
Abstract
In this study, the elastic characteristics of reservoir rocks and their relationship to porosity and pore fluid were predicted using the fluid substitution method in combination with machine learning techniques. We first discarded the data at gas points to remove the erroneous effect of gas on the prediction process of Poisson’s ratio using the three proposed machine learning models. Then, the prediction was carried out after substituting the gas zones by oil and by water. As a result, the prediction was enhanced and showed stronger correlation coefficient values. The integration of fluid substitution and machine learning methods was applied in the reservoir of Scarab field as a case study from the Eastern Mediterranean to detect the effect of different pore fluids (gas, oil, and water) on Poisson's ratio estimation. The main objective of the study was to analyze the seismic and well log data to estimate and predict the Poisson’s ratio in four fluid-content cases; these are gas-bearing reservoir, reservoir after removal of log data of gas-bearing zones, and reservoirs after gas-substitution with oil and with water. These four cases were dealt with directly and by using the machine learning algorithms based on the proposed model of random vector functional link (RVFL), which was enhanced by the Cheetah optimizer (CO). This study shows how the performance of RVFL is affected by the presence or absence of gas zones. It is shown that the Poisson’s ratio value increases when gas is substituted with water more than when gas is substituted with oil. For validation of these results, regression analysis technique was used and the correlation coefficient of the CO–RVFL model increased after removing well log data of gas zones and was more enhanced after fluid substitution from gas to oil or to water.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
Introduction
One of the primary goals of petroleum exploration using seismic data is to differentiate whether a water-saturated rock or a hydrocarbon-saturated rock produced the reflection of interest. This may be accomplished by estimating the difference in rock properties between the fluid-saturated states, either water or hydrocarbon (Hilterman, 2001), based on basic relationships of rock physics between seismic rock properties and elastic constants.
Rock physics is a way to establish the relationships between qualitative geological parameters and quantitative geophysical measurements (Simm & Bacon, 2014). In the last few years, rock physics has played an essential role in quantitative seismic interpretation and emerged as a main tool in petroleum geophysical exploration. In addition, the use of elastic properties such as velocity, density, acoustic impedance, Poisson’s ratio, and velocity ratio (Vp/Vs) and their relations to reservoir properties play an important role in reservoir characterization studies. Among the reservoir, properties are porosity, shale content, water saturation, and hydrocarbon saturation. In the same manner, rock-physics modeling was used to create templates for characterizing an efficient reservoir (Avseth & Odegaard, 2004; Avseth et al., 2006; Andersen & van Wijngaarden, 2007).
The Poisson’s ratio is an important property that is usually used to predict the geo-mechanical behavior of wells as they are drilled and during the subsequent recovery processes. Strength parameters have a significant impact on hydraulic fracturing, well instability, and sand production and may be correlated with its magnitude (Zhang & Bentley, 2005). The Poisson’s ratio is one of the vital rock-physics parameters that is affected by the presence of gas zones. Therefore, in this study, the fluid substitution method was used to measure the different saturation behavior to predict the Poisson's ratio parameter in the presence of different types of fluids.
Fluid substitution has a vital role for the seismic rock-physics analysis, e.g., amplitude versus offset (AVO), which offers a tool for fluid discrimination and quantification in a reservoir. This is generally made using Gassmann’s equation (Gassmann, 1951). The fluid substitution method is a crucial technique for forecasting the elastic characteristics of reservoir rocks and their relationship to pore fluid and porosity (Wang et al., 2022). With the use of this technique, it is feasible to forecast changes in a rock's elastic response to various fluids (Gommesen et al., 2002). Several authors have studied the use of fluid substitution for reservoir characterization (e.g., Batzle & Wang, 1992; Berryman, 1999; Wang, 2001; Russell et al., 2003; Smith et al., 2003; Han & Batzle, 2004; Adam et al., 2006; Misaghi et al., 2010; Abe et al., 2018; Magoba & Opuwari, 2019).
Fluid substitution alters the pore fluid type in reservoir intervals to examine how a new fluid type affects the AVO response (El-Bahiry et al., 2017). The aim of fluid substitution is to make a simulation for seismic properties (seismic velocities) and density of the reservoir at a certain reservoir condition (e.g., temperature, pressure, mineral type, water salinity and porosity) and pore fluid saturation whether it is mixed saturation or only one fluid saturation case. Among the various significant ideas relating to rock physics, the Gassmann’s model is probably the most well-known. P- and S-wave velocities are predicted using the Biot and Gassmann theories as saturation changes; the basic presumptions of them were covered by Misaghi et al. (2010).
Machine learning (ML) techniques have proven outstanding routine in diverse disciplines of geoscience. For instance, in Dorrington and Link (2004), a ML model merged a genetic algorithm with artificial neural network (ANN) for predicting reservoirs in the Stratton field using seismic data. Chakiet et al. (2018) used an ANN and a neuro–fuzzy system for reservoir evaluation. In Priezzhev et al. (2019), several ML models such as random forest, linear regression, and ANN were used to integrate well logs and seismic data for identifying the petrophysical parameters. Farsi et al. (2021) predicted pore pressure using a three-hybrid ML optimization with multi-layer perceptron (MLP) neural network. Random forest has been realized by Feng (2021) as a ML technique to overcome uncertainty in well log classification. Zahmatkesh et al. (2021) recognized seismic facies using ANN in the Iranian Mansuri field. Moreover, several ML techniques have been accomplished for well logs (e.g., Ali et al., 2021; Garia et al., 2021; Iturrarán-Viveros et al., 2021; Yasin et al., 2021; Abd Elaziz et al., 2022; Nabih et al., 2022).
Materials
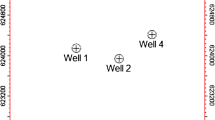
The study area is in the Scarab field in the concession of the Western Delta Deep Marine (WDDM) (Fig. 1). This area covers 6150 km2 (Samuel et al., 2003). At depths of 1600–1900 m, the field consists of a sequence of deep marine slope channels as revealed from the four wells in the study area. The main hydrocarbon-bearing zone is the Late Pliocene El-Wastani Formation. The main reservoirs are located in two channels (Ch-1, Ch-2) in El-Wastani Formation (Abd El-Gawad et al., 2019; Ghoneimi et al., 2021; Nabih et al., 2022).

WDDM concession location map, containing the Scarab field (left) and the well data and seismic survey (right). (Universal Transverse Mercator (UTM) WGS-84 zone 36 N)
The main structures in the WDDM concession are attributed to the Rosetta fault of NE–SW and ENE–WNW trends (related to Nile Delta offshore anticline) (Mokhtar et al., 2016). Activities of recent exploration are focused on Pliocene–Pleistocene sequences, where the principal gas reservoirs are found. Among the most distinct seismic, horizons in this area are the tops of Sidi Salem and Abu-Madi, in addition to Kafr El-Sheikh base (Raslan, 2002).
The El-Wastani Formation is the main reservoir of the Scarab gas field. It consists of thick sand interbedded with thin clays that thin toward its top. The sands are quartzose, coarse- to medium-grained, with little feldspar and lithic fragments. The clays are soft and very sandy. The upper boundary of this formation is uncertain, but it is delineated where the series becomes sandier for several tens of meters. This formation is assigned to the Late Pliocene (Aly Ismail et al., 2010), and it is 123 m thick in the El-Wastani well 1 (Ismail, 1984).
The seismic data used in this study comprise 3D post-stack time migration seismic data that cover the area of Scarab field. In addition, well logs (gamma ray (GR), resistivity (LLD), density (RHOB), neutron (APLC), and compressional sonic (DTCO) logs) of the four wells are available. In Figure 2, the used wells are correlated referring to a datum at depth of 1580 m (TVDSS) to demonstrate the channel system and its litho-facies distribution.

Correlation of the studied wells in the Scarab field illustrating the gamma ray log (left), the channel surfaces, and their main lithology
Methodology
In this study, fluid substitution and ML techniques were performed using the available borehole logs in Scarab-Db well in the reservoir of Scarab field. The well logs analyzed in these wells were the GR, LLD, RHOB, APLC, and DTCO and DTSM logs (Fig. 3). The petrophysical parameters (shale content (VSH), effective porosity (PHIE), water saturations (SW), and net pay (PayFlag)) calculated using well log interpretation were used as input in ML and fluid substitution estimations. The seismic amplitude readings were derived from the seismic traces extracted from the SEGY seismic cube (Fig. 1). The used seismic traces were extracted near the studied wells. The extraction of the seismic traces was done using a free software named SeiSee (https://seisee.software.informer.com/). All these log and seismic data were used as inputs in ML algorithms for predicting the Poisson’s ratio parameter in the studied four fluid-content cases. These cases are the reservoir saturated with gas, reservoir without gas, reservoir saturated with oil, and reservoir saturated with water. In the ML training, three Scarab wells (named -1, -Da, and -Dd) were employed. To validate the applicability of the ML algorithms, the Scarab-Db well was utilized as the test well. The Poisson’s ratio was calculated and utilized for rock-physics analysis using the following equations:
where \(\sigma\) is Poisson’s ratio, \(\rho\) is density, \({V}_{P}\) is compressional wave velocity, and \({V}_{\mathrm{S}}\) is shear wave velocity.

Scarab (1, Db, Da, Dd) wells, respectively, input data (from left, GR, resistivity, neutron-density, DTCO, seismic trace) and output (Vsh, PHIE, Sw, Sh, and net pay thickness)
Well Log Analysis
Formation evaluation is essentially targeted from well log analysis to estimate the shale content (VSH), effective porosity (PHIE), water saturation (SW), hydrocarbon saturation (SH), and net pay thickness. The principle interpretation steps utilized to calculate the petrophysical parameters for the present study are shown in a flowchart in Figure 4 (Abd Elaziz et al., 2022; Nabih et al., 2022). The GR log was used to determine the VSH (Atlas, 1979), which aids in the differentiation of non-reservoir and reservoir rocks. PHIE is a crucial parameter for reservoir characterization. Generally, the most favorable tool for PHIE determination is the neutron-density (N-D) logs combination. Here, PHIE was estimated from the RHOB–APLC relations using the equations shown in the workflow in Figure 4 (Asquith et al., 2004; Bateman, 2012).

The fluid saturation estimation leads to discriminate between the various types of fluid components (water or hydrocarbons). Figure 4 shows the workflow of estimating water saturation (SW) using the Indonesian equation (Schlumberger, 1972). The net pay was calculated by applying suitable cutoffs for output petrophysical properties because the unproductive layers were not estimated. Cutoffs were applied mainly to effective porosity, shale volume, and water saturation. The used cutoffs were VSHmax 35%, PHIEmin 10%, and SWmax 50%. Figure 3 displays the VSH, PHIE, SW, SH, and net pay computed from the well logs. The borehole log data and the results of petrophysical analysis were used as inputs in the following step of fluid substitution method.
Fluid Substitution Method
In seismic rock physics, fluid substitution is useful for simulating various pore fluid types (Smith et al., 2003). The work of Gassmann (1951) represents the most widely utilized fluid substitution technique. His approach links the porosity to the bulk moduli of saturated rock and its porous rock frame, the mineral matrix, and the pore-filling fluids (Gassmann, 1951). The effects of fluid substitution on seismic properties utilizing rock frame properties were calculated using the Gassmann equation (El-Bahiry et al., 2017). These equations deal with the rock's bulk modulus, frame, pore, and fluid characteristics. Before modeling the new fluid, the effect of the original fluid must first be removed (Smith et al., 2003) as the following workflow (Fig. 5).

Fluid substitution workflow
Fluid substitution calculations were applied in one well (i.e., Scarab-Db) in the study area focusing on the gas-bearing Scarab channel. Fluid substitution was carried out to investigate the changes of fluid saturation and its effect to density, Vp, and Poisson’s ratio logs in the presence of fluid of this reservoir. Fluid substitution analysis was performed in the Scarab-Db well based on the following data: formation temperature (reservoir), 120 °FFootnote 1; formation pressure (reservoir), 3500 psiFootnote 2; formation water resistivity (Rw), 0.1 Ω m; salinity, 41,225 ppm; and gas gravity, 0.57 g/cc.
Input data required in this analysis were the fluid substitution compressional and shear sonic, density, porosity, water saturation. Matrix properties should also be used as input in the analysis of fluid substitution. In this study, quartz mineral was used as a default. Based on average Gassmann calculation, fluid substitution can be visualized in a cross-plot, with the assumption that pore bulk modulus and dry rock Poisson’s ratio are fixed although the porosity of rock changes (Fig. 5).
Machine Learning Techniques
Here, we present the basic steps of the Cheetah optimizer (CO) and the RVFL network.
Cheetah Optimizer (CO)
The CO is a metaheuristic algorithm recently proposed as swarm intelligence by Akbari et al. (2022). The CO is inspired by the four hunting strategies of cheetahs in the wild, namely search, set and wait, and attacking as the primary strategies, in addition to premature converge avoidance strategy called leave the prey and go back home strategy that strengthen the search’s chance of converging to the optimal solution.
The cheetah is a large cat breed predator, native to Asia and Africa and considered the fastest land mammal. The cheetah’s physical traits give it advantages in hunting such as excellent eyesight to spot far away preys, spotted body works as natural camouflage in the territory. Their aerodynamic light weighted body is designed for swift sprint attacks, reaching speeds of over 120 km/h (Marker et al., 2018), which drain the cheetah’s energy, therefore lasting for small intervals of time estimated to be less than half a minute. Because the duration of chasing a prey is limited, the majority of hunting time is spent selecting and stalking prey, while lurking from minimum distance without being discovered then swiftly ambushing and chasing the prey. Their impressive acceleration is the main factor for a successful hunt, yet it limits the hunting time duration. The algorithm is designed in three main simple strategies used by hunting cheetahs in the wild and an additional strategy tackling the lack of diversity and premature convergence, which are challenges common in optimization problems. The mathematical modeling of the cheetah’s hunting routine is simple and flexible, proven to effectively solve large-scaled optimization problems. The CO depicted in Figure 6 as a flowchart demonstrates the algorithm’s flow from start to end, highlighting the main steps in the blue boxes. The CO can be summarized in three main steps summarized as follows.

RVFL network
Step 1: Initialization of the CO
In this step, the parameters (see Table 1) of the CO are initialized. In addition, because the CO is a population-based metaheuristic, the population of cheetahs has a size of (\(n, D\)) where \(n\) is the number of cheetahs in the population (rows), and \(D\) refers to the optimization problem’s dimensions (columns). Each cheetah position \({X}_{i}^{t}\) is initialized stochastically within the problem’s domain, thus:
Each \({X}_{i}^{t}\) is initialized randomly within the domain of each dimension [\(lb,ub\)]. Therefore, \({X}_{i,\mathrm{j}}^{t}\) refers to the position of cheetah (\(i\)) in the arrangement (\(j\)) where \(i=\mathrm{1,2},\dots ,n\) and \(j=\mathrm{1,2},\dots , D\) at the current hunt time (\(t\)). Then, the fitness of each cheetah is calculated with the aim of sorting the population by the fitness thereby electing best fitness chetah as the leader. Also, the parameters of the CO algorithm are initialized such as the current hunting time (\(t\)) to zero and the current iteration number (\(\mathrm{iter})\) to one as well as limiting the number of iterations and the hunting time such that number of iterations (\(\mathrm{max}\_\mathrm{iter}\)) of the algorithm is estimated according to the problem in-hand, while the maximum hunting time (\(T\)) is set in Akbari et al. (2022) as follows:
The \(T\) parameter simulates the cheetah’s energy during the hunting trip. As result of their swift speedy attack, their energy is quickly consumed, therefore limiting the hunt time, which is modeled in Eq. 4 as independent of the prey, a function of the problem dimension (\(D\)).
Step 2: Improve the cheetahs population based on their hunting strategies
In the real hunting operations of the cheetahs, the group hunting behavior is adapted where each cheetah can be seen moving differently than the others such that in each dimension, each cheetah could be in a different hunting mode. Modeling this behavior in the algorithm, at each iteration, a subset of the cheetah’s population is randomly picked with a subset size of (\(m\)) such that \(2\le m\le n\) to participate by updating their position according to the selected hunting strategy. After the updating process is done, the hunting time is incremented followed by execution of leave prey and go home strategy; if its condition is met, then, the global best solution is updated accordingly.
Step 2.1: Select strategy and computing the new position of each solution
The primary hunting strategies, namely search strategy, sit-and-wait strategy, and attack strategy as demonstrated in Algorithm 1, are selected for each solution based on five variables:\({r}_{1}, {r}_{2}, {r}_{3}, {r}_{4}, H\). The first four variables are uniform random numbers, such that the first three variables are within the range [0,1], while \({r}_{4}\) is from the range [0,3], and \(H\) is computed according to Eq. 5 using the generated random number (\({r}_{1}\)), the current hunting time (\(t\)), and maximum hunting time (\(T\)).
The selection process compares \({r}_{2}\) and \({r}_{3}\) values, and so, the sit-and-wait strategy is selected only when \({r}_{2}>{r}_{3}\); otherwise, the selected strategy is either search or attack. Attack strategy is chosen over the search strategy if \(H\ge {r}_{4};\) else, the strategy choice is search. Although the selection decision between attack and search is random, it is deduced that search is much more likely chosen over time (\(t\)) due to depletion of energy at later stages. After that, the solutions and the leader of the cheetahs must be updated accordingly.

-
Search Strategy
The search strategy simulates the scanning phase of the hunt whereby cheetahs inspect the territory, actively moving or stationarily scanning, depending on the size, speed of the prey, and energy level of the cheetah. An arbitrary search is modeled in Eq. 6 by updating the current cheetah location by a randomization parameter (\(\widehat{r}\)), which is a normal random number, and a random step size (\(\alpha\)), which is computed as Eq. 7 for most cases:
-
Attack Strategy
Similar to search strategy, attack strategy is a random operation with turning factor \(\left( {\check{r}_{i,j} } \right)\) as a randomization factor with interaction factor (\({\beta }_{i,j}^{t})\) between the cheetah and its neighbor or the leader of the cheetahs. Unlike search strategy, the updated position in Eq. 8 is computed by adding the prey position (\({X}_{B,j}^{t}\)) to the random term discussed earlier. The first \(\left( {\check{r}_{i,j} } \right)\) is computed using \({r}_{i,j}\) (normally distributed random number) in Eq. 9 then used in Eq. 8. The main distinction between the attack strategy and search strategy is that attacking is computing the new position of the cheetah to a position relative to prey position instead of the current cheetah position, which is done in search mode:
-
Sit-and-Wait Strategy
A waiting and siting strategy in a hideout behavior is observed on cheetahs in scenarios whereby the animal is in danger of being exposed to the prey, which is modeled in Eq. 10 as maintaining the same position vector for each solution as hunting time passes. This strategy enhances the algorithm’s ability to avoid converging on a local optimum by keeping part of the cheetah group unchanged:
Step 2.2: Leave the prey and go back home strategy
Indeed, cheetah hunters have limited energy that is depleted as time passes by. The cheetah’s reaction to multiple failed attempts of hunting is leaving the current area and returning back to home area. This strategy improves the diversity of the solutions in the population as well as boosts the algorithm’s ability to converge on the optimal solution. The main indicator of the need of this strategy is reaching performance plateau, like in the wild the cheetahs either choose to change their hunting place, or return home. This stage is only reached upon satisfying two conditions, set here to be (a) \(t<T\) and (b) leader position not improving for a time.
Step 3: Termination
The algorithm increments the current number of iterations executed after each group update loop execution then re-runs again the code until a termination condition is satisfied (the condition in Akbari et al. (2022) is reaching the maximum number of iterations). In case, the termination condition is met, the execution is stopped, and the algorithm returns the global best solution found by the algorithm.
The CO algorithm procedure is further explained in Algorithm 1, in which all steps are re-written in pseudocode form and a table providing details on the notations used throughout the algorithm. The algorithm starts with the initialization step of population and parameters, followed by defining group of the population, then updating their position according to the appropriate hunting strategy, i.e., switching between exploitation phase and exploration phase. In addition, a premature converge avoidance mechanism “leave prey and go home” is integrated to the hunting operation, which proves to improve the overall performance of the algorithm.
Random Vector Functional Link
In general, the RVFL can be considered as a type of ANN with single-hidden layer but contains a direct link between the input nodes and output nodes (as in Fig. 6; Pao et al., 1994; Chan and Elsheikhm 2019)). In RVFL, the weights between the input and output nodes are required to be determined; however, the other weights are put randomly and not changed during the prediction process.
The first step in RVFL prediction model is to split the input data into training and testing sets, then using the training set to learn the model and evaluate it using the testing set. The data can be represented as pair of values \({(a}_{i}, {b}_{i})\), where \({a}_{i}\in {\Gamma }^{n}, {b}_{i}\in {\Gamma }^{m}, i=1,\dots ,M\) and M refers to the total number of samples in the training set, whereas \({a}_{i}\) and \({b}_{i}\) denote the sample i and their targets, respectively.
Thereafter, the output of the jth hidden node is computed as follows:
where \({c}_{j}\) represents the weights of the input and the hidden nodes, \({d}_{j}\) refers to the bias, and \(\xi\) denotes a scalar factor. Then, the output of the RVFL network is computed as follows:
where \({K}\) is the input data that depends on \({K}_{1}\) and \({K}_{2}\), which are formulated as:
In Eq. 13, \(C\) and \(I\) are the coefficients of the trade-off and the identity matrices, respectively. In Eq. 12, \(w\) is the output weights and the next process is to update its value using either Eqs. 14 or 15:
where \(\dag\) is the Moore–Penrose pseudoinverse or the ridge regression.
The Proposed CO–RVFL Method
First of all, the main target is to determine the best parameters and structure of the RVFL by considering it as an optimization problem and using the operators of the CO to handle this problem. Secondly, using this enhanced version of the RVFL to improve the performance of prediction the fluid substitution.
The framework of the developed method is given in Figure 7, where the first step is to split the data into two parts, namely training and testing sets, which represent 70% and 30% of the data, respectively. The next process is to construct the set of solutions \(X\) that represents the structure of the RVFL and this can be formulated as follows:
where \(\mathrm{dim}=3\) is the dimension of each solution and indicates the number of parameters of the RVFL; \(N\) is the number of solutions, and \(u\) and \(l\) refer to the upper and lower boundaries, respectively, of the search domain.

Proposed CO–RVFL for predicting rock-physics parameters of gas-bearing reservoirs
For clarity, consider the following representation of \({X}_{i}=[\mathrm{3,100,1}]\), which means that there are three parameters and according to the domain of each parameter the value of first parameter \({X}_{i1}=3\), which refers to the kind of activation function that will be used. In this study, we can switch between five types of activations, namely hardlim, tribas, radbas, sign, and sig, and we used the encoding from 1 to 5 to refer to them, respectively. Whereas the \({X}_{i2}\) is the number of hidden nodes and we set its range to be [1200], the \({X}_{i3}\) is the kind of approach that was used to generate the weights, and here, we used either uniform and Gaussian, which are encoded using 1 and 2, respectively. After that, we used the following fitness function to assess the efficiency of each structure of the RVFL according to the values of \({X}_{i}\):
In Eq. 17, \({Y}_{P}\) refers to the output obtained from using the RVFL based on \({X}_{i}\), and \({Y}_{T}\) is the original output; \(\mathrm{Ns}\) represents the number of samples in the training set. Thereafter, the best structure is determined and using it to update the value of other solutions per the operators of the CO as defined in Eqs. 5–10. This process is conducted until the stop conditions are met, which returns the best solution and then, evaluate it using the testing sample and finally compute the performance of the structure of RVFL.
Results and Discussion
In the case of the gas-bearing reservoir, regression analysis was performed to show the reliability of the relations of the log-calculated Poisson's ratio (σG) to the predicted Poisson's ratio (σG1, σG2, σG3) based on SCAFootnote 3–RVFL, WOAFootnote 4–RVFL, and CO–RVFL models, respectively (Table 2), by using these models on the fourth test well (Scarab-Db). The relationship of σG versus σG1, σG2, σG3 shows low r values of 0.11, 0.22, and 0.3, respectively (Fig. 8a, b and c). This shows a weak match between log-calculated Poisson’s ratio in the case of gas zones and predicted Poisson’s ratio using the ML techniques on the Scarab-Db test well (Fig. 8d).

Regression analysis and resulting logs of calculated and predicted Poisson’s ratio in case of presence of gas. (a), (b), (c): relationships and correlation coefficient. (d): correlation between output Poisson’s ratio logs
Because of the low correlation coefficient values, we removed the log data of gas zones from the well log data and applied these models again. The correlation coefficient of σGr, after removing log data of gas zones, with the predicted (σGr1 and σGr2) (Table 2) increased to 0.24 and 0.33, respectively (Fig. 9a and b), while the relation of σGr with the predicted σGr3 shows higher correlation coefficient of 0.83 (Fig. 9c). Figure 9d shows the very good match between the log-calculated Poisson’s ratio (σGr) and predicted Poisson’s ratio using the proposed CO model (σGr3), while those using the SCA and WOA (σGr1 and σGr2) are still weak.

Regression analysis and resulting logs of calculated and predicted Poisson’s ratio in case of removal of gas. (a), (b), (c): relationships and correlation coefficient. (d): correlation between output Poisson’s ratio logs
As shown in the results, the ML results were expected to be decrease because of the presence of gas zones. Therefore, fluid substitution method was employed, reflecting a particular fluid response before and after the change in fluid type. Figure 10 shows the comparison between the Poisson’s ratio log after fluid substitution as if the original content of the Poisson’s ratio log was 100% gas saturation (gas case), Poisson’s ratio log after fluid replacement as if the reservoir was 100% oil saturation (oil case), and the reservoir was 100% water saturation (brine case).

Scarab-Db well input data (from left, GR, neutron-density, seismic trace) and fluid substitution between Poisson’s ratio in the presence of gas zoned (black color), Poisson’s ratio in the presence of oil (green color), and Poisson’s ratio in the presence of water (red color)
In addition, after the reservoir fluid was replaced by oil and water instead of gas, the ML algorithms were applied on the two cases. The results improved in the presence of oil and water compared to original case (gas). The relationship between the Poisson’s ratio after gas was substituted by oil (σO) and predicted σO3 displayed an excellent correlation coefficient of 0.99 (Fig. 11c), while the correlation coefficients of σO and predicted σGr1 and σGr2 (Table 2) decreased to 0.63 and 0.65, respectively (Fig. 11a and b). In addition, Figure 11d shows the excellent match between log-calculated Poisson’s ratio in the case of oil and predicted Poisson’s ratio using the CO model. Also, in the case of gas replaced by water, the relationship between σW and predicted σW3 showed excellent correlation coefficient of 0.99 (Fig. 12c), while the correlation coefficient of σW versus predicted σW1 and σW2 (Table 2) increased to 0.66 and 0.67, respectively (Fig. 12a and b). Figure 12d demonstrates the excellent match between log-calculated Poisson’s ratio and predicted Poisson’s ratio using the CO model. The results in the case of reservoir saturated with water slightly increased in case of oil.

Regression analysis and resulting logs of calculated and predicted Poisson’s ratio in case of fluid substitution with oil. (a), (b), (c): relationships and correlation coefficient. (d): correlation between output Poisson’s ratio logs

Regression analysis and resulting logs of calculated and predicted Poisson’s ratio in case of fluid substitution with water. (a), (b), (c): relationships and correlation coefficient. (d): correlation between output Poisson’s ratio logs
The correlation coefficients calculated for the Scarab-Db test well in four cases are presented in Table 3 and demonstrated in histograms in Figure 13, which show the increase in the correlation coefficients after removing the log data of gas zones and further increase when the replaced oil and water log data were used instead of the original log data (gas). In addition, the proposed model’s (CO) correlation coefficients were superior to those of the other two models (SCA and WOA).

Histograms of correlation coefficients (r) for the test well Scarab-Db in the four cases
Conclusions
The Poisson’s ratio is a valuable rock-physics parameter for gas-bearing reservoir discrimination. This study presented an approach to avoid the erroneous effect of gas on determining or predicting rock-physics parameters, such as Poisson's ratio, without removing the gas points from the well log data. This can be achieved by using the fluid substitution method before applying the proposed ML models.
This study demonstrated how the efficiency of ML models is impacted by the presence of gas zones. This has been achieved by using a modified version of the RVFL model per the operators of the CO. Three fluid substitution models (gas, oil, and water) were proposed for pure sandstone and were utilized to measure the various sandstone saturations behavior. A significant increased enhancement was observed in the Poisson’s ratio parameter when the initial gas saturation was replaced with the water in the Scarab-Db well.
Removal of log data of gas-bearing zones increases the correlation coefficient of the CO–RVFL model and fluid substitution from gas to oil, or water further enhances the correlation coefficient of all the models and largely optimizes it for the CO–RVFL model. Gassmann’s fluid substitution was utilized to forecast the behavior of Poisson's ratio of the rock, and it was observed that the predicted Poisson's ratio matching validity increased for 100% oil and water saturation. The integration of fluid substitution and ML techniques improves the quality and reliability of the results.
Notes
°C = (32 °F − 32) × 5/9.
1 psi = 6.895 kPa.
Sine cosine algorithm.
Whale optimization algorithm.
References
Abd Elaziz, M., Ghoneimi, A., Elsheikh, A. H., Abualigah, L., Bakry, A., & Nabih, M. (2022). Predicting shale volume from seismic traces using modified random vector functional link based on transient search optimization model: A case study from Netherlands North Sea. Natural Resources Research, 31(3), 1775–1791.
Abd El-Gawad, E., Abdelwahhab, M., Bekiet, M., Nooh, A. Z., Abd El-Aziz, N. M., & Fouda, A.E.-H. (2019). Reservoir quality determination through petrophysical analysis of El Wastani formation in scarab field, offshore Nile Delta, Egypt. Al-Azhar Bulletin of Science, 30(1), 1–12.
Abe, J. S., Edigbue, P. I., & Lawrence, S. G. (2018). Rock physics analysis and Gassmann’s fluid substitution for reservoir characterization of “G” field, Niger Delta. Arabian Journal of Geosciences, 11(21), 656.
Adam, L., Batzle, M., & Brevik, I. (2006). Gassmanns fluid substitution and shear modulus variability in carbonates at laboratory seismic and ultrasonic frequencies. Geophysics, 71(6), F173–F183.
Akbari, M. A., Zare, M., Azizipanah-Abarghooee, R., Mirjalili, S., & Deriche, M. (2022). The cheetah optimizer: A nature-inspired metaheuristic algorithm for large-scale optimization problems. Scientific Reports, 12(1), 1–20.
Ali, M., Jiang, R., Ma, H., Pan, H., Abbas, K., Ashraf, U., & Ullah, J. (2021). Machine learning: A novel approach of well logs similarity based on synchronization measures to predict shear sonic logs. Journal of Petroleum Science and Engineering, 203, 108602.
Aly Ismail, A., Abdel Kader Boukhary, M., & Ibrahim AbdelNaby, A. (2010). Subsurface stratigraphy and micropaleontology of the Neogene rocks, Nile Delta, Egypt. Geologia Croatica, 63(1), 1–26.
Andersen, C. F., & van Wijngaarden, A. -J. (2007). Interpretation of 4D AVO inversion results using rock-physics templates and virtual-reality visualization, North Sea examples. In SEG technical program expanded abstracts 2007 (pp. 2934–2938). Society of Exploration Geophysicists. https://doi.org/10.1190/1.2793080
Asquith, G., Krygowski, D., Henderson, S., & Hurley, N. (2004). Basic well log analysis. American Association of Petroleum Geologists. https://doi.org/10.1306/Mth16823
Atlas, D. (1979). Log interpretation charts. Dresser Industries Inc.
Avseth, P., van Wijngaarden, A.-J., Mavko, G., & Johansen, T. A. (2006). Combined porosity, saturation and net-to-gross estimation from rock physics templates. In SEG technical program expanded abstracts 2006. Society of Exploration Geophysicists. https://doi.org/10.1190/1.2369887
Avseth, P. A., & Odegaard, E. (2004). Well log and seismic data analysis using rock physics templates. First Break. https://doi.org/10.3997/1365-2397.2004017
Bateman, R. M. (2012). Openhole log analysis and formation evaluation (4th ed.). Society of Petroleum Engineers (SPE).
Batzle, M., & Wang, Z. (1992). Seismic properties of pore fluids. Geophysics, 57(11), 1396–1408.
Berryman, J. G. (1999). Origin of Gassmann’s equations. Geophysics, 64(5), 1627–1629.
Chaki, S., Routray, A., & Mohanty, W. K. (2018). Well-log and seismic data integration for reservoir characterization: A signal processing and machine-learning perspective. IEEE Signal Processing Magazine, 35(2), 72–81.
Chan, S., & Elsheikh, A. H. (2019). Parametric generation of conditional geological realizations using generative neural networks. Computational Geosciences, 23(5), 925–952.
Crain, E. R. (1986). Log analysis handbook. PennWell Books.
Dorrington, K. P., & Link, C. A. (2004). Genetic-algorithm/neural-network approach to seismic attribute selection for well-log prediction. Geophysics, 69, 212–221.
El-Bahiry, M., El-Amir, A., & Abdelhay, M. (2017). Reservoir characterization using fluid substitution and inversion methods, offshore West Nile Delta, Egypt. Egyptian Journal of Petroleum, 26(2), 351–361.
Farsi, M., Mohamadian, N., Ghorbani, H., Wood, D. A., Davoodi, S., Moghadasi, J., & Ahmadi Alvar, M. (2021). Predicting formation pore-pressure from well-log data with hybrid machine-learning optimization algorithms. Natural Resources Research, 30, 3455–3481.
Feng, R. (2021). Improving uncertainty analysis in well log classification by machine learning with a scaling algorithm. Journal of Petroleum Science and Engineering, 196, 107995.
Garia, S., Pal, A. K., Ravi, K., & Nair, A. M. (2021). Prediction of petrophysical properties from seismic inversion and Neural Network: A case study. In EGU general assembly conference abstracts (pp. EGU21–11824).
Gassmann, F. (1951). Elastic waves through a packing of spheres. Geophysics, 16(4), 673–685.
Ghoneimi, A., Farag, A. E., Bakry, A., & Nabih, M. (2021). A new deeper channel system predicted using seismic attributes in scarab gas field, west delta deep marine concession, Egypt. Journal of African Earth Sciences, 177, 1–18.
Gommesen, L., Mavko, G., Mukerji, T., & Fabricius, I. L. (2002). Fluid substitution studies for North Sea chalk logging data. In SEG technical program expanded abstracts 2002. Society of Exploration Geophysicists. https://doi.org/10.1190/1.1817247
Han, D., & Batzle, M. L. (2004). Gassmanns equation and fluid-saturation effects on seismic velocities. Geophysics, 69(2), 398–405.
Hilterman, F. J. (2001). Seismic amplitude interpretation. Society of Exploration Geophysicists and European Association of Geoscientists and Engineers.
Ismail, A. A. (1984). Quantitative well logging analysis on some subsurface successions in the Nile Delta area. (Ms. C.). Faculty of Science, Ain Shams University, Cairo, Egypt.
Iturrarán-Viveros, U., Muñoz-García, A. M., Castillo-Reyes, O., & Shukla, K. (2021). Machine learning as a seismic prior velocity model building method for full-waveform inversion: A case study from Colombia. Pure and Applied Geophysics, 178(2), 423–448.
Larionov, Vv. (1969). Radiometry of boreholes (p. 127). Nedra.
Magoba, M., & Opuwari, M. (2019). Petrophysical interpretation and fluid substitution modelling of the upper shallow marine sandstone reservoirs in the Bredasdorp Basin, offshore South Africa. Journal of Petroleum Exploration and Production Technology, 10(2), 783–803.
Marker, L., Boast, L. K., & Schmidt-Küntzel, A. (2018). Cheetahs: Biology and conservation. Academic Press.
Misaghi, A., Negahban, S., Landrø, M., & Javaherian, A. (2010). A comparison of rock physics models for fluid substitution in carbonate rocks. Exploration Geophysics, 41(2), 146–154.
Mokhtar, M., Saad, M., & Selim, S. (2016). Reservoir architecture of deep marine slope channel, Scarab field, offshore Nile Delta, Egypt: Application of reservoir characterization. Egyptian Journal of Petroleum, 25(4), 495–508.
Nabih, M., Ghoneimi, A., Bakry, A., Chelloug, S. A., Al-Betar, M. A., & Elaziz, M. A. (2022). Rock physics analysis from predicted Poisson’s ratio using RVFL based on Wild Geese Algorithm in scarab gas field in WDDM concession, Egypt. Marine and Petroleum Geology, 147, 105949.
Pao, Y.-H., Park, G. H., & Sobajic, D. J. (1994). Learning and generalization characteristics of the random vector Functional-link net. Neurocomputing, 6, 163–180.
Priezzhev, I. I., Veeken, P. C. H., Egorov, S., & v, & Strecker, U. (2019). Direct prediction of petrophysical and petroelastic reservoir properties from seismic and well-log data using nonlinear machine learning algorithms. The Leading Edge. https://doi.org/10.1190/tle38120949.1
Raslan, S. (2002). Sedimentology and sequence stratigraphic studies for Scarab Saffron field. Ph. D. Thesis. Faculty of Science, Ain Shams University, Cairo, Egypt.
Russell, B. H., Hedlin, K., Hilterman, F. J., & Lines, L. R. (2003). Fluid-property discrimination with AVO: A Biot-Gassmann perspective. Geophysics, 68(1), 29–39.
Samuel, A., Kneller, B., Raslan, S., Sharp, A., & Parsons, C. (2003). Prolific deep-marine slope channels of the Nile Delta, Egypt. AAPG Bulletin, 87(4), 541–560.
Schlumberger. (1972). The essential of log interpretation practice. France.
Schlumberger. (1974). Log interpretation manual/principles (Vol. 2). Schlumberger Well Services Inc.
Simm, R., & Bacon, M. (2014). Seismic amplitude. Cambridge University Press. https://doi.org/10.1017/cbo9780511984501
Smith, T. M., Sondergeld, C. H., & Rai, C. S. (2003). Gassmann fluid substitutions: A tutorial. Geophysics, 68(2), 430–440.
Wang (Zee), Z. (2001). Fundamentals of seismic rock physics. Geophysics, 66(2), 398–412.
Wang, P., Cui, Y., & Liu, J. (2022). Fluid discrimination based on inclusion-based method for tight sandstone reservoirs. Surveys in Geophysics. https://doi.org/10.1007/s10712-022-09712-5
Yasin, Q., Sohail, G. M., Khalid, P., Baklouti, S., & Du, Q. (2021). Application of machine learning tool to predict the porosity of clastic depositional system, Indus Basin, Pakistan. Journal of Petroleum Science and Engineering, 197, 107975.
Zahmatkesh, I., Kadkhodaie, A., Soleimani, B., & Azarpour, M. (2021). Integration of well log-derived facies and 3D seismic attributes for seismic facies mapping: A case study from mansuri oil field, SW Iran. Journal of Petroleum Science and Engineering, 202, 108563.
Zhang, J. J., & Bentley, L. R. (2005). Factors determining Poisson’s ratio: CREWES Research Report. Volume.
Acknowledgment
The authors very much appreciate EGPC and RASHPETCO for offering the well log and seismic data utilized in the present study. This research received no funding.
Funding
Open access funding provided by The Science, Technology & Innovation Funding Authority (STDF) in cooperation with The Egyptian Knowledge Bank (EKB).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of Interest
There is no financial or non-financial interests that are directly or indirectly related to the current work.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Abd Elaziz, M., Ghoneimi, A., Nabih, M. et al. Contribution of Fluid Substitution and Cheetah Optimizer Algorithm in Predicting Rock-Physics Parameters of Gas-Bearing Reservoirs in the Eastern Mediterranean Sea, Egypt. Nat Resour Res 32, 1987–2005 (2023). https://doi.org/10.1007/s11053-023-10219-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11053-023-10219-y