
Abstract
It is well known that the processing parameters of selective laser melting (SLM) highly influence mechanical and physical properties of the manufactured parts. Also, the energy density is insufficient to detect the process window for producing full dense components. In fact, parts produced with the same energy density but different combinations of parameters may present different properties even under the microstructural viewpoint. In this context, the need to assess the influence of the process parameters and to select the best parameters set able to optimize the final properties of SLM parts has been capturing the attention of both academics and practitioners. In this paper different hybrid prediction-optimization approaches for maximizing the relative density of Ti6Al4V SLM manufactured parts are proposed. An extended design of experiments involving six process parameters has been configured for constructing two surrogate models based on response surface methodology (RSM) and artificial neural network (ANN), respectively. The optimization phase has been performed by means of evolutionary computations. To this end, three nature-inspired metaheuristic algorithms have been integrated with the prediction modelling structures. A series of experimental tests has been carried out to validate the results from the proposed hybrid optimization procedures. Also, a sensitivity analysis based on the results from the analysis of variance was executed to evaluate the influence of the processing parameter and their reciprocal interactions on the part porosity.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
Introduction
Compared to conventional manufacturing techniques in which the part is produced by subtractive and/or mass conserving process, Additive Manufacturing (AM) is a new way to operate where the object is fabricated layer by layer from a CAD model without any geometry limitation, thus promoting the production of complex part (Guo and Leo, 2013). Moreover, AM technology do not require additional resources like coolants, cutting tool, fixtures, resulting in resource efficiency and production flexibility. Another advantage is to produce low waste and to have a low environmental impact. All these factors make AM suitable for the fabrication of metal parts (Huang et al., 2013). The AM technologies for metallic components can be divided into three main groups, based on material feedstock and its delivery method: (1) powder bed systems, (2) powder feed systems, and (3) wire feed systems (Frazier, 2014). In powder bed systems a powder bed is deposited on the entire working area by means of a rake and only a selected zone is melted by the energy source. The most popular Powder Bed Fusion (PBF) techniques are Selective Laser Melting (SLM) and Electron Beam Melting (EBM) where the powders are melted via laser and electron beam, respectively (Murr et al., 2012). SLM is today a widespread technology deployed by industries to produce metal components due to the good compromise between quality of the manufactured part and cost of the equipment. In particular, SLM is broadly employed to produce Ti–6Al–4V part for automotive, aerospace, and biomedical applications where good mechanical properties are requested (Herzog et al., 2016).
This paper focuses on the optimal selection of process parameters for the density maximization in Ti–6Al–4V SLM additive manufacturing processes. A comprehensive design of experiments has been configured and two distinct prediction modelling approaches based on RSM and ANN have been used for building the mathematical relationship between the density function and six process parameters. Then, in order to maximize the density variable, several metaheuristic algorithms have been implemented and compared in terms of actual density value and relative percentage deviation of the predicted value with respect to the actual one.
The rest of the paper is organized as follows. Section 2 deals with the literature review of the main contributions regarding the SLM process on Ti–6Al–4V alloy, also including specific insights about the prediction-optimization strategies. Section 3 describes material and experimental procedure. Section 4 presents the process modelling. Section 5 discusses the numerical results. Section 6 illustrates the results from the experimental analysis and the validation of the proposed prediction-optimization strategies. Section 7 reports conclusions and future research.
Background of literature
The two following sub-sections deal with the literature background on the SLM additive manufacturing process. Notably, contributions in which the porosity or the relative density is assumed as target function and the raw material is Ti6Al4V titanium alloy are reviewed. The former section focuses on the contributions that studied how a set of processing parameters affects the porosity. The latter reviews the prediction-optimization strategies employed in the SLM research area, also mentioning the seminal additive manufacturing studies in which hybrid optimization tools are introduced.
Investigating density in SLM
The leading role of density in the quality assessment of additive manufactured products has been widely proved by the literature. Maximizing part density is one of the principal purposes due to the bad influence of pores on mechanical properties (Kladovasilakis et al., 2021). Indeed, even a porosity level of 1–5 vol.% can strongly affect tensile and fatigue properties of the final part (Gong et al., 2015), being lack of fusion and gas porosity the major common defects in SLM that induce low density (DebRoy et al., 2018). Although in SLM manufacturing the melting pool instability may be responsible of microstructural defects and porosity, it was demonstrated that the density of SLM manufactured products is strictly depending on some major process parameters and detrimental implications may occur if such parameters are inaccurately set during an experimental analysis (Shipley et al., 2018).
In their review work Shipley et al. (2018) identified the state-of-the-art in SLM process optimization on Ti–6Al–4V parts, also dedicating a specific section to the porosity issue. They stated that density maximization is a primary objective when selecting process parameters and the energy density should be monitored to define a process window for fully dense components. However, different combinations of process parameters can be associated to the same energy density, but different porosity values can be, in turn, observed (Kasperovich et al., 2016). Many literary contributions analyzed the effect of scanning speed and laser power on porosity, which have been varied in [100, 4500] mm/and from 40 to 400 W, respectively. Gong et al. (2014) investigated the influence of laser power and scan speed on porosity. They established a process window that can be divided into four zones. Only for zone I it was possible to produce fully-dense parts, otherwise defects generation was observed. In detail, when the energy density is too high, gas porosity takes place. On the other hand, for insufficient energy input, a lack of fusion defect occurs. To evaluate the porosity of the samples, the density of each specimen was measured by Archimedes method and then compared with the nominal density of Ti64.
Qiu et al. (2013) investigated the influence of laser power and scan speed for two different build orientations and four scanning strategies. They found that porosity generally decreases when increasing laser power and laser scanning speed, due to the reduction in energy input and lack of fusion defect. Moreover, horizontally built samples showed a lower density level than vertically built specimens. No evident effect of the scan strategy on the porosity emerged from this study. Montalbano et al. (2021) varied both laser power and scan speed to correlate defect generation with energy density keeping constant hatch distance and layer thickness. They found two types of porosity defect, lack of fusion and keyhole. The former occurs when there is too low energy to fully melt the metal powder bed, while keyhole takes place when too high energy density is provided causing a fluid dynamic instability in the melt pool.
The inadequacy in considering only scanning speed and laser power to identify an optimal processing window clearly emerged from the earlier studies on SLM. Hatch distance is demonstrated to have a low impact on porosity (Han et al., 2017), but the presence of pores at the boundary regions has been observed when small hatch distances are set (e.g., \(\approx 60 \mathrm{\mu m}\)). As for the layer thickness, many commercial additive manufacturing machines work by keeping constant this parameter, thus it is a quite unexplored aspect under the optimization viewpoint. However, Xu et al. (2015) observed that layer thickness in the range [30, 90] mm is adequate for producing samples with density greater than 99.5%, while Qiu et al. (2015) asserted that an increase in the layer thickness entails an increase in the overall porosity. Sun et a. (2013), studied the effect of layer thickness, energy density and hatch distance on the density at a constant speed.
Porosity in parts manufactured by SLM is also influenced by scanning strategies and build orientations. Khorasani et al. (2019) studied the combined effect of laser power, scan speed, hatch spacing, scanning pattern and heat treatment temperature on the quality of Ti–6Al–4V parts keeping constant layer thickness, for maximizing microhardness and density. They observed that combining a high scan pattern angle with a low laser power or, alternatively, with a high scanning speed, would have a detrimental effect on the density. In terms of impact of the building orientation on the density, not so many studies appeared in the literature so far. However, vertical and horizontal orientations should lead to slightly lower values than diagonal orientations for samples in as-built conditions, i.e., with no post-process heat treatment (Wauthle et al., 2015).
Prediction-optimization strategies in SLM
The studies mentioned in the previous section confirm how a series of processing parameters have a strong influence on the porosity of SLM manufactured components. Besides, it emerges that a complex relationship exists between density and the interactions among such parameters. At the same time, the inadequacy of the energy density in justifying mechanical and physical properties of SLMed parts led both academics and practitioners to study alternative ways to select the most suitable process parameters in a cost-effective manner. In the last decade, a few approaches for the optimal selection of process parameters have been proposed by literature, based on both statistical methods and machine learning techniques.
As for the statistical approach, Bartolomeu et al. (2016) presented a study on the influence of several process parameters (such as laser power, scan speed and scan spacing) on density, hardness and shear strength of Ti6Al4V parts produced by SLM process. Particularly, they performed an analysis of variance to investigate the main effect of the aforementioned process parameters, also including their interactions, on the mentioned response measures. Sun et al. (2013) used a statistical design of experiment technique based on Taguchi method to optimize the density of Ti6Al4V samples manufactured by SLM at varying scanning speed, powder thickness, hatching space and scanning strategy, while keeping fixed the laser power. Kuo et al. (2017), used the analysis of variance to investigate the impact of laser power, exposure duration and layer thickness on the material porosity and on the dimensional accuracy as well. The last 15 years have seen the widespread application of RSM to optimize processes and product designs (Myers et al., 2004). Li, Kucukkoc, et al. (2018), Li, Wang, et al. (2018)) adopted a response surface methodology (RSM) approach for selecting the process parameters (i.e., laser power, scan speed and hatch spacing) able to optimize the surface roughness of selective laser molten Ti6Al4V parts. Zhuang et al. (2018) applied the RSM to derive a regression model involving four processing parameters (namely laser power, scanning speed, preheating temperature and hatch distance) for predicting the dimensions of the melt pool in SLM of Ti6Al4V.
ANOVA and RSM-based approaches are commonly used for investigating the influence of some parameters individually or for drawing the squared or cubic prediction model of the process under investigation. Beyond these methods, machine learning (ML) approaches have captured a great amount of attention from the literature in the last decade for both prediction and optimization purposes.
Artificial Neural Networks (ANN) belong to the family of Machine Learning (ML) algorithms, and emulate the biological neural networks to approximate non-linear regression models of real-life phenomena, which in turn depend on complex relationships between input and output variables (Du & Swamy, 2013). ANN has been capturing the attention of both academics and practitioners working on different research areas, such as computer vision (Krizhevsky et al., 2012), autonomous driving (Li, Kucukkoc, et al., 2018; Li, Wang, et al., 2018), speaker and language recognition (Richardson et al., 2015), intelligent manufacturing (Dagli, 2012) and even additive manufacturing (Qi et al., 2019).
The remarkable impact of ML in the additive manufacturing research stream can be easily evaluated by two recent review papers (Wand et al., 2020; Meng et al., 2020), but some contributions consistent with the present papers are worthy to be mentioned in the following. Park et al. (2021) adopted a supervised learning deep neural network based on the backpropagation algorithm to select the optimal input parameters (laser power, scanning speed, layer thickness and hatch distance) for a set of quality measures outputs (density ratio and surface roughness) related to biomedical applications. The same machine learning technique along with the same processing parameter have been used in another research work in which a user-friendly module for pre-processing SLM printing is presented (Nguyen et al., 2020). An ANN model with a backpropagation (BP) algorithm was employed to describe the stress–strain relationship of SLM-manufactured Ti6Al4V in dynamic compression processes (Tao et al., 2019).
A data-driven approach has been recently proposed to investigate the influence of the major fabrication parameters in the laser-based additively manufactured Ti6Al4V (Sharma et al., 2021). Particularly, four fabrication parameters (scanning speed, laser power, hatch spacing, and powder layer thickness) and three post-fabrication parameters (heating temperature, heating time, and hot isostatically pressed or not) have been used as input variables and three static mechanical properties (i.e., yielding strength, ultimate tensile strength, and elongation) as target variables. To identify the behavior of the relationship between the input and output parameters, an artificial neural network (ANN) back-propagation model was developed using 100 trials.
Further worthy contributions in the field of ANN applied to SLM manufacturing processes employing different materials are as follows. Tapia et al. (2016) used a Gaussian process-based predictive model for the learning and prediction of the porosity in 17–4 PH stainless steel parts produced using selective laser melting AM process. Two input parameters are considered (laser power and scanning speed), while the other parameters (hatch distance, layer thickness and beam size) are kept constant. Some years later, Tapia et al. (2018) applied the same surrogate modelling approach to construct a process map depending on laser power and scanning speed 316L stainless steel for predicting melt pool depth. Another interesting contribution regards the feed-forward back-propagation neural networks used to predict porosity and microhardness of bronze EOS DM20 laser sintering molten parts as a function of laser power, scanning speed and hatch distance (Singh et al., 2012).
A new trend in the optimization of manufacturing processes focuses on hybrid optimization techniques, which combine prediction modelling techniques (e.g., RSM or ANN) and metaheuristic algorithms (e.g., genetic algorithms) to select the best process parameters to minimize/maximize a certain physical or mechanical performance measure. In the additive manufacturing area, a few contributions appeared in the literature so far, concerning fused deposition modelling (FDM) technique (Deswal et al., 2019; Deswal et al., 2020; Saad et al., 2021) Selective Laser Sintering of polymers (Rong-Ji et al., 2009) and wire arc additive manufacturing (Xia et al., 2021).
Contribution of the paper
In this paper different hybrid prediction-optimization methods to optimally select the process parameters of Ti6Al4V parts manufactured by SLM process are proposed. To the best of our knowledge, this paper represents the first attempt of integration between machine learning and evolutionary computation for prediction-optimization of SLM processes. To make the present research robust and reliable, two prediction modelling approaches have been considered, namely response surface methodology (RSM) and Artificial Neural Network (ANN). Besides, three different metaheuristic algorithms have been employed for processing parameters optimization purposes, i.e., genetic algorithm (GA), particle swarm optimization (PSO) and self-adaptive harmony search (SAHS). Another source of novelty regards the set of processing parameters involved in the proposed prediction-optimization analysis. In fact, a total of six independent parameters, i.e., laser power, scanning speed, hatch distance, layer thickness, scanning strategy and building orientation are considered as input variables to be selected with the aim of maximizing the density. To the best of the authors’ knowledge, hybrid optimization techniques involving so many processing parameters and regarding Ti6Al4V SLM never have been studied by the literature so far.
Due to the high number of processing parameters, a high number of experimental trials should be required to make robust and reliable prediction-optimization analysis. Therefore, a dataset of 130 experimental tests has been exploited for assuring the robustness of the prediction models and the effectiveness of the optimization algorithms as well. In particular, a design of experiments of 61 trials has been used for a customized RSM approach; also, to strengthen the efficacy of the ANN model, 30 trials have been added to the previous set. Subsequently, 39 samples have been constructed to validate and evaluate the effectiveness of the tested prediction-optimization procedures.
Material and equipment
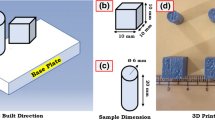
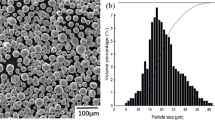
Ti6Al4V ELI (Grade 23) spherical powder provided by SLM Solutions Group AG (Lübeck, Germany) was used for the experimental analysis. The powder (Fig. 1) is characterized by particle size of 20–63 µm and a mass density of 4.43 g/cm3. In total, 130 rectangular samples were fabricated using a SLM® 280HL machine with different process parameters. Figure 2a shows seven samples produced with different building orientation, while in Fig. 2b a sketch with dimensions of the sample is presented. Each sample was built on a Ti6Al4V solid substrate preheated at 200 °C and the build chamber (280 × 280 × 365 mm) was filled with argon to reduce the oxygen level to 0.1%. After removing the specimen from the plate, the density measurement was carried out using Archimedes method at room temperature according to ASTM B962-08. All the samples were polished before density measurements with a Branson 2510 ultrasonic cleaner. A Mettler Toledo™ balance with the accuracy of ± 0.1 mg was used to measure the mass in air and in the fluid for each specimen.

SEM image of the utilized powder

a Samples built with different building orientation for the RSM and ANN and b sketch with dimensions of the fabricated samples
Research methodology
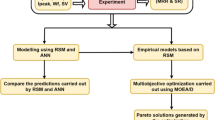
This section deals with a detailed description of the prediction-optimization methodology used to select the most suitable process parameters able to maximize the density of the SML process at hand (See Fig. 3). First, the structure of the experimental dataset is presented, i.e., the design of experiments (DOE). Then, the predictive techniques that make use of the experimental data to generate the surrogate model of the SLM process (namely RSM and ANN) are introduced. Finally, three distinct metaheuristic algorithms exploiting the process meta-models to maximize the relative density are described. The output from the metaheuristic optimization consists of the optimal processing parameters for density maximization.

Prediction-optimization framework
Design of experiments
The effect of several process parameters on the relative density has been investigated. Differently from other relevant contributions on the same topic, in this paper six independent factors are considered as follows: laser power P, scanning speed v, hatch distance h, building orientation o, building strategy s and layer thickness t. In particular, the scanning strategy refers to the scanning pattern angle increment followed by the energy beam when passing from one layer to the next one. The range of variation of processing parameters has been chosen on the basis of both preliminary experiments and literature. As for example, Fig. 4a shows the unsuccessful production of a sample characterized by P = 60 W, v = 2200 mm/s, h = 150 µm, o = 75°, s = 5° and t = 40 µm, while Fig. 4b shows the unsuccessful production of a sample characterized by P = 400 W, v = 500 mm/s, h = 80 µm, o = 45°, s = 45° and t = 40 µm. Additionally, according to Shipley et al. (2018), more studies are required to fully understand the density when laser power is above 190 W. Table 1 reports notation, unit of measure, type and bounds assumed for each processing parameter. To arrange an appropriate design of experiments, the first four process parameters (namely P, v, h and o) have been handled as continuous variables within the related domains [min, max], the scanning strategy was varied through six discrete values (\(s\in \{0, 15, 30, 45, 60, 90\}\)), while the layer thickness was run as a categorical variable at two levels, i.e., 30 and 60 μm, respectively.

Unsuccessful production of samples fabricated with a insufficient energy input and b excess of energy input
The energy density (Ev in Eq. 1) variable is commonly used as a way to define a process window for full dense components, even though the state of the art proved that the same energy density may lead to different parts density. The linear energy density (El in Eq. 2) is considered as a means to control the balling phenomenon, which in turn may affect the part density.
According to the ranges reported in Table 1, the linear energy density may assume values in \(\left[{E}_{L}^{min},{E}_{L}^{max}\right]=\)[0.15, 0.38] while the volumetric energy density in \(\left[{E}_{V}^{min},{E}_{V}^{max}\right]=\) [17.0, 115.2].
Process modelling
Response surface methodology (RSM)
Usually, a response surface methodology approach is used to investigate the relationship between a response variable and a set of independent variables, with the aim of selecting the sequence of factors capable of assuring an optimal response. To relate the response variable with the provided influencing factors, RSM exploits an appropriate design of experiments to fit a polynomial regression model up to the third power, which includes the cross-product terms of the variables. The formalization of the model, which includes the interactions among the provided independent variables, is reported in Eq. 3.
where, y’ is the transformed predicted density depending on the influencing factors \({x}_{i}\), \({x}_{j}\), \({x}_{k}\), \({\beta }_{0}\) is the constant coefficient, \({\beta }_{i}\) are related to linear coefficients, \({\beta }_{i}\) refer to the quadratic coefficients while \({\beta }_{ij}\) and \({\beta }_{ijk}\) are the interaction coefficient, being n the number of independent variables. By doing so, the actual predicted values in terms of density should be derived by using the inverse transformation function.
To infer the significance of the prediction model as well as the sensitivity of the response variable to the independent variables, the analysis of variance (ANOVA) must be studied. Two major assumptions have to be ascertained in ANOVA: (i) the data are normally distributed; thus, they are free to vary around the mean with no imposed limits, and (ii) homogeneity of variance, i.e., the variance among the groups should be approximately equal. Clearly the former assumption cannot be true for percentages values, such as the density, which cannot be neither lower than 0 nor greater than 100%. In this case, especially when such data are close to either the lower or the upper limit, a transformation function is needed. A simple way of doing this is to convert the percentage responses in the range [0,1] to logit or arcsin values and then to use the obtained results for the ANOVA. The logit function is a well-known transformation associated with the standard logistic distribution for linearizing sigmoid distributions of proportions (Stevens et al., 2016), widely used in data analysis and machine learning. When a response y is bounded between a lower and an upper limit the following transformation equation holds:
The arcsine transformation (also called the arcsine square root transformation, or the angular transformation) is computed as two times the arcsine of the square root of the response (Sokal & Rohlf, 1995). When a response y has the form of a percentage or a proportion, the angular transformation equation is as follows:
Once the transformation of the response has been carried out, the obtained values are more suitable for being fitted by a kind of regression model up to the third power and the three fundamental steps of RSM, namely ANOVA, regression model and optimization can be performed.
Multilayer artificial neural network
In order to numerically replicate the behavior of the observed AM process, i.e., to generate a robust regression model capable of mapping the dataset of inputs and targets arising from the experimental runs, a multilayer artificial neural network has been developed. Notably, in this paper a multilayer feed-forward neural network (MFFNN) is chosen to estimate the density performance indicator as a function of the six input variables. In addition, the Levenberg–Marquardt Backpropagation algorithm is used with the performance function, which in turn consists of a function of the ANN-based estimation and the ground truth of density. A MFFNN involves one input layer, at least one hidden layer and one output layer. Figure 5 shows the structure of a MFFNN with two hidden layers.

Scheme of a multi-layer ANN
In brief, the basic structure of a MFFNN is the neuron, which receives information from several inputs that are properly weighted by the elements of a specific matrix. Also, every neuron has a bias to be summed with the weighted inputs to generate the net input, which in turn is transformed into a neuron output by means of a specific activation function. Particularly, activation functions play a twofold role, i.e., they convert one or more input signals of a node into an output and decide if a neuron in the neural network has to be activated or not. In this study the log-sigmoidal activation function (Eq. 6) (Narayan, 1997), which is one of the most popular non-linear activation functions for neural network, is employed and a backpropagation (BP) algorithm is used to train the proposed MFFNN. In Eq. 6, variable x is the weighted sum of the neuron inputs and \(f\left(x\right)\) is the output of the activation function (in this case always between 0 and 1), which in turns may serve as an input for the next layer.
The BP algorithm makes use of the mean square error to adjust the network parameters by: (i) propagating the inputs forward through the network; (ii) propagating the network sensitivity backward, from the last layer to the first one; (iii) updating both weights and biases through an approximate descent procedure. As for the latter step, in machine learning the training process aims at minimizing the cost function of the neural network by varying the values of both weights and biases. To this end, the gradient descent is considered as one of the most popular optimization algorithms (Rumelhart et al., 1986), which is based on two distinct steps iteratively performed through the training dataset. For the sake of brevity, the rationale of such gradient descent algorithm has been omitted in the present manuscript. Finally, a common strategy to generate a robust and reliable prediction model by ANN consists in avoiding or at least reducing the model overfitting. In machine learning overfitting is the situation in which the neural network tends to extremely fit the training dataset, while a poor performance emerges when the same neural network makes predictions for new data, such as the testing related ones. To this end, the k-fold cross-validation technique (Refaeilzadeh et al., 2009) can be adopted. In brief, it consists of a statistical method that divides the whole dataset into k equal-sized smaller datasets. Then, (k-1) datasets are used for training the neural network, while one of them is used as a validation dataset for testing purposes.
Metaheuristic optimization
In general, traditional optimization methods may be classified in two groups: direct search methods and gradient methods. The former methods, such as simplex algorithm, exploit the relationship between objective function and constraints to search for the optimal solution. Conversely, gradient methods use the differentiation method to achieve the optimal solution. Both of them suffer for some shortcomings such as the computational slowness for the direct search ones and the inability of solving discontinuous or nondifferentiable functions for the gradient methods. These drawbacks gave rise to the development of population-based metaheuristics algorithms that nowadays are constantly employed in several areas of research. In this paper, three distinct metaheuristic algorithms (particle swarm optimization, harmony search, genetic algorithms) are tested for selecting the best SLM process parameters capable of maximizing the density response variable. The selection of these nature-inspired techniques was motivated by their different algorithmic structures, which in turn may affect the search mechanism and the quality of solutions as well (Yang, 2010). Each algorithm makes use of a population of NP solutions. Each solution can be denoted as \({{\varvec{x}}}_{i}={x}_{i1}, \dots ,{x}_{ij},\dots ,{x}_{iD} (\mathrm{with} i=1,\dots ,NP;j=1,\dots ,D|D=6\)) and evolves generation-by-generation by means of one or more perturbation criteria, with the aim of maximizing the density objective function, whose mathematical expression can be given as follows:
where \(\varphi \) represents either the RSM or the ANN predictive function that yields y.
Notably, each variable \({x}_{ij}\) may vary within a specific domain \([{x}_{j}^{min}\), \({x}_{j}^{max}\)] according to the bounds reported in Table 1. The following subsections deal with a more detailed description of each metaheuristic. For the sake of fairness, the same maximum number of generations (Kmax = 100) have been set for each metaheuristic. The rest of control parameters of each algorithm has been set at the values recommended by the original authors. Finally, the following strategy has been adopted with the aim of enhancing the exploration ability of the tested metaheuristics. Whenever a variable \({x}_{ij}\), at any generation, is lower than its lower domain limit (\({x}_{j}^{min}\)) or greater than its upper domain limit (\({x}_{j}^{max}\)), it is replaced with a value randomly selected in [\({x}_{j}^{min}\), \({x}_{j}^{max}\)].
Particle swarm optimization
Particle swarm optimization (PSO) is an evolutionary algorithm developed by Eberhart and Kennedy (1995), which belongs to the class of bio-inspired algorithms as it emulates the social behavior of birds and fish. It consists of a computational method for optimization that makes use of a population of particles, i.e., a swarm, which moves around in the space of solution by varying both position and velocity of each particle. Notably, each particle moves on the basis of its local best-known position, but it is also influenced by the global best-known solution, i.e., the position of the best solution achieved so far. In words, PSO evolves by exploiting both a communication and a learning mechanism; in fact, every particle learns by its local best-known position and communicates with the global best position generation-by-generation. In this paper, a quasi-standard PSO has been implemented for density optimization purposes. The control parameters of the algorithm were set to the values suggested by the reference literature (Poli et al., 2007). Besides, as the inertia weight is a sensitive parameter controlling the balance between exploration and exploitation (Nickabadi et al., 2011), a linear time-varying adaptation mechanism inspired by the relevant literature (Eberhar and Shi, 2001) has been employed. Therefore, the population size (NP) has been set to 40, the inertia coefficient w ranges in [0.3; 0.9], while both acceleration coefficients, i.e., C1 and C2, are set to 2.
Self-adaptive harmony search
Harmony Search (HS) is a performing evolutionary algorithm inspired by the approach of musicians when they search for a better harmony (Geem et al., 2001) that has been successfully applied to several intelligent manufacturing applications (Yi et al., 2019). Similar to other bio-inspired metaheuristics, the convergence performance of HS is sensitive to control parameters; thus, a demanding tuning analysis should be executed to choose the most suitable values of such parameters. Particularly, two control parameters named harmony memory consideration rate (HMCR) and pitch adjustment rate (PAR) are responsible for convergence ability and quality of solutions of HS (Wang & Huang, 2010). Recently, adaptive or self-adaptive HS variants, which automatically tune the control parameters during the evolutionary path, have been proposed by literature in many fields of research, such as statistical quality control (Costa & Fichera, 2017), water flow control (M’zoughi et al., 2020), resource leveling problem (Ponz-Tienda et al., 2017). In this paper, the self-adaptive harmony search (SAHS) version proposed by Costa and Fichera (2017) has been implemented to select the best process parameters of the SLM process under investigation. For the sake of clarity, and conforming to the original algorithm configuration, the following values have been considered for the control parameters: NP = 40, HMCR \(\in [0.7, 0.95]\), PAR \(\in [0.1, 0.5]\).
Genetic algorithm
Genetic algorithm (GA) is a metaheuristic that belongs to the nature-inspired optimization algorithms and pursues the survival of the fittest philosophy, which in turn is based on the theory of evolution laid by Charles Darwin. Once the first population of chromosomes (i.e., solutions) is generated, a series of generations are carried out and the major genetic operators (selection, crossover and mutation) are deployed to drive the convergence towards the most effective near-optimal solution. Although the earlier implementation of GA made use of a binary encoding, further studies (Bianco et al., 2001; Deep & Thakur, 2007) demonstrated the superiority of the real-coded GA in solving continuous optimization problems, under both the efficacy and the efficiency viewpoint. In this paper, a standard real-coded genetic algorithm employing an arithmetic crossover method and a heuristic mutation operator (Michalewicz, 1996) has been used for density optimization purposes. Precisely, if \({x}_{1}\) and \({x}_{2}\) are the parent chromosomes, the arithmetic crossover generates offspring \({y}_{1}\) and and \({y}_{2}\) as follows: \({y}_{1}=\alpha {x}_{1}+(1-\alpha ){x}_{2}\), \({y}_{2}=\alpha {x}_{2}+(1-\alpha ){x}_{1}\), where \(\alpha \) is a random number in [\(\gamma ,1+\gamma \)]. Instead, the new chromosome obtained by the heuristic mutation is \(y={x}^{min}+r({x}^{max}-{x}^{min})\), being r a random number from a uniform distribution U[0,1]. For the sake of replicability, probability of crossover, probability of mutation and \(\gamma \) have been respectively set to 0.9, 0.1 and 0.7 according to the indication from the source contribution.
Results and discussions
Response prediction from RSM
In light of both number and type of process parameters described in Table 1, a flexible design of experiments has been generated by Design Expert™ 11 to accommodate a RSM custom model. It consists of 27 required points with 24 additional model points, 5 lack-of-fit points and 5 replicate points. As a result, 61 total runs have been considered for the proposed RSM custom design. Design Expert generated a completely randomized design to assure that all experiments have the same chance to be assigned to any run (Kirk, 2012). For the sake of clarity, Table 7 in Appendix A shows the 61 experimental scenarios in terms of independent variables. After a series of preliminary analyses, the arcsin-square-root transformation on the response variable y has been adopted. Several models such as linear, 2FI (two factor interaction), quadratic and cubic can be selected by the fit summary software interface, with exception of the aliased ones, that cannot be accurately fit with the design and should generally not be considered for analysis. Although the statistical software automatically suggested the quadratic model, being the related R2 value equal to 0.80, to improve the model fitting performance some influencing third-order terms were introduced. Therefore, in this study a not aliased reduced cubic regression model considering the density response variable as a function of six process parameters, i.e., (A) laser power P, (B) scan speed v, (C) hatching distance h, (D) build orientation o, (E) building strategy s and F) layer thickness t, has been adopted.
To infer about the cause-effect relationships between the independent variables, i.e., the process parameters, and the dependent variable (namely the density), the statistical significance of such interactions and the model itself have been assessed by a proper analysis of variance. Table 2 reports the numerical results from the ANOVA, in which P-values and F-values reveal the significance of the obtained model and associated factors. In other words, if the P-value is lower than 0.05 it means that such a factor or combinations of factors influence the response variable in a statistically significant manner. Conversely, the higher the F-value the greater is the impact of a factor or a combination of factors on the model and on the relative density as well. Therefore, P-values lower than 0.05 associated with higher F-values indicate the most significant contributions to the density model, while some insignificant terms (P-value > 0.05) have been deliberately removed from the model to enhance the statistical significance of the model itself. Besides, the lack-of-fit in the ANOVA table confirms that the model residual is not-significant compared with the replicate error. However, the statistical significance of the model is demonstrated by the high R-squared and adjusted R-squared indicators, properly combined with a very high Adeq. Precision measure (Zhang et al., 2020).
To further assess the model accuracy, the normal plot of the studentized residuals for the target response and the model residuals versus the runs are depicted in Fig. 6a and Fig. 6b, respectively. As the reader can notice, in Fig. 6a the studentized residuals fits the straight line with small deviations only for some out-layer points, while in Fig. 6b residuals are independent with each other and no specific trend emerges, thus excluding any influence of the test order on the density response variable. Once both robustness and significance of the derived model is demonstrated, the cubic regression model, which predicts the density response variable by combining all input variables, can be used for sensitivity analysis and optimization. Table 3 reports the coefficients pertaining to the recued cubic model (See Eq. 3) in actual units. Of course, being the layer thickness modelled as a categorical variable at two levels (i.e., t = 30 and t = 60), two sets of regression coefficients are indicated. Figure 7 allows comparing the deviation between predicted and actual density over the provided 61 observations. A satisfying fitting can be appreciated even though the prediction model is not able to properly match the low-density trials.

Analysis of residuals: a normal plot of residuals, b residuals vs. run plot

Line-plot of predicted and target density related to RSM
Sensitivity analysis from RSM
In order to infer about the way each factor and any combination of two factors affect the model, a series of plots provided by the statistical software deserve to be investigated. It is worth pointing out that all plots in this section have been generated by setting the other independent variables to the average value of the ranges in Table 1. Particularly, starting with the findings from the ANOVA analysis (See Table 2), this section deals with a sensitivity analysis focused only on the significant (P-value < 0.05) one-way and two-ways interactions. Figure 8 shows the main-effect plots on the density response variable regarding the scanning speed (v), the hatching distance (h) and the building strategy (s), also indicated as coded variables B, C, and E, respectively. Although the ANOVA reveals that the thickness is not a statistically significant influencing factor, being t a categorical value, two sets of main-effect plots are reported in Fig. 8. Figure 8a and 8b show how the first-order contributions related to v and h impact on the density when t is equal to 30 μm. Clearly, both of them are able to maximize the response variable when they are set at the lowest value, i.e., 1000 mm/s and 110 μm, respectively. Conversely, moderately high values of building strategy allow enhancing the density, as depicted in Fig. 8c. When the layer thickness is set to 60 μm (See Fig. 8d–f) the way each process parameter influences the response variable is not so dissimilar from the findings described above. What emerges is that a higher layer thickness has a detrimental impact on the density when v and h are set to higher values. Likewise, it seems that a layer thickness equal to 30 μm allows reaching a higher density than the one achievable when t is set to 60. However, when t = 30 the density is maximized by assigning the scanning strategy angle in the rough range [60–75]; on the other hand, if t = 60 the best performance requires a scanning strategy roughly ranging in [35–55]. Following the same criterion, Fig. 9 reports the contour-plots concerning solely the statistically significant (see P-value < 0.05 in the ANOVA table) two-way interactions by distinguishing the graphs assuming t = 30 (Figs. 9a–d) from the ones related to t = 60 (Figs. 9e–f). Again, with exception of the layer thickness, each contour plot in Fig. 9 implies the other factors set to the average values conforming to the provided ranges of variation. Figure 9a and e depict how the combination of laser power P and scanning speed v affect the density when t is equal to 30 μm and 60 μm, respectively.

Main effect plot: t = 30 (a, b, c) and t = 60 (d, e, f)

Two-order interaction contour plots: t = 30 (a, b, c, d) and t = 60 (e, f, g, h)
Clearly, no remarkable difference emerges under the graphical viewpoint, thus confirming the weak role of the layer thickness. However, the ranges of values in terms of P and v able to maximize the density (i.e., medium–low values for both of them) can be easily detected. As for the interaction contour plots involving the hatch distance and the scanning speed no substantial difference appears because of the layer thickness (See Fig. 9b and f). Also in this case, medium–low values for both h and v should be the more suitable for enhancing the response variable. Contour plots related to the combined effect of building strategy (s) and scanning speed (v) show a slight difference as the layer thickness changes (See Fig. 9c and g). In fact, when t is equal to 30, a density maximization would be expected when the scanning speed is set in the range [1100–1400] m/min and the building strategy in [40–70] deg. On the other hand, if t is set to 60, the building strategy should vary in the range [20–60], while the scanning speed should assume a value ranging between 1000 and 1200 m/min. Finally, the effect of the layer thickness when investigating the combined effects of both building orientation (o) and building strategy (s) on the density response appears more interesting. If the layer thickness is fixed to the lowest value, then a higher density may be achieved by setting s at medium–high values, while the building orientation should assume medium–low values. Whether the layer thickness assumes the highest value, a small surface portion confined between h varying in [20–40] and o in [80–90] is useful for assuring the highest density.
Response prediction by ANN
Although a neural network with one hidden layer is capable of running most complex functions (Chen et al. 2018), after a series of trial-and-error attempts as well as on the basis of prior studies (Qi et al., 2019), two hidden layers, each one holding a number of five neurons, were selected to strengthen the neural network response. The number of neurons for the hidden layers has to be set accurately as it may cause either overfitting or underfitting problems in machine learning (Xu & Chen, 2008). Notably, the neural network architecture 6–5–5–1 has been selected (See Fig. 10a), where the number of neurons in the input layer entails the six process parameters and the single output node refers to the density (Park et al., 2021). To prevent any risk of overfitting the K-fold cross-validation by 10 folds has been performed (Jung & Hu, 2015), similarly being done in other studies regarding the additive manufacturing topic (Xia et al., 2021). The above-described machine learning procedure has been implemented on Matlab® R2020b software. In respect to the 10-folds cross-validation, 80%, 10% and 10% of the dataset have been designated to training, validation and testing, respectively. The selected neural network regression model assures a coefficient of determination (R2) for training, testing and validation datasets equal to 0.98, 0.81 and 0.96, respectively. Interestingly, the coefficient of determination of the whole model is equal to 0.968.

ANN: a configuration data; b convergence plot; c coefficients of determination
Figure 10b shows the ANN performance in terms of mean-squared error for training, testing and validation. The training procedure stops conforming to the adopted early stop criterion. The best validation performance was achieved when MSE is about 9.5E-06 at epoch 10, and after six error repetitions at epoch 16 the process ends as reported in the x-axis of the plot. Such result in terms of validation performance suggests that after epoch 10 the network attains its best learning stage, as the MSE of both validation and testing increases from that iteration on. Figure 10c shows the regression plots for training, validation and testing data as well as a plot for the combined regression. The dashed line represents the perfect condition when the predicted outputs equal the target ones, i.e., a 45-deg line. Conversely, the solid line is the best fit linear regression between outputs and targets. The R-value (correlation coefficient) is a metric indicating the correlation between the output values and the target ones, being R = 1 the exact relationship between them. According to the MATLAB neural network toolbox, R-values should be greater than 0.9; thus, the obtained values for the proposed neural network model (namely 0.98885, 0.97954 and 0.89806 for training, validation and testing, respectively) allow asserting that the model presents very significant fitting performances for all datasets, with enough degree of generalization and without overfitting. The slight gap in the R-value regarding the testing stage shows a lack of data for the network testing. Although this gap does not significantly affect the overall neural network performance, it highlights that a dataset larger than 15% would have been preferable for the network testing.
To assess the ability of the ANN regression model in fitting the experimental targets in terms of density, a line-plot reporting both predicted and target values has been arranged (Fig. 11). As the reader can notice, the proposed prediction model is able to properly fit the main density falls, while some observations highlight an evident deviation of the predicted responses over the target ones, thus confirming that the model overfitting has been adequately prevented.

Line-plot of predicted and target density related to ANN
Although the accuracy of RSM and ANN prediction models have been already assessed in terms of coefficient of determination R2 (equal to 0.90 and 0.97, respectively), Table 4 compares the predictive performance of such surrogate models in terms of three alternative performance metrics, namely Mean Absolute Error (MAE), Mean Squared Error (MSE) and Mean Absolute Percentage Error (MAPE). The small values of MAE, MSE and MAPE near to zero, as well as R2 close to 1, confirm that high predictive accuracy can be obtained by both models, even though a slight advantage emerges for the ANN modelling approach.
Processing parameters optimization
The following paragraphs deal with the performance obtained by the proposed metaheuristic algorithms (namely PSO, SAHS, GA) for maximizing the density objective function, also distinguishing between ANN and RSM prediction models. Due to stochasticity of metaheuristic algorithms, 50 runs at different random seeds have been executed for each metaheuristic configuration. All metaheuristics have been implemented in MATLAB™ 2020b on an iMac equipped with a i3 quad-core 3.6 GHz processor and 8 GB 2400 MHz DDR4 RAM by the same code developer. In order to infer both effectiveness and efficiency of the tested techniques, several key performance indicators (KPIs) have been adopted. Particularly, average density value (ave), standard deviation (stdev), maximum (max) and minimum (min) density values and average computational times (ACT) over the 50 replicates are reported in Table 5. It is noted that two distinct analyses should be carried out on the numerical results, depending on the prediction model used for the density optimization. In fact, as emerges from Table 5, the density regression model provided by ANN allows reaching density values greater than 100%, while the surrogate model based on RSM never overcomes the 100% density value, due to the adopted arcsin-square-root transformation function. As for the ANN model, SAHS appears as the most performing optimization approach (see bold values in Table 5) in terms of average density value. It also assures the smallest variability due to stochasticity (i.e., standard deviation). All metaheuristics achieve the same maximum density (max) for one run over 50 at least, while SAHS is able to guarantee a density greater than 100% for all runs out of 50. Due to the high complexity of the ANN prediction model, every metaheuristic takes about 30 s to converge after 100 generations, while the RSM-based algorithms need less than one tenth of a second. Looking at the results involving the RSM model, SAHS again comes out as the most performing optimization method under every KPI viewpoint. As a further insight to motivate the difference of performance of the proposed algorithms, the convergence graphs related to the first run of each metaheuristic are reported in Fig. 12. It is worth noting that every algorithm has been designed for the objective function minimization; thus, the reciprocal of the density is indicated in the y-axis. As the reader can notice, GA assures a fast convergence to the local optimum while the graphs related to PSO and SAHS highlight a smoother solution improvement through the generations, which in turn suggests a better balance between exploration and exploitation. To sum up, all the tested metaheuristics demonstrate a comparable efficacy in solving the optimization problem at hand, even though SAHS appears as the most suitable alternative; also, the mentioned graphs confirm that Kmax = 100 generations are enough to assure any algorithm convergence.

Convergence graphs of metaheuristics
Experimental analysis and validation
In order to evaluate the ability of the proposed hybrid prediction-optimization tools, a set of experimental analyses have been performed. Metaheuristic algorithms work on the basis of a stochastic evolutionary criterion; thus, different near-optimal solutions may arise from a set of runs, as described in the previous section. Hence, two optimal solutions (the former being the best one assuring the maximum predicted density and the latter being the second-best one in the remaining set) have been experimentally tested for each algorithm. For each optimal solution to be tested, three distinct samples have been processed by the SLM machine. In addition, the maximization of the desirability function (DF) provided by the statistical software has been used as a further optimization method. Since two predictive models (ANN and RSM), two solutions and four optimization methods (PSO, SAHS, GA and DF only for RSM) have been considered in the experimental analysis, a number of 39 samples has been produced by SLM and tested in terms of density. Table 6 reports the process parameters for each solution pertaining to a given optimization method. Both volumetric density and linear density dependent variables are also indicated. Then, the optimal predicted density (Pred) and the actual one (Act) obtained as the mean value over the three experimental replicates can be compared for each optimization scenario. The Relative Percentage Deviation (RPD) of the predicted density over the actual one can be used to assess the reliability of the optimal solutions. In addition, the average RDP (ARPD) is considered as an aggregate measure of robustness. Regardless of the specific optimization algorithm, the ANN model appears the most appropriate means to emulate the behavior of the SLM process under investigation and to maximize the density response variable as well. Such finding can be further evaluated by the interval plot at 95% confidence level in Fig. 13a. Each interval plot gathers six experimental data, namely the density values of the three replicates for each optimal solution. Motivated by the slight overlap between the interval plots in Fig. 13a, RSM remains a valid alternative to model the SLM process at hand.

Plots at 95% confidence interval: a Prediction models; b ANN algorithms; c RSM algorithms
Looking at the ANN-related optimal solutions in Table 6, GA-ANN appears the most promising optimization approach, because of the highest mean density value achieved by GA-ANN(1) (Act = 99.967%), though PSO-ANN and SAHS-ANN provide higher values in terms of predicted density. In this regard, GA-ANN emerges as the most reliable algorithm as it provides the lowest ARPD. Indeed, SAHS-ANN is not far from the performance of GA-ANN. In fact, Fig. 13b shows that the mean density obtained by GA is higher than the one assured by SAHS-ANN, but the related confidence interval is remarkably larger; thus, we may assert that SAHS is more robust than GA in providing optimal solutions for density maximization. Conversely, the combination between ANN and PSO seems to be slightly worse than the other algorithm configurations (see the lower mean value and the larger interval plot relate to PSO-ANN in Fig. 13b).
Whether the RSM prediction model is considered, SAHS emerges as the best optimization approach. In fact, the second run of SAHS (See SAHS-RSM(2) in Table 6) is able to assure an actual density value equal to 99.882%, with a small relative deviation (RPD = 0.11%) from the actual value. The ability of SAHS-RSM in fitting the actual density is further confirmed by the aggregate metric ARPD equal to 0.16%. On the other hand, PSO-RSM and GA-RSM are slightly dominated by SAHS-RSM and appear quite similar with each other in terms of ARPD. Such remarks can be confirmed by observing Fig. 13c, where the SAHS interval plot is higher and tighter than the ones related to PSO and GA.
To sum up, although no statistically significant difference from the interval plots, ANN is the recommended approach to predict the density response variable. In this context, testing three metaheuristic algorithms, which in turns present different evolutionary structures, allowed validating the proposed prediction-optimization approach. Particularly, GA and SAHS appear the most suitable metaheuristic techniques for selecting the process parameters able to maximize the density. However, SAHS assures a higher robustness in finding optimal solutions in terms of density (also in terms of predicted solutions, as described in Sec. 5.4) and the self-adaptive mechanism that avoid any parameter calibration may represent a further adding-value.
Interestingly, Table 6 shows that the best solutions obtained by adopting ANN entail lower Ev values, on the average, than the ones related to the RSM approach. Conversely, no significant difference comes out in terms of El. Besides, it is worth noting that only two solutions out of 13 hold a layer thickness equal to 30 μm, as it has no influence on the density, as confirmed by the sensitivity analysis in Sec. 5.2.
Beyond the numerical analysis concerning the ability of the proposed prediction-optimization approaches in maximizing the predicted/actual density, the diverse processing parameters found by the different algorithms (see Table 6) deserve a further investigation. First, it is worth pointing out that such diversity can be considered as physiological as two sources of uncertainty affect such a prediction-optimization approach, namely: (i) any prediction model (ANN or RSM) basically consists of regression models with a degree of deviation on the actual response; (ii) as mentioned earlier, metaheuristics are subjected to stochasticity (i.e., different runs may yield slightly different optimal solutions). However, despite these aspects, a quantitative analysis on the optimal solutions can be supported by Fig. 14, which refers only to the ANN-based approaches. Figure 14 allows assessing the relative percentage deviation between the processing parameters related a given solution and the ones pertaining to the best solution. As for example, as GA-ANN(1) is the best solution, the RPD on the laser power in PSO-ANN(1) is equal to 100x(260.7–263.8)/263.8 = -1.18. Notably, since large deviations emerge from the scanning strategy parameter, the related bars in Fig. 14 ignore the percentage value. In addition, since all optimal solutions take on the same layer thickness (i.e., 60 μm), it has been omitted in the bar chart. Although, in general, it is hard assessing the effect of multiple parameter interactions on a response variable, the following insights can be extracted by observing Fig. 14. The second-best solution (i.e., SAHS-ANN (2)) and the worst one (PSO-ANN (2)) are very similar in terms of parameter percentage deviation (PPD), the only difference being that SAHS-ANN (2) make use of a lower building orientation (o). Hence, such parameter should have a moderate impact on the density, even if a non-negligible difference emerges also in terms of scanning hatching distance (h) and scanning pattern angle (s).

ANN: Optimal solutions analysis
The set of optimal parameters for SAHS-ANN (1) are quite the same of the best solutions (small PPD values only for P, h, s), so it would justify the quality of the SAHS-ANN (1) solution in terms of density (99.84%). The quality of both SAHS solutions and, at the same time, the diversity of parameters they adopt, confirm that there exist different parameter combinations able to assure high density values. In brief, we may assert that the density function is a complex function whose domain presents different areas at maximum density. The same remarks could be extended to the worst solutions. In fact, both PSO solutions present a high diversity on the processing parameters. Interestingly, the PSO-ANN (1) solution is very similar to SAHS-ANN (1) but, some non-negligible differences in terms of building orientation and scanning strategy (see also Table 6) are likely responsible for the gap of quality. The influence of building orientation and scanning strategy is also confirmed by the GA-ANN (2) solution. Figure 14 reveals that GA-ANN (2) is very similar to the best solution (GA-ANN (1)), with exception of o (55.1 Vs 90) and s (20.5 Vs 6.2). Looking at the bars related to SAHS-ANN (2), PSO-ANN (2) and marginally GA-ANN (2), it seems that the tendency to overheating due to higher value of P and lower value of h can be prevented by simultaneously increasing v and s, and by decreasing the building orientation o as well.
For the sake of brevity, no bar chart for the PPD analysis of the RSM optimal solutions is reported. However, Table 6 is enough to feed the following remarks. The two best solutions (SAHS-ANN (2) and GA-ANN (2)) are quite similar in terms of process parameters, the only difference being on the layer thickness. It confirms that t does not impact on the density optimization. Then, regardless of t, the main differences exist only in terms of P, v and partially under the scanning pattern angle viewpoint. However, it is clear from Table 6 that the best parameter combinations are quite consistent with the finding obtained by the sensitivity analysis in Sec. 5.4.
Regardless of the specific optimization algorithm, interesting insights come out by comparing the optimal processing parameters achieved by the two prediction models. Specifically, it is clear that optimal ANN-based solutions take on smaller P values, higher h values and smaller s values than the RSM-based parameter configurations. Interestingly, the parameters of the DF solution based on RSM are quite similar to those achieved by the ANN-based approaches (See Table 6), with exception of v and h, thus confirming that the higher accuracy of the ANN model is strategic in finding better parameter configurations.
To associate these last findings to the process physics underlying SLM, it is worth noting that high values of P and Ev can lead to gas porosity due to excessive energy provided to the powder (Larimian et al., 2020). As regards the hatch spacing, choosing higher values seem counterintuitive with respect to the results from the sensitivity analysis in Sec. 5.3. However, a too small or a too big hatching distance may lead to an excess or a lack of fusion, respectively, which in turns may be responsible for porosity (Khorasani et al., 2019). Moreover, low values of the scan angle rotation between consecutive layers may result in a more heterogeneous distribution of the vectors, thus favoring the density improvement (Robinson et al., 2019).
Conclusions
In this paper the optimal selection of processing parameters for the density in TI6Al4V parts manufactured by SLM additive process is investigated by means of a series of hybrid prediction-optimization techniques. To this end, an extended design of experiments involving six leading processing parameters has been arranged and both response surface methodology and artificial neural networks have been adopted for regression purposes. Specifically, an adequate angular transformation function has been used in the RSM to match predictions with the actual relative density values. Then, the regression models have been powered by a metaheuristic algorithm for the optimal selection of processing parameters. Three distinct evolutionary algorithms (namely PSO, GA and SAHS) from the relevant literature have been tested under the prediction ability and the actual response viewpoint.
From the obtained results the following main conclusions can be drawn:
-
ANN is the most suitable technique to build the surrogate model of the SLM process sunder investigation. However, RSM remains a valid approach to be used.
-
The sensitivity analysis performed on the basis of the results from the ANOVA, which in turn is attached to the RSM, revealed that scanning speed, hatch distance and scanning pattern angle are significant influencing factors. Also, it exhibits that the best combination of scanning and building strategies strongly depends on the selected layer thickness level, though this latter is not a statistically influencing parameter among the first-order terms.
-
The numerical results in terms of predicted and actual density values confirm that the self-adaptive harmony search is an appropriate optimization technique also assuring a high robustness of results, regardless of the specific regression model adopted. However, the genetic algorithm is even strong in finding local optima when the ANN model is considered. On the other hand, particle swarm optimization appears more dependent on stochasticity and, as a result, the weakest in finding high density parameter configurations.
-
The analysis of the processing parameters pertaining to the optimal solutions allowed to yield further insights on the Ti6Al4V SLM process at hand. The optimal ANN-based solutions take on smaller laser power values, higher hatching values and smaller scanning pattern angles than the RSM-based parameter configurations. Finally, if the ANN surrogate model is considered, a non-negligible impact of the building orientation emerges.
Future research should be oriented to investigate the efficacy of the same techniques on the optimal selection of processing parameters for strength maximization and/or surface roughness optimization. Further efforts can be performed on the machine learning side by testing alternative AI techniques.
Change history
21 July 2022
The original online version of this article was revised: Missing Open Access funding information has been added in the Funding Note.
References
Blanco, A., Delgado, M., & Pegalajar, M. C. (2001). A real-coded genetic algorithm for training recurrent neural networks. Neural Networks, 14(1), 93–105. https://doi.org/10.1016/s0893-6080(00)00081-2
Costa, A., & Fichera, S. (2017). Economic statistical design of ARMA control chart through a modified fitnessbased selfadaptive differential evolution. Computers & Industrial Engineering, 105, 174–189. https://doi.org/10.1016/j.cie.2016.12.031
Dagli, C. H. (Ed.). (2012). Artificial neural networks for intelligent manufacturing. Springer.
DebRoy, T., Wei, H. L., Zuback, J. S., Mukherjee, T., Elmer, J. W., Milewski, J. O., Beese, A. M., Wilson-Heid, A. D., De, A., & Zhang, W. (2018). Additive manufacturing of metallic components–process, structure and properties. Progress in Materials Science, 92, 112–224. https://doi.org/10.1016/j.pmatsci.2017.10.001
Deep, K., & Thakur, M. (2007). A new mutation operator for real coded genetic algorithms. Applied Mathematics and Computation, 193(1), 211–230. https://doi.org/10.1016/j.amc.2007.03.046
Deshwal, S., Kumar, A., & Chhabra, D. (2020). Exercising hybrid statistical tools GA-RSM, GA-ANN and GA-ANFIS to optimize FDM process parameters for tensile strength improvement. CIRP Journal of Manufacturing Science and Technology, 31, 189–199. https://doi.org/10.1016/j.cirpj.2020.05.009
Deswal, S., Narang, R., & Chhabra, D. (2019). Modeling and parametric optimization of FDM 3D printing process using hybrid techniques for enhancing dimensional preciseness. International Journal on Interactive Design and Manufacturing (IJIDeM), 13(3), 1197–1214. https://doi.org/10.1007/s12008-019-00536-z
Du, K. L., & Swamy, M. N. (2013). Neural networks and statistical learning. Springer
Eberhart, R., & Kennedy, J. (1995, November). Particle swarm optimization. In Proceedings of the IEEE international conference on neural networks (Vol. 4, pp. 1942–1948). https://doi.org/10.1109/ICNN.1995.488968.
Eberhart, R. C., & Shi, Y. (2001, May). Tracking and optimizing dynamic systems with particle swarms. In Proceedings of the 2001 congress on evolutionary computation (IEEE Cat. No. 01TH8546) (Vol. 1, pp. 94–100). IEEE. https://doi.org/10.1109/CEC.2001.934376.
Frazier, W. E. (2014). Metal additive manufacturing: A review. Journal of Materials Engineering and Performance, 23(6), 1917–1928. https://doi.org/10.1007/s11665-014-0958-z
Geem, Z. W., Kim, J. H., & Loganathan, G. V. (2001). A new heuristic optimization algorithm: Harmony search. SIMULATION, 76(2), 60–68. https://doi.org/10.1177/003754970107600201
Guo, N., & Leu, M. C. (2013). Additive manufacturing: Technology, applications and research needs. Frontiers of Mechanical Engineering, 8(3), 215–243. https://doi.org/10.1007/s11465-013-0248-8
Gong, H., Rafi, K., Gu, H., Ram, G. J., Starr, T., & Stucker, B. (2015). Influence of defects on mechanical properties of Ti–6Al–4 V components produced by selective laser melting and electron beam melting. Materials & Design, 86, 545–554. https://doi.org/10.1016/j.matdes.2015.07.147
Gong, H., Rafi, K., Gu, H., Starr, T., & Stucker, B. (2014). Analysis of defect generation in Ti–6Al–4V parts made using powder bed fusion additive manufacturing processes. Additive Manufacturing, 1, 87–98.
Han, J., Yang, J., Yu, H., Yin, J., Gao, M., Wang, Z., & Zeng, X. (2017). Microstructure and mechanical property of selective laser melted Ti6Al4V dependence on laser energy density. Rapid Prototyping Journal, 23(2), 217–226. https://doi.org/10.1108/RPJ-12-2015-0193
Herzog, D., Seyda, V., Wycisk, E., & Emmelmann, C. (2016). Additive manufacturing of metals. Acta Materialia, 117, 371–392. https://doi.org/10.1016/j.actamat.2016.07.019
Huang, S. H., Liu, P., Mokasdar, A., & Hou, L. (2013). Additive manufacturing and its societal impact: A literature review. The International Journal of Advanced Manufacturing Technology, 67(5), 1191–1203. https://doi.org/10.1007/s00170-012-4558-5
Jung, Y., & Hu, J. (2015). A K-fold averaging cross-validation procedure. Journal of Nonparametric Statistics, 27(2), 167–179. https://doi.org/10.1080/10485252.2015.1010532
Kasperovich, G., Haubrich, J., Gussone, J., & Requena, G. (2016). Correlation between porosity and processing parameters in TiAl6V4 produced by selective laser melting. Materials & Design, 105, 160–170. https://doi.org/10.1016/j.matdes.2016.05.070
Kirk, R. E. (2012). Experimental design: Procedures for the behavioral sciences. Sage Publications.
Kladovasilakis, N., Charalampous, P., Kostavelis, I., Tzetzis, D., & Tzovaras, D. (2021). Impact of metal additive manufacturing parameters on the powder bed fusion and direct energy deposition processes: A comprehensive review. Progress in Additive Manufacturing, 6, 349–365. https://doi.org/10.1007/s40964-021-00180-8
Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). ImageNet classification with deep convolutional neural networks. Advances in Neural Information Processing Systems, 25, 1097–1105.
Khorasani, A., Gibson, I., Awan, U. S., & Ghaderi, A. (2019). The effect of SLM process parameters on density, hardness, tensile strength and surface quality of Ti-6Al-4V. Additive Manufacturing, 25, 176–186. https://doi.org/10.1016/j.addma.2018.09.002
Kuo, C., Su, C., & Chiang, A. (2017). Parametric optimization of density and dimensions in three-dimensional printing of Ti-6Al-4V powders on titanium plates using selective laser melting. International Journal of Precision Engineering and Manufacturing, 18(11), 1609–1618. https://doi.org/10.1007/s12541-017-0190-5
Larimian, T., Kannan, M., Grzesiak, D., AlMangour, B., & Borkar, T. (2020). Effect of energy density and scanning strategy on densification, microstructure and mechanical properties of 316L stainless steel processed via selective laser melting. Materials Science and Engineering A, 770, 138455. https://doi.org/10.1016/j.msea.2019.138455
Li, Z., Kucukkoc, I., Zhang, D. Z., & Liu, F. (2018a). Optimising the process parameters of selective laser melting for the fabrication of Ti6Al4V alloy. Rapid Prototyping Journal, 24(1), 150–159
Li, P., Wang, D., Wang, L., & Lu, H. (2018). Deep visual tracking: Review and experimental comparison. Pattern Recognition, 76, 323–338. https://doi.org/10.1016/j.patcog.2017.11.007
Meng, L., McWilliams, B., Jarosinski, W., Park, H. Y., Jung, Y. G., Lee, J., & Zhang, J. (2020). Machine learning in additive manufacturing: A review. JOM Journal of the Minerals Metals and Materials Society, 72(6), 2363–2377. https://doi.org/10.1007/s11837-020-04155-y
Michalewicz, Z. (1996). Genetic algorithms+ data structures = evolution programs. Springer
Montalbano, T., Briggs, B. N., Waterman, J. L., Nimer, S., Peitsch, C., Sopcisak, J., Trigg, D., & Storck, S. (2021). Uncovering the coupled impact of defect morphology and microstructure on the tensile behavior of Ti-6Al-4V fabricated via laser powder bed fusion. Journal of Materials Processing Technology, 294, 117113. https://doi.org/10.1016/j.jmatprotec.2021.117113
Murr, L. E., Gaytan, S. M., Ramirez, D. A., Martinez, E., Hernandez, J., Amato, K. N., Shindo, P. W., Medina, F. R., & Wicker, R. B. (2012). Metal fabrication by additive manufacturing using laser and electron beam melting technologies. Journal of Materials Science & Technology, 28(1), 1–14. https://doi.org/10.1016/S1005-0302(12)60016-4
Myers, R. H., Montgomery, D. C., Vining, G. G., Borror, C. M., & Kowalski, S. M. (2004). Response surface methodology: A retrospective and literature survey. Journal of Quality Technology, 36(1), 53–77. https://doi.org/10.1080/00224065.2004.11980252
M’zoughi, F., Garrido, I., Garrido, A. J., & De La Sen, M. (2020). Selfa-daptive global-best harmony search algorithmbased airflow control of a wells-turbine-based oscillating-water column. Applied Sciences, 10(13), 4628. https://doi.org/10.3390/app10134628
Narayan, S. (1997). The generalized sigmoid activation function: Competitive supervised learning. Information Sciences, 99(1–2), 69–82. https://doi.org/10.1016/S0020-0255(96)00200-9
Nguyen, D. S., Park, H. S., & Lee, C. M. (2020). Optimization of selective laser melting process parameters for Ti-6Al-4V alloy manufacturing using deep learning. Journal of Manufacturing Processes, 55, 230–235. https://doi.org/10.1016/j.jmapro.2020.04.014
Nickabadi, A., Ebadzadeh, M. M., & Safabakhsh, R. (2011). A novel particle swarm optimization algorithm with adaptive inertia weight. Applied Soft Computing, 11(4), 3658–3670. https://doi.org/10.1016/j.asoc.2011.01.037
Park, H. S., Nguyen, D. S., Le-Hong, T., & Van Tran, X. (2021). Machine learning-based optimization of process parameters in selective laser melting for biomedical applications. Journal of Intelligent Manufacturing. https://doi.org/10.1007/s10845-021-01773-4
Poli, R., Kennedy, J., & Blackwell, T. (2007). Particle Swarm Optimization. Swarm Intelligence, 1(1), 33–57. https://doi.org/10.1007/s11721-007-0002-0
Ponz-Tienda, J. L., Salcedobernal, A., Pellicer, E., & Benlloch-Marco, J. (2017). Improved adaptive harmony search algorithm for the resource leveling problem with minimal lags. Automation in Construction, 77, 82–92. https://doi.org/10.1016/j.autcon.2017.01.018
Qi, X., Chen, G., Li, Y., Cheng, X., & Li, C. (2019). Applying neural-network-based machine learning to additive manufacturing: Current applications, challenges, and future perspectives. Engineering, 5(4), 721–729. https://doi.org/10.1016/j.eng.2019.04.012
Qiu, C., Adkins, N. J., & Attallah, M. M. (2013). Microstructure and tensile properties of selectively laser-melted and of HIPed laser-melted Ti–6Al–4V. Materials Science and Engineering: A, 578, 230–239. https://doi.org/10.1016/j.msea.2013.04.099
Qiu, C., Panwisawas, C., Ward, M., Basoalto, H. C., Brooks, J. W., & Attallah, M. M. (2015). On the role of melt flow into the surface structure and porosity development during selective laser melting. Acta Materialia, 96, 72–79. https://doi.org/10.1016/j.actamat.2015.06.004
Refaeilzadeh, P., Tang, L., & Liu, H. (2009). Cross-Validation. Encyclopedia of Database Systems, 5, 532–538. https://doi.org/10.1007/978-0-387-39940-9_565
Richardson, F., Reynolds, D., & Dehak, N. (2015). Deep neural network approaches to speaker and language recognition. IEEE Signal Processing Letters, 22(10), 1671–1675. https://doi.org/10.1109/LSP.2015.2420092
Robinson, J. H., Ashton, I. R. T., Jones, E., Fox, P., & Sutcliffe, C. (2019). The effect of hatch angle rotation on parts manufactured using selective laser melting. Rapid Prototyping Journal, 25(2), 289–298. https://doi.org/10.1108/RPJ-06-2017-0111
Rong-Ji, W., Xin-Hua, L., Qing-Ding, W., & Lingling, W. (2009). Optimizing process parameters for selective laser sintering based on neural network and genetic algorithm. The International Journal of Advanced Manufacturing Technology, 42(11), 1035–1042. https://doi.org/10.1007/s00170-008-1669-0
Saad, M. S., Nor, A. M., Zakaria, M. Z., Baharudin, M. E., & Yusoff, W. S. (2021). Modelling and evolutionary computation optimization on FDM process for flexural strength using integrated approach RSM and PSO. Progress in Additive Manufacturing, 6(1), 143–154. https://doi.org/10.1007/s40964-020-00157-z
Sharma, A., Chen, J., Diewald, E., Imanian, A., Beuth, J., & Liu, Y. (2021). Data-driven sensitivity analysis for static mechanical properties of additively manufactured Ti–6Al–4V. ASCE-ASME Journal of Risk and Uncertainty in Engineering Systems, Part b: Mechanical Engineering, 8(1), 011108. https://doi.org/10.1115/1.4051799
Shipley, H., McDonnell, D., Culleton, M., Coull, R., Lupoi, R., O’Donnell, G., & Trimble, D. (2018). Optimisation of process parameters to address fundamental challenges during selective laser melting of Ti-6Al-4V: A review. International Journal of Machine Tools and Manufacture, 128, 1–20. https://doi.org/10.1016/j.ijmachtools.2018.01.003
Singh, A., Cooper, D. E., Blundell, N. J., Gibbons, G. J., & Pratihar, D. K. (2012, October). Modelling of direct metal laser sintering of EOS DM20 bronze using neural networks and genetic algorithms. In Proceedings of the 37th International MATADOR Conference (p. 395). Springer. https://doi.org/10.1007/978-1-4471-4480-9_11.
Sokal, R. R., & Rohlf, F. J. (1995). Biometry: The principles and practice of statistics in biological research (3rd ed.). W.H. Freeman and Co.
Stevens, S., Valderas, J. M., Doran, T., Perera, R., & Kontopantelis, E. (2016). Analysing indicators of performance, satisfaction, or safety using empirical logit transformation. BMJ, 352.
Sun, J., Yang, Y., & Wang, D. (2013). Parametric optimization of selective laser melting for forming Ti6Al4V samples by Taguchi method. Optics & Laser Technology, 49, 118–124. https://doi.org/10.1016/j.optlastec.2012.12.002
Tao, P., Zhong, J., Li, H., Hu, Q., Gong, S., & Xu, Q. (2019). Microstructure, mechanical properties, and constitutive models for Ti–6Al–4V alloy fabricated by selective laser melting (SLM). Metals, 9(4), 447. https://doi.org/10.3390/met9040447
Tapia, G., Elwany, A. H., & Sang, H. (2016). Prediction of porosity in metal-based additive manufacturing using spatial Gaussian process models. Additive Manufacturing, 12(B), 282–290. https://doi.org/10.1016/j.addma.2016.05.009.
Tapia, G., Khairallah, S., Matthews, M., King, W. E., & Elwany, A. (2018). Gaussian process-based surrogate modeling framework for process planning in laser powder-bed fusion additive manufacturing of 316L stainless steel. The International Journal of Advanced Manufacturing Technology, 94(9), 3591–3603. https://doi.org/10.1007/s00170-017-1045-z
Wang, C. M., & Huang, Y. F. (2010). Selfad-aptive harmony search algorithm for optimization. Expert Systems with Applications, 37(4), 2826–2837. https://doi.org/10.1016/j.eswa.2009.09.008
Wang, C., Tan, X. P., Tor, S. B., & Lim, C. S. (2020). Machine learning in additive manufacturing: State-of-the-art and perspectives. Additive Manufacturing, 36, 101538.
Wauthle, R., Vrancken, B., Beynaerts, B., Jorissen, K., Schrooten, J., Kruth, J. P., & Van Humbeeck, J. (2015). Effects of build orientation and heat treatment on the microstructure and mechanical properties of selective laser melted Ti6Al4V lattice structures. Additive Manufacturing, 5, 77–84. https://doi.org/10.1016/j.addma.2014.12.008
Xia, C., Pan, Z., Polden, J., Li, H., Xu, Y., & Chen, S. (2021). Modelling and prediction of surface roughness in wire arc additive manufacturing using machine learning. Journal of Intelligent Manufacturing. https://doi.org/10.1007/s10845-020-01725-4
Xu, S., & Chen, L. (2008). A novel approach for determining the optimal number of hidden layer neurons for FNN’s and its application in data mining.
Xu, W., Brandt, M., Sun, S., Elambasseril, J., Liu, Q., Latham, K., Xia, K., & Qian, M. (2015). Additive manufacturing of strong and ductile Ti–6Al–4V by selective laser melting via in situ martensite decomposition. Acta Materialia, 85, 74–84. https://doi.org/10.1016/j.actamat.2014.11.028
Yang, X. S. (2010). Nature-inspired metaheuristic algorithms. Luniver press.
Yi, J., Lu, C., & Li, G. (2019). A literature review on latest developments of Harmony Search and its applications to intelligent manufacturing. Mathematical Biosciences and Engineering, 16(4), 2086–2117. https://doi.org/10.3934/mbe.2019102
Zhang, H., Choi, J. P., Moon, S. K., & Ngo, T. H. (2020). A hybrid multi-objective optimization of aerosol jet printing process via response surface methodology. Additive Manufacturing, 33, 101096. https://doi.org/10.1016/j.addma.2020.101096
Zhuang, J. R., Lee, Y. T., Hsieh, W. H., & Yang, A. S. (2018). Determination of melt pool dimensions using DOE-FEM and RSM with process window during SLM of Ti6Al4V powder. Optics & Laser Technology, 103, 59–76. https://doi.org/10.1016/j.optlastec.2018.01.013
Funding
Open access funding provided by Università degli Studi di Palermo within the CRUI-CARE Agreement.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix A
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Costa, A., Buffa, G., Palmeri, D. et al. Hybrid prediction-optimization approaches for maximizing parts density in SLM of Ti6Al4V titanium alloy. J Intell Manuf 33, 1967–1989 (2022). https://doi.org/10.1007/s10845-022-01938-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10845-022-01938-9