
Abstract
Fire insurance is a crucial component of property insurance, and its rating depends on the forecast of insurance loss claim data. Fire insurance loss claim data have complicated characteristics such as skewness and heavy tail. The traditional linear mixed model is commonly difficult to accurately describe the distribution of loss. Therefore, it is crucial to establish a scientific and reasonable distribution model of fire insurance loss claim data. In this study, the random effects and random errors in the linear mixed model are firstly assumed to obey the skew-normal distribution. Then, a skew-normal linear mixed model is established using the Bayesian MCMC method based on a set of U.S. property insurance loss claims data. Comparative analysis is conducted with the linear mixed model of logarithmic transformation. Afterward, a Bayesian skew-normal linear mixed model for Chinese fire insurance loss claims data is designed. The posterior distribution of claim data parameters and related parameter estimation are employed with the R language JAGS package to obtain the predicted and simulated loss claim values. Finally, the optimization model in this study is used to determine the insurance rate. The results demonstrate that the model established by the Bayesian MCMC method can overcome data skewness, and the fitting and correlation with the sample data are better than the log-normal linear mixed model. Hence, it can be concluded that the distribution model proposed in this paper is reasonable for describing insurance claims. This study innovates a new approach for calculating the insurance premium rate and expands the application of the Bayesian method in the fire insurance field.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The impact of fire on the social environment and people’s lives should not be underestimated, and major fire accidents occur frequently in the world, resulting in severe casualties and property losses. Property insurance should be established for compensating economic losses in fire accidents. Therefore, it is imperative to determine insurance rates scientifically and reasonably and forecast fire insurance loss claim for insurance rate determination.
It is particularly complicated for setting insurance rates due to the heterogeneity of insurance portfolios and different insurance risks in the fire insurance field. Hence, a linear mixed model (LMM) is typically employed to handle this heterogeneity. Random effects and random errors are commonly assumed to follow a normal distribution in the typical linear mixed model framework Zhang and Davidian [1], Ghidey and Lesaffre [2], Frees and Young [3]. The typical distribution of fire insurance loss claims is characterized by asymmetry and a thick tail. some researchers have changed the distribution to eliminate the complicated characteristics of insurance. For example, the log-phase type (Log PH) distribution was introduced to fit the heavy-tail distribution of fire losses in Ahn and Kim [4] study. Huang and Meng [5] corrected the skewness and heavy tail problem of insurance loss using a Bayesian nonparametric regression model based on Gaussian distribution. Escobar and Pflug [6] determined the worst case of insurance distribution with the distance variance of the probability model. These methods can produce more appropriate empirical results. Nevertheless, data transformation may reduce the information provided by the original data’s potential generation mechanism, and only applies to a single individual and does not guarantee joint normality, presenting some limitations. Furthermore, the accuracy of a normal hypothesis is difficult to be verified, and accurate estimation of inter-subject variation cannot be guaranteed.
Consequently, the hypothesis method of skew distribution is gradually considered by many researchers. The linear mixed model could be expanded for a better understanding of asymmetric insurance loss claim data, and one plausible modification is to assume the random errors following a skewed distribution. Numerous researchers Azzalini and Capitanio [7], Capitanio and Azzalini [8]; Sahu and Dey [9]; Arellano-Valle and Bolfarine [10]; Huang et al. [11], Jung and Lee [12] have explored linear regression models with skewed distribution, systematically introduced the family of skew distribution, and established a method to obtain skew distribution by symmetric distribution.
Some researchers have applied a skew linear mixed model to medical research and the economic field Bandyopadhyay et al. [13], Huang and Chen [14], Leisen and Marin [15]. They fitted different experimental data and achieved more robust estimation results, while its application in insurance loss claims has caused little attention. In the fire insurance actuarial, the Bayesian method is mainly used for problems such as estimating loss distribution, adjusting rates, and corrections. De Simone and Piangerelli [16] applied Bayesian procedures to quantify the impact of COVID-19 epidemic cases in eight different countries and all regions of Italy on determining effective reproduction numbers. Meanwhile, a considerable number of researchers (Jara and Quintana [17]; Scollnik [18]; Bermúdez and Bermúdez [19]; Esmaeili and Klüppelberg [20]; Moreno and Jiménez et al. [21]) investigated the application of the Markov Chain Monte Carlo (MCMC) Bayesian method to estimate and fit insurance losses through different regression models. The corresponding studies mentioned above demonstrate the potential of the Bayesian method in insurance actuarial.
This paper aims to investigate the use of a skew linear mixed model in the prediction of fire insurance loss claims and propose a Bayesian skew-normal linear mixed model to describe the relationship between covariates and response variables flexibly. The random errors and random effects are assumed to obey skew-normal distribution in comparison to the traditional linear mixed model for eliminating the influence of the loss distribution’s skewed characteristics. The MCMC method makes Bayesian inference a viable alternative for this prediction model. Regarding parameter estimation, the Bayesian method and the MCMC method apply to the prior distribution and the posterior distribution, respectively. The parameter posterior means are Gibbs sampling using the JAGS package in R language. This approach can improve the flexibility of the Bayesian method.
Linear mixed models (LMM) are often used to analyze repeated measurement data because they are more flexible in modeling intra-subject correlations, which are usually present in such data. The most popular continuous response LMM assumes that both the random effects and the internal errors of the subjects are normally distributed, which may be an unrealistic assumption that conceals important features of changes within and between units (or groups). In this work, a skew normal linear mixed model (SNLMM) is proposed, which relaxes the normality assumption by using multivariate skew normal distribution, including normal distribution as a special case, and is suitable for the structure of repeated measurement data and clustering data analysis. The Bayesian skew-normal linear mixed model proposed in this study outperforms the log-linear mixed model and the regression model on two fire insurance real loss datasets, expanding the method’s application in the fire insurance business.
2 Data Sources
The correctness of the Bayesian skew-normal linear mixed model is verified on two different property insurance datasets. The first dataset is the U.S. employer liability insurance loss claims data from Klugman [22], which is originally sourced from the National Council on Compensation Insurance and contains a large sample and small categorical covariates. The second dataset consists of a significant number of continuous covariates by introducing mainland China property insurance claims data, sourced from the China Statistics Bureau and the China Insurance Regulatory Commission (CIRC) website (http://www.stats.gov.cn/tjsj/ndsj/).
Employer liability insurance, classified as property insurance, is mainly used to manage claims for permanent or partial incapacity of employees. A total of 121 risk categories are included in the longitudinal dataset, and 847 data are collected in seven observation years, including occupational categories, income, and compensation. The applicability of the model is verified by exploring the data characteristics of the pure premium (PP) (PP = claim amount/income) data features.
Property insurance in mainland China is majorly employed to handle fire losses claims. The property insurance loss claims data and the gross regional product (GRP) dataset of various regions for 2011–2020 in mainland China are cited in this study. The panel data contains 340 data items for 34 regional categories over 10 observation years and are adopted in the study owing to the strong regional characteristics of property insurance business size and claims. The model is applied for this dataset to investigate and estimate the association between property premium loss claims and GRP.
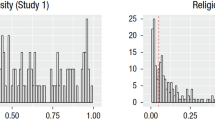
Figure 1 illustrates the histograms of frequency distributions of pure premiums of employer liability insurance and property insurance loss claims. As observed in Figure 1, both insurance datasets exhibit remarkable right skew and heavy tail characteristics. Thus, it is difficult for them to accurately apply to the traditional actuarial model. Fortunately, the application of the skewness distribution proposed in this study can better tackle this problem.

Frequency distribution histogram of two different datasets
3 Methodology
3.1 Bayesian Skew-Normal Linear Mixed Model
The skew-normal distribution is a further extension of the normal distribution. The Bayesian method is primarily applied to parameter estimation of the loss distribution. The traditional linear mixed model is generally insufficient to describe the insurance loss claim due to the complicated characteristics of skewness, heavy tail, and multimodality. As a result, the mature application of the Bayesian method and skewness distribution is required. Bayesian skew-normal linear mixed model (SNLMM) can better handle this type of panel data. Sahu et al. [9], Arellano-Valle and Genton [10], Arellano-Valle et al. [23], Bernardi and Petrella [26], Miljkovic and Grün [27], and other researchers have conducted correlation studies on the Bayesian skew-normal linear mixed model. In this section, the expression function studied by the previous researchers is introduced to define the Bayesian skew-normal linear mixed model (SNLMM).
3.1.1 Skew-Normal Linear Mixed Model
Firstly, multivariate skew-normal distribution is introduced to define the proposed SNLMM. According to the multivariate skew-normal distribution studied by Arellano-Valle and Genton [10], the density function of e-element skew-normal distribution of random variable X = (X1,…,Xe) T at point x is defined as
where Σ denotes the positive definite covariance matrix, σ represents the diagonal matrix \(\sum = \sigma \overline{\sum }\sigma\) formed by the standard deviation in Σ, and \(\overline{\Sigma }\) indicates the correlation matrix. The density function of e-element normal distribution Ne (μ, Σ) at point x is expressed as ψe (x-μ; Σ), and the corresponding distribution function is expressed as Ψe (x-μ; Σ).
The most commonly used linear mixed model (LMM) was proposed by Laird and Ware [28] for a continuous response. Assuming that the loss data come from m different individual risks, there are ki (i = 1,2,…,m) observations at different stages for each risk. Additionally, Yi represents the ki dimension vector of the continuous measurement of individual i. Then, the linear mixed model of Yi is expressed as
where Xi (ki × p) indicates the explanatory variable matrix corresponding to the fixed effect vector β, and Zi (ki × q) denotes the explanatory variable matrix corresponding to the random effect vector bi. The random effect bi and the random error εi are independent of each other and obey the mean value of 0. The normal distribution of the covariance matrix is determined by Σb and σe2: bi ~ Nq (0, Σb) and εi ~ N (0,σe2). Covariance matrixes Σb and σe2 represent the variance between individuals and within individuals, respectively.
Generally, the parameter estimation of skew distribution is complicated. The skew-normal distribution linear mixing model proposed in this study extends the general linear mixed model, defined based on the linear model in Eq. (2). Assuming that the random effects and random errors obey the skew-normal distribution, the specific distribution is expressed as
The assumptions of random effects and random errors are independent of each other, contributing to the following hierarchical structure.
where αei and αb are vectors, containing shape parameters αei1,…, αeini and αb1,…, αbq, respectively. It is assumed that Σi = σe2Ini and αei = αe1ni, i = 1,…, m, where 1 g denotes the g-dimensional vector of ones. The standard diagonal matrix of matrix Σi is σi = σeIki, where σe a real number. According to the characteristics of skew normal distribution, the expectation and variance of response variable Yi are obtained as follows.
where бei = (1 + αeiT·αei)−1/2αei; the observation value y = (y1T,…, ymT)T is conditionally distributed for a given random effect b = (b1T,…, bmT)T; other parameters are shown as
The model mainly infers parameter vector θ = (βT, σeT, αT)T, α = (αe, αbT)T, αb = (αb1, …, αbq)T. This model is based on the distribution of response variable Yi. Random effects and random errors are not limited to the normal distribution and can be used to evaluate asymmetric data.
3.1.2 Bayesian Estimation of SNLMM
The loss distribution is estimated using the Bayesian method by specifying the prior distribution of unknown parameters to determine the posterior distribution of parameters. The prior distribution of the fixed effect vector β is usually taken as multivariate Gaussian distribution N (β | μβ, σβ2), with density function given by
The prior covariance structure of scale parameter σe2 is the inverse Wishart distribution IG (σe2 | τe, Te) of matrix Tb, with density function given by
The prior distribution of scale matrix Σ with random effect is τb degrees of freedom and the variable covariance structure is inverse Wishart distribution IW (Σ | Tb) of matrix Tb. The prior distribution of skewness parameters αe and αb is a normal distribution N (αe | μe, γe2) I {αe > 0} and a multivariate truncated Gaussian distribution Nq (αb | μb, γb2) I {αb > 0}, respectively, where γb2 denotes a positive definite matrix, and I{A} represents the indicative value of dataset A, with density function given by
and
Assuming that the prior distribution of the above parameters is independent of each other, according to the conditional distribution of the parameters, the posterior distribution of all relevant parameters can be obtained by
However, it is quite complicated a to obtain the marginal distribution of the amount of interest involved in Eq. (13) from an analytical perspective. The MCMC method is adopted in this study to perform Bayesian analysis, considering that the traditional Bayesian method is difficult to conduct on such models. In this study, the MCMC method is used to simulate the posterior distribution of each parameter, and Gibbs sampling is applied to the conditional posterior distribution of each parameter to simplify its sophisticated formula.
3.2 MCMC Simulation Analysis
The MCMC method involves the skew-normal distribution function, which is difficult to establish the model. The hierarchical structure studied by Arellano-Valle et al. [23] is employed in this paper to solve the complicated skew problem. The skew-normal linear mixed model is expressed in the equivalent form of simple normal distribution, making it convenient to use Gibbs sampling for posterior distribution. The complete layered structure of the model is expressed as
The corresponding programming code can be easily obtained according to the layered expressions. According to Eqs. (14)–(22), the complete conditional distribution required to realize the Gibbs sampler can be directly derived and sampled. The algorithm starts from the initial value and cycle of all variables mentioned, which generates samples from the above conditional distribution until convergence. The method mentioned by Gelman and Rubin [24] is utilized to verify the conditions, such as running several parallel chains. Regarding unbalanced datasets, existing statistical software, such as MATLAB, can be used to easily calculate the above equations. For balanced datasets, the Gibbs sampler can be implemented by OpenBUGS or JAGS software. Besides, the R language jags programming is employed to perform Gibbs sampling in this study.
4 Case Study
In this section, the Bayesian skew-normal linear mixed model is established and compared with Frees et al. [3] model to verify the accuracy of SNLMM model based on the US employer liability insurance loss claim data Klugman [22]). Then, the SNLMM model is applied to China’s mainland property insurance statistics [29] (http://www.stats.gov.cn/tjsj/ndsj/) to explore the relationship between the relevant variables. Additionally, the premium claims are estimated to determine the premium rate based on variance analysis to determine the premium rate.
4.1 U.S. Employer Liability Insurance Claims Data
Pure premium (PP) is defined as the loss of income per dollar due to permanent, partial disability. Frees selected the logarithm of pure premium (LnPP) as the response variable Y; other explanatory variables were the observation year t and the occupation category w. Frees established a logarithmic normal linear mixed model, which used logarithmic transformation to explain heteroscedasticity. Figure 1 demonstrates that the pure premium claim data are panel data with right deviation and heavy tail. The correlation between the same set of data needs to be considered, and the logarithmic transformation exhibits data information loss and increase errors. In this study, the model is optimized by establishing a Bayesian skew-normal linear mixed model, so as to improve the reliability of data prediction.
4.1.1 Model Analysis
Frees conducted logarithmic transformation of pure premiums under the consideration of the right-deviation characteristics of data. After logarithmic transformation, the right-deviation of the data was offset. The distribution map of logarithmic pure premium data presented symmetry. The established logarithmic linear mixed Model I was
where w denotes the occupational category and t represents the observation year. Since the pure premium does not change with the observation year, the model only contains a constant term γ1 as a fixed effect variable. The value of the observation year is (Year-4) /8. Additionally, the model is a general linear mixed model. The random effect dw and the random error term ewt are subject to the normal distribution with the mean value of zero, and the random effect dw follows the binary normal distribution. Frees used t statistics and likelihood statistics to judge the adequacy of the model, which fitted the panel data model with the data to create a credibility predictor to solve the skew problem of the model.
Logarithmic transformation reduces the correlation of the same group of data. After the establishment of the linear mixed model, there are some defects in the internal structure, and the prediction data lacks certain authenticity. This study uses the proposed Bayesian skew-normal linear mixed model to analyze pure premium data. Normal distribution is a special case of skew normal distribution. Therefore, the skewed normal linear mixed model can process both skewed data and symmetric distribution data.
According to the evaluation results of the Bayesian model, DIC statistics Spiegelhalter et al. [29] and BIC criterion Yuan and Lu [30] are employed in this paper to analyze the accuracy of the three models. The expressions of DIC and BIC are
where D (θ) is equal to the logarithmic likelihood function of negative twice, k denotes the number of effective parameters of the model, and L indicates the likelihood function. As suggested in the previous studies, smaller DIC and BIC were better in fitting and prediction effects of the model.
In this paper, the partial normal distribution is used to define the random effect dw and the random error term ewt to form a partial normal linear mixed model. This paper will compare and analyze the two models, and the response variables are pure premium logarithm. The first model is a general linear mixed model, and the random effects and random errors obey the normal distribution. The second model introduces skew normal distribution, assuming that both random errors and random effects obey skew normal distribution. Suppose that the random error term obeys the normal distribution, that is, the Frees model.
In order to facilitate the comparison of the same parameters of the two models, the same prior distribution is given. In each simulation,100 Monte Carlo data sets are simulated from Eq. (23) according to additional specification described below, and Eq. (23) is fit to each data set via the strategy in Proposition 1 (see Appendix) using the R software jointly with the R2WinBUGS package and the following prior specifications. The prior distribution of the fixed effect is regarded as a normal distribution γ0 ~ N (0,102). The prior distribution of the scale parameter of the error distribution is assumed to obey inverse gamma distribution σe2 ~ IG (0.01,0.01). The prior distribution of the scale matrix of the random effect prior distribution dw is inverse Wishart distribution ∑ ~ IW2 (I2). The skewness parameter is αe ~ N (0,102) I{αe > 0}, αw ~ N (0,102) I{ab > 0}. The prior distributions of parameters ωe and ωw are assumed as ωe ~ N (0,1) I{ωe > 0}, ωd ~ N (0,1) I{ωd > 0}. The prior distribution considered is close to the non-informative distribution, that is, the prior distribution with large variance is considered. The parameter estimates and standard deviations of various models are shown in Table 1.
Σ11 is the variance of the random effect d1w, Σ12 is the covariance of the random effects d1w and d2w, Σ22 is the variance of the random effect d2w. The last two lines are negative twice the log-likelihood function value and DIC information for comparative analysis of the model.
It can be seen from Table 1 that when the random error term obeys the partial normal distribution, the DIC value of the model is obviously the smallest, indicating that the model has the best fitting effect on the pure premium logarithm. However, comparing the fitting values of the models with the actual values, it can be found that the fitting values of these models for the logarithm of pure premiums are not much different. See Figures 2 and 3, this is mainly because the logarithm of pure premiums presents an approximate symmetrical shape, so the superiority of skewed distribution is not fully reflected.

Scatter plot of pure premium and fitting value

Residual and compensation scatter plot
4.1.2 Model Optimization
Logarithmic transformation reduces the correlation of the same group of data. After the establishment of the linear mixed model, there are some defects in the internal structure, and the prediction data lacks certain authenticity. This study uses the proposed Bayesian skew-normal linear mixed model to analyze the pure premium observation data directly.
The skew-normal linear mixed model for the pure premium claim dataset is established directly in this study, and the explanatory variables mentioned above are the same as Model II. Therefore, the Bayesian skew-normal linear mixed Model III can be obtained as
In this model, the random effects and random errors are assumed to follow the skew-normal distribution, and the pure premium is considered the response variable.
The skew-normal linear mixed model does not need to transform the data and can directly calculate the pure premium data on the right. In this way, the explanatory ability of the model to the data is significantly improved, and the influence of the correlation of the same set of data caused by the transformation is avoided. For the convenience of comparison, the same meaning parameters give the same prior distribution.
The prior distribution of parameters is obtained based on the Bayesian method, and the hierarchical expression of the model is acquired using the equivalent form of the skew-normal linear mixed model. In this paper, the hierarchical expression operation code is programmed by JAGS in R language through Gibbs sampling of MCMC method, with 30,000 iterations. The first 10,000 iterations are abandoned until the sample converges. Then, the parameter posterior distribution sample value is obtained. Meanwhile, the lag value is set as 4 to avoid related problems in the generated Markov chain. The mean value and standard deviation of the estimated values of each parameter are obtained using the sample values of the posterior distribution, as listed in Table 2.
Table 2 implies that the posterior distribution mean of the skewness parameter is close to 0.5, and the variance interval of the error parameter is relatively narrow. The dotted line in Figure 4 represents the median of the skewness parameter and error parameter. The median of skewness parameter is close to 0.5, and the median of error parameter is close to the mean, suggesting that the established skew-normal linear mixed model is more suitable for this dataset.

The posterior distribution frequency distribution curve of parameters. (a) The posterior distribution frequency curve of the skewness parameter αd1. (b) The posterior distribution frequency curve of the error parameter σe2
4.1.3 Comparative Analysis
Since the response variables used in Tables 2 and 1 are completely different, one is the pure premium and the other is the logarithm of the pure premium, their DIC values cannot be directly compared, but the fitting values and model residuals of different models can be compared and analyzed.
Figure 5 is a scatter plot between the observed values of the residuals and pure premiums of the partial slash linear mixed model and their fitted values. It can be seen that the fitted value and the observed value of the model III with the pure premium as the response variable are closer to the diagonal, and the fitting effect is better than that of the Figure 2. It can be seen that the fitted values and observed values of the partial slash linear mixed model are closer to the diagonal, and the residual fluctuation range is smaller. The residuals are concentrated near the zero value, and the fitting effect is significantly better than the normal linear mixed model shown in Figures 3 and 4, which further indicates that the model has a better fitting effect on the pure premium data.

Scatter plot of observations and fitting values of net premiums
Figure 6 represents the scatter plot of residuals. From the graph, it can be seen that the residual fluctuation range is small and gathers near the zero value. The fitting effect is obviously better than the model I and model II shown in Figure 3, which further shows that the model III fitting of pure premium data greatly improves the model’s ability to interpret data.

Residual scatter plot
4.2 Mainland China Property Insurance Statistics
Property insurance business scale and loss claims have strong regional characteristics. In this study, the relationship between regional property insurance loss claims and regional economy GRP is mainly discussed. The data of the two over the years are fitted and analyzed. The claims for property insurance losses in the next 3 years are further predicted.
4.2.1 Variable Assumptions
Figure 7 illustrates the relationship between total property insurance losses with GDP and economic growth over the past decade. The total insurance loss claims and GDP increase with time; the total amount of insurance loss claims grows faster when GDP grows faster; the growth rate of total insurance loss claims decreases when GDP growth slows down, implying a linear relationship between the two parameters. In recent years, China has entered a transitional period, with a large GDP base and rapid growth of per capita GDP, while the growth rate has declined.

Comparison and growth of premium claim with GDP
Figure 8 exhibits the time series of claims for property insurance losses in the regions over the past decade with the observation year. Figure 8 reveals that the level of insurance loss claims increases with the increasing observation years for most regions, while there are significant differences in the level of insurance loss claims among regions with different economic levels.

Property insurance claims in different regions
According to the property insurance loss claim data in China Statistical Yearbook and China Fire Yearbook, these data variables are summarized in Table 3. As suggested in Table 3, the trend of insurance loss claims and regional economy with time is somewhat consistent, and their variances are relatively large.
A preliminary analysis indicates that it is somewhat similar to the linear trend of regional economies GRP with time, though the level of claims for property insurance losses may depend on the complicated characteristics of different regions. Moreover, the dataset demonstrates the distribution characteristics of right deviation, thick tail, and asymmetry. In this study, regional property insurance loss claim is designated as response variable Y (billion). Random variables include observation year t, regional economy GRP (billion), observation area category n, explanatory variable n = 34, and t = 10 (2011,…, 2020). Different letters instead of region names are used to protect data sources and information security. Meanwhile, no more information about the region category is provided.
4.2.2 Model Establishment
The above analysis implies a certain linear trend between the amount of property insurance loss compensation and the observation year, as well as a correlation between the amount of property insurance loss compensation and the regional economy GRP. Furthermore, the residual error of the amount of property insurance loss compensation fitted from a single region does not exhibit a special trend. Then, the following skew-normal linear mixed model expression is obtained by
where, Ytn represents the claim for property insurance loss with time t and regional category change n, and the constant term β0 denotes the fixed effect variable. The random effects include the constant term bon, the observation year b1n and the regression coefficient β1 of the observation region. It mainly manages the correlation between different observation years and the observation regions. The value of the observation year is (Year-5) /10, which is convenient for calculation and statistics. Three different distribution models of random effects and random errors are adopted in this study to make a comparative analysis.
Model 1: The random error term en = (e1n,…, e10n)T and the random effect are assumed to obey the multivariate skew-normal distribution model;
Model 2: A model with the random error term en = (e1n,…, e10n)T for a multivariate normal distribution, and the random effect for the multivariate skew-normal distribution model;
Model 3: The response variable is the logarithm of premium claims, random effects and random errors obey the Gaussian distribution model.
The prior distributions of the same parameters of the three models are assumed to be the same to perform comparative analysis. This study is based on a large variance. The prior distribution of the fixed effect is set to independent distribution γ0 ~ N (0,102), and the prior distribution of the scale parameter of the error distribution is set to σe2 ~ IG (0.01,0.01). Hence, the mean value of the distribution is 2. The prior distribution of the scale matrix of the prior distribution dn of random effects is considered inverse Wishart distribution ∑ ~ IW2 (I2); the skewness parameter is assumed to αe ~ N (0,102) I{αe > 0}, αb0 ~ N (0,102) I{ab0 > 0}, and αb1 ~ N (0,102) I{ab1 > 0}. It is demonstrated that the results of the analysis are quite robust since all previous considerations are based on large variances.
4.2.3 Data Analysis
The 40,000 iterations were conducted after the previous 10,000 iterations were abandoned, so as to analyze the data. The lag value is set as 5 to avoid the related problems in the generation chain. The JAGS programming code in Model 1 is provided in the appendix, and the posterior estimation average of model parameters are presented in Table 4.
The results of parameter estimation (posterior mean) are listed in Table 4. Following the analysis of the Table 4, BIC and DIC criteria suggest that model 1 is most suitable for data.
Figure 9 provides the Markov data chain and posterior distribution sample frequency histogram of some parameters in Model 1. As observed in Figure 9, the skewness parameter is closer to 0.5, and the error confidence interval is relatively narrow. It can be seen from the figure that there is no convergence problem in the chain generated by the parameters. Figure 10 exhibits the comparison curve between the estimated value and the real value of each region. The analysis results in Figure 10 reveal that the values of the two curves are very close, and the changing trends are consistent. Hence, Model 1 has a high fitting degree.

Sample chain of simulated data (left image) and histogram of posterior distribution of parameters (right image). a is Identified as σe2 Sample chain, b is Identified as σe2 posterior distribution histogram, c is Identified as β0 Sample chain, d is Identified as β0 posterior distribution histogram, e is Identified as D11 Sample chain, f is Identified as D11 posterior distribution histogram, g is Identified as αb0 Sample chain, h is Identified as αb0 posterior distribution histogram

Comparison of actual values and fitting values for each region
Figure 11 demonstrates the prediction values of regional property insurance loss claims in the following 3 years. The previous analysis implied that the insurance loss claims significantly varied in different regions, and the insurance loss claims generally changed little in small regions, otherwise changed dramatically. The development trend of insurance loss claims in Figure 9 meets this result analysis.

Forecast value of property insurance claims in regions in the next 3 years
In summary, the proposed Bayesian SNLMM model has superior performance in intra-sample fitting and sample prediction and provides a reasonable model to analyze the influence of covariates.
5 Discussions
An essential aspect of analyzing insurance loss claim data is that they tend to follow a skew distribution, because extreme events are not uncommon and exhibit a heavy tail. A Bayesian linear mixed model is proposed in this paper. Its random effects and random errors belong to skew-normal distribution. This model can identify non-normal and asymmetric behaviors that may occur in the random errors or effects. Firstly, the methods used and the Bayesian skew-normal linear mixed model are introduced. Secondly, the data fitting results of logarithmic linear mixed model and Bayesian skew-normal linear mixed model are compared based on the dataset of American Employers liability industrial insurance to empirically tests the superiority of the Bayesian skew-normal linear mixed model (Pure premium is the response variable). Finally, the Bayesian SNLMM model is applied to the property insurance loss dataset in mainland China to explore the relationship between insurance claims and the regional economy GRP and predict insurance loss claims.
The results of this study suggest that both the US employer liability insurance claim dataset and the Chinese mainland property insurance loss dataset have complicated characteristics of right deviation and heavy tail. As revealed by asymmetric pure premium panel data analysis, the Bayesian skew-normal linear mixed model has a more accurate fitting effect and higher data accuracy compared with the logarithmic linear mixed model. The research based on property insurance loss claim datasets demonstrates a certain linear relationship between regional economy and insurance claims, and the trend is consistent. It is assumed that the first model simulation is more advantageous among the three different linear mixed models. Then, the insurance loss claims in different regions in the next 3 years present a trend of first decreasing and then increasing. This flexibility that other linear models cannot achieve highlights the advantages of Bayesian methods over existing actuarial models.
In previous linear mixed model research, a robust reasoning method using heavy tail distribution is proposed. For example, Pinheiro and Vidakovic [31] used maximum likelihood to describe the robust Gaussian LMM model proposed by Laird and Ware [28]. They assumed that the distribution of errors had the same degree of freedom as the distribution of random effects, and the random effects were independent. Two different stochastic processes are difficult to be controlled by the same degree of freedom parameters. The method designed in this paper can solve this problem by allocating different parameters. Modeling by modifying the known distribution is a hot topic. Many alternative structures of Arellano-Valle et al. [23] are based on Genton [10]. In this study, the structure proposed by Arellano-Valle et al. [23] is selected mainly for simple calculation.
The fourth section analyzes the Frees data case. When the data is converted, some information may be lost. The fitting results between the models are not much different, and the superiority of the skewed distribution model is not fully reflected. When analyzing data directly, the fitting results and residual values of the SNLMM model are more accurate. Although the related density function is difficult to handle, the MCMC method can easily fit the model. This method can be implemented on computing by using simple and accessible software (such as R language, WinBUGS). Other skewed distribution variants currently available are not so easy to implement. The MCMC method and standard information standards are very effective in identifying correct normal asymmetric models, as shown in simulation studies. A relatively large advantage of this model is that it can give more flexible assumptions about the random effects and random errors of the model. However, when applying the SNLMM model to analyze the data, the prior distribution of the parameters considered is close to the non-informative distribution, that is, the prior distribution with large variance is considered, and the model is suitable for asymmetric longitudinal data.
To sum up, the same method can also be applied to other types of data, and these data have similar skewness characteristics. In other words, the Bayesian SNLMM model for objective Bayesian analysis of data, including parameter distribution and prior, is applicable to other disciplines, such as engineering and environmental science.
6 Conclusions
Forecasting fire insurance loss claims is a critical part of rate determination analysis. However, the insurance rates calculation is still in the exploring stage for fire insurance loss claim data, which usually has a characteristic of right skew and heavy tail and is difficult to be described by the traditional normal distribution linear mixed model.
In this paper, an asymmetric fire insurance loss claim prediction model is proposed by combining the Bayesian method with the skew-normal linear mixed model. Based on the traditional linear mixed model, it is assumed that the random effects and random errors obey the skew-normal distribution. Then, it can describe the complicated characteristics of skewness and the heavy tail of insurance loss claim data. Moreover, the Bayesian MCMC method is adopted to estimate the model parameters, and the posterior parameter mean estimation is obtained using Gibbs sampling, contributing to addressing complicated operational problems. These improvements have achieved better results compared to the normal linear mixed model in theory and practice.
Additionally, the proposed Bayesian SNLMM model has been validated on two property insurance loss claims datasets, including the latest insurance data statistics. Firstly, this model demonstrates better goodness of fitting for pure premium data, better data interpretation ability, and lower DIC compared with the log linear mixed model. Secondly, in the process of predicting the number of fire insurance claims, the accuracy of the model is high, and the influence of different data characteristics is small. Finally, the method estimates parameter samples by simple and easy-to-use software (such as R language, WinBUGS). The Bayesian skew-normal linear mixed model can describe the specific form of claim data in different categories by identifying skew patterns. This model has great flexibility and is suitable for modeling and analysis in various complicated situations.
In addition, the estimation model proposed in this paper also has shortcomings and needs further study. Firstly, the random model of different factors in MCMC simulation is explored to reduce the influence of variable weight structure and improve the accuracy. Secondly, when the model is applied to the prediction of fire insurance loss claim data, it is necessary to directly model and analyze the original longitudinal data to improve the accuracy of data prediction.
References
Zhang D, Davidian M (2001) Linear mixed models with flexible distributions of random effects for longitudinal data. Biometrics 57(3):795–802. https://doi.org/10.1111/j.0006-341X.2001.00795x
Ghidey W, Lesaffre E, Eilers P (2004) Smooth random effects distribution in a linear mixed model. Biometrics 60(4):945–953. https://doi.org/10.1111/j.0006-341X.2004.00250x
Frees EW, Young VR, Luo Yu (2001) Case studies using panel data models. North Am Actuarial J 5(4):24–42. https://doi.org/10.1080/10920277.2001.10596010
Ahn S, Kim JHT, Ramaswami V (2012) A new class of models for heavy tailed distributions in finance and insurance risk. Insurance: Math Econ 51(1):43–52. https://doi.org/10.1016/j.insmatheco.2012.02.002
Huang Y, Meng S (2020) A Bayesian nonparametric model and its application in insurance loss prediction. Insurance: Math Econ 93:84–94. https://doi.org/10.1016/j.insmatheco.2020.04.010
Escobar DD, Pflug GCh (2020) The distortion principle for insurance pricing: properties, identification and robustness. Ann Oper Res 292(2):771–794. https://doi.org/10.1007/s10479-018-3119-1
Azzalini A, Capitanio A (1999) Statistical applications of the multivariate skew-normal distribution. J R Stat Soc 61(3):579–602. https://doi.org/10.1111/1467-9868.00194
Capitanio A, Azzalini A, Stanghellini E (2003) Graphical models for skew-normal variates. Scand J Stat 30(1):129–144. https://doi.org/10.1111/1467-9469.00322
Sahu SK, Dey DK, Branco MD (2003) A new class of multivariate skew distributions with applications to Bayesian regression models. Can J Stat 31(2):22
Arellano-Valle RB, Genton MG (2005) On fundamental skew distributions. J Multivar Anal 96(1):93–116. https://doi.org/10.1016/j.jmva.2004.10.002
Huang Y, Chen R, Dagne G, Zhu Y, Chen H (2015) Bayesian bivariate linear mixed-effects models with skew-normal/independent distributions, with application to aids clinical studies. J Biopharm Stat 25(3):373–396. https://doi.org/10.1080/10543406.2014.920660
Jung D, Lee J (2017) New composite distributions for insurance claim sizes. Kor J Appl Stat 30(3):363–376. https://doi.org/10.5351/KJAS.2017.30.3.363
Bandyopadhyay D, Lachos VH, Castro LM, Dey DK (2012) Skew-normal/independent linear mixed models for censored responses with applications to HIV viral loads: skew normal/independent censored linear mixed models. Biom J 54(3):405–425. https://doi.org/10.1002/bimj.201000173
Huang Y, Chen J (2016) Bayesian quantile regression-based nonlinear mixed-effects joint models for time-to-event and longitudinal data with multiple features: quantile regression joint models for event time-longitudinal data. Stat Med 35(30):5666–5685. https://doi.org/10.1002/sim.7092
Leisen F, Miguel Marin J, Villa C (2017) Objective Bayesian modelling of insurance risks with the skewed student- t distribution: F Leisen, J. Miguel Marin and C. Villa. Appl Stochastic Models Bus Ind. https://doi.org/10.1002/asmb.2227
De Simone A, Piangerelli M (2020) A Bayesian approach for monitoring epidemics in presence of undetected cases. Chaos, Solitonsand Fractals 140:110167. https://doi.org/10.1016/j.chaos.2020.110167
Jara A, Quintana F, Martín ES (2008) Linear mixed models with skew-elliptical distributions: a Bayesian approach. Comput Stat Data Anal 52(11):5033–5045. https://doi.org/10.1016/j.csda.2008.04.027
Scollnik DPM (1993) A Bayesian analysis of a simultaneous equations model for insurance rate-making. Insurance: Math Econ 12(3):265–286. https://doi.org/10.1016/0167-6687(93)90238-K
BermúdezBermúdez L, Karlis D (2011) Bayesian multivariate Poisson models for insurance ratemaking. Insurance: Math Econ 48(2):226–236. https://doi.org/10.1016/j.insmatheco.2010.11.001
Esmaeili H, Klüppelberg C (2010) Parameter Estimation of a bivariate compound poisson process. Insurance: Math Econ 47(2):224–233. https://doi.org/10.1016/j.insmatheco.2010.04.005
Moreno-Jiménez JM, Salvador M, Gargallo P, Altuzarra A (2016) systemic decision making in AHP: A Bayesian approach. Ann Oper Res 245(1–2):261–284. https://doi.org/10.1007/s10479-014-1637-z
Klugman SA (1992) Bayesian statistics in actuarial science: with emphasis on credibility. Kluwer Academic Publishers, Boston
Arellano-Valle RB, Bolfarine H, Lachos VH (2007) Bayesian inference for skew-normal linear mixed models. J Appl Stat 34(6):663–682. https://doi.org/10.1080/02664760701236905
Gelman A, & Rubin DB (1992) Inference from iterative simulation using multiple sequences. Stat Sci 7(4):457–472. https://doi.org/10.1214/ss/1177011136
China Statistics Bureau (INP) 2011–2020. Population figures. http://www.stats.gov.cn/tjsj/ndsj/. Accessed 1 March 2022
Bernardi M, Maruotti A, Petrella L (2012) Skew mixture models for loss distributions: a Bayesian approach. Insurance: Math Econ 51(3):617–623. https://doi.org/10.1016/j.insmatheco.2012.08.002
Miljkovic T, Grün B (2016) Modeling loss data using mixtures of distributions. Insurance Math Econ 70:387–396. https://doi.org/10.1016/j.insmatheco.2016.06.019
Laird NM, Ware JH (1982) Random-effects models for longitudinal data. Biometrics 38(4):963. https://doi.org/10.2307/2529876
Spiegelhalter DJ, Best NG, Carlin BP, van der Linde A (2002) Bayesian measures of model complexity and fit. J R Stat Soc B 64(4):583–639. https://doi.org/10.1111/1467-9868.00353
Yuan L, Ya Yan Lu (2021) Conditional robustness of propagating bound states in the continuum in structures with two-dimensional periodicity. Phys Rev A 103(4):043507. https://doi.org/10.1103/PhysRevA.103.043507
Pinheiro A , Vidakovic B (1997) Estimating the square root of a density via compactly supported wavelets. Comput Stat Data Anal 25. https://doi.org/10.1016/S0167-9473(97)00013-3
Acknowledgements
The authors would like to acknowledge the financial support of Natural Science Foundation of Hebei Province (G2021507001) and China People’s Police University Project (2019sycxpd006). The authors would also like to thank Intelligent Transportation Institute of Zhejiang Communication Investment Group Co., Ltd. for their great help.
Funding
The research is funded by Natural Science Foundation of Hebei Province (G2021507001) and China People’s Police University Project (2019sycxpd006).
Author information
Authors and Affiliations
Contributions
MG: Conceptualization, Methodology, Software, Validation, Formal analysis, Writing—original draft. ZM: Revising the manuscript critically for important intellectual content. DZ: Validation. JR: Formal analysis. SZ: data Investigation.
Corresponding author
Ethics declarations
Competing interest
The authors declare that there is no conflict of interests regarding the publication of this article.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
To obtain the marginal distribution of Yj, we drop the subscript j, corresponding to the j the group (or individual) to simplify notation. From Eqs. (5, 6) and the definition of skew-normal multivariate distribution in Eq. (3) with k = n and D = diag (δ), it follows that the marginal density of Y is obtained by computing the following integral:
For which the following proposition will be used.
The values of standard information standards in the SNLMM model can be used to detect deviations from normal conditions, which will be seen in the simulation study. The specific algorithm is as follows.
Let \(Y_{i} = {\mathbf{X}}_{i} {{\varvec{\upbeta}}} + {\mathbf{Z}}_{i} {\mathbf{b}}_{i} + \epsilon_{i}\),where \(b_{i} \mathop \sim \limits^{iid} SN_{q} \left( {0,\Sigma ,\alpha_{b} } \right)\) and \(\varepsilon_{i} \mathop \sim \limits^{ind} SN_{ki} \left( {0,\Sigma_{i} ,\alpha_{ei} } \right)\) are independent. Then, the marginal distribution of Yi is given by
where
Thus, denoting the log-likelihood function for θ and λ given the observed sample y = (y1T,…, ymT) T by \(\ell ({{\varvec{\uptheta}}},{{\varvec{\uplambda}}}|{\mathbf{y}})\), it can be written as
The results are important because it allows to find values of standard information criteria which may be used to detect departures from normality, as shown in the simulation study. Besides, a closing form of this likelihood may be used to carry out classical inference with standard optimization techniques. For instance, in the R software, the mvtnorm package and the optim routine.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Gong, M., Mao, Z., Zhang, D. et al. Study on Bayesian Skew-Normal Linear Mixed Model and Its Application in Fire Insurance. Fire Technol 59, 2455–2480 (2023). https://doi.org/10.1007/s10694-023-01436-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10694-023-01436-1