
Abstract
In modern manufacturing, assembly tasks are a major challenge for robotics. In the manufacturing industry, a wide range of insertion tasks can be found, from peg-in-hole insertion to electronic parts assembly. Robotic stations designed for this problem often use conventional hybrid force-position control to perform preprogrammed trajectories, such as e.g. a spiral path. However, electronic parts require more sophisticated techniques due to their complex geometry and susceptibility to damage. Production line assembly tasks require high robustness to initial position and rotation variations due to component grip imperfections. Robustness to partially obscured camera view is also mandatory due to multi stage assembly process. We propose a stereo-view method based on reinforcement learning (RL) for the robust assembly of electronic parts. Applicability of our method to real-world production lines is verified through test scenarios. Our approach is the most robust to applied perturbations of all tested methods and can potentially be transferred to environments unseen during learning.
Article PDF
Similar content being viewed by others
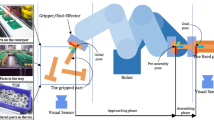
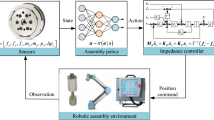

Avoid common mistakes on your manuscript.
Code or Data Availability
Data sharing not applicable to this article.
References
Xu, J., Hou, Z., Liu, Z., Qiao, H.: Compare contact model-based control and contact model-free learning: a survey of robotic peg-in-hole assembly strategies (2019)
Kroemer, O., Niekum, S., Konidaris, G.: A review of robot learning for manipulation: challenges, representations, and algorithms. J. Mach. Learn. Res. 22(30), 1–82 (2021)
Whitney, D.E.: Force feedback control of manipulator fine motions. J. Dyn. Syst. Meas. Control. 99(2), 91–97 (1977). https://doi.org/10.1115/1.3427095
Park, H., Bae, J.H., Park, J.H., Baeg, M.H., Park, J.: Intuitive peg-in-hole assembly strategy with a compliant manipulator. In: Ieee Isr 2013, pp. 1–5 (2013)
Huang, S., Murakami, K., Yamakawa, Y., Senoo, T., Ishikawa, M.: Fast peg-and-hole alignment using visual compliance. In: 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems, pp. 286–292 (2013)
Triyonoputro, J.C., Wan, W., Harada, K.: Quickly inserting pegs into uncertain holes using multi-view images and deep network trained on synthetic data. In: 2019 IEEE/RSJ International conference on Intelligent Robots and Systems (IROS), p. 5792–5799 (2019)
Yu, C., Cai, Z., Pham, H., Pham, Q.C.: Siamese convolutional neural network for sub-millimeter-accurate camera pose estimation and visual servoing. In: 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 935–941 (2019)
Inoue, T., De Magistris, G., Munawar, A., Yokoya, T., Tachibana, R.: Deep reinforcement learning for high precision assembly tasks. In: 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 819–825 (2017)
Johannink, T., Bahl, S., Nair, A., Luo, J., Kumar, A., Loskyll, M., et al.: Residual reinforcement learning for robot control. In: 2019 International Conference on Robotics and Automation (ICRA), pp. 6023–6029 (2019)
Luo, J., Solowjow, E., Wen, C., Ojea, J.A., Agogino, A.M., Tamar, A., et al.: Reinforcement learning on variable impedance controller for high-precision robotic assembly. In: 2019 International Conference on Robotics and Automation (ICRA), pp. 3080–3087 (2019)
Schoettler, G., Nair, A., Luo, J., Bahl, S., Aparicio Ojea, J., Solowjow, E., et al.: Deep reinforcement learning for industrial insertion tasks with visual inputs and natural rewards. In: 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 5548–5555 (2020)
Vecerik, M., Sushkov, O., Barker, D., Rothörl, T., Hester, T., Scholz, J.: A practical approach to insertion with variable socket position using deep reinforcement learning. In: 2019 International Conference on Robotics and Automation (ICRA), pp. 754–760 (2019)
Xie, L., Yu, H., Zhao, Y., Zhang, H., Zhou, Z., Wang, M., et al.: Learning to fill the seam by vision: sub-millimeter peg-in-hole on unseen shapes in real world. In: 2022 International Conference on Robotics and Automation (ICRA), pp. 2982–2988 (2022)
Sathirakul, K., Sturges, R.H.: Jamming conditions for multiple peg-in-hole assemblies. Robotica 16(3), 329–345 (1998). https://doi.org/10.1017/s0263574798000393
Fei, Y., Zhao, X.: An assembly process modeling and analysis for robotic multiple peg-in-hole. J. Intell. Robot. Syst. 36(2), 175–189 (2003). https://doi.org/10.1023/a:1022698606139
Hou, Z., Li, Z., Hsu, C., Zhang, K., Xu, J.: Fuzzy logic-driven variable time-scale prediction-based reinforcement learning for robotic multiple peg-in-hole assembly. IEEE Trans. Autom. Sci. Eng. 19(1), 218–229 (2022). https://doi.org/10.1109/tase.2020.3024725
Lillicrap, T.P., Hunt, J.J., Pritzel, A., Heess, N., Erez, T., Tassa, Y., et al.: Bengio, Y., LeCun, Y., (eds.) Continuous control with deep reinforcement learning
Hou, Z., Dong, H., Zhang, K., Gao, Q., Chen, K., Xu, J.: Knowledge-driven deep deterministic policy gradient for robotic multiple peg-in-hole assembly tasks. In: 2018 IEEE International Conference on Robotics and Biomimetics (ROBIO), pp. 256–261 (2018)
Xu, J., Hou, Z., Wang, W., Xu, B., Zhang, K., Chen, K.: Feedback deep deterministic policy gradient with fuzzy reward for robotic multiple peg-in-hole assembly tasks. IEEE Transactions on Industrial Informatics 15(3), 1658–1667 (2019). https://doi.org/10.1109/tii.2018.2868859
Ma, Y., Xu, D., Qin, F.: Efficient insertion control for precision assembly based on demonstration learning and reinforcement learning. IEEE Transactions on Industrial Informatics 17(7), 4492–4502 (2021). https://doi.org/10.1109/tii.2020.3020065
Haarnoja, T., Zhou, A., Abbeel, P., Levine, S.: Soft actor-critic: off-policy maximum entropy deep reinforcement learning with a stochastic actor. In: Dy, J., Krause, A., (eds.) Proceedings of the 35th International Conference on Machine Learning, vol. 80, pp. 1861–1870. Proceedings of Machine Learning Research. Stockholm, Sweden: Pmlr (2018)
Haarnoja, T., Ha, S., Zhou, A., Tan, J., Tucker, G., Levine, S.: Learning to walk via deep reinforcement learning. In: Proceedings of Robotics: Science and Systems. Freiburgim-Breisgau, Germany (2019)
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., Klimov, O.: Proximal policy optimization algorithms. arXiv:1707.06347 (2017)
Fujimoto, S., van Hoof, H., Meger, D.: Addressing function approximation error in actor-critic methods. In: Dy, J., Krause, A., (eds.) Proceedings of the 37th International Conference on Machine Learning. vol. 80, pp. 1587–1596. Proceedings of Machine Learning Research. Stockholm, Sweden: Pmlr (2018)
Sutton, R.S., Barto, A.G.: Reinforcement learning: an introduction. A Bradford Book, Cambridge, MA, USA (2018)
Kingma, D.P., Welling, M.: Auto-encoding variational bayes. In: Bengio, Y., LeCun, Y., (eds.) 2nd International Conference on Learning Representations (2014)
Haarnoja, T., Zhou, A., Hartikainen, K., Tucker, G., Ha, S., Tan, J., et al.: Soft Actor-Critic algorithms and applications. arXiv
Villani, L., Schutter, J.D., Khatib, O.: Force control. In: Siciliano, B., (ed.) Springer Handbook of Robotics. Springer International Publishing, pp. 195–220 (2016)
Horgan, D., Quan, J., Budden, D., Barth-Maron, G., Hessel, M., van Hasselt, H., et al.: Distributed prioritized experience replay. In: International Conference on Learning Representations (2018)
Maas, A.L., Hannun, A.Y., Ng, A.Y.: Rectifier nonlinearities improve neural network acoustic models. In: ICML Workshop on Deep Learning for Audio, Speech and Language Processing, vol. 30 (2013)
Yarats, D., Zhang, A., Kostrikov, I., Amos, B., Pineau, J., Fergus, R.: Improving sample efficiency in model-free reinforcement learning from images. Proceedings of the AAAI Conference on Artificial Intelligence 35(12), 10674–10681 (2021). https://doi.org/10.1609/aaai.v35i12.17276
Macenski, S., Foote, T., Gerkey, B., Lalancette, C., Woodall, W.: Robot operating system 2: design, architecture, and uses in the wild. Science Robotics 7(66), eabm6074 (2022). https://doi.org/10.1126/scirobotics.abm6074
Liang, E., Liaw, R., Nishihara, R., Moritz, P., Fox, R., Goldberg, K., et al.: RLlib: abstractions for distributed reinforcement learning. In: International Conference on Machine Learning (ICML) (2018)
Marvel, J.A., Bostelman, R., Falco, J.: Multi-robot assembly strategies and metrics. ACM Comput. Surv. 51(1) (2018). https://doi.org/10.1145/3150225
Huang, S.H., Papernot, N., Goodfellow, I.J., Duan, Y., Abbeel, P.: Adversarial attacks on neural network policies. In: 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24–26, 2017, Workshop Track Proceedings; (2017)
Kos, J., Song, D.: Delving into adversarial attacks on deep policies. In: 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24–26, 2017, Workshop Track Proceedings; 2017
Funding
The research was carried out in collaboration with the company Fitech as part of the project funded by the Polish National Centre for Research and Development. Project title: ”Intelligent robot for autonomous handling of assembly of electronic components based on artificial intelligence and neural networks” and number: POIR.01.01.01-00-0123/19
Author information
Authors and Affiliations
Contributions
All authors contributed to the proposed approach. The development of the SAC-SV algorithm was performed by G. Bartyzel. The implementation of the algorithm and the control system on the robot was performed by G. Bartyzel. The test scenarios were designed by G. Bartyzel, W. Półchłopek and D. Rzepka. The figures were prepared by G. Bartyzel. The first draft of the manuscript was written by G. Bartyzel and all authors commented on previous versions of the manuscript. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethics approval
This study did not require ethics approval.
Consent to Participate
Not applicable. This study did not involve human subjects.
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix A: Experimental Setup - Additional Information
1.1 A.1 Combined View Setup
In the SAC-CV experiments, we followed the procedure described by [6] to obtain the combined view as a visual observation. Images acquired from two cameras attached on the robot’s end-effector are merged into an output image of 1024\(\times \)1024 pixels and then down-sampled to 128\(\times \)128 pixels. Camera 1 points to the left side of the gripper and camera 2 points to the right. Such an approach provides a 360-degree-like vision in one image. The concept scheme is presented in Fig. 8

Concept scheme of the image concatenation process for SAC-CV method

The test bed for external camera experiments. The test-bed for external camera experiments. The camera was set up in the robot’s workspace to achieve the field of view focusing on the one PCB from the panel
1.2 A.2 External Camera Setup
For the SAC-EC experiments, we placed an external camera in the robot’s workspace (the detailed setup is presented in Fig. 9a). We set up the camera to get the field of view on the one PCB from the panel. The image acquired from this setup is illustrated in Fig. 9b (Tables 4, 5 and 6).
Appendix B: Additional Results
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Bartyzel, G., Półchłopek, W. & Rzepka, D. Reinforcement Learning With Stereo-View Observation for Robust Electronic Component Robotic Insertion. J Intell Robot Syst 109, 57 (2023). https://doi.org/10.1007/s10846-023-01970-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10846-023-01970-8