
Abstract
A common approach to solve or find bounds of polynomial optimization problems like Max-Cut is to use the first level of the Lasserre hierarchy. Higher levels of the Lasserre hierarchy provide tighter bounds, but solving these relaxations is usually computationally intractable. We propose to strengthen the first level relaxation for sparse Max-Cut problems using constraints from the second order Lasserre hierarchy. We explore a variety of approaches for adding a subset of the positive semidefinite constraints of the second order sparse relaxation obtained by using the maximum cliques of the graph’s chordal extension. We apply this idea to sparse graphs of different sizes and densities, and provide evidence of its strengths and limitations when compared to the state-of-the-art Max-Cut solver BiqCrunch and the alternative sparse relaxation CS-TSSOS.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
The Lasserre hierarchy (Lasserre 2001) is a powerful relaxation for polynomial optimization problems (POPs). Its power comes from the fact that, in practice, the optimal value of the hierarchy converges faster than theoretical results indicate. In practice, the first and second levels often provide a good solution of the original POP. Along with the efficiency of interior point methods to solve semidefinite programming problems, the Lasserre hierarchy can, in theory, solve POPs in polynomial time. However, not even the second hierarchy level can be solved by interior point methods for medium or large problems. This paper explores the idea of partially strengthening the first level relaxation with a subset of the second level relaxations constraints for sparse instances of the classical Max-Cut problem. This idea was originally used in the Optimal Power Flow problem in Josz and Molzahn (2018) in what the authors called a multi-order relaxation. Similarly, in Chen et al. (2020) the first order of the sparse Lasserre hierarchy is strengthened to calculate upper bounds of the Lipschitz constant for neural networks by only adding second order information for constraints that do not destroy the sparsity pattern of the POP; and Pál and Vértesi (2009) uses intermediate levels of a nonconmutative generalisation of the Lasserre hierarchy to find upper limits for the maximum quantum violation of the Bell inequalities. In this paper, and in the context of the Max-Cut problem, we use the basic multi-order approach (which is equivalent to what we called the partial relaxation), proposed an augmented version, as well as different heuristics to improve the bounds of the first order level of the original Lasserre hierarchy. As the integrality constraints of the Max-Cut problem do not affect the sparsity pattern of the POP, the sparse hierarchy depends exclusively on the sparsity of the graph, and the strengthening of the first order relaxation is done by restricting the size and/or selecting a subset of the maximal cliques used in the second order relaxation. After we pre-printed this paper, Chen et al. (2022) generalized (i) the ideas proposed in this paper and Josz and Molzahn (2018), and (ii) created what they call the sublevel hierarchy (which includes the heuristics used in Chen et al. (2020) as a particular case). This hierarchy provide intermediate levels of the SDP relaxations for any arbitrary level d. The authors use the sublevel hierarchy as well as some of the heuristics proposed in this paper, and provide numerical results showing how these techniques can also be useful outside the context of the Max-Cut problem.
Given a graph \(G = (V,E)\) with nodes \(V=\{v_1,\dots , v_n\}\), a set of edges \(E=\{(i,j): 1\le i,j \le n, \text { if }i\text { is connected to }j\}\) and a symmetric matrix \(W \in S^n\) with value \(w_{i,j} \ne 0\) in position (i, j) if \((i,j) \in E\) and 0 otherwise, the Max-Cut problem can be written as the integer program:
Approaches for rigorously computing upper bounds for the Max-Cut problem include linear, semidefinite programming (SDP), convex quadratic and second order cone relaxations. These relaxations may be strengthened with cuts, e.g. triangle or cycle inequalities, or a branch-and-bound algorithm (Barahona et al. 1989; Barahona and Ladanyi 2006; Billionnet and Elloumi 2007; Fischer et al. 2006; Kim and Kojima 2001). Codes like Biq Mac (Rendl et al. 2010) and BiqCrunch (Krislock et al. 2014, 2017), which implement the SDP relaxation together with triangle inequalities, successfully solve difficult Max-Cut instances. The SDP relaxation corresponds to the first Lasserre hierarchy level (Lasserre 2001). Alternative Lasserre hierarchy versions are relevant for sparse graphs (Lasserre 2006; Waki et al. 2006). These alternatives only add a subset of the dense relaxation and thereby reduce the SDP size considerably at every hierarchy level.
In our computational experience, the sparse SDP relaxation of reasonably-sized Max-Cut instances is still too big to be solved at the second hierarchy level or higher. So, our numerical experiments explore different heuristics to add second order information to the standard sparse SDP relaxation of Waki et al. (2006). We show the advantages and limitations of this partial relaxation by comparing with (i) state-of-the-art Max-Cut solver BiqCrunch and (ii) CS-TSSOS (Wang et al. 2020b), a recently-developed sparse POP hierarchy. The results indicate that, for sufficiently sparse problems, there is rich information to be added to strengthen the first order relaxation without using the entire second hierarchy level. The partial Lasserre relaxation is particularly useful if the maximal cliques of a chordal extension of the graph’s correlative sparsity matrix are small.
Previous work considered block-diagonal relaxations between the first and second order relaxations (Gvozdenović and Laurent 2008; Gvozdenović et al. 2009). Specific to Max-Cut, Wiegele (2006) proposes a submatrix of the second order relaxation constraint to solve Max-Cut problems for dense graphs. Similarly, works like Adams et al. (2015) and Ghaddar et al. (2016) construct hierarchies by strenghtening the first level of the Lasserre hierarchy. But our paper is, to the best of our knowledge, the first to computationally study sparse versions of the Lasserre hierarchy to form intermediate relaxations between levels. Our work also resembles prior work approximating semidefinite relaxations with linear cutting planes (Baltean-Lugojan et al. 2018; Qualizza et al. 2012; Saxena et al. 2011; Sherali et al. 2012) or nonlinear cutting surfaces (Dong 2016). These works developing cutting surfaces typically approximate the first order of the Lasserre hierarchy, while we relax the second order (Baltean-Lugojan et al. 2018; Qualizza et al. 2012; Saxena et al. 2011; Sherali et al. 2012). Like Baltean-Lugojan et al. (2018), we select submatrices of a semidefinite relaxation. Differently to Baltean-Lugojan et al. (2018), we use clique patterns in the Max-Cut graph to select submatrices (rather than data-driven methods).
It is important to note that there are efficient linear methods to solve sparse Max-Cut problems. For example, the linear branch-and-cut algorithm of Liers et al. (2004) is faster than Biq Mac when solving the Max-Cut for sparse toroidal grid graphs (Rendl et al. 2010). This paper uses Max-Cut because it is a well-studied problem, but the ideas explored here apply to any sparse POP. Finally, the ideas studied in this paper could also be used in other sparse semidefinite relaxations like CS-TSSOS (Wang et al. 2020b.
The rest of the paper is structured as follows. Section 2 provides the notation. Section 3 introduces the dense and sparse hierarchies. Sections 4 and 5 contain our numerical experiments and the conclusions, respectively.
2 Notation
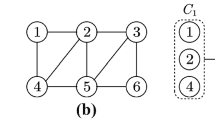
The monomial \(x_1^{\alpha _1} x_2^{\alpha _2} \dots x_n^{\alpha _n}\) will be denoted by \({\mathbf {x}}^{{\varvec{\alpha }}}\), where \({\varvec{\alpha }}= [\alpha _1,\alpha _2,\dots ,\alpha _n] \in {\mathbb {N}}^n\). If \(\phi \subset \{1,2,\dots ,n\}\) and d a positive integer, then \({\mathbb {A}}^{\phi }_d = \{{\varvec{\alpha }}\in {\mathbb {N}}^n:\alpha _i = 0 \text { if } i \notin \phi , \sum _i \alpha _i \le d\}\), and \(u_{d}(x,\phi )\) is the vector containing all the monomials \({\mathbf {x}}^{\varvec{\alpha }}\) such that \({\varvec{\alpha }}\in {\mathbb {A}}^{\phi }_d\), e.g. if \(\phi = \{2,4\}\), \(n=4\) and \(d=2\), \({\mathbb {A}}^{\phi }_d=\{[0,0,0,0],[0,1,0,0],[0,0,0,1],[0,2,0,0],[0,1,0,1],[0,0,0,2]\}\), \(u_{d}(x,\phi ) = [1,x_2,x_4,x_2^2,x_2x_4,x_4^2]^\top \).
If \(A \in {\mathbb {R}}^{m \times n}\) is a matrix, then the element in position (i, j) will be denoted by \(A_{i,j}\) (if \(m=1\) or \(n=1\), the \(i^{th}\) element of the vector will be denoted by \(A_i\)). Likewise, if \(A, B \in {\mathbb {R}}^{m \times n}\), we will use the Frobenius inner product \(\left\langle A,B \right\rangle = \sum _{1\le i \le m}\sum _{1\le j \le n} A_{i,j} B_{i,j}\) and its induced norm \(\Vert A \Vert ^2 = \left\langle A,A \right\rangle \). \(\text {Diag}(x_1,x_2,\dots ,x_n)\) is the function returning a diagonal matrix of dimensions \(n \times n\) with \(x_i\) in the entry (i, i) for \(i=1,2,\dots ,n\). The set of symmetric matrices will be denoted by \({\mathcal {S}}\), and for any matrix \(X \in {\mathcal {S}}\), \(X \succeq 0\) (\(\succ 0\)) means that X is positive semidefinite (resp., definite). \(e \in {\mathbb {R}}^n\) will denote the vector of ones, and if \(i \in {\mathbb {N}}\), \(e_i \in {\mathbb {R}}^n\) is a vector with one in position \(i^{th}\) and zeros everywhere else. Finally, the cardinality of any set \(\phi \) will be denoted by \(|\phi |\), the set \(\{1,2,\dots ,n\}\) will be written as [n], and \(\left\lceil {x} \right\rceil \) is the smallest integer such that \(\left\lceil {x} \right\rceil \ge x\) for any \(x \in {\mathbb {R}}\) .
3 Lasserre dense, sparse and partial relaxations
The Lasserre hierarchy can be obtained by lifting the monomials of the POP. Replace the objective of Problem (1) by \(\frac{1}{4}\left\langle L,[x_1,x_2,\dots ,x_n]^\top [x_1,x_2,\dots ,x_n] \right\rangle \), where L is the Laplacian matrix \(L = \text {Diag}(We)- W\); and the integer constraint \(x_i \in \{-1,1\}\) with the equivalent equation \(x_i^2 -1 = 0\). Problem (1) can be written:
Using the fact that \(zz^\top \succeq 0\) for any vector z, we can add the redundant constraints \(M_d^{[n]}(x) =u_{d}(x,[n])u_{d}(x,[n])^\top \succeq 0\) to obtain:
where \(d \ge 1\) is a positive integer. Let \({\widehat{M}}_d^{[n]}(x)\) be the matrix obtained after replacing all the occurrences of the monomial \(x_i^2\) by 1 (\(i \in [n]\)) in the matrix \(M_d^{[n]}(x)\), and then deleting the rth column and row if there is \(p<r\) such that the pth column is identical to the rth column. Lifting all the variables by replacing the monomial \({\mathbf {x}}^{\varvec{\alpha }}\) by the real variable \(y_{\varvec{\alpha }}\), and deleting the integrality constraints we obtain the following SDP,
where y is a real vector indexed by the set \({\mathbb {A}}^{[n]}_{2d}\), and \({\hat{L}} = \begin{bmatrix} {\mathbf {0}} &{} {\mathbf {0}}\\ {\mathbf {0}} &{} L\end{bmatrix}\). Matrix \({\widehat{M}}_d^{[n]}(y)\) is the moment matrix of order d. In Lasserre (2002) it is proved that the optimal relaxation value converges to the optimal value of the original POP, and that the convergence is finite: if \(d\ge n\) then \(Q_d = p^\star \). Practically, the optimal value \(p^\star \) is found usually for d considerably smaller than n, e.g. small Max-Cut instances have been solved using only the second relaxation (Campos et al. 2019; Lasserre 2002).
Although, in theory, the SDP relaxation of Max-Cut can be solved using interior point methods, the relaxation size grows exponentially as d increases and using interior point methods is no longer possible. Hence, the relaxation is only useful for small graphs, or for small values of d. Our computational experience on modern desktops is that, for graphs larger than 30 nodes, typically only the first order relaxation can be solved.
For sparse graphs, Waki et al. (2006) developed a sparse version of the Lasserre hierarchy that reduces the size of the dense SDP. Using a similar approach as the one for the dense relaxation, we obtain the relaxation:
where y is a vector indexed by the set \(\cup _{k=1}^m {\mathbb {A}}^{\phi _k}_{2d}\), \(\{\phi _k\}_{k=1}^m\) correspond to the maximal cliques of a chordal extension of the graph \(G=(V,E)\), and the matrices \({\hat{L}}_k\) are such that \(\sum _{k=1}^m\left\langle {\hat{L}}_k,{\widehat{M}}_1^{\phi _k}(y) \right\rangle = \left\langle {\hat{L}},{\widehat{M}}_1^{[n]}(y) \right\rangle \). For more information about chordal extensions and algorithms to find maximal cliques, see Blair and Peyton (1993), Bomze et al. (1999), Golumbic (2004). Lasserre (2006) proves that if the sets \(\{\phi _k\}_{k=1}^m\) satisfy the running intersection property, which is the case for the maximal cliques used in Waki et al. (2006), and some redundant constraints are added to SDP (5), the optimal relaxation value converges to the optimal value of the original polynomial optimization problem as the value of d tends to infinity.
For sparse graphs, i.e. graphs with small |E|, Relaxation (5) reduces considerably the size of Problem (4). However, even for sparse graphs, the sparse relaxation of Max-Cut is too large and can not be solved using interior point methods for \(d>1\). For example, we generated graphs with 300 nodes using the package SparsePOP (see Sect. 4.1) and tried unsuccessfully to solve the Sparse Relaxation (5) for \(d=2\) for many graphs even with a \(2\%\) sparsity, i.e. \(2|E|/(n^2)\approx 0.02\) (we used Mosek version 8.1 in an Intel Core i7-6700 CPU @ 3.40 Gigahertz Ubuntu 16.04 workstation with 16 gigabytes of RAM).
3.1 A partial and partial augmented second order sparse relaxation
Not all the moment matrices of the sparse second order relaxation can be included, so we propose including a subset. “Partial” Second Order Relaxation (6) relaxes maximal cliques with more than (fewer than or equal to) r nodes using the first (second) level of the Lasserre hierarchy.
where \(\varGamma _r = \{k \in [m]: \left| \phi _k\right| \le r\}\) and the real vector y is indexed by the set \(\{\cup _{k\in \varGamma _r} {\mathbb {A}}^{\phi _k}_{4}\} \cup \{\cup _{k \notin \varGamma _r} {\mathbb {A}}^{\phi _k}_{2}\}\); note that this set is contained in the set \(\cup _{k=1}^m {\mathbb {A}}^{\phi _k}_{4}\) corresponding to the space of the second order sparse relaxation. Partial Relaxation (6) reduces the number of constraints and variables by including only a subset of the second order semidefinite constraints of the second level of the Lasserre hierarchy.
We consider also an “augmented” version of the previous problem, by also including second order constraints for subsets of the maximal cliques with sizes larger than r.
where p denotes the number of second order constraints added for each maximal clique \(\phi _k\) such that \(\left| \phi _k\right| > r\), while H denotes the heuristic that selects the sets \(\phi _{k,i}\). We construct these subsets \(\phi _{k,i}\) sequentially, starting by selecting the smallest maximal clique (if there’s more than 1 smallest maximal clique, then we select randomly), and making sure that we are not adding repeated subsets. For fixed r, Augmented Partial Relaxation (7) increases the number of constraints over Partial Relaxation (6) by including the semidefinite constraints corresponding to the second order moment matrices of the subsets \(\phi _{k,i} \subset \phi _k,\; \left| \phi _{k,i}\right| = r, \left| \phi _{k}\right| > r\).
We use five heuristics to select the sets \(\{\phi _{k,i}\}\). If the total number of subsets of size r of \(\phi _k\) is \(q_k\) and \(I = \{i_1,i_2,\dots ,i_p\} \subseteq [q_k]\) is a set of sub-indices, then we select the subsets \(\{\phi _{k,i_1},\phi _{k,i_2},\dots ,\phi _{k,i_p}\}\) where:
-
(H1)
I is selected randomly and uniformly from the set \([q_k]\).
-
(H2)
I is such that \(\Vert L_{\phi _{k,i_1}}\Vert \ge \Vert L_{\phi _{k,i_2}}\Vert \ge \dots \ge \Vert L_{\phi _{k,i_{q_k}}}\Vert \), where \(L_{\phi }\) is the sub-matrix created by deleting columns and rows corresponding to indices not contained in \(\phi \) from the Laplacian matrix. H2 selects variable subsets with large absolute value weights in the graph.
-
(H3)
I is such that \(\left| \varOmega _{k,i_1}\right| \ge \left| \varOmega _{k,i_2}\right| \ge \dots \ge | \varOmega _{k,i_{q_k}}|\), where for every set \(\phi _{k,i} \subset \phi _k\) of size r, \(\varOmega _{k,i} = \{l: \phi _{k,i} \subseteq \phi _l,l \in [m], l \ne k\}\). H3 selects subsets contained in many maximal cliques.
-
(H4)
I is such that \(\left| \varOmega _{k,i_1}\right| \le \left| \varOmega _{k,i_2}\right| \le \dots \le | \varOmega _{k,i_{q_k}}|\). H4 selects subsets contained in few maximal cliques.
-
(H5)
I combines H2 and H4: we select subsets that are not repeated in other maximal cliques and contain variables with large weights in absolute value in the graph. Specifically, let \(\{i_1, i_2,\dots , i_z\}\) be the indices of the subsets \(\{\phi _{k,i_j}\}\) such that \(\left| \varOmega _{k,i_j}\right| = 0\) and \(\Vert L_{\phi _{k,i_j}}\Vert \ge \Vert L_{\phi _{k,i_{j+1}}}\Vert \) for \(1\le j \le z\). Then: if \(p \le z\) we select the subsets \(\{\phi _{k,i_1},\dots ,\phi _{k,i_p}\}\), if \(z<p\) we select the subsets \(\{\phi _{k,i_1},\dots ,\phi _{k,i_z}\}\), and if \(z=0\) we apply the heuristic H2.
The next section explores the power of Relaxations (6) and (7) for sparse graphs.
4 Numerical experiments
This section solves relaxations of the Max-Cut problems using Partial Relaxation (6) and Augmented Partial Relaxation (7). All the experiments were run in an Intel Core i7-6700 CPU @ 3.40 GHz Ubuntu 18.04 workstation with 16 GB RAM. MATLAB version 2018a generated the set of maximal cliques using the code genClique.m contained in the package SparsePOP version 3.01 (Waki et al. 2008) (https://sparsepop.sourceforge.io/), an implementation of the sparse relaxation developed in Waki et al. (2006). We created and solved SDPs (6) and (7) with C++ and Fusion-API Mosek version 8.1. All the times are elapsed real times in seconds. We limit the time of each interior point run to 5 hours.
4.1 Randomly generated problems
The first set of problems are created randomly using the objective sparsity structure obtained by SparsePOP’s randomUnconst.m. This function takes as arguments the number of polynomial variables (the graph size n), a lower and upper integer bound (l and u, respectively), and a maximal degree (2). With these parameters, randomUnconst.m first constructs randomly a set of maximal cliques \(\{\omega _k\}_{k=1}^m\) such that \(l\le \left| \omega _k \right| \le u\) for all k, and then generates a quadratic objective function (see Section 6.1 in Waki et al. (2006)). For a given set of parameters (n, l, u), and by setting the maximal degree equal to 2, we construct a graph by assigning a weight \(w_{ij} \ne 0\) to the edge \(\{i,j\}\) if the monomial \(x_ix_j\) has a non-zero coefficient in the function f(x). We select the weight \(w_{ij}\) randomly and uniformly from a discrete set \({\mathcal {W}}\). The graph sparsity depends on parameter u. Note that we only use the sparsity structure of the function f(x) to construct the graph, i.e. the specific function values are irrelevant for constructing the graph, what matters is which coefficients are non-zero. Also note that the resulting graph may not be chordal, and therefore the size of the maximal cliques \(\{\phi _k\}_k\) of the chordal extension of the graph (which are the ones used in the actual SDP relaxation) are not necessarily bounded by the parameters l and u.
Taking \(n=300,500\), \(l = 2\) and \(u = 4,6,8,10\), we generated 3 different graphs for every combination of the previous parameters by setting \({\mathcal {W}}\) equal to \(\{-1,1\}\), \(\{1,2, \dots ,10\}\) and \(\{-10,-9,\dots ,-1,1,2,\dots ,10\}\). In this set-up, the sparsity structure of the 3 graphs is identical but the non-zero weights are different. We repeat this procedure 10 times to obtain a total of 240 graphs. Table 1 summarizes the mean of the sparsity of the graphs for the different parameters and presents the mean of different size measures of the maximal cliques found after using the SparsePOP heuristic. Note that, while the parameter u controls the graph sparsity by limiting the maximal clique size, this maximal clique size is not bounded by the parameter u.
4.1.1 Strength of the partial relaxation
We solved Partial Relaxation (6) for every graph using \(r = 3,4,\dots ,20\). Notice: (i) given the computational limitations it is not always possible to solve the partial relaxation for all r and (ii) a graph might not contain maximal cliques of a certain size and therefore there is no need to solve the problem for that size, e.g. if a graph does not have maximal cliques of size 7 the set \(\varGamma _6\) is equal to \(\varGamma _7\) and the relaxation does not change from \(r=6\) to \(r=7\).
We denote \({\hat{r}} = \text {argmin}_{r} \{Q^{P}_{r}\}_{r \in \{3,4,\dots ,20\}}\) where \(Q^{P}_{r}\) is the solution of Partial Relaxation (6) for each graph. In theory, the best solution is obtained for \(r=20\), but (i) we may not be computationally able to solve SDP (6) for such a large r or (ii) we may find the solution for some \(r < 20\) (in this case we set \({\hat{r}}\) as the minimum integer r such that \(Q^{P}_{r}\) solves the Max-Cut).
Let gap\(_{r}=\frac{Q^{P}_{r}}{f^\star } - 1\), where \(f^\star \) is the optimal solution of Max-Cut Problem (1). BiqCrunch calculated the optimal solution \(f^\star \) for each graph. We limited the total BiqCrunch time to five hours and used default parameters (BiqCrunch\({\backslash }\)problems\({\backslash }\) max-cut\({\backslash }\)biq_crunch.param). We set \(f^\star \) equal to the best feasible solution found by BiqCrunch (we did not obtain a certificate of optimality for all problems). Table 2 groups the results by dimension and the parameter u that controls the graph sparsity. The third column contains the mean of the gaps for \(r=0\) and \(r={\hat{r}}\), i.e. the gap for the first order relaxation and the best solution found using the partial relaxation respectively (\({\textbf {gap}}_0\) is missing information from 7 problems that Mosek could not solve), while the fourth column shows the mean of the differences between the size of the largest maximal clique and \({\hat{r}}\). The fifth column presents the total number of problems with a gap smaller than \(1 \times 10^{-7}\) (30 problems in total). Additionally, given that all the weights of the graphs are integer numbers, the last column presents how many of the partial relaxation solutions are at most a unit away from the Max-Cut solutions, i.e. \(Q^{P}_{{{\hat{r}}}} -f^\star \le 1\).
The partial relaxation reaches a gap smaller than \(1\%\) in average for the sparser problems corresponding to \(u=4,6\) (these problems have in average maximal cliques with size smaller than 7, see Sect. 1), and solves most of the problems for \(u=4\). Also notice that these results are achieved without using all the possible maximal cliques, with an average difference between \({\hat{r}}\) and the largest maximal cliques ranging from 4 to 40. When the graph density increases, the partial relaxation starts to lose its effectiveness. Table 3 additionally groups results by the weights generating the graph and shows that the average gap for the graphs with weights in the set \(\{1,2,\dots ,10\}\) are smaller than for the other two types of weights.
4.1.2 Comparison with triangle inequalities
When using SDP relaxations for the Max-Cut problem, one of the most common and efficient approaches combines the triangle inequalities with the first level of the dense Lasserre hierarchy. State-of-the-art codes Biq Mac (Rendl et al. 2010; Wiegele 2006) and BiqCrunch (Krislock et al. 2014) (approximately) solve this relaxation at every branch-and-bound node. Given \(r< s < t \le n\), the triangle inequalities are:
The metric polytope (MET) is the space defined by the vectors satisfying the set of Inequalities (8) for all \(r< s < t \le n\). The vertices of this convex set contain all the possible cuts of a graph with n nodes, and is therefore a relaxation for the Max-Cut problem by itself. Laurent (1996) further discusses the MET vertices. Laurent Laurent and Poljak (1995) also characterizes the vertices of the dense Lasserre relaxation of order 1 and proves that they correspond exactly to the cuts of the graph. Furthermore, the second order dense relaxation is contained in the metric polytope (see Anjos and Wolkowicz (2002)Footnote 1), which means that the second level of the Lasserre dense relaxation is contained in the intersection of the metric polytope and the first level of the hierarchy (we will refer to this intersection as MET\(^{1st}_+\)).
For every solution \(Q^P_{{{\hat{r}}}}\), we calculated the time that BiqCrunch takes to find a solution as good as \(Q^P_{{{\hat{r}}}}\) (software download: https://biqcrunch.lipn.univ-paris13.fr/). For each instance, we ran four implementations of BiqCrunch:
-
1.
Standard branch-and-bound using defaults: BiqCrunch\({\backslash }\)problems\({\backslash }\) max-cut \({\backslash }\)biq_crunch.param,
-
2.
Root node solve only with default parameter change: \(\texttt {minAlpha} = 1 \times 10^{-12}\),
-
3.
Root node solve only with default parameter change: \(\texttt {minTol} = 1 \times 10^{-12}\), or
-
4.
Root node solve only with default parameter change: \(\texttt {minAlpha} = 1 \times 10^{-12}\) and \(\texttt {minTol} = 1 \times 10^{-12}\).
For each Max-Cut instance, our comparisons are with respect to the fastest time of these four implementations that reached the solution \(Q^P_{{\hat{r}}}\). These changes improve the accuracy of the root node solution to prevent an early stop of the algorithm (see Section 4.1 of Krislock et al. (2014) and Section 2.1 of the BiqCrunch manual (Krislock et al. 2016) for more information). Finally, we set a limit of 5 hours to BiqCrunch. Given that the weights of all the graphs are integers, the solution found using BiqCrunch is not strictly better than \(Q^P_{{{\hat{r}}}}\), in particular if \(BC^\star \) is the BiqCrunch solution then \(BC^\star < \left\lceil Q^P_{{{\hat{r}}}} \right\rceil \).
Table 4 compares the times of the partial relaxation (t) and BiqCrunch (\(t_{BC}\)), grouping the instances by the type of weight in the graph, the parameter u (see Sect. 4.1), and the size of the graph (10 instances in total for a fixed type of weight, value of u and size of the graph). Table 4 shows the average of the ratio of the times (\(t_{BC}/t\)), number of problems where the partial relaxation was faster than BiqCrunch out of the 10 instances (\(t_{BC} > t\)), and the average time taken by the partial relaxation (t). The partial relaxation is faster than BiqCrunch for the problems with the smallest maximal cliques (\(u=4\)) independent of the size (one particular instance of size 500 could not be solved by BiqCrunch for any of the 4 implementations), but loses its efficiency as the size of the maximal cliques increases. For instances generated using \(u=8,10,\) BiqCrunch is always faster. As the size of the graphs increases from 300 to 500, the number of problems solved faster by the partial relaxation increases for some cases, and for those where it does not (remaining at zero) the average ratio of the times has a small increase. With respect to the type of weight, BiqCrunch tends to perform better for weights in \(\{-10,\dots ,10\}\).
The feasible space of the partial relaxation depends on the parameter r. If \(r = 0\), this space is equivalent to the feasible space of Relaxation (5) with \(d=1\), and MET\(^{1st}_+\) is then a tighter relaxation. Recall that, for graphs of size 3 or 4, the vertices of the metric polytope correspond exactly to the cuts of the graph (Laurent 1996). Therefore, if \(r\le 4\), the space defined by MET\(^{1st}_+\) is at least as tight or tighter than the feasible space of Partial Relaxation (6). However, it is not difficult to find a point y belonging to MET\(^{1st}_+\) that does not satisfy \({\widehat{M}}_2^{\phi _k}(y) \succeq 0\) for \(\left| \phi _k \right| \ge 5 \).Footnote 2 Given that the feasible space MET\(^{1st}_+\) is not contained in the feasible space of the partial relaxation if \(r \ge 5\), these two feasible spaces are then not equal for \(r \ge 5\). Although the feasible spaces are not the same, Tables 2, 3, and 4 show that, for sparse graphs, the partial relaxation can provide competitive solutions compared to the standard MET plus first order Lasserre relaxation.
4.1.3 Augmented relaxation
This section concentrates on Augmented Partial Relaxation (7). First we compare heuristics H1–H5 and then compare the partial and the augmented partial relaxations. In the implementation of the heuristics H1 to H5 for the augmented formulation, we did not consider all the possible subsets of \(\phi _k\) as this number can be very large. Instead, we select randomly 20 subsets and apply the heuristics to those sets. For example, if \(r=5\) and the maximal clique k contains 10 elements (\(\left| \phi _k \right| = 10\)), the total number of possible subsets of size 5 is \(q_k = 252\). Rather than considering all 252 subsets when applying any particular heuristic, we select randomly 20 subsets and assume those are all the possible subsets of size 5 for the maximal clique k and then apply the heuristic. If \(p>q_k\), we include all the subsets (without adding repeated subsets).
We solved every Augmented Partial Relaxation (7) using \(r = 3,4,\dots ,20\), \(p = 1,2,3\), and the 5 types of heuristics, i.e. for a fixed r and p we have 5 different solutions. For each value of r and p, we ranked the optimal solutions found by the different heuristics from the best (ranked 1) to worst (rank 5): the best heuristic produces the augmented partial relaxation with the smallest optimal objective value. If two or more heuristics produce the same solution, we assign the same rank. Table 5 presents the performance of each heuristic (the results do not change drastically between the type of weight used in the graph, or the number of subsets p). For example, the third row and second column indicates that, in 428 out of the 8905 solutions (\(4.8 \%\)), the random heuristic H1 found the best possible solution out of all the heuristics. Notice that the total number of problems is not the same between the 5 heuristics, this is because we exclude the solution of the augmented partial relaxations that do not improve the objective value, i.e. if \(Q^a_{{r},p,H}\) is already the solution of the original Max-Cut problem we do not include \(Q^a_{{r+j},p,H}\) for \(j>0\). Therefore, heuristics that perform better will have fewer total problems. The results indicate that the best heuristic, with more than \(90\%\) of its solutions ranked first or second, consists on selecting the subsets that do not repeat in other maximal cliques and for which the norm of the weights between the variables of the subset is as large as possible H5. Interestingly, the random heuristic H1 performed better than trying to select the most repeated subsets H3.
For fixed p and H, let \(r_a\) be the minimum value such that the solution \(Q^a_{{r_a},p,H}\) of the augmented partial relaxation satisfies \(Q^a_{{r_a},p,H} \le Q^P_{{{\hat{r}}}}\). We found \(Q^a_{{r_a},p,H} \) for the 240 random graphs using H5 as heuristic, \(p=1,2,3\), and calculated: the time t and \(t_a\) needed to obtain \(Q^P_{{{\hat{r}}}}\) and \(Q^a_{{r_a},p,H} \) respectively, and \(\varDelta r = {\hat{r}} - r_a\). Recall that \({\hat{r}}\) and \(r_a\) will typically have different values, so a large value of \(\varDelta r\) indicates that Augmented Partial Relaxation (7) is working particularly well. Table 6 compares the two relaxations grouped by the size of the graph, the upper bound parameter (u) used to construct the random graph, and three different values of p, i.e. for a fixed n, u and p, Table 6 represents 30 problems. For the three values of p, Table 6 shows the mean of \(\varDelta r\), the mean of the ratios of the time (\(t/t_a\)), and how many problems out of 30 were solved faster using the augmented partial relaxation (\(t>t_a\)). For Table 6, the times t and \(t_a\) include: time to create the maximal cliques and the subsets, time to formulate the relaxation in Mosek, and the relaxation solution time used by the interior point method. As expected, increasing the number of included subsets (p) reduces the largest clique size (smaller \(r_a\), larger \(\varDelta r\)). Table 6 shows that the augmented partial relaxation may often be more efficient, but there is not a clear pattern.
Our code for creating the maximal cliques and the subsets (which is written in MATLAB) can be improved considerably as our intention was not at this point to generate a very efficient code for these heuristics. Table 7 is equivalent to Table 6 except that Table 7 excludes from t and \(t_a\) the time spent constructing the maximal cliques and the subsets (the values of \(\varDelta r\) do not change and are not included again). In Table 7, a clearer pattern appears: larger values of p and sparser problems (smaller values of u) make the augmented partial relaxation faster than the partial one (the only exception is for \(n=300\) and \(u=4\)). Finally, there were not substantial differences when the results were also grouped by the type of weight of the graph.
4.2 Max-Cut instances from applications in statistical physics
Now that we have established the usefulness of the SDP relaxations (6) and (7) for random instances, we apply the partial and augmented partial relaxations to toroidal grid graphs (Liers 2004; Liers et al. 2004). These problems are in the Biq Mac library (http://biqmac.aau.at/biqmaclib.html). There are 6 different graphs structures and, for each structure, there are 3 different sets of weights, i.e. same set of edges but with different weights. Table 8 summarizes the 6 graph structures and the maximal cliques obtained using the SparsePOP heuristics. Note that t3 instances have larger maximal cliques in average (around 13) compared with t2 (approximately 8).
We found (if possible) the smallest \(r \in \{3,4,\dots ,20\}\) such that \(\frac{Q^a_{{r},p,H}}{f^\star } -1 \le 1 \times 10^{-7}\), for \(p = 0,1,2,3\) and \(H= H5\). Note that \(p=0\) corresponds to Partial Relaxation (6) (heuristic H does not apply in this case), and \(p=1,2,3\) to Augmented Partial Relaxation (7). For each p value, we calculated the time BiqCrunch needs to find a solution at least as good as \(Q^a_{{r_a},p,H}\). We used the same 4 parameter settings used in Sect. 4.1.2, and additionally we repeated the 4 experiments but now using the default parameters provided by BiqCrunch for Ising problems (BiqCrunch\({\backslash }\) problems\({\backslash }\)max-cut\({\backslash }\)biq_crunch.param.ising). Since the graphs only contain integer weights, we again consider a solution \(BC^\star \) from BiqCrunch as good as \(Q^a_{{r},p,H} \) if \(BC^\star < \left\lceil {Q^a_{{r},p,H} } \right\rceil \). We selected the best BiqCrunch time from the 8 parameter settings (once more we limit the experiment to a 5 hour limit)Footnote 3.
Once more, t and \(t_a\) correspond to the time (including creation of maximal cliques and subsets) to solve the partial relaxation (\(p=0\)) and the augmented one (\(p=1,2,3\)), and \(t_{BC}\) the time used by BiqCrunch. Table 9 presents the minimum value r, t, \(t_a\), and gap, as well as the time ratios \(t_{BC}/t\) and \(t_{BC}/t_a\), for each instance for the different values of p. Partial Relaxation (6) finds the solution for all the t2 instances at least 6 times faster than BiqCrunch, except for \(t2g20\_6666\) where even using \(r=19\) is only enough to reduce the gap to \(4 ^{-4}\). For the t3 instances, which have larger maximal cliques, the partial relaxation can not find the solution for all the problems and is slower than BiqCrunch. Increasing the value of p and using the heuristic H5, Augmented Partial Relaxation (7) improves the gap for all the problems (when \(p=2\) all the gaps are smaller than \(1 \times 10^{-7}\) except one), and for some of the t3 problems the augmented partial relaxation is faster than BiqCrunch. The augmented partial relaxation is slower than the partial one for many problems. Most of this difference is explained by the time selecting the subsets in the augmented partial relaxation.
4.3 Comparison with CS-TSSOS
This section compares the partial relaxation with the moment-SOS hierarchy CS-TSSOS (Wang et al. 2020b). This 2 level hierarchy exploits sparsity by combining the correlative sparsity used in Waki et al. (2006) (which is the same one used for constructing the maximal cliques in our partial and augmented partial relaxations) with term sparsity (Wang et al. 2019a, b, 2020a). Wang et al. (2020b) use large-scale, sparse randomly generated graphs to show the efficiency of CS-TSSOS as a relaxation of the Max-Cut. For the instances generated, the second order sparse Relaxation (5), i.e. second level of the Waki et al. (2006) relaxation, is too large to be solved, while the second level of CS-TSSOS is not only solvable but also provides better bounds than the first order of the sparse Relaxation (5).
We solved the 10 instances in Wang et al. (2020b) using Partial Relaxation (6) for values of \(r = 4,5,\dots ,10\), and using the CS-TSSOS second level relaxation. Both the instances and the code to generate and solve the CS-TSSOS relaxations (which also uses Mosek to solve the SDP) can be found in https://wangjie212.github.io/jiewang/code.html (accessed 25/06/2020). We did not use Augmented Partial Relaxation (7) because generating the subsets of the maximal cliques with any of the heuristics takes considerable time compared to the time of solving the resulting relaxation. These instances are larger than the graphs studied so far (the largest graph has 5005 nodes), have maximal cliques with average size no larger than 8, and the largest maximal clique have 16 elements (see Table 10).
Table 11 shows the results. Because our code is specific to construct the partial relaxation for the Max-Cut problem while the CS-TSSOS code is general for any POP, we included the time used by the interior point method to solve the SDP relaxation (Time IPM), besides the total time used by each method (Total time), which includes the time to create the relaxation and solve it. In general, Partial Relaxation (6) achieves better solutions faster (both in terms of the total time and the interior point time) than the CS-TSSOS relaxation after adding maximal cliques of size 7 or smaller (\(r \le 7\)). In particular, for the largest instances, \(r=4\) was enough to improve the bound found by CS-TSSOS. These solutions can be improved using larger values of r and while still obtaining competitive times compared to CS-TSSOS.
5 Conclusions
We explored the idea of using information of the second order of the Lasserre hierarchy to strengthen the standard relaxation used to solve Max-Cut in the case of sparse graphs. We used two basic formulations by: (i) limiting the size of the maximal cliques added to the relaxation and (ii) including subsets of the maximal cliques that were too large.
We tested these ideas on randomly generated graphs of different densities and sizes, as well as on sparse graphs coming from applications of statistical physics. Our results showed that Partial Relaxation (6) and Augmented Partial Relaxation (7) can be very effective for solving sparse graphs with small maximal cliques but lose power as the density and/or the size of the maximal cliques increases. The results also showed that this idea provides strong bounds when compared with CS-TSSOS.
Although the partial relaxation showed potential, there is still the question of how to select the parameters r and p in the partial relaxation. This is an interesting question for future work. In particular, multilevel techniques like the ones used in Campos and Parpas (2018), Campos et al. (2019), Ma et al. (2019) can be useful in this context.
Notes
Anjos and Wolkowicz (2002) prove this result for a different hierarchy than that of Lasserre. But the latter is contained in the former and the proof directly applies to the Lasserre case.
Let \(\phi _k = [5]\) and the set \(\varOmega = \{y: y_{{\varvec{\alpha }}} = 0 \text { if } \sum _i\alpha _i = 2 \text { and } \alpha _i =0 \text { for } i \in [5], y_{e_1+e_2}=-0.907, y_{e_1+e_3}=0.668, y_{e_1+e_4}=-0.591, y_{e_1+e_5}=-0.907, y_{e_2+e_3}=-0.761, y_{e_2+e_4}=0.498, y_{e_2+e_5}=0.814, y_{e_3+e_4}=-0.737, y_{e_3+e_5}=-0.761, y_{e_4+e_5}=0.498\}\). Any \(y \in \varOmega \) satisfies MET\(^{1st}_+\), but we can numerically verify that the feasibility problem of finding y such that \({\widehat{M}}_2^{\phi _k}(y) \succeq 0\) and \(y \in \varOmega \) does not have a solution.
For the instance \(t2g20\_6666\) when \(Q^a_{{r_a},p,H}\) provided an accuracy to the \(10^{-7}\) or lower, BiqCrunch was not able to find a solution with any setting under the time limit. In this case we found that the following setting was able to find a solution: default Ising parameters changing minAlpha and minTol to \(10^{-12}\), nitermax to 20000, and maxNiter to 1000.
References
Adams E, Anjos MF, Rendl F, Wiegele A (2015) A hierarchy of subgraph projection-based semidefinite relaxations for some NP-hard graph optimization problems. INFOR Inf Syst Oper Res 53(1):40–48
Anjos MF, Wolkowicz H (2002) Strengthened semidefinite relaxations via a second lifting for the Max-Cut problem. Discrete Appl Math 119(1–2):79–106
Baltean-Lugojan R, Bonami P, Misener R, Tramontani A (2018) Scoring positive semidefinite cutting planes for quadratic optimization via trained neural networks. http://www.optimization-online.org/DB_FILE/2018/11/6943.pdf
Barahona F, Ladanyi L (2006) Branch and cut based on the volume algorithm: steiner trees in graphs and Max-Cut. RAIRO Oper Res 40(1):53–73
Barahona F, Jünger M, Reinelt G (1989) Experiments in quadratic 0–1 programming. Math Program 44(1–3):127–137
Billionnet A, Elloumi S (2007) Using a mixed integer quadratic programming solver for the unconstrained quadratic 0–1 problem. Math Program 109(1):55–68
Blair JR, Peyton B (1993) An introduction to chordal graphs and clique trees. Springer, pp 1–29
Bomze IM, Budinich M, Pardalos PM, Pelillo M (1999) The maximum clique problem. Handbook of combinatorial optimization. Springer, pp 1–74
Campos JS, Parpas P (2018) A multigrid approach to SDP relaxations of sparse polynomial optimization problems. SIAM J Optim 28(1):1–29
Campos JS, Misener R, Parpas P (2019) A multilevel analysis of the Lasserre hierarchy. Eur J Oper Res 277(1):32–41
Chen T, Lasserre JB, Magron V, Pauwels E (2020) Semialgebraic optimization for Lipschitz constants of Relu networks. Adv Neural Inf Process Syst 33:19189–19200
Chen T, Lasserre JB, Magron V, Pauwels E (2022) A sublevel moment-SOS hierarchy for polynomial optimization. Comput Optim Appl 81(1):31–66
Dong H (2016) Relaxing nonconvex quadratic functions by multiple adaptive diagonal perturbations. SIAM J Optim 26(3):1962–1985
Fischer I, Gruber G, Rendl F, Sotirov R (2006) Computational experience with a bundle approach for semidefinite cutting plane relaxations of max-cut and equipartition. Math Program 105(2–3):451–469
Ghaddar B, Vera JC, Anjos MF (2016) A dynamic inequality generation scheme for polynomial programming. Math Program 156(1–2):21–57
Golumbic MC (2004) Algorithmic graph theory and perfect graphs, vol 57. Elsevier
Gvozdenović N, Laurent M (2008) Computing semidefinite programming lower bounds for the (fractional) chromatic number via block-diagonalization. SIAM J Optim 19(2):592–615
Gvozdenović N, Laurent M, Vallentin F (2009) Block-diagonal semidefinite programming hierarchies for 0/1 programming. Oper Res Lett 37(1):27–31
Josz C, Molzahn DK (2018) Lasserre hierarchy for large scale polynomial optimization in real and complex variables. SIAM J Optim 28(2):1017–1048
Kim S, Kojima M (2001) Second order cone programming relaxation of nonconvex quadratic optimization problems. Optim Methods Softw 15(3–4):201–224
Krislock N, Malick J, Roupin F (2014) Improved semidefinite bounding procedure for solving Max-Cut problems to optimality. Math Program 143(1–2):61–86
Krislock N, Malick J, Roupin F (2016) BiqCrunch 2.0 user guide. https://biqcrunch.lipn.univ-paris13.fr/BiqCrunch/repository/papers/biqcrunch-manual.pdf. Accessed 06 Aug 2020
Krislock N, Malick J, Roupin F (2017) Biqcrunch: a semidefinite branch-and-bound method for solving binary quadratic problems. ACM Trans Math Softw 43(4):32
Laurent M (1996) Graphic vertices of the metric polytope. Discrete Math 151(1–3):131–153
Lasserre JB (2001) Global optimization with polynomials and the problem of moments. SIAM J Optim 11(3):796–817
Lasserre JB (2002) An explicit equivalent positive semidefinite program for nonlinear 0–1 programs. SIAM J Optim 12(3):756–769
Lasserre JB (2006) Convergent SDP-relaxations in polynomial optimization with sparsity. SIAM J Optim 17(3):822–843
Laurent M, Poljak S (1995) On a positive semidefinite relaxation of the cut polytope. Linear Algebra Appl 223:439–461
Liers F (2004) Contributions to determining exact ground states of Ising spin glasses and to their physics. PhD Thesis, Verlag nicht ermittelbar
Liers F, Jünger M, Reinelt G, Rinaldi G (2004) Computing exact ground states of hard Ising spin glass problems by branch-and-cut. New Optim Algorithms Phys 50(47–68):6
Ma WJ, Marecek J, Mevissen M (2019) A fine-grained variant of the hierarchy of Lasserre. In: 2019 57th annual Allerton conference on communication, control, and computing (Allerton), IEEE, pp 580–586
Pál KF, Vértesi T (2009) Quantum bounds on bell inequalities. Phys Rev A 79(2):022120
Qualizza A, Belotti P, Margot F (2012) Linear programming relaxations of quadratically constrained quadratic programs. In: Mixed integer nonlinear programming, Springer, pp 407–426
Rendl F, Rinaldi G, Wiegele A (2010) Solving Max-Cut to optimality by intersecting semidefinite and polyhedral relaxations. Math Program 121(2):307
Saxena A, Bonami P, Lee J (2011) Convex relaxations of non-convex mixed integer quadratically constrained programs: projected formulations. Math Program 130(2):359–413
Sherali HD, Dalkiran E, Desai J (2012) Enhancing RLT-based relaxations for polynomial programming problems via a new class of v-semidefinite cuts. Comput Optim Appl 52(2):483–506
Waki H, Kim S, Kojima M, Muramatsu M (2006) Sums of squares and semidefinite program relaxations for polynomial optimization problems with structured sparsity. SIAM J Optim 17(1):218–242
Waki H, Kim S, Kojima M, Muramatsu M, Sugimoto H (2008) Algorithm 883: Sparsepop—a sparse semidefinite programming relaxation of polynomial optimization problems. ACM Trans Math Softw 35(2):15
Wang J, Li H, Xia B (2019a) A new sparse SOS decomposition algorithm based on term sparsity. In: Proceedings of the 2019 on international symposium on symbolic and algebraic computation, pp 347–354
Wang J, Magron V, Lasserre JB (2019b) TSSOS: a moment-SOS hierarchy that exploits term sparsity. arXiv preprint arXiv:1912.08899
Wang J, Magron V, Lasserre JB (2020a) Chordal-TSSOS: a moment-SOS hierarchy that exploits term sparsity with chordal extension. arXiv preprint arXiv:2003.03210
Wang J, Magron V, Lasserre JB, Mai NHA (2020b) CS-TSSOS: correlative and term sparsity for large-scale polynomial optimization. arXiv preprint arXiv:2005.02828
Wiegele A (2006) Nonlinear optimization techniques applied to combinatorial optimization problems. Ph.D. Thesis, Alpen-Adria-Universität Klagenfurt
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This work was funded by Engineering and Physical Sciences Research Council Grant Numbers EP/W003317/1 and EP/P016871, a BASF/Royal Academy of Engineering Research Chair to RM, and a J.P. Morgan A.I. Faculty Award.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Campos, J.S., Misener, R. & Parpas, P. Partial Lasserre relaxation for sparse Max-Cut. Optim Eng 24, 1983–2004 (2023). https://doi.org/10.1007/s11081-022-09763-y
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11081-022-09763-y