
Abstract
Artificial Intelligence (AI) implementation incorporates challenges that are unique to the context of AI, such as dealing with probabilistic outputs. To address these challenges, recent research suggests that organizations should develop specific capabilities for AI implementation. Currently, we lack a thorough understanding of how certain capabilities facilitate AI implementation. It remains unclear how they help organizations to cope with AI’s unique characteristics. To address this research gap, we employ a qualitative research approach and conduct 25 explorative interviews with experts on AI implementation. We derive four organizational capabilities for AI implementation: AI Project Planning and Co-Development help to cope with the inscrutability in AI, which complicates the planning of AI projects and communication between different stakeholders. Data Management and AI Model Lifecycle Management help to cope with the data dependency in AI, which challenges organizations to provide the proper data foundation and continuously adjust AI systems as the data evolves. We contribute to our understanding of the sociotechnical implications of AI’s characteristics and further develop the concept of organizational capabilities as an important success factor for AI implementation. For practice, we provide actionable recommendations to develop organizational capabilities for AI implementation.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
While many organizations have reached a stage where they experiment and develop early prototypes based on Artificial Intelligence (AI), most fail to effectively deploy and maintain AI systems in productive use (Benbya et al., 2020). Indeed, 83% of data science projects reportedly never make it into productive use (Venturebeat, 2019). Similarly, 76% of organizations report problems implementing AI systems throughout the organization (Awalegaonkar et al., 2019). Recent Information Systems (IS) research suggests that AI technology is fundamentally different from traditional information technology (IT) (Berente et al., 2021). For example, today’s AI systems mostly employ machine learning to learn from data and derive their own rules instead of having predetermined rules (Ågerfalk, 2020; Jordan & Mitchell, 2015). AI’s unique characteristics induce novel challenges to IS implementation (Dwivedi et al., 2021), such as the identification of suitable AI problems, preparation of training data, and evaluation of AI systems (Lebovitz et al., 2021; van den Broek et al., 2021; Zhang et al., 2020). As a result, AI implementation proves to be difficult in practice, and much of the expected value remains unrealized (Tarafdar et al., 2019)
From a strategic management perspective, organizations must adequately “prepare” themselves to drive AI implementation and realize the value of AI (Brock & Von Wangenheim, 2019; Coombs et al., 2020; Jöhnk et al., 2021; Tarafdar et al., 2019). This preparation includes the strategic investment in specific organizational resources, such as human or IT resources (Enholm et al., 2021; Mikalef & Gupta, 2021). For example, organizations should ensure enough technical AI expertise (Anton et al., 2020), invest in appropriate AI infrastructure (Watson, 2017), and embrace an open and experimental culture (Fountaine et al., 2019). However, organizational resources alone do not create value (Peppard & Ward, 2004). Following the knowledge-based view of the firm, it is more important how organizations can use, combine, and integrate those resources as organizational capabilities to achieve certain outcomes (Dosi et al., 2000; Kogut & Zander, 1992). Therefore, organizational capabilities represent a promising theoretical lens to study how organizations can successfully cope with the AI implementation challenge to create value from AI.
Against this background, IS and management research have started to analyze the role of organizational capabilities in the context of AI implementation (e.g., Mikalef & Gupta, 2021; Mikalef et al., 2021; Sjödin et al., 2021). For example, Mikalef and Gupta (2021) conceptualized an overarching AI capability based on a set of organizational resources. Moreover, Sjödin et al. (2021) identified three capabilities and principles that drive business model innovation with AI. Nevertheless, research on organizational capabilities for AI implementation is still at an early stage, and more research is needed to develop further and ground the concept (Mikalef & Gupta, 2021; Sjödin et al., 2021). Specifically, we currently lack a thorough understanding of how specific capabilities facilitate AI implementation. It remains unclear how certain capabilities help to cope with challenges that stem from AI’s unique characteristics (cf. Berente et al., 2021), explaining why those capabilities are needed and potentially unique to the context of AI. To address this research gap, we ask the following research question: How do organizational capabilities help to cope with AI’s unique characteristics?
To answer this research question, we employ a qualitative research approach that compromises two stages. First, we derive organizational capabilities for AI implementation from primary data. For data collection, we conduct a series of explorative interviews (Myers & Newman, 2007) with a total of 25 experts from industry, consulting, and academia. These experts report on their experience with AI implementation projects by sharing illustrative real-world examples, important success factors, and obstacles during implementation with the research team. For data analysis, we rely on established guidelines and principles from qualitative research (Miles et al., 2018; Strauss & Corbin, 1990). We employ an iterative coding procedure with increasing levels of abstraction to derive organizational capabilities for AI implementation. Second, we propose an explanatory framework on how these organizational capabilities facilitate AI implementation by coping with AI’s characteristics. This framework results from further reflections and sensemaking processes against the background of prior research on AI technology and organizational capabilities in IS. Thereafter, we discuss our contributions to theory, implications for practice, the limitations of this study, and avenues for future research.
This study contributes to the ongoing discourse in IS research on how to drive and manage AI implementation in organizations (Benbya et al., 2021; Berente et al., 2021; Dwivedi et al., 2021). Specifically, we further develop and ground the concept of organizational capabilities in the context of AI technology (Mikalef & Gupta, 2021; Sjödin et al., 2021). Most notably, we explain how organizational capabilities help to cope with certain characteristics in AI, contributing to our understanding of how organizations can deal with AI’s unique characteristics (Berente et al., 2021). Furthermore, we provide valuable insights and actionable recommendations for practitioners to overcome the AI implementation challenge observed in practice (Benbya et al., 2020).
2 Theoretical Background
The theoretical background of this study is three-fold: First, we provide background on AI and outline AI’s unique characteristics. Second, we introduce the concept of organizational capabilities and summarize relevant IS capabilities discussed in prior research. Third, we outline related work on organizational factors for AI implementation.
2.1 Artificial Intelligence and Machine Learning
AI refers to a broad and long-established research field in computer science concerned with making machines intelligent (Stone et al., 2016). AI is typically associated with machines performing functions such as perceiving, learning, reasoning, decision-making, and demonstrating creativity (Rai et al., 2019). AI systems build on a variety of techniques, including machine learning (ML), natural language processing, computer vision, knowledge-based reasoning, and robotics (Benbya et al., 2020; Stone et al., 2016). We summarize these techniques under the term AI technology. This study focuses on software-based AI systems that include an ML component, because many of today’s applications labeled “AI” are using ML or deep learning at the core (Berente et al., 2021; Janiesch et al., 2021). Examples can be found in visual object detection on social media or speech recognition on smart assistants (Haenlein & Kaplan, 2019). ML addresses how to build machines that improve performance through data and experience (Jordan & Mitchell, 2015). ML techniques are commonly divided into supervised learning, unsupervised learning, and reinforcement learning, whereas supervised learning is most widely applied today (Jordan & Mitchell, 2015). Here, data in the form of (x; y) is used to train a model that predicts y given x as input (Jordan & Mitchell, 2015). Deep learning represents a subfield of ML that uses multiple processing layers for learning (LeCun et al., 2015). Deep learning has caused breakthroughs in many areas, including speech recognition and object detection (Stone et al., 2016).
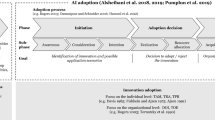
IS research has started to conceptualize the unique characteristics of today’s AI systems that build on ML (e.g., Ågerfalk, 2020; Benbya et al., 2021; Berente et al., 2021). In this study, we follow Berente et al. (2021), who proposed three interrelated characteristics of today’s AI systems: autonomy, learning, and inscrutability (cf. Figure 1). Autonomy refers to the increasing degree that AI systems can act without human intervention. Learning refers to the AI system’s ability to improve through data and experience (Ågerfalk, 2020; Janiesch et al., 2021). Inscrutability refers to the unintelligibility of AI systems to some audiences, given their complex inner workings and probabilistic outputs (Asatiani et al., 2021; Jöhnk et al., 2021). These characteristics are expected to even exacerbate as the field of AI moves forward and new techniques and approaches emerge. Organizations striving to create value from AI (cf. Böttcher et al., 2022) need to deal with these unique characteristics and their sociotechnical implications (Berente et al., 2021).

Key characteristics of today’s AI systems (Berente et al., 2021)
2.2 Organizational Capabilities in IS
Organizational capabilities are defined as the ability of a firm to use, combine and integrate its organizational resources to achieve a desirable outcome (Dosi et al., 2000; Kogut & Zander, 1992). Capabilities result from the complex interplay of resources given organizational roles, structures, and processes (Peppard & Ward, 2004). According to the knowledge-based view, these intangible capabilities are more critical for organizations than physical resources, such as human resources or IT resources (Dosi et al., 2000; Kogut & Zander, 1992). With the growing importance of IT for organizations, IS scholars investigated the role of IT for organizational capabilities. On the one hand, IT use enables particular organizational capabilities, such as big data analytics capability (Günther et al., 2017). On the other hand, organizational capabilities are needed to create value from IT, for example, an IS development capability (Ravichandran et al., 2005). IS research has identified many essential capabilities (cf. Peppard & Ward, 2004; Tarafdar & Gordon, 2007). There is considerable theoretical evidence that these capabilities are linked with organizational performance and value creation from IT (e.g., Aral & Weill, 2007; Bharadwaj, 2000; Mithas et al., 2011). Table 1 summarizes IS capabilities relevant to the context of this study.
2.3 Organizational Factors for AI Implementation
IS implementation is the activity of planning, developing, deploying, and maintaining IT systems in a way that ensures their continued use and their benefit for the organization (Cooper & Zmud, 1990). We define AI implementation as the implementation of IT systems with an AI component. The study of what influences the success and failure of IS implementation is among the most prominent research streams within IS research (Dwivedi et al., 2015). Determinants of success and failure can be structured as organizational, project, individual, technological, and task-related factors (Dwivedi et al., 2015). In this study, we focus on organizational capabilities as organizational success factors for AI implementation.
Prior research on organizational factors for AI implementation has primarily focused on the necessary organizational resources (e.g., Enholm et al., 2021; Jöhnk et al., 2021; Mikalef & Gupta, 2021; Mikalef et al., 2021; Nam et al., 2020; Pumplun et al., 2019). For example, research suggests that organizations require specific human skills and roles (Anton et al., 2020), data in enough quantity and quality (Pumplun et al., 2019), an appropriate IT infrastructure (Watson, 2017), strong relationships between AI and business departments (Jöhnk et al., 2021), and an experimental and data-driven culture (Fountaine et al., 2019). Organizations that possess these resources are linked with more successful AI implementation and value creation from AI. For example, the study of Mikalef and Gupta (2021) suggests that AI-related resources lead to enhanced organizational performance and creativity. Table 2 summarizes the organizational resources discussed in the literature as organizational success factors for AI implementation. Following Bharadwaj (2000), we can broadly group these resources into human, IT, and intangible resources.
However, these resources alone do not create value (Peppard & Ward, 2004). Following the knowledge-based view, it is more important to consider the organizational capabilities that result from the use, integration, and combination of the previously identified resources (Dosi et al., 2000; Kogut & Zander, 1992). This theoretical perspective has proven valuable in other contexts, such as understanding the role of capabilities in process innovation (Tarafdar & Gordon, 2007) or platform ecosystem orchestration (Schreieck et al., 2021). An early study by Sjödin et al. (2021) has proposed three organizational capabilities likely to drive AI-enabled business model innovation: data pipeline, algorithm development, and AI democratization. Nevertheless, more research is needed to develop further and ground the concept of organizational capabilities in the context of AI (Mikalef & Gupta, 2021; Sjödin et al., 2021). Specifically, we currently do not understand how certain capabilities facilitate AI implementation by coping with AI’s unique characteristics, explaining why those capabilities are needed in the context of AI. In this study, we intend to address this research gap.
3 Research Approach
To explore how organizational capabilities facilitate AI implementation, we took on an interpretivist research stance (Walsham, 2006), as AI implementation only recently gained momentum and is evolving dynamically as organizations gain further experience with AI. To capture many different voices and viewpoints on our research subject (Myers & Newman, 2007), we conducted a series of 25 explorative interviews with experts from industry, consulting, and academia. This allowed us to collect data on real-world AI implementation projects, success factors, and obstacles, that our interview partners had experienced in organizational practice. For data analysis, we had to keep in mind that our interview partners reported on their interpretation of what they observe and do (Klein & Myers, 1999). After further sensemaking, we could derive four organizational capabilities and propose an explanatory framework of how these capabilities facilitate AI implementation. In the following, we describe our data collection in more detail and explain how we analyzed and interpreted the data.
3.1 Data Collection
For data collection, we relied on exploratory interviews with experts on AI implementation. As interview partners, we looked for experts with different backgrounds and professional roles driving AI implementation in organizations, including data scientists, system architects, project managers, product owners, business developers, and strategy managers. By that, we could capture diverse viewpoints on AI implementation, including operational and strategic perspectives. Furthermore, we ensured to cover an internal and external perspective on AI implementation in organizations. Therefore, we looked for experts from industry, consulting, and academia. We interviewed eleven industry experts, who reported on AI implementation initiatives within their organization, thus providing an internal perspective on organizational capabilities. We contacted experts from different organizations in different industries, including retail, telecommunications, and manufacturing. Thereby, we complement prior work on organizational capabilities for AI implementation, which focused on a particular industry (e.g., Sjödin et al., 2021). Furthermore, we interviewed eleven consultants, who provided an external perspective and shared their experience on AI implementation across organizations. The consultants were part of different projects to implement AI use cases and develop strategic roadmaps for AI adoption and capability building. In addition, we interviewed three academics who provided technical details on AI implementation, reported on their experience from industry-academia collaborations, and shared insights from educating AI-relevant skills.
We used semi-structured interview guidelines to prepare for the interviews, while also retaining the flexibility to explore interesting directions during the interview (Myers & Newman, 2007). At the beginning, we asked our interview partners on their personal perspective on AI. Thereafter, we asked them to report on real-world AI implementation projects. We were interested in the implementation process, interaction with stakeholders, important success factors, and obstacles during AI implementation. When appropriate, we asked the interview partners to describe important capabilities and the organization’s current roadmap for AI adoption and capability building. Table 6 provides an overview of the interview guidelines employed in this study. To embrace the depth and richness of the data, we iteratively revised our interview guidelines based on the insights of previous interviews (Strauss & Corbin, 1990). For example, we added questions related to organizational capabilities for AI implementation after three initial interviews, as organizational capabilities emerged as a promising theoretical lens for this study. Overall, we conducted a total of 25 interviews between 2018 and 2020. After about 20 interviews, no more relevant concepts could be identified in the data, which suggested that theoretical saturation was reached. The interviews lasted 29 minutes on average. We used the mother tongue of the interview partners (German or English). Each interview was recorded and transcribed for data analysis and interpretation. Table 3 provides an overview of the interviews.
3.2 Data Analysis and Interpretation
For data analysis, we followed an iterative approach that included the coding of our interview data with increasing levels of abstraction and the repeated reflection of our preconceptions (Klein & Myers, 1999). Following the principle of constant comparison (Miles et al., 2018; Strauss & Corbin, 1990), we went back and forth between data collection and analysis to guide additional data collection as well as to challenge and refine our emergent findings with the support of memoing. We coded our interview data using a three-step procedure that consists of open, axial, and selective coding (Strauss & Corbin, 1990; Wiesche et al., 2017). In line with our research goal, the coding and interpretation of the data were informed by our theoretical understanding of organizational capabilities in IS and prior research on AI implementation (cf. Section 2).
The application of open, in-vivo coding resulted in 319 coded segments using 150 open codes. We primarily coded segments that hinted toward an important organizational capability in the context of AI implementation. This was either be the case if directly stated so by the experts, or if indirectly stated by reporting on a major challenge (that would have been needed to overcome). In some cases, we also coded contextual information that helped us with data interpretation, such as the interviewee’s professional role or personal perspective on AI. Following the axial and selective coding steps, we employed abductive reasoning to derive four organizational capabilities that are likely to facilitate AI implementation. These four organizational capabilities are the highest-level categories of our coding. They build on twelve sub-categories that represent concrete manifestations of the capabilities in organizational practice. After involving in further reflections and sensemaking processes, we link these four capabilities with AI’s unique characteristics. These characteristics cause specific challenges in practice, which the four capabilities proposedly help to cope with. Table 4 illustrates our coding procedure. Table 7 in the appendix provides a detailed overview of the coding scheme and exemplary interview data.
4 Findings
We identified four organizational capabilities that facilitate AI implementation: AI Project Planning, Co-Development of AI systems, Data Management, and AI Model Lifecycle Management. Each capability can be explained by its manifestations in organizational practice, which emerged through our data analysis (Table 5). Overall, there was consensus among the interviewees that AI is a broad field that encompasses many different techniques. However, the interviewees exclusively reported on real-world examples of software-based AI systems that rely on ML. The exemplary use cases that have been frequently reported include predictive maintenance, industrial quality assurance, recommender systems, chatbots for customer management, administrative automation, and demand forecasting. In the following, we will present the identified capabilities and their manifestations in more detail. After that, we will discuss how these capabilities help to cope with AI’s unique characteristics (cf. Section 5.1).
4.1 AI Project Planning
Our data suggest that many organizations are struggling with AI project planning and portfolio management. On the one hand, AI is a rather generic concept that can be applied to many problems, resulting in a long list of potential AI projects. However, not every problem is equally suited for AI. On the other hand, there is much hype and confusion about AI itself, which causes high and unrealistic expectations. This situation makes it challenging to find suitable AI use cases that are feasible and deliver added value to the business. Achieving such a fit is essential for the success of AI implementation. Therefore, organizations require an AI Project Planning capability, which we define as the ability to identify, evaluate and prioritize suitable use cases for AI implementation in the organization’s context. We identify three manifestations of this capability.
First, organizations need to develop an understanding of AI. Importantly, AI technology does not possess real intelligence and is nowhere near superintelligence (CON-1). Instead, “AI is very much focused on specific use cases at the moment, and you have to get rid of the preconception that it is applicable anywhere” (CON-5). The hype about AI is mostly based on the upswing of ML, which enables systems to learn from data and derive predictions subsequently (CON-7). Understanding the possibilities and limitations of today’s AI can help develop more realistic expectations and target more meaningful AI projects. As IND-7 puts it:
“So simply, they get some problem and then try to put AI on top of it. That leads to waste of time and waste of resources. […] It is very important to know what AI can do and what AI cannot do.” (IND-7, Operations Lead AI)
Second, organizations need to systematically identify AI use cases that support their business. While there are many well-known use cases, our data suggests there is much confusion about AI and its inner workings, which makes it challenging to find those use cases that are suitable to the organization (IND-6). Such suitable use cases can potentially stem from many sources, including business managers, IT managers, the IT department, or the workforce. There is much value in professionalizing and democratizing the process of use case generation to collect fruitful AI use cases (IND-3). Having clear use cases couples AI implementation with business outcomes, which is of importance according to CON-3:
“A successful implementation can only work if you have a very clear value proposition, where you say this is the benefit that should come from it, so don't just use AI because it's hip right now and everyone should do it.” (CON-3, Consultant Data Science)
Third, organizations need to assess and prioritize AI use cases to guide meaningful AI implementation. One aspect to be considered is the expected business outcome and its overall fit to business. Another aspect is the feasibility of implementation. CON-10 explains: “Sometimes it’s not easy for [organizations] to say in advance what exactly will be successful. You have to somehow develop a feeling for the organization.” Besides, organizations should also critically reflect on whether AI technology is really needed or whether the problem can be solved otherwise (ACA-1). The assessment of AI use cases can then guide AI implementation:
“At the end of the day, we will talk with the board and say 'OK, so we have a list of use cases, prioritized by value. From this list of use cases: What is your budget? How much do you want to spend?'. [… These] use cases will drive all your transformation.” (CON-11, Managing Consultant AI Strategy)
4.2 Co-Development of AI Systems
We found that organizations need to integrate diverse stakeholders into the development of AI systems to facilitate AI implementation. On the one hand, AI implementation typically requires the integration of diverse expertise into the projects. On the other hand, AI implementation is facilitated by effective outward communication, for example, the translation to business and explaining AI initiatives to the workforce. In other words, AI implementation should not happen in isolation. Instead, organizations require a collaborative approach to the development of AI systems. Hence, we conclude that organizations need to build a cross-functional Co-Development capability, which we define as the ability to communicate with and integrate stakeholders into AI implementation. We found three manifestations of this capability.
First, organizations need to integrate diverse expertise into AI implementation. This step includes data scientists, AI experts, domain experts, end-users, IT security, and ethics experts. IND-5 states, “those areas are immensely important and need to work well together, without which the success is a big question mark.” Collaboration is, for example, important to understand the data, select appropriate features, and evaluate the AI system. IND-11 highlights the importance of integrating diverse expertise:
“So cross-functional teams, for me, are a massive success factor. […] There's often a massive gap between business and data science, [… but AI development is] not something you solve in isolation. Like you need a lot of context of […] what is valuable for the business. It's not just being able to predict something with a 90 percent level of accuracy. So, the whole cross-functional teamwork, business, user, data understanding, that together is very important.” (IND-11, Head of Strategy)
Second, organizations need to manage the translation of AI systems to business functions. AI implementation projects require business input, but the AI systems also need to be appropriately explained and transferred to the business side. As CON-3 states, “many people have a certain expectation and still want to have an explanation of what this artificial intelligence does in detail and how it works.” AI systems appear to be rather complex and unintuitive, which is why the business side needs appropriate explanations for the features being used and why specific outcomes have been produced. IND-7 depicts this point:
“We also educate them a little about the model, how it works […] Building a model is something data scientists do, but business also needs to know. For example, if you are building a credit rating system, how does it work, what are the parameters, what are the priorities, these are all things that business needs to know as well.” (IND-7, Operations Lead AI)
Third, organizations should also consider the workforce as an important stakeholder in AI implementation. As CON-4 reports from his experience with clients, “if the people who will later work with it […] are involved in the pilot right from the start, the transition to the rollout is usually much easier.” Not only do AI implementation projects need direct input from their potential users for AI systems design, but the effort also needs to be put into communicating and explaining the reasons behind AI initiatives to address potential fear of AI systems. Otherwise, the impression might be created that the workforce first supports AI implementation “and in the end, an AI emerges to replace their jobs” (CON-6). CON-3 summarizes this aspect:
“Very important: Because people are often afraid of [AI], you have to be transparent and explain how you implement it, why you do it, what advantages it has and what disadvantages it can have, […] because it is often […] a perceived contradiction that you either use artificial intelligence or a human being for a task.” (CON-3, Consultant Data Science)
4.3 Data Management
We found that AI implementation is often thrown back by the lack of available data in enough quantity and quality for the training of AI models. Experts even report that AI projects were stopped entirely and frozen, as the data foundation had to be laid out first (IND-3). Therefore, we conclude that organizations require a Data Management capability to facilitate AI implementation. We define this as the ability of an organization to effectively collect, prepare, and provide data for AI implementation. We found three manifestations of this capability.
First, AI-relevant data needs to be made available for AI implementation. This step requires integrating multiple data sources, developing a unified data structure, creating transparency, and making data accessible for AI implementation. Other than that, AI projects typically face technical and political challenges when accessing data, for example, when the data resides in organizational silos. Each AI project needs to approach the data owners, which can sometimes be “laborious” (IND-3). Making data available can also help to increase transparency to identify new use cases potentially:
“It is not just a question of this data not existing at all, but also that […] for example in insurance companies, some of this data already exists, but is not available centrally, and that it is not known centrally that it exists.” (CON-10, Managing Director AI Consulting)
Second, in some cases organizations need to collect data specifically for AI implementation. For example, in the case of industrial applications, machine states need to be stored consistently over a long time to have enough data to predict the failure of machines. If such data is missing, it is hard to implement such AI use cases. Hence, organizations need to anticipate the data needed for future AI models and create awareness for this issue (CON-3). CON-6 describes the need for AI-driven data collection as follows:
“The other thing is understanding what data is relevant and needs to be stored - not just from today's business perspective, but from an understanding of statistics and machine learning. I don't need to store reports, they end up being witless, but I need to store sales figures or operating states from the machines.” (CON-6, Managing Director Consulting)
Third, organizations need to curate data for AI implementation. Many experts describe data quality as a central issue. “If the data is not available, either in poor quality or incomplete, then nothing can be done [using AI]” (ACA-2). However, determining what data quality means is a complicated task, and it highly depends on each use case (CON-3). For example, in the case of time-series data from sensors, one could ask at which time interval the data needs to be measured to achieve high quality. These questions should already be addressed at the data collection stage, as specific issues cannot be corrected in hindsight:
“The challenge is to gain understanding about the data. This then inevitably gives rise to numerous quality issues that often cannot be corrected by data cleansing alone, but where processes need to be adjusted to improve data quality” (IND-3, Data Scientist Procurement)
4.4 AI Model Lifecycle Management
We found that organizations develop many AI models during AI implementation, which are to be managed throughout their lifecycle. These AI models are based on and tightly coupled with the respective training data and the input data during productive use. As the underlying data may shift over time, these AI models need to be adapted continuously. Furthermore, existing AI models typically require adaptation to be deployed to different contexts. Our data suggests that organizations struggle to cope with the lifecycle management of AI models, which prevents organizations from scaling up AI implementation. Hence, we conclude that organizations need to build an AI Model Lifecycle Management capability, which we define as the ability to manage the evolution of AI models over time, including development, deployment, and maintenance. We found three manifestations of this capability.
First, organizations need to orchestrate an iterative development procedure, as AI development is highly iterative and compromises multiple cycles. CON-1 highlights that “it is important to arrange and validate the correct cycles around the model training.” Within each iteration, the AI model needs to be evaluated against business requirements and potentially tested live. Our experts report that multiple iterations are required to try other parameters and algorithms (IND-7). But new iterations can also be triggered after gathering more data throughout the process, as IND-10 states:
“I think the thing with machine learning again is there's going to be […] model releases every month. So, as you'll get more and more data, of course, as you get smarter, as you onboard more, there is a release planned every month.” (IND-10, Business Product Manager)
Second, organizations often want to deploy AI models to multiple contexts throughout the organization. And typically, for each new case, the AI model needs to be slightly adapted because the individual cases “are very specific and transferability is not seamless” (IND-2). For example, we observed this challenge in the industrial context (e.g., predictive maintenance), where AI models need to be adjusted from machine to machine and from line to line. Organizations need to manage these variants in AI implementation. IND-1 highlights this:
“All these variations have to be mapped via the images and the model training. This requires a very strong individualization in code and deployment. However, it is our goal of achieving a high level of penetration of the use cases with as little effort as possible” (IND-1, Requirements Engineer AI)
Third, organizations need to be able to operate AI systems in productive use. This step encompasses integrating existing IT infrastructures and business processes. It also encompasses the continuous monitoring and evaluation of AI systems (CON-7). For example, to detect concept and model drift issues, which occur when input data changes over time and model performance decrease. IND-6 describes the challenge of AI operation clearly:
“You can imagine that it happens in the lab, so to speak. With some data scientists on a development machine. But then the whole thing really must be operated in an enterprise-compatible way: someone must take care of it, it must be monitored, and, above all, it must be integrated into existing systems. I see that as a major challenge for customers, which often requires a huge effort.” (IND-6, Technical Architect & Data Scientist)
5 Discussion
AI implementation often fails in practice, and much of the potential value of AI remains unrealized (Benbya et al., 2020; Tarafdar et al., 2019). To cope with the unique challenges of AI implementation, organizations must develop specific organizational capabilities (Sjödin et al., 2021). Interpreting the data from 25 expert interviews, we presented four organizational capabilities for AI implementation: AI Project Planning, Co-Development of AI systems, Data Management, and AI Model Lifecycle Management. Our findings suggest that these organizational capabilities are important success factors for AI implementation. In the following, we will further elaborate on how these capabilities facilitate AI implementation. Specifically, we seek to explain how they help organizations to cope with AI’s unique characteristics. Furthermore, we situate the identified capabilities within prior research on AI implementation and IS capabilities (cf. Section 2) and distill our contributions to theory. Thereafter, we discuss implications for practice, limitations of this study, and avenues for future research.
5.1 Coping with Inscrutability and Data Dependency in AI
We propose that the identified capabilities help organizations cope with two characteristics in AI: inscrutability and data dependency. Inscrutability refers to the unintelligibility of AI systems to some audiences due to their complex inner workings and probabilistic nature (Asatiani et al., 2021; Berente et al., 2021; Jöhnk et al., 2021). Data dependency refers to the high dependence of AI systems on the underlying data, as these systems are typically built by learning and generalizing from data (Ågerfalk, 2020; Berente et al., 2021; Janiesch et al., 2021). These two characteristics appear to pose challenges specific to the context of AI implementation. We propose that AI Project Planning and Co-Development of AI Systems help organizations cope with AI’s inscrutability, which complicates the planning of AI projects and communication between different stakeholders. Data Management and AI Model Lifecycle Management help organizations cope with AI’s data dependency, which challenges organizations to provide a proper data foundation and continuously adjust AI systems as the data evolves. Figure 2 presents how the four organizational capabilities help to cope with inscrutability and data dependency in AI. In the following, we explain these relations in more detail.

Explanatory framework of organizational capabilities for AI implementation
AI Project Planning refers to the selection of suitable AI use cases in the context of the organization. It impacts the planning of AI projects and therefore is related to the IS planning capability (Peppard & Ward, 2004; Wade & Hulland, 2004). AI Project Planning highlights the importance of transferring the concept of AI into valuable use cases for the organization. We propose that this capability is essential to address the inscrutability in AI, which appears to add much uncertainty to the planning of AI projects. First, a thorough understanding of the AI concept is needed to identify valuable use cases for the organization because it is typically not easy to identify and define problems where AI technology is instrumental and the best choice (Weber et al. 2022; (Zhang et al., 2020). An important driver for this might be a broad AI awareness in the organization (Jöhnk et al., 2021; Sjödin et al., 2021), as our data showed that many valuable use cases for AI originate from the business side. Second, the inscrutability in AI complicates the assessment of use cases, as it is hard for decision-makers to predict whether a use case will work in production. For example, the input data used in the training environment might differ significantly in the natural environment (Baier et al., 2019). Therefore, today, many AI projects are of experimental nature to determine whether and how AI technology could work for a problem (Davenport & Ronanki, 2018; Keller et al., 2019). Third, the inscrutability in AI causes some managers to develop overly high expectations for AI projects (May et al., 2020), which frequently leads to disappointing outcomes and the termination of AI projects. In conclusion, the inscrutability in AI causes multiple problems of uncertainty during early planning activities. As a response, our findings suggest that organizations should develop an AI project planning capability as a vital part of the future IS planning capability.
Co-Development of AI systems refers to the communication and integration of stakeholders during the development of AI systems. Therefore, it is related to the IS development capability known from general IS research (Peppard & Ward, 2004; Wade & Hulland, 2004). It particularly highlights the importance of collaboration for AI implementation projects, as also noted by prior research (Fountaine et al., 2019; Jöhnk et al., 2021; May et al., 2020; Mikalef & Gupta, 2021; Sjödin et al., 2021; Tarafdar et al., 2019; van den Broek et al., 2021). While collaboration represents a well-known factor in IS implementation research (Dwivedi et al., 2015), our data supports the view that it plays an even more significant role in developing AI systems. We propose this capability is essential due to the inscrutability in AI, which intensifies the information gap between the IT department and other business functions. On the one hand, the IT departments require input from business functions to design AI systems appropriately, select meaningful features and evaluate their performance. These tasks are typically challenging in AI implementation (Baier et al., 2019; Lebovitz et al., 2021; Zhang et al., 2020). On the other hand, business functions require transparency and explanations from the IT department regarding the inner functioning, performance, and limitations of the developed AI system (Watson, 2017). Business functions need to understand how an AI system works to deal with its potential limitations (Asatiani et al., 2021). Explaining the workings of AI systems can also help address potential user resistance caused by misconceptions about the developed AI system (Reis et al., 2020). In conclusion, the inscrutability in AI causes multiple problems related to the information gap between the different stakeholders of AI implementation projects. As a response, our findings suggest that organizations should develop a co-development capability for AI implementation.
Data Management refers to the collection, curation, and provision of data for AI implementation. Therefore, it is closely related to the data management capability from research on big data analytics, which is essential to the value creation from big data (Chiusano et al., 2021; Günther et al., 2017; Gupta & George, 2016). Similarly, data management in the AI context highlights the importance of providing appropriate data for building AI systems, as noted by prior research (Enholm et al., 2021; Jöhnk et al., 2021; Mikalef & Gupta, 2021; Pumplun et al., 2019; Sjödin et al., 2021). We propose that data management is essential due to the data dependency in AI, as AI systems are typically built by learning from data (Berente et al., 2021). First, the organization’s existing data needs to be made easily accessible for AI implementation (e.g., process-related data). Otherwise, AI implementation projects are thrown back by efforts to collect new data and the laborious task of getting access to data in organizations (Watson, 2017). However, in some instances, the data was not needed prior to specific AI implementation projects and is nonexistent. For example, image data of damaged production parts are typically collected specifically for AI projects. Hence, organizations should think about how to proactively collect data specifically needed for AI implementation and share this AI-related data for other AI projects. Second, the data needs to be appropriately curated and prepared for AI implementation (Asatiani et al., 2021). In other words, data needs to adhere to specific quality standards that need to be defined (Jöhnk et al., 2021; Mikalef & Gupta, 2021). The quality of the underlying data is essential for the performance of AI systems and the avoidance of unintended outcomes, such as biased decisions (Lebovitz et al., 2021). In conclusion, the data dependency in AI causes multiple problems in providing the proper foundation for AI implementation projects. As a response, our findings suggest that organizations should develop a data management capability for AI implementation.
AI Model Lifecycle Management refers to the technical development, deployment, and continued operation of AI systems. It can be related to the IS development and IS operation capabilities known from the literature (Peppard & Ward, 2004; Wade & Hulland, 2004). It highlights the importance of managing the evolution of AI models throughout their lifecycle to enable continued use and operation in organizational practice. This finding strengthens the perception that AI implementation projects are never completely finished (Tarafdar et al., 2019), which has only received little attention in the literature. We propose that this capability is essential due to the data dependency in AI, because the underlying training and input data of AI systems might evolve, which demands adjustments to the AI systems (Baier et al., 2019). First, data is typically collected continuously during multiple AI training cycles, until a desirable performance of AI systems is reached (van den Broek et al., 2021). Here, it is important to keep track of all AI training cycles and the data that has been used. Second, after initial deployment, changes in the input data or environment can cause an AI system to produce wrong outputs because the initial model was trained on different assumptions (Baier et al., 2019). Furthermore, some AI systems can constantly learn as new data becomes available (Alahakoon et al., 2020; Berente et al., 2021; Sjödin et al., 2021). Therefore, organizations need to constantly monitor, evaluate, and retrain AI systems in productive use to avoid any unintended outcomes of changes in the data (Tarafdar et al., 2019). In conclusion, the data dependency in AI systems induces multiple problems related to the evolution of AI systems’ training and input data. As a response, our findings suggest that organizations should develop an AI model lifecycle capability for AI implementation.
5.2 Contributions to Theory
This study contributes to the ongoing discourse in IS research on how to drive and manage AI implementation in organizations (Benbya et al., 2021; Berente et al., 2021; Dwivedi et al., 2021). We contribute to research on organizational success factors for AI implementation. Specifically, we further develop and ground the concept of organizational capabilities in the context of AI technology (Mikalef & Gupta, 2021; Sjödin et al., 2021). Our findings support prevalent views that data needs to be managed as a critical driver for AI implementation (e.g., Mikalef & Gupta, 2021; Sjödin et al., 2021) and that collaboration is a vital element in AI implementation projects (e.g., May et al., 2020; Sjödin et al., 2021). Beyond that, our findings highlight the need for an AI project planning capability. This finding stands in contrast to the view that AI projects are typically experimental (Davenport & Ronanki, 2018; Keller et al., 2019). Our findings propose that organizations move beyond this experimental stage toward more structured planning and execution of AI projects. For this, it will be indispensable to map out the factors that can predict AI project success to better guide the planning of AI projects. In addition, our findings highlight the ongoing nature of AI implementation projects, an aspect that so far only received little attention (e.g., Tarafdar et al., 2019). Organizations need to manage AI models throughout their lifecycle as the data and environment evolve continuously, which is likely to involve novel practices such as feedback loops between users and developers (e.g., Grønsund & Aanestad, 2020).
Most notably, we link organizational factors for AI implementation with AI’s unique characteristics, explaining why certain factors are important and potentially unique to the context of AI. Thereby, we contribute to our understanding of the sociotechnical implications of the characteristics in AI and how they can be handled in organizational practice (Berente et al., 2021). First, we add to the current discourse on the implications of AI’s inscrutability. Previously, the inscrutability in AI was linked with the risk that occurs with the interpretation and use of an AI system’s output (e.g., Asatiani et al., 2021). Our findings suggest that inscrutability in AI also causes uncertainty in the planning of AI projects and intensifies the information gap between different stakeholders. Second, we introduce data dependency in AI as the central source of challenges related to providing proper data as the foundation for AI systems and the continuous need to adjust AI systems as the underlying data and environment evolve. We view data dependency as a characteristic that is inherited from the learning characteristic in AI (Berente et al., 2021), but that can only be attributed to AI systems that use data for learning (e.g., in contrast to knowledge-based inferring or reinforcement learning).
5.3 Implications for Practice
This study provides valuable insights for practice, especially given that many organizations are struggling with AI implementation (Benbya et al., 2020). Our findings help practitioners, especially top managers, to understand which organizational capabilities are needed to facilitate AI implementation. Practitioners can use these insights as a starting point to orchestrate their organizational resources accordingly and drive strategic decisions on AI adoption and implementation. Based our findings, we can give actionable recommendations to organizations. First, to support the planning of AI projects, organizations should focus on creating a broad awareness of AI technology on the business side (Jöhnk et al., 2021; Sjödin et al., 2021), as typically the best use cases come from outside the IT department. Moreover, organizations should focus on providing suitable ways of exchanging knowledge between different AI projects to aggregate experiences and better plan future AI projects. Second, organizations should focus on involving different stakeholders, including the workforce, early in the process to avoid misconceptions. Furthermore, they should appoint specific communication roles in AI projects, such as AI translators (Fountaine et al., 2019) that can help to bridge information gaps by translating between business and IT side. Third, our findings suggest to put much effort into the provision of a proper data foundation and pipelines that can facilitate current and future AI implementation projects (Sjödin et al., 2021). Here, organizations should also try to anticipate which AI use cases might be of value in near future. Otherwise, new AI projects might be thrown back by the tedious task of collecting and labelling data for more than one year before the first models can be built. Fourth, organizations should think of AI projects as ongoing projects, as AI systems typically require constant monitoring and adjustment. In addition, we shed light on two characteristics of AI systems, namely inscrutability, and data dependency, which aim to explain why AI implementation is often challenging in practice. Thereby, we create a richer understanding of the special context of AI implementation. Ultimately, we envision our findings to support practitioners in putting more AI systems to productive use.
5.4 Limitations and Future Research
This study comes with certain limitations. First, we followed an interpretive, qualitative research approach to explore organizational capabilities and their impact on AI implementation. While this research approach is well aligned with our research goals, it is prone to several issues. Amongst others, we needed to account for researchers’ bias as we interpreted the interview data (Strauss & Corbin, 1990; Walsham, 2006). While it is not possible to fully erase the researchers’ personal views and preconceptions, we mitigated bias by collecting data on multiple perspectives on AI implementation, and by the constant comparison of theory and data (Strauss & Corbin, 1990). Second, with our purposive cross-organizational and cross-industry sample, we were not able to capture potential specificities of organizations or industries in-depth. However, this sampling strategy helped us to reduce bias and provide a certain level of confidence in the generalizability of our findings to organizations that implement ML-based AI systems. Furthermore, we must mention to not have considered users of AI systems as an important stakeholder in AI implementation projects.
Our findings open several opportunities for future research. First, we propose that quantitative studies are needed to validate and further ground our results. For example, scholars could operationalize these organizational capabilities and quantitatively investigate their influence on AI implementation success and failure. This would also reveal potential weightings of the capabilities, which suggests different levels of importance for each capability. Second, future research could explore how organizations arrange and govern their roles, structures, and processes to build the identified organizational capabilities (Peppard & Ward, 2004). Of particular interest could be the formation of new institutions, such as an AI center of excellence or an AI ethics council (Fountaine et al., 2019), the composition of AI project teams, and the role of AI development and operation (MLOps) as a promising way of working (Benbya et al., 2020). Third, while our findings suggest that the capabilities help organizations to cope with inscrutability and data dependency in AI, we did not find any capability that addresses challenges that stem from the autonomy in AI (Berente et al., 2021). Perhaps this is because today’s AI systems are predominately used to support human workers, instead of automating tasks completely (Coombs et al., 2020). However, as the frontiers of AI move forward and more autonomous AI systems are implemented, this could present a fruitful opportunity to refine our identified set of capabilities.
6 Conclusion
Many AI implementation projects fail and never reach productive use. To address the unique challenges of AI implementation, organizations need to strategically prepare themselves, which includes the development of specific organizational capabilities. However, our understanding of these organizational capabilities was limited. Specifically, it remained unclear how certain capabilities help to cope with AI’s unique characteristics. To address this research gap, we conducted 25 interviews with experts on AI implementation. We discovered four organizational capabilities for AI implementation: AI Project Planning, Co-Development of AI systems, Data Management, and AI Model Lifecycle Management. In addition, we explained how these capabilities help organizations to cope with two characteristics in AI: inscrutability and data dependency.
This study contributes to the ongoing discourse in IS research on how to drive and manage AI implementation in organizations. Specifically, we strengthen the concept of organizational capabilities as a success factor for AI implementation. Our findings support prevalent views that collaborative development and data management are important factors for AI implementation. Beyond that, our findings suggest that a more structured AI project planning appears beneficial, which stands in contrast to the experimental nature of many AI projects. Furthermore, our findings highlight the ongoing nature of AI projects and the need to manage AI systems throughout their lifecycle. In addition, we explained how specific capabilities help to cope with inscrutability and data dependency in AI. We propose that these characteristics are the source of many challenges in AI implementation and that the identified capabilities can help organizations to cope with them. Thereby, we add to our understanding of the sociotechnical implications of AI’s unique characteristics and show ways to address them in practice.
References
Ågerfalk, P. J. (2020). Artificial intelligence as digital agency. European Journal of Information Systems, 29(1), 1–8.
Alahakoon, D., Nawaratne, R., Xu, Y., De Silva, D., Sivarajah, U., & Gupta, B. (2020). Self-building artificial intelligence and machine learning to empower big data analytics in smart cities. Information Systems Frontiers. https://doi.org/10.1007/s10796-020-10056-x
Anton, E., Behne, A., & Teuteberg, F. (2020). The Humans behind Artificial Intelligence-an operationalisation of AI Competencies. 28th European Conference on Information Systems (ECIS), Virtual Conference. https://aisel.aisnet.org/ecis2020_rp/141
Aral, S., & Weill, P. (2007). IT assets, organizational capabilities, and firm performance: How resource allocations and organizational differences explain performance variation. Organization Science, 18(5), 763–780.
Asatiani, A., Malo, P., Nagbøl, P. R., Penttinen, E., Rinta-Kahila, T., & Salovaara, A. (2021). Sociotechnical envelopment of artificial intelligence: An approach to organizational deployment of inscrutable artificial intelligence systems. Journal of the Association for Information Systems, 22(2), 325–352.
Awalegaonkar, K., Berkey, R., Douglass, G., & Reilly, A. (2019). AI: Built to scale - From experimental to exponential [Survey Report]. Retrieved May 05, 2021, from https://www.accenture.com/us-en/insights/artificial-intelligence/ai-investments
Baier, L., Jöhren, F., & Seebacher, S. (2019). Challenges in the deployment and operation of machine learning in practice. 27th European Conference on Information Systems (ECIS).
Benbya, H., Davenport, T. H., & Pachidi, S. (2020). Artificial intelligence in organizations: Current state and future opportunities. MIS Quarterly Executive, 19(4), ix–xxi.
Benbya, H., Pachidi, S., & Jarvenpaa, S. (2021). Special issue editorial: Artificial intelligence in organizations: Implications for information systems research. Journal of the Association for Information Systems, 22(2), 10.
Berente, N., Gu, B., Recker, J., & Santhanam, R. (2021). Managing artificial intelligence. MIS Quarterly, 45(3), 1433–1450.
Bharadwaj, A. S. (2000). A resource-based perspective on information technology capability and firm performance: An empirical investigation. MIS Quarterly, 24(1), 169–196.
Böttcher, T. P., Weber, M., Weking, J., Hein, A., & Krcmar, H. (2022). Value Drivers of Artificial Intelligence. 28th Americas Conference on Information Systems (AMCIS), Minneapolis, USA
Brock, J. K.-U., & Von Wangenheim, F. (2019). Demystifying AI: What digital transformation leaders can teach you about realistic artificial intelligence. California Management Review, 61(4), 110–134.
van den Broek, E., Sergeeva, A., & Huysman, M. (2021). When the machine meets the expert: An ethnography of developing AI for hiring. MIS Quarterly, 45(3), 1557–1580.
Chiusano, S., Cerquitelli, T., Wrembel, R., & Quercia, D. (2021). Breakthroughs on cross-cutting data management, data analytics, and applied data science. Information Systems Frontiers, 23(1), 1–7.
Coombs, C., Hislop, D., Taneva, S. K., & Barnard, S. (2020). The strategic impacts of intelligent automation for knowledge and service work: An interdisciplinary review. The Journal of Strategic Information Systems, 29(4), 101600.
Cooper, R. B., & Zmud, R. W. (1990). Information technology implementation research: A technological diffusion approach. Management Science, 36(2), 123–139.
Davenport, T., & Ronanki, R. (2018). Artificial intelligence for the real world. Harvard Business Review, 96(1), 108–116.
Dosi, G., Nelson, R. R., & Winter, S. G. (2000). The nature and dynamics of organizational capabilities. Oxford University Press.
Dwivedi, Y. K., Wastell, D., Laumer, S., Henriksen, H., Myers, M., Bunker, D., Elbanna, A. R., Ravishankar, M., & Srivastava, S. C. (2015). Research on information systems failures and successes: Status update and future directions. Information Systems Frontiers, 17, 143–157.
Dwivedi, Y. K., Hughes, L., Ismagilova, E., Aarts, G., Coombs, C., Crick, T., Duan, Y., Dwivedi, R., Edwards, J., & Eirug, A. (2021). Artificial intelligence (AI): Multidisciplinary perspectives on emerging challenges, opportunities, and agenda for research, practice and policy. International Journal of Information Management, 57, 101994.
Enholm, I. M., Papagiannidis, E., Mikalef, P., & Krogstie, J. (2021). Artificial intelligence and business value: A literature review. Information Systems Frontiers. https://doi.org/10.1007/s10796-021-10186-w
Feeny, D. F., & Willcocks, L. P. (1998). Core IS capabilities for exploiting information technology. MIT Sloan Management Review, 39(3), 9–21.
Fountaine, T., McCarthy, B., & Saleh, T. (2019). Building the AI-powered organization. Harvard Business Review, 97(4), 62–73.
Grønsund, T., & Aanestad, M. (2020). Augmenting the algorithm: Emerging human-in-the-loop work configurations. The Journal of Strategic Information Systems, 29(2), 101614.
Günther, W. A., Mehrizi, M. H. R., Huysman, M., & Feldberg, F. (2017). Debating big data: A literature review on realizing value from big data. The Journal of Strategic Information Systems, 26(3), 191–209.
Gupta, M., & George, J. F. (2016). Toward the development of a big data analytics capability. Information & Management, 53(8), 1049–1064.
Haenlein, M., & Kaplan, A. (2019). A brief history of artificial intelligence: On the past, present, and future of artificial intelligence. California Management Review, 61(4), 5–14.
Janiesch, C., Zschech, P., & Heinrich, K. (2021). Machine learning and deep learning. Electronic Markets, 31, 685–695. https://doi.org/10.1007/s12525-021-00475-2
Jöhnk, J., Weißert, M., & Wyrtki, K. (2021). Ready or not, AI comes—An interview study of organizational AI readiness factors. Business & Information Systems Engineering, 63(1), 5–20.
Jordan, M. I., & Mitchell, T. M. (2015). Machine learning: Trends, perspectives, and prospects. Science, 349(6245), 255–260.
Keller, R., Stohr, A., Fridgen, G., Lockl, J., & Rieger, A. (2019). Affordance-experimentation-actualization theory in artificial intelligence research–a predictive maintenance story. 40th International Conference on Information Systems (ICIS).
Klein, H. K., & Myers, M. D. (1999). A set of principles for conducting and evaluating interpretive field studies in information systems. MIS Quarterly, 23(1), 67–93.
Kogut, B., & Zander, U. (1992). Knowledge of the firm, combinative capabilities, and the replication of technology. Organization Science, 3(3), 383–397.
Lebovitz, S., Levina, N., & Lifshitz-Assaf, H. (2021). Is AI ground truth really true? The dangers of training and evaluating AI tools based on experts’ know-what. MIS Quarterly, 45(3), 1501–1525.
LeCun, Y., Bengio, Y., & Hinton, G. (2015). Deep learning. nature, 521(7553), 436–444.
May, A., Sagodi, A., Dremel, C., & van Giffen, B. (2020). Realizing digital innovation from artificial intelligence. 41th International Conference on Information Systems (ICIS), Virtual Conference.
Mikalef, P., & Gupta, M. (2021). Artificial intelligence capability: Conceptualization, measurement calibration, and empirical study on its impact on organizational creativity and firm performance. Information & Management, 58(3), 103434.
Mikalef, P., Lemmer, K., Schaefer, C., Ylinen, M., Fjørtoft, S. O., Torvatn, H. Y., Gupta, M., & Niehaves, B. (2021). Enabling AI capabilities in government agencies: A study of determinants for European municipalities. Government Information Quarterly, 101596. https://doi.org/10.1016/j.giq.2021.101596
Miles, M. B., Huberman, A. M., & Saldaña, J. (2018). Qualitative data analysis: A methods sourcebook. Sage publications.
Mithas, S., Ramasubbu, N., & Sambamurthy, V. (2011). How information management capability influences firm performance. MIS Quarterly, 35(1), 237–256.
Myers, M. D., & Newman, M. (2007). The qualitative interview in IS research: Examining the craft. Information and Organization, 17(1), 2–26.
Nam, K., Dutt, C. S., Chathoth, P., Daghfous, A., & Khan, M. S. (2020). The adoption of artificial intelligence and robotics in the hotel industry: Prospects and challenges. Electronic Markets, 31, 553–574. https://doi.org/10.1007/s12525-020-00442-3
Peppard, J., & Ward, J. (2004). Beyond strategic information systems: Towards an IS capability. The Journal of Strategic Information Systems, 13(2), 167–194.
Pumplun, L., Tauchert, C., & Heidt, M. (2019). A new organizational chassis for artificial intelligence-exploring organizational readiness factors. 27th European Conference on Information Systems (ECIS).
Rai, A., Constantinides, P., & Sarker, S. (2019). Editor'S comments: Next-generation digital platforms: Toward human–AI hybrids. MIS Quarterly, 43(1), iii–x.
Ravichandran, T., Lertwongsatien, C., & Lertwongsatien, C. (2005). Effect of information systems resources and capabilities on firm performance: A resource-based perspective. Journal of Management Information Systems, 21(4), 237–276.
Reis, L., Maier, C., Mattke, J., Creutzenberg, M., & Weitzel, T. (2020). Addressing user resistance would have prevented a healthcare AI project failure. MIS Quarterly Executive, 19(4), 279–296.
Schreieck, M., Wiesche, M., & Krcmar, H. (2021). Capabilities for value co-creation and value capture in emergent platform ecosystems: A longitudinal case study of SAP’s cloud platform. Journal of Information Technology, 02683962211023780.
Sjödin, D., Parida, V., Palmié, M., & Wincent, J. (2021). How AI capabilities enable business model innovation: Scaling AI through co-evolutionary processes and feedback loops. Journal of Business Research, 134, 574–587.
Stone, P., Brooks, R., Brynjolfsson, E., Calo, R., Etzioni, O., Hager, G., Hirschberg, J., Kalyanakrishnan, S., Kamar, E., Kraus, S., Leyton-Brown, K., Parkes, D., Press, W., Saxenian, A., Shah, J., Tambe, M., & Teller, A. (2016). "Artificial intelligence and life in 2030." one hundred year study on artificial intelligence (report of the 2015-2016e study panel). Stanford University. Retrieved May 05, 2021, from http://ai100.stanford.edu/2016-report
Strauss, A., & Corbin, J. (1990). Basics of qualitative research. Sage publications.
Tarafdar, M., & Gordon, S. R. (2007). Understanding the influence of information systems competencies on process innovation: A resource-based view. The Journal of Strategic Information Systems, 16(4), 353–392.
Tarafdar, M., Beath, C. M., & Ross, J. W. (2019). Using AI to enhance business operations. Sloan Management Review, 60(4), 37–44.
Venturebeat. (2019). Why do 87% of data science projects never make it into production?. Retrieved May 05, 2021, from https://venturebeat.com/2019/07/19/why-do-87-of-data-science-projects-never-make-it-into-production/
Wade, M., & Hulland, J. (2004). The resource-based view and information systems research: Review, extension, and suggestions for future research. MIS Quarterly, 28(1), 107–142.
Walsham, G. (2006). Doing interpretive research. European Journal of Information Systems, 15(3), 320–330.
Watson, H. J. (2017). Preparing for the cognitive generation of decision support. MIS Quarterly Executive, 16(3), 153–169.
Weber, M., Limmer, N., & Weking, J. (2022). Where to start with AI?— Identifying and prioritizing use cases for health insurance. 55th Hawaii International Conference on System Sciences (HICSS), Maui, Hawaii, USA
Wiesche, M., Jurisch, M. C., Yetton, P. W., & Krcmar, H. (2017). Grounded theory methodology in information systems research. MIS Quarterly, 41(3), 685–701.
Zhang, Z., Nandhakumar, J., Hummel, J., & Waardenburg, L. (2020). Addressing the key challenges of developing machine learning AI systems for knowledge-intensive work. MIS Quarterly Executive, 19(4), 221–238.
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of Interest
The authors did not receive support from any organization for the submitted work. The authors have no competing interests to declare that are relevant to the content of this article.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix A
Appendix A
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Weber, M., Engert, M., Schaffer, N. et al. Organizational Capabilities for AI Implementation—Coping with Inscrutability and Data Dependency in AI. Inf Syst Front 25, 1549–1569 (2023). https://doi.org/10.1007/s10796-022-10297-y
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10796-022-10297-y