
Abstract
In curriculum learning the order of concepts is determined by the teacher but not the examples for each concept, while in machine teaching it is the examples that are chosen by the teacher to minimise the learning effort, though the concepts are taught in isolation. Curriculum teaching is the natural combination of both, where both concept order and the set of examples can be chosen to minimise the size of the whole teaching session. Yet, this simultaneous minimisation of teaching sets and concept order is computationally challenging, facing issues such as the “interposition” phenomenon: previous knowledge may be counter-productive. We build on a machine-teaching framework based on simplicity priors that can achieve short teaching sizes for large classes of languages. Given a set of concepts, we identify an inequality relating the sizes of example sets and concept descriptions. This leverages the definition of admissible heuristics for A* search to spot the optimal curricula by avoiding interposition, being able to find the shortest teaching sessions in a more efficient way than an exhaustive search and with the guarantees we do not have with a greedy algorithm. We illustrate these theoretical findings through case studies in a drawing domain, polygonal strokes on a grid described by a simple language implementing compositionality and recursion.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Humans are able to learn a new concept from very little information. However, a large majority of machine learning algorithms needs a substantial amount of data to perform similarly. In particular, successful models such as deep learning are among the most data-hungry (Marcus, 2018). Additionally, humans are able to identify more complex object categories than machines by composing simpler objects, but the best deep learning techniques usually struggle in compositional settings (Shrestha & Mahmood, 2019). How is it possible that humans perform such a rich learning from so scarce information? (Lake et al., 2015)
In essence, education in humans is organised through curricula, starting with simple concepts and gradually increasing the complexity. Bengio et al. (2009) initiated the formalisation of curriculum learning (CL) in the context of machine learning. It inspired new applications in machine learning to an extensive variety of tasks (Tang et al., 2018; Wang et al., 2018, 2019). The empirical results showed advantages of CL over random training. Nevertheless, CL is still limited by two issues: (1) the need to find a way of ordering the examples according to their difficulty and (2) the correct order of the concepts involved (Soviany et al., 2022).
Machine teaching (MT) is the area of AI that looks for optimal examples that a teacher should utilise to make a student identify a concept (Zhu et al., 2018). It is of extreme importance in applications such as digital assistants, where we would like to teach them new concepts or procedures with limited data, in the same way humans teach or communicate with other humans (Degen et al., 2020).
MT is often understood as an inverse problem to machine learning (Zhu, 2015). For one single concept machine teaching works as follows: the teacher generates a training—or witness—set of examples, either positive or negative, from which the learner identifies a concept. For instance, consider a teacher who wants a student to acquire the concept “red ball”; the teacher knows the student’s learning algorithm and may provide it with the following witness set: a red tennis ball picture labelled as positive and a blue one labelled as negative.
For humans and many other animals it is assumed that once a concept has been captured it is possible to reuse it to learn another one. Previous work (Zhou & Bilmes, 2018) has tried to optimise the teaching of one concept, e.g., through a partial minimax approach. However, not only do we want to consider the sequence of training sets for a concept, but also the best order to teach a given set of concepts. MT for several concepts was restricted to sequences where every acquired concept becomes background knowledge (Clayton & Abbass, 2019; Wang et al., 2021). Pentina et al. (2015), who had studied CL from an experimental approach, proposed that future work should identify a valid theoretical framework that would allow for a more generic distribution of tasks and the realisation of the advantages of forgetting or using independent sessions. This is in line with neurological studies such as Richards and Frankland (2017) and recent animal cognition research (Dong et al., 2016; Epp et al., 2016; Shuai et al., 2010), showing “evidence that forgetting is necessary for flexible behavior in dynamic environments”.
The first full theoretical framework of CL in MT was introduced in Garcia-Piqueras and Hernández-Orallo (2021). Using simplicity priors it identifies the optimal tree-distribution of concepts by means of the \(\mathbb {I}\)-search algorithm (Garcia-Piqueras & Hernández-Orallo, 2021). The framework defines an instructional curriculum as the set of alternative partial sequences, such as the upper and lower branch of Fig. 1.

Instructional curriculum for a set of concepts, where concept − is taught before \(\angle \) and these two before \(\bigtriangleup \), in one session, and concept \(\wr \) is taught in an independent session or lesson
The order between the branches is irrelevant, but the order of the concepts in each branch is crucial. The MT framework implementing CL proposed in Garcia-Piqueras and Hernández-Orallo (2021) not only meets the specifications in Pentina et al. (2015), but is also consistent with Richards and Frankland (2017) by handling a new phenomenon called interposition: previous knowledge is not always useful. This issue increases the difficulty of finding optimal curricula.
Under general conditions, \(\mathbb {I}\)-search is able to overcome interposition, but it is computationally intractable in general. The computational cost is one of the reasons why CL is not sufficiently used in AI (Forestier et al., 2022), despite existing solutions with search algorithms like \(A^*\) (Pearl, 1984). Heuristic estimates enhance those procedures by making less node expansion in the graph search, which drastically reduces computational costs (Rios & Chaimowicz, 2010). To our knowledge, there are no such estimators for CL.
Here we introduce new theoretical results, such as Inequality (2): a relation between the sizes of the examples and concept descriptions with and without background knowledge. Such inequality is key to define a new family of heuristics to effectively identify minimal curricula. The heuristics are elegantly defined using a “ratio of similarity” between the sizes of the sets of examples with and without previous knowledge. Such ratio is the quotient of the lengths of the descriptions of a concept with and without background knowledge.
Theoretical results are illustrated on a drawing domain, where curricula can exploit that some drawings built on substructures previously learnt (e.g., a flag is depicted as a rectangle and a straight pole). Experiments show the effect of interposition in CL and how it is overcome through our novel approach. This contribution, based on compositional simplicity priors and exemplified using a drawing domain, follows the direction of other important efforts in compositional AI (Lake et al., 2015; Wu et al., 2016; Tenenbaum et al., 2000; Wong et al., 2021).
2 The machine teaching framework
In this section we give more details about the interaction between the teacher and the learner as distinct entities. The teacher-learner protocol (Telle et al., 2019) is based on the following statements. Let \(\Sigma ^*\) be the set of all possible strings formed from combinations of symbols of an alphabet \(\Sigma \). We label such strings as positive or negative. An example is an input–output pair where the input is a string of \(\Sigma ^*\) and the output is \(+\) or − (outputs might be strings in the most general case of the framework).
Definition 1
The example (or instance) space is defined as the infinite set
There is a total order \(\lessdot \) in X and there is a metric \(\delta \) that gives the size of any set of examples.
Definition 2
We define the infinite concept class \(C=2^X\) consisting of concepts that are a subset of X.
The objective is that for any concept \(c\in C\) the teacher must find a small witness set of examples from which the learner is able to uniquely identify the concept. The learner tries to describe concepts through a language L.
Definition 3
A program p in language L satisfies the example \(\langle \texttt{i}, \texttt{o}\rangle \), denoted by \(p(\texttt{i})=\texttt{o}\), when p outputs \(\texttt{o}\) on input \(\texttt{i}\)Footnote 1 . We say that a program p is compatible with the set of examples \(S \subset X\), if p satisfies every example of S and we denote \(p \vDash S\).
Two programs are equivalent if they compute the same function mapping strings of \(\Sigma ^*\) to \(\{+,-\}\). There is a total order \(\prec \) defined over the programs in L. For any program p in L there is a metric \(\ell \) that calculates its length.
We say that c is an L-concept if it is a total or partial function \(c:\Sigma ^* \!\rightarrow \! \{+,-\}\) computed by at least a program in L. Let \(C_L\) be the set of concepts that are described by L. Given \(c \in C_L\), we denote \([c]_L\) as the equivalence class of programs in L that compute the function defined by c.
Definition 4
We define the first program, in order \(\prec \), returned by the learner \(\Phi \) for the example set S as
We say that w is a witness set of concept \(c \in C_L\) for learner \(\Phi \), if w is a finite example set such that \(p = {\Phi _{\ell }} (w)\) and \(p \in [c]_L\).
The teacher \(\Omega \) has a concept \(c \in C_L\) in mind and knows how the learner works. With this information, the teacher provides the learner with the witness set w.
Definition 5
We define the simplest witness set that allows the learner to identify a concept c as
We define the teaching size of a concept c as \({TS_{\ell }} (c) = \delta ({\Omega _{\ell }} (c))\).
We exemplify our discourse with a drawing domain: polygonal strokes on a grid. The details about the definition of a language L and a example space X are given in Section A. In short, we deal with an example space generated by commands North, South, East and West, for the four possible axis-parallel directions in a plane. In Fig. 2, starting at the black dot, the frieze is described by \(\mathsf{ENESENES\ldots }\) Examples are labelled positive or negative, e.g., \(\textsf{EN}^+\) or \(\textsf{E}^-\).

Polygonal on a grid
The learner is able to capture concepts using a language L with the following instructions: \(\textsf{U}\)p, \(\textsf{D}\)own, \(\textsf{R}\)ight and \(\textsf{L}\)eft, \(\varvec{)}\) and \(\varvec{@}\). The symbol \(\varvec{)}\) refers to a non-deterministic choice between going to the beginning of the program or continue with the next instruction. For instance, the concept a defined by the frieze in Fig. 2, could be expressed in L as \(\mathsf {RURD)}\). The instruction \(\varvec{@}\) stands for library calls to implement background knowledge; for instance, \(\textsf{RU}\varvec{@}\) is equivalent to \(\mathsf {RURD\varvec{)}}\) when the library points to subroutine \(\mathsf {RD\varvec{)}}\).
For example, the teacher receives or thinks about such concept a. The teacher selects the witness set, \(w=\{\textsf{ ENESEN}^+\}\) and provides the learner with it. At that point, the learner outputs the first program that satisfies w, i.e., \({\Phi _{\ell }} (w)=\mathsf {RURD\varvec{)}} \in [a]_L\) (see Fig. 3). We usually drop the index \(\ell \) if it is clear from the context. The teaching size of concept a is the size of the witness set, i.e., \(TS(a)=\delta (\{\textsf{ ENESEN}^+\})=21\) (3 bits per symbol as it is stated in Section A).

The teacher-learner protocol for a given concept a
As we have seen, the teacher-learner protocol makes it possible to define the teaching size of a concept. The MT framework was adapted to implement background knowledge through the notion of conditional teaching size (Garcia-Piqueras & Hernández-Orallo, 2021). We discuss this approach in the following section, along with a phenomenon called interposition.
3 Conditional teaching size and interposition
Let a library be a possibly empty ordered set of programs. We denote \(B=\langle p_1, \ldots , p_k\rangle \), where each \(p_i\) identifies concept \(c_i\) and \(|B |\) denotes the number of primitives k. We use \(|B |=0\) to indicate that B is empty. A program p, identified by the learner, might be included in a library B as a primitive for later use.
In order to avoid old references when the library is expanded, we replace every instruction \(\varvec{@}\) of a program identified by the learner by the corresponding primitive. For example, if \(B=\langle \mathsf {D\varvec{)}} \rangle \) and the learner identifies \(\textsf{RU}\varvec{@}\), then the library is extended as \(B=\langle \mathsf {D\varvec{)}}, \mathsf {RUD\varvec{)}} \rangle \).
We define the conditional teaching size of concept c, using library B (background knowledge), as the size in bits of the first witness set w such that \({\Phi _{\ell }} (w \vert B)=p \in [c]_L\). Let us see an example.
Example 1
Let us consider \(Q=\{a, b, c\}\), where programs \(\textsf{RURD}\varvec{)} \in [a]_L\), \(\textsf{RRURD}\varvec{)} \in [b]_L\) and \(\textsf{R}\varvec{)}\textsf{URD}\varvec{)} \in [c]_L\) (polygonal chains as shown in the 2nd, 3rd and 4th rows of Fig. 6, respectively in Section A). These programs are placed first in their equivalent classes regarding the total order \(\prec \).
Graphical instances of a and b are, for example, the polygonal chains of the 2nd and 3rd rows of Fig. 6, respectively. We get \(TS(b \vert a)=12\) as the teaching size, in bits, of concept b using a as prior knowledge, i.e., the learner employs library \(B=\langle \textsf{RURD}\varvec{)} \rangle \) as background knowledge. In our particular case, the learner outputs \(\Phi (\{\textsf{RRN}^+\} \vert B)=\textsf{R}\varvec{@}\) when using library \(B=\langle \textsf{RURD}\varvec{)} \rangle \).
In such case, there is a reduction of the teaching size of concept b using a as prior knowledge: \(TS(b \vert a)=12<24=TS(b)\) (see Table 1). However, it may happen that background knowledge increases the teaching size of an object. This phenomenon is what we call interposition: some prior knowledge causes interposition to a given concept.
For instance, let us consider \(\textsf{R}\varvec{)}\textsf{URD}\varvec{)} \in [c]_L\), with graphical instances such as the chain of the fourth row of Fig. 6. Using library \(B=\langle \textsf{R}\varvec{)}\textsf{URD}\varvec{)}\rangle \), we get that \(\Phi (\{ \mathsf {ENESEN^+}, \mathsf {EE^-}\} \vert B)=\textsf{RURD}\varvec{)}\) (see Table 1), so that:
In other words, concept c causes interposition to concept a. This phenomenon increases the difficulty of finding the curriculum with minimum overall teaching size for a given set of concepts. We must take this issue into account in the following sections.
4 An optimisation problem: minimal curricula
In this section, we will deal with the following problem: if we want to teach a given set of concepts, which curriculum minimises the overall teaching size?
In our approach, given a set of concepts, a curriculum is a set of disjoint sequences covering all the concepts. Our view of curricula is more general than just simple sequences. Our choice is motivated by the interposition phenomenon seen in the previous section, since some concepts may increase the teaching size of some other concepts coming after those previous ones. If some branches are disconnected, a curriculum should not specify which branch comes first, since they are considered independent lessons. We will show below how the algorithms that find optimal curricula manage this flexibility.
For instance, Fig. 4 shows how a set of concepts \(\{x, y, r, s, t, w, z\}\) is partitioned into three branches: \(\{x \!\rightarrow \! y \!\rightarrow \! r \!\rightarrow \! s,\, t \!\rightarrow \! w,\, z\}\), where \(x \!\rightarrow \! y\) means that y must come after x in the curriculum. For each branch, there is no background knowledge or library at the beginning. The library grows as the teacher-learner protocol progresses in each branch.

Curriculum \(\{x \!\rightarrow \! y \!\rightarrow \! r \!\rightarrow \! s, t \!\rightarrow \! w, z\}\) for a set of concepts \(\{x, y, r, s, t, w, z\}\)
Let \(Q=\{c_i\}_{i=1}^n\) be a set of labelled concepts, a curriculum \(\pi = \{ \sigma _1, \cdots ,\sigma _m \}\) is a full partition of Q, where each of the m subsets \(\sigma _j \subset Q\) has a total order, being a sequence.
Definition 6
Let Q be a set of concepts. Let \(\pi = \{ \sigma _1, \sigma _2, \cdots , \sigma _m \}\) a curriculum in Q. We define the teaching size of each sequence \(\sigma = \{ c_1, c_2,..., c_k \}\) as \({TS_{\ell }} (\sigma ) = {TS_{\ell }} (c_1) + \sum _{j=2}^{k} {TS_{\ell }} (c_j \vert c_1, \ldots , c_{j-1})\). The overall teaching size of \(\pi \) is just \({TS_{\ell }} (\pi ) = \sum _{i=1}^{m} {TS_{\ell }} (\sigma _i)\).
We denote \(\overline{Q}\) as the set of all the possible curricula with Q. The order in which the subsets are chosen does not matter, but the order each subset is threaded does. For example, the curriculum \(\pi = \{x \!\rightarrow \! y \!\rightarrow \! r \!\rightarrow \! s, t \!\rightarrow \! w, z\}\) has many paths, such as xyrstwz or zxyrstw. But note that \(\pi \) is different from \(\pi '=\{y \!\rightarrow \! x \!\rightarrow \! r \!\rightarrow \! s, w \!\rightarrow \! t, z \}\).
The number of possible curricula given a number of concepts grows fast and this will motivate the heuristic we will introduce later on. In particular, the number of distinct curricula is given by the following calculation:
Proposition 1
For any Q with n concepts, the number of different curricula is
Proof
For any set \(Q=\{c_1, \dots , c_n\}\) of n concepts, there are n! permutations of n labelled elements. For each permutation, there are \(n-1\) possibilities of starting a branch. Consequently, we can choose k positions out of \(n-1\). This implies that there will be \(k+1\) subsets which can change its order, i.e., \((k+1)!\) different permutations of the subsets express the same case.
Therefore, there are \(n! \cdot \left( {\begin{array}{c}n-1\\ k\end{array}}\right) \cdot {{1}\over {(k+1)!}}\) cases. Since \(k \in \{0, 1, \ldots , n-1\}\), Eq. (1) gives the total number of distinct curricula.
\(\square \)
Once that we know how many different curricula there are, we can try to identify which ones have lowest overall teaching size, denoted by \(TS^*_Q\). A curriculum \(\pi \) is hence minimal if \(TS(\pi ) = TS^*_Q \le TS(\pi ')\), \(\forall \pi ' \in \overline{Q}\).
Regarding Example 1, there are thirteen distinct curricula in \(\overline{Q}\) according to Proposition 1. Using Table 1, we can build Table 2, showing the overall teaching size for each curriculum in \(\overline{Q}\).

Concerning all the teaching sizes taken as a whole and the descriptions measured in bits, Fig. 5 compares some relevant curricula from Table 2.
In terms of overall teaching size, there is a tie between \(\pi _1\) and \(\pi _7\), both being minimal (Fig. 5). However, we observe that there are big differences when considering overall teaching size for other curricula. For example, if we choose option \(\pi _4\) instead of \(\pi _1\) (or \(\pi _7\)), we get \(\approx 63.3\%\) extra cost, even though there are just three concepts.
Further examples with more concepts and slightly different situations can be found in Section B.
From these examples, we ask ourselves whether it is necessary to calculate all the teaching sizes, as we have already done in Table 1 (or Tables 9 and 11 of Section B), to find minimal curricula. The answer is negative, as we will see, but how can such a reduction of calculations be achieved? Moreover, is there a less costly procedure that could provide a close-to-optimal solution? We will deal with these issues in the following section.
5 Sufficient conditions to infer conditional teaching size
We first ask the question of whether it is possible to approximate the conditional teaching size of a concept c if the learner is given a new primitive for the library. Namely, given that \(\Phi (w_c \vert B)=p_c \in [c]_L\), could it be possible to approximate \(TS(c \vert \langle B, p\rangle )\), where p is a new primitive? It is also very important not only to identify a good approximation, but not to overestimate the real conditional teaching size. We will employ this conservative property (in Sect. 6) to define an algorithm that outputs minimal curricula.
Firstly, we give a sufficient condition, valid for any kind of language, either universal or not, that provides an underestimation of conditional teaching size. Secondly, we identify when such sufficient condition applies for our particular drawing domain.
The following corollary provides that sufficient condition. It is proved in Section D as a consequence of Lemma 4.
Corollary 2
Let \(w_c\), \(w'_c \subset X\) such that \(p_c={\Phi _{\ell }} (w_c \vert B)\) and \(p'_c={\Phi _{\ell }} (w'_c \vert B')\), where \(B'\) is a library that extends, with a new primitive, the library B. Let us suppose that the following conditions are met:
-
I
\({\textstyle \exists k_1, k_2 \in \mathbb {N}}\) such that \(\delta (w_c)=\ell (p_c)+k_1\) and \(\delta (w'_c)=\ell (p'_c)+k_2\)
-
II
\(\delta (w_c)-\delta (w'_c) \le \ell (p_c) - \ell (p'_c)\)
-
III
\(\ell (p'_c) \le \ell (p_c)\)
Then,
It is important to note that Inequality (2) does not overstimate \(\delta (w'_c)\); this fact will be key in Sect. 6 to define an algorithm that ouputs optimal curricula.
With respect to our drawing domain, Condition I (Corollary 2) is always true, since the language L has equivalent instructions for every command in \(\Sigma \). Also, the concepts of the drawing domain meet Condition II (Corollary 2), as a result of Theorem 3 (Section C), when \(w_c\) has no negative examples. Otherwise, let us suppose that \(w_c=\{ e^+, (e_i^-)\}\), such that \(\exists p_i\) in \(L_B\) with \(p_i {\vDash } e_i^+\) and \(p_i \notin [c]_L\). In general, we could not assure that adding a new primitive to \(B'\) would make \(\Phi (w'_c \vert B') \prec p_i\), \(\forall i\). If so, it would be unnecessary to include negative examples in \(w'_c\), and Condition II would not be met. However, if concepts can be taught initially in language L (\(|B |=0\)) without negative examples, then we can always estimate successively the teaching size of such concepts. In other words, we will consider \(\frac{\ell (p'_c)}{\ell (p_c)} \cdot TS(c) \le TS(c \vert B')\) (instead of \(TS(c \vert B)\) on the left side of the inequality).
Finally, we assumed in Condition III (Corollary 2) that the length in bits of a library call, \(\varvec{@}\textsf{i}\), is the same as the new call \(\varvec{@}\mathsf{i'}\). But there exist cases such as \(\Phi (\{\mathsf{ENESEE^+}\} \vert \langle \textsf{RD}\varvec{)}\rangle )=\textsf{R}\varvec{)}\textsf{U}\varvec{@} \in [c]_L\) and \(\Phi (\{\mathsf{ENESEE^+}\} \vert \langle \textsf{RD}\varvec{)}, \textsf{RURD}\varvec{)}\rangle )=\textsf{R}\varvec{)}\textsf{U}\varvec{@}0 \in [c]_L\). In such cases, \(\frac{\ell (p^*_{c \vert B'})}{\ell (p^*_{c \vert B})}>1\) and Inequality (2) is not ensured, where \(p^*_{c \vert B}\) is the first expression in language L enhanced with library B, using order \(\prec \), that identifies concept cFootnote 2 (we denote \(\ell ({p^*_{c \vert B}}) = \ell (p^*_c)\) when \( |B |=0\)).
However, in those situations (\(\ell (p^*_{c \vert B'}) > \ell (p^*_{c \vert B})\)), we consider \(\delta (w_c) = \delta (w'_c)\), since \(\delta (w'_c)\) cannot reduce \(\delta (w_c)\).
These considerations lead us to the definition of a valid family of heuristics that always output optimal curricula without calculating all the teaching sizes.
6 Heuristic search for optimal curricula
In our case, the search space is given by all the curricula, \(\overline{Q}\), and we need to find at least one \(\pi \) such that \(TS(\pi ) = TS^*_Q\). Each internal node in the search graph is a partial curriculum (not covering all concepts), while each leaf (node with no children at the bottom level) is a full curriculum belonging to \(\overline{Q}\), and an edge means adding a new concept to a branch of the curriculum (remember a curriculum is actually a tree). For instance, for two concepts a and b, the root \(n_1\) would be the empty curriculum. The children at level 2 would be \(n_{1,1}=\{a\}\) and \(n_{1,2}=\{b\}\). Finally, at level 3, the children of \(n_{1,1}\) would be \(n_{1,1,1}=\{a \!\rightarrow \! b\}\), \(n_{1,1,2}=\{a,b\}\) and the children of \(n_{1,2}\) would be \(n_{1,2,1}=\{b \!\rightarrow \! a\}\), \(n_{1,2,2}=\{b,a\}\), which means that we have two nodes that would be equal, and we see that the search space is a directed acyclic graph.
Let us start with a simple graph traversal algorithm and then evolve it into more sophisticated procedures. The standard \(A^*\) search is a baseline graph traversal algorithm Russell and Norvig (2020). \(A^*\) is based on a node evaluation function
where g(n) is the overall cost of getting to node n from the beginning and h(n) is the heuristic function, i.e., the estimated cost of getting to a target node (leaf node) from node n. \(A^*\) search guarantees an optimal solution when the heuristic function meets the following conditions:
-
1.
\(h(n) \ge 0\), for every node n.
-
2.
\(h(n)=0\), if n is a target node.
-
3.
h(n) is admissible, i.e., h(n) never overestimates.
A popular variant of \(A^*\) is Weighted \(A_{\alpha }^*\) (\(\textrm{WA}^*\)), another graph traversal algorithm that guides the search with \(h'(n)=\alpha \cdot h(n)\), where \(\alpha \) is a parameter. Remember that if h(n) is admissible then \(\textrm{WA}^*\) guarantees the optimal solution when \(0 < \alpha \le 1\). Sometimes, it is useful to employ \(\textrm{WA}^*\), because it often gives a close-to-optimal solution with less node expansions (Hansen & Zhou, 2007).
Let us look for admissible heuristics not only because they guarantee success for algorithm \(A^*\), but also because they help to assess other close-to-optimal solutions (Hansen & Zhou, 2007).
Definition 7
(Node cost) Let Q be a set of concepts and n be a node of the search space \(\overline{Q}\). We define the teaching size cost of node n, which we denote by g(n), as the overall teaching size of the curriculum, either partial or complete, that represents node n.
Note that any path of the search graph uniquely generates a library B as background knowledge. For instance, the path \((a \!\rightarrow \! b \!\rightarrow \! c)\) generates library \(B=\langle p^*_a, p^*_{b \vert \langle p_a \rangle } \rangle \) when reaching concept c, while the path \((a \!\rightarrow \! b, c)\) generates no prior knowledge, i.e., \(|B |= 0\), when getting to concept c.
We now proceed with the theoretical results that will allow us to define an admissible heuristic. But, firstly, we need to define the cost of crossing an edge of the search graph.
Definition 8
(Estimated edge cost) Let Q be a set of concepts and n be a node of the search space \(\overline{Q}\); the last edge of node n is \(\textsf{e}\). Let concepts a and b be the vertices of edge \(\textsf{e}\), either \(\textsf{e}=[a \!\rightarrow \! b]\) or \(\textsf{e} = [a, b]\). Let B be the library employed to reach concept b through the edge \(\textsf{e}\), where \(0 \le |B |\). We define the estimated cost of crossing \(\textsf{e}\) as
If \(|B |=0\) then \(\ell ({p^*_{b \vert B}})=\ell (p^*_b)\) and \(h_B(\textsf{e})=TS(b)\).
We note that it would also be possible to define the estimated edge cost using the new primitive employed between one node and its child. That is to say, if B is the library employed to reach a, and \(B'\) is the library used to get to b, then we could define
Note that \(h_B(\textsf{e}) \le h_{B' {\setminus } B}(\textsf{e}), \forall \textsf{e}\). Consequently, \(h_B(\textsf{e})\) is less dominant than \(h_{B' \setminus B}(\textsf{e})\). Accordingly, if the former reduces the computational cost to identify optimal curricula, the latter will perform even better.
We now extend Definition 8 to a path of the search graph.
Definition 9
Let n, m be nodes of the search space \(\overline{Q}\), where m is a child of n that might be several levels after n. Let \(\{\textsf{e}_i\}\) be a path from node n to node m; as a special notation case we use \(\{\textsf{e}_i\}=\{\emptyset \}\) when there is no path between n and m throughout the search space. Let \(B_i\), with \(0 \le |B_i |, \forall i\), be the library employed to cross the edge \(\textsf{e}_i\). We define the estimated cost of getting from node n to node m as
We now employ Definition 9 to define the estimated cost of a node.
Definition 10
(Estimated cost of node n) Let n be a node of \(\overline{Q}\), we define the estimated cost of node n as
The leaf nodes considered in Definition 10 are any leaf node of the search graph, not only the ones that are descendants of a given node n. The following Examples 2 and 3 illustrate how to calculate estimated costs in particular situations.
Example 2
Let a and b be the concepts of Example 1; where \(p^*_a=\textsf{RURD}\varvec{)}\) and \(p^*_b=\textsf{RRURD}\varvec{)}\). We consider the node \(\{a\}\) in the search space whose leaf nodes are \(\{a, b\}\), \(\{b \!\rightarrow \! a\}\) and \(\{a \!\rightarrow \! b\}\). We want to calculate \(\mathcal {H}(\{a\})\); since we are already in node \(\{a\}\) the calculations are
Therefore, \(\mathcal {H}(\{a\})= min \{ 24, \infty , 8\} = 8\).
Example 3
Let a, b and c be the concepts of Example 1, where \(p^*_c= \textsf{R}\varvec{)}\textsf{URD}\varvec{)}\) . The leaf nodes with bounded estimation cost from node \(\{a\}\) are \(\{a, b, c\}\), \(\{a \!\rightarrow \! b, c\}\), \(\{a \!\rightarrow \! c, b\}\), \(\{a \!\rightarrow \! b \!\rightarrow \! c\}\) and \(\{a \!\rightarrow \! c \!\rightarrow \! b\}\). For instance, the estimated cost of node \(\{ a\!\rightarrow \! b, c\}\) from node \(\{a\}\) is
Similarly, \(H_{\{a\}}(\{a \!\rightarrow \! c, b\})= h_{\langle p^*_a \rangle }([a \!\rightarrow \! c]) + h_{\emptyset }([c,b])= \frac{\ell (p^*_{c \vert \langle p^*_a\rangle })}{\ell (p^*_c)} \cdot TS(c)+TS(b) = 1 \cdot 24 + 24 = 48 \),
Therefore, \(\mathcal {H}(\{a\})=min\{\infty , 69, 48, 32, 33.\dot{3}\}=32\).
The heuristic of Definition 10 never overstimates the teaching size of a node if conditions expressed in Theorem 3 apply. As a result, \(A^*\) will output minimal curricula if we define the heuristic \(h(n)=\mathcal {H}(n)\). Let us show some experiments.
7 Empirical results
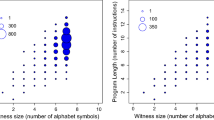
We experimented with three sets of concepts: \(Q=\{a,b,c\}\) (Example 1 in Sect. 3), \(Q'=\{a',b',c\}\) and \(Q''=\{a,b,c,d\}\) (Examples 4 and 5, respectively, in Section B). We studied all the possible different curricula for each set of concepts. Thus, we had to calculate all the teaching sizes of Tables 1, 9 and 11. Calculations took a long time even that we utilised a HPCx clusterFootnote 3. It was a server shared with other users, but there were reserved three cores for every teaching size calculation. Namely, it took approximately nine days to compute \(TS(c \vert a)\) (Table 1) and when the library had more primitives then the calculations increased explosively. For instance, it took more than two months to calculate \(TS(c \vert a, b, d)\) (Table 11).
As we mentioned before, the admissible heuristic \(h(n)=\mathcal {H}(n)\) is valid for every set of concepts Q of our drawing domain, when each concept \(c \in Q\) can be taught in L (\(|B |=0\)) without negative examples. We implemented the \(A^*\) search using such heuristic and applied it to the examples.
In Example 1 the algorithm finds a minimal curriculum \(\pi _7\) in 4 steps, through 8 effective calculations of teaching size against the overall 15 edges. Regarding Example 4, \(A^*\) finds the minimal curriculum in 4 steps, effectively calculating 7 teaching sizes against 15 overall.
Considering Example 5 (Section B), there are two curricula that maximise the teaching size with, approximately, 66% more effort than the optimal. The \(A^*\) search showed \(\pi ^*=\{d \!\rightarrow \! a \!\rightarrow \! b \!\rightarrow \! c\}\) as minimal curriculum in 6 steps, through 13 teaching size calculations against 64 (20% teaching size calculations). Experiments show that there is only one optimal curriculum (\(TS(\pi ^*)=63)\), and it coincides with the one that identifies the \(A^*\) search.
Tables 3, 4 and 5 summarise the experimental results obtained for Examples 1, 4 and 5, respectively, using the following distinct algorithms:
-
Dijkstra’s algorithm (D) Dijkstra (1959). It always identifies an optimal curriculum, since teaching sizes are positive Barbehenn (1998).
-
Dijkstra’s modified algorithm (\(D'\)): it stops when it goes through all the concepts. It does not necessarily get an optimal curriculum, but the computational cost is lower than Dijkstra’s algorithm in terms of teaching size calculations.
-
Greedy algorithm (G): from any given state, it always chooses the bifurcation that involves the least teaching size. In general, it does not identify an optimal curriculum.
-
\(A^*\) search algorithm Hart et al. (1968). The heuristic given in Definition 10, \(\mathcal {H}\), guarantees an optimal curriculum.
-
\(A^*_{\alpha }\) search, i.e., \(\textrm{WA}^*\) algorithm with parameter \(\alpha \): since the heuristic \(\mathcal {H}(n)\) is admissible, it will identify optimal solutions when \(0 \le \alpha \le 1\)Footnote 4.
As we can see in Tables 3, 4 and 5, there are big differences in terms of computational costs when using procedures ensuring optimal teaching curricula as an output. For instance, in Example 1, the computational cost of D performs an extra \(40\%\) with regard to \(A^*_{\alpha =1}\) (\(33.3\%\) when \(\alpha =0.8\)); in Example 4 the comparative between D and \(A^*_{\alpha =1}\) shows a \(46.7\%\) extra cost for D (\(40\%\) when \(\alpha =0.8\)). Furthermore, when we increase the number of concepts involved, as in Example 5, \(A^*_{\alpha =1}\) makes \(61\%\) less computing than D. It is reasonable to think that the tendency might double the computational reduction of \(A^*\) with respect to \(A^*\) when we add a new concept.
It is true that the greedy algorithm G identifies an optimal curriculum in all the Examples (1, 4 and 5), with even less computational effort. However, such procedure is risky, since an optimality is not guaranteed then and the difference in TS-calculations % is \(13.3\%\) in Example 1, \(6.6\%\) in Example 4 and \(7.8\%\) in Example 5, which is not so high with respect to the option ensuring optimal teaching curricula \(A^*_{\alpha =1}\).
8 Discussion
In this paper, we provided sufficient conditions to define a procedure that effectively identifies optimal curricula. This is used in an \(A^*\) search enhanced by the heuristic given in Definition 10, for a given set of concepts.
Inequality (2) can be applied to similar machine-teaching settings using different languages L, either universal or not. It is sufficient to consider a similar machine-teaching scenario and a set of concepts that meet the conditions.
Thus, we may introduce new instructions such as ‘\(\varvec{\vert }\)’ (logical OR operator), and even discard instructions like ‘\(\varvec{)}\)’. In particular, the previous results, dedicated to obtaining a heuristic, can be applied to any language \(L'\) that meets these statements:
-
(i)
\(L'\) should contain equivalent instructions for every command of \(\Sigma \).
-
(ii)
The size in bits of the equivalent instructions in \(L'\) should be less or equal than their counterpart commands in \(\Sigma \).
-
(iii)
There is an instruction, similar to \(\varvec{@}\), that is able to retrieve primitives in language \(L'\) and is the last instruction considering the lexicographical order.
We have shown that it is possible to apply a heuristic search to those MT scenarios that satisfy the above conditions (i), (ii) and (iii), having the following properties:
-
1.
For all the cases studies shown, it provides a reduction of the computational effort involved.
-
2.
The identification of optimal curricula is guaranteed.
Our approach is defined for compositional languages of discrete character and, correspondingly, a discrete optimisation process over a discrete space. As a result, it is not straightforward to adapt the setting to continuous representations, including neural networks. However, the general framework may adapt to a language L that might be based on continuous principles: instructions in L might be given different weights, so that the total order \(\prec \) might be defined through a distribution of probabilities. However, our MT framework is more indicated in situations where we want to understand –and explain– how each concept builds on previous concepts compositionally. For instance, given an observation, what is the best explanation for that information? In fact, programs in the language L of our particular 2D drawing domain (Section A) can be described in terms of automata, which have also been utilised recently in AI to spot patterns describing data sets in 2D too (Das et al., 2023). We can see the discrete character of our approach and the language we have used as a limitation, but it can also be seen as an opportunity for other researchers to investigate the performance of our heuristic search in other MT settings (even continuous) and domains.
Overall, our starting point was the realisation that curriculum learning for a given set of compositional concepts is underdeveloped mainly because of computational costs. Thanks to the new heuristics introduced in this paper, we are now able to effectively implement CL in MT, not only at the level of improving a sequence of training examples for a given task, but also considering the combinatorial explosion of interlocking concepts.
Availability of data and materials
All data of the experiments are synthetic and they can be found at https://github.com/mgpiqueras/curricula_data.git.
Code availability
The software was developed specifically for this study and it can be found at https://github.com/mgpiqueras/curricula_code.git
Notes
The general framework also considers when the program does not halt by means of complexity functions.
The conditional Kolmogorov complexity of concept c given the library B is defined as \(K_L(c \vert B)= \ell ({p^*_{c \vert B}}) \).
Note that \(A^*\) search is useful when we do know a heuristic, which is one reason why identifying a good heuristic is so important. Whether we use \(\textrm{WA}^*\) or \(A^*\), it is key to know an admissible heuristic. Anytime \(A^*\), a version of \(\textrm{WA}^*\) algorithm with weight \(\alpha \) gradually reducing until \(\alpha =1\), can use non-admissible heuristics, but knowing h(n), together with an upper bound on the optimal solution, helps pruning the search space and detects convergence to an optimal solution Hansen and Zhou (2007).
There are more efficient codings, but by using \(+\) and − as extra symbols, we can also use them as delimiters. We use 3 bits for each character instead of \(log_2(6)\), as this only affects size by a multiplicative factor.
References
Barbehenn, M. (1998). A note on the complexity of Dijkstra’s algorithm for graphs with weighted vertices. IEEE Transactions on Computers, 47(2), 263. https://doi.org/10.1109/12.663776
Bengio, Y., Louradour, J., Collobert, R., & Weston, J. (2009). Curriculum learning. In Proceedings of the 26th annual international conference on machine learning, pp. 41–48.
Clayton, N.R., & Abbass, H. (2019). Machine teaching in hierarchical genetic reinforcement learning: Curriculum design of reward functions for swarm shepherding. In 2019 IEEE congress on evolutionary computation (CEC), pp. 1259–1266 . https://doi.org/10.1109/CEC.2019.8790157.
Das, R., Tenenbaum, J. B., Solar-Lezama, A., & Tavares, Z. (2023). Combining Functional and Automata Synthesis to Discover Causal Reactive Programs. In Proceedings of the ACM on Programming Languages, 7(56), 1–31. https://doi.org/10.1145/3571249
Degen, J., Hawkins, R. D., Graf, C., Kreiss, E., & Goodman, N. D. (2020). When redundancy is useful: A Bayesian approach to “overinformative’’ referring expressions. Psychological Review, 127(4), 591.
Dijkstra, E. W., et al. (1959). A note on two problems in connexion with graphs. Numerische mathematik, 1(1), 269–271.
Dong, T., He, J., Wang, S., Wang, L., Cheng, Y., & Zhong, Y. (2016). Inability to activate Rac1-dependent forgetting contributes to behavioral inflexibility in mutants of multiple autism-risk genes. Proceedings of the National Academy of Sciences, 113(27), 7644–7649. https://doi.org/10.1073/pnas.1602152113
Epp, J. R., Mera, R. S., Köhler, S., Josselyn, S. A., & Frankland, P. W. (2016). Neurogenesis-mediated forgetting minimizes proactive interference. Nature Communications, 7, 10838. https://doi.org/10.1038/ncomms10838
Forestier, S., Portelas, R., Mollard, Y., & Oudeyer, P.-Y. (2022). Intrinsically motivated goal exploration processes with automatic curriculum learning. Journal of Machine Learning Research, 23(152), 1–41.
Garcia-Piqueras, M., & Hernández-Orallo, J. (2021). Optimal teaching curricula with compositional simplicity priors. In Joint european conference on machine learning and knowledge discovery in databases, pp. 1–16 . Springer.
Hansen, E. A., & Zhou, R. (2007). Anytime heuristic search. Journal of Artificial Intelligence Research, 28, 267–297.
Hart, P. E., Nilsson, N. J., & Raphael, B. (1968). A formal basis for the heuristic determination of minimum cost paths. IEEE Transactions on Systems Science and Cybernetics, 4(2), 100–107.
Lake, B., Salakhutdinov, R., & Tenenbaum, J. (2015). Human-level concept learning through probabilistic program induction. Science, 350(6266), 1332–1338. https://doi.org/10.1126/science.aab3050
Marcus, G. (2018) Deep learning: A critical appraisal. https://doi.org/10.48550/ARXIV.1801.00631
McCulloch, W. S., & Pitts, W. (1943). A logical calculus of the ideas immanent in nervous activity. The Bulletin of Mathematical Biophysics, 5(4), 115–133.
Pearl, J. (1984). Heuristics: Intelligent search strategies for computer problem solving. Boston: Addison-Wesley Longman Publishing Co., Inc.
Pentina, A., Sharmanska, V., & Lampert, C.H. (2015). Curriculum learning of multiple tasks. In Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR).
Richards, B. A., & Frankland, P. W. (2017). The persistence and transience of memory. Neuron, 94(6), 1071–1084. https://doi.org/10.1016/j.neuron.2017.04.037
Rios, L. H. O., & Chaimowicz, L. (2010). A survey and classification of A* based best-first heuristic search algorithms. In A. C. da Rocha Costa, R. M. Vicari, & F. Tonidandel (Eds.), Advances in artificial intelligence - SBIA 2010 (pp. 253–262). Berlin: Springer.
Russell, S. J., & Norvig, P. (2020). Artificial intelligence: A modern approach. Hoboken: Pearson.
Shrestha, A., & Mahmood, A. (2019). Review of deep learning algorithms and architectures. IEEE Access, 7, 53040–53065. https://doi.org/10.1109/ACCESS.2019.2912200
Shuai, Y., Lu, B., Hu, Y., Wang, L., Sun, K., & Zhong, Y. (2010). Forgetting is regulated through Rac activity in drosophila. Cell, 140(4), 579–589. https://doi.org/10.1016/j.cell.2009.12.044
Soviany, P., Ionescu, R. T., Rota, P., & Sebe, N. (2022). Curriculum learning: A survey. International Journal of Computer Vision, 130(6), 1526–1565. https://doi.org/10.1007/s11263-022-01611-x
Tang, Y., Wang, X., Harrison, A.P., Lu, L., Xiao, J., & Summers, R.M. (2018). Attention-guided curriculum learning for weakly supervised classification and localization of thoracic diseases on chest radiographs. In International workshop on machine learning in medical imaging, pp. 249–258. Springer.
Telle, J. A., Hernández-Orallo, J., & Ferri, C. (2019). The teaching size: Computable teachers and learners for universal languages. Machine Learning, 108(8), 1653–1675.
Tenenbaum, J. B., De Silva, V., & Langford, J. C. (2000). A global geometric framework for nonlinear dimensionality reduction. Science, 290(5500), 2319–2323.
Wang, W., Caswell, I., & Chelba, C. (2019). Dynamically composing domain-data selection with clean-data selection by “co-curricular learning” for neural machine translation. In Proceedings of the 57th annual meeting of the association for computational linguistics. Association for Computational Linguistics, Florence, Italy, , pp. 1282–1292. https://doi.org/10.18653/v1/P19-1123.
Wang, J., Wang, X., & Liu, W. (2018). Weakly-and semi-supervised faster r-CNN with curriculum learning. In 2018 24th international conference on pattern recognition (ICPR), pp. 2416–2421. IEEE.
Wang, X., Chen, Y., & Zhu, W. (2021). A survey on curriculum learning. IEEE Transactions on Pattern Analysis and Machine Intelligence. https://doi.org/10.1109/TPAMI.2021.3069908
Wong, C., Friedman, Y., Andreas, J., & Tenenbaum, J. (2021). Language as a bootstrap for compositional visual reasoning. In Proceedings of the annual meeting of the cognitive science society, Vol. 43.
Wu, J., Zhang, C., Xue, T., Freeman, W.T., & Tenenbaum, J.B. (2016). Learning a probabilistic latent space of object shapes via 3d generative-adversarial modeling. In Proceedings of the 30th international conference on neural information processing systems, pp. 82–90.
Zhou, T., & Bilmes, J. (2018). Minimax curriculum learning: Machine teaching with desirable difficulties and scheduled diversity. In International conference on learning representations.
Zhu, X. (2015). Machine teaching: An inverse problem to machine learning and an approach toward optimal education. In 29th AAAI conference on artificial intelligence, pp. 4083–4087.
Zhu, X., Singla, A., Zilles, S., & Rafferty, A. (2018). An overview of machine teaching. arXiv:1801.05927.
Funding
Open Access funding provided thanks to the CRUE-CSIC agreement with Springer Nature. This work was funded by the Norwegian Research Council grant 329745 Machine Teaching for Explainable AI, the EU (FEDER) and Spanish grant RTI2018-094403-B-C32 funded by MCIN/AEI/10.13039/501100011033 and by “ERDF A way of making Europe”, Generalitat Valenciana under PROMETEO/2019/098, EU’s Horizon 2020 research and innovation programme under grant agreement No. 952215 (TAILOR) and and Spanish grant PID2021-122830OB-C42 (SFERA) funded by MCIN/AEI/10.13039/501100011033 and ERDF A way of making Europe.
Author information
Authors and Affiliations
Contributions
MGP and JHO conceived the main ideas of the paper and wrote the paper. The theoretical and experimental results were performed by MGP.
Corresponding author
Ethics declarations
Conflict of interest
None.
Ethical approval
N/A.
Consent to participate
N/A.
Consent for publication
Everything included in this paper has been produced by the authors and both give their consent for publication.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Editors: Alireza Tamaddoni-Nezhad, Alan Bundy, Luc De Raedt, Artur d’Avila Garcez, Sebastijan Dumanić, Cèsar Ferri, Pascal Hitzler, Nikos Katzouris, Denis Mareschal, Stephen Muggleton, Ute Schmid.
Appendices
Appendix A: The drawing domain
In this section we establish the setting used by the teacher to generate examples and the language employed by the learner to interpret them.
1.1 A.1. The space of examples: polygonal chains
Given a point, consider that we draw a polygonal chain, using 2D axis-parallel unit segments from that initial point, such that the end of a segment coincides with the beginning of another segment (hence the term chain). We use the unit strokes North, South, East and West as commands (Sect. 2), to define a quaternary alphabet \(\Sigma _4=\{\textsf{N}, \textsf{S}, \textsf{E}, \textsf{W}\}\). Note that different chains may lead to the same shape.

Different shapes derived from polygonal chains
We consider \(\Sigma _4^*\), which is formed by all possible concatenations of zero or more symbols in \(\Sigma _4\); note that it also includes the empty string, which is denoted by \(\varepsilon \). We define an order \(\lessdot \) over \(\Sigma _4^*\) by first considering the size and, for ties, the lexicographical order: N, S, E and W.
For example, in Fig. 6, starting at the black dot, the square in the upper left corner can be described by the chains ENWS, NESW or even NESWNE. The only condition is that such sequences must be built with a single drawing, i.e., the pen cannot be lifted from the paper until the end. For instance, to draw a T-shape (second drawing on the top of Fig. 6), we need four strokes at least, NWEE or NEWW, even though the shape only has three segments.
We label such examples as positive (\(+\)) and negative (−).
There are six symbols to produce examples: N, S, E, W, \(+\) and −; the last two indicate whether the example is positive or negative. We will use \(\lceil log_2(6) \rceil =3\) binary digits to express each symbol.Footnote 5 Note that + and − are useful for the teacher and the learner when exchanging sets of examples, not only to express which ones are positive or negative, but also to identify when an example terminates and a new one begins. The size in bits of an example, denoted by \(\delta (x)\), either positive or negative, is the length in bits of its representation. For example, \(\delta (\mathsf {NESW^+})=15\) bits.
We can also extend the total order \(\lessdot \) to X by first considering the size and, for ties, the lexicographical order: N, S, E, W, \(+\) and −.
The infinite concept class C is the set of all subsets of X. For any concept \(c\in C\) the teacher’s objective is to find the shortest set of examples from which the learner will precisely distinguish the concept.
1.2 A.2. Language syntax (instructions) and semantics (automata)
We now define a language that is employed by the learner to identify concepts from a set of examples provided by the teacher. Let us consider the instruction alphabet \(L_6=\{\textsf{U}, \textsf{D}, \textsf{R}, \textsf{L}, \varvec{)}, \varvec{@}\}\) to define the syntax of the programs of the language \(L=L_6^*\) as the set of programs that the teacher and the learner use to think of and identify concepts. The meaning of the symbols is already given in Sect. 2.
We denote the number of bits of p in language L as \(\ell (p)\); \(\dot{\ell }(p)\) denotes its number of instructions. Since the alphabet size \(|L_6 |=6\), we will have a total of 6 symbols that will need 3 bits for each instruction. For instance, in our setting, \(\ell (\textsf{URRRD})=15\) bits.
Regarding the implementation of prior knowledge, we consider that the language works with a library of primitives, which is simply a possibly empty ordered set of programs \(B=\langle p_1, p_2,... \rangle \), with \(p_j\) in L. The instruction \(\varvec{@}\) represents a call for the library B, when there is just one primitive. The expression \(\varvec{@}\textsf{i}\) calls the primitive indexed with a binary string \(\textsf{i}\) representing natural number \(j-1\), where j is the position in the library. For example, \(\textsf{R}\varvec{@}\), is equivalent to \(\mathsf {RD\varvec{)}}\) when \(B=\langle \textsf{D}\varvec{)} \rangle \). For instance, the library \(B=\langle \textsf{R}, \textsf{RR}, \textsf{RRR} \rangle \) makes the expressions \(\textsf{U}\varvec{@}10\textsf{D}\) and \(\textsf{URRRD}\) as it is calling the third primitive (indexed by 10). Since the dimension of the library is already known by the learner and all the instructions can be translated into binary strings, we consider that it is not necessary to explicitly add the two binary digits for composing binary strings to index library calls. In the end, any expression in language L is uniquely translated into a binary string. We denote \(L_B\) as the language L that employs library B.
The size in bits of a call to the library is \(\ell (@\textsf{i})=\ell (\varvec{@})+\lceil \log _2(|B |)\rceil \) bits. In this way, \(\ell (\textsf{U}\varvec{@}01\textsf{D})=11\) bits, i.e., four bits less than the equivalent program \(\textsf{URRRD}\) when using library \(B=\langle \textsf{R}, \textsf{RR}, \textsf{RRR} \rangle \). Note that binary representations utilise trailing zeros, e.g., 00 or 01. We observe that, every chain in language L can be uniquely translated into \(L_5^*\), where \(L_5=L_6 {\setminus } \{\varvec{@}\}\), by substituting the corresponding primitive for its corresponding library call.
There is a total order, \(\prec \), over the language \(L_B\) defined by two criteria: (i) length and (ii) lexicographic order, \(\textsf{U} \prec \textsf{D} \prec \textsf{R} \prec \textsf{L} \prec \varvec{)} \prec \varvec{@}\), only applied when two expressions have equal size; when considering library calls, 0 is lexicographically previous to 1, e.g., \(\textsf{U}\varvec{@}00\textsf{D} \prec \textsf{U}\varvec{@}01\textsf{D}\).
We will consider that a command of \(\Sigma _4\) is equivalent to a single instruction of the visual language when they represent the same phenomenon. For instance, the unit stroke \(\textsf{N}\) of X is equivalent to instruction \(\textsf{U}\) of L, since both represent equal moves on the grid.
In our particular setting, we will employ the function \(\phi :L_6 \!\rightarrow \! \Sigma _4\), such that \(\phi (\textsf{U})=\textsf{N}\), \(\phi (\textsf{D})=\textsf{S}\), \(\phi (\textsf{R})=\textsf{E}\) and \(\phi (\textsf{L})=\textsf{W}\) to identify stroke-instruction equivalences.
To complete the representation mapping between \(L_6\) and \(\Sigma _4\), i.e., the semantics of L, we will uniquely associate a deterministic finite automaton, DFA (McCulloch & Pitts, 1943), for each program p in language L. In our particular setting, an automaton represents the semantics of a program p in L. In other words, the set of examples S the program covers (or can generate) is equal to the set of strings that the corresponding automaton can accept.
For example, the program \(\textsf{RU}\) in language L uniquely represents the automaton of Fig. 7. Such automaton recognises the concept \(\{ \textsf{E}^+, \textsf{EN}^+\}\). \(\textsf{RU}\) also recognises \(\{\textsf{E}^+\}\), a behaviour similar to some spellcheckers. Among other tools, automata are employed in AI to capture latent patterns (Das et al., 2023).

Automaton built from expression \(\textsf{RU}\)
Regarding the instruction \(\varvec{)}\), for instance, Figs. 8 and 9 represent the automata \(\mathsf {RU)}\) and \(\mathsf {RRU)L}\), respectively. Note that the automaton \(\mathsf {RU)}\) accepts \(\textsf{ENE}\), since we can employ the empty string \(\varepsilon \) to follow \(\varvec{)}\), i.e., \(\mathsf {EN \varepsilon E}\).

Automaton identified by the expression \(\textsf{RU}\varvec{)}\)

Automaton identified by the expression \(\mathsf {RRU)L}\)
Specifically, we give the following procedure to uniquely associate an automaton to a program in L. But firstly, we will restrict such association to \(L_5^*\), where \(L_5=L_6 {\setminus } \{@\}\). As we already mentioned, every program in language L can be translated into \(L_5^*\) by replacing the library calls. Also, for simplification purposes, we will not consider \(\varvec{)}\) redundancies, i.e., we substitute any \(\varvec{))}\) occurrences by \(\varvec{)}\).
For instance, let us consider the expression \(\textsf{R}\varvec{@)}\) in the visual language L, when \(B=\langle \textsf{D}\varvec{)} \rangle \). If we eliminate \(\varvec{))}\) redundancies, then \(\textsf{R}\varvec{@)}\) is uniquely translated into \(L_5^*\) as \(\mathsf {RD\varvec{)}}\). Thus, we get the DFA expressed by the transition diagram of Table 6, where all the states are of acceptance.
However, there can be more complex programs. For example, let us consider another program like \(\textsf{R}\varvec{))}\textsf{URD}\varvec{)}\). Firstly, we eliminate redundancies for instruction \(\varvec{)}\), so that we get \(\textsf{R}\varvec{)}\textsf{URD}\varvec{)}\). Then we parse the latter expression to distinguish instructions equivalent to commands in \(\Sigma _4\):
-
We denote \(\sigma _1=\alpha _1=\textsf{R}\) as the first \(\phi \)-equivalent instruction.
-
We denote \(\sigma _2=\beta _1=\varvec{)}\), as the first instruction \(\varvec{)}\). Since there is only one previous \(\phi \)-equivalent instruction, we use the subindex 1 for \(\beta \).
-
Similarly, we continue parsing the program as \(\sigma _3=\alpha _2=\textsf{U}\), \(\sigma _4=\alpha _3=\textsf{R}\), \(\sigma _5=\alpha _4=\textsf{D}\) and \(\sigma _6=\beta _4=\varvec{)}\).
Note that there are \(m=4\) \(\phi \)-equivalent instructions in p and \(n-m=2\) instructions \(\varvec{)}\). Now we are able to build the DFA automaton \(M=(\Theta , \Xi , s, F, \delta )\) where:
-
\(\Theta =\{q_0, q_1, q_2, q_3, q_4 \}\) is the set of states.
-
\(\Xi =\{ \phi (\alpha _1)=\textsf{E}, \phi (\beta _1)=\varepsilon , \phi (\alpha _2)=\textsf{N}, \phi (\alpha _3)=\textsf{E}, \phi (\alpha _4)=\textsf{S}, \phi (\beta _4)=\varepsilon \}\) is the set of input symbols.
-
The start state is \(s=q_0\).
-
The set of accept states is \(F=\Theta \).
-
We now consider the function \(\delta ' :\Theta \times \{\sigma _i\}_{i=1}^n \!\rightarrow \! \Theta \), given by Table 7.
-
Using \(\delta '\), we define the transition function through the translation of \(\{\sigma _i\}_{i=1}^n\) into \(\Xi \), using \(\phi : L_5 \!\rightarrow \! \Sigma _4 \cup \{\varepsilon \}\), as
$$\begin{aligned} \delta (q, \phi (\sigma _i))=\delta '(q, \sigma _i), \forall q \in \Theta , \forall i \end{aligned}$$, which is expressed in Table 8.
Now, we are able to draw the graph associated to the program \(\textsf{R}\varvec{)}\textsf{URD}\varvec{)}\), represented in Fig. 10.

Automaton identified by the expression \(\textsf{R}\varvec{)}\textsf{URD}\varvec{)}\)
We can generalise the process that uniquely identifies the semantics of a program as an automaton through Definition 11.
Definition 11
Let \(p=\sigma _1 \cdots \sigma _n \in L_5^*\) be a program such that:
-
\(\not \exists i \in \{1, \ldots , n-1\}\) with \(\sigma _i=\sigma _{i+1}=\varvec{)}\).
-
We parse p from beginning to end and with \(\alpha _{j}\) we denote every \(\sigma _i\) such that \(\sigma _i \ne \varvec{)}\), where j increases succesively from 0 to m, with \(m \le n\) being the number of instructions of p different from \(\varvec{)}\).
-
Such parsing of p also makes \(\beta _{k}\) denote every \(\sigma _i\) such that \(\sigma _i =\varvec{)}\), where k is the number of instructions previous to \(\sigma _i\) different from \(\varvec{)}\).
-
We will extend \(\phi :L_5 \!\rightarrow \! \Sigma _4 \cup \{\varepsilon \}\) by considering \(\phi (\varvec{)})=\varepsilon \). Thus, we associate p with the DFA denoted as \(M=(Q, \Xi , s, F, \delta )\), where:
-
1.
The set of states is \(\Theta = \{q_0, \ldots , q_m\}\)
-
2.
The set of input symbols is \(\Xi =\{ \phi (\sigma _{i}) \}_{i=1}^{n}\)
-
3.
The start state is \(s = q_0\)
-
4.
The set of accept states is \(F = \Theta \)
-
5.
The transition function is \(\delta :\Theta \times \Xi \!\rightarrow \! \Theta \), with
5.1) \(\delta (q_{r}, \phi (\alpha _{r+1}))=q_{r+1}\), \(\forall {r} \in \{1, \ldots , m-1\}\) (and \(\emptyset \) otherwise)
5.2) \(\delta (q_{r}, \phi (\beta _{r}))=q_0\), \(\forall {r} \in \{0, \ldots , m\}\) (and \(\emptyset \) otherwise)
As a result, we identify a program p in language L with the DFA that it defines. Now, we say that program p in L identifies a concept \(c \in 2^X\), and we denote \(p \in [c]_L\), if the DFA defined by p recognises c. For example, \(\textsf{RU} \in [\{ \textsf{E}^+, \textsf{EN}^+\}]_L\).
We denote \([c]_L\), or simply [c] when L is clear from the context, as the equivalence class of programs in language L that identify the same concept c. For example, \(\mathsf {RU\varvec{)}R}\) and \(\mathsf {RU\varvec{)}}\) identify the same concept, so they are equivalent.
We say that the program p in the visual language L satisfies a positive example, \(e^+\), if the DFA defined by p accepts the word \(e \in \Sigma _4^*\). For instance, \(\mathsf {RU\varvec{)}}\) satisfies \(\textsf{ENE}^+\). Regarding negative examples, a program satisfies a negative example, \(e^-\), if it does not satisfy its positive counterpart, \(e^+\). For instance, since \(\mathsf {RD\varvec{)}}\) does not satisfy \(\textsf{EN}^+\), then it satisfies \(\textsf{EN}^-\). Conversely, \(\mathsf {R\varvec{)}}\) satisfies \(\textsf{EEE}^+\), but it does not satisfy \(\textsf{EEE}^-\).
Given a set of examples \(w \subset X\), a program satisfies w if it satisfies each example of w. For instance, \(\mathsf {RURD)}\) satisfies the example set \(\mathsf {\{ N^-, ENESEN^+\}}\).
Given an example \(e^+\) with n unit strokes, we can restrict the search for the automaton that satisfies \(e^+\), by generating up to \(n+1\) states maximum. In other words, we use the complexity function \(\textsf{f}(n)=n+1\) as an upper bound of the necessary states. For instance, the example \(\textsf{EEN}^+\), with \(n=3\) unit strokes, is satisfied by a DFA represented by the program \(\textsf{RRU}\) using four states (\(4 \le \textsf{f}(3)\)), or even \(\mathsf {R\varvec{)}U}\), with just three states. However, given the example \(\textsf{EEN}^+\), we will not consider automata like \(\textsf{RRUU}\) or \(\textsf{RRUUU}\), because their number of states are higher than the bound given by the complexity function \(\textsf{f}\).
We can see that in general the maximum number of states considered to test whether an automaton p satisfies a given positive example \(e^+\) with n unit strokes is given by a complexity function \(\textsf{f}(n)\), such that \(n \le \textsf{f}(n)\), \(\forall n\). Thus, we say that p is \(\textsf{f}-\)compatible with example \(e^+\), and we denote \(p \vDash _{\textsf{f}} e^+\) (otherwise, \(p \nvDash _{\textsf{f}} e^+\)). Regarding such bounds for positive examples, we can similarly extend them to negative examples and sets of examples.
In this domain, we guarantee complete calculations just taking \(\textsf{f}(n)= n+1\), and \(p \vDash S\) denotes that p satisfies every example of \(S \subset X\) (in the general framework, \(p \vDash _{\textsf{f}} S\) denotes that p satisfies every example of \(S \subset X\) within a common maximum value of time steps that depends on \(\textsf{f}\)).
Also, it is important to note that even employing large enough complexity functions, language L is not universal in the sense that it cannot identify every concept \(c \in C\). For instance, given the concept \(c=\{ \textsf{NE}^+, \textsf{W}^+\}\), then \([c]_L=\{\emptyset \}\), i.e., there are no programs in language L that satisfies both \(\textsf{NE}^+\) and \(\textsf{W}^+\). This is because the initial state, \(q_0\), can connect with just one different state \(q_{1}\). In other words, you cannot choose moving to \(q_1\) or \(q_2\) from state \(q_0\) in just one edge crossing (see Fig. 11).

The visual language L does not allow to build the edges \({{q_0}{q_1}}\) and \({{q_0}{q_2}}\) simultaneously
Appendix B: Examples
In this section we will analyse other examples with more situations and concepts slightly different than in Example 1.
Let us consider another set of concepts where there is just one minimal curriculum: there is no draw between the overall teaching sizes of optimal curricula (as it happens in Example 1).
Example 4
Let us consider the set of concepts \(Q'=\{a', b', c\}\), where \(\textsf{RURD} \in [a']_L\), \(\textsf{RRURD} \in [b']_L\) and \(\textsf{R}\varvec{)}\textsf{URD}\varvec{)} \in [c]_L\), are the first programs in their equivalent classes with respect to \(\prec \).
Regarding the overall teaching sizes and the descriptions measured in bits (Table 9), Fig. 12 compares some relevant curricula registered in Table 10 for \(Q'=\{a', b', c\}\).
As we can see in Table 10 (and Fig. 12), there is only one minimal teaching size curriculum (with no ties). Such minimal curriculum, \(\pi _7'\), minimises the overall teaching size, placing concept c in a separate branch. If we choose curriculum \(\pi '_4\), instead of \(\pi '_7\), we get \(\approx 53.3\%\) extra cost.
We observe that for this particular set of concepts \(Q'\), if the learner identifies concept c, it should not implement such concept to identify the rest of the concepts for the purpose of minimising the overall teaching size.
As before, we utilise Table 9, containing the teaching sizes associated to Example 4, to build another Table 10 showing the overall teaching size for all the curricula associated.

Finally, we examine another set of concepts, but now with four elements.
Example 5
Let \(Q''=\{a, b, c, d\}\) be the set of concepts where \(\textsf{RURD}\varvec{)} \in [a]_L\), \(\textsf{RRURD}\varvec{)} \in [b]_L\), \(\textsf{R}\varvec{)}\textsf{URD}\varvec{)} \in [c]_L\) and \(\mathsf {RD\varvec{)}} \in [d]_L\) are the first programs in their equivalent classes with respect to \(\prec \).
Now, there are 73 different curricula (according to Proposition 1) and 64 teaching size values associated to Example 5.
Regarding the overall teaching sizes and the descriptions measured in bits, Fig. 13 compares some relevant curricula registered in Table 12 for Example 5. If we choose \(\pi ''_{22}\) or \(\pi ''_{26}\), instead of the optimal curriculum \(\pi ''_{10}\), we get \(\approx 66.6\%\) extra cost.

Appendix C Some requirements for our drawing domain
This section aims to identify the conditions for our drawing domain to verify Corollary 2. This section relies in Section A to deal with the notation and the settings of our drawing domain.
Firstly, it is important to know how many commands are necessary to identify a given program. In order to do so, we will consider some kind of paths, as short as possible, on the graph defined by the DFA corresponding to a given program. Those paths would be denoted as sequences of commands that represent the successive edges included. For instance, the DFA of Fig. 7, given by the program \(\textsf{RU} \in L\), starting at \(q_0\) has just one path that includes all its edges: \(\textsf{EN}\) ( i.e., \(\overrightarrow{q_0q_1}\) and \(\overrightarrow{q_1q_2}\) in that order).
If the program has non-equivalent instructions, like \(\textsf{RURD}\varvec{)}\), the learner needs not only \(\textsf{ENESE}\), i.e., a path that includes every edge of the DFA, starting at \(q_0\), but also, crossing the edge labelled as \(\varepsilon \) implies going through \(\overrightarrow{q_0q_1}\) too. For instance, if we provide the learner with \(\mathsf{ENESE^+}\), the learner does not output \(\mathsf{RURD\varvec{)}}\), but \(\textsf{RURDR}\), because of lexicographical order; that is why we need to add one more command \(\mathsf{ENESEN^+}\) to make \(\mathsf{RURD\varvec{)}}\) elegible by the learner.
These kind of paths define a polygonal chain \(s \in \Sigma _4^*\) and we denote its length as \(\dot{\delta }(s)\). We extend such notation to any set \(S \subset X\), as \(\dot{\delta }(S)\), by considering the number of commands included in S. For instance, \(\dot{\delta }(\{\mathsf{EEN^+, EE^- }\})=5\).
Note that every time we go through an \(\varepsilon \)-edge of the DFA, it is compulsory to subsequently include the edge starting at \(q_0\) labelled with a command. As a result, the learner needs at least seven commands to identify program \(\textsf{R}\varvec{)}\textsf{URD}\varvec{)}\) (Fig. 10). In short, \(\Phi (w)=\textsf{R}\varvec{)}\textsf{URD}\varvec{)}\) implies \(\dot{\delta }(w) \ge 7\); in fact, \(\Phi (\{\textsf{ENESEEE}^+ \})=\textsf{R}\varvec{)}\mathsf {URD)}\) (see Table 1).
There are some programs that show even more differences between its number of instructions and the length of examples accepted. For instance, the program \(\textsf{UDRL}\varvec{)}\textsf{DLUR}\) defines the DFA of Fig. 14 with nine instructions, but the learner needs at least a sequence of thirteen commands labelled as a positive example to identify such program.

Automaton identified by the expression \(\textsf{UDRL}\varvec{)}\textsf{DLUR}\)
Apart from that, it is useful to know the number of instructions of a program when its library calls are unfolded, i.e., given a program p and a library B, we use \(\circ (p)\) to denote the program that is equivalent to p, where each primitive call \(\varvec{@}\) has been replaced by the instructions of the primitive in B. We suppose that \(\circ (p)\) works exactly equal in L as p in \(L_B\), i.e., the language L using library B.
Let us suppose now that we use library \(B=\langle \textsf{DLUR}\rangle \). In such particular case, \(\textsf{UDRL}\varvec{)}\textsf{DLUR}\) in L is expressed as \(\textsf{UDRL}\varvec{)@}\) in \(L_B\), by removing \(4-1=3\) instructions, i.e., \(\dot{\ell }(\textsf{UDRL}\varvec{)}\textsf{DLUR})=\dot{\ell }(\circ (\textsf{UDRL}\varvec{)@}))\)+3.
With respect to the minimum length of the paths associated to \(\textsf{UDRL}\varvec{)@}\), in \(L_B\) we reduce such minimum length in \(4-2=2\) units; so that the learner needs at least a sequence of eleven succesive commands to identify \(\textsf{UDRL}\varvec{)@}\). This is because when a library call is the last instruction, it only needs to be fed twice, i.e., it needs two commands. For instance, in our case we just feed instruction \(\varvec{@}\) in \(\textsf{UDRL}\varvec{)@}\) with \(\textsf{SW}\), i.e., two commands corresponding to the first two instructions of primitive \(\textsf{DLUR}\).
It can happen that the primitive referred by \(\varvec{@}\), as a final instruction, might include non-equivalent instructions (\(\varvec{)}\)-instructions). For instance, if \(\varvec{@}\) points to \(\textsf{D}\varvec{)}\textsf{LUR}\), we could skip instruction \(\varvec{)}\), if possible; that is to say, if there are sufficient equivalent instructions in the primitive. For example, we should feed \(\varvec{@}\) with \(\textsf{SW}\), corresponding to the 1st and 3rd instructions of primitive \(\textsf{D}\varvec{)}\textsf{LUR}\). Of course, if the primitive were to be \(\textsf{D}\varvec{)}\), we could not skip the 2nd instruction.
In the event that the library call is not the last instruction, we just need to feed all the equivalent instructions of the primitive. For instance, if we employ \(B=\langle \textsf{UDRL}\varvec{)}\rangle \) as library, \(\textsf{UDRL}\varvec{)}\textsf{DLUR}\) in L is expressed as \(\varvec{@}\textsf{DLUR}\) in \(L_B\), whose shortest path, elegible by the learner is at least nine units length.
We do not consider programs with consecutive ocurrences of \(\varvec{)}\)-instructions, like \(\varvec{))}\) or \(\varvec{)))}\). Then a program with n instructions, without library calls, has \(\lfloor \frac{n}{2}\rfloor \) equivalent instructions minimum and \(\lceil \frac{n}{2}\rceil \) maximum.
Once that we have shown some particular examples, we are able to give a definition of minimum eligible path.
We will consider programs without library calls in this definition. If we get a program p with library calls, we will consider \(\circ (p)\) instead but with the following exception: if the last instruction of p is a library call, we will only consider two instructions of the primitive referred by strict order of appearance and skipping instructions \(\varvec{)}\), if the length of the primitive facilitates it.
Definition 12
Let p be a program in language L without library calls. We say that a path on the DFA corresponding to p is minimum eligible when satisfies the following properties: (1) The path goes through every edge of the graph, (2) If the path crosses an edge labelled as \(\varepsilon \), it is subsequently followed by the edge \(\overrightarrow{q_0q_1}\) and 3) If there is any edge labelled as \(\varepsilon \), then any path according to previous conditions, 1 ) and 2 ), increases its length one more unit.
We now aim to identify sufficient conditions that, in language L, guarantee Inequality (2).
We consider language \(L_B\) where \(0 \le |B |\); \(\varvec{@}\textsf{i}\) denote library calls when \(|B |>1\) (@ if \(|B |=1\)). We hold that the value of the instructions of language L, except instructions \(@\textsf{i}\), have the same value in bits as commands of \(\Sigma _4\).
We also take the extension for \(L_{B'}\) with \(B'=\langle B, p \rangle \), where p is a primitive without library calls. Though it is not true in general, we assume that the size in bits of a library call, \(\varvec{@}\textsf{i}\) in \(L_B\) is equal to a call, \(\varvec{@}\mathsf{i'}\) in \(L_{B'}\).
Theorem 3
Let \(c \in C_L\) and B, \(B'\) libraries such that \(\ell (@\textsf{i})=\ell (@\mathsf{i'})\), where \(\varvec{@}\textsf{i}\) and \(\varvec{@}\mathsf{i'}\) are in language \(L_B\) and \(L_{B'}\), respectively. Let \(w_c, w'_c \subset X\) be witness sets with \(p^*_{c \vert B}={\Phi _{\ell }} (w_c \vert B)\) and \(p^*_{c \vert B'}={\Phi _{\ell }} (w'_c \vert B')\). If \(w_c\) has no negative examples, then:
Proof
Since \(c \in C_L\), we can take a large enough complexity function \(\textsf{f}\). Also, we consider that there is just one positive example in \(w_c\), since the learner is always given the shortest witness set. Moreover, such positive example defines a minimum eligible path, otherwise the learner would not be given the simplest witness set. In other words, we can assume the following statements:
-
1.
\(\exists w_c, w'_c \subset X\) such that \(p^*_{c \vert B}= {\Phi _{\ell }} (w_c \vert B)\), \(p^*_{c \vert B'}={\Phi _{\ell }} (w'_c \vert B')\)
-
2.
The witness set is \(w_c=\{e^+\}\), and \(e^+\) is a minimum eligible path on the DFA defined by \(p^*_{c \vert B}\)
The number of steps in such minimum path defined by \(e^+\) is given by \(\dot{\delta }(w_c)\), while the number of instructions of \(p^*_{c \vert B}\) is \(\dot{\ell }(p^*_{c \vert B})\). Then,
Let us suppose that \(\dot{\ell }(p^*_{c \vert B'})=\dot{\ell }(p^*_{c \vert B})\), i.e., language \(L_{B'}\) does not reduce the number of instructions of \(p^*_{c \vert B}\), then \(p^*_{c \vert B'}=p^*_{c \vert B}\). So that, \(w'_c=w_c\), and the conclusion (C1) is guaranteed.
Let us suppose that \(\dot{\ell }(p^*_{c \vert B'}) < \dot{\ell }(p^*_{c \vert B})\). Worst-case scenario implies just one new library call, denoted by \(\varvec{@}\mathsf{i'}\), to reduce \(p^*_{c \vert B}\) to \(p^*_{c \vert B'}\). So that, \(\dot{\ell }(p^*_{c \vert B'})\) decreases \(\dot{\ell }(p^*_{c \vert B})\) in \(\dot{\ell }(\circ (\varvec{@}\mathsf{i'}))-1\) units. We observe that, if there were more library calls \(\varvec{@}\mathsf{i'}\) in \(p^*_{c \vert B'}\), the reduction would be larger. Hence,
We now distinguish three sub-cases according to its position and the number of instructions of the new primitive, \(@\mathsf{i'}\), included in \(B'\).
Case 1: We suppose that \(\dot{\delta }(\circ (\varvec{@}\mathsf{i'})) > 2\) and \(\varvec{@}\mathsf{i'}\) is the last instruction in \(p^*_{c \vert B'}\). In this case, we can feed \(\varvec{@}\mathsf{i'}\) with just two commands.
Hence, considering the library call, the path expressed by the positive example included in \(w'_c\) will verify at the very least:
Substituting (C3) and (C4) in (C2) we obtain
Therefore:
Using equalities (C2) and (C5), we get
Now, we consider that \(p^*_{c \vert B'}\) has the same number of library calls \(\varvec{@}\textsf{i}\) (except \(\varvec{@}\mathsf{i'}\) ). Otherwise, the difference \(\ell (p^*_{c \vert B}) - \ell (p^*_{c \vert B'})\) would be even greater, since the learner always retrieves the shortest option.
So that, we can express in bits (C6) as the following inequality
which is the conclusion (C1).
Case 2: Now, we suppose that \(\dot{\delta }(\circ (\varvec{@}\mathsf{i'}))=2\) and \(\varvec{@}\mathsf{i'}\) is the last instruction of \(p^*_{c \vert B'}\). Then, we need to feed \(\varvec{@}\mathsf{i'}\) with two commands: one to feed the call and another to avoid the substitution of such call by an instruction equivalent to a command; otherwise, the learner would have chosen a program previous to \(p^*_{c \vert B'}\), which is not possible.
Hence, \(\dot{\delta }(w'_c)=\dot{\delta }(w_c)\), i.e., we can not reduce the teaching size and we get that \(\delta (w_c)-\delta (w'_c)=0\). Since \(\ell (p^*_{c \vert B})-\ell (p^*_{c \vert B'}) \ge 0\), then we get the conclusion (C1).
Case 3: In this case, the library call \(\varvec{@}\mathsf{i'}\) is not the last instruction. At most, we could skip the \(\varvec{)}\)-instructions included in \(\circ (\varvec{@}\mathsf{i'})\), but we should feed its equivalent instructions. So that, at the very least, there must be \(m = \lfloor \frac{\dot{\ell }(\circ (\varvec{@}\mathsf{i'}))}{2}\rfloor \) instructions equivalent to commands in \(\varvec{@}\mathsf{i'}\), with \(m \ge 1\).
Therefore, at the very least we have \(\dot{\delta }(w'_c)=\dot{\delta }(w_c)-(\dot{\ell }(\circ (\varvec{@}\mathsf{i'})) - m)\).
Also, we can remove \(\dot{\ell }(p^*_{c \vert B'})=\dot{\ell }(p^*_{c \vert B}) - (\dot{\ell }(\circ (\varvec{@}\mathsf{i'})-1))\). Using (C2) we get that
Then, we obtain \( \dot{\delta }(w'_c) = \dot{\ell }(p^*_{c \vert B'}) + n + (m-1)\), which together with (C2) provides:
Since \(m \ge 1\) and making a translation into bits, similar to the one already done in Case 1, we get the conclusion (C1).\(\square \)
Appendix D: Some proofs
In this section we will include the proofs of two theoretical statements. The following result is useful to prove Corollary 2.
Lemma 4
Let x, \(x'\), y, \(y' \in \mathbb {N^*}\) verify the following conditions:
-
1.
\({\textstyle \exists k_1, k_2 \in \mathbb {N}}\) such that \(x = y + k_1\) and \(x' = y' + k_2\)
-
2.
\(x - x' \le y - y'\)
-
3.
\(y' \le y\)
Then, \(\frac{y'}{y} \le \frac{x'}{x}\).
Proof
Using Condition 1, we know that
Condition 2 provides that \(\exists \epsilon \ge 0\) such that
From (D8) and (D9), we get that
Now, the first part of Condition 1 assures that
If we substitute (D11) in (D10), we get that
In other words: \(\exists \epsilon \ge 0\) such that \(k_2 = k_1 + \epsilon \). Therefore:
Utilising Condition 3 we observe that
Also, since \(k_2 \ge k_1\) (D12) we can state that
As a consequence of (D13) and (D14) we get \(\frac{y'}{y} \le \frac{x'}{x}\), which completes the proof.\(\square \)
We now provide the proof of Corollary 2 (Sect. 5).
Proof
Lemma 4 can be applied to those situations where \(x=\delta (w_c)\), \(x'=\delta (w'_c)\), \(y=\ell (p_c)\) and \(y'=\ell (p'_c)\). In such state, it provides a sufficient condition to obtain a lower bound of the unknown conditional teaching size using a new primitive. Thus, \(\frac{\ell (p'_c)}{\ell (p_c)} \le \frac{\delta (w'_c)}{\delta (w_c)}\) implies the conclusion of Corollary 2. \(\square \)
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Garcia-Piqueras, M., Hernández-Orallo, J. Heuristic search of optimal machine teaching curricula. Mach Learn 112, 4049–4080 (2023). https://doi.org/10.1007/s10994-023-06347-4
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10994-023-06347-4