
Abstract
Bayesian uncertainty quantification of reservoir prediction is a significant area of ongoing research, with the major effort focussed on estimating the likelihood. However, the prior definition, which is equally as important in the Bayesian context and is related to the uncertainty in reservoir model description, has received less attention. This paper discusses methods for incorporating the prior definition into assisted history-matching workflows and demonstrates the impact of non-geologically plausible prior definitions on the posterior inference. This is the first of two papers to deal with the importance of an appropriate prior definition of the model parameter space, and it covers the key issue in updating the geological model—how to preserve geological realism in models that are produced by a geostatistical algorithm rather than manually by a geologist. To preserve realism, geologically consistent priors need to be included in the history-matching workflows, therefore the technical challenge lies in defining the space of all possibilities according to the current state of knowledge. This paper describes several workflows for Bayesian uncertainty quantification that build realistic prior descriptions of geological parameters for history matching using support vector regression and support vector classification. In the examples presented, it is used to build a prior description of channel dimensions, which is then used to history-match the parameters of both fluvial and deep-water reservoir geostatistical models. This paper also demonstrates how to handle modelling approaches where geological parameters and geostatistical reservoir model parameters are not the same, such as measured channel dimensions versus affinity parameter ranges of a multi-point statistics model. This can be solved using a multilayer perceptron technique to move from one parameter space to another and maintain realism. The overall workflow was implemented on three case studies, which refer to different depositional environments and geological modelling techniques, and demonstrated the ability to reduce the volume of parameter space, thereby increasing the history-matching efficiency and robustness of the quantified uncertainty.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
The main problem in forecasting reservoir behaviour is the lack of information available to populate any reservoir model of a heterogeneous geological system away from the wellbores. A good analogy to the problems faced in creating reservoir models was supplied by Christie et al. (2005), who likened forecasting reservoir production to drawing a street map and then predicting traffic flows based on what you see from several street corners in thick fog. Expanding on Christie’s analogy, geological modelling is the equivalent of knowing that roads can be classified by the number of lanes of traffic in each direction, their location, their ranges of speed limit and the common features that can exist on them. It will not tell us how long or tortuous the road is, how often the road type changes, nor which features that affect the flow of traffic are present.
Bayesian uncertainty quantification is a commonly used approach in reservoir engineering, where the model mismatch to some data (e.g. production data) is used to estimate the likelihood and, based on some assumption of the prior, infer the posterior. It is useful as it is a quantitative way of estimating uncertainty and allows reservoir engineers to define reservoir prior probability based on distributions of model parameters. For much of the research carried out in this area, the aim has been to improve the efficiency of discovering minima in parameter space to achieve good history matches. Less effort has been applied to the prior, its importance and how to encapsulate it in the uncertainty quantification workflows, in short how to encapsulate geological features into parameters that can be sampled (a process called geological parameterisation).
Geological priors have the added complexity of potentially being highly non-uniform/non-Gaussian, while uniform or Gaussian are the typical models used to describe prior uncertainty. Therefore, applying simple definitions of prior probability can result in production of models that are geologically unrealistic, creating history matches that potentially lead to poor forecasts. The differences between available geological modelling approaches also complicate matters, as the parameter set for each approach differs, thus each modelling method potentially requires the creation of a set of unique prior probabilities describing the geological uncertainties for each approach.
Elicitation of prior probabilistic information is also a complex issue, as discussed in Baddeley et al. (2004) and Curtis and Wood (2004). Geologists deal with the sparsity of data by using prior knowledge about what is and is not geologically possible, to reduce the number of possible models. These expert judgements are based on the experience of the geologist in inferring probabilities about the data using different but related data sources. An example of this may be to infer porosity and net/gross values to estimate hydrocarbon volumes for an undrilled exploration well, based on previously drilled wells in the region or outcrops of reservoir facies exposed at the surface. Such data are qualitative rather than quantitative, thus any estimates of uncertainty for these data/parameters are based on the judgements of the geologist.
This paper proposes a set of novel workflows that encapsulate the geological prior, then demonstrates their benefits, showing improvements to model predictions and estimates of uncertainty over the use of non-geological priors. The work is illustrated by using three example data sets and increasing complexity of workflow to deal with them. Sections 2 and 3 describe the background of the uncertainty quantification approaches and how to integrate these into geological modelling workflows, demonstrated on a simple case study. In Sect. 4, a machine learning approach to encapsulate more complex geological prior probabilities into Bayesian workflows is described and then demonstrated using two different case studies.
2 Assisted History Matching, Likelihood Estimation and Uncertainty Quantification
There are a plethora of uncertainty quantification techniques available to reservoir engineers, developed for the purposes of using history-match quality to predict reservoir uncertainty. This work applies a general Bayesian workflow for uncertainty quantification, updating model descriptions based on production response.
Bayes’ theorem is a statistical method that allows one to update the estimates of probability given an initial set of prior beliefs and some new data. This can be applied to the problem of predicting reservoir model parameters by updating the parameter probabilities based on field observations such as oil/water production rates. If m are model parameters to be estimated based on some observations O, then Bayes’ theorem can be described by
where p(m) is the prior probability of the model parameters and p(m|O) is the posterior probability given the likelihood p(O|m). The denominator term is often considered a normalisation constant on Bayesian evidence (Elsheik et al. 2015).
The likelihood is calculated from the misfit M between the production data and the model response, where the lower the value of M, the higher the likelihood of the model
M is calculated using one of a range of misfit functions, most commonly the least-squares misfit. The choice of the misfit function and the handling of any associated error have been shown to have a significant impact on Bayesian estimates (O’Sullivan and Christie 2005). This work uses a standard least-squares definition throughout in order to demonstrate the impact of the prior in isolation, however equal care must be taken for both the likelihood and prior to produce robust uncertainty estimates.
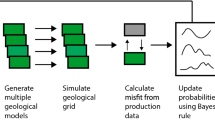
A general workflow for uncertainty quantification and assisted history matching, taken from Christie et al. (2006) and shown in Fig. 1, is used as the basis for all workflows generated in this work. In Fig. 1, an optimisation algorithm is used to generate multiple realisations of the reservoir model, which are then simulated and compared with the measured production using a misfit objective function such as the least-squares misfit. Several stochastic optimisation algorithms are available for this task, including particle swarm optimisation (PSO) (Mohamed et al. 2010), differential evolution (DE) (Hajizadeh et al. 2010) and the Bayesian optimisation algorithm (BOA) (Abdollahzadeh et al. 2012). The loop shown in Fig. 1 continues until some predefined criterion has been met, typically a set number of iterations, a minimum misfit being reached or a lack of improvement in reducing misfit value.

A simple uncertainty quantification workflow [from Christie et al. (2005)]
Stochastic optimisers are used for their ability to find multiple different clusters of models (minima) that provide similar match quality with varying forecasts, and the example algorithms above are used particularly for their efficiency in locating minima from small numbers of simulation runs. This outcome may be further enhanced by the use of multi-objective versions of the algorithms (MOO) (Christie et al. 2013).
The final step is to apply a post-processor such as NAB (Sambridge 1999a, b) to calculate the Bayesian credible intervals from the entire ensemble of history-matched models, then forecast with uncertainty to produce good approximations to the results of a thorough Markov chain Monte Carlo (MCMC) analysis (Mohamed et al. 2010). NAB does this by employing Voronoi cells to tessellate the parameter space of the misfit ensemble, creating a cell for each iteration of the ensemble, where the cell size depends on the sample density.
Each cell represents a region of equal misfit in parameter space around a particular history-matched iteration, where the volume is inversely proportional to the sampling density in that area. Across the cell, the misfit is set equal to the misfit value of that iteration. A Gibbs sampler is run over the Voronoi space, and a sample is accepted/rejected based on the visited cell’s misfit. The sampling is therefore dependent on both the misfit of a particular cell as well as the chance of visiting that cell. Low-likelihood samples tend to have fewer neighbouring samples and therefore have larger cells. These cells get more visits, but the samples are accepted less frequently. Higher-likelihood cells tend to be in refined regions of space, thus the cells are typically smaller, but they will be accepted more often.
3 Incorporating Geological Modelling Workflows in History Matching
For ease of implementation in real-world settings, the workflow shown in Fig. 1 is typically applied to the parameters of the dynamic simulation model that are easiest to adjust algorithmically by practising engineers. Parameters of the geological model, such as statistical model parameters, object sizes or the complex set of properties that must be changed to adjust faults, surfaces or horizons are less frequently adjusted in practice. The two main reasons for this are (i) most static models are populated by some form of geostatistical approach, and commercial modelling approaches rely on complex workflows that are hard to interact with, and (ii) that geostatistical models are typically built by geoscientists, therefore multiple technical disciplines must interact in the history-matching process for these models to be included. For simplicity, most companies keep the history-matching workflow under the control of only the reservoir engineer. Parameters such as skin, productivity index, relative permeability and porosity/permeability multipliers are typically applied to tune the geological uncertainties, however these change the continuity and structure of the geological model which was built to represent the likely correlation structure of the reservoir, potentially in ways that are not geologically possible.
To fully include geological uncertainties as parameters into the history-matching process, the geostatistical model must be included in any workflow, which requires the solution of the following challenges: (i) how to create the new workflow to include the appropriate (not just easy) geostatistical model so that its parameters can be updated by the optimisation approach, and (ii) how to define the prior ranges of the geostatistical model parameters based on the real-world geological measurements.
Broadly, there are three main approaches available to geostatistical modelling that can be applied: (i) Two-point statistical approaches based on kriging and variography to define the correlation structure of the geological features. The most common of these are methods such as sequential indicator simulation (SIS) and truncated Gaussian simulation (TGS) for modelling discrete parameters and sequential Gaussian simulation (SGS) for continuous parameters (Pyrcz and Deutsch 2014); (ii) Object modelling approaches (Pyrcz and Deutsch 2014) using pre-defined objects to represent geobodies in the reservoir (e.g. a channel, lobe or sheet) rather than a statistical representation of the correlation structure. The object is parameterised by a set of physically definable dimensions to describe its shape and size plus a proportion objective that the algorithm aims to achieve; (iii) Multi-point statistics (MPS), which uses a training image instead of a variogram or object shape/dimensions to represent the correlation model. The training image is a rich representation of the reservoir correlation that describes the spatial relationships of several facies types. Like its simpler two-point counterpart, MPS can quickly produce realisations of the reservoir model, however MPS can apply multiple training images to allow different, complex representations of the correlation structure for different geological interpretations.
Several authors have updated the geostatistical model reservoir properties directly using a variety of methods such as gradual deformation (Hu 2000) or assimilation methods such as EnKF (Evensen et al. 2007; Chang et al. 2015). Changing the structural model also requires more complex geological parameterisations such as the example shown in Cherpeau et al. (2012), which demonstrated an approach to history-match a reservoir model by automatically relocating faults whose location was uncertain. In all this work, the geological prior is of critical importance to maintain the belief in model forecasts, thus the impact of geological priors on uncertainty quantification workflows is discussed next. Preserving geological realism through the model update has attracted increasing interest in several publications that address different aspects of this issue: conditioning geological models to geophysical observation (Jessell et al. 2010), uncertainty quantification using several scenarios using a metric space approach (Scheidt and Caers 2009a), scenario discovery based on different reservoir performance metrics (Jiang et al. 2016), posterior inference based on training images (Melnikova et al. 2015), inverse modelling in seismic inversion (Linde et al. 2015) and inverse modelling with different fracture scenarios (Sun et al. 2017).
4 Geological Priors in History Matching and Uncertainty Quantification
Defining geomodel priors and their interdependence from measured data is less commonly tackled. Wood and Curtis (2004) illustrated an example by incorporating all geological sources, including static and dynamic data, into a model of stacked marine sequences, where a good definition of the geological prior allowed good geological matches to wells. The next section describes the importance of applying geological priors to quantifying reservoir uncertainty.
4.1 An Example of a Geological Prior
Figure 2 demonstrates an example of two different prior descriptions for two uncertain parameters in a channelised fluvial environment, viz. channel width and depth. The red dashed line represents a non-geologically informed description as the bounds of two uniform distributions for each parameter, while the purple shaded area represents the space of observed channel dimensions. The relationships between channel dimensions have been well studied in the works of Williams (1986), Crane (1982), Leeder (1973), and Bridge and Mackey (1993) and represent bounds of clouds of data taken from modern rivers, as such can be assumed to represent the likely space of geologically plausible models. Recent studies from Parquer et al. (2017) showed an alternative data set that could be used for developing priors based on reconstructing the evolution of ancient rivers.

From Fig. 2, it is clear that (i) the correlations differ from each other, such that no one correlation can predict all fluvial systems, (ii) the likely space of possible models is bounded by the spread of the correlations, and (iii) this space is much smaller and unusually shaped in comparison with the uniform prior.
By using the purple-shaded geological prior in Fig. 2, the volume of parameter space is significantly reduced and highly unlikely/unrealistic model definitions are avoided, saving computational effort and increasing accuracy of forecasting. An idealised workflow for this approach is given in Fig. 3 and is applied to a simple case study below.

Geological history-matching workflow including realistic geological priors. Green boxes represent models while grey box represents data
4.2 Case Study 1: La Seretta Outcrop using Simple Geological Priors
The La Serreta outcrop was first studied in detail by Hirst (1991). Located in the Ebro Basin, Northern Spain, La Serreta is part of the Oligo–Miocene Huesca distributive fluvial system. Located in a proximal position in the system, the resulting architecture is of multilateral/multistorey sandbodies with high net/gross, connectivity and overall good reservoir quality. There are three types of channel facies identified at the outcrop, representing channelised flow in major and intermediate channels and overbank ribbon sands, here termed minor channels. The outcrop exposure was used as the basis for creating a box model with three distinct channel types and a background facies with dimensions of \(2.5\,\)km\(~\times 2\,\)km\(~\times 80\,\)m in size. A 700,000 (\(140 \times 125 \times 40\)) grid cell truth case model was created, and its production forecast, against which history matching would be carried out. The truth case was constructed using object models to create sinuous channels, where channel dimensions were set to values within the realistic prior range (purple) of Fig. 2. The model was constructed using the RMS™ software, then populated using object modelling for each of the three channel facies types and sequential Gaussian simulation (SGS) for the petrophysical properties.
Next, a 60,000 (\(30 \times 100 \times 20\)) grid cell model was built using the same modelling workflow as the truth case for the purposes of history matching. In this case, the object model parameters and net/gross (NTG) were unknown (a total of six object model parameters). These parameters plus their prior ranges are given in Table 1. A realisation of the history-matching model is shown in Fig. 4. The field operates a line drive from these wells, converted into an injector/producer pair, which are bottom-hole pressure (BHP) controlled. The field is matched to field oil rate and water rate.

A realisation of the La Seretta model
History matching was carried out on two cases, a Basecase using only uniform priors and a Geological Prior case that applies the purple prior definition shown in Fig. 2. History matching was carried out using the neighbourhood algorithm (NA) (Sambridge 1999a, b), using 6500 iterations for each case to achieve a match. All realisations of the model were conditioned to porosity and permeability data in the producer and injector wells (produced from the truth case model).
The geological prior was defined by using the Williams (1986) and Leeder (1973) correlations as upper and lower bounds to the prior space. The stochastic sampler was then applied to a uniform prior with an additional accept/reject step to exclude models outside of the prior bounds. The application of the generalised workflow is as follows:
-
1.
Sample from the uniform prior for each parameter;
-
2.
Where geological prior exists, apply the accept/reject step to see if the model is possible. The geological prior was encoded for the width/depth ratio shown in Fig. 2 then run as a pre-processor, taking the output from the sampling algorithm and checking its validity before deciding on running the reservoir simulator;
-
3.
If yes:
-
(a)
Change the RMS™ input parameters;
-
(b)
Create a realisation of the object model based on the new parameters;
-
(c)
Export the static grid into the reservoir simulator then run the model;
-
(d)
Calculate the misfit and update the optimisation algorithm.
-
(a)
The distribution of sampling for both the standard uniform prior and the geological prior are visualised in Fig. 5, showing that the misfit surface is much more restricted for the geological prior, as the prior pushes sampling into the realistic regions of parameter space. As a result, sampling is more concentrated within the smaller region of the geological prior, which allows a better definition of the complex misfit surface in this region that was not resolved with uniform sampling. The uniform prior has more widely spaced minima (shown by heavy clustering of samples) which are not selected in the geological prior case, and by contrast, the uniform prior shows several minima in parameter space that are outside of the realistic range of channel dimensions. This clearly demonstrates the issue with non-informative priors; i.e. that one can get great matches from unrealistic models, which will bias an inference of uncertainty.

Comparison of a case 1 (uniform prior) with b case 2 (geological prior) to show the distribution of good-fitting models for the width/depth parameters. All samples are shown in red, while lowest misfit samples are shown in black
NAB was subsequently run on the misfit ensembles of the uniform and geological prior cases, and the resampled subset of models were forecast to produce the P10–P90 interval (Fig. 6). The impact of more constrained sampling from the geological prior leads to a reduction in the spread of P10–P90 and a reduction in uncertainty in the reservoir forecasts. Unrealistic models contribute to making the estimated P10—P90 wider in the uniform prior case where extra minima exist in the unrealistic regions of parameter space, whose forecasts influence the inference.

Comparison of field oil rate (FOPR) P10–P90 predictions from both the base case (uniform prior) and “intelligent case” (geological prior). Geological prior significantly reduces the amount of forecast uncertainty in this example
This simple example clearly illustrates the benefit of using non-uniform (complex in shape) geological prior definitions. The prior definition can be improved by using all available channel dimensions data to capture non-linear multivariate dependences in the definition of the prior (rather than the correlations to the data), by including more measured properties/parameters and by improving the definition of the channel model. The additional complexity of these prior definitions is worth the effort by reducing compute times and by avoiding inaccurate uncertainty estimates.
5 Building Geological Priors Using Machine Learning
The application of a geological prior to object models of channelised reservoirs in Sect. 4.2 is relatively easy as it only deals with a two-dimensional problem and the model parameters are equivalent to the geological prior data from palaeohydrological measurements. Defining the prior for a large number of uncertainty geological parameters whose ranges must be elicited from available data is much more complex due to the difficulty of working in high dimension. Using other modelling methods, such as multi-point statistics, may provide a better characterisation of the reservoir, as it can capture complex geological structures while conditioning perfectly to well data. Using MPS in history matching however, adds complexity to the problem, as model tuning parameters no longer link directly to the geological properties (i.e. affinity and rotation are not properties of the geological system).
To work with larger numbers of dimensions and to work with a range of geostatistical methods, any new approach must solve: (i) how to define the complex shape of high-dimensional geological priors, elicited from all available data, (ii) how to apply this prior model to the inverse problem and (iii) how to implement useful relationships between geologically induced priors and model control parameters, which may not be described by direct observations, in the inverse modelling.
This paper presents three novel approaches that together aim to solve these problems. These are: (i) Explore relationships between geomorphic parameters and model multivariate dependencies using the machine learning approach support vector regression (SVR). SVR is tested as a suitable approach to describe the prior in Sect. 5.1. (ii) Build informative realistic multi-dimensional prior for geomorphic parameters by classifying the space of realistic models using one-class support vector machine (OC-SVM). This is described in Sect. 5.2. (iii) Apply a multi-layer perceptron (MLP) to link MPS model parameters with the measurable geomorphic parameters. This is described in Sect. 5.3. Sections 5.4 and 5.5 cover two case studies to demonstrate the impact of the new workflow (Fig. 15) on history-matching performance.
5.1 Machine Learning to Construct Geological Priors
Machine learning presents us with a set of tools that can elicit relationships between parameters directly from the data and encapsulate these relationships in a useful way. Unlike the deterministic approach presented in the previous case study, machine learning provides a way to develop an accurate representation of complex relationships between the data without embedding hard pre-determined assumptions lacking sufficient justification.
Therefore, machine learning representation is more flexible in accounting for uncertainty in the elicited relationships. We demonstrate this on a data set given in Fig. 7, which shows the measured data used to develop the correlations of channel width/depth shown in Fig. 2 based on several data sets (Gibling 2006; Chitale 1970; Kjemperud et al. 2008; Leeder 1973; Williams 1986). In comparison with the deterministic correlations of Fig. 2, the data are quite scattered and the quality of fit of any one correlation is poor and therefore fairly inflexible and limited in representing uncertainty of the natural variability within model calibration problems. The green-shaded area qualitatively defines a realistic region of parameter space which avoids the corner regions of the uniform prior ranges, where the parameter combinations would be inconsistent with natural analogues.

Complete data sets for measured channel widths and thicknesses from several authors. Data scatter is significant, and single correlation models are probably not adequate to describe the distribution of data, therefore the green area shows the likely zone of plausible models
A contemporary, efficient data-driven method for capturing dependences from data is support vector regression (SVR) (Vapnik 1998). SVR creates robust and sparse non-linear regression models for high-dimensional and noisy data. SVR belongs to a family of kernel learning methods that are widely used in pattern analysis for classification and regression (Scholkopf and Smola 2002). A general form of a kernel model is a linear combination of the kernel functions \(K(x_{i},x)\)
where the kernel function K is a symmetric positive-definite function (e.g. a Gaussian of some width \(\sigma \)). The support vector coefficients \(\alpha _{i}\) identify the subset of the input data (\(x_{i}\)) and are determined through a training process.

Comparison of the SVR method (b) with standard linear regression (a) (Kanevski et al. 2009)
The training process is illustrated in Fig. 8 and compared with a linear regression model. In Fig. 8a, the linear regression function is fitted to data with known error intervals, showing that the ability of the function to fit the complex data is limited. In Fig. 8b, SVR creates a tube around a centre line kernel regression model (black line) with width \(\epsilon \) to create the support vectors (green lines). In this approach, the margin represents the window of acceptable fit to the data and is set as the spread of the support vectors with samples within the epsilon tube contributing zero weight. The complex non-linear kernel regression shown in Fig. 8b is first created linearly in feature space [reproducing kernel Hilbert space (RKHS)], then transformed back as a non-linear model within the input (in this case, model parameter) space. The fundamental property of kernel functions is that they actually provide a dot product between input samples in some high-dimensional space, the reproducing kernel Hilbert space (RKHS). This property is primarily used to introduce the non-linear extensions of the traditional methods (such as kernel principal component analysis).
It is necessary to tune SVR parameters by finding an optimal model that is not overfitted and has a predictive power to generalise. The parameters to tune are: the kernel width (\(\sigma \)), which controls the smoothing such that low \(\sigma \) overfits the data and generates high testing error and low training error; an \(\epsilon \)-insensitive loss function, to allow noise within the data, albeit with increased training error; and the factor C, which determines the balance between goodness of fit and training error.
SVR is trained in a way that minimises the complexity of the regression function with the trade-off penalty \(\xi \) (Fig. 8b) for outliers outside the support vectors (green lines in Fig. 8b). This problem is solved by standard quadratic programming for a given combination of C, \(\epsilon \) and kernel width (\(\sigma \)). These parameters can be tuned through cross-validation/testing (Kanevski et al. 2009) or inferred in a Bayesian way through an inverse problem (Demyanov et al. 2008). In this study, the SVR parameters were tuned in a manual way, just to demonstrate how the non-linear geomorphic relations can be captured from data, while fine-tuning of the SVR predictor lies beyond the scope of this study.
Figure 9 shows the SVR interpolated surface in three-dimensional space of geomorphic parameters: channel width, thickness and meander wavelength. We have identified the locations for several geomodels that can be interpreted as realistic or unrealistic according to the fluvial meandering depositional scenario. Here, unrealistic models are defined as those outside of the SVR interpolated region, while the shaded zone defined by SVR represents realistic models. Figure 9 demonstrates that support vector formalism is an efficient tool to represent the complex relationships between geomorphic parameters in high dimensions. Figure 10 shows that the technique can be applied to different geological environments and that the prior regions vary for different depositional environments: (i) fluvial channels (demonstrated in case study 2) and (ii) deep marine channels (case study 3).

SVR interpolated surface representing relationship between geomorphic parameters of fluvial channels: thickness, width and wavelength. Colour-coded points/balls represent the complex prior space constructed by SVR. The larger balls show the location of realistic and unrealistic realisations of the model

Channel dimension comparison between fluvial meandering and deep marine channels. In red: data points measured in deep marine channels; in blue: data from fluvial meandering channels. Data collected from Abreu et al. (2003), Callec et al. (2010), Damuth et al. (2006), Pirmez and Imran (2003), Posamentier (2003), Posamentier and Kolla (2003), Pyles et al. (2010) and Wood and Mize-Spansky (2009)
In order to apply this machine learning approach to history matching, it must be extended to deal with the problem of classifying which regions of parameter space contain realistic models (i.e. an informative high-dimensional prior). An approach to solving this is explained in the next section.
5.2 Applying a Machine Learning Prior to History Matching Using One-Class SVM Classification
To identify the realistic regions of parameter space from available data (e.g. Fig. 7), a one-class SVM (OC-SVM) is used, which is the SVM extension to the one-class classification problem. Scholkopf et al. (2001) defined OC-SVM as an unsupervised kernel-based method, which is used to estimate the support of probability density distributions. The main application of this technique is to detect novelty, outliers and rare events in a high-dimensional RKHS. A more thorough description of SVM is given in the part 2 paper (Demyanov et al. 2018).
The strategy is to map the data into the RKHS corresponding to the kernel, and to separate them from the origin with maximum margin. For a new point x, the value of f(x) is determined by evaluating which side of the hyperplane in the RKHS it falls on. When data are mapped in the RKHS by means of a kernel function, the data are linearly separated from the origin by maximising the margin of the hyperplane. Outliers are constrained to be close to the origin, while the core of the distribution is pushed away with a maximum margin.

Four-dimensional region (cloud) of realistic combinations of channel geomorphic parameters: a 715 data points used to generated the four-dimensional region; b in yellow: the four-dimensional region or cloud that encapsulates the realistic combination of geomorphic parameters
The results of applying a OC-SVM to construct a prior for a four-dimensional channel property data set can be seen in Fig. 11. Figure 11a shows the point cloud of data for four parameter dimensions of fluvial channels with clear correlation. Figure 11b shows the outcome of OC-SVM in defining the prior region of parameter space that is realistic, which is very similar in shape to that defined in Figs. 7 and 9. Probabilistic outcome of the classification is derived from Bayesian interpretation of SVM output through linearisation class-condition densities between the margins using a sigmoid form (Platt 1999).
The OC-SVM prior can now be used by allowing the history-matching (HM) workflow to test if a sample is inside (value = 1) or outside (value = 0) the prior space based on four supplied coordinate for the four-dimensional space. The stochastic sampling algorithm uses OC-SVM as an accept/reject step (as per the example in Sect. 4.2) to decide whether a proposed iteration should be evaluated.
5.3 Using Geological Priors with Other Modelling Approaches: a Multi-point Statistics Example
MPS uses a training image built by a geologist to represent the spatial distribution of facies (or other properties) in the interpreted depositional environment. While MPS is a stochastic algorithm and can generate realisations of the reservoir to account for some uncertainty, some key geometrical relations represented in the training image are not adjusted directly by the stochastic process.
It is possible to vary some of the geometrical relationships by applying the affinity transformation in one or more spatial directions. As the facies model gains extra flexibility with affinity transformation, it can be used as a parameter to account for prior uncertainty of geobody geometries and explore the range of possible models that provide history matches.
Affinity is a synthetic parameter that distorts the training image locally (or globally) in one or more dimensions (x, y, z) to provide the variations of the output facies geometry vs. with the ones in the training image, as described by Remy et al. (2009) and illustrated in Fig. 12. For an affinity parameter of [1 1 1], all the dimensions of the training image are preserved in the output model, but by increasing the affinity in the x axis by 2 to [2 1 1], the output model will double the dimensions from the training image along the x axis. By reducing the affinity parameter in the y axis by \( \frac{1}{4} \) to [1 0.25 1], the output model will be \( \frac{1}{4} \) of the training image size in y axis. Figure 12 illustrates the effect of the affinity variation into the output model compared with the training image when simulating fluvial channels and shows the useful flexibility in covering a range of geological outcomes from a limited set of training images.

Variation of channel geometry changing the SNESIM affinity parameter. The variation is subject to the effect of the affinity parameter over the training image (TI) (Rojas et al. 2011)
Affinity transformation is a model parameter, which is not observable or measurable in nature. Therefore, it is vital to establish a quantitative relation between affinity and geomorphic parameters, which can be measured on natural analogues (e.g. channel depth, width, wavelength and amplitude of the meander). Figure 13 shows the relationships between varying affinity and the geomorphic parameters for a given training image. A distribution of geomorphic parameters was derived from a set of 1055 stochastic (seeded) realisations of MPS simulations for each of the affinity parameter values. The stochastic nature of MPS allows variation of model geometries within a certain spread. Affinity transformation affects this spread and makes it even more difficult to predict relationship with geological object geometry, hence the error bars in Fig. 13. Modelling the relationship been the affinity parameters and the geomorphic parameters clearly requires a non-parametric data-driven approach. These relations are non-linear and also feature embedded uncertainty due to the stochastic nature of the geostatistical realisations—there is no 1 : 1 correlation.

Different responses of the channel geometry after varying affinity. The three charts illustrate the variation of a channel width, b amplitude and c wavelength for varying affinity ratios in x and y. The values of the channel parameters in the training image are represented by affinity [1 1 1]

Measures of channel properties extracted from the study’s training image. The key geometric features are extracted by first identifying a single, complete channel body then extracting width, amplitude and wavelength as shown (amplitude is L1–L2)
A critical step in this process is to extract the geometric parameters from the model in order to validate the MLP prediction for the training set using an R script. Channel facies bodies from the centre of the model were extracted to take representative sections of the channel sandbody. Figure 14 illustrates how the channel parameters were measured. The width was estimated as the minimum length perpendicular to the known flow direction, wavelength was the maximum inter-sand distance along the flow direction, and the amplitude was measured by obtaining the difference between the distances of the closest (L1) and farthest (L2) to the west border of the grid channel facies grid block perpendicular to the flow direction and subtracting the estimated channel width. This approach is simple and will not work where channels are oriented at anything other than \(0^\circ \), as the measures will no longer be orthogonal to gridding, but was applicable to this example.
A multilayer perceptron (MLP) neural network was used to predict the spread of the geomorphic parameters based on the combination of the MPS model affinity parameters. The MLP was trained with a set of initially simulated realisations that cover a range of affinity values and for which the spread of the geomorphic parameter values was estimated. In order to obtain a robust and reliable training database of channel geometry parameters affected by affinity variation, 81 different affinity combinations were considered with 5 stochastic realisations for each, which totals to 1055 realisations.
The methodology to predict the channel dimension using MLP is described here (Rojas et al. 2011):
-
1.
Measure all the geometrical parameters of the channel outputs (W channel width, wl meander wavelength, T channel thickness, A meander amplitude) after every realisation;
-
2.
Standardise the measures obtained in step (1) with the channel geometrical parameters of the training image in order to make these neural networks usable for any training image,
$$\begin{aligned} \text {Fraction}(W,T,a,wl)= \frac{\text {Realisation} X(W,T,a,wl)}{\text {TI}(W,T,a,wl)}, \end{aligned}$$(4)where X is a realisation, W is channel width, T is channel thickness, a is meander amplitude, wl is meander wavelength, and TI is training image.
-
3.
Build and train an MLP neural network using as inputs the x, y, z variations of affinity to predict the range of the simulated geometries based on the following MLP outputs: the mean (m) and the first and third quartiles (Q1 and Q3) of each of the channel geometrical parameters.
-
4.
The obtained results are expressed in fractions, then used as multipliers to the dimensions of the geometrical parameters of the training image in order to obtain geometrical parameters in distance units.
A new workflow that encompasses OC-SVM and MLP with MPS is given in Fig. 15. This workflow is applied to two new (i) fluvial and (ii) deep marine case studies in Sects. 5.3 and 5.4.

Extended geological history-matching workflow using OC-SVM to define the geological priors and MLP to allow the use of modelling methods such as MPS by mapping geological parameter space to geostatistical model parameter space
5.4 Case Study 2: Stanford VI Model Using SVM Machine Learning Priors
The case study reservoir was designed using the meandering fluvial section of the Stanford VI benchmark case (Castro et al. 2005). This stratigraphic unit was built by process-based modelling using the software SBED (Castro et al. 2005). The case study model was simplified to three facies: fluvial channel sands, point bar sands and floodplain shale (Fig. 16). The history-matching task was limited to modelling the facies spatial distribution parameters, while the petrophysical properties remained unchanged for each of the facies. The aim is to infer posterior uncertainty in the facies geometries, which can then be compared with the synthetic truth case characteristics given in Table 2. The petrophysical properties are summarised in Table 3.

The truth case facies model, taken from the second stratigraphic unit of the Stanford VI reservoir (Castro et al. 2005). Reservoir developed in a fluvial meandering system, with three facies: floodplain, point bars and channels

Input data for MPS Simulation using SNESIM: a training image with table specifying channel geomorphic parameters; b well data (facies); c seismic data (acoustic impedance) used as soft conditioning data
An MPS facies model was built for history matching using the SNESIM algorithm (Strebelle 2002) based on a training image of a meandering fluvial depositional environment. The training image was based on a channelised object facies model (Fig. 17a) which is different in terms of its geomorphic parameters from the truth case (Table 2). Conditioning data from 29 wells and soft probability (Doyen 2007) from the available seismic (synthetic) were used to constrain the geostatistical stochastic realisations (Fig. 17b, c).
Uncertainty in facies geometry was introduced in the MPS model through the variation of affinity parameters, which modifies the geometric relations embedded in the training image. This translates into the uncertainty of the geomorphic parameters channel width and thickness, channel meander amplitude and wavelength. The translation between affinity and the channel geometry is provided by the data-driven relationship obtained by MLP. The uniform prior ranges for the geomorphic parameters are given in Table 2.
A flow simulation black oil model was set up on a \(50 \times 50 \times 40\) grid with cell size of \(75 \times 100 \times 1\) m. The production from 18 wells was established by the water flood from 11 injection wells. The flow simulation has injection rate control and bottom hole pressure control at the production wells. The history-matching task was set up to minimise the misfit between the historical data and the simulated oil and water production rates across individual wells. The misfit was defined as a standard least-squares norm to oil and water rates, and history matching was performed using PSO.
The results of misfit evolution through history matching are presented in Fig. 18c, e, where the lowest misfit is achieved in fewer than 400 iterations. Figure 18a, b illustrates two realistic realisations from the evolution of models from history matching. Realisation (b) is produced after 300 iterations and is both realistic and provides a good match.

History-matching misfit evolution and model realisations: a realistic model with high misfit at early HM stage; b realistic model with low misfit at a later HM stage; c the misfit evolution of realistic model history matching; d unrealistic model that may match production data; e misfit evolution of the non-geological/uniform prior

Geo-parameters of the models using intelligent and flat priors and compared with the truth case value (red dashed line)

Comparison between history-matching and forecasting well oil production rate (WOPR) in some wells of the Stanford VI synthetic reservoir, using intelligent sedimentological prior information and models generated using flat priors
Table 2 compares HM using informative geological priors obtained with OC-SVM with HM using flat uninformative priors from the parameter intervals. The plot for the misfit evolution using HM with uniform priors (Fig. 18e) shows that models of comparable misfit quality can be obtained. However, there are many fewer low-misfit models when using HM with uniform priors, suggesting that it is far less efficient and does not produce enough low-misfit models.
Some of the low-misfit models produced with uniform priors may have unrealistic geomorphic parameter relationships. Figure 18d shows an unrealistic model realisation, which does not preserve the correct channel thickness/width ratio. Figure 19 further compares the geomorphic parameter values versus the model misfit obtained from HM with intelligent informative priors and uniform uninformative priors. The plots for meander amplitude, wavelength and channel width show that the HM models obtained with intelligent priors come closer to the values of the reference case than the model obtained from HM with uniform priors. The channel width parameter shows greater deviation of the lowest-misfit model from the true model parameter value, however there are still models with fair misfit that scatter around the width of the truth case model.
The final HM result in Fig. 20 shows the oil production rate history match and P10/P50/P90 forecast inferred from multiple HM models for wells 1, 5 and 12. It compares the forecasts obtained based on the models generated using intelligent and uniform priors. In general, the P10–P90 range of the well oil production rates (WOPR) in models generated using intelligent priors is smaller than the P10–P90 range of the models using the uniform ones. Another important aspect is that the P50 curve is closer to the history data of the model with intelligent priors than the models that used uniform prior information.
5.5 Case Study 3: Deep Water
Another case study was designed based on a different depositional environment, deep marine channels, to demonstrate the value of incorporating geological information in the form of informative priors in history matching. A synthetic reservoir (DM-Field) with facies geometry reflecting the description of deep marine channels of the Baliste–Crécerelle Canyon Fill (Wonham et al. 2000) was generated using unconditional object modelling with sinuous channels (Fig. 21a). DM-Field contains three facies: (i) pre-canyon deep marine pelagic and hemipelagic shales, (ii) muddy channel levees and canyon fill pelagic shales and (iii) deep marine channel sandy deposits. Table 4 gives the dimensions of the deep marine channel geomorphic parameters variation in the DM-Field. Petrophysical properties for these facies were set constant for each facies to analyse the effect of varying facies geometries on history-matching processes, and avoid a smearing effect possibly introduced by the variation of the petrophysical properties. Table 5 presents the relationships between sedimentary facies and petrophysical properties.
The model for history matching was designed using the SNESIM MPS algorithm (Strebelle 2002) with a training image containing sinuous channels (Fig. 21c). The geomorphic parameters in the training image have some variation and differ from those of the DM field truth case (Fig. 21a; Table 4). The model was conditioned to hard data from 15 wells and a seismic cube (synthetic) (Fig. 21b).

Deep marine reservoir case study: a DM field truth case; b synthetic seismic data used for soft probabilistic conditioning of the MPS model; c training image used as the MPS facies model concept

Comparison of the history-matching process and forecasting production rate for the DM-Field using intelligent prior information and uninformative priors: misfit evolution through HM iterations with intelligent informative priors (a) and with uniform uninformative priors (b); field oil production forecast based on the HM with intelligent informative priors (c) and with uniform uninformative priors (d)

HM models of DM field: a model with the largest misfit using intelligent geological priors; b model with the lowest misfit using intelligent prior; c model with the lowest misfit using uniform prior

Comparison of plots of parameter versus misfit related to the models generated using intelligent and uninformative geological prior information
The history-matching (HM) problem was set up in a similar way to case study 2, with the prior intervals for the channel geomorphic parameters given in Table 4. A black oil flow simulation model was matched to oil and water production rates at individual wells. The PSO algorithm was run for 1000 iterations to obtain multiple HM solutions.
A comparison of the history-matching results from both informative intelligent geological priors and uniform uninformative priors is presented in Fig. 22. Similar to case study 2, HM with informative priors showed fewer high-misfit models. This results in a tighter forecast P10/P90 interval when using informative priors than without. The ranges are wider for uninformative priors because of the impact of unrealistic models that are excluded from the sampling by the informative prior. Figure 23 illustrates examples of HM models obtained using geological priors and uniform priors. While Fig. 23a, b shows that the best and worst matches for the intelligent prior look similar, with clearly recognisable channel shapes, Fig. 23c shows that the best match for the non-geological prior has lost the shape and continuity patterns of the TI channels, resulting in a very non-geological scenario. The produced realisation has unrealistic combinations of channel amplitude (A) and wavelength (Wl) and also an inconsistent channel width/depth ratio. Figure 24 illustrates that the model obtained with intelligent geological priors tends to have geomorphic parameters that home in closer to the values for the truth case reservoir as a result of HM.
6 Conclusions
This paper demonstrates a workflow to deal with geological uncertainties in a manner that ensures that only geological realistic models are used in the quantification process based on creating high-dimensional representations of the geological prior using machine learning.
The workflow develops a geologically realistic prior definition using OC-SVM, then applies it to the MPS modelling approach using MLP to convert between the parameters of geological measurements and the affinity parameter space of MPS. This resulted in the ability to history-match MPS models using a single training image that is manipulated using the affinity parameter while ensuring that all models produced are realistic.
The workflow has two key benefits: (i) by using OC-SVM, a multi-dimensional set of geological information relevant to the problem can be encapsulated into geologically realistic numerical prior probability ranges, (ii) by using MLP, the geologically realistic SVM prior ranges can be linked to an equivalent realistic range of geostatistical algorithm parameters (such as object modelling and MPS), which are then sampled from in a history-matching workflow. The MLP approach allows one to freely tune more complex geostatistical models of the reservoir, such as multi-point statistical models, to match production data without the need to recreate the training image.
The overall workflow allows the application of the most appropriate modelling method to a reservoir, even when the model parameters do not relate to real-world, measurable properties, and can ensure that only realistic models are used in the uncertainty estimates.
These benefits were demonstrated, through three examples, to further increase the efficiency of history matching by ignoring unrealistic regions of parameter space and improve the accuracy of the quantified uncertainty by ignoring local minima in unrealistic regions of parameter space. The examples demonstrated a reduction in the estimated uncertainty, an improvement in convergence performance (by ignoring unrealistic regions of parameter space) and the ability to work with several modelling approaches that use either real-world (object models) or model space (MPS) parameters.
A subsequent (part 2) paper (Demyanov et al. 2018) demonstrates how to expand this workflow to deal with multiple geological scenarios/interpretations captured with different training images using further machine learning techniques.
References
Abdollahzadeh A, Reynolds A, Christie M, Corne DW, Davies B, Williams GJ (2012) Bayesian optimisation algorithm applied to uncertainty quantification. SPE J 17:865–873
Abreu V, Sullivan M, Pirmez C, Mohrig D (2003) Lateral accretion packages (laps): an important reservoir element in deep water sinuous channels. Mar Pet Geol 20(6):631–648
Baddeley MC, Curtis A, Wood R (2004) An introduction to prior information derived from probabilistic judgements: elicitation of knowledge, cognative bias and herding. In: Wood R, Curtis A (eds) Geological prior information, vol 239, no 1. Geological Society Special publication, London, pp 15–27
Bridge JS, Mackey SD (1993) A theoretical study of fluvial sandstone body dimensions. Blackwell, Oxford
Callec Y, Deville E, Desaubliaux G, Griboulard R, Huyghe P, Mascle A, Mascle G, Noble M, de Carillo CP, Schmitz J (2010) The Orinoco turbidite system: tectonic controls on sea-floor morphology and sedimentation. AAPG Bull 94(6):869–887
Castro SA, Caers J, Mukerji T (2005) The Stanford VI reservoir: 18th annual report. Stanford Centre for Reservoir Forecasting. Stanford University
Chang Y, Stordal AS, Valestrand R (2015) Preserving geological realism of facies estimation on the Brugge field. EAGE Petroleum Geostatistics, Biarritz
Cherpeau N, Caumon G, Caers J, Lévy B (2012) Method for stochastic inverse modeling of fault geometry and connectivity using flow data. Math Geosci 44(2):147–168
Chitale SV (1970) River channel patterns. J Hydraul Div HY1:201–221
Christie M, Eydinov D, Demyanov V, Talbot J, Arnold D, Shelkov V (2013) Use of multi-objective algorithms in history matching of a real field. In: Proceedings of SPE annual technical conference and exhibition, Houston
Christie M, Demyanov V, Erbas D (2006) Uncertainty quantification for porous media flows. J Comput Phys 217:143–158
Christie MA, Glimm J, Grove JW, Higdon DM, Sharp DH, Wood-Schultz MM (2005) Error analysis and simulations of complex phenomena. Los Alamos Sci 29:6–25
Crane RC (1982) A computer model for the architecture of avulsion-controlled alluvial suites, Ph.D thesis. University of Reading
Curtis A, Wood R (2004) Optimal elicitation of probabilistic information from experts. In: Wood R, Curtis A (eds) Geological prior information, vol 239, no 1. Geological Society Special publication, London, pp 127–145
Damuth JE, Flood RD, Kowsmann RO, Belderson RH, Gorini MA (2006) Anatomy and growth pattern of Amazon deep-sea fan as revealed by long-range side-scan sonar (GLORIA) and high-resolution seismic studies. AAPG Bull 72(8):885–911
Demyanov V, Pozdnoukhov A, Kanevski M, Christie M (2008) Geomodelling of a fluvial system with semi-supervised support vector regression. In: Proceedings of International geostatistics congress, Santiago, Chile
Demyanov V, Arnold DP, Rojas T, Christie M (2018) Uncertainty quantification in reservoir prediction: part 2—handling uncertainty in the geological scenario. Math Geol. https://doi.org/10.1007/s11004-018-9755-9
Doyen P (2007) Seismic reservoir characterization: an earth modelling perspective, vol 2. EAGE Publications
Elsheik A, Demyanov V, Tavakoli R, Christie MA, Wheeler MF (2015) Calibration of channelized subsurface flow models using nested sampling and soft probabilities. Adv Water Resour 75:14–30
Evensen G, Hove J, Meisingset HC, Reiso E, Seim KS, Espelid O (2007) Using the EnKF for assisted history matching of a north sea reservoir model. In: Proceedings of SPE reservoir simulation symposium, Houston, Texas
Gibling MR (2006) Width and thickness of fluvial channel bodies and valley fills in the geological record: a literature compilation and classification. J Sediment Res 76:731–770
Hajizadeh Y, Christie MA, Demyanov V (2010) History matching with differential evolution approach; a look at new search strategies. In: Proceedings of SPE EUROPEC/EAGE annual conference and exhibition, 14–17 June, Barcelona, Spain
Hirst JPP (1991) Variations in alluvial architecture across the Oligo-Miocene Huesca Fluvial system, Ebro Basin, Spain, In: Miall AD, Tyler N (eds) The three-dimensional facies architecture of terrigenous clastic sediments and its implications for hydrocarbon discovery and recovery. SEPM Society for Sedimentary Geology, vol 3, pp 111–121
Hu L (2000) Gradual deformation and iterative calibration of Gaussian-related stochastic models. Math Geol 32:87–108
Jessell MW, Ailleres L, Kemp AE (2010) Towards an integrated inversion of geoscientific data: what price of geology? Tectonophysics 490(2):294–306
Jiang R, Stern D, Halsey TC, Manzocchi T (2016) Scenario discovery workflow for robust petroleum reservoir development under uncertainty. Int J Uncertain Quantif 6(6):533–559
Kanevski M, Pozdnoukhov A, Timonin V (2009) Machine learning for spatial environmental data: theory, applications and software. EPFL Press, Lausanne
Kjemperud AV, Schomacker ER, Cross TA (2008) Architecture and stratigraphy of alluvial deposits, Morrison formation (Upper Jurassic), Utah. AAPG Bull 92:1055–1076
Leeder MR (1973) Fluviate fining upward cycles and the magnitude of palaeochannels. Geol Mag 110:265–276
Linde N, Renard P, Mukerji T, Caers J (2015) Geological realism in hydrogeological and geophysical inverse modeling: a review. Adv Water Resour 86:86–101
Melnikova Y, Zunino A, Lange K, Cordua K-S, Mosegaard K (2015) History matching through a smooth formulation of multiple-point statistics. Math Geosci 47(4):397–416
Mohamed L, Christie MA, Demyanov V (2010) Comparison of stochastic sampling algorithms for uncertainty quantification. SPE J 15:31–38
O’Sullivan A, Christie MA (2005) Error models for reducing history match bias. Comput Geosci 9:125–153
Parquer M, Collon P, Caumon G (2017) Reconstruction of channelized systems through a conditioned reverse migration method. Math Geosci 49(8):965–994
Pirmez C, Imran J (2003) Reconstruction of turbidity currents in the Amazon channel. Mar Pet Geol 20(6):823–849
Platt J (1999) Probabilistic outputs for support vector machines and comparison to regularized likelihood methods. MIT Press, Cambridge
Posamentier HW (2003) Depositional elements associated with a basin floor channel-levee system: case study from the Gulf of Mexico. Mar Pet Geol 20(6):677–690
Posamentier HW, Kolla V (2003) Seismic geomorphology and stratigraphy of depositional elements in deep-water settings. J Sediment Res 73(3):367–388
Pyles D, Jennette D, Tomasso M, Beaubouef R, Rossen C (2010) Concepts learned from a 3D outcrop of a sinuous slope channel complex: Beacon channel complex, Brushy Canyon formation, West Texas, USA. J Sediment Res 80(1):67–96
Pyrcz MJ, Deutsch CV (2014) Geostatistical reservoir modeling. Oxford University Press, Oxford, p 400
Remy N, Boucher A, Jianbing W (2009) Applied geostatistics with SGEMS. Cambridge University Press, Cambridge, p 322
Rojas T, Demyanov V, Christie MA, Arnold D (2011) Use of geological prior information in reservoir facies modelling. In: Proceedings of IAMG conference, Salzburg, Austria
Sambridge M (1999) Geophysical inversion with a neighbourhood algorithm-I. Searching a parameter space. Geophys J Int 138(2):479–494
Sambridge M (1999) Geophysical inversion with a neighbourhood algorithm-II. Appraising the ensemble. Geophys J Int 138(2):727–746
Scheidt C, Caers J (2009a) Representing spatial uncertainty using distances and kernels. Math Geosci 41(4):397–419
Scholkopf B, Smola AJ (2002) Learning with kernels: support vector machines, regularization, optimization and beyond. MIT Press, Boston
Scholkopf B, Platt J, Shawe-Taylor J, Smola AJ, Williamson RC (2001) Estimating the support of a high-dimensional distribution. Neural Comput 13:443–1471
Strebelle S (2002) Conditional simulation of complex geological structures using multiple-points statistics. Math Geol 34:1–21
Sun W, Hui MH, Durlofsky LJ (2017) Production forecasting and uncertainty quantification for naturally fractured reservoirs using a new data-space inversion procedure. Comput Geosci 21(5):1443–1458
Vapnik VN (1998) Statistical learning theory. Wiley, New York
Williams GP (1986) River meander channel size. J Hydrol 88:147–164
Wonham JP, Jayr SP, Mougamba R, Chuilon P (2000) 3D sedimentary evolution of a canyon fill (lower miocene age) from the Mandrove Formation, offshore Gabon. Mar Pet Geol 17:175–197
Wood LJ, Mize-Spansky KL (2009) Quantitative seismic geomorphology of a quaternary leveed-channel system, offshore eastern Trinidad and Tobago, northeastern South America. AAPG Bull 93(1):101–125
Wood R, Curtis A (2004) Geological prior information and its applications to geoscientific problems. In: Wood R, Curtis A (eds) Geological prior information, vol 239, no 1. Geological Society Special Publication, London, pp 1–14
Acknowledgements
The work was funded by the industrial sponsors of the Heriot-Watt Uncertainty Project (phase IV). The authors thank Stanford University for providing Stanford VI case study data and SGeMS geostatistical modelling software (Remy et al. 2009). The authors thank Prof. M. Kanevski of University of Lausanne for providing advice and ML Office software for MLP/SVM/SVR implementation. Authors acknowledge use of the Eclipse reservoir flow simulator provided by Schlumberger, tNavigator flow simulator provided by Rock Flow Dynamics, Raven history-matching software from Epistemy Ltd., Roxar RMS modelling suite provided by Emmerson and R package e1071 for OC-SVM.
Author information
Authors and Affiliations
Corresponding author
Appendix
Appendix
Nomenclature
-
HM
History matching
-
MCMC
Markov chain Monte Carlo
-
ML
Machine learning
-
MLP
Multi-layer perceptron
-
MOO
Multi-objective optimisation
-
MPS
Multi-point statistics
-
NAB
Neighbourhood approximation algorithm—Bayesian
-
OC-SVM
One-class support vector machine
-
PSO
Particle swarm optimisation
-
RKHS
Reproducing kernel Hilbert space
-
SGS
Sequential Gaussian simulation
-
SIS
Sequential indicator simulation
-
SVM
Support vector machine
-
SVR
Support vector regression
-
TGS
Truncated Gaussian simulation
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Arnold, D., Demyanov, V., Rojas, T. et al. Uncertainty Quantification in Reservoir Prediction: Part 1—Model Realism in History Matching Using Geological Prior Definitions. Math Geosci 51, 209–240 (2019). https://doi.org/10.1007/s11004-018-9774-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11004-018-9774-6