
Abstract
In this paper, we propose a framework capable of dealing with anaphora and ellipsis which is both general and algorithmic. This generality is ensured by the compination of two general ideas. First, we use a dynamic semantics which reperent effects using a monad structure. Second we treat scopes flexibly, extending them as needed. We additionally implement this framework as an algorithm which translates abstract syntax to logical formulas. We argue that this framework can provide a unified account of a large number of anaphoric phenomena. Specifically, we show its effectiveness in dealing with pronominal and VP-anaphora, strict and lazy pronouns, lazy identity, bound variable anaphora, e-type pronouns, and cataphora. This means that in particular we can handle complex cases like Bach–Peters sentences, which require an account dealing simultaneously with several phenomena. We use Haskell as a meta-language to present the theory, which also consitutes an implementation of all the phenomena discussed in the paper. To demonstrate coverage, we propose a test suite that can be used to evaluate computational approaches to anaphora.
Similar content being viewed by others



Avoid common mistakes on your manuscript.
1 Introduction
Anaphora is a vast topic that has been exploited and discussed from the point of view of different formal semantics systems, each focusing on different phenomena Cooper (1979); Evans (1980); Roberts (1989, 1990); Groenendijk and Stokhof (1991); Poesio and Zucchi (1992). A question which arises is to what extent these different aspect of anaphora can be considered as instances of a single phenomena. Furthermore, if they turn out to be related, can they be treated under a single unified appoach? Our overarching aim is to construct a system for a unified computational treatment of anaphora of all kinds.
In this paper, we propose an account of anaphora which captures simultaneously (at least) all of the following phenomena:
-
Basic anaphoric cases
-
Category-general anaphora (VP anaphora, sentential anaphora, etc.)
-
Strict and sloppy anaphora
-
Bound variable readings
-
E-type pronouns
-
Donkey anaphora
-
Cataphora
-
Bach–Peters sentences
In particular, we find that our treatment of E-type pronouns and Bach–Peters sentences is a novel one, and as such can be considered a contribution to formal semantics in their own right. Acknowledging this fact, we concentrate the discussion in this paper on the elements which build up to our accounts for these phenomena, and we direct the reader to the long version of this paper (Bernardy et al. 2020) for an even broader discussion of supported phenomena. As a witness to the completeness of our treatment, we provide a faithful formalization in Haskell (Marlow 2010). This formalization doubles up as an implementation. To demonstrate coverage of our theory, we have additionally tested on a suite of 65 representative examples presented in the “Appendix”.
The structure of the paper is as follows: in Sect. 2, we give the background theory to this paper and briefly introduce monads. In Sect. 3, we provide a unified monadic account for the range of phenomena listed above. In Sect. 4, we present the Haskell implementation of the system and evaluate it in Sect. 5. In Sect. 6, we discuss related work. Lastly, in Sect. 7, we conclude and propose directions for future research.
2 Background
2.1 Higher-Order Logic with Sorts and \(\Sigma \) Types
In this paper we interpret natural language phrases (with anaphoric elements) as logical formulas. Most of the particular details of the logic that we use are of limited importance to the dynamic semantics that we propose. Unless explicitly stated otherwise, our analysis transposes easily to any higher-order logic. Yet we find it convenient to use a few specific surface features from constructive type-theories, sometimes called Modern Type Theories (MTTs) in the literature.
First, we will specify the domain of quantification for all quantifiers. More specifically, we will write \(\forall (x:Man). Mortal(x)\) instead of \(\forall x. Man(x) \rightarrow Mortal(x)\) and thus Man should be understood as a type (not a predicate). In effect, we use type many-sortedness offered by MTTs and we take the CNs-as-Types view, notably used by Ranta (1994) and later by Boldini (2000). There is substantial literature on whether CNs should be interpreted as types or predicates. Within the MTT tradition, most of the approaches have been using the CNs-as-Types. Later work by Luo (2012), Chatzikyriakidis (2014), and Chatzikyriakidis and Luo (2017) have explicitly argued that the CNs-as-Types approach is to be preferred over the predicates one. The debate is still open on which approach is superior, but in this paper our choice of the CN-as-types approach is justified by its better fit with scope extension (see Sect. 3.4.4).
Second, if such domains need to embed predicates, we use \(\Sigma \)-types to embed them.
Third, as proposed by Chatzikyriakidis and Luo (2013), we make use of the following subtyping rule:
This rule is not critical, but allows to conveniently omit unessential projections. For example, it allows us to conveniently write \(\forall x:(\Sigma (y:Man). Wise(y)). Old(x)\) instead of \(\forall x:(\Sigma (y:Man). Wise(y)). Old(\pi _1(x))\).
Finally, we will use the record notation of \(\Sigma \) types. This is purely a convenience, because records are isomorphic to nested \(\Sigma \) types. Thus, for the above formula we can write \(\forall x:([y:Man ; p:Wise(y)]). Old(x.y)\). Note in particular the use of .y for projection of the field y.
2.2 Monads
Originating in Category Theory (Barr and Wells 1999), monads have been shown to be very useful for the semantics of programming languages and have been particularly widely used in functional programming languages. Monads have made it into the formal semantics of natural languages, succeeding in providing solutions to problems where the notions of context and context dynamics play an important role. Monadic treatments have been proposed for quantifiers (Barker and Shan 2004), anaphora (Unger 2011), conversational implicatures (Giorgolo and Asudeh 2012), interrogatives (Shan 2002) and linguistic opacity (Giorgolo and Asudeh 2014), among others.
Formally, a monad is a triple \(( M , return ,\mathbin {\star })\) where
-
M is a type-function: it maps any type a to a type \(Ma\). For our purposes, \(Ma\) can be understood as the type of effectful computations that yield a value of type a.
-
\( return \) is a function of type \(a \rightarrow Ma\) which turns a pure (effect-free) value to a computation without effect.
-
The operator \(\star \), pronounced “bind” is a function of type \(Ma \rightarrow (a \rightarrow Mb) \rightarrow Mb\) which composes two computations. That is, given an effectful computation of type Ma and a function mapping a to an effectful computation of type Mb, it returns a computation which in turn returns the result of the second computation. The effect of the composition is the composition of effects.
Additionally, for the triple to be a monad, the bind operator must be associative, and \( return \) must be its right and left unit. Formally:
-
\(( m \mathbin {\star } f )\mathbin {\star } g \mathrel {=} m \mathbin {\star }(\lambda x \mathbin {\rightarrow } f \; x \mathbin {\star } g )\)
-
\(( return \; x )\mathbin {\star } f \mathrel {=} f \; x \)
-
\( f \mathbin {\star } return \mathrel {=} f \)
2.3 Do-notation
An expression such as \(M \star \lambda x. (N \star \lambda y. O)\) is commonly used to bind the result of M as x in the expressions N and O; and y as the result of N in the expression O. An alternative notation for the same term, called the do-notation and originating from the Haskell language, is the following:

The do-notation has an advantage of emphasizing the order of composition of effects (top down), and that of omitting the groupings of sub-expressions—which does not matter according to the associativity law of monads.
3 Generalized Effectful Semantics for Anaphora: How to Account for Various Phenomena
We place ourselves in the tradition of Montague semantics, in the sense that we interpret syntax trees as logical formulas. Nevertheless, we depart from that tradition in two respects. First, the logical system that we target is not a plain higher-order logic, but one equipped with dependent types. Second, each constituent is not just interpreted as a logical formula, but as a pair of a formula and an effect, which captures the dynamic aspects of meaning. In fact, following Shan (2002), the effect is coupled with the MontagovianFootnote 1 interpretation using a monad structure. More precisely, as Unger (2011) does, we assert that the relevant effects include:
-
a lookup in an environment
-
the production of a new environment
This kind of effects can be realized by using the standard side-effects monad of Moggi (1991), also called more accurately the state monad. We recall its type-function (M above) below using Haskell notation:

Thus, if an effect-free semantic interpretation is \( a \), its effectful counterpart is a function from an assumed environment \( Env \) (or background, context) to a pair of the semantic content \( a \) and a new environment. As is standard, looking up the environment is done using the \( get \) function, while updating it is done using the \( set \) function.

In \( set \), the old environment \(\rho _0\) is ignored. Additionally \( set \) returns no useful value (only its dynamic effect matters), and thus we return a unit type \(\mathrm {1}\) which contains no useful information.
We take the type associated with syntactic categories to be the usual semantic interpretations assumed in Montague-style semantics. For example, the type associated with a verb phrase is \(object \rightarrow Prop\): a function from objects (individuals in Montague’s system) to propositions (truth values for Montague). For example, the semantic category corresponding to VP is:

or, after expansion

The monadic structure associated with \( Dynamic \)s has several pleasant properties. The existence of the \( return \) function ensures that any semantics cast in a Montagovian-style framework can be also embedded in our dynamic semantics (simply by associating it with the empty effect):

Furthermore, the bind operator ensures that any two effectful interpretations can be combined arbitrarily. Consequently any combination interpretations in Montague Semantics (MS) can be lifted to effectful MS.

Monadic associativity ensures that we do not have to worry about the order of grouping effects.
3.1 Structure of the Environment and Basic Anaphoric Cases
The environment (\( Env \)) is a mapFootnote 2 from atomic anaphoric expressions (such as pronouns) to semantic representations. For now, we restrict the domain of the environment to NP anaphora:

For example, if the discourse has introduced a male person whose denotation is \(\mathbin {\llbracket } Bill \mathbin {\rrbracket }\), the corresponding environment \(\rho \) can look like this:

Thus in most cases, the effect of a non-anaphoric noun phrase is to modify the environment, so that appropriate anaphoric expressions can be mapped to it. We say that we push the interpretation onto the environment. This is done by creating an environment which checks for a pronoun that can refer to the expression and returns the given interpretation exactly in that case, as follows:

Using \( pushNP \), we can implement (non-anaphoric) NPs easily. For example, the semantics of the proper name “Mary” is as follows, where \( mary \) is understood to be the underlying representation of the individual:

(In the full implementation we update all pronouns which can (co-)refer to “Mary”, such as “her”, “hers”, “herself”, etc.) We proceed with showing how anaphoric expressions can be interpreted. For instance, the pronoun “her” is implemented as follows:

Consider now the following full example:
-
(1)
John loves Mary. Bill likes her.
In (1), upon encountering the phrase “Mary”, our system will modify the environment such that further lookup for “her” will return \((\lambda P \mathbin {\rightarrow } P \; mary )\). More pedantically, any effect combined with the effect of \(\mathbin {\llbracket } Mary \mathbin {\rrbracket }\) will be affected in this manner. While straightforward, the mechanism described above accounts for a large number of anaphoric phenomena (sometimes requiring local extension). The rest of this section describes such an account.
3.2 Refinement: Category-General Anaphora
In the examples seen so far, anaphoric expressions have been referring to noun-phrases exclusively. Thus, the domain of the environment could be only NP anaphora. Yet, English features anaphoric expressions for many syntactic categories, including at least adjectival phrases (AP), common nouns (CN), two-place common-nouns (CN2), verb phrases (VP) and transitive verb phrases (VP2).Footnote 3
In the table below, we provide a number of examples of anaphora for various syntactic categories. We put the anaphora in square brackets and the referent in curly braces.

From these examples, we see that the syntactic form for the anaphoric expression determines the category of the referent. Thus, it is easy to choose the part of the environment to look for that referent. We can account for this phenomenon with a two-fold move:
-
extending the environment so that there is a map for every possible syntactic category. Ideally this would be done as follows:
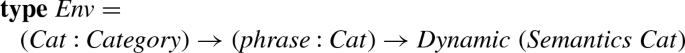
But since such dependent types are not supported by Haskell, we instead identify all categorical phrases for the second argument, using dynamic checks to tell them apart:
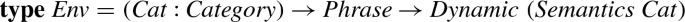
-
updating the environment for the appropriate category when encountering the referent and looking up the appropriate category when encountering the anaphora.
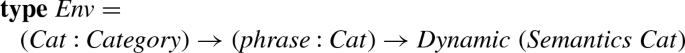
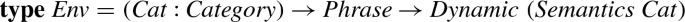
Using this technique we can account for cases such as the following:
-
(8)
Mary fell. John did too.
The interpretation of the relevant constituents are as follows. When interpreting “fell”, we push its semantics in the environment for VP’s, and when interpreting “did too”, we look up this information.

As an aside, one should note that, sometimes, the interpretation pushed in the environment should not be exactly the same as its pure semantics. We see an instance of this phenomenon in (7), where the sentence to put in the environment is that without the modal operator: “John arrives this evening”.
3.3 Strict and Sloppy Anaphora
Sometimes the referent of an anaphoric expression contains an anaphoric expression itself, as in the following example:
-
(9)
John loves his wife. Bill does too.
The following two readings of (9) are possible:
-
1.
love(wifeof(john),john) \(\times \)love(wifeof(john),bill)
-
2.
love(wifeof(john),john) \(\times \)love(wifeof(bill),bill)
We explain these interpretations as follows. In the so called strict reading (1.), the referent for “so does” is taken to be the interpretation of “his wife” in its context of occurrence (i.e. John’s wife), while in the second one, the reference is taken to be the effectful, dynamic semantics of “his wife” (i.e. the meaning should be re-interpreted in the environment at the point of occurrence of “so does”).
Our framework is equipped to account for either reading. The first reading can be explained with the following interpretation for “loves” :

The above says that one begins by evaluating the direct object of the verb to a pure interpretation, \( o' \) and push the semantic verb phrase \(\lambda x \mathbin {\rightarrow } love \;( x , o' )\) onto the environment, without any effect, by using \( return \). We can also explain the second reading, by adapting only the interpretation of “love”, as follows:

First, the effect of “loves his wife” is to push \(\mathbin {\llbracket } love \mathbin {\rrbracket }\mathbin {\llbracket } his \; wife \mathbin {\rrbracket }\) onto the environment. Then, upon resolution of “so does”, one will perform the following effects:
-
fetch (\(\llbracket \)love\(\rrbracket \) \(\llbracket \)his wife\(\rrbracket \)) from the environment
-
then evaluate (\(\llbracket \)love\(\rrbracket \) \(\llbracket \)his wife\(\rrbracket \)) in the environment \( \rho \), where in particular \( \rho (NP,``his'') = BILL\)
-
obtain \(\lambda x \mathbin {\rightarrow } love \;( x , wifeof \;(\mathbin {\llbracket } his \mathbin {\rrbracket }\rho ))\)
-
and finally evaluate the above to \(\lambda x \mathbin {\rightarrow } love \;( x , wifeof \;( bill ))\)
The careful reader may worry that, because the interpretation \(\mathbin {\llbracket } love \mathbin {\rrbracket } object \) contains a reference to itself, its evaluation may not terminate. First, let us note that \(\mathbin {\llbracket } love \mathbin {\rrbracket } object \) is itself a function, which is not called before being pushed into the environment: its invokation is delayed until it is looked up by \(\mathbin {\llbracket } so \; does \mathbin {\rrbracket }\). Second, even when it is called a second time, it is re-pushed onto the environment, but this time it will not be looked up again, and evaluation can terminate. Hence, unless the utterance itself contains recursive references, there is no termination issue.
The exact same mechanism accounts for “lazy pronouns” (Geach 1962), in sentences such as the following:
-
(10)
The man who gave {his paycheck} to his wife was wiser than the one who gave [it] to his mistress. (Karttunen 1969)
-
(11)
Bill wears {his hat} every day. John wears [it] only on Sundays.
In the above cases, we see that the referent itself contains an anaphoric expression, which is thus subject to the second stage of interpretation. As in the previous example, in certain contexts the strict interpretation is preferred. (Say if it is known that Bill shares a hat with John.) We can account for it by pushing the evaluated semantics in the environment. The selection between strict and sloppy readings can depend on various factors (lexical, pragmatic, etc.), which are out of scope of this paper.
3.4 Anaphoric Scope Flexibility: Donkey Sentences and E-Type Pronouns
In this section, we examine cases of anaphora that require some scope flexibility. We discuss simpler cases like (12) and proceed to more difficult cases of e-type and donkey anaphora, showing that our effectful semantics combined with intuitions from constructive type-theories gives a natural way of capturing the scope flexibility associated with anaphora in a natural language. We finish the section by describing a systematic, algorithmic procedure for scope extension which subsumes all the cases presented in the section.
-
(12)
Every student admits that [he] is tired
In (12), the pronoun “He” refers to the variable bound by “every”, which, strictly speaking, is not found in the syntax.
We can account for referents bound by quantifiers by using a suitable interpretation for quantifiers. We detail below the case of the quantifiers “every” and “some”. Other quantifiers can be dealt with in a similar manner.
To interpret the phrase “every CN”, we perform the following steps:
-
1.
allocate a fresh variable (say \( x \))
-
2.
evaluate the common noun CN, obtaining a type \( T \), and possibly affecting the environment.
-
3.
associate the appropriate pronouns to point to \( x \) (according to the gender and number of the common noun which the quantifier applies to). Such a pronoun is a donkey pronoun: it points to an object \( x \) which is valid semantically, but not manifest in the syntax.
-
4.
return the logical predicate \(\lambda p \mathbin {\rightarrow }\forall ( x \mathbin {:} T ).\; ( p \; x )\).
Formally:

Note that there cannot be a reference to \( x \) within \( cn \), because \( x \) is pushed onto the environment only after evaluating \( cn \).
3.4.1 Scoping with Universal Quantifiers
We underline that, according to our algorithm, all the effects associated with the quantifier persist even after closing the logical scope of a universal quantifier. This phenomenon is known as telescoping, which was introduced by Roberts (1987) (see also the work of Poesio and Zucchi (1992)). In particular, the referent is still accessible. This allows us to interpret sentences such as (13) below.
-
(13)
Every boy climbed on a tree. He is afraid to fall.
-
(14)
Every boy climbed on Mary’s shoulders. He likes her.
-
(15)
Every boy climbed on a tree and was afraid to fall.
-
(16)
Bill is old. Every boy climbed on a tree. He is afraid to fall.
Our system interprets (13) as

The above formula is not well scoped: \( x \) is unbound in the right conjunct. Yet, we regard our interpretation as as-satisfactory-as possible, because:
-
it reflects the infelicitous character of sentences such as (13) (which is perhaps more clear in (14)).
-
because any variable is bound at most once (every bound variable is fresh), it is possible to perform minimal scope extension separately from anaphora resolution to repair the sentence and obtain a reading equivalent to (15):
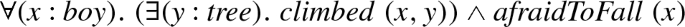
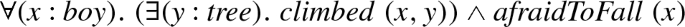
An alternative algorithm, proposed by Unger (2011), is to remove donkey pronouns from the context when the sentence which introduces them is complete. While logically consistent, such an approach has weaknesses. First, it precludes interpreting (13) at all, and thus (by default) also precludes any implicit repair by scope extension. Second, and perhaps worse, it makes further pronouns oblivious to quantifiers. Indeed, with this interpretation, in (16), the pronoun “he” refers unambiguously to “Bill”, while we believe that the preferred interpretation is that “He” attempts to refer to “Every boy” (embracing the awkwardness).
3.4.2 CN Scoping
Another consequence of letting all effects persist is that the referents introduced in the argument of the quantifier (CN) can be freely referred to later. This makes possible to correctly interpret (17), and even (18) albeit with a complicated scope-repair pass.
-
(17)
Every boy climbed on a tree. It fell.
-
(18)
Every committee has a chairman. He is appointed by its members.
We note in passing that in (17), after scope-resolution the existential quantifier will be the outermost one.
3.4.3 Scoping with Existential Quantifiers
While we regard the scope extension of universal quantification somewhat infelicitous, no such problem generally occurs with existential quantification alone.
-
(19)
A boy climbed on a tree. [He] is afraid to fall.
In (19), the pronoun “He” refers unambiguously to the boy introduced in the first sentence. Combined with Ranta’s analysis (Ranta 1994), our framework offers an explanation for lack of awkwardness by appealing to constructive logic. If one interprets existential quantification constructively, one obtains \(s : \Sigma (x:Boy) \Sigma (y:Tree). climbed(x,y)\) for the first sentence. But, when the scope of \(\Sigma \) is closed, one can substitute s.x (the first component of \(\Sigma \)) for x in the environment and interpret references without any need for scope extension.
We note in passing that if one uses a type-theory with records (be it the eponymous theory of Cooper (2017) or any proof assistant which happens to provide records), one can conveniently substitute the record meet operation for conjunction, thereby avoid any substitution in the environment.
(In Unger’s account (Unger 2011), existential quantifiers are left implicit. Only in a subsequent phase, existential quantification is added at the outermost possible scope. While this scheme works in many cases, it is unclear that using the outermost scope is always the best solution. We prefer to extend scope on a per-quantifier basis for a more fined-grained semantics.)
3.4.4 Scoping with Implication
-
(20)
If a man is tired, he leaves.
Our system interprets the above sentence as
where x as a free occurrence. As discussed above for simple existentials, constructive type-theory informs that scope extension poses no problem whatsoever. Thus our solution is to systematically lift quantifiers in the premise to scope over an implication. Such a lifting does not change the reading of the sentence when the variable does not occur in the conclusion. It should be noted however that the quantifier changes polarity in this case.Footnote 4 Thus we obtain:
The following example sheds some light as for why we attach the domains to the quantifiers.
-
(21)
A man leaves if he is tired.
If we use predicates for CN, then the direct interpretationFootnote 5 of the above sentence is
and in this case logic dictates that there should be no polarity shift when lifting the quantification, thus we would get
which appears nonsensical (being tired implies being a man). Now, if we extend the scope of the quantifier with a domain, we obtain instead the following much more sensible interpretation:
3.4.5 Prototypical Donkey Sentence
Consider the following sentence, famously referred to as the donkey sentence in the literature:
-
(22)
Every man that owns a donkey beats it.
The compositional interpretation of the donkey sentence is:
On the face of it, one must extend the scope of y so that y is accessible in \( beat \;( x , y )\). Extending the scope yields the following formula (Ranta 1994):
3.4.6 E-type Pronouns
Consider the following sentences:
-
(23)
Most boys climbed on a tree.
-
(24)
Most boys climbed on a tree. They were afraid to fall.
-
(25)
Most boys climbed on a tree. Every boy that climbed on a tree was afraid to fall.
-
(26)
Most boys climbed on a tree and were afraid to fall.
The generalized quantifier “most” can be interpreted as a weakened universal quantifier, hereafter written MOST, so that (23) would be interpreted as follows:
Consequently, it would be possible to interpret references to the quantified variable by using scope extension. If we do that, we would interpret (24) in the same way as (25):
However, according to Evans (1980), the above interpretation is incorrect. Instead, the pronoun should refer exactly to the boys that climbed the tree, and the semantics should be equivalent to that of (24):
Fortunately, there is a simple way to fix the problem. Namely, it suffices to re-introduce the variable with the appropriate quantification once the scope of MOST is closed. Thereby, if scope extension is needed, it is the latter quantifier (not MOST) whose scope will be extended. Thus, the interpretation of example (23) becomes:
Note in particular the use of a \(\Sigma \)-type to quantify over the appropriate set and the use of the constant \(\mathrm {true}\) to avoid making any statement when no continuation of the the sentence is present.
An advantage of this interpretation is that it works well with any location of the generalized quantifier. For example, the following sentence is interpreted correctly.
-
(27)
Mary owns a few donkeys. Bill beats them.
3.4.7 Scope Extension Algorithm
In sum, the fundamental idea is that we do not interpret linguistic strings directly to a well-behaved logic, but rather use an intermediate semantic representation where there is a biunique relation between variable names and variable binders. This representation allows us to identify the desired binder for anaphoric expression regardless of semantic context. Pragmatic conditions on pronoun accessibility are checked separately.
Having seen how this idea plays out empirically, we describe it in its full generality in the rest of this section. The goal is to make sure that every variable \( x \) is bound by a quantifier somewhere in the logical expression. Even though anaphora resolution can create a reference out of scope of the corresponding quantifier, the binder is guaranteed to exist somewhere in the formula. Hence, the algorithm proceeds as follows.
-
1.
If there is no free variable the expression is well-scoped and scope extension is thus complete. Otherwise, identify a variable which occurs free somewhere in the formula and call it \( x \). Locate its quantifier. Let us call this quantifier \(\mathbin {\nabla } x \) (where \(\mathbin {\nabla }\) can stand for \(\forall , \exists , etc.\)). Note that because we allocate a fresh variable for each of the quantifiers in our dynamic semantics, the correspondence between variables and quantifiers is unambiguous even when scoping is incorrect.
-
2.
Identify the innermost expression containing \(\mathbin {\nabla } x \). This expression has in general the form of an operator (which we write \(\mathbin {\circ }\) here). This operator can be applied to one or two operands. In the case of two operands, the expression involving the operator has the following form: \((\mathbin {\nabla } x .\; M )\mathbin {\circ } N \).
-
3.
Determine the polarity of lifting in this context. The polarity is a function of the operator and the position of the operand containing the qunatifier (see Table 1).
-
4.
Rewrite this expression by lifting the quantifier above the operator \(\mathbin {\circ }\). In our example the result would be \(\mathbin {\nabla } x .\; ( M \mathbin {\circ } N )\) if the operator is positive in its first operand, and \(\Delta x. (M \circ N)\) if the operator is negative in its first operand and \(\Delta \)is the quantifier dual to \(\mathbin {\nabla }\). (\(\forall \) is dual to \(\mathbin {\exists }\) and vice-versa.)Footnote 6
-
5.
Weigh down the likelihood of the interpretation according to the felicity factor (see table 1).
-
6.
If the free occurrence of \( x \) was contained in \( N \), it has now become bound. If not, we have extended the scope of \(\mathbin {\nabla } x \), and we can loop from step 2. Because the formula is finite and each iteration extends the scope by a strictly positive amount, we can be certain that this process terminates.
-
7.
Loop from step 1. until no free variable occurrence remains.
Finally we recall that for scope extension to work, the domain of discourse must be lifted together with the quantifier (see Sect. 3.4.4).
Our approach to pronouns and their binding shares similarities with Dynamic Predicate Logic (DPL) of Groenendijk and Stokhof (1991) as we treat pronouns as variables that are dynamically bound by quantifiers. That is, we allow quantified noun phrases to extend their operational scope beyond the clausal and sentential boundaries to bind variables that occur outside of the clause where their occur.
In contrast to DPL, where only an existential quantifier is capable of binding variables outside of its structural (standard) scope, in our approach, in addition to the existential quantifier, the universal quantifier can bind free variables outside of its scope. The reason for doing so is to be able to account for discourses such as (18), where universally quantified variables are referred by pronouns outside of the sentence where they occur.
-
(28)
John does not have a car. # It is fast.
-
(29)
A wolf might enter. It would growl.
-
(30)
A wolf might enter. # It will growl.
-
(31)
Either there is no bathroom here or it is hidden.
In addition, we do not block any discourse referent, which is the case for theories of dynamic semantics such as DPL: entities under the scope of negation are not accessible outside of the scope (e.g. (28)). There are several reasons for doing that. Firstly, when modal operators interact with negation, discourse referents introduced under the scope of negated formula could be still accessible, like it is in (29). Since the present approach does not deal with modals, to be still able to give account to cases like (29), we prefer to make everything accessible for further usage. Another reason is that dynamic theories, following DPL, treat disjunction as purely static. In particular, given \( \phi \vee \psi \), discourse referents of \(\phi \) are not accessible for \(\psi \). However, there is still no consensus about the issue (a commonly used counterexample to this static treatment is (31)).Footnote 7 We understand that the dynamization of all connectives (and, or, implication) and the universal quantifier can lead to various problems for logic based dynamic semantic theories as well as may allow for infelicitous discourses (e.g. (28) and (30)). However, since still there is no clear enough criteria for distinguishing phenomena that must be treated as dynamic from the ones that treated as static, we prefer to allow incorrect readings rather than block valid interpretations in certain cases. We provide Table 1 in lieu of the constraints found in dynamic semantic theories as a current heuristic while reasoning about anaphora and their bindings.
3.5 Cataphora
So far, our system captures cases where the referent precedes the anaphoric element exclusively. In this section, we explain how the system is extended to handle cataphora as well. Consider the following cataphoric cases:
-
(32)
[He] was tired. Bill left.
-
(33)
If Bill finds it, he will wear his coat.
Can we make “he” refer to “Bill”, even though the referent occurs after the pronoun?
This phenomena can be supported by using a backward-traveling state monad, whose \(\mathbin {\star }\) operator is defined as follows. Note how the environment is threaded between calls.

The above looks a priori problematic because of the circular dependency:
-
\( x \) depends on \(\rho _1\)
-
\(\rho _1\) depends on \( x \)
Yet, by using a non-strict evaluation strategy, such as Haskell implements, one can compute a result in all the cases where the cycle is broken dynamically. That is, if either
-
the value of \(x\) does not depend on \(\rho _1\) (for example if it does not contain a cataphoric reference), or
-
the value of \( f \) does not return an environment depending on \( x \) (the return value of \( m \)).
It should be underlined that both forward and backward-traveling states can be combined in a single monad, thus accounting for both anaphora and cataphora. The bind operation for such a monad is the following:

Finally, contexts could be equipped with a measure of distance and heuristics (lexical and pragmatic factors), which would allow us to choose between the possible readings. We do not do this here, and instead all interpretations are simply considered to be equally likely.
3.6 Bach–Peters Sentences
Karttunen (1971) defines a class of sentences, often referred to as Bach–Peters sentences in the literature, characterised by internal circular anaphoric dependency. Karttunen illustrates the issue with the following example:
-
(34)
The pilot who shot at it hit the Mig that chased him.
In (34), the pronoun “it” from the noun phrase “the pilot who shot at it” refers to the same entity that is described by the noun phrase “the Mig that chased him”, where the pronoun “him” refers to the entity referred by the noun phrase “the pilot who shot at it”, which in turn is built with the help of the pronoun “it”. So, there is a cyclic dependency between these two noun phrases.
As we discuss at length in the rest of the section, the definite determiner (“the”) is another critical element of this class of sentences. For this reason, we will be using a special-purpose quantifier in the object logic, written The(x : A)B which selects a member of the type A and makes it available in B as x. This is reminiscent of Hilbert’s epsilon operator. The epsilon operator is sometimes used in the literature (Egli et al. 1995) to deal with other phenomena discussed earlier. However, we prefer to use a quantifier which follows the form of \(\forall \) and \(\exists \) instead: this allows a more general kind of reasoning, and is more useful for scope extension.
In agreement with the algorithm for cataphora defined above, our framework produces the following formula for the example (34).
We see here that a well-formed logical formula can be produced. However, in the above form, the first occurence of c is not bound, and thus the scope of its binder should be extended. Unfortunately, one cannot apply the scope-extension algorithm exactly as described above in this case. Indeed, attempting to swap the order of the “The” quantifiers results in a formula where a is not bound.
It is sometimes believed that the main reason for the difficulty in such an analysis is the circularity of anaphoric expressions. However, another key ingredient is the use of a definite determiner in the second position. To see this, one can instead use an indefinite article for “Mig” (the second occurence of definite), and thus bind it existentially, as it is in the following example:
-
(35)
The pilot who shot at it hit a Mig that chased him.
Then, a possible interpretation is the following:
In this case, we can transform the formula to the following variant:
which could in turn be potentially scope-extended to:
The above formula is a direct interpretation of the following sentence:
-
(36)
The pilot shot at a Mig that chased him and hit it.
Notice that the sentence (36) is comprised of two statements connected by the conjunction and. There is no circularity in the anaphoric dependency any more. However, while the sentences (34) and (36) are similar, their truth conditions are different: (36) is false in the case the pilot did not shot at the Mig, whereas such a claim would not work in the case of (34), because the noun phrase already restricts the situations only to those where the pilot shot at the Mig. Therefore, the change of quantifier that we performed is not semantic-preserving.
Having seen that the existential representation must be rejected, we return to the original form
There is in fact a possible scope-transformation which makes both the pilot (a) and the Mig (c) in scope for hit(a, c). The key is to simultaneously choose both the pilot and the Mig as a pair (out of the product of the two domains) using the quantifier The. We write the result using record notation, as follows:
For completeness, we can examine what happens when the “the” quantifier in the first position is substituted by a universal quantifier:
-
(37)
Every pilot who shot at it hit the Mig that chased him.
The interpretation exhibits the same substitution:
Here, again, quantifiers cannot be swapped, but it is valid to transform the pair of quantifiers into a universal quantifier over a pair:
In sum, to handle Bach–Peters sentences we need the following elements:
-
a specific \( \varepsilon \)-like quantifier (“The”) must be used to represent definites;
-
a specific scope-extension rule dealing with this quantifier must be added: when the quantifer The is a candidate for scope extension over another quantifer \(\nabla x:C\), and the domain of “The” mentions the variable of this domain, we transform the formula into a \(\nabla \)-quantification over a pair (otherwise the usual transformation applies):
$$\begin{aligned} \nabla (x:A).The(y:B).C \end{aligned}$$becomes
$$\begin{aligned} \nabla (p:[x:A, y:B]).C \end{aligned}$$where we subsitute p.x for x and p.y for y in C. (We stress that \(\nabla \) can itself stand for a definite “The” quantifier.)
4 Implementation
If we have already presented snippets of code in the above, they have been often simplified, for pedagogical purposes. In this section we will show and comment a portion of the actual implementation, so one can see how big the gap between theory and practice is. In this section we will assume familiarity with Haskell and its standard library.
4.1 Dynamic Semantics
First we show the definition of types which serve as the interpretation of syntactic categories.

The above types are already informative: they limit the way the dynamic semantics can be influenced by generated propositions. For the sake of example, let us consider the case with VP. We see that to obtain the proposition one must first evaluate the effect, and only then one can obtain a predicate on objects. Thus the content of the predicate cannot influence the effect associated with the VP. (However, in the scope extension phase there is a deep interaction between effects and propositions, via variable bindings.)

The environment contains:
-
For each category, the phrases which can be possibly referred to by anaphora.
-
A list of fresh variables, to be used with binders. (To avoid variable capture.)
In \( objEnv \), descriptors allow to determine whether a pronoun can refer to its associated NP or not.

The code which is responsible for pushing and looking up objects in the environment follows.

5 Evaluation
To evaluate our framework, we have constructed an implementation, as described above. We have then fed it a set of examples and checked the output for correctness. These examples are meant to showcase the strengths of our framework, but also reveal some of its weak spots.
A question that might arise is: why did we not simply use the FraCaS suite, which provides a section on anaphora with 27 examples? The answer is multi-fold:
-
1.
FraCaS assumes a fully-fledged inference engine. In this paper we only propose a method to generate formulas.
-
2.
Additionally, FraCaS tests success via inference problems only. This methodology tends to require examples with more context than necessary, and thus distract from the point at hand (was the anaphora properly resolved?). It even sometimes requires to infer the background (116) (in this paragraph numbers refer to examples in the anaphora section of FraCaS (27 examples numbered from 114 to 141).)
-
3.
Additionally, FraCaS does not test for several phenomena that we capture (definite articles, sentential anaphora, reference to recent occurrences, etc.)
-
4.
Several examples (117, 123–126, 131, 132, 138, 140, 141) rely on pragmatic factors and world knowledge, which we do not support.
-
5.
Several examples have ambiguous readings (129, 130, 135, 136).
Regardless, some of the examples of our suite are either inspired by, or taken straight from FraCaS (122, 133). In fact, while this paper was under review, Bernardy and Chatzikyriakidis (2019) have implemented a variant of the algorithms presented here together and integrated it with an inference system. We refer the interested readers to their work for more details on the combined system performance.
The complete results are shown in the “Appendix”. The first few entries match the examples shown in the body of the paper. The remaining entries test additional less important features and/or combinations of features. For every example, we show:
-
1.
An English sentence
-
2.
A possible parsing of that sentence, rendered with the operators that we have defined in our library
-
3.
The first possible interpretation of the above including anaphora resolution done by our implementation.
If all anaphoric expressions can be resolved, then we show the corresponding result. If not, we show one with explicit missing referents.
-
4.
The above interpretation, after applying our algorithm for scope extension.
-
5.
Optionally, a brief commentary of the example.
We stress that the formulas that we propose are not meant as the definitive interpretation for any given example. They are meant simply to demonstrate by example what our system is capable of (and what it is not capable of). Yet, we believe that the set of examples itself can be used as a stepping stone to construct an exhaustive test-suite for anaphora-resolution systems.
6 Related Work
Among other sources, this work builds upon previous work dealing with anaphora either using constructive logics (Ranta 1994) or monads on top of more standard logics, usually some variant of Montague Semantics (Unger 2011; Charlow 2015, 2017). For some authors, including Ranta (1994), the algorithmic aspects of anaphora resolution are left unspecified and only the existence of the referent in the logical formula seem to matter to the authors. The work presented in this paper can be seen as making such systems more precise.
Ideas similar to those presented here can be found in a number of papers by de Groote and colleagues (de Groote 2006; Qian et al. 2016). In their work, continuations are used to get dynamic effects similar to the ones presented in this paper.Footnote 8 It is important to note that continuations have the same expressive power as monads, and thus we could have equally built our system around continuations. The continuation/monad distinction being a matter of taste, what are the essential differences between this work and that of de Groote and colleagues? First, while we embrace out-of-scope variables and repair interpretations when possible, while de Groote et al. interpret scope rigidly in function of syntax. Their approach means that either some references will not be resolved, or that quantifiers scope can never be closed. This is why we propose the above account, at the expense of not rejecting some incorrect sentences. It would be illuminating to compare the predictions that our account makes compared to the ones proposed by de Groote and colleagues on a large representative corpus, but we are lacking the parsed data to do so. Second, we have a focus on an automated implementation (witnessed by the test suite). Third, de Groote et al. aim at supporting more linguistic phenomena, such as modal subordination. While de Groote’s approach to dynamics of language allows one to interpret a discourse as a logical form in a purely compositional manner, the anaphoric antecedents of pronouns that are out of structural scope of quantifiers are left unspecified; only the context from which they should be selected is given. Yet another step is needed to select from the context the right antecedents for the pronouns. The present work, by contrast, does that: anaphoric pronouns are resolved to their antecedents, and it is a part of a compositional interpretation. Since the basic premises of de Groote’s work are compatible with ours, we believe that integrating their ideas with our work is possible and can be beneficial. In particular, we would like to support modal subordination as described by Qian et al. (2016).
Another related approach to study natural language semantics, including certain kinds of anaphora, was proposed by Maršík and Amblard (2016). They instead of monads use effects and handlers, a theory developed by Plotkin and Pretnar (2009). Effects and handlers can be encoded by monads, but combining them is easer than to combine monads in general Hyland et al. (2006).
Lastly, the idea of using re-interpreting effects to account for sloppy readings has been proposed before by Charlow (2015, 2017). In the way we see it, our account takes the idea further by making systematic use of the idea. Namely, every phrase should push itself into the environment for further reference. Additionally, the account proposed here offers more flexible scoping rules and a complete, tested implementation, as well as scope extension.
7 Discussion and Conclusion
In this paper, we have proposed a framework for dynamic semantics which is comprised of the following two parts:
-
1.
An anaphora-resolution mechanism which is based on context-dependent re-evaluation of referents
-
2.
A scope-extension mechanism
Either of these components, taken in isolation, is of moderate complexity. Yet, together, they can account for a wide range of anaphoric phenomena. This latter fact, together with a clear implementation as well as a test suite to measure the effectiveness of the present account are the main merits of the present work as we see it.
In the future, we would like to extend our account to more anaphoric phenomena that have been puzzling in the literature. One such phenomenon is modal subordination, in particular accounting for contrasts similar to the ones shown in the above listed examples, repeated as follows:
-
(38)
A wolf might enter. It would growl.
-
(39)
A wolf might enter. # It will growl.
Another issue that we would like to explore is the extension of the anaphora test suite presented in this paper. The idea would be to build a complete anaphora test suite, which could be used as a benchmark for various computational semantics systems for anaphora.
Notes
Or indeed any interpretation which uses a logical system, such as dependent types, TTR, System F, etc.
This function may be partial if the discourse is incomplete or incoherent.
The semantic interpretations of these categories are given in Sect. 4.1. In traditional terms, CN and CN2 anaphora correspond to NP and complex NP anaphora respectively. Similarly, VP2 anaphora is known as Antecedent Contained Deletion.
In dynamic semantics, the observation that \(\exists x. \phi \rightarrow \psi \Leftrightarrow \forall x. (\phi \rightarrow \psi ) \) is known as Egli’s corollary (Egli 1979); it is a consequence of declaring that \((\exists x. \phi ) \wedge \psi \) and \(\exists x. (\phi \wedge \psi ) \) are equivalent without requiring that x is not free in \(\psi \) (when x is not free in \(\psi \), this equivalence holds in usual logics).
In examples such as the above the indefinite article often has an universal meaning, and thus should simply be interpreted as a universal. However, this is not the effect that we wish to capture here.
The dualisation of MOST and FEW can be problematic, but fortunately they rarely need to be scope-extended. Indeed, we have seen that in our interpretation of e-type pronouns that the variable bound by them is re-bound to a universal.
We believe that pragmatic devices should be integrated more within dynamic semantics in order to provide a more complete characterization of accessibility constraints (see Shelley 2011 for discussion).
While this paper was under review, Itegulov et al. (2018) presented a demo to analyze anaphora within and across the sentences, including event ones, based on de Groote and colleagues’ earlier work.
References
Barker, C., & Shan, C. (2004). Continuations in natural language. In: Proceedings of the fourth ACM SIGPLAN workshop on continuations, Hayo Thielecke (pp. 55–64).
Barr, M., & Wells, C. (1999). Category theory for computing science (3rd ed.). Upper Saddle River: Prentice Hall.
Bernardy, J.-P., & Chatzikyriakidis, S. (2019). A wide-coverage symbolic natural language inference system. In: Proceedings of the 22nd nordic conference on computational linguistics. ACL.
Bernardy, J.-P., Chatzikyriakidis, S., & Maskharashvili, A. (2020). A computational treatment of anaphora and its algorithmic implementation: Extended version. Available on the author’s homepage: https://jyp.github.io/pdf/phoroi.pdf.
Boldini, P. (2000). Formalizing contexts in intuitionistic type theory. In Fundamenta Informaticae 4(2).
Charlow, S. (2015). Monadic dynamic semantics for anaphora. In: Ohio State dynamic semantics workshop.
Charlow, S. (2017). A modular theory of pronouns and binding. In Logic and engineering of natural language semantics (LENLS) (vol. 14). Springer.
Chatzikyriakidis, S. (2014). Adverbs in a modern type theory. In: N. Asher, & S. Soloviev (Eds.), Proceedings of LACL2014. LNCS 8535 (pp. 44–56).
Chatzikyriakidis, S., & Luo, Z. (2013). Adjectives in a modern type-theoretical setting. In: Formal grammar (pp. 159–174). Springer.
Chatzikyriakidis, S., & Luo, Z. (2017). On the interpretation of common nouns: Types versus predicates. In: Modern perspectives in type-theoretical semantics (pp. 43–70). Springer.
Cooper, R. (1979). The interpretation of pronouns. In: F. Heny & H. Schnelle (Eds.), Syntax and semantics (vol. 10, pp. 535–561).
Cooper, R. (2017). Adapting type theory with records for natural language semantics. In: S. Chatzikyriakidis, & Z. Luo (Eds.) Modern perspectives in type-theoretical semantics (pp. 71–94). Springer.
de Groote, P. (2006). Towards a Montagovian account of dynamics. In Semantics and linguistic theory (Vol. 16, pp. 1–16).
Egli, U. (1979). The stoic concept of anaphora. In R. Bäuerle, U. Egli, & A. von Stechow (Eds.), Semantics from different points of view (pp. 266–283). Springer.
Egli, U., Von Heusinger, K., et al. (1995). The epsilon operator and E-type pronouns. In Amsterdam studies in the theory and history of linguistic science series (vol 4).
Evans, G. (1980). Pronouns. Linguistic Inquiry, 11(2), 337–362.
Geach, Peter Thomas. (1962). Reference and generality. New York: Cornell University Press.
Giorgolo, G., & Asudeh, A. (2012). Monads for conventional implicatures. In Proceedings of Sinn und Bedeutung 16. MIT-Working Papers in Linguistics.
Giorgolo, G., & Asudeh, A. (2014). Monads as a solution for generalized opacity. In EACL 2014 (p. 19).
Groenendijk, J., & Stokhof, M. (1991). Dynamic predicate logic. Linguistics and Philosophy, 14(1), 39–100.
Hyland, M., Plotkin, G., & Power, J. (2006). Combining effects: Sum and tensor. Theoretical Computer Science, 357(1), 70–99. https://doi.org/10.1016/j.tcs.2006.03.013.
Itegulov, D., Lebedeva, E., & Paleo, B. W. (2018). Sensala: A dynamic semantics system for natural language processing. In Proceedings of the 27th international conference on computational linguistics: System demonstrations (pp. 123–127). Santa Fe, New Mexico: Association for Computational Linguistics. https://www.aclweb.org/ anthology/C18-2027.
Karttunen, L. (1969). Discourse referents. In Proceedings of the 1969 conference on computational linguistics (pp. 1–38). COLING’69. Stockholm: Association for Computational Linguistics. https://doi.org/10.3115/990403.990490.
Karttunen, L. (1971). Definite descriptions with crossing coreference: A study of the Bach–Peters paradox. Foundations of Language, 7(2), 157–182.
Luo, Z. (2012). Common nouns as types. In D. Bechet, & A. Dikovsky (Eds.), Logical aspects of computational linguistics (LACL’2012). LNCS 7351.
Marlow, S. (2010). Haskell 2010 language report. http://haskell.org/definition/haskell2010.pdf.
Maršík, J., & Amblard, M. (2016). Introducing a calculus of effects and handlers for natural language semantics. In A. Foret et al. (Eds.), Formal grammar (pp. 257–272). Berlin: Springer. ISBN: 978-3-662-53042-9.
Moggi, E. (1991). Notions of computation and monads. Information and Computation, 93(1), 55–92.
Plotkin, G., & Pretnar, M. (2009). Handlers of algebraic effects. In Proceedings of the 18th European symposium on programming languages and systems: held as part of the joint European conferences on theory and practice of software, ETAPS 2009. ESOP’09 (pp. 80–94). York: Springer. ISBN: 978-3-642-00589-3. https://doi.org/10.1007/978-3-642-00590-9_7.
Poesio, M., & Zucchi, A. (1992). On telescoping. In C. Barker, & D. Dowty (Eds.) SALT II-proceedings from the conference on semantics and linguistic theory (Columbus, Ohio, May 1–3) (pp. 347–366).
Qian, S., de Groote, P., & Amblard, M. (2016). Modal subordination in type theoretic dynamic logic. In LiLT (Linguistic Issues in Language Technology) 14.
Ranta, A. (1994). Type-theoretical grammar. Oxford: Oxford University Press.
Roberts, C. (1987). Modal subordination, anaphora, and distributivity. https://www.asc.ohio-state.edu/roberts.21/dissertation.pdf.
Roberts, C. (1989). Modal subordination and pronominal anaphora in discourse. Linguistics and Philosophy, 12(6), 683–721. https://doi.org/10.1007/BF00632602.
Roberts, C. (1990). Modal subordination, anaphora, and distributivity. New York: Garland Press.
Shan, C. (2002). Monads for natural language semantics. In CoRR cs.CL/0205026. arXiv:CL/0205026
Shelley, L. K. (2011). Understanding dynamic discourse. Ph.D. Thesis. Rutgers, The State University of New Jersey.
Unger, C. (2011) Dynamic semantics as monadic computation. In JSAI International symposium on artificial intelligence (pp. 68–81). Springer.
Acknowledgements
We warmly thank anonymous reviewers of earlier drafts of this paper, whose suggestions have led to much improvement of the contents. The research in this paper is supported by grant 2014-39 from the Swedish Research Council, which funds the Centre for Linguistic Theory and Studies in Probability (CLASP) in the Department of Philosophy, Linguistics, and Theory of Science at the University of Gothenburg.
Funding
Open access funding provided by University of Gothenburg.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Appendix: Test Suite
Appendix: Test Suite
In the test suite we make heavy use of operators, to keep the examples concise, and in fact, readable at all. The operators are infix notations for combinators presented above, or variants thereof. We list only their types here. The complete code (including all combinators and lexical items) is available as supplementary material.

Sometimes the environment does not contain any appropriate referent for NPs. In such a case we output “assumedNP”; If the NP is of the form “the cn” and no object satisfying cn can be found, we output \(\mathbf {U}(cn)\).
-
1.
John loves Mary. Bill likes her.
\(( johnNP \mathbin {!}( lovesVP' \mathbin {?} maryNP ))\mathbin {\#\#\#}( billNP \mathbin {!}( likeVP \mathbin {?} herNP ))\)
\(\mathrm {love}(\mathrm {john},\mathrm {mary}) \wedge \mathrm {like}(\mathrm {bill},\mathrm {mary})\)
-
2.
John owns an {old} car. He loves [such] cars.
\(( johnNP \mathbin {!}( own \mathbin {?} aDet \;( oldAP \mathbin {\#} carCN )))\mathbin {\#\#\#}( heNP \mathbin {!}( lovesVP' \mathbin {?}( suchDet \; carsCN )))\)
\((\exists (a:[b : \mathrm {car};\;p : \mathrm {old}( b )]).\; \mathrm {own}(\mathrm {john}, a )) \wedge (\forall (d:[c : \mathrm {cars};\;p : \mathrm {old}( c )]).\; \mathrm {love}(\mathrm {john}, d ))\)
-
3.
Mary owns an old car. John owns a red one.
\(( maryNP \mathbin {!}( own \mathbin {?} aDet \;( oldAP \mathbin {\#} carCN )))\mathbin {\#\#\#}( johnNP \mathbin {!}( own \mathbin {?}( aDet \;( redAP \mathbin {\#} one ))))\)
\((\exists (a:[b : \mathrm {car};\;p : \mathrm {old}( b )]).\; \mathrm {own}(\mathrm {mary}, a )) \wedge (\exists (c:[d : \mathrm {car};\;p : \mathrm {red}( d )]).\; \mathrm {own}(\mathrm {john}, c ))\)
-
4.
The population of France is larger than that of Germany
\( the \;( populationCN2 \mathbin {` \_ of `} francePN )\mathbin {!}( is\_ larger\_ thanV2 \mathbin {?} thatOf \; germanyPN )\)
\(\mathrm {larger}(\mathbf {U}(\mathrm {population}(\mathrm {france})),\mathbf {U}(\mathrm {population}(\mathrm {germany})))\)
-
5.
Mary fell. John did too.
\(( maryNP \mathbin {!} fellVP )\mathbin {\#\#\#}( johnNP \mathbin {!} doesTooVP )\)
\(\mathrm {fell}(\mathrm {mary}) \wedge \mathrm {fell}(\mathrm {john})\)
-
6.
Mary has read all the books that john has.
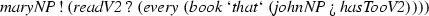
\(\forall (a:[b : \mathrm {book};\;p : \mathrm {read}(\mathrm {john}, b )]).\; \mathrm {read}(\mathrm {mary}, a )\)
-
7.
John may arrive this evening. If [so] Bill will be happy.
\( johnNP \mathbin {!}( may \;( arriveVP \mathbin {` adVP `} thisEvening ))\mathbin {\#\#\#}( so \mathbin {==>}( billNP \mathbin {!} ishappy ))\)
\(\mathrm {may}(\mathrm {this\_evening}(\mathrm {arrive}(\mathrm {john}))) \wedge (\mathrm {may}(\mathrm {this\_evening}(\mathrm {arrive}(\mathrm {john}))) \rightarrow \mathrm {happy}(\mathrm {bill}))\)
Remark: Incorrect: the sentence needs to be re-interpreted with another mood.
-
8.
Mary fell. John did too.
\(( maryNP \mathbin {!} fellVP )\mathbin {\#\#\#}( johnNP \mathbin {!} doesTooVP )\)
\(\mathrm {fell}(\mathrm {mary}) \wedge \mathrm {fell}(\mathrm {john})\)
-
9.
A donkey leaves. The donkey is tired.
\(( aDet \; donkey )\mathbin {!} leavesVP \mathbin {\#\#\#}( the \; donkey \mathbin {!} isTiredVP )\)
\((\exists (a:\mathrm {donkey}).\; \mathrm {leaves}( a )) \wedge \mathrm {tired}( a )\)
\(\exists (a:\mathrm {donkey}).\; \mathrm {leaves}( a ) \wedge \mathrm {tired}( a )\)
-
10.
A donkey leaves. The mule is tired.
\(( aDet \; donkey )\mathbin {!} leavesVP \mathbin {\#\#\#}( the \; mule \mathbin {!} isTiredVP )\)
\((\exists (a:\mathrm {donkey}).\; \mathrm {leaves}( a )) \wedge \mathrm {tired}(\mathbf {U}(\mathrm {mule}))\)
-
11.
A donkey and a mule walked in. The donkey was sad. It brayed.
\((( aDet \; donkey )\mathbin {` andNP `}( aDet \; mule )\mathbin {!} walkedInVP )\mathbin {\#\#\#}( the \; donkey \mathbin {!} was\_ sadVP )\mathbin {\#\#\#}( itNP \mathbin {!} brayedVP )\)
\((\exists (a:\mathrm {donkey}).\; \mathrm {walkedin}( a )) \wedge (\exists (b:\mathrm {mule}).\; \mathrm {walkedin}( b )) \wedge \mathrm {was\_sad}( a ) \wedge \mathrm {brayed}( a )\)
\(\exists (a:\mathrm {donkey}).\; \mathrm {walkedin}( a ) \wedge (\exists (b:\mathrm {mule}).\; \mathrm {walkedin}( b )) \wedge \mathrm {was\_sad}( a ) \wedge \mathrm {brayed}( a )\)
-
12.
A donkey and a mule walked in. The mule was sad. It brayed.
\((( aDet \; donkey )\mathbin {` andNP `}( aDet \; mule )\mathbin {!} walkedInVP )\mathbin {\#\#\#}( the \; mule \mathbin {!} was\_ sadVP )\mathbin {\#\#\#}( itNP \mathbin {!} brayedVP )\)
\((\exists (a:\mathrm {donkey}).\; \mathrm {walkedin}( a )) \wedge (\exists (b:\mathrm {mule}).\; \mathrm {walkedin}( b )) \wedge \mathrm {was\_sad}( b ) \wedge \mathrm {brayed}( b )\)
\((\exists (a:\mathrm {donkey}).\; \mathrm {walkedin}( a )) \wedge (\exists (b:\mathrm {mule}).\; \mathrm {walkedin}( b ) \wedge \mathrm {was\_sad}( b ) \wedge \mathrm {brayed}( b ))\)
-
13.
{John} slapped Bill. [He] hurt his hand.
\(( johnNP \mathbin {!}( slappedV2 \mathbin {?} billNP ))\mathbin {\#\#\#}( heNP \mathbin {!}( hurtV2 \mathbin {?} his \; handCN2 ))\)
\(\mathrm {slapped}(\mathrm {john},\mathrm {bill}) \wedge \mathrm {hurt}(\mathrm {bill},\mathrm {the}(\mathrm {hand}(\mathrm {bill})))\)
Remark: Incorrect: we do not report all readings in this prototype. Choosing the correct reading depends on pragmatic and lexical factors.
-
14.
John loves his wife. Bill does too.
\( johnNP \mathbin {!}( lovesVP' \mathbin {?} his \; wifeCN2 )\mathbin {\#\#\#}( billNP \mathbin {!} doesTooVP )\)
\(\mathrm {love}(\mathrm {john},\mathrm {the}(\mathrm {wife}(\mathrm {john}))) \wedge \mathrm {love}(\mathrm {bill},\mathrm {the}(\mathrm {wife}(\mathrm {bill})))\)
Remark: Sloppy reading
-
15.
The man who gave his paycheck to his wife was wiser than the one who gave it to his mistress.
\( the \;( man \mathbin {` that `}(( gaveV3 \mathbin {` appVP3 `} his \; paycheckCN2 )\mathbin {?} his \; wifeCN2 ))\mathbin {!}( is\_ wiser\_ thanV2 \mathbin {?}( the \;( one \mathbin {` that `}(( gaveV3 \mathbin {` appVP3 `} itNP )\mathbin {?} his \; mistressCN2 ))))\)


-
16.
Bill wears his hat every day. John wears it on Sundays.
\(( billNP \mathbin {!}(( wearV2 \mathbin {?}( his \; hatCN2 ))\mathbin {` adVP `} everyday ))\mathbin {\#\#\#}( johnNP \mathbin {!}(( wearV2 \mathbin {?} itNP )\mathbin {` adVP `} onSundays ))\)
\(\mathrm {everyday}(\mathrm {wear}(\mathrm {bill},\mathrm {the}(\mathrm {hat}(\mathrm {bill})))) \wedge \mathrm {on\_sundays}(\mathrm {wear}(\mathrm {john},\mathrm {the}(\mathrm {hat}(\mathrm {john}))))\)
-
17.
John wears his hat on Sundays. Mary does too.
\(( johnNP \mathbin {!}(( wearV2 \mathbin {?}( his \; hatCN2 ))\mathbin {` adVP `} onSundays ))\mathbin {\#\#\#}( maryNP \mathbin {!} doesTooVP )\)
\(\mathrm {on\_sundays}(\mathrm {wear}(\mathrm {john},\mathrm {the}(\mathrm {hat}(\mathrm {john})))) \wedge \mathrm {on\_sundays}(\mathrm {wear}(\mathrm {mary},\mathrm {the}(\mathrm {hat}(\mathrm {mary}))))\)
-
18.
John wears his hat on Sundays. His colleagues do too.
\(( johnNP \mathbin {!}(( wearV2 \mathbin {?}( his \; hatCN2 ))\mathbin {` adVP `} onSundays ))\mathbin {\#\#\#}( his \; colleaguesCN2 \mathbin {!} doesTooVP )\)
\(\mathrm {on\_sundays}(\mathrm {wear}(\mathrm {john},\mathrm {the}(\mathrm {hat}(\mathrm {john})))) \wedge \mathrm {on\_sundays}(\mathrm {wear}(\mathrm {the}(\mathrm {colleagues}(\mathrm {john})),\mathrm {the}(\mathrm {hat}(\mathrm {the}(\mathrm {colleagues}(\mathrm {john}))))))\)
-
19.
Bill is handsome. John loves him.
\(( billNP \mathbin {!} isHandsomeVP )\mathbin {\#\#\#}( johnNP \mathbin {!}( lovesVP' \mathbin {?} himNP ))\)
\(\mathrm {handsome}(\mathrm {bill}) \wedge \mathrm {love}(\mathrm {john},\mathrm {bill})\)
-
20.
Bill is handsome. John loves himself.
\(( billNP \mathbin {!} isHandsomeVP )\mathbin {\#\#\#}( johnNP \mathbin {!}( lovesVP' \mathbin {?} himSelfNP ))\)
\(\mathrm {handsome}(\mathrm {bill}) \wedge \mathrm {love}(\mathrm {john},\mathrm {john})\)
-
21.
Bill’s wife loves him.
\((( billNP \mathbin {` poss `} wifeCN2 )\mathbin {!}( lovesVP' \mathbin {?} himNP ))\)
\(\mathrm {love}(\mathrm {the}(\mathrm {wife}(\mathrm {bill})),\mathrm {bill})\)
-
22.
Bill’s wife loves himself.
\((( billNP \mathbin {` poss `} wifeCN2 )\mathbin {!}( lovesVP' \mathbin {?} himSelfNP ))\)
\(\mathrm {love}(\mathrm {the}(\mathrm {wife}(\mathrm {bill})),\mathrm {assumednp})\)
Remark: “himself” cannot be resolved in this instance. This is expected given the usual interpretation.
-
23.
This car is so much better than that one.
\( unsupported \)
\(\mathrm {unsupported}\)
Remark: There is no exophoric context in the prototype
-
24.
A man is standing over there.
\( unsupported \)
\(\mathrm {unsupported}\)
Remark: There is no deictic context in the prototype
-
25.
He is not the managing director. He is.
\( unsupported \)
\(\mathrm {unsupported}\)
Remark: There is no exophoric context in the prototype
-
26.
Every student admits that he is tired.
\(( every \; studentCN \mathbin {!}( admitVP \;( heNP \mathbin {!} isTiredVP )))\)
\(\forall (a:\mathrm {student}).\; \mathrm {admit}(\mathrm {tired}( a ), a )\)
-
27.
Every boy climbed on a tree. He is afraid to fall.
\(( every \; boyCN \mathbin {!}( climbedOnV2 \mathbin {?}( aDet \; treeCN )))\mathbin {\#\#\#}( heNP \mathbin {!} isAfraid )\)
\((\forall (a:\mathrm {boy}).\; \exists (b:\mathrm {tree}).\; \mathrm {climbed\_on}( a , b )) \wedge \mathrm {afraid\_to\_fall}( a )\)
\(\forall (a:\mathrm {boy}).\; (\exists (b:\mathrm {tree}).\; \mathrm {climbed\_on}( a , b )) \wedge \mathrm {afraid\_to\_fall}( a )\)
-
28.
Every boy climbed on Mary’s shoulders. He likes her.
\(( every \; boyCN \mathbin {!}( climbedOnV2 \mathbin {?}( maryNP \mathbin {` poss `} shouldersCN2 )))\mathbin {\#\#\#}( heNP \mathbin {!}( likeVP \mathbin {?} herNP ))\)
\((\forall (a:\mathrm {boy}).\; \mathrm {climbed\_on}( a ,\mathrm {the}(\mathrm {shoulders}(\mathrm {mary})))) \wedge \mathrm {like}( a ,\mathrm {mary})\)
\(\forall (a:\mathrm {boy}).\; \mathrm {climbed\_on}( a ,\mathrm {the}(\mathrm {shoulders}(\mathrm {mary}))) \wedge \mathrm {like}( a ,\mathrm {mary})\)
-
29.
Every boy climbed on a tree and was afraid to fall.
\(( every \; boyCN \mathbin {!}(( climbedOnV2 \mathbin {?} aDet \; treeCN )\mathbin {` andVP `} isAfraid ))\)
\(\forall (a:\mathrm {boy}).\; (\exists (b:\mathrm {tree}).\; \mathrm {climbed\_on}( a , b )) \wedge \mathrm {afraid\_to\_fall}( a )\)
-
30.
Bill is old. Every boy climbed on a tree. He is afraid to fall.
\(( billNP \mathbin {!} isOld )\mathbin {\#\#\#}( every \; boyCN \mathbin {!}( climbedOnV2 \mathbin {?}( aDet \; treeCN )))\mathbin {\#\#\#}( heNP \mathbin {!} isAfraid )\)
\(\mathrm {old}(\mathrm {bill}) \wedge (\forall (a:\mathrm {boy}).\; \exists (b:\mathrm {tree}).\; \mathrm {climbed\_on}( a , b )) \wedge \mathrm {afraid\_to\_fall}( a )\)
\(\mathrm {old}(\mathrm {bill}) \wedge (\forall (a:\mathrm {boy}).\; (\exists (b:\mathrm {tree}).\; \mathrm {climbed\_on}( a , b )) \wedge \mathrm {afraid\_to\_fall}( a ))\)
-
31.
Every boy climbed on a tree. It fell.
\(( every \; boyCN \mathbin {!}( climbedOnV2 \mathbin {?}( aDet \; treeCN )))\mathbin {\#\#\#}( itNP \mathbin {!} fellVP )\)
\((\forall (a:\mathrm {boy}).\; \exists (b:\mathrm {tree}).\; \mathrm {climbed\_on}( a , b )) \wedge \mathrm {fell}( b )\)
\(\exists (b:\mathrm {tree}).\; (\forall (a:\mathrm {boy}).\; \mathrm {climbed\_on}( a , b )) \wedge \mathrm {fell}( b )\)
Remark: Scope extension can forces the order of quantifiers.
-
32.
Every commitee has a chairman. He is appointed by its members.
\( every \; commitee \mathbin {!}( has \mathbin {?}( aDet \; chairman ))\mathbin {\#\#\#}( heNP \mathbin {!}( isAppointedBy \mathbin {?}( its \; members )))\)
\((\forall (a:\mathrm {commitee}).\; \exists (b:\mathrm {chairman}).\; \mathrm {have}( a , b )) \wedge \mathrm {appoint}(\mathrm {the}(\mathrm {members}( a )), b )\)
\(\forall (a:\mathrm {commitee}).\; \exists (b:\mathrm {chairman}).\; \mathrm {have}( a , b ) \wedge \mathrm {appoint}(\mathrm {the}(\mathrm {members}( a )), b )\)
-
33.
A boy climbed on a tree. He is afraid to fall.
\(( aDet \; boyCN \mathbin {!}( climbedOnV2 \mathbin {?}( aDet \; treeCN )))\mathbin {\#\#\#}( heNP \mathbin {!} isAfraid )\)
\((\exists (a:\mathrm {boy}).\; (\exists (b:\mathrm {tree}).\; \mathrm {climbed\_on}( a , b ))) \wedge \mathrm {afraid\_to\_fall}( a )\)
\(\exists (a:\mathrm {boy}).\; (\exists (b:\mathrm {tree}).\; \mathrm {climbed\_on}( a , b )) \wedge \mathrm {afraid\_to\_fall}( a )\)
-
34.
If a man is tired, he leaves.
\(((( aDet \; man )\mathbin {!} isTiredVP )\mathbin {==>}( heNP \mathbin {!} leavesVP ))\)
\((\exists (a:\mathrm {man}).\; \mathrm {tired}( a )) \rightarrow \mathrm {leaves}( a )\)
\(\forall (a:\mathrm {man}).\; \mathrm {tired}( a ) \rightarrow \mathrm {leaves}( a )\)
-
35.
A man leaves if is he tired.
\(((( aDet \; man )\mathbin {!} leavesVP )\mathbin {<==}( heNP \mathbin {!} isTiredVP ))\)
\(\mathrm {tired}( a ) \rightarrow (\exists (a:\mathrm {man}).\; \mathrm {leaves}( a ))\)
\(\exists (a:\mathrm {man}).\; \mathrm {tired}( a ) \rightarrow \mathrm {leaves}( a )\)
Remark: Scope extension does not dualize the quantifier when lifting from positive position.
-
36.
Every man that owns a donkey beats it.
\(( every \;( man \mathbin {` that `}( own \mathbin {?}( aDet \; donkey )))\mathbin {!}( beatV2 \mathbin {?} itNP ))\)
\(\forall (a:[b : \mathrm {man};\;c : \mathrm {donkey};\;p : \mathrm {own}( b , c )]).\; \mathrm {beat}( a , a .c)\)
-
37.
Most boys climbed on a tree.
\(( most \; boysCN \mathbin {!}( climbedOnV2 \mathbin {?}( aDet \; treeCN )))\)
\((MOST (a:\mathrm {boy}).\; \exists (c:\mathrm {tree}).\; \mathrm {climbed\_on}( a , c )) \wedge (\forall (b:[a : \mathrm {boy};\;c : \mathrm {tree};\;p : \mathrm {climbed\_on}( a , c )]).\; \mathrm {true})\)
-
38.
Most boys climbed on a tree. They were afraid to fall.
\(( most \; boysCN \mathbin {!}( climbedOnV2 \mathbin {?}( aDet \; treeCN )))\mathbin {\#\#\#}( theyPlNP \mathbin {!} isAfraid )\)
\((MOST (a:\mathrm {boy}).\; \exists (c:\mathrm {tree}).\; \mathrm {climbed\_on}( a , c )) \wedge (\forall (b:[a : \mathrm {boy};\;c : \mathrm {tree};\;p : \mathrm {climbed\_on}( a , c )]).\; \mathrm {true}) \wedge \mathrm {afraid\_to\_fall}( b .a)\)
\((MOST (a:\mathrm {boy}).\; \exists (c:\mathrm {tree}).\; \mathrm {climbed\_on}( a , c )) \wedge (\forall (b:[a : \mathrm {boy};\;c : \mathrm {tree};\;p : \mathrm {climbed\_on}( a , c )]).\; \mathrm {true} \wedge \mathrm {afraid\_to\_fall}( b .a))\)
-
39.
Most boys climbed on a tree. Every boy that climbed on a tree was afraid to fall.
\(( most \; boysCN \mathbin {!}( climbedOnV2 \mathbin {?}( aDet \; treeCN )))\mathbin {\#\#\#}( every \;( boyCN \mathbin {` that `}( climbedOnV2 \mathbin {?}( aDet \; treeCN )))\mathbin {!} isAfraid )\)
\((MOST (a:\mathrm {boy}).\; \exists (c:\mathrm {tree}).\; \mathrm {climbed\_on}( a , c )) \wedge (\forall (b:[a : \mathrm {boy};\;c : \mathrm {tree};\;p : \mathrm {climbed\_on}( a , c )]).\; \mathrm {true}) \wedge (\forall (d:[e : \mathrm {boy};\;f : \mathrm {tree};\;p : \mathrm {climbed\_on}( e , f )]).\; \mathrm {afraid\_to\_fall}( d ))\)
-
40.
Most boys climbed on a tree and were afraid to fall.
\(( most \; boysCN \mathbin {!}(( climbedOnV2 \mathbin {?}( aDet \; treeCN ))\mathbin {` andVP `} isAfraid ))\)
\((MOST (a:\mathrm {boy}).\; (\exists (c:\mathrm {tree}).\; \mathrm {climbed\_on}( a , c )) \wedge \mathrm {afraid\_to\_fall}( a )) \wedge (\forall (b:[a : \mathrm {boy};\;p : (\exists (c:\mathrm {tree}).\; \mathrm {climbed\_on}( a , c )) \wedge \mathrm {afraid\_to\_fall}( a )]).\; \mathrm {true})\)
-
41.
Mary owns a few donkeys. Bill beats them.
\( maryNP \mathbin {!}( own \mathbin {?}( few \; donkeys ))\mathbin {\#\#\#}( billNP \mathbin {!}( beatV2 \mathbin {?} theyPlNP ))\)
\((FEW (a:\mathrm {donkeys}).\; \mathrm {own}(\mathrm {mary}, a )) \wedge (\forall (b:[a : \mathrm {donkeys};\;p : \mathrm {own}(\mathrm {mary}, a )]).\; \mathrm {true}) \wedge \mathrm {beat}(\mathrm {bill}, b .a)\)
\((FEW (a:\mathrm {donkeys}).\; \mathrm {own}(\mathrm {mary}, a )) \wedge (\forall (b:[a : \mathrm {donkeys};\;p : \mathrm {own}(\mathrm {mary}, a )]).\; \mathrm {true} \wedge \mathrm {beat}(\mathrm {bill}, b .a))\)
-
42.
John does not have a car. # It is fast.
\( negation \;( johnNP \mathbin {!}( has \mathbin {?} aDet \; carCN ))\mathbin {\#\#\#}( itNP \mathbin {!} isFastVP )\)
\(\lnot (\exists (a:\mathrm {car}).\; \mathrm {have}(\mathrm {john}, a )) \wedge \mathrm {fast}( a )\)
\(\forall (a:\mathrm {car}).\; \lnot \mathrm {have}(\mathrm {john}, a ) \wedge \mathrm {fast}( a )\)
Remark: The sentence is infelicitous, but our algorithm produces a (dubious) interpretation anyway
-
43.
A wolf might enter. It would growl.
\(( aDet \; wolf \mathbin {!}( might \; enterVP ))\mathbin {\#\#\#}( itNP \mathbin {!} would \; growlVP )\)
\((\exists (a:\mathrm {wolf}).\; \mathrm {enter}( a )) \wedge \mathrm {growl}( a )\)
\(\exists (a:\mathrm {wolf}).\; \mathrm {enter}( a ) \wedge \mathrm {growl}( a )\)
Remark: Modals not supported
-
44.
A wolf might enter. # It will growl.
\(( aDet \; wolf \mathbin {!}( might \; enterVP ))\mathbin {\#\#\#}( itNP \mathbin {!} will \; growlVP )\)
\((\exists (a:\mathrm {wolf}).\; \mathrm {enter}( a )) \wedge \mathrm {growl}( a )\)
\(\exists (a:\mathrm {wolf}).\; \mathrm {enter}( a ) \wedge \mathrm {growl}( a )\)
Remark: Modals not supported
-
45.
Either there is no bathroom here or it is hidden.
\( negation \;( thereIs \; bathroomCN )\mathbin {` orS `}( itNP \mathbin {!} isHiddenVP )\)
\(\lnot (\exists (a:\mathrm {bathroom}).\; \mathrm {here}( a )) \vee \mathrm {hidden}( a )\)
\(\forall (a:\mathrm {bathroom}).\; \lnot \mathrm {here}( a ) \vee \mathrm {hidden}( a )\)
-
46.
He was tired. Bill left.
\(( heNP \mathbin {!} isTiredVP )\mathbin {\#\#\#}( billNP \mathbin {!} leavesVP )\)
\(\mathrm {tired}(\mathrm {bill}) \wedge \mathrm {leaves}(\mathrm {bill})\)
-
47.
If bill finds it, he will wear his coat.
\(( billNP \mathbin {!}( findV2 \mathbin {?} itNP ))\mathbin {==>}( heNP \mathbin {!}( wearV2 \mathbin {?} his \; coatCN2 ))\)
\(\mathrm {find}(\mathrm {bill},\mathrm {the}(\mathrm {coat}(\mathrm {bill}))) \rightarrow \mathrm {wear}(\mathrm {bill},\mathrm {the}(\mathrm {coat}(\mathrm {bill})))\)
-
48.
The pilot who shot at it hit the Mig that chased him.
\( epsilon \;( pilot \mathbin {` that `}( shotAtV2 \mathbin {?} itNP ))\mathbin {!}( hitV2 \mathbin {?}( epsilon \;( mig \mathbin {` that `}( chasedV2 \mathbin {?} himNP' ))))\)
\(The(a:[b : \mathrm {pilot};\;p : \mathrm {shotat}( b , c )]).\; (The(c:[d : \mathrm {mig};\;p : \mathrm {chased}( d , a )]).\; \mathrm {hit}( a , c ))\)
-
49.
The pilot who shot at it hit a Mig that chased him.
\( epsilon \;( pilot \mathbin {` that `}( shotAtV2 \mathbin {?} itNP ))\mathbin {!}( hitV2 \mathbin {?}( aDet \;( mig \mathbin {` that `}( chasedV2 \mathbin {?} himNP' ))))\)
\(The(a:[b : \mathrm {pilot};\;p : \mathrm {shotat}( b , c )]).\; \exists (c:[d : \mathrm {mig};\;p : \mathrm {chased}( d , a )]).\; \mathrm {hit}( a , c )\)
\(\exists (c:[d : \mathrm {mig};\;p : \mathrm {chased}( d , a )]).\; (The(a:[b : \mathrm {pilot};\;p : \mathrm {shotat}( b , c )]).\; \mathrm {hit}( a , c ))\)
-
50.
The pilot shot a Mig that chased him and hit it.
\(( the \; pilot )\mathbin {!}(( shotAtV2 \mathbin {?}( aDet \;( mig \mathbin {` that `}( chasedV2 \mathbin {?} himNP' ))))\mathbin {` andVP `}( hitV2 \mathbin {?} itNP ))\)
\((\exists (a:[b : \mathrm {mig};\;p : \mathrm {chased}( b ,\mathbf {U}(\mathrm {pilot}))]).\; \mathrm {shotat}(\mathbf {U}(\mathrm {pilot}), a )) \wedge \mathrm {hit}(\mathbf {U}(\mathrm {pilot}), a )\)
\(\exists (a:[b : \mathrm {mig};\;p : \mathrm {chased}( b ,\mathbf {U}(\mathrm {pilot}))]).\; \mathrm {shotat}(\mathbf {U}(\mathrm {pilot}), a ) \wedge \mathrm {hit}(\mathbf {U}(\mathrm {pilot}), a )\)
-
51.
Everyone admits that they are tired. Mary does too
\((( everyone \mathbin {!}( admitVP \;( theySingNP \mathbin {!} isTiredVP )))\mathbin {\#\#\#}( maryNP \mathbin {!} doesTooVP ))\)
\((\forall (a:\mathrm {person}).\; \mathrm {admit}(\mathrm {tired}( a ), a )) \wedge \mathrm {admit}(\mathrm {tired}(\mathrm {mary}),\mathrm {mary})\)
-
52.
A lawyer signed every report. So did an auditor.
\(( aDet \; lawyerCN \mathbin {!}( signV2 \mathbin {?}( every \; reportCN )))\mathbin {\#\#\#}( aDet \; auditorCN \mathbin {!} doesTooVP )\)
\((\exists (a:\mathrm {lawyer}).\; (\forall (b:\mathrm {report}).\; \mathrm {sign}( a , b ))) \wedge (\exists (c:\mathrm {auditor}).\; (\forall (d:\mathrm {report}).\; \mathrm {sign}( c , d )))\)
-
53.
John loves his spouse. Mary does too.
\( johnNP \mathbin {!}( lovesVP' \mathbin {?} his \; marriedCN2 )\mathbin {\#\#\#}( maryNP \mathbin {!} doesTooVP )\)
\(\mathrm {love}(\mathrm {john},\mathrm {the}(\mathrm {married}(\mathrm {john}))) \wedge \mathrm {love}(\mathrm {mary},\mathrm {the}(\mathrm {married}(\mathrm {mary})))\)
-
54.
Few congressmen love bill. They are tired.
\(( few \; congressmen \mathbin {!}( lovesVP \; billNP ))\mathbin {\#\#\#}( theyPlNP \mathbin {!} isTiredVP )\)
\((FEW (a:\mathrm {congressmen}).\; \mathrm {love}(\mathrm {bill}, a )) \wedge (\forall (b:[a : \mathrm {congressmen};\;p : \mathrm {love}(\mathrm {bill}, a )]).\; \mathrm {true}) \wedge \mathrm {tired}( b .a)\)
\((FEW (a:\mathrm {congressmen}).\; \mathrm {love}(\mathrm {bill}, a )) \wedge (\forall (b:[a : \mathrm {congressmen};\;p : \mathrm {love}(\mathrm {bill}, a )]).\; \mathrm {true} \wedge \mathrm {tired}( b .a))\)
-
55.
Few congressmen love bill. He is tired.
\((( few \; congressmen \mathbin {!}( lovesVP \; billNP ))\mathbin {\#\#\#}( heNP \mathbin {!} isTiredVP ))\)
\((FEW (a:\mathrm {congressmen}).\; \mathrm {love}(\mathrm {bill}, a )) \wedge (\forall (b:[a : \mathrm {congressmen};\;p : \mathrm {love}(\mathrm {bill}, a )]).\; \mathrm {true}) \wedge \mathrm {tired}(\mathrm {bill})\)
Remark: The e-type pronoun is plural.
-
56.
John is tired. Bill loves him.
\(( johnNP \mathbin {!} isTiredVP )\mathbin {\#\#\#}( billNP \mathbin {!}( lovesVP \; himNP ))\)
\(\mathrm {tired}(\mathrm {john}) \wedge \mathrm {love}(\mathrm {john},\mathrm {bill})\)
Remark: (Bill loves John, not himself.)
-
57.
John is tired. Bill loves himself.
\(( johnNP \mathbin {!} isTiredVP )\mathbin {\#\#\#}( billNP \mathbin {!}( lovesVP \; himSelfNP ))\)
\(\mathrm {tired}(\mathrm {john}) \wedge \mathrm {love}(\mathrm {bill},\mathrm {bill})\)
-
58.
Few men that love their wife annoy them.
\(( few \;( men \mathbin {` that `}( lovesVP \;( their \; wifeCN2 ))))\mathbin {!}( annoyV2 \mathbin {?} themSingNP )\)

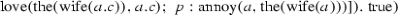
Remark: Donkey pronoun
-
59.
A donkey is tired. It leaves.
\(((( aDet \; donkey )\mathbin {!} isTiredVP )\mathbin {\#\#\#}( itNP \mathbin {!} leavesVP ))\)
\((\exists (a:\mathrm {donkey}).\; \mathrm {tired}( a )) \wedge \mathrm {leaves}( a )\)
\(\exists (a:\mathrm {donkey}).\; \mathrm {tired}( a ) \wedge \mathrm {leaves}( a )\)
Remark: Existentially-bound referrent
-
60.
If a man beats a donkey, it is tired.
\(( aDet \; man \mathbin {!}( beatV2 \mathbin {?}( aDet \; donkey )))\mathbin {==>}( itNP \mathbin {!} isTiredVP )\)
\((\exists (a:\mathrm {man}).\; (\exists (b:\mathrm {donkey}).\; \mathrm {beat}( a , b ))) \rightarrow \mathrm {tired}( b )\)
\(\forall (b:\mathrm {donkey}).\; (\exists (a:\mathrm {man}).\; \mathrm {beat}( a , b )) \rightarrow \mathrm {tired}( b )\)
Remark: Change of polarity when doing scope extension under implication
-
61.
Bill owns a donkey. He beats it.
\((( billNP \mathbin {!}( own \mathbin {?}( aDet \; donkey )))\mathbin {\#\#\#}( heNP \mathbin {!}( beatV2 \mathbin {?} itNP )))\)
\((\exists (a:\mathrm {donkey}).\; \mathrm {own}(\mathrm {bill}, a )) \wedge \mathrm {beat}(\mathrm {bill}, a )\)
\(\exists (a:\mathrm {donkey}).\; \mathrm {own}(\mathrm {bill}, a ) \wedge \mathrm {beat}(\mathrm {bill}, a )\)
-
62.
A man that owns a donkey beats it.
\(( aDet \;( man \mathbin {` that `}( own \mathbin {?}( aDet \; donkey )))\mathbin {!}( beatV2 \mathbin {?} itNP ))\)
\(\exists (a:[b : \mathrm {man};\;c : \mathrm {donkey};\;p : \mathrm {own}( b , c )]).\; \mathrm {beat}( a , a .c)\)
-
63.
If a man owns a donkey, he beats it.
\(( aDet \; man \mathbin {!}( own \mathbin {?}( aDet \; donkey )))\mathbin {==>}( heNP \mathbin {!}( beatV2 \mathbin {?} itNP ))\)
\((\exists (a:\mathrm {man}).\; (\exists (b:\mathrm {donkey}).\; \mathrm {own}( a , b ))) \rightarrow \mathrm {beat}( a , b )\)
\(\forall (a:\mathrm {man}).\; (\forall (b:\mathrm {donkey}).\; \mathrm {own}( a , b ) \rightarrow \mathrm {beat}( a , b ))\)
-
64.
every man beats every donkey that he owns.

\(\forall (a:\mathrm {man}).\; (\forall (b:[c : \mathrm {donkey};\;p : \mathrm {own}( a , c )]).\; \mathrm {beat}( a , b ))\)
-
65.
John leaves. He is tired.
\(( johnNP \mathbin {!} leavesVP )\mathbin {\#\#\#}( heNP \mathbin {!} isTiredVP )\)
\(\mathrm {leaves}(\mathrm {john}) \wedge \mathrm {tired}(\mathrm {john})\)
-
66.
Bill owns a donkey. John owns one too.
\( billNP \mathbin {!}( own \mathbin {?}( aDet \; donkey ))\mathbin {\#\#\#}( johnNP \mathbin {!}( own \mathbin {?} oneToo ))\)
\((\exists (a:\mathrm {donkey}).\; \mathrm {own}(\mathrm {bill}, a )) \wedge (\exists (b:\mathrm {donkey}).\; \mathrm {own}(\mathrm {john}, b ))\)
Remark: One-anaphora
-
67.
John leaves. Mary does too.
\((( johnNP \mathbin {!} leavesVP )\mathbin {\#\#\#}( maryNP \mathbin {!} doesTooVP ))\)
\(\mathrm {leaves}(\mathrm {john}) \wedge \mathrm {leaves}(\mathrm {mary})\)
-
68.
John loves his wife. Bill does too.
\(( johnNP \mathbin {!}( lovesVP \;( his \; wifeCN2 ))\mathbin {\#\#\#}( billNP \mathbin {!} doesTooVP ))\)
\(\mathrm {love}(\mathrm {the}(\mathrm {wife}(\mathrm {john})),\mathrm {john}) \wedge \mathrm {love}(\mathrm {the}(\mathrm {wife}(\mathrm {john})),\mathrm {bill})\)
Remark: Strict reading
-
69.
If she loves him, Mary hug her husband.
\(( sheNP \mathbin {!} lovesVP \; himNP )\mathbin {==>}( maryNP \mathbin {!}( hugV2 \mathbin {?} herHusbandNP ))\)
\(\mathrm {love}(\mathrm {the}(\mathrm {married}(\mathrm {mary})),\mathrm {mary}) \rightarrow \mathrm {hug}(\mathrm {mary},\mathrm {the}(\mathrm {married}(\mathrm {mary})))\)
-
70.
Every woman that loves their husband hug him.
\( every \;( woman \mathbin {` that `}( lovesVP' \mathbin {?} herHusbandNP ))\mathbin {!}( hugV2 \mathbin {?} himNP )\)
\(\forall (a:[b : \mathrm {woman};\;p : \mathrm {love}( b ,\mathrm {the}(\mathrm {married}( b )))]).\; \mathrm {hug}( a ,\mathrm {the}(\mathrm {married}( a )))\)
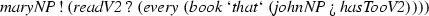



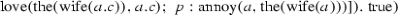

Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Bernardy, JP., Chatzikyriakidis, S. & Maskharashvili, A. A Computational Treatment of Anaphora and Its Algorithmic Implementation. J of Log Lang and Inf 30, 1–29 (2021). https://doi.org/10.1007/s10849-020-09322-7
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10849-020-09322-7