
Abstract
This paper seeks to identify the causal impact of educational human capital on social distancing behavior at workplace in Turkey using district-level data for the period of April 2020 - February 2021. We adopt a unified causal framework, predicated on domain knowledge, theory-justified constraints anda data-driven causal structure discovery using causal graphs. We answer our causal query by employing machine learning prediction algorithms; instrumental variables in the presence of latent confounding and Heckman’s model in the presence of selection bias. Results show that educated regions are able to distance-work and educational human capital is a key factor in reducing workplace mobility, possibly through its impact on employment. This pattern leads to higher workplace mobility for less educated regions and translates into higher Covid-19 infection rates. The future of the pandemic lies in less educated segments of developing countries and calls for public health action to decrease its unequal and pervasive impact.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
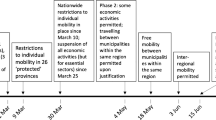
With the outbreak of Severe Acute Respiratory Syndrome Coronavirus 2 or SARS-CoV-2 in December 2019, leading to Covid-19, the cumulative number of cases reached 596 million and the cumulative death toll has risen to 6.45 million worldwide as of August 2022. Countries adopted different nationwide and local measures to mitigate the impact of Covid-19. On April 11, 2020, new daily cases peaked at 5,138 and Turkey implemented a series of partial lockdown episodes that lasted until the end of May 2020. By the re-opening of business activity in June, daily mobility soared and accelerated the transmission of the virus. The government reported a record high daily cases of 30,000, placing Turkey among the top three countries worldwide as of December the 2nd. This second wave is followed by a semi-restrictive lockdown period until the beginning of March 2021 after which government started to implement place-based re-opening and imposed restrictions based on provincial risk levels. This short-lived re-opening period resulted in a record jump of new daily cases (approximately 60,000), placing Turkey the highest daily case reporting country in Europe and the second highest in the World. As the country is riding out the fourth wave, the cumulative number of cases reached 16.7 million and the death toll has risen to 100,000 in Turkey, as of August 2022.
Following the onset of the Covid-19 pandemic, scholarly literature examined the impact of mobility on the spread of the pandemic. Human mobility manifests as a key cause of the rapid spillover of the pandemic across European countries (Iacus et al. 2020) and policy measures to control and reduce mobility is an important part of the containment of the spread of Covid-19 (Cartenì et al. 2020; Kraemer et al. 2020). An examination of Europe and US policy responses during the first wave of the pandemic suggests that policy measures to control daily mobility reduce Covid-19 transmission within two to five weeks (Cot et al. 2021). Specifically, evidence shows that countries that provide income support to reduce workplace mobility are successful in reducing Covid-19 transmission (Asfaw 2021). Such policy measures alleviate the burden on the healthcare system of countries (Anderson et al. 2020; Atkeson 2020).
The existing imbalance in labor markets and the historical origins of disparities make Turkey a good candidate for understanding the background of the link between workplace mobility and Covid-19 transmission. This study focuses on extracting, devising and identifying the causes of mobility and understanding the causal mechanisms at the smallest geographic unit of observation possible (district-level) through which human mobility can be reduced by policy interventions. We argue that districts with higher education levels are more flexible in adjusting themselves to distance work and potentially more likely to realize lower workplace mobility. Identifying the causes of mobility and the modus operandi of these factors are the building blocks of sound policy prescriptions to mitigate the detrimental impact of Covid-19 on the socio-economic environment of localities.
Given the discussions on class-based sources of mobility, the virus is far from being an equalizer: the pandemic disproportionately affects certain socio-economic classes, employment groups and industries. While white-collar employees with higher education levels are able to distance-work and therefore exhibit lower workplace mobility, blue-collar and less educated employees whose physical presence in the workplace is essential continue to work face-to-face to sustain their jobs and income. This results in higher mobility for the latter working class. Understanding the varying adjustment capacity of different segments of the society is essential in constructing an adequate policy mix to mitigate the pervasive and unequal impact of the pandemic.
Motivated by these facts, our objective is to unravel the role of human capital and the causal mechanism behind mobility amid the pandemic. We are concerned about the extent to which education, as a form of human capital, causes changes in mobility. We also aim to investigate the causal mechanisms and the particular causal process through which the effect of education on Covid-19 mobility comes about. The findings of our study help identify high-risk groups and guide policy makers to consider social policies to support the most vulnerable segments of the society.
Various dimensions of the consequences of Covid-19 pandemic have been investigated. Outside of labor market, a number of papers focus on the impact of the pandemic on consumer behavior (Safara 2020), stock markets (Alsayed 2022; Gupta et al. 2021), bank demand deposits (Cherrat and Prigent 2022), inter-country Covid-19 incidence prediction (Basu and Sen 2022) and spatial interactions (Zhang and Zhang 2022) whereas others focus on gender gap (Ham 2021), labor market structure and occupational differences (Cortes and Forsythe 2020; Kikuchi et al. 2021). Yet, our knowledge on the causes of the spread of the pandemic from a labor market perspective is still limited. Besides, mobility and education are seldom linked at the very local level (district) in a causal setup to understand the background of Covid-19 transmission. Local policy construction, which limits the capacity to mitigate the pandemic, is challenging because of a lack of district-level data on Covid-19 incidence in countries like Turkey. Our approach is instrumental for how socio-economic and policy-sensitive factors can be used to understand the black box behind the local spread of the pandemic. Therefore, more effort will be required in the future to evaluate the extent to which socioeconomic and demographic regional composition has explanatory power in order to assess the gravity of health care crises.
In Sect. 2, we develop a causal framework using a set of directed acyclic graphs (\(\mathrm {\textbf{DAG}}\)). Specifically, Sect. 2.1 lays out our background knowledge on the causes of workplace mobility; Sect. 2.2 performs a constraint-based causal discovery algorithm to help build a \(\mathrm {\textbf{DAG}}\), in conjunction with our knowledge; Sect. 2.3 states our causal query and search for admissible sets to identify the causal effect of interest using d-separation and do-calculus that serves as the building blocks of our subsequent analyses. In Sects. 2.4 and 2.5, we assess our causal query in the presence of latent confounding and sample selection, respectively. Sect. 3 presents the data and lays out our empirical strategy. Section 4 reports the results; and Sect. 5 concludes. We relegate a number of robustness checks and sensitivity analyses to the appendix.
2 Causal Graph Analysis
In order to understand the modus operandi of the causes of workplace mobility in Turkey, we invoke a causal graph analysis using \(\mathrm {\textbf{DAG}}\) (Pearl 1995, 2000). A \(\mathrm {\textbf{DAG}}\) shows the importance of specific types of endogenous variables of a system of causal relations in a nonparametric framework and consist of a set of nodes and directed edges where causation is unidirectional (i.e. no reverse causation).
However, the construction of an approximately correct \(\mathrm {\textbf{DAG}}\) is a complex process. Even with background knowledge, \(\mathrm {\textbf{DAG}}\) construction is challenging due to latent confounding that may not be known to exist. Further, there may be a plethora of models that are compatible with background knowledge and conditional independencies, but that may lead to entirely different causal inferences (Scheines et al. 1998). For this purpose, we first lay out our background knowledge to provide theory-justified constraints and then use a data-driven causal structure discovery algorithm to help assist in our \(\mathrm {\textbf{DAG}}\) construction.
2.1 Background Knowledge
Used throughout the paper, the following notation lists all nodes or causal variables that we are able to identify, given our research, and that are theoretically good candidates to examine the impact of education of workplace mobility. The observability of the node is determined upon the availability of data for that node/variable whose details are given in Sect. 3.1.
Notation 1
Observable nodes/variables:
\(M_{j}:\) workplace mobility at period j (outcome), \(j=1,2,3\)
X : education (exposure)
D : population density
N : total population
O : elderly composition
Y : income (wage proxy)
P : lockdown policy measure (period 1 only)
F : fertility
S : sample selection
Notation 2
Unobservable nodes/variables:
W : wages
L : employment (share of blue/white collar or teleworkable/non-teleworkable employees)
C : past information on confirmed cases or deaths
E : past education policies
U : latent confounder between any two nodes
R : bundle of sample selection constraints
The following fourteen propositions state our background knowledge on observable and unobservable causes, defined above. Whenever possible, we comment on the sign of the edge.
Proposition 1
(Required edge) Our main hypothesis is that education (X) affects workplace mobility (\(M_{j}\)) indirectly through unobservable employment L (\(X\rightarrow L\rightarrow M_{j}\)). L could be the share of blue/white collar employees or the share of teleworkable/non-teleworkable employees. Higher human capital should increase the share of white-collar employment (\(X\overset{+}{\rightarrow }L\)). Teleworkable or white-collar individuals are more likely to restrict their workplace mobility relative to factory employees whose physical presence in the work environment is essential or required. Therefore, places with higher share of white-collar employees should exhibit lower workplace mobility (\(L\overset{-}{\rightarrow }M_{j}\)). Since the sign of every directed path is the product of the signs of the edges that constitute that path (VanderWeele and Robins 2010), it must be the case that higher human capital reduces workplace mobility (\(X\overset{-}{\rightarrow }M_{j}\)).
Proposition 2
By virtue of Mincer’s earnings function, educated individuals are more likely to earn higher wages W (\(X\overset{+}{\rightarrow }W\)) (Mincer 1958, 1974). Since W is unobservable in this model due to lack of data, node Y acts as a measured proxy for W (\(W\overset{+}{\rightarrow }Y\)). This suggests that \(X\overset{+}{\rightarrow }Y\). There might be unobservable common causes of W and X (\(W\leftarrow U_{WX}\rightarrow X\)). Examples include skills, ability and intelligence.
Proposition 3
There is no causal relation between W and \(M_{j}\) although places of higher wages would show lower workplace mobility. Recent evidence shows that workers in lowest paying jobs in the US have less chance to work distantly and are among the most-affected ones from the pandemic (Papanikolaou and Schmidt 2020). The only reason we observe an association between wages and workplace mobility is due to employment, L that causes both wages W and mobility, \(M_{j}\) (\(M_{j}\leftarrow L\rightarrow W\)).
Proposition 4
(Required edge) One direct objective of policy measure P is to inhibit Covid-19 transmission in the population through lockdown and stay-at-home orders (\(P\overset{-}{\rightarrow }M_{1}\)) (Lytras and Tsiodras 2020). However, there might be latent common causes of P and \(M_{1}\). For example, past information on confirmed cases or deaths, C, would cause the government to impose lockdowns and stay-at-home orders (\(C\overset{+}{\rightarrow }P\)). Past Covid-19 cases would also cause individuals to restrict mobility voluntarily (\(C\overset{-}{\rightarrow }M_{1}\)) (Chernozhukov et al. 2021).
Proposition 5
Places of greater elderly population share tend to be less mobile because older individuals are more likely to have to comply with restricted mobility due to high risk of infection and/or age-induced restrictions on daily activities (\(O\overset{-}{\rightarrow }M_{j}\)). Evidence shows that countries with higher elderly population are at a greater risk of SARS-CoV-2 infection (Oztig and Askin 2020; Ferguson et al. 2020; Glynn 2020).
Proposition 6
Following the outbreak, large-scale policy measures, such as lockdowns, stay-at-home orders, business closures and mandatory mask use may be implemented based on population density with increases in the population implying higher density (\(N\overset{+}{\rightarrow }D\overset{+}{\rightarrow }P\)).
Proposition 7
Individuals in populated or high-density areas more prone to be infected with SARS-Cov-2 virus (Carozzi 2020). Therefore, we expect dense and more populated regions to show lower workplace mobility due to high risk of SARS-CoV-2 transmission in congested areas, (\(D\overset{-}{\rightarrow }M_{j}\overset{-}{\leftarrow }N\)).
Proposition 8
A central dimension of urban economics is the circular links among urbanization, education and wages (Glaeser and Mare 2001). Places of higher density (D) would show higher wages (W) and higher education levels (X) due to a multitude of mechanisms: (1) D may be a direct cause of W or X (\(D\overset{+}{\rightarrow }W\), \(D\overset{+}{\rightarrow }X\)) and/or (2) accumulated human capital and/or wealth may induce individuals to move to metropolitan areas (i.e. agglomeration or urbanization effect). This suggests that either W and/or X is a direct cause of D (\(W\overset{+}{\rightarrow }D\), \(X\overset{+}{\rightarrow }D\)) or W and X are related by a third factor that causes both (\(D\leftarrow U_{DW}\rightarrow W\) and \(D\leftarrow U_{DX}\rightarrow X\)).
Proposition 9
Lockdown and stay-at-home-orders were not implemented with the aim of restricting activity in high-wage clusters. However, provinces in which these policy measures were implemented would show higher wages (W). A possible explanation is due to a third factor that causes W and P (\(W\leftarrow U_{WP}\rightarrow P\)).
Proposition 10
There is no causal relation between elderly composition (O) and education levels (X) although places of higher elderly composition would show lower education levels. We argue that O and X are related due to latent confounder (\(O\leftarrow E\rightarrow X\)). Examples include past education or past education policies.
Proposition 11
(Instrumental variable) Patriarchal structure (A) directly constrains education, X (\(A\overset{-}{\rightarrow }X\)) and indirectly boosts N through raising total fertility, F (\(A\overset{+}{\rightarrow }F\overset{+}{\rightarrow }N\)).
Proposition 12
(Instrumental variable) Age and therefore higher elderly composition is a direct cause of lower fertility rates (\(O\overset{-}{\rightarrow }F\)).
Proposition 13
(Forbidden edges) For the fact that population (P), density (D), elderly composition (O), education (X) and wage proxy (Y) are measured prior to Covid-19 workplace mobility (M) or to lockdowns and stay-at-home orders (P), M and P cannot be a cause of these variables ( ,
,  ,
,  ,
,  ,
,  ,
,  ,
,  ,
,  ,
,  ). Due to our adherence to acyclic associations, we assume that wage cannot be a cause of education (
). Due to our adherence to acyclic associations, we assume that wage cannot be a cause of education ( ) although there might be latent confounder(s).
) although there might be latent confounder(s).
Proposition 14
(Forbidden edges, Instrumental variable) Neither fertility nor workplace mobility is the cause of the other ( ,
,  ) and neither density nor lockdown policy would cause fertility (
) and neither density nor lockdown policy would cause fertility ( ,
,  )
)
2.2 Constraint-Based Causal Structure Discovery
Our background knowledge is unfortunately half of the story: (1) there might be more latent confounding than our knowledge might identify; (2) knowledge is yet to be confirmed by data; (3) even if knowledge had been accurate and conditional independencies had been confirmed, a very large number of models may be consistent with them. Constraint-based causal discovery algorithms, in conjunction with our knowledge, help fill this gap.
Fast Causal Inference (FCI) algorithm is a constrained-based and data-driven algorithm that uses background knowledge and sample data as inputs and allows for latent confounding (Spirtes et al. 1999, 2000). FCI algorithm consists of two stages: In the first stage called adjacency phase, the algorithm starts with a complete undirected graph and performs a sequence of conditional independence tests. If two adjacent variables are judged to be independent conditional on a subset of observables, then the edge between the two is removed. The algorithm then stores the conditioning sets that led to the removal of an adjacency. In the second stage called orientation phase, FCI uses these stored conditional sets to orient as many edges as possible. The output of this two-step process is a partial ancestral graph (\(\mathrm {\textbf{PAG}}\)) (Spirtes et al. 2000). A modified version of the FCI is the Really Fast Causal Inference (RFCI) algorithm that is faster than but equally informative as the FCI (Colombo et al. 2012). One downside of causal structure discovery algorithms is that they cannot identify common latent confounders.Footnote 1
We use our background knowledge and define a minimal set of required and forbidden edges that the resulting \(\mathrm {\textbf{PAG}}\) should conform to. The required edges are simply \(X\rightarrow M_{j}\) (proposition 1) and \(P\rightarrow M_{1}\) (proposition 4). We also define a minimal set of forbidden edges. Since all observable and continuous variables (N, O, D, Y) other than the outcome M are observed before lockdown and stay-at-home-orders, the policy measure P cannot be the cause of N, O, D and Y. Similarly, the outcome M cannot be the cause of N, O, D, Y, P because both mobility M is a consequence of policy measure P and all remaining observables are measured prior to M. Finally, there should be no reverse causation that goes from the wage proxy Y to education X (proposition 13).
We partitioned our workplace mobility measure into three periods on the grounds that each implies a distinct large-scale policy regime that may have a unique behavioral impact on M. On April 11, 2020, Turkish government imposed a series of lockdowns, first four of which were effective in all 30 metropolitans and the province of Zonguldak and sealed-off inter-province mobility. All restrictions were lifted on June 1, 2020 and this period lasted until November 30, 2020. On December 1, 2020, a partial lockdown was introduced, implementing stay-at-home orders on weekdays between 9:00 PM and 05:00 AM and on weekends starting from Friday 09:00 PM until Monday 05:00 AM. Therefore, the first period is the most restrictive and spans the interval of 11 April - 31 May 2020; the second period is the most lenient and spans the interval of 1 June 2020 - 30 November 2020 and the third period is not as restrictive as the first or as lenient as the second period and spans the interval of 1 December 2020 - 28 February 2021.
The RFCI algorithm is performed separately for each period on the grounds that large-scale cross-section-invariant policies that characterized each period (measured), or any other period-specific events (unmeasured) may have behavioral implications on how demographic attributes could have affected mobility. This implies that any edge that distinguishes a \(\mathrm {\textbf{PAG}}\) of period j from a \(\mathrm {\textbf{PAG}}\) of period i should include an incoming arrow to M. For any pair of observables, say A and B that are invariant across periods (i.e. any node but M), it seems inconceivable to think of a (un)directed edge between A and B (if any), however it may be defined, to change from period to period. On the other hand, the outcome M varies across periods. Therefore, it seems plausible that a discovered (un)directed edge with an incoming arrow to M in period j does not need to hold in period i.
The results of the causal structure discovery are displayed in Table 1. The RFCI algorithm uses conditional Gaussian likelihood ratio (CGLR) test to determine conditional independence among the observables.Footnote 2 The second column for each period shows a synthesis of the edges produced by the algorithm and our knowledge to construct our \(\mathrm {\textbf{DAG}}\). Each line in Table 1 shows the type of edge between any pair of observables for which data are used as input.Footnote 3 A detailed explanation of the type of edges is given in footnote of Table 1. Notice that any edge that involves P only appears for period 1. The reason is that a cross-sectionally-varying policy regime was implemented during period 1 only. Therefore such edges are absent for periods 2 and 3, indicated by “NA” in Table 1.
Overall, the edges produced by the discovery are by and large in line with our background knowledge albeit they are not perfectly aligned with our propositions. As a result, two types of inconsistent patterns emerge. The first type (type I) consists of those our background knowledge suggests yet not discovered by the algorithm. The second type (type II) consists of those our background knowledge did not identify yet discovered by the algorithm. For all type II patterns, we abide by the results of the discovery. These edges are shown in the last five rows of Table 1. For type I patterns, we abide by our knowledge whenever such knowledge is either required to meet conditional independencies in the resulting \(\mathrm {\textbf{DAG}}\) (type I-A), or strong enough not to be overruled by the discovery (type I-B). Otherwise, we abide by the discovery.
Remark 1
Type I-A patterns:
Proposition 5 argues that O may cause M and/or they may be confounded. Our proposition is only confirmed by the discovery in period 3 (\(O\rightarrow M\)). However, as we show in Sect. 2.3, the edge \(O\rightarrow M\) in period 1 is imposed to meet conditional independencies.
Proposition 7 argues that N and D are causes of M; yet the edge \(N\rightarrow M\) is only confirmed by the discovery in period 2 and the edge \(D\rightarrow M\) is only confirmed in period 1. The \(N\rightarrow M\) and the \(D\rightarrow M\) edges are retained in both periods.
Remark 2
Type I-B patterns:
For the directed edge between X and M shown in the first row of Table 1, RFCI algorithm suggests that X is a possibly direct cause of M. However, by virtue of proposition 1, X indirectly affects M through the unobservable L. As we show in Sect. 2.3, whether X is a direct or an indirect cause of M has no bearing in our identification of the causal estimand since L cannot be observed.
For any edge between Y and another observable regardless of whether Y is the head or the tail of the arrow, Y must be replaced by \(W\rightarrow Y\) in our final \(\mathrm {\textbf{DAG}}\) because Y is defined as a proxy for wages W. Therefore, wages must be a mediator between X and Y(these edges are given in rows 2, 11 and 13 of Table 1).
Proposition 3 argues that L is a latent confounder of W and M. Since W is unobservable, we use the proxy for W in the RFCI algorithm, which is Y. However, causal discovery does not suggest a latent confounder between Y and M. Our synthesis keeps this latent confounding in all three periods. As we show in Sect. 2.3, whether Y and M are confounded by L has no bearing in our identification of the causal estimand.
By virtue of proposition 10, we retain a latent confounder between X and O throughout all of our final \(\mathrm {\textbf{DAG}}\)s despite such an edge is not discovered by the algorithm in any period.
By virtue of proposition 11, current fertility will always affect current population size even though this edge \(F\rightarrow N\) is not discovered by the algorithm.
The final and complete set of edges that we use for each period’s \(\mathrm {\textbf{DAG}}\)s in the following section are given in the column labeled “Synthesis” of Table 1.
2.3 Query and the Identification of the Causal Estimand
Do-calculus is a causal inference engine that takes a causal query, \(\mathrm {{\textbf{Q}}}\); a model \(\mathrm {{\textbf{G}}}\) that encodes our understanding about the structural dependencies between the variables under our study and a dataset and observable probability distributions, \(\Pr \left( \upsilon \mid \centerdot \right) \) (Hünermund and Bareinboim 2019). Our causal query is to identify the causal effect of education (X) on workplace mobility (M). While the identification of the association between X and M can be achieved by calculating the expected value of M given an observation of \(X=x\), or \(\textrm{E}\left( M\mid X=x\right) \), the identification of the causal effect of X on M requires a manipulation or intervention on X. This task inquires about the expected value of M if we make \(X=x\) and requires the use of the do-operator that can be written as \(\textrm{E}\left( M\mid do\left( X=x\right) \right) \). Our aim is to find a strategy that will enable us to remove the do-expression so that \(\textrm{E}\left( M\mid do\left( X=x\right) \right) =\textrm{E}\left( M\mid X=x\right) \). To obtain \(\textrm{E}\left( M\mid do\left( X=x\right) \right) \), the causal graph \({\textbf{G}}\) is modified by performing a surgery (i.e. removing all arrows going into X) using the do-calculus. \(\textrm{E}\left( M\mid do\left( X=x\right) \right) \) can be inferred in the post-surgery model from the joint distribution of all observables in the pre-surgery model by conditioning on a set of variables or by statistical adjustment (Pearl and Mackenzie 2018). The inference engine of our study is displayed in Fig. 1.
Fig. 2a, b and c display the associated causal graph \({\textbf{G}_{\textbf{j}}}\) that explicitly shows the unobservables W and L in the model by a gray filling.Footnote 4 Unobservable confounding is further incorporated by the bidirected dashed arcs. Among all unobservables, W and L are explicitly shown in Fig. 2a, b and c for they are critical descendants of X. Particularly, L being the mediator in the relationship between X and M provides an insight into the causal mechanism.
The following simplification transforms Fig. 2a, b and c into an equivalent causal graph by reducing the clutter of latent variables in the model.Footnote 5
Simplification 1
Let A and B be the ancestors and C, D and E be the descendants of the latent node U in causal graph \({\mathcal {G}}\). Then, U can be transformed in the following way such that the resulting \(\mathrm {\textbf{DAG}}\) (marginalized \({\mathcal {G}}\) or \(\mathcal {{\textbf{m}}G}\)) is marginally equivalent (\(\underline{\underline{{\mathcal {M}}}}\)) to \({\mathcal {G}}\).


Inference engine of the study. Note The inference engine is inspired by Pearl and Mackenzie (2018)

Causal graphs \({\textbf{G}_{\textbf{j}}}\) and \({\textbf{mG}_{\textbf{j}}}\). Notes M : Covid-19 workplace mobility, X : education, W : wages (latent), Y : income (wage proxy), L : employment type (latent), P : policy measure, D : population density, O : elderly composition, N : total population. Bidirected ashed arcs signify latent confounding. Green nodes denote backdoor-admissible sets
The equivalent \({\textbf{DAG}}\)s (\({\textbf{mG}_{\textbf{j}}}\)) are given in Fig. 2b, d and f. The causal graphs imply the following sets of conditional independencies respectively for period 1, 2 and 3:



We are interested in the total effect of X on \(M_{j}\). The total effect asks what difference in workplace mobility will result if one intervenes on the level of schooling. For this purpose, all backdoor paths, that is, any path from X to \(M_{j}\) that begins with an arrow pointing to X, should be blocked. For any set to be backdoor-admissible, the following conditions must hold:
Condition 1
The backdoor admissble set should block every path between X and \(M_{j}\) that contains an arrow into X.
Condition 2
No node in the backdoor-admissible set is a descendant of X.
Consequently, the sets \(\Omega _{1}=\left\{ D,N,O,P\right\} \), \(\Omega _{2}=\left\{ D\right\} \) and \(\Omega _{3}=\left\{ O\right\} \), respectively for periods 1, 2 and 3, given in Fig. 2b, d, f satisfy conditions 1 and 2 and are backdoor-admissible. It would be a disaster to control for Y, since Y is a descendant of X in all three graphs, violating condition 2. For better visualization, all \(\mathrm {\textbf{DAG}}\)s, causal estimands and the associated models in this paper are color coordinated with red indicating the outcome, blue indicating the exposure, green indicating the minimal set of backdoor-admissible nodes or variables, magenta indicating instrumental variable, orange indicating selection variable and black indicating other nodes or variables.
Theorem 1
The causal effect of X on \(M_{j}\) is identifiable from a distribution over the observed variables \(\Pr \left( D,X,M_{j},N,O,P,Y\right) \). The causal estimand of the total effect of X on \(M_{j}\), is obtained by a backdoor adjustment with minimal admissible set \(\Omega _{j}\) for any period \(j=1,2,3\) and is given by the formula:
where \(\Omega _{1}=\left\{ D,N,O,P\right\} \), \(\Omega _{2}=\left\{ D\right\} \) and \(\Omega _{3}=\left\{ O\right\} \).
Proofs are given in section S.1.1 of the appendix. The backdoor-admissible sets \(\Omega _{j}\) are minimal in the sense that one may additionally adjust for N or O or \(\left\{ N,O\right\} \) in period 2; and D or N or \(\left\{ D,N\right\} \) in period 3.

Causal graphs \({\textbf{mG}_{\textbf{j}}^{{\textbf{Z}}}}\): IV setup. Notes M : Covid-19 workplace mobility, X : education, W : wages (latent), Y : income (wage proxy), L : employment type (latent), P : policy measure, D : population density, O : elderly composition, N : total population, F : fertility rate (instrument). Green nodes denote backdoor-admissible sets, magenta nodes denote IV-admissible sets
2.4 Latent Outcome-Exposure Confounding
The causal graphs \({\textbf{G}_{\textbf{j}}}\) do not account for the possibility of latent confounders that cause both X and \(M_{j}\). These unobservables render the causal effect of X on \(M_{j}\) unidentifiable without imposing stronger assumptions, such as shape restrictions or distributional assumptions. This situation is given in the causal graphs \({\textbf{mG}_{\textbf{j}}^{{Z}}}\), shown in Fig. 3. The bidirected dashed arc between X and \(M_{j}\) in Fig. 3a, b and c indicates a latent common cause that confounds the relationship. There is a backdoor path from X to \(M_{j}\) ( ) and it cannot be blocked since the confounder is unobservable. When backdoor adjustment is not possible, one can obtain the causal effect of X on \(M_{j}\) by an adjustment with an \(\mathrm {{{\textbf{I}}}{{\textbf{V}}}}\)-admissible set Z. For Z to be \(\mathrm {{{\textbf{I}}}{{\textbf{V}}}}\)-admissible, the following conditions must hold:
) and it cannot be blocked since the confounder is unobservable. When backdoor adjustment is not possible, one can obtain the causal effect of X on \(M_{j}\) by an adjustment with an \(\mathrm {{{\textbf{I}}}{{\textbf{V}}}}\)-admissible set Z. For Z to be \(\mathrm {{{\textbf{I}}}{{\textbf{V}}}}\)-admissible, the following conditions must hold:
Condition 3
The set \(\left\{ Z\mid \bullet \right\} \) is d-separated from \(M_{j}\) in \(G_{{\underline{X}}}\).
Condition 4
The set \(\left\{ Z\mid \bullet \right\} \) is d-connected to X.
Condition 5
No node in the set \(\left\{ Z\right\} \) is a descendant of X.
Condition 6
No node in the set \(\left\{ \bullet \right\} \) is a descendant of X.
Remark 3
For all periods, conditions 3 and 4 are satistifed by the rules of d-separation (Verma and Pearl 1988). It states that F and \(M_{1}\), \(Z=\left\{ F,O\right\} \) and \(M_{2}\) and F and \(M_{3}\) are independent of each other given X, and that F and X are d-connected (not d-separated) conditional on \(\left\{ D,N,O,P\right\} \) in period 1; \(Z=\left\{ F,O\right\} \) and X are d-connected (not d-separated) conditional on \(\left\{ D,N\right\} \) in period 2; and F and X are d-connected (not d-separated) conditional on O in period 3.
The way a potential \(\mathrm {{{\textbf{I}}}{{\textbf{V}}}}\)-admissible set Z is positioned in causal graph \({\textbf{mG}_{\textbf{j}}^{{Z}}}\) relies on our background knowledge only because its validity is untestable. Stated in proposition 11, we expect fertility rate to be (strongly) correlated with education. Further, we do not conceive any channel through which fertility might be associated with workplace mobility other than education.
For all periods, conditions 5 and 6 are also satisfied because neither F nor \(\left\{ D,N,O,P\right\} \) in period 1; neither \(Z=\left\{ F,O\right\} \) nor \(\left\{ D,N\right\} \) in period 2 and neither F nor O in period 3 is a child or a descendant of X. It would be a disaster to control for Y because doing so violates conditions 3 and 6. Hence, the causal effect of X on \(M_{j}\) can be identified in the presence of latent outcome-exposure confounding. O is the minimal adjustment set and one can additionally control for D in period 3.

Causal graphs \({\textbf{mG}_{\textbf{S,j}}}\). Notes M : Covid-19 workplace mobility, X : education, W : wages (latent), Y : income (wage proxy), P : policy measure, D : population density, O : elderly composition, N : total population, L : employment type (latent), S : sample selection (=1 if selected), R : bundle of constraints (e.g. broadband access, connectivity, privacy) (latent). Green nodes denote backdoor-admissible sets
Causal graphs \({\textbf{G}_{\textbf{2}}^{{Z}}}\) do not imply any conditional independencies; however, \({\textbf{G}_{\textbf{1}}^{{Z}}}\) implies the following conditional independency:

With an \(\mathrm {{{\textbf{I}}}{{\textbf{V}}}}\)-admissible variable F or a set \(Z=\left\{ F,O\right\} \), the causal effect of X on \(M_{j}\) can be estimated only parametrically using instrumental variables methods. With a continuous instrument set Z, an exposure X and an outcome M, the \(\mathrm {{{\textbf{I}}}{{\textbf{V}}}}\) estimand at period j is \(\beta _{IV,j}=\frac{\textrm{Cov}\left( {Z_{j}},{M_{j}}\right) }{\textrm{Cov}\left( {Z_{j}},{X}\right) }\).
2.5 Selection Bias
Selection bias is a common threat to valid causal inference that jeopardizes identification. It occurs when information on the members of a population that possess specific characteristics is the only observed phenomenon (Hünermund and Bareinboim 2019). For example, Covid-19 mobility measures are reported if user settings and connectivity allowed and if privacy thresholds have been met. When the quality and privacy thresholds are not met, these mobility measures are not available for that district. This creates selection bias since sampled and non-sampled districts are likely to be systematically different from each other.
We capture selection in our causal graphs by explicitly modeling the sample selection mechanism. This situation is given in causal graphs \({\textbf{mG}_{\textbf{S,j}}}\) in Fig. 4, with two additional nodes over Fig. 2b, d and f: The first of these is the double-circled node S, which takes the value of 1 if the district is sampled and 0 otherwise. The second is the node R, which represents the bundle of constraints that determine which districts are selected and which are not. This bundle may include whether the individual has a smart phone and GSM data available for roaming, allow user settings and meet privacy thresholds. In our context, they represent the proportion of individuals having smart phone or GSM data or the proportion of individuals that meet privacy thresholds etc...
Although R is unobservable, a number of factors are likely to cause changes in R. First, a higher elderly composition (O) contributes to a lower likelihood of being selected because these individuals are less likely to use smartphones or GSM data (\(O\rightarrow R\)). On the other hand, higher density (D), higher population (N), higher income (Y) and higher education levels (X) are likely to increase one’s propensity to use GSM data and smartphone (\(D\rightarrow R,N\rightarrow R,Y\rightarrow R,X\rightarrow R\)).
Remark 4
The causal effect of X on \(M_{j}\) is recoverable from selection-biased data. The following theorem ensures recoverability of eq. (4) from selection-biased data that preserves the nonparametric nature of causal graph and follows the recoverability conditions of Bareinboim et al. (2014); Bareinboim and Tian (2015).
Theorem 2
Given external data on D, N, O, P for all districts \(i=1,\ldots ,N\), the causal effect of X on \(M_{j}\) is recoverable from selection-biased data by a generalized adjustment and is given by the formula:
where \(\Omega _{1}=\left\{ D,N,O,P\right\} \), \(\Omega _{2}=\left\{ D\right\} \) and \(\Omega _{3}=\left\{ O\right\} \).
Proofs are given in section S.1.2 of the appendix.
3 Empirical Strategy
3.1 Data and Sample
Our research uses a mix of provincial (Nomenclature of Units for Territorial Statistics 3 - NUTS-3) and district-level cross-sectional data that comes from the Turkish Statistical Office (Turkstat 2019b, c, a, 2020) and the Google mobility report (Google 2020), covering 973 districts in 81 provinces in Turkey in 2020. A detailed description of our dataset is given in Table 2.
Google workplace mobility data show the change in the length of stay at workplace compared to a baseline, measured before the outbreak. This baseline is the median for the corresponding day of the week during the five weeks between January 3 and February 6, 2020. For each period, we calculated the median value of workplace mobility (\(M_{j}\)), which is shown in the top of Table 2. Expectedly, period 1 is characterized by a sharp decline in workplace mobility with an average median percentage change from the baseline of \(-\)41.55 percent. Within two weeks following the end of lockdown, the total number of cases reached 14,297 and the total number of deaths in this two-week period was only 267. During the most lenient phase (period 2), there was still a reduction in workplace mobility, although conspicuously lenient relative to period 1. Within two weeks following the end of this period, the total number of deaths was a whopping 2900. Finally, the third period average is somewhere between the first two periods, with an average median percentage change of about -23 percent. Notice that the min. and the max. values of workplace mobility show how wildly it varies, especially in the second period with a range that indicates increases in workplace mobility. The density distribution of workplace mobility at each period is displayed in Fig. 5.

Density of workplace mobility by period
Turkish Statistical Office does not report district-level or provincial data on wages. Our socioeconomic measures consist of a wage proxy (income per capita) and our causal variable of interest, education (X), measured by mean years of schooling between the ages of 25-64. As noted above, in the absence of data on wages, the next best alternative is to gather data on district-level income. However, per capita income levels are measured at the province level due to lack of data on district-level income. Years of schooling in 2019 ranges between 5 to 13 years with an average of about 8.5 years of education. Our policy measure is exclusive to period 1 and is a multi-valued discrete variable that represents the proportion of days under lockdown in province i between 11 April and 31 May 2020.Footnote 6 The last row shows descriptive statistics for the instrumental variable that we consider in Sect. 3.3.
Our next task is to check the consistency of the conditional independencies implied by causal graphs \({\textbf{G}_{\textbf{j}}}\) and \({\textbf{G}_{\textbf{j}}^{{Z}}}\) and \({\textbf{mG}_{\textbf{j}}^{{Z}}}\)) against those in the data. If these conditional independencies are unsupported by the data, causal graphs \({\textbf{G}_{\textbf{j}}}\) should be revised. For the fact that d-separation relationships should hold by construction after causal discovery and that our background knowledge help orient undirected/undecided edges, the conditional independencies should be consistent. We test the implied conditional independencies, respectively given in eqs. (1)-(3) and eq. (5) against those of the data. The results, respectively reported in Table 3, show that the null hypothesis of conditional independency cannot be rejected even at 10% significance level.
3.2 Machine Learning (ML) algorithms
In the absence of latent exposure-outcome confounding, the causal effect of education on mobility can be estimated using ML algorithms. These tree-based ensemble algorithms have a number of advantages over the others. First, they are nonparametric and do not require distributional assumptions about the data. Second, they can handle skewed, multi-modal or categorical variables. Third, they are quite robust to overfitting, multicollinearity, outliers and noise in the data. We provide a brief overview of three algorithms to answer our causal query.
Given causal graph \({\textbf{mG}_{\textbf{j}}}\), our empirical strategy uses multiple decision trees to estimate the expected value of \(M\mid do\left( X\right) \) in three types of ensembles called bagging (Random Forests), boosting (Gradient Boosting Machine)and a third ensemble that uses both (Extreme Gradient Boosting). Random forests, developed by Breiman (2001), is an ensemble technique for regression and classification that uses bootstrap aggregation, or bagging. Bagging is a combination of bootstrapping and parallel decision trees. It is built upon obtaining B bootstrap resamples of the training sample with replacement, growing a large tree, and averaging predictions from all of the trees. In the context of regression, this amounts to taking the mean of the B predictions. This procedure decreases the variance without increasing the bias.
In order to estimate the test error of the model, we invoke k-folds cross-validation (CV) technique. For this purpose, we split the data into K folds. For each iteration, we bootstrap \(K-1\) folds for training to generate B bootstrap resamples and hold one out for testing. For each bootstrap sample, we build a tree, generate “bagged” predictions for each \(K-1\) folds, compute an accuracy measure from these predictions, and average the K accuracy measures.
Generalized boosted model or gradient boosting machine (GBM), developed by Friedman (2001), repeatedly fits decision trees to improve the accuracy of the model. For each new tree, a random subset of all the data is selected using the boosting method. Boosting is a sequential machine learning algorithm that combines multiple weak learners (a model that predicts slightly better than random) into strong learners (a model that accurately predicts the outcomes). The most remarkable advantage of boosting is its ability to bypass the bias-variance tradeoff. While a highly complex model leads to a low bias at the cost of a high variance, less complex models do just the opposite. However, since the expected squared error is the sum of the squared bias and the variance, both cases lead to larger total errors. Boosting has the ability to decrease both bias and variance. For each new tree, GBM iteratively reweights the data so that data which was poorly modelled by previous trees has a higher probability of being selected in the new tree. This leads to a reduced bias. By averaging weak learners, it also decreases the variance compared to a single weak learner.
Extreme gradient boosting (xgboost), developed by Chen and Guestrin (2016), is an ensemble technique that uses both bagging and boosting. While Random Forest is non-sequential, xgboost is a sequential machine learning algorithm that combines multiple weak learners into strong learners. With boosting, decision trees are repeatedly fit to improve the accuracy of the model. This allows the algorithm to learn from prior iterations and to correct the errors in the previous ones.
3.3 Instrumental Variables (IV)
Remark 3 of Sect. 2.4 showed that there are IV-admissible sets in all periods and that the causal effects are identified. With a continuous outcome \(M_{j}\) and a continuous treatment X given causal graphs \({\textbf{mG}_{\textbf{j}}^{{Z}}}\), we fit a linear model via IV/GMM that takes into account the endogeneity of X (i.e. the correlation between X and the unobservable confounder). The first- and the second-stage regressions for each period j are respectively given as:
where i denotes districts, \(i=1,\ldots ,N\), \(X_{i}\) denotes mean years of schooling, \(M_{ij}\) denotes workplace mobility of district i at period j where \(j=1,2,3\), \(\Omega _{j}\) is a \(1\times k\) vector of included instruments that consists of \(\Omega _{1}=\left\{ D,N,O,P\right\} \) in period 1 (see Fig. 3a), \(\Omega _{2}=\left\{ D,N\right\} \) in period 2 (see Fig. 3b) and \(\Omega _{3}=\left\{ O,D\right\} \) in period 3 (see Fig. 3c), \({\textbf{Z}_{\textbf{1}}}\) and \({\textbf{Z}_{\textbf{3}}}\) are the total fertility rate (F) as the single excluded instrument, \({\textbf{Z}_{\textbf{2}}}\) is a \(1\times 2\) vector of excluded instruments that consists of total fertility rate (F) and old dependency ratio (O) and \(u_{i}\) and \(\upsilon _{i}\) are the respective stochastic disturbance terms that comprise idiosyncratic shocks, measurement errors in X and \(M_{j}\) and aggregation errors.Footnote 7
3.4 Heckman’s Sample Selection Model
Table 4 shows in fact that sampled and non-sampled districts are systematically different from each other at every period. In Sect. 2.5, the explicit modeling of selection mechanism (causal graphs \({\textbf{G}_{\textbf{S,j}}}\)) showed that the causal effect of X on \(M_{j}\), that is \(\textrm{E}\left( M_{j}\mid do\left( X\right) \right) \) is recoverable from selection-biased data. In this section, we explore another estimation strategy that imposes stronger assumptions but may be used when \(\textrm{E}\left( M\mid do\left( X\right) \right) \) is not recoverable. To deal with sample selection, we estimate the following Heckman model separately for each period j via maximum likelihood:
where \(\Omega _{j}\) is a \(1\times k\) vector of backdoor-admissible variables in period j, \(S_{ij}\) denotes non-random selection at period \(j=1,2,3\) and \(Y_{i}\) denotes the natural log of per capita GDP. Workplace mobility in period j is observed if \(\alpha _{j}+\varphi _{j}X_{i}+\lambda _{j}Y_{i}+\varvec{\Omega }_{ij}\tau _{j}+u_{ij}>0\) where \(\textrm{corr}\left( \upsilon _{ij},u_{ij}\right) =\rho _{j}\). Based on causal graphs \({\textbf{G}_{\textbf{S,j}}}\) of Fig. 4, Y affects the likelihood of observing mobility due to reasons mentioned in Sect. 2.5 but must not appear in the outcome (\(M_{j}\)) equation. This exclusion restriction is shown by the inclusion of Y in eq. (10). If \(\rho _{j}\ne 0\), the standard regression methods yield biased estimates in eq. (9).

Causal effect of X on M, Random Forests. Note Each experimental distribution shows the effect of intervening on education on the expected change in workplace mobility relative to baseline. Each observational distribution shows the effect of education on the expected change in workplace mobility, conditional on education. The prediction algorithm uses three folds for cross-validation at 5% significance level. The shaded area shows 95% basic bootstrap interval. The “experimental” distribution over the variables is generated by reweighting the observational distribution

Causal effect of X on M, Generalized Boosted Model. Note Each experimental distribution shows the effect of intervening on education on the expected change in workplace mobility relative to baseline. Each observational distribution shows the effect of education on the expected change in workplace mobility, conditional on education. The prediction algorithm uses three folds for cross-validation at 5% significance level. The shaded area shows 95% basic bootstrap interval. The “experimental” distribution over the variables is generated by reweighting the observational distribution

Causal effect of X on M, Extreme Gradient Boosting. Note Each experimental distribution shows the effect of intervening on education on the expected change in workplace mobility relative to baseline. Each observational distribution shows the effect of education on the expected change in workplace mobility, conditional on education. The prediction algorithm uses three folds for cross-validation at 5% significance level. The shaded area shows 95% basic bootstrap interval. The “experimental” distribution over the variables is generated by reweighting the observational distribution
4 Findings
Based on our identification strategy of Sect. 2.3, Sect. 4.1 reports the results of the nonparametric analyis using ML algorithms, ignoring the possible endogenous nature of education, X. Based on our identification strategy of Sects. 2.4 and 2.5, Sects. 4.2 and 4.3 respectively report the results of the parametric analysis using IV model to account for the endogenous nature of X and Heckman’s model to account for sample selection.
4.1 ML Algorithms
The total effect of education X on workplace mobility M at period j, that is \(E\left( M_{j}\mid do\left( X\right) \right) \), is shown in Figs. 6, 7 and 8, respectively for random forests, generalized boosted model and extreme gradient boosting. Figures 6b, 7b and 8b show the observational distributions and Figs. 6a, 7a and 8a show the “experimental” distributions, generated from the former using reweighting methods such as inverse probability reweighting. The descriptive statistics of the “experimental” and observational distributions are given in Tables S.1, S.2 and S.3 of the Appendix.
Both the “experimental” and the observational data are obtained using a sampling with replacement performed 500 times. The average of these values is computed to obtain, \(E\left( M_{j}\mid do\left( X\right) \right) \) and \(E\left( M_{j}\mid X\right) \) for fifty equidistant values of X (i.e. increments of 0.1553) along with a 95% confidence interval obtained via basic bootstrap (also known as reverse bootstrap percentile interval).Footnote 8 For cross-validation, both ML algorithms employ 2 folds for training the sample and hold 1 fold for testing for a total of 3 folds.Footnote 9
For all three prediction algorithms for a given period, the “experimental” distributions are similar to each other; however, they are different from their observational counterparts as a consequence of the fact that \(E\left( M_{j}\mid do\left( X\right) \right) \ne E\left( M_{j}\mid X\right) \) given causal graph \({\textbf{mG}_{\textbf{j}}}\) (See eq. (4)). On the other hand, the “experimental” distributions across periods show conspicuous differences in the ranges of M, albeit they are still similar to one another in the range of X. Between 11 April and 31 May 2020 (period 1) that covers the period from the first episode of lockdown to the reopening of businesses, the reduction in the mean workplace mobility following an intervention on education are the largest (between -30 to -50 percent). Between 1 June and 30 November 2020 (period 2) that covers the period from the reopening of businesses to partial lockdown, there is still a reduction in workplace mobility although this change is relatively small (from about -5 to -20 percent). Finally, between 1 December 2020 to 28 February 2021 (period 3) that covers the period of the onset of partial lockdown, the expected reduction in workplace mobility relative to the baseline is somewhere between those of periods 1 and 2 (between -15 to -35 percent). For all prediction algorithms and periods, the “experimental” distributions indicate that intervening on education, X, (i.e. doing X) lowers the expected change in workplace mobility relative to the baseline. Notice that for the generalized boosted model in Fig. 7b, the experimental distributions are flat for regions with an average schooling equivalent to at most a secondary school degree (\(X<7\)) and an average schooling equivalent to at least a high school degree (\(X>12\)).
Our results show that the causal impact of education varies each period, with the highest impact in the first wave; the most restrictive period. The estimate for the second period of “back to normal” with no direct public policy shows that regions with higher education levels are continuing to work remotely. On the contrary, without any direct pharmaceutical intervention, less educated districts are back at workplace and their ability to work remotely is limited.
4.2 Instrumental Variables
Table 5 reports the first- and the second-stage results of a linear IV model, along with the diagnostics reported at the bottom for each period in order to address latent confounding.Footnote 10 Education is instrumented by total fertility rate in period 1 and 3, and by total fertility and old dependency ratio in period 2. The statistically significant IV coefficients in the first-stage regressions along with high first-stage F statistics show that the excluded instruments have high explanatory power. The Anderson-Rubin weak instrument-robust inference test (Anderson and Rubin 1949) result given at the bottom of Table 5 suggests that the coefficient of education is negative and statistically significantly different from zero at conventional test levels in all periods.
The \(\mathrm {{{\textbf{I}}}{{\textbf{V}}}}\)-admissible set in period 2, \(Z_{2}=\left\{ F,O\right\} \) includes two instruments, namely, total fertility rate and the old dependency ratio. Therefore, the overidentifying restrictions can be assessed by the Hansen J statistic reported at the bottom of column (2.2) of Table 5. The Hansen J statistic shows that the instruments are uncorrelated with the unobservable factors of workplace mobility and are correctly excluded from the outcome equation.Footnote 11 Thus, the IV diagnostics provide evidence that the excluded instruments can be used to isolate the causal effect of education on mobility.Footnote 12
Next, we estimate the causal effect of X on \(M_{j}\), given causal graphs \({\textbf{mG}_{\textbf{j}}^{{Z}}}\) and the IV model and calculate \(E\left( M_{j}\mid X\right) \) for fifty equidistant values of X as before and obtain an original sample. Using the original sample, we perform a sampling with replacement 500 times and obtain a bootstrapped sample from which the mean is calculated along with a 95% confidence interval. The results are displayed in Fig. 9.
For all periods, education level has a negative causal impact on workplace mobility, supporting the main argument of the paper. However, the confidence interval for the expected change in workplace mobility in period 3, relative to the baseline, includes zero and is statistically indistinguishable from zero if district education is set anywhere below 7 years of education. This finding supports our argument, suggesting that in the third period, characterized by lenient and barely enforced restrictions, chances are low to be employed in flexible, remote jobs in regions with an average years of schooling below 7 years. Less educated segments of the society are typically employed in blue-collar jobs and are unable to benefit from a policy that aims to preserve public health by allowing some flexibility via remote working in the labor market.

Causal effect of X on M, linear IV. Note \(E\left( M\mid X\right) \) is the mean of the bootstrapped (500 replications) values accounting for endogeneity, obtained from a linear IV model (See Sect. 3.3). The shaded area shows the 95% basic bootstrap interval
4.3 Heckman’s Sample Selection Model
Columns (X.1) and (X.2) of Table 6 respectively report the estimates for the selection and the outcome equations of Heckman model for each period in order to address selection bias.Footnote 13 The Wald test of independency reported at the bottom of Table 6 shows that the use of Heckman selection model is justified for the first two periods with a negative error correlation of \(-\)0.75 and \(-\)0.38 respectively. On the other hand, the error correlation is \(-\)0.19 and evidence shows that the selection and the outcome equations are independent in period 3. The coefficient on the natural logarithm of per capita GDP in columns (X.1) of Table 6 indicates that income is an important factor in the selection mechanism. In columns (X.2) of Table 6, the magnitude of the impact of education on workplace mobility is aligned with our expectations and with the period-specific large-scale lockdown regimes although the differences in the size of the estimates are trivial: it is lowest (in absolute value) in period 1 during which a full lockdown was imposed; highest in period 2 of no lockdown and somewhere in between in period 3 during which a partial lockdown was in effect. All in all, every additional year of schooling translates into 3 percentage points drop in workplace mobility.
Given causal graphs \({\textbf{G}_{\textbf{S,j}}}\) and the outcome equation of the Heckman model, \(E\left( M_{j}\mid X\right) \) for fifty equidistant values of X is displayed in Fig. 10 along with a 95% basic bootstrap confidence interval. Again, for all three periods, workplace mobility is decreasing upon intervening on education; however, the confidence interval for the expected change in workplace mobility in period 2, relative to the baseline, includes zero and is statistically indistinguishable if district education is set anywhere below 10 years of education. Given that period 2 is devoid of any lockdown measure, districts with an average years of schooling equivalent to a university or higher degree maintain decreasing workplace mobility relative to the baseline.
The causal effect of education (X) on mobility (M) is likely to be mediated by the unobservable employment (L), \(X\rightarrow L\rightarrow M\) and declines in workplace mobility due to higher educational human capital are unlikely to realize if one considers the nature of the occupation (i.e. adjusting for L in Fig. 2 if observed). In other words, the only reason we observe declining workplace mobility as a result of accumulated human capital is probably due to the fact that educated individuals are more likely to be employed in white-collar jobs and are therefore able to distance-work and hence exhibit lower mobility. However, those with below-university or high-school degree are clustered within blue-collar or non-teleworkable occupations that require them to show up in the workplace. This pattern results in higher workplace mobility for individuals with limited human capital that translates into higher rates of Covid-19 infections. Although we cannot prove this because L is unobservable, anecdotal evidence suggests that an overwhelming proportion of Covid-19 infections are workplace-related, exacerbated by infecting family members at home.
5 Conclusion
Educational human capital is an important cause of district-level workplace mobility in Turkey. In an attempt to identify this causal effect, our analysis faces a number of threats to the validity of causal inference with purely observational data. In order to address these challenges, we first combine our theoretical knowledge and a data-driven causal structure discovery algorithm to build a number of causal graphs that make our assumptions transparent and tractable. Then, we identify the causal estimand with and without latent confounding and with sample selection. For each causal model, we assess whether the causal query can be answered using do-calculus. We show that in the absence of latent confounding, the causal effect of educational human capital on workplace mobility can be identified via do-calculus and estimated using a host of ML algorithms.
Judea Pearl notes that “an IV earns its instrumental qualities by virtue of its position in a DAG.” In order to deal with latent outcome-exposure confounding, we adopt this view and incorporate total fertility rate as a potential IV into our DAG. Although instrument validity is untestable, we substantiate the validity of the IV by our knowledge and provided a sensitivity analysis for latent confounding as well as for invalid IV (See section S.5 of the appendix). Results from both sensitivity analyses indicate that latent confounding is very likely; however, the null hypothesis of no effect can be rejected in favor of a negative impact of education on changes in workplace mobility even if the IV is invalid.
The nature of missing observations on district-level workplace mobility points out to a selection bias problem. For this purpose, we first assess whether the do-expression can be recovered from selection-biased data. Then, we invoke a Heckman sample selection model in situations in which the causal effect is not recoverable. Despite the use of observational data, our methodological framework help formulate and answer our causal query.
All three cases unequivocally show a strong and robust causal impact of education on social distancing in Turkey. Districts with higher education levels are able to adjust themselves to Covid-19 outbreak by decreasing daily workplace mobility. On the contrary, we find strong evidence that higher workplace mobility, relative to baseline, persists in less educated districts even under periods of mild non-pharmaceutical interventions (NPI). For regions with higher education levels, there is a clear, endogenous restriction of workplace mobility, lubricated by the ability to distant-work. These findings point out to the lack of equality and the vulnerability against Covid-19. Given the developing nature of the Turkish economy and the existence of a spatial duality across its territory, our findings are likely to set a precedent for other developing countries with similar developmental problems. As the global struggle with the pandemic continues, cross-country differences in the response stand as an important challenge for policy makers. Actions that disregard local imbalances in the response and mitigation capacity of developing countries stand as an obstacle for the full cohesion across the globe.
The major takeaway of our study is two-fold. First, despite higher risks of infections at work, greater physical presence or higher mobility at workplace, being the prevalent behavior due to the type of employment that is determined by low education levels, undermine public health efforts to contain the spread of the virus. Second, our study helps accelerate the changing paradigm toward incorporating graphical causal models in applied economics. Graphical causal models are not a panacea to causal inference; however, they are powerful and transparent tools to assess potential threats to inference, interventions and counterfactuals.
Some of the propositions and prior constraints on the causal structure are grounded in individual characteristics. However, our analyses are based upon ecological aggregates due to lack of individual-level data. A fundamental limitation of this study is that working with ecological aggregates of individual level characteristics with causal processes operating at the individual level may induce aggregation bias leading to ecological fallacy, that is, the causal relationships between mobility and educational attainment for the individual does not imply the same relationship will hold for the district.
First, the aggregates in this study are based on geography and district boundaries in Turkey depend on a complex set of factors such as topography or growth prospects. Second, our outcome variable, mobility, is not a determining factor of the individual’s residential choice. Individuals are more likely to factor in employment opportunities, market access, prospects for higher wages and demographic attributes in this choice. Third, the direction of causal effects estimates from aggregate data are aligned with those of the individual causal processes although the magnitude may differ. We conjecture that as long as the model is correctly specified, the aggregation bias should not be severe. We have no way of quantifying this bias; therefore our results should be interpreted in the shadow of these limitations.

Causal effect of X on M, Heckman sample selection model. Note \(E\left( M\mid X\right) \) is the mean of the bootstrapped (500 replications) values accounting for selection bias, obtained from a Heckman model (See Sect. 3.4). The shaded area shows the 95% basic bootstrap interval
An important dimension of Covid-19 pandemic is the vulnerability of different segments of the society. During the first year of the pandemic, various measures were proposed to smooth out the unequal impact of the pandemic. Social cash transfers, incentive support programs to businesses, fiscal and monetary measures to mitigate the economic impact at the macro level has been a challenge worldwide (Elgin et al. 2020). How Covid-19 creates an unequal environment at the local level remains to be explored. Human capital has been the root cause of economic development for decades (Benhabib and Spiegel 1994). The main mechanism is the productivity and technological advances as an outcome of rising education level. This growth-enhancing impact is an important motivation for many studies that investigate the economic implications of human capital differences. For one, lockdown measures and stay-at-home orders have large economic costs (Deb et al. 2022). These costs are even larger for workers with less ability to adjust to remote working, highlighted by the rising remote working experiences among more educated segments of the population (Foucault et al. 2020). In contrast, blue collar workers with lower education level are not able to continue working on a remote basis. This translates into job and income losses for the uneducated. Disregarding the local differences limits the effectiveness of social and economic policies during the pandemic. Our study allows us to define the causal mechanisms to understand how educational human capital influences mobility. It highlights the importance of human capital not only as the main determinant of economic growth but also as a core catalyst that smooths out the impact of Covid-19 on labor markets. Our results suggest that higher human capital at the local level is the cause of lower mobility, which in more educated districts, limits the exposure to the ongoing waves of Covid-19. First, the existing regional human capital differences translate into a potential vulnerability disparity between developed and less developed regions. This raises a concern about the capacity of healthcare system in less developed regions. Second, as the less educated population is less likely to adapt to remote working, they face higher job and income loss during the pandemic. This results in higher economic vulnerability for regions with lower human capital development and stands as one of the most striking long-term economic implications of the vulnerability disparities. These two points set the ground for a potential polarization between developed and less developed regions in countries with higher disparities.
The impact of educational human capital on mobility is a key tool for an inclusive policy mix in the long-run and for the future of the pandemic. Identifying the local variation in educational human capital is an important departure point for determining the vulnerability against Covid-19 pandemic. Although our research does not directly assess the role of geography, the spatial dimension is critical in designing effective policy measures to mitigate the overall impact of the pandemic.
Another limitation of our study in terms of the breadth of policy prescriptions is the unavailability of district- or provincial-level data on employment structure and Covid-19 cases and deaths. Several causal questions of contemporary policy that we were unable to tackle might have been assessed had district-level employment and Covid-19 infection data been available. Prominent examples include how employment structure could have affected social distancing behavior or health outcomes amid the pandemic or how educational human capital can help contain the spread of the virus by changing behavior through various channels.
Following vaccination efforts, a growing body of literature discussed how vaccination and other NPIs are being carried out in a harmonized manner. Recent studies assert that in addition to large effects that decrease Covid-19 transmission (Alagoz et al. 2021), vaccination has other effects on human behavior through increasing daily mobility and less willingness to use masks (Iftekhar et al. 2021; Kim and Lee 2022). This partially results from the belief of a new normalization with rising vaccine effectiveness. Moreover, vaccination also imposes a loosening of public restrictions that indirectly increases individual daily mobility. Vaccination, mobility and vaccine effectiveness are related with each other (Guo et al. 2021). Despite the success in decreasing Covid-19 transmission, its effectiveness is lower with weak NPIs. Therefore, vaccination and mobility should be used in a cohesive way to control the transmission of Covid-19 even after the vaccination surge (Huang et al. 2021). These aspects can assign changes in vaccine-related human behavior a potential role for understanding the link between human capital and mobility. However, we argue that this potential does not exist or is negligible. Even though the ongoing clinical vaccine trials are on public spot, there were no approved vaccine during the first two periods of our study. The first authorized vaccine (Sinovac) in Turkey was administered on January 13, 2021. While this might have some positive effects on people’s perception of the future of the pandemic, it is naïve to predict that this will have a mobility-increasing impact in Turkey. One reason is the slow growth of vaccination uptake in Turkey during the early 2021, exacerbated by supply-related issues with Sinovac. Second, there was a sharp fall in the effectiveness of Sinovac - the dominant vaccine in Turkey by that time - with the rise of new variants during the early 2021.Footnote 14 Therefore, even if vaccine announcements have had any impact on human behavior and mobility, it would have been limited in the Turkish case, especially during the early 2021.
As of 2022, vaccination is spreading out in the developed core and it would take more time for developing and less developed world to reach a level that will bring a sustainable normalization at workplace. Therefore, localities that fail to adjust to remote working due to low educational human capital are potential sources of a prolonged pandemic. While local variations in vulnerability can be a challenge at the country level in the short run, a full normalization at the global level seems unwarranted without a proper understanding of the spatial sources of the pandemic’s evolution.
Notes
Causal discovery is performed using Tetrad (version 6.7.1), developed by Joseph Ramsey, Clark Glymour, Richard Scheines and Peter Spirtes, available at: https://github.com/cmu-phil/tetrad.
For the fact that our sample includes a mixture of continuous and discrete variables in period 1, the CGLR test is the only available independence test. The CGLR test assumes that the continuous variables are Gaussian conditional on each combination of values for discrete variables. It works well even if the Gaussian assumption does not hold strictly. For a sample of continuous variables only, as in periods 2 and 3, another option is the kernel conditional independence (KCI) test. The KCI test is a general independence test that does not assume any functional form, including the errors. A downside of KCI is that it is slow for large samples since it relies on bootstrapping.
For any given \(\mathrm {\textbf{PAG}}\), there might exist a prohibitively large number of \(\mathrm {\textbf{DAG}}\)s, each with an identical set of conditional independencies. Therefore, our background knowledge is crucial at this point in order to reduce this number to a single \(\mathrm {\textbf{DAG}}\) for each period that is an approximately correct and accurate representation.
Causal graph analysis was performed using the Causal Fusion (beta testing) software, available at: causalfusion.net It is built on the methodology discussed in Bareinboim and Pearl (2016) and developed by Elias Bareinboim, Juan, D. Correa and Chris Jeong (login required).
The only assumption being made about latent variables is that they are non-binary.
There were a total of seven episodes of partial lockdowns in Turkey between 11 April and 31 May 2020. The first four partial lockdowns were implemented in 31 provinces between 11 April and 3 May 2020. The fifth partial lockdown covered only 24 provinces on 9-10 May 2020. The sixth partial lockdown covered 15 provinces between 16 and 19 May 2020, and the seventh lockdown covered all 81 provinces between 23 and 26 May 2020. We created a binary variable that takes the value of 1 if a lockdown is imposed in province i at day t. Then this binary variable is averaged for each province over the period of 11 April -31 May 2020 to create our multi-valued discrete policy variable.
Based on \({\textbf{mG}_{\textbf{3}}^{{Z}}}\) of Fig. 3c, as long as the linear IV model for period 3 includes O as the control variable in both stages of the IV, D and N may additionally be controlled for and doing so would not violate backdoor admissibility rules. In the final estimation of eqs. (7) and (8) for \(j=3\), we control for \(\Omega _{3}=\left\{ D,O\right\} \) for the fact that N is highly correlated with D. However, for \(j=2\), causal graph \({\textbf{mG}_{\textbf{2}}^{{Z}}}\) of Fig. 3b dictates that \(\Omega _{2}=\left\{ D,N\right\} \) should be controlled for for backdoor admissibility even though this might create multicollinearity bias. In our preliminary analysis with F being the instrument, we ran eqs. (7) and (8) controlling for O, \(\left\{ O,D\right\} \), \(\left\{ O,N\right\} \) and \(\left\{ O,D,N\right\} \) and obtained similar results on the causal effect estimate of X on \(M_{3}\).
The confidence interval of the basic bootstrap is \(2{\hat{\theta }}-\theta _{1-\alpha /2}^{*},2{\hat{\theta }}-\theta _{\alpha /2}^{*}\), where \({\hat{\theta }}\) denotes the mean and \(\theta _{1-\alpha /2}^{*}\) denote the \(1-\alpha /2\) percentile of the bootstrapped \(\theta ^{*}\) (See Davison and Hinkley 1997, eq.5.18 p.203; Tibshirani and Efron 1993, eq. 13.5 p.171 and Hesterberg 2015 eq. 3 p.381). The confidence interval of the basic bootstrap converges at a rate of \(\sqrt{N}\) (i.e. it is first-order accurate). For the problem of constructing a confidence interval for the sample mean, the bootstrap t interval can also be used. The confidence interval of bootstrap t is \({\hat{\theta }}-SEq_{1-\alpha /2},{\hat{\theta }}-SEq_{\alpha /2}\), where SE and \(q_{1-\alpha /2}\) respectively denote the standard error calculated from the original sample and the \(1-\alpha /2\) percentile of the bootstrap t-distribution (See Davison and Hinkley 1997, eq.5.7 p.194; Tibshirani and Efron 1993, eq. 12.22 p.160 and Hesterberg 2015 eq. 4 p.381). While some advocate the use of bootstrap t interval for it is shown to have optimal properties (Hesterberg 2015), this interval provides the same asymptotic correctness and narrower empirical coverage compared to basic bootstrap in finite small samples (Yonghan Jung, personal communication, January 10, 2021). The observational and the “experimental” distributions for each of the ML algorithms using the 95% confidence intervals obtained via bootstrap t are available upon request.
See section S.3 of the appendix for the sensitivity of our results to other fold values.
We use weakiv command in Stata (Finlay et al. 2013) for additional diagnostics, available at: http://ideas.repec.org/c/boc/bocode/s457684.html
Section S.5 of the appendix provides sensitivity analyses for latent confounding and invalid IV.
Heckman’s sample selection models are estimated using Stata 15/MP (Stata Corp.).
Turkey started to use mRNA vaccine Pfizer-BioNTech by April 12, 2021.
References
Alagoz, O., Sethi, A. K., Patterson, B. W., Churpek, M., Alhanaee, G., Scaria, E., & Safdar, N. (2021). The impact of vaccination to control covid-19 burden in the united states: a simulation modeling approach. PloS One, 16(7), e0254456.
Alsayed, A. R. (2022). Turkish stock market from pandemic to russian invasion, evidence from developed machine learning algorithm. Computational Economics. https://doi.org/10.1007/s10614-022-10293-z:1-17
Anderson, R., Heesterbeek, H., Klinkenberg, D., & Hollingsworth, T. D. (2020). How will country-based mitigation measures influence the course of the covid-19 epidemic? The Lancet, 395(10228), 931–934.
Anderson, T., & Rubin, H. (1949). Estimation of the parameters of a single equation in a complete system of stochastic equations. The Annals of Mathematical Statistics, 20(1), 46–63.
Asfaw, A. (2021). The effect of income support programs on job search, workplace mobility and covid-19: International evidence. Economics & Human Biology, p 100997.
Atkeson, A. (2020). What will be the economic impact of covid-19 in the us? rough estimates of disease scenarios. Technical Report 26867, National Bureau of Economic Research.
Bareinboim, E. and Pearl, J. (2016). Causal inference and the data-fusion problem. In Shiffrin, R. M., editor, Proceedings of the National Academy of Sciences, volume 113, pages 7345–7352. National Academy of Sciences.
Bareinboim, E. and Tian, J. (2015). Recovering causal effects from selection bias. In Twenty-Ninth AAAI Conference on Artificial Intelligence.
Bareinboim, E., Tian, J., and Pearl, J. (2014). Recovering from selection bias in causal and statistical inference. In in Proceedings of the Twenty-Eight AAAI Conference on Artificial Intellgence, pp. 2410–2416. Citeseer.
Basu, S., & Sen, S. (2022). Covid 19 pandemic, socio-economic behaviour and infection characteristics: An inter-country predictive study using deep learning. Computational Economics. https://doi.org/10.1007/s10614-021-10223-5:1-32
Baum, C., Schaffer, M., & Stillman, S. (2003). Instrumental variables and gmm: estimation and testing. The Stata Journal, 3(1), 1–31.
Baum, C., Schaffer, M., & Stillman, S. (2007). Enhanced routines for instrumental variables/generalized method of moments estimation and testing. The Stata Journal, 7(4), 465–506.
Benhabib, J., & Spiegel, M. M. (1994). The role of human capital in economic development evidence from aggregate cross-country data. Journal of Monetary economics, 34(2), 143–173.
Breiman, L. (2001). Random forests. Machine learning, 45(1), 5–32.
Carozzi, F. (2020). Urban density and covid-19. Technical report, IZA discussion paper, No 13440.
Cartenì, A., Di Francesco, L., & Martino, M. (2020). How mobility habits influenced the spread of the covid-19 pandemic: results from the Italian case study. Science of the Total Environment, 741, 140489.
Chen, T. and Guestrin, C. (2016). Xgboost: a scalable tree boosting system. In Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining, p 785–794.
Chernozhukov, V., Kasahara, H., & Schrimpf, P. (2021). Causal impact of masks, policies, behavior on early covid-19 pandemic in the US. Journal of Econometrics, 220(1), 23–62.
Cherrat, H., & Prigent, J.-L. (2022). On the hedging of interest rate margins on bank demand deposits. Computational Economics. https://doi.org/10.1007/s10614-022-10287-x:1-33
Colombo, D., Maathuis, M., Kalisch, M., & Richardson, T. (2012). Learning high-dimensional directed acyclic graphs with latent and selection variables. The Annals of Statistics, 40, 294–321.
Cortes, G. M. and Forsythe, E. (2020). Heterogeneous labor market impacts of the covid-19 pandemic. ILR Review, p. 00197939221076856.
Cot, C., Cacciapaglia, G., & Sannino, F. (2021). Mining google and apple mobility data: temporal anatomy for covid-19 social distancing. Scientific Reports, 11(1), 1–8.
Davison, A., & Hinkley, D. (1997). Bootstrap methods and their application. Cambridge: Cambridge University Press.
Deb, P., Furceri, D., Ostry, J. D., & Tawk, N. (2022). The economic effects of covid-19 containment measures. Open Economies Review, 33(1), 1–32.
Elgin, C., Basbug, G., & Yalaman, A. (2020). Economic policy responses to a pandemic: developing the covid-19 economic stimulus index. Covid Economics, 1(3), 40–53.
Ferguson, N., Laydon, D., Nedjati-Gilani, G., Imai, N., Ainslie, K., Baguelin, M., Bhatia, S., Boonyasiri, A., Cucunubá, Z., Cuomo-Dannenburg, G., et al. (2020). Report 9: impact of non-pharmaceutical interventions (NPIs) to reduce covid19 mortality and healthcare demand. Imperial College London, 10(77482), 491–497.
Finlay, K., Magnusson, L., and Schaffer, M. (2013). weakiv: Weak-instrument-robust tests and confidence intervals for instrumental-variable (iv) estimation of linear, probit and tobit models.
Foucault, M., Galasso, V., et al. (2020). Working after covid-19: cross-country evidence from real-time survey data. Science Po CEVIPOF Research Note, 9.
Friedman, J. (2001). Greedy function approximation: a gradient boosting machine. Annals of Statistics, 29, 1189–1232.
Glaeser, E., & Mare, D. (2001). Cities and skills. Journal of Labor Economics, 19(2), 316–342.
Glynn, J. (2020). Protecting workers aged 60–69 years from covid-19. The Lancet Infectious Diseases, 20(10), 1123.
Google (2020). Google covid-19 community mobility reports. https://www.google.com/covid19/mobility/Accessed:17February2021.
Guo, J., Deng, C., & Gu, F. (2021). Vaccinations, mobility and covid-19 transmission. International Journal of Environmental Research and Public Health, 19(1), 97.
Gupta, A., Shaju, C., et al. (2021). A study of the international stock market behavior during covid-19 pandemic using a driven iterated function system. Computational Economics. https://doi.org/10.1007/s10614-021-10199-2:1-12
Ham, S. (2021). Explaining gender gaps in the south korean labor market during the covid-19 pandemic. Feminist Economics, 27(1–2), 133–151.
Hesterberg, T. (2015). What teachers should know about the bootstrap: resampling in the undergraduate statistics curriculum. The American Statistician, 69(4), 371–386.
Huang, B., Wang, J., Cai, J., Yao, S., Chan, P. K. S., Tam, T.H.-W., Hong, Y.-Y., Ruktanonchai, C. W., Carioli, A., Floyd, J. R., et al. (2021). Integrated vaccination and physical distancing interventions to prevent future covid-19 waves in chinese cities. Nature Human Behaviour, 5(6), 695–705.
Hünermund, P. and Bareinboim, E. (2019). Causal inference and data-fusion in econometrics. arXiv preprint arXiv:1912.09104, pp 1–60.
Iacus, S. M., Santamaria, C., Sermi, F., Spyratos, S., Tarchi, D., & Vespe, M. (2020). Human mobility and covid-19 initial dynamics. Nonlinear Dynamics, 101(3), 1901–1919.
Iftekhar, E. N., Priesemann, V., Balling, R., Bauer, S., Beutels, P., Valdez, A. C., Cuschieri, S., Czypionka, T., Dumpis, U., Glaab, E., et al. (2021). A look into the future of the covid-19 pandemic in Europe: an expert consultation. The Lancet Regional Health-Europe, 8, 100185.
Kikuchi, S., Kitao, S., & Mikoshiba, M. (2021). Who suffers from the covid-19 shocks? labor market heterogeneity and welfare consequences in Japan. Journal of the Japanese and International Economies, 59, 101117.
Kim, D., & Lee, Y. J. (2022). Vaccination strategies and transmission of covid-19: Evidence across advanced countries. Journal of Health Economics, 82, 102589.
Kraemer, M., Yang, C., Gutierrez, B., Wu, C., Klein, B., Pigott, D., Du Plessis, L., Faria, N., Li, R., & Hanage, W. (2020). The effect of human mobility and control measures on the covid-19 epidemic in China. Science, 368(6490), 493–497.
Lytras, T., & Tsiodras, S. (2020). Lockdowns and the covid-19 pandemic: what is the endgame? Scandinavian Journal of Public Health, 49(1), 37–40.
Mincer, J. (1958). Investment in human capital and personal income distribution. Journal of Political Economy, 66(4), 281–302.
Mincer, J. (1974). Schooling, experience, and earnings. New York: NBER Press.
Moreira, M. (2003). A conditional likelihood ratio test for structural models. Econometrica, 71(4), 1027–1048.
Oztig, L., & Askin, O. (2020). Human mobility and coronavirus disease 2019 (covid-19): a negative binomial regression analysis. Public health, 185, 364–367.
Papanikolaou, D., & Schmidt, L. D. (2020). Working remotely and the supply-side impact of covid-19. National Bureau of Economic Research: Technical report.
Pearl, J. (1995). Causal diagrams for empirical research. Biometrika, 82(4), 669–688.
Pearl, J. (2000). Causality: models, reasoning, and inference (Vol. 521). Cambridge: Cambridge University Press.
Pearl, J., & Mackenzie, D. (2018). The book of why: the new science of cause and effect. New York: Basic Books.
Safara, F. (2020). A computational model to predict consumer behaviour during covid-19 pandemic. Computational Economics. https://doi.org/10.1007/s10614-020-10069-3:1-14
Scheines, R., Spirtes, P., Glymour, C., Meek, C., & Richardson, T. (1998). The tetrad project: constraint based aids to causal model specification. Multivariate Behavioral Research, 33(1), 65–117.
Spirtes, P., Glymour, C., & Scheines, R. (2000). Causation, prediction, and search. Cambridge, Massachusetts: MIT Press Books.
Spirtes, P., Meek, C., & Richardson, T. (1999). An algorithm for causal inference in the presence of latent variables and selection bias. Computation, causation, and discovery, 21, 1–252.
Stock, J. and Yogo, M. (2005). Testing for weak instruments in linear iv regression. in: Identification and Inference for Econometric Models: Essays in Honor of Thomas Rothenberg.
Tibshirani, R., & Efron, B. (1993). An introduction to the bootstrap. Monographs on statistics and applied probability, 57, 1–436.
Turkstat (2019a). Address-based population registry system. Turkish Statistics Office, https://biruni.tuik.gov.tr/medas.
Turkstat (2019b). Birth and death statistics. Turkish Statistics Office, https://biruni.tuik.gov.tr/medas.
Turkstat (2019c). National education statistics. Turkish Statistics Office, https://biruni.tuik.gov.tr/medas.
Turkstat (2020). Provincial gdp, 2019. Turkish Statistics Office, https://data.tuik.gov.tr/Bulten/Index?p=Il-Bazinda-Gayrisafi-Yurt-Ici-Hasila-2019-33663.
VanderWeele, T., & Robins, J. (2010). Signed directed acyclic graphs for causal inference. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 72(1), 111–127.
Verma, T., & Pearl, J. (1988). Influence diagrams and d-separation. California: Computer Science Department UCLA.
Zhang, C., & Zhang, D. (2022). Spatial interactions and the spread of covid-19: a network perspective. Computational Economics. https://doi.org/10.1007/s10614-022-10278-y:1-23
Acknowledgements
The authors would like to thank Paul Hünermund and Maria Glymour for their helpful comments.
Funding
The authors declare that no funds, grants, or other support were received during the preparation of this manuscript.
Author information
Authors and Affiliations
Contributions
All authors contributed to the study conception and design. Material preparation, data collection and analysis were performed by Fırat Bilgel and Burhan Can Karahasan. The first draft of the manuscript was written by Burhan Can Karahasan and all authors commented on previous versions of the manuscript. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Conflict of Interests
The authors have no relevant financial or non-financial interests to disclose.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Bilgel, F., Karahasan, B.C. Understanding Covid-19 Mobility Through Human Capital: A Unified Causal Framework. Comput Econ 63, 793–833 (2024). https://doi.org/10.1007/s10614-023-10359-6
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10614-023-10359-6
Keywords
- Workplace mobility
- Causal structure discovery
- Do-calculus
- Machine learning
- Instrumental variables
- Sample selection