
Abstract
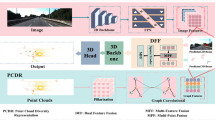
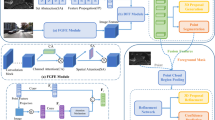
To address the problem that image and point cloud features are fused in a coarse fusion way and cannot achieve deep fusion, this paper proposes a multimodal 3D object detection architecture based on a mutual feature gating mechanism. First, since the feature aggregation approach based on the set abstraction layer cannot obtain fine-grained features, a point-based self-attention mechanism module is designed. This module is added to the extraction branch of point cloud features to achieve fine-grained feature aggregation while maintaining accurate location information. Second, a new gating mechanism is designed for the deep fusion of image and point cloud. Deep fusion is achieved by mutual feature weighting between the image and the point cloud. The newly fused features are then fed into a feature refinement network to extract classification confidence and 3D target bounding boxes. Finally, a multi-scale detection architecture is proposed to obtain a more complete object shape. The location-based encoding feature algorithm is also designed to focus the interest points in the region of interest adaptively. The whole architecture shows outstanding performance on the KITTI3D and nuSenece datasets, especially at the difficult level. It shows that the framework solves the problem of low detection rates in LiDAR mode due to the low number of surface points obtained from distant objects.
Article PDF
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Availability of data and materials
Public dataset is used.
Code Availability
Available.
References
Zhou, Y., Tuzel, O.: Voxelnet: end-to-end learning for point cloud based 3d object detection. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 4490–4499 (2018)
Shi, S., Wang, X., Li, H.: Pointrcnn: 3d object proposal generation and detection from point cloud. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 770–779 (2019)
Shi, S., Guo, C., Jiang, L., Wang, Z., Shi, J., Wang, X., Li, H.: Pv-rcnn: point-voxel feature set abstraction for 3d object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 10529–10538 (2020)
Zheng, W., Tang, W., Jiang, L., Fu, C.-W.: Se-ssd: self-ensembling single-stage object detector from point cloud. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 14494–14503 (2021)
Deng, J., Shi, S., Li, P., Zhou, W., Zhang, Y., Li, H.: Voxel r-cnn: towards high performance voxel-based 3d object detection. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 35, pp. 1201–1209 (2021)
Xu, W., Zou, L., Fu, Z., Wu, L., Qi, Y.: Two-stage 3d object detection guided by position encoding. Neurocomputing 501, 811–821 (2022)
Chen, X., Ma, H., Wan, J., Li, B., Xia, T.: Multi-view 3d object detection network for autonomous driving. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1907–1915 (2017)
Ku, J., Mozifian, M., Lee, J., Harakeh, A., Waslander, S.L.: Joint 3d proposal generation and object detection from view aggregation. In: 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 1–8. IEEE (2018)
Liang, M., Yang, B., Wang, S., Urtasun, R.: Deep continuous fusion for multi-sensor 3d object detection. In: Proceedings of the European Conference on Computer Vision (ECCV), pp. 641–656 (2018)
Huang, T., Liu, Z., Chen, X., Bai, X.: Epnet: enhancing point features with image semantics for 3d object detection. In: European Conference on Computer Vision, pp. 35–52. Springer (2020)
Zhang, Y., Zhu, Z., Zheng, W., Huang, J., Huang, G., Zhou, J., Lu, J.: Beverse: Unified perception and prediction in birds-eye-view for vision-centric autonomous driving. arXiv:2205.09743 (2022)
Yang, Z., Sun, Y., Liu, S., Shen, X., Jia, J.: Std: Sparse-to-dense 3d object detector for point cloud. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 1951–1960 (2019)
Shi, S., Wang, Z., Shi, J., Wang, X., Li, H.: From points to parts: 3d object detection from point cloud with part-aware and part-aggregation network. IEEE Trans. Pattern Anal. Mach. Intell. (2020)
Deng, J., Shi, S., Li, P., Zhou, W., Zhang, Y., Li, H.: Voxel r-cnn: towards high performance voxel-based 3d object detection. arXiv:2012.15712 (2020)
Yan, Y., Mao, Y., Li, B.: Second: sparsely embedded convolutional detection. Sensors 18(10), 3337 (2018)
Lang, A.H., Vora, S., Caesar, H., Zhou, L., Yang, J., Beijbom, O.: Pointpillars: fast encoders for object detection from point clouds. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 12697–12705 (2019)
Vora, S., Lang, A.H., Helou, B., Beijbom, O.: Pointpainting: sequential fusion for 3d object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 4604–4612 (2020)
Wang, C., Ma, C., Zhu, M., Yang, X.: Pointaugmenting: cross-modal augmentation for 3d object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 11794–11803 (2021)
Yoo, J.H., Kim, Y., Kim, J., Choi, J.W.: 3d-cvf: generating joint camera and lidar features using cross-view spatial feature fusion for 3d object detection. In: Proceedings of European Conference on Computer Vision, pp. 720–736. Springer (2020)
Liang, T., Xie, H., Yu, K., Xia, Z., Lin, Z., Wang, Y., Tang, T., Wang, B., Tang, Z.: Bevfusion: a simple and robust lidar-camera fusion framework. arXiv:2205.13790 (2022)
Liu, Z., Tang, H., Amini, A., Yang, X., Mao, H., Rus, D.L., Han, S.: Bevfusion: multi-task multi-sensor fusion with unified bird’s-eye view representation. In: 2023 IEEE International Conference on Robotics and Automation (ICRA), pp. 2774–2781. IEEE (2023)
Yin, T., Zhou, X., Krähenbühl, P.: Multimodal virtual point 3d detection. Adv. Neural. Inf. Process. Syst. 34, 16494–16507 (2021)
Liu, Z., Tang, H., Amini, A., Yang, X., Mao, H., Rus, D., Han, S.: Bevfusion: multi-task multi-sensor fusion with unified bird’s-eye view representation. arXiv:2205.13542 (2022)
Wang, X., Girshick, R., Gupta, A., He, K.: Non-local neural networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 7794–7803 (2018)
Huang, Z., Wang, X., Huang, L., Huang, C., Wei, Y., Liu, W.: Ccnet: criss-cross attention for semantic segmentation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 603–612 (2019)
Woo, S., Park, J., Lee, J.-Y., Kweon, I.S.: Cbam: convolutional block attention module. In: Proceedings of the European Conference on Computer Vision (ECCV), pp. 3–19 (2018)
Fu, J., Liu, J., Tian, H., Li, Y., Bao, Y., Fang, Z., Lu, H.: Dual attention network for scene segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 3146–3154 (2019)
Feng, M., Zhang, L., Lin, X., Gilani, S.Z., Mian, A.: Point attention network for semantic segmentation of 3d point clouds. Pattern Recogn. 107, 107446 (2020)
Qiu, S., Anwar, S., Barnes, N.: Geometric back-projection network for point cloud classification. IEEE Trans. Multimedia (2021)
Guo, M.-H., Cai, J.-X., Liu, Z.-N., Mu, T.-J., Martin, R.R., Hu, S.-M.: Pct: point cloud transformer. Comput. Vis. Media. 7(2), 187–199 (2021)
Zhao, H., Jiang, L., Jia, J., Torr, P.H., Koltun, V.: Point transformer. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 16259–16268 (2021)
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, Ł., Polosukhin, I.: Attention is all you need. In: Advances in Neural Information Processing Systems, pp. 5998–6008 (2017)
Ku, J., Mozifian, M., Lee, J., Harakeh, A., Waslander, S.L.: Joint 3d proposal generation and object detection from view aggregation. In: 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) (2019)
Lee, K.H., Xi, C., Gang, H., Hu, H., He, X.: Stacked cross attention for image-text matching (2018)
Deng, J., Zhou, W., Zhang, Y., Li, H.: From multi-view to hollow-3d: hallucinated hollow-3d r-cnn for 3d object detection (2021)
Mao, J., Niu, M., Bai, H., Liang, X., Xu, H., Xu, C.: Pyramid r-cnn: towards better performance and adaptability for 3d object detection. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 2723–2732 (2021)
Dai, A., Chang, A.X., Savva, M., Halber, M., Funkhouser, T., Nießner, M.: Scannet: richly-annotated 3d reconstructions of indoor scenes. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 5828–5839 (2017)
Qiu, S., Anwar, S., Barnes, N.: Pnp-3d: a plug-and-play for 3d point clouds. IEEE Trans. Pattern Anal. Mach. Intell. (2021)
Liu, Z., Tang, H., Lin, Y., Han, S.: Point-voxel cnn for efficient 3d deep learning. In: Advances in Neural Information Processing Systems (2019)
Geiger, A., Lenz, P., Urtasun, R.: Are we ready for autonomous driving? the kitti vision benchmark suite. In: 2012 IEEE Conference on Computer Vision and Pattern Recognition, pp. 3354–3361. IEEE (2012)
Geiger, A., Lenz, P., Stiller, C., Urtasun, R.: The kitti vision benchmark suite, 2. http://www.cvlibs.net/datasets/kitti (2015)
Caesar, H., Bankiti, V., Lang, A.H., Vora, S., Liong, V.E., Xu, Q., Krishnan, A., Pan, Y., Baldan, G., Beijbom, O.: nuscenes: a multimodal dataset for autonomous driving. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 11621–11631 (2020)
Loshchilov, I., Hutter, F.: Fixing weight decay regularization in Adam. arXiv:1711.05101 (2017)
Qi, C.R., Su, H., Mo, K., Guibas, L.J.: Pointnet: deep learning on point sets for 3d classification and segmentation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 652–660 (2017)
Pang, S., Morris, D., Radha, H.: Clocs: camera-lidar object candidates fusion for 3d object detection. In: Proceedings of 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 10386–10393. IEEE (2020)
Hu, P., Ziglar, J., Held, D., Ramanan, D.: What you see is what you get: exploiting visibility for 3d object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 11001–11009 (2020)
Chen, Q., Sun, L., Cheung, E., Yuille, A.L.: Every view counts: cross-view consistency in 3d object detection with hybrid-cylindrical-spherical voxelization. Adv. Neural. Inf. Process. Syst. 33, 21224–21235 (2020)
Yin, J., Shen, J., Guan, C., Zhou, D., Yang, R.: Lidar-based online 3d video object detection with graph-based message passing and spatiotemporal transformer attention. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 11495–11504 (2020)
Wen, X., Xiang, P., Han, Z., Cao, Y.-P., Wan, P., Zheng, W., Liu, Y.-S.: Pmp-net: point cloud completion by learning multi-step point moving paths. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 7443–7452 (2021)
Zhu, X., Ma, Y., Wang, T., Xu, Y., Shi, J., Lin, D.: Ssn: shape signature networks for multi-class object detection from point clouds. In: European Conference on Computer Vision, pp. 581–597. Springer (2020)
Zhu, B., Jiang, Z., Zhou, X., Li, Z., Yu, G.: Class-balanced grouping and sampling for point cloud 3d object detection. arXiv:1908.09492 (2019)
Yin, T., Zhou, X., Krahenbuhl, P.: Center-based 3d object detection and tracking. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 11784–11793 (2021)
Hu, Y., Ding, Z., Ge, R., Shao, W., Huang, L., Li, K., Liu, Q.: Afdetv2: rethinking the necessity of the second stage for object detection from point clouds. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 36, pp. 969–979 (2022)
Funding
This research was supported in part by Guangdong Major Project of Basic and Applied Basic Research under Grant No. 2019B030302002, Major Research and Development Program of PCL, China under Grant No. PCL2021A.
Author information
Authors and Affiliations
Contributions
W.X. conceived and designed the method; W.X. and Zh.F performed the experiment tests; and W.X. wrote the paper. All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no conflict of interest.
Ethics approval
Not applicable.
Consent to participate
Not applicable.
Consent for publication
All authors agree to publish.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Xu, W., Fu, Z. MMFG: Multimodal-based Mutual Feature Gating 3D Object Detection. J Intell Robot Syst 110, 85 (2024). https://doi.org/10.1007/s10846-024-02119-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10846-024-02119-x