
Abstract
It has been shown that dimension reduction methods such as Principal Component Analysis (PCA) may be inherently prone to unfairness and treat data from different sensitive groups such as race, color, sex, etc., unfairly. In pursuit of fairness-enhancing dimensionality reduction, using the notion of Pareto optimality, we propose an adaptive first-order algorithm to learn a subspace that preserves fairness, while slightly compromising the reconstruction loss. Theoretically, we provide sufficient conditions that the solution of the proposed algorithm belongs to the Pareto frontier for all sensitive groups; thereby, the optimal trade-off between overall reconstruction loss and fairness constraints is guaranteed. We also provide the convergence analysis of our algorithm and show its efficacy through empirical studies on different datasets, which demonstrates superior performance in comparison with state-of-the-art algorithms. The proposed fairness-aware PCA algorithm can be efficiently generalized to multiple group sensitive features and effectively reduce the unfairness decisions in downstream tasks such as classification.
Similar content being viewed by others
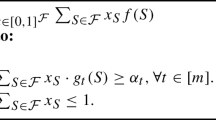


Avoid common mistakes on your manuscript.
1 Introduction
Recent advances in machine learning (ML) have vastly improved the capabilities of computational reasoning in complex domains. From tasks like image and video processing, game playing, text classification, to complex data analysis, machine learning is continually finding new applications and exceeding human-level performance in some cases. Nevertheless, when machine learning models are trained on real data, the existing societal inequalities in data are manifested on the systems built upon them that could mislead models in ways that can have profound fairness implications such as being biased to sensitive features like race or gender. As more critical systems employ ML, such as financial systems, hiring and admissions, healthcare, and law, it is vitally important that we develop rigorous fair algorithms that are as accurate as possible.
Recently, the growing attention to the fairness problem in algorithmic decision-making systems has led to unprecedented attempts to revisit machine learning models for supervised and unsupervised tasks to satisfy fairness constraints (Munoz et al. 2016). An expanding line of works are dedicated to define different metrics for fairness problems and mechanisms to satisfy those measures in learning tasks such as Hardt et al. (2016), Zafar et al. (2015, 2017a, 2017b), Calders et al. (2009), Calders and Verwer (2010), Kamishima et al. (2011), and Agarwal et al. (2018). The work on this realm is focused on biased data or biased algorithms; however, using these biased algorithms in decision-making systems would lead to generating more biased data. This makes the causality of the fairness problem more complicated that exacerbates the problem even further (Barocas et al. 2017; Ghili et al. 2019).
Notwithstanding these efforts for fairness problem in supervised learning, fairness in unsupervised learning tasks has not been explored thoroughly. This is despite the fact that unsupervised learning tasks such as dimension reductions are mostly preceding those supervised ones, in the training procedures. Hence, having fair unsupervised learning models is as crucial as supervised ones. For instance, Principal Component Analysis (PCA) is widely used to reduce the dimension of the data before applying classification models. In addition to that, these unsupervised methods such as dimension reductions or clustering methods are commonly used for data visualizations, identifying common behaviors or trends, reducing the size of data, to name but a few. This ubiquitousness of unsupervised methods in machine learning models can affect decision-making systems if they unfairly treat different groups in data. Unlike the supervised approaches, the fairness in an unsupervised approach depends only on the feature data since the labels are not available. This means that these approaches can handle the representation bias and not the labeling bias as defined in Blum and Stangl (2019).
In this paper, we aim at defining a fairness measure for dimension reduction algorithms like PCA and propose an algorithm to enforce these criteria in finding the subspace with minimum reconstruction loss. It is important to note that, despite supervised learning that fairness metrics are mostly focused on the beneficial outcome (usually the positive label), in an unsupervised task, there is no label to be used. Hence, we seek to find a subspace that is “good” enough for each protected group in the data. Indeed, when we apply PCA on a dataset, the resulting subspace found by a standard algorithm is different from what we achieve when only using the data of each group individually. This difference can be reflected as the difference between the reconstruction error of each group’s data on both subspaces. Thus, when a dimension reduction algorithm is applied to the joint data, the reconstruction loss of some of the groups is degraded (from what they can achieve with their data only), while others are benefiting from joint learning. Here, a fair algorithm is the one that can find a subspace with optimal trade-offs between these degradations and benefits.
An attempt to impose the fairness constraint on learning the optimal subspace for two protected groups has been made recently in Samadi et al. (2018), Olfat and Aswani (2018) and Tantipongpipat et al. (2019), where the fair subspace learning is sought by minimizing the maximum deviation of reconstruction error suffered by any protected group (i.e., the difference of per group reconstruction error and joint reconstruction error). Interestingly, it has been shown that at any optimal local solution of the optimization problem associated with learning such a fair subspace, all the groups suffer the same loss. Motivated by this observation, a semi-definite programming relaxation followed by linear programming is proposed to find a fair subspace (Samadi et al. 2018; Tantipongpipat et al. 2019). In addition to the computational inefficiency of algorithms proposed by these works, the generalization of them to multiple group sensitive features is not conspicuous. Furthermore, since all optimal solutions do not incur the same loss for all groups, extra dimensions are needed to ensure that the total loss of the projection remains at most the optimal objective in the original target dimension [in particular, \(k -1\) extra dimensions are needed for k groups in Samadi et al. (2018) which is further tightened to \(\sqrt{k}\) in a followup work (Tantipongpipat et al. 2019)].
The overarching goal of this paper is to define a fairness metric for dimension reduction, dubbed as pairwise disparity error, and propose a computationally efficient dimensional reduction algorithm to learn a fair subspace from multiple group sensitive features. Towards this end, we cast the problem of fairness in the PCA dimension reduction algorithm as a multi-objective optimization problem and propose an adaptive gradient descent based approach to find the optimal trade-offs with provable convergence rates. Interestingly, the proposed framework is not bounded to any specific notion of fairness metric and can be effortlessly applied to other metrics as well. Moreover, unlike the aforementioned prior works, no extra dimension is needed to ensure the loss suffered by each group matches the optimal fairness loss. The comparison of time complexity of exiting algorithms and current work is summarized in Table 1.
1.1 Contributions
The main contributions of this paper can be summed up as follows:
-
We introduce the notion of Pareto fair PCA to ponder conflicting objectives and achieve optimal trade-offs between them. Also, we introduce the notion of pairwise disparity error as a more efficient objective to learn fair subspaces. In addition, we provide conditions, under which a Pareto optimal solution exists.
-
We propose a gradient descent algorithm to efficiently solve the obtained multi-objective optimization problem which is interesting by its own right, and provide theoretical guarantees on its convergence to optimal compromises or a Pareto stationary point.
-
We empirically develop this algorithm and compare it to the state-of-the-art algorithm on two real-world datasets to demonstrate its efficacy that complements our theoretical results.
-
We investigate the effect of fair projection on supervised tasks such as classification empirically and show that it can significantly eliminate the unfairness in downstream tasks.
2 Related work
In this section, we review existing works on fairness-enhanced learning models and discuss recent studies on fair PCA, multi-objective optimization, which are most relevant to the present work.
2.1 Fairness notions
The efforts to address fairness in algorithmic decision-making systems have roughly fallen into three different categories. Some scholars believe data itself could be biased, leading to unfair results; thus, they seek to solve this problem on data level and as a preprocessing step to the main learning task (Dwork et al. 2012; Feldman et al. 2015; Kamiran and Calders 2009; Calders et al. 2009). The goal is achieved by either changing the value of sensitive feature or label data or find a subspace, where labels and sensitive features are independent. However, since the main objective of the learning is not involved in this process, the optimal solution for the main objective is not guaranteed. The second category includes methods that try to impose the fairness criteria after the learning, in order to attain a fair model (Hardt et al. 2016; Kamishima et al. 2011; Goh et al. 2016; Calders and Verwer 2010). The third approach, includes methods that try to satisfy fairness constraint during the training procedure, usually by imposing them as a constraint to the main learning objective (Donini et al. 2018; Tantipongpipat et al. 2019; Zafar et al. 2015; Samadi et al. 2018; Pleiss et al. 2017). For instance, difference of equality of opportunity (DEO) proposed by Donini et al. (2018) to be added as a constraint to the optimization problem of the learning task. Some of these approaches treat the fairness problem similar to imbalanced data or rare event prediction (Yao and Huang 2017; Kamani et al. 2019, 2018, 2016). While these approaches can achieve the state-of-the-art results in some problems, they still suffer from several issues. Solving a constrained optimization could be a very hard non-convex problem; hence, relaxation is needed to solve the problem that leads to sub-optimal solutions efficiently. Moreover, finding the optimal penalization parameter could be a difficult task, as discussed in Donini et al. (2018). Our approach belongs to the third category, yet, it differs from the prevailing trend of formulating the fairness problem as a constrained optimization. We will cast the fairness problem as a multi-objective optimization that can efficiently satisfy fairness objectives as well as the main learning objective and converge to a point with optimal compromises between objectives.
2.2 Fairness in dimension reduction
Fairness in dimension reduction algorithms is recently being vetted by Samadi et al. (2018), through which they propose a semi-definite programming and prove that its solution satisfies the proposed notion of fairness. Aside from the inefficiency of solving the SDP, their approach is developed for binary sensitive features and requires one extra dimension to guarantee fairness. To generalize it for multiple group sensitive features with k groups, they propose to add \(k-1\) dimensions, which is impractical. The follow-up studies by Olfat and Aswani (2018) and Tantipongpipat et al. (2019) are still in line with the previous one, trying to relax and solve an SDP. We, on the other hand, propose an efficient gradient-based method to solve the aforementioned multi-objective optimization, with the capability of generalizing to multiple group sensitive features smoothly.
2.3 Multi-objective optimization
Although it has been asserted that fairness problems are multi-objective problems in nature (Kearns and Roth 2019; Lipton et al. 2017; Tantipongpipat et al. 2019), as mentioned before, most of the existing works apply different forms of relaxations and approximations to reduce the problem into a scalar-valued optimization problem. In this paper, we design the fairness problem at hand as a multi-objective optimization and solve it directly. Multi-objective or vector optimization is a well-studied problem in different domains for many years. The goal in this optimization is to achieve an optimal trade-off point between different objectives, known as Pareto optimal, named after Italian economist Vilfredo Pareto. We refer the reader to Miettinen (2012), Das and Dennis (1997) and Fonseca et al. (2003) and the references therein as a rich resource on multi-objective optimization and its associated notions such as dominance and Pareto efficiency. We will elaborate that directly solving the vector-valued problem associated with fair learning is appealing to reduction based counterparts (Ehrgott 2006; Mahdavi et al. 2013) by being computationally efficient and providing provable guarantees on the fairness metric.
2.4 Fairness in composition
Beyond achieving fairness in unsupervised tasks such as PCA, the main goal of fairness in machine learning is to design a fair system as a whole. As it is noted by Dwork et al. (2018), these machine learning models in isolation do not necessarily result in a fair system together and should be considered in composition with each other. Hence, in addition to what introduced by Dwork and Ilvento (2018) as compositions in fairness, we advocate for considering the composition of a stream of machine learning models together. Thus, we should investigate the effect of imposing fairness constraints on a machine learning model on downstream tasks using its output. For instance, the goal of defining such a metric for fairness, in our paper and other related works, is that having a fair loss in reducing the dimension would have a fair reduction in the quality of different groups in the new projection; then, it can have a balanced impact on the quality of a subsequent classifier learned on that projection. We empirically investigate the effect of this composition and leave its theoretical understanding to the future work.
3 Problem formulation
We start by mathematically defining the problem we ought to solve, and then discuss what is the notion of fairness in PCA algorithm, which could be quite different from what is known as fairness measures in supervised learning. In what follows we adapt the following notation. We use bold face upper case letters such as \(\mathbf {X}\) to denote matrices and bold face lower case to denote vectors such as \(\mathbf {f}\). The Frobenius norm and trace of a matrix \(\mathbf {X}\) are denoted by \(\Vert \mathbf {X}\Vert _{\mathrm {F}}\) and \({\mathsf {tr}}\left( {\mathbf {X}}\right)\), respectively. The eigenvalues of a positive semi-definite matrix \(\mathbf {\Sigma } \in {\mathbb {R}}^{d \times d}\) are denoted by \(\gamma _{\max }(\mathbf {\Sigma }) = \gamma _1(\mathbf {\Sigma }) \ge \gamma _2(\mathbf {\Sigma }) \ge \ldots \ge \gamma _d(\mathbf {\Sigma }) = \gamma _{\min }(\mathbf {\Sigma })\). The set of integers, \(\{1,2,\ldots ,m\}\), is represented by \(\left[ m\right]\). We denote the PCA without any fairness condition as Normal PCA, and those with some fairness measures as Fair PCA in the rest of this manuscript.
3.1 PCA
The main objective of the PCA is to find the best representation of the data \(\mathbf {X} \in {\mathbb {R}}^{n\times d}\) with n data points in d-dimensional space, in a lower dimension \(r \le d\) using a linear transformation, in order to have the minimum reconstruction error. This linear transformation can be represented by a projection matrix \(\mathbf {U} \in {\mathbb {R}}^{d \times r}\). Thus, the objective of PCA is to find a projection matrix \(\mathbf {U}\) and a recovery matrix \(\mathbf {W} \in {\mathbb {R}}^{r \times d}\) to minimize this reconstruction error similar to Shalev-Shwartz and Ben-David (2014):
It can be proved that in the solution of (1), we have \(\mathbf {W}=\mathbf {U}^\top\), and columns of \(\mathbf {U}\) are orthonormal (i.e. \(\mathbf {U}^\top \mathbf {U} = \mathbf {I}_{r \times r}\)). Therefore we can define the reconstruction loss for any PCA projection as follows:
Definition 1
(Reconstruction Loss) For any given dataset \(\mathbf {X}\) and any projection matrix \(\mathbf {U}\), the total reconstruction loss of \(\mathbf {X}\) using \(\mathbf {U}\) is defined as:
The optimal subspace with minimum reconstruction loss given \(\mathbf {X}\) can be found by solving the above non-convex optimization problem. In fact the columns of optimal projection matrix \(\mathbf {U}^* = \arg \min _{\mathbf {U}}{\mathcal {L}}(\mathbf {U})\) obtained by solving above optimization problem are eigenvectors corresponding to top r eigenvalues of \(\mathbf {X}^{\top }\mathbf {X}\). In this case, the reconstructed data matrix \(\hat{\mathbf {X}} = \mathbf {X}\mathbf {U}_*\mathbf {U}_*^{\top }\) is an optimal rank r approximation of the original data matrix \(\mathbf {X}\), i.e., \(\hat{\mathbf {X}} = \arg \min _{\mathbf {Y},\texttt {rank}(\mathbf {Y})\le r} \Vert \mathbf {Y} - \mathbf {X}\Vert _{\mathrm {F}}\), where the solution space for \(\mathbf {Y}\) is limited to matrices with rank at most r (\(r \le d\)).
3.2 Fair PCA
In this section, we will formally define the notion of fairness in dimension reduction algorithms such as PCA. As it was discussed before, the problem arises from having different reconstruction losses on different sensitive groups in a dataset. This means that finding an optimal projection matrix \(\mathbf {U}^*\) by solving the minimization problem in (2), would have different reconstruction loss on data partitions from each sensitive group. However, in this problem, unlike supervised problems previously discussed, we are not able to reach equality between these reconstruction losses for different groups. The reason for that is the subspace for each group’s data is different, and so is the reconstruction error of that data for that projection. We note that while learning a separate (local) subspace for each individual group has the optimal reconstruction error, our focus here is to learn a single global subspace for all groups due to statistical and ethical concerns. In particular, from a statistical standpoint, since the number of training samples for some groups might be small for skewed data sets, joint learning to have more samples to learn a subspace is preferable. Ethically, as elaborated in Lipton et al. (2017) and Kannan et al. (2019), learning separate subspaces (having disparate treatment like in affirmative action) constructs no trade-offs, and it poses several ethical and legal concerns. We note that the case of fairness with decoupled model representations has been investigated by several other works (Dwork et al. 2018; Ustun et al. 2019; Creager et al. 2019).
In order to quantify to what extent each group suffers or benefits from joint subspace learning, we should compare the subspaces learned from each group’s data alone and the one with other groups’ data included. Then, the idea of fairness is to reach a balance between these sacrifices and benefits of different groups. Formally, consider one of the d features of \(\mathbf {X}\) as a sensitive feature with k different groups, \({\mathcal {S}} = \left\{ s_1, \ldots ,s_k\right\}\). We denote the matrix of each group’s data points as \(\mathbf {X}_i \in {\mathbb {R}}^{n_i \times d}\), where \(n_i\) is the number of samples belonging to the sensitive group \(s_i\). Hence for any projection matrix \(\mathbf {U} \in {\mathbb {R}}^{d \times r}\), the reconstruction loss for each group is defined as:
Then, if we only use the dataset \(\mathbf {X}_i\) to learn the projection matrix, we can find the subspace represented by \(\mathbf {U}_i^*\) that has the optimal reconstruction loss on that dataset, denoted by \({\mathcal {L}}_i(\mathbf {U}_i^*)\). Therefore, a fair dimension reduction algorithm is the one that can learn a global projection matrix \(\mathbf {U}^*\) on all data points with having equal distance between each group’s reconstruction loss on the subspace learned by the whole data with the subspace learned only by its own data. To formally define these fairness criteria, we introduce the notion of disparity error as follows:
Definition 2
(Disparity Error) Consider a dataset \(\mathbf {X} \in {\mathbb {R}}^{n \times d}\) with k sensitive groups with data matrix \(\mathbf {X}_i, i=1,2,\ldots , k\) representing each sensitive group’s data samples. Let \(\mathbf {U}_i^* = \arg \min _{\mathbf {U}}{\mathcal {L}}_i(\mathbf {U})\) denote the projection matrix learned only based on \(\mathbf {X}_i\). Then for any projection matrix \(\mathbf {U}\) the disparity error for each sensitive group is defined as:
This measure shows that how much reconstruction loss we are suffering or enjoying for any global projection matrix \(\mathbf {U}\), with respect to the reconstruction loss of optimal projection matrix, we can learn locally based on data points \(\mathbf {X}_i\). Note that calculating the optimal rank r subspace for each group in \({\mathcal {L}}_i(\mathbf {U}_i^*)\) has a one-time overhead to the algorithm’s time complexity overall. However, we ignore this overhead, as did other algorithms we are comparing to and leave the joint learning of both local and global subspaces as future work. We also note that here our goal is to learn a single projection matrix for different sensitive groups.
Using the Definition 2, we can define a fair PCA algorithm as follows:
Definition 3
(Fair PCA) A PCA algorithm with projection matrix \(\mathbf {U}^*\) is called fair, if the disparity error among different groups are equal. That is:
A subspace \(\mathbf {U}^*\) that archives the same disparity error for all groups is called a fair subspace.
4 Pareto fair subspace
In this section, we discuss the key challenges in finding a fair subspace using relaxation methods and motivate our formulation of Pareto fair subspace followed by providing conditions sufficient to guarantee the existence of such subspaces.
4.1 Relaxation methods and their limitations
A major challenge to find a fair subspace as defined in Definition 3 is to solve the optimization problem that satisfies (5), which is essentially a multiple objective optimization problem by nature. To illustrate this and for ease of exposition, let us focus on the binary sensitive feature (\(k = 2\)), i.e., there are only two groups in the sensitive feature of the data (e.g., male and female), in which the goal of fair PCA is to satisfy:
Samadi et al. (2018), it has been shown that by casting the multiobjective optimization problem as a minmax problem of the form
and using an additional dimension for the projection, the optimal solution of minmax problem results in the same loss for both groups (i.e., \({\mathcal {E}}_1\left( \mathbf {U}^*\right) = {\mathcal {E}}_2\left( \mathbf {U}^*\right) )\). As discussed by Tantipongpipat et al. (2019), the fair PCA problem is NP-hard problem, hence, a relaxation is required to solve this problem in a polynomial time to achieve an \(\epsilon\)-fair solution.
Motivated by this observation, a semi-definite relaxation to solve the optimization problem is proposed, which is not efficient for a large number of training samples. Also, to achieve their fairness criteria and ensure that the obtained local solution achieves the optimal fairness objective for all groups, the proposed solution requires adding an extra dimension for a binary sensitive feature and \(k-1\) additional dimensions for a k-group sensitive feature, which is not reasonable for a large k. We note that in Tantipongpipat et al. (2019), the requirement of extra dimension is improved to \(\lfloor \sqrt{2k+\frac{1}{4}} - \frac{3}{2}\rfloor\), but it still requires extra projection dimensions to satisfy the fairness constraint. Finally, the optimal trade-offs between fairness objectives and total reconstruction loss, in the case of the same target dimension, is not guaranteed, which would lead to a solution that sacrifices too much of the total reconstruction loss to achieve the fairness criteria. In fact, in order to guarantee that the solution of minmax optimization results in a rank r subspace with optimal fairness objective, one could choose the target dimension to be \(r-s\), where s is the extra dimensions needed with \({\mathcal {O}}\left( \sqrt{k}\right)\) followed by a rounding to reach to the target r dimensional subspace as proposed in Tantipongpipat et al. (2019); but this remedy hurts the optimal objective value by a multiplicative factor of s/r. This issue becomes more concerning as the number of groups k, and hence s increases due to the fact that all local optimal solutions might not achieve the same loss for all groups. Consequently, any solution to fair PCA necessitates jointly minimizing the main objective, which is total reconstruction loss in (2), and fairness criteria to balance the trade-off between them.
An alternative solution to alleviate aforementioned issues which is explored in Donini et al. (2018) is to impose fairness constraints in minimizing the reconstruction loss in (1) as additional constraints, i.e.,
which reduces the problem into an instance of non-convex constrained optimization problem to find a fair subspace to all sensitive groups. Relaxing the problem of finding the fair subspace as a constrained optimization similar to (8), apart from being a hard non-convex problem which is not evident to solve due to presence of non-convex constraints, requires the optimal constraint violation parameter, \(\varvec{\epsilon }\), to be decided heuristically which is a burden on the use and makes the problem even harder. Although using the Lagrangian method we can turn the problem into an unconstrained non-convex optimization problem– a method known as scalarization relaxation for multi-objective optimization counterpart (e.g., please see Ehrgott 2006), deciding the Lagrangian multipliers is as hard as solving the original problem and does not guarantee the optimally of the obtained solution. Also, since the scale of the objectives might be different, it could lead to infeasibility issues in the optimization problem, or some points from the Pareto frontier could not be attained.
To address challenges arising from the above reduction methods, and in order to achieve the optimal trade-offs between objectives and satisfy equality between disparity errors, we aim at directly solving the multi-objective programming (Miettinen 2012). Towards this end, we note that the optimization problem in (8) is a relaxation of the following generalized multi-objective optimization problem:
where \(\psi (\cdot ):{\mathbb {R}}\rightarrow {\mathbb {R}}_{+}\) is any penalization function, such as \(\psi (z)=|z|\), \(\psi (z)=\frac{1}{2}z^2\), or \(\psi (z)=e^{-z}\), however, for convergence analysis we will stick to squared or exponential penalization due to their smoothness. We will use the smoothness property of the overall objective in the convergence analysis. In Appendix C, we show the effect of the penalization function on the smoothness of the overall objective. We will define the optimization problem in more detail in the next section and then will introduce an adaptive gradient descent approach to solve it.
4.2 Pareto fair subspace
To characterize the solutions obtained by directly solving the multi-objective optimization problem in (9), we have to compare the objective vector of different solutions with each other, analogous to the what we do in a scalar or single-objective optimization problem. If we only have a single objective function \(f(\mathbf {U})\), we can say the solution \(\mathbf {U}_1\) is better than \(\mathbf {U}_2\) if \(f(\mathbf {U}_1) < f(\mathbf {U}_2)\). Similarly, in multi-objective programming, we define the notion of dominance as follows:
Definition 4
(Dominance) Let \({\mathbf{f}}(\mathbf {U}) = \left[ {f}_1(\mathbf {U}), \ldots , f_m(\mathbf {U})\right] ^\top\) denote a vector-valued objective function with m objectives. We say the solution \(\mathbf {U}_1\) dominates the solution \(\mathbf {U}_2\) if \({f}_i(\mathbf {U}_1) \le {f}_i(\mathbf {U}_2)\) for all \(i \in \left[ m\right]\), and \({f}_j(\mathbf {U}_1) < {f}_j(\mathbf {U}_2)\) for at least one \(j \in \left[ m\right]\). We denote this dominance as:
The definition of dominance implies that when a solution cannot be dominated by any other solution in the search space, we cannot find any direction, to move to, from this solution without at least hurting one objective in the objective vector. The reader can refer to Miettinen (2012) for more explanation regarding the definition of dominance in vector optimization. Using this, now, we can define our notion of Pareto fair subspace as follows:
Definition 5
(Pareto Fair Subspace) Let \({\mathbf {f}}(\mathbf {U}) = \left[ {\mathcal {L}}(\mathbf {U}), {f}_1(\mathbf {U}), \ldots , f_{m-1}(\mathbf {U})\right] ^\top\) denote a vector-valued objective function with m objectives in the Fair PCA problem. Then, consider a set of fairness trade-off objectives \({f}_{i}(\mathbf {U}), i \in \left[ m-1\right]\), (e.g. \(\psi \left( {\mathcal {E}}_i\left( \mathbf {U}\right) \right)\) as in (9)) that ought to be minimized in addition to the main objective, \({\mathcal {L}}(\mathbf {U})\). The solution \(\mathbf {U}^*\) is called Pareto fair subspace, if it is not dominated by any other feasible solution.
The Pareto fair subspace is not unique, and the set of Pareto optimal solutions is called Pareto frontier (Miettinen 2012). Thereupon, the ultimate goal of a fair PCA reduces to finding a Pareto optimal solution via solving the problem (9).
4.3 Proof of existence
The following theorem establishes the conditions under which the set of Pareto optimal solutions exists and is non-empty. We emphasize that compared to methods that optimize Lagrangian function or other scalarization approaches, we aim at finding this Pareto fair frontier completely without any prior information such as weight for each objective.
Theorem 1
(Existence) Consider the vector-valued optimization problem in (9). If the individual functions are convex and bounded, then the set of Pareto optimal solutions is non-empty.
Proof
The proof is deferred to Appendix A. \(\square\)
To guarantee the existence of a Pareto optimal solution, in Sect. 5, we convexify the objectives by properly regularizing them. Thereafter, we propose an efficient gradient-based algorithm to find a subspace that is a Pareto stationary point of the fair PCA problem.
Although solving the optimization problem in (9) results in an efficient trade-off between different objectives, this does not reflect on balanced disparity errors among different groups, which is the ultimate goal of the fair PCA problem. As been explained by Samadi et al. (2018), this issue would be exacerbated in problems with \(k > 2\), that having a balanced disparity error among all groups is not always possible due to the fact that all optimal solutions will not incur the same loss for all groups. To alleviate this issue and ensure that the loss of each group remains at most the optimal fairness objective in the original target dimension r, we introduce the notion of pairwise disparity error, that would address this issue.
Definition 6
(Pairwise Disparity Error) Consider the disparity errors for any projection matrix \(\mathbf {U}\) and sensitive groups of i and j among k different groups, then the pairwise disparity error between these two groups is defined as:
Thus, the optimization in (9) becomes:
where we have \(k\atopwithdelims ()2\) objectives in addition to the main objective. The pairwise objectives in optimization problem (12) intends to minimize the difference between the disparity error of different sensitive groups. In conjunction with the main objective of reconstruction loss, we can both reduce the disparity error of each group as well as their differences among different groups by optimizing this objective. We will show the efficacy of pairwise disparity error over single disparity error in practice in Sect. 6.
5 Adaptive optimization
In this section, we will develop a gradient descent (GD) based algorithm to solve the optimization problems in (9) or (12). To lay the groundwork for this algorithm, we review how to solve the original PCA problem using gradient descent, and then we propose our proposed algorithm to solve the aforementioned multi-objective problem.
5.1 Gradient descent for PCA
To solve the PCA problem using the gradient descent approach, we need to iteratively update the projection matrix \(\mathbf {U}\), based on the gradient of the total reconstruction loss with respect to it. Expanding the total reconstruction loss in (2) and removing the constant terms that will not affect the optimization, following Shalev-Shwartz and Ben-David (2014), we can write the optimization problem:
Using (13), we can calculate the gradient of the total reconstruction loss with respect to \(\mathbf {U}\) as follows:
The projection can be learned using the gradient descent by iteratively updating an initial solution by:
where \(\eta _t\) is the learning rate and \(\varPi _{{\mathcal {P}}_r}\left( .\right)\) is the projection operator onto \({{\mathcal {P}}_r} = \left\{ \mathbf {U}\in {\mathbb {R}}^{d\times r} \,\big |\, \mathbf {U}^\top \mathbf {U}=\mathbf {I}_r \right\}\).
For a single-objective optimization like normal PCA, at each iteration, we take a step toward the negative of the gradient at that point. However, when we are dealing with multiple objectives, the key question is what would be the best direction at each iteration to take, in order to decrease all the objectives. We answer this question in the next section by proposing an optimization problem to find such a descent direction.
5.2 Pareto fair PCA

In order to efficiently solve the multi-objective optimization problem in (9) or (12), we propose a gradient descent approach, that can guarantee convergence to a Pareto stationary point. For the ease of exposition, we consider the following general multi-objective problem with m objectives:
In a single-objective problem with gradient descent method, we always choose the opposite direction of the gradient on that point as the descent direction to decrease the objective function for the next iteration point. However, this notion in multi-objective programming is more complicated, as we have to find the direction that is a descent direction for all objectives based on their gradients on that point. In order to find a descent direction, let \(\left[ \mathbf {G}_1^{(t)}, \ldots , \mathbf {G}_m^{(t)}\right]\) denote the gradient of individual objectives at point \(\mathbf {U}_t\). To find a descent direction with respect to all of the objectives at point \(\mathbf {U}_t\), we solve the following minmax optimization problem (Fliege and Svaiter 2000):
We note that for a single objective case, that is \(m=1\), the solution of above minimax is the opposite of the gradient, i.e. \(\mathbf {D}_t = -\mathbf {G}_1^{(t)}\). Using the KKT optimally conditions, it is easy to show that the dual problem becomes a quadratic programming and can be efficiently solved to identify a descent direction \(\mathbf {D}_t\), for which all the objectives are non-increasing. The following lemma states this characteristic of the descent direction:
Lemma 1
(Descent Direction) The solution found in the optimization problem (18) has one of the following two conditions. Either \(\mathbf {D}_t = \mathbf {0}\), which means the point \(\mathbf {U}_t\) is a Pareto stationary point, or \(\mathbf {D}_t\) is a descent direction to all objectives, that is:
Then, the obtained descent direction is in the form of \(\mathbf {D}_t = -\sum _{i=1}^m \lambda _i^{(t)} \mathbf {G}_i^{(t)}\), where \(\sum _{i=1}^m \lambda _i^{(t)} = 1\) and \(\lambda _i^{(t)} \ge 0\) for \(1 \le i \le m\).
Proof
The proof is provided in Appendix B. \(\square\)
As elaborated in the proof in Appendix B, the theorem implies that the descent direction is the minimum norm matrix in the convex hull of the gradients of all objectives and is the non-increasing direction with respect to each objective. Understanding this, the following corollary is palpable:
Corollary 1
The first order Pareto stationary point holds for a solution \(\mathbf {U}\) when the mentioned minimum norm is zero, i.e., there is no descent direction that is non-increasing for all objectives. In other words, there exists a \({\varvec{\lambda }}\in \varDelta _m\) such that \(\mathbf {D} = -\sum _{i=1}^m {\lambda }_i \mathbf {G}_i = \mathbf {0}\) where \(\mathbf {G}_i = \nabla f_i(\mathbf {U})\).
Having a descent direction at hand, we can use it to decrease all the objectives in every iteration, similar to the procedure defined in Algorithm 1. Based on the first-order optimality condition of this problem, we know that at a Pareto optimal solution, the direction found in (18) should be \(\mathbf {0}\), meaning, that it cannot further improve any objective without hurting others. Equipped with this descent direction and first-order optimality condition, we can iteratively update the initial solution in the direction of the descent direction, until it converges to a Pareto stationary point.
Remark 1
One crucial step before finding the descent direction is to balance out the scale of different gradients. Since they are calculated based on very different and possibly contradictory objective functions, their Frobenius norm would vary a lot; hence, by a normalization step, we can avoid the dominance of the descent direction by some gradients with high Frobenius norm.
Since the disparity errors, as well as the main PCA objective, are weakly convex functions, following Theorem 1, to guarantee the existence of Pareto optimal subspace, we add a regularization term to each objective to make them convex functions– with which we also stabilize the solutions and guarantee convergence. As a result, the optimization in (12) becomes:
where \(\alpha\) is the regularization parameter to make the Hessian matrices of objectives positive semi-definite and needs to be decided based on the maximum eigen-gap between covariance matrices of each pair of sensitive groups. Having k different groups, each with data matrix of \(\mathbf {X}_i\), \(i \in [k]\), we set \(\gamma =\underset{i,j \in [k]}{\max } \gamma _d\left( \mathbf {X}_i^\top \mathbf {X}_i \right) - \gamma _1\left( \mathbf {X}_j^\top \mathbf {X}_j\right)\) to denote the maximum eigen-gap. Then, we should have \(\alpha \ge \gamma\). We now turn to prove the convergence rate of Algorithm 1 for convex objectives, as stated in the following theorem.
Theorem 2
(Convex Objectives) Let \({\mathbf {f}} = \left[ f_1(\mathbf {U}),\ldots ,f_m(\mathbf {U}) \right]\) be convex component-wise Lipchitz continuous with constants \(L_1, L_2, \ldots , L_m\). Then, for the sequence of the solutions \(\mathbf {U}_1,\ldots ,\mathbf {U}_T\) generated iteratively by Algorithm 1, and the sequence of \(\hat{\varvec{\lambda }}^{(1)},\ldots ,\hat{\varvec{\lambda }}^{(T)}\) generated by (38) during T iterations, by setting \(\eta =\frac{R}{L\sqrt{T}}\) and \(\beta = \sqrt{T}/R\), we have:
where \(R^2 = \Vert \mathbf {U}_1 - \mathbf {U}^* \Vert ^2_{\mathrm {F}}\), \(L = \max _{i=1, \ldots , m} L_i\), \({\bar{\lambda }}_i = \frac{1}{T}\sum _{t=1}^T {\hat{\lambda }}_i^{(t)}\), and \(\mathbf {U}^*\) is a Pareto efficient solution.
Proof
The detailed proof is deferred to Appendix C. \(\square\)
Remark 2
As explained in Appendix C, the learning rate is set in order to match convergence rate of the error term with \({\mathcal {O}}\left( \frac{1}{\sqrt{T}}\right)\). By setting the learning rate as suggested by the Theorem 2, we can set the \(\beta\) to a number that the condition in (16) is satisfied using smoothness assumption.
Theorem 2 indicates that, using the Pareto descent direction, we can achieve an \(\epsilon\)-accurate Pareto efficient solution with taking \({\mathcal {O}}\left( \frac{1}{\epsilon ^2}\right)\) gradient descent steps. Using (21), we can bound the average deviation of each objective from its respective value in the Pareto efficient solution of \(\mathbf {U}^*\).
Remark 3
We note that Algorithm 1 is guaranteed to converges to a single Pareto fair subspace, starting from a fixed initial solution \(\mathbf {U}_0\). Using different random starting points, we can find different Pareto fair subspaces and form the Pareto fair frontier of the problem. From an algorithmic point of view, we can not distinguish between different Pareto optimal subspaces, but as discussed by Kearns and Roth (2019), based on the preference of different objectives, we can choose a desirable Pareto fair subspace from the frontier set.
We note that when the regularization is not added to convexify the main objective, we have to deal with non-convex objectives in the optimization problem. In the following theorem, we investigate the convergence of Algorithm 1 for non-convex objectives that guarantees the gradient vanishes over iterations.
Theorem 3
(Nonconvex Objectives) Let \({\mathbf {f}}(\mathbf {U}) = \left[ f_1(\mathbf {U}),\ldots ,f_m(\mathbf {U}) \right]\) be the multi-objective function to be minimized to find a fair subspace with respect to k sensitive groups. Let \(\mathbf {U}_1, \mathbf {U}_2, \ldots , \mathbf {U}_T\) be the sequence of solutions generated by Algorithm 1 updated using descent directions \(\mathbf {D}_1, \mathbf {D}_2, \ldots , \mathbf {D}_T\). Then, if we choose the regularization parameter as \(\alpha \ge \gamma\), we have the following:
where \({\mathsf {M}}_l\) is a lower bound for the values of all objective functions, \({\mathsf {M}}_u\) is the maximum of the values of all functions at initial point, and C is a constant depending on the smoothness of objectives.
Proof
The proof can be found in Appendix D. \(\square\)
An immediate consequence of the above theorem is that the gradient of Pareto descent directions vanishes and converges to zero and thereby the solutions generated by the algorithm converges to a stationary fair subspace. In particular, only \({\mathcal {O}}\left( \frac{1}{\epsilon ^2}\right)\) iterations are required to obtain an \(\epsilon\)-close fair subspace. The analysis of Theorem 3 follows the standard analysis of gradient descent for non-convex smooth optimization where the obtained bound matches the known achievable convergence rate for the norm of the gradients. We want to sketch another alternative method that results in the same rate with careful analysis. Specifically, observe that the descent direction can be considered as an inexact gradient from the viewpoint of individual functions with perturbation \({{\mathbf {D}}}_t - {{\mathbf {G}}}_i^{(t)}\). Noting that \({\mathsf {tr}}\left( {{\mathbf {D}}}_t^\top {{\mathbf {G}}}_j^{(t)}\right) \le -\left\| {{\mathbf {D}}}_t \right\| _{\text {F}}^2\) as shown in the proof of Lemma 1 and following the standard analysis of convergence of non-convex functions, we can show that norm of descent directions vanishes as algorithm proceeds, thereby the proposed algorithm can find a stationary point. However, the obtained solution is not guaranteed to be an optimal Pareto due to the non-convexity of the objectives and might be a saddle point.
5.3 Comparison with other approaches
As it was discussed, one approach to solve a multi-objective optimization is to make it constrained optimization, in which we keep the main objective and change all other objectives to inequality constraints with parameters \(\varvec{\epsilon }\). Hence, constrained optimization is a relaxation of multi-objective optimization, where finding the best constraint parameter (\(\varvec{\epsilon }\)) for each constraint could be very challenging as discussed in Donini et al. (2018). It also lacks theoretical guarantees due to the non-convex nature of constraints. Lagrangian method of multipliers is equivalent to constraint optimization problems, but not exactly to multi-objective counterpart. To see this, we note that by applying GD to Lagrangian function, the contribution of the gradient of each individual function, \(\mathbf {G}_i^{(t)}\), is weighted by its Lagrangian multiplier, while in our case the weights are adaptively learned by finding a Pareto decent direction. We note that while (Tantipongpipat et al. 2019) improves the requirement of extra dimensions over (Samadi et al. 2018), it still needs \(\lfloor \sqrt{2k+\frac{1}{4}} - \frac{3}{2}\rfloor\) extra dimensions for a k-group sensitive feature and has to solve an SDP which has the time complexity of \({\mathcal {O}}\left( d^{6.5}\log \left( \frac{1}{\epsilon }\right) \right)\) or \({\mathcal {O}}\left( d^3/\epsilon ^2\right)\) with multiplicative weight update. On the other hand, our method enjoys the efficiency of GD with an overhead to solve the quadratic problem over the simplex for finding the descent direction. Also, at each step, we need to project the solution to find the orthonormal bases for the updated solution, which could be done using SVD with an overhead of \({\mathcal {O}}\left( r^2d\right)\) or more efficiently using variance-reduced SGD (Shamir 2015). Using vanilla SVD for per-iteration projection brings the overall time complexity of the proposed algorithm to \({\mathcal {O}}\left( r^2d/\epsilon ^2\right)\). We note that the convex formulation in Olfat and Aswani (2018) also requires solving an SDP programming (e.g., ellipsoid method to interior point method), which suffers from high computational cost as well.
This is for the first time that we are solving the exact multi-objective problem, rather than its min-max relaxation using SDP in a fairness problem. Tantipongpipat et al. (2019) is suggesting that for \(k=2\) their approximation is exact, meaning their algorithm will find the fair representation in the exact r dimension they aim to reach. However, in practice, even for \(k=2\), we can show that our algorithm can achieve a smaller disparity error, as shown in Fig. 2, which indicates that pairwise disparity error can achieve a better subspace in terms of fairness. For \(k>2\), they are still solving an inefficient SDP problem to exact same problem we are proposing. Hence, the novelty of our approach lies in solving this problem using gradient descent and ensuring to reach a Pareto stationary point, which even does not require extra dimensions to satisfy fairness. This setting and its proposed gradient descent algorithm to solve it can be applied to other unsupervised and supervised fairness problems. Thus, it could open up new perspectives on all other fairness problems in learning tasks, by advocating optimal trade-offs between main learning objectives and fairness criteria using Pareto efficiency.
6 Experiment
In this section, we empirically examine the introduced algorithm for fair PCA with the Adult datasetFootnote 1 and the Credit dataset.Footnote 2 The Adult dataset consists of census data to predict whether the income of a person exceeds 50K per year or not. The Credit dataset contains clients’ credit history information to predict whether they would default in the future or not. For PCA, we will omit the label data and work with the rest of it, which contains 14 feature space dimension for the Adult dataset, including gender and race, which we consider as sensitive features in this dataset. In the Credit dataset, we will have 23 feature space dimension, including sensitive features of sex and marriage. The gender feature in the Adult dataset and sex in the Credit dataset are binary features with two values, namely, Male and Female. Race from the Adult dataset, on the other side, is a multiple group feature, with 5 different groups, including White, Asian-Pac-Islander, Amer-Indian-Eskimo, Black, and Other. Marriage in the Credit dataset is also a multiple group feature with 3 groups of Single, Married, and Other.
For the Adult dataset, we use the training dataset, which has 32, 561 number of samples, among which 10, 548 belongs to the Female group and 22, 013 to the Male group. The distribution of samples among race groups are as follows: Black 30, 47, White 27, 994, Asian-Pac-Islander 312, Amer-Indian-Eskimo 962, and Other 246. In the Credit dataset, we have 30, 000 training samples, out of which there are 18, 112 Female and 11, 888 Male samples. The distribution of the Marriage feature is 13, 659 married, 15, 964 single, and 323 other samples. We first apply the fair PCA method to binary sensitive feature, in which we set the learning rate to a decreasing sequence of \(1/\sqrt{t}\), where t is the iteration number. This condition on the learning rate satisfies the maximum decrease condition by backtracking line search in (16) as well.
6.1 Binary sensitive feature

Applying normal PCA and fair PCA to the Adult dataset with gender as its sensitive feature. The first two figures show the reconstruction error of normal PCA (trained on all data) applied to each group, fair PCA (trained on all data) applied to each group, and normal PCA trained on the data of each group individually. The last figure reveals the difference between normal and fair PCA reconstruction loss on all data, which is very tiny and negligible
In the Adult dataset, we observed that the Female group is benefiting from normal PCA on the whole dataset, while the Male group is sacrificing its reconstruction error. Hence, by applying the Fair PCA algorithm, we can perfectly decrease these trade-offs, while suffering an insignificant loss to the total reconstruction error, compared to normal PCA. The results are depicted in Fig. 1, where the trade-offs and how Fair PCA is addressing them is noticeable. To compare the introduced Pareto fair PCA with algorithms using SDP in Samadi et al. (2018) and Tantipongpipat et al. (2019), we will use the average disparity errors across sensitive groups in both Adult and Credit datasets. Fig. 2 shows the average disparity errors of Pareto fair PCA with single and pairwise disparity error objectives, SDP fair PCA, and normal PCA on binary features (gender and sex) of Adult and Credit datasets. First, it reveals that there is a huge gap between normal PCA and fair PCA algorithms in terms of disparity errors, which is indicating that these algorithms are decreasing this disparity error. Second, it shows the superiority of Pareto fair PCA over SDP relaxation methods in both datasets (especially with pairwise objectives), where Pareto fair PCA has a smaller average disparity error close to zero. Also, to show that what is the exact price of fairness that each algorithm pays, we show the total reconstruction loss of our algorithm and other fair PCA methods with respect to normal PCA in Fig. 3. It can be noted that the Pareto fair PCA incurs a slight degradation in total reconstruction loss in exchange for fairness, while this price is much higher in the other state-of-the-art algorithms. In addition to the trade-off between reconstruction error and fairness, Fig. 4, we compare the time complexity of these two fair PCA algorithms. We should note that, the main algorithm proposed by Samadi et al. (2018) and Tantipongpipat et al. (2019) is based on SDP, which is highly inefficient. In fact, they use multiplicative weight approach with linear programming instead of the SDP, which greatly reduces their computational complexity. However, their computational complexity is still higher than our approach based on the convergence analysis. In reality, this difference, can be well spotted in datasets that have a very large feature dimension. However, both the Adult and Credit datasets do not have a very large feature dimension. We run the experiments for both datasets to reduce the feature space dimension to 1, and repeat the experiments 10 times, to calculate the time complexity of both algorithms. The results are depicted in Fig. 4, which can show that in even these two small datasets, our algorithm can converge faster to the solution.

Comparing Pareto fair PCA algorithm introduced in this paper (pairwise and single disparity error) with fair PCA algorithms using SDP relaxation introduced in Samadi et al. (2018) and Tantipongpipat et al. (2019). The experiment is on binary features of Adult and Credit datasets (gender and sex). The average disparity error of algorithms on the Adult dataset clearly shows the superiority of the Pareto fair PCA with pairwise disparity error objectives and then the single disparity error objectives. In the Credit dataset, Pareto fair PCA with pairwise objectives has a slightly better performance with respect to two other methods

Comparing the total reconstruction loss of Pareto fair PCA algorithm introduced in this paper (with pairwise objectives), with fair PCA algorithms using SDP relaxation introduced in Samadi et al. (2018) and Tantipongpipat et al. (2019). The experiment is on binary features of Adult and Credit datasets (gender and sex). From both figures, it can be inferred that Pareto fair PCA satisfies the fairness objective better, while it incurs a tiny increase in the total reconstruction loss with respect to the normal PCA. On the other hand, Fair PCA with SDP suffers from a huge increase in the total reconstruction loss to satisfy the fairness objective

Comparing the time complexity of Pareto fair PCA algorithm introduced in this paper with fair PCA algorithms using SDP relaxation introduced in Samadi et al. (2018); Tantipongpipat et al. (2019) on the Adult and Credit datasets. The experiment shows the time required for each algorithm to find a 1-dimensional subspace in both datasets
6.2 Multiple group sensitive feature
The proposed Algorithm 1, can efficiently generalize to the multiple group sensitive features, by adding pairwise disparity errors of each pair of groups to the objective vector and minimize the overall vector to reach a Pareto optimal or stationary point. However, adding more objectives, introduces more trade-offs, makes the optimization over all objectives more difficult.
First, we start with the Adult dataset with race as the sensitive feature. In this dataset, race has 5 categories, makes it a multiple group sensitive feature. The reconstruction error of the Pareto fair PCA and normal PCA is shown in Fig. 5, where the trade-offs between benefits and sacrifices of different groups are clearly noticeable. The fair PCA algorithm can superbly decrease these trade-offs for all but one group, with a negligible increase in overall reconstruction loss. Following the same step as in the binary case, we show the disparity error of different groups in Fig. 6, which reveals that fair PCA clearly outperforms normal PCA in most of the groups. Figure 7 depicts the reconstruction loss and average disparity error of fair and normal PCA. The results indicate that even in a dataset with a multiple group sensitive feature, the increase in the reconstruction loss of fair PCA compared to the normal PCA is slim, while the gap between their disparity errors is huge. This means that normal PCA is unfairly treating different groups in its learned representation subspace.

Applying normal and fair PCA on the Adult dataset with “race” as its sensitive feature. Each plot shows the reconstruction error of the normal PCA (trained on the whole data) applied to each group’s data, fair PCA (trained on the whole data) applied to each group’s data, and normal PCA trained on each group’s data individually

Disparity error of normal and fair PCA trained on the Adult dataset with “race” as its sensitive feature. Each plot depicts the disparity errors of different groups with normal and fair PCA

Applying normal and fair PCA on the Adult dataset with “race” as its multiple group sensitive feature. Left shows the difference between reconstruction loss of fair and normal PCA, which is infinitesimal. On the other hand, the right plot shows their difference in terms of average disparity error, which is huge and demonstrating the efficacy of fair PCA in addressing fairness even in multiple group sensitive feature cases
As for the Credit dataset, we also test it on its multiple group sensitive feature, marriage, which has 3 different groups. The result of reconstruction error on Pareto fair PCA, normal PCA and normal PCA on each group’s data individually is depicted in Fig. 8, where it is clear that fair PCA is very close to each group’s PCA (except for the “other” group, because the number of samples in that group is too low), while its reconstruction error is very close to that of normal PCA. Also, the disparity error and average disparity error of fair PCA versus normal PCA is shown in Fig. 9, where the superiority of fair PCA is noticeable.

Applying normal and fair PCA on the Credit dataset with “Marriage” as its sensitive feature. Each plot shows the reconstruction error of the normal PCA (trained on the whole data) applied to each group’s data, fair PCA (trained on the whole data) applied to each group’s data, and normal PCA trained on each group’s data individually. The last figure shows the reconstruction error of normal PCA and fair PCA on this dataset with multiple group sensitive feature of marriage

Disparity error of normal and fair PCA trained on the Credit dataset with “Marriage” as its sensitive feature. Each plot depicts the disparity errors of different groups with normal and fair PCA. The last figure shows the average of disparity errors across groups
6.3 Fairness in composition
Most of the time, when we use a dimension reduction algorithm, it is accompanied by some downstream tasks such as classifiers. Hence, it is important to investigate the effects of our fairness dimension reduction algorithm on those downstream tasks. Here, we empirically examine this effect on a simple classifier. The ultimate goal of this experiment is to show how neglecting the fairness in an unsupervised task such as dimension reduction can affect the supervised downstream task. The designed experiment intends to evaluate the effects of Pareto fair PCA on systems in composition as well as in isolation, which have been explored in previous part.
To that end, we use both the Adult and Credit datasets and first reduce the dimension of their feature space to 10, and then use the new projection to learn a standard linear SVM (Cortes and Vapnik 1995) model. The SVM model aims to learn a hyper-plane in the decision space that has the largest distance to the nearest datapoints. One standard fairness measure in the supervised domain is called Equality of Opportunity (Hardt et al. 2016), where the goal is to ensure that the true positive rate among different sensitive features does not differ significantly. For a binary sensitive group (Donini et al. 2018) introduced a measure called difference of equality of opportunity, which is \(\text {DEO} = | \texttt {TP}_1 - \texttt {TP}_2|\) with \(\texttt {TP}_i\) representing true positive rate of the ith group in a sensitive feature. This measure shows the gap between the two groups’ true positive rates. As can be inferred from Fig. 10, applying Pareto fair PCA can boost fairness of the downstream model and dramatically drop the gap between two groups’ true positive rates (DEO) with respect to the normal PCA.

The effect of Pareto fair PCA on a downstream SVM classification task. The first row is using the Adult dataset with gender as its sensitive feature, and the second row is using the Credit dataset with sex as its sensitive feature. In both datasets, we reduce their feature space dimension to 10 once using normal PCA and once using Pareto fair PCA. Then use the new representation to learn a linear SVM. Column a is the accuracy among different groups, b is the true positive rate, and c is the DEO introduced by Donini et al. (2018) (the lower is better), all on the test dataset. It clearly can be noted that applying Pareto fair PCA can reduce the gap between true positive rates of different groups and enhance the fairness of downstream models
7 Conclusion
In this paper, we cast the fairness problem in dimension reduction algorithms such as PCA as a multi-objective programming. Unlike supervised learning, there is not a clear definition of fairness in unsupervised learning tasks. Thus, we use the notion of balancing between sacrifices and benefits each sensitive group makes or enjoys to define a fairness metric for this problem. These sacrifices or benefits are the consequence of finding the optimal subspace over the whole data rather than using only each protected group’s data. Hence, the notion of fairness is to have an equal contribution from each group to the overall reconstruction loss with respect to the reconstruction loss they have on the subspace learned by their own data. This introduces a trade-off between these contributions and overall reconstruction loss. We propose an efficient multi-objective optimization procedure that can guarantee the convergence to a Pareto stationary point, which has an efficient trade-off between these objectives.
This paper also introduces some interesting problems worthy of future investigations. First, the generalization of the proposed disparity error and pairwise disparity error as fairness metrics in other dimension reduction algorithms and, also, other unsupervised learning tasks. Moreover, it is interesting to investigate the stochastic version of the proposed algorithm and its convergence analysis since finding a descent direction where gradients are noisy might be a challenging task. Also, as noted before, the existing methods, including the one proposed in the present work, require learning a local optimal projection subspace for each group before learning the global fair subspace. One interesting direction is to extend these works to efficiently learn all subspaces together while preserving the fairness of the global subspace. Also, a thorough theoretical investigation of the composition effects of the proposed fairness measure on downstream tasks such as classification is an interesting open problem. Finally, based on the nature of biases introduced by Blum and Stangl (2019), in this paper we are only focusing on the representation bias and not the labeling bias since we are not using labels in PCA. Hence, an interesting extension to this work is to consider the fairness problem in dimension reduction approaches, where they use label information as well, such as linear discriminant analysis.
References
Agarwal, A., Beygelzimer, A., Dudík, M., Langford, J., & Wallach, H. (2018). A reductions approach to fair classification. arXiv:180302453
Barocas, S., Hardt, M., & Narayanan, A. (2017). Fairness in machine learning. NIPS Tutorial.
Blum, A., & Stangl, K. (2019). Recovering from biased data: Can fairness constraints improve accuracy? arXiv:191201094
Calders, T., & Verwer, S. (2010). Three Naive Bayes approaches for discrimination-free classification. Data Mining and Knowledge Discovery, 21(2), 277–292.
Calders, T., Kamiran, F., & Pechenizkiy, M. (2009). Building classifiers with independency constraints. In IEEE International Conference on Data Mining Workshops (pp. 13–18).
Cortes, C., & Vapnik, V. (1995). Support-vector networks. Machine Learning, 20(3), 273–297.
Creager, E., Madras, D., Jacobsen, J. H., Weis, M. A., Swersky, K., Pitassi, T., & Zemel, R. (2019). Flexibly fair representation learning by disentanglement. arXiv:190602589
Cunningham, J. P., & Ghahramani, Z. (2015). Linear dimensionality reduction: Survey, insights, and generalizations. The Journal of Machine Learning Research, 16(1), 2859–2900.
Das, I., & Dennis, J. E. (1997). A closer look at drawbacks of minimizing weighted sums of objectives for pareto set generation in multicriteria optimization problems. Structural Optimization, 14(1), 63–69.
Donini, M., Oneto, L., Ben-David, S., Shawe-Taylor, J. S., & Pontil, M. (2018). Empirical risk minimization under fairness constraints. In Advances in neural information processing systems (pp. 2791–2801).
Dwork, C., & Ilvento, C. (2018). Fairness under composition. arXiv:180606122
Dwork, C., Hardt, M., Pitassi, T., Reingold, O., & Zemel, R. (2012). Fairness through awareness. Proceedings of the 3rd innovations in theoretical computer science conference (pp. 214–226).
Dwork, C., Immorlica, N., Kalai, A. T., & Leiserson, M. (2018). Decoupled classifiers for group-fair and efficient machine learning. In Conference on fairness, accountability and transparency (pp. 119–133).
Ehrgott, M. (2006). A discussion of scalarization techniques for multiple objective integer programming. Annals of Operations Research, 147(1), 343–360.
Feldman, M., Friedler, S. A., Moeller, J., Scheidegger, C., & Venkatasubramanian, S. (2015). Certifying and removing disparate impact. In Proceedings of the international conference on knowledge discovery and data mining (pp. 259–268). ACM SIGKDD.
Fliege, J., & Svaiter, B. F. (2000). Steepest descent methods for multicriteria optimization. Mathematical Methods of Operations Research, 51(3), 479–494.
Fonseca, C. M., Fleming, P. J., Zitzler, E., Deb, K., & Thiele, L. (2003). Evolutionary multi-criterion optimization. Berlin: Springer.
Ghili, S., Kazemi, E., & Karbasi, A. (2019). Eliminating latent discrimination: Train then mask. Proceedings of the AAAI Conference on Artificial Intelligence, 33, 3672–3680.
Goh, G., Cotter, A., Gupta, M., & Friedlander, M. P. (2016). Satisfying real-world goals with dataset constraints. In Advances in neural information processing systems (pp. 2415–2423).
Hardt, M., Price, E., & Srebro, N., et al. (2016). Equality of opportunity in supervised learning. In Advances in neural information processing systems (pp. 3315–3323).
Kamani, M. M., Farhat, F., Wistar, S., & Wang, J. Z. (2016). Shape matching using skeleton context for automated bow echo detection. In IEEE International Conference on Big Data (pp. 901–908).
Kamani, M. M., Farhat, F., Wistar, S., & Wang, J. Z. (2018). Skeleton matching with applications in severe weather detection. Applied Soft Computing, 70, 1154–1166.
Kamani, M. M., Farhang, S., Mahdavi, M., & Wang, J. Z. (2019). Targeted meta-learning for critical incident detection in weather data. In International Conference on Machine Learning, Workshop on “Climate Change: How Can AI Help?”.
Kamiran, F., & Calders, T. (2009). Classifying without discriminating. In 2009 2nd international conference on computer (pp. 1–6). IEEE: Control and Communication.
Kamishima, T., Akaho, S., & Sakuma, J. (2011). Fairness-aware learning through regularization approach. In IEEE International Conference on Data Mining Workshops (pp. 643–650).
Kannan, S., Roth, A., & Ziani, J. (2019). Downstream effects of affirmative action. In Proceedings of the Conference on Fairness, Accountability, and Transparency (pp. 240–248).
Kearns, M., & Roth, A. (2019). The ethical algorithm: The science of socially aware algorithm design. Oxford University Press.
Lipton, ZC., Chouldechova, A., & McAuley, J. (2017). Does mitigating ml’s disparate impact require disparate treatment? Stat 1050: 19.
Mahdavi, M., Yang, T., & Jin, R. (2013). Stochastic convex optimization with multiple objectives. In: Advances in neural information processing systems (pp. 1115–1123).
Miettinen, K. (2012). Nonlinear multiobjective optimization (Vol. 12). Springer.
Munoz, C. (2016). Of the President EO, , Director DPC, of Science MUCTOSO, Policy)) T, for Data Policy DDCTO, of Science CDSPO, Policy)) T Big data: A report on algorithmic systems, opportunity, and civil rights. Executive Office of the President.
Olfat, M., & Aswani, A. (2018). Convex formulations for fair principal component analysis. arXiv:180203765.
Pleiss, G., Raghavan, M., Wu, F., Kleinberg, J., & Weinberger, K. Q. (2017). On fairness and calibration. In Advances in neural information processing systems (pp. 5680–5689).
Samadi, S., Tantipongpipat, U., Morgenstern, J. H., Singh, M., & Vempala, S. (2018). The price of fair pca: One extra dimension. In Advances in neural information processing systems (pp. 10976–10987).
Shalev-Shwartz, S., & Ben-David, S. (2014). Understanding machine learning: From theory to algorithms. Cambridge University Press.
Shamir, O. (2015). A stochastic pca and svd algorithm with an exponential convergence rate. In International Conference on Machine Learning (pp. 144–152).
Tantipongpipat, U., Samadi, S., Singh, M., Morgenstern, J. H., & Vempala, S. (2019). Multi-criteria dimensionality reduction with applications to fairness. In Advances in neural information processing systems (pp. 15161–15171).
Ustun, B., Liu, Y., & Parkes, D. (2019). Fairness without harm: Decoupled classifiers with preference guarantees. In International Conference on Machine Learning (pp. 6373–6382).
Yao, S., & Huang, B. (2017). Beyond parity: Fairness objectives for collaborative filtering. In Advances in Neural Information Processing Systems (pp. 2921–2930).
Zafar, M. B., Valera, I., Rodriguez, M. G., & Gummadi, K. P. (2015). Fairness constraints: Mechanisms for fair classification. arXiv:150705259
Zafar, M. B., Valera, I., Rodriguez, M. G., & Gummadi, K. P. (2017a). Fairness beyond disparate treatment and disparate impact: Learning classification without disparate mistreatment. In Proceedings of the International Conference on World Wide Web (pp. 1171–1180).
Zafar, M. B., Valera, I., Rodriguez, M. G., Gummadi, K., & Weller, A. (2017b). From parity to preference-based notions of fairness in classification. In Advances in neural information processing systems (pp. 229–239).
Funding
Not applicable.
Author information
Authors and Affiliations
Contributions
All authors, Mohammad Mahdi Kamani, Farzin Haddadpour, Rana Forsati, and Mehrdad Mahdavi, contributed to this work.
Corresponding author
Ethics declarations
Conflict of interest
Not applicable.
Ethics approval
Not Applicable
Consent to participate
Not applicable.
Consent for publication
Not applicable
Availability of data and material
The data used in this paper are publicly available and appropriate references are cited for those datasets in Sect. 6.
Code availability
The Python implementation of the proposed algorithm is available upon request from the corresponding author. It will be publicly available at https://github.com/mmkamani7/FairPCA later.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Editors: João Gama, Alípio Jorge, Salvador García.
Appendices
Appendix A: Proof of Theorem 1
Proof
Consider the following constrained optimization problem:
where \(\widetilde{\mathbf {U}}\) is any feasible subspace. By assuming that \(f_i(.)\) is convex for \(i \in \left[ m\right]\), if there is no finite maximum value for this optimization, then the set of proper Pareto optimal solutions is empty. The main immediate implication of this theorem is that if the objectives are bounded, then a Pareto optimal solution exists for this optimization problem. More specifically, if the solution of this optimization is the objective value of zero, then the \(\widetilde{\mathbf {U}}\) is a Pareto optimal solution. To prove this theorem, we consider \(\mathbf {U}^*\) to be a proper Pareto optimal solution to the problem (23), then there exists a vector \(\varvec{\lambda } \in {\mathbb {R}}^m_{+}\), such that the point \(\mathbf {U}^*\) is a Pareto optimal solution to the problem:
Then, from the Pareto optimality we have for every feasible \(\mathbf {U}\):
By setting \(\mathbf {U} = \widetilde{\mathbf {U}}\), we can write:
Also, from the optimization problem (23) since there is not a finite maximum objective value available, for every \({\widehat{M}} \ge 0\) we can find a \(\widehat{\mathbf {U}}\) such that:
Then, if we set \(\lambda _{\text {min}} = \min \left\{ \lambda _1,\ldots ,\lambda _m\right\}\), we have:
If the \(\widehat{\mathbf {U}}\) is chosen to satisfy \(\lambda _{\text {min}}{\widehat{M}} = M^\dagger\), then we have:
which contradicts the assumption of Pareto optimality of \(\mathbf {U}^*\), and hence, Pareto optimal set is empty. \(\square\)
Appendix B: Proof of Lemma 1
Proof
The proof is straightforward and directly follows from KKT optimally conditions for problem (30), however, we show the derivation here for completeness.
First, we note that the minmax optimization problem introduced in (19) to find the descent direction \({{\mathbf {D}}}_t\), can be rewritten as the following equivalent constrained optimization problem:
Forming the Lagrangian of the constrained problem as follows
and writing the KKT conditions gives:
From (32) we have the following that holds for the descent direction:
where \(\varvec{\lambda }^{(t)}=\left[ \lambda _1^{(t)},\ldots ,\lambda _m^{(t)}\right] ^\top\) belongs to \(\varDelta _m\)– the m-dimensional simplex. By plugging these conditions back to the main problem, the dual problem can be simplified as:
By solving the dual problem, which is a quadratic programming and using (37) we can find the descent direction from optimal dual variables.
Next, we need to show that the obtained direction is either \(\mathbf {0}\) or a descent direction to all objectives. If the point \(\mathbf {U}_t\) is a Pareto stationary point, then it means that we cannot find a direction that can decrease all the objectives, without increasing one. Hence, there is no such a \({{\mathbf {D}}}\) that \({\mathsf {tr}}\left( {{\mathbf {D}}}^\top {{\mathbf {G}}}_i^{(t)}\right) \le 0\) for all \(1 \le i \le m\), unless \({{\mathbf {D}}} = \mathbf {0}\). For points that are not Pareto stationary, consider the following quadratic optimization for every \(1 \le j \le m\):
We can see that this optimization problem is equivalent to the optimization problem in (38), with \(\lambda _i = \beta {\hat{\lambda }}_i\) for \(1\le i \le m, \; i\ne j\), and \(\lambda _j = 1 - \beta (1-{\hat{\lambda }}_j)\). This means that the optimum of the quadratic optimization in (39) happens at \(\beta =1\). Then by using the first order optimally condition at optimum point we get:
which clearly shows that \({{\mathbf {D}}}_t\) is a descent direction for all objectives. \(\square\)
Appendix C: Proof of Theorem 2
To prove the Theorems 2 and 3 , we first need to show that by properly choosing the regularization parameter \(\alpha\) our objectives are smooth. Recall that, our goal is to solve the following multi-objective optimization problem with non-convex components:
where \(m = 1 + {k \atopwithdelims ()2}\) with k being the number of groups in the sensitive feature. Also, recall that in the case of fair PCA, we have \(f_1(\mathbf {U}) = -\frac{1}{2}{\mathsf {tr}}\left( \mathbf {U}^\top \mathbf {X}^\top \mathbf {X}\mathbf {U}\right)\) is the overall reconstruction loss, and \(f_i(\mathbf {U}), i = 2, 3, \ldots , m\) are disparity errors for pair of groups. In what follows we use \(\Vert \cdot \Vert\) and \(\Vert \cdot \Vert _{\text {F}}\) to denote the spectral and Frobenius norms of a matrix, respectively.
To prove the theorem, we first show that all the the individual objective functions are smooth with bounded gradient (i.e., \(\mathbf { {f}}(\cdot )\) is component-wise smooth), conditioned that the regularization parameter \(\alpha\) satisfies \(\alpha \ge \underset{i,j \in [k]}{\max } \gamma _d\left( \mathbf {X}_i^\top \mathbf {X}_i \right) - \gamma _1\left( \mathbf {X}_j^\top \mathbf {X}_j\right)\) (recall that \(\gamma _d(\cdot )\) is the smallest eigenvalue of input PSD matrix). To this end, we follow the definition of the smooth functions, i.e., \(\Vert \nabla f(\mathbf {U}) - \nabla f(\mathbf {V})\Vert _{\text {F}} \le L \Vert \mathbf {U} - \mathbf {V}\Vert _{\text {F}}^2\).
In particular, for \(f_1(\mathbf {U})\) we have:

where the first inequality ① follows from the fact that for any two matrices \(\mathbf {A}\) and \(\mathbf {B}\) it holds that \(\Vert \mathbf {A} \mathbf {B}\Vert _{\text {F}} \le \Vert \mathbf {A}\Vert \Vert \mathbf {B}\Vert _{\text {F}}\), and ② follows from the definition of spectral norm. The above inequality indicates that the objective corresponding to the overall reconstruction error is smooth with parameter \(\gamma _{\max }(\mathbf {X}^{\top }\mathbf {X})\).
To show the smoothness of disparity errors, for simplicity, we only focus on one of the objectives between a single pair of sensitive features, say \(s_i, s_j\), as the argument easily generalizes to other objectives/pairs due to symmetry. We also drop the subscript from function and use \(f(\mathbf {U})\) to denote the regularized disparity error between groups \(s_i\) and \(s_j\) defined as
Following the definition of smoothness, we have
Again, we can further upper bound the right hand side by using the definition of the spectral norm of a matrix:
where \({\mathbb {S}}^{d-1} = \{\mathbf {x} \in {\mathbb {R}}^d \; |\; \Vert \mathbf {x}\Vert _2 = 1\}\) is the sphere in d dimensions.
As a result, as long as the regularization parameter \(\alpha\) satisfies the following condition
the disparity error objective between groups \(s_i\) and \(s_j\) is smooth with smoothness parameter \(\gamma _{\max }\left( \mathbf {X}_i^{\top }\mathbf {X}_i \right) - \gamma _{\min }\left( \mathbf {X}_j^{\top }\mathbf {X}_j \right) + \alpha > 0\). By symmetry, we can derive the smoothness condition for other pairs of groups as well, which results in the following condition on the regularization parameter:
to satisfy the smoothness of all objectives \(f_i(\cdot ), i=2, \ldots , m\). We note that one can use different regularization parameters for each pair depending on the eigen-gap between their covariance matrices as well.
We now turn to prove the convergence rate of the proposed algorithm to a Pareto fair subspace in general case as stated in (41), where we assume that the individual loss functions \(f_i(\mathbf {U}), i=1,2, \ldots , m\) satisfy Lipschitz continuous gradient condition (smoothness) with smoothness parameters \(L_i, i=1,2, \ldots , m\). We also use L to denote the maximum smoothness parameter, i.e., \(L = \max _{i=1, 2, \ldots , m} L_i\).
Proof
The proof begins by first bounding the difference in function values of each objective \(f_i\left( \mathbf {U}_{t}\right) - f_i(\mathbf {U}^*)\), individually, following the convexity assumption:
Then we can multiply both sides by \({\hat{\lambda }}_i\) and sum over i:

where in ①, as discussed by Cunningham and Ghahramani (2015), the projection on to Stiefel manifold could be considered as a two-step projection. First, a projection in to the tangent space of the manifold, and then a projection on to the manifold itself. It can be shown that this projection is a contraction operation and this inequality holds. Also, ② follows from the smoothness assumption and definition of L. By summing up above inequality for all iterations \(t=1,2,\ldots , T\) gives:
For the left hand side, since the \(f_i(\mathbf {U}_{t})\) is a decreasing function by increasing t, we can bound it by:
where \({\bar{\lambda }}_i = \frac{1}{T}\sum _{t=1}^T {\hat{\lambda }}_i^{(t)}\). By plugging (45) back into (44) we have:
where \(\Vert \mathbf {U}_{1} - \mathbf {U}^* \Vert ^2_{\text {F}} = R^2\). By setting \(\eta =\frac{R}{L\sqrt{T}}\), the convergence inequality reduces to:
We note that by setting \(\beta = \sqrt{T}/R\), the sufficient decrease condition in (16) is satisfied if the backtacking is employed. \(\square\)
Appendix D: Proof of Theorem 3
Proof of Theorem 3
The proof proceeds using the smoothness condition. In particular, for a smooth function \(f:{\mathbb {R}}^{d \times r} \mapsto {\mathbb {R}}\) with smoothness parameter L it holds that (descent lemma),
From the backtracking line search we can find the learning rate at each step that gives us the maximum decrease. To that end, we will start from \(\frac{1}{2}\) and decrease it each time by half until all the objective have a maximum decrease defined in (16). Thus, if an \(\eta\) satisfies the condition the one step before that, \(2\eta ^*\), there is at least one objective not satisfying the condition. For instance, we consider the ith objective does not satisfy the condition with \(2\eta ^*\):
Now from the Lipschitz continuity of the function as:
We proceed by combining (48) with this Lipschitz continuity (49) inequality which results in:
Also, from (40), we note that the left hand side term has a upper bound of \(-\Vert {{\mathbf {D}}}_t\Vert _{\text {F}}^2\), implying
which we can replace \(L_i\) with \(L_{\text {max}} = \underset{1\le i \le m}{\max } L_i\), to obtain the lower bound on learning rate, that is \(\eta _t \ge C_1 = \min \{1,\frac{1-\beta }{L_{\text {max}}}\}\). Hence, by the choice of learning rate, we know that at every step, we have the maximum decrease for every objective \(1\le i \le m\):

where ① comes from Lemma 1 and (40), and ② follows from the bound on \(\eta _t\) in (51).
Summing up the last inequality for all iterations \(t=1,\ldots ,T\) and setting \(C=\beta C_1\), we obtain:
In (52), the left hand side is greater than \(\underset{t=1, 2, \ldots , T}{\min } CT \Vert {{\mathbf {D}}}_t\Vert _{\text {F}}^2\); and the right hand telescopes and can be upper bounded by \({\mathsf {M}}_u - {\mathsf {M}}_l\), where \({\mathsf {M}}_u=\underset{i=1, 2, \ldots , m }{\max }f_i(\mathbf {U}_1)\) is the maximum value among objective functions at starting point and \({\mathsf {M}}_l\) is the lower bound on all objectives. Then the inequality becomes:
indicating that the proposed algorithm convergence to a Pareto stationary point (a point where the descent direction is \(\mathbf {0}\) and none of the objectives can be further improved). \(\square\)
Rights and permissions
About this article

Cite this article
Kamani, M.M., Haddadpour, F., Forsati, R. et al. Efficient fair principal component analysis. Mach Learn 111, 3671–3702 (2022). https://doi.org/10.1007/s10994-021-06100-9
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10994-021-06100-9