
Abstract
For many problems, some of which are reviewed in the paper, popular algorithms like Douglas–Rachford (DR), ADMM, and FISTA produce approximating sequences that show signs of spiraling toward the solution. We present a meta-algorithm that exploits such dynamics to potentially enhance performance. The strategy of this meta-algorithm is to iteratively build and minimize surrogates for the Lyapunov function that captures those dynamics. As a first motivating application, we show that for prototypical feasibility problems the circumcentered-reflection method, subgradient projections, and Newton–Raphson are all describable as gradient-based methods for minimizing Lyapunov functions constructed for DR operators, with the former returning the minimizers of spherical surrogates for the Lyapunov function. As a second motivating application, we introduce a new method that shares these properties but with the added advantages that it: (1) does not rely on subproblems (e.g. reflections) and so may be applied for any operator whose iterates have the spiraling property; (2) provably has the aforementioned Lyapunov properties with few structural assumptions and so is generically suitable for primal/dual implementation; and (3) maps spaces of reduced dimension into themselves whenever the original operator does. This makes possible the first primal/dual implementation of a method that seeks the center of spiraling iterates. We describe this method, and provide a computed example (basis pursuit).
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Many important optimization problems are computationally tackled by repeated application of an operator T, whose fixed points allow one to recover a solution. Under very minimal assumptions, whenever the iterates exhibit local convergence to a fixed point, a particular function V exists. This function V, called a Lyapunov function, describes the behaviour of the discrete dynamical system admitted by repeated application of the operator (see [28, Theorem 2.7]).
The zeroes that minimize the Lyapunov function are the fixed points for the operator. Thus, if one did have some knowledge—or a reasonable guess—about the structure of the Lyapunov function, one could consider the equivalent problem of seeking a minimizer for the Lyapunov function directly. We will introduce a class of methods—based on operators in \(\mathbf {MSS}(V)\)—that do exactly this, by minimizing spherical surrogates for the Lyapunov function.
We suggest implementing such methods when an algorithm’s change from iterate to iterate resembles the oscillations in Figs. 1 and 5. This phenomenon has been observed for many problems; in addition to the examples in this paper, see also [1, 2, 4, 13, 16, 17, 20,21,22, 26, 29, 31, 33, 35]. In such a case, we will say that an algorithm shows signs of spiraling. This definition, though informal and subjective, is useful in practice, because this pattern is very easy to check for. For many known examples, this pattern is co-present with a special property (A1) that we will formally call the spiraling property. It is on this latter, formal, difficult-to-check definition that we will build our theory, while the former, informal definition is easy to check in applications.
Fascinatingly, the Circumcentered-Reflection Method (CRM), for certain, highly structured feasibility problems, is an existing example from the broader class of algorithms we introduce. However, CRM does not succeed for a primal/dual implementation of the basis pursuit problem, for reasons we discover and describe in this paper. Motivated by our theoretical understanding of the new, broader class \(\mathbf {MSS}(V)\), we introduce a novel operator (Definition 5) that performs very well in our experiments for the primal/dual framework.
1.1 Background
Algorithms like the fast iterative shrinkage-thresholding algorithm (FISTA) [31, 35], alternating direction method of multipliers (ADMM) [19, 23, 24], and Douglas–Rachford method (DR) [20, 26, 33] seek to solve problems of the form
where E, Y are Hilbert (here Euclidean) spaces, \(M:E \rightarrow Y\) is a linear map, and \(f,g:E \rightarrow {\mathbb R}\cup \{+\infty \}\) are proper, extended real valued functions. For a common example, when \(M=\mathrm{Id}\) is the identity map and \(f=\iota _A, g=\iota _B\) with
for closed constraint sets A, B with \(A \cap B \ne \emptyset\), (1) becomes the feasibility problem:
For many problems of interest, ADMM, DR, and FISTA exhibit signs of spiraling [29, 31, 35], such as those shown at right in Fig. 1.
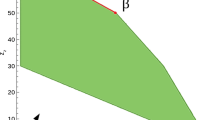
Borwein and Sims provided the first local convergence result for DR applied to solving the nonconvex feasibility problem when A is a sphere and B a line [17]. Aragón Artacho and Borwein later provided a conditional global proof [1] for starting points outside of the axis of symmetry, while behaviour on the axis is described in [6]. Borwein et al. adapted Borwein and Sims’ approach to show local convergence for lines and more general plane curves [16]. In each of these settings, the local convergence pattern resembles the spiral shown at left in Fig. 1; Poon and Liang have also documented signs of spiraling in the context of the more general problem (1) [35]. Benoist showed global convergence for DR outside of the axis of symmetry for Borwein and Sims’ circle and line problem [13] by constructing the Lyapunov function whose level curves are shown in Fig. 2. Dao and Tam extended Benoist’s approach to function graphs more generally [20]. Most recently, Giladi and Rüffer broadly used local Lyapunov functions to construct a global Lyapunov function when one set is a line and the other set is the union of two lines [26]. Altogether, Lyapunov functions have become the definitive approach to proving KL-stability and describing the basins of attraction for DR in the setting of nonconvex feasibility problems.

A plot of change from iterate to iterate for shadow sequence for an ellipse and line (right) when governing Douglas–Rachford sequence is spiraling (left)

CRM for \(T_{A,B}\) (left) versus CRM for \(T_{B,A}\) (right) for circle B and line A, together with level curves for Benoist’s Lyapunov function
At the same time, a parallel branch of research has grown from the Douglas–Rachford feasibility problem tree. Behling, Bello Cruz, and Santos introduced what has become known as the circumcentered reflection method (CRM) [8, 10]. As is locally true of the work of Giladi and Rüffer, the prototypical setting of Behling, Bello Cruz, and Santos was the convex feasibility problem of finding intersections of affine subspaces. The authors of [22] illuminated a connection between CRM and Newton–Raphson method, and used it to show super-linear and quadratic local convergence for prototypical problems. Behling, Bello Cruz, and Santos have since used a similar geometric argument to show that the circumcentered reflection method outperforms alternating projections and Douglas–Rachford method for the product space convex feasibility problem [11]. See also [3].
1.2 Contributions and outline
In Sects. 1 and 2, we introduce preliminaries.
In Sect. 3, we show that for many prototypical feasibility problems for which the Lyapunov functions for the Douglas–Rachford dynamical system are known, CRM may be characterized as a gradient descent method applied to the Lyapunov function with a special step size (Theorem 2, Corollary 1). We also uncover Lyapunov function gradient relationships for subgradient descent methods and Newton–Raphson method (Proposition 2).
In Sect. 4, we introduce the class of operators \(\mathbf {MSS}(V)\) that minimize spherical surrogates for Lyapunov functions. We then show that for the class of problems considered in Sect. 3, CRM actually returns the minimizer of a spherical surrogate for the Lyapunov function (Theorem 3). We then introduce a new operator (Definition 5) that belongs to \(\mathbf {MSS}(V)\) with very few assumptions (Theorem 4). We design this new operator to depend only on the governing sequence. This means it can be implemented in a much more general setting than feasibility problems with reflection substeps. For example, one could apply it with black box applications when only the governing sequence is known and subproblem solutions (e.g. proximal points, reflections) are not available. Naturally, this also means that the new method can be used in circumstances when algorithm parameters are fixed (e.g. black box scenarios) or a theoretically optimal choice for them is unknown (such as [21, 29]).
In Sect. 5, we apply this new operator to the dual of ADMM for the basis pursuit problem (Sect. 5). In this setting, its lack of dependence on substeps allows it to succeed where a generalization of CRM fails (for reasons we describe). This is also the first primal/dual framework and implementation for a method that uses the circumcenter. For warm-started applications (e.g. optimal power flow), one might expect the starting point of iteration to lie near or within the local basin of attraction to a fixed point, so that steps obtained by our approach—minimizing a surrogate for the Lyapunov function for the dual iterates—may be the preferred updates from early on in the computation. For continuous optimization problems, one can use objective function checks to choose between Lyapunov surrogate updates and regular updates, as we do for our basis pursuit example. One can compute both such updates in parallel.
In Sect. 6, we conclude with suggested further research.
2 Preliminaries
The following introduction to the Douglas–Rachford method is quite standard. We closely follow [22], which is an abbreviated version of that found in the survey of Lindstrom and Sims [33].
2.1 The Douglas–Rachford operator and method
The problem (1) is frequently presented in the slightly different form
where \(\mathbb A\) and \(\mathbb B\) are often (not always) maximally monotone operators. When the operators are subdifferential operators \(\partial f\) and \(\partial (g\circ M)\) for the convex functions f and \(g\circ M\), one recovers (1). Whenever a set S is closed and convex, its indicator function \(\iota _S\), defined in (2), is lower semicontinuous and convex, while its subdifferential operator is the normal cone operator of set S. The resolvent \(J_{\gamma F} := (\mathrm{Id}+\gamma F)^{-1}\) for a set-valued mapping F generalizes the proximity operator
In particular, the resolvent \(J_{N_S}\) of the normal cone operator \(N_S\) for a closed set S is simply the projection operator given by
When S is nonconvex, \(\mathbb {P}_S\) is generically a set-valued map whose images may contain more than one point. For the prototypical problems we discuss, \(\mathbb {P}_S\) is always nonempty, and we work with a selector \(P_S:E \rightarrow S: x \mapsto P_S(x) \in \mathbb {P}_S(x)\). The Douglas–Rachford method is defined by letting \(\lambda >0, x_0\in X\), and setting
is the reflected resolvent operator. Though many newer results exist, the classical convergence result for the Douglas–Rachford method was given by Lions and Mercier [34] and relies on maximal monotonicity [5, 20.2] of \(\mathbb A,\mathbb B,\mathbb A+\mathbb B\). When the operators \(\mathbb A\) and \(\mathbb B\) are the normal cone operators \(N_A=\partial \iota _A\) and \(N_B=\partial \iota _A\), the associated resolvent operators \(J_{N_A}\) and \(J_{N_B}\) are the proximity operators \({\text {prox}}_{\iota _A}\) and \({\text {prox}}_{\iota _B}\), which may be seen from (3) to just be the projection operators \(P_A\) and \(P_B\) respectively. In this case, (4) becomes
is the reflection operator for the set S. The operator described in (5) for solving (FEAS) is a special case of the Douglas–Rachford operator described in (4) for solving (1). One application of the operators \(T_{A,B}\) and \(T_{B,A}\) is shown in Fig. 2, where B is a circle and A is a line. From this picture and from (5), one may understand why DR is also known as reflect-reflect-average (see [33] for other names).
The final averaging step apparent in the form of (4) serves to make the operator T firmly nonexpansive in the convex setting [5], but Eckstein and Yao actually note that this final averaging step of blending the identity with the nonexpansive operator \(R_BR_A\) serves the important geometric task of ensuring that the dynamical system admitted by repeated application of \(T_{A,B}\) does not merely orbit the fixed point at a constant distance without approaching it [23]. In this sense, the tendency of splitting methods to spiral actually motivates the final step of construction for DR: averaging may be viewed as a centering method. It is a safe centering method in the variational sense that it adds theoretically advantageous nonexpansivity properties to the operator T rather than risking those properties in the way that a more bold centering step, like circumcentering, does.
While fixed points may not be feasible, they allow for quick recovery of feasible points, since \((x \in {\text {Fix}}T_{A,B}) \implies P_A x \in A \cap B\) (see, for example, [33]). Because of this, the sequence \(P_A x_n\) is sometimes referred to as the shadow sequence of \(x_n\) (on A). While fixed points may not be feasible, they allow for quick recovery of feasible points, since \((x \in {\text {Fix}}T_{A,B}) \implies P_A x \in A \cap B\) (see, for example, [33]). Similarly, for the more general operator \(T_{\mathbb A,\mathbb B}\) in (4), maximal monotonicity of \(\mathbb A\) and \(\mathbb B\) is sufficient to guarantee that the points in \(J_{\mathbb A}({\text {Fix}}T_{\mathbb A,\mathbb B})\) solve (P); see [5, Proposition 26.1].
While the convergence of DR for convex problems is well-known, the method also solves many nonconvex problems. In addition to [33], we refer the interested reader to the excellent survey of Aragón Artacho, Campoy, and Tam [2]. Li and Pong have also provided some local convergence guarantees for the more general optimization problem (1) in [30]. Critically for us, DR also has a dual relationship with ADMM, which we will describe and exploit in Sect. 5.
2.2 Lyapunov functions and stability
This abbreviated introduction to Lyapunov functions follows those of greater detail in the works of Giladi and Rüffer [26] and of Kellett and Teel [27, 28].
Let \(U \subset E\) where E is a Euclidean space, \(T:U \rightrightarrows U\) be a set-valued operator, and define the difference inclusion: \(x_{n+1} \in Tx_n, \quad n \in {\mathbb N}\). We say that \(\varphi (x_0,\cdot ):{\mathbb N}\rightarrow E\) is a solution for the difference inclusion, with initial condition \(x_0 \in U\), if it satisfies
Definition 1
(Lyapunov function [28, Definition 2.4]) Let \(\omega _1,\omega _2:E \rightarrow {\mathbb R}_+\) be continuous functions and \(T:U \rightrightarrows U\). A function \(V:U \rightarrow {\mathbb R}_{+}\) is said to be a Lyapunov function with respect to \((\omega _1,\omega _2)\) on U for the difference inclusion \(x^+ \in Tx\), if there exist continuous, zero-at-zero, monotone increasing, unbounded \(\alpha _1,\alpha _2:{\mathbb R}_{+}\rightarrow {\mathbb R}_{+}\) such that for all \(x \in U\),
When \(\omega _1=\omega _2=\omega\), \(\mathcal {A}\) is closed and \(\mathcal {A}:=\{x \in U\;:\; \omega (x)=0 \}\).
We forego the usual definition of robust \(\mathcal{KL}\)-stability (see, for example, [28, Definition 2.3] or [26, Definition 3.2]) in favor of remembering the contribution of Kellett and Teel [28, Theorem 2.10] that robust stability is equivalent to \(\mathcal{KL}\)-stability when T satisfies certain conditions on U.
Theorem 1
(Existence of a Lyapunov function [28, Theorem 2.7]) Let \(T:U \rightrightarrows U\) be upper semicontinuous on U (in the sense of [28, Definition 2.5]), and T(x) be nonempty and compact for each \(x \in U\). Then, for the difference inclusion \(x^+ \in Tx\), there exists a smooth Lyapunov function with respect to \((\omega _1,\omega _2)\) on U if and only if the inclusion is robustly \(\mathcal{KL}\)-stable with respect to \((\omega _1,\omega _2)\) on U.
For us, the principal importance of this result is captured by Giladi and Rüffer’s summary that: “in essence, asymptotic stability implies the existence of a Lyapunov function.” They used a related result to guarantee robust \(\mathcal{KL}\)-stability for their setting, by means of constructing the prerequisite Lyapunov function [26]. Similarly, Benoist and Dao and Tam constructed Lyapunov functions to show KL-stability in their respective settings [13, 20].
2.3 The circumcentering operator and algorithms
Behling, Bello Cruz, and Santos introduced the circumcentered-reflections method (CRM) for feasibility problems involving affine sets [12]. The idea is to update by
where C(x, y, z) denotes the point equidistant to x, y, z and lying on the affine subspace defined by them: \({\text {aff}}\{x,y,z\}\). If x, y, z are not colinear (so their affine hull \({\text {aff}}\{x,y,z\}\) has dimension 2) then C(x, y, z) is the center of the circle containing all three points. If \(\{x,y,z\}\) has cardinality 2, C(x, y, z) is the average (the midpoint) of the two distinct points. If \(\{x,y,z\}\) has cardinality 1, \(C(x,y,z)=x=y=z\). The circumcenter of three points is easy to compute; for a simple expression, see [9, Theorem 8.4].
When \(R_B R_A(x),R_A(x),x\) are distinct and colinear, then \((R_B R_A(x),R_A(x),x) \notin {\text {dom}}C\) and so \(x \notin {\text {dom}}C_T\). When \({\text {dom}}C_T=E\), we say \(C_T\) is proper; this is the case in Behling, Bello Cruz, and Santos’ prototypical setting of affine sets [10, 12]. Bauschke, Ouyang, and Wang have provided sufficient conditions to ensure that \(C_T\) is proper [8, 9].
Because \(C_T\) is not generically proper, the authors of [22] suggested the modest piecewise remedy of iterating
\(\mathcal {C}_{T_{A,B}}\) specifies to \(C_T\) when \(C_T\) is proper—except in the case \(R_BR_Ax = x \ne R_Ax\), in which case \(P_Ax \in {\text {Fix}}T_{A,B}\) solves (FEAS).
3 Spiraling, and subdifferentials of Lyapunov functions
We next show how CRM is related to known Lyapunov functions for nonconvex Douglas–Rachford iteration.
3.1 Known Lyapunov constructions
For the sphere and line, Benoist remarked that the spiraling apparent at left in Fig. 1 suggests the possibility of finding a suitable Lyapunov function that satisfies
- A1:
-
\((\forall x \in U) \quad \langle \nabla V(x^+), x-x^+ \rangle = 0\).
The condition A1 is visible in Fig. 2, where the level curves of the Benoist’s Lyapunov function are tangent to the line segments connecting x and \(x^+\). Whenever A1 holds, we will say that the algorithm \(x^+ \in Tx\) is spiraling on U. In order to reformulate A1 as an explicit differential equation that may be solved for V, one must invert the operator T locally. For this reason, it is often difficult to show A1 explicitly. Notwithstanding, this spiraling property has been present for both the Lyapunov constructions of Dao and Tam [20] and of Giladi and Rüffer [26].
Dao and Tam’s results are broad, but we are most interested in a lemma they provided while outlining a generic process for building a Lyapunov function V that satisfies A1 for \(x^+ \in T_{A,B}x\). Specifically, we consider the case when \(f:X \rightarrow ] -\infty ,+\infty ]\) is a proper function on a Euclidean space X with closed graph
In what follows, \(E=X \times {\mathbb R}\), while \(\partial f\) and \(\partial ^0f\) respectively denote the limiting subdifferential and the symmetric subdifferential of f; see, for example, [20, 2.3].
Lemma 1
([20, Lemma 5.2]) Suppose that \(D\subset {\text {dom}}f\) is convex and nonempty, and that \(F:D \rightarrow ]-\infty ,+\infty ]\) is convex and satisfies
Let \(x=(y,\rho ) \in {\text {dom}}f \times {\mathbb R}\) and \(x^+=(y^+,\rho ^+) \in T_{A,B}(y,\rho )\). Then the following hold.
-
(a)
V is a proper convex function on \(D \times {\mathbb R}\) whose subdifferential is given by
$$\begin{aligned} (\forall y \in {\text {dom}}\partial F)\quad \partial V(y,\rho )=\partial F(y)\times \{\rho \}. \end{aligned}$$(10) -
(b)
Suppose either \(y^+ \in D \setminus (\partial ^0f)^{-1}(0)\) and f is Lipschitz continuous around \(y^+\), or that \(y^+ \in D \cap f^{-1}(0)\). Then there exists \(\bar{x}^+ = (\bar{y}^+,\rho ^+) \in \partial V(x^+)\) with \(\bar{y}^+ \in \partial F(y^+)\) such that
$$\begin{aligned} \langle \bar{x}^+,x-x^+ \rangle = \langle (\bar{y}^+,\rho ^+),(y,\rho )-(y^+,\rho ^+) \rangle = 0. \end{aligned}$$(11)
The next example is a special case of [20, Example 6.1] and illustrates Lemma 1.
Example 1
(Constructing V for \(T_{A,B}\) when A, B are lines [20, Example 6.1]) Let \(f:{\mathbb R}\rightarrow {\mathbb R}\) be the linear function \(f:y\rightarrow \arctan (\theta ) y\) for some \(\theta \in ]-\pi /2,\pi /2 [\). Then (8) amounts to \(\nabla F(y) = f(y)/\nabla f(y)=y\), and so \(F:y \rightarrow y^2/2+c\) and \(V(y,\rho ) =(y^2+\rho ^2)/2+c/2\).

Construction of \(L_{T_{B,A}}\) for Example 1 (left), and for the circle B and line A (right), together with level curves for Lyapunov functions
Example 1, for which the modulus of linear convergence of \(T_{A,B}\) is known to be \(\cos (\theta )\) [4] (see also [26, Figure 2]), is shown in Fig. 3 (left), where we abbreviate \({\text {gra}}f\) by f. In the case when A is the union of two lines and B is a third line, Giladi and Rüffer used two local quadratic Lyapunov functions of this type \(V_i(x)=\Vert x-p_i\Vert ^2, i=1,2,\) [26, Proposition 5.1] for the two respective feasible points \(p_1,p_2 \in A \cap B\) in their construction of a global Lyapunov function [26, Theorem 5.3].
3.2 Circumcentered reflections method and gradients of V
Now we will explore the relationship between circumcentering methods and the underlying Lyapunov functions that describe local convergence of the operator T. The following definition will simplify the exposition.
Definition 2
For \(y,z \in E\) we define
to be the perpendicular bisector of the line segment adjoining y and z.
We will also make use of the following properties (which have been used in various places; for example, [1, 20]).
Proposition 1
Let A, B be as in (7), and let D, V, F be as in Lemma 1. Then the following hold.
-
(i)
\(R_A\) is an indirect motion in the sense that it preserves pairwise distancesFootnote 1and angles. In other words:
$$\begin{aligned} (\forall x_1,x_2 \in X \times {\mathbb R})\quad \langle x_1,x_2 \rangle = \langle R_Ax_1,R_Ax_2 \rangle . \end{aligned}$$ -
(ii)
V is symmetric about A on \(D\times {\mathbb R}\) in the sense that
$$\begin{aligned}&(\forall (y,\rho ) \in D \times {\mathbb R}) \quad V(y,\rho )=V(y,-\rho ),\quad \text {and so}\quad V=V\circ R_A \end{aligned}$$(12a)$$\begin{aligned}&\text {and} \quad (y^*,\rho ^*) \in \partial V(y,\rho ) \;\; \iff \;\; (y^*,-\rho ^*) \in \partial V(y,-\rho ), \end{aligned}$$(12b)$$\begin{aligned}&\text {which allows us to write}\quad R_A \partial V = \partial V \circ R_A. \end{aligned}$$(12c) -
(iii)
\(T_{B,A}\) and \(T_{A,B}\) are equivalent across the axis of symmetry A in the sense that
$$\begin{aligned} T_{B,A} = R_A T_{A,B} R_A\quad \text {and}\quad T_{A,B} = R_AT_{B,A}R_A \end{aligned}$$
Proof
(i): Let \(x_1=(y_1,\rho _1),x_2=(y_2,\rho _2) \in X \times {\mathbb R}\). Then
(ii): We have (12a) as an immediate consequence of (9), and (12b) as an immediate consequence of (10).
(iii): This follows readily from the linearity and self-inverse properties of \(R_A\). See, for example, [7, Proposition 2.5 and Theorem 2.7]. \(\square\)
3.2.1 A motivating example
We next prove a theorem that establishes a relationship between subgradients of V and circumcentered reflection method (CRM). Let us first explain a prototypical example of this relationship, before proving it formally. At left in Fig. 2, we see that
where V is Benoist’s Lyapunov function. Likewise, at right in Fig. 2, we see that
In other words, the CRM updates for the chosen point x in both cases may be characterized as gradient descent applied to Benoist’s Lyapunov function with the special step sizes determined by (13) and (14) for the two operators \(T_{A,B}\) and \(T_{B,A}\) respectively.
In Theorem 2, we show that a weaker version of this holds in higher dimensional Euclidean spaces for a broader class of problems covered by the framework of Dao and Tam. Specifically, we show that, under mild conditions, the perpendicular bisector of any given side of the triangle \((x,R_Ax,R_BR_Ax)\) or the triangle \((x,R_Bx,R_AR_Bx)\) with midpoint p contains \(p+{\mathbb R}p^*:=\{p+\mu p^*\;|\; \mu \in {\mathbb R}\}\) for some \(p^* \in \partial V(p)\).
3.2.2 The general case in Euclidean space
Theorem 2
Let A, B be as specified in (7). Let f be Lipschitz continuous on D, and let D, V, F be as in Lemma 1. Suppose further that
Let \(x \in D\times {\mathbb R}\) and \(P_B\) be single-valuedFootnote 2on \(D\times {\mathbb R}\) (combined with the single-valuedness \(P_A\), this forces \(T_{A,B},T_{B,A}\) to be single-valued, simplifying the notation). Then we have the following:
-
(i)
There exists \(\bar{x}^+\in \partial V(T_{A,B}x)\) such that
$$\begin{aligned} (\forall \mu \in {\mathbb R})\;\; T_{A,B}x-\mu \bar{x}^+ \in H(x,R_BR_Ax). \end{aligned}$$ -
(ii)
\(\partial V(P_Ax) \ne \emptyset\) and
$$\begin{aligned} (\forall \mu \in {\mathbb R})(\forall \bar{x} \in \partial V(P_Ax)) \quad P_Ax - \mu \bar{x} \in H(x,R_Ax). \end{aligned}$$(16) -
(iii)
There exists \(x^* \in \partial V(P_Bx)\) such that
$$\begin{aligned} (\forall \mu \in {\mathbb R}) \quad P_Bx - \mu x^* \in H(x,R_Bx). \end{aligned}$$(17) -
(iv)
There exists \(\bar{x}^* \in \partial V(T_{B,A}x)\) such that
$$\begin{aligned} (\forall \mu \in {\mathbb R})\;\; T_{B,A}x-\mu \bar{x}^+ \in H(x,R_AR_Bx). \end{aligned}$$
Proof
(i): Because the conditions of Lemma 1(b) are satisfied, we have that there exists \(\bar{x}^+ \in \partial V(T_{A,B}x)\) that satisfies (11), and so \(\bar{x}^+ \in \{x-T_{A,B}x\}^\perp =\{x-R_B R_A x\}^\perp\). Using the fact that \(\{x-R_B R_A x\}^\perp\) is a subspace and \(T_{A,B}x \in H(x,R_B R_A x)\), we obtain that
This shows (i).
(ii): Because \(x \in D \times {\mathbb R}\), we have that \(x=(y,\rho )\) for some \(y \in D\), and so \(P_Ax = (y,0) \in D\times \{0\}\). We will consider two cases: \(f(y)=0\) and \(f(y)\ne 0\).
Case 1 Let \(f(y)=0\). Combining \((f(y)=0)\) together with the fact that \(y \in D\), we obtain
Here (a) is from (10) while (b) uses (8) together with the fact that \(f(y)=0\). Now, combining (18) with the fact that \(A = H(x,R_Ax)\) is a subspace and \(P_A(x) \in A\), we have
which shows (ii) in the case when \(f(y)=0\), and consequently for all cases when \(0 \in \partial f^0(y)\).
Case 2 Now suppose \(f(y) \ne 0\). Then, by our assumption (15), we have that \(0 \notin \partial ^0f(y)\). Consequently, we have from (8) and the Lipschitz continuity of f that \(\partial F(y) \ne \emptyset\). Applying Lemma 1(a), we have from (10) that
Combining (19) with the fact that \(\partial F(y)\ne \emptyset\), we have that \(\partial V(P_Ax)\) is nonempty. Again combining with the fact that \(H(x,R_Ax)=A\) is a subspace and \(P_Ax \in A\), we obtain (16).
(iii): Because \(x\in D \times {\mathbb R}\), set \(x=(y,\rho )\) with \(y\in D, \rho \in {\mathbb R}\). Since \(P_Bx \in B = {\text {gra}}f\), we have that \(P_Bx=(q,f(q))\) for some \(q \in X\). We will show that \(q \in D\). First notice that \(x'=(y,-\rho ) \in D \times {\mathbb R}\) and that \(P_Bx = P_BR_Ax'\), because \(x=(y,\rho )=R_A(y,-\rho )=R_Ax'\). Then notice that we may use the linearity of \(R_A\) to write
which shows that \(P_Bx \in D \times {\mathbb R}\), and so \(q \in D\). We will consider two cases: \(0 \in \partial ^0f(q)\) and \(0 \notin \partial ^0f(q)\).
Case 1 Let \(0 \in \partial ^0f(q)\). Then we have by assumption that \(f(q)=0\), and so from (8) that \(\{0\} \subset \partial F(q)\). Using this fact together with (10), we have that
Clearly \(x^*=0 \in \{x-R_Bx\}^\perp\). Using this, together with the fact that \(P_Bx \in H(x-R_Bx)^\perp\), we have that (17) holds.
Case 2 Let \(0 \notin \partial ^0f(q)\). We have from [20, Lemma 3.4] that the relationship \((q,f(q))=P_B(y,\rho )\) is characterized by the existence of \(q^* \in \partial ^0f(q)\) such that
Because \(0 \notin \partial ^0f(q)\), we have from (8) that
Using (21) together with (10), we have that
Thus we have that
Here (23a) is true from the definitions \(x=(y,\rho )\) and \(P_Bx=(q,f(q))\), (23b) uses the equality (20), (23c) uses the identity (22), (23d) splits the single dot product term on \(X \times {\mathbb R}\) into a sum of two dot product terms on X and \({\mathbb R}\), and what remains is linear algebra.
Altogether, (23) shows that \(x^* \in \{x-P_Bx\}^\perp = \{x-R_Bx \}^\perp\). Combining this with the fact that \(\{x-R_Bx \}^\perp\) is a subspace and that \(P_Bx \in H(x,R_Bx)\), we obtain (17). This concludes the proof of (iii).
(iv): Let \(x = (y,\rho ) \in D \times {\mathbb R}\). We know from (i) of this Theorem that
Consequently, we obtain that
where (25a) is true from (24), (25b) follows from Proposition 1(i), and (25c) uses Proposition 1(iii). We also have that
where (a) uses (12c) from Proposition 1(ii) and (b) uses Proposition 1(iii). Now combining (26) with the fact that \(x^* \in \partial V(T_{A,B}(y,-\rho )\) from (24), we have that
Combining (25) and (27), we have that
Combining (28) with the fact that \(\{x-R_AR_Bx\}^\perp\) is a subspace and \(T_{A,B}x \in H(x,R_AR_Bx)\), we have that \(\bar{x}^*\) satisfies (iv). This concludes the proof of (iv), completing the proof of the theorem. \(\square\)
Theorem 2 makes the following result on \({\mathbb R}^2\) easy to show.
Corollary 1
Let \(f:{\mathbb R}\rightarrow {\mathbb R}\) be continuous and differentiable, let A, B be as in (7), and let D, V, F be as in Lemma 1. Suppose further that \((\forall y \in D)\;f'(y) \ne 0\). Let \(x \in D\times {\mathbb R}\). Then the following hold.
-
(a)
If \(x,P_Ax,P_BR_Ax \notin A \cap B\) are not colinear, then (13) holds.
-
(b)
If \(x,P_Bx,P_AR_Bx \notin A \cap B\) are not colinear, then (14) holds.
Recall the aforementioned results of Dizon, Hogan, and Lindstrom [22] that guarantee quadratic convergence of CRM for many choices of f. Corollary 1 may be seen as showing that the specific gradient descent method for V that corresponds to CRM in \({\mathbb R}^2\) actually has quadratic rate of convergence for choices of f covered by their results. Interestingly, connections with Newton–Raphson in \({\mathbb R}^2\) do not end there.
3.3 Newton–Raphson method and subgradient descent on f as gradient descent on V
The following proposition shows that Newton–Raphson and subgradient projections method for \(f:X \rightarrow {\mathbb R}\) may also be characterized as gradient descent on V with step size 1.
Proposition 2
Let \(f:X \rightarrow {\mathbb R}\) be continuous, A, B be as in (7), and D, V, F be as in Lemma 1. Let \(x=(y,0) \in D \times {\mathbb R}\) and \(0\notin \partial ^0f(y)\). Let \({\mathcal N}\) be the Newton–Raphson method. The following hold.
-
(i)
If \(X = \mathbb{R}\) and f is differentiable, then
$$\begin{aligned} ({\mathcal N}(y),0) = x-\nabla V(x). \end{aligned}$$ -
(ii)
Otherwise, let \(y^* \in \partial ^0f(y)\), and we have
$$\begin{aligned} \left( y-\frac{f(y)}{\Vert y^*\Vert ^2}y^*,0 \right) = x-x^*,\quad \text {for some}\;x^* \in \partial V(x). \end{aligned}$$(29)
Proof
(i): Simply notice that, by (8) and (9),
This choice of \(x^*\) clearly satisfies the requirements of (29), showing (ii). \(\square\)
For many choices of f, the explicit equivalence with Newton–Raphson method given by Proposition 2(i) actually guarantees quadratic convergence of gradient descent on V with step size 1 for x started in A. Altogether, we have shown that CRM on \({\mathbb R}^2\), Newton–Raphson on \({\mathbb R}\), and subgradient projection methods on \({\mathbb R}^n\) may all be characterized as gradient descent applied to Lyapunov functions constructed to describe the Douglas–Rachford method for many prototypical problems. More importantly, we have Theorem 2, which relates the subgradients of V to the perpendicular bisectors of the triangles that are the basis of CRM in Euclidean space more generally.
4 Spherical surrogates for Lyapunov Functions
From now on, we assume T, U, V together satisfy A1. We are particularly interested in operators of the following form, which will be illustrated by Corollary 2 and whose significance is made clear by Theorem 3.
Definition 3
Let V be a smooth Lyapunov function with respect to \((\omega _1,\omega _2)\) on U for the difference inclusion \(x^+ \in Tx\). Let \(\varOmega _T,\varLambda ,\psi :E \rightarrow E\) satisfyFootnote 3
Then we say \(\varOmega _T\) minimizes a circumcenter-defined spherical surrogate for V, or \(\varOmega _T \in \mathbf {MCS}(V)\) for short.
The following corollary is an immediate consequence of Theorem 2.
Corollary 2
Let A1 hold and \(D,T_{A,B},T_{B,A}\) be as in Theorem 2, with \(U=D\times {\mathbb R}\), and \(\mathcal {C}_{T_{A,B}}\) as defined in (6). Then
Next, in Theorem 3, we show that an operator in \(\mathbf {MCS}(V)\) may be characterized as returning the minimizer of a spherical surrogate for the Lyapunov function V. Figure 4 illustrates this for \(C_T\), and for the new operator \(L_T\) that we will introduce, when T is the Douglas–Rachford operator. Before proving it, let us first formalize the notion.
Definition 4
Let \(n,m \in {\mathbb N}\) and \(\varTheta _T:E \rightarrow E\). Further suppose that there exist maps \(\sigma _1,\dots ,\sigma _m,\varGamma _1,\dots ,\varGamma _{n}:E \rightarrow E\) such that whenever \({\text {aff}}\{x,\varGamma _1x, \dots , \varGamma _{n}x\}\) has dimension n, the function \(Q: u \mapsto d(u,\varTheta _T x)^2\) satisfies
Then we say that \(\varTheta _T\) minimizes a n-dimensional spherical surrogate for V, fitted at m-points, or \(\varTheta _T \in \mathbf {MSS}(V)_m^n\) for short.
Now we will show that \(\mathbf {MCS}(V) \subset \mathbf {MSS}(V)\).
Theorem 3
(\(\mathbf {MCS}(V) \subset \mathbf {MSS}(V)\)) Let \(\varOmega _T \in \mathbf {MCS}(V)\), and let \(Q:u \mapsto d(u,\varOmega _T x)^2\). Then whenever \(x,2x^+-x,\varLambda x\) are not colinear, the following hold:
-
(i)
\(P_{{\text {aff}}\{x,2x^+-x,\varLambda x \}-x}(\nabla V(x^+)) \in \mathrm{span}\{(\nabla Q)(x^+) \}\); and
-
(ii)
\(P_{{\text {aff}}\{x,2x^+-x,\varLambda x \}-x}(\nabla V(\psi x)) \in \mathrm{span}\{(\nabla Q)(\psi x) \}\).
Accordingly, \(\mathbf {MCS}(V) \subset \mathbf {MSS}(V)_2^2\) with \(\varGamma _1:x\mapsto 2x^+-x\), \(\varGamma _2:x \mapsto \varLambda x\), \(\sigma _1:x \mapsto x^+\) and \(\sigma _2:x \mapsto \psi x\).
Proof
Fix x. We can handle both cases (i) and (ii) with the same argument: by letting \((a,b,c):=(x,2x^+-x,x^+)\) in the former case or \((a,b,c):=(x,\varLambda x,\psi x)\) in the latter. Let \(x,2x^+-x,\varLambda x\) be not colinear. Then \(\varOmega _T x=C(x,2x^+-x,\varLambda x)\) exists and so satisfies
is an affine subspace of dimension 1. Next, notice that
Here (a) holds because \(\varOmega _Tx \in {\text {aff}}\{x,2x^+-x,\varLambda x \}\), and so \(\varOmega _Tx-x \in {\text {aff}}\{x,2x^+-x,\varLambda x \} -x\), where the latter is a subspace and therefore invariant under translation by any of its members (including, specifically \(\varOmega _Tx -x\)). The problem thus simplifies to showing
By a suitable translation and with no loss of generality, we may let \(\varOmega _T x = 0\), which simplifies our notation and allows the problem to be written as:
Moreover, because \(\varOmega _Tx=0\), we have that \(C_{ab}\), H(a, b), and \({\text {aff}}\{x,2x^+-x,\varLambda x \}\) are all subspaces. Since H(a, b) is a subspace, it is invariant under translation by any of its members; in particular we have all the equalities:
Furthermore, because \(\varOmega _T \in \mathbf {MCS}(V)\), we have \(c+{\mathbb R}\nabla V(c) \subset H(a,b)\), and so
where the equality is from (33). From (34), we may write
Consequently, we have that
Now since \(\varOmega _T x = 0\), we have \(Q = \Vert \cdot \Vert ^2\), and so \(\nabla Q(w)=2w\) for all w. In particular, \(\nabla Q(c)=2c\) where \(c \ne \varOmega _T x = 0\). From the definition of \(\varOmega _T\), it is clear that \(c \in C_{ab}\). Altogether,
Here (i) is true from (35), (j) holds because \(c\ne 0\) and \(c \in C_{ab}\) where \(C_{ab}\) is a subspace of dimension 1, and (k) holds because \(\nabla Q(c)=2c\). This shows the result. \(\square\)

When V is Benoist’s Lyapunov function, \(C_{T_{A,B}},C_{T_{B,A}},L_{T_{A,B}} \in \mathbf {MCS}(V)\) (respectively from left to right) and so they minimize spherical surrogates as described in Theorem 3
Now we will introduce a new operator in \(\mathbf {MCS}(V)\) that has the additional property that it is defined for a general operator T and does not depend on substeps (e.g. reflections). This is highly advantageous. For example, this property allows the new operator to be used for the basis pursuit problem in Sect. 5, where \(T_{\mathbb A,\mathbb B}\) is as in (4), the problem (P) is more general than (FEAS), and the proximity operator \(\mathbb A:={\text {prox}}_{cd_2}\) is no longer a projection.
Definition 5
Denote \(x^+\in Tx\) and \(x^{++}\in Tx^+\). Let \(L_T,\pi _T\) be as follows:
The construction of the operator \(L_T\) is principally motivated by minimizing the spherical surrogate of a Lyapunov function for T.
One step of \(L_{T_{B,A}}\) is shown for Example 1 in Fig. 3 (left), together with reflection substeps. In Fig. 3 (right), where B is a circle and A a line, we omit the reflections in order to highlight that the construction of \(L_T\) for a general operator T depends only on \((x,x^+,x^{++})\). Now we have the main result about \(L_T\).
Theorem 4
Let A1 hold. Then \(L_T \in \mathbf {MCS}(V)\) with \(\varLambda = \pi _T\) and \(\psi = T^2\).
Proof
Let, \(\psi x=x^{++}\) and \(\varLambda x=\pi _T x\) and let \(x,2x^+-x,\pi _Tx\) be not colinear. Then we need only show that
The first inclusion (36a) is a straightforward consequence of A1, and so also is
Thus we may show (36b) by showing
which is what we now do. Because \(\pi _Tx-x \in \mathrm{span}(x^{++}-x^+)\), we have that
Now, for simplicity, set
Then we have that
Here (40a) uses the definition of \(\pi _T\) together with the simplified notation from (39), (40b) substitutes for \(x^+\) using (39), and the inclusion in (40c) is true from the definition of y in (39). Altogether, we have
Here (41a) applies (40), (41b) uses (38), and (41c) shows (37), completing the result. \(\square\)
In view of Theorem 3 and Theorem 4, \(L_T \in \mathbf {MSS}(V)_2^2\) with \(\varGamma _1,\sigma _{1}:x \mapsto x^+\) and \(\varGamma _2,\sigma _2:x \mapsto x^{++}\).
4.1 Additional properties of \(L_T\)
One of DR’s advantageous qualities is thought to be that it often searches in a subspace of reduced dimension; for example, it solves the feasibility problem of two lines in E by searching within a subspace of dimension 2. The following proposition shows that \(L_T\) maps spaces of reduced dimension into themselves whenever T does.
Proposition 3
The following hold.
-
(i)
\(L_Tx \in {\left\{ \begin{array}{ll} \mathrm{aff}\{x,x^+,x^{++}\} &{} \text {if} \;\;x,x^+,x^{++}\;\;\text {are not colinear;}\\ Tx^{++} &{}\text {otherwise.}\end{array}\right. }\)
-
(ii)
If U is an affine subspace and \(T(U) \subset U\), then \(L_T (U) \subset U\).
Proof
Here (i) follows from the definition of \(L_T\), and (ii) follows from (i). \(\square\)
As Fig. 3 (left) would suggest, Proposition 3 makes it straightforward to prove the following.
Proposition 4
Let A, B be lines in E. Then for any \(x \in E\), \(L_{T_{A,B}}x \in {\text {Fix}}T_{A,B}\).
Proof
For this problem, the Douglas–Rachford sequence converges in a subspace U of reduced dimension 2 and is equivalent to the problem for two lines in U. Therefore, by a suitable translation and without loss of generality, we may reduce to considering the problem in \({\mathbb R}^2\) from Example 1. If the two lines are perpendicular, \(x^+ \in {\text {Fix}}T_{A,B}\) and so \(L_T x = x^{+} \in {\text {Fix}}T_{A,B}\). If the two lines are not perpendicular, the result follows from Theorem 4 and the fact that the Lyapunov function on the subspace of reduced dimension 2 is simply the spherical function in Example 1 whose gradient descent trajectories all intersect only in \({\text {Fix}}T_{A,B}\). \(\square\)
Another characterization of Proposition 4 is that, for two lines, the spherical surrogate Q constructed by \(L_{T_{A,B}}\), as described in Theorem 3, is equal (up to rescaling) to the Lyapunov function V for the Douglas–Rachford operator. Proposition 4 highlights another difference between \(L_T\) and \(C_T\), because CRM may not converge finitely for this same problem [12, Corollary 2.11]. Other known results in the literature may also be easily proven via this explicit connection with Lyapunov functions, including results about CRM (e.g. [11, Lemma 2]).
Of course, it should be noted that CRM sometimes also converges in lower dimensional subspaces, as in Fig. 2 where CRM converges within the set B. This invariance was exploited in [22] and [11], as described in Sect. 2.3. By contrast, \(L_T\) does not converge within B, which highlights another difference between the methods.
However, the most important advantage of \(L_T\) is that it does not depend on the substeps involved in computing Tx from x (e.g. reflections). This makes it a potential candidate for algorithms that show signs of spiraling admitted by any operator T, wherefore one might suspect that the Lyapunov function satisfies the spiraling condition A1 . The inclusion \(C_T \in \mathbf {MCS}(V)\) from Corollary 2 uses additional assumptions on the structure of \(T_{A,B}\) that may not be satisfied for the more general operator in (4). In fact, in Sect. 5, we will actually show that CRM’s dependence on the subproblems renders it useless for the basis pursuit problem, even though the iterates generated by \(T_{A,B}\) show signs of spiraling. On the other hand, \(L_T \in \mathbf {MCS}(V)\) whenever A1 is satisfied, and \(L_T\) shows very promising performance for the basis pursuit problem.
5 Primal/dual implementation
In Sect. 4 we introduced the operator \(L_T\), whose inclusion in \(\mathbf {MCS}(V)\) we showed with very few assumptions about the specific problem and operator structure. In this section, we describe how one may use a method from \(\mathbf {MSS}(V)\) for the general optimization problem (1) by exploiting a duality relationship and demonstrating with \(L_T\). The basic strategy is to reconstruct the spiraling dual iterates from their primal counterparts, and then to apply a surrogate-minimizing step. One then obtains a multiplier update candidate from the shadow of the minimizer for the surrogate, propagates this update back to the primal variables insofar as is practical, and then can compare this candidate against a regular update before returning to primal iteration.
We illustrate, in particular, with ADMM, which solves the augmented Lagrangian system associated with (1) where \(E={\mathbb R}^n\) and \(Y={\mathbb R}^m\) via the iterated process
When f, g are convex, ADMM is dual to DR for solving the associated problem:
Here \(f^*,g^*\) denote the Fenchel–Moreau conjugates of f and g. For brevity, we state only how to recover the dual updates from the primal ones; for a detailed explanation, we refer the reader to the works of Eckstein and Yao [23, 24], whose notation we closely follow, and also to Gabay’s early book chapter [25], and to the references in [33]. For strong duality and attainment conditions, see, for example, [15, Theorem 3.3.5]. For a broader introduction to Langrangian duality, see, for example, [14, 36]. The dual (DR) updates \((y_k)_{k \in {\mathbb N}}\) may be computed from the primal (ADMM) thusly:
Here the reflected resolvents
are the reflected proximity operators for \(d_1,d_2\) (3). They are denoted by \(N_{cd_1},N_{cd_2}\) in [23, 24]. The sequence of multipliers for ADMM corresponds to what is frequently called the “shadow” sequence for DR: \((\lambda _k)_{k \in {\mathbb N}} = ({\text {prox}}_{cd_2}y_k)_{k \in {\mathbb N}}\). The difference of subsequent iterates thereof, \(\Vert \lambda _{k+1}-\lambda _k\Vert\), is \(\Vert P_Ax-P_Ax^+\Vert\) in Fig. 1(right) for \(d_2 = \iota _{A}\) where A is the line in Fig. 1(left). For feasibility problems (FEAS), the visible shadow oscillations have been consistently associated with showing signs of spiraling observed in Fig. 1(left). This suggests that primal problems eliciting such multiplier update oscillations—whereby we suspect that the dual sequence \((y_k)_{k \in {\mathbb N}} \subset {\mathbb R}^m\) may be spiraling in the sense of A1—are natural candidates for primal/dual \(\mathbf {MSS}(V)\) methods. For example, one may consider applying
The former (43) is the \(L_T\) method associated to the Douglas–Rachford operator \(T_{\partial d_2, \partial d_1}\) as described in (4) for the maximal monotone operators \(\partial d_2\) and \(\partial d_1\). The latter (44) may be seen as a generalization of the circumcentered reflection method that uses reflected proximity operator substeps in place of reflected projections. Remember that this second method may not be in \(\mathbf {MSS}(V)\) for this more general optimization problem, even if A1 holds; in fact, we will see its failure for the basis pursuit problem.
Once the update \(\mathbf {y}_{\varOmega _T}\) is computed, its shadow—\({\text {prox}}_{cd_2}\mathbf {y}_{\varOmega _T} \in {\mathbb R}^m\)—is a candidate for the updated multiplier \(\lambda ^+\). One may evaluate the objective function in order to decide whether to accept it or reject it in favor of a regular multiplier update. Naturally, in the case when the components are colinear, one would proceed with a regular update.
5.1 Example: basis pursuit

\(L_T\) (with objective function check) versus regular ADMM for the basis pursuit problem
We will apply the algorithm to the basis pursuit problem, for which the dual (DR) frequently shows signs of spiraling, as in Figs. 5 and 6. Of course, a complete theoretical investigation of this specific problem—including the construction of the associated Lyapunov function for the dual—would likely constitute multiple further articles. In the conclusion, we will suggest those projects as a natural further step of investigation; of course, such extensive and structure-specific work is beyond the scope and purpose of the present work. We include this experiment to demonstrate the implementation and success of our new algorithm for a primal/dual implementation, and not to make any absolute theoretical claims about convergence or rates. The basis pursuit problem,
may be tackled by ADMM (42) via the reformulation:
The first update (42a) is given by \(x_{k+1}:=P_S(z_k-\lambda _k)\), and the second (42b) by \(z_{k+1}:=\mathrm{Shrinkage}_{1/c}(x_{k+1}+\lambda _k)\). They may be computed efficiently; see the work of Boyd, Parikh, Chu, Peleato, and Eckstein [19, Section 6.2]. We also have that
is computable. After computing three updates of the dual (DR) sequence, \((y_k, y_{k+1}, y_{k+2})\), we update the DR sequence by using \(L_T\) as in (43). Our multiplier update candidate is then \(\lambda _{L_T} =P_{\mathcal {B}_\infty }\mathbf {y}_{L_T}\), and we propagate this update to the second variable (42b) by \(z_{L_T}=\mathbf {y}_{L_T}-\lambda _{L_T}\). We assess these against the regular update candidates by comparing their resultant objective function values,
and updating \(\lambda _{k+2},x_{k+3}\) to match the winning candidate.

The failure of \(C_T\) for the basis pursuit problem
Figure 5 shows the \(L_T\) primal/dual approach together with vanilla ADMM for comparison. This juxtaposition of \(L_T\) primal/dual method with vanilla ADMM resembles what has already been observed with CRM and Douglas–Rachford for nonconvex feasibility problems [22]. The problem used was a randomlyFootnote 4 generated instance with \(\text {seed}=0,n=30,\nu =10,c=1\), and the horizontal axis reports the number of passes through (42). This is the example problem from Boyd, Parikh, Chu, Peleato, and Eckstein’s ADMM code, available at [18]. Our Matlab code is a modified version of theirs, and it is available at [32], together with the Cindrella scripts used to produce the other images in this paper. For 1,000 similar problems with \(c=1\) and “solve” criterion
\(L_T\) and vanilla ADMM solved all problems and performed as in the following table. The column “wins” reports the number of problems (out of 1,000) for which a given method was faster than the other. Where an algorithm requires \(n_k\) iterates to solve problem k, the statistics min, max, and quartiles Q1, Q2 (median), and Q3 describe the distribution of the set \(\{n_1,\dots ,n_{1,000}\}\).
Wins | min | Q1 | Q2 | Q3 | max | |
|---|---|---|---|---|---|---|
Vanilla ADMM | 1 | 278 | 995 | 1582 | 2932 | 761,282 |
\(L_T\) | 999 | 87 | 165 | 221 | 324 | 94,591 |
The performance in Fig. 5 is typical of what we observed. Attempts to update the dual by using \(C_T\) as in (44) yielded an algorithm that consistently failed to solve the problem. Figure 6 shows why we would not expect \(C_T\) to work. For \(y_k\) among the spiraling DR iterates \((y_k)_{k \ge 4}\) on the right, \(H(y_k,R_{\mathcal {B}_\infty }y_k)\) is the vertical line containing the right side of the unit box. The CRM update \(C_Ty_k\) will lie in this line, and so we would not expect it to be anywhere near the spiraling DR iterates, nor would we expect \(P_{\mathcal {B}_\infty }{C_T}y_k\) to closely approximate the limit of the dual shadow (multiplier) sequence \((\lambda _k)_{k \in {\mathbb N}}\). In the figure, we have plotted and enlarged these points of the construction with \(k=4\). In contradistinction, the operator \(L_T\) depends only on the governing DR sequence, and so it is immune to this problem.
6 Conclusion
The ubiquity of Lyapunov functions (as recalled in Sect. 2.2), and the tendency of algorithms that show signs of spiraling to satisfy A1 (as in [13, 20, 26]) suggest that future works should consider Lyapunov surrogate methods for other general optimization problems of form (1) via the duality framework we introduced in Sect. 5. We have shown how such an extension is made broadly possible with generically computable operators selected from \(\mathbf {MSS}(V)\). Moreover, we have already constructed one example, \(L_T\), and experimentally demonstrated its success for a primal/dual adaptation.
We should emphasize that \(L_T\) is only one natural example from the much broader class of surrogate-motivated algorithms, and we have only focused on it to draw attention to the broader reasons for studying \(\mathbf {MSS}(V)\). Naturally, one need not be limited to algorithms in \(\mathbf {MCS}(V)\), which minimize spherical surrogates on affine subspaces of dimension 2. One could easily work with spherical surrogates built from more iterates and higher dimensional affine subspaces. In fact, one could generalize even further, from minimizing spherical surrogates to minimizing ellipsoidal ones, or even general quadratic ones. The specific example \(L_T\) is only the beginning.
Convergence results for nonconvex problems are generally more challenging than for convex ones, and Lyapunov functions have already played an important role for the understanding of nonconvex DR. The Lyapunov function surrogate characterization of CRM in E from Theorems 2 and 3 illuminates the geometry of CRM well beyond the limited analysis provided in [22], and it provides an explicit bridge to state-of-the-art theoretical results for nonconvex DR. Future works may now use Lyapunov functions to study not only the broadly usable method \(L_T\), but the feasibility method CRM as well.
Convergence guarantees for a class of problems as broad as those considered here do not exist for any algorithm. Even for the special case of nonconvex feasibility problems and the Douglas–Rachford operator, such results are few, require significant structure on the objective [1, 13, 16, 20], and are quite complicated to prove. For the more general nonconvex optimization problem, the broadest is the work of Li and Pong [30]. Even the “specific” \(\mathbf {MSS}(V)\) candidate we demonstrated with, \(L_T\), is defined for a general operator T, uses multiple steps of T in its construction, and may take bolder steps than T does. For all of these reasons, convergence guarantees that involve \(L_T\)—and other members of \(\mathbf {MSS}(V)\)—will almost certainly have to consider the specific structure not only of the objective, but of the chosen operator T as well. Two perfect examples of such specific T present themselves, and we recommend these as yet two more specific steps of investigation.
Firstly, we already have the finite convergence of \(L_T\) when T is the Douglas–Rachford operator for the feasibility problem of two lines in \({\mathbb R}^n\). This, together with the outstanding performance of \(L_T\) for ADMM with the basis pursuit problem, suggests that this analysis should be extended for DR for more general affine and convex feasibility problems.
Secondly, [19, Appendix A] provides a proof of convergence for ADMM by means of a dilated quadratic Lyapunov function. An important future work is to study whether \(L_T\) minimizes quadratic surrogates related to this specific Lyapunov function, or whether a new, analogous algorithm based upon this Lyapunov function may be designed.
Data availability
The code for generating the images and experimental data in this article are available on the author’s Github repository: [32].
Notes
To see why distances are preserved, set \(x_1=x_2=x_3-x_4\) and notice that \(\langle x_1,x_2 \rangle = \langle R_A x_1,R_Ax_2 \rangle\) becomes \(\Vert x_3-x_4\Vert =\Vert R_A(x_3-x_4)\Vert =\Vert R_Ax_3-R_Ax_4\Vert\) where the final equality simply uses the linearity of \(R_A\)
This assumption is not strictly necessary, but the greater generality of forgoing it does not merit the burdensome notation that would be needed to do so.
How exactly one defines the otherwise (colinear) case is of little practical importance for our analysis. By setting it to be \(x^+\), one re-attempts a surrogate-minimizing step after the computation of one more update of T. By setting it to be \(Tx^{+}\), one computes two more updates. One could choose either value, or something else.
Matlab code rand(’seed’, k); randn(’seed’, k); for k=1..1000
References
Aragón Artacho, F.J., Borwein, J.M.: Global convergence of a non-convex Douglas–Rachford iteration. J. Glob. Optim. 57(3), 753–769 (2013)
Aragón Artacho, F.J., Campoy, R., Tam, M.K.: The Douglas–Rachford algorithm for convex and nonconvex feasibility problems. Math. Methods Oper. Res. 91(2), 201–240 (2020)
Arefidamghani, R., Behling, R., Bello-Cruz, Y., Iusem, A.N., Santos, L.R.: The circumcentered-reflection method achieves better rates than alternating projections. Comput. Optim. Appl. 79, 1–24 (2021)
Bauschke, H.H., Bello Cruz, J., Nghia, T.T., Phan, H.M., Wang, X.: The rate of linear convergence of the Douglas–Rachford algorithm for subspaces is the cosine of the Friedrichs angle. J. Approx. Theory 185, 63–79 (2014)
Bauschke, H.H., Combettes, P.L.: Convex Analysis and Monotone Operator Theory in Hilbert Spaces, 2nd edn. CMS Books in Mathematics/Ouvrages de Mathématiques de la SMC. Springer, Cham (2017)
Bauschke, H.H., Dao, M.N., Lindstrom, S.B.: The Douglas–Rachford algorithm for a hyperplane and a doubleton. J. Glob. Optim. 74(1), 79–93 (2019)
Bauschke, H.H., Moursi, W.M.: On the order of the operators in the Douglas–Rachford algorithm. Optim. Lett. 10(3), 447–455 (2016)
Bauschke, H.H., Ouyang, H., Wang, X.: On circumcenter mappings induced by nonexpansive operators. Pure Appl. Funct. Anal. 6(2), 257–288 (2021)
Bauschke, H.H., Ouyang, H., Wang, X.: On circumcenters of finite sets in Hilbert spaces. Linear Nonlinear Anal. 271–295 (2018)
Behling, R., Bello-Cruz, J.Y., Santos, L.R.: On the linear convergence of the circumcentered-reflection method. Oper. Res. Lett. 46(2), 159–162 (2018)
Behling, R., Bello-Cruz, J.Y., Santos, L.R.: On the circumcentered-reflection method for the convex feasibility problem. Numer. Algorithms 84, 1475–1494 (2021)
Behling, R., Cruz, J.Y.B., Santos, L.R.: Circumcentering the Douglas–Rachford method. Numer. Algorithms 78, 759–776 (2018)
Benoist, J.: The Douglas–Rachford algorithm for the case of the sphere and the line. J. Glob. Optim. 63, 363–380 (2015)
Bertsekas, D.P.: Convex Optimization Theory. Athena Scientific, Belmont (2009)
Borwein, J.M., Lewis, A.S.: Convex Analysis and Nonlinear Optimization: Theory and Examples, 2nd edn. Springer (2006)
Borwein, J.M., Lindstrom, S.B., Sims, B., Skerritt, M., Schneider, A.: Dynamics of the Douglas–Rachford method for ellipses and p-spheres. Set-Valued Anal. 26(2), 385–403 (2018)
Borwein, J.M., Sims, B.: The Douglas–Rachford algorithm in the absence of convexity. In: Bauschke, H.H., Burachik, R.S., Combettes, P.L., Elser, V., Luke, D.R., Wolkowicz, H. (eds.) Fixed Point Algorithms for Inverse Problems in Science and Engineering, Springer Optimization and Its Applications, vol. 49, pp. 93–109. Springer (2011)
Boyd, S., Parikh, N., Chu, E., Peleato, B., Eckstein, J.: Matlab scripts for alternating direction method of multipliers. Available at https://web.stanford.edu/~boyd/papers/admm/
Boyd, S., Parikh, N., Chu, E., Peleato, B., Eckstein, J.: Distributed optimization and statistical learning via the alternating direction method of multipliers. Found. Trends® Mach. Learn. 3(1), 1–122 (2011)
Dao, M.N., Tam, M.K.: A Lyapunov-type approach to convergence of the Douglas–Rachford algorithm. J. Glob. Optim. 73(1), 83–112 (2019)
Dizon, N., Hogan, J., Lindstrom, S.B.: Centering projection methods for wavelet feasibility problems. In: Cerejeiras, P., Reissig, M., Sabadini, I., Toft, J. (eds.) ISAAC 2019: The 30th International Symposium on Algorithms and Computation proceeding volume Current Trends in Analysis, its Applications and Computation, Birkhäuser series Research Perspectives, vol. in press (2021)
Dizon, N., Hogan, J., Lindstrom, S.B.: Circumcentering reflection methods for nonconvex feasibility problems. Set-Valued Var. Anal. 30, 943–973 (2022)
Eckstein, J., Yao, W.: Augmented Lagrangian and alternating direction methods for convex optimization: a tutorial and some illustrative computational results. RUTCOR Res. Rep. 32(3), 44 (2012)
Eckstein, J., Yao, W.: Understanding the convergence of the alternating direction method of multipliers: theoretical and computational perspectives. Pac. J. Optim. 11(4), 619–644 (2015)
Gabay, D.: Applications of the method of multipliers to variational inequalities. In: Studies in Mathematics and its Applications, vol. 15, chap. ix, pp. 299–331. Elsevier (1983)
Giladi, O., Rüffer, B.S.: A Lyapunov function construction for a non-convex Douglas–Rachford iteration. J. Optim. Theory Appl. 180(3), 729–750 (2019)
Kellett, C.M.: Advances in converse and control Lyapunov functions. (2003)
Kellett, C.M., Teel, A.R.: On the robustness of \(\cal{KL}\)-stability for difference inclusions: smooth discrete-time Lyapunov functions. SIAM J. Control Optim. 44(3), 777–800 (2005)
Lamichhane, B.P., Lindstrom, S.B., Sims, B.: Application of projection algorithms to differential equations: boundary value problems. ANZIAM J. 61(1), 23–46 (2019)
Li, G., Pong, T.K.: Douglas–Rachford splitting for nonconvex optimization with application to nonconvex feasibility problems. Math. Program. 159(1–2, Ser. A), 371–401 (2016). https://doi.org/10.1007/s10107-015-0963-5
Liang, J., Schönlieb, C.B.: Improving “fast iterative shrinkage-thresholding algorithm’’: faster, smarter and greedier. Convergence 50, 12 (2022)
Lindstrom, S.B.: Code for the article, “Computable centering methods for spiraling algorithms and their duals, with motivations from the theory of Lyapunov functions”. Available at https://github.com/lindstromscott/Computable-Centering-Methods (2020)
Lindstrom, S.B., Sims, B.: Survey: sixty years of Douglas–Rachford. J. AustMS 110, 333–70 (2021)
Lions, P.L., Mercier, B.: Splitting algorithms for the sum of two nonlinear operators. SIAM J. Numer. Anal. 16(6), 964–979 (1979). https://doi.org/10.1137/0716071
Poon, C., Liang, J.: Trajectory of alternating direction method of multipliers and adaptive acceleration. Advances in Neural Information Processing Systems, vol. 32. (2019)
Rockafellar, R.T., Wets, R.J.B.: Variational Analysis. Springer (1998)
Acknowledgements
The author was supported by Hong Kong Research Grants Council PolyU153085/16p and by the Alf van der Poorten Traveling Fellowship (Australian Mathematical Society). The author especially thanks Brailey Sims for his careful reading and many helpful comments.
Funding
Open Access funding enabled and organized by CAUL and its Member Institutions.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Lindstrom, S.B. Computable centering methods for spiraling algorithms and their duals, with motivations from the theory of Lyapunov functions. Comput Optim Appl 83, 999–1026 (2022). https://doi.org/10.1007/s10589-022-00413-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10589-022-00413-8
Keywords
- ADMM
- Douglas–Rachford
- Projection methods
- Reflection methods
- Iterative methods
- Discrete dynamical systems
- Lyapunov functions
- Primal/dual
- Circumcenter
- Circumcentered-reflection method