
Abstract
This paper presents a comprehensive study of non-linear systems of multi-order fractional differential equations from aspects of theory and numerical approximation. In this regard, we first establish the well-posedness of the underlying problem by investigations concerning the existence, uniqueness, and influence of perturbed data on the behavior of the solutions as well as smoothness of the solutions under some assumptions on the given data. Next, from the numerical perspective, we develop and analyze a well-conditioned and high-order numerical approach based on an operational spectral Galerkin method. The main advantage of our strategy is that it characterizes the approximate solution via some recurrence formulas, instead of solving a complex non-linear block algebraic system that requires high computational costs. Moreover, the familiar spectral accuracy is justified in a weighted \(L^2\)-norm, and some practical test problems are provided to approve efficiency of the proposed method.
Similar content being viewed by others
1 Introduction
Recently the fractional calculus has attracted the attention of many researchers due to its capability in the modeling of problems influenced by memory properties and having non-local behavior [18]. Among them, there are diverse physical phenomena for which their separated elements make tight contact with each other. Thus, their mathematical modeling of these phenomena may result in the systems of fractional differential equations (FDEs). These systems appear in numerous fields of science and technology, such as the fractional-order SEIR epidemic model [1], pollution problems [4], hepatitis B disease [5], HIV/AIDS fractional model [12], nuclear magnetic resonance (NMR) [13], magnetic resonance imaging (MRI) [15], fractional-order COVID-19 model [16] and electron spin resonance (ESR) [19].
It turned out that the process of finding the analytical solution for systems of FDEs is a challenging task, and even in some cases is impossible. Therefore, designing efficient numerical methods plays a crucial role in examining the solutions of these equations. Systems of FDEs are generally divided into single-order and multi-order categories, which contain fixed and various orders of fractional derivative operators, respectively. Researchers have recently developed different approximate methods for the numerical solution of systems of single-order FDEs (SSFDEs), such as fractional-order generalized Laguerre pseudo-spectral method [2], Petrov-Galerkin method [9], fractional-order Jacobi Tau method [3], hybrid non-polynomial collocation method [10], spline Collocation method [14] and Jacobi-Gauss collocation method [20].
Systems of multi-order fractional differential equations (SMFDEs) seem to be investigated less frequently than SSFDEs. For example, in papers [7, 8] Chebyshev Tau and fractional collocation methods have introduced for the numerical solution of constant and variable coefficients linear SMFDEs, respectively. Most of the used methods for obtaining the approximate solutions of non-linear SMFDEs suffer from the following crucial items, which play a key role in establishing an efficient numerical scheme:
-
Lack of comprehensive analysis regarding the well-posedness of the problem, including existence, uniqueness, the effects of perturbations on the solutions and absence of a robust smoothness investigation which is essential in designing high-order approaches such as spectral methods.
-
Solving complex non-linear algebraic systems with high computational costs that significantly affects the accuracy of approximate solutions. Clearly, this weakness typically causes even efficient numerical methods can not provide suitable approximations for the solutions of equations arising from real-world phenomena, which are mostly considered on the long integration domain.
-
Ignoring the singularity arising from the fractional derivative operators in adopting appropriate basis functions that leads to characterize the approximate solutions by a linear combination of infinitely smooth basis functions such as polynomials. In fact, one of the requirements of producing high-order methods is to establish a consistency between the asymptotic behavior of the exact solution, and the degree of smoothness of the basis functions, which has been ignored in many of the methods presented so far.
In this paper, we intend to provide a comprehensive study taking the approach of removing the above drawbacks to the following non-linear SMFDEs
where \(\gamma _{j}=\frac{\eta _{j}}{\lambda _{j}}\) is a positive rational number with the co-prime integers \(\eta _{j} \ge 1\) and \(\lambda _{j} \ge 2\), X is a finite positive real number, and \(\lceil . \rceil \) is the ceiling function. \(g_j(x,\mathbf{z }(x)): \chi \times {\mathbb {R}}^n \rightarrow {\mathbb {R}}\) are continuous functions, and \(\mathbf{z }(x)=[z_{1}(x),z_{2}(x),\ldots ,z_{n}(x)]^{T}: \chi \rightarrow {\mathbb {R}}^n\) is the vector of unknowns. \(D^{\gamma _{j}}_{C}\) is Caputo fractional derivative of order \(\gamma _{j}\) defined by
in which \(I^{\lceil \gamma _j \rceil -\gamma _{j}}\) denotes the Riemann–Liouville fractional integral operator of order \(\lceil \gamma _j \rceil -\gamma _{j}\) [6].
To this end, we first present a comprehensive analysis around the existence, uniqueness, smoothness properties, and influence of perturbed data of (1.1), and then an efficient spectral approximation using the fractional Jacobi functions is introduced to (1.1). Although spectral methods are capable of providing highly accurate solutions to smooth problems, there are some disadvantages, including the need to solve complex and ill-conditioned algebraic systems. Moreover, the accuracy of the solutions would be significantly reduced in attacking the problems with non-smooth solutions. However, during this investigation, the numerical scheme is designed in such a way that it incorporates both high accuracy in dealing with non-smooth solutions and computing approximate solutions through recurrence relations rather than solving non-linear complex algebraic systems.
The rest of this paper is organized as follows. In Sect. 2, the well-posedness of (1.1) including existence, uniqueness, and influence of perturbed data along with some smoothness properties of (1.1) are established. Our analysis will reveal that the problem (1.1) is well-posed, and some derivatives of the solutions may have a discontinuity at the origin. In Sect. 3, a novel spectral Galerkin method based on the fractional Jacobi basis functions for the numerical solution of (1.1) is implemented. In this regard, the numerical solvability and complexity analysis of the corresponding non-linear block algebraic system are investigated. In Sect. 4, the convergence analysis of the proposed method is rigorously studied. To support our analysis, some examples are illustrated in Sect. 5. Finally, some concluding remarks are expressed in Sect. 6.
2 Well-Posedness and Smoothness Properties
Before implementing our numerical approach, we investigate some results on the well-posedness and smoothness of solutions of (1.1). Commonly, a problem is called well-posed if it has a unique solution, and the solution depends on the given data continuously. In this regard, we first recall the following existence and uniqueness theorem.
Theorem 2.1
(Existence and uniqueness [6]) Let the continuous functions \(g_j\) in (1.1) satisfy a Lipschitz condition with respect to all their variables except for the first one, i.e.,
with some constant \(L>0\), where \(||.||_{\infty }\) is the max norm on \({\mathbb {R}}^{n}\), i.e.,
for all \(\mathbf{u }_{1}=[u_{1,1},u_{1,2},\ldots ,u_{1,n}]^{T} \in {\mathbb {R}}^{n}\). Then, the problem (1.1) has a unique continuous solution on \(\chi \).
Now, we investigate the dependence of the exact solution on some small perturbations in the input data. Clearly, this is an important factor in the numerical solution of (1.1) because the influence of perturbations on the discretized equation is a fundamental item in determining the effect of roundoff errors. The next theorems will show that the solution of (1.1) depends continuously on the given data. First, we investigate the dependence of the solution of (1.1) on the initial values and the given function of the right-hand side.
Theorem 2.2
Assume that the conditions of Theorem 2.1 hold for both equation (1.1) and the perturbed equation
In addition, let
If \(\epsilon _j^{1}\) and \(\epsilon _{j}^{2}\) are sufficiently small, then we have
Proof
Subtracting (2.1) from (1.1), and defining \(\varDelta _{j}(x)=z_j(x)-{\tilde{z}}_j(x)\), we find that
which is equivalent to the following system involving Volterra integral equations of the second kind
It can be concluded that
In view of the Lipschitz assumption on \(g_{j}\) and definition of max norm on \({\mathbb {R}}^{n}\), we have
and thereby
where \({\widetilde{L}}=L \max \limits _{j \in \aleph _{n}}\frac{X^{\gamma _{j}-\min \limits _{1 \le s \le n}\{\gamma _{s}\}}}{\varGamma {(\gamma _j)}}\). The above inequality can be rewritten as the following vector-matrix form
where I denotes a matrix of order n with entries one. In addition, we have \({\underline{\varDelta }}(x)=\big [\vert \varDelta _{1}(x)\vert ,\vert \varDelta _{2}(x)\vert ,\ldots ,\vert \varDelta _{n}(x)\vert \big ]^{T}\) and \({\underline{\Pi }}=\big [ \Pi _{1} , \Pi _{2} ,\ldots , \Pi _{n} \big ]^T\) with
Equivalently, we arrive at
in view of the fact that n is the max norm of matrix I on \({\mathbb {R}}^{n \times n}\). Gronwall’s inequality [7] yield
where C is a generic positive constant, and equivalently
which proves the theorem. \(\square \)
Next, we survey the influence of changes in the fractional derivative orders.
Theorem 2.3
Suppose that the assumptions of Theorem 2.1 hold for both equation (1.1) and the perturbed equation
where \({\tilde{\gamma }}_{j} > \gamma _{j}\). Moreover, let \(\epsilon _j^{3}={\tilde{\gamma }}_{j}-\gamma _{j}\) and
If \(\epsilon _j^{3}\) and \(\epsilon _{j}^{4}\) are sufficiently small, then for \(j \in \aleph _{n}\), we have
Proof
Rewriting the equation (1.1) and the perturbed equation (2.4) as equivalent systems of Volterra integral equations and subtracting the tow resulting systems from each other yields
From (2.3), we have
Proceeding in exactly the same way as the previous theorem, we can rewrite (2.6) as the following vector-matrix form
in which \({\underline{\varPsi }}=\big [ \varPsi _{1} , \varPsi _{2} ,\ldots , \varPsi _{n} \big ]^T\), with
Now, we can bound the integral on the right-hand side of \(\varPsi _{j}\) in accordance with
Indeed, the integral can be computed explicitly: One first has to find the zero of the integrand, which is located at \((\varGamma (\tilde{\gamma _{j}})/\varGamma (\gamma _{j}))^{1/(\tilde{\gamma _{j}}-\gamma _{j})}\). If X is smaller than this value, then the integrand has no change of sign, and we can move the absolute value operation outside the integral. Otherwise we must split the interval of integration at this point, and each integral can be handled in this way. In either case, we may use the Mean Value Theorem of Differential Calculus to see that the resulting expression is bounded by \(O(\tilde{\gamma _{j}}-\gamma _{j})=O(\epsilon _j^{3})\). Using Gronwall’s inequality [7], we have
where C is a generic positive constant, and thereby
which concludes the relation (2.5). \(\square \)
Clearly, Theorems 2.1–2.3 deduce the well-posedness of (1.1). In particular, Theorems 2.2 and 2.3 assert that small perturbations in the input data cannot have a meaningful effect on the exact solution. Indeed, the existence of small perturbations in the right-hand sides of (2.2) and (2.5) will translate into small discrete perturbations in the numerical solution due to roundoff errors, and the well-posedness property does not allow a meaningful effect to enter the accuracy of the approximate solution. In what follows, we will discuss the properties dealing with the solution smoothness of the problem (1.1). Since the Caputo fractional derivative is a weakly singular integral operator, we cannot typically expect the solutions of FDEs to be smooth, even for smooth input functions. Clearly, this can lead to a challenge of constructing the numerical methods with reasonable orders of convergence. Hence, recognizing the singularity behavior of the solutions under imposing some conditions on the given functions \(g_{j}\) is crucial to design high-order numerical methods. In this regard, in the next theorem, the regularity of solutions of (1.1) is explored by obtaining their series representations in a neighborhood of the origin.
Theorem 2.4
(Smoothness of the solutions) Under the assumptions of Theorem 2.1, suppose that
where \(\lambda \) is the least common multiple of \(\lambda _{j}\), and \({\bar{g}}_j\) is an analytic function in the neighborhood of \((0,z_{1,0}^{(0)},\ldots ,z_{n,0}^{(0)})\). Then the solution \(z_j(x)\) has the following series representation around the origin
where \(\psi _j(x)=\sum \limits _{k=0}^{\lceil \gamma _j \rceil -1}{\frac{z_{j,0}^{(k)}}{k!}x^k}\), and \({\bar{z}}_{j,\rho }\) are known coefficients.
Proof
Let us assume the following representation of \(z_j(x)\)
We find the unknown coefficients \(\{{\bar{z}}_{j,\rho }\}_{j=1}^{n}\) such that the representation (2.9) converges and satisfies (1.1). Using the series expansion of \({\bar{g}}_j\) around the point \((0,z_{1,0}^{(0)},\ldots ,z_{n,0}^{(0)})\), we obtain
By rearranging, it can be concluded that
where
The case \(\sigma _k = 0\) in the sum on the right-hand side only occurs for \(\theta _{k} = 0\). Meanwhile, the equation (1.1) can be considered as the following system involving Volterra integral equations of the second kind
Therefore, substituting the relation (2.11) into (2.10), we find
Assuming uniform convergence, the coefficients \({\bar{z}}_{j,\rho }\) satisfy the following equality
where \(\zeta _{j}=\frac{\varGamma (\frac{\rho +\sum \limits _{k=1}^{n}{\sigma _{k}}}{\lambda }+1)}{\varGamma (\gamma _{j}+\frac{\rho +\sum \limits _{k=1}^{n}{\sigma _{k}}}{\lambda }+1)}\). Inserting \(\rho =\rho -\gamma _j \lambda -\sum \limits _{k=1}^{n}{\sigma _{k}}\) in the series of the right-hand side of (2.14), we obtain
in which \({\bar{\zeta }}_{j}=\frac{\varGamma (\frac{\rho }{\lambda }-\gamma _{j}+1)}{\varGamma (\frac{\rho }{\lambda }+1)}\). Now, by comparing the coefficients of \(x^{\frac{\rho }{\lambda } }\) on both sides of (2.15), the unknown coefficients \({\bar{z}}_{j,\rho }\) can be derived. Clearly for \(\rho <\gamma _{j} \lambda \), we have
and for \(\rho \ge \gamma _{j} \lambda \), the following recursive formula is inferred
such that the coefficients \(g_{j,\rho -\gamma _j \lambda - \sum \limits _{k=1}^{n}{\sigma _{k}},\{\theta _k\}_{k=1}^n}\) with negative indices are considered as zero, and in the case \(\rho -\gamma _j \lambda - \sum \limits _{k=1}^{n}{\sigma _{k}} \ge 0\), we have
In other words, \({\bar{z}}_{j,\rho }\) can be expressed in terms of coefficients with lower indices. This means, the solution of the problem (1.1) can be described by the series representation (2.8).
Now, we verify that the series converges uniformly and absolutely in the neighborhood of origin. To this, we apply a suitable modification of Lindelof’s majorant method [6]. Let us consider the following system involving Volterra integral equations of the second kind
where \({\bar{\psi }}_j(x)=\sum \limits _{k=0}^{\lceil \gamma _j \rceil -1}{\frac{x^k}{k!}|z_{j,0}^{(k)}|}\), and
Clearly, \(\{Z_j(x)\}_{j=1}^n\) is a majorant for \(\{z_j(x)\}_{j=1}^n\), and that all coefficients of \(\{Z_j(x)\}_{j=1}^n\) are positive. The formal solution \(\{Z_j(x)\}_{j=1}^n\) may be computed in exactly the same way as the previous step. Thus, we now need to prove that the series \(Z_j(x)\) converges absolutely over \([0,\eta _j]\), with some \(\eta _j>0\). For this purpose, it suffices to show that the finite partial sum of \(Z_j(x)\) is uniformly bounded on \([0,\eta _j]\). Considering
as the finite partial sum of \(Z_j(x)\), we have
that follows from the recursive computation of the coefficients. Indeed, if we expand the right-hand side of the above inequality, all coefficients \({\bar{Z}}_{j,\rho }\) with indices satisfying the inequality \(\frac{\rho }{\gamma }\le \frac{({\mathscr {L}}+1)}{\gamma }\) are omitted from both sides, while there will in general be additional positive terms of higher-order in the right-hand side. Assuming
we define
Now, we show that \(|S_{j,{\mathscr {L}}}(x)| \le 2 B_{1,j}\) for \(j \in \aleph _{n}, x \in [0, \eta _j]\). The proof is done using mathematical induction on \({\mathscr {L}}\). The statement for \({\mathscr {L}}=0\) is evident since
We assume that it holds for \({\mathscr {L}}\) and transit to \({\mathscr {L}}+1\) as
which proves that \(S_{j,{\mathscr {L}}+1}(x)\) is uniformly bounded over interval \([0, \eta _j]\). Since all its coefficients are positive, it is also monotone. Hence, in view of the power series structure of \(Z_j(x)\), it is absolutely and uniformly convergent on \([0,\eta _j]\) and the compact subsets of \([0,\eta _j)\), respectively. Thanks to Lindelof’s theorem, it ultimately concludes the same properties for series representation \(z_j(x)\). Thus, it allows us to interchange integration and series. \(\square \)
Indeed, Theorem 2.4 shows that the \(\lceil \gamma _j \rceil \)-th derivative of \(z_{j}(x)\) may have a discontinuity at the initial point. This would have a great impact on accuracy in implementing the classical spectral methods to approximate the solutions. In this sense, we are going to introduce a new spectral method to calculate better approximate solutions for the problem (1.1) having non-smooth behavior. In what follows, we will construct our numerical approach under the conditions of Theorems 2.1–2.4.
3 Numerical Approach
This section is going to develop an effective and applicable numerical scheme based on the operational fractional Jacobi Galerkin method to estimate the solution of problem (1.1). In order to do so, we first discuss some imperative theoretical consequences dealt with the classical Jacobi polynomials and fractional Jacobi functions.
3.1 Jacobi Polynomials
The Jacobi polynomials \(J_n^{(\mu ,\nu )}(s)\) with the parameters \(\mu ,\nu >-1\), and \(s \in I=[-1,1]\) are orthogonal associated with the weight function \(w^{(\mu ,\nu )}(s)=(1-s)^{\mu }(1+s)^{\nu }\), i.e., [17]
where
and \(\delta _{mn}\) is known as the Kronecker delta function. These polynomials are explicitly signified as follows
where
Since \(\{J_n^{(\mu ,\nu )}\}_{n \ge 0}\) forms a complete \(L_{w^{(\mu ,\nu )}}^2(I)\)-orthogonal system, defining
along with the related orthogonal projection \(\pi _{N}^{(\mu ,\nu )}:L_{w^{(\mu ,\nu )}}^2(I)\rightarrow \mathbf{U }_{N}^{(\mu ,\nu )}\) given by
concludes
Considering the Sobolev space
associated with the norm and semi-norm
a suitable bound of the truncation error \(\pi _{N}^{(\mu ,\nu )}F-F\) can be established as follows.
Theorem 3.1
[17] For each \(F \in H_{w^{(\mu ,\nu )}}^{m}(I)\), \(0 \le m \le N+1\), and \(m \in {\mathbb {N}}\), the following inequality is satisfied
where C is a positive constant independent of N.
In order to find more properties of the Jacobi polynomials, one can refer to [17].
3.2 Fractional Jacobi Functions
The essence of the fractional Jacobi functions (FJFs) \(J_n^{(\mu ,\nu ,\tau )}(x)\) with \(\tau \in (0,1]\) and \(x \in \chi \) comes from the Jacobi polynomials with coordinate transformation \(s=2 (\frac{x}{X})^{\tau }-1\) as [3, 21]
From (3.1), one can check that these functions are mutually orthogonal with respect to the weight function \(w^{(\mu ,\nu ,\tau )}(x)= x^{\tau \nu +\tau -1}(X^{\tau }-x^{\tau })^{\mu }\), i.e.,
where \(\lambda _{n}^{(\mu ,\nu ,\tau )}=\frac{X^{\tau (\mu +\nu +1)}}{\tau 2^{\mu +\nu +1}}\lambda _{n}^{(\mu ,\nu )}\). Regarding (3.2), the FJFs satisfy the following explicit formula
Due to the completeness of the FJFs in \(L_{w^{(\mu ,\nu ,\tau )}}^2(\chi )\), we state
and define the corresponding orthogonal projection \(\pi _{N}^{(\mu ,\nu ,\tau )}:L_{w^{(\mu ,\nu ,\tau )}}^2(\chi )\rightarrow \mathbf{U }_{N}^{(\mu ,\nu ,\tau )}\) as
Trivially, by the relations (3.4) and (3.5), we have
Now, we try to find an appropriate error bound of the truncation error \(f-\pi _{N}^{(\mu ,\nu ,\tau )}f\). To this end, we suppose that the functions f(x) and F(s) are related by coordinate transformation \(s = 2 (\frac{x}{X})^{\tau }-1 \). Their derivatives are related in the following sense
in which \(\partial _s x=\frac{X}{2\tau }\big (\frac{x}{X}\big )^{1-\tau }\). Moreover, it can be readily inferred that
where \(d^{(\mu ,\nu )}=\frac{\tau 2^{\mu +\nu +1}}{X^{\tau (\mu +\nu +1)}}\).
To obtain the upper bound for truncation error \(\pi _{N}^{(\mu ,\nu ,\tau )}f-f\), we define the transformed space
equipped with the following norm and semi-norm
and give the following theorem.
Theorem 3.2
For \(f \in H_{w^{(\mu ,\nu ,\tau )}}^{m}(\chi ),~ 0 \le m \le N+1\), and \( m \in {\mathbb {N}}\), the following inequality holds
where C is a positive constant independent of N.
Proof
Applying coordinate transformation \(s = 2 (\frac{x}{X})^{\tau }-1\) and also relation (3.6), one has
The desired consequence can be derived by Theorem 3.1 and the relation (3.6). \(\square \)
3.3 Operational Fractional Jacobi Galerkin Method
The aim of this section is to establish the operational fractional Jacobi Galerkin method to approximate the solutions of (1.1). In this scheme, the Galerkin approximate solutions are presented as a linear combination of fractional Jacobi functions, and the corresponding non-linear algebraic representation of the problem is constructed utilizing a sequence of matrix operations. Due to the equivalence of the equation (1.1) and (2.13), we implement our strategy on the equivalent equation (2.13). Inserting \(\tau =\frac{1}{\lambda }\) into (3.3), the fractional Jacobi Galerkin approximation \(z_{j,N}(x)\) of the exact solution \(z_{j}(x)\) is defined in the following sense
where \({\underline{v}}_j=[v_{j,0},v_{j,1},\ldots ,v_{j,N},0,\ldots ]\), and
indicating the vector of fractional Jacobi basis functions with degree \((J_{i}^{(\mu ,\nu ,\tau )}(x))\le i \tau \), J is an infinite order lower-triangular matrix and \({\underline{X}}_x=[1,x^{\tau },x^{2\tau },\ldots ,x^{N\tau },\ldots ]^{T}\). Assume that
Moreover, the relation (2.10) can be rewritten as
where \(\{l_{1},l_{2},\ldots ,l_{r}\} \subseteq \aleph _{n}\), and for \(r \in \aleph _{n}\), we have \(\theta _{l_{1}}, \theta _{l_{2}},\ldots ,\theta _{l_{r}}\ne 0\).
Inserting the relations (3.7), (3.8) into (2.13) and using (3.9), we obtain
Now, we intend to derive a matrix representation for the right-hand side of (3.10). To this end, we first give the following lemma which transforms \(z_{l_{k},N}^{\theta _{l_{k}}}(x),~k=1,2,\ldots ,r\) into a suitable matrix form.
Lemma 3.1
The following relation holds
where \({\mathscr {M}}_{l_{k}}\) is the following infinite upper-triangular matrix
with \(J_{s}=\{J_{m,s}\}_{m=0}^{\infty },~s=0,1,\ldots ~\).
Proof
We proceed using mathematical induction on \(\theta _{l_{k}}\). For \(\theta _{l_{k}}=1\), the lemma is valid. We assume that it holds for \(\theta _{l_{k}}\), and transit to \(\theta _{l_{k}}+1\) as follows
Next, it is enough to show that
For this purpose, it can be written
which deduces (3.12). Clearly, substituting (3.12) into (3.11) concludes the desired result. \(\square \)
Now, we can construct the matrix representation of \(\prod \limits _{k=1}^r{z_{l_{k},N}^{\theta _{l_{k}}}(x)}\). To this end, let us consider the following lemma.
Lemma 3.2
We have
in which matrix \(\{{\mathscr {M}}_{\theta _{l_{k}}}^{*}\}_{k=2}^r\) has the following upper-triangular structure
where \((J{\mathscr {M}}_{l_{k}}^{\theta _{l_{k}}-1})_{s},~s=0,1,\ldots \) denotes the s-th column of the matrix \(J{\mathscr {M}}_{l_{k}}^{\theta _{l_{k}}-1}\).
Proof
We apply the principle of mathematical induction on r. In view of Lemma 3.1, the induction basis \(r = 1\) is evident. We will show that if the statement is hold up for r, then it is also hold up for \(r+1\). We have
Proceeding the same way as (3.13), we derive
which completes the proof by employing (3.15) into (3.14). \(\square \)
In this stage, we apply Lemmas 3.1 and 3.2 to the second term of the right-hand side of (3.10) which yields
Evidently, we have [6]
in which \({A}_{j,\rho }^{m}=\frac{\varGamma ((\rho +m) \tau +1)}{\varGamma ((\rho +m) \tau +\gamma _j+1)}\). Therefore, the equality (3.16) can be rewritten as
where \({Q}_{j,\{\theta _k\}_{k=1}^n}\) is an infinite upper-triangular matrix with the following entries
In this step, to derive the algebraic form of the fractional Jacobi Galerkin discretization of (2.13), it suffices to insert the relations (3.7) and (3.17) into (3.10). Thus, we have
which can be rewritten as
Projecting (3.18) onto \(\langle J_{0}^{(\mu ,\nu ,\tau )}(x), J_{1}^{(\mu ,\nu ,\tau )}(x),\ldots , J_{N}^{(\mu ,\nu ,\tau )}(x)\rangle \) concludes
where the index N at the top of the vectors and matrices dictates the principle sub-vectors and sub-matrices of order \(N+1\) respectively. Here, we point out that the unknown vectors can be found by solving a system of \(n(N + 1)\) non-linear algebraic equations (3.19). In the next section, we present more details regarding the numerical solvability and practical implementation of this system.
3.4 Numerical Solvability and Practical Implementation
Trivially, the non-linear algebraic system (3.19) is complex, and its solution requires high computational costs, especially for large values of n and N, and thereby possibly low accuracy. In this subsection, to overcome this weakness, we proceed with a well-conditioned and practical implementation that finds the unknowns of (3.19) using some recurrence formulas without the need to solve any non-linear algebraic system. In this regard, multiplying both sides of (3.19) by \(J^{N}\) and defining
yields
In view of Lemma 3.1, we can write
From [11], we observe that \(\{\big ({\mathscr {M}}_{l_{k}}^{\theta _{l_{k}}-1}\big )^{N}\}_{k=1}^r\) has the following upper-triangular Toeplitz structure
where \(\{{\mathscr {M}}_{l_{k},0,s}^{\theta _{l_{k}}-1}\}_{s=0}^N\) are non-linear functions of the elements \(\underline{{\underline{v}}}_{l_{k},0},~\underline{{\underline{v}}}_{l_{k},1},\ldots ,~\underline{{\underline{v}}}_{l_{k},s}\).
In addition, from (3.20) and (3.22), the matrices \(\{{\mathscr {M}}_{\theta _{l_{k}}}^{*^{N}}\}_{k=2}^r\) can be rewritten as the following upper-triangular Toeplitz structure
in which
are non-linear functions of the components \(\underline{{\underline{v}}}_{l_{k},0},~\underline{{\underline{v}}}_{l_{k},1},\ldots ,~\underline{{\underline{v}}}_{l_{k},s}\).
Consequently, the matrix \(\varOmega ^{\{l_{k}\}_{k=1}^{r}}\) defined by
has an upper-triangular Toeplitz structure, in which \(\{\varOmega _{0,s}^{\{l_{k}\}_{k=1}^{r}}\}_{s=0}^N\) are non-linear functions of the elements
and obtained by
Finally, defining \(\varLambda _{j}^{\{\theta _k\}_{k=1}^n}=\varOmega ^{\{l_{k}\}_{k=1}^{r}} {Q}_{j,\{\theta _k\}_{k=1}^n}^{N}\), \(j \in \aleph _{n}\), it can be derived
Next, in accordance with the structure of the upper-triangular matrix \(\varLambda _{j}^{\{\theta _k\}_{k=1}^n}\), we have
Now, considering the above relation, for \(j \in \aleph _{n}\) we can write
where \(\{\mathbf{G }_{\gamma _{j}\lambda +s}^{\{\theta _k\}_{k=1}^n}\}_{s=0}^{N-\gamma _{j}\lambda }\) are non-linear functions of the elements
Substituting (3.23) into (3.21), the unknown components of the unknown vectors \(\{\underline{{\underline{v}}}_j\}_{j=1}^{n}\) can be evaluated by the following recurrence relations
Finally, the unknowns \(\{{\underline{v}}_j^{N}\}_{j=1}^{n}\) are achieved by solving the lower-triangular system (3.20), and thereby the fractional Jacobi Galerkin solutions (3.7) can be computed.
4 Convergence Analysis
The aim of this section is to provide convergence properties for the presented method via establishing a suitable error bound in a weighted \(L^{2}\)- norm.
Theorem 4.1
Suppose that \(z_{j,N}(x)\) given by (3.7) are the approximate solutions of (1.1). If we have
then for sufficiently large values of N the following inequality holds
where \(e_{j,N}(x)=z_{j}(x)-z_{j,N}(x)\) denotes the error function, and \(C>0\) is a constant independent of N.
Proof
In according to the proposed numerical scheme in Sect. 3, we first consider (3.10) and substitute the approximate solutions (3.7) into the equation (2.13) and obtain
where \(\mathbf{z }_{N}(x)=[z_{1,N}(x),z_{2,N}(x),\ldots ,z_{n,N}(x)]^{T}\). Then, from (3.19), we multiply both sides of (4.1) by \(J_k^{(\mu ,\nu ,\tau )}(x) w^{(\mu ,\nu ,\tau )}(x)\) and integrate on \(\chi \), which concludes
Now, multiplying both sides of (4.2) by \(\frac{J_k^{(\mu ,\nu ,\tau )}(x)}{\lambda _k^{(\mu ,\nu ,\tau )}}\) and summing up from \(k=0\) to \(k=N\) deduces
and equivalently we have
since we have \(z_{j,N}(x),~ \psi _j(x) \in \text {Span}\{J_0^{(\mu ,\nu ,\tau )}, J_1^{(\mu ,\nu ,\tau )},\ldots ,J_N^{(\mu ,\nu ,\tau )}\}\). Subtracting (4.3) from (2.13) yields
which can be rewritten in the following sense
where \(e_{\pi _{N}^{(\mu ,\nu ,\tau )}} (f)=f-\pi _{N}^{(\mu ,\nu ,\tau )}(f)\) and \({\bar{g}}_j=g_j(x,\mathbf{z }_{N}(x))\). Similar to (2.3), we infer that
where \({B}_j=e_{\pi _{N}^{(\mu ,\nu ,\tau )}}(I^{\gamma _{j}}{\bar{g}}_j)\). Defining the vectors
and proceeding in exactly the same way as the proof of Theorem 2.2, we can rewrite the equation (4.4) as the following matrix formulation
Applying Gronwall’s inequality [7] concludes
and consequently
Using Theorem 3.2, we deduce
in view of employing the first order Taylor formula. Inserting (4.6) into (4.5) gives
in which \( H_{j}=N^{-\varepsilon _j}|I^{\gamma _{j}}g_j|_{\varepsilon _j,w^{(\mu ,\nu ,\tau )}}\).
Trivially, the relation (4.7) can be rewritten as the following vector-matrix form
where
and P is a diagonal matrix of order n with the entries
Evidently, for sufficiently large values of N, the matrix P tends to the identity matrix. Therefore, the inequality (4.8) yields
which is the desired result. \(\square \)
5 Illustrative Examples
In this section, to confirm the accuracy and efficiency of the strategy, the numerical results obtained from the implementation of the proposed scheme are illustrated for some non-linear systems of FDEs. For this purpose, we organize this section as follows
-
Some crucial items such as numerical errors \((\mathbf{E }(N))\) and CPU-time used are reported to monitor the computational performance of the suggested method. In all of the examples, the numerical errors are calculated through \(L^{2}_{w^{(\mu ,\nu ,\tau )}}(\chi )\) -norm by
$$\begin{aligned} \mathbf{E }(N)=\max \limits _{j \in \aleph _{n}}\Vert e_{j,N}\Vert _{w^{(\mu ,\nu ,\tau )}}, \end{aligned}$$and in the lack of access to the exact solutions, the numerical errors are estimated by means of
$$\begin{aligned} \mathbf{E }(N)=\max \limits _{j \in \aleph _{n}}\Vert z_{j,2N}(x)-z_{j,N}(x)\Vert _{w^{(\mu ,\nu ,\tau )}}. \end{aligned}$$ -
To approve the superiority of the proposed method over other existed methods, we compare our results with those obtained by the spectral collocation method introduced in [20].
-
To demonstrate the applicability of the method, some examples are selected from real-world problems.
-
To confirm the stability of the approach, the performance of this strategy is investigated for problems with the long integration domain \(\chi \) and large degrees of approximation N.
The process of calculations is done via Mathematica v11.2, running in a computer system with an Intel (R) Core (TM) i5-4210U CPU @ 2.40 GHz.
Example 5.1
Consider the following non-linear SMFDEs
where \(\gamma _{1}=\frac{3}{4},~ \gamma _{2}=\frac{5}{4},~ \gamma _{3}=\frac{3}{2}\) and the source functions \(q_{j}(x)\) with \(j=1,2,3\) are chosen in a way that the exact solutions are as follows
Trivially, we have
which confirms Theorem 2.4. \(E_{\delta }(x)\) is known for Mittag-Leffler function, \(J_{c}(x)\) denotes the Bessel function for integer number c, and \({_{\xi }F_{\xi }}(\{a_{1},\ldots ,a_{\xi }\};\{b_{1},\ldots ,b_{\xi }\};x)\) is generalized hypergeometric function.
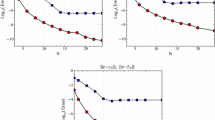
This problem is solved by our method, and the obtained results are presented in Table 1 and Fig. 1. From Table 1, one can deduce that the proposed strategy provides approximate solutions with high accuracy, mainly because the numerical errors are considerably reduced in short elapsed CPU-time corresponding to the large values of N. Moreover, the semi-log representation of the numerical errors with \(\mu =\nu =-\frac{1}{2}\) depicted in Fig. 1, justifies the familiar spectral accuracy which predicted in Theorem 4.1 because the numerical errors in the semi-log report linearly varied versus N (note that we have \(\{\varepsilon _{j}\}_{j=1}^{3}=\infty \) in Theorem 4.1).

Illustration for semi-log errors of Example 5.1 in the case of fixed \(\mu =\nu =-\frac{1}{2}\)
To solve a more challenging problem, we set \(\gamma _{1}=\frac{1}{3},~ \gamma _{2}=\frac{5}{4},~ \gamma _{3}=\frac{13}{5}\) in (5.1), and the forcing functions \(q_{j}(x)\) with \(j=1,2,3\) are chosen such that the exact solutions are
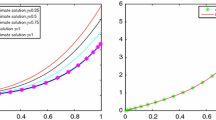
The numerical errors and the approximate solutions obtained by applying the introduced method are presented in Tables 2 and 3, respectively. Notably, in this case, we have \(\tau =1/\lambda =1/60\) and we can’t expect the numerical errors to decay very fast. However, From Table 2, it can be seen that the effective computational performance of our method lets us give reasonable errors even for a large degree of approximation \(N=320\).
In the next example, we will compare our method with the proposed method in [20].
Example 5.2
[20] Consider the following non-linear SSFDEs
where the functions \(q_{j}(x)\), \(j=1,2\) are chosen in a way that the true solutions are
The equation (5.2) is solved via the implemented scheme for the values \(\gamma =\frac{1}{5}, \frac{1}{2}, \frac{3}{4}\), and the parameters \(\mu =\nu =-\frac{1}{2}\) and \(\mu =0,\nu =\frac{1}{2}\). Implementing the proposed scheme, the exact solutions are obtained with the degree of approximations 2, 2, 6, respectively. Also, in [20], the approximate solutions of (5.2) are computed by applying a spectral collocation method, and the numerical errors are obtained in \(L^{\infty }\)-norm. The maximum of the errors presented in Ref. [20] for different values of N and \(\gamma \) are listed in Table 4. Clearly, comparison results confirm the superiority of our proposed scheme over the method presented in [20].
Example 5.3
(Hepatitis B [5]) The fractional-order model for hepatitis B with drug therapy can be written as the following non-linear SSFDEs
considering three state variables at time t: target cells T(t), infected cells I(t), and free virus V(t).
Following [5], the description of parameters and their values are given in Table 5. We note that the units of all the parameters are \((\text {day}^{-1})\).
We set \(T_{0}=14\), \(I_{0}=13\), \(V_{0}=10\) and \(\gamma =\frac{7}{10}\), and solve the problem via the proposed approach. Table 6 and Fig. 2 report the attained numerical results. Undeniably, the reported results indicate the high accuracy of the presented scheme in solving real-world problems due to the absence of unwanted oscillation in errors, in particular for long integration domain \(\chi \) and large values of N. Obviously, obtaining the regular error reduction in a complex non-linear problem, despite the large integration domain, especially in a short CPU time and large degrees of approximation, is a very powerful feature that has been presented in fewer numerical approaches so far.

Illustration for semi-log errors of Example 5.3 for \(\chi =[0,10]\) (the left one) and \(\chi =[0,20]\) (the right one) in the case of fixed \(\mu =\nu =-\frac{1}{2}\)
Example 5.4
(COVID-19 [16]) Consider the following non-linear dynamical model of COVID-19 disease

Illustration for semi-log errors of Example 5.4 for \(\gamma =\frac{1}{2}\) (the left one) and \(\gamma =\frac{2}{3}\) (the right one) for \(\mu =\nu = -\frac{1}{2}\)
where \({\bar{K}}=\frac{R_{0}{\bar{d}}_{0}({\bar{d}}_{0}+{\bar{\kappa }})({\bar{\beta }}+{\bar{d}}_{0}+{\bar{\delta }})}{{\hat{\alpha }}{\bar{a}}}\) is proportionality constant. This model contains four compartments at time t (day): healthy or susceptible population S(t), the exposed class E(t), the infected population I(t) and the removed class R(t).
The details of the parameters written in the model (5.4) and their values are given in Table 7.
Applying the proposed method, we evaluate this example by setting the initial conditions \(S(0)=0.323\), \(E(0)=0.21\), \(I(0)=0.22\) and \(R(0)=0.21\) scaled in million. The numerical results are illustrated in Table 8 and Fig. 3. From these results, one is thus led to conclude that the numerical errors are decreased as N is increased. Furthermore, the decay of the errors in short elapsed CPU-time corresponding to the large values of N reveals that the introduced strategy is well-conditioned.
Example 5.5
(HIV/AIDS [12]) Let us consider the HIV/AIDS epidemic model with treatment as
The total population is divided into a susceptible class of size S, an infectious class before the onset of AIDS, and a full-blown AIDS group of size A, which is removed from the active population. The infection population is classified into two groups, the asymptomatic stage of size I and the symptomatic stage of size J. \({\hat{\beta }}{\hat{k}}\) represents the recruitment rate of the population, and the parameter \({\hat{a}} > 1\) captures the fact that the individuals in the symptomatic stage J are more infectious than the asymptomatic stage I. The description and values of the other parameters are depicted in Table 9. It is noticed that the unit of time is the year. For more explanations about the model, we also refer to [12].
Inserting \(S(0)=300,~I(0)=60,~J(0)=30,~A(0)=5,~{\hat{k}}=120,~{\hat{a}}=0.3\) and \(\gamma =\frac{4}{5}\), we compute the approximate solutions of (5.5), and the numerical results are illustrated in Table 10 and Fig. 4.

Illustration for semi-log errors of Example 5.5 in the case of fixed \(\mu =\nu =-\frac{1}{2}\)
6 Conclusion
In this paper, the well-posedness and smoothness properties of the solutions of (1.1) were presented. Furthermore, a suitable operational Galerkin approach based on the fractional Jacobi functions was presented, and a practical implementation process was introduced which finds the unknowns via some recurrence relations without solving any non-linear algebraic system. Convergence analysis of the presented method was justified that confirmed the high accuracy of the scheme without enforcing the problematic regularity assumptions on the given data. Finally, through the numerical solution of various examples, the well-conditioning and high-order accuracy of the presented method was emphasized.
Data Availability
Enquiries about data availability should be directed to the authors.
References
AL-Smadi, M.H., Gumah, G.N.: On the homotopy analysis method for fractional SEIR epidemic model. Res. J. Appl. Sci. 7(18), 3809–3820 (2014)
Bhrawy, A., Alhamed, Y., Baleanu, D., Al-Zahrani, A.: New spectral techniques for systems of fractional differential equations using fractional-order generalized Laguerre orthogonal functions. Fract. Calc. Appl. Anal. 17(4), 1137–1157 (2014)
Bhrawy, A.H., Zaky, M.A.: Shifted fractional-order Jacobi orthogonal functions: application to a system of fractional differential equations. Appl. Math. Model. 40(2), 832–845 (2016)
Biazar, J., Farrokhi, L., Islam, M.R.: Modeling the pollution of a system of lakes. Appl. Math. Comput. 178(2), 423–430 (2006)
Cardoso, L.C., Dos Santos, F.L.P., Camargo, R.F.: Analysis of fractional-order models for hepatitis B. Comput. Appl. Math. 37(4), 4570–4586 (2018)
Diethelm, K.: The Analysis of Fractional Differential Equations. Springer, Berlin (2010)
Faghih, A., Mokhtary, P.: An efficient formulation of Chebyshev Tau method for constant coefficients systems of multi-order FDEs. J. Sci. Comput. 82(1), 1–25 (2020)
Faghih, A., Mokhtary, P.: A new fractional collocation method for a system of multi-order fractional differential equations with variable coefficients. J. Comput. Appl. Math. 383, 113139 (2021)
Faghih, A., Mokhtary, P.: A novel Petrov–Galerkin method for a class of linear systems of fractional differential equations. Appl. Numer. Math. 169, 396–414 (2021)
Ferrás, L.L., Ford, N.J., Morgado, M.L., Rebelo, M.: High-order methods for systems of fractional ordinary differential equations and their application to time-fractional diffusion equations, Math. Comput. Sci. 1–17 (2020)
Ghoreishi, F., Hadizadeh, M.: Numerical computation of the Tau approximation for the Volterra Hammerstein integral equations. Numer. Algorithms 52, 541–559 (2009)
Kheiri, H., Jafari, M.: Optimal control of a fractional-order model for the HIV/AIDS epidemic. Int. J. Biomath. 11(7), 1850086 (2018)
Magin, R., Feng, X., Baleanu, D.: Solving the fractional order Bloch equation. Concepts Magn. Reson. 34(1), 16–23 (2009)
Pellegrino, E., Pezza, L., Pitolli, F.: A collocation method in spline spaces for the solution of linear fractional dynamical systems. Math. Comput. Simul. 176, 266–278 (2019)
Qin, S., Liu, F., Turner, I., Vegh, V., Yu, Q., Yang, Q.: Multi-term time-fractional Bloch equations and application in magnetic resonance imaging. J. Comput. Appl. Math. 319, 308–319 (2017)
Rahman, M., Arfan, M., Shah, K., Gómez-Aguilar, J.F.: Investigating a nonlinear dynamical model of COVID-19 disease under fuzzy caputo, random and ABC fractional order derivative. Chaos Solitons Fract. 140, 110232 (2020)
Shen, J., Tang, T., Wang, L.L.: Spectral Methods: Algorithms, Analysis and Applications. Springer, Berlin (2011)
Uchaikin, V.V.: Fractional Derivatives for Physicists and Engineers, vol. II. Applications, Springer, Berlin (2013)
Yu, Q., Liu, F., Turner, I., Burrage, K.: Numerical simulation of the fractional Bloch equations. J. Comput. Appl. Math. 255, 635–651 (2014)
Zaky, M.A.: An accurate spectral collocation method for nonlinear systems of fractional differential equations and related integral equations with nonsmooth solutions. Appl. Numer. Math. 154, 205–222 (2020)
Zaky, M.A., Doha, E.H., Tenreiro Machado, J.A.: A spectral framework for fractional variational problems based on fractional Jacobi functions. Appl. Numer. Math. 132, 51–72 (2018)
Funding
This research received no specific grant from any funding agency in the public, commercial, or not-for-profit sectors.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Faghih, A., Mokhtary, P. Non-linear System of Multi-order Fractional Differential Equations: Theoretical Analysis and a Robust Fractional Galerkin Implementation. J Sci Comput 91, 35 (2022). https://doi.org/10.1007/s10915-022-01814-x
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10915-022-01814-x
Keywords
- Non-linear systems of multi-order fractional differential equations (SMFDEs)
- Well-posedness
- Spectral Galerkin method
- Fractional Jacobi functions (FJFs)
- Convergence analysis