ijk}\right) \quad \,\forall\, i\in I,j\in {J}_{i}, k\in {K}_{ij}\) would need to be added to such a system to ensure that no more than 1 literal, \({W}_{ijkl}\), is set to True. A more compact form would be to use the predicate constraint, \({\varvec{\Xi}}\left({1}_{\left\{True\right\}}\left({Y}_{ij}\right),{W}_{ijkl} \quad \,\forall\, l\in {L}_{ijk}\right)\), where \({1}_{\left\{True\right\}}\left(\cdot \right)\) is the indicator function that returns 1 when the input is True and 0 otherwise. In other words, the indicator function maps a Boolean variable to its binary counterpart. For simplicity, we make a slight abuse of notation by dropping the indicator function and using the expression \({\varvec{\Xi}}\left({Y}_{ij},{W}_{ijkl} \quad \,\forall\, l\in {L}_{ijk}\right)\) instead.
This model can be generalized to a multi-level nested GDP (ML-GDP) with \(n\) levels, where the superscript on the Boolean variables, constraints, and sets indicates the level \(k\in \{1,\dots ,n\}\) of the hierarchy that these belong to.

It should be noted that nested disjunctions should generally not include negations of Boolean variables (see “Appendix B”).
3.2 Equivalent single-level GDP
Previous references to GDP with nested disjunctions in literature have proposed transforming the 2L-GDP model into the equivalent single-level GDP (2E-GDP) given below (Grossmann and Trespalacios 2013; Vecchietti and Grossmann 2000). Here, the nested disjunction is extracted and a dummy or “slack” disjunct is added to preserve feasibility. Thus, if none of the nested disjuncts is selected, the slack disjunct is selected, which contains the entire feasible set for \(x\). The exclusive cardinality rule on the inner Boolean variables, \(W\), is also augmented to include the slack Boolean variable, \({W}_{ijk0}\). This slack variable is, however, not included in the linking logic constraint for the upper and lower-level decisions. This ensures that the nested decisions are only selected if their master Boolean is True. This method for transforming a nested disjunction can also be applied to the multi-level system ML-GDP.
Although the above formulation, allows modeling hierarchical systems in the standard GDP notation, it has two major drawbacks: (1) the explicit hierarchical structure is lost, and (2) although the Equivalent Single-Level GDP model is logically equivalent to the nested GDP model, it requires introducing additional disjuncts and Boolean variables. Introducing “slack” disjuncts and “slack” Boolean variables results in models whose continuous relaxations are less tight, as described in the next section.
3.3 Tightness of continuous relaxations
The following two theorems and their associated proofs establish the advantages of modeling multi-level decisions problems via nested GDP, rather than the Equivalent Single-Level GDP approach. The advantages are shown by discussing the tightness of the continuous relaxations of both the Hull reformulation (HR) and Big-M reformulation (BM) of these two GDP models.
Theorem 1
Let rML-GDP-HR denote the continuous relaxation of the mixed-integer program (MIP) obtained from a Multi-Level nested GDP via the Hull reformulation, and let rME-GDP-HR denote the continuous relaxation of the MIP obtained from its respective Equivalent Single-Level GDP representation via the Hull reformulation. The feasible space of the former is contained within the feasible space of the latter, namely, rML-GDP-HR \(\subseteq \) rME-GDP-HR.
Proof
Without loss of generality, the above theorem is proved by establishing that the Hull reformulation of the 2-Level nested GDP model (r2L-GDP-HR) is contained in the Hull reformulation of its equivalent single-Level GDP representation (r2E-GDP-HR):
The Hull reformulation for 2L-GDP is given below, where the continuous variable \(x\) is disaggregated in each disjunct (\(x\) is disaggregated into \({u}_{ij}\) for each upper-level disjunct, and \({u}_{ij}\) is disaggregated into \({v}_{ijkl}\) for each lower-level disjunct) and the Boolean variables are replaced by their corresponding binary variable (\(Y\) becomes \(y\), and \(W\) becomes \(w\)). \(A\) and \(B\) are matrices of scalars, and \(c\) is a vector of scalars. These are used to map the logic constraints into their algebraic counterparts obtained after converting the logic propositions into conjunctive normal form (CNF) and transforming each clause into its equivalent algebraic constraint (Williams 1985). Note that the disaggregated variables are bounded between \(\mathrm{min}\left(0,{x}^{LB}\right)\) and \(\mathrm{max}\left(0,{x}^{UB}\right)\) instead of the traditional bounds of \(0\) and \({x}^{UB}\) because we do not assume that \(x\) is nonnegative. As a result, the min and max operators in these bounds are required to guarantee that the domain of the disaggregated variables contains the origin (0). This is necessary to ensure that the disaggregation constraints remain feasible when the disaggregated variables are forced to 0 for the disjuncts that are not selected.

The Hull reformulation for 2E-GDP is given below, where \(x\) is disaggregated into \({u}_{ij}\) for the upper-level disjunctions, and is also disaggregated into \({v}_{ijkl}\) for the lower-level disjuncts, which are extracted when transforming the model into an Equivalent Single-Level GDP.

The difference between 2L-GDP-HR and 2E-GDP-HR is in the highlighted constraints in the variable disaggregation and cardinality rules sections. The proof for the Hull reformulation case is given by applying Fourier–Motzkin elimination (Dantzig 1972) to eliminate the slack Binary variable (\({w}_{ijk0}\)) and its corresponding disaggregated variable (\({v}_{ijk0}\)) from 2E-GDP-HR. We first combine the last two cardinality rules in 2E-GDP-HR to obtain (1).
Equating the two variable aggregation constraints in 2E-GDP-HR and solving for \({v}_{ijk0}\) gives (2).
Substituting (1) and (2) into the bounding constraint for \({v}_{ijk0}\) gives (3), which can be rearranged into (4).
Summing the bounding constraint for \({x}_{ij}\) over \({j}^{\prime}\in {J}_{i}\) for \({j}^{\prime}\ne j\), results in (5). Using the cardinality rule \({\sum }_{j\in {J}_{i}}{y}_{ij}=1\), (5) can be written as given in (6), which has two parts, (6a) and (6b). Substituting these into (4) proves that (4) is a relaxation of the disaggregation constraint in 2L-GDP-HR (\({\sum }_{l\in {L}_{ijk}}{v}_{ijkl}={u}_{ij}\), which can be written as \({u}_{ij}\le {\sum }_{l\in {L}_{ijk}}{v}_{ijkl}\le {u}_{ij}\)).
It should also be noted that the cardinality rule on the extracted lower-level decisions in 2E-GDP-HR (\({w}_{ijk0}+{\sum }_{l\in {L}_{ijk}}{w}_{ijkl}=1\)) is redundant with respect to the other two cardinality rules. This can be shown by noting that \({w}_{ijk0}\) acts like a slack variable, which allows writing the mentioned cardinality rule as \({\sum }_{l\in {L}_{ijk}}{w}_{ijkl}\le 1\). This expression is contained in the first two cardinality rules since \({y}_{ij}\le 1\) and \({\sum }_{l\in {L}_{ijk}}{w}_{ijkl}={y}_{ij}\). Therefore, the Hull reformulation of the Equivalent Single-Level GDP produces constraints with continuous relaxations that are weaker than those resulting from the Hull reformulation of the nested GDP, proving that 2L-GDP-HR \(\subseteq \) 2E-GDP-HR. QED
Theorem 2.
Let rML-GDP-BM denote the continuous relaxation of the mixed-integer program (MIP) obtained from a Multi-Level nested GDP via the Big-M reformulation, and let rME-GDP-BM denote the continuous relaxation of the MIP obtained from its respective Equivalent Single-Level GDP representation via the Big-M reformulation. The feasible space of the former is contained within the feasible space of the latter, namely, rML-GDP-BM \(\subseteq \) rME-GDP-BM, if tight values for the M parameters are used.
Proof.
Without loss of generality, the above theorem is proved by establishing that the Big-M reformulation of the 2-Level nested GDP model (r2L-GDP-BM) is contained in the Big-M reformulation of its Equivalent Single-Level GDP representation (r2E-GDP-BM), when tight M values are used:
The Big-M reformulation for the nested GDP model is given in 2L-GDP-BM, where \({M}_{ij}\) is the Big-M value for the constraints in the \({j}^{th}\) disjunct in disjunction \(i\), \({M}_{ijkl}^{\prime}\) is the Big-M value associated with the upper-level decision on the nested constraints, and \({m}_{ijkl}^{\prime}\) is the Big-M value associated with the lower-level decision on the nested constraints. The Big-M reformulation for the equivalent single-level GDP is given in 2E-GDP-BM, where \({M}_{ij}\) is the same as in 2L-GDP-BM, and \({m}_{ijkl}\) is the Big-M value associated with the extracted lower-level decisions.


Finding the tightest Big-M values requires solving multiple optimization problems to maximize the value of each constraint function over the complete model’s feasible region, or over the corresponding feasible region of the disjunction (Grossmann and Trespalacios 2013). For the proof we calculate tight Big-M values using only the global constraints or upper-level constraints in the case of the nested constraints. The following mathematical optimization problems are solved to obtain tight \(M\) values: (7) for \({M}_{ij}\), (8a) for \({m}_{ijkl}^{\prime}\), (8b) for \({M}_{ijkl}^{\prime}\), and (9) for \({m}_{ijkl}\). It should be noted that \({m}_{ijkl}^{\prime}\) accounts for the upper-level constraints \({g}_{ij}\left(x\right)\le 0\), meaning it is localized to the parent disjunct that it belongs to. \({M}_{ijkl}^{\prime}\) subtracts \({m}_{ijkl}^{\prime}\) from the traditional Big-M value to ensure that when both upper and lower-level decisions are not selected (\({y}_{ij}=0\) and \({w}_{ijkl}=0\)), the resulting Big-M value is equivalent to the global Big-M value for that constraint.
The proof lies in establishing that the feasible space of 2L-GDP-BM is contained in 2E-GDP-BM. The difference between these two models is shown in the highlighted constraints above. It was previously shown that the cardinality rule \({w}_{ijk0}+{\sum }_{l\in {L}_{ijk}}{w}_{ijkl}=1\) is redundant (see Theorem 1). Thus, the proof is given by establishing that the right-hand-sides of the highlighted Big-M constraints satisfy (10), meaning that the Big-M constraint from 2L-GDP-BM is contained in the Big-M constraint from 2E-GDP-BM. Substituting (9) in (8b), results in (11). Substituting (11) in (10) and simplifying the resulting expression produces (12). From the cardinality constraint \({\sum }_{l\in {L}_{ijk}}{w}_{ijkl}={y}_{ij}\), it is clear that \({w}_{ijkl}\le {y}_{ij}\), meaning that the expressions in parenthesis in (12) can be dropped without changing the sign on the inequality. Thus, \({m}_{ijkl}^{\prime}\le {m}_{ijkl}\), which is true considering that (9) is a relaxation of (8a). Therefore, 2L-GDP-BM \(\subseteq \) 2E-GDP-BM.
QED
4 Examples
Each of the examples in this section are implemented in the Julia programming language (version 1.9.0) (Bezanson et al. 2017) using various packages within the ecosystem. These include JuMP (version 1.11.0) (Dunning et al. 2017) for modeling mathematical programs, DisjunctiveProgramming (version 0.3.6) (Perez et al. 2023) for reformulating GDPs (both nested and single-level) into MIPs, and Polyhedra (version 0.7.6) (Legat et al. 2021) for projecting mathematical programming models onto 2D space (see Sect. 4.1). For the numerical examples (Sects. 4.2 and 4.3), the reformulated MI(N)LP models are solved on an Ubuntu Server with 82 GB of RAM and an Intel(R) Xeon(R) CPU E5-2630 v4 @ 2.20GHz processor. CPLEX (version 22.1.1) is used as the MILP solver and BARON (version 23.1.5) as the MINLP solver.
4.1 Illustrative example
Consider the nested GDP constraint system given in (13), which can be expressed as the Equivalent Single-Level GDP in (14), where \({W}_{3}\) is the slack Boolean variable associated with the dummy disjunct. Each of these models is reformulated into a MIP using the Big-M reformulation, with both a loose (large) M value and a tight M value, and the Hull reformulation. Their continuous relaxations are then projected onto the \({x}_{1},{x}_{2}\) plane in Fig. 3.

Projections of the continuous relaxations of (13) and (14) onto the \({x}_{1},{x}_{2}\) plane. Three reformulations are shown (Big-M = Big-M Reformulation, Tight-M = Big-M Reformulation with tight M values, Hull = Hull Reformulation). The 2-Level nested GDP given in (13) is indicated with nested. The Equivalent Single-Level GDP given in (14) is indicated with equivalent. Projection areas, relative to the Big-M case are indicated in %.
Explicitly preserving the hierarchical relationship in the nested GDP representation reduces the feasible region of the continuous relaxation more than when the equivalent single-Level GDP representation is used. This is observed in both the tight-M (Big-M reformulation with a tight M) and Hull reformulation cases. Furthermore, in this example the tight-M reformulation of the nested GDP model produces the same relaxation as the Hull reformulation of the equivalent single-level GDP model with only a fraction of the model size (see Table 1). It should also be noted that the convex hull of the system is obtained when either the hull reformulation is applied to the nested GDP or when it is applied to the flattened GDP. As a result, the continuous relaxation of either formulation will yield the optimum.
4.2 Example 1: linear model
Consider the superstructure optimization problem with technology selection and scheduling for a plant that is to produce and sell material D (see Fig. 4). Material D can be produced from material C (reaction: C → D), which can be purchased from a third party or produced from material B (reaction: B → C), which can in turn be purchased or produced from material A (reaction: A → B). The plant has two types of multipurpose reactors, each with a backup unit, that can be used for the material transformation steps (see Fig. 5). Each of these has a maximum installed capacity of 100 kg. Up to one tank for each material in the system can be installed for storage with a maximum installed capacity of 300 kg. There are two candidate chemical processes to perform each material transformation step, giving a total of six processes in the process superstructure. There are two potential technologies (catalysts) that can be used in each process, each with a unique cost and yield, giving a total of 12 candidate process-catalysts combinations in the system. The plant process and equipment superstructures are given in Figs. 4 and 5, respectively. The former illustrates the candidate processes in the superstructure in the state-task network representation (Kondili et al. 1993). The latter depicts the equipment options (reactor type and units, and tanks) in the superstructure.

Process superstructure for Example 1 with 4 materials, 6 processes, 4 tanks, and 16 streams.

Equipment superstructure (process flow diagram) for Example 1 with 4 tanks and 2 reactor types, each with 2 identical units.
The objective of the optimization problem is to maximize system profit over a 30-day schedule by making the following decisions:
-
Which material storage tanks to install.
-
How many shared reactors to install.
-
Which processes to install for each material transformation step.
-
Which technologies (catalysts) to use in each of the selected processes.
-
Which reactor type to use in each of the selected processes.
-
How many reactors to operate in each time period.
-
How much to produce in each batch of material.
-
How much material to purchase for A, B, and C in each time period.
The hierarchy of these decisions is indicated by the bullet indentation above. Thus, the technology and reactor type selections are second-level decisions, and the operating schedule and batch sizes are third-level decisions. For simplicity, any changeover or setup times are not considered.
Model: The model for this system consists of the following linear constraints. Resource balances are enforced around each resource \(k\) at timepoint \(t\) with the global constraints in (15) and (16). The level of material at each tank, \({L}_{k,t}\), is updated based on the material flowing in and out of the tank (material balance). The availability of each reactor, \({R}_{k,t}\), is updated based on the reactor usage, \(\Delta {R}_{i,k,t}\). A reactor unit is locked (unavailable) when it begins a processing task \(i\) at time \(t\). At time \(t+{\tau }_{i}\), the processing task ends (\({\tau }_{i}\) is the duration), and the reactor unit is released (becomes available). The values used for the task durations, \({\tau }_{i}\), are \({\tau }_{i}=5 \,\forall\, i\in \left\{\mathrm{1,4},\mathrm{5,6}\right\}\), \({\tau }_{2}=3\), and \({\tau }_{3}=4\) (days). For greater detail on resource balances, the reader is referenced to the review paper on the resource-task network by Perez et al. (2022).
The decision to install a resource (tank or reactor) is governed by the disjunctions in (17) and (18), where the decision is to determine how many units \(u\) to install. In this example, \({U}_{k}=\{\mathrm{0,1},2\}\) for each reactor type (at most 2 identical units can be installed for each reactor type \(k\)), and \({U}_{k}=\{\mathrm{0,1}\}\) for each tank (at most 1 tank can be installed for each material). The installation cost, \({CI}_{k}\), is calculated as the sum of a fixed charge, \({\alpha }_{k}\), and a variable cost coefficient, \({\beta }_{k}\), times the total resource capacity. If no units are installed (\(u=0\)), the installation cost and resource capacity, \({Q}_{k}\), drop to zero. (17) and (18) also set the initial condition for the resource availability, \({L}_{k,0}\) and \({R}_{k,0}\): if installed, tanks are full, and all reactor units are available, respectively. (17) also tracks the slack on the tank level at the final timepoint \(\left|T\right|\), \({\widehat{L}}_{k}\), which refers to the amount below the full tank capacity, and is penalized in the objective function to reduce the likelihood of depleting the inventory at the end of the scheduling horizon (see (41)). These constraints ensure that the schedule obtained is a feasible schedule for normal operation with monthly cycles. For startup operations the optimal schedule can be obtained by fixing the design decisions and rerunning the model with the initial tank levels set to zero. The cardinality constraint (19) ensures that exactly one of the disjuncts is selected. The values for the cost coefficients are given in Table 2. Since the plant lifetime is greater than the scheduling horizon, resource installation costs coefficients have been scaled to the appropriate order of magnitude. Installation costs for pipelines between tanks and reactors are assumed to be negligible.
The multi-level disjunction in (20) represents the decision to install process \(i\) or not. When installed, the total batch size, \({B}_{i,t}\), is equal to the flow entering the process at time \(t\). There are two nested disjunctions if a process is installed. The first of these relates to which reactor type \(k\) is assigned to the process, \({W}_{i,k}\). The second one pertains to which technology (catalyst) is used for that particular process, \({\widehat{W}}_{i,j}\). Once a reactor type is assigned, the per unit batch size, \({\widehat{B}}_{i,t}\), is bounded by the installed capacity of each unit, \({Q}_{k}\), and the operating cost, \(C{O}_{i,t}\), is proportional to the total batch size with a cost coefficient \({\gamma }_{i,k}\) (given in Table 3). The nested technology selection disjunction specifies the amount of material leaving the process when the batch is completed. This is governed by the yield, \(\nu \), which is specific to the technology \(j\) (given in Table 4). There is then a third-level set of disjunctions inside the reactor type assignment disjunction, which determines the number of units, \(u\), that are used for a batch at time, \(t\), \({N}_{i,k,t,u}\). The number of units selected indicates the number of units that are locked at time \(t\) and is also used to determine the total batch size from the per unit batch size. Note that for this system, it is assumed that if multiple units are used, their loads are equally distributed. Finally, when a process is not installed (\(\neg {Y}_{i}\)), all pertinent variables are set to zero, and the reactor capacity is only bounded by the maximum allowed capacity. The cardinality rules in (21–23) are the linking constraints between the different levels of this multi-level disjunction.

An additional logic proposition must be included to ensure that if a process \(i\) is triggered on reactor type \(k\) at time \(t\) with \(u\) units (\({N}_{i,k,t,u}=True\)), the reactor type \(k\) must have been installed with at least \(u\) units (\(\exists {u}^{\prime}\in {U}_{k}:{u}^{\prime}\ge u,{X}_{k,{u}^{\prime}}=True\)). For example, if \({N}_{i,k,t,1}=True\), then either \({X}_{k,1}=True\) or \({X}_{k,2}=True\) (one or two units must have been installed when the plant was built). This condition is enforced with the at least predicate in (24), which is equivalent to the propositional logic constraint \({N}_{i,k,t,u}\Rightarrow {\bigvee }_{{u}^{\prime}\in {U}_{k}:{u}^{\prime}\ge u}{X}_{k,{u}^{\prime}}\).
The variable bounds and domains are given in (25)-(27) and (29)-(40). The upper bound resource capacities are, \({Q}_{k}^{UB}=300kg \,\forall\, k\in {K}^{tank}\) and \({Q}_{k}^{UB}=100kg \,\forall\, k\in {K}^{react}\). The term \(\left|{U}_{k}\right|-1\) represents the maximum number of units available to install since we consider the option of not installing a tank or reactor \(k\). The initialization constraint in (28) is used to ensure that there is no flow leaving a reactor in the first \({\tau }_{i}\) periods since it is assumed that all reactors are idle at the beginning of the scheduling horizon. Thus, if production starts at \(t=1\), the first batch of product is produced at \(t={\tau }_{i}+1\).
The objective of this optimization problem is to maximize profit, as given by (41), where \({p}_{s}\) is the price/cost of each external flow \(s\in {S}^{ext}\) (\({p}_{13}=-\$1/kg A\), \({p}_{14}=-\$7/kg B\), \({p}_{15}=-\$8/kg C\), and \({p}_{16}=\$10/kg D\)). The tank level slacks are penalized with a penalty coefficient equal to the absolute value of the material price.
The resulting model is the linear nested GDP given in (15–41). This hierarchical model is reformulated into a mixed-integer linear program (MILP) using both Big-M (with both loose and tight M values) and Hull reformulations. The hierarchical GDP model is also transformed into its Equivalent Single-Level GDP and reformulated with both Big-M and Hull methods.
The optimum solution yields a cumulative profit of $2,085. The process network and equipment network designs are given in Figs. 6 and 7, respectively. The Gantt charts for procurement/sales and production are shown in Figs. 8 and 9, respectively. The tank levels are displayed in Fig. 10. The optimal design requires the installation of Processes 1, 3–5; Tanks B and C; and both reactor types, each with two units available. Reactors of type 1 focus almost exclusively on Process 1 with Technology 2, with one batch of Process 3 (Technology 1). Rectors of type 2 are used for Processes 4 and 5, each using Technology 1. Procurement of A occurs every 5 days, with sales of D typically spaced out every 10 days. By the end of the scheduling horizon, both tank levels have been restored to their initial levels (full).

Optimal process network design (edge thickness is proportional to the maximum flow on that line).

Optimal equipment network design

Material procurement and sales schedule

Plant operations schedule (text in each bar, i-j, indicates process number i and technology number j for that event)

Amount of material in each tank (and maximum tank level) throughout the scheduling horizon
The model sizes and computational statistics for each of the reformulated MILP models are given in Table 5, where the continuous (LP) relaxation gap is calculated with respect to the optimal MIP solution. Two additional scenarios are evaluated, where the sales price of material D is increased or decreased by 10%. The computational results for these cases are given in Tables 6 and 7. As can been observed, all formulations, except the hull reformulation of the nested GDP, have poor continuous relaxations with very large relaxation gaps. The hull reformulated nested GDP, on the other hand, has a tight relaxation with an 8–9% relative gap. In this example, both the Big-M and Tight-M reformulations have similar performance, with the equivalent single-level models solving faster than the nested models (except for the case with a 10% decrease in the sales price). For these models, the weak relaxations annul any potential advantage from using nested disjunctions. The MILP model obtained by applying the Hull reformulation to the nested GDP model outperforms the other models, finding the optimum in approximately half of the time required relative to its equivalent single-level counterpart. Compared to the Big-M models, this model solves faster by one order of magnitude, with significantly fewer cuts and nodes explored. This superior performance is due to the tighter LP relaxation and reduced model size. The Hull reformulated nested GDP has fewer binary variables (25% and 4% less, before and after presolve, respectively), continuous variables (10% and 26% less, before and after presolve, respectively), and constraints (5% and 25% less, before and after presolve, respectively) than its equivalent single-level counterpart. Although it seems surprising that a model with fewer variables and constraints is tighter than an equivalent model of greater size, this occurs because of the absence of slack disjuncts in the nested formulation, which make the equivalent formulation less tight.
4.3 Example 2: nonlinear model
Example 2 is based on Example 4.1 in the work by van den Heever and Grossmann (1999), which consists of an integrated superstructure optimization problem with long term operational and expansion planning. The problem has three potential processes (1, 2, and 3), each with its dedicated processing unit, and three materials (A, B, and C) as shown in Fig. 11. Material C is the final product (price: $10,800/ton) and is produced from Material B in Process 1. Material B can be purchased externally (cost: $7,000/ton) or produced from Material A (cost: $1,800/ton) in either Process 2 or Process 3. It is assumed that each process includes any required separation steps, such that the respective exit streams are single-component streams containing the pure product of each process. The objective here is to minimize cost (maximize profit) by making the following decisions:
-
Which processes should be used.
-
Which processes to operate in each period.
-
Which processes to undergo a capacity expansion in each period.
-
How much new processing capacity to install in each period.

Process superstructure for Example 2
The hierarchical GDP model is given as follows. The material balance constraints in the two stream junction points are given in (42) and (43), where \({F}_{s,t}\) is the flow (tons) in stream \(s\) in period \(t\) (where \(t\) is in years). The amount of imported B and exported C are constrained by (44) and (45), respectively.
The installation and planning decisions are made in the nested disjunction given in (46), where the top-level decision is to install Process \(i\) or not (\({Y}_{i}\) or \(\neg {Y}_{i}\)). If a process is installed, the respective nonlinear production yield constraint is enforced, where \({g}_{1}\left({F}_{7,t}\right)=0.9\cdot {F}_{7,t}\), \({g}_{2}\left({F}_{2,t}\right)=\mathrm{ln}\left(1+{F}_{2,t}\right)\), and \({g}_{3}\left({F}_{3,t}\right)=1.2\cdot \mathrm{ln}\left(1+{F}_{3,t}\right)\). A process capacity balance is also applied to update the current capacity, \({Q}_{i,t}\), with the capacity in the previous period and the current capacity expansion, \(Q{E}_{i,t}\). The secondary level decision is to operate the installed process, \({N}_{i,t}^{\left(1\right)}\), or not, \({N}_{i,t}^{\left(2\right)}\). If the process is operated in period \(t\), the exit flow is bounded by the process capacity, and the operating cost, \(C{O}_{i,t}\), is determined with the parameter \({\gamma }_{i}\) (\({\gamma }_{1}=\$900\), \({\gamma }_{2}=\$\mathrm{1,000}\), and \({\gamma }_{3}=\$\mathrm{1,200}\)). The tertiary level decision is to expand the process capacity, \({Z}_{i,t}^{\left(1\right)}\), or not, \({Z}_{i,t}^{\left(2\right)}\). The expansion cost, \(C{E}_{i,t}\), is calculated with the fixed cost parameter, \({\alpha }_{i}\) (\({\alpha }_{1}=\$\mathrm{3,500}\), \({\alpha }_{2}=\$\mathrm{1,000}\), and \({\alpha }_{3}=\$\mathrm{1,500}\)), and the variable cost parameter, \({\beta }_{i}\) (\({\beta }_{1}=\$\mathrm{1,200}/ton\), \({\beta }_{2}=\$700/ton\), and \({\beta }_{3}=\$\mathrm{1,100}/ton\)). It should be noted that each of the parameters used can also be indexed by time period if desired.
Additional logic constraints are given in (50–53). The cardinality clause in (50) allows installing at most 1 of Process 2 or Process 3. This is equivalent to the proposition \(\neg {Y}_{2}\vee \neg {Y}_{3}\) used in the original paper, but generalizes for cases in which there are more than two potential processes in parallel. The implication in (51) ensures that Process 1 is installed if either Process 2 or Process 3 are installed. (52) and (53) enforce that process \(i\) operate at least once if installed, with at least one expansion event scheduled between the beginning of the planning horizon (period 1) and each period \(t\) in which the process is operated, respectively.
The variable domains are given in (54–60), where \({F}_{s}^{UB}=5 ton \,\forall\, s\in S\), \(Q{E}_{1}^{UB}=0.4 ton\), \(Q{E}_{2}^{UB}=0.3 ton\), and \(Q{E}_{3}^{UB}=0.3 ton\).
The objective function is to minimize the system cost, as given in (61), where the stream costs, \({p}_{s}\), are given in Table 8. The model for Example 2 is thus given by (42–61).
There are some differences between this formulation and the one in the original paper by van den Heever and Grossmann (1999). The original formulation has the process capacity evolution constraint in the disjunct governed by \({Z}_{i,t}^{\left(1\right)}\). This requires specifying a new constraint, \({Q}_{i,t}={Q}_{i,t-1}\), for the disjunct governed by \({Z}_{i,t}^{\left(2\right)}\), which would also be required for the disjunct governed by \({N}_{i,t}^{\left(2\right)}\). This is avoided by moving the process capacity balance to the upper-level constraints in \({Y}_{i}\). The same is true for the yield constraint, which we move from the \({N}_{i,t}^{\left(1\right)}\) disjunct to the \({Y}_{i}\) disjunct constraints. This requires that we only constrain the flow exiting the process in the secondary level disjunction, rather than both the entrance and exit flows. It is also more intuitive to specify the yield constraints when the processes are selected. Another major difference is that the original model does not use the cardinality constraints in (48) and (49). Instead, it uses the logic propositions (62) and (63). These propositions are contained in (48) and (49), but do not establish a proper hierarchical relationship since there is no link between \({N}_{i,t}^{\left(2\right)}\) and \({Y}_{i}\), and \({Z}_{i,t}^{\left(2\right)}\) and \({N}_{i,t}^{\left(1\right)}\).
An important thing to note is that the model in Example 2 is an example of a type of hierarchical GDP, that need not be hierarchical at all. This occurs when every disjunction has only two disjuncts, representing an on and an off state, where the off state has all relevant variables set to zero. When this occurs, (46) can actually be split into three sets of disjunctions without adding the “slack” disjunct observed in the Equivalent Single-Level GDP model. These three sets of disjunctions are given in (64–66). The cardinality constraints in (48–49) can be replaced by (62–63), and (67–68). The model composed of (42–45), (47), and (50–68) is referred to here as the Non-hierarchical formulation.
The nested GDP model is compared against its equivalent single-level formulation, and the Non-hierarchical formulation, by reformulating each of these into mixed-integer nonlinear programs (MINLPs) using the Hull reformulation. Since the models are nonlinear, the perspective functions were reformulated using the \(\epsilon \)-approximation from Furman et al. (2020), with \(\epsilon ={10}^{-9}\), which is the default nonlinear Hull reformulation method in the disjunctive programming library. As in Example 1, two additional scenarios are run where the product (stream 8) sales price is increased and decreased by 10%. The model statistics are given in Tables 9 (nominal case), 10 (10% increase), and 11 (10% decrease). The Nested formulation is faster than the Equivalent Single-Level formulation by a factor of 1.8–4.2. When local search and range reduction are disabled in BARON, the difference in CPU time becomes more significant (one order of magnitude difference). The continuous relaxations for the Nested and Non-hierarchical formulations are equal (23—37% gap) and tighter than that of the Equivalent Single-Level formulation (57—89% gap). The performance of the Nested formulation is comparable to that of the Non-hierarchical one, with the latter having less continuous variables and constraints. This example highlights the fact that models with on/off disjunctions do not require a hierarchical representation to attain the same performance gains of the nested models.
The optimal expansion profile for the nominal case is given in Fig. 12, where it can be seen that Process 2 is not installed, but Processes 1 and 3 are, where the capacity in Process 1 increases to 1 ton/year by the third year, and Process 3 increases to 1.11 ton/year by the fourth year. The optimal system cost is − $95 thousand, meaning that plant generates profit.

Capacity expansion profiles for each of the processes in Example 2
5 Conclusions
Two main contributions are made in this paper to the generalized disjunctive programming (GDP) modeling framework. The first one is to add cardinality rules to the logic constraints to allow for constraints of the form choose exactly m Boolean variables to be True (or at least m, or at most m). For more than two Boolean variables, modeling these types of constraints via propositional logic (zeroth-order logic) is cumbersome. Thus, introducing predicate logic (first-order logic) to express this new constraint form in GDP adds more expressiveness to logic-based models. The second contribution is to extend GDP for modeling hierarchical systems via nested disjunctions. Such an approach results in more intuitive models, but had not been formalized in the past, as classical GDP does not consider disjunction nesting. The notation and logic constraints for such structures are provided, along with theoretical proofs to the tightness of such models, versus equivalent single-level GDP models. It is shown that mixed-integer programming reformulations of nested GDP models have continuous relaxations that are as tight or tighter than the reformulations of their single-level counterparts in both the Hull reformulation, as well as the Big-M reformulation when tight M values are used. In some cases, the nested models result in tighter continuous relaxations, as shown in the illustrative and numerical examples presented. It was also observed that when large M values are used, the reformulated nested models show worse performance due to the presence of multiple large M parameters in the nested constraints. Finding tight M values requires additional work, and can be done by applying interval arithmetic when the models are linear. However, for nonlinear models, a separate optimization model must be solved for each constraint to find the tightest M values.
Three examples are presented to show the advantages of using nested structures. In the illustrative example, the tightness of the continuous relaxations of nested linear models are compared geometrically with the relaxations of equivalent single-level models. In this example, the models that preserve nested structures have smaller continuous relaxations than their single-level counterparts. This is promising as it may result in computational savings when optimizing nested models. Example 1, a linear GDP, and Example 2, a nonlinear GDP, illustrate the computational advantages of nested GDP models for problems that integrate superstructure design, technology selection, and operations scheduling, and superstructure design, long-term operations planning, and capacity expansion planning, respectively. It is also shown that for systems with bi-disjunct constraints (disjunctions with only two disjunctions), where one disjunct represents an off state with all pertinent variables set to zero (e.g., zero flow), there is no advantage to modeling such systems as hierarchical, even when there may be several levels of decisions. Such systems can be modelled more simply with single-level disjunctions and the necessary linking constraints.
Future work includes investigating how explicit hierarchical structures can be exploited for informed model decomposition methods and branching strategies. Exploring applications of hierarchical GDP to other fields, such as decision trees and stochastic optimization with event constraints, is another potential area for development.
Abbreviations
- \(i\in I\) :
-
Processes
- \(j\in J\) :
-
Technologies
- \(k\in K\) :
-
Resources
- \(k\in {K}^{react}\) :
-
Reactors
- \(k\in {K}^{tank}\) :
-
Tanks
- \(s\in S\) :
-
Streams
- \(s\in {S}^{ext}\) :
-
External material streams
- \(s\in {S}_{x}^{in}\) :
-
Streams entering \(x\)
- \(s\in {S}_{x}^{out}\) :
-
Streams exiting \(x\)
- \(t\in T\) :
-
Time periods
- \(u\in {U}_{k}\) :
-
Number of installed units for resource \(k\)
- \(\alpha \) :
-
Fixed installation/expansion cost
- \(\beta \) :
-
Variable installation/expansion cost coefficient
- \(\gamma \) :
-
Variable operating cost coefficient
- \(\nu \) :
-
Yield coefficient
- \({\tau }_{i}\) :
-
Processing time for process \(i\)
- \({F}_{s}^{UB}\) :
-
Upper bound on stream \(s\)
- \({p}_{x}\) :
-
Price/cost of stream/material \(x\)
- \({Q}_{k}^{UB}\) :
-
Upper bound on the capacity of resource \(k\)
- \({QE}_{i}^{UB}\) :
-
Upper bound on the capacity expansion of process \(i\)
- \({B}_{i,t}\) :
-
Total batch size for process \(i\) starting in period \(t\)
- \({\widehat{B}}_{i,t}\) :
-
Unit batch size for process \(i\) starting in period \(t\)
- \(C{E}_{i,t}\) :
-
Expansion cost for process \(i\) in period \(t\)
- \(C{I}_{k}\) :
-
Installation cost for resource \(k\)
- \(C{O}_{i,t}\) :
-
Operating cost of process \(i\) in period \(t\)
- \({F}_{s,t}\) :
-
Flow in stream \(s\) in period \(t\)
- \({L}_{k,t}\) :
-
Level in tank \(k\) in period \(t\)
- \({\widehat{L}}_{k}\) :
-
Level slack in tank \(k\) in the final period (end of scheduling horizon)
- \({Q}_{k}\) :
-
Capacity of resource \(k\)
- \({Q}_{i,t}\) :
-
Capacity of process \(i\) in period \(t\)
- \(Q{E}_{i,t}\) :
-
Capacity expansion for process \(i\) in period \(t\)
- \({R}_{k,t}\) :
-
Availability of resource \(k\) in period \(t\)
- \(\Delta {R}_{i,k,t}\) :
-
Number of resources of type \(k\) consumed for process \(i\) in period \(t\)
- \({N}_{i,k,t,u}\) :
-
Process \(i\) is started on \(u\) units of resource \(k\) at period \(t\)
- \({N}_{i,t}^{\left(n\right)}\) :
-
Operation of process \(i\) in period \(t\)
- \({\widehat{W}}_{i,j}\) :
-
Technology \(j\) is used for process \(i\)
- \({W}_{i,k}\) :
-
Resource \(k\) is assigned to process \(i\)
- \({X}_{k,u}\) :
-
Resource \(k\) installed with \(u\) units
- \({Y}_{i}\) :
-
Process \(i\) is installed
- \({Z}_{i,t}^{\left(n\right)}\) :
-
Capacity expansion of process \(i\) in period \(t\,{\text{in}} \, disjunct \, \text{n}\)
References
Agarwal A (2015) A novel MINLP reformulation for nonlinear generalized disjunctive programming (GDP) problems. ArXiv. https://doi.org/10.48550/arxiv.1510.01791
Balas E (1985) Disjunctive programming and a hierarchy of relaxations for discrete optimization problems. SIAM J Algebraic Discrete Methods 6(3):466–486. https://doi.org/10.1137/0606047
Bernal DE, Grossmann I E (2021) Convex mixed-integer nonlinear programs derived from generalized disjunctive programming using cones. https://doi.org/10.48550/arxiv.2109.09657
Bezanson J, Edelman A, Karpinski S, Shah VB (2017) Julia: A fresh approach to numerical computing. SIAM Rev 59(1):65–98. https://doi.org/10.1137/141000671
Brunaud B, Grossmann IE (2017) Perspectives in multilevel decision-making in the process industry. Front Eng Manag, 4(3):256–270. https://doi.org/10.15302/J-FEM-2017049
Castro P, Rodrigues D, Matos HA (2014) Cyclic scheduling of pulp digesters with integrated heating tasks. Ind Chem Eng Res 53:17098–17111. https://doi.org/10.1021/ie403822z
Castro P (2017) Optimal scheduling of multiproduct pipelines in networks with reversible flow. Ind Chem Eng Res 56:9638–9656. https://doi.org/10.1021/acs.iecr.7b01685
Chen Q, Johnson ES, Bernal DE, Valentin R, Kale S, Bates J, Siirola JD, Grossmann IE (2022) Pyomo.GDP: an ecosystem for logic based modeling and optimization development. Optim Eng 23(1):607–642. https://doi.org/10.1007/S11081-021-09601-7/FIGURES/13
Dantzig GB (1972) Fourier-Motzkin elimination and its dual. Department of Operations Research, Stanford University, CA. https://apps.dtic.mil/sti/citations/AD0750674
Dunning I, Huchette J, Lubin M (2017) JuMP: a modeling language for mathematical optimization. SIAM Rev 59(2):295–320. https://doi.org/10.1137/15M1020575
Furman KC, Sawaya NW, Grossmann IE (2020) A computationally useful algebraic representation of nonlinear disjunctive convex sets using the perspective function. Comput Optim Appl 76(2):589–614. https://doi.org/10.1007/S10589-020-00176-0/TABLES/7
Grossmann IE (2012) Advances in mathematical programming models for enterprise-wide optimization. Comput Chem Eng 47:2–18. https://doi.org/10.1016/j.compchemeng.2012.06.038
Grossmann IE, Lee S (2003) Generalized convex disjunctive programming: nonlinear convex hull relaxation. Comput Optim Appl 26(1):83–100. https://doi.org/10.1023/A:1025154322278
Grossmann IE, Trespalacios F (2013) Systematic modeling of discrete–continuous optimization models through generalized disjunctive programming. AIChE J 59(9):3276–3295. https://doi.org/10.1002/AIC.14088
Kondili E, Pantelides CC, Sargent RWH (1993) A general algorithm for short-term scheduling of batch operations-I. MILP Formul Comput Chem Eng 17(2):211–227. https://doi.org/10.1016/0098-1354(93)80015-F
Lee S, Grossmann IE (2000) New algorithms for nonlinear generalized disjunctive programming. Comput Chem Eng 24(9–10):2125–2141. https://doi.org/10.1016/S0098-1354(00)00581-0
Legat B, Deits R, Goretkin G, Koolen T, Huchette J, Oyama D, Forets M (2021) JuliaPolyhedra/Polyhedra.jl: v0.6.16. Zenodo. https://doi.org/10.5281/zenodo.4993670
Maravelias CT, Sung C (2009) Integration of production planning and scheduling: Overview, challenges and opportunities. Comput Chem Eng 33(12):1919–1930. https://doi.org/10.1016/J.COMPCHEMENG.2009.06.007
Muñoz E, Capón-García E, Moreno-Benito M, Espuña A, Puigjaner L (2011) Scheduling and control decision-making under an integrated information environment. Comput Chem Eng 35(5):774–786. https://doi.org/10.1016/J.COMPCHEMENG.2011.01.025
Perez HD, Amaran S, Iyer S, Wassick JM, Grossmann IE (2022) Applications of the RTN scheduling model in the chemical industry. In Bortz M, Asprion N (eds), Simulation and optimization in process engineering: the benefit of mathematical methods in applications of the chemical industry. Elsevier, New York, pp 365–400. https://doi.org/10.1016/B978-0-323-85043-8.00006-4
Perez, H. D., Joshi, S., Grossmann, I. E. (2023). DisjunctiveProgramming.jl: generalized disjunctive programming models and algorithms for JuMP. ArXiv. https://doi.org/10.48550/arXiv.2304.10492
Raman R, Grossmann IE (1994) Modelling and computational techniques for logic based integer programming. Comput Chem Eng 18(7):563–578. https://doi.org/10.1016/0098-1354(93)E0010-7
Rodriguez MA, Vecchietti A (2009) Logical and generalized disjunctive programming for supplier and contract selection under provision uncertainty. Ind Eng Chem Res 48(11):5506–5521. https://doi.org/10.1021/IE801614X/ASSET/IMAGES/MEDIUM/IE-2008-01614X_0005.GIF
Ruiz JP, Grossmann IE (2012) A hierarchy of relaxations for nonlinear convex generalized disjunctive programming. Eur J Oper Res 218(1):38–47. https://doi.org/10.1016/J.EJOR.2011.10.002
Sawaya NW, Grossmann IE (2005) A cutting plane method for solving linear generalized disjunctive programming problems. Comput Chem Eng 29(9):1891–1913. https://doi.org/10.1016/J.COMPCHEMENG.2005.04.004
Sokoler LE, Dinesen PJ, Jorgensen JB (2017) A Hierarchical algorithm for integrated scheduling and control with applications to power systems. IEEE Trans Control Syst Technol 25(2):590–599. https://doi.org/10.1109/TCST.2016.2565382
Trespalacios F, Grossmann IE (2015) Improved Big-M reformulation for generalized disjunctive programs. Comput Chem Eng 76:98–103. https://doi.org/10.1016/J.COMPCHEMENG.2015.02.013
Trespalacios F, Grossmann IE (2016) Cutting plane algorithm for convex generalized disjunctive programs. Informs J Comput 28(2):209–222. https://doi.org/10.1287/IJOC.2015.0669
Türkay M, Grossmann IE (1996a) Logic-based MINLP algorithms for the optimal synthesis of process networks. Comput Chem Eng 20(8):959–978. https://doi.org/10.1016/0098-1354(95)00219-7
van den Heever SA, Grossmann IE (1999) Disjunctive multiperiod optimization methods for design and planning of chemical process systems. Comput Chem Eng 23(8):1075–1095. https://doi.org/10.1016/S0098-1354(99)00273-2
Vecchietti A, Grossmann IE (2000) Modeling issues and implementation of language for disjunctive programming. Comput Chem Eng 24(9–10):2143–2155. https://doi.org/10.1016/S0098-1354(00)00582-2
Williams HP (1985) Model building in linear and integer programming. Comput Math Program. https://doi.org/10.1007/978-3-642-82450-0_2
Yan H, Hooker JN (1999) Tight representation of logical constraints as cardinality rules. Math Program 85(2):363–377. https://doi.org/10.1007/S101070050061
Acknowledgements
The authors gratefully acknowledge the financial support from the Center of Advanced Process Decision-making at Carnegie Mellon University.
Funding
Open Access funding provided by Carnegie Mellon University.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix A: Challenges with exclusive OR operator
The exclusive OR (XOR) returns true whenever an odd number of literals are True. As a binary operator, it is equivalent to exactly one of the literals being true. However, when disjunctions have three or more disjuncts, using an XOR operator can be problematic when the disjunction is not proper, meaning that there is an overlap between the feasible regions of the disjuncts. Specifically, issues arise when a GDP model is reformulated into a MIP model via the Hull reformulation. When the Hull reformulation is applied, each variable in the disjunction is disaggregated, and it is assumed that exactly one of the disaggregated variables takes a non-zero value, such that the sum of the disaggregated variables becomes the original variable. However, for an improper disjunction, there can exist a scenario where a feasible point is at the intersection of an odd number of disjuncts. When this occurs, an odd number of disaggregated variables can become non-zero, resulting in an erroneous solution.
Consider the simple improper disjunction in (A1), where \(x\) is bounded between 0 and 20. The Hull reformulation of (A1) is given in (A2), where \({y}_{i}\) is the binary counterpart of the Boolean \({Y}_{i}\). At the feasible point \(x=5\), all three disjuncts are valid, and the XOR operator \({Y}_{1}{\underline{\vee}}{Y}_{2}{\underline{\vee}}{Y}_{3}\), will return True if all Boolean variables \({Y}_{i}\) are True. In this scenario, \({x}_{i}=5 \quad \,\forall\, i\in \left\{\mathrm{1,2},3\right\}\), making the aggregated variable \(x=15\), which is not correct. Note that if the upper bound on \(x\) is less than 15, this solution becomes infeasible. Although this is a simple example that could be avoided by using strict inequalities on the first and third disjunct, there may be more complex disjunctions where it may not be as apparent that they are improper.
Appendix B: Negations in nested disjunctions
Nesting disjunctions involves linking cardinality constraints of the form \({\varvec{\Xi}}(Y,{W}_{i} \quad \,\forall\, i\in I\)), which indicates that exactly one Boolean \({W}_{i}\) is allowed to be True if and only if \(Y\) is True. Otherwise, exactly zero Booleans \({W}_{i}\) are True. To illustrate this, consider Example 2 (Sect. 4.3), where the upper-level decision is to install or not install a process (indicated by the Boolean variable \(Y\) below), and the lower-level decision is to operate or not operate the process in a given time period (indicated by the Boolean variable \(N\) below). The modeler might consider writing such a nested disjunction as (B1). However, this is not correct from a logic standpoint because the cardinality rule \({\varvec{\Xi}}\left(Y,\left\{N,\neg N\right\}\right)\) is infeasible. This is because \(N\) must either be True or False, and \(\neg N\) is the complement of \(N\). If \(Y=False\), the cardinality rule implies that all the literals must be False, but \(N\) and \(\neg N\) cannot both be False. The correct form of writing this nested disjunction is given in (B2), where \({N}^{\left(1\right)}\) indicates operating the process given the process is installed, and \({N}^{\left(2\right)}\) indicates not operating the process given the process is installed.
Appendix C: Flattening nested disjunctions via basic steps
The third approach to modeling hierarchical GDP is to flatten the nested disjunctions by applying sufficiently many basic steps (Ruiz and Grossmann 2012; Grossmann and Trespalacios 2013) within each disjunction until the nested system is transformed into a system with single-level disjunctions. Consider the simple nested disjunction in (C1). This disjunction constraint can be flattened by applying two basic steps to introduce \({g}_{1}\left(x\right)\le 0\) into the nested disjunctions, resulting in (C2), where \({Z}_{1}={Y}_{1}\wedge {W}_{1}\) and \({Z}_{2}={Y}_{1}\wedge {W}_{2}\).
For disjunctions with a single nested disjunction, applying a basic step is quite inexpensive. However, once there is more than one nested disjunction inside a single disjunct, the number of basic steps required to flatten the hierarchical GDP grows exponentially. Consider the disjunction with two nested disjunctions in (C3). Flattening the disjunction is a set covering problem and requires eight basic steps (four for each combination of two disjuncts and four more to introduce \({g}_{1}\left(x\right)\le 0\) in the resulting disjuncts) to obtain the equivalent disjunction in (C4).
Generalizing this to the notation of 2L-GDP, a disjunction with \(k\in {K}_{ij}\) nested disjunctions, each of which has \(l\in {L}_{ijk}\) disjuncts, requires the number of basic steps given in (17), where the notation \(\left(\genfrac{}{}{0pt}{}{a}{1}\right)\) is the binomial coefficient (choose 1 from a group with \(a\) elements). The coefficient \(2\) accounts for introducing \({g}_{ij}\left(x\right)\le 0\) into each of the resulting disjuncts, and can be replaced by the \(1+\left|{g}_{ij}\left(x\right)\right|\) if \({g}_{ij}(x)\) represents a vector of functions, where \(\left|{g}_{ij}\left(x\right)\right|\) is the number of functions within \({g}_{ij}\left(x\right)\). A hybrid approach is also possible, where some basic steps are performed and then the resulting nested disjunction is flattened as in the Equivalent Single-Level GDP approach. However, as the number of nested disjunctions increases, this hybrid approach yields many more disjunctions than those given in (C5). Although flattening via basic steps may produce models that are tighter than the inside-out reformulation of the nested GDP, the combinatorial growth of such systems makes this approach prohibitive for multi-level decision systems with multiple disjuncts in each nested disjunction. It is for this reason that this approach is not considered in the main body of the paper. However, it is presented here as a reference for the reader.
Supplementary material
All source code for the figures and examples in this paper can be found at https://github.com/hdavid16/Extensions-to-GDP-paper.
Rights and permissions
Open Access This article isvariables are forced to 0 for licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

{kind=link}
{kind=link}
{kind=link}
Cite this article
Perez, H.D., Grossmann, I.E. Extensions to generalized disjunctive programming: hierarchical structures and first-order logic. Optim Eng 25, 959–998 (2024). https://doi.org/10.1007/s11081-023-09831-x
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11081-023-09831-x