
Abstract
3D object detection is a critical task in the fields of virtual reality and autonomous driving. Given that each sensor has its own strengths and limitations, multi-sensor-based 3D object detection has gained popularity. However, most existing methods extract high-level image semantic features and fuse them with point cloud features, focusing solely on consistent information from both sensors while ignoring their complementary information. In this paper, we present a novel two-stage multi-sensor deep neural network, called the adaptive learning point cloud and image diversity feature fusion network (APIDFF-Net), for 3D object detection. Our approach employs the fine-grained image information to complement the point cloud information by combining low-level image features with high-level point cloud features. Specifically, we design a shallow image feature extraction module to learn fine-grained information from images, instead of relying on deep layer features with coarse-grained information. Furthermore, we design a diversity feature fusion (DFF) module that transforms low-level image features into point-wise image features and explores their complementary features through an attention mechanism, ensuring an effective combination of fine-grained image features and point cloud features. Experiments on the KITTI benchmark show that the proposed method outperforms state-of-the-art methods.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
3D object detection is a challenging problem in computer vision that can be approached through various methods, including image-based, point cloud-based, and multimodal-based approaches. Image-based methods [2, 3, 15, 18, 20, 27, 34] rely on cameras and can capture rich semantic features, but may not provide accurate depth information and can be affected by exposure and occlusion, leading to low detection performance. On the other hand, point cloud-based methods [25, 26, 29, 30, 40] use Lidar sensors and can provide reliable depth information, but are limited by the sparsity, unorderedness, and uneven distribution of LiDAR points. Therefore, the recognition accuracy obtained by only Lidar sensors can be low in cases where objects have similar geometric structures, are close to each other, or are occluded or truncated. As a result, discerning closely packed objects with similar geometric structures from LiDAR point clouds alone remains a challenging task. To address these limitations, researchers have increasingly focused on multi-sensor 3D object detection, such as combining images and Lidar sensors [1, 12, 24, 37, 42], to improve the accuracy of 3D object detection.
Some fusion methods [4, 5, 38] use high-level semantic features, which refer to coarse-grained image information, to enhance point cloud information. Although such features, extracted from deep layer networks, can capture complex semantic and global information, they may overlook local and spatial information. For instance, AutoAlign [5] utilizes FasterRCNN with ResNet50 to extract image features, which are then fused with voxel features. Low layer networks tend to prioritize detail information, such as texture, contours, and corners, etc., which can enhance the object detection performance of Lidar information. In the proposed network, we extract low-level image features to capture fine-grained image information and integrate low-level image features with point cloud features to explore the complementary of both modalities. Our main contributions are as follows:
-
1.
we propose a novel two-stage multi-sensor 3D object detection network, named adaptive learning point cloud and image diversity feature fusion network for 3D object detection (APIDFF-Net), which uses fine-grained image information to enhance the point cloud information by combining low-level image features and high-level point cloud features.
-
2.
Instead of obtaining high-level image semantic information, we design an adaptive Fine-Grained Image Feature Extraction (FGFE) module, which preserves fine-grained information in image low-level features.
-
3.
We develop a Diversity Feature Fusion (DFF) module that transforms low-level image features into point-wise image features and uses an attention mechanism to explore the complementary features for more accurate feature fusion.
Related work
3D object detection based on the camera
Over the past few years, a large number of 3D detection base on the camera methods have been proposed, including monocular [9, 20, 27, 47] and stereo [3, 15, 34]. For example, GUPNet [20] was developed to address the error amplification issue during inference and training, and improve training efficiency. CaDDN [27] utilized classified depth distribution and projection geometry to generate high-quality Bird’s Eye View (BEV) scene representations from a single image. Nonetheless, 3D bounding box accuracy remains a challenge for monocular camera image-based methods due to the absence of depth information. Chen et al. [3] used the left view image and the predicted disparity map to generate a virtual right view image at the image level. However, binocular stereo images offer limited and imprecise depth information compared to LiDAR point cloud information.
3D object detection method based on LiDAR
LiDAR point cloud data [10, 41, 43, 46] are usually spatially disordered. Some methods [6, 28, 48] process the raw point cloud into voxels, which may lead to the loss of the original position information of the points. Some methods [25, 26, 29, 40] directly process the raw point cloud, such as PointNet [25] and PointNet++ [26], which are popular in extracting point cloud features and are used as the backbone in many 3D object detection methods. PointRCNN [29], a two-stage network, employs PointNet++ in the first stage to generate a set of rough candidate boxes. Then, a refinement network is used to extract these candidate boxes and generate the final predicted 3D box. STD [40] proposes a spherical anchor mechanism, which reduces the computational burden and improves the recall rate simultaneously. This algorithm uses the predicted IOU score multiplied by the classification score as the NMS standard, rather than just the classification score, to improve positioning accuracy and detection performance. BtcDet [38] learns the prior information of the object shape and estimates the shape of the complete object partially occluded in the point cloud. RangeIoUDet [16] enhances point-wise features by supervising point-based IOUs, and designs HyGIoU loss to improve the detection quality of 3D boxes. Voxel RoI pooling was designed by Voxel R-CNN [7] to aggregate the spatial context information of voxel. SPG[39] generates semantic point clouds for the foreground points and restores the missing parts of the objects in the foreground points, and then fuses the semantic point cloud and the original point cloud. In these methods, powerful Ground Truth (GT) augmentation techniques are adopted to sample ground truth boxes from additional point clouds within the dataset. As a result, these methods increase the complexity of the scenarios, more robust for the model training. However, since LiDAR point cloud data is typically sparse, unordered, and unevenly distributed, these methods that only consider the geometric information of the point cloud are difficult to improve detection performance.
3D object detection based on multiple sensors
Some methods [1, 13, 42] map the point cloud to 2D spaces, such as Bird’s Eye View (BEV), Front View (FV), or Range View (RV), and then fuse the resulting features with image features. For instance, MV3D [1] maps the point cloud to FV and BEV, fuses the resulting features with image features, and predicts the 3D bounding box based on the BEV features. However, this method can be computationally expensive and time-consuming. Other methods [24, 35] project the bounding boxes onto the point cloud to form a 3D search space in the shape of a frustum, and then predict the 3D bounding box based on the features of the point cloud within the frustum. For example, Frustum PointNet [24] obtains the object’s 2D bounding box and category through a 2D CNN, maps the 2D bounding box into a 3D frustum proposal, and then uses a T-Net network based on PointNet to align the input points and predict the 3D bounding box. The frustum-based method relies on the 2D bounding box generated by the 2D backbone network.

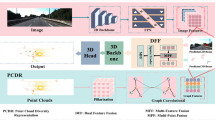
The overall network architecture. The network architecture consists of a two-stage network, including a coarse region proposal network and a refined region proposal network. Our network primarily focuses on the first stage, which incorporates an adaptive Fine-Grained Image Feature Extraction (FGFE) module and a Multi-Sensor Diversity Feature Fusion (DFF) module. The FGFE module is utilized to capture fine-grained features of images. Meanwhile, the DFF module is specifically designed to combine the features of both modalities and explore their diverse characteristics
Some methods [12, 37, 42] employ specialized backbone networks for different dimensions of data, utilizing 2D and 3D networks to extract features, which are then fused to predict the 3D bounding box. For instance, 3D-CVF [42] employs auto-calibrated projection to convert image features extracted by a 2D backbone into BEV features, followed by a gated feature fusion network designed to mix image and point cloud features using a spatial attention mechanism. EPNet [12] integrates image and point cloud features in different stages of the network to improve prediction performance. Pi-RCNN [37] first performs corresponding semantic segmentation and proposals for 2D images and 3D point clouds, respectively, and then fuses their features through the PACF model, finally predicting a 3D bounding box based on the fused features. These methods use independent feature extractors for data from different sensors, which can further enhance their performance.

The proposed Fine-Grained Image Feature Extraction (FGFE) module. The bottom figure shows the attention module adopted by the image feature extraction network, including spatial attention and channel attention
Proposed method
In this section, we present a novel two-stage multi-sensor 3D object detection network, APIDFF-Net, as illustrated in Fig. 1. The network consists of a coarse region proposal network and a refined region proposal network, with our focus on the first-stage network. Specifically, we introduce an adaptive Fine-Grained Image Feature Extraction (FGFE) module, a multi-sensor Diversity Feature Fusion (DFF) module, and a Region Proposal Network (RPN) to extract fine-grained image and point cloud features and generate rough 3D boxes. In the first stage, we use the proposed FGFE module and PointNet++ [26] to extract image and point cloud features, respectively, and then use the DFF module to explore the diversity of the features before generating 3D boxes with the RPN. In the second stage, the refined network of PointRCNN [29] is applied to predict the final 3D box. In the following section, we will provide detailed explanations of our FGFE module and DFF module.
FGFE module
Classical image backbone networks such as ResNet50 [11] and VGG16 [32] are known for accurately extracting high-level semantic features to obtain coarse-grained information. However, these networks often ignore the fine-grained information of the image, such as color, texture, and contour. The fine-grained image information can effectively enhance the geometric information of the point cloud. Therefore, in our designed image feature extraction network, we focus on preserving fine-grained information, rather than obtaining coarse-grained information by extracting high-level semantic features.
We designed a feature extraction module that includes three convolutional blocks and utilizes both channel and spatial attention mechanisms. As depicted in Fig. 2, we aim to minimize the loss of feature map resolution and preserve the spatial information of the feature map. To achieve this, we only introduce MaxPooling in the first convolutional layer, which not only reduces the computational burden but also makes the image features invariant to translation. To adaptively learn meaningful features of the image, we use the channel and spatial mechanisms to estimate the location of important information. In channel attention, we use MaxPooling and AvgPooling to compress the spatial dimension of the image \((C \times H \times W)\) to one dimension \((C \times 1 \times 1)\), respectively, so as to aggregate the information of feature maps. Then, a shared MLP network is used to learn high-semantic feature. The activation function is used to generate the final channel attention feature weight map. The formula can be expressed as follows:
where \(\textbf{M}_\textbf{c}\) is the channel attention feature weight map, \(\textbf{F}_\textbf{c}\) is the feature map, \(\textbf{F}_\textbf{a v g}\) and \(\textbf{F}_\textbf{m a x}\) are AvgPooling and MaxPooling respectively, \(\sigma \) is the activation function sigmoid, and \(\textbf{W}_\textbf{0}\) and \(\textbf{W}_\textbf{1}\) are the shared weights of the MLP.
In spatial attention, to generate the final spatial attention feature map, we first perform AvgPooling and MaxPooling in the channel dimension, which converts the three-dimensional features \((C \times H \times W)\) into two-dimensional features \((1 \times H \times W)\). The two-dimensional features are then concatenated to form a spliced feature map. Finally, we use a convolution operation on the spliced feature map to generate the final spatial attention feature map. The formula for the convolution operation is expressed as follows:
where \(\textbf{M}_{\textbf{s}}\) is the spatial attention feature weight map. \(\textbf{F}_\textbf{s}\) is the feature map, \(\textbf{F}_\textbf{a v g}\) and \(\textbf{F}_\textbf{m a x}\) are AvgPooling and MaxPooling respectively, \(\sigma \) is the sigmoid function, and [ ] represents the concatenate operation.
Diversity feature fusion module

The proposed fusion module consists of Point-wise Correspondence and DFF. The former projects the image to the point-wise image to unify the dimension of the point-wise image and the point cloud, while the latter is used to learn the diversity features of the point-wise image and the original point cloud
Lidar point clouds provide valuable geometric information for object recognition. However, due to the density of points in close proximity and sparsity at a distance, Lidar point clouds present challenges for accurate recognition. For example, dense points in close proximity can result in the network confusing the boundaries of two objects; objects with similar geometric structures but different colors and textures are difficult to differentiate through geometric information alone. To address these challenges, we propose a Diversity Feature Fusion (DFF) module that incorporates low-level image features (such as color, texture, and contour) with high-level point cloud features. This is achieved through a point-wise image feature transformation and an attention mechanism that effectively explores and fuses complementary features for more accurate recognition. The resulting features are used to generate rough 3D boxes through the Region Proposal Network (RPN) in the first stage of the network.
To integrate the 3D and 2D features, as illustrated in Fig. 3, we map the 3D point cloud to the 2D image plane using the mapping matrix \(\textbf{H}\), and obtain point-wise image features through bilinear interpolation. As shown in the equation:
where \(\textbf{P}_{\text{ rect }}\) is the projection matrix, \(\textbf{R}_{L i D}^{c a m}\) is the rotation matrix, and \(\textbf{t}_{L i D}^{c a m}\) is the translation vector.
The DFF module is designed to leverage fine-grained image information to enhance the point cloud information by exploring the features between point-wise image features and point cloud features. Specifically, the module adaptively learns the importance of point-wise image features, and then connects them with the point cloud features to explore their diversity. The fusion features are then obtained by a set of convolution operations. The calculation process can be expressed as follows:
where \(\textbf{F}_i\) and \(\textbf{F}_l\) represent point-wise image features and point cloud features, \(\textbf{F}_i'\) is the adaptively adjusted point-wise image features, \(\textbf{F}_f\) is the fused features, \(\textbf{W}_i\) is the weight matrix, \(f^{1 \times 1}\) is the 1D convolution, \(\sigma \) is the sigmoid function, and MLP is the fully connected layer.
Overall loss function
The total loss function \(\mathscr {L}_{\text{ total } }\) is defined as the sum of the training objectives of the RPN and the refined network, which can be formulated as
where \(\mathscr {L}_{ {rpn }}\) represents the loss of the RPN network, and \(\mathscr {L}_{ {refine }}\) represents the loss of the refined network. Both use the same loss to optimize the network, namely classification loss and regression loss, as well as consistency enforcing loss (CE loss) [12]. Their same loss can be expressed as
where \(\mathscr {L}_{ {cls }}\) is classification loss, \(\mathscr {L}_{{reg }}\) is regression loss, and \(\mathscr {L}_{ {ce }}\) is CE loss. The \(\lambda \) is used to balance the weight of CE loss. Here, we set \(\lambda \)= 5.
For the classification loss, the loss [17] is used to discriminate the positive and negative samples. The loss can be expressed as
where \(q_t\) represents the probability of the foreground point and \(1-q_t\) represents the probability of the background point. r denotes a tunable focusing parameter. c denotes a balanced variant. In our experiment, we set \(c=0.25\) and \(r=2\).
The final predicted 3D bounding box of the network includes the center point (x, y, z), size (H, W, L) and direction \(\theta \). For the 3D bounding box, the bin-based regression loss is applied to the x-axis, z-axis and direction \(\theta \), and the smooth L1 loss is applied on the y-axis and size (H, W, L). \(\mathscr {L}_{ {reg }}\) is the regression loss based on bin. The calculation process of \(\mathscr {L}_{ {reg }}\) can be described as
where E and S are, respectively, the cross-entropy loss used for classification and the smooth L1 loss used for calculating residuals, \(\hat{b}_u\) represents the bin where the predicted point is located, and \({b}_u\) is the bin where the real point is located, \(\hat{r}_u\) and \({r}_u\) are the residuals of the former two, and the \({N_{\text{ pos } }}\) are the number of foreground points.
The localization confidence and classification confidence of 3D bounding box are often not compatible. In order to maintain high localization and classification confidence of 3D bounding box, the CE loss [12] is introduced and presented as follows:
where D and G are the predicted 3D box and the ground truth, respectively, and K is the classification confidence of the predicted 3D box.
Experimental results
Dataset and implementation
The KITTI 3D object detection benchmark [8] comprises a total of 14,999 samples, including 7,481 training samples and 7,518 testing samples, each accompanied by corresponding point cloud data and image data. The annotated dataset contains a total of 80,256 target objects, which are distributed across both training and test images.
To evaluate the detection performance, we divided the 7481 training samples in our method into two subsets: 3712 samples for training and 3769 samples for validation in the validation experiment, following the methodology outlined in [22, 36], and [35]. In the testing experiment, we maintained the same splitting ratio (3712 for training and 3769 for validation) as used in the validation experiment, following the experimental protocol presented in [22, 28, 35, 36], and [37].
For the comparison methods, according to their own descriptions, in the validation experiment, all of these methods split the training set into two sets with 3712 training samples and 3769 validation samples (an approximate 1:1 ratio). In the testing experiment, these methods, including SECOND [37], F-Convnet [35], PointRCNN [28], PI-RCNN [36], CLOCs [23], Association-3D [7], and MAFF [42], still maintained an approximate 1:1 split ratio (3712:3769) for the testing experiment. However, these comparative methods, including three single-modality methods (PointPillars [12], TANet [17], HVPR [19]) and one multi-modality method (PointPainting [31]), re-divided the training samples into the training and validation sets based on their respective ratios. Specifically, TANet [17] and HVPR [19] split the training set using an approximate ratio of 5:1 for testing. PointPillars [12] and PointPainting [31] split the training set into two subsets with a ratio of approximately 9:1 to train their models for testing. In this paper, to ensure a consistent comparison among the multi-modality methods, we re-split the training samples for the PointPainting method into a ratio (3712:3769), referred to as PointPainting+. In the test experiment, both the PointPainting and PointPainting+ methods were compared with the proposed method.
For all the methods, the trained models were evaluated using the complete set of 7518 test samples. The test results were obtained by submitting the predictions to the official KITTI server for evaluation. The results of the evaluation are presented for three difficulty levels, namely Easy, Moderate, and Hard. These levels are determined by considering factors such as the size, occlusion, truncation, and classification of the detected objects, specifically pedestrians and cars. We employs these levels to evaluate the performance of the proposed network.
Evaluation metric and comparative methods
According to the official evaluation requirements of the KITTI dataset, we used the average precision (AP) as the evaluation metric for all our experiments. The KITTI 3D object detection benchmark adopts a new evaluation protocol [31], which updates the metric of recall positions from the previous 11 positions to 40 positions. This updated protocol offers a more comprehensive and fairer evaluation of the algorithms’ performance.
To evaluate the effectiveness of our APIDFF-Net, we compared it against 12 state-of-the-art methods, including SECOND [39], F-Convnet [36], PointPillars [14], PointRCNN [29], TANet [19], Associate-3D [7], PI-RCNN [37], MAFF [44], PointPainting [33], CLOCs [23], 3D-CVF [42], RangeRCNN [16], HVPR [21], VoxelNet [48], F-PointPillars [22] and MLF [45]. By comparing our method with these existing approaches, we can better understand the strengths and limitations of our approach.
Implementation details
In our proposed approach, the original LiDAR point cloud is downsampled to 16,384 points to reduce the computational cost. We employ four Set Abstraction (SA) modules [26] to encode the input point cloud, with encoding parameters of 4,096, 1,024, 256, and 64. We then use four Feature Propagation (FP) modules [26] to up-sample the point cloud with sampling parameters of 128, 256, 512, and 512, respectively. The point cloud data for each 3D scene has a range of [-40, 40] m along the X (right), [−1, 3] m along the Y (bottom), and [0, 70.4] m along the Z (front) axis, with the orientation of \(\theta \) set from \(-\pi \) to \(\pi \).
In the proposed image feature extraction module, we take images with a resolution of 1,280\(\circ \)384 as input. We use convolution kernels of size 3\(\circ \)3, 5\(\circ \)5, and 3\(\circ \)3 to extract features, with a step size of 1. We apply ReLU activation after each convolution and introduce MaxPooling after the first convolution with a kernel size of 2. To compress the images in both spatial and feature dimensions, we use MaxPooling and AvgPooling in the channel and spatial attention layer. For the DFF module, we set up an MLP with two fully connected layers. The first fully connected layer reduces the channel dimension by a factor of 16, and the second fully connected layer restores the channel dimension.
Experimental results
Table 1 presents a comparison of average precision (AP) scores for car classification between our proposed APIDFF-Net and several state-of-the-art methods on the KITTI validation set using an IoU threshold of 0.7.
PointPillars uses Pillar coding to represent 3D points as a 2D pseudo image, which is then processed by a 2D convolutional network to extract features. Despite this conversion, the method still suffers from the limitation of a single sensor network, resulting in lower accuracy for the AP 3D and AP BEV metrics at IoU=0.7. The one-stage object detection model HVPR uses a memory module to integrate voxel-based and point-based features efficiently, achieving fast computation and good detection performance for the Moderate difficulty AP 3D metric at IoU=0.7. However, its overall detection performance is lower compared to two-stage methods. EPNet designs a multi-level deep fusion strategy, which combines low-level image features and low-level point cloud features to enhance the high-level point cloud features. After the multiple deep fusion, the low-level image features, which contain fine-grained information (texture, contour, and corners), will be weakened. However, due to the sparsity characteristics of point cloud, when two objects are close to each other, their boundaries may be confused due to the dispersion of dense points. The fine-grained information (color, texture, contour, and so on) of images should be preserve to complement the point cloud features. The AP 3D values of our method are higher than those of other methods in Easy, Moderate, and Hard difficulty, and the AP BEV value in Easy and Hard difficulty is higher than that of other methods. However, the result of the proposed method is lower than the result of MLF on the moderate difficulty of AP BEV. The main reason is MLF encodes point clouds as BEV, which can intuitively reflect the relative position relationship between objects and alleviating the interference of overlapping and occlusion problems.
Compared with other methods, the proposed network extracts low-level features to capture fine-grained image information, moreover, the DFF module is designed to combine the high-level point cloud and fine-grained image features to avoid the interference of the underlying functions of the network, and finally, the diversity features of the point cloud and image are explored to enhance the final detection results. The proposed method has better performance than most existing methods. The AP 3D value of our method is higher than that of other methods in Easy, Moderate, and Hard difficulty, and the AP BEV value in Easy and Hard difficulty is higher than that of other methods. We show the results of utilizing only LiDAR point cloud data in last line of Table 1. The conduction process of utilizing only LiDAR point cloud data can be outlined as follows: we remove the proposed Fine-Grained Image Feature Extraction (FGFE) module and Diversity Feature Fusion (DFF) module from the network, retaining only the LiDAR network. In the first stage of the LiDAR network, four Set Abstraction (SA) modules[24] and four Feature Propagation (FP) modules [24] are used to encode and decode LiDAR features, predicting rough 3D bounding boxes, then use a refined network of PointRCNN [27] to predict the precise 3D bounding box. Compared to the results of our single-modal method in the last line, our multi-modal method obtains better results.
Table 2 shows the AP comparison results between our method and other methods for pedestrian classification. The pedestrian category is more challenging for 3D object detection than the car category due to its non-rigid structure and small size. In order to fully certify the effectiveness of our APIDFF-Net, we report the AP 3D and AP BEV results in this category compared with other methods. The results are shown in Table 2. From this table, we can see that the proposed methods obtain better results than the former five methods. However, the proposed method only is higher than the results of F-PointPillars on the Easy indicator. The F-PointPillars method firstly searches for 2D boxes that may contain objects in the image and projects these boxes into Frustum space to improve 3D detection performance. Since some severely truncated and occluded objects were easy to be found in the image, the method improves the detection accuracy of Moderate and Hard indicators. Different from this method, the proposed method does not need to search the 2D box, but directly extract low-level image features to complement high-level point cloud features. We may consider to combine the idea of F-PointPillars and the proposed method to improve the performance in Moderate and Hard indicators in the future work.
Table 3 presents a comparison of average precision (AP) scores for car classification on the KITTI test set using an IoU threshold of 0.7. From this table, we can see that the proposed method obtains better or comparative results than other methods. Our method is superior to the PointPainting method in AP 3d metric, but is lower than the PointPainting method in AP Bev metric. This method leveraged an image-only semantic segmentation network and appended the class scores to each point, and then fed the appended point cloud to any Lidar only method. However, the results of the PointPainting method rely on the results of the semantic segmentation network. In the inference time comparison, since the proposed method is a multimodal detector, it is inevitably slower than the single-modal detectors. Compared to these multimodal methods, the inference time of the proposed method is approximately 220 ms (4.5 FPS), which is superior to the results of the PointPainting (400 ms, 2.5 FPS) and F-Convnet (336 ms, 2.1 FPS). Despite our method having a lower inference time than the other multimodal methods, we are able to achieve better detection precision in AP 3D and AP Bev.
In Table 3, all the multi-modality methods, except for PointPainting, used a split ratio of approximately 1:1 for testing. Hence, to ensure a consistent comparison among multi-modality methods, we re-split the training samples into a 1:1 ratio for the PointPainting method, which we refer to as PointPainting+. The comparison results for the test samples are presented in Table 3. From this table, we see that the results of PointPainting+ are higher than the results of PointPainting in the metric AP 3D. This demonstrates that the PointPainting+ method, using a 1:1 ratio, alleviates the over-fitting issue observed with PointPainting using a 9:1 ratio in the AP 3D metric, however, it is lower than the results of PointPainting in the metric AP Bev. Under the same splitting ratio, the proposed method outperforms PointPainting+. This superiority arises from our more advanced fusion strategy. Specifically, PointPainting projects a point cloud onto the output of the image segmentation network and appends semantic prediction scores to the point cloud information. However, their fusion method is limited by the results of the semantic segmentation network-DeepLabv3+, which is unable to differentiate targets within the same class, such as cars, vans, and trucks. As a result, PointPainting may mistakenly identify a truck as a car due to their similar geometric contours. This issue is particularly prominent in the KITTI test set, where rectangular cuboids like trucks and vans located far away on the road can closely resemble cars in close proximity. In contrast, the proposed method extracts low-level image features to capture fine-grained information (color, texture, contour, and corners), and use the proposed Diversity Feature Fusion module to fuse these low-level image features and the high-level point features, thereby enhance the geometric information of point cloud features, moreover, improve the detection performance of the proposed method. From Table 3, we can see the results of the proposed method outperforms those of PointPainting+.
We have also conducted an experiment to demonstrate the influence of different splitting ratios, including approximate 9:1 (6733:784), 8:2 (5985:1496), 7:3 (5237:2244), and 6:4 (4489:2992), on the detection performance of PointPainting method. The results are shown in Table 4. From this table, we can see that as we change the splitting ratio from a 9:1 to a 6:4 ratio, the performance in AP 3D improves, which suggests an over-fitting issue due to an excessively large number of training samples. However, the number of training samples become smaller to the splitting ratio 1:1, the performance decreases, demonstrating the smaller training samples can make the performance decrease. This highlights the complexity involved in selecting the appropriate splitting ratio. In this paper, we do not focus on how to select the appropriate splitting ration to obtain best performance. In our paper, we opted for the splitting ratio, a choice commonly utilized by all most multi-modality 3D object detection methods to make consistent and fair comparison. In our comparative test experiment, all the multi-modality methods, except for PointPainting, used a split ratio of approximately 1:1 for testing. Hence, we re-split the training samples into a approximate 1:1 ratio (3712:3769) for the PointPainting method, which we refer to as PointPainting+. From this comparative results, we can see that the proposed method is superior to the results of the PointPainting+.
Ablation study
In this section, to verify the effectiveness of the proposed FGFE module and the DFF module, we conduct a ablation study using car class. Table 5 presents the results of the ablation study. Specifically, we compare the performance of our proposed method with two other approaches: one using ResNet50 to generate image features and another that fuses point-wise image features into point cloud features by the direct summation way.
We observe that when ResNet50 features are used instead of our FGFE module, the performance is lower, especially in the Moderate difficulty AP 3D metric. This is because ResNet50 features are coarse-grained features in high-layer, and thus lack fine-grained information necessary for high-quality 3D detection. However, when our FGFE module is used, the detection performance is improved. Moreover, we see that combining both the FGFE module and DFF module further improves the detection results, with all evaluation metrics showing improvement compared to other methods. Therefore, our APIDFF-Net method, which extracts low-level features to capture fine-grained image information and combines high-level point cloud features and fine-grained image features, demonstrates superior performance.
To further verify the effectiveness of DFF module, we compare two alternative fusion schemes in Table 6. One alternative is simple concatenation feature fusion (SCF), and the other is multi-level feature pyramid fusion (MFPF). In the SCF, we concatenate the original camera image and LiDAR point cloud to input our point cloud network. Compared with the DFF module, the result of the SCF module decreases 0.83\(\%\) in the Moderate difficulty AP 3D metric. The MFPF denotes a multi-level feature pyramid fusion. In the MFPF network, the image feature extraction network consists of four bottom-up convolution layers and four top-down convolution layers. The features generated by the top-down four convolutions are fused with the point cloud features generated by the corresponding four SA modules. We shows the MFPF process in Fig. 4. Compared with the DFF module, the result of the MFPF module decreases 0.53\(\%\) in the Moderate difficulty AP 3D metric. Therefore, the DFF module fuses the high-level point cloud features and low-level image features at the end of the first stage of the network, which preserve image fine-grained information and point cloud semantic information. The DFF module achieves the best results.

The multi-scale feature pyramid fusion network (MFPF)

Qualitative results of our method in the KITTI validation set. The green box in the 2D image is ground truth. The green box in the 3D point cloud is ground truth, and the red box is the predicted 3D box
To further verify the effectiveness of the FGFE module, it is compared with the classical coarse-grained backbone in Table 7. We replace the proposed fine-grained image feature extraction network with ResNet [11] and VGG16 [32] of different depths. We make some fine adjustments to the structure of these networks. For example, for ResNet34, we remove the last layer of the full connection so that it can be applied to our network. In the ResNet network, the multi-convolution layer and pooling layer are used to extract high-level semantic features, which obtain coarse-grained information and moreover lead to lose the spatial information of the features. From this table, we can see the performance is lower than that of the proposed method, although they use deeper convolution layer than the proposed method. The proposed FGFE module pays more attention to fine-grained information, does not need to use a large number of convolution kernels, and only uses a simple structure to get the best AP in the Car 3D metric with Iou=0.7. The experiment demonstrates the effectiveness of the FGFE module.
Qualitative results
In addition to quantitative comparison, we also present some visual results of 3D object detection on the KITTI dataset in Fig. 5. The first two rows of images show the detection results of objects with dense points at close range, while the middle two rows show detection results of remote sparse point objects. The last two rows show the detection results of scenes with a large number of dense point objects. As seen in the figure, the proposed APIDFF-Net performs well in all scenarios, accurately estimating 3D bounding boxes that are well aligned with the front view of the point cloud.
Conclusions
In this study, we present a novel two-stage network for 3D object detection that integrates information from both images and LiDAR data. Our approach is different from existing methods that rely on deep layer network architectures to capture high-level semantic information. Instead, we introduce the Fine-Grained Feature Encoding (FGFE) module, which focuses on learning adaptive low-level features to preserve fine-grained image information, such as texture and contour features. Moreover, we develop a Diversity Feature Fusion (DFF) module to fuse low-level image features and high-level point cloud features, which transforms low-level image features into point-wise image features and uses an attention mechanism to explore the complementary characteristics. Experimental results demonstrate that our APIDFF-Net obtains higher performance than other methods.
Data Availability
In our paper, we use KITTI dataset, it is a public available dataset, and from the reference [8].
References
Chen X, Ma H, Wan J, Li B, Xia T (2017) Multi-view 3d object detection network for autonomous driving. In: Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, pp. 1907–1915
Chen Y, Liu S, Shen X, Jia J (2020) Dsgn: Deep stereo geometry network for 3d object detection. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 12536–12545
Chen YN, Dai H, Ding Y (2022) Pseudo-stereo for monocular 3d object detection in autonomous driving. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 887–897
Chen Z, Li Z, Zhang S, Fang L, Jiang Q, Zhao F (2022) Autoalignv2: Deformable feature aggregation for dynamic multi-modal 3d object detection. arXiv preprint arXiv:2207.10316
Chen Z, Li Z, Zhang S, Fang L, Jiang Q, Zhao F, Zhou B, Zhao H (2022) Autoalign: Pixel-instance feature aggregation for multi-modal 3d object detection. arXiv preprint arXiv:2201.06493
Deng J, Shi S, Li P, Zhou W, Zhang Y, Li H (2021) Voxel r-cnn: Towards high performance voxel-based 3d object detection. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 35, pp. 1201–1209
Du L, Ye X, Tan X, Feng J, Xu Z, Ding E, Wen S (2020) Associate-3ddet: Perceptual-to-conceptual association for 3d point cloud object detection. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 13329–13338
Geiger A, Lenz P, Urtasun R (2012) Are we ready for autonomous driving? the kitti vision benchmark suite. In 2012 IEEE conference on computer vision and pattern recognition, IEEE, pp. 3354–3361
Guanghui Y, Xiao H, Xie H, Zhou T, Zhou W, Yan W, Zhao B, Wang T, Jiang Q (2023) Dual-constraint coarse-to-fine network for camouflaged object detection. IEEE Transactions on Circuits and Systems for Video Technology
He C, Zeng H, Huang J, Hua XS, Zhang L (2020) Structure aware single-stage 3d object detection from point cloud. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 11873–11882
He K, Zhang X, Ren S, Sun J (2016) Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 770–778
Huang T, Liu Z, Chen X, Bai X (2020) Epnet: Enhancing point features with image semantics for 3d object detection. In: European Conference on Computer Vision, pp. 35–52. Springer
Ku J, Mozifian M, Lee J, Harakeh A, Waslander SL (2018) Joint 3d proposal generation and object detection from view aggregation. In: 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 1–8. IEEE
Lang AH, Vora S, Caesar H, Zhou L, Yang J, Beijbom O (2019) Pointpillars: Fast encoders for object detection from point clouds. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 12697–12705
Li P, Chen X, Shen S (2019) Stereo r-cnn based 3d object detection for autonomous driving. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 7644–7652
Liang Z, Zhang M, Zhang Z, Zhao X, Pu S (2020) Rangercnn: Towards fast and accurate 3d object detection with range image representation. arXiv preprint arXiv:2009.00206
Lin TY, Goyal P, Girshick R, He K, Dollár P (2017) Focal loss for dense object detection. In: Proceedings of the IEEE international conference on computer vision, pp. 2980–2988
Liu X, Xue N, Wu T (2022) Learning auxiliary monocular contexts helps monocular 3d object detection. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 36, pp. 1810–1818
Liu Z, Zhao X, Huang T, Hu R, Zhou Y, Bai X (2020) Tanet: Robust 3d object detection from point clouds with triple attention. In: Proceedings of the AAAI conference on artificial intelligence, vol. 34, pp. 11677–11684
Lu Y, Ma X, Yang L, Zhang T, Liu Y, Chu Q, Yan J, Ouyang W (2021) Geometry uncertainty projection network for monocular 3d object detection. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 3111–3121
Noh J, Lee S, Ham B (2021) Hvpr: Hybrid voxel-point representation for single-stage 3d object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 14605–14614
Paigwar A, Sierra-Gonzalez D, Erkent Ö, Laugier C (2021) Frustum-pointpillars: A multi-stage approach for 3d object detection using rgb camera and lidar. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 2926–2933
Pang S, Morris D, Radha H (2020) Clocs: Camera-lidar object candidates fusion for 3d object detection. In: 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 10386–10393. IEEE
Qi CR, Liu W, Wu C, Su H, Guibas LJ (2018) Frustum pointnets for 3d object detection from rgb-d data. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 918–927
Qi CR, Su H, Mo K, Guibas LJ (2017) Pointnet: Deep learning on point sets for 3d classification and segmentation. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 652–660
Qi CR, Yi L, Su H, Guibas LJ (2017) Pointnet++: Deep hierarchical feature learning on point sets in a metric space. Advances in neural information processing systems 30
Reading C, Harakeh A, Chae J, Waslander SL (2021) Categorical depth distribution network for monocular 3d object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8555–8564
Shi S, Guo C, Jiang L, Wang Z, Shi J, Wang X, Li H (2020) Pv-rcnn: Point-voxel feature set abstraction for 3d object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 10529–10538
Shi S, Wang X, Li H (2019) Pointrcnn: 3d object proposal generation and detection from point cloud. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 770–779
Shi S, Wang Z, Shi J, Wang X, Li H (2020) From points to parts: 3d object detection from point cloud with part-aware and part-aggregation network. IEEE Trans Pattern Anal Mach Intell 43(8):2647–2664
Simonelli A, Bulo SR, Porzi L, López-Antequera M, Kontschieder P (2019) Disentangling monocular 3d object detection. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 1991–1999
Simonyan K, Zisserman A (2014) Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556
Vora S, Lang AH, Helou B, Beijbom O (2020) Pointpainting: Sequential fusion for 3d object detection. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 4604–4612
Wang Y, Chao WL, Garg D, Hariharan B, Campbell M, Weinberger KQ (2019) Pseudo-lidar from visual depth estimation: Bridging the gap in 3d object detection for autonomous driving. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8445–8453
Wang Z, Jia K (2019) Frustum convnet: Sliding frustums to aggregate local point-wise features for amodal 3d object detection. In: 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 1742–1749. IEEE
Wang Z, Jia K (2019) Frustum convnet: Sliding frustums to aggregate local point-wise features for amodal 3d object detection. In: 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 1742–1749. IEEE
Xie L, Xiang C, Yu Z, Xu G, Yang Z, Cai D, He X (2020) Pi-rcnn: An efficient multi-sensor 3d object detector with point-based attentive cont-conv fusion module. In: Proceedings of the AAAI conference on artificial intelligence, vol. 34, pp. 12460–12467
Yan W, Gu M, Ren J, Yue G, Liu Z, Xu J, Lin W (2023) Collaborative structure and feature learning for multi-view clustering. Information Fusion 98:101832
Yan Y, Mao Y, Li B (2018) Second: Sparsely embedded convolutional detection. Sensors 18(10):3337
Yang Z, Sun Y, Liu S, Shen X, Jia J (2019) Std: Sparse-to-dense 3d object detector for point cloud. In: Proceedings of the IEEE/CVF international conference on computer vision, pp. 1951–1960
Yin T, Zhou X, Krahenbuhl P (2021) Center-based 3d object detection and tracking. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 11784–11793
Yoo JH, Kim Y, Kim J, Choi JW (2020) 3d-cvf: Generating joint camera and lidar features using cross-view spatial feature fusion for 3d object detection. In: European Conference on Computer Vision, pp. 720–736. Springer
Zhang Y, Hu Q, Xu G, Ma Y, Wan J, Guo Y (2022) Not all points are equal: Learning highly efficient point-based detectors for 3d lidar point clouds. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 18953–18962
Zhang Z, Zhang M, Liang Z, Zhao X, Yang M, Tan W, Pu S (2020) Maff-net: Filter false positive for 3d vehicle detection with multi-modal adaptive feature fusion. arXiv e-prints pp. arXiv–2009
Zhao K, Ma L, Meng Y, Liu L, Wang J, Junior JM, Gonçalves WN, Li J (2022) 3d vehicle detection using multi-level fusion from point clouds and images. IEEE Transactions on Intelligent Transportation Systems
Zheng W, Tang W, Jiang L, Fu CW (2021) Se-ssd: Self-ensembling single-stage object detector from point cloud. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 14494–14503
Zhou W, Zhu Y, Lei J, Yang R, Yu L (2023) Lsnet: Lightweight spatial boosting network for detecting salient objects in rgb-thermal images. IEEE Trans Image Process 32:1329–1340
Zhou Y, Tuzel O (2018) Voxelnet: End-to-end learning for point cloud based 3d object detection. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 4490–4499
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This work was supported by the Youth Innovation Team Project of Higher Education Institutions in Shandong Province No. 2022KJ268, the Science and Technology Innovation Foundation of Yantai No. 2023YT06000119, and the National Natural Science Foundation of China No. 61801414.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Yan, W., Liu, S., Liu, H. et al. Adaptive learning point cloud and image diversity feature fusion network for 3D object detection. Complex Intell. Syst. 10, 2825–2837 (2024). https://doi.org/10.1007/s40747-023-01295-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40747-023-01295-x