
Abstract
In this paper, we present new second-order methods with convergence rate \(O\left( k^{-4}\right) \), where k is the iteration counter. This is faster than the existing lower bound for this type of schemes (Agarwal and Hazan in Proceedings of the 31st conference on learning theory, PMLR, pp. 774–792, 2018; Arjevani and Shiff in Math Program 178(1–2):327–360, 2019), which is \(O\left( k^{-7/2} \right) \). Our progress can be explained by a finer specification of the problem class. The main idea of this approach consists in implementation of the third-order scheme from Nesterov (Math Program 186:157–183, 2021) using the second-order oracle. At each iteration of our method, we solve a nontrivial auxiliary problem by a linearly convergent scheme based on the relative non-degeneracy condition (Bauschke et al. in Math Oper Res 42:330–348, 2016; Lu et al. in SIOPT 28(1):333–354, 2018). During this process, the Hessian of the objective function is computed once, and the gradient is computed \(O\left( \ln {1 \over \epsilon }\right) \) times, where \(\epsilon \) is the desired accuracy of the solution for our problem.
Similar content being viewed by others
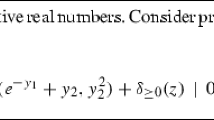


Avoid common mistakes on your manuscript.
1 Introduction
In the last years, the theory of high-order methods in convex optimization was developed seemingly up to its natural limits. After discovering the simple fact that the auxiliary problem in tensor methods can be posed as a problem of minimizing a convex multivariate polynomial [15], very soon the performance of these methods was increased up to the maximal limits [6, 7, 9], given by the theoretical lower complexity bounds [1, 2].
It is interesting that the first accelerated tensor methods were analyzed in the unpublished paper [3], where the author did not express any hope for their practical implementations in the future. In [3] and [15], it was shown that the p-th order methods can accelerate up to the level \(O\left( k^{-(p+1)}\right) \), where k is the iterations counter. The main advantage of the theory in [15] is that it corresponds to the methods with convex polynomial subproblems.
However, the fastest tensor methods [6, 7, 9] are based on the trick discovered in [11] for the second-order methods. It allows to increase the rate of convergence of tensor methods up to the level \(O\left( k^{-(3p+1)/2}\right) \), which matches the lower complexity bounds for functions with Lipschitz-continuous pth derivative. Thus, for example, the best possible rate of convergence of the second-order methods on the corresponding problem class is of the order \(O\left( k^{-7/2}\right) \).
Unfortunately, this advanced technique requires finding at each iteration a root of a univariate nonlinear non-monotone equation defined by inverse Hessians of the objective function. Hence, from the practical point of view, the methods proposed in [15] remain the most attractive.
The developments of this paper are based on one simple observation. In [15], it was shown that the accelerated tensor method of degree three with the rate of convergence \(O\left( k^{-4}\right) \) can be implemented by using at each iteration a simple gradient method based on the relative non-degeneracy condition [4, 10]. This auxiliary method has to minimize an augmented Taylor polynomial of degree three, computed at the current test point \(x \in {\mathbb {R}}^n\):
At each iteration of this linearly convergent scheme, we need to compute the gradient of the auxiliary objective function in h. The only non-trivial part of this gradient comes from the gradient of the third derivative. This is the vector \(D^3f(x)[h]^2 \in {\mathbb {R}}^n\). It is the only place where we need the third-order information. However, it is well known that
In other words, the vector \(D^3f(x)[h]^2\) can be approximated with any accuracy by the first-order information. This means that we have a chance to implement the third-order method with the convergence rate \(O\left( k^{-4}\right) \) using only the second-order information.
So, formally our method will be of the order two. However, it will have the rate of convergence, which is higher than the formal lower bound \(O\left( k^{-7/2}\right) \) for the second-order schemes. Of course, the reason for this is that it will work with the problem class initially reserved for the third-order methods. However, interestingly enough, our method will demonstrate on this class the same rate of convergence as the third-order schemes.
In order to implement our hint into rigorous statements, we need to introduce in the constructions of Section 5 in [15] some modifications related to the inexactness of the available information. This is the subject of the remaining sections of this paper.
Contents. The paper is organized as follows: In Sect. 2, we introduce a convenient definition of the acceptable neighborhood of the exact tensor step. It differs from the previous ones (e.g. [5, 8, 13]) since for its verification it is necessary to call the oracle of the main objective function. However, we will see that it significantly simplifies the overall complexity analysis. We prove that every point from this neighborhood ensures a good decrease of the objective functions, which is sufficient for implementing the Basic Tensor Method and its accelerated version without spoiling their rates of convergence.
In Sect. 3, we analyze the rate of convergence of the gradient method based on the relative smoothness condition [4, 10], under the assumption that the gradient of the objective function is computed with a small absolute error. We need this analysis for replacing the exact value of the third derivative along two vectors by a finite difference of the gradients. We show that the perturbed method converges linearly to a small neighborhood of the exact solution.
In Sect. 4, we put all our results together in order to justify a second-order implementation of the accelerated third-order tensor method. The rate of convergence of the resulting algorithm is of the order \(O\left( k^{-4}\right) \), where k is the iteration counter. At each iteration, we compute the Hessian once and the gradient is computed \(O\left( \ln {1 \over \epsilon }\right) \) times, where \(\epsilon \) is the desired accuracy of the solution of the main problem. Recall that this rate of convergence is impossible for the second-order schemes working with the functions with Lipschitz-continuous third derivative (see [1, 2]). However, our problem class is smaller (see Lemma 4.1).
In Sect. 5, we show how to ensure boundedness of the constants, essential for our minimization schemes. Finally, we conclude the paper with Sect. 6, containing a discussion of our results and directions for future research.
Notation and generalities. In what follows, we denote by \({\mathbb {E}}\) a finite-dimensional real vector space and by \({\mathbb {E}}^*\) its dual spaced composed by linear functions on \({\mathbb {E}}\). For such a function \(s \in {\mathbb {E}}^*\), we denote by \(\langle s, x \rangle \) its value at \(x \in {\mathbb {E}}\).
If it is not mentioned explicitly, we measure distances in \({\mathbb {E}}\) and \({\mathbb {E}}^*\) in a Euclidean norm. For that, using a self-adjoint positive-definite operator \(B: {\mathbb {E}}\rightarrow {\mathbb {E}}^*\) (notation \(B = B^* \succ 0\)), we define
In the formulas involving products of linear operators, it will be convenient to treat \(x \in {\mathbb {E}}\) as a linear operator from \({\mathbb {R}}\) to \({\mathbb {E}}\), and \(x^*\) as a linear operator from \({\mathbb {E}}^*\) to \({\mathbb {R}}\). In this case, \(xx^*\) is a linear operator from \({\mathbb {E}}^*\) to \({\mathbb {E}}\), acting as follows:
For a smooth function \(f: \mathrm{dom \,}f \rightarrow {\mathbb {R}}\) with convex and open domain \(\mathrm{dom \,}f \subseteq {\mathbb {E}}\), denote by \(\nabla f(x)\) its gradient, and by \(\nabla ^2 f(x)\) its Hessian evaluated at point \(x \in \mathrm{dom \,}f \subseteq {\mathbb {E}}\). Note that
In our analysis, we use Bregman divergence of function \(f(\cdot )\) defined as follows:
We often work with directional derivatives. For \(p \ge 1\), denote by
the directional derivative of f at x along directions \(h_i \in {\mathbb {E}}\), \(i = 1, \dots , p\). Note that \(D^p f(x)[ \cdot ]\) is a symmetric p-linear form. Its norm is defined as follows:
In terms of our previous notation, for any \(x \in \mathrm{dom \,}f\) and \(h_1, h_2 \in {\mathbb {E}}\), we have
For Hessian, this gives the spectral norm of self-adjoint linear operator (the maximal module of all eigenvalues computed with respect to operator B).
If all directions \(h_1, \dots , h_p\) are the same, we apply notation
Then, Taylor approximation of function \(f(\cdot )\) at \(x \in \mathrm{dom \,}f\) can be written as
Note that, in general, we have (see, for example, Appendix 1 in [16])
Similarly, since for \(x, y \in \mathrm{dom \,}f\) being fixed, the form \(D^pf(x)[\cdot , \dots , \cdot ] - D^pf(y)[\cdot , \dots , \cdot ]\) is p-linear and symmetric, we also have
In this paper, we consider functions from the problem classes \({{{\mathcal {F}}}}_p\), which are convex and p times differentiable on \({\mathbb {E}}\). Denote by \(L_p\) its uniform bound for the Lipschitz constant of their pth derivative:
If an ambiguity can arise, we use notation \(L_p(f)\). Sometimes it is more convenient to work with uniform bounds on the derivatives:
If both values are well defined, we suppose that \(L_p(f) = M_{p+1}(f)\), \(p \ge 1\).
Let \(F(\cdot )\) be a sufficiently smooth vector function, \(F: \mathrm{dom \,}F \rightarrow {\mathbb {E}}_2\). Then, by the well-known Taylor formula, we have
Hence, we can bound the following residual:
By the same reason, for functions \(\nabla f(\cdot )\) and \(\nabla ^2 f(\cdot )\), we get
which are valid for all \(x, y \in \mathrm{dom \,}f\).
Finally, for simplifying long expressions, we often use the trivial inequality
which is valid for all \(a, b \ge 0\) and \(p \ge 1\).
2 Tensor Methods with Inexact Iteration
Consider the following unconstrained optimization problem:
where \(f(\cdot )\) is a convex function with Lipschitz-continuous pth derivative:
In this section, we work only with Euclidean norms.
We are going to solve problem (12) by tensor methods. Their performance crucially depends on ability to achieve a significant improvement in the objective function at the current test point.
Definition 2.1
We say that point \(T \in {\mathbb {E}}\) ensures \(\underline{p \,th-order \,improvement}\) of some point \(x \in {\mathbb {E}}\) with factor \(c > 0\) if it satisfies the following inequality:
This terminology has the following justification. Consider the augmented Taylor polynomial of degree \(p \ge 1\):
By (8), for \(H \ge L_p\), this function gives us an upper estimate for the objective. Moreover, for \(H \ge p L_p\) this function is convex (see Theorem 1 in [15]).
We are going to generate new test point T as a close approximation to the minimum of function \(\hat{\varOmega }_{x,p,H}(\cdot )\). Namely, we are interested in points from the following nested neighborhoods:
where \(\gamma \in \left[ 0,1\right) \) is an accuracy parameter. The smallest set \({{{\mathcal {N}}}}^0_{p,H}(x)\) contains only the exact minimizers of the augmented Taylor polynomial. Note that \({\hat{\varOmega }}_{x,p,H}(x) = \nabla f(x)\). Hence, if \(\nabla f(x) \ne 0\), then \(x \not \in {{{\mathcal {N}}}}^{\gamma }_{p,H}(x)\) for any \(\gamma \in [0,1)\).
These neighborhoods are important by the following reason.
Theorem 2.1
Let \(x \in {\mathbb {E}}\) and parameters \(\gamma \), H satisfy the following condition:
Then, any point \(T \in {{{\mathcal {N}}}}^{\gamma }_{p,H}(x)\) ensures a pth-order improvement of x with factor
Consequently, we have
Proof
Let \(T \in {{{\mathcal {N}}}}^{\gamma }_{p,H}(x)\). Denote by \(r = \Vert x - T \Vert \). Then,
Therefore,
In other words,
Function \(\varkappa (r)\) is convex in \(r \ge 0\). Its derivative in r is
Note that
Thus, \(r \ge r_* {\mathop {=}\limits ^{\mathrm {def}}}\left[ {(1-\gamma )p! \,\Vert \nabla f(T) \Vert _*\over L_p+H} \right] ^{1 \over p}\). At the same time,
So by convexity of \(\varkappa (\cdot )\) and \(r \ge r_*\), we have \(\varkappa (r) \ge \varkappa (r_*)\). Therefore,
Inequality (18) is valid since our function is convex:
We have proved that the pth-order improvement at point \(x \in {\mathbb {E}}\) can be ensured by inexact minimizers of the augmented Taylor polynomials of degree \(p \ge 1\). Let us present the efficiency estimates for corresponding methods.
From now on, let us assume that the constant \(L_p\) is known. For the sake of notation, we fix the following values of the parameters:
Then, we can use a shorter notation for the following objects:
As a consequence of all these specifications, we have the following result.
Corollary 2.1
For any \(x \in {\mathbb {E}}\), all points from the neighborhood \({{{\mathcal {N}}}}_p(x)\) ensure the pth-order improvement of x with factor \(c_p\).
Let us start from the simplest Inexact Basic Tensor Method:

Denote \(R(x_0) = \max \limits _{y \in {\mathbb {E}}} \{ \Vert y - x^* \Vert : \; f(y) \le f(x_0) \}\).
Theorem 2.2
Let the sequence \(\{ x_k \}_{k \ge 0}\) be generated by method (21). Then, for any \(k \ge 1\) we have
Proof
In view of inequality (18), we have \(f(x_k) \le f(x_0)\) for all \(k \ge 0\). Therefore,
Consequently,
Denoting \(\xi _k = {c^p_p \over R^{p+1}_0}(f(x_k)- f^*)\), we get inequality \(\xi _k - \xi _{k+1} \ge \xi _{k+1}^{p+1 \over p}\). Hence, in view of Lemma 11 in [13], we have
This is exactly the estimate (22). \(\square \)
Let us present a convergence analysis for Inexact Accelerated Tensor Method. We need to choose the degree of the method and define the prox-function
This is a uniformly convex function of degree \(p+1\): for all \(x,y \in {\mathbb {E}}\) we have
(see, for example, Lemma 4.2.3 in [14]). Define the sequence
Note that for all values \(B_k = \left( k \over p+1\right) ^{p+1}\) with \(k \ge 0\) we have
Therefore, the elements of sequence \(\{ A_k \}_{k \ge 0}\) satisfy the following inequality:

First of all, note that by induction it is easy to see that
In particular, for \(\psi ^*_k {\mathop {=}\limits ^{\mathrm {def}}}\min \limits _{x \in {\mathbb {E}}} \psi _k(x)\) and all \(x \in {\mathbb {E}}\), we have
Let us prove by induction the following relation:
For \(k = 0\), we have \(\psi _0^* = 0\) and \(A_0 = 0\). Hence, (29) is valid. Assume it is valid for some \(k \ge 0\). Then,
Note that
Further, in view of inequality \({\alpha \over p+1} \tau ^{p+1} - \beta \tau \ge - {p \over p+1} \alpha ^{-1/p} \beta ^{(p+1)/p}\), \(\tau \ge 0\), for all \(x \in {\mathbb {E}}\) we have
Finally, since \(x_{k+1} \in {{{\mathcal {N}}}}_p(y_k)\), by Corollary 2.1 we get
Putting all these inequalities together, we obtain
Thus, we have proved the following theorem.
Theorem 2.3
Let sequence \(\{ x_k \}_{k \ge 0}\) be generated by method (26). Then, for any \(k \ge 1\), we have
Proof
Indeed, in view of relations (27) and (29), we have
\(\square \)
3 Relative Non-degeneracy and Approximate Gradients
In this section, we measure distances in \({\mathbb {E}}\) by general norms. Consider the following composite minimization problem:
where the convex function \(\varphi (\cdot )\) is differentiable, and \(\psi (\cdot )\) is a simple closed convex function. The most important example of function \(\psi (\cdot )\) is an indicator function for a closed convex set. Denote by \(x^*\) one of the optimal solutions of problem (31), and let \(F^* = F(x^*)\).
Let \(\varphi (\cdot )\) be non-degenerate with respect to some scaling function \(d(\cdot )\):
where \(0 \le \mu _d (\varphi ) \le L_d(\varphi )\). Denote by \(\gamma _d(\varphi ) = {\mu _d (\varphi ) \over L_d(\varphi )} \le 1\) the condition number of function \(\varphi (\cdot )\) with respect to the scaling function \(d(\cdot )\). Sometimes it is more convenient to work with the second-order variant of the condition (32):
We are going to solve problem (31) using an approximate gradient of the smooth part of the objective function. Namely, at each point \(x \in {\mathbb {E}}\) we use a vector \(g_{\varphi }(x)\) such that
where \(\delta \ge 0\) is an accuracy parameter.
Our first goal is to describe the influence of parameter \(\delta \) onto the quality of the computed approximate solutions to problem (31). For this, we need to assume that function \(d(\cdot )\) is uniformly convex of degree \(p+1\) with \(p \ge 1\):
Consider the following Bregman Distance Gradient Method (BDGM), working with inexact information.

Lemma 3.1
Let the approximate gradient \(g_{\varphi }(x_k)\) satisfy the condition (34). Then, for any \(x \in {\mathbb {E}}\) and \(k \ge 0\) we have
where \({\hat{\delta }} {\mathop {=}\limits ^{\mathrm {def}}}{2p \over p+1} \delta ^{p+1 \over p} \left( {(p+1)(2+\gamma _d(\varphi )) \over \sigma _{p+1}(d) \, \gamma _d(\varphi )}\right) ^{1 \over p}\).
Proof
The first-order optimality condition defining \(x_{k+1}\) is as follows:
for all \(x \in \mathrm{dom \,}\psi \). Therefore, denoting \(r_k(x) = \beta _d(x_k,x)\), we have
Note that \(\langle g_{\varphi }(x_k), x - x_{k+1} \rangle = \langle g_{\varphi }(x_k) - \nabla \varphi (x_k) , x - x_{k+1} \rangle + \langle \nabla \varphi (x_k) , x - x_{k+1} \rangle \), and
Hence,
Since \(\Vert x \Vert = \Vert - x \Vert \) for all x in \({\mathbb {E}}\), the minimum in \(x_k\) of the expression in brackets is attained at some \(x_k = (1-\alpha ) x_{k+1} + \alpha x\) with \(\alpha \in (0,1)\). On the other hand, the minimum of the function
is attained at \({\bar{\alpha }} ={ \beta \over 1 + \beta }\) with \(\beta = \left( {1 \over 2}\gamma _d(\varphi ) \right) ^{1 \over p}\). This is
Thus,
Applying inequality (37) with \(x = x^*\) recursively to all \(k = 0, \dots ,T-1\), we get the following relation:
where \(\gamma = {1 \over 4} \gamma _d(\varphi )\), and \(S_T = \sum \limits _{k=0}^{T-1} (1- \gamma )^{T-k-1} \; = \; {1 \over \gamma } \Big ( 1 - (1-\gamma )^{T}\Big )\).
Thus, denoting \(F^*_T = \min \limits _{0 \le k \le T} F(x_k)\), we get the following bound:
Note that \(\lim \limits _{\gamma \downarrow 0} {\gamma (1-\gamma )^T \over 1 - (1-\gamma )^T} = {1 \over T}\). Hence, for \(\mu _d(\varphi ) = 0\) we get the convergence rate
\(\square \)
In our main application, presented in Sect. 4, we need to generate points with small norm of the gradient. In order to achieve this goal with method (36), we need one more assumption on the scaling function \(d(\cdot )\).
From now on, we consider the unconstrained minimization problems. This means that in (31) we have \(\psi (x) = 0\) for all \(x \in {\mathbb {E}}\).
Definition 3.1
We call the scaling function \(d(\cdot )\) \(\underline{{norm-dominated}}\) on the set \(S \subseteq {\mathbb {E}}\) by some function \(\theta _{S}(\cdot ): {\mathbb {R}}_+ \rightarrow {\mathbb {R}}_+\) if there exists a convex function \(\theta _S(\cdot )\) with \(\theta _{S}(0)=0\) such that
for all \(x \in S\) and \(y \in {\mathbb {E}}\).
Clearly, if function \(d(\cdot )\) is norm-dominated by function \(\theta _S(\cdot )\) and \(\eta _S(\tau ) \ge \theta _S(\tau )\) for all \(\tau \ge 0\), then \(d(\cdot )\) is also norm-dominated by function \(\eta _S(\cdot )\).
Let us give an important example of a norm-dominated scaling function.
Lemma 3.2
Function \(d_4(\cdot )\) is norm-dominated on the Euclidean ball
by the function
Proof
Let \(x \in B_R\) and \(y = x + h \in {\mathbb {E}}\). Then,
Thus, we can take \(\theta _R(\tau ) = {1 \over 4} (\tau ^2 + 2 R \tau )^2 + {1 \over 2}R^2 \tau ^2\). \(\square \)
Note that the statement of Lemma 3.2 can be extended onto all convex polynomial scaling functions.
Norm-dominated scaling functions are important in view of the following.
Lemma 3.3
Let scaling function \(d(\cdot )\) be norm-dominated on the level set
by some function \(\theta (\cdot )\). Then, for any \(x \in {{{\mathcal {L}}}}_{\varphi }({\bar{x}})\) we have:
where \(\theta ^*(\tau ) = \max \limits _{\lambda } [ \lambda \tau - \theta (\tau )]\).
Proof
Indeed, for any \( x \in {{{\mathcal {L}}}}_{\varphi }({\bar{x}})\) and \(y \in {\mathbb {E}}\) we have
Therefore,
Thus, for norm-dominated scaling functions, the rate of convergence in function value can be transformed into the rate of decrease of the norm of the gradient of function \(\varphi (\cdot )\). This feature is very important for practical implementations of Inexact Tensor Methods presented in Sect. 2. In the next section, we discuss in details how it works for inexact third-order methods. \(\square \)
4 Second-Order Implementations of the Third-Order Methods
In this section, we are going to solve the unconstrained minimization problem
where the objective function is convex and smooth, using the second-order implementations of the third-order methods. For the pure second-order methods, the standard assumption on the objective function in (45) is Lipschitz continuity of the second derivative (see, for example, [12, 17]). We are going to replace it by a stronger assumption, using the following fact.
Lemma 4.1
Let constants \(M_2(f)\) and \(M_4(f)\) be finite. Then
Proof
Let \(x \in \mathrm{dom \,}f\). Then, for any direction \(h \in {\mathbb {E}}\) and \(\tau > 0\) small enough, we have \(x - \tau h \in \mathrm{dom \,}f\) and
Thus, \(D^3f(x) [h]^3 \le {1 \over \tau } \langle \nabla ^2 f(x) h, h \rangle + {\tau \over 2} M_4(f) \Vert h \Vert ^4\). Minimizing this inequality in \(\tau > 0\) and taking the supremum of the result in \(h \in {\mathbb {E}}\), we get (46). \(\square \)
Thus, from now on, we assume that
Assumption \(M_2(f) < +\infty \) is not so necessary. We will discuss different variants of its replacements in Sect. 5.
In our situation, we can apply to (45) the third-order tensor method \(\hbox {ATMI}_3\) (see 26). At each iteration of this method, we need to minimize the augmented third-order Taylor polynomial \(\hat{\varOmega }_{x,3,H}(\cdot )\). As it was shown in [15], this can be done by an auxiliary scheme based on the relative smoothness condition. This approach is based on the following matrix inequality (see Lemma 3 in [15]):
which is valid for all \(x \in \mathrm{dom \,}f\), \(h \in {\mathbb {E}}\) and \(\xi > 0\).
As compared with [15], our situation is more complicated. Firstly, we are not going to use the exact minimum of function \({\hat{\varOmega }}_{x,3,H}(\cdot )\). And secondly, we are going to minimize this function using its approximate gradients.
Let us start from discussion of the second issue. Let us fix a parameter \(\tau > 0\) and for all \(x,y \in {\mathbb {E}}\), consider the following vector functions:
the finite-difference approximations of third derivative along direction \([x-y]^2\).
Lemma 4.2
For any \(x , y \in {\mathbb {E}}\), we have
Proof
Denote \(h = \tau (x-y)\). Then, by Taylor formula we have
Applying a uniform upper bound for the fourth derivative to the right-hand side of this representation, we get inequality (49). Further,
Adding these two representations, we get
and we obtain inequality (50). If the fourth derivative derivative is Lipschitz continuous, then
and this is inequality (51). \(\square \)
In this paper, we usually employ the approximation \(g_y^{\tau }(\cdot )\). Note that
where \(h = x-y\). Thus, we can easily compute approximate gradients of function \({\hat{\varOmega }}_{y,3,H}(\cdot )\) using the first-order information on function \(f(\cdot )\). Let us show that this can help us to minimize the augmented Taylor polynomial of degree three by the machinery presented in Sect. 3.
At each iteration k of \(\hbox {ATMI}_3\), we need to find point \(x_{k+1} \in {{{\mathcal {N}}}}_3(y_k)\). For the sake of notation, let us assume that \(y_k = 0\). We need to find a point \(x_+ \in {{{\mathcal {N}}}}_3(0)\) by minimizing the function
Thus, our auxiliary problem is as follows:
Denote \(x^*_k = \arg \min \limits _{x \in {\mathbb {E}}} \varphi _k(x)\) and \(\varphi ^*_k = \varphi _k(x^*_k)\). Note that
Therefore,
Now it is clear that in our case a good scaling function is as follows:
Indeed, applying the relations (56) with \(\xi = \sqrt{2}\), we get
Thus, we can take
and obtain for function \(\varphi _k(\cdot )\) the condition number bounded by a constant:
The second condition for applicability of method (36) is the uniform convexity of the Bregman distance. In our case, this is true since
Thus, in terms of inequality (35), we have \(\sigma _4(\rho _k) = {1 \over 4}L_3\). This property is important for bounding the size of the set
Lemma 4.3
For any \(x \in {{{\mathcal {L}}}}_k\), we have
Proof
Indeed,
Consequently, we have the following bound:
Further, for \(x \in {{{\mathcal {L}}}}_k\), we have
Thus, \(\Vert x \Vert \le \left[ {16 \over \mu L_3} \Vert \nabla f(0) \Vert * \right] ^{1 \over 3} = 2^{1/3} R_k\). \(\square \)
The third condition is the possibility of approximating the gradient of function \(\varphi _k(\cdot )\). In our case, in view of Lemma 4.2, we can take
where \(g^{\tau }_0(x) = {1 \over \tau ^2} [\nabla f(\tau x) + \nabla f(-\tau x) - 2 \nabla f(0)]\). In this case,
Thus, in order to ensure condition (34) and keep \(\tau \) separated from zero (this is necessary for stability of the process), we need to guarantee the boundedness of the minimizing sequence for function \(\varphi _k(\cdot )\). However, since we know an explicit upper bound (60) on the size of the optimal point, it is possible to ensure this by introducing an additional constraint on the size of variables. Let us replace the problem (53) by the following one:
In view of Lemma 4.3, the optimal solutions of problems (53) and (64) coincide.
Consider a variant of method (36) with \(\psi \equiv 0\) and accuracy \(\delta > 0\).

Note that the auxiliary problem in this method has now an additional ball constraint (64). However, this does not increase significantly its complexity since the Euclidean norm is already present in the objective function.
Let us mention the main properties of this minimization process. First of all, since all points \(x_i\) belong to \(S_k\), for all \(i \ge 0\) we have
This means, in particular, that the sopping criterion at Step 2 of method (65) is correct: if it is satisfied, then
which implies \(x_i \in {{{\mathcal {N}}}}_3(0)\).
Moreover, we can apply Lemma 3.1 to the following objects:
Therefore, in our case, inequality (37) with \(p = 3\) can be rewritten as
In view of (57), \(\beta _{\rho _k}(x_0, x ) \le {1 \over 2}L_1R_k^2 + {1 \over 4} L_3 R_k^4\). Hence, by (40) we have
where \(L_1\) is any upper estimate for the value \(\Vert \nabla ^2f(0) \Vert \).
From this bound, we have a natural limit for the number of iterations of method (65), sufficient for obtaining the following inequality:
where \({\hat{x}}_T = \arg \min \limits _x \Big \{ \varphi _k(x): \; x \in \{ 0, x_1, \dots , x_T\} \Big \} \in {{{\mathcal {L}}}}_k\). Indeed, for this it is enough to have
Hence, we have the following bound:
However, the upper-level method \(\hbox {ATMI}_3\) needs a point with small gradient:
In order to derive this bound from inequality (70) with an appropriate value of \(\hat{\delta }_+\), we use the fact that our scaling function \(\rho _k(\cdot )\) is norm-dominated. Indeed, in view of Lemma 3.2 and representation (57), this function is norm-dominated on any Euclidean ball \(B_r\) by the following function:
Hence, in view of Lemma 4.3, our scaling function \(\rho _k(\cdot )\) is norm-dominated on the set \({{{\mathcal {L}}}}_k\) by \(\theta _{{\hat{r}}_k}(\cdot )\) with
Thus, in order to apply Lemma 3.3, we need to estimate from above the inverse to its conjugate function.
Lemma 4.4
For any \(r>0\), we have
Proof
Consider the primal function \(\theta (\tau ) = {a \tau ^2 \over 2} + {b \tau ^4 \over 4} \) with \(a, b \ge 0\). Then, its conjugate function is defined as follows:
We need to find \(\lambda \ge 0\) from the equation \(\xi = \theta ^*(\lambda )\).
Note that the optimal solution \(\tau = \tau (\lambda )\) in the above maximization problem can be found from the equation
Therefore,
Thus, we can write down \(\tau (\lambda )\) as a function of \(\xi \):
Hence,
It remains to use the actual values \(a = L_1 + 5 L_3 r^2\) and \(b = 2 L_3\). \(\square \)
Now we can write down the condition for our parameter \(\delta \), which ensures the desired inequality (72). Indeed, in view of inequalities (70) and (44), after \(T_k(\delta )\) inner steps (see 71) we can guarantee that
where \(L {\mathop {=}\limits ^{(67)}} 1 + {1 \over \sqrt{2}}\). In order to stop method (65) at this moment, we need to guarantee that the norm of the approximate gradient is small enough. Hence, our condition for parameter \(\delta \) can be derived from the following reasoning. Since
in order to satisfy condition \(\Vert g_{\varphi _k,\tau }({\hat{x}}_T) \Vert _* \le {1 \over 6} \Vert \nabla f({\hat{x}}_T) \Vert - \delta \), by Lemma 4.4, it is sufficient to satisfy inequality
where \(\epsilon _g > 0\) is a lower bound for the norm of the gradients of the objective function during the whole minimization process. Recall that
Hence, this inequality can be rewritten in the following form:
Using the upper integer bounds on the coefficients, it can be strengthened:
where we take \(L_1 = \Vert \nabla ^2 f(0) \Vert \) since this corresponds to the actual role of this constant in the complexity analysis of method (65).
This means that, in accordance to (78), we need to choose
Since \(\Vert \nabla f(0) \Vert _* \ge \epsilon _g\), we always have \(\delta \le O(\epsilon _g)\).
Note that all coefficients in the condition (78) are known (provided that we have a good estimate for the Lipschitz constant \(L_3\)). Thus, we have
where G and H are the uniform upper bounds for the norms of the gradients and Hessians computed at the points generated by the main process. Validity of the assumption on finiteness of these bounds is discussed in Sect. 5.
Let us write down our inexact algorithmic schemes (21) and (26), employing the inner procedure (65). These methods have only one parameter \(\delta >0\), which must be chosen in accordance to (78). They need also the constant \(L_3\).
We start from the variant of Inexact Basic Tensor Method (21).

At each iteration of this method, we have \(O\left( \ln {G +H \over \epsilon _g}\right) \) iterations of the inner scheme. Each of them needs three calls of oracle of the main objective function (twice for computing the approximate gradient of function \(\varphi _k(\cdot )\) and once for verifying the stopping criterion). In view of Theorem 2.2, the rate of convergence of the main process is as follows:
Thus, the analytical complexity bound of the method (80) is of the order
where \(\epsilon _f>0\) is the desired accuracy in the function value. Note that this method uses only the second-order oracle.
Let us look now at the accelerated scheme.

As before, each iteration of this method needs at most \(O\left( \ln {G +H \over \epsilon _g}\right) \) iterations of the inner scheme. In view of Theorem 2.3, the rate of convergence of the main process in (83) is as follows:
Thus, the analytical complexity bound of this method is of the order
Recall that method (83) is a second-order scheme.
5 Bounds for the Derivatives
The complexity analysis in Sect. 4 is valid only if we can guarantee the finiteness of the constants G and H. The simplest way of doing this consists in considering the following class of functions:
This is a nontrivial class, but it is quite restrictive. In this section, we show that it is possible to derive the finiteness of G and H from our main assumption (47) and the properties of the minimization schemes.
Indeed, we can easily bound derivatives at test points from a bounded set. Let us present a trivial result, which follows from Taylor formula (7).
Lemma 5.1
For any \(x \in B_D(x_0) {\mathop {=}\limits ^{\mathrm {def}}}\{ x \in {\mathbb {E}}: \; \Vert x - x_0 \Vert \le D \}\), we have
We can use the right-hand sides of inequalities (87) as our constants G and H provided that the distance between \(x_0\) and the test points does not exceed some \(D < +\infty \). Note that we do not use D, G, and H in our methods. They appear only in the bounds for the number of inner steps and stay inside the logarithm. The important criterion (78), defining an appropriate value of the parameter \(\delta > 0\), is based on the available information about the first and second derivatives at the current test point.
Thus, we need to prove that the sequences of test points in our methods are bounded. Let us start from Inexact Basic Tensor Method (80). For this method, the situation is very simple. We have already assumed that the size of the level set \(R(x_0)\) is finite. Since the method (80) is monotone, for any \(x_k\) generated by this scheme, we have
Thus, we can take in (87) \(D = 2R(x_0)\).
Let us look now at Inexact Accelerated Tensor Method. Actually, for proving the boundedness of sequences of the test points \(\{ y_k \}_{k \ge 0}\), it is better to consider its monotone variant. The additional Step 4 of this method ensures monotonicity of the sequence \(\{ f(x_k) \}_{k\ge 0}\).

Complexity analysis, presented in Sect. 2, remains also valid for the monotone variant (88). Indeed, in the right-hand side of the relation (29), we can replace point \(x_k\) by any point with better value of the objective function.
Lemma 5.2
Let points \(\{ y_k \}_{k \ge 0}\) be generated by the method (88). Then,
Proof
Indeed, choosing in the relation (28) \(p = 3\) and \(x = x^*\), we get
At the same time, since \(f(x_k) \le f(x_0)\), we have \(\Vert x_k - x^* \Vert \le R(x_0)\). Hence, in view of the definition of \(y_k\) at Step 1 in (88),
Thus, for accelerated method (88) we can take \(D = (1+\sqrt{2})R(x_0)\). \(\square \)
6 Conclusion
From our results, we conclude that the existing classification of the problem classes, optimization schemes, and complexity bounds is not perfect. Traditionally, we put in one-to-one correspondence the type of numerical schemes (classified by its order) and the problem classes (classified by the Lipschitz condition for the highest derivative). In this way, we attach the \(1{\text{ st }}\)-order methods to functions with Lipschitz-continuous gradients. The \(2{\text{ nd }}\)-order methods correspond to the functions with Lipschitz-continuous Hessian, etc.
This picture allows us to speak about the optimal methods. For example, we say that the Fast Gradient Methods (FGM) with the convergence rate \(O\left( k^{-2}\right) \) are the optimal \(1{\text{ st }}\)-order methods. However, the only reason why FGM could be called optimal is that they implement the lower bound for a certain problem class, which is considered to be the natural field of application for the \(1{\text{ st }}\)-order methods only.
Now it is clear the above over-simplified picture of the world must be replaced by something more elaborated. We have seen that there exist problem classes for which the \(2{\text{ nd }}\)- and the \(3{\text{ rd }}\)-order methods demonstrate the same rate of convergence. So, the correct classification of problem classes and optimization methods must be at least two-parametric. This is, of course, an interesting topic for the further research.
Another interesting question is related to the \(1{\text{ st }}\)-order schemes. Indeed, if we managed to accelerate the \(2{\text{ nd }}\)-order methods above their ”natural” complexity limits, may be there exists a similar possibility for the \(1{\text{ st }}\)-order schemes? In our opinion, the answer is negative. Indeed, the lower complexity bounds for the \(1{\text{ st }}\)-order methods are supported by a worst-possible quadratic function. Quadratic functions already have zero high-order derivatives. Therefore, any assumptions on the high-order derivatives cannot eliminate this bad function from the problem class. For the \(2{\text{ nd }}\)-order methods, the worst-case function has discontinuous third derivative (see, for example, Section 4.3.1 in [14]). Therefore, assumptions on the fourth derivative can help.
References
Agarwal, N., Hazan, E.: Lower bounds for higher-order convex optimization. In: Proceedings of the 31st Conference On Learning Theory, PMLR, vol. 75, pp. 774–792 (2018)
Arjevani, O.S., Shiff, R.: Oracle complexity of second-order methods for smooth convex optimization. Math. Program. 178(1–2), 327–360 (2019)
Baes, M.: Estimate sequence methods: extensions and approximations. Optimization (2009)
Bauschke, H.H., Bolte, J., Teboulle, M.: A descent lemma beyond Lipschitz gradient continuity: first order methods revisited and applications. Math. Oper. Res. 42, 330–348 (2016)
Birgin, E.G., Gardenghi, J.L., Martinez, J.M., Santos, S.A., Toint, P.L.: Worst-case evaluation complexity for unconstrained nonlinear optimization using high-order regularized models. Math. Program. 163, 359–368 (2017)
Bubeck, S., Jiang, Q., Lee, Y.T., Li, Y., Sidford, A.: Near-optimal method for highly nonsmooth convex optimization. In: COLT, pp. 492–507 (2019)
Gasnikov, A., Gorbunov, E., Kovalev, D., Mohhamed, A., Chernousova, E.: The global rate of convergence for optimal tensor methods in smooth convex optimization. arXiv:1809.00382 (2018)
Grapiglia, G.N., Nesterov, Yu.: On inexact solution of auxiliary problems in tensor methods for convex optimization. Optim. Methods Softw. 36(1), 145–170 (2021)
Jiang, B., Wang, H., Zang, S.: An optimal high-order tensor method for convex optimization. In: Conference on Learning Theory, pp. 1799–1801 (2019)
Lu, H., Freund, R., Nesterov, Yu.: Relatively smooth convex optimization by first-order methods, and applications. SIOPT 28(1), 333–354 (2018)
Monteiro, R.D.C., Svaiter, B.F.: An accelerated hybrid proximal extragradient method for convex optimization and its implications to the second-order methods. SIOPT 23(2), 1092–1125 (2013)
Nesterov, Y.: Accelerating the cubic regularization of Newtons method on convex problems. Math. Program. 112(1), 159–181 (2008)
Nesterov, Y.: Inexact Basic Tensor Methods. CORE DP (# 2019/23) (2019)
Nesterov, Y.: Lectures on Convex Optimization. Springer, Berlin (2018)
Nesterov, Y.: Implementable tensor methods in unconstrained convex optimization. Math. Program. 186, 157–183 (2021)
Nesterov, Y., Nemirovskii, A.: Interior Point Polynomial Methods in Convex Programming: Theory and Applications. SIAM, Philadelphia (1994)
Nesterov, Y., Polyak, B.: Cubic regularization of Newtons method and its global performance. Math. Program. 108(1), 177–205 (2006)
Acknowledgements
This paper has received funding from the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation program (Grant Agreement No. 788368). It was also supported by Multidisciplinary Institute in Artificial intelligence MIAI@Grenoble Alpes (ANR-19-P3IA-0003). The author would like to thank Alexander Gasnikov for discussions. The comments of two anonymous referees were extremely useful.
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by Anil Aswani.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Nesterov, Y. Superfast Second-Order Methods for Unconstrained Convex Optimization. J Optim Theory Appl 191, 1–30 (2021). https://doi.org/10.1007/s10957-021-01930-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10957-021-01930-y